- @PrimaryKeyJoinColumn
-
Используется в случае стратегии наследования
JOINEDдля указания колонки внешнего ключа данной сущности, ссылающегося на первичный ключ сущности-предка.Параметры:
-
name- имя колонки внешнего ключа данной сущности -
referencedColumnName- имя колонки первичного ключа сущности предка
Пример:
@PrimaryKeyJoinColumn(name = "CARD_ID", referencedColumnName = "ID") -
Новое поколение платформы - Jmix.
Предисловие
Данное руководство содержит справочную информацию по платформе CUBA и охватывает наиболее важные темы разработки бизнес-приложений на платформе.
Для успешной работы с платформой требуется знание следующих технологий:
-
Java Standard Edition
-
Реляционные базы данных (SQL, DDL)
Для глубокого понимания принципов работы платформы полезным является знакомство со следующими технологиями и фреймворками:
Если у Вас имеются предложения по улучшению данного руководства, мы будем рады принять ваши pull request’ы и issues в исходниках документации на GitHub. Если вы увидели ошибку или несоответствие в документе - пожалуйста, форкните репозиторий и исправьте проблему. Заранее спасибо!
1. Установка и настройка
- Системные требования
-
-
64-битная операционная система - Windows, Linux или macOS.
-
Оперативная память - 8 ГБ для ведения разработки в CUBA Studio.
-
Свободное место на жестком диске - 10 ГБ.
-
- Java SE Development Kit (JDK)
-
-
Установите JDK 8 и проверьте его работоспособность, выполнив в консоли команду
java -versionВ ответ должно быть выведено сообщение с номером версии Java, например
1.8.0_202.CUBA 7.2 поддерживает Java 8, 9, 10 и 11. Если вам не нужно работать с проектами, основанными на предыдущих версиях CUBA (в том числе для их миграции на CUBA 7.2), то рекомендуется вместо Java 8 использовать Java 11.
Обратите внимание, что OpenJ9 JVM не поддерживается.
-
Установите путь к корневому каталогу JDK в переменной окружения
JAVA_HOME, напримерC:\Java\jdk8u202-b08.-
Для Windows это можно сделать, открыв Компьютер → Свойства системы → Дополнительные параметры системы → Дополнительно → Переменные среды, и задав значение переменной в списке Системные переменные.
-
Для macOS рекомендуется установить JDK в каталог
/Library/Java/JavaVirtualMachines, например/Library/Java/JavaVirtualMachines/jdk8u202-b08, и задатьJAVA_HOMEв~/.bash_profileследующей командой:export JAVA_HOME="$(/usr/libexec/java_home -v 1.8)"
-
-
Если для соединения с интернетом используется прокси-сервер, в JVM, исполняющие инструменты разработки и Gradle, необходимо передавать специальные системные свойства Java, описанные в документе http://docs.oracle.com/javase/8/docs/technotes/guides/net/proxies.html (см. свойства для протоколов HTTP и HTTPS). Рекомендуется установить нужные свойства в переменной окружения
JAVA_OPTSдля всей операционной системы.
-
- Cредства разработки
-
Следующие инструменты упрощают разработку на фреймворке CUBA:
-
CUBA Studio - интегрированная среда разработки (IDE), построенная на платформе IntelliJ и содержащая все необходимое для работы с проектами на CUBA. Ее можно установить либо как отдельное приложение для вашей операционной системы, либо в виде плагина для IntelliJ IDEA (Community or Ultimate). Подробнее см. CUBA Studio User Guide.
-
CUBA CLI - инструмент командной строки, предоставляющий базовую функциональность для создания проектов и их элементов: сущностей, экранов, сервисов и т.д. Этот инструмент позволяет использовать для разработки приложений на CUBA любую Java IDE. Подробнее см. страницу CUBA CLI на GitHub.
Если вы новичок в Java, мы рекомендуем использовать CUBA Studio, так как это наиболее продвинутый и интуитивно понятный инструмент.
-
- База данных
-
В простейшем случае в качестве сервера баз данных приложений используется встроенный HyperSQL (http://hsqldb.org), что вполне подходит для исследования возможностей платформы и прототипирования приложений. Для создания реальных приложений рекомендуется установить и использовать в проекте какую-либо из полноценных СУБД, поддерживаемых платформой, например PostgreSQL.
- Веб-браузер
-
Веб-интерфейс приложений, создаваемых на основе платформы, поддерживает все популярные современные браузеры, в том числе Google Chrome, Mozilla Firefox, Safari, Opera 15+, Internet Explorer 11, Microsoft Edge.
2. Быстрый старт
|
На сайте платформы в разделе Быстрый старт рассматриваются основные шаги, необходимые для разработки приложения: создание проекта и базы данных, проектирование модели данных и создание пользовательского интерфейса. На вашей рабочей машине уже должно быть установлено и настроено необходимое программное обеспечение, см. Установка и настройка. Для продолжения знакомства с платформой на примерах обращайтесь к разделу Обучение на сайте платформы. Следующим важным шагом в разработке приложения может быть реализация бизнес-логики. Смотрите руководство: Для проектирования более сложной модели данных обратите внимание на следующие руководства: Обзор использования чтения и записи данных в приложениях CUBA можно получить из руководства: Больше информации о работе с событиями, локализации сообщений, обеспечения пользовательского доступа и тестировании приложений вы можете найти на странице с руководствами. Большинство примеров кода в этом руководстве основаны на модели данных, используемой в приложении Sales. |
Больше информации |
Руководства и вебинары, детально объясняющие концепции и методики работы с платформой |
|
Пошаговые руководства, объясняющие специфичную для платформы функциональность |
|
Онлайн приложения, демонстрирующие функциональность платформы |
3. Устройство платформы
Данная глава содержит подробное описание архитектуры, компонентов и механизмов платформы.
3.1. Архитектура
В данной главе рассмотрена архитектура CUBA-приложений в различных разрезах: по уровням, блокам, модулям и компонентам.
3.1.1. Уровни и блоки приложения
Фреймворк позволяет строить многоуровневые приложения с выделенными клиентским уровнем, средним слоем и уровнем базы данных. В дальнейшем речь пойдет в основном о среднем слое и клиентах, поэтому для краткости выражение "все уровни" означает два этих уровня.
На каждом уровне возможно создание одного или нескольких блоков приложения. Блок представляет собой обособленную исполняемую программу, взаимодействующую с другими блоками приложения. Обычно блоки реализуются в виде веб-приложений выполняющихся на JVM.

Рисунок 1. Уровни и блоки приложения
- Middleware
-
Средний слой, содержащий основную бизнес-логику приложения и выполняющий обращения к базе данных. Представляет собой отдельное веб-приложение под управлением стандартного контейнера сервлетов Java. См. Компоненты среднего слоя.
- Web Client
-
Основной блок клиентского уровня. Содержит интерфейс, предназначенный, как правило, для внутренних (back-office) пользователей организации. Представляет собой отдельное веб-приложение под управлением стандартного контейнера сервлетов Java. Реализация пользовательского интерфейса основана на фреймворке Vaadin. См. Универсальный пользовательский интерфейс.
- Web Portal
-
Дополнительный блок клиентского уровня. Может содержать интерфейс для внешних пользователей и средства интеграции с мобильными устройствами и сторонними приложениями. Представляет собой отдельное веб-приложение под управлением стандартного контейнера сервлетов Java. Реализация пользовательского интерфейса основана на фреймворке Spring MVC. См. Компоненты портала.
- Frontend UI
-
Дополнительный клиентский блок, предоставляющий интерфейс для внешних пользователей. В отличие от Web Portal, является приложением, выполняющимся на стороне клиента (пример: JavaScript-приложение, выполняющееся в веб-браузере). Работает со средним слоем через REST API, запущенный в блоке Web Client или Web Portal. Может быть основан на React или других фронтенд библиотеках и фреймворках. См. Фронтенд интерфейс.
Обязательным блоком любого приложения является средний слой - Middleware. Для реализации пользовательского интерфейса, как правило, используется один или несколько клиентских блоков, например, Web Client и Web Portal.
Все основанные на Java клиентские блоки взаимодействуют со средним слоем одинаковым образом посредством протокола HTTP, что позволяет размещать средний слой произвольным образом, в том числе за сетевым экраном. Следует отметить, что при развертывании в простейшем случае среднего слоя и веб-клиента на одном сервере между ними организуется локальное взаимодействие в обход сетевого стека для снижения накладных расходов.
3.1.2. Модули приложения
Модуль – наименьшая структурная единица CUBA-приложения. Представляет собой один модуль проекта приложения и соответствующий ему JAR файл с исполняемым кодом.
Стандартные модули:
-
global – включает в себя классы сущностей, интерфейсы сервисов и другие общие для всех уровней классы. Используется во всех блоках приложения.
-
core – реализация сервисов и всех остальных компонентов среднего слоя.
-
gui – общие компоненты Универсальный пользовательский интерфейс. Используется в модуле Web Client.
-
web – реализация универсального пользовательского интерфейса на Vaadin.
-
portal – опциональный модуль – реализация веб-портала на Spring MVC.
-
front – опциональный модуль – реализация Фронтенд интерфейс на JavaScript.

Рисунок 2. Модули приложения
3.1.3. Компоненты приложения
Фреймворк позволяет разделять функциональность приложения на компоненты. Каждый компонент (называемый также add-on) может иметь собственную модель данных, бизнес-логику и пользовательский интерфейс. Приложение использует компоненты как библиотеки и включает их функциональность.
Концепция компонентов приложения позволяет нам сохранять фреймворк относительно небольшим, и при этом предоставлять опциональную бизнес-функциональность в компонентах, таких как Reporting, Full-Text Search, Charts, WebDAV и других. В то же время, разработчики приложений могут использовать этот же механизм для декомпозиции больших проектов в набор функциональных модулей, которые разрабатываются независимо и имеют различный цикл релизов. Естественно, компоненты приложений могут быть переиспользуемыми и обеспечивать проблемно-специфический уровень абстракции поверх фреймворка.
С технической точки зрения, ядро фреймворка также является компонентом под названием cuba. Единственное его отличие от других компонентов это то, что он обязателен для любого приложения. Все остальные компоненты зависят от cuba и могут также иметь зависимости между собой.
Ниже приведена диаграмма зависимостей между стандартными компонентами, часто используемыми в приложении. Сплошными линиями изображены обязательные зависимости, пунктирными − опциональные.

Ниже приведена диаграмма возможной структуры зависимостей между стандартными и кастомными компонентами приложения.

Любое CUBA-приложение может быть легко превращено в компонент и предоставлять функциональность другому приложению. Для того чтобы приложение можно было использовать в качестве компонента, оно должно содержать дескриптор app-component.xml и специальный элемент в манифесте JAR модуля global. CUBA Studio позволяет автоматически сгенерировать дескриптор и манифест для текущего проекта.
Практическое руководство по работе с собственным компонентом приложения приведено в разделе Пример создания и использования компонента.
3.1.4. Состав приложения
Вышеописанные архитектурные принципы напрямую отражаются в структуре собранного приложения. Рассмотрим ее на примере простого приложения, которое состоит из двух блоков – Middleware и Web Client; и включает в себя функциональность компонентов cuba и reports.

Рисунок 3. Состав простого приложения
На рисунке изображено содержимое некоторых каталогов сервера Tomcat с развернутым в нем приложением.
Блок Middleware реализован веб-приложением app-core, блок Web Client – веб-приложением app. Исполняемый код веб-приложений содержится в каталогах WEB-INF/lib в наборе JAR-файлов. Каждый JAR представляет собой результат сборки (артефакт) одного из модулей приложения или его компонента.
Например, состав JAR-файлов веб-приложения среднего слоя app-core определяется тем, что блок Middleware состоит из модулей global и core, и приложение использует компоненты cuba и reports.
3.2. Общие компоненты
В данной главе рассмотрены компоненты платформы, общие для всех уровней приложения.
3.2.1. Модель данных
Предметная область моделируется в приложении с помощью взаимосвязанных классов Java, называемых классами сущностей или просто сущностями.
Сущности подразделяются на две категории:
-
Персистентные – экземпляры таких сущностей хранятся в таблицах базы данных с помощью ORM.
-
Неперсистентные – экземпляры существуют только в оперативной памяти, или сохраняются где-то с помощью иных механизмов.
|
Руководство Data Modelling: Many-to-Many Association демонстрирует различные варианты использования ассоциаций many-to-many. В руководстве Data Modelling: Composition приведены примеры композиции между сущностями. |
Сущности характеризуются своими атрибутами. Атрибут соответствует полю класса и паре методов доступа (get / set) к полю. Чтобы атрибут был неизменяемым (read only), достаточно не создавать метод set.
Персистентные сущности могут включать в себя атрибуты, не хранящиеся в БД. В случае неперсистентного атрибута можно не создавать поле класса, ограничившись методами доступа.
Класс сущности должен удовлетворять следующим требованиям:
-
Наследоваться от одного из базовых классов, предоставляемых платформой (см. ниже).
-
Иметь набор полей и методов доступа, соответствующих атрибутам сущностей.
-
Класс и его поля (или методы доступа при отсутствии для атрибута соответствующего поля) должны быть определенным образом аннотированы для предоставления нужной информации фреймворкам JPA (в случае персистентной сущности) и метаданных.
Поддерживаются следующие типы атрибутов сущностей:
-
java.lang.String -
java.lang.Boolean -
java.lang.Integer -
java.lang.Long -
java.lang.Double -
java.math.BigDecimal -
java.util.Date -
java.time.LocalDate -
java.time.LocalTime -
java.time.LocalDateTime -
java.time.OffsetTime -
java.time.OffsetDateTime -
java.sql.Date -
java.sql.Time -
java.util.UUID -
byte[] -
enum -
Cущность
Базовые классы сущностей (см. ниже) переопределяют equals() и hashCode() таким образом, что экземпляры сущностей сравниваются по их идентификаторам. То есть экземпляры одного класса считаются равными, если равны их идентификаторы.
3.2.1.1. Базовые классы сущностей
Рассмотрим базовые классы и интерфейсы сущностей более подробно.
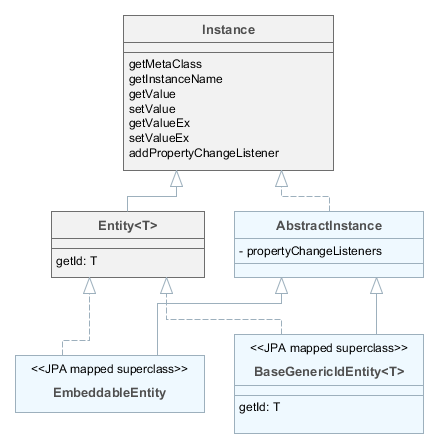
-
Instance– декларирует базовые методы работы с объектами предметной области:-
Получение ссылки на мета-класс объекта.
-
Генерация имени экземпляра.
-
Чтение/установка значений атрибутов по имени.
-
Добавление слушателей, получающих уведомления об изменениях атрибутов.
-
-
Entity– дополняетInstanceпонятием идентификатора сущности, причемEntityне определяет тип идентификатора, оставляя эту возможность наследникам. -
AbstractInstance– реализует логику работы со слушателями изменения атрибутов.AbstractInstanceхранит слушателей в коллекцииWeakReference, т.е. при отсутствии внешних ссылок на добавленного слушателя, он будет немедленно уничтожен сборщиком мусора. Как правило, слушателями изменения атрибутов являются визуальные компоненты и компоненты данных, на которые всегда имеются ссылки из других объектов, поэтому проблема исчезновения слушателей не возникает. Однако если слушатель создается прикладным кодом и на него никто не ссылается естественным образом, необходимо кроме добавления вInstanceсохранить его в некотором поле объекта. -
BaseGenericIdEntity- базовый класс персистентных и неперсистентных сущностей. РеализуетEntity, но не специфицирует тип идентификатора (то есть первичного ключа) сущности. -
EmbeddableEntity- базовый класс персистентных встраиваемых сущностей.
Ниже рассмотрены базовые классы, от которых рекомендуется наследовать сущности. Неперсистентные сущности наследуются от тех же классов, что и персистентные. Фреймворк определяет, является ли сущность персистентной или нет по файлу, в котором зарегистрирован класс: persistence.xml или metadata.xml.
- StandardEntity
-
Наследуйте от
StandardEntity, если необходим стандартный набор свойств сущности: первичный ключ типа UUID, экземпляры должны содержать информацию о том, кто и когда создал и изменил их, необходима оптимистичная блокировка и мягкое удаление.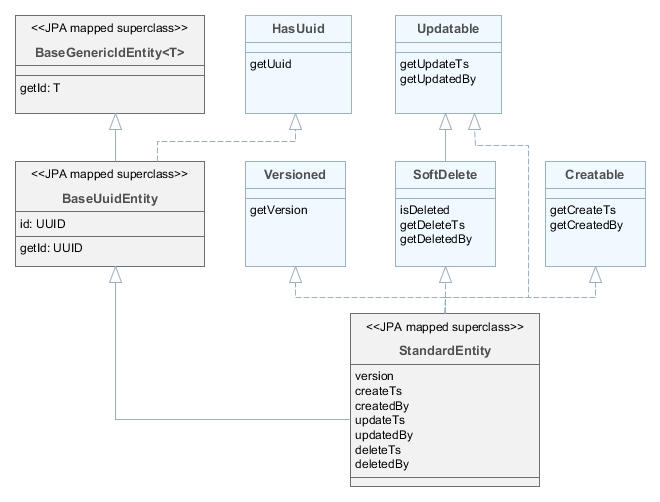
-
HasUuid– интерфейс сущностей имеющих глобальные уникальные идентификаторы -
Versioned– интерфейс сущностей, поддерживающих оптимистичную блокировку -
Creatable– интерфейс сущностей, для которых требуется сохранять информацию о том, кто и когда ее создал -
Updatable– интерфейс сущностей, для которых требуется сохранять информацию о том, кто и когда изменял экземпляр в последний раз -
SoftDelete– интерфейс сущностей, поддерживающих мягкое удаление
-
- BaseUuidEntity
-
Наследуйте от
BaseUuidEntity, если необходима сущность с идентификатором типа UUID, но не нужны все остальные свойстваStandardEntity. ИнтерфейсыCreatable,Versionedи др. можно выборочно реализовать в конкретном классе сущности.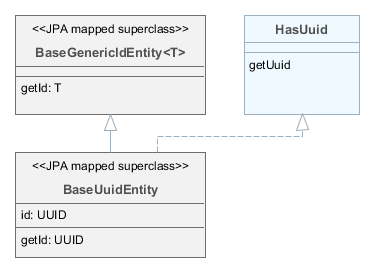
- BaseLongIdEntity
-
Наследуйте от
BaseLongIdEntityилиBaseIntegerIdEntity, если необходима сущность с идентификатором типаLongилиInteger. ИнтерфейсыCreatable,Versionedи др. можно выборочно реализовать в конкретном классе сущности. Рекомендуется реализоватьHasUuid, так как это позволяет платформе в некоторых случаях работать с сущностью более оптимально, а кроме того, сущность получает уникальный идентификатор в распределенном окружении.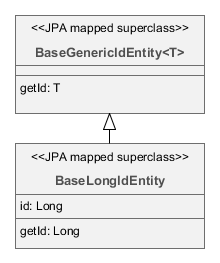
- BaseStringIdEntity
-
Наследуйте от
BaseStringIdEntity, если необходима сущность с идентификатором типаString. ИнтерфейсыCreatable,Versionedи др. можно выборочно реализовать в конкретном классе сущности. Рекомендуется реализоватьHasUuid, так как это позволяет платформе в некоторых случаях работать с сущностью более оптимально, а кроме того, сущность получает уникальный идентификатор в распределенном окружении. В конкретном классе сущности, унаследованной отBaseStringIdEntity, необходимо задать атрибут-идентификатор типаStringи добавить ему JPA-аннотацию@Id.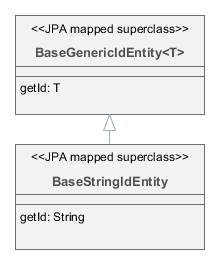
- BaseIdentityIdEntity
-
Наследуйте от
BaseIdentityIdEntity, если необходимо отобразить сущность на таблицу с первичным ключом типа IDENTITY. ИнтерфейсыCreatable,Versionedи др. можно выборочно реализовать в конкретном классе сущности. Рекомендуется реализоватьHasUuid, так как это позволяет платформе в некоторых случаях работать с сущностью более оптимально, а кроме того, сущность получает уникальный идентификатор в распределенном окружении. Атрибутidсущности (т.е. методыgetId()/setId()) будут иметь типIdProxy, который предназначен для использования вместо реального идентификатора, пока он не сгенерирован базой данных на вставке записи.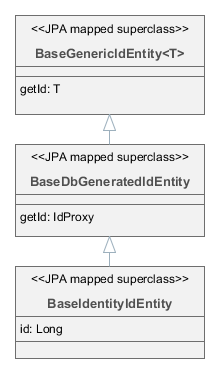
- BaseIntIdentityIdEntity
-
Наследуйте от
BaseIntIdentityIdEntity, если необходимо отобразить сущность на таблицу с целочисленным первичным ключом типа IDENTITY (в отличие отLongвBaseIdentityIdEntity). В остальных отношенияхBaseIntIdentityIdEntityповторяетBaseIdentityIdEntity.
- BaseGenericIdEntity
-
Наследуйте напрямую от
BaseGenericIdEntity, если необходимо отобразить сущность на таблицу с композитным первичным ключом. В этом случае в классе сущности необходимо создать поле встраиваемого типа, представляющего композитный ключ, и аннотировать его JPA-аннотацией@EmbeddedId.
3.2.1.2. Аннотации сущностей
В данном разделе описаны все поддерживаемые платформой аннотации классов и атрибутов сущностей.
Аннотации пакета javax.persistence обеспечивают работу JPA, аннотации пакетов com.haulmont.* предназначены для управления метаданными и другими механизмами платформы.
Если для аннотации указано только простое имя класса, подразумевается что это класс платформы, расположенный в одном из пакетов com.haulmont.*
3.2.1.2.1. Аннотации класса
- @Embeddable
-
Определяет встраиваемую сущность, экземпляры которой хранятся вместе с владеющей сущностью в той же таблице.
Для задания имени сущности требуется применение аннотации @MetaClass.
- @EnableRestore
-
Указывает, что экземпляры данной сущности доступны для восстановления после мягкого удаления в специальном экране
core$Entity.restore, доступном через пункт Administration > Data Recovery главного меню.
- @Entity
-
Объявляет класс сущностью модели данных.
Параметры:
-
name- имя сущности, обязательно должно начинаться с префикса, отделенного знаком_. Желательно использовать в качестве префикса короткое имя проекта для формирования отдельного пространства имен.
Пример:
@Entity(name = "sales_Customer") -
- @Extends
-
Указывает, что данная сущность является расширением и должна повсеместно использоваться вместо базовой. См. Расширение функциональности.
- @DiscriminatorColumn
-
Используется для определения колонки БД, отвечающей за различение типов сущностей в случае стратегий наследования
SINGLE_TABLEиJOINED.Параметры:
-
name- имя колонки-дискриминатора -
discriminatorType- тип данных колонки-дискриминатора
Пример:
@DiscriminatorColumn(name = "TYPE", discriminatorType = DiscriminatorType.INTEGER) -
- @DiscriminatorValue
-
Определяет значение колонки-дискриминатора для данной сущности. Эта аннотация должна быть помещена на конкретном классе сущности.
Пример:
@DiscriminatorValue("0")
- @IdSequence
-
Явно задает имя последовательности базы данных, используемой для генерации идентификаторов сущности, если она является подклассом
BaseLongIdEntityилиBaseIntegerIdEntity. Если сущность не аннотирована, то фреймворк создает последовательность с автоматически сгенерированным именем.Параметры:
-
name– имя последовательности. -
cached- необязательный параметр, определяющий что последовательность должена инкрементироваться через cuba.numberIdCacheSize для кэширования промежуточных значений в памяти. По умолчанию false.
По умолчанию последовательности создаются в основном хранилище. Если же свойство приложения cuba.useEntityDataStoreForIdSequence установлено в
true, последовательности будут создаваться в хранилище, к которому принадлежит данная сущность. -
- @Inheritance
-
Определяет стратегию наследования для иерархии классов сущностей. Данная аннотация должна быть помещена на корневом классе иерархии.
Параметры:
-
strategy- стратегия, по умолчаниюSINGLE_TABLE
-
- @Listeners
-
Определяет список слушателей, предназначенных для реакции на события жизненного цикла экземпляров сущности на уровне Middleware.
Значением аннотации должна быть строка или массив строк с именами бинов слушателей - см. Entity Listeners.
Примеры:
@Listeners("sample_UserEntityListener")@Listeners({"sample_FooListener","sample_BarListener"})
- @MappedSuperclass
-
Определяет, что данный класс является предком некоторых сущностей, и его атрибуты должны быть использованы в составе сущностей-наследников. Такой класс не сопоставляется никакой отдельной таблице БД.
Руководство Data Modelling: Entity Inheritance демонстрирует механизм наследования сущностей.
- @MetaClass
-
Используется для объявления неперсистентной или встраиваемой сущности (т.е. когда аннотация
@javax.persistence.Entityне применима)Параметры:
-
name- имя сущности, обязательно должно начинаться с префикса, отделенного знаком_. Желательно использовать в качестве префикса короткое имя проекта для формирования отдельного пространства имен.
Пример:
@MetaClass(name = "sales_Customer") -
- @NamePattern
-
Определяет способ получения имени экземпляра, т.е. строки, которая представляет экземпляр сущности. Имя экземпляра можно описать как метод
toString()прикладного уровня. Он повсеместно используется в UI при отображении экземпляров сущностей в отдельных полях подобныхTextFieldилиLookupField. Кроме того, имя экземпляра можно получить программно методомMetadataTools.getInstanceName().Значением аннотации должна быть строка вида
{0}|{1}, где:-
{0}- строка форматирования, которая может быть одной из следующих двух типов:-
Строка с символами
%sдля подстановки форматированных значений атрибутов. Значения форматируются в строки в соответствии с datatypes атрибутов. -
Имя метода данного объекта с префиксом
#. Метод должен возвращатьStringи не иметь параметров.
-
-
{1}- разделенный запятыми список имен атрибутов сущности, соответствующий формату{0}. В случае использования в{0}метода список полей все равно необходим, так как по нему формируется представление_minimal.
Примеры:
@NamePattern("%s|name")@NamePattern("%s - %s|name,date")@NamePattern("#getCaption|amount,customer") ... public String getCaption(){ String prefix = ""; if (amount > 5000) { prefix = "Grade 1 "; } else { prefix = "Grade 2 "; } return prefix + customer.name; } -
- @PostConstruct
-
Данная аннотация может быть указана для метода класса. Такой метод будет вызван сразу после создания экземпляра сущности методом Metadata.create() или аналогичными методами
DataManager.create()иDataContext.create().В руководстве Initial Entity Values приводится пример определения начального значения непосредственно в классе сущности с помощью аннотации
@PostConstruct.Аннотированный метод может принимать в качестве параметров Spring-бины, доступные в модуле
global. Например:@PostConstruct public void postConstruct(Metadata metadata, SomeBean someBean) { // ... }
- @PublishEntityChangedEvents
-
Указывает, что когда данная сущность изменяется в базе данных, фреймворк должен посылать EntityChangedEvent.
- @SystemLevel
-
Указывает, что данная сущность является системной и не должна быть доступна для выбора пользователем в различных списках сущностей, например, как тип параметра универсального фильтра или тип динамического атрибута.
- @Table
-
Определяет таблицу базы данных для данной сущности.
Параметры:
-
name- имя таблицы
Пример:
@Table(name = "SALES_CUSTOMER") -
- @TrackEditScreenHistory
-
Указывает, что для данной сущности будет запоминаться история открытия экранов редактирования (
{имя_сущности}.edit) с возможностью отображения в специальном экранеsec$ScreenHistory.browse, который можно подключить к главному меню с помощью следующего элемента web-menu.xml:
<item id="sec$ScreenHistory.browse" insertAfter="settings"/>3.2.1.2.2. Аннотации атрибутов
Аннотации атрибутов устанавливаются на соответствующие поля класса, за одним исключением: если требуется объявить неизменяемый (read only) неперсистентный атрибут foo, то достаточно создать метод доступа getFoo() и поместить на этот метод аннотацию @MetaProperty.
- @CaseConversion
-
Применяет автоматическую конвертацию регистра к текстовым полям ввода, связанным с аннотированным атрибутом.
Параметры:
-
type- тип конвертации:UPPER(по умолчанию),LOWER.
Пример:
@CaseConversion(type = ConversionType.UPPER) @Column(name = "COUNTRY_CODE") protected String countryCode; -
- @Column
-
Определяет колонку БД, в которой будут храниться значения данного атрибута.
Параметры:
-
name- имя колонки -
length- (необязательный параметр, по умолчанию255) - длина колонки. Используется также при формировании метаданных и, в конечном счете, может ограничивать максимальную длину вводимого текста в визуальных компонентах, работающих с данным атрибутом. Для отмены ограничения по длине атрибуту необходимо добавить аннотацию @Lob. -
nullable- (необязательный параметр, по умолчаниюtrue) - может ли атрибут содержатьnull. При указанииnullable = falseJPA контролирует наличие значения поля при сохранении, кроме того, визуальные компоненты, работающие с данным атрибутом, могут сигнализировать пользователю о необходимости ввода значения.
-
- @Composition
-
Указывает на то, что связь является композицией - более тесным вариантом ассоциации. Это означает, что связанная сущность имеет смысл только как часть владеющей сущности, т.е. создается и удаляется вместе с ней.
В руководстве Data Modelling: Composition приведены примеры композиции между сущностями.
Например, список пунктов в заказе (класс
Orderсодержит коллекцию экземпляровItem):@OneToMany(mappedBy = "order") @Composition protected List<Item> items;Другой пример - one-to-one отношение:
@Composition @OneToOne(fetch = FetchType.LAZY) @JoinColumn(name = "DETAILS_ID") protected CustomerDetails details;Указание для связи аннотации
@Compositionпозволяет организовать в экранах редактирования специальный режим коммита источников данных, при котором изменения экземпляров детализирующей сущности сохраняются в базе данных только при коммите основной сущности. Подробнее см. Редактирование композитных сущностей.
- @CurrencyValue
-
Указывает, что данный атрибут предназначен для хранения денежных единиц. Если указана эта аннотация, при генерации экрана редактирования сущности в Studio внутри Form будет автоматически использован компонент CurrencyField.
Параметры:
-
currency– текст, который будет отображаться в ярлыке валюты: например, USD, GBP, EUR, $. -
labelPosition- определяет положение ярлыка внутри текстового поля:RIGHT(по умолчанию),LEFT.
Пример:
@CurrencyValue(currency = "$", labelPosition = CurrencyLabelPosition.LEFT) @Column(name = "PRICE") protected BigDecimal price; -
- @Embedded
-
Определяет атрибут типа встраиваемой сущности, в свою очередь аннотированной
@Embeddable.Пример:
@Embedded protected Address address;
- @EmbeddedParameters
-
По умолчанию ORM не создает экземпляр встроенной сущности если все ее атрибуты равны null в базе данных. Аннотацию
@EmbeddedParametersможно использовать для указания того, что экземпляр всегда должен создаваться, например:@Embedded @EmbeddedParameters(nullAllowed = false) protected Address address;
- @Id
-
Указывает, что данный атрибут является первичным ключом сущности. Обычно эта аннотация присутствует на поле базового класса, такого как BaseUuidEntity. Использовать эту аннотацию в конкретном классе сущности необходимо только при наследовании от базового класса
BaseStringIdEntity(то есть при создании сущности со строковым первичным ключом).
- @IgnoreUserTimeZone
-
Для атрибутов типа timestamp с аннотацией
@javax.persistence.Temporal.TIMESTAMPзаставляет платформу игнорировать часовой пояс пользователя, если он задан для текущей сессии.
- @JoinColumn
-
Используется для указания колонки БД, определяющей ассоциацию между сущностями. Наличие этой аннотации указывает, что данная сторона отношения является владеющей (owning).
Параметры:
-
name- имя колонки
Пример:
@ManyToOne(fetch = FetchType.LAZY) @JoinColumn(name = "CUSTOMER_ID") protected Customer customer; -
- @JoinTable
-
Используется для указания таблицы связи на ведущей стороне
@ManyToManyассоциации.Параметры:
-
name- имя таблицы связи -
joinColumns- элемент@JoinColumn, определяющий колонку таблицы связей, соответствующую первичному ключу ведущей стороны ассоциации (т.е. содержащей аннотацию@JoinTable) -
inverseJoinColumns- элемент@JoinColumn, определяющий колонку таблицы связей, соответствующую первичному ключу ведомой стороны ассоциации
Пример атрибута
customersклассаGroup, являющегося ведущей стороной ассоциации:@ManyToMany @JoinTable(name = "SALES_CUSTOMER_GROUP_LINK", joinColumns = @JoinColumn(name = "GROUP_ID"), inverseJoinColumns = @JoinColumn(name = "CUSTOMER_ID")) protected Set<Customer> customers;Пример атрибута
groupsклассаCustomer, являющегося ведомой стороной этой же ассоциации:@ManyToMany(mappedBy = "customers") protected Set<Group> groups; -
- @Lob
-
Указывает, что данный атрибут не имеет ограничений длины. Применяется совместно с аннотацией
@Column. Если@Lobуказан, то длина, заданная в@Columnявно или по умолчанию, игнорируется.Пример:
@Column(name = "DESCRIPTION") @Lob private String description;
- @Lookup
-
Определяет тип просмотра ссылочных атрибутов.
Параметры:
-
type- по умолчанию имеет значениеSCREEN, при котором ссылки открываются через lookup-экран. ЗначениеDROPDOWNпозволяет открывать ссылки в виде выпадающего списка. Если за способ отображения выбранDROPDOWN, Studio создаст options collection container для выпадающего списка при генерации экрана редактирования. Таким образом, параметр Lookup type необходимо задать ДО генерации экрана редактирования сущности. Кроме того, компонент Filter позволит пользователям выбирать параметры фильтрации также из выпадающего списка вместо lookup-экрана. -
actions- определяет действия, которые будут использованы в компонентеPickerFieldв составеFieldGroupпо умолчанию. Возможные значения:lookup,clear,open.
@Lookup(type = LookupType.DROPDOWN, actions = {"open"}) @ManyToOne(fetch = FetchType.LAZY) @JoinColumn(name = "CUSTOMER_ID") protected Customer customer; -
- @ManyToMany
-
Определяет атрибут-коллекцию ссылок на сущность с типом ассоциации много-ко-многим.
Руководство Data Modelling: Many-to-Many Association демонстрирует различные варианты использования ассоциаций many-to-many.
Ассоциация много-ко-многим может иметь ведущую сторону и обратную - ведомую. На ведущей стороне указывается дополнительная аннотация
@JoinTable, на ведомой стороне - параметрmappedBy.Параметры:
-
mappedBy- поле связанной сущности, определяющее ассоциацию с ведущей стороны. Необходимо указывать только на ведомой стороне. -
targetEntity- тип связанной сущности. Необязательный параметр, если коллекция объявлена с использованием Java generics. -
fetch- (необязательный параметр, по умолчаниюLAZY) - определяет, будет ли JPA жадно загружать коллекцию связанных сущностей. Необходимо всегда оставлять значение по умолчаниюLAZY, так как в CUBA-приложении политика загрузки связей определяется динамически на основе механизма представлений.
Использование параметра
cascadeаннотации не рекомендуется. Сущности, сохраняемые неявно при использовании такого объявления, будут пропущены некоторыми системными механизмами. В частности, бин EntityStates некорректно определяет для них состояние managed, а entity listeners не вызываются вообще. -
- @ManyToOne
-
Определяет атрибут-ссылку на сущность с типом ассоциации много-к-одному.
Параметры:
-
fetch- (по умолчаниюEAGER) параметр, определяющий, будет ли JPA жадно загружать ассоциированную сущность. Данный параметр всегда должен быть установлен в значениеLAZY, так как в CUBA-приложении политика загрузки связей определяется динамически на основе механизма представлений. -
optional- (необязательный параметр, по умолчаниюtrue) - может ли атрибут содержатьnull. При указанииoptional = falseJPA контролирует наличие ссылки при сохранении, кроме того, визуальные компоненты, работающие с данным атрибутом, могут сигнализировать пользователю о необходимости ввода значения.
Например, несколько экземпляров
Order(заказов) ссылаются на один экземплярCustomer(покупателя), в этом случае классOrderдолжен содержать следующее объявление:@ManyToOne(fetch = FetchType.LAZY) @JoinColumn(name = "CUSTOMER_ID") protected Customer customer;Использование параметра
cascadeаннотации не рекомендуется. Сущности, сохраняемые неявно при использовании такого объявления, будут пропущены некоторыми системными механизмами. В частности, бин EntityStates некорректно определяет для них состояние managed, а entity listeners не вызываются вообще. -
- @MetaProperty
-
Указывает, что данный атрибут должен быть включен в метаданные. Данная аннотация может быть установлена как на поле класса, так и на метод доступа, в случае отсутствия соответствующего атрибуту поля.
Данная аннотация не обязательна для полей, снабженных следующими аннотациями пакета
javax.persistence:@Column,@OneToOne,@OneToMany,@ManyToOne,@ManyToMany,@Embedded. Такие поля отражаются в метаданных автоматически. Поэтому@MetaPropertyв основном применяется для определения неперсистентных атрибутов сущностей.Параметры (опционально):
-
mandatory- может ли атрибут содержатьnull. При указанииmandatory = trueвизуальные компоненты, работающие с данным атрибутом, могут сигнализировать пользователю о необходимости ввода значения. -
datatype- явно задает datatype, чтобы переопределить datatype задаваемый Java-типом атрибута. -
related- задает массив связанных персистентных атрибутов, которые должны быть загружены из БД, если данный атрибут включен в представление. Кроме того, если аннотация указана на методе-геттере, то есть атрибут сущности предназначен только для чтения, то изменения связанных атрибутов генерируютPropertyChangeEventдля данного неизменяемого атрибута. Эта особенность позволяет обновлять UI-компоненты, отображающие неизменяемые атрибуты, зависящие от других изменяемых атрибутов.
Пример использования для поля:
@Transient @MetaProperty protected String token;Пример использования для метода:
@MetaProperty(related = "firstName,lastName") public String getFullName() { return firstName + " " + lastName; } -
- @NumberFormat
-
Задает формат атрибута типа
Number(это может бытьBigDecimal,Integer,LongилиDouble). Значения такого атрибута будут форматироваться в пользовательском интерфейсе в соответствии с указанными параметрами аннотации:-
pattern- паттерн форматирования, задается по правилам, описанным в DecimalFormat. -
decimalSeparator- символ, используемый в качестве разделителя целой и дробной части (опционально). -
groupingSeparator- символ, используемый в качестве разделителя групп разрядов (optional).
Если
decimalSeparatorи/илиgroupingSeparatorне указаны, фреймворк использует соответствующие значения из format strings для локали текущего пользователя. При форматировании без учета локали в этом случае используются символы из системной локали сервера.Примеры:
@Column(name = "PRECISE_NUMBER", precision = 19, scale = 4) @NumberFormat(pattern = "0.0000") protected BigDecimal preciseNumber; @Column(name = "WEIRD_NUMBER", precision = 19, scale = 4) @NumberFormat(pattern = "#,##0.0000", decimalSeparator = "_", groupingSeparator = "`") protected BigDecimal weirdNumber; @Column(name = "SIMPLE_NUMBER") @NumberFormat(pattern = "#") protected Integer simpleNumber; @Column(name = "PERCENT_NUMBER", precision = 19, scale = 4) @NumberFormat(pattern = "#%") protected BigDecimal percentNumber; -
- @OnDelete
-
Определяет политику обработки связи в случае мягкого удаления сущности, содержащей данный атрибут. См. Мягкое удаление.
Пример:
@OneToMany(mappedBy = "group") @OnDelete(DeletePolicy.CASCADE) private Set<Constraint> constraints;
- @OnDeleteInverse
-
Определяет политику обработки связи в случае мягкого удаления сущности с обратной стороны ассоциации. См. Мягкое удаление.
Пример:
@ManyToOne @JoinColumn(name = "DRIVER_ID") @OnDeleteInverse(DeletePolicy.DENY) private Driver driver;
- @OneToMany
-
Определяет атрибут-коллекцию ссылок на сущность с типом ассоциации один-ко-многим.
Параметры:
-
mappedBy- поле связанной сущности, определяющее ассоциацию -
targetEntity- тип связанной сущности. Необязательный параметр, если коллекция объявлена с использованием Java generics. -
fetch- (необязательный параметр, по умолчаниюLAZY) - определяет, будет ли JPA жадно загружать коллекцию связанных сущностей. Необходимо всегда оставлять значение по умолчаниюLAZY, так как в CUBA-приложении политика загрузки связей определяется динамически на основе механизма представлений. -
cascade- (необязательный параметр, по умолчанию{}) - каскадирование операций определяет, какие операции над сущностью должны быть применены к ассоциированным сущностям. Каскадирование на данном уровне не рекомендуется использовать.
Например, несколько экземпляров
Item(пунктов заказа) ссылаются на один экземплярOrder(заказ) с помощью@ManyToOneполяItem.order, в этом случае классOrderможет содержать коллекцию экземпляровItem:@OneToMany(mappedBy = "order") protected Set<Item> items;Использование параметра
cascadeаннотации не рекомендуется. Сущности, сохраняемые неявно при использовании такого объявления, будут пропущены некоторыми системными механизмами. В частности, бин EntityStates некорректно определяет для них состояние managed, а entity listeners не вызываются вообще. ПараметрorphanRemovalне принимает во внимание механизм мягкого удаления. -
- @OneToOne
-
Определяет атрибут-ссылку на сущность с типом ассоциации один-к-одному.
Параметры:
-
fetch- (по умолчаниюEAGER) параметр, определяющий, будет ли JPA жадно загружать ассоциированную сущность. Данный параметр всегда должен быть установлен в значениеLAZY, так как в CUBA-приложении политика загрузки связей определяется динамически на основе механизма представлений. -
mappedBy- поле связанной сущности, определяющее ассоциацию. Требуется устанавливать только на ведомой стороне ассоциации. -
optional- (необязательный параметр, по умолчаниюtrue) - может ли атрибут содержатьnull. При указанииoptional = falseJPA контролирует наличие ссылки при сохранении, кроме того, визуальные компоненты, работающих с данным атрибутом, могут сигнализировать пользователю о необходимости ввода значения.
Пример ведущей стороны ассоциации, класс
Driver:@OneToOne(fetch = FetchType.LAZY) @JoinColumn(name = "CALLSIGN_ID") protected DriverCallsign callsign;Пример ведомой стороны ассоциации, класс
DriverCallsign:@OneToOne(fetch = FetchType.LAZY, mappedBy = "callsign") protected Driver driver; -
- @OrderBy
-
Определяет порядок элементов в атрибуте-коллекции на момент извлечения из базы данных. Данную аннотацию необходимо задавать для упорядоченных коллекций, таких как
ListилиLinkedHashSetдля получения предсказуемого порядка следования элементов.Параметры:
-
value- строка, определяющая порядок, в формате:orderby_list::= orderby_item [,orderby_item]* orderby_item::= property_or_field_name [ASC | DESC]
Пример:
@OneToMany(mappedBy = "user") @OrderBy("createTs") protected List<UserRole> userRoles; -
- @Temporal
-
Для атрибута типа
java.util.Dateуточняет тип хранимого значения: дата, время или дата+время.Параметры:
-
value- тип хранимого значения:DATE,TIME,TIMESTAMP
Пример:
@Column(name = "START_DATE") @Temporal(TemporalType.DATE) protected Date startDate; -
- @Transient
-
Указывает, что данное поле не хранится в БД, т.е. является неперсистентным.
Поля поддерживаемых JPA типов (см. http://docs.oracle.com/javaee/7/api/javax/persistence/Basic.html) по умолчанию являются персистентными, поэтому аннотация
@Transientобязательна для объявления неперсистентного атрибута такого типа.Для включения
@Transientатрибута в метаданные, необходимо также указать аннотацию @MetaProperty.
- @Version
-
Указывает, что данное поле хранит версию для поддержки оптимистичной блокировки сущностей.
Применение такого поля необходимо при реализации классом сущности интерфейса
Versioned(базовый классStandardEntityуже содержит такое поле).Пример:
@Version @Column(name = "VERSION") private Integer version;
3.2.1.3. Атрибуты типа enum
В стандартном варианте использования JPA для атрибутов типа enum в базе данных хранится целое число, получаемое методом ordinal() этого перечисления. Такой подход может привести к следующим проблемам при эксплуатации и развитии системы:
-
при появлении в БД значения, не равного ни одному
ordinalзначению перечисления, экземпляр сущности нельзя загрузить вообще; -
невозможно ввести новое значение между имеющимися, что актуально при использовании сортировки по значению перечисления (order by).
Чтобы решить эти проблемы, в подходе CUBA предлагается отвязать значение, хранимое в БД, от ordinal перечисления. Для этого необходимо поле класса сущности объявлять с типом, хранимым в БД (Integer или String), а методы доступа (getter / setter) создавать для типа самого перечисления.
Например:
@Entity(name = "sales_Customer")
@Table(name = "SALES_CUSTOMER")
public class Customer extends StandardEntity {
@Column(name = "GRADE")
protected Integer grade;
public CustomerGrade getGrade() {
return grade == null ? null : CustomerGrade.fromId(grade);
}
public void setGrade(CustomerGrade grade) {
this.grade = grade == null ? null : grade.getId();
}
...
}При этом сам класс перечисления может выглядеть следующим образом:
public enum CustomerGrade implements EnumClass<Integer> {
PREMIUM(10),
HIGH(20),
MEDIUM(30);
private Integer id;
CustomerGrade(Integer id) {
this.id = id;
}
@Override
public Integer getId() {
return id;
}
public static CustomerGrade fromId(Integer id) {
for (CustomerGrade grade : CustomerGrade.values()) {
if (grade.getId().equals(id))
return grade;
}
return null;
}
}Для правильного отражения в метаданных класс перечисления, используемый в качестве типа атрибута сущности, должен реализовывать интерфейс EnumClass.
Как видно из примеров, для атрибута grade в БД хранится значение типа Integer, задаваемое полем id перечисления CustomerGrade, а конкретно 10, 20 или 30. В то же время прикладной код и метаданные работают с самим типом CustomerGrade через методы доступа, которые и осуществляют конвертацию.
При наличии в поле БД значения, не соответствующего ни одному значению перечисления, метод getGrade() просто вернет null. Для ввода нового значения, например, HIGHER, между HIGH и PREMIUM, достаточно добавить это значение в перечисление с идентификатором 15, при этом сортировка по полю Customer.grade останется верной.
Тип поля Integer удобно использовать в случаях, когда необходим упорядоченный список констант, подлежащий сортировке, например, в запросах JPQL и SQL (>, <, >=, ⇐, order by), кроме того, он имеет незначительное преимущество перед String в плане производительности формата хранения и занимаемого места. С другой стороны, значения типа Integer сами по себе неочевидны и могут затруднять отладку и интерпретацию результатов запросов, они неудобны в работе с голыми данными и сериализованными форматами. Если отношение упорядочения между константами не требуется, удобнее использовать тип String.
Перечисления могут быть созданы в CUBA Studio в секции Data Model > New > Enumeration. Чтобы использовать перечисление в качестве атрибута сущности, в редакторе атрибута нужно выбрать ENUM в поле Attribute type и класс перечисления в поле Type. Значениям перечисления могут быть сопоставлены локализованные названия для отображения в пользовательском интерфейсе приложения.
3.2.1.4. Мягкое удаление
Платформа CUBA поддерживает режим "мягкого удаления" данных - когда вместо удаления записей из базы данных они только помечаются определенным образом и становятся недоступными для обычного использования. В дальнейшем такие записи можно либо совсем удалить из БД с помощью отдельной регламентной процедуры, либо восстановить.
Механизм мягкого удаления является "прозрачным" для прикладного программиста - достаточно убедиться, что класс сущности реализует интерфейс SoftDelete, и платформа сама нужным образом будет модифицировать запросы и операции с данными.
Режим мягкого удаления имеет следующие преимущества:
-
значительно снижается риск потери данных вследствие неверных действий пользователей
-
позволяет быстро сделать некоторые записи недоступными, даже если на них имеются ссылки.
Возьмем для примера модель данных
Заказы-Покупатели. Допустим, на некоторого покупателя оформлено несколько заказов, однако нам нужно сделать его недоступным для дальнейшей работы пользователей. Традиционным "жестким" удалением сделать это невозможно, так как для удаления покупателя нам нужно либо удалить все его заказы, либо обнулить в этих заказах ссылки на него (т.е. потерять информацию). При мягком удалении покупателя он становится недоступным для поиска и изменения, однако при просмотре заказов пользователь видит на экране имя покупателя, так как при загрузке связей признак удаления намеренно игнорируется.Описанное поведение является стандартным, но может быть модифицировано с помощью политики обработки связей при удалении.
Восстановить удалённые сущности можно через экран Restore Deleted Entities, по умолчанию доступный в стандартном меню Administration приложения. Эта функциональность предназначена для использования администраторами системы, имеющими разрешения на все сущности. Её следует использовать с осторожностью, также рекомендуется ограничить доступ к этому экрану для простых пользователей системы.
Отрицательной стороной мягкого удаления является увеличение объема базы данных и потенциальная необходимость дополнительных процедур ее очистки.
3.2.1.4.1. Использование
Для того чтобы экземпляры сущности удалялись мягко, класс сущности должен реализовывать интерфейс SoftDelete, а соответствующая таблица БД должна содержать колонки:
-
DELETE_TS- когда удалена запись -
DELETED_BY- логин пользователя, который удалил запись
Поведение системы по умолчанию - сущности, реализующие SoftDelete, удаляются мягко, удаленные сущности не возвращаются запросами и поиском по идентификатору. При необходимости такое поведение можно динамически отключить следующими способами:
-
для текущего экземпляра EntityManager - вызовом
setSoftDeletion(false) -
при запросе данных через DataManager - вызовом у передаваемого объекта
LoadContextметодаsetSoftDeletion(false) -
на уровне загрузчиков данных - используя метод
DataLoader.setSoftDeletion(false)или атрибутsoftDeletion="false"элементаloaderв XML-дескрипторе экрана.
В режиме мягкого удаления платформа автоматически отфильтровывает удаленные экземпляры при загрузке по идентификатору и по JPQL-запросу, а также удаленные элементы связанных сущностей в атрибутах-коллекциях. Однако связанные сущности в единичных (*ToOne) атрибутах загружаются независимо от того, удален связанный экземпляр или нет.
3.2.1.4.2. Политика обработки связей
Для мягко удаляемых сущностей, платформа предоставляет средство обработки связей при удалении экземпляров, во многом аналогичное правилам ON DELETE внешних ключей в базе данных. Это средство работает на уровне Middleware и использует аннотации @OnDelete, @OnDeleteInverse атрибутов сущности.
Аннотация @OnDelete обрабатывается при удалении той сущности, в которой она встретилась, а не той, на которую указывает аннотированный атрибут (в этом отличие от каскадных удалений на уровне БД).
Аннотация @OnDeleteInverse обрабатывается при удалении той сущности, на которую указывает аннотированный атрибут, (т.е. аналогично каскадному удалению на уровне внешних ключей в БД). Эта аннотация полезна при отсутствии в удаляемом объекте атрибута, который нужно проверять при удалении. При этом, как правило, в проверяемом объекте существует ссылка на удаляемый, на этот атрибут и устанавливается аннотация @OnDeleteInverse.
Значением аннотации может быть:
-
DeletePolicy.DENY- запретить удаление сущности, если аннотированный атрибут неnullили не пустая коллекция -
DeletePolicy.CASCADE- каскадно удалить аннотированный атрибут -
DeletePolicy.UNLINK- разорвать связь с аннотированным атрибутом. Разрыв связи имеет смысл указывать только на ведущей стороне ассоциации - той, которая в классе сущности аннотирована@JoinColumn.
Примеры:
-
Запрет удаления при наличии ссылки: при попытке удаления экземпляра
Customer, на который ссылается хотя бы одинOrder, будет выброшено исключениеDeletePolicyException.Order.java@ManyToOne(fetch = FetchType.LAZY) @JoinColumn(name = "CUSTOMER_ID") @OnDeleteInverse(DeletePolicy.DENY) protected Customer customer;Customer.java@OneToMany(mappedBy = "customer") protected List<Order> orders;Сообщения в окне исключения могут быть локализованы в главном пакете сообщений. Используйте для этого следующие ключи:
-
deletePolicy.caption- заголовок уведомления. -
deletePolicy.references.message- тело сообщения. -
deletePolicy.caption.sales_Customer- заголовок уведомления для конкретной сущности. -
deletePolicy.references.message.sales_Customer- тело сообщения для конкретной сущности.
-
-
Каскадное удаление элементов коллекции: при удалении экземпляра
Roleвсе экземплярыPermissionтакже будут удалены.Role.java@OneToMany(mappedBy = "role") @OnDelete(DeletePolicy.CASCADE) protected Set<Permission> permissions;Permission.java@ManyToOne(fetch = FetchType.LAZY) @JoinColumn(name = "ROLE_ID") protected Role role; -
Разрыв связи с элементами коллекции: удаление экземпляра
Roleприведет к установке вnullссылок со стороны всех входивших в коллекцию экземпляровPermission.Role.java@OneToMany(mappedBy = "role") protected Set<Permission> permissions;Permission.java@ManyToOne(fetch = FetchType.LAZY) @JoinColumn(name = "ROLE_ID") @OnDeleteInverse(DeletePolicy.UNLINK) protected Role role;
Особенности реализации:
-
Политика обработки связей обрабатывается на уровне Middleware при сохранении сущностей, реализующих интерфейс
SoftDelete, в БД. -
Нужно быть осторожным при использовании
@OnDeleteInverseс политикамиCASCADEиUNLINK, так как при этом происходит извлечение из БД на сервер приложения всех экземпляров ссылающихся объектов, изменение и затем сохранение.Например, в случае ассоциации
Customer-Jobи большого количества работ для одного заказчика, если поставить на атрибутJob.customerполитику@OnDeleteInverse(CASCADE), то при удалении экземпляра заказчика будет предпринята попытка извлечь и изменить все его работы. Это может привести к перегрузке сервера приложения и БД.С другой стороны, использование
@OnDeleteInverse(DENY)безопасно, так как при этом производится только подсчет количества ссылающихся объектов, и если оно больше0, выбрасывается исключение. Поэтому@OnDeleteInverse(DENY)для атрибутаJob.customerвполне допустимо.
3.2.1.4.3. Ограничение уникальности на уровне БД
В режиме мягкого удаления для ограничения уникальности некоторого значения необходимо обеспечить существование единственной неудаленной записи с этим значением, и произвольного количества удаленных записей с этим же значением.
Реализуется данная логика путем, специфичным для используемого сервера базы данных:
-
Если сервер БД поддерживает частичные (partial) индексы (например, PostgreSQL), то ограничение уникальности можно создать следующим образом:
create unique index IDX_SEC_USER_UNIQ_LOGIN on SEC_USER (LOGIN_LC) where DELETE_TS is null -
Если сервер БД не поддерживает частичные индексы (например, Microsoft SQL Server 2005), то в уникальный индекс можно включить поле DELETE_TS:
create unique index IDX_SEC_USER_UNIQ_LOGIN on SEC_USER (LOGIN_LC, DELETE_TS)3.2.2. Metadata Framework
Для эффективной работы с моделью данных в CUBA-приложениях используется фреймворк метаданных, который:
-
предоставляет удобный интерфейс для получения информации о сущностях, их атрибутах и отношениях между сущностями; а также для навигации по ссылкам
-
служит специализированной и более удобной в использовании альтернативой Java Reflection API
-
регламентирует допустимые типы данных и отношений между сущностями
-
позволяет создавать универсальные механизмы работы с данными
3.2.2.1. Интерфейсы метаданных
Рассмотрим основные интерфейсы метаданных.
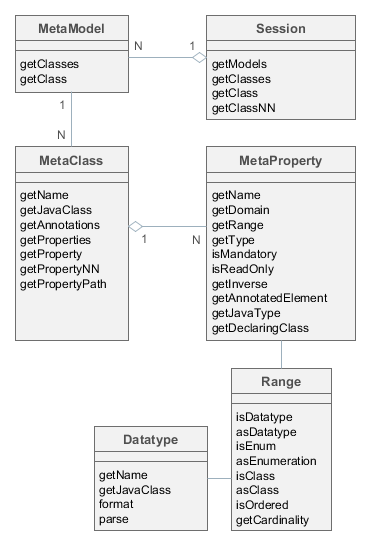
Рисунок 4. Интерфейсы фреймворка метаданных
- Session
-
Точка входа в фреймворк метаданных. Позволяет получать экземпляры
MetaClassпо имени и по соответствующему классу Java. Обратите внимание на различие методовgetClass()иgetClassNN()- первые могут возвращатьnull, вторые нет (NonNull).Объект
Sessionможет быть получен через интерфейс инфраструктуры Metadata.Пример:
@Inject protected Metadata metadata; ... Session session = metadata.getSession(); MetaClass metaClass1 = session.getClassNN("sec$User"); MetaClass metaClass2 = session.getClassNN(User.class); assert metaClass1 == metaClass2;
- MetaModel
-
Редко используемый интерфейс, служит для группировки мета-классов.
Группировка осуществляется по имени корневого Java пакета проекта, указываемого в файле metadata.xml.
- MetaClass
-
Интерфейс метаданных класса сущности.
MetaClassвсегда ассоциирован с классом Java, которого он представляет.Основные методы:
-
getName()– имя сущности, по соглашению первой частью имени до знака_является код пространства имен, например,sales_Customer -
getProperties()– список мета-свойств (MetaProperty) -
getProperty(),getPropertyNN()- получение мета-свойства по имени. Первый метод в случае отсутствия атрибута с указанным именем возвращаетnull, второй выбрасывает исключение.Пример:
MetaClass userClass = session.getClassNN(User.class); MetaProperty groupProperty = userClass.getPropertyNN("group");
-
getPropertyPath()- позволяет перемещаться по ссылкам. Данный метод принимает строковый параметр - путь из имен атрибутов, разделенных точкой. Возвращаемый объектMetaPropertyPathпозволяет обратиться к искомому (последнему в пути) атрибуту вызовомgetMetaProperty().Пример:
MetaClass userClass = session.getClassNN(User.class); MetaProperty groupNameProp = userClass.getPropertyPath("group.name").getMetaProperty(); assert groupNameProp.getDomain().getName().equals("sec$Group"); -
getJavaClass()– класс сущности, которому соответствует данныйMetaClass -
getAnnotations()– коллекция мета-аннотаций
-
- MetaProperty
-
Интерфейс метаданных атрибута сущности.
Основные методы:
-
getName()– имя свойства, соответствует имени атрибута сущности -
getDomain()– мета-класс, которому принадлежит данное свойство
-
getType()– тип свойства:-
простой тип:
DATATYPE -
перечисление:
ENUM -
ссылочный тип двух видов:
-
ASSOCIATION− простая ссылка на другую сущность. Например, отношение заказа и покупателя − ассоциация. -
COMPOSITION− ссылка на сущность, которая не имеет самостоятельного значения без владеющей сущности.COMPOSITIONможно считать "более тесным" отношением, чемASSOCIATION. Например, отношение заказа и пункта этого заказа −COMPOSITION, т.к. пункт не может существовать без заказа, которому он принадлежит.Вид ссылочного атрибута
ASSOCIATIONилиCOMPOSITIONвлияет на режим редактирования сущности: в первом случае сохранение связанной сущности в базу данных происходит независимо, а во втором − связанная сущность сохраняется в БД только вместе с владеющей сущностью.
-
-
-
getRange()– интерфейсRange, детально описывающий тип данного атрибута -
isMandatory()– признак обязательности атрибута. Используется, например, визуальными компонентами для сигнализации пользователю о необходимости ввода значения. -
isReadOnly()– признак неизменности атрибута -
getInverse()– для ссылочного атрибута возвращает мета-свойство с обратной стороны ассоциации, если таковое имеется -
getAnnotatedElement()– поле (java.lang.reflect.Field) или метод (java.lang.reflect.Method), соответствующие данному атрибуту сущности -
getJavaType()– класс Java данного атрибута сущности. Это либо тип поля класса, либо тип возвращаемого значения метода. -
getDeclaringClass()– класс Java, содержащий данный атрибут
-
-
Range -
Интерфейс, детально описывающий тип атрибута сущности.
Основные методы:
-
isDatatype()– возвращаетtrueдля атрибута простого типа -
asDatatype()- возвращает Datatype для атрибута простого типа -
isEnum()– возвращаетtrueдля атрибута типа перечисления -
asEnumeration()- возвращает Enumeration для атрибута типа перечисления -
isClass()– возвращаетtrueдля ссылочного атрибута типаASSOCIATIONилиCOMPOSITION -
asClass()- возвращает мета-класс ассоциированной сущности для ссылочного атрибута -
isOrdered()– возвращаетtrueесли атрибут представляет собой упорядоченную коллекцию (например,List) -
getCardinality()– вид отношения для ссылочного атрибута:ONE_TO_ONE,MANY_TO_ONE,ONE_TO_MANY,MANY_TO_MANY
-
3.2.2.2. Формирование метаданных
Основной источник формирования структуры метаданных - аннотированные классы сущностей.
Класс сущности отражается в метаданных в следующих случаях:
-
Класс персистентной сущности аннотирован
@Entity,@Embeddable,@MappedSuperclassи расположен в пределах корневого пакета, указанного в metadata.xml. -
Класс неперсистентной сущности аннотирован
@MetaClassи расположен в пределах корневого пакета, указанного в metadata.xml.
Все сущности внутри одного корневого пакета помещаются в один экземпляр MetaModel, которому присваивается имя этого пакета. Между сущностями внутри одной MetaModel можно устанавливать произвольные связи, между разными - в порядке объявления файлов metadata.xml в свойстве cuba.metadataConfig.
Атрибут сущности отражается в метаданных, если:
-
поле класса аннотировано
@Column,@OneToOne,@OneToMany,@ManyToOne,@ManyToMany,@Embedded -
поле класса или метод доступа на чтение (getter) аннотирован
@MetaProperty
Параметры мета-класса и мета-свойств формируются на основе параметров перечисленных аннотаций, а также типов полей и методов класса. Кроме того, если у атрибута отсутствует метод доступа на запись (setter), атрибут становится неизменяемым (read only).
3.2.2.3. Datatype
Интерфейс Datatype определяет методы конвертации значение в строку и из строки (formatting & parsing). Каждый атрибут сущности, не являющийся ссылкой, имеет некоторый Datatype, который и используется фреймворком для конвертации значений данного атрибута.
Экземпляры Datatype регистрируются в бине DatatypeRegistry, который выполняет загрузку и инициализацию классов реализации Datatype из файлов metadata.xml компонентов приложения и самого проекта.
Datatype атрибута сущности может быть получен из соответствующего meta-property методом getRange().asDatatype().
Кроме конвертации значений атрибутов сущностей, зарегистрированные экземпляры Datatype могут быть использованы для преобразования в строку и из строки произвольных значений поддерживаемых типов. Для этого необходимо получить экземпляр Datatype из DatatypeRegistry с помощью его методов get(Class) или getNN(Class), передавая тип Java, который необходимо конвертировать.
Datatype сопоставляется атрибуту сущности по следующим правилам:
-
Как правило, атрибуту сопоставляется экземпляр
Datatype, зарегистрированный вDatatypeRegistryи предназначенный для конвертации типа атрибута.Например, в данном случае атрибут
amountполучитBigDecimalDatatype:@Column(name = "AMOUNT") private BigDecimal amount;потому что в
com/haulmont/cuba/metadata.xmlесть следующий элемент:<datatype id="decimal" class="com.haulmont.chile.core.datatypes.impl.BigDecimalDatatype" default="true" format="0.####" decimalSeparator="." groupingSeparator=""/> -
Для поля или метода можно задать аннотацию @MetaProperty, указав в ней атрибут
datatype.Например, атрибут
issueYearполучит типYearDatatype:@MetaProperty(datatype = "year") @Column(name = "ISSUE_YEAR") private Integer issueYear;если файл
metadata.xmlпроекта содержит следующий элемент:<datatype id="year" class="com.company.sample.YearDatatype"/>Как видно, атрибут
datatypeаннотации@MetaPropertyуказывает на идентификатор, который использован при регистрации класса имплементацииDatatypeв файлеmetadata.xml.
Основные методы интерфейса Datatype:
-
format()- преобразовывает переданное значение в строку -
parse()- преобразовывает строку в значение нужного типа -
getJavaClass()– возвращает тип Java, для конвертации которого создан данныйDatatype. Этот метод имеет реализацию по умолчанию, которая считывает значение аннотации@JavaClass, если она присутствует на классе.
Datatype определяет два набора методов для форматирования/парсинга: с учетом локали и без учета локали. Преобразование с учетом локали используется повсеместно в пользовательском интерфейсе, преобразование без учета локали используется в системных механизмах, например, для сериализации в REST API.
Форматы для преобразований без учета локали задаются в коде имплементации или в файле metadata.xml.
В следующем разделе описано, как задать форматы преобразований с учетом локали.
3.2.2.3.1. Строки форматов Datatype
Форматы для преобразований с учетом локали задаются в главном пакете локализованных сообщений проекта или его компонентов, следуя логике стандартных классов Java SE, таких как DecimalFormat (см. https://docs.oracle.com/javase/tutorial/i18n/format/decimalFormat.html) и SimpleDateFormat (см. https://docs.oracle.com/javase/8/docs/api/java/text/SimpleDateFormat.html).
Форматы задаются в строках со следующими ключами:
-
numberDecimalSeparator- задает символ разделителя целой и дробной части для числовых типов, например:# использование запятой в качестве разделителя numberDecimalSeparator=, -
numberGroupingSeparator- задает символ разделителя групп разрядов для числовых типов# использование пробела в качестве разделителя numberGroupingSeparator = \u0020 -
integerFormat- формат для типовIntegerиLong# запретить отображение разделителя тысяч для целых чисел integerFormat = #0 -
doubleFormat- формат для типаDouble. Обратите внимание, что символы десятичного разделителя и разделителя групп разрядов задаются отдельно в своих собственных ключах (см. выше).# округление до трёх цифр после десятичного разделителя doubleFormat=#,##0.### -
decimalFormat- формат для типаBigDecimal. Обратите внимание, что символы десятичного разделителя и разделителя групп разрядов задаются отдельно в своих собственных ключах (см. выше).# всегда отображать две цифры после десятичного разделителя, например, в денежных единицах decimalFormat = #,##0.00 -
dateTimeFormat- формат для типаjava.util.Date# формат дата+время для России dateTimeFormat = dd.MM.yyyy HH:mm -
dateFormat- формат для типаjava.sql.Date# формат даты для США dateFormat = MM/dd/yyyy -
timeFormat- формат для типаjava.sql.Time# формат времени часы:минуты timeFormat=HH:mm -
offsetDateTimeFormat– формат для типаjava.time.OffsetDateTime# формат дата+время с отклонением от времени по Гринвичу offsetDateTimeFormat = dd/MM/yyyy HH:mm Z -
offsetTimeFormat– формат для типаjava.time.OffsetTime# формат времени часы:минуты с отклонением от времени по Гринвичу offsetTimeFormat=HH:mm Z -
trueString- строка, соответствующаяBoolean.TRUE# альтернативное отображение булевых значений trueString = да -
falseString- строка, соответствующаяBoolean.FALSE# альтернативное отображение булевых значений falseString = нет
|
Форматы для используемых в приложении языков могут быть заданы в Studio. Для этого откройте экран Project Properties, нажмите кнопку в поле Available locales, затем нажмите Show data format strings. |
Строки форматов могут быть получены из бина FormatStringsRegistry.
3.2.2.3.2. Пример специализированного Datatype
В качестве примера рассмотрим следующую задачу: в приложении есть атрибуты сущностей, хранящие годы в виде целых чисел. Пользователи должны иметь возможность просматривать и редактировать годы, причем если пользователь вводит только две цифры, приложение должно преобразовать их в год между 2000 и 2100. В противном случае, все введенное число считается годом.
Создайте класс в модуле global:
package com.company.sample.entity;
import com.google.common.base.Strings;
import com.haulmont.chile.core.annotations.JavaClass;
import com.haulmont.chile.core.datatypes.Datatype;
import javax.annotation.Nullable;
import java.text.DecimalFormat;
import java.text.ParseException;
import java.util.Locale;
@JavaClass(Integer.class)
public class YearDatatype implements Datatype<Integer> {
private static final String PATTERN = "##00";
@Override
public String format(@Nullable Object value) {
if (value == null)
return "";
DecimalFormat format = new DecimalFormat(PATTERN);
return format.format(value);
}
@Override
public String format(@Nullable Object value, Locale locale) {
return format(value);
}
@Nullable
@Override
public Integer parse(@Nullable String value) throws ParseException {
if (Strings.isNullOrEmpty(value))
return null;
DecimalFormat format = new DecimalFormat(PATTERN);
int year = format.parse(value).intValue();
if (year > 2100 || year < 0)
throw new ParseException("Invalid year", 0);
if (year < 100)
year += 2000;
return year;
}
@Nullable
@Override
public Integer parse(@Nullable String value, Locale locale) throws ParseException {
return parse(value);
}
}Затем добавьте элемент datatypes в файл metadata.xml вашего проекта:
<metadata xmlns="http://schemas.haulmont.com/cuba/metadata.xsd">
<datatypes>
<datatype id="year" class="com.company.sample.entity.YearDatatype"/>
</datatypes>
<!-- ... -->
</metadata>В элементе datatype можно также указать атрибут sqlType, содержащий SQL-тип вашей базы данных, подходящий для хранения значений нового типа. Этот SQL-тип будет использоваться CUBA Studio при генерации скриптов базы данных. Studio может автоматически определить SQL-тип для следующих типов Java:
-
java.lang.Boolean -
java.lang.Integer -
java.lang.Long -
java.math.BigDecimal -
java.lang.Double -
java.lang.String -
java.util.Date -
java.util.UUID -
byte[]
В нашем случае класс предназначен для работы с типом Integer (что декларируется аннотацией @JavaClass со значением Integer.class), поэтому атрибут sqlType можно не указывать.
Наконец, укажите новый тип данных для требуемых атрибутов (программно или с помощью интерфейса Studio):
@MetaProperty(datatype = "year")
@Column(name = "ISSUE_YEAR")
private Integer issueYear;После выполнения перечисленных действий атрибут issueYear везде в приложении будет отображаться в нужном формате.
3.2.2.3.3. Пример форматирования даты в UI
Рассмотрим отображение атрибута Order.date в таблице браузера заказов.
order-browse.xml
<table id="ordersTable">
<columns>
<column id="date"/>
<!--...-->Атрибут date в классе Order определен с типом "дата":
@Column(name = "DATE", nullable = false)
@Temporal(TemporalType.DATE)
private Date date;Если текущий пользователь зарегистрирован c русской локалью, то из главного пакета локализованных сообщений извлекается строка:
dateFormat=dd.MM.yyyyВ результате дата "2012-08-06" конвертируется в строку "06.08.2012" для отображения в ячейке таблицы.
3.2.2.3.4. Примеры форматирования дат и чисел в коде приложения
Если вам необходимо отформатировать или получить из строки значения BigDecimal, Integer, Long, Double, Boolean или Date учитывая локаль текущего пользователя, используйте бин DatatypeFormatter. Например:
@Inject
private DatatypeFormatter formatter;
void sample() {
String dateStr = formatter.formatDate(dateField.getValue());
// ...
}Ниже приведены примеры использования методов интерфейса Datatype напрямую.
-
Пример форматирования даты
@Inject protected UserSessionSource userSessionSource; @Inject protected DatatypeRegistry datatypes; void sample() { Date date; // ... String dateStr = datatypes.getNN(Date.class).format(date, userSessionSource.getLocale()); // ... } -
Пример форматирования числового значения с 5 знаками после запятой в Web Client:
com/sample/sales/web/messages_ru.propertiescoordinateFormat = #,##0.00000@Inject protected Messages messages; @Inject protected UserSessionSource userSessionSource; @Inject protected FormatStringsRegistry formatStringsRegistry; void sample() { String coordinateFormat = messages.getMainMessage("coordinateFormat"); FormatStrings formatStrings = formatStringsRegistry.getFormatStrings(userSessionSource.getLocale()); NumberFormat format = new DecimalFormat(coordinateFormat, formatStrings.getFormatSymbols()); String formattedValue = format.format(value); // ... }
3.2.2.4. Мета-аннотации
Мета-аннотации сущностей - набор пар ключ/значение, содержащих дополнительную информацию о сущностях.
Обращение к мета-аннотациям производится с помощью метода мета-класса getAnnotations().
Источниками мета-аннотаций сущности являются:
-
Аннотации
@OnDelete,@OnDeleteInverse,@Extends. При этом в мета-аннотациях создаются служебные объекты связей между сущностями. -
Расширяемые мета-аннотации, помеченные аннотацией
@MetaAnnotation. Эти аннотации конвертируются в мета-аннотации с ключом, соответствующими полному имени класса Java аннотации и значением, являющимся map атрибутов аннотации. Например, аннотация@TrackEditScreenHistoryбудет иметь значение, являющееся map с единственным элементом:value → true. Платформа предоставляет следующие аннотации такого вида:@NamePattern,@SystemLevel,@EnableRestore,@TrackEditScreenHistory. В вашем приложении или компоненте можно создать собственные аннотации и пометить их аннотацией@MetaAnnotation. -
Опционально: в файлах metadata.xml также могут быть определены мета-аннотации сущностей. Если мета-аннотация в XML имеет то же имя, что и мета-аннотация, созданная по Java аннотации класса сущности, первая переопределит значение второй.
Пример переопределения мета-аннотаций в metadata.xml:
<metadata xmlns="http://schemas.haulmont.com/cuba/metadata.xsd"> <!-- ... --> <annotations> <entity class="com.company.customers.entity.Customer"> <annotation name="com.haulmont.cuba.core.entity.annotation.TrackEditScreenHistory"> <attribute name="value" value="true" datatype="boolean"/> </annotation> <property name="name"> <annotation name="length" value="200"/> </property> <property name="customerGroup"> <annotation name="com.haulmont.cuba.core.entity.annotation.Lookup"> <attribute name="type" class="com.haulmont.cuba.core.entity.annotation.LookupType" value="DROPDOWN"/> <attribute name="actions" datatype="string"> <value>lookup</value> <value>open</value> </attribute> </annotation> </property> </entity> <entity class="com.company.customers.entity.CustomerGroup"> <annotation name="com.haulmont.cuba.core.entity.annotation.EnableRestore"> <attribute name="value" value="false" datatype="boolean"/> </annotation> </entity> </annotations> </metadata>
3.2.3. Представления
При извлечении сущностей из базы данных обычно встает вопрос - как обеспечить загрузку связанных сущностей на нужную глубину?
Например, для браузера Заказов нужно отобразить дату и сумму заказа совместно с названием Покупателя, т.е. загрузить связанный экземпляр Покупателя. А для экрана редактирования Заказа необходимо загрузить еще и коллекцию Пунктов заказа, причем каждый Пункт заказа должен содержать связанный экземпляр Товара для отображения его наименования.
Загрузка по требованию в большинстве случаев не может помочь, так как обработка данных, как правило, происходит не в транзакции, в которой загружаются сущности, а, например, на клиентском уровне в пользовательском интерфейсе. В то же время задание жадной загрузки в аннотациях сущностей недопустимо, так как приводит к постоянному извлечению всего графа связанных сущностей, который может быть очень большим.
Другой похожей проблемой является ограничение набора локальных атрибутов сущностей загружаемого графа: например, некоторая сущность имеет 50 атрибутов, в том числе BLOB, а в экране отображается только 10 атрибутов. Зачем загружать из БД, затем сериализовать и передавать клиенту 40 атрибутов, которые ему в данный момент не нужны?
Механизм представлений (views) решает эти проблемы, обеспечивая извлечение из базы данных и передачу клиенту графов сущностей, ограниченных в глубину и по атрибутам. Представление является описателем графа объектов, который требуется в некотором экране UI или другом процессе обработки данных.
Обработка представлений производится следующим образом:
-
Все связи в модели данных объявляются с признаком загрузки по требованию (
fetch = FetchType.LAZY, см. Аннотации сущностей). -
В процессе загрузки данных через DataManager клиентский код помимо JPQL-запроса указывает нужное представление.
-
На основе представления формируется так называемая FetchGroup - особенность лежащего в основе слоя ORM фреймворка EclipseLink. Fetch Group влияет на формирование SQL-запроса к базе данных: как на список возвращаемых полей, так и на соединения с другими таблицами, содержащими связанные сущности.
|
Независимо от набора атрибутов, определенного в представлении, всегда загружаются следующие атрибуты:
|
|
При попытке прочитать или установить значение незагруженного (не включенного в представление) атрибута генерируется исключение. Проверить, загружен ли некоторый атрибут можно методом |
В следующем разделе описываются способы создания представлений.
Ниже приведена информация о внутреннем устройстве механизма представлений.
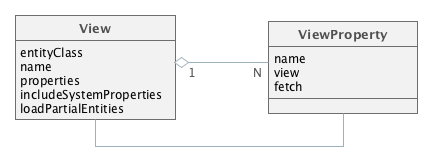
Рисунок 5. Классы представления
Представление определяется экземпляром класса View, в котором:
-
entityClass- класс сущности, для которого определено представление. Другими словами, "корень" дерева загружаемых сущностей. -
name- имя представления. Должно быть либоnull, либо уникальным в пределах данной сущности. -
properties- коллекция экземпляров класса ViewProperty, соответствующих загружаемым атрибутам сущности. -
includeSystemProperties- признак включения системных атрибутов (входящих в состав базовых интерфейсов персистентных сущностейBaseEntityиUpdatable).
-
loadPartialEntities- признак влияния представления на загрузку локальных (другими словами, непосредственных) атрибутов. Если false, представление влияет только на загрузку ссылочных атрибутов, а локальные атрибуты загружаются всегда, независимо от их присутствия или отсутствия в представлении.Данное свойство в некоторой степени контролируется механизмами загрузки данных платформы. См. разделы о загрузке частичных сущностей в DataManager и EntityManager.
Класс ViewProperty имеет следующие свойства:
-
name- имя атрибута сущности -
view- для ссылочных атрибутов задает представление, с которым необходимо загружать связанную сущность -
fetch- для ссылочных атрибутов задает способ загрузки связанной сущности из БД. Соответствует перечислениюFetchMode:-
AUTO- платформа автоматически выбирает оптимальный режим в зависимости от типа отношения. -
UNDEFINED- загрузка будет выполнена по правилам JPA, что означает загрузку отдельными SELECT-запросами. -
JOIN- загрузка в том же SELECT-запросе путем объединения с таблицей, содержащей ссвязанную сущность. -
BATCH- загрузка экземпляров связанной сущности будет осуществляться порциями. Подробнее см. здесь.
Если атрибут
fetchне указан, будет использоваться режимAUTO. Если атрибут представляет собой кэшируемую сущность, независимо от указанного значения будет использоватьсяUNDEFINED. -
3.2.3.1. Создание представлений
Представление может быть создано следующими способами:
-
Программно - созданием экземпляра
View. Как правило, таким способом создаются представления, используемые в бизнес-логике.Экземпляры представлений, включая вложенные, можно создавать с помощью конструктора:
View view = new View(Order.class) .addProperty("date") .addProperty("amount") .addProperty("customer", new View(Customer.class) .addProperty("name") );То же самое можно сделать с помощью
ViewBuilder:View view = ViewBuilder.of(Order.class) .addAll("date", "amount", "customer.name") .build();ViewBuilderможно также использовать в DataManager через его fluent interface:// explicit view builder dataManager.load(Order.class) .view(viewBuilder -> viewBuilder.addAll("date", "amount", "customer.name")) .list(); // implicit view builder dataManager.load(Order.class) .viewProperties("date", "amount", "customer.name") .list(); -
Декларативно в экранах - путем объявления внутри XML-дескриптора экрана, см. пример в разделе Декларативное создание компонентов данных. Это рекомендуемый способ при загрузке данных в экранах Generic UI для проектов, использующих CUBA 7.2+.
-
Декларативно в общем репозитории - путем объявления в файле views.xml проекта. Файл
views.xmlобрабабывается на старте приложения, созданные экземплярыViewкэшируются в репозитории представленийViewRepository. В дальнейшем в любом месте кода приложения требуемое представление можно получить вызовом репозитория с указанием класса сущности и имени представления.
Пример XML-описателя представления, которое должно обеспечить загрузку всех локальных атрибутов сущности Заказ, ассоциированного Покупателя и коллекции Пунктов заказа:
<view class="com.sample.sales.entity.Order"
name="order-with-customer"
extends="_local">
<property name="customer" view="_minimal"/>
<property name="items" view="item-in-order"/>
</view>- Работа с репозиторием представлений
-
ViewRepositoryявляется бином Spring, доступным для всех блоков приложения. Ссылка наViewRepositoryможет быть также получена инжекцией или через статические методы классаAppBeans. Для получения экземпляраView, содержащегося в репозитории, используются методыgetView().В репозитории для каждой сущности по умолчанию доступны три представления с именами
_local,_minimalи_base:-
_localвключает в себя все локальные атрибуты сущности -
_minimalвключает в себя атрибуты, входящие в имя экземпляра сущности, и задаваемые аннотацией @NamePattern. Если аннотация@NamePatternдля сущности не указана, данное представление не включает никаких атрибутов. -
_baseвключает в себя все локальные несистемные атрибуты и атрибуты, заданные в аннотации@NamePattern(т.е. фактически_minimal+_local).
CUBA Studio автоматически создает и поддерживает в проекте один файл views.xml. Однако при необходимости можно использовать и несколько таких файлов следующим образом:
-
В модуле
globalдолжен находиться файлviews.xmlсо всеми описателями представлений, которые должны быть доступны глобально, т.е. на всех уровнях приложения. Данный файл должен быть зарегистрирован в свойстве приложения cuba.viewsConfig всех блоков, т.е. в файлеapp.propertiesмодуляcore, в файлеweb-app.propertiesмодуляwebи так далее. Это по умолчанию обеспечивает Studio. -
Если в проекте имеется много общих представлений, их можно разместить в нескольких файлах, например в стандартном
views.xmlи в дополнительныхfoo-views.xml,bar-views.xml. Все файлы должны быть зарегистрированы в свойствеcuba.viewsConfig:cuba.viewsConfig = +com/company/sales/views.xml com/company/sales/foo-views.xml com/company/sales/bar-views.xml
-
Если существуют представления, которые необходимы только какому-то одному блоку приложения, то можно определить их в аналогичном файле данного блока, например,
web-views.xml, и добавить этот файл в свойствоcuba.viewsConfigэтого блока, т.е. в данном случае в файлweb-app.properties.
Если на момент развертывания некоторого представления в репозитории уже есть представление для этого же класса сущности и с таким же именем, то новое будет проигнорировано. Для того чтобы представление заменило имеющееся в репозитории и гарантированно было развернуто, в XML-описателе должен быть явно указан атрибут
overwrite = "true".Рекомендуется давать представлениям "описательные" имена. Например, не "browse", а "customer-browse". Это упрощает поиск XML-описателей представлений по имени в процессе разработки приложения.
-
3.2.4. Spring-бины
Spring-бины − это классы, созданием экземпляров которых и установкой в них зависимостей управляет контейнер фреймворка Spring. Бины предназначены для реализации бизнес-логики приложения.
|
Spring Bean представляет собой singleton, то есть в некотором блоке приложения существует только один экземпляр данного класса. Поэтому, если бин содержит изменяемые данные в полях (другими словами, имеет состояние), то обращение к таким данным необходимо синхронизировать. |
3.2.4.1. Создание бина
|
Руководство Create Business Logic in CUBA демонстрирует использование Spring-бина для реализации бизнес-логики. |
Для создания Spring-бина достаточно добавить классу Java аннотацию @org.springframework.stereotype.Component. Например:
package com.sample.sales.core;
import com.sample.sales.entity.Order;
import org.springframework.stereotype.Component;
@Component(OrderWorker.NAME)
public class OrderWorker {
public static final String NAME = "sales_OrderWorker";
public void calculateTotals(Order order) {
}
}Рекомендуется присваивать бину уникальное имя вида {имя_проекта}_{имя_класса}, и определять его в константе NAME.
|
Аннотация |
Класс Spring-бина должен находиться внутри дерева пакетов с корнем, заданным в элементе context:component-scan файла spring.xml. Для примера выше, файл spring.xml должен содержать элемент:
<context:component-scan base-package="com.sample.sales"/>что означает, что поиск аннотированных бинов для данного блока приложения будет происходить начиная с пакета com.sample.sales.
Spring-бины можно создавать на любом уровне приложения.
3.2.4.2. Использование бина
Ссылку на бин можно получить с помощью инжекции или класса AppBeans. В качестве примера использования бина рассмотрим реализацию сервиса OrderService, делегирующего выполнение бину OrderWorker:
package com.sample.sales.core;
import com.haulmont.cuba.core.Persistence;
import com.sample.sales.entity.Order;
import org.springframework.stereotype.Service;
import org.springframework.transaction.annotation.Transactional;
import javax.inject.Inject;
@Service(OrderService.NAME)
public class OrderServiceBean implements OrderService {
@Inject
protected Persistence persistence;
@Inject
protected OrderWorker orderWorker;
@Transactional
@Override
public BigDecimal calculateTotals(Order order) {
Order entity = persistence.getEntityManager().merge(order);
return orderWorker.calculateTotals(entity);
}
}В данном примере сервис стартует транзакцию, вносит полученный с клиентского уровня экземпляр сущности в персистентный контекст, и передает управление бину OrderWorker, который и содержит основную бизнес-логику.
3.2.5. JMX-бины
Иногда требуется предоставить администратору системы возможность просматривать и изменять состояние некоторого Spring-бина во время выполнения. В этом случае рекомендуется создать JMX-бин - программный компонент, имеющий JMX-интерфейс. Такой бин, как правило, делегирует вызовы управляемому бину, содержащему кэш, конфигурационные данные или статистику, к которым нужно обеспечить доступ через JMX.
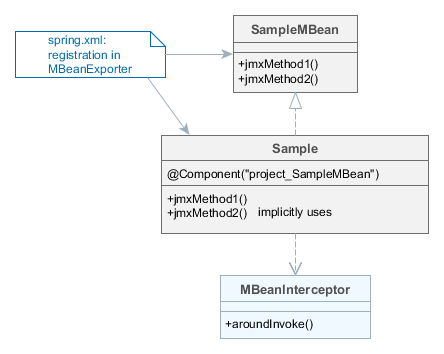
Как видно из диаграммы, JMX-бин состоит из интерфейса и класса реализации. Класс должен представлять собой Spring-бин, то есть иметь аннотацию @Component и уникальное имя. Интерфейс JMX-бина специальным образом регистрируется в spring.xml для создания в текущей JVM собственно JMX-интерфейса.
Вызовы всех методов интерфейса JMX-бина перехватываются с помощью Spring AOP классом−интерцептором MBeanInterceptor, который обеспечивает установку правильного ClassLoader в контексте потока выполнения, и журналирование необработанных исключений.
|
Интерфейс JMX-бина обязательно должен иметь имя вида |
С JMX-интерфейсом можно работать из внешних инструментов, таких как jconsole или jvisualvm. Кроме того, в состав блока Web Client платформы входит JMX-консоль, предоставляющая базовые средства просмотра состояния и вызова методов JMX-бинов.
3.2.5.1. Создание JMX-бина
Рассмотрим процесс создания JMX-бина на примере.
-
Интерфейс JMX-бина:
package com.sample.sales.core; import org.springframework.jmx.export.annotation.*; import com.haulmont.cuba.core.sys.jmx.JmxBean; @JmxBean(module = "sales", alias = "OrdersMBean") @ManagedResource(description = "Performs operations on Orders") public interface OrdersMBean { @ManagedOperation(description = "Recalculates an order amount") @ManagedOperationParameters({@ManagedOperationParameter(name = "orderId", description = "")}) String calculateTotals(String orderId); }-
Интерфейс и его методы могут содержать аннотации для задания описания JMX-бина и его операций. Это описание будет отображаться во всех инструментах, работающих с данным JMX-интерфейсом, тем самым помогая администратору системы.
-
Необязательная аннотация
@JmxBeanиспользуется для автоматической регистрации экземпляров класса на сервере JMX в соответствии с атрибутамиmoduleиalias. Вы можете зарегистрировать JMX-bean, используя эту аннотацию вместо регистрации в файле spring.xml. -
Аннотацию
@JmxRunAsyncможно использовать для указания длительных операций. Если такая операция запускается через встроенную консоль JMX, платформа отображает диалог с неопределенным индикатором прогресса и кнопкой Cancel. Пользователь может прервать операцию и продолжить работу с приложением. Аннотация может также содержать параметрtimeout, который устанавливает максимальное время выполнения в миллисекундах, например:@JmxRunAsync(timeout = 30000) String calculateTotals();Если таймаут превышен, диалог закрывается с сообщением об ошибке.
Пожалуйста имейте в виду, что если операция прервана пользователем или по таймауту, она все равно продолжает работать в фоне, то есть данные действия не прерывают самого выполнения, а только возвращают управление пользователю.
-
Так как инструменты JMX поддерживают ограниченный набор типов данных, параметры и результат метода желательно задавать типа
String, и при необходимости выполнять конвертацию внутри метода. ПомимоString, поддерживаются следующие типы параметров:boolean,double,float,int,long,Boolean,Integer.
-
-
Класс JMX-бина:
package com.sample.sales.core; import com.haulmont.cuba.core.*; import com.haulmont.cuba.core.app.*; import com.sample.sales.entity.Order; import org.apache.commons.lang.exception.ExceptionUtils; import org.springframework.stereotype.Component; import javax.inject.Inject; import java.util.UUID; @Component("sales_OrdersMBean") public class Orders implements OrdersMBean { @Inject protected OrderWorker orderWorker; @Inject protected Persistence persistence; @Authenticated @Override public String calculateTotals(String orderId) { try { try (Transaction tx = persistence.createTransaction()) { Order entity = persistence.getEntityManager().find(Order.class, UUID.fromString(orderId)); orderWorker.calculateTotals(entity); tx.commit(); }; return "Done"; } catch (Throwable e) { return ExceptionUtils.getStackTrace(e); } } }Аннотация
@Componentопределяет, что данный класс является Spring-бином с именемsales_OrdersMBean. Имя указано напрямую в аннотации, а не в константе, так как доступ к JMX-бину из кода Java не требуется.Рассмотрим реализацию метода
calculateTotals().-
Метод имеет аннотацию
@Authenticated, т.е. при входе в метод и при отсутствии в потоке выполнения пользовательской сессии выполняется системная аутентификация. -
Тело метода обернуто в блок try/catch, так что метод в случае успешного выполнения возвращает строку "Done", а в случае ошибки - stacktrace исключения в виде строки.
В данном случае все исключения обрабатываются, а значит, не попадают в
MBeanInterceptorи не выводятся в журнал автоматически. Поэтому при необходимости логировать исключения здесь нужно добавить вызов логгера в секцииcatch. -
Логика метода заключается в том, что он стартует транзакцию, загружает экземпляр сущности
Orderпо идентификатору и передает управление бинуOrderWorkerдля обработки.
-
-
Если вы не использовали аннотацию
@JmxBeanпри создании интерфейса JMX-бина, вам следует зарегистрировать JMX-бин в файлеspring.xml:<bean id="sales_MBeanExporter" lazy-init="false" class="com.haulmont.cuba.core.sys.jmx.MBeanExporter"> <property name="beans"> <map> <entry key="${cuba.webContextName}.sales:type=Orders" value-ref="sales_OrdersMBean"/> </map> </property> </bean>Все JMX-бины проекта объявляются в одном экземпляре
MBeanExporterв элементахmap/entryсвойстваbeans. Ключом элемента здесь является JMX ObjectName, значением - имя бина, заданное в аннотации@Component. ObjectName начинается с имени веб-приложения, так как в одном экземпляре сервера приложения (т.е. в одной JVM) может быть развернуто несколько веб-приложений, экспортирующих одинаковые JMX-интерфейсы.
3.2.5.2. JMX-бины платформы
В данном разделе описаны некоторые имеющиеся в платформе JMX-бины.
3.2.5.2.1. CachingFacadeMBean
CachingFacadeMBean предоставляет методы очистки различных кэшей в блоках Middleware и Web Client.
JMX ObjectName: app-core.cuba:type=CachingFacade и app.cuba:type=CachingFacade
3.2.5.2.2. ConfigStorageMBean
ConfigStorageMBean позволяет просматривать и задавать значения свойствам приложения в блоках Middleware, Web Client и Web Portal.
Данный интерфейс имеет отдельные наборы операций для работы с параметрами конфигурации и развертывания (*AppProperties) и с параметрами времени выполнения (*DbProperties). Эти операции отображают только свойства, явно заданные в хранилище. То есть если имеется конфигурационный интерфейс, определяющий некоторое свойство и его значение по умолчанию, но в базе данных или в файлах никакого значения не указано, данные операции не отобразят свойство и его текущее значение.
Заметьте, что изменения в свойствах, хранящихся в файлах, не персистентны и актуальны только до перезапуска блока приложения.
В отличие от операций, описанных выше, операция getConfigValue() всегда возвращает в точности то значение, какое вернул бы соответствующий метод конфигурационного интерфейса, вызванный из кода приложения.
JMX ObjectName:
-
app-core.cuba:type=ConfigStorage -
app.cuba:type=ConfigStorage -
app-portal.cuba:type=ConfigStorage
3.2.5.2.3. EmailerMBean
EmailerMBean позволяет просмотреть текущие значения параметров отсылки email, а также отправить тестовое сообщение.
JMX ObjectName: app-core.cuba:type=Emailer
3.2.5.2.4. PersistenceManagerMBean
PersistenceManagerMBean предоставляет следующие возможности:
-
управление механизмом статистики сущностей
-
отображение новых скриптов обновления БД методом
findUpdateDatabaseScripts()и запуск обновления методомupdateDatabase() -
запуск произвольных JPQL запросов в контексте Middleware методами
jpqlLoadList(),jpqlExecuteUpdate()
JMX ObjectName: app-core.cuba:type=PersistenceManager
3.2.5.2.5. ScriptingManagerMBean
ScriptingManagerMBean является JMX-фасадом для интерфейса инфраструктуры Scripting.
JMX ObjectName: app-core.cuba:type=ScriptingManager
JMX-атрибуты:
-
RootPath- абсолютный путь к конфигурационному каталогу блока приложения, в котором запущен данный бин.
JMX-операции:
-
runGroovyScript()- выполнить скрипт Groovy в контексте Middleware и вернуть результат. В скрипт передаются следующие переменные:-
persistenceтипа Persistence -
metadataтипа Metadata -
configurationтипа Configuration -
dataManagerтипа DataManagerДля отображения в JMX-интерфейсе результат должен быть типа
String. В остальном аналогичен методуScripting.runGroovyScript().Пример скрипта, создающего набор тестовых пользователей:
import com.haulmont.cuba.core.* import com.haulmont.cuba.core.global.* import com.haulmont.cuba.security.entity.* PasswordEncryption passwordEncryption = AppBeans.get(PasswordEncryption.class) Transaction tx = persistence.createTransaction() try { EntityManager em = persistence.getEntityManager() Group group = em.getReference(Group.class, UUID.fromString('0fa2b1a5-1d68-4d69-9fbd-dff348347f93')) for (i in (1..250)) { User user = new User() user.setGroup(group) user.setLogin("user_${i.toString().padLeft(3, '0')}") user.setName(user.login) user.setPassword(passwordEncryption.getPasswordHash(user.id, '1')); em.persist(user) } tx.commit() } finally { tx.end() }
-
3.2.5.2.6. ServerInfoMBean
ServerInfoMBean предоставляет общую информацию о данном блоке Middleware: номер и дату сборки, идентификатор сервера.
JMX ObjectName: app-core.cuba:type=ServerInfo
3.2.6. Интерфейсы инфраструктуры
Интерфейсы инфраструктуры обеспечивают доступ к часто используемой функциональности платформы. Большинство из этих интерфейсов расположены в модуле global и могут быть использованы как на среднем слое, так и в блоках клиентского уровня, но некоторые (например, Persistence) доступны только коду среднего слоя.
Интерфейсы инфраструктуры реализуются бинами Spring Framework, поэтому они могут быть инжектированы в любые другие управляемые компоненты (бины, сервисы среднего слоя, контроллеры экранов универсального пользовательского интерфейса).
Кроме того, как и любые другие бины, интерфейсы инфраструктуры могут быть получены с помощью статических методов класса AppBeans и использоваться в неуправляемых компонентах (POJO, вспомогательных классах и пр.).
3.2.6.1. Configuration
Позволяет получать ссылки на конфигурационные интерфейсы там, где невозможна их инжекция.
Пример:
// field injection
@Inject
protected Configuration configuration;
...
String tempDir = configuration.getConfig(GlobalConfig.class).getTempDir();// setter injection
protected GlobalConfig globalConfig;
@Inject
public void setConfiguration(Configuration configuration) {
this.globalConfig = configuration.getConfig(GlobalConfig.class);
}// location
String tempDir = AppBeans.get(Configuration.class).getConfig(GlobalConfig.class).getTempDir();3.2.6.2. DataManager
Интерфейс DataManager является универсальным средством для загрузки графов сущностей из базы данных, и для сохранения изменений, произведенных в detached экземплярах сущностей.
|
Руководство Introduction to Working with Data содержит различные варианты использования программного доступа к данным с помощью DataManager API. |
|
В разделе DataManager vs. EntityManager приведена информация о различиях между DataManager и EntityManager. |
DataManager на самом деле делегирует выполнение реализациям DataStore, и поддерживает ссылки между сущностями из разных хранилищ. Большинство деталей реализации, описанных ниже, актуальны только когда производится работа через RdbmsStore с сущностями, хранящимися в реляционной БД. Для другого типа хранилища все, кроме сигнатур методов, может отличаться. Для простоты изложения, далее, когда мы говорим просто DataManager, мы будем иметь в виду DataManager через RdbmsStore.
Методы DataManager:
-
load(Class)- загружает сущности указанного типа. Данный метод является точкой входа в fluent API:@Inject private DataManager dataManager; private Book loadBookById(UUID bookId) { return dataManager.load(Book.class).id(bookId).view("book.edit").one(); } private List<BookPublication> loadBookPublications(UUID bookId) { return dataManager.load(BookPublication.class) .query("select p from library_BookPublication p where p.book.id = :bookId") .parameter("bookId", bookId) .view("bookPublication.full") .list(); } -
loadValues(String query)- загружает пары ключ-значение по запросу, возвращающему скалярные значения. Данный метод является точкой входа в fluent API:List<KeyValueEntity> list = dataManager.loadValues( "select o.customer, sum(o.amount) from demo_Order o " + "where o.date >= :date group by o.customer") .store("legacy_db") (1) .properties("customer", "sum") (2) .parameter("date", orderDate) .list();1 - укажите хранилище, в котором находится сущность. Данный метод можно опустить, если сущность находится в главном хранилище. 2 - перечислите имена атрибутов результирующей KeyValueEntity. Порядок имен должен соответствовать колонкам результирующего набора в запросе. -
loadValue(String query, Class valueType)- загружает единственное значение по запросу. Данный метод является точкой входа в fluent API:BigDecimal sum = dataManager.loadValue( "select sum(o.amount) from demo_Order o " + "where o.date >= :date group by o.customer", BigDecimal.class) .store("legacy_db") (1) .parameter("date", orderDate) .one();1 - укажите хранилище, в котором находится сущность. Данный метод можно опустить, если сущность находится в главном хранилище. -
load(LoadContext),loadList(LoadContext)- загружает сущности в соответствии с параметрами переданного объектаLoadContext. ВLoadContextобязательно должен быть передан либо JPQL-запрос, либо идентификатор сущности. Если передано и то и другое, используется запрос, а идентификатор игнорируется. Примеры:@Inject private DataManager dataManager; private Book loadBookById(UUID bookId) { LoadContext<Book> loadContext = LoadContext.create(Book.class) .setId(bookId).setView("book.edit"); return dataManager.load(loadContext); } private List<BookPublication> loadBookPublications(UUID bookId) { LoadContext<BookPublication> loadContext = LoadContext.create(BookPublication.class) .setQuery(LoadContext.createQuery("select p from library_BookPublication p where p.book.id = :bookId") .setParameter("bookId", bookId)) .setView("bookPublication.full"); return dataManager.loadList(loadContext); } -
loadValues(ValueLoadContext)- загружает список пар ключ-значение. Метод принимает объектValueLoadContext, в котором задается запрос и список ключей. Возвращаемый список содержит экземплярыKeyValueEntity. Например:ValueLoadContext context = ValueLoadContext.create() .setQuery(ValueLoadContext.createQuery( "select o.customer, sum(o.amount) from demo_Order o " + "where o.date >= :date group by o.customer") .setParameter("date", orderDate)) .addProperty("customer") .addProperty("sum"); List<KeyValueEntity> list = dataManager.loadValues(context); -
getCount(LoadContext)- возвращает количество записей для запроса, переданного в метод. Когда возможно, для максимальной производительности, стандартная реализация в классеRdbmsStoreвыполняет запросselect count()с условиями исходного запроса. -
commit(CommitContext)- сохраняет в базе данных набор сущностей, переданный в объектеCommitContext. Отдельно указываются коллекции сущностей, которые нужно сохранить и которые нужно удалить.Метод возвращает набор экземпляров сущностей, возвращенных из метода EntityManager.merge(), то есть по сути свежие экземпляры, только что обновленные в БД. Дальнейшая работа должна производиться именно с этими возвращенными экземплярами, чтобы предотвратить потерю данных или исключения оптимистичной блокировки. Для того, чтобы обеспечить наличие нужных атрибутов у возвращенных сущностей, с помощью мэп
CommitContext.getViews()можно указать представление для каждого сохраняемого экземпляра.DataManagerможет выполнять валидацию сохраняемых сущностей.Примеры сохранения коллекций сущностей:
@Inject private DataManager dataManager; private void saveBookInstances(List<BookInstance> toSave, List<BookInstance> toDelete) { CommitContext commitContext = new CommitContext(toSave, toDelete); dataManager.commit(commitContext); } private Set<Entity> saveAndReturnBookInstances(List<BookInstance> toSave, View view) { CommitContext commitContext = new CommitContext(); for (BookInstance bookInstance : toSave) { commitContext.addInstanceToCommit(bookInstance, view); } return dataManager.commit(commitContext); } -
reload(Entity, View)- удобный метод для перезагрузки экземпляра сущности с требуемым представлением. Делегирует выполнение методуload(). -
remove(Entity)- удаляет экземпляр сущности из базы данных. Делегирует выполнение методуcommit(). -
create(Class)- создает экземпляр данной сущности в памяти. Этот метод просто делегирует вMetadata.create(). -
getReference(Class, Object)- возвращает экземпляр сущности, который может быть использован в качестве ссылки на объект, существующий в базе данных.Например, если вы создаете экземпляр сущности
User, вам необходимо установить ссылку наGroup, в которую данный пользователь будет входить. Если вам известен id группы, то вы могли бы загрузить данную группу из БД. Данный метод позволяет получить экземплярGroupбез ненужного обращения к БД:user.setGroup(dataManager.getReference(Group.class, groupId)); dataManager.commit(user);Ссылка может также быть использована для удаления существующего объекта по идентификатору:
dataManager.remove(dataManager.getReference(Customer.class, customerId));
- Запросы
-
При работе с реляционными базами данных для загрузки данных используются запросы на JPQL. В разделах Функции JPQL, Поиск подстроки без учета регистра и Макросы в JPQL приведена информация о том, как JPQL в CUBA отличается от стандартного JPA. Кроме того, имейте в виду, что
DataManagerможет выполнять только "select"-запросы.Метод
query()fluent-интерфейса принимает строку запроса как в полном, так и в сокращенном формате. Сокращенный запрос формируется следующим образом:-
Выражение
"select <alias>"всегда можно опустить. -
Если выражение
"from"содержит одну сущность, и вам не нужен особенный алиас, то выражение"from <entity> <alias> where"можно опустить. В этом случае фреймворк будет использовать алиасe. -
Можно использовать позиционные параметры и передавать их значения прямо в метод
query()в дополнительных аргументах.
Например:
// named parameter dataManager.load(Customer.class) .query("e.name like :name") .parameter("name", value) .list(); // positional parameter dataManager.load(Customer.class) .query("e.name like ?1", value) .list(); // case-insensitive positional parameter dataManager.load(Customer.class) .query("e.name like ?1 or e.email like ?1", "(?i)%joe%") .list(); // multiple positional parameters dataManager.load(Order.class) .query("e.date between ?1 and ?2", date1, date2) .list(); // omitting "select" and using a positional parameter dataManager.load(Order.class) .query("from sales_Order o, sales_OrderLine l " + "where l.order = o and l.product.name = ?1", productName) .list();Имейте в виду, что позиционные параметры поддерживаются только в fluent-интерфейсе. В
LoadContext.Queryможно использовать только именованные параметры. -
- Транзакции
-
DataManagerвсегда стартует новую транзакцию и по завершении работы выполняет коммит, таким образом возвращая сущности в detached состоянии. На среднем слое можно использовать TransactionalDataManager, если необходимо реализовать сложное транзакционное поведение.
- Частичные сущности
-
Частичная сущность - это экземпляр сущности, в котором может быть загружена только часть локальных атрибутов. По умолчанию, DataManager загружает частичные сущности в соответствии с указанными представлениями. (на самом деле,
RdbmsStoreпросто устанавливает свойство loadPartialEntities у представления в true и передает его дальше в EntityManager).В некоторых случаях DataManager загружает все локальные атрибуты и представление определяет только загрузку связей:
-
Загружаемая сущность кэшируется.
-
Для сущности заданы in-memory "read" ограничения.
-
Для сущности задан динамический контроль доступа к атрибутам.
-
Атрибут
loadPartialEntitiesобъектаLoadContextустановлен в false.
-
3.2.6.2.1. DataManager vs. EntityManager
И DataManager и EntityManager предназначены для выполнения операций с сущностями (CRUD). Ниже приведены различия между этими интерфейсами.
| DataManager | EntityManager |
|---|---|
DataManager доступен и на среднем слое и на клиентском уровне. |
EntityManager доступен только на среднем слое. |
DataManager является синглтон-бином. |
Ссылку на EntityManager необходимо получать через интерфейс Persistence. |
DataManager содержит несколько высокоуровневых методов для работы с detached сущностями: |
EntityManager в большой степени повторяет стандартный |
DataManager может выполнять bean validation при сохранении сущностей. |
EntityManager не выполняет bean validation. |
DataManager на самом деле делегирует выполнение реализациям DataStore, поэтому особенности DataManager, перечисленные ниже, актуальны только для наиболее часто встречающегося случая, когда вы работаете с сущностями, хранящимися в реляционной базе данных.
| DataManager | EntityManager |
|---|---|
DataManager всегда стартует новую транзакцию внутри. На среднем слое можно использовать TransactionalDataManager, если необходимо реализовать сложное транзакционное поведение. |
Для работы с EntityManager необходима открытая транзакция. |
DataManager загружает частичные сущности в соответствие с представлением. Есть некоторые исключения, см. подробности. |
EntityManager всегда загружает все локальные атрибуты. Если используется представление, оно влияет только на загрузку ссылочных атрибутов. См. подробности. |
DataManager выполняет только JPQL запросы. Кроме того, он имеет отдельные методы для загрузки сущностей: |
EntityManager может выполнять любые JPQL или native (SQL) запросы. |
DataManager проверяет права доступа, когда вызывается с клиентского уровня. |
EntityManager не проверяет права доступа. |
При работе на клиентском уровне доступен только DataManager. На среднем слое, используйте TransactionalDataManager когда необходимо реализовать атомарную логику внутри транзакции, или EntityManager если он лучше подходит для решения задачи. Вообще, на среднем слое можно использовать любой из этих интерфейсов.
Если вам нужно обойти ограничения DataManager при работе на клиентском уровне, создайте свой сервис и используйте TransactionalDataManager или EntityManager для работы с данными. В сервисе можно проверять права пользователя с помощью интерфейса Security и возвращать клиенту данные в виде персистентных или неперсистентных сущностей или произвольных значений.
3.2.6.2.2. TransactionalDataManager
TransactionalDataManager - это бин среднего слоя, который во многом повторяет интерфейс DataManager, но при этом может присоединяться к существующей транзакции. Он имеет следуюшие особенности:
-
При наличии активной транзакции, выполняет действия в ее контексте, в противном случае стартует и коммитит новую транзакцию так же как
DataManager. -
Принимает и возвращает сущности в состоянии detached. Разработчик должен загружать сущности с необходимыми представлениями и явно вызывать метод
save()для сохранения измененных экземпляров в БД. -
Применяет ограничения row-level security, работает с динамическими атрибутами и ссылками между хранилищами так же как
DataManager.
Ниже приведен простейший пример использования TransactionalDataManager в некотором методе сервиса:
@Inject
private TransactionalDataManager txDataManager;
@Transactional
public void transfer(Id<Account, UUID> acc1Id, Id<Account, UUID> acc2Id, Long amount) {
Account acc1 = txDataManager.load(acc1Id).one();
Account acc2 = txDataManager.load(acc2Id).one();
acc1.setBalance(acc1.getBalance() - amount);
acc2.setBalance(acc2.getBalance() + amount);
txDataManager.save(acc1);
txDataManager.save(acc2);
}Более сложный пример можно найти в тесте фреймворка: DataManagerTransactionalUsageTest.java
|
|
3.2.6.2.3. Права доступа в DataManager
Методы load(), loadList(), loadValues() и getCount() проверяют наличие у пользователя права READ на загружаемую сущность. Кроме того, при извлечении сущностей из БД накладываются ограничения групп доступа.
Метод commit() проверяет наличие у пользователя права UPDATE на изменяемые сущности и DELETE на удаляемые.
По умолчанию, DataManager проверяет права на операции (READ/CREATE/UPDATE/DELETE) с сущностями, когда вызывается с клиентской стороны, и игнорирует их, когда вызывается из кода middleware. Права на атрибуты по умолчанию не проверяются.
Если вы хотите, чтобы DataManager проверял права на операции и при вызове на среднем слое, получите методом DataManager.secure() специальный объект-обертку и вызывайте методы у него. В качестве альтернативы, вы можете установить свойство приложения cuba.dataManagerChecksSecurityOnMiddleware, чтобы проверка прав работала для всего приложения.
Права на атрибуты будут проверяться на среднем слое только если вы дополнительно установите свойство приложения cuba.entityAttributePermissionChecking в true. Это имеет смысл, если средний слой обслуживает также клиентов, которые теоретически могут быть взломаны, например, десктоп-клиент. В этом случае, установите также свойство cuba.keyForSecurityTokenEncryption в уникальное значение. Если ваше приложение использует только Web или Portal клиентов, то оба данных свойства можно безопасно оставить со значениями по умолчанию.
Имейте в ввиду, что ограничения групп доступа (row-level security) применяются всегда, независимо от того, был ли вызов с клиентского или со среднего слоя.
См. раздел Проверки доступа к данным для получения полной картины того, как разрешения и ограничения доступа к данным используются различными механизмами фреймворка.
3.2.6.2.4. Запросы с distinct
В JPQL запросах для экранов со списками сущностей, в которых включено постраничное отображение и возможна непредсказуемая модификация запроса универсальным фильтром или механизмом ограничений групп доступа, при отсутствии в запросе оператора distinct может возникать следующий эффект:
-
при объединении с коллекцией на уровне извлечения из базы данных возникает набор с дубликатами строк
-
на клиентском уровне в источнике данных дубликаты исчезают, т.к. попадают в мэп (
java.util.Map) -
при постраничном отображении на одной странице оказывается меньшее количество строк, чем запрошено, общее количество строк наоборот завышено.
Таким образом, рекомендуется в JPQL запросы браузеров включать предложение distinct, которое гарантирует отсутствие дубликатов записей при выборке из базы данных. Однако в некоторых серверах БД (в частности PostgreSQL) при большом количестве извлекаемых записей (более 10000) SQL запрос с distinct выполняется недопустимо долго.
Для решения этой проблемы в платформе реализована возможность корректной работы без distinct на уровне SQL. Данный механизм включается свойством приложения cuba.inMemoryDistinct, при активации которого выполняется следующее:
-
В JPQL запросе должен по-прежнему присутствовать
select distinct -
В
DataManagerиз JPQL запроса перед отправкой в ORMdistinctвырезается -
После загрузки страницы данных на Middleware удаляются дубликаты и выполняются дополнительные запросы к БД для получения нужного количества строк, которые затем и возвращаются клиенту.
3.2.6.2.5. Последовательная выборка
DataManager может выполнять последовательную выборку данных из результатов предыдущего запроса. Эта возможность используется в универсальном фильтре при последовательном наложении фильтров.
Данный механизм работает следующим образом:
-
При получении
LoadContextс установленными атрибутамиprevQueriesиqueryKeyDataManagerвыполняет выборку по предыдущему запросу и сохраняет идентификаторы полученных сущностей в таблицеSYS_QUERY_RESULT(соответствующей сущностиsys$QueryResult), разделяя наборы записей по идентификаторам пользовательских сессий и ключу сеанса выборкиqueryKey. -
Текущий запрос модифицируется для объединения с результатами предыдущего, так что в итоге возвращает данные, соответствующие условиям обоих запросов, объединенных по "И".
-
Далее процесс может повторяться, при этом уменьшающийся набор предыдущих результатов удаляется из таблицы
SYS_QUERY_RESULTи заполняется заново.
Таблица SYS_QUERY_RESULT периодически очищается от ненужных результатов запросов, оставленных завершенными пользовательскими сессиями. Для этого предназначен метод deleteForInactiveSessions бина QueryResultsManagerAPI, который вызывается шедулером Spring, объявленным в cuba-spring.xml. По умолчанию это происходит раз в 10 минут, но вы можете задать другой интервал в миллисекундах, используя свойство приложения cuba.deleteOldQueryResultsInterval в модуле core.
3.2.6.3. EntityStates
Интерфейс для получения информации о персистентных сущностях, сохраняемых через ORM. В отличие от бинов Persistence и PersistenceTools доступен на всех уровнях приложения.
Методы EntityStates:
-
isNew()- определяет, является ли переданный экземпляр только что созданным. Он может быть либо в состоянии New, либо Managed, но только что сохраненным в текущей транзакции. Также возвращаетtrueдля неперсистентных сущностей. -
isManaged()- определяет, находится ли переданный экземпляр в состоянии Managed, то есть присоединен к персистентному контексту. -
isDetached()- определяет, находится ли переданный экземпляр в состоянии Detached. Возвращаетtrue, также если экземпляр не является персистентной сущностью. -
isLoaded()- определяет, загружен ли данный атрибут сущности. Атрибут загружается, если он включен в представление, или если это локальный атрибут и никакое представление не использовалось в процессе загрузки через EntityManager или DataManager. Данный метод поддерживает проверку только непосредственных атрибутов сущностей. -
checkLoaded()- то же самое что иisLoaded(), но выбрасываетIllegalArgumentExceptionесли хотя бы один из переданных атрибутов не загружен. -
isLoadedWithView()- принимает экземпляр сущности и представление, и возвращает true если все атрибуты требуемые в представлении на самом деле загружены. -
checkLoadedWithView()- то же самое что иisLoadedWithView(), но выбрасываетIllegalArgumentExceptionвместо возврата false. -
makeDetached()- принимает только что созданный экземпляр сущности и переводит его в состояние detached. Detached-объект можно передать вDataManager.commit()илиEntityManager.merge()для сохранения его состояния в базе данных. Подробнее см. API docs. -
makePatch()- принимает только что созданный экземпляр сущности и превращает его в patch-объект. Patch-объект можно передать вDataManager.commit()илиEntityManager.merge()для сохранения его состояния в базе данных, при этом в отличие от detached-объекта, будут сохранены только не-null атрибуты. Подробнее см. API docs.
3.2.6.3.1. PersistenceHelper
Вспомогательный класс со статическими методами, делегирующий выполнение бину EntityStates.
3.2.6.4. Events
|
Руководство Decouple Business Logic with Application Events содержит примеры использования событий в приложениях. |
Бин Events реализует функциональность публикации объектов-событий уровня приложения. События могут использоваться для передачи данных между слабо связанными компонентами приложения. Бин Events является простым фасадом для объекта ApplicationEventPublisher Spring Framework.
public interface Events {
String NAME = "cuba_Events";
void publish(ApplicationEvent event);
}Этот бин имеет только один метод - publish(), принимающий объект события. Метод Events.publish() уведомляет все слушатели, зарегистрированные в приложении и подписанные на события того же типа, что и переданный объект. Вы может использовать класс-обёртку PayloadApplicationEvent для публикации любых объектов в качестве событий.
См. также руководство Spring Framework.
- Обработка событий в компонентах приложения
-
Прежде всего, необходимо создать класс события. Он должен быть наследником класса
ApplicationEvent. Класс события может включать любые дополнительные данные. Например:package com.company.sales.core; import com.haulmont.cuba.security.entity.User; import org.springframework.context.ApplicationEvent; public class DemoEvent extends ApplicationEvent { private User user; public DemoEvent(Object source, User user) { super(source); this.user = user; } public User getUser() { return user; } }Бины могут публиковать события, используя бин
Events:package com.company.sales.core; import com.haulmont.cuba.core.global.Events; import com.haulmont.cuba.core.global.UserSessionSource; import com.haulmont.cuba.security.global.UserSession; import org.springframework.stereotype.Component; import javax.inject.Inject; @Component public class DemoBean { @Inject private Events events; @Inject private UserSessionSource userSessionSource; public void demo() { UserSession userSession = userSessionSource.getUserSession(); events.publish(new DemoEvent(this, userSession.getUser())); } }По умолчанию все события обрабатываются синхронно.
Есть два способа обработки событий:
-
Реализовать интерфейс
ApplicationListener. -
Использовать аннотацию
@EventListenerдля метода.
В первом случае, мы должны создать бин, реализующий интерфейс
ApplicationListenerс указанием типа события:@Component public class DemoEventListener implements ApplicationListener<DemoEvent> { @Inject private Logger log; @Override public void onApplicationEvent(DemoEvent event) { log.debug("Demo event is published"); } }Второй способ может использоваться для сокрытия деталей реализации обработчика событий и обработки множества различных событий в одном бине:
@Component public class MultipleEventListener { @Order(10) @EventListener protected void handleDemoEvent(DemoEvent event) { // handle event } @Order(1010) @EventListener protected void handleUserLoginEvent(UserLoggedInEvent event) { // handle event } }По умолчанию, события в Spring требуют модификаторов доступа
protected,packageилиpublicдля методов, аннотированных@EventListener. Обратите внимание, что модификаторprivateне поддерживается.Методы, аннотированные
@EventListener, не работают в services, JMX-бинах и других бинах с интерфейсами. При использовании@EventListenerв таком бине на старте приложения будет выброшено исключение:BeanInitializationException: Failed to process @EventListener annotation on bean. Need to invoke method declared on target class, but not found in any interface(s) of the exposed proxy type. Either pull the method up to an interface or switch to CGLIB proxies by enforcing proxy-target-class mode in your configuration.
Если необходимо обрабатывать событие в бине с интерфейсом, реализуйте в нем также интерфейс
ApplicationListenerс типом нужного события.Вы можете использовать интерфейс
Orderedи аннотацию@OrderSpring Framework для указания порядка исполнения обработчиков событий. Все бины и обработчики событий платформы используют значениеorderот 100 до 1000, таким образом, вы можете добавить обработчик событий как до, так и после обработчиков события платформы. Если вы хотите добавить свой обработчик события до обработчиков из платформы, то используйте значение меньше 100.См. также События логина.
-
- Обработка событий в экранах
-
Обычно, бин
Eventsделегирует публикацию события объектуApplicationContext. Для блока Web Client это поведение отличается от стандартного, вы можете использовать дополнительный интерфейс для классов событий -UiEvent. Это интерфейс-маркер для событий, которые должны быть доставлены в экраны пользовательского интерфейса текущего экземпляра UI (текущей вкладки веб-браузера).Важно отметить, что экземпляры событий, реализующих
UiEvent, не доставляются в бины Spring и не могут быть обработаны за пределами UI.Пример класса события:
package com.company.sales.web; import com.haulmont.cuba.gui.events.UiEvent; import com.haulmont.cuba.security.entity.User; import org.springframework.context.ApplicationEvent; public class UserRemovedEvent extends ApplicationEvent implements UiEvent { private User user; public UserRemovedEvent(Object source, User user) { super(source); this.user = user; } public User getUser() { return user; } }События публикуются при помощи бина
Eventsиз контроллера экрана так же, как и из бинов Spring:@Inject Events events; // ... UserRemovedEvent event = new UserRemovedEvent(this, removedUser); events.publish(event);Чтобы обработать событие, вы должны объявить в экране метод с аннотацией
@EventListener(ИнтерфейсApplicationListenerне поддерживается):@Order(15) @EventListener protected void onUserRemove(UserRemovedEvent event) { notifications.create() .withCaption("User is removed " + event.getUser()) .show(); }Вы можете использовать аннотацию
@Order, чтобы задать порядок вызова обработчиков события.Если класс события реализует
UiEvent, и объект такого события опубликован при помощи бинаEventsиз потока UI, то будут вызваны обработчики событий этого типа в открытых на данный момент окнах и фреймах. Обработка событий синхронная. Только экраны и фреймы текущей активной вкладки веб-браузера получат уведомление о событии.
3.2.6.5. Messages
Интерфейс Messages обеспечивает получение локализованных строк сообщений.
Рассмотрим методы интерфейса подробнее.
-
getMessage()- возвращает локализованное сообщение по ключу, имени пакета сообщений и требуемой локали. Существует несколько модификаций данного метода в зависимости от набора параметров. Если локаль не указана в параметре метода, используется локаль текущего пользователя.Примеры:
@Inject protected Messages messages; ... String message1 = messages.getMessage(getClass(), "someMessage"); String message2 = messages.getMessage("com.abc.sales.web.customer", "someMessage"); String message3 = messages.getMessage(RoleType.STANDARD); -
formatMessage()- находит локализованное сообщение по ключу, имени пакета сообщений и требуемой локали, и использует его для форматирования переданных параметров. Формат задается по правилам методаString.format(). Существует несколько модификаций данного метода в зависимости от набора параметров. Если локаль не указана в параметре метода, используется локаль текущего пользователя.Пример:
String formattedValue = messages.formatMessage(getClass(), "someFormat", someValue); -
getMainMessage()- возвращает локализованное сообщение из главного пакета данного блока приложения.Пример:
protected Messages messages = AppBeans.get(Messages.class); ... messages.getMainMessage("actions.Ok"); -
getMainMessagePack()- возвращает имя главного пакета сообщений данного блока приложения.Пример:
String formattedValue = messages.formatMessage(messages.getMainMessagePack(), "someFormat", someValue); -
getTools()- возвращает экземпляр интерфейсаMessageTools(см. ниже).
3.2.6.5.1. MessageTools
ManagedBean, содержащий вспомогательные методы работы с локализованными сообщениями. Интерфейс MessageTools можно получить либо методом Messages.getTools(), либо как любой другой бин - инжекцией или через класс AppBeans.
Методы MessageTools:
-
loadString()- возвращает локализованное сообщение, заданное ссылкой видаmsg://{messagePack}/{key}.Составные части ссылки:
-
msg://- обязательный префикс. -
{messagePack}- необязательное имя пакета сообщения. Если не указано, предполагается, что имя пакета передается вloadString()отдельным параметром. -
{key}- ключ сообщения в пакете.Примеры ссылок на сообщения:
msg://someMessage msg://com.abc.sales.web.customer/someMessage
-
-
getEntityCaption()- возвращает локализованное название сущности. -
getPropertyCaption()- возвращает локализованное название атрибута сущности. -
hasPropertyCaption()- определяет, задано ли для атрибута сущности локализованное название. -
getMessageRef()- формирует для мета-свойства ссылку на сообщение, по которой можно получить локализованное название атрибута сущности. -
getDefaultLocale()- возвращает локаль приложения по умолчанию, то есть указанную первой в списке свойства cuba.availableLocales. -
useLocaleLanguageOnly()- возвращаетtrue, если в списке поддерживаемых приложением локалей, заданном свойством cuba.availableLocales, для всех локалей определен только язык, аcountryиvariantне указаны. Этим методом пользуются механизмы платформы, которым необходимо найти наиболее подходящую локаль из списка поддерживаемых на основе локали, полученной из внешних источников, таких как операционная система или HTTP запрос. -
trimLocale()- удаляет из переданной локали все кроме языка, если методuseLocaleLanguageOnly()возвращаетtrue.
Для расширения набора вспомогательных методов в конкретном приложении бин MessageTools можно переопределить. Примеры работы с расширенным интерфейсом:
MyMessageTools tools = messages.getTools();
tools.foo();((MyMessageTools) messages.getTools()).foo();3.2.6.6. Metadata
Интерфейс Metadata обеспечивает доступ к сессии метаданных и репозиторию представлений.
Методы интерфейса:
-
getSession()- возвращает экземпляр сессии метаданных -
getViewRepository()- возвращает экземпляр репозитория представлений -
getExtendedEntities()- возвращает экземплярExtendedEntities, предназначенный для работы с расширенными сущностями. Подробнее см. Расширение сущности -
create()- создать экземпляр сущности, учитывая возможность расширения.Для персистентных наследников
BaseLongIdEntityиBaseIntegerIdEntityданный метод также присваивает идентификаторы. Значения идентификаторов получаются из автоматически создаваемых в базе данных последовательностей. По умолчанию последовательности создаются в основном хранилище. Если же свойство приложения cuba.useEntityDataStoreForIdSequence установлено в true, последовательности будут создаваться в хранилище, к которому принадлежит данная сущность. -
getTools()- возвращает экземпляр интерфейсаMetadataTools(см. ниже).
3.2.6.6.1. MetadataTools
ManagedBean, содержащий вспомогательные методы работы с метаданными. Интерфейс MetadataTools можно получить либо методом Metadata.getTools(), либо как любой другой бин - инжекцией или через класс AppBeans.
Методы MetadataTools:
-
getAllPersistentMetaClasses()- возвращает коллекцию мета-классов персистентных сущностей -
getAllEmbeddableMetaClasses()- возвращает коллекцию мета-классов встраиваемых сущностей -
getAllEnums()- возвращает коллекцию классов перечислений, используемых в качестве типов атрибутов сущностей -
format()- форматирует переданное значение в соответствии с типом данных заданного мета-свойства -
isSystem()- определяет, является ли переданное мета-свойство системным, т.е. заданным в одном из базовых интерфейсов сущностей -
isPersistent()- определяет, является ли переданное мета-свойство персистентным, т.е. хранимым в БД -
isTransient()- определяет, является ли переданное мета-свойство или произвольный атрибут неперсистентным -
isEmbedded()- определяет, является ли переданное мета-свойство встроенным объектом -
isAnnotationPresent()- определяет наличие указанной аннотации на классе или его предках -
getNamePatternProperties()- возвращает коллекцию мета-свойств атрибутов, входящих в имя экземпляра, возвращаемого методомInstance.getInstanceName(). См. @NamePattern.
Для расширения набора вспомогательных методов в конкретном приложении бин MetadataTools можно переопределить. Примеры работы с расширенным интерфейсом:
MyMetadataTools tools = metadata.getTools();
tools.foo();((MyMetadataTools) metadata.getTools()).foo();3.2.6.7. Resources
Обеспечивает загрузку ресурсов по следующим правилам:
-
если указанное местонахождение представляет собой URL, ресурс загружается из этого URL;
-
если указанное местонахождение начинается с префикса
classpath:, ресурс загружается из classpath; -
если не URL и не начинается с
classpath:, то:-
в каталоге конфигурации приложения ищется файл, используя указанное местонахождение как относительный путь. Если файл найден, ресурс загружается из него;
-
если ресурс не найден на предыдущих этапах, он загружается из classpath.
-
На практике явное указание URL или префикса classpath: используется редко, т.е. обычно ресурсы загружаются либо из конфигурационного каталога, либо из classpath. Ресурс в конфигурационном каталоге замещает одноименный ресурс в classpath.
Методы Resources:
-
getResourceAsStream()- возвращаетInputStreamдля указанного ресурса, либоnull, если ресурс не найден. Поток должен быть закрыт после использования, например:@Inject protected Resources resources; ... InputStream stream = null; try { stream = resources.getResourceAsStream(resourceLocation); ... } finally { IOUtils.closeQuietly(stream); }Возможно использование "try with resources":
try (InputStream stream = resources.getResourceAsStream(resourceLocation)) { ... } -
getResourceAsString()- возвращает указанный ресурс в виде строки, либоnull, если ресурс не найден
3.2.6.8. Scripting
Интерфейс Scripting позволяет динамически (т.е. во время работы приложения) компилировать и загружать классы Java и Groovy, а также выполнять скрипты и выражения на Groovy.
Методы Scripting:
-
evaluateGroovy()- выполняет выражение на Groovy и возвращает его результат.Свойство приложения cuba.groovyEvaluatorImport позволяет определить общий набор импортируемых классов, подставляемых в каждое выполняемое выражение. По умолчанию все стандартные блоки приложения импортируют класс PersistenceHelper.
Скомпилированные выражения кэшируются, что значительно ускоряет повторное выполнение.
Пример:
@Inject protected Scripting scripting; ... Integer intResult = scripting.evaluateGroovy("2 + 2", new Binding()); Binding binding = new Binding(); binding.setVariable("instance", new User()); Boolean boolResult = scripting.evaluateGroovy("return PersistenceHelper.isNew(instance)", binding);
-
runGroovyScript()- выполняет скрипт Groovy и возвращает его результат.Скрипт должен быть расположен либо в конфигурационном каталоге приложения, либо в classpath (текущая реализация
Scriptingподдерживает ресурсы classpath только внутри JAR-файлов). Скрипт в конфигурационном каталоге замещает одноименный скрипт в classpath.Путь к скрипту указывается с разделителями
/, в начале пути символ/не требуется.Пример:
@Inject protected Scripting scripting; ... Binding binding = new Binding(); binding.setVariable("itemId", itemId); BigDecimal amount = scripting.runGroovyScript("com/abc/sales/CalculatePrice.groovy", binding); -
loadClass()- загружает Java или Groovy класс, используя следующую последовательность действий:-
Если класс уже загружен, возвращает его.
-
Ищет исходный текст Groovy (файл
*.groovy) в каталоге конфигурации. Если найден, компилирует его, загружает и возвращает класс. -
Ищет исходный текст Java (файл
*.java) в каталоге конфигурации. Если найден, компилирует его, загружает и возвращает класс. -
Ищет скомпилированный класс в classpath, если найден - загружает и возвращает его.
-
Если ничего не найдено, возвращает
null.Файлы исходных текстов Java и Groovy в каталоге конфигурации можно изменять во время работы приложения. При следующем вызове
loadClass()соответствующий класс будет перекомпилирован и возвращен новый, однако существуют следующие ограничения:-
нельзя изменять тип исходного текста с Groovy на Java
-
если существовал исходный текст Groovy, и был однажды скомпилирован, то удаление файла исходного текста не приведет к загрузке другого класса из classpath - будет по-прежнему возвращаться класс, скомпилированный из удаленного исходника.
Пример:
@Inject protected Scripting scripting; ... Class calculatorClass = scripting.loadClass("com.abc.sales.PriceCalculator");
-
-
-
getClassLoader()- возвращаетClassLoader, способный работать по правилам, описанным выше для методаloadClass().
Кэш скомпилированных классов можно очистить во время выполнения с помощью JMX-бина CachingFacadeMBean.
См. также ScriptingManagerMBean.
3.2.6.9. Security
Обеспечивает авторизацию - проверку прав пользователя на различные объекты системы. Перед вызовом соответствующих методов UserSession выполняется поиск исходного мета-класса сущности, что является важным при наличии расширений. Кроме методов, дублирующих методы UserSession, данный интерфейс имеет методы isEntityAttrReadPermitted() и isEntityAttrUpdatePermitted(), предназначенные для определения доступности пути к атрибуту с учетом доступности атрибутов и сущностей, входящих в этот путь.
Интерфейс Security рекомендуется использовать в прикладном коде вместо вызовов методов UserSession.isXYXPermitted().
Подробнее см. Аутентификация пользователей.
3.2.6.10. TimeSource
Обеспечивает получение текущего времени. Применение new Date() и т.п. в прикладном коде не рекомендуется.
Примеры:
@Inject
protected TimeSource timeSource;
...
Date date = timeSource.currentTimestamp();long startTime = AppBeans.get(TimeSource.class).currentTimeMillis();3.2.6.11. UserSessionSource
Обеспечивает получение объекта сессии текущего пользователя. Подробнее см. Аутентификация пользователей.
3.2.6.12. UuidSource
Обеспечивает получение значений UUID, в том числе для идентификаторов сущностей. Применение UUID.randomUUID() в прикладном коде не рекомендуется.
Для вызова из статического контекста можно использовать класс UuidProvider, который имеет также дополнительный метод fromString(), работающий быстрее, чем стандартный метод UUID.fromString().
3.2.7. AppContext
AppContext - системный класс, в статических полях которого хранятся ссылки на некоторые общие для любого блока приложения компоненты:
-
ApplicationContextфреймворка Spring -
Набор свойств приложения, загруженных из файлов
app.properties -
ThreadLocalпеременная, хранящая экземплярыSecurityContext -
Коллекция слушателей жизненного цикла приложения (
AppContext.Listener)
AppContext инициализируется на запуске приложения классами-загрузчиками, специфичными для типа блока приложения:
-
загрузчик Middleware -
AppContextLoader -
загрузчик Web Client -
WebAppContextLoader -
загрузчик Web Portal -
PortalAppContextLoader
AppContext может быть использован в прикладном коде для решения следующих задач:
-
Получения значений свойств приложения, хранимых в файлах
app.properties, если они недоступны через конфигурационные интерфейсы. -
Передачи
SecurityContextв новые потоки выполнения, см. Аутентификация пользователей. -
Регистрации слушателей, срабатывающих после полной инициализации и перед закрытием приложения, например:
AppContext.addListener(new AppContext.Listener() { @Override public void applicationStarted() { System.out.println("Application is ready"); } @Override public void applicationStopped() { System.out.println("Application is closing"); } });Рекомендуемый способ выполнения кода в момент запуска и остановки приложения - это использование События жизненного цикла.
3.2.8. События жизненного цикла
В приложении на CUBA существуют следующие типы событий жизненного цикла:
- AppContextInitializedEvent
-
Посылается сразу после инициализации AppContext. В этот момент:
-
Полностью инициализированы все бины, в том числе выполнены их методы
@PostConstruct. -
Можно использовать статические методы получения бинов
AppBeans.get(). -
Метод
AppContext.isStarted()возвращаетfalse. -
Метод
AppContext.isReady()возвращаетfalse.
-
- AppContextStartedEvent
-
Посылается после
AppContextInitializedEventи после запуска всехAppContext.Listener.applicationStarted(). В этот момент:-
Метод
AppContext.isStarted()возвращаетtrue. -
Метод
AppContext.isReady()возвращаетfalse. -
В блоке Middleware: если свойство приложения cuba.automaticDatabaseUpdate включено, все скрипты обновления БД успешно выполнены.
-
- AppContextStoppedEvent
-
Посылается перед остановкой приложения и после запуска всех
AppContext.Listener.applicationStopped(). В этот момент:-
Все бины работоспособны и доступны через статические методы
AppBeans.get(). -
Метод
AppContext.isStarted()возвращаетfalse. -
Метод
AppContext.isReady()возвращаетfalse.
-
Порядком исполнения слушателей можно управлять с помощью аннотации @Order. Константы Events.HIGHEST_PLATFORM_PRECEDENCE и Events.LOWEST_PLATFORM_PRECEDENCE определяют диапазон значений, используемый слушателями платформы.
Пример:
package com.company.demo.core;
import com.haulmont.cuba.core.global.Events;
import com.haulmont.cuba.core.sys.events.*;
import org.slf4j.Logger;
import org.springframework.context.event.EventListener;
import org.springframework.stereotype.Component;
import javax.inject.Inject;
@Component
public class MyAppLifecycleBean {
@Inject
private Logger log;
// event type is defined by annotation parameter
@EventListener(AppContextInitializedEvent.class)
// run after all platform listeners
@Order(Events.LOWEST_PLATFORM_PRECEDENCE + 100)
protected void appInitialized() {
log.info("Initialized");
}
// event type is defined by method parameter
@EventListener
protected void appStarted(AppContextStartedEvent event) {
log.info("Started");
}
@EventListener
protected void appStopped(AppContextStoppedEvent event) {
log.info("Stopped");
}
}- ServletContextInitializedEvent
-
Посылается сразу после инициализации контекстов
ServletContextи AppContext. В этот момент:-
Можно использовать статические методы получения бинов
AppBeans.get(). -
Событие содержит в себе контексты, позволяющие зарегистрировать собственные сервлеты, фильтры и слушатели, см. раздел Регистрация сервлетов и фильтров.
-
- ServletContextDestroyedEvent
-
Посылается перед уничтожением контекстов
ServletContextиAppContextи позволяет вручную освободить ресурсы.Пример использования:
@Component public class MyInitializerBean { @Inject private Logger log; @EventListener public void foo(ServletContextInitializedEvent e) { log.info("Application and servlet context is initialized"); } @EventListener public void bar(ServletContextDestroyedEvent e) { log.info("Application is about to shut down, all contexts are now destroyed"); } }
3.2.9. Свойства приложения
Свойства приложения − именованные значения различных типов, определяющие всевозможные аспекты конфигурации и функционирования приложения. Свойства приложения широко используются в платформе, и могут применяться в приложении для решения аналогичных задач.
По назначению свойства приложения можно классифицировать следующим образом:
-
Конфигурационные параметры - задают наборы конфигурационных файлов и некоторые параметры пользовательского интерфейса, т.е. определяют функциональность приложения. Значения конфигурацинных параметров обычно задаются при разработке приложения.
Например: cuba.springContextConfig.
-
Параметры развертывания - различные URL для соединения блоков приложения, тип используемой БД, настройки безопасности и т.д. Значения параметров развертывания обычно зависят от окружения, в котором устанавливается данный экземпляр приложения.
-
Параметры времени выполнения - активность аудита, параметры отсылки email и т.д. Параметры времени выполнения могут быть изменены при необходимости во время работы приложения без его перезапуска.
Например: cuba.entityLog.enabled, cuba.email.smtpHost.
- Задание свойств приложения
-
Значения свойств приложения могут быть заданы в базе данных, в файлах свойств, через системные свойства Java или переменные окружения ОС. Если свойство с некоторым именем задано в нескольких источниках, его значение определяется в следующем приоритете:
-
Системное свойство Java (высший приоритет)
-
Переменная окружения ОС
-
Файл свойств
-
База данных (низший приоритет)
Например, значение, заданное в файле, переопределяет одноименное значение, заданное в БД.
Для переменных окружения ОС фреймворк пытается сначала найти точное соответствие по имени свойства, и если такой переменной нет, то ищется переменная с именем в верхнем регистре и с подчеркиваниями вместо точек. Например, переменная окружения
MYAPP_SOMEPROPERTYможет задать значение свойствуmyapp.someProperty. Для того, чтобы запретить возможность использования имен в верхнем регистре с подчеркиваниями, установите свойство приложенияcuba.disableUppercaseEnvironmentPropertiesв true.Некоторые свойства не поддерживают установку свойств в базе данных по причине того, что их значения требуются еще до того, как БД становится доступной приложению. Это параметры конфигурации и развертывания. Поэтому их можно устанавливать только в файлах свойств, через системные свойства Java или переменные окружения ОС. Параметры времени выполнения всегда могут быть установлены в базе данных (и, возможно, переопределены в файле или системными свойствами).
Как правило, некоторое свойство используется только в одном или нескольких блоках приложения. Например, cuba.persistenceConfig необходимо только для Middleware, cuba.web.appWindowMode − только для Web Client, а cuba.springContextConfig − для всех блоков. Это означает, что если нужно задать значение некоторому свойству, это необходимо сделать во всех блоках, в которых данное свойство используется. Свойства, хранящиеся в БД, доступны всем блокам, поэтому они устанавливаются в одном месте (в таблице базы данных), независимо от того, в каких блоках они используются. Более того, платформа предоставляет экран Administration > Application Properties для управления свойствами, хранящимися в БД. Свойства, хранящиеся в файлах, должны быть установлены одновременно в соответствующих файлах блоков приложения.
Когда вам необходимо установить значение свойству приложения, определенному платформой, найдите это свойство в документации. Если в документации сказано, что свойство хранится в БД, для установки значения используйте экран Administration > Application Properties. В противном случае выясните в документации, какие блоки приложения используют свойство, и установите значение в файлах
app.propertiesэтих блоков. Например, если в документации сказано, что свойство используется во всех блоках, а ваше приложение состоит из Middleware и Web Client, установите свойство в файлеapp.propertiesмодуля core и в файлеweb-app.propertiesмодуля web. Параметры развертывания можно также установить вне проекта в файлеlocal.app.properties. Подробнее см. Хранение свойств в файлах. -
- Свойства из компонентов приложения
-
Компонент приложения может предоставлять свойства путем объявления их в файле app-component.xml. Тогда если приложение, использующее компонент, не задает собственное значение свойства, значение будет получено из компонента. Если приложение использует несколько компонентов, предоставляющих одно и то же свойство, значение будет получено из компонента, который является ближайшим предком в иерархии зависимостей между компонентами. Если существует несколько компонентов на одном уровне иерархии, то значение свойства непредсказуемо.
- Аддитивные свойства
-
Иногда необходимо получить объединенное значение свойства из всех компонентов, используемых в приложении. Это особенно актуально для конфигурационных параметров, которые позволяют механизмам платформы конфигурировать приложение на основании свойств, предоставляемых компонентами приложения.
Такие свойства должны быть сделаны аддитивными путем добавления знака плюс в начале значения. Этот знак говорит о том, что значение свойства во время выполнения должно быть собрано из компонентов приложения. Например, cuba.persistenceConfig - аддитивное свойство. В вашем проекте оно задает файл
persistence.xml, определяющий модель данных проекта. Однако вследствие того, что реальное значение свойства будет также включать файлыpersistence.xmlкомпонентов приложения, полная модель данных вашего приложения будет включать также и сущности, определенные в компонентах.Если знак
+опустить, то значение будет получено только из текущего проекта. Это может быть полезным в случае, если наследование некоторой конфигурации из компонентов не требуется, например, при определении структуры главного меню.Значение аддитивного свойства, полученное во время выполнения, состоит из отдельных значений, разделенных пробелом.
- Программный доступ к свойствам приложения
-
Доступ к свойствам из кода приложения можно получить следующими способами:
-
Через конфигурационный интерфейс. Если определить свойства с помощью аннотированных методов конфигурационного интерфейса, то код приложения будет иметь типизированный доступ к этим свойствам. Конфигурационные интерфейсы позволяют работать со свойствами всех типов хранения: в базе данных, в файлах и системных свойствах.
-
Методом
getProperty()класса AppContext. Если вы установили свойство в файле или в системном свойстве Java, то код приложения может прочитать значение с помощью этого метода. Данный подход имеет следующие недостатки:-
Не поддерживаются свойства, хранящиеся в базе данных.
-
В отличие от вызова метода интерфейса, вам необходимо передавать имя свойства в строке.
-
В отличие от получения результата нужного типа, вы можете получить только строковое значение свойства.
-
-
3.2.9.1. Хранение свойств в файлах
Свойства, определяющие конфигурацию и параметры развертывания, задаются в специальных файлах свойств, имеющих имя вида *app.properties. Каждый блок приложения имеет набор таких файлов, который задается в web.xml в параметре appPropertiesConfig.
Например, набор файлов свойств блока Middleware задается в файле web/WEB-INF/web.xml модуля core, и выглядит следующим образом:
<context-param>
<param-name>appPropertiesConfig</param-name>
<param-value>
classpath:com/company/sample/app.properties
/WEB-INF/local.app.properties
"file:${app.home}/local.app.properties"
</param-value>
</context-param>Здесь префикс classpath: означает, что данный файл нужно искать в Java classpath, префикс file: − в файловой системе. Путь без такого префикса означает путь внутри веб-приложения относительно его корня. Возможно использование системных свойств Java, в данном случае app.home содержит путь к домашнему каталогу приложения.
Порядок перечисления файлов важен, так как значения, указанные в каждом последующем файле, заменяют значения одноименных свойств, заданные в предыдущих файлах. Если некоторого файла нет, он игнорируется.
Последний файл в приведенном наборе − local.app.properties. Он может использоваться для переопределения свойств приложения при развертывании.
|
Правила задания информации в файлах
|
3.2.9.2. Хранение свойств в базе данных
Свойства приложения, представляющие собой параметры времени выполнения, хранятся в таблице SYS_CONFIG базы данных.
Такие свойства имеют следующие особенности:
-
Так как значение свойства хранится в базе данных, оно задается в одном месте, независимо от того, в каких блоках приложения оно используется.
-
Значение может быть изменено и сохранено во время работы приложения следующими способами:
-
Через экран Administration > Application Properties.
-
Через JMX бин ConfigStorageMBean.
-
Если конфигурационный интерфейс, содержащий это свойство, имеет соответствующий setter, то свойство может изменено кодом приложения.
-
-
Значение свойства может быть переопределено для конкретного блока приложения в его файле
app.properties, системным свойством Java или переменной окружения ОС.
Следует иметь в виду, что на клиентском уровне чтение свойства, хранящегося в БД, приводит к запросу к Middleware, что менее эффективно, чем чтение свойства из локального файла app.properties. Для уменьшения количества таких запросов клиент кэширует все свойства, хранящиеся в БД, на время жизни экземпляра реализации конфигурационного интерфейса. Поэтому если, например, в некотором экране UI необходимо несколько раз обратиться к свойствам одного конфигурационного интерфейса, лучше получить ссылку на него при инициализации экрана, и сохранить в поле для последующих обращений к одному и тому же экземпляру.
3.2.9.3. Конфигурационные интерфейсы
Данный механизм позволяет работать со свойствами приложения через методы Java-интерфейсов, что дает следующие преимущества:
-
Типизированность - прикладной код работает с нужными типами (String, Boolean, Integer и пр.), а не только со строками.
-
В прикладном коде вместо строковых идентификаторов свойств используются методы интерфейсов, имена которых проверяются компилятором и подсказываются средой разработки.
Пример получения значения таймаута транзакции в блоке Middleware:
@Inject
private ServerConfig serverConfig;
public void doSomething() {
int timeout = serverConfig.getDefaultQueryTimeoutSec();
...
}При невозможности инжекции можно получить ссылку на конфигурационный интерфейс через Configuration:
int timeout = AppBeans.get(Configuration.class)
.getConfig(ServerConfig.class)
.getDefaultQueryTimeoutSec();|
Конфигурационные интерфейсы не являются нормальными бинами Spring, не пытайтесь получить их через |
3.2.9.3.1. Использование
Для создания конфигурационного интерфейса необходимо:
-
Создать интерфейс, унаследованный от
com.haulmont.cuba.core.config.Config(не путать с классом сущностиcom.haulmont.cuba.core.entity.Config) -
Добавить интерфейсу аннотацию
@Sourceдля указания источника (способа хранения) параметров:-
SourceType.SYSTEM- значение свойства будет взято из системных свойств данной JVM, т.е. методомSystem.getProperty(). -
SourceType.APP- значение свойства будет взято из файловapp.properties. -
SourceType.DATABASE- значение свойства будет взято из базы данных.
-
-
Создать методы доступа к свойству (getter / setter). Если значение свойства не предполагается изменять из кода приложения, метод доступа на запись не нужен. Тип, вовращаемый методом доступа на чтение, определяет тип свойства. Возможные типы рассмотрены ниже.
-
Добавить методу доступа на чтение аннотацию
@Property, определяющую имя свойства. -
Опционально аннотацию
@Sourceможно задать для отдельного свойства в интерфейсе, если его источник отличается от заданного для всего интерфейса. -
Если аннотация
@Sourceимеет значениеSourceType.DATABASE, то свойство можно редактировать на экране Administration > Application Properties. Если вы хотите, чтобы значение свойства было замаскировано, задайте на свойстве аннотацию@Secret. В этом случае на данном экране будет использован компонент PasswordField вместо обычного текстового поля.
|
Конфигурационный интерфейс должен быть определен внутри корневого пакета приложения (или во внутренних пакетах корневого пакета). |
Например:
@Source(type = SourceType.DATABASE)
public interface SalesConfig extends Config {
@Property("sales.companyName")
String getCompanyName();
@Property("sales.ftpPassword")
@Secret
String getFtpPassword();
}Создавать класс реализации конфигурационного интерфейса не нужно - при получении ссылки на интерфейс инжекцией или через Configuration будет автоматически создан необходимый прокси-объект.
3.2.9.3.2. Типы свойств
"Из коробки" платформой поддерживаются следующие типы свойств:
-
String, простые типы и их объектные обертки (boolean,Boolean,int,Integer, etc.). -
Перечисления (
enum). Значение свойства сохраняется в файле или БД в виде имени значения перечисления.Если перечисление реализует интерфейс
EnumClassи имеет статический методfromId()для получения значения по идентификатору, с помощью аннотации@EnumStoreможно задать хранение значения в виде идентификатора. Например:@Property("myapp.defaultCustomerGrade") @DefaultInteger(10) @EnumStore(EnumStoreMode.ID) CustomerGrade getDefaultCustomerGrade(); @EnumStore(EnumStoreMode.ID) void setDefaultCustomerGrade(CustomerGrade grade); -
Классы персистентных сущностей. При обращении к свойству типа сущности происходит загрузка из БД экземпляра, заданного значением свойства.
Для поддержки произвольного типа необходимо реализовать классы TypeStringify и TypeFactory для преобразования значения в строку и из нее, и указать эти классы для свойства с помощью аннотаций @Stringify и @Factory.
Рассмотрим этот процесс на примере типа UUID.
-
Создаем класс
com.haulmont.cuba.core.config.type.UuidTypeFactoryунаследованный отcom.haulmont.cuba.core.config.type.TypeFactoryи реализуем в нем метод:public Object build(String string) { if (string == null) { return null; } return UUID.fromString(string); } -
TypeStringifyсоздавать не нужно, т.к. по умолчанию будет использован методtoString()− в данном случае он нам подходит. -
Аннотируем свойство в конфигурационном интерфейсе:
@Factory(factory = UuidTypeFactory.class) UUID getUuidProp(); void setUuidProp(UUID value);
В платформе определены реализации TypeFactory и Stringify для следующих типов:
-
UUID-UuidTypeFactory, см. пример выше.TypeStringifyздесь не требуется, так как реализация методаtoString()по умолчанию подходит для типаUUID. -
java.util.Date-DateFactoryиDateStringify. Значение даты должно быть указано в форматеyyyy-MM-dd HH:mm:ss.SSS, например:cuba.test.dateProp = 2013-12-12 00:00:00.000Пример описания свойства с типом
Dateв конфигурационном интерфейсе:@Property("cuba.test.dateProp") @Factory(factory = DateFactory.class) @Stringify(stringify = DateStringify.class) Date getDateProp(); void setDateProp(Date date); -
List<Integer>(список целых чисел) -IntegerListTypeFactoryиIntegerListStringify. Значение свойства должно быть указано в виде списка чисел, разделенных пробелами, например:cuba.test.integerListProp = 1 2 3Пример описания свойства с типом
List<Integer>в конфигурационном интерфейсе:@Property("cuba.test.integerListProp") @Factory(factory = IntegerListTypeFactory.class) @Stringify(stringify = IntegerListStringify.class) List<Integer> getIntegerListProp(); void setIntegerListProp(List<Integer> list); -
List<String>(список строк) -StringListTypeFactoryиStringListStringify. Значение свойства должно быть указано в виде списка строк, разделенных символом "|", например:cuba.test.stringListProp = aaa|bbb|cccПример описания свойства с типом
List<String>в конфигурационном интерфейсе:@Property("cuba.test.stringListProp") @Factory(factory = StringListTypeFactory.class) @Stringify(stringify = StringListStringify.class) List<String> getStringListProp(); void setStringListProp(List<String> list);
3.2.9.3.3. Значения по умолчанию
Для свойств конфигурационных интерфейсов могут быть заданы значения по умолчанию. Эти значения будут возвращаться вместо null, если данный параметр не задан в месте хранения - в БД или в файле app.properties.
Значение по умолчанию может быть задано в виде строки с помощью аннотации @Default, либо в виде конкретного типа с помощью других аннотаций пакета com.haulmont.cuba.core.config.defaults:
@Property("cuba.email.adminAddress")
@Default("address@company.com")
String getAdminAddress();
@Property("cuba.email.delayCallCount")
@Default("2")
int getDelayCallCount();
@Property("cuba.email.defaultSendingAttemptsCount")
@DefaultInt(10)
int getDefaultSendingAttemptsCount();
@Property("cuba.test.dateProp")
@Default("2013-12-12 00:00:00.000")
@Factory(factory = DateFactory.class)
Date getDateProp();
@Property("cuba.test.integerList")
@Default("1 2 3")
@Factory(factory = IntegerListTypeFactory.class)
List<Integer> getIntegerList();
@Property("cuba.test.stringList")
@Default("aaa|bbb|ccc")
@Factory(factory = StringListTypeFactory.class)
List<String> getStringList();Для сущностей значение по умолчанию задается строкой вида {entity_name}-{id}-{optional_view_name}, например:
@Default("sec$User-98e5e66c-3ac9-11e2-94c1-3860770d7eaf-browse")
User getAdminUser();
@Default("sec$Role-a294aef0-3ac9-11e2-9433-3860770d7eaf")
Role getAdminRole();3.2.10. Локализация сообщений
Приложение на основе платформы CUBA поддерживает локализацию сообщений, то есть вывод всех элементов пользовательского интерфейса на языке, выбранном пользователем.
|
Руководство Localization in CUBA applications демонстрирует определение и использование локализованных сообщений в CUBA-приложениях. |
Возможности выбора языка пользователем определяются комбинацией свойств приложения cuba.localeSelectVisible и cuba.availableLocales.
Для того, чтобы некоторое сообщение могло быть локализовано, т.е. представлено пользователю на нужном языке, его необходимо поместить в так называемый пакет сообщений. Ниже рассмотрены принципы работы механизма локализации и правила создания сообщений.
3.2.10.1. Пакеты сообщений
Пакет сообщений представляет собой набор файлов свойств с именами вида messages{_XX}.properties, расположенных в одном Java-пакете. Суффикс XX определяет язык, для которого в данном файле содержатся сообщения, и соответствует коду языка в Locale.getLanguage(). Возможно также использование остальных атрибутов Locale, например, country. В этом случая файл пакета будет иметь вид messages{XX_YY}.properties. Один из файлов пакета может быть без суффикса языка - это _файл по умолчанию. Именем пакета сообщений считается имя Java-пакета, в котором расположены файлы пакета.
Рассмотрим пример:
/com/abc/sales/gui/customer/messages.properties
/com/abc/sales/gui/customer/messages_fr.properties
/com/abc/sales/gui/customer/messages_ru.properties
/com/abc/sales/gui/customer/messages_en_US.propertiesДанный пакет состоит из 4 файлов - один для русского языка, один для французского, один для американского английского (с кодом страны US) и один по умолчанию. Имя пакета - com.abc.sales.gui.customer
Файлы сообщений содержат пары ключ-значение, где ключ - это идентификатор сообщения, на который ссылается код приложения, а значение - само сообщение на языке данного файла. Правила задания пар аналогичны правилам файлов свойств java.util.Properties, со следующими особенностями:
-
Кодировка файла - обязательно
UTF-8 -
Поддерживается включение других пакетов сообщений с помощью ключа
@include, в том числе нескольких сразу - перечислением через запятую. При этом если некоторый ключ сообщения встречается и во включаемом пакете, и в текущем, будет использовано сообщение из текущего. Пример включения пакетов:@include=com.haulmont.cuba.web, com.abc.sales.web someMessage=Some Message ...
Получение сообщений из пакетов производится с помощью методов интерфейса Messages по следующим правилам:
-
Сначала производится поиск в конфигурационном каталоге приложения
-
Ищется файл
messages_XX.propertiesв каталоге, задаваемом именем пакета сообщений, гдеXX- код требуемого языка -
Если такого файла нет, в этом же каталоге ищется файл по умолчанию
messages.properties -
Если найден или файл нужного языка, или файл по умолчанию, он загружается вместе со всеми
@include, и в нем ищется ключ сообщения -
Если файл не найден, либо нужный ключ в нем отсутствует, производится смена каталога на родительский, и процедура поиска повторяется. И так до достижения корня конфигурационного каталога.
-
-
Если в конфигурационном каталоге сообщение не найдено, производится поиск в classpath по такому же алгоритму.
-
Если сообщение найдено, оно кэшируется и возвращается. Если не найдено - кэшируется факт отсутствия сообщения и возвращается ключ, который был передан для поиска. Таким образом, сложная процедура поиска выполняется только один раз, в дальнейшем результат загружается из локального для блока приложения кэша.
|
Рекомендуется организовывать пакеты сообщений следующим образом:
|
3.2.10.2. Главный пакет сообщений
Каждый стандартный блок приложения определяет для себя один главный пакет сообщений. Для блоков клиентского уровня этот пакет содержит названия пунктов главного меню и общих элементов UI (например, названия кнопок OK и Cancel). Для всех блоков приложения, включая Middleware, главный пакет определяет форматы преобразований Datatype.
Для указания главного пакета сообщений используется свойство приложения cuba.mainMessagePack. Значением свойства может быть либо один пакет, либо список пакетов, разделенный пробелами. Например:
cuba.mainMessagePack=com.haulmont.cuba.web com.abc.sales.webВ данном случае сообщения, заданные во втором пакете списка, будут перекрывать сообщения из первого пакета. Таким образом, в проекте приложения можно переопределять сообщения, заданные в пакетах компонентов приложения.
Сообщения, заданные в пакетах базовых проектов CUBA, также можно переопределять в главном пакете сообщений проекта:
com.haulmont.cuba.gui.backgroundwork/backgroundWorkProgress.timeoutMessage = Новое сообщение об ошибкеДля локализации сообщений о нарушении ограничения уникальности в базе данных используются ключи, соответствующие именам индексов. Обратите внимание, что имя ключа должно быть написано заглавными буквами.
IDX_SEC_USER_UNIQ_LOGIN = A user with the same login already exists3.2.10.3. Локализация названий сущностей и атрибутов
Для отображения в UI локализованных названий сущностей и их атрибутов необходимо создать специальные пакеты сообщений в тех же Java-пакетах, что и сами сущности. Формат файлов сообщений должен быть следующим:
-
Ключ названия сущности - простое имя класса (без пакета)
-
Ключ названия атрибута - простое имя класса, затем через точку имя атрибута
Пример русской локализации сущности com.abc.sales.entity.Customer - файл /com/abc/sales/entity/messages_ru.properties:
Customer=Покупатель
Customer.name=Имя
Customer.email=Email
Order=Заказ
Order.customer=Покупатель
Order.date=Дата
Order.amount=СуммаТакие пакеты сообщений, как правило, используются неявно для разработчика, например, визуальными компонентами Table и FieldGroup. Кроме того, названия сущностей и атрибутов могут быть также получены следующими методами:
-
программно - методами MessageTools
getEntityCaption(),getPropertyCaption() -
в XML-дескрипторе экрана - указанием ссылки на сообщение по правилам
MessageTools.loadString:msg://{entity_package}/{key}, например,caption="msg://com.abc.sales.entity/Customer.name"
3.2.10.4. Локализация enum
Для локализации названий и значений перечислений необходимо в пакет сообщений, находящийся в Java-пакете класса перечисления добавить сообщения со следующими ключами:
-
Ключ названия перечисления - простое имя класса (без пакета)
-
Ключ значения - простое имя класса, затем через точку имя значения
Например, для перечисления
package com.abc.sales;
public enum CustomerGrade { PREMIUM, HIGH, STANDARD }файл русской локализации /com/abc/sales/messages_ru.properties должен содержать строки:
CustomerGrade=Уровень покупателя
CustomerGrade.PREMIUM=Премиум
CustomerGrade.HIGH=Высокий
CustomerGrade.STANDARD=СтандартныйЛокализованные значения перечислений автоматически используются различными визуальными компонентами, например, LookupField. Для программного получения локализованного значения перечисления можно использовать метод getMessage() интерфейса Messages, просто передавая в него экземпляр enum.
3.2.11. Аутентификация пользователей
В данном разделе рассмотрены некоторые аспекты управления доступом с точки зрения разработчика приложения. Для получения полной информации о возможностях и настройке ограничения доступа пользователей к данным см. Подсистема безопасности.
3.2.11.1. UserSession
Основной элемент подсистемы контроля доступа в CUBA-приложении - пользовательская сессия. Это объект класса UserSession, который ассоциирован с аутентифицированным в данный момент в системе пользователем, и содержит информацию о правах доступа пользователя к данным. Объект текущей сессии может быть получен в любом блоке приложения через интерфейс инфраструктуры UserSessionSource.
Пользовательская сессия создается на Middleware при выполнении метода AuthenticationManager.login() после аутентификации пользователя по переданному имени и паролю. Объект UserSession затем кэшируется в данном блоке Middleware, и возвращается на клиентский уровень. При работе в кластере объект сессии реплицируется на соседние узлы кластера Middleware. Клиентский блок, получив объект сессии, также сохраняет его у себя, так или иначе ассоциируя с активным пользователем (например, в HTTP сессии). Далее все вызовы Middleware для данного пользователя сопровождаются передачей идентификатора сессии (типа UUID), причем прикладному коду не нужно об этом заботиться - идентификатор сессии передается автоматически, независимо от сигнатуры вызываемых методов среднего слоя. Обработка вызовов клиентов на Middleware начинается с извлечения из кэша сессии по полученному идентификатору и установки ее в потоке выполнения. Объект сессии удаляется из кэша при вызове метода AuthenticationService.logout(), либо при истечении времени бездействия, определяемого свойством приложения cuba.userSessionExpirationTimeoutSec.
Таким образом, идентификатор сессии, создаваемой при входе пользователя в систему, служит для аутентификации пользователя при каждом вызове среднего слоя.
Объект UserSession содержит также методы для авторизации текущего пользователя, т.е. проверки его прав на объекты системы: isScreenPermitted(), isEntityOpPermitted(), isEntityAttrPermitted(), isSpecificPermitted().
С объектом UserSession могут быть ассоциированы именованные атрибуты произвольного сериализуемого типа. Атрибуты устанавливаются методом setAttribute() и возвращаются методом getAttribute(). Последний может также возвращать следующие параметры сессии, как если бы они были атрибутами:
-
userId- ID текущего зарегистрированного или замещенного пользователя; -
userLogin- логин текущего зарегистрированного или замещенного пользователя в нижнем регистре.
Атрибуты реплицируются в кластере Middleware так же, как и все остальные данные сессии.
3.2.11.2. Вход в систему
Платформа предоставляет встроенные механизмы аутентификации, функциональность которых может быть расширена в приложениях. Они включают в себя различные схемы аутентификации, такие как вход по паролю, функциональность "Запомнить меня", доверенный и анонимный вход в систему.
|
Руководство Anonymous Access & Social Login содержит пример настройки публичного доступа к некоторым экранам приложения, а также реализации пользовательского входа в приложение с помощью учетной записи Google, Facebook или GitHub. |
Данный раздел преимущественно описывает механизмы аутентификации среднего слоя. Для информации об аутентификации веб-клиента см. Процесс входа в Web Client.
Платформа включает следующие механизмы среднего слоя:
-
AuthenticationManager, реализованный классомAuthenticationManagerBean -
Реализации интерфейса
AuthenticationProvider -
AuthenticationService, реализованный классомAuthenticationServiceBean -
UserSessionLog- см. журналирование пользовательских сессий.
Рисунок 6. Механизмы аутентификации среднего слоя
Также платформа включает следующие дополнительные компоненты:
-
TrustedClientService, реализованный классомTrustedClientServiceBean- предоставляет анонимную/системную сессию для доверенных приложений-клиентов. -
AnonymousSessionHolder- создаёт и хранит анонимную сессию для доверенных приложений-клиентов. -
UserCredentialsChecker- проверяет, могут ли быть использованы переданныеCredentials, например, для защиты от атак типа brute-force. -
UserAccessChecker- проверяет, может ли пользователь выполнять вход из данного контекста, например, в REST API или с указанного IP адреса.
Основной интерфейс аутентификации - AuthenticationManager, включающий 4 метода:
public interface AuthenticationManager {
AuthenticationDetails authenticate(Credentials credentials) throws LoginException;
AuthenticationDetails login(Credentials credentials) throws LoginException;
UserSession substituteUser(User substitutedUser);
void logout();
}Здесь есть два метода с похожей ответственностью: authenticate() и login(). Оба метода проверяют, являются ли переданные аутентификационные данные валидными и соответствуют ли они активному пользователю системы, затем возвращают объект AuthenticationDetails. Основное отличие в работе этих методов в том, что метод login() активирует сессию пользователя, так что она может использоваться в дальнейшем для вызова сервисов.
Объект Credentials представляет собой набор аутентификационных данных. Платформа поставляет несколько типов аутентификационных данных:
Доступные на всех слоях:
-
LoginPasswordCredentials -
RememberMeCredentials -
TrustedClientCredentials
Доступные только на среднем слое:
-
SystemUserCredentials -
AnonymousUserCredentials
Методы login / authenticate AuthenticationManager возвращают объект AuthenticationDetails, который содержит объект UserSession. Этот объект может быть использован для проверки дополнительных разрешений, чтения свойств объекта User и атрибутов сессии. В платформе есть встроенная реализация интерфейса AuthenticationDetails - SimpleAuthenticationDetails, который хранит только объект сессии пользователя, приложения могут предоставлять свою реализацию AuthenticationDetails с дополнительной инфомацией для приложений-клиентов.
AuthenticationManager может выполнить метод authenticate() с одним из следующих результатов:
-
вернуть объект
AuthenticationDetails, если он подтверждает, что переданные аутентификационные данные верны и соответствуют активному пользователю системы. -
выбросить
LoginException, если невозможно аутентифицировать пользователя, неверны аутентификационные данные или если пользователю запрещён доступ к системе. -
выбросить
UnsupportedCredentialsException, если переданный тип аутентификационных данных не поддерживается системой.
Реализация AuthenticationManager по умолчанию - AuthenticationManagerBean, который делегирует аутентификацию цепочке экземпляров AuthenticationProvider. AuthenticationProvider - это модуль аутентификации, который может обрабатывать объекты Credentials определённого типа. AuthenticationProvider также имеет специальный метод supports(), позволяющий узнать, поддерживается ли переданный тип аутентификационных данных.

Рисунок 7. Стандартный процесс входа пользователя
Стандартный процесс входа пользователя:
-
пользователь вводит свой логин и пароль
-
клиентский блок приложения вызывает метод
Connection.login(), передавая ему логин пользователя и пароль. -
Connectionсоздаёт объектCredentialsи вызывает методlogin()сервисаAuthenticationService. -
AuthenticationServiceделегирует выполнение бинуAuthenticationManager, который использует цепочку объектовAuthenticationProvider. В этой цепочке имеется бинLoginPasswordAuthenticationProvider, поддерживающий аутентификационные данные типаLoginPasswordCredentials. Он загружает объектUserпо полученному логину, хэширует полученный хэш пароля повторно, используя в качестве соли идентификатор пользователя, и сравнивает полученный хэш с сохраненным в БД хэшем пароля. В случае несовпадения выбрасывается исключениеLoginException. -
После успешной аутентификации в созданный экземпляр UserSession загружаются все параметры доступа данного пользователя: список ролей, права, ограничения и атрибуты сессии.
-
Если журналирование пользовательских сессий активировано, в базу данных сохраняется запись с информацией о текущей сессии.
См. также Специфика процесса входа в Web Client.
Алгоритм хэширования паролей реализуется бином типа EncryptionModule и задается в свойстве приложения cuba.passwordEncryptionModule. По умолчанию - BCrypt.
- Встроенные провайдеры аутентификации
-
Платформа включает следующие реализации интерфейса
AuthenticationProvider:-
LoginPasswordAuthenticationProvider -
RememberMeAuthenticationProvider -
TrustedClientAuthenticationProvider -
SystemAuthenticationProvider -
AnonymousAuthenticationProvider
Все реализации загружают пользователя из базы данных, проверяют переданные аутентификационные данные и создают неактивный экземпляр пользовательской сессии при помощи
UserSessionManager. Этот экземпляр может стать активным позднее, если вызывается методAuthenticationManager.login().Бины
LoginPasswordAuthenticationProvider,RememberMeAuthenticationProviderиTrustedClientAuthenticationProviderиспользуют дополнительные подключаемые проверки: бины, реализующие интерфейсUserAccessChecker. Если по крайней мере одна из таких проверок выбрасывает исключениеLoginException, то аутентификация не выполняется и исключениеLoginExceptionпередаётся вызывающему коду.Кроме того,
LoginPasswordAuthenticationProviderиRememberMeAuthenticationProviderпроверяют аутентификационные данные при помощи бинов UserCredentialsChecker. Имеется одна встроенная реализация этого интерфейса - BruteForceUserCredentialsChecker, который проверяет, пытается ли пользователь подобрать верные аутентификационные данные при помощи атаки brute-force. -
- Исключения
-
AuthenticationManagerиAuthenticationProviderмогут выбрасывать исключение LoginException или одного из его наследников из методовauthenticate()иlogin(). Исключение UnsupportedCredentialsException выбрасывается, если переданный объект аутентификационных данныхCredentialsне может быть обработан имеющимисяAuthenticationProvider.См. следующие классы исключений:
-
UnsupportedCredentialsException -
LoginException -
AccountLockedException -
UserIpRestrictedException -
RestApiAccessDeniedException
-
- События
-
Стандартная реализация
AuthenticationManager-AuthenticationManagerBeanпубликует следующие события во время аутентификации / входа пользователей:-
BeforeAuthenticationEvent/AfterAuthenticationEvent -
BeforeLoginEvent/AfterLoginEvent -
AuthenticationSuccessEvent/AuthenticationFailureEvent -
UserLoggedInEvent/UserLoggedOutEvent -
UserSubstitutedEvent
Бины Spring на среднем слое приложения могут обрабатывать эти события при помощи механизма подписок
@EventListener:@Component public class LoginEventListener { @Inject private Logger log; @EventListener protected void onUserLoggedIn(UserLoggedInEvent event) { User user = event.getUserSession().getUser(); log.info("Logged in user {}", user.getLogin()); } }Обработчики всех событий, перечисленных выше (кроме
AfterLoginEvent,UserSubstitutedEventиUserLoggedInEvent), могут выброситьLoginException, чтобы прервать процесс аутентификации / входа пользователя.Например, мы можем реализовать механизм режима обслуживания системы, который позволит запретить вход в систему на время её обслуживания.
@Component public class MaintenanceModeValve { private volatile boolean maintenance = true; public boolean isMaintenance() { return maintenance; } public void setMaintenance(boolean maintenance) { this.maintenance = maintenance; } @EventListener protected void onBeforeLogin(BeforeLoginEvent event) throws LoginException { if (maintenance && event.getCredentials() instanceof AbstractClientCredentials) { throw new LoginException("Sorry, system is unavailable"); } } } -
- Точки расширения
-
Вы можете расширить механизм аутентификации, используя следующие точки расширения:
-
AuthenticationService- заменить существующийAuthenticationServiceBean. -
AuthenticationManager- заменить существующийAuthenticationManagerBean. -
AuthenticationProvider- реализовать новый или заменить существующий бинAuthenticationProvider. -
Events - реализовать обработчик одного из доступных событий.
Вы можете заменить существующие бины, задействуя механизмы Spring Framework, например, зарегистрировав новую реализацию в XML конфигурации Spring модуля core:
<bean id="cuba_LoginPasswordAuthenticationProvider" class="com.company.authext.core.CustomLoginPasswordAuthenticationProvider"/>public class CustomLoginPasswordAuthenticationProvider extends LoginPasswordAuthenticationProvider { @Inject public CustomLoginPasswordAuthenticationProvider(Persistence persistence, Messages messages) { super(persistence, messages); } @Override public AuthenticationDetails authenticate(Credentials credentials) throws LoginException { LoginPasswordCredentials loginPassword = (LoginPasswordCredentials) credentials; // for instance, add new check before login if ("demo".equals(loginPassword.getLogin())) { throw new LoginException("Demo account is disabled"); } return super.authenticate(credentials); } }Обработчики событий могут быть упорядочены при помощи аннотации
@Order. Все бины и обработчики событий платформы используют значениеorderиз диапазона 100 и 1000, что позволяет добавлять обработчики на уровне проект как до, так и после кода платформы. Если вы хотите добавить свой обработчик до обработчиков/бинов платформы - используйте значение меньше 100.Задание
orderдля обработчика события:@Component public class DemoEventListener { @Inject private Logger log; @Order(10) @EventListener protected void onUserLoggedIn(UserLoggedInEvent event) { log.info("Demo"); } }Бины
AuthenticationProviderмогут реализовать интерфейс Ordered и методgetOrder()для определения очерёдности исполнения.@Component public class DemoAuthenticationProvider extends AbstractAuthenticationProvider implements AuthenticationProvider, Ordered { @Inject private UserSessionManager userSessionManager; @Inject public DemoAuthenticationProvider(Persistence persistence, Messages messages) { super(persistence, messages); } @Nullable @Override public AuthenticationDetails authenticate(Credentials credentials) throws LoginException { // ... } @Override public boolean supports(Class<?> credentialsClass) { return LoginPasswordCredentials.class.isAssignableFrom(credentialsClass); } @Override public int getOrder() { return 10; } } -
- Дополнительные возможности
-
-
В платформе имеется механизм защиты от взлома пароля методом перебора. Для его включения необходимо установить свойство приложения cuba.bruteForceProtection.enabled для блока Middleware. В этом случае после определенного количества неуспешных попыток входа для определенного имени пользователя с определенного IP-адреса вход для пары логин + IP-адрес блокируется на некоторое время. Допустимое количество попыток входа для пары логин + IP-адрес определяется свойством приложения cuba.bruteForceProtection.maxLoginAttemptsNumber (по умолчанию 5). Интервал блокировки пользователя в секундах задается свойством cuba.bruteForceProtection.blockIntervalSec (по умолчанию 60).
-
Возможен вариант, когда пароль пользователя (точнее, хэш пароля) не хранится в базе данных, а проверяется внешними средствами, например, путем интеграции с LDAP. В этом случае фактически аутентификацию выполняет клиентский блок, а Middleware "доверяет" клиенту, создавая сессию по одному только логину пользователя без пароля методом
AuthenticationService.login(), передаваяTrustedClientCredentials. Этот метод требует выполнения следующих условий:-
клиентский блок должен передать так называемый доверенный пароль, задаваемый на Middleware и на клиентском блоке свойством приложения cuba.trustedClientPassword
-
IP-адрес клиентского блока должен быть в списке, задаваемом свойством приложения cuba.trustedClientPermittedIpList
-
-
Вход в систему требуется также для автоматических процессов, запускаемых по расписанию, а также при подключении к бинам Middleware через JMX-интерфейс. Строго говоря, такие действия считаются административными и не требуют аутентификации до тех пор, пока не выполняется каких-либо изменений сущностей в базе данных. При записи сущностей в БД требуется проставить логин пользователя, который выполнил изменения, поэтому для работы таких процессов должен быть указан пользователь, от лица которого выполняются изменения.
Дополнительным плюсом входа в систему для автоматического процесса и для JMX-вызова является то, что вывод в журнал сообщений от логгеров сопровождается указанием логина текущего пользователя, если пользовательская сессия установлена в потоке выполнения. Это упрощает поиск сообщений от конкретного процесса при разборе журнала.
Вход в систему для процессов внутри Middleware выполняется вызовом
AuthenticationManager.login()с передачей объектаSystemUserCredentials, содержащего логин пользователя (без пароля), от имени которого будет работать данный процесс. В результате создается объект UserSession, который будет закэширован в данном блоке Middleware и не будет реплицироваться в кластере.
Более подробно аутентификация процессов внутри Middleware рассмотрена в разделе Системная аутентификация.
-
3.2.11.3. SecurityContext
Экземпляр класса SecurityContext хранит информацию о пользовательской сессии для текущего потока выполнения. Он создается и передается в метод AppContext.setSecurityContext() в следующие моменты:
-
для блоков Web Client и Web Portal - в начале обработки каждого HTTP-запроса от пользовательского браузера.
-
для блока Middleware - в начале обработки каждого запроса от клиентского уровня и от назначенных заданий CUBA.
По окончании выполнения запроса в первых двух случаях SecurityContext удаляется из потока выполнения.
При создании прикладным кодом нового потока выполнения в него необходимо передать текущий экземпляр SecurityContext, например:
final SecurityContext securityContext = AppContext.getSecurityContext();
executor.submit(new Runnable() {
public void run() {
AppContext.setSecurityContext(securityContext);
// business logic here
}
});То же самое можно сделать, используя обертки SecurityContextAwareRunnable или SecurityContextAwareCallable, например:
executor.submit(new SecurityContextAwareRunnable<>(() -> {
// business logic here
}));Future<String> future = executor.submit(new SecurityContextAwareCallable<>(() -> {
// business logic here
return some_string;
}));3.2.12. Обработка исключений
В данном разделе рассмотрены различные аспекты генерации и обработки исключений в CUBA-приложениях.
3.2.12.1. Классы исключений
При создании собственных классов исключений следует придерживаться следующих правил:
-
Если исключение является нормальной частью бизнес-логики и при его возникновении требуется предпринимать некоторые нетривиальные действия, то класс исключения следует делать декларируемым (наследником
Exception). Обработка таких исключений производится вызывающим кодом. -
Если исключение сигнализирует об ошибочной ситуации, и реакцией на него должно быть прерывание хода выполнения и простое действие типа отображения информации об ошибке пользователю, то класс исключения следует делать недекларируемым (наследником
RuntimeException). Обработка таких исключений производится специальными классами-обработчиками, зарегистрированными в клиентских блоках приложения. -
Если исключение выбрасывается и обрабатывается в рамках одного блока приложения, то класс исключения следует объявлять в соответствующем модуле. Если же исключение выбрасывается на Middleware, а обрабатывается на клиентском уровне, то класс исключения необходимо объявлять в модуле global.
Платформа содержит специальный класс недекларируемого исключения SilentException, который можно использовать для прерывания хода выполнения без выдачи каких-либо сообщений пользователю или в лог. SilentException объявлен в модуле global, поэтому доступен как на Middleware, так и в клиентских блоках.
3.2.12.2. Передача исключений Middleware
Если при выполнении запроса от клиента на Middleware возникает исключение, выполнение прерывается и на клиента возвращается объект исключения, как правило, включающий цепочку порождающих друг друга исключений. Так как цепочка исключений может содержать классы, недоступные клиентскому блоку (например, исключения JDBC-драйвера), на клиента передается не сама эта цепочка, а ее представление внутри специального создаваемого исключения RemoteException.
Информация об исключениях-причинах сохраняется в виде списка объектов RemoteException.Cause. Каждый объект Cause хранит обязательно имя класса исключения и его сообщение. Кроме того, если класс исключения "поддерживается клиентом", то Cause содержит также и сам объект исключения. Это дает возможность передать на клиента информацию в полях исключения.
Класс исключения, объекты которого нужно передавать на клиентский уровень именно в виде Java-объектов, нужно аннотировать @SupportedByClient, например:
@SupportedByClient
public class WorkflowException extends RuntimeException {
...Таким образом, при возникновении на Middleware исключения, не аннотированного @SupportedByClient, вызывающий клиентский код получит RemoteException, внутри которого будет находиться исходное исключение в виде строки. Если же исходное исключение аннотировано @SupportedByClient, то вызывающий код получит именно его. Это дает возможность в прикладном коде организовывать обработку декларируемых сервисами Middleware исключений традиционным образом - с помощью блоков try/catch.
Следует иметь в виду, что чтобы поддерживаемое клиентом исключение было действительно передано на клиента в виде объекта, оно не должно содержать внутри себя в цепочке getCause() неподдерживаемых исключений. Поэтому если вы создаете на Middleware экземпляр исключения и хотите передать его на клиента, указывайте для него параметр cause только если вы уверены, что он содержит только исключения, известные клиенту.
Упаковку объектов исключений в RemoteException перед передачей на клиентский уровень выполняет перехватчик вызовов сервисов - класс ServiceInterceptor. Кроме того, он же выполняет логирование исключений. По умолчанию в журнал выводится вся информация об исключении, включая полный stack trace. Если это нежелательно, можно добавить классу исключения аннотацию @Logging, указав в ней тип логирования:
-
FULL- (по умолчанию) полная информация, включая stacktrace -
BRIEF- только имя класса исключения и сообщение -
NONE- не выводить ничего
Например:
@SupportedByClient
@Logging(Logging.Type.BRIEF)
public class FinancialTransactionException extends Exception {
...3.2.12.3. Обработчики исключений клиентского уровня
Необработанные исключения, возникшие на клиентском уровне или переданные с Middleware, попадают в специальный механизм обработчиков блока Web Client.
Обработчик должен быть Spring-бином, реализовывать интерфейс UiExceptionHandler, в методе handle() которого производить обработку и возвращать true, либо сразу возвращать false, если данный обработчик не может обработать переданное ему исключение. Такое поведение позволяет организовать "цепочку ответственности" обработчиков.
Рекомендуется наследовать классы своих обработчиков от базового класса AbstractUiExceptionHandler, который умеет разбирать цепочку исключений (с учетом упакованных внутри RemoteException) и реагировать на конкретные типы исключений. Типы исключений, для которых предназначен данный обработчик, указываются в массиве строк, передаваемом в конструкторе обработчика базовому конструктору. Каждая строка массива должна содержать одно полное имя класса обрабатываемого исключения.
Предположим, имеется следующий класс исключения:
package com.company.demo.web;
public class ZeroBalanceException extends RuntimeException {
public ZeroBalanceException() {
super("Insufficient funds in your account");
}
}Тогда обработчик должен иметь следующий конструктор:
@Component("demo_ZeroBalanceExceptionHandler")
public class ZeroBalanceExceptionHandler extends AbstractUiExceptionHandler {
public ZeroBalanceExceptionHandler() {
super(ZeroBalanceException.class.getName());
}
...Если класс исключения недоступен на клиенте, следует указывать его имя строковым литералом:
@Component("sample_ForeignKeyViolationExceptionHandler")
public class ForeignKeyViolationExceptionHandler extends AbstractUiExceptionHandler {
public ForeignKeyViolationExceptionHandler() {
super("java.sql.SQLIntegrityConstraintViolationException");
}
...В случае использования в качестве базового класса AbstractUiExceptionHandler логика обработки располагается в методе doHandle(), и может выглядеть следующим образом:
package com.company.demo.web;
import com.haulmont.cuba.gui.Notifications;
import com.haulmont.cuba.gui.exception.AbstractUiExceptionHandler;
import org.springframework.stereotype.Component;
import javax.annotation.Nullable;
@Component("demo_ZeroBalanceExceptionHandler")
public class ZeroBalanceExceptionHandler extends AbstractUiExceptionHandler {
public ZeroBalanceExceptionHandler() {
super(ZeroBalanceException.class.getName());
}
@Override
protected void doHandle(String className, String message, @Nullable Throwable throwable, UiContext context) {
context.getNotifications().create(Notifications.NotificationType.ERROR)
.withCaption("Error")
.withDescription(message)
.show();
}
}Если имени класса исключения недостаточно для того, чтобы принять решение о применимости данного обработчика к исключению, следует определить метод canHandle(), получающий кроме прочего текст исключения. Метод должен вернуть true, если данный обработчик применим для исключения. Например:
package com.company.demo.web.exceptions;
import com.haulmont.cuba.gui.Notifications;
import com.haulmont.cuba.gui.exception.AbstractUiExceptionHandler;
import org.apache.commons.lang3.StringUtils;
import org.springframework.stereotype.Component;
import javax.annotation.Nullable;
@Component("demo_ZeroBalanceExceptionHandler")
public class ZeroBalanceExceptionHandler extends AbstractUiExceptionHandler {
public ZeroBalanceExceptionHandler() {
super(ZeroBalanceException.class.getName());
}
@Override
protected void doHandle(String className, String message, @Nullable Throwable throwable, UiContext context) {
context.getNotifications().create(Notifications.NotificationType.ERROR)
.withCaption("Error")
.withDescription(message)
.show();
}
@Override
protected boolean canHandle(String className, String message, @Nullable Throwable throwable) {
return StringUtils.containsIgnoreCase(message, "Insufficient funds in your account");
}
}Интерфейс Dialogs, доступный через параметр UiContext метода doHandle(), предоставляет специальный диалог для отображения исключений, содержащий схлопываемое поле с полным stack trace исключения. Данный диалог используется в обработчике по умолчанию, но вы можете использовать его и для конкретных исключений:
@Override
protected void doHandle(String className, String message, @Nullable Throwable throwable, UiContext context) {
if (throwable != null) {
context.getDialogs().createExceptionDialog()
.withThrowable(throwable)
.withCaption("Error")
.withMessage(message)
.show();
} else {
context.getNotifications().create(Notifications.NotificationType.ERROR)
.withCaption("Error")
.withDescription(message)
.show();
}
}3.2.12.3.1. Обработка исключений нарушения уникальности
Фреймворк предоставляет возможность установить собственное сообщение, отображаемое обработчиком для ошибки ограничения уникальности в базе данных.
Собственное сообщение нужно добавить в главный пакет сообщений модуля web с ключом, соответствующим имени уникального индекса базы данных в верхнем регистре. Например:
IDX_SEC_USER_UNIQ_LOGIN = Пользователь с таким логином уже существуетТак, например, если вы получили уведомление:

и затем добавили
IDX_DEMO_PRODUCT_UNIQ_NAME = A product with this name already existsк главному пакету сообщений, вы получите следующее уведомление:

Распознавание ошибок нарушения уникальности производится классом UniqueConstraintViolationHandler, который использует регулярные выражения, зависящие от типа используемой базы данных. Если стандартное выражение не распознает ошибки уникальности вашей БД, задайте подходящее выражение с помощью свойства приложения cuba.uniqueConstraintViolationPattern.
Вы также можете полностью заменить стандартный обработчик, предоставив свой собственный обработчик исключений с более высоким приоритетом, например @Order(HIGHEST_PLATFORM_PRECEDENCE - 10).
3.2.13. Bean Validation
Bean Validation - опциональный механизм, обеспечивающий единообразную валидацию данных на среднем слое, в Generic UI и в REST API. Он основан на спецификации JSR 380 - Bean Validation 2.0 и ее референсной имплементации: Hibernate Validator.
3.2.13.1. Задание ограничений
Ограничения bean validation задаются с помощью аннотаций пакета javax.validation.constraints или собственных аннотаций. Аннотации указываются на декларации класса сущности или POJO, на поле или getter-методе, а также на методе сервиса middleware.
Пример использования стандартных аннотаций валидации на полях сущности:
@Table(name = "DEMO_CUSTOMER")
@Entity(name = "demo_Customer")
public class Customer extends StandardEntity {
@Size(min = 3) // length of value must be longer then 3 characters
@Column(name = "NAME", nullable = false)
protected String name;
@Min(1) // minimum value
@Max(5) // maximum value
@Column(name = "GRADE", nullable = false)
protected Integer grade;
@Pattern(regexp = "\\S+@\\S+") // value must conform to the pattern
@Column(name = "EMAIL")
protected String email;
//...
}Пример использования собственной аннотации уровня класса (см. ниже):
@CheckTaskFeasibility(groups = {Default.class, UiCrossFieldChecks.class}) // custom validation annotation
@Table(name = "DEMO_TASK")
@Entity(name = "demo_Task")
public class Task extends StandardEntity {
//...
}Пример валидации параметров и возвращаемого значения метода сервиса:
public interface TaskService {
String NAME = "demo_TaskService";
@Validated // indicates that the method should be validated
@NotNull
String completeTask(@Size(min = 5) String comment, @Valid @NotNull Task task);
}Аннотация @Valid может быть использована для каскадной валидации параметров метода. В примере выше все ограничения, заданные для объекта Task, также будут валидированы.
- Группы ограничений
-
Группы ограничений позволяют применять подмножество всех заданных ограничений в зависимости от логики приложения. Например, вы можете заставить пользователя ввести значение некоторого атрибута сущности в UI, и в то же время иметь возможность установить данный атрибут в null в некотором внутреннем механизме. Для этого необходимо указать атрибут
groupsв аннотации ограничения, и оно будет действовать только когда эта же группа передается в механизм валидации.Платформа передает в механизм валидации следующие группы ограничений:
-
RestApiChecks- при валидации в REST API. -
ServiceParametersChecks- при валидации параметров сервисов. -
ServiceResultChecks- при валидации возвращаемых значений сервисов. -
UiComponentChecks- при валидации отдельных полей в UI. -
UiCrossFieldChecks- при валидации ограничений уровня класса на коммите экрана редактора сущности. -
javax.validation.groups.Default- данная группа передается во всех случаях кроме коммита экрана редактора сущности.
-
- Сообщения валидации
-
Ограничения могут иметь сообщения для отображения пользователям.
Сообщения могут быть указаны непосредственно в аннотациях валидации, например:
@Pattern(regexp = "\\S+@\\S+", message = "Invalid format") @Column(name = "EMAIL") protected String email;Сообщения можно также поместить в пакет локализованных сообщений и использовать следующий формат указания сообщения в аннотации:
{msg://message_pack/message_key}или, в сокращённом виде,{msg://message_key}(только для сущностей). Например:@Pattern(regexp = "\\S+@\\S+", message = "{msg://com.company.demo.entity/Customer.email.validationMsg}") @Column(name = "EMAIL") protected String email;или, если ограничение задано для сущности и сообщение находится в пакете сообщений данной сущности:
@Pattern(regexp = "\\S+@\\S+", message = "{msg://Customer.email.validationMsg}") @Column(name = "EMAIL") protected String email;Сообщения могут содержать параметры и выражения. Параметры заключаются в фигурные скобки
{}и представляют собой либо указатели на локализованные сообщения (см. выше) или параметры аннотации, например,{min},{max},{value}. Выражения заключаются в фигурные скобки со знаком доллара${}и могут включать валидируемое значение в виде переменнойvalidatedValue, параметры аннотации типаvalueилиmin, и выражения JSR-341 (EL 3.0). Например:@Pattern(regexp = "\\S+@\\S+", message = "Invalid email: ${validatedValue}, pattern: {regexp}") @Column(name = "EMAIL") protected String email;Значения локализованных сообщений также могут содержать параметры и выражения.
- Собственные ограничения
-
В проекте можно создать собственные ограничения с программной или декларативной валидацией.
Для создания ограничения с программной валидацией выполните следующее:
-
Создайте аннотацию в модуле global проекта и добавьте ей аннотацию
@Constraint. Ваша аннотация должна содержать атрибутыmessage,groupsиpayload:@Target({ ElementType.TYPE }) @Retention(RUNTIME) @Constraint(validatedBy = TaskFeasibilityValidator.class) public @interface CheckTaskFeasibility { String message() default "{msg://com.company.demo.entity/CheckTaskFeasibility.message}"; Class<?>[] groups() default {}; Class<? extends Payload>[] payload() default {}; } -
Создайте класс валидатора в модуле global проекта:
public class TaskFeasibilityValidator implements ConstraintValidator<CheckTaskFeasibility, Task> { @Override public void initialize(CheckTaskFeasibility constraintAnnotation) { } @Override public boolean isValid(Task value, ConstraintValidatorContext context) { Date now = AppBeans.get(TimeSource.class).currentTimestamp(); return !(value.getDueDate().before(DateUtils.addDays(now, 3)) && value.getProgress() < 90); } } -
Используйте аннотацию:
@CheckTaskFeasibility(groups = UiCrossFieldChecks.class) @Table(name = "DEMO_TASK") @Entity(name = "demo_Task") public class Task extends StandardEntity { @Future @Temporal(TemporalType.DATE) @Column(name = "DUE_DATE") protected Date dueDate; @Min(0) @Max(100) @Column(name = "PROGRESS", nullable = false) protected Integer progress; //... }
Собственные аннотации могут также быть созданы как композиции имеющихся, например:
@NotNull @Size(min = 2, max = 14) @Pattern(regexp = "\\d+") @Target({METHOD, FIELD, ANNOTATION_TYPE}) @Retention(RUNTIME) @Constraint(validatedBy = {}) public @interface ValidProductCode { String message() default "{msg://om.company.demo.entity/ValidProductCode.message}"; Class<?>[] groups() default {}; Class<? extends Payload>[] payload() default {}; }При использовании композитных ограничений результирующий набор нарушений
ConstraintViolationбудет содержать отдельные записи для каждого включенного ограничения. Для того, чтобы получить одну запись нарушения, добавьте@ReportAsSingleViolationклассу вашей аннотации. -
- Аннотации валидации, заданные в CUBA
-
Кроме стандартных аннотаций из пакета
javax.validation.constraintsможно использовать следующую аннотацию, определенную в платформе:-
@RequiredView- может быть добавлена на методы сервисов для того, чтобы во время выполнения убедиться, что в сущностях загружены все атрибуты, заданные в требуемых представлениях. Если аннотация задана на методе, то проверяется результат метода. Если аннотация задана на параметре, проверяется этот параметр. Если параметр или результат являются коллекцией, то проверяются все элементы этой коллекции. Пример использования:
public interface MyService { String NAME = "sample_MyService"; @Validated void processFoo(@RequiredView("foo-view") Foo foo); @Validated void processFooList(@RequiredView("foo-view") List<Foo> fooList); @Validated @RequiredView("bar-view") Bar loadBar(@RequiredView("foo-view") Foo foo); } -
3.2.13.2. Запуск валидации
- Валидация в UI
-
Компоненты Generic UI, соединенные с источником данных, получают экземпляр
BeanValidatorдля проверки значения. Валидатор вызывается из методаComponent.Validatable.validate(), реализуемого компонентом, и может выбрасывать исключениеCompositeValidationException, содержащее набор объектов нарушений.Стандартный валидатор может быть программно удален или проинициализирован другой группой ограничений:
@UiController("sample_NewScreen") @UiDescriptor("new-screen.xml") public class NewScreen extends Screen { @Inject private TextField<String> field1; @Inject private TextField<String> field2; @Subscribe protected void onInit(InitEvent event) { field1.getValidators().stream() .filter(BeanPropertyValidator.class::isInstance) .forEach(field1::removeValidator); (1) field2.getValidators().stream() .filter(BeanPropertyValidator.class::isInstance) .forEach(validator -> { ((BeanPropertyValidator) validator).setValidationGroups(new Class[] {UiComponentChecks.class}); (2) }); } }1 Полностью удаляем валидацию с компонента. 2 Здесь валидаторы будут проверять только ограничения, явно установленные группой UiComponentChecks, так как группа по умолчанию не передаётся. По умолчанию,
BeanValidatorсодержит две группы:DefaultиUiComponentChecks.Если атрибут сущности аннотирован
@NotNullбез группы ограничений, он будет помечен как обязательный в метаданных, и UI-компоненты работающие с данным атрибутом через источник данных, будут иметь свойствоrequired = true.Компоненты DateField и DatePicker автоматически устанавливают свои свойства
rangeStartиrangeEndв соответствии с аннотациями@Past,@PastOrPresent,@Future,@FutureOrPresent.Экраны редактирования выполняют валидацию ограничений уровня класса при коммите, если ограничения включают группу
UiCrossFieldChecksи все проверки ограничений уровня атрибутов прошли успешно. Валидацию данного типа можно отключить с помощью метода контроллераsetCrossFieldValidate():public class EventEdit extends StandardEditor<Event> { @Subscribe public void onInit(InitEvent event) { setCrossFieldValidate(false); } }
- Валидация в DataManager
-
DataManager может выполнять валидацию сохраняемых сущностей. Следующие параметры оказывают влияние на валидацию:
-
Свойство приложения cuba.dataManagerBeanValidation устанавливает глобальный признак, выполнять ли валидацию по умолчанию.
-
Глобальный признак можно переопределить, устанавливая значение типа
CommitContext.ValidationModeвCommitContextпри выполненииDataManager.commit(), или вDataContext.PreCommitEventпри сохранении данных в экране UI. -
В
CommitContextи вDataContext.PreCommitEventможно передать список групп валидации для применения некоторого подмножества определенных ограничений.
-
- Валидация сервисов Middleware
-
Сервисы среднего слоя выполняют валидацию параметров и результатов методов, если метод имеет аннотацию
@Validatedв интерфейсе сервиса. Например:public interface TaskService { String NAME = "demo_TaskService"; @Validated @NotNull String completeTask(@Size(min = 5) String comment, @NotNull Task task); }Аннотация
@Validatedможет содержать указание групп ограничений для применения подмножества имеющихся ограничений. Если группы не указаны, то по умолчанию используются следующие:-
DefaultиServiceParametersChecks- для параметров методов -
DefaultиServiceResultChecks- для возвращаемых результатов методов
При возникновении ошибок валидации выбрасываются исключения
MethodParametersValidationExceptionиMethodResultValidationException.При выполнении некоторой специфической программной валидации в сервисе, можно использовать исключение
CustomValidationExceptionдля того, чтобы клиенты получали информацию об ошибках в том же формате что и от стандартной валидации. Это может быть особенно актуально для клиентов REST API. -
- Валидация в REST API
-
Универсальный REST API автоматически выполняет bean validation для действий создания и изменения сущностей. Ошибки валидации передаются клиенту следующим образом:
-
MethodResultValidationExceptionиValidationExceptionпорождают HTTP статус500 Server error -
MethodParametersValidationException,ConstraintViolationExceptionиCustomValidationExceptionпорождают HTTP статус400 Bad request -
Тело ответа с
Content-Type: application/jsonбудет содержать список объектов со свойствамиmessage,messageTemplate,pathиinvalidValue, например:[ { "message": "Invalid email: aaa", "messageTemplate": "{msg://com.company.demo.entity/Customer.email.validationMsg}", "path": "email", "invalidValue": "aaa" } ]-
pathсодержит путь к невалидному атрибуту в валидируемом графе объектов -
messageTemplateсодержит сторку, заданную в атрибутеmessageаннотации -
messageсодержит сообщение ошибки валидации -
invalidValueвозвращается только если тип значения один из следующих:String,Date,Number,Enum,UUID.
-
-
- Программная валидация
-
Bean validation можно запустить программно используя интерфейс инфраструктуры
BeanValidation, доступный и на middleware и на клиентском уровне. Через данный интерфейс необходимо получить реализациюjavax.validation.Validator, которая и запускает валидацию. Результатом валидации является набор объектов типаConstraintViolation. Например:@Inject private BeanValidation beanValidation; public void save(Foo foo) { Validator validator = beanValidation.getValidator(); Set<ConstraintViolation<Foo>> violations = validator.validate(foo); // ... }
|
См. статью Валидация в Java-приложениях в нашем блоге для получения более подробной информации. Пример приложения, которое использовалось в этой статье, доступен на GitHub. |
3.2.14. Контроль доступа к атрибутам сущностей
Подсистема безопасности позволяет управлять доступом к атрибутам сущностей в соответствии с правами пользователя. Т.е. фреймворк может сделать атрибут read-only или скрыть его в зависимости от набора ролей, назначенных текущему пользователю. Однако, иногда может потребоваться изменять доступ к атрибуту в зависимости также от текущего состояния экземпляра сущности или связанных сущностей.
Механизм контроля доступа к атрибутам позволяет создавать правила того, какие атрибуты должны быть скрыты, нередактируемы или обязательны к заполнению для некоторого экземпляра сущности, и применять эти правила к компонентам Generic UI и в REST API.
Данный механизм работает следующим образом:
-
Когда DataManager загружает сущность, он находит бины, реализующие интерфейс
SetupAttributeAccessHandlerи вызывает их методsetupAccess(), передавая в них объект типаSetupAttributeAccessEvent. Данный объект содержит загруженный экземпляр в состоянии managed и три коллекции имен атрибутов: read-only, hidden и required (изначально они пустые). -
Имплементации
SetupAttributeAccessHandlerанализируют состояние сущности и заполняют списки имен атрибутов соответствующим образом. Данные классы являются по сути контейнерами правил, задающих доступ к атрибутам экземпляров. -
Описываемый механизм сохраняет имена атрибутов, заданные правилами, в самом экземпляре (в связанном объекте
SecurityState). -
На клиентском уровне, Generic UI и REST API используют объект
SecurityStateдля управления доступом к атрибутам сущностей.
Для создания правил для некоторого типа сущностей, необходимо выполнить следующее:
-
Создайте Spring-бин в модуле
coreпроекта и реализуйте в нем интерфейсSetupAttributeAccessHandler. Параметризуйте интерфейс типом обрабатываемой сущности. Бин должен иметь дефолтный singleton scope. Вам необходимо реализовать методы интерфейса:-
supports(Class)- возвращает true если данный обработчик предназначен для работы с сущностями переданного класса. -
setupAccess(SetupAttributeAccessEvent)- оперирует коллекциями атрибутов для настройки доступа. В данном методе необходимо заполнить коллекции скрываемых, только для чтения и обязательных атрибутов используя методыaddHidden(),addReadOnly()иaddRequired()объекта события. Экземпляр сущности, доступный через методgetEntity(), находится в состоянии managed, поэтому можно безопасно обращаться ко всем его атрибутам и атрибутам связанных сущностей.
-
Рассмотрим пример сущности Order, имеющей атрибуты customer и amount. Для ограничения доступа к атрибуту amount в зависимости от customer можно создать следующее правило:
package com.company.sample.core;
import com.company.sample.entity.Order;
import com.haulmont.cuba.core.app.SetupAttributeAccessHandler;
import com.haulmont.cuba.core.app.events.SetupAttributeAccessEvent;
import org.springframework.context.event.EventListener;
import org.springframework.stereotype.Component;
@Component("sample_OrderAttributeAccessHandler")
public class OrderAttributeAccessHandler implements SetupAttributeAccessHandler<Order> {
@Override
public boolean supports(Class clazz) {
return Order.class.isAssignableFrom(clazz);
}
@Override
public void setupAccess(SetupAttributeAccessEvent<Order> event) {
Order order = event.getEntity();
if (order.getCustomer() != null) {
if ("PLATINUM".equals(order.getCustomer().getGrade().getCode())) {
event.addHidden("amount");
} else if ("GOLD".equals(order.getCustomer().getGrade().getCode())) {
event.addReadOnly("amount");
}
}
}
}- Контроль доступа к атрибутам в Generic UI
-
Фреймворк автоматически применяет ограничения доступа к экрану в момент между посылкой BeforeShowEvent и AfterShowEvent. Если вы не хотите применять ограничения для некоторого экрана, добавьте контроллеру экрана аннотацию
@DisableAttributeAccessControl.Пересчитать и применить ограничения к экрану можно и когда он уже открыт, в ответ на действия пользователя. Для этого необходимо использовать бин
AttributeAccessSupport, передавая ему текущий экран и сущность, состояние которой изменилось. Например:@UiController("sales_Order.edit") @UiDescriptor("order-edit.xml") @EditedEntityContainer("orderDc") @LoadDataBeforeShow public class OrderEdit extends StandardEditor<Order> { @Inject private AttributeAccessSupport attributeAccessSupport; @Subscribe(id = "orderDc", target = Target.DATA_CONTAINER) protected void onOrderDcItemPropertyChange(InstanceContainer.ItemPropertyChangeEvent<Order> event) { if ("customer".equals(event.getProperty())) { attributeAccessSupport.applyAttributeAccess(this, true, getEditedEntity()); } } }Второй параметр метода
applyAttributeAccess()- булевское значение, которое указывает, нужно ли сбрасывать ограничения доступа к компонентам в дефолтные настройки перед тем, как применить новые. Если передано true, возможные программные изменения в этих настройках будут потеряны. Когда данный метод вызывается автоматически перед открытием окна, передается false. Когда же вы вызываете данный метод в ответ на UI-события, передавайте true, иначе ограничения компонентов будут суммироваться, а не заменяться.Ограничения доступа к атрибутам применяются только к компонентам, связанным с одним атрибутом сущности, например TextField или LookupField. Table и другие компоненты, реализующие интерфейс
ListComponent, не затрагиваются. Поэтому если вы пишете правило, скрывающее атрибут для некоторых экземпляров, рекомендуется не показывать этот атрибут в таблицах совсем.
3.3. Базы данных
В данном разделе приведена информация о возможных типах СУБД приложений на платформе CUBA. Кроме того, описан механизм миграции БД, с помощью которого можно создать новую базу данных, и в дальнейшем поддерживать ее в актуальном состоянии на протяжении всего цикла разработки и эксплуатации приложения.
Компоненты работы с базой данных принадлежат блоку Middleware, другие блоки приложения не имеют прямого доступа к БД.
3.3.1. Подключение к базам данных
CUBA-приложение получает соединение с базой данных через JDBC DataSource. Источник данных может быть сконфигурирован в приложении или получен из JNDI. Способ получения источника данных задается свойством приложения cuba.dataSourceProvider: его значение может быть либо application, либо jndi.
Соединения с главным и дополнительным хранилищами можно легко сконфигурировать в CUBA Studio, см. его документацию. Информация, приведенная ниже, может быть полезна при поиске проблем и при необходимости задания параметров, недоступных в Studio, например параметров пула соединений.
- Конфигурирование источника данных в приложении
-
Если источник данных сконфигурирован в приложении, фреймворк создает пул соединений используя HikariCP. При этом и параметры соединения, и параметры пула задаются свойствами приложения, расположенными в файле
app.propertiesмодуляcore. Данный способ является рекомендуемым, если вам не нужен специфический пул соединений, предоставляемый сервером приложения.Следующие свойства приложения задают тип БД и параметры соединения:
-
cuba.dbmsType- задает тип СУБД. -
cuba.dataSourceProvider- значениеapplicationуказывает, что источник данных должен быть сконфигурирован свойствами приложения. -
cuba.dataSource.username- имя пользователя БД. -
cuba.dataSource.password- пароль пользователя БД. -
cuba.dataSource.dbName- имя БД. -
cuba.dataSource.host- имя хоста сервера БД. -
cuba.dataSource.port- необязательный параметр, задает порт сервера БД, если он отличается от стандартного для данного типа СУБД. -
cuba.dataSource.jdbcUrl- необязательный параметр, задает полный JDBC URL если необходимо передать дополнительные параметры соединения. При этом все остальные отдельные параметры описанные выше все равно необходимы для работы задач миграции.
Для конфигурирования параметров пула соединений необходимо указать свойства HikariCP с префиксом
cuba.dataSource., напримерcuba.dataSource.maximumPoolSizeилиcuba.dataSource.connectionTimeout. См. полный список поддерживаемых свойств и их значений по умолчанию в документации по HikariCP.Если в вашем приложении используются дополнительные хранилища, необходимо указать такой же набор параметров для каждого хранилища. При этом имя хранилища добавляется ко второй части имени свойства:
Например:
# main data store connection parameters cuba.dbmsType = hsql cuba.dataSourceProvider = application cuba.dataSource.username = sa cuba.dataSource.password = cuba.dataSource.dbName = demo cuba.dataSource.host = localhost cuba.dataSource.port = 9111 cuba.dataSource.maximumPoolSize = 20 # names of additional data stores cuba.additionalStores = clients,orders # 'clients' data store connection parameters cuba.dbmsType_clients = postgres cuba.dataSourceProvider_clients = application cuba.dataSource_clients.username = postgres cuba.dataSource_clients.password = postgres cuba.dataSource_clients.dbName = clients_db cuba.dataSource_clients.host = localhost # 'orders' data store connection parameters cuba.dbmsType_orders = mssql cuba.dataSourceProvider_orders = application cuba.dataSource_orders.jdbcUrl = jdbc:sqlserver://localhost;databaseName=orders_db;currentSchema=my_schema cuba.dataSource_orders.username = sa cuba.dataSource_orders.password = myPass123 cuba.dataSource_orders.dbName = orders_db cuba.dataSource_orders.host = localhostКроме того, для каждого хранилища необходимо в файле
spring.xmlмодуляcoreзадать определение бинаCubaDataSourceFactoryBeanс соответствующим параметромstoreName. Например:<bean id="cubaDataSource_clients" class="com.haulmont.cuba.core.sys.CubaDataSourceFactoryBean"> <property name="storeName" value="clients"/> </bean> <bean id="cubaDataSource_orders" class="com.haulmont.cuba.core.sys.CubaDataSourceFactoryBean"> <property name="storeName" value="orders"/> </bean>Если источник данных сконфигурирован в приложении, задачи Gradle по миграции БД могут не иметь параметров, так как они могут быть получены из свойств приложения. Это является дополнительным преимуществом данного способа определения источника даннных. Например:
task createDb(dependsOn: assembleDbScripts, description: 'Creates local database', type: CubaDbCreation) { } task updateDb(dependsOn: assembleDbScripts, description: 'Updates local database', type: CubaDbUpdate) { } -
- Получение источника данных из JNDI
-
Если необходимо использовать источник данных, предоставляемый сервером приложения через JNDI, задайте следующие свойства приложения в файле
app.propertiesмодуляcore:-
cuba.dbmsType- задает тип СУБД. -
cuba.dataSourceProvider- значениеjndiуказывает, что источник данных должен быть получен из JNDI.
JNDI-имя источника данных задается свойством cuba.dataSourceJndiName, которое по умолчанию имеет значение
java:comp/env/jdbc/CubaDS. Для дополнительных хранилищ необходимо задать свойство с таким же именем, но с добавлением имени хранилища.Например:
# main data store connection parameters cuba.dbmsType = hsql cuba.dataSourceProvider = jndi # names of additional data stores cuba.additionalStores = clients,orders # 'clients' data store connection parameters cuba.dbmsType_clients = postgres cuba.dataSourceProvider_clients = jndi cuba.dataSourceJndiName_clients = jdbc/ClientsDS # 'orders' data store connection parameters cuba.dbmsType_orders = mssql cuba.dataSourceProvider_orders = jndi cuba.dataSourceJndiName_orders = jdbc/OrdersDSКроме того, для каждого хранилища необходимо в файле
spring.xmlмодуляcoreзадать определение бинаCubaDataSourceFactoryBeanс соответствующими параметрамиstoreNameиjndiNameAppProperty. Например:<bean id="cubaDataSource_clients" class="com.haulmont.cuba.core.sys.CubaDataSourceFactoryBean"> <property name="storeName" value="clients"/> <property name="jndiNameAppProperty" value="cuba.dataSourceJndiName_clients"/> </bean> <bean id="cubaDataSource_orders" class="com.haulmont.cuba.core.sys.CubaDataSourceFactoryBean"> <property name="storeName" value="orders"/> <property name="jndiNameAppProperty" value="cuba.dataSourceJndiName_orders"/> </bean>Источники данных, получаемые из JNDI конфигурируются специфичным для используемого сервера приложения способом. Для Tomcat это делается в файле context.xml. CUBA Studio записывает параметры соединения в файл
modules/core/web/META-INF/context.xmlи использует его в процессе стандартного развертывания при разработке приложения.Если источник данных сконфигурирован в
context.xml, задачи миграции БД должны иметь собственные параметры подключения к БД, например:task createDb(dependsOn: assembleDbScripts, description: 'Creates local database', type: CubaDbCreation) { dbms = 'hsql' host = 'localhost:9111' dbName = 'demo' dbUser = 'sa' dbPassword = '' } task updateDb(dependsOn: assembleDbScripts, description: 'Updates local database', type: CubaDbUpdate) { dbms = 'hsql' host = 'localhost:9111' dbName = 'demo' dbUser = 'sa' dbPassword = '' } -
3.3.1.1. Использование произвольной схемы БД
PostgreSQL и Microsoft SQL Server поддерживают подключение к произвольной схеме внутри базы данных. По умолчанию на PostgreSQL используется схема public, на SQL Server - схема dbo.
- PostgreSQL
-
При использовании Studio, добавьте параметр
currentSchemaв поле Connection params окна Data Store Properties. При этом Studio автоматически обновит файлы проекта в соответствии с выбранным способом конфигурации источника данных. В противном случае, укажите параметр соединения как описано ниже.Если источник данных конфигурируется в приложении, добавьте свойство с полным URL подключения, например:
cuba.dataSource.jdbcUrl = jdbc:postgresql://localhost/demo?currentSchema=my_schemaЕсли источник данных получается из JNDI, добавьте параметр
currentSchemaв URL подключения в определении источника данных (для Tomcat оно находится вcontext.xml) и в свойствоconnectionParamsзадач сборки createDb и updateDb, например:task createDb(dependsOn: assembleDbScripts, type: CubaDbCreation) { dbms = 'postgres' host = 'localhost' dbName = 'demo' connectionParams = '?currentSchema=my_schema' dbUser = 'postgres' dbPassword = 'postgres' }После этого можно запускать обновление или пересоздание БД, все таблицы будут созданы в указанной схеме.
- Microsoft SQL Server
-
На Microsoft SQL Server указания параметра подключения недостаточно, необходимо также создать связь между пользователем БД и схемой. Ниже приведен пример создания базы данных и использования схемы.
-
Создайте login:
create login JohnDoe with password='saPass1' -
Создайте новую БД:
create database my_db -
Подключитесь к новой БД как
sa, создайте схему, затем создайте пользователя и дайте ему права владельца:create schema my_schema create user JohnDoe for login JohnDoe with default_schema = my_schema exec sp_addrolemember 'db_owner', 'JohnDoe'
При использовании Studio, добавьте параметр
currentSchemaв поле Connection params окна Data Store Properties. При этом Studio автоматически обновит файлы проекта в соответствии с выбранным способом конфигурации источника данных. В противном случае, укажите параметр соединения как описано ниже.Если источник данных конфигурируется в приложении, добавьте свойство с полным URL подключения, например:
cuba.dataSource.jdbcUrl = jdbc:sqlserver://localhost;databaseName=demo;currentSchema=my_schemaЕсли источник данных получается из JNDI, добавьте параметр
currentSchemaв URL подключения в определении источника данных (для Tomcat оно находится вcontext.xml) и в свойствоconnectionParamsзадач сборки createDb и updateDb, например:task updateDb(dependsOn: assembleDbScripts, type: CubaDbUpdate) { dbms = 'mssql' dbmsVersion = '2012' host = 'localhost' dbName = 'demo' connectionParams = ';currentSchema=my_schema' dbUser = 'JohnDoe' dbPassword = 'saPass1' }Имейте в виду, что пересоздавать БД SQL Server из Studio или выполнением
createDbв командной строке нельзя, так как использование не-дефолтной схемы требует ассоциации с пользователем. Однако можно выполнять Update Database в Studio илиupdateDbв командной строке, и все необходимые таблицы будут созданы в существующей базе данных и в указанной схеме. -
3.3.2. Типы СУБД
Тип используемой СУБД определяется свойствами приложения cuba.dbmsType и (опционально) cuba.dbmsVersion, которые влияют на поведение механизмов, зависящих от типа базы данных.
Платформа "из коробки" поддерживает следующие СУБД:
| cuba.dbmsType | cuba.dbmsVersion | JDBC driver | |
|---|---|---|---|
HSQLDB |
hsql |
org.hsqldb.jdbc.JDBCDriver |
|
PostgreSQL 8.4+ |
postgres |
org.postgresql.Driver |
|
Microsoft SQL Server 2005 |
mssql |
2005 |
net.sourceforge.jtds.jdbc.Driver |
Microsoft SQL Server 2008 |
mssql |
com.microsoft.sqlserver.jdbc.SQLServerDriver |
|
Microsoft SQL Server 2012+ |
mssql |
2012 |
com.microsoft.sqlserver.jdbc.SQLServerDriver |
Oracle Database 11g+ |
oracle |
oracle.jdbc.OracleDriver |
|
MySQL 5.6+ |
mysql |
com.mysql.jdbc.Driver |
|
MariaDB 5.5+ |
mysql |
org.mariadb.jdbc.Driver |
Таблица ниже описывает рекомендованное соответствие типов данных между атрибутами сущностей в Java и колонками таблиц различных СУБД. Эти типы автоматически выбираются Studio при генерации скриптов создания и обновления БД, и для них гарантируется работоспособность всех механизмов платформы.
| Java | HSQL | PostgreSQL | MS SQL Server | Oracle | MySQL | MariaDB |
|---|---|---|---|---|---|---|
UUID |
varchar(36) |
uuid |
uniqueidentifier |
varchar2(32) |
varchar(32) |
varchar(32) |
Date |
timestamp |
timestamp |
datetime |
timestamp |
datetime(3) |
datetime(3) |
java.sql.Date |
timestamp |
date |
datetime |
date |
date |
date |
java.sql.Time |
timestamp |
time |
datetime |
timestamp |
time(3) |
time(3) |
BigDecimal |
decimal(p, s) |
decimal(p, s) |
decimal(p, s) |
number(p, s) |
decimal(p, s) |
decimal(p, s) |
Double |
double precision |
double precision |
double precision |
float |
double precision |
double precision |
Long |
bigint |
bigint |
bigint |
number(19) |
bigint |
bigint |
Integer |
integer |
integer |
integer |
integer |
integer |
integer |
Boolean |
boolean |
boolean |
tinyint |
char(1) |
boolean |
boolean |
String (limited) |
varchar(n) |
varchar(n) |
varchar(n) |
varchar2(n) |
varchar(n) |
varchar(n) |
String (unlimited) |
longvarchar |
text |
varchar(max) |
clob |
longtext |
longtext |
byte[] |
longvarbinary |
bytea |
image |
blob |
longblob |
longblob |
Как правило, всю работу по преобразованию данных между БД и кодом Java выполняет слой ORM совместно с соответствующим JDBC драйвером. Это означает, что при работе с данными через DataManager, EntityManager и запросы на JPQL никакой ручной конвертации выполнять не нужно - вы просто используете типы Java, перечисленные в левой колонке таблицы.
При использовании native SQL через EntityManager.createNativeQuery() или через QueryRunner для разных типов СУБД некоторые типы данных в Java коде будут отличаться от приведенных. В первую очередь это касается атрибутов типа UUID - только драйвер PostgreSQL возвращает значения соответствующих колонок в этом типе, для других серверов это будет String. Для обеспечения независимости кода от используемой СУБД рекомендуется конвертировать типы параметров и результатов запросов с помощью интерфейса DbTypeConverter.
3.3.2.1. Поддержка произвольных СУБД
На уровне прикладного проекта можно реализовать работу с любой СУБД, поддерживаемой фреймворком ORM (EclipseLink). Для этого достаточно выполнить следующее:
-
Указать тип СУБД в виде произвольного кода в свойстве cuba.dbmsType. Код должен отличаться от используемых в платформе кодов
hsql,postgres,mssql,oracle. -
Реализовать интерфейсы
DbmsFeatures,SequenceSupport,DbTypeConverterклассами с именами соответственноTypeDbmsFeatures,TypeSequenceSupport,TypeDbTypeConverter, гдеType- код типа СУБД. Пакет класса имплементации должен быть таким же, как у интерфейса. -
Если источник данных сконфигурирован в приложении, необходимо указать полный URL соединения в требуемом СУБД формате, как описано в разделе Подключение к базам данных.
-
Создать скрипты инициализации и обновления БД в каталогах с кодом СУБД. Скрипты инициализации должны включать создание всех объектов БД, необходимых для сущностей платформы (их можно скопировать из имеющихся в каталоге
10-cubaи др. скриптов и исправить для данной СУБД). -
Для создания и обновления БД задачами Gradle в build.gradle необходимо для этих задач указать дополнительные параметры:
task createDb(dependsOn: assemble, type: CubaDbCreation) { dbms = 'my' // DBMS code driver = 'net.my.jdbc.Driver' // JDBC driver class dbUrl = 'jdbc:my:myserver://192.168.47.45/mydb' // Database URL masterUrl = 'jdbc:my:myserver://192.168.47.45/master' // URL of a master DB to connect to for creating the application DB dropDbSql = 'drop database mydb;' // Drop database statement createDbSql = 'create database mydb;' // Create database statement timeStampType = 'datetime' // Date and time datatype - needed for SYS_DB_CHANGELOG table creation dbUser = 'sa' dbPassword = 'saPass1' } task updateDb(dependsOn: assemble, type: CubaDbUpdate) { dbms = 'my' // DBMS code driver = 'net.my.jdbc.Driver' // JDBC driver class dbUrl = 'jdbc:my:myserver://192.168.47.45/mydb' // Database URL dbUser = 'sa' dbPassword = 'saPass1' }
Также поддержку произвольной СУБД можно добавить и в CUBA Studio. После реализации интеграции Studio позволит разработчику использовать стандартные диалоги для изменения настроек хранилища данных. А также (самое важное) Studio сможет автоматически генерировать скрипты миграции БД для сущностей, как определенных в проекте, так и унаследованных из платформы и аддонов. Инструкции по интеграции доступны в соответствующей главе руководства пользователя Studio.
Работающий пример встраивания сторонней СУБД (Firebird) в платформу CUBA platform и CUBA Studio находится здесь: https://github.com/cuba-labs/firebird-sample.
3.3.2.2. Версия СУБД
В дополнение к свойству приложения cuba.dbmsType существует опциональное свойство cuba.dbmsVersion. Оно влияет на выбор имплементаций интерфейсов DbmsFeatures, SequenceSupport, DbTypeConverter, и на поиск скриптов создания и обновления БД.
Имя класса имплементации интеграционного интерфейса формируется следующим образом: TypeVersionName. Здесь Type - значение cuba.dbmsType с заглавной буквы, Version - значение cuba.dbmsVersion, Name - имя интерфейса. Пакет класса должен быть таким же, как у интерфейса. Если класс с таким именем отсутствует, предпринимается попытка найти класс с именем без версии: TypeName. Если и такого класса нет, выдается исключение.
Например, в платформе определен класс com.haulmont.cuba.core.sys.persistence.Mssql2012SequenceSupport, который вступит в силу, если в проекте указаны следующие свойства:
cuba.dbmsType = mssql
cuba.dbmsVersion = 2012При поиске скриптов создания и обновления БД каталог с именем type-version имеет приоритет над каталогом с именем type. Это значит, что скрипты каталога type-version заменяют одноименные скрипты каталога type. В каталоге type-version могут быть и скрипты с собственными именами, они будут также добавлены в общий набор скриптов для выполнения. Сортировка скриптов производится по пути начиная с каталога, вложенного в type или type-version, то есть без учета того, в каком каталоге (с версией или без) находится скрипт.
Например, следующим образом можно определить скрипты создания БД для Microsoft SQL Server для версий ниже и выше 2012:
modules/core/db/init/
mssql/
10.create-db.sql
20.create-db.sql
30.create-db.sql
mssql-2012/
10.create-db.sql3.3.2.3. Особенности MS SQL Server
Microsoft SQL Server использует кластерные индексы для таблиц.
По умолчанию кластерный индекс создается по первичному ключу таблицы, однако используемые в CUBA-приложении ключи типа UUID плохо подходят для кластерного индекса. Мы рекомендуем создавать первичные ключи типа UUID с модификатором nonclustered:
create table SALES_CUSTOMER (
ID uniqueidentifier not null,
CREATE_TS datetime,
...
primary key nonclustered (ID)
)^3.3.2.4. Особенности MySQL
|
Если в вашей базе данных используется кодировка, отличная от UTF-8, некоторые скрипты фреймворка не смогут быть выполнены. В этом случае необходимо изменить свойства базы данных Charset и Collation name, передав следующие параметры подключения в поле Connection params окна Data Store Properties: |
MySQL не поддерживает частичные (partial) индексы, поэтому единственная возможность создать ограничение уникальности для soft deleted сущности - это использовать в составе индекса колонку DELETE_TS. Однако, существует другая проблема: MySQL позволяет иметь несколько NULLs в колонке с ограничением уникальности. Так как стандартная колонка DELETE_TS является nullable, она не может быть использована в уникальном индексе. Рекомендуется следующий способ создания уникальных ограничений для сущностей с мягким удалением:
-
Создайте в таблице колонку
DELETE_TS_NNс параметром not null и значением по умолчанию:create table DEMO_CUSTOMER ( ... DELETE_TS_NN datetime(3) not null default '1000-01-01 00:00:00.000', ... ) -
Создайте триггер, изменяющий
DELETE_TS_NNкогда меняетсяDELETE_TS:create trigger DEMO_CUSTOMER_DELETE_TS_NN_TRIGGER before update on DEMO_CUSTOMER for each row if not(NEW.DELETE_TS <=> OLD.DELETE_TS) then set NEW.DELETE_TS_NN = if (NEW.DELETE_TS is null, '1000-01-01 00:00:00.000', NEW.DELETE_TS); end if -
Создайте уникальный индекс, включающий в себя уникальные колонки и
DELETE_TS_NN:create unique index IDX_DEMO_CUSTOMER_UNIQ_NAME on DEMO_CUSTOMER (NAME, DELETE_TS_NN)
3.3.3. Скрипты миграции БД
Проект CUBA-приложения всегда содержит два набора скриптов:
-
Скрипты создания БД, предназначенные для создания базы данных с нуля. Они содержат набор DDL и DML операторов, после выполнения которых на пустой БД схема базы данных полностью соответствует текущему состоянию модели данных приложения. Скрипты создания могут также наполнять БД необходимыми первичными данными.
-
Скрипты обновления БД - предназначены для поэтапного приведения структуры БД к текущему состоянию модели данных.
|
CUBA Studio автоматически создает скрипты миграции БД для изменяющейся модели данных вашего проекта, см. документацию. Информация, приведенная ниже, может быть полезна для лучшего понимания данного процесса, а также при создании Groovy-скриптов миграции, которые не поддерживаются в Studio. |
При изменении модели данных необходимо отразить соответствующее изменение схемы БД и в скриптах создания, и в скриптах обновления. Например, при добавлении атрибута address в сущность Customer, нужно:
-
Изменить оператор создания таблицы в скрипте создания:
create table SALES_CUSTOMER ( ID varchar(36) not null, CREATE_TS timestamp, CREATED_BY varchar(50), NAME varchar(100), ADDRESS varchar(200), -- added column primary key (ID) ) -
Добавить скрипт обновления, содержащий оператор модификации таблицы:
alter table SALES_CUSTOMER add ADDRESS varchar(200)Обратите внимание, что генератор скриптов Studio не отслеживает изменения Column definition атрибутов сущностей и
sqlTypeспециализированных datatype. Таким образом, при их изменении соответствующие скрипты обновления необходимо создавать вручную.
Скрипты создания располагаются в каталоге /db/init модуля core. Скрипты создания дополнительных хранилищ (если таковые необходимы) должны располагаться в каталогах вида /db/init_<datastore_name_in_lower_case>. Для каждого типа СУБД, поддерживаемой приложением, создается свой набор скриптов и располагается в подкаталоге с именем, соответствующим свойству приложения cuba.dbmsType, например, /db/init/postgres. Имена скриптов создания должны иметь вид {optional_prefix}create-db.sql.
Скрипты обновления располагаются в каталоге /db/update модуля core. Скрипты обновления дополнительных хранилищ (если таковые необходимы) должны располагаться в каталогах вида /db/update_<datastore_name_in_lower_case>. Для каждого типа СУБД, поддерживаемой приложением, создается свой набор скриптов и располагается в подкаталоге с именем, соответствующим свойству приложения cuba.dbmsType, например, /db/update/postgres.
Скрипты обновления могут быть двух типов: с расширением *.sql или с расширением *.groovy. SQL-скрипты являются основным средством обновления базы данных. Groovy-скрипты выполняются только механизмом запуска скриптов БД сервером, поэтому применяются в основном на этапе эксплуатации приложения - как правило, это процессы миграции или импорта данных, которые невозможно реализовать на SQL. Чтобы пропустить скрипты Groovy при обновлении, вы можете выполнить следующую команду из командной строки:
delete from sys_db_changelog where script_name like '%groovy' and create_ts > (now() - interval '1 hour')Скрипты обновления должны иметь имена, которые при сортировке в алфавитном порядке образуют правильную последовательность их выполнения (обычно это хронологическая последовательность их создания). Поэтому при ручном создании рекомендуется задавать имя скрипта обновления в виде {yymmdd}-{description}.sql, где yy - год, mm - месяц, dd - день, description - краткое описание скрипта. Например, 121003-addCodeToCategoryAttribute.sql. Studio при автоматической генерации скриптов также придерживается этого формата.
Чтобы groovy-скрипты также выполнялись командой updateDb, они обязательно должны иметь расширение .upgrade.groovy и ту же логику именования, что и sql-скрипты. Действия из набора Post update в этих скриптах не поддерживаются, для привязки к данным используются стандартные переменные ds (доступ к источнику данных) и log (доступ к журналу сервера). Выполнение groovy-скриптов можно запретить, прописав executeGroovy = false в команде updateDb в build.gradle.
Скрипты обновления можно группировать в подкаталоги, главное, чтобы путь к скрипту с учетом подкаталога не нарушал хронологической последовательности. Например, можно создавать подкаталоги по номеру года или по году и месяцу.
В развернутом приложении скрипты создания и обновления БД располагаются в специальном каталоге скриптов базы данных, задаваемым свойством приложения cuba.dbDir.
3.3.3.1. Структура SQL-скриптов
SQL-скрипты миграции представляют собой текстовые файлы с набором DDL и DML команд, разделенных символом “^”. Символ “^” применяется для того, чтобы можно было применять разделитель “;” в составе сложных команд, например, при создании функций или триггеров. Механизм исполнения скриптов разделяет входной файл на команды по разделителю “^” и выполняет каждую команду в отдельной транзакции. Это означает, что при необходимости можно сгруппировать несколько простых операторов (например, insert), разделенных точкой с запятой, и обеспечить их выполнение в одной транзакции.
|
Разделитель "^" может быть заэкранирован путем его удвоения. Например, если вам нужно передать значение |
Пример SQL-скрипта обновления:
create table LIBRARY_COUNTRY (
ID varchar(36) not null,
CREATE_TS time,
CREATED_BY varchar(50),
NAME varchar(100) not null,
primary key (ID)
)^
alter table LIBRARY_TOWN add column COUNTRY_ID varchar(36) ^
alter table LIBRARY_TOWN add constraint FK_LIBRARY_TOWN_COUNTRY_ID foreign key (COUNTRY_ID) references LIBRARY_COUNTRY(ID)^
create index IDX_LIBRARY_TOWN_COUNTRY on LIBRARY_TOWN (COUNTRY_ID)^3.3.3.2. Структура Groovy-скриптов
Groovy-скрипты обновления имеют следующую структуру:
-
Основная часть, содержащая код, выполняемый до старта контекста приложения. В этой части можно использовать любые классы Java, Groovy и блока Middleware приложения, но при этом необходимо иметь в виду, что никакие бины, интерфейсы инфраструктуры и прочие объекты приложения еще не инстанциированы, и с ними работать нельзя.
Основная часть предназначена в первую очередь, как и обычные SQL-скрипты, для обновления схемы данных.
-
PostUpdate часть - набор замыканий, которые будут выполнены после завершения процесса обновления и после старта контекста приложения. Внутри этих замыканий можно оперировать любыми объектами Middleware приложения.
В этой части скрипта удобно, например, выполнять импорт данных, так как в ней можно использовать интерфейс Persistence и объекты модели данных.
На вход Groovy-скриптов механизм выполнения передает следующие переменные:
-
ds- экземплярjavax.sql.DataSourceдля базы данных приложения. -
log- экземплярorg.apache.commons.logging.Logдля вывода сообщений в журнал сервера -
postUpdate- объект, содержащий методadd(Closure closure)для добавления замыканий, выполняющихся после старта контекста сервера.
|
Groovy-скрипты выполняются только механизмом запуска скриптов БД сервером. |
Пример Groovy-скрипта обновления:
import com.haulmont.cuba.core.Persistence
import com.haulmont.cuba.core.global.AppBeans
import com.haulmont.refapp.core.entity.Colour
import groovy.sql.Sql
log.info('Executing actions in update phase')
Sql sql = new Sql(ds)
sql.execute """ alter table MY_COLOR add DESCRIPTION varchar(100); """
// Add post update action
postUpdate.add({
log.info('Executing post update action using fully functioning server')
def p = AppBeans.get(Persistence.class)
def tr = p.createTransaction()
try {
def em = p.getEntityManager()
Colour c = new Colour()
c.name = 'yellow'
c.description = 'a description'
em.persist(c)
tr.commit()
} finally {
tr.end()
}
})3.3.3.3. Выполнение скриптов БД задачами Gradle
Данный механизм применяется обычно разработчиками приложения для собственного экземпляра базы данных. Выполнение скриптов в этом случае сводится к запуску специальных задач Gradle, описанных в скрипте сборки build.gradle. Это можно сделать как из командной строки, так и с помощью интерфейса Studio.
Для запуска скриптов создания БД служит задача createDb. В Studio ей соответствует команда главного меню CUBA → Create database. При запуске задачи происходит следующее:
-
В каталоге
modules/core/build/dbсобираются скрипты компонентов платформы и скриптыdb/**/*.sqlмодуля core текущего проекта. Наборы скриптов располагаются в подкаталогах с числовыми префиксами. Числовые префиксы необходимы для соблюдения алфавитного порядка выполнения скриптов - сначала выполняются скрипты cuba, затем других компонентов, затем текущего проекта. -
Если БД существует, она полностью очищается. Если не существует, то создается новая пустая БД.
-
Последовательно в алфавитном порядке выполняются все скрипты создания
modules/core/build/db/init/**/*create-db.sql, и их имена вместе с путем относительно каталогаdbрегистрируются в таблицеSYS_DB_CHANGELOG. -
В таблице
SYS_DB_CHANGELOGаналогично регистрируются все имеющиеся на данный момент скрипты обновленияmodules/core/build/db/update/**/*.sql. Это необходимо для будущего инкрементального обновления БД новыми скриптами.
Для запуска скриптов обновления БД служит задача updateDb. В Studio ей соответствует команда главного меню CUBA > Update Database. При запуске задачи происходит следующее:
-
Производится сборка скриптов аналогично описанному выше.
-
Производится проверка, выполнены ли все скрипты создания схемы компонентов приложения (путем выборки из таблицы
SYS_DB_CHANGELOG). Если обнаруживается, что БД не инициализирована для работы некоторого компонента, выполняются его скрипты создания. -
В каталогах
modules/core/build/db/update/**производится поиск скриптов обновления, не зарегистрированных в таблицеSYS_DB_CHANGELOG, то есть не выполненных ранее и содержимое которых не отражено в БД при ее инициализации. -
Последовательно в алфавитном порядке выполняются все найденные на предыдущем шаге скрипты, и их имена вместе с путем относительно каталога
dbрегистрируются в таблицеSYS_DB_CHANGELOG.
3.3.3.4. Выполнение скриптов БД сервером
Механизм выполнения скриптов сервером предназначен для приведения БД в актуальное состояние на старте сервера приложения, и активируется во время инициализации блока Middleware. Понятно, что при этом приложение должно быть собрано и развернуто на сервере, будь то собственный Tomcat разработчика или сервер в режиме эксплуатации.
Данный механизм в зависимости от описанных ниже условий выполняет либо скрипты создания, либо скрипты обновления, то есть он может и инициализировать БД с нуля, и обновлять ее. Однако, в отличие от описанной в предыдущем разделе задачи Gradle createDb, для выполнения инициализации базы она должна существовать - сервер не создает БД автоматически, а только прогоняет на ней скрипты.
Механизм выполнения скриптов сервером действует следующим образом:
-
Скрипты читаются из каталога скриптов базы данных, определяемого свойством приложения cuba.dbDir, установленного по умолчанию в
WEB-INF/db. -
Если в БД отсутствует таблица
SEC_USER, то считается, что база данных пуста, и запускается полная инициализация с помощью скриптов создания БД. После выполнения инициализирующих скриптов их имена запоминаются в таблицеSYS_DB_CHANGELOG. Кроме того, там же сохраняются имена всех доступных скриптов обновления, без их выполнения. -
Если в БД имеется таблица
SEC_USER, но отсутствует таблицаSYS_DB_CHANGELOG(это случай, когда в первый раз запускается описываемый механизм на имеющейся рабочей БД), никакие скрипты не запускаются. Вместо этого создается таблицаSYS_DB_CHANGELOGи в ней сохраняются имена всех доступных на данный момент скриптов создания и обновления. -
Если в БД имеются и таблица
SEC_USERи таблицаSYS_DB_CHANGELOG, то производится запуск скриптов обновления, и их имена запоминаются в таблицеSYS_DB_CHANGELOG. Причем запускаются только те скрипты, имен которых до этого не было в таблицеSYS_DB_CHANGELOG, т.е. не запускавшиеся ранее. Последовательность запуска скриптов определяется двумя факторами: приоритетом базового проекта (см. содержимое каталога скриптов базы данных:10-cuba,20-workflow, …) и именем файла скрипта (с учетом подкаталогов внутри каталогаupdate) в алфавитном порядке.Перед выполнением скриптов обновления производится проверка, все ли скрипты создания схемы компонентов приложения выполнены (путем выборки из таблицы
SYS_DB_CHANGELOG). Если обнаруживается, что БД не инициализирована для работы некоторого компонента, выполняются его скрипты создания.
Механизм выполнения скриптов на старте сервера включается свойством приложения cuba.automaticDatabaseUpdate.
В запущенном приложении механизм выполнения скриптов можно стартовать с помощью JMX-бина app-core.cuba:type=PersistenceManager, вызвав его метод updateDatabase() с параметром update. Понятно, что таким способом можно только обновить БД, а не проинициализировать новую, так как войти в систему для запуска метода JMX-бина при пустой БД невозможно. При этом следует иметь в виду, что если на старте Middleware или при входе пользователя в систему начнется инициализация той части модели данных, которая уже не соответствует устаревшей схеме БД, то произойдет ошибка, и продолжение работы станет невозможным. Именно поэтому универсальным является только автоматическое обновление БД на старте сервера перед инициализацией модели данных.
JMX-бин app-core.cuba:type=PersistenceManager имеет еще один метод, относящийся к механизму обновления БД: findUpdateDatabaseScripts(). Он возвращает список новых скриптов обновления, имеющихся в каталоге и не зарегистрированных в БД.
Практические рекомендации по использованию механизма обновления БД сервером приведены в Создание и обновление БД при эксплуатации приложения.
3.4. Компоненты среднего слоя
На следующем рисунке приведены основные компоненты среднего слоя CUBA-приложения.
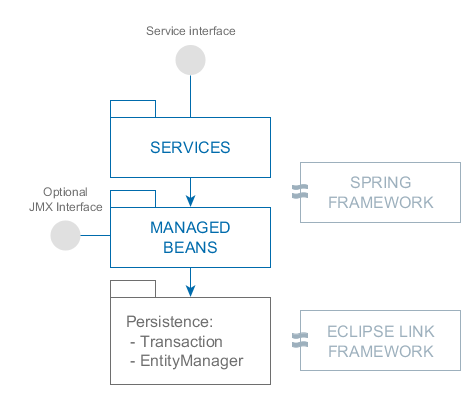
Рисунок 8. Компоненты среднего слоя
Services – Spring-бины, формирующие границу приложения и предоставляющие интерфейс клиентскому уровню приложения. Сервисы могут содержать бизнес-логику сами, либо делегировать выполнение managed beans.
Managed Beans – Spring-бины, содержащие бизнес-логику приложения. Вызываются сервисами, другими бинами или через опциональный JMX-интерфейс.
Persistence − инфраструктурный интерфейс для доступа к функциональности хранения данных: управлению транзакциями и ORM.
3.4.1. Сервисы
Сервисы образуют слой компонентов, определяющий множество операций Middleware, доступных клиентскому уровню приложения. Другими словами, сервис представляет собой точку входа в бизнес-логику среднего слоя. В сервисе можно управлять транзакциями, проверять права пользователей, работать с базой данных или делегировать выполнение другим Spring-бинам среднего слоя.
Диаграмма классов сервиса, отображающая основные компоненты сервиса:
Интерфейс сервиса располагается в модуле global и доступен на клиентском уровне и на Middleware. Во время выполнения, на клиентском уровне для интерфейса сервиса создается прокси-объект, который обеспечивает вызовы методов бина, реализующего сервис, с помощью механизма Spring HTTP Invoker.
Бин, реализующий сервис, располагается в модуле core и доступен только на среднем слое.
ServiceInterceptor автоматически вызывается для каждого метода сервиса через Spring AOP. Он проверяет наличие в потоке выполнения пользовательской сессии, а также трансформирует и логирует исключения, если сервис вызван с клиентского уровня.
3.4.1.1. Создание сервиса
|
Руководство Create Business Logic in CUBA демонстрирует использование среднего слоя для реализации бизнес-логики. |
Имена интерфейсов сервисов должны заканчиваться на Service, имена классов реализации на ServiceBean.
CUBA Studio позволяет легко создавать заглушки интерфейса и класса сервисов, а также автоматически регистрирует созданные сервисы в spring.xml. Для создания сервиса используйте команду New > Service в контекстном меню секции Middleware проектного дерева CUBA Studio.
При создании сервиса вручную без Studio необходимо выполнить следующее:
-
Создать интерфейс в модуле
global(т.к. интерфейс сервиса должен быть доступен на всех уровнях) и задать в нем имя сервиса. Имя рекомендуется задавать в формате{имя_проекта}_{имя_интерфейса}. Например:package com.sample.sales.core; import com.sample.sales.entity.Order; public interface OrderService { String NAME = "sales_OrderService"; void calculateTotals(Order order); } -
Создать класс сервиса в модуле
coreи добавить ему аннотацию@org.springframework.stereotype.Serviceс именем, заданным в интерфейсеpackage com.sample.sales.core; import com.sample.sales.entity.Order; import org.springframework.stereotype.Service; @Service(OrderService.NAME) public class OrderServiceBean implements OrderService { @Override public void calculateTotals(Order order) { } }
Класс сервиса, как и класс любого другого Spring-бина, должен находиться внутри дерева пакетов с корнем, заданным в элементе context:component-scan файла spring.xml. В нашем случае файл spring.xml содержит элемент:
<context:component-scan base-package="com.sample.sales"/>что означает, что поиск аннотированных бинов для данного блока приложения будет происходить начиная с пакета com.sample.sales.
Если некоторую бизнес-логику требуется вызывать из разных сервисов либо других компонентов Middleware, ее необходимо выделить и инкапсулировать внутри соответствующего Spring-бина. Например:
// service interface
public interface SalesService {
String NAME = "sample_SalesService";
BigDecimal calculateSales(UUID customerId);
}// service implementation
@Service(SalesService.NAME)
public class SalesServiceBean implements SalesService {
@Inject
private SalesCalculator salesCalculator;
@Transactional
@Override
public BigDecimal calculateSales(UUID customerId) {
return salesCalculator.calculateSales(customerId);
}
}// managed bean encapsulating business logic
@Component
public class SalesCalculator {
@Inject
private Persistence persistence;
public BigDecimal calculateSales(UUID customerId) {
Query query = persistence.getEntityManager().createQuery(
"select sum(o.amount) from sample_Order o where o.customer.id = :customerId");
query.setParameter("customerId", customerId);
return (BigDecimal) query.getFirstResult();
}
}3.4.1.2. Использование сервиса
Для того чтобы вызывать сервис, в клиентском блоке приложения для него должен быть создан соответствующий прокси-объект. Делается это путем объявления имени и интерфейса сервиса в параметрах фабрики прокси-объектов. Для блока Web Client это бин класса WebRemoteProxyBeanCreator, для Web Portal - PortalRemoteProxyBeanCreator.
Фабрика прокси-объектов конфигурируется в файле spring.xml соответствующего клиентского блока.
Например, чтобы в приложении sales вызвать с веб-клиента сервис sales_OrderService, необходимо добавить в файл web-spring.xml модуля web следующее:
<bean id="sales_proxyCreator" class="com.haulmont.cuba.web.sys.remoting.WebRemoteProxyBeanCreator">
<property name="serverSelector" ref="cuba_ServerSelector"/>
<property name="remoteServices">
<map>
<entry key="sales_OrderService" value="com.sample.sales.core.OrderService"/>
</map>
</property>
</bean>Все импортируемые сервисы объявляются в одном свойстве remoteServices в элементах map/entry.
|
CUBA Studio автоматически регистрирует сервисы во всех клиентских блоках приложения. |
С точки зрения прикладного кода прокси-объект сервиса на клиентском уровне является обычным бином Spring и может быть получен либо инжекцией, либо с помощью класса AppBeans, например:
@Inject
private OrderService orderService;
public void calculateTotals() {
orderService.calculateTotals(order);
}3.4.1.3. DataService
DataService является фасадом для вызова серверной реализации DataManager с клиентского уровня. DataService не рекомендуется использовать в прикладном коде. Вместо него и на клиентском уровне, и на Middleware следует использовать DataManager.
3.4.2. Data Stores
Предпочтительный способ работы с данными в CUBA-приложениях - использование сущностей: либо декларативно в связанных с данными визуальных компонентах, либо программно через DataManager или EntityManager. Сущности отображаются на данные в хранилище, которое обычно представляет собой реляционную БД. Приложение может работать с несколькими хранилищами, так что его модель данных будет содержать сущности, отображаемые на данные из разных БД.
Некоторая сущность может принадлежать только одному хранилищу. Сущности из разных хранилищ можно отображать на одном экране UI, при этом DataManager обеспечивает их чтение и запись в соответствующее хранилище. В зависимости от типа сущности, DataManager выбирает зарегистрированное хранилище, представленное реализацией интерфейса DataStore, и делегирует ему загрузку или сохранение. При управлении транзакциями и работе с сущностями через EntityManager необходимо явно указывать, какое хранилище использовать. Подробнее см. методы интерфейса Persistence и параметры аннотации @Transactional.
Платформа содержит единственную реализацию интерфейса DataStore: RdbmsStore, предназначенную для работы с реляционными СУБД через слой ORM. Кроме того, в проекте приложения можно реализовать DataStore для интеграции, например, с нереляционной СУБД или внешней системой, имеющей REST интерфейс.
Каждое CUBA-приложение имеет основное хранилище, которое содержит системные сущности и используется для входа пользователей в приложение. В данном руководстве под базой данных всегда имеется в виду основное хранилище, если явно не оговорено другое. Основное хранилище должно представлять собой реляционную БД, подключенную через источник данных JDBC. Дополнительное хранилище может быть любой реализацией интерфейса DataStore.
|
CUBA Studio позволяет настраивать дополнительные хранилища, см. документацию. Studio автоматически создает все необходимые свойства приложения и поддерживает соответствующие файлы |
Ниже приведена информация, которая может быть полезна при поиске проблем или если Studio не используется.
Имена дополнительных хранилищ указываются в свойстве приложения cuba.additionalStores. Если дополнительное хранилище является реляционной БД (RdbmsStore), необходимо указать для него следующие свойства приложения:
-
cuba.dbmsType_<store_name>- тип базы данных хранилища. -
cuba.persistenceConfig_<store_name>- путь к файлуpersistence.xmlхранилища. -
cuba.dataSource…- параметры подключения как описано в разделе Подключение к базам данных.
Если вы реализовали интерфейс DataStore в проекте, имя бина реализации должно быть указано в свойстве приложения cuba.storeImpl_<store_name>.
Предположим, что в вашем проекте два дополнительных хранилища: db1 (база данных PostgreSQL) and mem1 (некоторое in-memory хранилище, реализованное бином проекта). Тогда необходимо указать следующие свойства приложения в файле app.properties модуля core:
cuba.additionalStores = db1, mem1
# RdbmsStore for Postgres database with data source obtained from JNDI
cuba.dbmsType_db1 = postgres
cuba.persistenceConfig_db1 = com/company/sample/db1-persistence.xml
cuba.dataSourceJndiName_db1 = jdbc/db1
# Custom store
cuba.storeImpl_mem1 = sample_InMemoryStoreСвойства cuba.additionalStores и cuba.persistenceConfig_db1 необходимо также указать в файлах свойств всех используемых блоков приложения (web-app.properties, portal-app.properties, и т.д.).
- Ссылки между сущностями из разных хранилищ
-
DataManager может автоматически поддерживать TO-ONE ссылки между сущностями из разных хранилищ, если они объявлены нужным образом. Например, рассмотрим случай, когда необходимо в сущности
Order, находящейся в главном хранилище, иметь ссылку на сущностьCustomerиз дополнительного хранилища. Необходимо сделать следующее:-
В сущности
Orderопределить атрибут типа, соответствующего идентификаторуCustomer. Атрибут должен быть аннотирован как@SystemLevelчтобы исключить его из различных списков, доступных пользователям, в частности из атрибутов в Filter:@SystemLevel @Column(name = "CUSTOMER_ID") private Long customerId; -
В сущности
Orderопределить неперсистентный атрибут-ссылку наCustomerи указать атрибутcustomerIdкак "related":@Transient @MetaProperty(related = "customerId") private Customer customer; -
Включите неперсистентный атрибут
customerв нужные представления.
После этого, когда
Orderбудет загружаться с представлением, включающим атрибутcustomer,DataManagerбудет автоматически загружать связанные экземплярыCustomerиз дополнительного хранилища. Загрузка коллекций оптимизирована по производительности: после загрузки списка заказов загрузка покупателей из доп. хранилища производится пакетами. Размер пакета определяется свойством приложения cuba.crossDataStoreReferenceLoadingBatchSize.При коммите графа объектов, включающего
Orderсо ссылкой наCustomer,DataManagerсохранит сущности через соответствующие имплементацииDataStore, а затем сохранит идентификаторCustomerв атрибутеcustomerIdсущностиOrder.Ссылки между сущностями из разных хранилищ поддерживаются компонентом Filter.
CUBA Studio автоматически поддерживает набор атрибутов для ссылок между сущностями из разных хранилищ, если в качестве ассоциации выбирается сущность из другого хранилища.
-
3.4.3. Интерфейс Persistence
Интерфейс Persistence является точкой входа в функциональность хранения данных, предоставляемую слоем ORM.
Методы интерфейса:
-
createTransaction(),getTransaction()- получить интерфейс управления транзакциями. Методы могут принимать имя хранилища данных. Если хранилище не указано, подразумевается основная база данных. -
callInTransaction(),runInTransaction()- выполнить код в новой транзакции с возвратом значения или без возврата значения. Методы могут принимать имя хранилища данных. Если хранилище не указано, подразумевается основная база данных. -
isInTransaction()- определяет, существует ли в данный момент активная транзакция. -
getEntityManager()- возвращает экземпляр EntityManager для текущей транзакции. Метод может принимать имя хранилища данных. Если хранилище не указано, подразумевается основная база данных. -
isSoftDeletion()- позволяет определить, активен ли режим мягкого удаления -
setSoftDeletion()- устанавливает или отключает режим мягкого удаления. Влияет на аналогичный признак всех создаваемых экземпляровEntityManager. По умолчанию мягкое удаление включено. -
getDbTypeConverter()- возвращает экземпляр DbTypeConverter для основной базы данных или для дополнительного хранилища. -
getDataSource()- получитьjavax.sql.DataSourceдля основной базы данных или для дополнительного хранилища.Для всех объектов
javax.sql.Connection, получаемых методомgetDataSource().getConnection(), необходимо после использования соединения вызвать методclose()в секцииfinally. В противном случае соединение не вернется в пул, через какое-то время пул переполнится, и приложение не сможет выполнять запросы к базе данных. -
getTools()- возвращает экземпляр интерфейсаPersistenceTools(см. ниже).
3.4.3.1. PersistenceTools
ManagedBean, содержащий вспомогательные методы работы с хранилищем данных. Интерфейс PersistenceTools можно получить либо методом Persistence.getTools(), либо как любой другой бин - инжекцией или через класс AppBeans.
Методы PersistenceTools:
-
getDirtyFields()- возвращает коллекцию имен атрибутов сущности, измененных со времени последней загрузки экземпляра из БД. Для новых экземпляров возвращает пустую коллекцию. -
isLoaded()- определяет, загружен ли из БД указанный атрибут экземпляра. Атрибут может быть не загружен, если он не указан в примененном при загрузке представлении.Данный метод работает только для экземпляров в состоянии Managed.
-
getReferenceId()- возвращает идентификатор связанной сущности без загрузки ее из БД.Предположим, в персистентный контекст загружен экземпляр
Order, и нужно получить значение идентификатора экземпляраCustomer, связанного с данным Заказом. Стандартное решениеorder.getCustomer().getId()приведет к выполнению SQL запроса к БД для загрузки экземпляраCustomer, что в данном случае избыточно, так как значение идентификатора Покупателя физически находится также и в таблице Заказов. Выполнение жеpersistence.getTools().getReferenceId(order, "customer")
не вызовет никаких дополнительных запросов к базе данных.
Данный метод работает только для экземпляров в состоянии Managed.
Для расширения набора вспомогательных методов в конкретном приложении бин PersistenceTools можно переопределить. Примеры работы с расширенным интерфейсом:
MyPersistenceTools tools = persistence.getTools();
tools.foo();((MyPersistenceTools) persistence.getTools()).foo();3.4.3.2. DbTypeConverter
Интерфейс, определяющий методы для конвертации данных между значениями атрибутов модели данных и параметрами и результатами запросов JDBC. Объект данного интерфейса можно получить методом Persistence.getDbTypeConverter().
Методы DbTypeConverter:
-
getJavaObject()- конвертирует результат JDBC запроса в тип, подходящий для присвоения атрибуту сущности. -
getSqlObject()- конвертирует значение атрибута сущности в тип, подходящий для присвоения параметру JDBC запроса. -
getSqlType()- возвращает константу изjava.sql.Types, соответствующую переданному типу атрибута сущности.
3.4.4. Слой ORM
Object-Relational Mapping - объектно-реляционное отображение - технология связывания таблиц реляционной базы данных с объектами языка программирования. В платформе CUBA используется реализация ORM на основе фреймворка EclipseLink.
Использование ORM дает ряд очевидных преимуществ:
-
Позволяет работать с данными реляционной СУБД, манипулируя объектами Java.
-
Упрощает программирование, избавляя от рутины написания тривиальных SQL-запросов.
-
Упрощает программирование, позволяя извлекать и сохранять целые графы объектов одной командой.
-
Обеспечивает легкое портирование приложения на различные СУБД.
-
Позволяет использовать лаконичный язык запросов JPQL.
В то же время, имеются и некоторые недостатки. Во-первых, разработчик, использующий ORM непосредственно, должен хорошо понимать особенности работы этой технологии. Во-вторых, усложняется оптимизация SQL и использование особенности применяемой СУБД.
|
Если вы столкнулись с проблемами производительности при доступе к БД, начните с того, что проверьте, какие конкретно SQL-операторы выполняются в вашем приложении. Вы можете использовать логгер |
3.4.4.1. EntityManager
EntityManager - основной интерфейс ORM, служит для управления персистентными сущностями.
|
В разделе DataManager vs. EntityManager приведена информация о различиях между EntityManager и DataManager. |
Ссылку на EntityManager можно получить через интерфейс Persistence, вызовом метода getEntityManager(). Полученный экземпляр EntityManager привязан к текущей транзакции, то есть все вызовы getEntityManager() в рамках одной транзакции возвращают один и тот же экземпляр EntityManager. После завершения транзакции обращения к данному экземпляру невозможны.
Экземпляр EntityManager содержит в себе персистентный контекст – набор экземпляров сущностей, загруженных из БД или только что созданных. Персистентный контекст является своего рода кэшем данных в рамках транзакции.EntityManager автоматически сбрасывает в БД все изменения, сделанные в его персистентном контексте, в момент коммита транзакции, либо при явном вызове метода flush().
Интерфейс EntityManager, используемый в CUBA-приложениях, в основном повторяет стандартный javax.persistence.EntityManager. Рассмотрим его основные методы:
-
persist()- вводит новый экземпляр сущности в персистентный контекст. При коммите транзакции командой SQLINSERTв БД будет создана соответствующая запись. -
merge()- переносит состояние отсоединенного экземпляра сущности в персистентный контекст следующим образом: из БД загружается экземпляр с тем же идентификатором, в него переносится состояние переданного Detached экземпляра и возвращается загруженный Managed экземпляр. Далее надо работать именно с возвращенным Managed экземпляром. При коммите транзакции командой SQLUPDATEв БД будет сохранено состояние данного экземпляра. -
remove()- удалить объект из базы данных, либо, если включен режим мягкого удаления, установить атрибутыdeleteTsиdeletedBy.Если переданный экземпляр находится в Detached состоянии, сначала выполняется
merge(). -
find()- загружает экземпляр сущности по идентификатору.При формировании запроса к БД учитывается представление, переданное в параметре данного метода. В результате в персистентном контексте окажется граф объектов, для которого загружены все атрибуты представления. Если не передано никакого представления, по умолчанию будет использовано представление
_local.В отличие от DataManager, все локальные атрибуты сущностей загружаются независимо от того, указаны ли они в представлении или нет. В
EntityManagerпредставление влияет только на загрузку атрибутов-ссылок. -
createQuery()- создать объектQueryилиTypedQueryдля выполнения JPQL запроса. -
createNativeQuery()- создать объектQueryдля выполнения SQL запроса. -
addView()- аналогичен методуsetView(), но в случае наличия уже установленного вEntityManagerпредставления, не заменяет его, а добавляет атрибуты переданного представления. -
reload()- перезагрузить экземпляр сущности с указанным представлением. -
isSoftDeletion()- проверяет, находится ли данныйEntityManagerв режиме мягкого удаления. -
setSoftDeletion()- устанавливает режим мягкого удаления для данного экземпляраEntityManager. -
getConnection()- возвращаетjava.sql.Connection, через который выполняет запросы данный экземплярEntityManager, и, соответственно, текущая транзакция. Закрывать такое соединение не нужно, оно будет закрыто при завершении транзакции. -
getDelegate()- возвращаетjavax.persistence.EntityManager, предоставляемый реализацией ORM.
Пример использования EntityManager в сервисе:
@Service(SalesService.NAME)
public class SalesServiceBean implements SalesService {
@Inject
private Persistence persistence;
@Override
public BigDecimal calculateSales(UUID customerId) {
BigDecimal result;
// start transaction
try (Transaction tx = persistence.createTransaction()) {
// get EntityManager for the current transaction
EntityManager em = persistence.getEntityManager();
// create and execute Query
Query query = em.createQuery(
"select sum(o.amount) from sample_Order o where o.customer.id = :customerId");
query.setParameter("customerId", customerId);
result = (BigDecimal) query.getFirstResult();
// commit transaction
tx.commit();
}
return result != null ? result : BigDecimal.ZERO;
}
}- Частичные сущности
-
По умолчанию, представления в EntityManager влияют только на загрузку связей, т.е. все локальные атрибуты всегда загружаются.
Вы можете заставить EntityManager загружать частичные сущности, если установите свойство loadPartialEntities представления в true (например, так делает DataManager). Однако, если загружаемая сущность кэшируется, то данный признак игнорируется, и сущность все равно будет загружена со всеми локальными атрибутами.
3.4.4.2. Состояния сущности
- New
-
Только что созданный в памяти экземпляр, например:
Car car = new Car(). Новый экземпляр может быть передан вEntityManager.persist()для сохранения в БД, при этом он переходит в состояние Managed. - Managed
-
Загруженный из БД или новый, переданный в EntityManager.persist(), экземпляр. Принадлежит некоторому экземпляру
EntityManager, другими словами, находится в его персистентном контексте.Любые изменения экземпляра в состоянии Managed будут сохранены в БД в случае коммита транзакции, к которой принадлежит данный
EntityManager. - Detached
-
Экземпляр, загруженный из БД и отсоединенный от своего персистентного контекста (вследствие завершения транзакции или сериализации).
Изменения, вносимые в Detached экземпляр, запоминаются в самом этом экземпляре (в полях, добавленных с помощью bytecode enhancement). Эти изменения будут сохранены в БД, только если данный экземпляр будет снова переведен в состояние Managed путем передачи в метод
EntityManager.merge().
3.4.4.3. Загрузка по требованию
Загрузка по требованию (lazy loading) позволяет загружать связанные сущности отложенно, т.е. только в момент первого обращения к их свойствам.
Загрузка по требованию в сумме порождает больше запросов к БД, чем жадная загрузка (eager fetching), однако нагрузка при этом растянута во времени.
-
Например, при извлечении списка N экземпляров сущности A, содержащих ссылку на экземпляр сущности B, в случае загрузки по требованию будет выполнено N+1 запросов к базе данных.
-
Как правило, для минимизации времени отклика и снижения нагрузки необходимо стремиться к меньшему количеству обращений к БД. Для этого в платформе используется механизм представлений, с помощью которого в вышеописанном случае ORM может сформировать один запрос к БД с объединением таблиц.
Загрузка по требованию работает только для экземпляра в состоянии Managed, то есть внутри транзакции, загрузившей данный экземпляр.
3.4.4.4. Выполнение JPQL запросов
В данном разделе описывается интерфейс Query, предназначенный для выполнения JPQL запросов на уровне ORM. Ссылку на Query можно получить у текущего экземпляра EntityManager вызовом метода createQuery(). Если запрос предполагается использовать для извлечения сущностей, рекомендуется вызывать createQuery() с передачей типа результата, что приведет к созданию TypedQuery.
Методы Query в основном соответствуют методам стандартного интерфейса JPA javax.persistence.Query. Рассмотрим отличия.
-
setView(),addView()- устанавливают представление, используемое при загрузке данных. -
getDelegate()- возвращает экземплярjavax.persistence.Query, предоставляемый реализацией ORM.
Если для Query установлено представление, то по умолчанию Query имеет FlushModeType.AUTO, что влияет на случай, когда в текущем персистентном контексте содержатся измененные экземпляры сущностей: эти экземпляры будут сохранены в БД перед выполнением запроса. Другими словами, ORM сначала синхронизирует состояние сущностей в персистентном контексте и в БД, а уже потом выполняет запрос. Этим гарантируется, что в результаты запроса попадут все соответствующие экземпляры, даже если они еще не были сохранены в базе данных явно. Обратной стороной этого является неявный flush, т.е. выполнение команд SQL update для всех измененных в данном контексте сущностей, что может повлиять на производительность.
Если же Query выполняется без представления, то по умолчанию Query имеет FlushModeType.COMMIT, что означает, что неявный flush вызван не будет, и запрос не будет учитывать содержимое текущего персистентного контекста.
В большинстве случаев игнорирование текущего персистентного контекста допустимо, и является предпочтительным поведением, так как не вызывает дополнительных команд SQL. Однако, при использовании представлений существует следующая проблема: если в персистентном контексте есть измененный экземпляр сущности, и выполняется запрос с представлением и FlushModeType.COMMIT, загружающий этот же экземпляр, то изменения будут потеряны. Поэтому по умолчанию мы используем FlushModeType.AUTO для запросов с представлением.
Вы также можете явно установить flush mode с помощью метода setFlushMode() интерфейса Query, чтобы переопределить режим по умолчанию.
- Using DELETE FROM with soft-deleted entities
-
Если в проекте используется мягкое удаление, то при выполнении JPQL-запроса
DELETE FROMдля сущности, удалённой через мягкое удаление, будет выброшено исключение. Дело в том, что такой запрос, по сути, будет трансформирован в запрос SQL для удаления всех сущностей, не помеченных для удаления. По умолчанию такое неочевидное поведение запрещено, но его можно разрешить с помощью свойства приложения cuba.enableDeleteStatementInSoftDeleteMode.
- Query Hints
-
Метод
Query.setHint()позволяет добавить некоторые подсказки (hints) в генерируемые команды SQL. Подсказки обычно используются для указания того, как запрос должен использовать индексы, или другую специфику СУБД. Фреймворк определяет следующие константы, которые можно использовать в качестве имен задаваемых подсказок:-
QueryHints.SQL_HINT- значение подсказки будет добавлено после сгенерированной команды SQL. Указывайте полный текст подсказки, включая разделители комментариев, если они требуются. -
QueryHints.MSSQL_RECOMPILE_HINT- будет добавлено выражениеOPTION(RECOMPILE)для СУБД MS SQL Server. Значение подсказки при этом игнорируется.
При работе с DataManager подсказки в запрос можно передать, используя метод
LoadContext.setHint(). -
3.4.4.4.1. Функции JPQL
В таблице ниже описаны функции JPQL, поддерживаемые и не поддерживаемые платформой CUBA.
| Функция | Поддерживается | Пример запроса |
|---|---|---|
Агрегатные функции |
ДА |
|
НЕТ: агрегатные функции со скалярными выражениями (особенность EclipseLink) |
|
|
ALL, ANY, SOME |
ДА |
|
Арифметические функции (INDEX, SIZE, ABS, SQRT, MOD) |
ДА |
|
CASE |
ДА |
|
НЕТ: CASE в UPDATE-запросе |
|
|
Функции даты и времени (CURRENT_DATE, CURRENT_TIME, CURRENT_TIMESTAMP) |
ДА |
|
Функции EclipseLink (CAST, REGEXP, EXTRACT) |
ДА |
|
НЕТ: CAST в запросе GROUP BY |
|
|
Операторы типов сущности |
ДА: тип сущности передаётся как параметр |
|
НЕТ: прямая ссылка на сущность |
|
|
Вызов функций |
ДА: результат с операторами сравнения |
|
НЕТ: прямое использование результата функции |
|
|
IN |
ДА |
|
IS EMPTY для коллекций |
ДА |
|
KEY/VALUE |
НЕТ |
|
Литералы |
ДА |
|
НЕТ: литералы даты и времени |
|
|
MEMBER OF |
ДА: для полей и запросов |
|
НЕТ: для литералов |
|
|
NEW в SELECT |
ДА |
|
NULLIF/COALESCE |
ДА |
|
NULLS FIRST, NULLS LAST в order by |
ДА |
|
Строковые функции (CONCAT, SUBSTRING, TRIM, LOWER, UPPER, LENGTH, LOCATE) |
ДА |
|
НЕТ: TRIM не поддерживается с trim char |
|
|
Вложенные запросы |
ДА |
|
НЕТ: path-выражения вместо имени сущности в FROM подзапроса |
|
|
TREAT |
ДА |
|
НЕТ: TREAT в WHERE-выражениях |
|
3.4.4.4.2. Поиск подстроки без учета регистра
Для удобного формирования условия поиска без учета регистра символов и по любой части строки можно использовать префикс (?i) в значении параметра запроса. Например, имеется запрос:
select c from sales_Customer c where c.name like :nameЕсли в значении параметра name передать строку (?i)%doe%, то при наличии в БД записи со значением John Doe она будет найдена, несмотря на различие в регистре символа. Это произойдет потому, что ORM выполнит SQL с условием вида lower(C.NAME) like ?.
Следует иметь в виду, что при таком поиске индекс, созданный в БД по полю NAME, не используется.
3.4.4.4.3. Макросы в JPQL
Текст JPQL запроса может включать макросы, которые обрабатываются перед выполнением и превращаются в исполняемый JPQL, дополнительно модифицируя набор параметров.
Макросы решают следующие задачи:
-
Позволяют обойти принципиальную невозможность средствами JPQL выразить условие зависимости значения поля от текущего момента времени (не работает арифметика типа current_date-1)
-
Позволяют сравнивать с датой поля типа Timestamp (содержащие дату+время)
Рассмотрим их подробно:
- @between
-
Имеет вид
@between(field_name, moment1, moment2, time_unit)или@between(field_name, moment1, moment2, time_unit, user_timezone), где-
field_name- имя атрибута для сравнения -
moment1,moment2- моменты времени, в которые должно попасть значение атрибутаfield_name. Каждый из моментов должен быть определен выражением с участием переменнойnow, к которой может быть прибавлено или отнято целое число -
time_unit- определяет единицу измерения времени, которое прибавляется или вычитается изnowв выражениях моментов, а также точность округления моментов. Может быть следующим:year,month,day,hour,minute,second. -
user_timezone- необязательный аргумент, указывающий, что в запросе необходимо использовать часовой пояс текущего пользователя.
Макрос преобразуется в следующее выражение JPQL:
field_name >= :moment1 and field_name < :moment2Пример 1. Покупатель создан сегодня:
select c from sales_Customer where @between(c.createTs, now, now+1, day)Пример 2. Покупатель создан в течение последних 10 минут:
select c from sales_Customer where @between(c.createTs, now-10, now, minute)Пример 3. Документы, датированные последними 5 днями и с учетом часового пояса текущего пользователя:
select d from sales_Doc where @between(d.createTs, now-5, now, day, user_timezone) -
- @today
-
Имеет вид
@today(field_name)или@today(field_name, user_timezone)и обеспечивает формирование условия попадания значения атрибута в текущий день. По сути это частный случай макроса@between.Пример. Пользователь создан сегодня:
select d from sales_Doc where @today(d.createTs) - @dateEquals
-
Имеет вид
@dateEquals(field_name, parameter)или@dateEquals(field_name, parameter, user_timezone)и позволяет сформировать условие попадания значения поляfield_nameтипаTimestampв дату, задаваемую параметромparameter.Пример:
select d from sales_Doc where @dateEquals(d.createTs, :param)Текущую дату можно передать с помощью атрибута
now. Для сдвига на определенное количество дней используйтеnowс+или-, к примеру:select d from sales_Doc where @dateEquals(d.createTs, now-1) - @dateBefore
-
Имеет вид
@dateBefore(field_name, parameter)или@dateBefore(field_name, parameter, user_timezone)и позволяет сформировать условие, что дата значения поляfield_nameтипаTimestampменьше даты, задаваемой параметромparameter.Пример:
select d from sales_Doc where @dateBefore(d.createTs, :param)Текущую дату можно передать с помощью атрибута
now. Для сдвига на определенное количество дней используйтеnowс+или-, к примеру:select d from sales_Doc where @dateBefore(d.createTs, now+1) - @dateAfter
-
Имеет вид
@dateAfter(field_name, parameter)или@dateAfter(field_name, parameter, user_timezone)и позволяет сформировать условие, что дата значения поляfield_nameтипаTimestampбольше или равна дате, задаваемой параметромparameter.Пример:
select d from sales_Doc where @dateAfter(d.createTs, :param)Текущую дату можно передать с помощью атрибута
now. Для сдвига на определенное количество дней используйтеnowс+или-, к примеру:select d from sales_Doc where @dateAfter(d.createTs, now-1) - @enum
-
Позволяет использовать полное имя константы enum вместо ее идентификатора в БД. Это упрощает поиск использований enum в коде приложения.
Пример:
select r from sec$Role where r.type = @enum(com.haulmont.cuba.security.entity.RoleType.SUPER) order by r.name
3.4.4.5. Выполнение SQL запросов
ORM позволяет выполнять SQL запросы к базе данных, возвращая как списки отдельных полей, так и экземпляры сущностей. Для этого необходимо создать объект Query или TypedQuery вызовом одного из методов EntityManager.createNativeQuery().
Если выполняется выборка отдельных колонок таблицы, то результирующий список будет содержать строки в виде Object[]. Например:
Query query = persistence.getEntityManager().createNativeQuery(
"select ID, NAME from SALES_CUSTOMER where NAME like ?1");
query.setParameter(1, "%Company%");
List list = query.getResultList();
for (Iterator it = list.iterator(); it.hasNext(); ) {
Object[] row = (Object[]) it.next();
UUID id = (UUID) row[0];
String name = (String) row[1];
}Если выполняется выборка единственной колонки или агрегатной функции, то результирующий список будет содержать эти значения непосредственно:
Query query = persistence.getEntityManager().createNativeQuery(
"select count(*) from SEC_USER where login = #login");
query.setParameter("login", "admin");
long count = (long) query.getSingleResult();Если вместе с текстом запроса передан класс результирующей сущности, то возвращается TypedQuery и после выполнения производится попытка отображения результатов запроса на атрибуты сущности. Например:
TypedQuery<Customer> query = em.createNativeQuery(
"select * from SALES_CUSTOMER where NAME like ?1",
Customer.class);
query.setParameter(1, "%Company%");
List<Customer> list = query.getResultList();Следует иметь в виду, что при использовании SQL колонки, соответствующие атрибутам сущностей типа UUID, возвращаются в виде UUID или в виде String, в зависимости от используемой СУБД:
-
HSQLDB -
String -
PostgreSQL -
UUID -
Microsoft SQL Server -
String -
Oracle -
String -
MySQL –
String
Параметры этого типа также должны задаваться либо как UUID, либо своим строковым представлением, в зависимости от используемой СУБД. Для обеспечения независимости кода от используемой СУБД рекомендуется использовать DbTypeConverter, который обеспечивает конвертацию данных между объектами Java и параметрами и результатами JDBC.
В SQL запросах можно использовать позиционные или именованные параметры. Позиционные параметры обозначаются ? с последующим номером параметра начиная с 1. Именованные параметры обозначаются знаком #. См. примеры выше.
Поведение SQL запросов, возвращающих сущности, и модифицирующих запросов (update, delete), по отношению к текущему персистентному контексту аналогично описанному для JPQL запросов.
См. также Выполнение SQL с помощью QueryRunner.
3.4.4.6. Entity Listeners
Entity Listeners предназначены для реакции на события жизненного цикла экземпляров сущностей на уровне Middleware.
Слушатель представляет собой класс, реализующий один или несколько интерфейсов пакета com.haulmont.cuba.core.listener. Слушатель будет реагировать на события типов, соответствующих реализуемым интерфейсам.
- BeforeDetachEntityListener
-
Метод
onBeforeDetach()вызывается перед отделением объекта от EntityManager при коммите транзакции.Данный слушатель можно использовать, например, для заполнения неперсистентных атрибутов сущности перед отправкой ее на клиентский уровень.
- BeforeAttachEntityListener
-
Метод
onBeforeAttach()вызывается перед введением объекта в персистентный контекст при выполнении операцииEntityManager.merge().Данный слушатель можно использовать, например, для заполнения персистентных атрибутов сущности перед сохранением ее в базе данных.
- BeforeInsertEntityListener
-
Метод
onBeforeInsert()вызывается перед выполнением вставки записи в БД. В данном методе возможны любые операции с текущимEntityManager. - AfterInsertEntityListener
-
Метод
onAfterInsert()вызывается после выполнения вставки записи в БД, но до коммита транзакции. В данном методе нельзя модифицировать текущий персистентный контекст, однако можно производить изменения в БД с помощью QueryRunner. - BeforeUpdateEntityListener
-
Метод
onBeforeUpdate()вызывается перед изменением записи в БД. В данном методе возможны любые операции с текущимEntityManager. - AfterUpdateEntityListener
-
Метод
onAfterUpdate()вызывается после изменения записи в БД, но до коммита транзакции. В данном методе нельзя модифицировать текущий персистентный контекст, однако можно производить изменения в БД с помощьюQueryRunner. - BeforeDeleteEntityListener
-
Метод
onBeforeDelete()вызывается перед удалением записи из БД (или в случае мягкого удаления - перед изменением записи). В данном методе возможны любые операции с текущимEntityManager. - AfterDeleteEntityListener
-
Метод
onAfterDelete()вызывается после удаления записи из БД (или в случае мягкого удаления - после изменения записи), но до коммита транзакции. В данном методе нельзя модифицировать текущий персистентный контекст, однако можно производить изменения в БД с помощьюQueryRunner.
Entity Listener должен являться Spring-бином, поэтому в нем можно использовать инжекцию в поля и сеттеры. Для всех экземпляров некоторого класса сущности создается один экземпляр слушателя определенного типа, поэтому слушатель не должен иметь изменяемого состояния.
Следует иметь в виду, что для BeforeInsertEntityListener фреймворк гарантирует managed state только для корневой сущности, принимаемой слушателем. Ее ссылки, встречающиеся в графе объектов, могут быть в состоянии detached. Поэтому если вам необходимо изменять эти объекты, используйте метод EntityManager.merge(), а если только иметь возможность обращаться к любым их атрибутам, то метод EntityManager.find(). Например:
package com.company.sample.listener;
import com.company.sample.core.DiscountCalculator;
import com.company.sample.entity.*;
import com.haulmont.cuba.core.EntityManager;
import com.haulmont.cuba.core.listener.*;
import org.springframework.stereotype.Component;
import javax.inject.Inject;
import java.math.BigDecimal;
@Component("sample_OrderEntityListener")
public class OrderEntityListener implements
BeforeInsertEntityListener<Order>,
BeforeUpdateEntityListener<Order>,
BeforeDeleteEntityListener<Order> {
@Inject
private DiscountCalculator discountCalculator; // a managed bean of the middle tier
@Override
public void onBeforeInsert(Order entity, EntityManager entityManager) {
calculateDiscount(entity.getCustomer(), entityManager);
}
@Override
public void onBeforeUpdate(Order entity, EntityManager entityManager) {
calculateDiscount(entity.getCustomer(), entityManager);
}
@Override
public void onBeforeDelete(Order entity, EntityManager entityManager) {
calculateDiscount(entity.getCustomer(), entityManager);
}
private void calculateDiscount(Customer customer, EntityManager entityManager) {
if (customer == null)
return;
// Delegate calculation to a managed bean of the middle tier
BigDecimal discount = discountCalculator.calculateDiscount(customer.getId());
// Merge customer instance because it comes to onBeforeInsert as part of another
// entity's object graph and can be detached
Customer managedCustomer = entityManager.merge(customer);
// Set the discount for the customer. It will be saved on transaction commit.
managedCustomer.setDiscount(discount);
}
}Все слушатели кроме BeforeAttachEntityListener выполняются внутри транзакции. Это значит, что если внутри слушателя выбрасывается исключение, текущая транзакция откатывается и все изменения в базе данных теряются.
Если вам необходимо выполнить некоторые действия после успешного завершения транзакции, используйте callback-интерфейс TransactionSynchronization фреймворка Spring для того чтобы отложить выполнение до нужной фазы транзакции. Например:
package com.company.sales.service;
import com.company.sales.entity.Customer;
import com.haulmont.cuba.core.EntityManager;
import com.haulmont.cuba.core.listener.BeforeInsertEntityListener;
import com.haulmont.cuba.core.listener.BeforeUpdateEntityListener;
import org.springframework.stereotype.Component;
import org.springframework.transaction.support.TransactionSynchronizationAdapter;
import org.springframework.transaction.support.TransactionSynchronizationManager;
@Component("sales_CustomerEntityListener")
public class CustomerEntityListener implements BeforeInsertEntityListener<Customer>, BeforeUpdateEntityListener<Customer> {
@Override
public void onBeforeInsert(Customer entity, EntityManager entityManager) {
printCustomer(entity);
}
@Override
public void onBeforeUpdate(Customer entity, EntityManager entityManager) {
printCustomer(entity);
}
private void printCustomer(Customer customer) {
System.out.println("In transaction: " + customer);
TransactionSynchronizationManager.registerSynchronization(new TransactionSynchronizationAdapter() {
@Override
public void afterCommit() {
System.out.println("After transaction commit: " + customer);
}
});
}
}- Регистрация entity listeners
-
Entity Listener может быть задан двумя способами:
-
Статически - имена бинов слушателей указываются в аннотации @Listeners на классе сущности:
@Entity(...) @Table(...) @Listeners("sample_MyEntityListener") public class MyEntity extends StandardEntity { ... } -
Динамически - имя бина слушателя передается в метод
addListener()бинаEntityListenerManager. Таким способом можно добавить слушатель для сущности, находящейся в компоненте приложения. В примере ниже слушатель, реализованный биномsample_UserEntityListener, добавляется сущностиUser, которая определена во фреймворке:package com.company.sample.core; import com.haulmont.cuba.core.global.Events; import com.haulmont.cuba.core.sys.events.AppContextInitializedEvent; import com.haulmont.cuba.core.sys.listener.EntityListenerManager; import com.haulmont.cuba.security.entity.User; import org.springframework.context.event.EventListener; import org.springframework.core.annotation.Order; import org.springframework.stereotype.Component; import javax.inject.Inject; @Component("sample_AppLifecycle") public class AppLifecycle { @Inject private EntityListenerManager entityListenerManager; @EventListener(AppContextInitializedEvent.class) // notify after AppContext is initialized @Order(Events.LOWEST_PLATFORM_PRECEDENCE + 100) // run after all framework listeners public void initEntityListeners() { entityListenerManager.addListener(User.class, "sample_UserEntityListener"); } }
Если для сущности объявлены несколько слушателей одного типа (например, аннотациями класса сущности и его предков, плюс динамически), то их вызов будет выполняться в следующем порядке:
-
Для каждого предка, начиная с самого дальнего, вызываются его динамически добавленные слушатели, затем статически назначенные.
-
После всех предков вызываются динамически добавленные слушатели данного класса, затем статически назначенные.
-
3.4.5. Управление транзакциями
В данном разделе рассмотрены различные аспекты управления транзакциями в CUBA-приложениях.
3.4.5.1. Программное управление транзакциями
Программное управление транзакциями осуществляется с помощью интерфейса com.haulmont.cuba.core.Transaction, ссылку на который можно получить методами createTransaction() или getTransaction() интерфейса инфраструктуры Persistence.
Метод createTransaction() создает новую транзакцию и возвращает интерфейс Transaction. Последующие вызовы методов commit(), commitRetaining(), end() этого интерфейса управляют созданной транзакцией. Если в момент создания существовала другая транзакция, то она будет приостановлена, и возобновлена после завершения созданной.
Метод getTransaction() вызывает либо создание новой, либо присоединение к текущей транзакции. Если в момент вызова существовала активная транзакция, то метод успешно завершается, и последующие вызовы commit(), commitRetaining(), end() не оказывают никакого влияния на существующую транзакцию. Однако если end() вызван без предварительного вызова commit(), то текущая транзакция помечается как RollbackOnly.
Примеры программного управления транзакцией:
@Inject
private Metadata metadata;
@Inject
private Persistence persistence;
...
// try-with-resources style
try (Transaction tx = persistence.createTransaction()) {
Customer customer = metadata.create(Customer.class);
customer.setName("John Smith");
persistence.getEntityManager().persist(customer);
tx.commit();
}
// plain style
Transaction tx = persistence.createTransaction();
try {
Customer customer = metadata.create(Customer.class);
customer.setName("John Smith");
persistence.getEntityManager().persist(customer);
tx.commit();
} finally {
tx.end();
}Интерфейс Transaction имеет также метод execute(), принимающий на вход класс-действие или lambda-выражение, которое нужно выполнить в данной транзакции. Это позволяет организовать управление транзакциями в функциональном стиле, например:
UUID customerId = persistence.createTransaction().execute((EntityManager em) -> {
Customer customer = metadata.create(Customer.class);
customer.setName("ABC");
em.persist(customer);
return customer.getId();
});
Customer customer = persistence.createTransaction().execute(em ->
em.find(Customer.class, customerId, "_local"));Следует иметь в виду, что метод execute() у некоторого экземпляра Transaction можно вызвать только один раз, так как после выполнения кода действия транзакция завершается.
3.4.5.2. Декларативное управление транзакциями
Любой метод Spring-бина Middleware можно пометить аннотацией @org.springframework.transaction.annotation.Transactional, что вызовет автоматическое создание транзакции при вызове этого метода. В таком методе не нужно вызывать Persistence.createTransaction(), а можно сразу получать EntityManager и работать с ним.
Для аннотации @Transactional можно указать параметры, в том числе:
-
propagation- режим создания транзакции. ЗначениеREQUIREDсоответствуетgetTransaction(), значениеREQUIRES_NEW-createTransaction(). По умолчаниюREQUIRED.@Transactional(propagation = Propagation.REQUIRES_NEW) public void doSomething() { } -
value- имя хранилища данных. Если опущено, подразумевается основная БД. Например:@Transactional("db1") public void doSomething() { }
Декларативное управление транзакциями позволяет уменьшить количество boilerplate кода, однако имеет следующий недостаток: коммит транзакции происходит вне прикладного кода, что часто затрудняет отладку, т.к. скрывается момент отправки изменений в БД и перехода сущностей в состояние Detached. Кроме того, следует иметь в виду, что декларативная разметка сработает только в случае вызова метода контейнером, т.е. вызов транзакционного метода из другого метода того же самого объекта не приведет к старту транзакции.
В связи с этим рекомендуется применять декларативное управление транзакциями только для простых случаев, таких как методы сервисов, читающих некоторый объект и возвращающих его клиенту.
3.4.5.3. Примеры взаимодействия транзакций
3.4.5.3.1. Откат вложенной транзакции
Если вложенная транзакция создана через getTransaction(), то ее откат приведет к невозможности коммита охватывающей транзакции. Например:
void methodA() {
Transaction tx = persistence.createTransaction();
try {
methodB(); (1)
tx.commit(); (4)
} finally {
tx.end();
}
}
void methodB() {
Transaction tx = persistence.getTransaction();
try {
tx.commit(); (2)
} catch (Exception e) {
return; (3)
} finally {
tx.end();
}
}| 1 | вызываем метод, создающий вложенную транзакцию |
| 2 | предположим, что здесь выбрасывается исключение |
| 3 | обрабатываем исключение и выходим |
| 4 | здесь будет выброшено исключение, так как транзакция помечена как rollback only |
Если же транзакция в methodB() будет создана через createTransaction(), то ее откат не окажет никакого влияния на коммит охватывающей транзакции в methodA().
3.4.5.3.2. Чтение и изменение данных во вложенной транзакции
Рассмотрим сначала зависимую вложенную транзакцию, создаваемую через getTransaction():
void methodA() {
Transaction tx = persistence.createTransaction();
try {
EntityManager em = persistence.getEntityManager();
Employee employee = em.find(Employee.class, id); (1)
assertEquals("old name", employee.getName());
employee.setName("name A"); (2)
methodB(); (3)
tx.commit(); (8)
} finally {
tx.end();
}
}
void methodB() {
Transaction tx = persistence.getTransaction();
try {
EntityManager em = persistence.getEntityManager(); (4)
Employee employee = em.find(Employee.class, id); (5)
assertEquals("name A", employee.getName()); (6)
employee.setName("name B");
tx.commit(); (7)
} finally {
tx.end();
}
}| 1 | загружаем сущность, где name == "old name" |
| 2 | указываем новое значение для поля |
| 3 | вызываем метод, создающий вложенную транзакцию |
| 4 | получаем тот же экземпляр EntityManager, что и в methodA |
| 5 | загружаем сущность с тем же идентификатором |
| 6 | значение поля новое, так как мы работаем в том же persistent context, и запросов к БД не было |
| 7 | commit в этот момент не происходит |
| 8 | изменения сохраняются в БД, в них будет содержаться "name B" |
Теперь рассмотрим тот же самый пример с независимой вложенной транзакцией, создаваемой через createTransaction():
void methodA() {
Transaction tx = persistence.createTransaction();
try {
EntityManager em = persistence.getEntityManager();
Employee employee = em.find(Employee.class, id); (1)
assertEquals("old name", employee.getName());
employee.setName("name A"); (2)
methodB(); (3)
tx.commit(); (8)
} finally {
tx.end();
}
}
void methodB() {
Transaction tx = persistence.createTransaction();
try {
EntityManager em = persistence.getEntityManager(); (4)
Employee employee = em.find(Employee.class, id); (5)
assertEquals("old name", employee.getName()); (6)
employee.setName("name B"); (7)
tx.commit();
} finally {
tx.end();
}
}| 1 | загружаем сущность, где name == "old name" |
| 2 | указываем новое значение для поля |
| 3 | вызываем метод, создающий вложенную транзакцию |
| 4 | создаём новый экземпляр EntityManager, т.к. это новая транзакция |
| 5 | загружаем сущность с тем же идентификатором |
| 6 | значение поля старое, так как из БД загружен старый экземпляр сущности |
| 7 | изменения сохраняются в БД, значение "name B" теперь будет храниться в БД |
| 8 | из-за оптимистичной блокировки выбрасывается исключение, commit не выполняется |
В последнем случае исключение в точке (8) возникнет, только если сущность является оптимистично блокируемой, т.е. если она реализует интерфейс Versioned.
3.4.5.4. Параметры транзакций
- Таймаут транзакции
-
Для создаваемой транзакции может быть указан таймаут в секундах, при превышении которого транзакция будет прервана и откачена. Таймаут транзакции ограничивает максимальную длительность запросов к базе данных.
При программном управлении транзакциями таймаут включается путем передачи объекта
TransactionParamsв методPersistence.createTransaction(). Например:Transaction tx = persistence.createTransaction(new TransactionParams().setTimeout(2));При декларативном управлении транзакциями используется параметр
timeoutаннотации@Transactional, например:@Transactional(timeout = 2) public void someServiceMethod() { ...Таймаут по умолчанию может быть задан в свойстве приложения cuba.defaultQueryTimeoutSec.
- Read-only транзации
-
Транзакцию можно пометить как read-only если она предназначена только для чтения данных из БД. Например, все методы
loadв DataManager используют read-only транзакции по умолчанию. Read-only транзакции улучшают производительность системы, потому что платформа не выполняет код, обрабатывающий возможные изменения в сущностях. Кроме того, не вызываютсяBeforeCommittransaction listeners.Если персистентный контекст read-only транзакции содержит измененные сущности, то при попытке коммита транзакции будет выброшено исключение
IllegalStateException. Это означает, что помечать транзакцию как read-only следует только если вы уверены, что она не модифицирует никакие сущности.При программном управлении транзакциями признак read-only включается путем передачи объекта
TransactionParamsв методPersistence.createTransaction(). Например:Transaction tx = persistence.createTransaction(new TransactionParams().setReadOnly(true));При декларативном управлении транзакциями используется параметр
readOnlyаннотации@Transactional, например:@Transactional(readOnly = true) public void someServiceMethod() { ...
3.4.5.5. Transaction Listeners
Transaction listeners предназначены для реакции на события жизненного цикла транзакций. В отличие от entity listeners, они не привязаны к типу сущности и вызываются для каждой транзакции.
Слушатель должен быть Spring-бином, реализующим один или оба интерфейса BeforeCommitTransactionListener и AfterCompleteTransactionListener.
- BeforeCommitTransactionListener
-
Метод
beforeCommit()вызывается перед коммитом транзакции после всех entity listeners если транзакция не является read-only. Метод принимает текущийEntityManagerи коллекцию сущностей текущего персистентного контекста.Данный слушатель можно использовать для обеспечения сложных бизнес-правил, вовлекающих различные сущности. В примере ниже атрибут
amountсущностиOrderдолжен рассчитываться на основе значенияdiscount, находящегося в заказе, и атрибутовpriceиquantityэкземпляров сущностиOrderLine, составляющих заказ.@Component("demo_OrdersTransactionListener") public class OrdersTransactionListener implements BeforeCommitTransactionListener { @Inject private PersistenceTools persistenceTools; @Override public void beforeCommit(EntityManager entityManager, Collection<Entity> managedEntities) { // gather all orders affected by changes in the current transaction Set<Order> affectedOrders = new HashSet<>(); for (Entity entity : managedEntities) { // skip not modified entities if (!persistenceTools.isDirty(entity)) continue; if (entity instanceof Order) affectedOrders.add((Order) entity); else if (entity instanceof OrderLine) { Order order = ((OrderLine) entity).getOrder(); // a reference can be detached, so merge it into current persistence context affectedOrders.add(entityManager.merge(order)); } } // calculate amount for each affected order by its lines and discount for (Order order : affectedOrders) { BigDecimal amount = BigDecimal.ZERO; for (OrderLine orderLine : order.getOrderLines()) { if (!orderLine.isDeleted()) { amount = amount.add(orderLine.getPrice().multiply(orderLine.getQuantity())); } } BigDecimal discount = order.getDiscount().divide(BigDecimal.valueOf(100), 2, BigDecimal.ROUND_DOWN); order.setAmount(amount.subtract(amount.multiply(discount))); } } } - AfterCompleteTransactionListener
-
Метод
afterComplete()вызывается после завершения транзакции. Метод принимает параметр, указывающий, была ли транзакция успешно закоммичена, и коллекцию detached сущностей, содержавшихся в персистентном контексте завершенной транзакции.Пример использования:
@Component("demo_OrdersTransactionListener") public class OrdersTransactionListener implements AfterCompleteTransactionListener { private Logger log = LoggerFactory.getLogger(OrdersTransactionListener.class); @Override public void afterComplete(boolean committed, Collection<Entity> detachedEntities) { if (!committed) return; for (Entity entity : detachedEntities) { if (entity instanceof Order) { log.info("Order: " + entity); } } } }
3.4.6. Кэши сущностей и запросов
- Кэш сущностей (Entity Cache)
-
Кэш сущностей предоставляется ORM фреймворком EclipseLink. Он хранит в памяти недавно прочитанные или записанные экземпляры сущностей, тем самым сокращая доступ к базе данных и увеличивая производительность.
Кэш сущностей используется только при извлечении сущностей по идентификатору, поэтому запросы по другим атрибутам по-прежнему выполняются на базе данных. Тем не менее, эти запросы могут стать проще и быстрее, если связанные сущности находятся в кэше. Например, если вы запрашиваете Заказы вместе со связанными Заказчиками, и не используете кэш, то SQL-запрос будет содержать JOIN с таблицей заказчиков. Если же сущность Заказчик закэширована, SQL-запрос будет только по таблице заказов, а связанные заказчики будут извлечены из кэша.
Для того, чтобы включить кэш сущностей, установите следующие свойства приложения в файле app.properties модуля core вашего проекта:
-
eclipselink.cache.shared.sales_Customer = true- включает кэширование сущностиsales_Customer. -
eclipselink.cache.size.sales_Customer = 500- устанавливает размер кэша для сущностиsales_Customerв 500 экземпляров.Если кэширование включено, всегда рекомендуется увеличить размер кэша (по умолчанию - 100). В противном случае, если запрос вернёт более 100 записей, то каждая запись будет извлечена отдельной операцией.
Факт кэширования сущности влияет на то, какой fetch mode выбирается платформой при загрузке графов сущностей. Если некоторый ссылочный атрибут представляет собой кэшируемую сущность, то fetch mode всегда будет
UNDEFINED, что позволяет ORM извлекать ссылку из кэша вместо добавления в запрос JOIN или выполнения отдельного batch-запроса.Платформа обеспечивает координацию кэша сущностей в кластере middleware. Когда кэшированный экземпляр сущности обновляется или удаляется на одном узле кластера, тот же экземпляр на других узлах (если он загружен) будет инвалидирован, что приведет к загрузке свежего состояния из БД при следующей операции с данным экземпляром.
-
- Кэш запросов (Query Cache)
-
Кэш запросов сохраняет идентификаторы экземпляров сущностей, возвращаемых JPQL-запросами, тем самым естественно дополняя кэш сущностей.
Например, если для сущности
sales_Customerразрешен entity cache, и запросselect c from sales_Customer c where c.grade = :gradeвыполняется первый раз, происходит следующее:-
ORM выполняет запрос в базе данных.
-
Загруженные экземпляры сущности
Customerпомещаются в entity cache. -
В кэш запросов помещается соответствие между текстом запроса вместе с параметрами и списком идентификаторов загруженных экземпляров.
Когда этот же запрос с такими же параметрами выполняется второй раз, платформа находит запрос в кэше запросов и загружает экземпляры сущностей по идентификаторам из кэша сущностей, не обращаясь к базе данных.
Запросы по умолчанию не кэшируются. Указать, что запрос должен кэшироваться, можно на различных уровнях приложения:
-
Методом
setCacheable()интерфейса Query при работе с EntityManager. -
Методом
setCacheable()интерфейсаLoadContext.Queryпри работе с DataManager. -
Методом
setCacheable()интерфейсаCollectionLoaderили в XML-атрибутеcacheableпри работе с загрузчиками данных.
Кэшируемые запросы следует использовать только если для возвращаемой сущности разрешен entity cache. В противном случае при каждом запросе экземпляры сущности будут загружаться из базы данных по идентификаторам по одному.
Кэш запросов автоматически инвалидируется, когда через ORM выполняются операции создания, изменения или удаления с сущностями соответствующего типа. Инвалидация работает по всему кластеру среднего слоя.
JMX-бин
app-core.cuba:type=QueryCacheSupportможно использовать для мониторинга состояния кэша и для удаления запросов из кэша. Например, если вы изменили некоторый экземпляр сущностиsales_Customerнапрямую в БД, необходимо удалить все закэшированные запросы по этой сущности с помощью операцииevict()с аргументомsales_Customer.На поведение кэша запросов оказывают влияние следующие свойства приложения:
-
3.4.7. EntityChangedEvent
|
Руководство Decouple Business Logic with Application Events демонстрирует использование |
EntityChangedEvent - это ApplicationEvent, который посылается фреймворком на среднем слое, когда некоторый экземпляр сущности сохраняется в базу данных. Данное событие может быть обработано как внутри текущей транзакции (используя @EventListener), так и после ее завершения (при использовании @TransactionalEventListener).
|
Событие посылается только если на сущности есть аннотация |
Объект EntityChangedEvent содержит не сам измененный экземпляр сущности, а только его id. Кроме того, метод getOldValue(attributeName) возвращает идентификаторы ссылок вместо самих объектов. Поэтому при необходимости, разработчик должен загрузить требуемые сущности с указанием требуемого представления и других параметров.
Ниже приведен пример обработки EntityChangedEvent для сущности Customer в текущей транзакции и после ее завершения:
package com.company.demo.core;
import com.company.demo.entity.Customer;
import com.haulmont.cuba.core.app.events.AttributeChanges;
import com.haulmont.cuba.core.app.events.EntityChangedEvent;
import com.haulmont.cuba.core.entity.contracts.Id;
import org.springframework.context.event.EventListener;
import org.springframework.stereotype.Component;
import org.springframework.transaction.event.TransactionalEventListener;
import java.util.UUID;
@Component("demo_CustomerChangedListener")
public class CustomerChangedListener {
@EventListener (1)
public void beforeCommit(EntityChangedEvent<Customer, UUID> event) {
Id<Customer, UUID> entityId = event.getEntityId(); (2)
EntityChangedEvent.Type changeType = event.getType(); (3)
AttributeChanges changes = event.getChanges();
if (changes.isChanged("name")) { (4)
String oldName = changes.getOldValue("name"); (5)
// ...
}
}
@TransactionalEventListener (6)
public void afterCommit(EntityChangedEvent<Customer, UUID> event) {
(7)
}
}| 1 | - данный обработчик вызывается внутри текущей транзакции. |
| 2 | - id измененной сущности. |
| 3 | - тип изменения: CREATED, UPDATED or DELETED. |
| 4 | - можно проверить, изменился ли определенный атрибут. |
| 5 | - можно получить старое значение измененного атрибута. |
| 6 | - данный обработчик вызывается после коммита транзакции. |
| 7 | - после коммита событие содержит те же значения что и внутри транзакции. |
Если обработчик вызывается внутри транзакции, ее можно откатить путем выбрасывания исключения. При этом в БД никакие изменения не сохранятся. Если вы не хотите, чтобы пользователь получил какое-либо оповещение, используйте SilentException.
Если "after commit" обработчик выбрасывает исключение, оно будет залоггировано, но не передано клиенту (т.е. пользователь не получит сообщения об ошибке в UI).
|
При обработке В обработчике, вызываемом после коммита транзакции ( |
Ниже приведен пример использования EntityChangedEvent для изменения связанных сущностей.
Предположим, имеются сущности Order, OrderLine и Product, как в приложении Sales, но сущность Product дополнительно имеет булевский атрибут special, а у сущности Order есть атрибут numberOfSpecialProducts, который должен быть пересчитан при создании и удалении экземпляров OrderLine в составе Order.
Создадим следующий класс с методом, аннотированным @EventListener, который будет вызываться при изменении сущностей OrderLine перед коммитом транзакции:
package com.company.sales.listener;
import com.company.sales.entity.Order;
import com.company.sales.entity.OrderLine;
import com.haulmont.cuba.core.TransactionalDataManager;
import com.haulmont.cuba.core.app.events.EntityChangedEvent;
import com.haulmont.cuba.core.entity.contracts.Id;
import org.springframework.context.event.EventListener;
import org.springframework.stereotype.Component;
import javax.inject.Inject;
import java.util.UUID;
@Component("sales_OrderLineChangedListener")
public class OrderLineChangedListener {
@Inject
private TransactionalDataManager txDm;
@EventListener
public void beforeCommit(EntityChangedEvent<OrderLine, UUID> event) {
Order order;
if (event.getType() != EntityChangedEvent.Type.DELETED) { (1)
order = txDm.load(event.getEntityId()) (2)
.view("orderLine-with-order") (3)
.one()
.getOrder(); (4)
} else {
Id<Order, UUID> orderId = event.getChanges().getOldReferenceId("order"); (5)
order = txDm.load(orderId).one();
}
long count = txDm.load(OrderLine.class) (6)
.query("select o from sales_OrderLine o where o.order = :order")
.parameter("order", order)
.view("orderLine-with-product")
.list().stream()
.filter(orderLine -> Boolean.TRUE.equals(orderLine.getProduct().getSpecial()))
.count();
order.setNumberOfSpecialProducts((int) count);
txDm.save(order); (7)
}
}| 1 | - если экземпляр OrderLine не удален, можно загрузить его из БД по идентификатору. |
| 2 | - метод event.getEntityId() возвращает id измененного экземпляра OrderLine. |
| 3 | - используем представление, которое содержит OrderLine вместе с Order, которому он принадлежит. Представление должно содержать атрибут Order.numberOfSpecialProducts, так как его необходимо будет обновить. |
| 4 | - получаем Order из загруженного OrderLine. |
| 5 | - если экземпляр OrderLine был только что удален, его нельзя загрузить из БД, но метод event.getChanges() возвращает все атрибуты удаленной сущности, включая идентификаторы связанных сущностей. Поэтому можно загрузить связанный Order по его id. |
| 6 | - загружаем все экземпляры OrderLine для данного Order, отфильтровываем по Product.special и считаем их. Представление должно содержать OrderLine вместе со связанным Product. |
| 7 | - сохраняем Order после изменения его атрибута. |
3.4.8. EntityPersistingEvent
EntityPersistingEvent - это ApplicationEvent, который посылается фреймворком на среднем слое, перед тем как новый экземпляр сущности сохраняется в базу данных. В момент отсылки данного события существует открытая транзакция.
EntityPersistingEvent можно использовать для инициализации атрибутов сущности перед ее созданием в БД:
package com.company.demo.core;
import com.company.demo.entity.Customer;
import com.haulmont.cuba.core.app.events.EntityPersistingEvent;
import org.springframework.context.event.EventListener;
import org.springframework.stereotype.Component;
@Component("demo_CustomerChangedListener")
public class CustomerChangedListener {
@EventListener
void beforePersist(EntityPersistingEvent<Customer> event) {
Customer customer = event.getEntity();
customer.setCode(obtainNewCustomerCode(customer));
}
// ...
}3.4.9. Системная аутентификация
При выполнении пользовательских запросов программному коду Middleware через интерфейс UserSessionSource всегда доступна информация о текущем пользователе. Это возможно потому, что при получении запроса с клиентского уровня в потоке выполнения автоматически устанавливается соответствующий объект SecurityContext.
Однако существуют ситуации, когда текущий поток выполнения не связан ни с каким пользователем системы: например, при вызове метода бина из планировщика, либо через JMX-интерфейс. Если при этом бин выполняет изменение сущностей в базе данных, то ему потребуется информация о том, кто выполняет изменения, то есть аутентификация.
Такого рода аутентификация называется системной, так как не требует участия пользователя - средний слой приложения просто создает (или использует имеющуюся) пользовательскую сессию, и устанавливает в потоке выполнения соответствующий объект SecurityContext.
Обеспечить системную аутентификацию некоторого участка кода можно следующими способами:
-
явно используя бин
com.haulmont.cuba.security.app.Authentication, например:@Inject protected Authentication authentication; ... authentication.begin(); try { // authenticated code } finally { authentication.end(); } -
добавив методу бина аннотацию
@Authenticated, например:@Authenticated public String foo(String value) { // authenticated code }
Во втором случае также используется бин Authentication, но неявно, через интерцептор AuthenticationInterceptor, который перехватывает вызовы всех методов бинов с аннотацией @Authenticated.
В приведенных примерах пользовательская сессия будет создаваться от лица пользователя, логин которого указан в свойстве приложения cuba.jmxUserLogin. Если требуется аутентификация от имени другого пользователя, нужно воспользоваться первым вариантом и передать в метод begin() логин нужного пользователя.
|
Если в момент выполнения Например, вызов метода JMX-бина из встроенной в Web Client консоли JMX, если бин находится в той же JVM, что и блок WebClient, к которому в данный момент подключен пользователь, будет выполнен от имени текущего зарегистрированного в системе пользователя, независимо от наличия системной аутентификации. |
3.5. Универсальный пользовательский интерфейс
Подсистема универсального пользовательского интерфейса (Generic UI, GUI) позволяет разрабатывать экраны UI, используя Java и XML. Использование XML не обязательно, но позволяет описывать компоновку экрана декларативно и снижает объем кода, требуемого для создания пользовательского интерфейса.

Рисунок 9. Структура универсального пользовательского интерфейса
Экраны приложения состоят из следующих частей:
-
Дескрипторы - XML-файлы, содержащие информацию о компоновке экрана и компонентах данных.
-
Контроллеры - классы Java, содержащие логику инициализации и обработки событий от экрана и его компонентов.
Код экранов приложения взаимодействует с интерфейсами визуальных компонентов (VCL Interfaces). Эти интерфейсы реализованы с использованием компонентов фреймворка Vaadin.
Библиотека визуальных компонентов (Visual Components Library, VCL) содержит большой набор готовых компонентов.
Компоненты данных (Data components) предоставляют унифицированный интерфейс для связывания визуальных компонентов с сущностями модели данных и для работы с сущностями в контроллерах экранов.
Инфраструктура (Infrastructure) включает в себя главное окно приложения и другие общие клиентские механизмы.
3.5.1. Экраны
Экран - основной элемент пользовательского интерфейса. Экран состоит из визуальных компонентов, контейнеров данных и других невизуальных компонентов. Экраны отображаются внутри главного окна приложения, в отдельной его вкладке либо в виде модального окна.
Основу экрана составляет Java- или Groovy-класс, который называется контроллером. Компоновка экрана обычно определяется в XML-файле, именуемом дескриптором экрана.
Чтобы отобразить экран, платформа создаёт новый экземпляр визуального компонента Window, подключает его к контроллеру экрана и загружает компоненты, входящие в компоновку экрана, в качестве дочерних компонентов окна. Затем окно этого экрана добавляется к главному экрану приложения.
Фрагмент - это еще один структурный элемент UI, который можно использовать в качестве компонента экранов или других фрагментов. Внутреннее устройство фрагмента аналогично экрану, но фрагмент имеет специфический жизненный цикл, а в корне иерархии визуальных компонентов находится Fragment вместо Window. Фрагменты, также как экраны, состоят из контроллеров и XML-дескрипторов.
3.5.1.1. Контроллер экрана
Контроллер экрана - это Java или Groovy класс, который содержит в себе логику инициализации экрана и обработки событий. Чаще всего контроллер связан с XML-дескриптором экрана, который декларативно описывает компоновку экрана и контейнеры данных, однако и в контроллере можно программно создавать визуальные и невизуальные компоненты.
Все контроллеры экранов реализуют интерфейс-маркер FrameOwner. Название этого интерфейса означает, что в нём содержится ссылка на фрейм, то есть визуальный компонент, представляющий собой экран при его отображении в главном окне приложения. Существует два типа фреймов:
-
Window- самостоятельное окно, которое можно отобразить внутри главного окна приложения во вкладке или в виде модального диалогового окна. -
Fragment- легковесный компонент, который можно добавлять к окнам или к другим фрагментам.
Контроллеры также подразделяются на две отдельные категории по типам используемых фреймвов:
-
Screen- базовый класс контроллеров окон. -
ScreenFragment- базовый класс контроллеров фрагментов.

Рисунок 10. Контроллеры и фреймы
Класс Screen предоставляет базовую функциональность для любого типа самостоятельных экранов. Для экранов, предназначенных для работы с сущностями, существуют отдельные, более специфичные классы:
-
StandardEditor- базовый класс контроллеров экранов редактирования. -
StandardLookup- базовый класс контроллеров экранов просмотра и выбора. -
MasterDetailScreen- комбинированный экран, отображающий список экземпляров сущностей слева и детали выбранной сущности справа.

Рисунок 11. Базовые классы контроллеров
3.5.1.1.1. Аннотации контроллеров
Аннотации на классе контроллера используются для предоставления фреймворку информации об экране. Некоторые аннотации применимы для любого типа экрана, некоторые должны быть использованы только в экранах редактирования или поиска.
Следующий пример демонстрирует использование общих аннотаций:
package com.company.demo.web.screens;
import com.haulmont.cuba.gui.screen.*;
@UiController("demo_FooScreen")
@UiDescriptor("foo-screen.xml")
@LoadDataBeforeShow
@MultipleOpen
@DialogMode(forceDialog = true)
public class FooScreen extends Screen {
}-
@UiController- указывает, что данный класс является контроллером экрана. Значение аннотации задает id экрана, который используется для ссылки на экран из главного меню или при открытии экрана программно.
-
@UiDescriptor- соединяет контроллер с XML-дескриптором. Значение аннотации указывает путь к файлу. Если значение содержит только имя файла, подразумевается что файл находится в том же пакете что и класс контроллера.
-
@LoadDataBeforeShow- указывает, что все загрузчики данных должны быть запущены автоматически перед показом экрана. Точнее, данные загружаются после вызова всех обработчиков BeforeShowEvent, но до обработчиков AfterShowEvent. Если вам необходимо выполнить какие-либо действия при загрузке данных перед показом экрана, удалите данную аннотацию или установите ее значение вfalseи используйте методgetScreenData().loadAll()или методыload()нужных загрузчиков в слушателе событияBeforeShowEvent. Рассмотрите также использование фасета DataLoadCoordinator для декларативного управления загрузкой данных.
-
@MultipleOpen- указывает, что из главного меню можно открыть несколько экземпляров данного экрана. По умолчанию, когда пользователь выбирает пункт главного меню, фреймворк проверяет, не открыт ли уже наверху какой-либо вкладки главного окна экран с тем же классом и id. Если такой экран найден, он закрывается, и новый экран открывается в новой вкладке. Когда на экране присутствует аннотация@MultipleOpen, никаких проверок не производится, и новый экземпляр экрана просто открывается в новой вкладке.Можно предоставить собственный способ проверки, является ли экран тем же самым, если переопределить метод
isSameScreen()контроллера.
-
@DialogMode- позволяет указать параметры геометрии и поведения экрана при открытии его в диалоговом окне. Данная аннотация соответствует элементу<dialogMode>дексриптора экрана и может быть использована вместо него. Значения из XML имеют более высокий приоритет для всех параметров кромеforceDialog. Значение параметраforceDialogобъединяется: если оно установлено в true или в XML, или в аннотации, то экран всегда открывается в диалоге.
Пример аннотаций, специфичных для экранов выбора:
package com.company.demo.web.screens;
import com.haulmont.cuba.gui.screen.*;
import com.company.demo.entity.Customer;
// common annotations
@UiController("demo_Customer.browse")
@UiDescriptor("customer-browse.xml")
@LoadDataBeforeShow
// lookup-specific annotations
@LookupComponent("customersTable")
@PrimaryLookupScreen(Customer.class)
public class CustomerBrowse extends StandardLookup<Customer> {
}-
@LookupComponent- указывает id UI-компонента, который должен быть использован для получения значения из экрана выбора.Вместо использования данной аннотации, можно указать компонент выбора программно, если переопределить метод контроллера
getLookupComponent().
-
@PrimaryLookupScreen- указывает, что данный экран является экраном выбора по умолчанию для сущностей заданного типа. Данная аннотация имеет больший приоритет чем конвенция{entity_name}.lookup / {entity_name}.browse.
Пример аннотаций, специфичных для экранов редактирования:
package com.company.demo.web.data.sort;
import com.haulmont.cuba.gui.screen.*;
import com.company.demo.entity.Customer;
// common annotations
@UiController("demo_Customer.edit")
@UiDescriptor("customer-edit.xml")
@LoadDataBeforeShow
// editor-specific annotations
@EditedEntityContainer("customerDc")
@PrimaryEditorScreen(Customer.class)
public class CustomerEdit extends StandardEditor<Customer> {
}-
@EditedEntityContainer- указывает контейнер данных, содержащий редактируемую сущность.Вместо использования данной аннотации, можно указать контейнер программно, если переопределить метод контроллера
getEditedEntityContainer()
-
@PrimaryEditorScreen- указывает, что данный экран является экраном редактирования по умолчанию для сущностей заданного типа. Данная аннотация имеет больший приоритет чем конвенция{entity_name}.edit.
3.5.1.1.2. Методы контроллеров
В данном разделе описаны некоторые методы базовых классов контроллеров экранов, которые можно вызывать или переопределять в коде приложения.
- Общие для всех экранов методы
-
-
show()- отображает экран. Данный метод обычно вызывается после создания экрана, как описано в разделе Открытие экранов. -
close()- закрывает экран с переданным значениемStandardOutcomeили объектомCloseAction. Например:@Subscribe("closeBtn") public void onCloseBtnClick(Button.ClickEvent event) { close(StandardOutcome.CLOSE); }Значение параметра доступно в BeforeCloseEvent и AfterCloseEvent, поэтому информация о причине закрытия экрана может быть получена в слушателях этих событий. Подробная информация об использовании этих слушателей приведена в разделе Выполнение кода после закрытия и возврат значений.
-
getScreenData()- возвращает объектScreenData, в котором зарегистрированы все компоненты данных, объявленные в XML-дескрипторе экрана. МетодloadAll()этого объекта можно вызывать для срабатывания всех загрузчиков данных экрана:@Subscribe public void onBeforeShow(BeforeShowEvent event) { getScreenData().loadAll(); } -
getSettings()- возвращает объектSettings, который может быть использован для чтения и записи специфичных настроек, ассоциированных с экраном для данного пользователя. -
saveSettings()- сохраняет настройки экрана, представляемые объектомSettings. Данный метод вызывается автоматически, если свойство приложения cuba.gui.manualScreenSettingsSaving установлено в false (что является значением по умолчанию).
-
- Методы StandardEditor
-
-
getEditedEntity()- когда экран открыт, возвращает экземпляр редактируемой сущности. Это экземпляр, установленный в контейнере данных, указанном аннотацией @EditedEntityContainer.В слушателях InitEvent и AfterInitEvent данный метод возвращает null. В слушателе BeforeShowEvent данный метод возвращает экземпляр, переданный в экран для редактирования (позднее в процессе открытия экрана сущность перезагружается, и другой ее экземпляр устанавливается в контейнере данных).
Для закрытия экрана редактирования можно использовать следующие методы:
-
closeWithCommit()- валидирует и сохраняет данные, затем закрывает экран сStandardOutcome.COMMIT. -
closeWithDiscard()- игнорирует несохраненные изменения и закрывает экран сStandardOutcome.DISCARD.
Если в экране есть несохраненные изменения в DataContext, при закрытии экрана отображается соответствующее сообщение. Вид данного сообщения можно настроить с помощью свойства приложения cuba.gui.useSaveConfirmation. Если экран закрывается методом
closeWithDiscard()илиclose(StandardOutcome.DISCARD)то несохраненные изменения игнорируются без каких-либо сообщений.-
commitChanges()- сохраняет изменения не закрывая экран. Данный метод можно вызвать из собственного слушателя события (например нажатия кнопки), или переопределить слушатель действияwindowCommit, чтобы выполнить какие-либо операции после сохранения данных. Пример переопределения стандартного действияwindowCommit:@Override protected void commit(Action.ActionPerformedEvent event) { commitChanges().then(() -> { // this flag is used for returning correct outcome on subsequent screen closing commitActionPerformed = true; // perform actions after the data has been saved }); }Стандартная реализация метода
commit()отображает сообщение об успешном сохранении. Ее можно отключить, вызвав методsetShowSaveNotification(false)при инициализации экрана. -
Метод
validateAdditionalRules()можно переопределить для выполнения дополнительной валидации перед сохранением данных. Данный метод должен сохранить информацию об ошибках валидации в переданном ему объектеValidationErrors. Впоследствии эта информация будет отображена вместе с ошибками стандартной процедуры валидации. Например:
private Pattern pattern = Pattern.compile("\\d"); @Override protected void validateAdditionalRules(ValidationErrors errors) { if (getEditedEntity().getAddress().getCity() != null) { if (pattern.matcher(getEditedEntity().getAddress().getCity()).find()) { errors.add("City name cannot contain digits"); } } super.validateAdditionalRules(errors); } -
- Методы MasterDetailScreen
-
-
getEditedEntity()- когда когда находится в режиме редактирования, возвращает экземпляр редактируемой сущности. Это экземпляр, установленный в контейнере данных компонентаform. Если экран не в режиме редактирования, данный метод выбрасываетIllegalStateException. -
Метод
validateAdditionalRules()можно переопределить для выполнения дополнительной валидации перед сохранением данных, как описано выше дляStandardEditor.
-
3.5.1.1.3. События Screen
Ниже описаны события жизненного цикла экрана, на которые можно подписаться в контроллере для реализации необходимой бизнес-логики.
|
Руководство Decouple Business Logic with Application Events содержит примеры использования событий в UI. |
- InitEvent
-
InitEventпосылается, когда контроллер экрана и все его компоненты, заданные декларативно, созданы, а инжекция зависимостей завершена. Вложенные фрагменты на этом этапе ещё не инициализированы. Некоторые визуальные компоненты инициализированы не полностью: например, кнопки ещё не связаны с действиями.@Subscribe protected void onInit(InitEvent event) { Label<String> label = uiComponents.create(Label.TYPE_STRING); label.setValue("Hello World"); getWindow().add(label); }
- AfterInitEvent
-
AfterInitEventпосылается, когда контроллер экрана и все его компоненты, заданные декларативно, созданы, инжекция зависимостей завершена, и все компоненты завершили свою внутреннюю процедуру инициализации. Вложенные фрагменты (при наличии) опубликовали свои событияInitEventиAfterInitEvent. В слушателе этого события можно создавать визуальные компоненты и компоненты данных, а также выполнить дополнительную инициализацию, если она зависит от инициализации вложенных фрагментов.
- InitEntityEvent
-
InitEntityEventпосылается в экранах, унаследованных отStandardEditorиMasterDetailScreen, перед тем, как новый экземпляр сущности будет установлен для контейнера редактируемой сущности.Руководство Initial Entity Values содержит пример инициализации сущности с помощью
InitEntityEvent.Используйте слушатель этого события, чтобы инициализировать значения по умолчанию для новых экземпляров сущностей, например:
@Subscribe protected void onInitEntity(InitEntityEvent<Foo> event) { event.getEntity().setStatus(Status.ACTIVE); }
- BeforeShowEvent
-
BeforeShowEventпосылается непосредственно перед тем, как экран будет отображён, иными словами, на этом этапе он ещё не добавлен к интерфейсу приложения. Ограничения безопасности уже применены к компонентам UI. Сохранённые настройки состояния компонентов UI ещё не применены. Данные ещё не загружены в экраны с аннотацией@LoadDataBeforeShow. В слушателе этого события можно загружать данные, проверять разрешения безопасности, а также изменять компоненты интерфейса. Например:@Subscribe protected void onBeforeShow(BeforeShowEvent event) { customersDl.load(); }
- AfterShowEvent
-
-
AfterShowEventпосылается сразу после отображения экрана, то есть тогда, когда экран уже добавлен к интерфейсу приложения. На этом этапе применены сохранённые настройки состояния компонентов UI. В слушателе этого события можно отображать уведомления, диалоговые окна или другие экраны. Например:
@Subscribe protected void onAfterShow(AfterShowEvent event) { notifications.create().withCaption("Just opened").show(); } -
- BeforeCommitChangesEvent
-
BeforeCommitChangesEventпосылается в экранах, унаследованных отStandardEditorиMasterDetailScreen, перед сохранением измененных данных методомcommitChanges(). В слушателе этого события можно проверить какие-либо условия и прервать или продолжить операцию сохранения с помощью методовpreventCommit()иresume()объекта события.Рассмотрим некоторые варианты использования.
-
Прервать операцию сохранения с выводом уведомления:
@Subscribe public void onBeforeCommitChanges(BeforeCommitChangesEvent event) { if (getEditedEntity().getStatus() == null) { notifications.create().withCaption("Enter status!").show(); event.preventCommit(); } } -
Прервать операцию сохранения, показать диалог и продолжить после подтверждения пользователем:
@Subscribe public void onBeforeCommitChanges(BeforeCommitChangesEvent event) { if (getEditedEntity().getStatus() == null) { dialogs.createOptionDialog() .withCaption("Confirmation") .withMessage("Status is empty. Do you really want to commit?") .withActions( new DialogAction(DialogAction.Type.OK).withHandler(e -> { // resume with default behavior event.resume(); }), new DialogAction(DialogAction.Type.CANCEL) ) .show(); // abort event.preventCommit(); } } -
Прервать операцию сохранения, показать диалог и повторить
commitChanges()после подтверждения пользователем:@Subscribe public void onBeforeCommitChanges(BeforeCommitChangesEvent event) { if (getEditedEntity().getStatus() == null) { dialogs.createOptionDialog() .withCaption("Confirmation") .withMessage("Status is empty. Do you want to use default?") .withActions( new DialogAction(DialogAction.Type.OK).withHandler(e -> { getEditedEntity().setStatus(getDefaultStatus()); // retry commit and resume action event.resume(commitChanges()); }), new DialogAction(DialogAction.Type.CANCEL) ) .show(); // abort event.preventCommit(); } }
-
- AfterCommitChangesEvent
-
AfterCommitChangesEventпосылается в экранах, унаследованных отStandardEditorиMasterDetailScreen, после сохранения измененных данных методомcommitChanges(). Пример использования:@Subscribe public void onAfterCommitChanges(AfterCommitChangesEvent event) { notifications.create() .withCaption("Saved!") .show(); }
- BeforeCloseEvent
-
BeforeCloseEventпосылается непосредственно перед закрытием экрана с помощью методаclose(CloseAction). На этом этапе экран ещё отображается и полностью функционален. Настройки состояния компонентов ещё не сохранялись. В слушателе этого события можно проверить некоторые условия и предотвратить закрытие экрана, используя метод событияpreventWindowClose(), например:@Subscribe protected void onBeforeClose(BeforeCloseEvent event) { if (Strings.isNullOrEmpty(textField.getValue())) { notifications.create().withCaption("Input required").show(); event.preventWindowClose(); } }Одноимённый метод также определён в интерфейсе
Window. Он вызывается перед тем, как экран будет закрыт неким внешним (относительно контроллера) действием, таким как нажатие кнопки во вкладке окна или клавиши Esc на клавиатуре. Способ, которым экран был закрыт, можно получить с помощью методаgetCloseOrigin(), который возвращает значение в виде объекта, реализующего интерфейсCloseOrigin. Реализация этого интерфейса по умолчаниюCloseOriginTypeвключает в себя три значения:-
BREADCRUMBS- экран закрыт по клику на цепочке ссылок (breadcrumbs). -
CLOSE_BUTTON- экран закрыт по нажатию на кнопку закрытия в заголовке окна, на кнопку закрытия вкладки или через действия в контекстном меню: Close, Close All, Close Others. -
SHORTCUT- экран закрыт нажатием горячих клавиш, определённых в свойстве приложения cuba.gui.closeShortcut.
Вы можете подписаться на событие
Window.BeforeCloseEvent, указавTarget.FRAMEв аннотации@Subscribe:@Subscribe(target = Target.FRAME) protected void onBeforeClose(Window.BeforeCloseEvent event) { if (event.getCloseOrigin() == CloseOriginType.BREADCRUMBS) { event.preventWindowClose(); } } -
- AfterCloseEvent
-
AfterCloseEventпосылается после того, как экран будет закрыт методомclose(CloseAction), и после событияScreen.AfterDetachEvent. Настройки состояния компонентов сохранены. Слушатель этого события можно использовать для вывода уведомлений или диалоговых окон после закрытия экрана, например:@Subscribe protected void onAfterClose(AfterCloseEvent event) { notifications.create().withCaption("Just closed").show(); }
- AfterDetachEvent
-
AfterDetachEventпосылается после того, как экран удаляется из интерфейса приложения после закрытия экрана пользователем или выхода пользователя из системы. Слушатель этого события можно использовать для освобождения ресурсов, захваченных экраном. Обратите внимание, что при истечении HTTP-сессии это событие не публикуется.
- UrlParamsChangedEvent
-
UrlParamsChangedEventпосылается, когда изменяются параметры URL браузера, соответствующие данному экрану. Событие вызывается перед отображением экрана, что позволяет произвести некоторую подготовительную работу. В слушателе этого события можно загружать данные или изменять состояние элементов управления в экране в соответствии с новыми параметрами:@Subscribe protected void onUrlParamsChanged(UrlParamsChangedEvent event) { Map<String, String> params = event.getParams(); // handle new params }
3.5.1.1.4. События ScreenFragment
Ниже описаны события жизненного цикла фрагмента, на которые можно подписаться в контроллере для реализации необходимой бизнес-логики.
-
InitEventпосылается, когда контроллер фрагмента и все его компоненты, заданные декларативно, созданы, а инжекция зависимостей завершена. Вложенные фрагменты на этом этапе ещё не инициализированы. Некоторые визуальные компоненты инициализированы не полностью: например, кнопки ещё не связаны с действиями. Если фрагмент подключается к хост-экрану декларативно в XML, данное событие посылается после InitEvent контроллера хоста. В противном случае событие посылается, когда фрагмент подключается к дереву компонентов хост-экрана.
-
AfterInitEventпосылается, когда контроллер фрагмента и все его компоненты, заданные декларативно, созданы, инжекция зависимостей завершена, и все компоненты завершили свою внутреннюю процедуру инициализации. Вложенные фрагменты (при наличии) опубликовали свои событияInitEventиAfterInitEvent. В слушателе этого события можно создавать визуальные компоненты и компоненты данных, а также выполнить дополнительную инициализацию, если она зависит от инициализации вложенных фрагментов.
-
AttachEventпосылается после того, как фрагмент добавлен к дереву компонентов хост-экрана. В этот момент фрагмент полностью инициализирован, событияInitEventиAfterInitEventотосланы. В слушателе данного события можно обращаться к хост-экрану, используя методыgetHostScreen()иgetHostController().
-
DetachEventпосылается после того, как фрагмент удален из дерева компонентов хост-экрана. В слушателе данного события нельзя обращаться к хост-экрану.
Пример подписки на события фрагмента:
@UiController("demo_AddressFragment")
@UiDescriptor("address-fragment.xml")
public class AddressFragment extends ScreenFragment {
private static final Logger log = LoggerFactory.getLogger(AddressFragment.class);
@Subscribe
private void onAttach(AttachEvent event) {
Screen hostScreen = getHostScreen();
FrameOwner hostController = getHostController();
log.info("onAttach to screen {} with controller {}", hostScreen, hostController);
}
@Subscribe
private void onDetach(DetachEvent event) {
log.info("onDetach");
}
}В контроллере фрагмента можно также подписаться на события включающего экрана путем указания значения PARENT_CONTROLLER в атрибуте target аннотации, например:
@Subscribe(target = Target.PARENT_CONTROLLER)
private void onBeforeShowHost(Screen.BeforeShowEvent event) {
//
}Таким способом можно обработать любое событие, в том числе InitEntityEvent, посылаемое экранами редактирования.
3.5.1.2. XML-дескриптор экрана
Дескриптор экрана - это файл формата XML, декларативно описывающий визуальные компоненты, компоненты данных и некоторые параметры экрана.
Пример:
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<window xmlns="http://schemas.haulmont.com/cuba/screen/window.xsd"
caption="Sample Screen"
messagesPack="com.company.sample.web.screens.monitor">
<layout>
</layout>
</window>Схема XML доступна по адресу http://schemas.haulmont.com/cuba/7.2/screen/window.xsd.
Дескриптор содержит корневой элемент window.
Атрибуты корневого элемента:
-
class− имя класса контроллера. -
messagesPack− пакет сообщений данного экрана по умолчанию. Он будет использован при получении локализованных строк без указания пакета из XML-дескриптора и из контроллера методомgetMessage(). -
caption− заголовок экрана, может содержать ссылку на сообщение из вышеуказанного пакета, например,caption="msg://credits" -
focusComponent− идентификатор компонента, который получит фокус ввода при отображении экрана.
Элементы дескриптора:
-
data− описывает компоненты данных экрана. -
dialogMode- определяет параметры геометрии и поведения экрана при открытии его в виде диалогового окна.Атрибуты
dialogMode:-
closeable- определяет наличие в диалоговом окне кнопки закрытия. Возможные значения:true,false. -
closeOnClickOutside- определяет возможность закрыть окно кликом по окружающей области, если диалог открыт в модальном режиме. Возможные значения:true,false. -
forceDialog- указывает, что экран должен всегда открываться в режиме диалога, независимо от того, какойWindowManager.OpenTypeбыл выбран в вызывающем коде. Возможные значения:true,false. -
height- устанавливает высоту диалогового окна. -
maximized- если выбрано значениеtrue, диалог будет развёрнут во весь экран. Возможные значения:true,false. -
modal- устанавливает модальный режим диалогового окна. Возможные значения:true,false. -
positionX- задаёт положение левого верхнего угла диалога по осиx. -
positionY- задаёт положение левого верхнего угла диалога по осиy. -
resizable- определяет возможность пользователя изменять размеры диалога. Возможные значения:true,false. -
width- устанавливает ширину диалогового окна.
Пример использования
dialogMode:<dialogMode height="600" width="800" positionX="200" positionY="200" forceDialog="true" closeOnClickOutside="false" resizable="true"/> -
-
actions– определяет список действий данного экрана. -
timers– определяет список таймеров данного экрана. -
layout− корневой элемент компоновки экрана.
3.5.1.3. Открытие экранов
Экран может быть открыт из главного меню, навигацией к URL, стандартным действием (при работе с экранами просмотра и редактирования), или программно из другого экрана. В данном разделе мы рассмотрим, как открывать экраны программно.
- Интерфейс Screens
-
Интерфейс
Screensпозволяет создавать и отображать экраны всех типов.Предположим, у нас есть экран для демонстрации сообщения с особым форматированием:
Контроллер экрана@UiController("demo_FancyMessageScreen") @UiDescriptor("fancy-message-screen.xml") @DialogMode(forceDialog = true, width = "300px") public class FancyMessageScreen extends Screen { @Inject private Label<String> messageLabel; public void setFancyMessage(String message) { (1) messageLabel.setValue(message); } @Subscribe("closeBtn") protected void onCloseBtnClick(Button.ClickEvent event) { closeWithDefaultAction(); } }1 - параметр экрана XML-дескриптор экрана<?xml version="1.0" encoding="UTF-8" standalone="no"?> <window xmlns="http://schemas.haulmont.com/cuba/screen/window.xsd" caption="Fancy Message"> <layout> <label id="messageLabel" value="A message" stylename="h1"/> <button id="closeBtn" caption="Close"/> </layout> </window>В этом случае мы можем создать и открыть его из другого экрана следующим образом:
@Inject private Screens screens; private void showFancyMessage(String message) { FancyMessageScreen screen = screens.create(FancyMessageScreen.class); screen.setFancyMessage(message); screens.show(screen); }Обратите внимание, что мы сначала создаём экземпляр экрана, передаём в него параметр, а затем отображаем экран.
Если экран не требует передачи параметров из вызывающего кода, его можно создать и открыть одной строкой:
@Inject private Screens screens; private void showDefaultFancyMessage() { screens.create(FancyMessageScreen.class).show(); }Screensне является Spring-бином, поэтому его можно только инжектировать в контроллер экрана или получить его с помощью статического методаComponentsHelper.getScreenContext(component).getScreens().
- Бин ScreenBuilders
-
Бин
ScreenBuildersпозволяет открывать все типы экранов с различными параметрами.Руководство Initial Entity Values демонстрирует пример внешней инициализации с помощью
ScreenBuilders.Ниже приведён пример вызова экрана и выполнения некоторого кода после того, как экран закрывается (более подробно см. здесь):
@Inject private ScreenBuilders screenBuilders; @Inject private Notifications notifications; private void openOtherScreen() { screenBuilders.screen(this) .withScreenClass(OtherScreen.class) .withAfterCloseListener(e -> { notifications.create().withCaption("Closed").show(); }) .build() .show(); }Далее мы рассмотрим работу с экранами редактирования и выбора сущностей. Следует иметь в виду, что в большинстве случаев такие экраны открываются с помощью стандартных действий (таких как CreateAction или LookupAction), поэтому нет необходимости использовать
ScreenBuildersAPI напрямую. Однако, примеры приведенные ниже могут быть полезны, если стандартные действия не используются, и экран открывается из обработчика BaseAction или Button.Пример открытия редактора по умолчанию для сущности
Customer:@Inject private ScreenBuilders screenBuilders; private void editSelectedEntity(Customer entity) { screenBuilders.editor(Customer.class, this) .editEntity(entity) .build() .show(); }В данном примере редактор изменит экземпляр сущности
Customer, но вызывающий экран не получит назад обновлённую сущность.Часто требуется отредактировать сущность, отображаемую, к примеру, компонентом
TableилиDataGrid. В этом случае следует использовать другую форму вызова редактора, она короче и позволяет автоматически обновить исходный экземпляр в таблице:@Inject private GroupTable<Customer> customersTable; @Inject private ScreenBuilders screenBuilders; private void editSelectedEntity() { screenBuilders.editor(customersTable).build().show(); }Чтобы создать новый экземпляр сущности и открыть экран его редактирования, достаточно вызвать метод
newEntity()builder’а:@Inject private GroupTable<Customer> customersTable; @Inject private ScreenBuilders screenBuilders; private void createNewEntity() { screenBuilders.editor(customersTable) .newEntity() .build() .show(); }Редактор сущности по умолчанию определяется по следующей схеме:
-
Если существует экран редактирования с аннотацией @PrimaryEditorScreen, будет использован он.
-
Если такого экрана нет, будет использован экран с идентификатором вида
<entity_name>.edit(например,sales_Customer.edit).
Builder предоставляет множество методов для передачи дополнительных параметров в открываемый экран. К примеру, следующий код создаёт сущность, сначала инициализируя новый экземпляр, в конкретном экране редактирования, открываемом в режиме диалогового окна:
@Inject private GroupTable<Customer> customersTable; @Inject private ScreenBuilders screenBuilders; private void editSelectedEntity() { screenBuilders.editor(customersTable).build().show(); } private void createNewEntity() { screenBuilders.editor(customersTable) .newEntity() .withInitializer(customer -> { // lambda to initialize new instance customer.setName("New customer"); }) .withScreenClass(CustomerEdit.class) // specific editor screen .withLaunchMode(OpenMode.DIALOG) // open as modal dialog .build() .show(); }Экраны выбора сущностей также можно открывать с различными параметрами.
Пример открытия экрана выбора по умолчанию для сущности
User:@Inject private TextField<String> userField; @Inject private ScreenBuilders screenBuilders; private void lookupUser() { screenBuilders.lookup(User.class, this) .withSelectHandler(users -> { User user = users.iterator().next(); userField.setValue(user.getName()); }) .build() .show(); }Если нужно установить выбранную сущность в качестве значения поля, используйте краткую форму вызова:
@Inject private PickerField<User> userPickerField; @Inject private ScreenBuilders screenBuilders; private void lookupUser() { screenBuilders.lookup(User.class, this) .withField(userPickerField) // set result to the field .build() .show(); }Экран выбора сущности по умолчанию определяется по следующей схеме:
-
Если существует экран выбора с аннотацией @PrimaryLookupScreen, будет использован он.
-
Если такого экрана нет, будет использован экран с идентификатором вида
<entity_name>.lookup(например,sales_Customer.lookup). -
Если и такого экрана нет, будет использован экран с идентификатором вида
<entity_name>.browse(например,sales_Customer.browse).
Как и в случае с экранами редактирования, вы можете использовать методы builder’а для передачи дополнительных параметров в открываемые экраны. Например, следующий код поможет выбрать сущность
Userв конкретном экране выбора, открываемом в режиме диалогового окна:@Inject private TextField<String> userField; @Inject private ScreenBuilders screenBuilders; private void lookupUser() { screenBuilders.lookup(User.class, this) .withScreenId("sec$User.browse") // specific lookup screen .withLaunchMode(OpenMode.DIALOG) // open as modal dialog .withSelectHandler(users -> { User user = users.iterator().next(); userField.setValue(user.getName()); }) .build() .show(); } -
- Передача параметров в экраны
-
Рекомендуемый способ передачи параметров в открываемый экран - использование публичных setter-методов контроллера, как продемонстрировано в примере выше.
С помощью такого подхода можно передавать параметры в экраны любого типа, в том числе экраны редактирования и выбора сущностей, открываемые через ScreenBuilders или из главного меню. Пример вызова того же самого экрана
FancyMessageScreenс передачей параметра и использованиемScreenBuilders:@Inject private ScreenBuilders screenBuilders; private void showFancyMessage(String message) { FancyMessageScreen screen = screenBuilders.screen(this) .withScreenClass(FancyMessageScreen.class) .build(); screen.setFancyMessage(message); screen.show(); }Если экран открывается из стандартного действия, такого как CreateAction, используйте его обработчик
screenConfigurerдля передачи параметров через публичные сеттеры контроллера экрана.Другой способ - определить специальный класс для параметров и передавать экземпляр этого класса в стандартный метод
withOptions()билдера. Класс параметров должен реализовывать маркер-интерфейсScreenOptions. Например:import com.haulmont.cuba.gui.screen.ScreenOptions; public class FancyMessageOptions implements ScreenOptions { private String message; public FancyMessageOptions(String message) { this.message = message; } public String getMessage() { return message; } }В открываемом экране
FancyMessageScreen, объект параметров может быть получен в обработчиках InitEvent и AfterInitEvent:@Subscribe private void onInit(InitEvent event) { ScreenOptions options = event.getOptions(); if (options instanceof FancyMessageOptions) { String message = ((FancyMessageOptions) options).getMessage(); messageLabel.setValue(message); } }Пример вызова экрана
FancyMessageScreenчерезScreenBuildersс передачейScreenOptions:@Inject private ScreenBuilders screenBuilders; private void showFancyMessage(String message) { screenBuilders.screen(this) .withScreenClass(FancyMessageScreen.class) .withOptions(new FancyMessageOptions(message)) .build() .show(); }Как видите, данный подход требует приведения типов в контроллере, получающем параметры, поэтому используйте его только когда это необходимо и предпочитайте type-safe подход с setter-методами, описанный выше.
Если экран открывается из стандартного действия, такого как CreateAction, используйте его обработчик
screenOptionsSupplierдля создания и инициализации требуемого объектаScreenOptions.Использование объекта
ScreenOptionsявляется единственным способом получения параметров, если экран открывается из другого экрана, основанного на устаревшем API. В этом случае, объект параметров имеет типMapScreenOptionsи может быть обработан следующим образом:@Subscribe private void onInit(InitEvent event) { ScreenOptions options = event.getOptions(); if (options instanceof MapScreenOptions) { String message = (String) ((MapScreenOptions) options).getParams().get("message"); messageLabel.setValue(message); } }
- Выполнение кода после закрытия и возврат значений
-
Каждый экран посылает событие
AfterCloseEventпосле своего закрытия. Экрану можно добавить слушатель для нотификации об этом событии, например:@Inject private Screens screens; @Inject private Notifications notifications; private void openOtherScreen() { OtherScreen otherScreen = screens.create(OtherScreen.class); otherScreen.addAfterCloseListener(afterCloseEvent -> { notifications.create().withCaption("Closed " + afterCloseEvent.getScreen()).show(); }); otherScreen.show(); }При использовании
ScreenBuilders, слушатель можно передать в методеwithAfterCloseListener():@Inject private ScreenBuilders screenBuilders; @Inject private Notifications notifications; private void openOtherScreen() { screenBuilders.screen(this) .withScreenClass(OtherScreen.class) .withAfterCloseListener(afterCloseEvent -> { notifications.create().withCaption("Closed " + afterCloseEvent.getScreen()).show(); }) .build() .show(); }Объект события предоставляет информацию о том, как экран был закрыт. Эта информация может быть получена двумя способами: проверкой, был ли экран закрыт с одним из стандартных значений перечисления
StandardOutcome, либо получением объектаCloseAction. Первый способ проще, второй более гибкий.Рассмотрим первый подход: закрытие экрана с указанием
StandardOutcomeи его проверкой в вызывающем коде.Вызывается следующий экран:
package com.company.demo.web.screens; import com.haulmont.cuba.gui.components.Button; import com.haulmont.cuba.gui.screen.*; @UiController("demo_OtherScreen") @UiDescriptor("other-screen.xml") public class OtherScreen extends Screen { private String result; public String getResult() { return result; } @Subscribe("okBtn") public void onOkBtnClick(Button.ClickEvent event) { result = "Done"; close(StandardOutcome.COMMIT); (1) } @Subscribe("cancelBtn") public void onCancelBtnClick(Button.ClickEvent event) { close(StandardOutcome.CLOSE); (2) } }1 - при нажатии кнопки "OK", установить некоторое результирующее значение и закрыть экран с StandardOutcome.COMMIT.2 - при нажатии кнопки "Cancel", закрыть экран с StandardOutcome.CLOSE.Теперь в слушателе
AfterCloseEventможно проанализировать, как экран был закрыт, с помощью методаclosedWith()события, и, если необходимо, прочитать возвращаемое экраном значение:@Inject private ScreenBuilders screenBuilders; @Inject private Notifications notifications; private void openOtherScreen() { screenBuilders.screen(this) .withScreenClass(OtherScreen.class) .withAfterCloseListener(afterCloseEvent -> { OtherScreen otherScreen = afterCloseEvent.getScreen(); if (afterCloseEvent.closedWith(StandardOutcome.COMMIT)) { String result = otherScreen.getResult(); notifications.create().withCaption("Result: " + result).show(); } }) .build() .show(); }Другим способом возврата значений из экранов является использование собственных реализаций
CloseAction. Перепишем пример, приведенный выше, с использованием следующего класса действия закрытия:package com.company.demo.web.screens; import com.haulmont.cuba.gui.screen.StandardCloseAction; public class MyCloseAction extends StandardCloseAction { private String result; public MyCloseAction(String result) { super("myCloseAction"); this.result = result; } public String getResult() { return result; } }Теперь можно использовать данное действие при закрытии экрана:
package com.company.demo.web.screens; import com.haulmont.cuba.gui.components.Button; import com.haulmont.cuba.gui.screen.*; @UiController("demo_OtherScreen2") @UiDescriptor("other-screen.xml") public class OtherScreen2 extends Screen { @Subscribe("okBtn") public void onOkBtnClick(Button.ClickEvent event) { close(new MyCloseAction("Done")); (1) } @Subscribe("cancelBtn") public void onCancelBtnClick(Button.ClickEvent event) { closeWithDefaultAction(); (2) } }1 - при нажатии кнопки "OK", создать экземпляр CloseActionи передать ему результирующее значение.2 - при нажатии кнопки "Cancel", закрыть экран с действием закрытия по умолчанию, предоставляемым фреймворком. В слушателе
AfterCloseEventможно получитьCloseActionиз объекта события и прочитать результирующее значение:@Inject private Screens screens; @Inject private Notifications notifications; private void openOtherScreen() { Screen otherScreen = screens.create("demo_OtherScreen2", OpenMode.THIS_TAB); otherScreen.addAfterCloseListener(afterCloseEvent -> { CloseAction closeAction = afterCloseEvent.getCloseAction(); if (closeAction instanceof MyCloseAction) { String result = ((MyCloseAction) closeAction).getResult(); notifications.create().withCaption("Result: " + result).show(); } }); otherScreen.show(); }Как видно из примера кода, при возврате значений через собственный
CloseAction, вызывающий код не обязан знать класс открываемого экрана, так как ему не нужено вызывать его методы. Поэтому экран можно создавать по его строковому идентификатору.Разумеется, данный подход к возврату значений через действия закрытия может использоваться и при открытии экранов с помощью
ScreenBuilders.
3.5.1.4. Использование фрагментов экранов
В данном разделе рассматриваются примеры определения и использования фрагментов экранов. См. также раздел События ScreenFragment для получения информации о событиях жизненного цикла фрагментов.
- Декларативное использование фрагмента
-
Предположим, имеется фрагмент для ввода адреса:
AddressFragment.java@UiController("demo_AddressFragment") @UiDescriptor("address-fragment.xml") public class AddressFragment extends ScreenFragment { }address-fragment.xml<fragment xmlns="http://schemas.haulmont.com/cuba/screen/fragment.xsd"> <layout> <textField id="cityField" caption="City"/> <textField id="zipField" caption="Zip"/> </layout> </fragment>Он может быть включен в некоторый экран с помощью элемента
fragmentс атрибутомscreen, указывающим на id фрагмента, который задан в аннотации@UiController:host-screen.xml<window xmlns="http://schemas.haulmont.com/cuba/screen/window.xsd" caption="Some Screen"> <layout> <groupBox id="addressBox" caption="Address"> <fragment screen="demo_AddressFragment"/> </groupBox> </layout> </window>Элемент
fragmentможет быть добавлен в любой UI-контейнер экрана, в том числе в корневой элементlayout.
- Программное использование фрагмента
-
Тот же самый фрагмент может быть включен в экран программно в обработчике InitEvent или AfterInitEvent как показано ниже:
host-screen.xml<window xmlns="http://schemas.haulmont.com/cuba/screen/window.xsd" caption="Some Screen"> <layout> <groupBox id="addressBox" caption="Address"/> </layout> </window>HostScreen.java@UiController("demo_HostScreen") @UiDescriptor("host-screen.xml") public class HostScreen extends Screen { @Inject private Fragments fragments; (1) @Inject private GroupBoxLayout addressBox; @Subscribe private void onInit(InitEvent event) { AddressFragment addressFragment = fragments.create(this, AddressFragment.class); (2) addressBox.add(addressFragment.getFragment()); (3) } }1 - инжекция бина Fragments, который предназначен для инстанциирования фрагментов2 - создание экземпляра контроллера фрагмента по его классу 3 - получение визуального компонента Fragmentиз контроллера и добавление его в UI-контейнерЕсли фрагменту нужны какие-либо параметры, установите их через публичные сеттеры перед добавлением фрагмента в экран. Тогда параметры будут доступны в обработчиках событий
InitEventиAfterInitEventконтроллера фрагмента.
- Передача параметров в фрагменты
-
Контроллер фрагмента может иметь публичные сеттеры для получения параметров, как это делается при открытии экранов. Если фрагмент открывается программно, то сеттеры можно вызвать явно:
@UiController("demo_HostScreen") @UiDescriptor("host-screen.xml") public class HostScreen extends Screen { @Inject private Fragments fragments; @Inject private GroupBoxLayout addressBox; @Subscribe private void onInit(InitEvent event) { AddressFragment addressFragment = fragments.create(this, AddressFragment.class); addressFragment.setStrParam("some value"); (1) addressBox.add(addressFragment.getFragment()); } }1 - передача параметра перед добавлением фрагмента в экран. Если фрагмент добавляется в экран декларативно в XML, для передачи параметров можно использовать элемент
properties, например:<window xmlns="http://schemas.haulmont.com/cuba/screen/window.xsd" caption="Some Screen"> <data> <instance id="someDc" class="com.company.demo.entity.Demo"/> </data> <layout> <textField id="someField"/> <fragment screen="demo_AddressFragment"> <properties> <property name="strParam" value="some value"/> (1) <property name="dataContainerParam" ref="someDc"/> (2) <property name="componentParam" ref="someField"/> (3) </properties> </fragment> </layout> </window>1 - передача строкового параметра в метод setStrParam().2 - передача контейнера данных в метод setDataContainerParam().3 - передача компонента TextFieldв методsetComponentParam().Атрибут
valueиспользуется для указания значений, атрибутref- для указания идентификаторов компонентов экрана. Сеттеры должны иметь параметры подходящего типа.
- Компоненты данных в фрагментах
-
Фрагмент экрана может иметь свои собственные контейнеры и загрузчики данных, определенные в XML-элементе
data. В то же время, фреймворк создает единственный экземпляр DataContext для экрана и всех его фрагментов. Поэтому все загруженные сущности помещаются в один контекст и их изменения сохраняются, когда экран выполняет коммит.Далее рассматривается пример использования собственных компонентов данных в фрагменте.
Предположим, имеется сущность
City, и во фрагменте вместо текстового поля необходимо отобразить выпадающий список с имеющимися городами. Во фрагменте можно определить компоненты данных точно так же, как в обычном экране:address-fragment.xml<fragment xmlns="http://schemas.haulmont.com/cuba/screen/fragment.xsd"> <data> <collection id="citiesDc" class="com.company.demo.entity.City" view="_base"> <loader id="citiesLd"> <query><![CDATA[select e from demo_City e ]]></query> </loader> </collection> </data> <layout> <lookupField id="cityField" caption="City" optionsContainer="citiesDc"/> <textField id="zipField" caption="Zip"/> </layout> </fragment>Для того, чтобы загрузить данные в момент открытия включающего экрана, необходимо подписаться на событие экрана:
AddressFragment.java@UiController("demo_AddressFragment") @UiDescriptor("address-fragment.xml") public class AddressFragment extends ScreenFragment { @Inject private CollectionLoader<City> citiesLd; @Subscribe(target = Target.PARENT_CONTROLLER) (1) private void onBeforeShowHost(Screen.BeforeShowEvent event) { citiesLd.load(); } }1 - подписка на BeforeShowEvent включающего экрана Аннотация
@LoadDataBeforeShowв фрагментах экранов не действует.
- Контейнеры данных, предоставляемые экраном
-
Следующий пример демонстрирует использование контейнеров данных, предоставляемых включающим экраном.
host-screen.xml<window xmlns="http://schemas.haulmont.com/cuba/screen/window.xsd" caption="Some Screen"> <data> <instance id="addressDc" class="com.company.demo.entity.Address"/> (1) </data> <layout> <groupBox id="addressBox" caption="Address"> <fragment screen="demo_AddressFragment"/> </groupBox> </layout> </window>1 - контейнер данных, который используется фрагментом ниже address-fragment.xml<fragment xmlns="http://schemas.haulmont.com/cuba/screen/fragment.xsd"> <data> <instance id="addressDc" class="com.company.demo.entity.Address" provided="true"/> (1) <collection id="citiesDc" class="com.company.demo.entity.City" view="_base"> <loader id="citiesLd"> <query><![CDATA[select e from demo_City e]]></query> </loader> </collection> </data> <layout> <lookupField id="cityField" caption="City" optionsContainer="citiesDc" dataContainer="addressDc" property="city"/> (2) <textField id="zipField" caption="Zip" dataContainer="addressDc" property="zip"/> </layout> </fragment>1 - provided="true"означает, что контейнер с таким же id должен существовать во включающем экране или фрагменте, т.е. должен быть предоставлен извне2 - UI-компоненты соединены с предоставленным контейнером данных В XML-элементе, имеющем
provided="true", все атрибуты за исключениемidигнорируются, но могут присутствовать для обеспечения работы инструментов разработки.
3.5.1.5. Примеси экранов
Примеси позволяют создавать функциональность, которая может быть переиспользована во разных экранах без необходимости наследования этих экранов от общих базовых классов. Примеси реализуются с помощью интерфейсов Java с default-методами.
Примеси имеют следующие характеристики:
-
Экран может иметь несколько примесей.
-
В интерфейсе примеси можно подписываться на события экрана.
-
Если необходимо, примесь может сохранять некоторое состояние в экране.
-
Примесь может обращаться к компонентам экрана и инфраструктурным бинам, например Dialogs, Notifications, и пр.
-
Для параметризации поведения примеси, она может полагаться на аннотации экрана или вводить абстрактные методы, которые должен будет реализовать экран.
Обычно использование примеси заключается просто в реализации определенного интерфейса в контроллере экрана. В примере ниже, экран CustomerEditor получает функциональность примесей, реализованных интерфейсами HasComments, HasHistory и HasAttachments:
public class CustomerEditor extends StandardEditor<Customer>
implements HasComments, HasHistory, HasAttachments {
// ...
}Примесь может использовать следующие классы для работы с экраном и инфраструктурой:
-
com.haulmont.cuba.gui.screen.Extensionsпредоставляет статические методы для сохранения и извлечения состояния из экрана, в котором примесь используется, а также для получения бинаBeanLocator, который в свою очередь позволяет получить любой Spring бин. -
UiControllerUtilsпредоставляет доступ к UI-компонентам и компонентам данных экрана.
В примерах ниже демонстрируется создание и использование примесей.
- Примесь DeclarativeLoaderParameters
-
Следующая примесь помогает устанавливать отношения master-detail между контейнерами данных. Обычно для этого необходимо подписаться на
ItemChangeEventmaster-контейнера и задать параметр для detail-загрузчика, как описано в разделе Зависимости между компонентами данных. Примесь сможет сделать это автоматически, если параметр будет иметь специальное имя, указывающее на master-контейнер.Создаваемая примесь будет использовать объект-состояние для передачи информации между обработчиками событий экрана. Это сделано в основном для целей демонстрации, так как в данном случае можно было бы разместить всю логику в единственном обработчике
BeforeShowEvent.Сначала создадим класс объекта состояния. Он содержит единственное поле для сохранения набора загрузчиков, которые должны сработать в обработчике
BeforeShowEvent:package com.company.demo.web.mixins; import com.haulmont.cuba.gui.model.DataLoader; import java.util.Set; public class DeclarativeLoaderParametersState { private Set<DataLoader> loadersToLoadBeforeShow; public DeclarativeLoaderParametersState(Set<DataLoader> loadersToLoadBeforeShow) { this.loadersToLoadBeforeShow = loadersToLoadBeforeShow; } public Set<DataLoader> getLoadersToLoadBeforeShow() { return loadersToLoadBeforeShow; } }Теперь создадим интерфейс примеси:
package com.company.demo.web.mixins; import com.haulmont.cuba.gui.model.*; import com.haulmont.cuba.gui.screen.*; import java.util.HashSet; import java.util.Set; import java.util.regex.Matcher; import java.util.regex.Pattern; public interface DeclarativeLoaderParameters { Pattern CONTAINER_REF_PATTERN = Pattern.compile(":(container\\$(\\w+))"); @Subscribe default void onDeclarativeLoaderParametersInit(Screen.InitEvent event) { (1) Screen screen = event.getSource(); ScreenData screenData = UiControllerUtils.getScreenData(screen); (2) Set<DataLoader> loadersToLoadBeforeShow = new HashSet<>(); for (String loaderId : screenData.getLoaderIds()) { DataLoader loader = screenData.getLoader(loaderId); String query = loader.getQuery(); Matcher matcher = CONTAINER_REF_PATTERN.matcher(query); while (matcher.find()) { (3) String paramName = matcher.group(1); String containerId = matcher.group(2); InstanceContainer<?> container = screenData.getContainer(containerId); container.addItemChangeListener(itemChangeEvent -> { (4) loader.setParameter(paramName, itemChangeEvent.getItem()); (5) loader.load(); }); if (container instanceof HasLoader) { (6) loadersToLoadBeforeShow.add(((HasLoader) container).getLoader()); } } } DeclarativeLoaderParametersState state = new DeclarativeLoaderParametersState(loadersToLoadBeforeShow); (7) Extensions.register(screen, DeclarativeLoaderParametersState.class, state); } @Subscribe default void onDeclarativeLoaderParametersBeforeShow(Screen.BeforeShowEvent event) { (8) Screen screen = event.getSource(); DeclarativeLoaderParametersState state = Extensions.get(screen, DeclarativeLoaderParametersState.class); for (DataLoader loader : state.getLoadersToLoadBeforeShow()) { loader.load(); (9) } } }1 - подписка на InitEvent. 2 - получение объекта ScreenData, в котором зарегистрированы все контейнеры и загрузчики данных, объявленные в XML-дескрипторе.3 - проверка, соответствует ли имя параметра загрузчика паттерну`:container$masterContainerId`. 4 - извлечение id master-контейнера из имени параметра и регистрация обработчика ItemChangeEventдля этого контейнера.5 - перезагрузка detail-загрузчика для нового выбранного элемента в master-контейнере. 6 - добавление master-загрузчика в набор для вызова позже в обработчике BeforeShowEvent.7 - создание объекта состояния и сохранение его в экране с помощью класса Extensions.8 - подписка на BeforeShowEvent. 9 - вызов всех master-загрузчиков в обработчике InitEvent.Определим master и detail контейнеры и загрузчики в XML-дескрипторе экрана. Detail-загрузчик должен иметь параметр с именем вида
:container$masterContainerId:<collection id="countriesDc" class="com.company.demo.entity.Country" view="_local"> <loader id="countriesDl"> <query><![CDATA[select e from demo_Country e]]></query> </loader> </collection> <collection id="citiesDc" class="com.company.demo.entity.City" view="city-view"> <loader id="citiesDl"> <query><![CDATA[ select e from demo_City e where e.country = :container$countriesDc ]]></query> </loader> </collection>В контроллере экрана достаточно добавить интерфейс примеси, и она будет вызывать загрузчики нужным образом:
package com.company.demo.web.country; import com.company.demo.entity.Country; import com.company.demo.web.mixins.DeclarativeLoaderParameters; import com.haulmont.cuba.gui.screen.*; @UiController("demo_Country.browse") @UiDescriptor("country-browse.xml") @LookupComponent("countriesTable") public class CountryBrowse extends StandardLookup<Country> implements DeclarativeLoaderParameters { }
3.5.1.6. Корневые экраны
Корневой экран - это экран Generic UI, который отображается непосредственно во вкладке веб-браузера. Существует два типа таких экранов: экран логина и главный экран. Помимо обычных компонентов, любой корневой экран может содержать компонент WorkArea, который позволяет открывать другие экраны приложения во внутренних вкладках. Если корневой экран не содержит WorkArea, то экраны приложения могут быть открыты только в режиме DIALOG.
- Экран логина
-
Экран логина отображается до регистрации пользователя в системе. Данный экран можно кастомизировать с помощью расширения существующего экрана, предоставляемого фреймворком, либо создать новый экран с нуля.
Для расширения существующего экрана используйте шаблон Login screen в мастере создания экранов Studio. В результате Studio создаст экран, расширяющий стандартный. Этот экран будет использоваться вместо стандартного, так как он будет имеет такой же идентификатор: см. значение
loginв аннотации@UiController.Для создания нового экрана используйте шаблон Blank screen. Пример кода минималистичного экрана логина:
my-login-screen.xml<window xmlns="http://schemas.haulmont.com/cuba/screen/window.xsd" caption="Login" messagesPack="com.company.sample.web"> <layout> <label value="Hello World"/> <button id="loginBtn" caption="Login"/> </layout> </window>MyLoginScreen.javapackage com.company.sample.web; import com.haulmont.cuba.gui.Route; import com.haulmont.cuba.gui.components.Button; import com.haulmont.cuba.gui.screen.*; import com.haulmont.cuba.security.auth.LoginPasswordCredentials; import com.haulmont.cuba.web.App; @UiController("myLogin") @UiDescriptor("my-login-screen.xml") @Route(path = "login", root = true) public class MyLoginScreen extends Screen { @Subscribe("loginBtn") private void onLoginBtnClick(Button.ClickEvent event) { App.getInstance().getConnection().login( new LoginPasswordCredentials("admin", "admin")); } }Для использования данного экрана вместо дефолтного, установите его id в свойстве приложения
cuba.web.loginScreenIdв файлеweb-app.properties:cuba.web.loginScreenId = myLoginВместо регистрации нового экрана в свойстве приложения, можно просто дать новому экрану дефолтный идентификатор
login.
- Главный экран
-
Главный экран – это корневой экран, отображаемый после регистрации пользователя в системе. По умолчанию фреймворком предоставляется главный экран с боковым меню.
Studio содержит несколько шаблонов для создания кастомного главного экрана. Все они используют класс
MainScreenв качестве базового класса контроллеров.-
Main screen with side menu создает расширение стандартного главного экрана с идентификатором
main. Главный экран с боковым меню по умолчанию предоставляет возможность разворачивать и сворачивать боковое меню с помощью кнопки Collapse, находящейся в нижнем левом углу меню.Поведение бокового меню можно настроить с помощью переменных SCSS (эти переменные можно изменить в визуальном редакторе после расширения темы или создания новой темы):
-
$cuba-sidemenu-layout-collapse-enabledвключает или выключает режим сворачивания бокового меню. По умолчанию имеет значениеtrue. -
$cuba-sidemenu-layout-collapsed-widthопределяет ширину свёрнутого бокового меню. -
$cuba-sidemenu-layout-expanded-widthопределяет ширину развёрнутого бокового меню. -
$cuba-sidemenu-layout-collapse-animation-timeопределяет время анимации сворачивания и разворачивания бокового меню в секундах.Если переменная
$cuba-sidemenu-layout-collapse-enabledимеет значениеfalse, кнопка Collapse скрыта, а боковое меню развёрнуто.
-
-
Main screen with responsive side menu создает похожий экран, но боковое меню является responsive и сворачивается на узких экранах. Экран будет иметь собственный id, который необходимо зарегистрировать в
web-app.properties:cuba.web.mainScreenId = respSideMenuMainScreen -
Main screen with top menu создает экран с верхним меню и возможностью использования панели папок слева. Экран будет иметь собственный id, который необходимо зарегистрировать в
web-app.properties:cuba.web.mainScreenId = topMenuMainScreen
Следующие специальные компоненты могут быть использованы в главном экране в дополнение к стандартным UI-компонентам:
-
SideMenu– боковое меню приложения в виде вертикального дерева. -
AppMenu– главное меню. -
FoldersPane– панель папок поиска и папок приложения. -
AppWorkArea– рабочая область, обязательный компонент для работы с экранами в режимахTHIS_TAB,NEW_TABиNEW_WINDOW. -
UserIndicator– поле, отображающее имя текущего пользователя, а при наличии замещаемых пользователей позволяет переключаться между ними.Метод
setUserNameFormatter()используется для отображения имени пользователя в виде, отличном от стандартного имени экземпляра сущностиUser:userIndicator.setUserNameFormatter(value -> value.getName() + " - [" + value.getEmail() + "]");
-
NewWindowButton– кнопка открытия нового окна приложения.
-
UserActionsButton– если сессия не аутентифицирована, отображает ссылку на экран логина. В противном случае, отображает меню со ссылкой на экран настроек пользователя и возможностью выйти из системы.Вы можете использовать обработчики событий
LoginHandlerилиLogoutHandlerв контроллере главного экрана для реализации кастомной логики:@Install(to = "userActionsButton", subject = "loginHandler") private void loginHandler(UserActionsButton.LoginHandlerContext ctx) { // do custom logic } @Install(to = "userActionsButton", subject = "logoutHandler") private void logoutHandler(UserActionsButton.LogoutHandlerContext ctx) { // do custom logic } -
LogoutButton– кнопка выхода из приложения. -
TimeZoneIndicator– надпись, которая отображает часовой пояс пользователя. -
FtsField– поле полнотекстового поиска.
Следующие свойства приложения могут влиять на главный экран:
-
cuba.web.appWindowMode - задает начальный режим главного окна: с вкладками или одноэкранный (
TABBEDилиSINGLE). Пользователь впоследствии может задать желаемый режим через экран Settings, доступный через UserActionsButton. -
cuba.web.maxTabCount - в режиме представления главного окна с вкладками задает максимальное количество вкладок, которое может открыть пользователь. По умолчанию 20.
-
cuba.web.foldersPaneEnabled - включает отображение панели папок для экрана, созданного по шаблону Main screen with top menu.
-
cuba.web.defaultScreenId - задает экран по умолчанию, который должен быть открыт в главном экране автоматически.
-
cuba.web.defaultScreenCanBeClosed - указывает, может ли пользователь закрыть экран по умолчанию.
-
cuba.web.useDeviceWidthForViewport - определяет ширину области просмотра (viewport). Если установлено значение
true, за ширину области просмотра будет принята ширина устройства. Также может быть полезно свойство cuba.web.pageInitialScale.
-
3.5.1.7. Валидация в экранах
Бин ScreenValidation может использоваться для запуска валидации в экранах. Он имеет следующие методы:
-
ValidationErrors validateUiComponents()- используется при коммите изменений в экранахStandardEditor,InputDialog, иMasterDetailScreen. Принимает на вход коллекцию из компонентов или контейнер компонентов и возвращает ошибки валидации в этих компонентах (объектValidationErrors). МетодvalidateUiComponents()также может быть использован в произвольном экране. Например:@UiController("demo_DemoScreen") @UiDescriptor("demo-screen.xml") public class DemoScreen extends Screen { @Inject private ScreenValidation screenValidation; @Inject private Form demoForm; @Subscribe("validateBtn") public void onValidateBtnClick(Button.ClickEvent event) { ValidationErrors errors = screenValidation.validateUiComponents(demoForm); if (!errors.isEmpty()) { screenValidation.showValidationErrors(this, errors); return; } } } -
showValidationErrors()- показывает нотификацию со всеми ошибками и проблемными компонентами. Метод принимает на вход экран и объектValidationErrors. Также используется по умолчанию в экранахStandardEditor,InputDialog, иMasterDetailScreen. -
validateCrossFieldRules()- принимает на вход экран и сущность и возвращает объектValidationErrors. Выполняет правила перекрестной проверки, установленные на поля сущности. Экраны редактирования выполняют валидацию ограничений уровня класса при коммите, если ограничения включают группуUiCrossFieldChecks, и все проверки ограничений уровня атрибутов прошли успешно (больше информации см. в разделе Собственные ограничения). Валидацию данного типа можно отключить с помощью метода контроллераsetCrossFieldValidate(). По умолчанию используется в экранахStandardEditor,MasterDetailScreen, в редактореDataGrid. МетодvalidateCrossFieldRules()также может быть использован в произвольном экране.В качестве примера рассмотрим сущность
Event, для которой мы можем определить аннотацию уровня класса, для проверки того, что дата Start date должна быть раньше даты End date.Сущность Event@Table(name = "DEMO_EVENT") @Entity(name = "demo_Event") @NamePattern("%s|name") @EventDate(groups = {Default.class, UiCrossFieldChecks.class}) public class Event extends StandardEntity { private static final long serialVersionUID = 1477125422077150455L; @Column(name = "NAME") private String name; @Temporal(TemporalType.TIMESTAMP) @Column(name = "START_DATE") private Date startDate; @Temporal(TemporalType.TIMESTAMP) @Column(name = "END_DATE") private Date endDate; ... }Определение аннотации выглядит следующим образом:
@Target(ElementType.TYPE) @Retention(RetentionPolicy.RUNTIME) @Constraint(validatedBy = EventDateValidator.class) public @interface EventDate { String message() default "The Start date must be earlier than the End date"; Class<?>[] groups() default {}; Class<? extends Payload>[] payload() default {}; }EventDateValidatorpublic class EventDateValidator implements ConstraintValidator<EventDate, Event> { @Override public boolean isValid(Event event, ConstraintValidatorContext context) { if (event == null) { return false; } if (event.getStartDate() == null || event.getEndDate() == null) { return false; } return event.getStartDate().before(event.getEndDate()); } }Далее вы можете использовать метод
validateCrossFieldRules()в произвольном экране.@UiController("demo_DemoScreen") @UiDescriptor("demo-screen.xml") public class DemoScreen extends Screen { @Inject protected Metadata metadata; @Inject protected ScreenValidation screenValidation; @Inject protected TimeSource timeSource; @Subscribe("validateBtn") public void onValidateBtnClick(Button.ClickEvent event) { Event event = metadata.create(Event.class); event.setName("Demo event"); event.setStartDate(timeSource.currentTimestamp()); // We make the endDate earlier than the startDate event.setEndDate(DateUtils.addDays(event.getStartDate(), -1)); ValidationErrors errors = screenValidation.validateCrossFieldRules(this, event); if (!errors.isEmpty()) { screenValidation.showValidationErrors(this, errors); } } } -
showUnsavedChangesDialog()- показывает стандартный диалог несохраненных изменений ("Вы действительно хотите закрыть экран?") с кнопками Да и Нет. Используется в экране редактораStandardEditor. МетодshowUnsavedChangesDialog()имеет обработчик, который реагирует на действия пользователя (кнопку, которую он нажал):screenValidation.showUnsavedChangesDialog(this, action) .onDiscard(() -> result.resume(closeWithDiscard())) .onCancel(result::fail); -
showSaveConfirmationDialog()- показывает стандартный диалог подтверждения сохранения измененных данных ("Сохранить изменения перед закрытием экрана?") с кнопками Сохранить, Не сохранять, Отмена. Используется в экране редактораStandardEditor. МетодshowSaveConfirmationDialog()имеет обработчик, который реагирует на действия пользователя (кнопку, которую он нажал):screenValidation.showSaveConfirmationDialog(this, action) .onCommit(() -> result.resume(closeWithCommit())) .onDiscard(() -> result.resume(closeWithDiscard())) .onCancel(result::fail);
Вы можете настроить тип диалога с помощью свойства приложения cuba.gui.useSaveConfirmation.
3.5.2. Библиотека визуальных компонентов
3.5.2.1. Компоненты
Меню |
|
|
|
|
|
Кнопки |
|
|
|
|
|
|
|
Текст |
|
|
|
Ввод текста |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Ввод даты |
|
|
|
|
|
|
|
Поля выбора |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Загрузка |
|
|
|
Таблицы и деревья |
|
|
|
|
|
|
|
|
|
|
|
|
|
Другое |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|






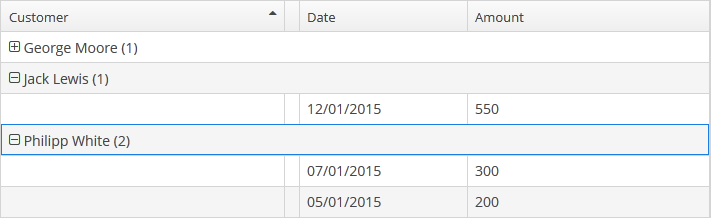

3.5.2.1.1. AppMenu
Компонент AppMenu позволяет динамически управлять элементами главного меню в главном экране приложения.

CUBA Studio предоставляет готовые шаблоны главного экрана на основе стандартного экрана MainScreen платформы. В примере ниже приведён шаблон, расширяющий класс MainScreen и обеспечивающий прямой доступ к экземпляру компонента AppMenu:
public class ExtMainScreen extends MainScreen implements Window.HasFoldersPane {
@Inject
private Notifications notifications;
@Inject
private AppMenu mainMenu;
@Subscribe
public void onInit(InitEvent event) {
AppMenu.MenuItem item = mainMenu.createMenuItem("shop", "Shop");
AppMenu.MenuItem subItem = mainMenu.createMenuItem("customer", "Customers", null, menuItem -> {
notifications.create()
.withCaption("Customers menu item clicked")
.withType(Notifications.NotificationType.HUMANIZED)
.show();
});
item.addChildItem(subItem);
mainMenu.addMenuItem(item, 0);
}
}Методы интерфейса AppMenu:
-
addMenuItem()- добавляет элемент меню в конец списка элементов или на позицию с указанным индексом.
-
createMenuItem()- фабричный метод для создания нового элемента меню. Не добавляет элемент к меню.idдолжен быть уникальным внутри всего меню.
-
createSeparator()- создаёт разделитель элементов меню. -
getMenuItem()/getMenuItemNN()- возвращает объект элемента меню по его идентификатору. -
getMenuItems()- возвращает список элементов меню. -
hasMenuItems()- возвращаетtrue, если меню содержит элементы.
Методы интерфейса MenuItem:
-
addChildItem() / removeChildItem()- добавляет/удаляет элемент меню в конец или на указанную позицию в списке дочерних элементов. -
getCaption()- возвращает строковый заголовок элемента меню. -
getChildren()- возвращает список дочерних элементов.
-
setCommand()- используется для описания действия, которое должно быть выполнено при выборе этого элемента меню кликом мыши. -
setDescription()- устанавливает строковое описание элемента меню, отображаемое в виде всплывающей подсказки. -
setIconFromSet()- устанавливает значок элемента меню. -
getId()- возвращает идентификатор элемента меню. -
getMenu()- возвращает родительский экземплярAppMenu. -
setStylename()- устанавливает один или более пользовательских стилей для компонента, заменяя все ранее заданные стили. Имена стилей при перечислении отделаются пробелами. Имя стиля должно быть названием существующего CSS-класса. -
hasChildren()- возвращаетtrue, если у элемента меню есть дочерние элементы. -
isSeparator()- возвращаетtrue, если элемент является разделителем. -
setVisible()- управляет видимостью элемента меню.
Внешний вид компонента AppMenu можно настроить с помощью переменных SCSS с префиксами $cuba-menubar-* и $cuba-app-menubar-*. Эти переменные можно изменить в визуальном редакторе после расширения темы или создания новой темы.
- API
3.5.2.1.2. BrowserFrame
Компонент BrowserFrame предназначен для включения веб-страницы на страницу приложения. Это аналог HTML-элемента iframe.
XML-имя компонента: browserFrame
Компонент реализован для блока Web Client.
Пример использования компонента browserFrame в XML-дескрипторе экрана:
<browserFrame id="browserFrame"
height="280px"
width="600px"
align="MIDDLE_CENTER">
<url url="https://www.cuba-platform.com/blog/cuba-7-the-new-chapter"/>
</browserFrame>Подобно компоненту Image, BrowserFrame также можно использовать для отображения графического содержимого из различных источников. Тип ресурса можно указать декларативно с помощью элементов browserFrame, перечисленных ниже:
-
classpath- ресурс, расположенный в classpath.<browserFrame> <classpath path="com/company/sample/web/screens/myPic.jpg"/> </browserFrame>
-
file- файл с изображением.<browserFrame> <file path="D:\sample\modules\web\web\VAADIN\images\myImage.jpg"/> </browserFrame>
-
relativePath- относительный путь к файлу в каталоге приложения.<browserFrame> <relativePath path="VAADIN/images/myImage.jpg"/> </browserFrame>
-
theme- ресурс из темы приложения, например:<browserFrame> <theme path="../halo/com.company.demo/myPic.jpg"/> </browserFrame>
-
url- ресурс, загружаемый по URL.<browserFrame> <url url="http://www.foobar2000.org/"/> </browserFrame>
Атрибуты browserFrame:
-
Атрибут
allowопределяет Feature Policy для компонента. Значение атрибута может быть списком разделенных пробелами допустимых свойств:-
autoplay– определяет, разрешено ли текущему документу автоматически воспроизводить медиа, запрашиваемое через интерфейс. -
camera– определяет, разрешено ли текущему документу использовать внешние видеоустройства. -
document-domain– определяет, разрешено ли текущему документу устанавливатьdocument.domain. -
encrypted-media– определяет, разрешено ли текущему документу использовать Encrypted Media Extensions API (EME). -
fullscreen– определяет, разрешено ли текущему документу использоватьElement.requestFullScreen(). -
geolocation– определяет, разрешено ли текущему документу использовать Geolocation Interface. -
microphone– определяет, разрешено ли текущему документу использовать внешние аудиоустройства. -
midi– определяет, разрешено ли текущему документу использовать Web MIDI API. -
payment– определяет, разрешено ли текущему документу использовать Payment Request API. -
vr– определяет, разрешено ли текущему документу использовать WebVR API.
-
-
alternateText– устанавливает альтернативный текст на случай, если ресурс недоступен или не задан.
-
Атрибут
referrerpolicyуказывает, какой реферер отправлять при извлечении ресурса фрейма.ReferrerPolicy– перечисление возможных значений атрибута:-
no-referrer– заголовок реферера не будет отправлен. -
no-referrer-when-downgrade– заголовок реферера не будет отправлен в источник без TLS (HTTPS). -
origin– отправленный реферер будет ограничен источником ссылающейся страницы: ее схемой, хостом и портом. -
origin-when-cross-origin– реферер, отправленный в другие источники, будет ограничен схемой, хостом и портом. Навигация по тому же источнику будет по-прежнему включать путь. -
same-origin– реферер будет отправлен для того же источника, но перекрестные запросы не будут содержать информацию о реферере. -
strict-origin– отправляет источник документа в качестве реферера только тогда, когда уровень безопасности протокола остается прежним (HTTPS→HTTPS), но не отправляет его в менее безопасное место назначения (HTTPS→HTTP). -
strict-origin-when-cross-origin– отправляет полный URL-адрес при выполнении запроса из того же источника только тогда, когда уровень безопасности протокола остается прежним (HTTPS→HTTPS), но не отправляет его в менее безопасное место назначения (HTTPS→HTTP). -
unsafe-url– реферер будет включать в себя источник и путь. Это значение небезопасно, поскольку оно приводит к утечке источников и путей из защищенных TLS ресурсов в небезопасные источники.
-
-
Атрибут
sandboxнакладывает дополнительные ограничения на содержимое фрейма. Если значение атрибута пустое, то применяются все ограничения. Если значение атрибута представляет собой разделенный пробелами список ограничений, то указанные ограничения снимаются.Sandbox– перечисление возможных значений атрибута:-
allow-forms– позволяет содержимому фрейма отправлять формы. -
allow-modals– позволяет содержимому фрейма открывать модальные окна. -
allow-orientation-lock– позволяет содержимому фрейма блокировать ориентацию экрана. -
allow-pointer-lock– позволяет содержимому фрейма использовать Pointer Lock API. -
allow-popups– позволяет содержимому фрейма использовать всплывающие окна (например, такие какwindow.open(),target="_blank", илиshowModalDialog()). -
allow-popups-to-escape-sandbox– позволяет содержимому фрейма открывать новые всплывающие окна, создавая чистый контекст просмотра. -
allow-presentation– позволяет содержимому фрейма использовать Presentation API. -
allow-same-origin– позволяет загружать содержимое фрейма, воспринимая его из того же источника, что и родительский документ. -
allow-scripts– разрешает запуск и выполнение скриптов. -
allow-storage-access-by-user-activation– позволяет ресурсу запрашивать доступ к возможностям родительского хранилища с помощью Storage Access API. -
allow-top-navigation– позволяет содержимому фрейма получать доступ к элементам верхнего уровня (с именем_top). -
allow-top-navigation-by-user-activation– позволяет содержимому фрейма получать доступ к элементам верхнего уровня, если это инициировано пользователем. -
allow-downloads-without-user-activation– позволяет загружать файлы без инициации пользователем. -
""– применяются все ограничения.
-
-
Атрибут
srcdocопределяет HTML-контент для отображения во встроенном фрейме. Если атрибутыsrcиsrcdocуказаны вместе, то атрибутsrcdocимеет приоритет. Браузеры IE и Edge не поддерживают этот атрибут. Вы также можете указать значение атрибутаsrcdocс помощью атрибутаsrcdocFileв xml, передав путь к файлу с HTML-кодом.
-
Атрибут
srcdocFile– путь к файлу, содержимое которого будет установлено в атрибутsrcdoc. Содержимое файла получается с помощью ресурсаclasspath. Значение атрибута можно задать только в XML-дескрипторе.
Параметры ресурсов browserFrame:
-
bufferSize- размер буфера, используемого для загрузки этого ресурса, в байтах.<browserFrame> <file bufferSize="1024" path="C:/img.png"/> </browserFrame>
-
cacheTime- время хранения объекта в кэше в миллисекундах.<browserFrame> <file cacheTime="2400" path="C:/img.png"/> </browserFrame>
-
mimeType- MIME-тип ресурса.<browserFrame> <url url="https://avatars3.githubusercontent.com/u/17548514?v=4&s=200" mimeType="image/png"/> </browserFrame>
Методы интерфейса BrowserFrame:
-
addSourceChangeListener()- добавляет слушатель для отслеживания изменений источника содержимого.@Inject private Notifications notifications; @Inject BrowserFrame browserFrame; @Subscribe protected void onInit(InitEvent event) { browserFrame.addSourceChangeListener(sourceChangeEvent -> notifications.create() .withCaption("Content updated") .show()); }
-
setSource()- устанавливает источник содержимого фрейма. Метод принимает тип ресурса и возвращает объект ресурса, который может быть сконфигурирован далее. Для каждого типа ресурсов есть свои методы, например,setPath()дляThemeResourceилиsetStreamSupplier()дляStreamResource:BrowserFrame frame = uiComponents.create(BrowserFrame.NAME); try { frame.setSource(UrlResource.class).setUrl(new URL("http://www.foobar2000.org/")); } catch (MalformedURLException e) { throw new RuntimeException(e); }Вы можете использовать те же типы ресурсов, что и для компонента
Image.
-
createResource()- создаёт ресурс фрейма указанного типа. Созданный объект может быть позже передан в методsetSource():UrlResource resource = browserFrame.createResource(UrlResource.class) .setUrl(new URL(fromString)); browserFrame.setSource(resource);
- Отображение HTML в BrowserFrame:
-
Компонент
BrowserFrameможно использовать для встраивания HTML-разметки в приложение. К примеру, вы можете генерировать HTML на лету, используя пользовательский ввод в качестве ресурса:<textArea id="textArea" height="250px" width="400px"/> <browserFrame id="browserFrame" height="250px" width="500px"/>textArea.addTextChangeListener(event -> { byte[] bytes = event.getText().getBytes(StandardCharsets.UTF_8); browserFrame.setSource(StreamResource.class) .setStreamSupplier(() -> new ByteArrayInputStream(bytes)) .setMimeType("text/html"); });
- Отображение PDF в BrowserFrame:
-
Кроме HTML,
BrowserFrameтакже может отображать содержимое PDF-файлов. Задайте путь к файлу в качестве ресурса для компонента и укажите для него соответствующий MIME-тип:@Inject private BrowserFrame browserFrame; @Inject private Resources resources; @Subscribe protected void onInit(InitEvent event) { browserFramePdf.setSource(StreamResource.class) .setStreamSupplier(() -> resources.getResourceAsStream("/com/company/demo/" + "web/screens/CUBA_Hands_on_Lab_6.8.pdf")) .setMimeType("application/pdf"); }
- Атрибуты browserFrame
-
align - allow - alternateText - caption - captionAsHtml - contextHelpText - contextHelpTextHtmlEnabled - colspan - css - description - descriptionAsHtml - enable - box.expandRatio - height - htmlSanitizerEnabled - icon - id - referrerpolicy - responsive - rowspan - sandbox - srcdoc - srcdocFile - stylename - visible - width
- Атрибуты ресурсов browserFrame
- Элементы browserFrame
-
classpath - file - relativePath - theme - url
- API
3.5.2.1.3. Button
Кнопка (Button) − компонент, обеспечивающий выполнение действия при нажатии.
XML-имя компонента: button
Кнопка может содержать текст или значок (или и то и другое). На рисунке ниже отображены разные виды кнопок.
Пример кнопки с названием, взятым из пакета локализованных сообщений, и с всплывающей подсказкой:
<button id="textButton" caption="msg://someAction" description="Press me"/>Название кнопки задается с помощью атрибута caption, всплывающая подсказка − с помощью атрибута description.
Если атрибут disableOnClick имеет значение true, кнопка будет автоматически отключена после клика по ней. Обычно это делается для того, чтобы предотвратить случайные повторные клики по кнопке. Впоследствии, вы можете снова включить кнопку с помощью вызова метода setEnabled(true).
Атрибут icon указывает на местоположение значка в каталоге темы или имя элемента в используемом наборе значков. Подробную информацию о том, где следует располагать файлы значков, можно прочитать в разделе Значки.
Пример создания кнопки со значком:
<button id="iconButton" caption="" icon="SAVE"/>Основная функция кнопки − выполнить некоторое действие при нажатии на нее. Определить метод контроллера, который будет вызываться при нажатии на кнопку, можно с помощью атрибута invoke. Значением атрибута должно быть имя метода контроллера, удовлетворяющего следующим условиям:
-
Метод должен быть
public. -
Метод должен возвращать
void. -
Метод должен либо не иметь аргументов, либо иметь один аргумент типа
Component. Если метод имеет аргументComponent, то при вызове в него будет передан экземпляр вызвавшей кнопки.
В качестве примера показано описание кнопки, вызывающей метод someMethod:
<button invoke="someMethod" caption="msg://someButton"/>В контроллере экрана необходимо определить метод someMethod:
public void someMethod() {
//some actions
}Атрибут invoke игнорируется, если для кнопки задан атрибут action. Атрибут action содержит имя действия, соответствующего данной кнопке.
Пример кнопки с атрибутом action:
<actions>
<action id="someAction" caption="msg://someAction"/>
</actions>
<layout>
<button action="someAction"/>
</layout>Кнопке можно назначить любое действие, имеющееся в каком-либо компоненте, реализующем интерфейс Component.ActionsHolder (это актуально для Table, GroupTable, TreeTable, Tree). Причем неважно, каким образом эти действия добавлены - декларативно в XML-дескрипторе или программно в контроллере. В любом случае для использования такого действия достаточно в атрибуте action указать через точку имя компонента и идентификатор нужного действия. Например, в следующем примере кнопке назначается действие create таблицы coloursTable:
<button action="coloursTable.create"/>Действие для кнопки можно также создавать программно, в контроллере экрана, используя наследование от класса BaseAction.
|
Если для Если свойства действия меняются уже после установки этого |
С помощью атрибута shortcut можно задать комбинацию клавиш для кнопки. Возможные модификаторы: ALT, CTRL, SHIFT − отделяются символом "-". Например:
<button id="button" caption="msg://shortcutButton" shortcut="ALT-C"/>- Стили компонента Button
-
Атрибут
primaryпозволяет задать подсветку отдельных кнопок. Подсветка автоматически применится к кнопке, если у действия, вызываемого этой кнопкой, атрибут primary имеет значениеtrue.<button primary="true" invoke="foo"/>В теме Hover подсветка доступна по умолчанию; для её активации в теме, основанной на Halo, установите значение
trueдля переменной стиля$cuba-highlight-primary-action.
Далее, в веб-клиенте с темой, основанной на Halo, к компоненту
Buttonможно применить предопределенные стили. Стили задаются в XML-дексрипторе или контроллере экрана с помощью атрибутаstylename:<button id="button" caption="Friendly button" stylename="friendly"/>Чтобы применить стиль программно, выберите одну из констант класса
HaloThemeс префиксом компонентаBUTTON_:button.setStyleName(HaloTheme.BUTTON_FRIENDLY);
Внешний вид компонента Button можно настроить с помощью переменных SCSS с префиксом $cuba-button-*. Эти переменные можно изменить в визуальном редакторе после расширения темы или создания новой темы.
- Атрибуты button
-
action - align - caption - captionAsHtml - css - description - descriptionAsHtml - disableOnClick - enable - box.expandRatio - htmlSanitizerEnabled - icon - id - invoke - shortcut - stylename - tabIndex - visible - width
- Предопределенные стили button
-
borderless - borderless-colored - danger - friendly - huge - icon-align-right - icon-align-top - icon-only - large - primary - quiet - small - tiny
3.5.2.1.4. BulkEditor
BulkEditor - компонент, позволяющий менять значения атрибутов сразу нескольких выбранных экземпляров сущностей. Компонент представляет собой кнопку, добавляющуюся к таблице или дереву и при нажатии открывающую редактор сущностей.
XML-имя компонента: bulkEditor
|
|
Для использования BulkEditor у таблицы или дерева должен быть задан атрибут multiselect="true".
Экран редактирования сущностей генерируется автоматически на основе заданного представления (содержащего только поля данной сущности, в том числе ссылки), динамических атрибутов данной сущности (если есть) и разрешений пользователя. Системные атрибуты в редакторе также не отображаются.
Атрибуты сущности в редакторе сортируются по алфавиту. По умолчанию они пусты. При коммите экрана заданные на экране непустые значения атрибутов проставляются всем выбранным экземплярам сущности.
Редактор позволяет удалить значение определенного поля в БД у всех выбранных сущностей, установив его в null. Для этого необходимо нажать на кнопку  рядом с соответствующим полем. После этого поле становится нередактируемым. Разблокировать поле можно, нажав на кнопку эту же кнопку снова.
рядом с соответствующим полем. После этого поле становится нередактируемым. Разблокировать поле можно, нажав на кнопку эту же кнопку снова.
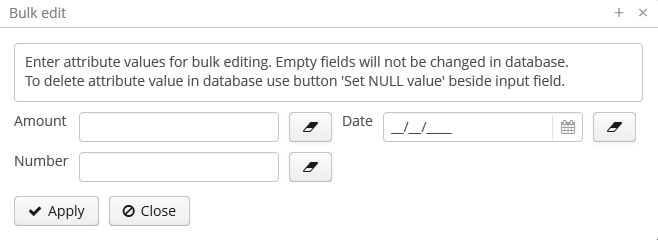
Пример описания компонента bulkEditor для таблицы:
<table id="invoiceTable"
multiselect="true"
width="100%">
<actions>
<!-- ... -->
</actions>
<buttonsPanel>
<!-- ... -->
<bulkEditor for="invoiceTable"
exclude="customer"/>
</buttonsPanel>-
Атрибуты
bulkEditor -
-
Атрибут
excludeможет содержать регулярное выражения для явного исключения определенных полей из списка редактируемых. Например:date|customer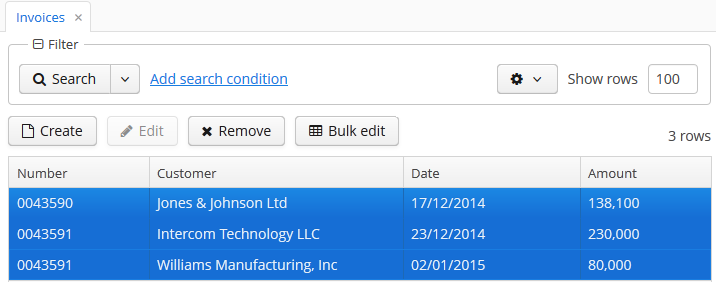
-
Атрибут
includePropertiesуказывает список атрибутов сущности, которые должны отображаться в окне редактораbulkEditor. Если список задан, все прочие атрибуты сущности будут игнорироваться.includePropertiesне распространяется на динамические атрибуты сущности.Чтобы указать атрибуты декларативно, перечислите их через запятую в дескрипторе экрана:
<bulkEditor for="ordersTable" includeProperties="name, description"/>Список атрибутов также может быть программно задан в контроллере экрана:
bulkEditor.setIncludeProperties(Arrays.asList("name", "description"));
-
Атрибут
loadDynamicAttributesуправляет отображением динамических атрибутов редактируемой сущности в окне редактораbulkEditor. Значение по умолчаниюtrue.
-
useConfirmDialogуправляет отображением диалогового окна подтверждения перед сохранением изменений. Значение по умолчаниюtrue.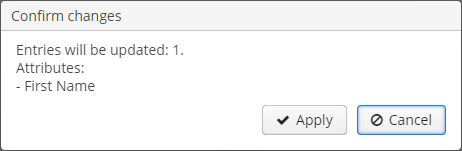
-
columnsMode− количество колонок в окне редактораbulkEditor, задаваемое значением перечисленияColumnsMode. По умолчаниюTWO_COLUMNS. Например:<groupTable id="customersTable" width="100%"> <actions>...</actions> <columns>...</columns> <buttonsPanel id="buttonsPanel" alwaysVisible="true"> ... <bulkEditor for="customersTable" columnsMode="ONE_COLUMN"/> </buttonsPanel> </groupTable>
Внешний вид редактора
bulkEditorможно настроить с помощью переменных SCSS с префиксом$c-bulk-editor-*. Эти переменные можно изменить в визуальном редакторе после расширения темы или создания новой темы. -
- Атрибуты bulkEditor
-
align - caption - captionAsHtml - columnsMode - css - description - descriptionAsHtml - enable - exclude - box.expandRatio - for - htmlSanitizerEnabled - icon - id - includeProperties - loadDynamicAttributes - openType - stylename - tabIndex - useConfirmDialog - visible - width
3.5.2.1.5. Calendar
Компонент Calendar предназначен для организации и отображения событий календаря.

XML-имя компонента: calendar.
Компонент реализован для блока Web Client.
Пример описания компонента в XML-дескрипторе экрана:
<calendar id="calendar"
captionProperty="caption"
startDate="2016-10-01"
endDate="2016-10-31"
height="100%"
width="100%"/>Режим отображения определяется временным диапазоном календаря, который задаётся его начальной и конечной датой. По умолчанию используется режим отображения недели, работающий с диапазонами до семи дней. Для отображения календаря на один день используйте диапазон в пределах одной календарной даты. Режим отображения месяца применяется, если заданный диапазон превышает одну неделю (семь дней).
Кнопки навигации для перелистывания календаря на одну неделю вперёд/назад по умолчанию отключены. Чтобы кнопки были видны в режиме отображения недели, используйте атрибут navigationButtonsVisible:
<calendar width="100%"
height="100%"
navigationButtonsVisible="true"/>
Атрибуты calendar:
-
endDate- конечная дата диапазона календаря. Значение даты должно быть указано в формате "yyyy-MM-dd" или "yyyy-MM-dd HH:mm".
-
endDateProperty- имя атрибута сущности, содержащего конечную дату события.
-
datatype- datatype для атрибутовstartDate,endDateи событий календаря. Используются следующие типы данных:-
date -
dateTime -
localDate -
localDateTime -
offsetDateTimedateTimeустановлен по умолчанию. В случае, еслиstartDatePropertyиendDatePropertyустановлены, тогда будет использоваться datatype этих атрибутов.
-
-
descriptionProperty- имя атрибута сущности, содержащего описание события.
-
isAllDayProperty- имя атрибута сущности, отвечающего за отображение события в течение всего дня.
-
startDate- начальная дата диапазона календаря. Значение даты должно быть указано в формате "yyyy-MM-dd" или "yyyy-MM-dd HH:mm".
-
startDateProperty- имя атрибута сущности, содержащего начальную дату события.
-
stylenameProperty- имя атрибута сущности, содержащего имя стиля события.
-
timeFormat- формат времени: 12H or 24H.
- Использование событий календаря:
Для отображения событий в ячейках календаря их можно прямо добавлять в объект Calendar при помощи метода addEvent() или использовать интерфейс CalendarEventProvider. Пример добавления события напрямую:
@Inject
private Calendar<Date> calendar;
public void generateEvent(String caption, String description, Date start, Date end, boolean isAllDay, String stylename) {
SimpleCalendarEvent<Date> calendarEvent = new SimpleCalendarEvent<>();
calendarEvent.setCaption(caption);
calendarEvent.setDescription(description);
calendarEvent.setStart(start);
calendarEvent.setEnd(end);
calendarEvent.setAllDay(isAllDay);
calendarEvent.setStyleName(stylename);
calendar.getEventProvider().addEvent(calendarEvent);
}Метод removeEvent() интерфейса CalendarEventProvider позволяет удалить конкретное событие по его индексу:
CalendarEventProvider eventProvider = calendar.getEventProvider();
List<CalendarEvent> events = new ArrayList<>(eventProvider.getEvents());
eventProvider.removeEvent(events.get(events.size()-1));Метод removeAllEvents, в свою очередь, удаляет все доступные события:
CalendarEventProvider eventProvider = calendar.getEventProvider();
eventProvider.removeAllEvents();Интерфейс CalendarEventProvider имеет две готовые реализации: ListCalendarEventProvider (создаваемый по умолчанию) и ContainerCalendarEventProvider.
ListCalendarEventProvider заполняется данными с помощью метода addEvent(), принимающего объект CalendarEvent в качестве параметра:
@Inject
private Calendar<LocalDateTime> calendar;
public void addEvents() {
ListCalendarEventProvider listCalendarEventProvider = new ListCalendarEventProvider();
calendar.setEventProvider(listCalendarEventProvider);
listCalendarEventProvider.addEvent(generateEvent("Training", "Student training",
LocalDateTime.of(2016, 10, 17, 9, 0), LocalDateTime.of(2016, 10, 17, 14, 0), false, "event-blue"));
listCalendarEventProvider.addEvent(generateEvent("Development", "Platform development",
LocalDateTime.of(2016, 10, 17, 15, 0), LocalDateTime.of(2016, 10, 17, 18, 0), false, "event-red"));
listCalendarEventProvider.addEvent(generateEvent("Party", "Party with friends",
LocalDateTime.of(2016, 10, 22, 13, 0), LocalDateTime.of(2016, 10, 22, 18, 0), false, "event-yellow"));
}
private SimpleCalendarEvent<LocalDateTime> generateEvent(String caption, String description, LocalDateTime start, LocalDateTime end, Boolean isAllDay, String stylename) {
SimpleCalendarEvent<LocalDateTime> calendarEvent = new SimpleCalendarEvent<>();
calendarEvent.setCaption(caption);
calendarEvent.setDescription(description);
calendarEvent.setStart(start);
calendarEvent.setEnd(end);
calendarEvent.setAllDay(isAllDay);
calendarEvent.setStyleName(stylename);
return calendarEvent;
}ContainerCalendarEventProvider получает данные напрямую из атрибутов сущности. Чтобы ContainerCalendarEventProvider мог использовать сущность, она должна иметь как минимум следующие атрибуты: дата начала события, дата окончания события (один из типов datatype) и заголовок события (тип String).
В следующем примере мы предположим, что сущность в источнике данных имеет все необходимые атрибуты: eventCaption, eventDescription, eventStartDate, eventEndDate, eventStylename, и укажем их имена в качестве значений атрибутов calendar:
<calendar id="calendar"
dataContainer="calendarEventsDc"
width="100%"
height="100%"
startDate="2016-10-01"
endDate="2016-10-31"
captionProperty="eventCaption"
descriptionProperty="eventDescription"
startDateProperty="eventStartDate"
endDateProperty="eventEndDate"
stylenameProperty="eventStylename"/>Для пользовательского взаимодействия с элементами Calendar, такими как подписи даты и номера недель, выбор диапазона даты/времени, перетаскивание событий и изменение их размера, могут быть заданы различные слушатели. Слушатели также используются для кнопок навигации, листающих диапазон календаря вперёд и назад. Ниже приведён список слушателей по умолчанию:
-
addDateClickListener(CalendarDateClickListener listener);- добавляет слушатель кликов по дате.calendar.addDateClickListener( calendarDateClickEvent -> notifications.create() .withCaption(String.format("Date clicked: %s", calendarDateClickEvent.getDate().toString())) .show());
-
addWeekClickListener()- добавляет слушатель кликов по номеру недели.
-
addEventClickListener()- добавляет слушатель кликов по событию календаря.
-
addEventResizeListener()- добавляет слушатель изменения размеров события календаря.
-
addEventMoveListener()- добавляет слушатель перетаскивания события.
-
addForwardClickListener()- добавляет слушатель перелистывания календаря вперёд во времени.
-
addBackwardClickListener()- добавляет слушатель перелистывания календаря назад во времени.
-
addRangeSelectListener()- добавляет слушатель выбора диапазона календаря.
Событиям календаря можно задавать стили с помощью CSS. Для настройки стиля задайте имя стиля и его параметры в файле .scss. Пример настройки цвета фона события:
.v-calendar-event.event-green {
background-color: #c8f4c9;
color: #00e026;
}Затем вызовите метод setStyleName для нужного события:
calendarEvent.setStyleName("event-green");В результате, цвет фона события стал зелёным:
Для компонента Calendar можно изменить названия дней недели и месяцев по умолчанию, используя методы setDayNames() и setMonthNames():
Map<DayOfWeek, String> days = new HashMap<>(7);
days.put(DayOfWeek.MONDAY,"Heavens and earth");
days.put(DayOfWeek.TUESDAY,"Sky");
days.put(DayOfWeek.WEDNESDAY,"Dry land");
days.put(DayOfWeek.THURSDAY,"Stars");
days.put(DayOfWeek.FRIDAY,"Fish and birds");
days.put(DayOfWeek.SATURDAY,"Animals and man");
days.put(DayOfWeek.SUNDAY,"Rest");
calendar.setDayNames(days);- Атрибуты calendar
-
caption - captionAsHtml - captionProperty - colspan - contextHelpText - contextHelpTextHtmlEnabled - css - dataContainer - datatype - description - descriptionAsHtml - descriptionProperty - endDateProperty - endDate - box.expandRatio - height - htmlSanitizerEnabled - icon - id - isAllDayProperty - rowspan - startDate - startDateProperty - stylename - stylenameProperty - timeFormat - visible - width
- API
-
addEvent - removeAllEvents - removeEvent - setEventProvider - setDayNames
- Слушатели calendar
-
CalendarBackwardClickListener - CalendarDateClickListener - CalendarEventClickListener - CalendarEventMoveListener - CalendarEventResizeListener - CalendarForwardClickListener - CalendarRangeSelectListener - CalendarWeekClickListener
3.5.2.1.6. CapsLockIndicator
Поле, отображающее состояние клавиши Caps Lock при вводе пароля в поле PasswordField.
XML-имя компонента: capsLockIndicator.
Атрибуты capsLockOnMessage и capsLockOffMessage позволяют задать сообщения, которые будут отображаться компонентом в зависимости от того, нажата ли клавиша Caps Lock.
Примеры использования:
<hbox spacing="true">
<passwordField id="passwordField"
capsLockIndicator="capsLockIndicator"/>
<capsLockIndicator id="capsLockIndicator"/>
</hbox>CapsLockIndicator capsLockIndicator = uiComponents.create(CapsLockIndicator.NAME);
capsLockIndicator.setId("capsLockIndicator");
passwordField.setCapsLockIndicator(capsLockIndicator);Компонент CapsLockIndicator предназначен для использования совместно с PasswordField и отслеживает состояние Caps Lock только тогда, когда поле ввода пароля находится в фокусе. Когда поле теряет фокус, состояние Caps Lock автоматически становится неактивным.
Динамическое изменение видимости компонента CapsLockIndicator с помощью атрибута visible после открытия экрана может работать некорректно.
Внешний вид компонента CapsLockIndicator можно настроить с помощью переменных SCSS с префиксом $cuba-capslockindicator-*. Эти переменные можно изменить в визуальном редакторе после расширения темы или создания новой темы.
- Атрибуты capsLockIndicator
-
align - capsLockOffMessage - capsLockOnMessage - colspan - css - box.expandRatio - height - id - rowspan - stylename - visible - width
3.5.2.1.7. CheckBox
Флажок (CheckBox) − компонент, имеющий два состояния: выбран, не выбран.

XML-имя компонента: checkBox.
Пример флажка с надписью, взятой из пакета локализованных сообщений:
<checkBox id="accessField" caption="msg://accessFieldCaption"/>Сброс или установка флажка изменяет его значение: Boolean.TRUE или Boolean.FALSE. Значение может быть получено с помощью метода getValue() и установлено с помощью метода setValue(). Если в setValue() передать null, то устанавливается значение Boolean.FALSE и флажок снимается.
Изменение значения флажка, так же как и любого другого компонента, реализующего интерфейс Field, можно отслеживать с помощью слушателя ValueChangeListener. Источник события ValueChangeEvent можно отследить с помощью метода isUserOriginated(). Например:
@Inject
private CheckBox accessField;
@Inject
private Notifications notifications;
@Subscribe
protected void onInit(InitEvent event) {
accessField.addValueChangeListener(valueChangeEvent -> {
if (Boolean.TRUE.equals(valueChangeEvent.getValue())) {
notifications.create()
.withCaption("set")
.show();
} else {
notifications.create()
.withCaption("not set")
.show();
}
});
}Для создания флажка, связанного с данными, необходимо использовать атрибуты dataContainer и property.
<data>
<instance id="customerDc" class="com.company.sales.entity.Customer" view="_local">
<loader/>
</instance>
</data>
<layout>
<checkBox dataContainer="customerDc" property="active"/>
</layout>Как видно из примера, в экране описывается data container customerDs для некоторой сущности Покупатель (Customer), имеющей атрибут active. В компоненте checkBox в атрибуте dataContainer указывается ссылка на контейнер данных, а в атрибуте property − название атрибута сущности, значение которого должно быть отображено флажком. Атрибут должен быть типа Boolean. Значением атрибута может быть null, при этом флажок снимается.
Внешний вид компонента CheckBox можно настроить с помощью переменных SCSS с префиксом $cuba-checkbox-*. Эти переменные можно изменить в визуальном редакторе после расширения темы или создания новой темы.
- Атрибуты checkBox
-
align - caption - captionAsHtml - contextHelpText - contextHelpTextHtmlEnabled - css - dataContainer - description - descriptionAsHtml - editable - enable - box.expandRatio - height - htmlSanitizerEnabled - icon - id - property - stylename - tabIndex - visible - width
- API
-
addValueChangeListener commit - discard - isModified - setContextHelpIconClickHandler
3.5.2.1.8. CheckBoxGroup
Компонент, который обеспечивает выбор нескольких значений из списка опций, используя группу флажков (чекбоксов).
XML-имя компонента: checkBoxGroup.
Компонент CheckBoxGroup реализован для блока Web Client.
Список опций для компонента можно указать с помощью методов setOptions(), setOptionsList(), setOptionsMap() и setOptionsEnum(), а также атрибута optionsContainer.
-
Простейший вариант использования
CheckBoxGroup- выбор значения перечисления (enumeration). К примеру, сущностьRoleимеет атрибутtypeтипаRoleType, который является перечислением. Тогда для отображения этого атрибута можно использоватьCheckBoxGroupследующим образом, с помощью атрибутаoptionsEnum:<checkBoxGroup optionsEnum="com.haulmont.cuba.security.entity.RoleType" property="type"/>Метод
setOptionsEnum()принимает в качестве параметра класс перечисления. Список опций будет состоять из локализованных названий значений перечисления, значением компонента будет являться выбранное значение перечисления.@Inject private CheckBoxGroup<RoleType> checkBoxGroup; @Subscribe protected void onInit(InitEvent event) { checkBoxGroup.setOptionsEnum(RoleType.class); }Того же результата можно достигнуть, используя метод
setOptions(), который позволяет работать со всеми типами опций:@Inject private CheckBoxGroup<RoleType> checkBoxGroup; @Subscribe protected void onInit(InitEvent event) { checkBoxGroup.setOptions(new EnumOptions<>(RoleType.class)); }
-
setOptionsList()позволяет программно задать список опций компонента. Для этого объявляем компонент в XML-дескрипторе:<checkBoxGroup id="checkBoxGroup"/>Затем инжектируем компонент в контроллер и задаем ему список опций:
@Inject private CheckBoxGroup<Integer> checkBoxGroup; @Subscribe protected void onInit(InitEvent event) { List<Integer> list = new ArrayList<>(); list.add(2); list.add(4); list.add(5); list.add(7); checkBoxGroup.setOptionsList(list); }Компонент примет следующий вид:

При этом метод
getValue()компонента в зависимости от выбранной опции будет возвращатьIntegerзначения 2, 4, 5, 7.
-
setOptionsMap()позволяет задать строковые названия и значения опций по отдельности. Например, для инжектированного в контролллер экрана компонентаcheckBoxGroupзадаём мэп опций:@Inject private CheckBoxGroup<Integer> checkBoxGroup; @Subscribe protected void onInit(InitEvent event) { Map<String, Integer> map = new LinkedHashMap<>(); map.put("two", 2); map.put("four", 4); map.put("five", 5); map.put("seven", 7); checkBoxGroup.setOptionsMap(map); }Компонент примет следующий вид:
При этом метод
getValue()компонента в зависимости от выбранной опции будет возвращатьIntegerзначения 2, 4, 5, 7, а не строки, отображаемые на экране.
-
Компонент может принимать список опций из data container. Для этого используется атрибут
optionsContainer. Например:<data> <collection id="employeesCt" class="com.company.demo.entity.Employee" view="_minimal"> <loader> <query><![CDATA[select e from demo_Employee e]]></query> </loader> </collection> </data> <layout> <checkBoxGroup optionsContainer="employeesCt"/> </layout>В данном случае компонент
checkBoxGroupотобразит имена экземпляров сущностиEmployee, находящихся в контейнереemployeesCt, а его методgetValue()вернёт выбранный экземпляр сущности.
С помощью атрибута captionProperty можно указать, какой атрибут сущности использовать вместо имени экземпляра для строковых названий опций.
Программно можно задать options container для компонента с помощью метода
setOptions()интерфейсаCheckBoxGroup:@Inject private CheckBoxGroup<Employee> checkBoxGroup; @Inject private CollectionContainer<Employee> employeesCt; @Subscribe protected void onInit(InitEvent event) { checkBoxGroup.setOptions(new ContainerOptions<>(employeesCt)); }
OptionDescriptionProvider используется для генерации всплывающих подсказок. Для создания подсказок вы можете использовать как метод setOptionDescriptionProvider(), так и аннотацию @Install:
@Inject
private CheckBoxGroup<Product> checkBoxGroup;
@Subscribe
public void onInit(InitEvent event) {
checkBoxGroup.setOptionDescriptionProvider(product -> "Price: " + product.getPrice());
}@Install(to = "checkBoxGroup", subject = "optionDescriptionProvider")
private String checkBoxGroupOptionDescriptionProvider(Experience experience) {
switch (experience) {
case HIGH:
return "Senior";
case COMMON:
return "Middle";
default:
return "Junior";
}
}Атрибут orientation задаёт расположение элементов группы. По умолчанию элементы располагаются по вертикали. Значение horizontal задаёт горизонтальное расположение.
- Атрибуты CheckBoxGroup
-
align - box.expandRatio - caption - captionAsHtml - captionProperty - colspan - contextHelpText - contextHelpTextHtmlEnabled - css - dataContainer - description - descriptionAsHtml - editable - enable - height - htmlSanitizerEnabled - icon - id - optionsContainer - optionsEnum - orientation - property - required - requiredMessage - responsive - rowspan - stylename - tabIndex - visible - width
- API
-
addValueChangeListener - setContextHelpIconClickHandler - setOptions - setOptionCaptionProvider - setOptionDescriptionProvider - setOptionsEnum - setOptionsList - setOptionsMap
3.5.2.1.9. ColorPicker
ColorPicker представляет собой поле для предпросмотра и выбора цвета. Компонент возвращает шестнадцатеричный (HEX) код цвета в виде строки.
Пример использования ColorPicker с надписью, взятой из пакета локализованных сообщений:
<colorPicker id="colorPicker" caption="msg://colorPickerCaption"/>Пример ColorPicker с закрытым окном палитры.
Для создания ColorPicker, связанного с данными, необходимо использовать атрибуты dataContainer и property.
<data>
<collection id="carsDc" class="com.company.sales.entity.Car" view="_local">
<loader>
<query>
<![CDATA[select e from sales_Car e]]>
</query>
</loader>
</collection>
</data>
<layout>
<colorPicker id="colorPicker" dataContainer="carsDc" property="color"/>
</layout>Атрибуты colorPicker:
-
defaultCaptionEnabled- если установленоtrueи не задан атрибутbuttonCaption, в качестве надписи кнопки используется HEX-код текущего цвета.
-
historyVisible- определяет видимость истории последних выбранных цветов в окне палитры.
Видимость вкладок окна палитры можно определить с помощью атрибутов:
-
swatchesVisible- определяет видимость вкладки палитры. -
rgbVisible- определяет видимость вкладки селектора RGB. -
hsvVisible- определяет видимость вкладки селектора HSV.
По умолчанию включена только вкладка селектора RGB.
Надписи окна палитры можно переопределить:
-
popupCaption- надпись заголовка окна палитры. -
confirmButtonCaption- надпись кнопки подтверждения. -
cancelButtonCaption- надпись кнопки отмены. -
swatchesTabCaption- заголовок вкладки палитры. -
lookupAllCaption- надпись элемента выпадающего списка, отвечающего за все цвета. -
lookupRedCaption- надпись элемента выпадающего списка, отвечающего за оттенки красного. -
lookupGreenCaption- надпись элемента выпадающего списка, отвечающего за оттенки зеленого. -
lookupBlueCaption- надпись элемента выпадающего списка, отвечающего за оттенки синего.
Метод компонента getValue() возвращает строку, содержащую HEX-код цвета.
- Атрибуты colorPicker
-
align - buttonCaption - cancelButtonCaption - caption - captionAsHtml - confirmButtonCaption - contextHelpText - contextHelpTextHtmlEnabled - css - dataContainer - defaultCaptionEnabled - description - descriptionAsHtml - editable - box.expandRatio - height - historyVisible - hsvVisible - htmlSanitizerEnabled - icon - id - lookupAllCaption - lookupBlueCaption - lookupGreenCaption - lookupRedCaption - popupCaption - rgbVisible - required - stylename - swatchesTabCaption - swatchesVisible - tabIndex - visible - width
- API
3.5.2.1.10. CurrencyField
CurrencyField - это разновидность текстового поля, предназначенная для ввода денежных единиц. CurrencyField используется по умолчанию при генерации экранов в Studio для атрибутов, помеченных аннотацией @CurrencyValue. Поле содержит ярлык с обозначением валюты и по умолчанию имеет выравнивание по правому краю.

XML-имя компонента: currencyField.
Компонент CurrencyField реализован только для блока Web Client.
CurrencyField в основном повторяет функциональность TextField: вы так же можете указать тип данных для поля, за исключением того, что CurrencyField поддерживает только числовые типы данных, унаследованные от NumericDatatype. Если установлен иной тип данных, будет выброшено исключение.
CurrencyField можно привязать к контейнеру данных с помощью атрибутов dataContainer и property:
<currencyField currency="$"
dataContainer="orderDc"
property="amount"/>Компонент currencyField имеет следующие специфические атрибуты:
-
currency- текст, который будет отображаться в ярлыке валюты.<currencyField currency="USD"/>
-
currencyLabelPosition- определяет положение ярлыка внутри текстового поля:-
LEFT- слева от поля ввода, -
RIGHT- справа от поля ввода (значение по умолчанию).
-
-
showCurrencyLabel- управляет видимостью ярлыка со значком валюты.
- Атрибуты currencyField
-
align - caption - captionAsHtml - colspan - contextHelpText - contextHelpTextHtmlEnabled - conversionErrorMessage - css - currency - currencyLabelPosition - dataContainer - datatype - description - descriptionAsHtml - editable - enable - box.expandRatio - height - htmlSanitizerEnabled - icon - id - property - required - requiredMessage - rowspan - showCurrencyLabel - stylename - visible - width
- Предопределенные стили currencyField
- API
-
addValidator - addValueChangeListener - commit - discard - isModified - setContextHelpIconClickHandler - setCurrency - setCurrencyLabelPosition - setShowCurrencyLabel
3.5.2.1.11. DataGrid
В этом разделе:
DataGrid, подобно компоненту Table, позволяет выводить информацию в виде таблицы, сортировать её, вызывать действия для выбранных строк, а также более эффективно управлять строками и колонками таблицы за счёт отложенной загрузки данных при прокрутке.
XML-имя компонента: dataGrid.
Пример описания компонента в XML-дескрипторе экрана:
<data>
<collection id="ordersDc" class="com.company.sales.entity.Order" view="order-with-customer">
<loader id="ordersDl">
<query>
<![CDATA[select e from sales_Order e order by e.date]]>
</query>
</loader>
</collection>
</data>
<layout>
<dataGrid id="ordersDataGrid" dataContainer="ordersDc" height="100%" width="100%">
<columns>
<column id="date" property="date"/>
<column id="customer" property="customer.name"/>
<column id="amount" property="amount"/>
</columns>
</dataGrid>
</layout>В данном примере атрибут id - это идентификатор колонки, а атрибут property содержит имя атрибута сущности, содержащейся в источнике данных, который следует использовать в качестве данных для колонки.
Если вы хотите указать источник данных для таблицы программно в контроллере экрана, используйте атрибут metaClass вместо декларативного указания значения dataContainer в XML.
Элементы dataGrid
-
columns- элемент, определяющий набор колонокDataGrid. Если не задан, то столбцы таблицы будут автоматически определены из атрибутов представления, используемого при загрузке данных из контейнера данных. Элементcolumnsимеет следующие атрибуты:-
includeAll– загружает все атрибуты представления, используемого при загрузке данных из контейнера данных.В приведенном ниже примере мы покажем все атрибуты из представления, используемого в
customersDc. Если представление содержит системные свойства, они также будут показаны.<dataGrid id="dataGrid" width="100%" height="100%" dataContainer="customersDc"> <columns includeAll="true"/> </dataGrid>Если представление сущности содержит ссылочный атрибут, этот атрибут выводится в соответствии с его шаблоном @NamePattern. Если вы хотите показать какой-то конкретный атрибут, он должен быть определен в представлении, а также в элементе
column:<columns includeAll="true"> <column id="address.street"/> </columns>Если представление не указано, атрибут
includeAllзагрузит все атрибуты из данной сущности и ее предков.
-
exclude– разделенный запятыми список атрибутов, которые не должны быть загружены вDataGrid.В приведенном ниже примере мы покажем все атрибуты, за исключением атрибутов
nameиorder:<dataGrid id="dataGrid" width="100%" height="100%" dataContainer="customersDc"> <columns includeAll="true" exclude="name, order"/> </dataGrid>
Каждая колонка описывается во вложенном элементе
columnсо следующими атрибутами:-
id- необязательный атрибут, содержит строковый идентификатор колонки. Если не задан, в качестве идентификатора колонки будет использоваться строковое значение атрибутаproperty. В этом случае проставление атрибутаpropertyявляется обязательным, в противном случае будет брошено исключениеGuiDevelopmentException. Атрибутidпо-прежнему является обязательным для колонки, создаваемой программно.
-
property- необязательный атрибут, содержит название атрибута сущности, выводимого в колонке. Может быть как непосредственным атрибутом сущности, находящейся в источнике данных или data container, так и атрибутом связанной сущности; переход по графу объектов обозначается точкой. Например:<columns> <column id="date" property="date"/> <column id="customer" property="customer"/> <column id="customerName" property="customer.name"/> <column id="customerCountry" property="customer.address.country"/> </columns> -
caption- необязательный атрибут, содержит заголовок колонки. Если не задан, будет отображено локализованное название атрибута сущности.
-
expandRatio- необязательный атрибут, устанавливает соотношение, с которым столбец расширяется. По умолчанию все колонки расширяются равномерно (словно все колонки имеютexpandRatio = 1). Если хотя бы одной колонке установлено иное значение, все неявные значения удаляются и учитываются только проставленные.
-
collapsible- необязательный атрибут, определяющий, может ли пользователь управлять отображением колонок с помощью меню (sidebar menu) в правой верхней частиDataGrid. По умолчанию имеет значениеtrue.
-
collapsed- необязательный атрибут, при указанииtrueколонка будет изначально скрыта. По умолчанию имеет значениеfalse.
-
collapsingToggleCaption- необязательный атрибут, задает имя колонки в меню в правой верхней частиDataGrid. По умолчанию имеет значениеnull, и в этом случае берется значение из заголовка колонки, доступного из свойстваcaption.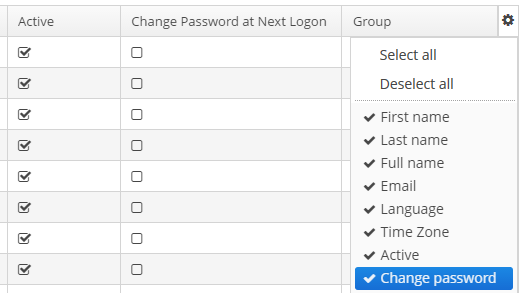
-
resizable- необязательный атрибут, определяет, может ли пользователь изменять размер колонки.
-
sortable- необязательный атрибут, позволяющий запретить сортировку колонки. Вступает в действие, если атрибутsortableвсегоDataGridустановлен вtrue(что имеет место по умолчанию). -
width- необязательный атрибут, отвечает за изначальную ширину колонки. Может принимать только числовые значения в пикселах.
-
minimumWidth- необязательный атрибут, отвечает за минимальную ширину колонки. Может принимать только числовые значения в пикселах.
-
maximumWidth- необязательный атрибут, отвечает за максимальную ширину колонки. Может принимать только числовые значения в пикселах.
Элемент
columnможет содержать вложенный элемент formatter для представления значения атрибута в виде, отличном от стандартного для данного DataType:<column id="date" property="date"> <formatter class="com.haulmont.cuba.gui.components.formatters.DateFormatter" format="yyyy-MM-dd HH:mm:ss" useUserTimezone="true"/> </column> -
-
actions- необязательный элемент для описания действий, связанных сDataGrid. Кроме описания произвольных действий, поддерживаются следующие стандартные действия, определяемые перечислениемListActionType: create, edit, remove, refresh, add, exclude.
-
rowsCount- необязательный элемент, создающий дляDataGridкомпонентRowsCount, который позволяет загружать вDataGridданные постранично. Размер страницы задается путем ограничения количества записей в data loader’е методомCollectionLoader.setMaxResults()в контроллере экрана. Также можно управлять количеством записей, используя универсальный компонентFilter, связанный с источником данныхDataGrid.Компонент
RowsCountможет также отобразить общее число записей, возвращаемых текущим запросом в источнике данных, без извлечения этих записей. По клику пользователя на знак "?" вызываетсяcom.haulmont.cuba.core.global.DataManager#getCount, что приводит к выполнению в БД запроса с такими же, как у текущего запроса, условиями, но с агрегатной функциейCOUNT(*)вместо результатов. Полученное число отображается вместо знака "?".Атрибут
autoLoadкомпонентаRowsCount, установленный в значениеtrue, позволяет автоматически загружать общее число записей. Его можно установить в XML-дескрипторе:<rowsCount autoLoad="true"/>Также включить или отключить автоматическую загрузку количества записей можно с помощью API в контроллере экрана:
boolean autoLoadEnabled = rowsCount.getAutoLoad(); rowsCount.setAutoLoad(false);
Атрибуты dataGrid
-
Атрибут
aggregatableвключает режим агрегации строк вDataGrid. Поддерживаются следующие операции:-
SUM− сумма -
AVG− среднее значение -
COUNT− количество -
MIN− минимальное значение -
MAX− максимальное значение
Для агрегируемых колонок необходимо указать элемент
aggregationс атрибутомtype, задающим функцию агрегации. По умолчанию в агрегируемых колонках поддерживаются только числовые типы данных, такие какInteger,Double,LongиBigDecimal. Агрегированные значения столбцов выводятся в дополнительной строке вверхуDataGrid. Агрегирование в компонентеDataGridфункционирует также, как и в компоненте Table. Это означает, что вы можете использовать strategyClass, valueDescription и formatter для агрегации.Пример описания
DataGridс агрегацией:<dataGrid id="ordersDataGrid" dataContainer="ordersDc" aggregationPosition="BOTTOM" aggregatable="true"> <columns> <column id="customerGrade" property="customer.grade"> <aggregation strategyClass="com.company.sample.CustomerGradeAggregation" valueDescription="msg://customerGradeAggregationDesc"/> </column> <column id="amount" property="amount"> <aggregation type="SUM"> <formatter class="com.company.sample.MyFormatter"/> </aggregation> </column> ... </columns> ... </dataGrid> -
-
Атрибут
aggregationPositionпозволяет задать положение строки агрегации:TOPилиBOTTOM. По умолчанию используетсяTOP.
-
columnResizeMode- устанавливает режим изменения размера колонок пользователем. Поддерживаются следующие режимы (по умолчанию ANIMATED):-
ANIMATED- размер колонки меняется сразу вслед за курсором. -
SIMPLE- размер колонки меняется только после того, как курсор будет отпущен.
Изменение размера колонок можно отслеживать с помощью слушателя
ColumnResizeListener. Источник события изменения размера можно отследить с помощью метода isUserOriginated(). -
-
columnsCollapsingAllowed- разрешает или запрещает пользователю скрывать колонки с помощью меню (sidebar menu) в правой части шапкиDataGrid. Существуют дополнительные пункты меню:-
Select all− показать все колонки; -
Deselect all− спрятать все колонки.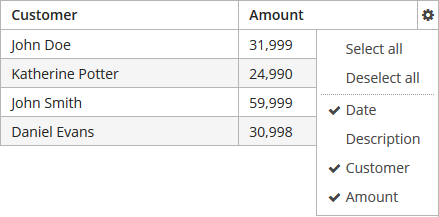
Флажками в меню отмечаются отображаемые в данный момент колонки. В момент установки перезаписывает значение
collapsedкаждой отдельной колонки. Установка значения вfalseне позволяет атрибутуcollapsedотдельной колонки принять значениеtrue.Скрытие и отображение колонок можно отслеживать с помощью слушателя
ColumnCollapsingChangeListener. Источник события можно отследить с помощью метода isUserOriginated().
-
-
contextMenuEnabled- включает или выключает контекстное меню вDataGrid. По умолчанию имеет значениеtrue.Щелчки правой кнопкой мыши по области компонента
DataGridможно отслеживать с помощью слушателяContextClickListener.
-
editorBuffered- включает буферизацию в режиме внутристрочного редактирования. По умолчанию буферизация разрешена (true).
-
editorCancelCaption- устанавливает заголовок кнопки отмены в режиме редактированияDataGrid.
-
editorCrossFieldValidate- включает перекрестную проверку полей во встроенном редакторе. По умолчанию имеет значениеtrue.
-
editorEnabled- включает отображение UI для внутристрочного редактирования ячеек. ЕслиdataGridпривязан к источнику данных с типом KeyValueCollectionContainer, предполагается, что он используется только для чтения, и использование атрибутаeditorEnabledв этом случае бессмысленно.
-
editorSaveCaption- устанавливает заголовок кнопки сохранения изменений в режиме редактированияDataGrid.
-
frozenColumnCount- устанавливает количество фиксированных колонок вDataGrid. Значение0означает, что фиксированных колонок не будет, кроме встроенной колонки с чекбоксами для множественного выбора, если она используется. Значение-1означает, что фиксированных колонок не будет вообще.
-
headerVisible- определяет видимость заголовкаDataGrid. По умолчанию имеет значениеtrue.
-
htmlSanitizerEnabled- разрешает или запрещает санитизацию HTML. КомпонентDataGridимеет несколько провайдеров, которые могут отображать HTML:-
HtmlRenderer -
RowDescriptionProvider с режимом
ContentMode.HTML -
DescriptionProvider с режимом
ContentMode.HTMLРезультат выполнения этих провайдеров будет санитизирован, если для компонента
DataGridатрибутhtmlSanitizerEnabledустановлен в значениеtrue.protected static final String UNSAFE_HTML = "<i>Jackdaws </i><u>love</u> <font size=\"javascript:alert(1)\" " + "color=\"moccasin\">my</font> " + "<font size=\"7\">big</font> <sup>sphinx</sup> " + "<font face=\"Verdana\">of</font> <span style=\"background-color: " + "red;\">quartz</span><svg/onload=alert(\"XSS\")>"; @Inject private DataGrid<Customer> customersDataGrid; @Inject private DataGrid<Customer> customersDataGrid2; @Inject private DataGrid<Customer> customersDataGrid3; @Subscribe public void onInit(InitEvent event) { customersDataGrid.setHtmlSanitizerEnabled(true); customersDataGrid.getColumn("name") .setRenderer(customersDataGrid.createRenderer(DataGrid.HtmlRenderer.class)); customersDataGrid2.setHtmlSanitizerEnabled(true); customersDataGrid2.setRowDescriptionProvider(customer -> UNSAFE_HTML, ContentMode.HTML); customersDataGrid3.setHtmlSanitizerEnabled(true); customersDataGrid3.getColumn("name").setDescriptionProvider(customer -> UNSAFE_HTML, ContentMode.HTML); }Значение атрибута
htmlSanitizerEnabledимеет приоритет над значением глобального свойства cuba.web.htmlSanitizerEnabled.Если вы хотите использовать
HtmlRendererс пользовательскимpresentationProvider, результирующее значение не будет санитизировано по умолчанию. Если вам нужно санитизировать значение, вы должны это сделать самостоятельно:protected static final String UNSAFE_HTML = "<i>Jackdaws </i><u>love</u> <font size=\"javascript:alert(1)\" " + "color=\"moccasin\">my</font> " + "<font size=\"7\">big</font> <sup>sphinx</sup> " + "<font face=\"Verdana\">of</font> <span style=\"background-color: " + "red;\">quartz</span><svg/onload=alert(\"XSS\")>"; @Inject private DataGrid<Customer> customersDataGrid; @Inject private HtmlSanitizer htmlSanitizer; @Subscribe public void onInit(InitEvent event) { customersDataGrid.getColumn("name") .setRenderer(customersDataGrid.createRenderer(DataGrid.HtmlRenderer.class), (Function<String, String>) nameValue -> htmlSanitizer.sanitize(UNSAFE_HTML)); }
-
-
reorderingAllowed- разрешает или запрещает пользователю менять местами колонки, перетаскивая их с помощью мыши. По умолчанию имеет значениеtrue.Изменение расположения колонок можно отслеживать с помощью слушателя
ColumnReorderListener. Источник события изменения порядка колонок можно отследить с помощью метода isUserOriginated().
-
selectionMode- определяет режим выделения строк. Поддерживаются следующие режимы:-
SINGLE- единичный выбор строки. -
MULTI- множественный выбор строк как в таблице. -
MULTI_CHECK- множественный выбор строк с использованием встроенной колонки с чекбоксами. -
NONE- выбор строк отключен.Выделение строк можно отслеживать с помощью слушателя
SelectionListener. Источник события выделения можно отследить с помощью метода isUserOriginated().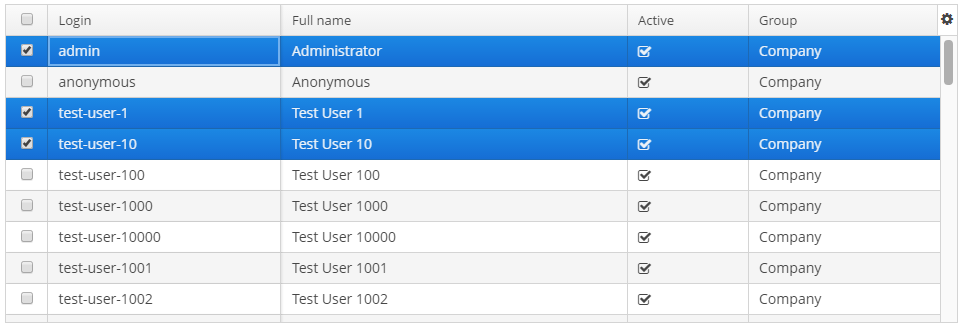
-
-
sortable- разрешает или запрещает сортировку вDataGrid. По умолчанию имеет значениеtrue. Если сортировка разрешена, то при нажатии на название колонки справа от названия появляется соответствующий значок. Сортировку некоторой отдельной колонки можно запретить с помощью атрибутаsortableэтой колонки.События сортировки
DataGridможно отслеживать с помощью слушателяSortListener. Источник события сортировки можно отследить с помощью метода isUserOriginated().
-
textSelectionEnabled- разрешает или запрещает выделение текста в ячейкахDataGrid. По умолчанию имеет значениеfalse.
Методы интерфейса DataGrid
-
getColumns()- возвращает текущий набор колонокDataGridв порядке их текущего отображения. -
getSelected(),getSingleSelected()- возвращают экземпляры сущностей, соответствующие выделенным в таблице строкам. Коллекцию можно получить вызовом методаgetSelected(). Если ничего не выбрано, возвращается пустой набор. Если установленSelectionMode.SINGLE, удобно пользоваться методомgetSingleSelected(), возвращающим одну выбранную сущность илиnull, если ничего не выбрано. -
getVisibleColumns()- возвращет набор видимых колонокDataGridв порядке их текущего отображения.
-
scrollTo()- позволяет программно прокрутитьDataGridдо нужной записи. Метод принимает экземпляр сущности, определяющий нужную строку вDataGrid. Перегруженный метод, помимо сущности, принимаетScrollDestination, имеющий следующие возможные значения:-
ANY- прокрутить как можно меньше, чтобы показать нужную запись. -
START- прокрутить так, чтобы нужная запись оказалась в начале видимой областиDataGrid. -
MIDDLE- прокрутить так, чтобы нужная запись оказалась в центре видимой областиDataGrid. -
END- прокрутить так, чтобы нужная запись оказалась в конце видимой областиDataGrid.
-
-
scrollToStart()andscrollToEnd()- позволяют прокрутитьDataGridв начало и конец соответственно.
-
addCellStyleProvider()- позволяет добавить стиль отображения ячеекDataGrid.
-
addRowStyleProvider()- позволяет добавить стиль отображения строкDataGrid.
-
setEnterPressAction()- позволяет задать действие, выполняемое при нажатии клавиши Enter. Если такое действие не задано, таблица пытается найти среди своих действий подходящее в следующем порядке:-
действие, назначенное методом
setItemClickAction(). -
действие, назначенное на клавишу Enter посредством свойства
shortcut. -
действие с именем
edit. -
действие с именем
view.
Если такое действие найдено и имеет свойство
enabled = true, оно выполняется. -
-
setItemClickAction()- позволяет задать действие, выполняемое при двойном клике на строке таблицы. Если такое действие не задано, при двойном клике таблица пытается найти среди своих действий подходящее в следующем порядке:-
действие, назначенное на клавишу Enter посредством свойства
shortcut. -
действие с именем
edit. -
действие с именем
view.
Если такое действие найдено и имеет свойство
enabled = true, оно выполняется.События клика по элементу
DataGridможно отслеживать с помощью слушателяItemClickListener. -
-
sort()- сортирует данные в переданной колонке в направлении, заданном одним из двух доступных значений перечисленияSortDirection:-
ASCENDING- сортировка по возрастанию (например, A-Z, 1..9). -
DESCENDING- сортировка по убыванию (например, Z-A, 9..1).
-
-
Метод
getAggregationResults()возвращает мэп с результатами агрегации, где ключи в мэп − идентификаторы столбцовDataGrid, а значения − значения агрегации.
Использование всплывающих подсказок
-
setDescriptionProvider()- используется для генерации всплывающих подсказок для отдельных колонокDataGrid. Строка описания может содержать HTML-разметку.@Inject private DataGrid<Customer> customersDataGrid; @Subscribe protected void onInit(InitEvent event) { customersDataGrid.getColumnNN("age").setDescriptionProvider(customer -> getPropertyCaption(customer, "age") + customer.getAge(), ContentMode.HTML); customersDataGrid.getColumnNN("active").setDescriptionProvider(customer -> getPropertyCaption(customer, "active") + getMessage(customer.getActive() ? "trueString" : "falseString"), ContentMode.HTML); customersDataGrid.getColumnNN("grade").setDescriptionProvider(customer -> getPropertyCaption(customer, "grade") + messages.getMessage(customer.getGrade()), ContentMode.HTML); }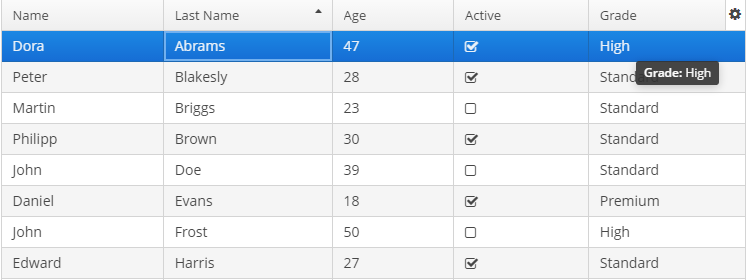
-
setRowDescriptionProvider()- используется для генерации всплывающих подсказок для строкDataGrid. Если подсказки для колонок также установлены, подсказка, сгенерированная для строки, будет использована только для тех ячеек, для которых не задана подсказка колонки.customersDataGrid.setRowDescriptionProvider(Instance::getInstanceName);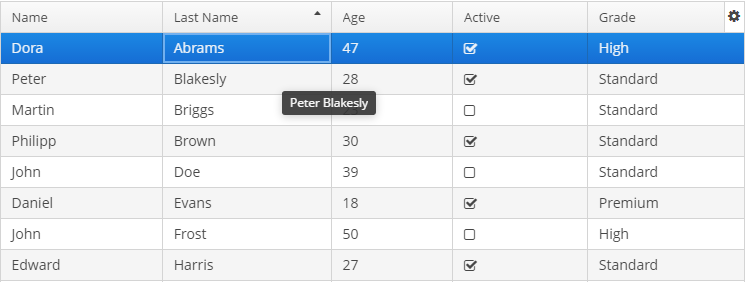
Использование интерфейса DetailsGenerator
Интерфейс DetailsGenerator позволяет задать свой компонент для отображения информации о выбранной строке DataGrid с помощью метода setDetailsGenerator():
@Inject
private DataGrid<Order> ordersDataGrid;
@Inject
private UiComponents uiComponents;
@Install(to = "ordersDataGrid", subject = "detailsGenerator")
protected Component ordersDataGridDetailsGenerator(Order order) {
VBoxLayout mainLayout = uiComponents.create(VBoxLayout.NAME);
mainLayout.setWidth("100%");
mainLayout.setMargin(true);
HBoxLayout headerBox = uiComponents.create(HBoxLayout.NAME);
headerBox.setWidth("100%");
Label infoLabel = uiComponents.create(Label.NAME);
infoLabel.setHtmlEnabled(true);
infoLabel.setStyleName("h1");
infoLabel.setValue("Order info:");
Component closeButton = createCloseButton(order);
headerBox.add(infoLabel);
headerBox.add(closeButton);
headerBox.expand(infoLabel);
Component content = getContent(order);
mainLayout.add(headerBox);
mainLayout.add(content);
mainLayout.expand(content);
return mainLayout;
}
private Component createCloseButton(Order entity) {
Button closeButton = uiComponents.create(Button.class);
// ... (1)
return closeButton;
}
private Component getContent(Order entity) {
Label<String> content = uiComponents.create(Label.TYPE_STRING);
content.setHtmlEnabled(true);
StringBuilder sb = new StringBuilder();
// ... (2)
content.setValue(sb.toString());
return content;
}| 1 | – Смотрите код метода createCloseButton целиком в классе DataGridDetailsGeneratorSample. |
| 2 | – Смотрите код метода getContent целиком в классе DataGridDetailsGeneratorSample. |
Результат:
Использование режима внутристрочного редактирования
У компонента DataGrid есть API, позволяющий напрямую редактировать записи в ячейках. Во время редактирования ячейки будет отображён UI с кнопками для сохранения и отмены изменений.
Методы API встроенного редактора:
-
getEditedItem()- возвращает редактируемую запись. -
isEditorActive()- возвращаетtrue, если в момент вызова редактируется какая-либо запись.
-
editItem(Object itemId)(устаревший) - открывает интерфейс внутристрочного редактора для идентификатора указанной записи. Пролистывает таблицу до нужной записи, если в момент вызова она не была видна на экране.
-
edit(Entity item)- открывает интерфейс внутристрочного редактора для указанной записи. Пролистывает таблицу до нужной записи, если в момент вызова она не была видна на экране.
Встроенный редактор DataGrid может учитывать ограничения сущностей (перекрестная проверка полей). Если есть ошибки валидации, DataGrid покажет сообщение об ошибке. Чтобы включить/отключить проверку или получить текущее состояние, используйте следующие методы:
-
setEditorCrossFieldValidate(boolean validate)- включает или отключает перекрестную проверку полей во встроенном редакторе. По умолчанию имеет значениеtrue. -
isEditorCrossFieldValidate()- возвращает значениеtrue, если для встроенного редактора включена перекрестная проверка полей.
Вы также можете добавить к встроенному редактору или удалить слушатели, использовав следующие методы:
-
addEditorOpenListener(),removeEditorOpenListener()- слушатель открытия встроенного редактораDataGrid.Данный слушатель обрабатывает событие открытия встроенного редактора
DataGridпо двойному щелчку и позволяет получить доступ к полям редактируемой строки. Это даёт возможность обновлять значения в отдельных полях в зависимости от изменения значений в других полях, не закрывая встроенный редактор.Например:
customersTable.addEditorOpenListener(editorOpenEvent -> { Map<String, Field> fieldMap = editorOpenEvent.getFields(); Field active = fieldMap.get("active"); Field grade = fieldMap.get("grade"); ValueChangeListener listener = e -> active.setValue(true); grade.addValueChangeListener(listener); });
-
addEditorCloseListener(),removeEditorCloseListener()- слушатель закрытия встроенного редактораDataGrid.
-
addEditorPreCommitListener(),removeEditorPreCommitListener()- слушатель редактораDataGrid, срабатывающий в процессе коммита изменений.
-
addEditorPostCommitListener(),removeEditorPostCommitListener()- слушатель, срабатывающий на финальной стадии коммита изменений.
Коммит изменений сохраняет их в источнике данных. Логику сохранения изменений в базу данных необходимо задать отдельно.
Само поле редактирования также может быть изменено с помощью класса EditorFieldGenerationContext. Используйте метод setEditFieldGenerator() для определённой колонки таблицы, чтобы указать компонент для отображения в режиме редактирования этой колонки:
@Inject
private DataGrid<Order> ordersDataGrid;
@Inject
private UiComponents uiComponents;
@Subscribe
protected void onInit(InitEvent event) {
ordersDataGrid.getColumnNN("amount").setEditFieldGenerator(orderEditorFieldGenerationContext -> {
LookupField<BigDecimal> lookupField = uiComponents.create(LookupField.NAME);
lookupField.setValueSource((ValueSource<BigDecimal>) orderEditorFieldGenerationContext
.getValueSourceProvider().getValueSource("amount"));
lookupField.setOptionsList(Arrays.asList(BigDecimal.ZERO, BigDecimal.ONE, BigDecimal.TEN));
return lookupField;
});
}Результат:
Использование интерфейса ColumnGenerator
DataGrid имеет возможность добавлять генерируемые, или высчитываемые, колонки. Существует два пути создания таких колонок:
-
Декларативно, используя аннотацию
@Installв контроллере экрана:@Inject private UiComponents uiComponents; @Install(to = "dataGrid.fullName", subject = "columnGenerator") protected Component fullNameColumnGenerator(DataGrid.ColumnGeneratorEvent<Customer> e) { Label<String> label = uiComponents.create(Label.TYPE_STRING); label.setValue(e.getItem().getFirstName() + " " + e.getItem().getLastName()); return label; }ColumnGeneratorEventхранит информацию о сущности, которая отображается в текущей строкеDataGrid, и идентификатор колонки. -
Программно с помощью следующих методов:
-
addGeneratedColumn(String columnId, ColumnGenerator generator) -
addGeneratedColumn(String columnId, ColumnGenerator generator, int index)
ColumnGenerator- это специальный интерфейс, который описывает генерируемую колонку:-
значение для каждой строки колонки,
-
тип значения - общий для всей колонки.
Например, для добавления генерируемой колонки, которая будет отображать логин пользователя в верхнем регистре, можно использовать следующий код:
@Subscribe protected void onInit(InitEvent event) { DataGrid.Column column = usersGrid.addGeneratedColumn("loginUpperCase", new DataGrid.ColumnGenerator<User, String>(){ @Override public String getValue(DataGrid.ColumnGeneratorEvent<User> event){ return event.getItem().getLogin().toUpperCase(); } @Override public Class<String> getType(){ return String.class; } }, 1); column.setCaption("Login Upper Case"); }Результат:

По умолчанию, генерируемая колонка добавляется в конец таблицы. Управлять расположением генерируемых колонок можно либо вставляя колонку по индексу, либо предварительно добавив колонку в XML с
id, который потом передавать в методaddGeneratedColumn. -
Использование рендереров
Отображение данных в колонках может быть изменено с помощью параметризованных декларативных рендереров. Некоторые рендереры DataGrid задаются специальными XML-элементами с параметрами, определенными в соответствующих атрибутах. Рендереры могут быть объявлены также и для не генерируемых колонок.
Список рендереров, поддерживаемых платформой:
-
ButtonRenderer– рендерер, который использует строковое значение в качестве заголовка кнопки.ButtonRendererне может быть объявлен в XML-дескрипторе, так как в нем невозможно определить слушатель отслеживания кликов по кнопке. Studio сгенерирует код объявленияButtonRendererв методеinit()контроллера экрана:@Inject private DataGrid<Customer> customersDataGrid; @Inject private Notifications notifications; @Subscribe public void onInit(InitEvent event) { DataGrid.ButtonRenderer<Customer> customersDataGridNameRenderer = customersDataGrid.createRenderer(DataGrid.ButtonRenderer.class); customersDataGridNameRenderer.setRendererClickListener(clickableButtonRendererClickEvent -> { notifications.create() .withType(Notifications.NotificationType.TRAY) .withCaption("ButtonRenderer") .withDescription("Column id: " + clickableButtonRendererClickEvent.getColumnId()) .show(); }); customersDataGrid.getColumn("name").setRenderer(customersDataGridNameRenderer); }
-
CheckBoxRenderer– рендерер, который отображает булево значение в виде значков чек-бокса.Элемент
columnимеет вложенный элементcheckBoxRenderer:<column property="checkBoxRenderer" id="checkBoxRendererColumn"> <checkBoxRenderer/> </column>
-
ClickableTextRenderer– отображает простой текст в виде ссылки. Позволяет задать обработчик, который будет вызван после нажатия на ссылку.ClickableTextRendererне может быть объявлен в XML-дескрипторе, так как в нем невозможно определить слушатель отслеживания нажатий на ссылку. Studio сгенерирует код объявленияClickableTextRendererв методеinit()контроллера экрана:@Inject private DataGrid<Customer> customersDataGrid; @Inject private Notifications notifications; @Subscribe public void onInit(InitEvent event) { DataGrid.ClickableTextRenderer<Customer> customersDataGridNameRenderer = customersDataGrid.createRenderer(DataGrid.ClickableTextRenderer.class); customersDataGridNameRenderer.setRendererClickListener(clickableTextRendererClickEvent -> { notifications.create() .withType(Notifications.NotificationType.TRAY) .withCaption("ClickableTextRenderer") .withDescription("Column id: " + clickableTextRendererClickEvent.getColumnId()) .show(); }); customersDataGrid.getColumn("name").setRenderer(customersDataGridNameRenderer); }
-
ComponentRenderer– рендерер для компонентов UI.Элемент
columnимеет вложенный элементcomponentRenderer:<column property="componentRenderer" id="componentRendererColumn"> <componentRenderer/> </column>
-
DateRenderer– рендерер для отображения дат в заданном формате.Элемент
columnимеет вложенный элементdateRendererс необязательным атрибутомnullRepresentationи обязательным строковым атрибутомformat:<column property="dateRenderer" id="dateRendererColumn"> <dateRenderer nullRepresentation="null" format="yyyy-MM-dd HH:mm:ss"/> </column>
-
IconRenderer– рендерер, который представляетCubaIcon.Элемент
columnимеет вложенный элементiconRenderer.Ниже приведен пример рендеринга строкового атрибута сущности в виде
CubaIcon:<column id="iconOS" property="iconOS"> <iconRenderer/> </column>@Install(to = "devicesTable.iconOS", subject = "columnGenerator") private Icons.Icon devicesTableIconOSColumnGenerator(DataGrid.ColumnGeneratorEvent<Device> event) { return CubaIcon.valueOf(event.getItem().getIconOS()); }Результат:
-
ImageRenderer– рендерер, который использует строковое значение в качестве пути до изображения.ImageRendererне может быть объявлен в XML-дескрипторе, так как в нем невозможно определить слушатель отслеживания нажатий на изображение. Studio сгенерирует код объявленияImageRendererв методеinit()контроллера экрана:@Inject private DataGrid<TestEntity> testEntitiesDataGrid; @Inject private Notifications notifications; @Subscribe public void onInit(InitEvent event) { DataGrid.ImageRenderer<TestEntity> imageRenderer = testEntitiesDataGrid.createRenderer(DataGrid.ImageRenderer.class); imageRenderer.setRendererClickListener(imageRendererClickEvent -> notifications.create() .withType(Notifications.NotificationType.TRAY) .withCaption("ImageRenderer") .withDescription("Column id: " + imageRendererClickEvent.getColumnId()) .show()); testEntitiesDataGrid.getColumn("imageRendererColumn").setRenderer(imageRenderer); }
-
HtmlRenderer– рендерер для отображения HTML-разметки.Элемент
columnимеет вложенный элементhtmlRendererс необязательным атрибутомnullRepresentation:<column property="htmlRenderer" id="htmlRendererColumn"> <htmlRenderer nullRepresentation="null"/> </column>
-
LocalDateRenderer– рендерер для отображения дат как значений типаLocalDate.Элемент
columnимеет вложенный элементlocalDateRendererс необязательным атрибутомnullRepresentationи обязательным строковым атрибутомformat:<column property="localDateRenderer" id="localDateRendererColumn"> <localDateRenderer nullRepresentation="null" format="dd/MM/YYYY"/> </column>
-
LocalDateTimeRenderer– рендерер для отображения дат как значений типаLocalDateTime.Элемент
columnимеет вложенный элементlocalDateTimeRendererс необязательным атрибутомnullRepresentationи обязательным строковым атрибутомformat:<column property="localDateTimeRenderer" id="localDateTimeRendererColumn"> <localDateTimeRenderer nullRepresentation="null" format="dd/MM/YYYY HH:mm:ss"/> </column>
-
NumberRenderer– рендерер для отображения чисел в заданном формате.Элемент
columnимеет вложенный элементnumberRendererс необязательным атрибутомnullRepresentationи обязательным строковым атрибутомformat:<column property="numberRenderer" id="numberRendererColumn"> <numberRenderer nullRepresentation="null" format="%f"/> </column>
-
ProgressBarRenderer– рендерер, который отображаетdouble-значения от 0 до 1 в виде компонентаProgressBar.Элемент
columnимеет вложенный элементprogressBarRenderer:<column property="progressBar" id="progressBarColumn"> <progressBarRenderer/> </column>
-
TextRenderer– рендерер для отображения простого текста.Элемент
columnимеет вложенный элементtextRendererс необязательным атрибутомnullRepresentation:<column property="textRenderer" id="textRendererColumn"> <textRenderer nullRepresentation="null"/> </column>
Интерфейс WebComponentRenderer позволяет настроить отображение веб-компонентов различных типов в ячейках DataGrid. Интерфейс реализован только для блока Web Module. Ниже приведён пример создания колонки для отображения компонента LookupField:
@Inject
private DataGrid<User> usersGrid;
@Inject
private UiComponents uiComponents;
@Inject
private Configuration configuration;
@Inject
private Messages messages;
@Subscribe
protected void onInit(InitEvent event) {
Map<String, Locale> locales = configuration.getConfig(GlobalConfig.class).getAvailableLocales();
Map<String, String> options = new TreeMap<>();
for (Map.Entry<String, Locale> entry : locales.entrySet()) {
options.put(entry.getKey(), messages.getTools().localeToString(entry.getValue()));
}
DataGrid.Column column = usersGrid.addGeneratedColumn("language",
new DataGrid.ColumnGenerator<User, Component>() {
@Override
public Component getValue(DataGrid.ColumnGeneratorEvent<User> event) {
LookupField<String> component = uiComponents.create(LookupField.NAME);
component.setOptionsMap(options);
component.setWidth("100%");
User user = event.getItem();
component.setValue(user.getLanguage());
component.addValueChangeListener(e -> user.setLanguage(e.getValue()));
return component;
}
@Override
public Class<Component> getType() {
return Component.class;
}
});
column.setRenderer(new WebComponentRenderer());
}Результат:
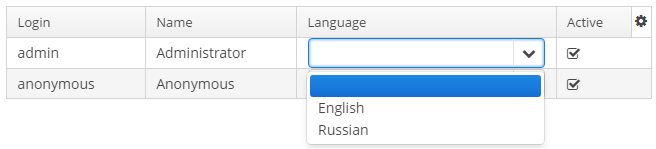
Когда тип поля не совпадает с типом данных, принимаемых рендерером, можно при создании рендерера создать функцию для конвертации между типами данных модели и представления. К примеру, чтобы отобразить булево значение в виде значка, можно использовать HtmlRenderer, который умеет отображать HTML-разметку, и добавить логику, которая будет превращать булево значение в подходящую разметку для отображения значков.
@Inject
private DataGrid<User> usersGrid;
@Subscribe
protected void onInit(InitEvent event) {
DataGrid.Column<User> hasEmail = usersGrid.addGeneratedColumn("hasEmail", new DataGrid.ColumnGenerator<User, Boolean>() {
@Override
public Boolean getValue(DataGrid.ColumnGeneratorEvent<User> event) {
return StringUtils.isNotEmpty(event.getItem().getEmail());
}
@Override
public Class<Boolean> getType() {
return Boolean.class;
}
});
hasEmail.setCaption("Has Email");
hasEmail.setRenderer(
usersGrid.createRenderer(DataGrid.HtmlRenderer.class),
(Function<Boolean, String>) hasEmailValue -> {
return BooleanUtils.isTrue(hasEmailValue)
? FontAwesome.PLUS_SQUARE.getHtml()
: FontAwesome.MINUS_SQUARE.getHtml();
});
}Результат:
Создавать рендереры можно тремя способами:
-
декларативно, используя специальные вложенные элементы у элемента
column. -
через метод-фабрику интерфейса
DataGrid, передавая в него интерфейс рендерера, для которого нужно создать имплементацию. Подходит для GUI и Web модулей. -
непосредственно создавая имплементацию рендерера для соответствующего модуля:
dataGrid.createRenderer(DataGrid.ImageRenderer.class) → new WebImageRenderer()На данный момент этот способ реализован только для модуля Web.
Header и Footer
Интерфейсы HeaderRow и FooterRow предназначены для отображения ячеек заголовков и строк с итогами таблицы соответственно. Эти ячейки могут быть объединёнными для нескольких колонок.
Для создания и настройки заголовков и итогов используются следующие методы:
-
appendHeaderRow(),appendFooterRow()- добавляет новую строку внизу секции заголовков/итогов. -
prependHeaderRow(),prependFooterRow()- добавляет новую строку наверху секции заголовков/итогов. -
addHeaderRowAt(),addFooterRowAt()- вставляет новую строку на заданную позицию в секции. Текущая строка на этой позиции, а также все следующие ниже, сдвигаются вниз с увеличением их индекса на 1. -
removeHeaderRow(),removeFooterRow()- удаляет указанную строку в секции. -
getHeaderRowCount(),getFooterRowCount()- возвращает количество строк в секции. -
setDefaultHeaderRow()- устанавливает заголовок таблицы по умолчанию. Интерфейс стандартного заголовка по умолчанию включает в себя элементы для сортировки колонок таблицы.
Интерфейсы HeaderCell и FooterCell позволяют управлять статическими ячейками:
-
setStyleName()- устанавливает пользовательский стиль для данной ячейки. -
getCellType()- возвращает тип содержимого данной ячейки. ПеречислениеDataGridStaticCellTypeсодержит 3 стандартных типа статических ячеек:-
TEXT -
HTML -
COMPONENT
-
-
getComponent(),getHtml(),getText()- возвращает содержимое данной ячейки в зависимости от её типа.
Ниже приведён пример таблицы DataGrid с заголовком, содержащим объединённые ячейки, и строкой итогов, в которой отображаются вычисляемые значения:
<dataGrid id="dataGrid" dataContainer="countryGrowthDs" width="100%">
<columns>
<column property="country"/>
<column property="year2017"/>
<column property="year2018"/>
</columns>
</dataGrid>@Inject
private DataGrid<CountryGrowth> dataGrid;
@Inject
private UserSessionSource userSessionSource;
@Inject
private Messages messages;
@Inject
private CollectionContainer<CountryGrowth> countryGrowthsDc;
private DecimalFormat percentFormat;
@Subscribe
protected void onBeforeShow(BeforeShowEvent event) {
initPercentFormat();
initHeader();
initFooter();
initRenderers();
}
private DecimalFormat initPercentFormat() {
percentFormat = (DecimalFormat) NumberFormat.getPercentInstance(userSessionSource.getLocale());
percentFormat.setMultiplier(1);
percentFormat.setMaximumFractionDigits(2);
return percentFormat;
}
private void initRenderers() {
dataGrid.getColumnNN("year2017").setRenderer(new WebNumberRenderer(percentFormat));
dataGrid.getColumnNN("year2018").setRenderer(new WebNumberRenderer(percentFormat));
}
private void initHeader() {
DataGrid.HeaderRow headerRow = dataGrid.prependHeaderRow();
DataGrid.HeaderCell headerCell = headerRow.join("year2017", "year2018");
headerCell.setText("GDP growth");
headerCell.setStyleName("center-bold");
}
private void initFooter() {
DataGrid.FooterRow footerRow = dataGrid.appendFooterRow();
footerRow.getCell("country").setHtml("<strong>" + messages.getMainMessage("average") + "</strong>");
footerRow.getCell("year2017").setText(percentFormat.format(getAverage("year2017")));
footerRow.getCell("year2018").setText(percentFormat.format(getAverage("year2018")));
}
private double getAverage(String propertyId) {
double average = 0.0;
List<CountryGrowth> items = countryGrowthsDc.getItems();
for (CountryGrowth countryGrowth : items) {
Double value = countryGrowth.getValue(propertyId);
average += value != null ? value : 0.0;
}
return average / items.size();
}
Стили DataGrid
К компоненту DataGrid можно применить заданные стили. Стиль задается в XML-дескрипторе с помощью атрибута stylename.
<dataGrid id="dataGrid"
width="100%"
height="100%"
stylename="borderless"
dataContainer="customersDc">
</dataGrid>Также стиль можно задать программно в контроллере экрана.
dataGrid.setStyleName("borderless");Предопределенные стили:
-
borderless- удаляет внешнюю рамку.
-
no-horizontal-lines- удаляет горизонтальные строковые разделители.
-
no-vertical-lines- удаляет вертикальные разделители столбцов.
-
no-stripes- отключает чередование цветов строк таблицы.
Внешний вид компонента DataGrid можно настроить с помощью переменных SCSS с префиксом $cuba-datagrid-*. Эти переменные можно изменить в визуальном редакторе после расширения темы или создания новой темы.
- Атрибуты dataGrid
-
aggregatable - aggregationPosition - align - caption - captionAsHtml - colspan - columnResizeMode - columnsCollapsingAllowed - contextHelpText - contextHelpTextHtmlEnabled - contextMenuEnabled - css - dataContainer - description - descriptionAsHtml - editorBuffered - editorCancelCaption - editorCrossFieldValidate - editorEnabled - editorSaveCaption - emptyStateLinkMessage - emptyStateMessage - enable - box.expandRatio - frozenColumnCount - headerVisible - height - htmlSanitizerEnabled - icon - id - metaClass - reorderingAllowed - responsive - rowspan - selectionMode - settingsEnabled - sortable - stylename - tabIndex - textSelectionEnabled - visible - width
- Элементы dataGrid
-
actions - buttonsPanel - columns - rowsCount
- Атрибуты columns
- Атрибуты column
-
caption - collapsed - collapsible - collapsingToggleCaption - editable - expandRatio - id - maximumWidth - minimumWidth - property - resizable - sort - sortable - width
- Элементы column
-
aggregation - checkBoxRenderer - componentRenderer - dateRenderer - formatter - iconRenderer - htmlRenderer - localDateRenderer - localDateTimeRenderer - numberRenderer - progressBarRenderer - textRenderer
- Атрибуты aggregation
- API
-
addGeneratedColumn - applySettings - createRenderer - edit - getAggregationResults - saveSettings - getColumns - setDescriptionProvider - addCellStyleProvider - setConverter - setDetailsGenerator - setEditorCrossFieldValidate - setEmptyStateLinkClickHandler - setEnterPressAction - setItemClickAction - setRenderer - setRowDescriptionProvider - addRowStyleProvider - sort
- Слушатели dataGrid
-
ColumnCollapsingChangeListener - ColumnReorderListener - ColumnResizeListener - ContextClickListener - EditorCloseListener - EditorOpenListener - EditorPostCommitListener - EditorPreCommitListener - ItemClickListener - SelectionListener - SortListener
- Предопределенные стили
-
borderless - no-horizontal-lines - no-vertical-lines - no-stripes
3.5.2.1.12. DateField
Поле для отображения и ввода даты и времени. Представляет собой поле даты, внутри которого имеется кнопка с выпадающим календарем, а правее находится поле для ввода времени.
XML-имя компонента: dateField.
-
Для создания поля даты, связанного с данными, необходимо использовать атрибуты dataContainer и property:
<data> <instance id="orderDc" class="com.company.sales.entity.Order" view="_local"> <loader/> </instance> </data> <layout> <dateField dataContainer="orderDc" property="date"/> </layout>Как видно из примера, в экране описывается источник данных
orderDcдля некоторой сущности Заказ (Order), имеющей атрибутdate. В компоненте ввода даты в атрибуте dataContainer указывается ссылка на источник данных, а в атрибуте property − название атрибута сущности, значение которого должно быть отображено в поле. -
Если поле связано с атрибутом сущности, то оно автоматически принимает соответствующий вид:
-
Если атрибут типа
java.sql.Dateили указана аннотация@Temporal(TemporalType.DATE), то поле времени не отображается. Формат даты определяется типом данныхdateи задается в главном пакете локализованных сообщений в ключеdateFormat. -
В противном случае отображается также поле времени с часами и минутами. Формат времени определяется типом данных
timeи задается в главном пакете локализованных сообщений в ключеtimeFormat.
-
-
Если поле не связано с атрибутом сущности (то есть не указан контейнер данных и название атрибута), то можно указать тип данных с помощью атрибута
datatype. ВDateFieldиспользуются следующие типы данных:-
date -
dateTime -
localDate -
localDateTime -
offsetDateTime
-
-
Изменить формат представления даты и времени можно с помощью атрибута
dateFormat. Значением атрибута может быть либо сама строка формата, либо ключ в пакете сообщений (если значение начинается сmsg://).Формат задается по правилам класса
SimpleDateFormat(http://docs.oracle.com/javase/8/docs/api/java/text/SimpleDateFormat.html). Если в формате отсутствуют символыHилиh, то поле времени не выводится.<dateField dateFormat="MM/yy" caption="msg://monthOnlyDateField"/>
DateFieldв основном предназначен для быстрого ввода с клавиатуры путем заполнения маски. Поэтому компонент поддерживает только форматы с цифрами и разделителями. Сложные форматы с текстовым представлением дня недели или месяца не будут работать.
-
Диапазон доступных дат можно указать с помощью атрибутов
rangeStartиrangeEnd. Если данные атрибуты установлены, все даты, выходящие за пределы диапазона, будут отключены. Значения доступных даты можно установить в XML в формате "yyyy-MM-dd", или программно с помощью соответствующих сеттеров.<dateField id="dateField" rangeStart="2016-08-15" rangeEnd="2016-08-19"/>
-
Атрибут
autofill, установленный в значениеtrue, включает автоматическое заполнение значений месяца и года текущими значениями после ввода дня. Если автозаполнение отключено, значение даты сбрасывается при неполном вводе.В случае, если автозаполнение включено и установлены атрибуты
rangeStartилиrangeEnd, значения этих атрибутов будут учитываться при заполнении даты.
-
Точность представления даты и времени можно определить с помощью атрибута
resolution. Значение атрибута должно соответствовать перечислениюDateField.Resolution−SEC,MIN,HOUR,DAY,MONTH,YEAR. По умолчанию -MIN, то есть до минут.Если
resolution="DAY"и не указан атрибутdateFormat, то в качестве формата будет взят формат, указанный в главном пакете сообщений с ключомdateFormat.Если
resolution="MIN"и не указан атрибутdateFormat, то в качестве формата будет взят формат, указанный в главном пакете сообщений с ключомdateTimeFormat.Ниже показано определения поля для ввода даты с точностью до месяца.
<dateField resolution="MONTH" caption="msg://monthOnlyDateField"/>
-
Изменение значения поля
DateField, так же, как и любого другого компонента, реализующего интерфейсField, можно отслеживать с помощью слушателяValueChangeListener. Источник событияValueChangeEventможно отследить с помощью метода isUserOriginated(). -
Если для пользователя методом
setTimeZone()задан часовой пояс, тоDateFieldможет преобразовывать значения типа timestamp между часовыми поясами сервера и пользователя. Если компонент привязан к атрибуту типа timestamp, часовой пояс автоматически берется из текущей пользовательской сессии. Если нет, то можно вызвать методsetTimeZone()в контроллере экрана, чтобыDateFieldвыполнил необходимые преобразования.
-
В веб-клиенте с темой, основанной на Halo, к компоненту
DateFieldможно применить заданный стильborderless, чтобы удалить рамку и фон поля. Стили задаются в XML-дексрипторе или контроллере экрана с помощью атрибутаstylename:<dateField id="dateField" stylename="borderless"/>Чтобы применить стиль программно, выберите константу класса
HaloThemeс префиксом компонентаDATEFIELD_:dateField.setStyleName(HaloTheme.DATEFIELD_BORDERLESS);
- Атрибуты dateField
-
align - autofill - caption - captionAsHtml - contextHelpText - contextHelpTextHtmlEnabled - css - dataContainer - datatype - dateFormat - description - descriptionAsHtml - editable - enable - box.expandRatio - height - htmlSanitizerEnabled - icon - id - property - stylename - rangeEnd - rangeStart - required - requiredMessage - resolution - tabIndex - visible - width
- Элементы dateField
- Предопределенные стили dateField
-
borderless - small - tiny
- API
-
addValueChangeListener - commit - discard - isModified - setContextHelpIconClickHandler
3.5.2.1.13. DatePicker
DatePicker это компонент для выбора даты. Он выглядит так же, как выпадающий календарь в DateField.
XML-имя компонента: datePicker.
DatePicker реализован для блока Web Client.
-
Для создания
DatePicker, связанного с данными, необходимо использовать атрибуты dataContainer и property:<data> <instance id="orderDc" class="com.company.sales.entity.Order" view="_local"> <loader/> </instance> </data> <layout> <datePicker id="datePicker" dataContainer="orderDc" property="date"/> </layout>Как видно из примера, в экране описывается источник данных
orderDcдля некоторой сущности Заказ (Order), имеющей атрибутdate. В компоненте ввода даты в атрибуте dataContainer указывается ссылка на источник данных, а в атрибуте property − название атрибута сущности, значение которого должно быть отображено в компоненте.
-
Вы можете указать доступные для выбора даты с помощью атрибутов
rangeStartиrangeEnd. Если вы их установите, даты, выходящие за пределы указанного промежутка, будут недоступны.<datePicker id="datePicker" rangeStart="2016-08-15" rangeEnd="2016-08-19"/>
-
Точность выбора даты определяется атрибутом
resolution. Значение атрибута должно соответстовать перечислениюDatePicker.Resolution−DAY,MONTH,YEAR. Значение по умолчанию:DAY.<datePicker id="datePicker" resolution="MONTH"/>
<datePicker id="datePicker" resolution="YEAR"/>
- Атрибуты datePicker
-
align - caption - captionAsHtml - contextHelpText - contextHelpTextHtmlEnabled - css - dataContainer - datatype - description - descriptionAsHtml - editable - enable - box.expandRatio - height - htmlSanitizerEnabled - id - property - rangeEnd - rangeStart - resolution - stylename - tabIndex - visible - width
- API
3.5.2.1.14. Embedded (Deprecated)
|
Начиная с версии 6.8 платформы, компонент |
Компонент Embedded предназначен для вывода изображений и встраивания в экран произвольных веб-страниц.
XML-имя компонента: embedded
Рассмотрим пример использования компонента для вывода изображения из файла, сохраненного в FileStorage.
-
Объявляем компонент в XML-дескрипторе экрана:
<groupBox caption="Embedded" spacing="true" height="250px" width="250px" expand="embedded"> <embedded id="embedded" width="100%" align="MIDDLE_CENTER"/> </groupBox> -
В контроллере экрана инжектируем компонент и интерфейс
FileStorageService. Затем в методеinit()получаем из параметров экрана переданный из вызывающего кодаFileDescriptor, загружаем соответствующий файл в байтовый массив, создаем для негоByteArrayInputStreamи передаем в методsetSource()компонента:@Inject private Embedded embedded; @Inject private FileStorageService fileStorageService; @Override public void init(Map<String, Object> params) { FileDescriptor imageFile = (FileDescriptor) params.get("imageFile"); byte[] bytes = null; if (imageFile != null) { try { bytes = fileStorageService.loadFile(imageFile); } catch (FileStorageException e) { showNotification("Unable to load image file", NotificationType.HUMANIZED); } } if (bytes != null) { embedded.setSource(imageFile.getName(), new ByteArrayInputStream(bytes)); embedded.setType(Embedded.Type.IMAGE); } else { embedded.setVisible(false); } }
Компонент Embedded может отображать содержимое различных типов, которые по-разному отрисовываются в HTML. Тип содержимого можно задать методом setType(). Поддерживаются следующие типы:
-
OBJECT- позволяет встраивать файлы некоторых типов в элементы HTML <object> и <embed>. -
IMAGE- встраивает изображения в HTML-элемент <img>. -
BROWSER- встраивает контейнер для отображения других независимых документов внутри элемента HTML <iframe>.
В веб-клиенте компонент позволяет отображать файлы, находящиеся внутри каталога VAADIN. Например:
<embedded id="embedded"
relativeSrc="VAADIN/themes/halo/my-logo.png"/>или
embedded.setRelativeSource("VAADIN/themes/halo/my-logo.png")Кроме того, можно определить каталог ресурсных файлов в свойстве приложения cuba.web.resourcesRoot, и указать для компонента Embedded имя файла внутри этого каталога с префиксом значения атрибута: file:// , url:// или theme://:
<embedded id="embedded"
src="file://my-logo.png"/>или
embedded.setSource("theme://branding/app-icon-menu.png");Для встраивания в экран веб-клиента внешней веб-страницы необходимо передать компоненту URL:
try {
embedded.setSource(new URL("http://www.cuba-platform.com"));
} catch (MalformedURLException e) {
throw new RuntimeException(e);
}- Атрибуты embedded
-
align - caption - captionAsHtml - contextHelpText - contextHelpTextHtmlEnabled - description - descriptionAsHtml - height - htmlSanitizerEnabled - id - relativeSrc - src - stylename - visible - width
3.5.2.1.15. FieldGroup
Компонент FieldGroup предназначен для совместного отображения и редактирования нескольких атрибутов сущностей.
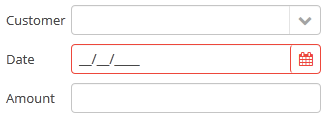
XML-имя компонента: fieldGroup
|
|
Пример описания группы полей в XML-дескрипторе экрана:
<dsContext>
<datasource id="orderDs"
class="com.sample.sales.entity.Order"
view="order-with-customer">
</datasource>
</dsContext>
<layout>
<fieldGroup id="orderFieldGroup" datasource="orderDs" width="250px">
<field property="date"/>
<field property="customer"/>
<field property="amount"/>
</fieldGroup>
</layout>Здесь в элементе dsContext определен источник данных datasource, который содержит один экземпляр сущности Order. Для компонента fieldGroup в атрибуте datasource указывается используемый источник данных, а в элементах field - какие атрибуты сущности, содержащейся в источнике данных, необходимо отобразить.
Элементы fieldGroup:
-
column- необязательный элемент, позволяющий располагать поля в несколько колонок. Для этого элементыfieldдолжны находиться не непосредственно внутриfieldGroup, а внутри своегоcolumn. Например:<fieldGroup id="orderFieldGroup" datasource="orderDs" width="100%"> <column width="250px"> <field property="num"/> <field property="date"/> <field property="amount"/> </column> <column width="400px"> <field property="customer"/> <field property="info"/> </column> </fieldGroup>В данном случае поля будут расположены в две колонки, причем в первой колонке все поля будут шириной
250px, а во второй -400px.Атрибуты
column:-
width- задает ширину полей данной колонки. По умолчанию ширина полей -200px. В данном атрибуте ширина может быть задана как в пикселах, так и в процентах от общего размера колонки по горизонтали.
-
flex- число, задающее степень изменения общего размера данной колонки по горизонтали относительно других колонок при изменении ширины всего компонентаfieldGroup. Например, можно задать одной колонкеflex=1а другойflex=3.
-
id- необязательный идентификатор колонки, позволяющий ссылаться на нее в случае расширении экрана.
-
-
field- основной элемент компонента, описывает одно поле компонента.Собственные настраиваемые поля можно определить внутри элемента
field:<fieldGroup> <field id="demo"> <lookupField id="demoField" datasource="userDs" property="group"/> </field> </fieldGroup>Атрибуты элемента
field:-
id- обязательный атрибут в случае, если не определён атрибутproperty; в противном случае по умолчанию принимает то же значение, что иproperty. Атрибутidдолжен содержать произвольный уникальный идентификатор либо поля с заданным атрибутомproperty, либо программно определяемого поля. В последнем случае элементfieldдолжен иметь также атрибутcustom="true"(см. далее).
-
property- обязательный атрибут в случае, если не определён атрибутid; должен содержать название атрибута сущности, выводимого в поле, для связывания поля и данных.
-
caption− позволяет задать заголовок поля. Если не задан, будет отображено локализованное название атрибута сущности. -
inputPrompt- если для компонента, представляющего данное поле, доступен атрибут inputPrompt, его значение можно установить напрямую для этого поля.
-
visible− позволяет скрыть поле вместе с заголовком.
-
datasource− позволяет задать для данного поля источник данных, отличный от заданного для всего компонентаfieldGroup. Таким образом в группе полей могут отображаться атрибуты разных сущностей. -
optionsDatasource− задает имя источника данных, используемого для формирования списка опций. Данный атрибут можно задать для поля, связанного со ссылочным атрибутом сущности. По умолчанию выбор связанной сущности производится через экран выбора, а еслиoptionsDatasourceуказан, то связанную сущность можно выбирать из выпадающего списка опций. Фактически указаниеoptionsDatasourceприводит к тому, что вместо компонента PickerField в поле используется LookupPickerField.
-
width− позволяет задать ширину поля без учета заголовка. По умолчанию ширина поля -200px. Ширина может быть задана как в пикселах, так и в процентах от общего размера колонки по горизонтали. Для указания ширины всех полей одновременно можно использовать атрибутwidthэлементаcolumn, описанный выше.
-
custom- установка этого атрибута вtrueпозволяет задать собственное представление поля, или говорит о том, что идентификатор поля не ссылается на атрибут сущности, и компонент, находящийся в поле, будет задан программно с помощью методаsetComponent()компонентаFieldGroup(см. ниже).
-
атрибут
generatorпозволяет декларативно создавать собственные представления полей, указав имя метода, возвращающего компонент для данного поля:<fieldGroup datasource="productDs"> <column width="250px"> <field property="description" generator="generateDescriptionField"/> </column> </fieldGroup>public Component generateDescriptionField(Datasource datasource, String fieldId) { TextArea textArea = uiComponents.create(TextArea.NAME); textArea.setRows(5); textArea.setDatasource(datasource, fieldId); return textArea; }
-
link- установка атрибута вtrueпозволяет отобразить вместо поля выбора сущности ссылку на экран просмотра экземпляра сущности (поддерживается только для Web Client). Такое поведение может быть необходимо, если требуется дать пользователю возможность просматривать связанную сущность, но саму связь он менять не должен.
-
linkScreen- позволяет указать идентификатор экрана, который будет открыт по нажатию на ссылку, включенную свойствомlink.
-
linkScreenOpenType- задает режим открытия экрана редактирования (THIS_TAB,NEW_TABилиDIALOG).
-
linkInvoke- позволяет заменить открытие окна на вызов метода контроллера.
Следующие атрибуты элемента
fieldможно применять в зависимости от типа атрибута сущности, отображаемого полем:-
Если для текстового атрибута сущности задать значение атрибута
mask, то в поле вместо компонента TextField будет использоваться компонент MaskedField с соответствующей маской. В этом случае можно также задать атрибутvalueMode.
-
Если для текстового атрибута сущности задать значение атрибута
rows, то в поле вместо компонента TextField будет использоваться компонент TextArea с соответствующим количеством строк. В этом случае можно также задать атрибутcols. -
Для текстового атрибута сущности можно задать атрибут
maxLengthаналогично описанному для TextField. -
Для атрибута сущности типа
dateилиdateTimeможно задать атрибутыdateFormatиresolutionдля параметризации находящегося в поле компонента DateField. -
Для атрибута сущности типа
timeможно задать атрибутshowSecondsдля параметризации находящегося в поле компонента TimeField.
-
Атрибуты fieldGroup:
-
Атрибут
borderможет принимать значениеhiddenилиvisible. По умолчанию -hidden. При установке в значениеvisibleкомпонентfieldGroupвыделяется рамкой. В веб-реализации компонента отображение рамки осуществляется добавлением CSS-классаcuba-fieldgroup-border.
-
captionAlignmentопределяет расположение заголовков относительно полей компонентаFieldGroup. Принимает два значения:LEFTиTOP.
-
fieldFactoryBean: декларативные поля, объявленные в XML-дескрипторе, создаются с помощью интерфейсаFieldGroupFieldFactory. Чтобы переопределить эту фабрику, используйте атрибутfieldFactoryBeanс именем вашей реализацииFieldGroupFieldFactory.Для элемента
FieldGroup, полностью созданного программно, для этой цели используется методsetFieldFactory().
Методы интерфейса FieldGroup:
-
addFieldпозволяет добавлять поля в FieldGroup на лету. В качестве параметра принимает экземплярFieldConfig, также можно указать положение нового поля в FieldGroup с помощью параметровcolIndexиrowIndex.
-
метод
bind()необходимо применить к полю после вызова методаsetDatasource(), чтобы вызвать создание компонентов поля.
-
createField()используется для создания элементов FieldGroup, реализующих интерфейсFieldConfig:fieldGroup.addField(fieldGroup.createField("newField"));
-
Метод
getComponent()возвращает визуальный компонент, находящийся в поле с указанным идентификатором. Это может потребоваться для дополнительной параметризации компонента, недоступной через атрибуты XML-элементаfield, описанные выше.Вместо явного вызова
getFieldNN("id").getComponentNN()для получения ссылки на компонент поля в контроллере экрана можно использовать инжекцию. Для этого следует использовать аннотацию@Namedс указанием идентификатора самогоfieldGroup, и через точку - идентификатора поля.Например, следующим образом в поле выбора связанной сущности можно добавить действие открытия экземпляра и убрать действие очистки поля:
<fieldGroup id="orderFieldGroup" datasource="orderDs"> <field property="date"/> <field property="customer"/> <field property="amount"/> </fieldGroup>@Named("orderFieldGroup.customer") protected PickerField customerField; @Override public void init(Map<String, Object> params) { customerField.addOpenAction(); customerField.removeAction(customerField.getAction(PickerField.ClearAction.NAME)); }Для использования метода
getComponent()или инжекции компонентов полей необходимо знать тип компонента, находящегося в поле. В следующей таблице приведено соответствие типов атрибутов сущностей и создаваемых для них компонентов:Тип атрибута сущности Дополнительные условия Тип компонента поля Связанная сущность
Задан атрибут
optionsDatasourceПеречисление (
enum)stringЗадан атрибут
maskЗадан атрибут
rowsbooleandate,dateTimetimeint,long,double,decimalЗадан атрибут
maskUUIDMaskedField с hex-маской
-
removeField()позволяет удалять поля на лету поid.
-
Метод
setComponent()задаёт собственное представление поля. Он может быть использован вместе с атрибутомcustom="true"элементаfieldили с полем, созданным программно методомcreateField()(см. выше). При использовании сcustom="true"необходимо вручную указать источник данных и свойство.Экземпляр FieldConfig можно получить с помощью методов
getField()илиgetFieldNN(), и затем вызвать методsetComponent(), как показано в следующем примере:@Inject protected FieldGroup fieldGroup; @Inject protected UiComponents uiComponents; @Inject private Datasource<User> userDs; @Override public void init(Map<String, Object> params) { PasswordField passwordField = uiComponents.create(PasswordField.NAME); passwordField.setDatasource(userDs, "password"); fieldGroup.getFieldNN("password").setComponent(passwordField); }
- Атрибуты fieldGroup
-
align - border - caption - captionAsHtml - captionAlignment - contextHelpText - contextHelpTextHtmlEnabled - css - datasource - description - descriptionAsHtml - editable - enable - box.expandRatio - fieldFactoryBean - height - htmlSanitizerEnabled - id - stylename - visible - width
- Атрибуты column
- Атрибуты field
-
caption - captionProperty - cols - custom - datasource - dateFormat - description - editable - enable - generator - id - link - linkInvoke - linkScreen - linkScreenOpenType - mask - maxLength - optionsDatasource - property - required - requiredMessage - resolution - rows - showSeconds - tabIndex - visible - width
- Элементы field
-
column - field - inputPrompt - validator
- API
-
addField - bind - createField - getComponent - removeField - setComponent - setFieldFactory
3.5.2.1.16. FileMultiUploadField
Компонент FileMultiUploadField позволяет пользователю загружать файлы на сервер. Компонент представляет собой кнопку, при нажатии на которую на экране отображается стандартное для операционной системы окно выбора файлов, в котором можно выбрать сразу несколько файлов для загрузки.
XML-имя компонента: multiUpload.
Рассмотрим пример использования компонента.
-
Объявляем компонент в XML-дескрипторе экрана:
<multiUpload id="multiUploadField" caption="Upload Many"/> -
В контроллере экрана инжектируем сам компонент, а также интерфейсы FileUploadingAPI и DataManager.
@Inject private FileMultiUploadField multiUploadField; @Inject private FileUploadingAPI fileUploadingAPI; @Inject private Notifications notifications; @Inject private DataManager dataManager; @Subscribe protected void onInit(InitEvent event) { (1) multiUploadField.addQueueUploadCompleteListener(queueUploadCompleteEvent -> { (2) for (Map.Entry<UUID, String> entry : multiUploadField.getUploadsMap().entrySet()) { (3) UUID fileId = entry.getKey(); String fileName = entry.getValue(); FileDescriptor fd = fileUploadingAPI.getFileDescriptor(fileId, fileName); (4) try { fileUploadingAPI.putFileIntoStorage(fileId, fd); (5) } catch (FileStorageException e) { throw new RuntimeException("Error saving file to FileStorage", e); } dataManager.commit(fd); (6) } notifications.create() .withCaption("Uploaded files: " + multiUploadField.getUploadsMap().values()) .show(); multiUploadField.clearUploads(); (7) }); multiUploadField.addFileUploadErrorListener(queueFileUploadErrorEvent -> { notifications.create() .withCaption("File upload error") .show(); }); }1 Затем в методе onInit()добавляем слушателей, которые будут реагировать на события успешной загрузки или ошибки:2 Компонент загружает выбранные файлы во временное хранилище клиентского уровня и вызывает слушатель, добавленный методом addQueueUploadCompleteListener().3 В данном слушателе вызовом метода getUploadsMap()у компонента можно получить мэп идентификаторов файлов во временном хранилище на имена файлов.4 Далее для каждого элемента мэп создается соответствующий объект FileDescriptorпутем вызоваFileUploadingAPI.getFileDescriptor(). Объектcom.haulmont.cuba.core.entity.FileDescriptor(не путать сjava.io.FileDescriptor) является персистентной сущностью, которая однозначно идентифицирует загруженный файл и впоследствии используется для выгрузки файла из системы.5 Метод FileUploadingAPI.putFileIntoStorage()используется для перемещения загружаемого файла из временного хранилища клиентского уровня в FileStorage. Параметрами этого метода являются идентификатор файла во временном хранилище и объектFileDescriptor.6 После загрузки файла в FileStorageвыполняется сохранение экземпляраFileDescriptorв базе данных посредством вызоваDataManager.commit(). Возвращаемый этим методом сохраненный экземпляр может быть установлен в атрибут какой-либо сущности предметной области, связанной с данным файлом. В данном же случаеFileDescriptorпросто сохраняется в базе данных. Соответствующий файл будет доступен через экран Administration > External Files.7 После обработки файлов необходимо очистить список файлов вызовом clearUploads()на случай повторной загрузки.
Ниже приведён список доступных слушателей для отслеживания процесса загрузки:
-
FileUploadErrorListener,
-
FileUploadStartListener,
-
FileUploadFinishListener,
-
QueueUploadCompleteListener.
Максимальный размер загружаемого файла определяется свойством приложения cuba.maxUploadSizeMb и по умолчанию равен 20MB. При выборе пользователем файла большего размера выдается соответствующее сообщение и загрузка прерывается.
Атибуты multiUpload:
-
XML-атрибут
accept(и соответствующий методsetAccept()) может быть использован для установки маски расширений файлов в диалоге выбора файла. Пользователи будут иметь возможность выбрать "All files" и загрузить произвольные файлы.Значением атрибута должен быть список масок, разделенных запятыми. Например:
*.jpg,*.png.
-
XML-атрибут
fileSizeLimit(и соответствующий методsetFileSizeLimit()) может быть использован для установки максимально допустимого размера файла. Значением атрибута должно быть целое число для указания количества байт. Данный лимит устанавливает ограничение для каждого файла.<multiUpload id="multiUploadField" fileSizeLimit="200000"/>
-
XML-атрибут
permittedExtensions(и соответствующий методsetPermittedExtensions()) может быть использован для установки "белого списка" допустимых расширений загружаемых файлов.Значением атрибута должен быть набор строк, в котором каждая строка - это допустимое расширение с лидирующей точкой. Например:
uploadField.setPermittedExtensions(Sets.newHashSet(".png", ".jpg"));
-
XML-атрибут
dropZoneиспользуется для указания BoxLayout, который будет использован в качестве целевой площадки для перетаскивания файлов извне браузера. Если стиль контейнера не переопределён, выбранный контейнер будет подсвечиваться, когда пользователь переносит над ним файлы, без наведения файла контейнер не отображается.
В руководстве Working with Images приведены более сложные примеры работы с загруженными файлами.
- Атрибуты multiUpload
-
accept - align - caption - captionAsHtml - css - description - descriptionAsHtml - dropZone - enable - box.expandRatio - fileSizeLimit - height - htmlSanitizerEnabled - icon - id - pasteZone - permittedExtensions - stylename - tabIndex - visible - width
- Слушатели multiUpload
-
FileUploadErrorListener - FileUploadFinishListener - FileUploadStartListener - QueueUploadCompleteListener
3.5.2.1.17. FileUploadField
Компонент FileUploadField позволяет пользователю загружать файлы на сервер. Компонент может содержать заголовок, ссылку на загруженный файл и две кнопки: для загрузки файла и для очистки. При нажатии на кнопку загрузки на экране отображается стандартное для операционной системы окно, в котором можно выбрать один файл. Чтобы дать пользователю возможность загружать сразу несколько файлов, используйте компонент FileMultiUploadField.
XML-имя компонента: upload.
Для атрибутов сущности с типом FileDescriptor компонент может использоваться внутри FieldGroup с атрибутом datasource, внутри Form с атрибутом dataContainer, либо независимо. Если компонент связан с данными, загруженный файл сразу же сохраняется в file storage, а соответствующий FileDescriptor - в базу данных.
<upload fileStoragePutMode="IMMEDIATE"
dataContainer="personDc"
property="photo"/>Сохранением файла и FileDescriptor можно также управлять программно:
-
Объявляем компонент в XML-дескрипторе экрана:
<upload id="uploadField" fileStoragePutMode="MANUAL"/>
-
В контроллере экрана инжектируем сам компонент, а также интерфейсы FileUploadingAPI и DataManager. Затем подпишемся на события успешной загрузки или ошибки:
@Inject private FileUploadField uploadField; @Inject private FileUploadingAPI fileUploadingAPI; @Inject private DataManager dataManager; @Inject private Notifications notifications; @Subscribe("uploadField") public void onUploadFieldFileUploadSucceed(FileUploadField.FileUploadSucceedEvent event) { File file = fileUploadingAPI.getFile(uploadField.getFileId()); (1) if (file != null) { notifications.create() .withCaption("File is uploaded to temporary storage at " + file.getAbsolutePath()) .show(); } FileDescriptor fd = uploadField.getFileDescriptor(); (2) try { fileUploadingAPI.putFileIntoStorage(uploadField.getFileId(), fd); (3) } catch (FileStorageException e) { throw new RuntimeException("Error saving file to FileStorage", e); } dataManager.commit(fd); (4) notifications.create() .withCaption("Uploaded file: " + uploadField.getFileName()) .show(); } @Subscribe("uploadField") public void onUploadFieldFileUploadError(UploadField.FileUploadErrorEvent event) { notifications.create() .withCaption("File upload error") .show(); }
| 1 | Здесь при необходимости можно получить загруженный файл из временного хранилища. |
| 2 | Обычно требуется сохранить файл в хранилище на среднем слое. |
| 3 | Сохраняем файл в FileStorage. |
| 4 | Сохраняем объект FileDescriptor в БД. |
Компонент загружает файл во временное хранилище клиентского уровня и вызывает слушатель события FileUploadSucceedEvent. В этом слушателе у компонента запрашивается объект FileDescriptor, соответствующий загруженному файлу. Объект com.haulmont.cuba.core.entity.FileDescriptor является персистентной сущностью, которая однозначно идентифицирует загруженный файл и впоследствии используется для выгрузки файла из системы.
Метод FileUploadingAPI.putFileIntoStorage() используется для перемещения загружаемого файла из временного хранилища клиентского уровня в FileStorage. Параметрами этого метода являются идентификатор файла во временном хранилище и объект FileDescriptor. Оба эти параметра предоставляет FileUploadField.
После загрузки файла в FileStorage выполняется сохранение экземпляра FileDescriptor в базе данных посредством вызова DataManager.commit(). Возвращаемый этим методом сохраненный экземпляр может быть установлен в атрибут какой-либо сущности предметной области, связанной с данным файлом. В данном же случае FileDescriptor просто сохраняется в базе данных. Соответствующий файл будет доступен через экран Administration > External Files.
Слушатель события FileUploadErrorEvent вызывается в случае ошибки загрузки файла во временное хранилище клиентского уровня.
Ниже приведён полный список доступных событий, на которые можно подписаться для отслеживания процесса загрузки:
-
AfterValueClearEvent,
-
BeforeValueClearEvent,
-
FileUploadErrorEvent,
-
FileUploadFinishEvent
-
FileUploadStartEvent, -
FileUploadSucceedEvent,
-
ValueChangeEvent.
Атрибуты fileUploadField:
-
fileStoragePutMode- задает режим сохранения файла и соответствующегоFileDescriptor.-
В режиме
IMMEDIATEэто делается автоматически сразу после загрузки файла во временное хранилище клиентского уровня. -
В режиме
MANUALнеобходимо сделать это в листенереFileUploadSucceedListener.
Режим
IMMEDIATEвыбирается по умолчанию, когдаFileUploadFieldиспользуется внутриFieldGroup. В противном случае, по умолчанию выбираетсяMANUAL. -
-
XML-атрибуты
uploadButtonCaption,uploadButtonIconиuploadButtonDescriptionпозволяют задать параметры кнопки загрузки.
-
showFileName- управляет отображением имени загруженного файла рядом с кнопкой загрузки. По умолчаниюfalse.
-
showClearButton- управляет видимостью кнопки очистки. По умолчаниюfalse.
-
XML-атрибуты
clearButtonCaption,clearButtonIconиclearButtonDescriptionпозволяют задать параметры кнопки очистки, если она видима.
-
XML-атрибут
accept(и соответствующий методsetAccept()) может быть использован для установки маски расширений файлов в диалоге выбора файла. Пользователи будут иметь возможность выбрать "All files" и загрузить произвольные файлы.Значением атрибута должен быть список масок, разделенных запятыми. Например:
*.jpg,*.png. -
Максимальный размер загружаемого файла определяется свойством приложения cuba.maxUploadSizeMb и по умолчанию равен 20MB. При выборе пользователем файла большего размера выдается соответствующее сообщение и загрузка прерывается.
-
XML-атрибут
fileSizeLimit(и соответствующий методsetFileSizeLimit()) может быть использован для установки максимально допустимого размера файла. Значением атрибута должно быть целое число для указания количества байт.<upload id="uploadField" fileSizeLimit="2000"/>
-
XML-атрибут
permittedExtensions(и соответствующий методsetPermittedExtensions()) может быть использован для установки "белого списка" допустимых расширений загружаемых файлов.Значением атрибута должен быть набор расширений с лидирующими точками, разделенных запятыми. Например:
uploadField.setPermittedExtensions(Sets.newHashSet(".png", ".jpg"));
-
dropZone- используется для указания BoxLayout, который будет использован в качестве целевой площадки для перетаскивания файлов извне браузера. Зона перетаскивания может занимать всю площадь диалогового окна. Выбранный контейнер будет подсвечиваться, когда пользователь переносит над ним файлы, без наведения файла контейнер не отображается.<layout spacing="true" width="100%"> <vbox id="dropZone" height="AUTO" spacing="true"> <textField id="textField" caption="Title" width="100%"/> <textArea id="textArea" caption="Description" width="100%" rows="5"/> <checkBox caption="Is reference document" width="100%"/> <upload id="upload" dropZone="dropZone" showClearButton="true" showFileName="true"/> </vbox> <hbox spacing="true"> <button caption="mainMsg://actions.Apply"/> <button caption="mainMsg://actions.Cancel"/> </hbox> </layout>
Чтобы сделать область dropZone статической и отображать её постоянно, необходимо назначить её контейнеру готовый стиль
dropzone-container. В этом случае контейнер необходимо оставить пустым, поместив в него только текстовый компонентlabel:<layout spacing="true" width="100%"> <textField id="textField" caption="Title" width="100%"/> <checkBox caption="Is reference document" width="100%"/> <upload id="upload" dropZone="dropZone" showClearButton="true" showFileName="true"/> <vbox id="dropZone" height="150px" spacing="true" stylename="dropzone-container"> <label stylename="dropzone-description" value="Drop file here" align="MIDDLE_CENTER"/> </vbox> <hbox spacing="true"> <button caption="mainMsg://actions.Apply"/> <button caption="mainMsg://actions.Cancel"/> </hbox> </layout>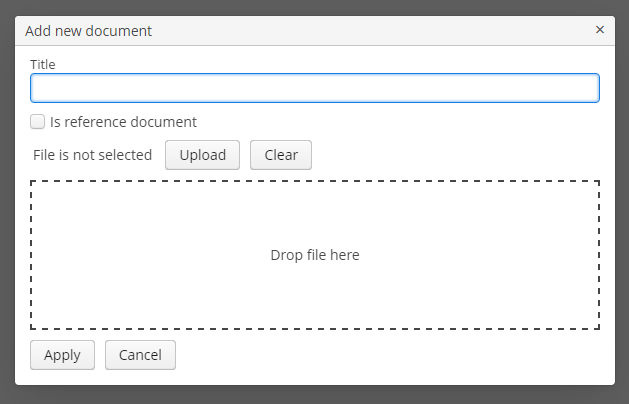
-
pasteZone- используется для указания контейнера, который будет использован для обработки нажатий горячих клавиш вставки, когда текстовое поле внутри этого контейнера находится в фокусе. Это свойство поддерживается семейством браузеров на базе Chromium.<upload id="uploadField" pasteZone="vboxId" showClearButton="true" showFileName="true"/>
В руководстве Working with Images приведены более сложные примеры работы с загруженными файлами.
- Атрибуты upload
-
accept - align - caption - captionAsHtml - clearButtonCaption - clearButtonDescription - clearButtonIcon - contextHelpText - contextHelpTextHtmlEnabled - css - dataContainer - description - descriptionAsHtml - dropZone - editable - enable - box.expandRatio - fileSizeLimit - fileStoragePutMode - height - htmlSanitizerEnabled - icon - id - pasteZone - permittedExtensions - property - showClearButton - showFileName - stylename - tabIndex - uploadButtonCaption - uploadButtonDescription - uploadButtonIcon - visible - width
- API
-
addValueChangeListener - commit - discard - isModified - setContextHelpIconClickHandler
- События upload
-
AfterValueClearEvent - BeforeValueClearEvent - FileUploadErrorEvent - FileUploadFinishEvent - FileUploadStartEvent - FileUploadSucceedEvent - ValueChangeEvent
3.5.2.1.18. Filter
В этом разделе:
Компонент Filter − универсальное средство фильтрации списков сущностей, извлекаемых из базы данных для отображения в табличном виде. Компонент позволяет производить быструю фильтрацию данных по произвольному набору условий, а также создавать фильтры для многократного использования.
Filter должен быть связан с загрузчиком данных, заданным для CollectionContainer или KeyValueCollectionContainer. Загрузчик должен содержать запрос на JPQL. Фильтр действует путем модификации этого запроса в соответствии с критериями, заданными пользователем. Таким образом, фильтрация осуществляется на уровне БД при выполнении транслированного из JPQL в SQL запроса, и на Middleware и клиентский уровень загружаются только отобранные данные.
Использование фильтра
Типичный фильтр выглядит следующим образом:
По умолчанию, компонент находится в режиме быстрой фильтрации. Это означает, что пользователь может добавить набор условий для однократного поиска данных. После закрытия экрана просмотра экземпляров сущности условия будут удалены.
Для того чтобы создать быстрый фильтр, нажмите на ссылку Add search condition (Добавить условие поиска). Отобразится экран выбора условий:
Рассмотрим возможные типы условий:
-
Properties (Атрибуты) – атрибуты данной сущности и связанных с ней сущностей. Отображаются персистентные атрибуты, явно заданные в элементе
propertyXML-описателя фильтра, либо соответствующие правилам, указанным в элементе properties. -
Custom conditions (Специальные условия) – условия, заданные разработчиком в элементах
customXML-дескриптора фильтра. -
Create new (Создать новое) – позволяет создать новое произвольное условие на JPQL. Данный пункт доступен пользователю, если у него есть специфическое разрешение
cuba.gui.filter.customConditions.
Выбранные условия отображаются в верхней части панель фильтра. Рядом с каждым условием находится кнопка  , позволяющая удалить их из набора.
, позволяющая удалить их из набора.
Быстрый фильтр можно сохранить для повторного использования в дальнейшем. Для этого нажмите на кнопку настроек фильтра и выберите Save/Save as (Сохранить/Сохранить как). Во всплывающем окне задайте имя нового фильтра:
Фильтр будет сохранен в выпадающем меню кнопки Search (Поиск).
Пункт меню Reset filter (Сбросить фильтр) позволяет сбросить все текущие условия поиска.
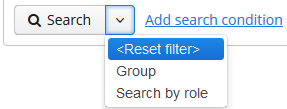
Кнопка настроек фильтра содержит выпадающий список опций для управления фильтром:
-
Save (Сохранить) – сохранить изменения в текущем фильтре.
-
Save with values (Сохранить со значениями) – сохранить изменения в текущем фильтре, использовав значения в редакторах параметров фильтра как значения по умолчанию.
-
Save as (Сохранить как) – сохранить фильтр под новым именем.
-
Edit (Редактировать) – открыть редактор фильтра (см. ниже).
-
Make default (Установить по умолчанию) – установить фильтр по умолчанию для данного экрана. Фильтр будет автоматически выводиться на панель при каждом открытии экрана.
-
Remove (Удалить) – удалить текущий фильтр.
-
Pin applied (Закрепить) – использовать результаты последнего поиска для последовательной фильтрации данных (см. Последовательное наложение фильтров).
-
Save as search folder (Сохранить как папку поиска) – создать папку поиска на основе текущего фильтра.
-
Save as application folder (Сохранить как папку приложения) – создать папку приложения на основе текущего фильтра. Эта опция доступна только пользователям со специфическим разрешением
cuba.gui.appFolder.global.
Опция Edit открывает редактор фильтра, который дает возможность расширенной настройки текущего фильтра:
Название фильтра указывается в поле Filter name (Имя фильтра). Это имя будет отображаться в списке доступных фильтров для текущего экрана.
Фильтр можно сделать global (то есть доступным для всех пользователей) с помощью установки флажка Available for all users (Общий) для всех пользователей и global default с помощью флажка Global default. Для этих операций пользователю требуется специфическое разрешение CUBA > Фильтр > Создание/изменение глобальных фильтров. Если фильтр помечен как global default, то он будет автоматически выбран при открытии экрана пользователями. Каждый пользователь может установить свой собственный фильтр по умолчанию с помощью флажка Default (По умолчанию). Эта настройка имеет приоритет над global default.
В дереве содержатся условия фильтра. Условия можно добавлять с помощью кнопки Add (Добавить) менять местами при помощи кнопок  /
/ или удалять с помощью кнопки Remove (Удалить).
или удалять с помощью кнопки Remove (Удалить).
Группировку условий по И или ИЛИ можно добавить с помощью соответствующих кнопок. Все добавленные на верхний уровень (то есть без явной группировки) условия объединяются по И.
При выборе условия в дереве в правой части редактора открывается список его свойств.
С помощью соответствующих флажков можно сделать выбранное в таблице условие скрытым или обязательным для заполнения. Параметр скрытого условия не отображается пользователю, поэтому он должны быть введен во время редактирования фильтра.
Свойство Width позволяет задать ширину поля ввода параметра для текущего условия. По умолчанию, условия на панели фильтров отображаются в три колонки. Ширина поля равняется количеству колонок, которое оно может занять (1, 2 или 3).
Значение параметра текущего условия по умолчанию можно задать в поле Default value (Значение по умолчанию).
Специальный заголовок условия фильтрации можно задать в поле Caption (Заголовок).
Поле Operation позволяет выбрать оператор поиска. Список доступных операторов зависит от типа атрибута.
При поиске по атрибуту сущности с типом DateTime и без аннотации @IgnoreUserTimeZone по умолчанию будет учитываться часовой пояс текущего пользователя. Чтобы учитывать часовой пояс для атрибута с типом Date, необходимо установить флаг Use time zone в редакторе нового условия.
Описание компонента Filter
XML-имя компонента: filter.
Пример объявления компонента в XML-дескрипторе экрана:
<data readOnly="true">
<collection id="carsDc" class="com.haulmont.sample.core.entity.Car" view="carBrowse">
<loader id="carsDl" maxResults="50">
<query>
<![CDATA[select e from sample_Car e order by e.createTs]]>
</query>
</loader>
</collection>
</data>
<layout expand="carsTable" spacing="true">
<filter id="filter" applyTo="carsTable" dataLoader="carsDl">
<properties include=".*"/>
</filter>
<table id="carsTable" width="100%" dataContainer="carsDc">
<columns>
<column id="vin"/>
<column id="colour"/>
<column id="model"/>
</columns>
<rowsCount/>
</table>
</layout>Здесь data container содержит коллекцию экземпляров сущности Car. Загрузчик загружает коллекцию используя JPQL-запрос. Запрос модифицируется компонентом filter, который соединен с загрузчиком с помощью атрибута dataLoader. Данные отображаются компонентом Table, связанным с контейнером.
Элемент filter может содержать вложенные элементы. Все они описывают условия, доступные пользователю для выбора в диалоге добавления условий:
-
properties- позволяет сделать доступными сразу несколько атрибутов сущности. Данный элемент может иметь следующие атрибуты:-
include- обязательный атрибут, содержит регулярное выражение, которому должно соответствовать имя атрибута сущности.
-
exclude- содержит регулярное выражение, при соответствии которому атрибут сущности исключается из ранее включенных с помощьюinclude.
-
excludeProperties– содержит список атрибутов, разделённых запятыми, которые должны быть исключены из фильтрации. В отличие отexclude, этот атрибут поддерживает путь по графу сущностей для указания каждого свойства в списке. Например,customer.name.
-
excludeRecursively- указывает, должны ли атрибуты, перечисленные вexcludeProperties, быть рекурсивно исключены из полного графа сущностей. Если установленоtrue, указанный атрибут и все одноименные атрибуты вглубь по графу сущностей не будут использоваться в фильтре.Пример:
<filter id="filter" applyTo="ordersTable" dataLoader="ordersDl"> <properties include=".*" exclude="(amount)|(id)" excludeProperties="version,createTs,createdBy,updateTs,updatedBy,deleteTs,deletedBy" excludeRecursively="true"/> </filter>Чтобы программно исключить атрибуты из фильтра, используйте метод
setPropertiesFilterPredicate()компонентаFilter:filter.setPropertiesFilterPredicate(metaPropertyPath -> !metaPropertyPath.getMetaProperty().getName().equals("createTs"));
При использовании элемента
propertiesавтоматически игнорируются следующие атрибуты сущности:-
Недоступные в связи с разрешениями подсистемы безопасности.
-
Коллекции (
@OneToMany,@ManyToMany). -
Неперсистентные атрибуты.
-
Атрибуты, не имеющие локализованного названия.
-
Атрибуты, аннотированные
@SystemLevel. -
Атрибуты типа
byte[]. -
Атрибут
version.
-
-
property- явно включает атрибут сущности по имени. Данный элемент может иметь следующие атрибуты:-
name- обязательный атрибут, содержит имя включаемого атрибута сущности. Может быть путем (через ".") по графу сущностей. Например:<filter id="transactionsFilter" dataLoader="transactionsDl" applyTo="table"> <properties include=".*" exclude="(masterTransaction)|(authCode)"/> <property name="creditCard.maskedPan" caption="msg://EmbeddedCreditCard.maskedPan"/> <property name="creditCard.startDate" caption="msg://EmbeddedCreditCard.startDate"/> </filter>
-
caption- локализованное название атрибута сущности для отображения условия фильтра. Как правило, представляет собой строку с префиксомmsg://по правилам MessageTools.loadString().Если в атрибуте
nameуказан путь (через ".") по графу сущностей, то атрибутcaptionявляется обязательным.
-
paramWhere− задает выражение на JPQL для отбора списка значений параметра условия, если параметр является связанной сущностью. Вместо алиаса сущности параметра в выражении нужно использовать метку (placeholder){E}.Например, предположим, что сущность
Carимеет ссылку на сущностьModel. Тогда список возможных значений параметра может быть ограничен только моделямиAudi:<filter id="carsFilter" dataLoader="carsDl"> <property name="model" paramWhere="{E}.manufacturer = 'Audi'"/> </filter>В выражении JPQL можно использовать параметры экрана, атрибуты сессии, а также компоненты экрана, в том числе отображающие другие параметры. Правила задания параметров запроса описаны в Dependencies Between Data Components и Запросы в CollectionDatasourceImpl.
Пример использования параметра сессии и параметра экрана:
{E}.createdBy = :session$userLogin and {E}.name like :param$groupNameИспользуя
paramWhereможно вводить зависимости между параметрами. Например, предположим, чтоManufacturerявляется отдельной сущностью. То естьCarссылается наModel, которая в свою очередь ссылается наManufacturer. Тогда для фильтра поCarможно создать два условия: первое для выбораManufacturerи второе для выбораModel. Чтобы ограничить список моделей выбранным перед этим производителем, добавьте в выражениеparamWhereпараметр:{E}.manufacturer.id = :component$filter.model_manufacturer90062Здесь параметр ссылается на компонент, отображающий параметр Manufacturer. Имя компонента, отображающего параметр условия, можно узнать, вызвав контекстное меню на строке таблицы условий в редакторе фильтра:
-
paramView− задает представление, с которым будет загружаться список значений параметра условия, если параметр является связанной сущностью. Например,_local. Если не указано, используется_minimal.
-
-
custom- элемент, определяющий произвольное условие. Содержимым элемента должно быть выражение на JPQL (возможно использование JPQL Macros), которое будет добавлено в условиеwhereзапроса контейнера данных. Вместо алиаса отбираемой сущности в выражении нужно использовать метку (placeholder){E}. Параметр условия может быть только один, и если он есть, обозначается символом?.Значение условия может содержать спецсимволы, например "%" или "_" для оператора "like". Если вам нужно экранировать эти символы, добавьте в условие
escape '<char>', например:{E}.name like ? escape '\'Тогда если в значении параметра условия будет передано
foo\%, поиск будет интерпретировать "%" как символ в имени а не как спецсимвол.Пример фильтра с произвольными условиями:
<filter id="carsFilter" dataLoader="carsDl"> <properties include=".*"/> <custom name="vin" paramClass="java.lang.String" caption="msg://vin"> {E}.vin like ? </custom> <custom name="colour" paramClass="com.company.sample.entity.Colour" caption="msg://colour" inExpr="true"> ({E}.colour.id in (?)) </custom> <custom name="repair" paramClass="java.lang.String" caption="msg://repair" join="join {E}.repairs cr"> cr.description like ? </custom> <custom name="updateTs" caption="msg://updateTs"> @between({E}.updateTs, now-1, now+1, day) </custom> </filter>Созданные
customусловия отображаются в секции Специальные условия диалога добавления условий:
Атрибуты элемента
custom:-
name− обязательный атрибут - имя условия.
-
caption− обязательный атрибут - локализованное название условия. Как правило, представляет собой строку с префиксомmsg://по правилам MessageTools.loadString().
-
paramClass− Java-класс параметра условия. Если параметр отсутствует, то данный атрибут не обязателен.
-
inExpr− должен быть установлен вtrue, если выражение JPQL содержит условиеin (?). При этом пользователь будет иметь возможность ввести несколько значений параметра данного условия.
-
join− необязательный атрибут для задания строки, которая будет добавлена в секциюfromзапроса контейнера данных. Это может потребоваться для создания условия по атрибуту связанной коллекции. Значение данного атрибута должно включать в себя предложенияjoinилиleft join.Например, предположим что сущность
Carимеет атрибутrepairs, который представляет собой коллекцию экземпляров связанной сущностиRepair. Тогда для фильтрацииCarпо атрибутуdescriptionсущностиRepairможно написать следующее условие:<filter id="carsFilter" dataLoader="carsDl"> <custom name="repair" caption="msg://repair" paramClass="java.lang.String" join="join {E}.repairs cr"> cr.description like ? </custom> </filter>При использовании такого условия исходный запрос контейнера:
select c from sample_Car c order by c.createTsбудет трансформирован в следующий:
select c from sample_Car c join c.repairs cr where (cr.description like ?) order by c.createTsКроме того, есть возможность создать произвольное условие, содержащее несвязанную сущность, и использовать эту сущность далее в секции
whereусловия. В таком случае следует использовать", "вместо предложенийjoinилиleft joinв значении атрибутаjoin.Ниже приведен пример произвольного условия для поиска автомобилей, которые были назначены водителям после указанной даты:
<filter id="carsFilter" dataLoader="carsLoader" applyTo="carsTable"> <custom name="carsFilter" caption="carsFilter" paramClass="java.util.Date" join=", ref$DriverAllocation da"> da.car = {E} and da.createTs >= ? </custom> </filter> -
paramWhere− задает выражение на JPQL для отбора списка значений параметра условия, если параметр является связанной сущностью. См. описание одноименного атрибута элементаproperty. -
paramView− задает представление, с которым будет загружаться список значений параметра условия, если параметр является связанной сущностью. См. описание одноименного атрибута элементаproperty.
-
Атрибуты filter:
-
editable- если значение этого атрибута равноfalse, то кнопка Фильтр скрывается.
-
applyImmediately– указывает, когда применять фильтр. Если значение атрибутаfalse, то фильтр будет применен только после нажатия кнопки Search. Если значение атрибутаtrue, фильтр применяется сразу после изменения условий фильтрации. Общие случаи, когда фильтр применяется немедленно:-
После изменения значения поля ввода параметра условия;
-
После изменения условия поиска;
-
После удаления условия из фильтра;
-
После изменения значения в поле Show rows;
-
При нажатии на кнопку OK в диалоговом окне редактора фильтра;
-
После очистки всех значений.
В режиме немедленного исполнения вместо кнопки Search будет использоваться кнопка Refresh.
Атрибут
applyImmediatelyимеет приоритет над свойством приложения cuba.gui.genericFilterApplyImmediately. -
-
manualApplyRequired− определяет, в какой момент будет применяться фильтр. Если значение атрибута равноfalse, то фильтр (пустой или по умолчанию) будет применяться сразу при открытии экрана. Это означает, что контейнер данных будет обновлен и связанные компоненты (например,Table) отобразят данные. Если значение атрибута равноtrue, то фильтр будет применяться только после нажатия на кнопку Search.Данный атрибут имеет приоритет над свойством приложения cuba.gui.genericFilterManualApplyRequired.
-
useMaxResults− ограничивает размер страницы загружаемых в контейнер данных экземпляров сущности. По умолчаниюtrue.Если значение этого атрибута равно
false, то фильтр не будет отображать поле Show rows. Количество записей в контейнере (и соответственно, показываемых таблицей) будет ограничено только параметромMaxFetchUIмеханизма статистики сущностей, по умолчанию - 10000.Если данный атрибут не указан, или равен
true, то поле Show rows отображается, если у пользователя также есть специфическое разрешение cuba.gui.filter.maxResults. Если разрешениеcuba.gui.filter.maxResultsотсутствует, то фильтр будет принудительно отбирать только первые N строк без возможности пользователя отключить это или указать другое N. Число N определяется параметрамиFetchUI,DefaultFetchUI, получаемыми из механизма статистики сущностей.На рисунке далее показан вид фильтра со значением атрибута
useMaxResults="true", запретом специфического разрешенияcuba.gui.filter.maxResultsи параметромDefaultFetchUI=2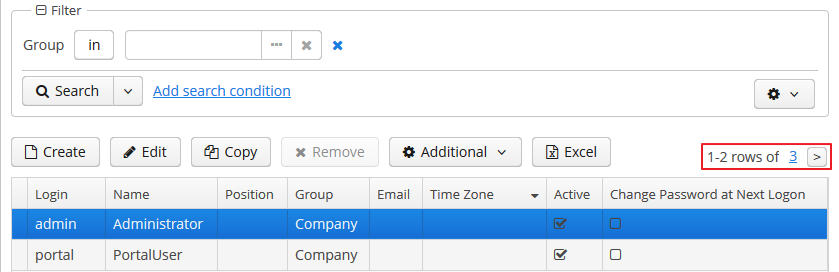
-
textMaxResults- позволяет использовать текстовое поле вместо выпадающего списка в качестве поля Show rows. По умолчаниюfalse.
-
folderActionsEnabled− при указании значенияfalseпозволяет скрыть следующие действия с фильтром: Сохранить как папку поиска, Сохранить как папку приложения. По умолчанию значение атрибута равноtrue, действия Сохранить как папку поиска, Сохранить как папку приложения доступны.
-
applyTo− необязательный атрибут, содержит идентификатор компонента, с которым связан фильтр. Используется в случае, когда необходимо иметь доступ к представлениям связанного компонента-таблицы. Например, сохраняя фильтр как папку поиска или как папку приложения, можно указать, какое представление будет применяться при просмотре этой папки.
-
caption- позволяет задать заголовок панели фильтров.
-
columnsCount- задает количество колонок с условиями для конкретного фильтра. Значение по умолчанию - 3.
-
controlsLayoutTemplate- определяет расположение элементов внутри фильтра. Формат шаблона можно увидеть в описании свойства приложения cuba.gui.genericFilterControlsLayout.
-
defaultMode- задает режим фильтра при открытии экрана. Возможные значения:genericиfts. При указании значенияftsфильтр будет открыт в режиме полнотекстового поиска (если сущность индексируется). Значение по умолчанию -generic.
-
modeSwitchVisible- определяет видимость чек-бокса для перевода фильтра в режим полнотекстового поиска. Если полнотекстовый поиск невозможен, то чек-бокс будет невидим независимо от указанного значения. Возможные значения атрибута:trueиfalse.
Методы интерфейса Filter:
-
setBorderVisible()- определяет видимость границы фильтра. Значение по умолчанию -true.
Слушатели компонента Filter:
-
ExpandedStateChangeListener- позволяет отслеживать изменения состояния компонента (свёрнутое/развёрнутое).
-
FilterEntityChangeListener- срабатывает при первом выборе фильтра и дальнейшем выборе сохранённых фильтров.
Внешний вид компонента Filter можно настроить с помощью переменных SCSS с префиксом $cuba-filter-*. Эти переменные можно изменить в визуальном редакторе после расширения темы или создания новой темы.
- Атрибуты filter
-
applyImmediately - applyTo - caption - captionAsHtml - columnsCount - controlsLayoutTemplate - css - dataLoader - defaultMode - description - descriptionAsHtml - editable - enable - box.expandRatio - folderActionsEnabled - htmlSanitizerEnabled - id - manualApplyRequired - margin - modeSwitchVisible - settingsEnabled - stylename - textMaxResults - useMaxResults - visible - width
- Элементы filter
-
custom - properties - property
- Атрибуты properties
- Атрибуты property
-
caption - name - paramView - paramWhere
- Атрибуты custom
-
caption - name - inExpr - join - paramClass - paramView - paramWhere
- API
-
addExpandedStateChangeListener - addFilterEntityChangeListener - applySettings - getMargin - saveSettings - setMargin
Права пользователей
-
Для создания/изменения/удаления глобальных (доступных всем пользователям) фильтров пользователь должен иметь разрешение
cuba.gui.filter.global. -
Для создания/изменения
customусловий пользователь должен иметь разрешениеcuba.gui.filter.customConditions. -
Чтобы иметь возможность изменять максимальное количество строк на странице таблицы с помощью флажка и поля Show rows пользователь должен иметь разрешение
cuba.gui.filter.maxResults. См. также атрибут фильтра useMaxResults.
Информация о том, как настраивать специфические разрешения, приведена в руководстве Подсистема безопасности.
Внешние параметры для управления фильтрами
-
Общесистемные параметры
Следующие свойства приложения влияют на поведение фильтров:
-
cuba.gui.genericFilterApplyImmediately позволяет управлять режимом фильтрации по умолчанию. См. также атрибут фильтра applyImmediately.
-
cuba.gui.genericFilterManualApplyRequired − позволяет отключить автоматическое применение фильтра (то есть загрузку данных) сразу при открытии экрана. См. также атрибут фильтра manualApplyRequired.
-
cuba.gui.genericFilterChecking − позволяет включить проверку заполненности хотя-бы одного условия перед применением фильтра.
-
cuba.gui.genericFilterControlsLayout − определяет расположение элементов внутри фильтра.
-
cuba.allowQueryFromSelected позволяет отключить механизм последовательного наложения фильтров.
-
cuba.gui.genericFilterColumnsCount - задает количество колонок по умолчанию для размещения условий фильтра. См также атрибут фильтра columnsCount.
-
cuba.gui.genericFilterConditionsLocation - задает расположение панели условий.
-
cuba.gui.genericFilterPopupListSize - задает количество позиций в выпадающем списке кнопки Search.
-
cuba.gui.genericFilterPropertiesHierarchyDepth - oпределят глубину вложенности атрибутов сущности в диалоговом окне "Добавить условие".
-
cuba.gui.genericFilterTrimParamValues - определяет, нужно ли обрезать пробелы в начале и конце строки текстового поиска.
-
-
Параметры вызова экрана
При вызове экрана можно указать, какой фильтр и с какими параметрами должен быть применен сразу после открытия экрана. Для этого фильтр должен быть заранее создан, сохранен в базе данных, и соответствующая запись в таблице
SEC_FILTERдолжна иметь заполненное полеCODE. Параметры вызова экрана задаются в конфигурационном файлеweb-menu.xml.Чтобы сохранить фильтр в базе данных, необходимо добавить скрипт вставки фильтра в скрипт
30.create-db.sqlсущности. Для генерации скрипта найдите фильтр в справочнике Entity Inspector меню Administration, в контекстном меню выберите System Information, нажмите на кнопку Script for insert и скопируйте текст скрипта.Теперь можно добавить скрипт к экрану. Для указания кода фильтра в экран следует передать параметр с именем, равным идентификатору компонента фильтра в данном экране. Значением параметра должен быть код фильтра, который нужно установить и применить.
Для установки значений параметров фильтра в экран нужно передать параметры с именами, равными именам параметров, и значения в виде строк.
Пример описателя пункта главного меню, устанавливающего в открываемом экране
sample_Car.browseв компонентеcarsFilterфильтр с кодомFilterByVIN, с подстановкой в параметр условияcomponent$carsFilter.vin79216значенияTMA:<item id="sample_Car.browse"> <param name="carsFilter" value="FilterByVIN"/> <param name="component$carsFilter.vin79216" value="TMA"/> </item>Следует отметить, что фильтр с установленным полем
CODEобладает особыми свойствами:-
Его не могут редактировать пользователи.
-
Название такого фильтра можно отображать на нескольких языках. Для этого в главном пакете сообщений приложения должна быть строка с ключом, равным коду фильтра.
-
Последовательное наложение фильтров
При включенном свойстве приложения cuba.allowQueryFromSelected в пользовательском интерфейсе компонента можно закреплять последний примененный фильтр и текущие результаты фильтрации. После этого можно выбрать другой фильтр или параметры и применить их на уже выбранных записях.
Данный подход позволяет решить две проблемы:
-
Декомпозировать сложные фильтры.
-
Применять фильтры на записи, отобранные с помощью папок приложения или поиска.
Чтобы применить этот механизм в пользовательском интерфейсе, выберите и примените один из фильтров. Затем нажмите на кнопку настроек фильтра и выберите Pin applied (Закрепить). Фильтр закрепится в верхней части панели фильтров. Далее можно применить к выбранным записям другой фильтр. Так последовательно можно накладывать друг на друга любое количество фильтров. Также фильтры можно удалять последовательно с помощью кнопки  .
.
Механизм последовательного наложения фильтров основан на возможности DataManager выполнять последовательные запросы.
API для работы с параметрами фильтра
Интерфейс Filter предоставляет методы для установки и чтения значений параметра фильтра из кода контроллера экрана:
-
setParamValue(String paramName, Object value) -
getParamValue(String paramName)
paramName - имя параметра фильтра. Имя параметра фильтра является составной частью имени компонента, отображающего значение параметра фильтра. Как получить имя компонента рассматривалось выше. Имя параметра - это часть имени компонента, находящаяся после последней точки. Например, если имя компонента component$filter.model_manufacturer90062, то имя параметра фильтра model_manufacturer90062.
Обратите внимание, что в обработчике InitEvent контроллера экрана данные методы использовать нельзя, т.к. в этот момент фильтр еще не проинициализирован. Вы можете работать с параметрами фильтра в обработчике BeforeShowEvent.
Режим полнотекстового поиска в фильтре
Если контейнер данных фильтра содержит сущности, индексируемые системой полнотекстового поиска (см. Платформа CUBA. Полнотекстовый поиск), то в фильтре становится доступным режим полнотекстового поиска. Чтобы переключиться в него, используйте флажок Full-Text Search ("Полнотекстовый поиск").
В этом режиме фильтр имеет поля для ввода критериев поиска, и поиск производится по индексируемым подсистемой FTS полям сущности.
Если таблица указана в атрибуте applyTo, становится возможным отобразить информацию, в каких полях сущности было найдено условие поиска. Если свойство приложения cuba.gui.genericFilterFtsDetailsActionEnabled установлено в true, то в таблицу будет добавлено действие Full-Text Search Details. Если кликнуть правой кнопкой мыши на строку таблицы и выбрать данный пункт меню, то появится диалоговое окно, содержащее информацию о деталях полнотекстового поиска.
Если свойство cuba.gui.genericFilterFtsTableTooltipsEnabled установлено в true, то при наведении указателя мыши на строку таблицы во всплывающем окне будет написано, в каких полях сущности было найдено условие поиска. Обратите внимание, что генерация таких всплывающих сообщений может занимать значительное время, по умолчанию она отключена.
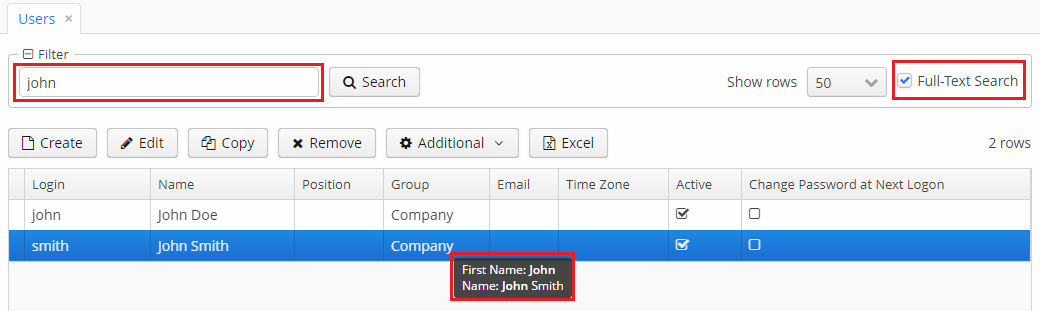
Для скрытия переключателя режима фильтра установите значение false атрибуту фильтра modeSwitchVisible.
Если необходимо, чтобы фильтр по умолчанию открывался в режиме полнотекстового поиска, установите значение fts атрибуту defaultMode.
Полнотекстовый поиск может использоваться совместно с любым количеством условий универсального фильтра:
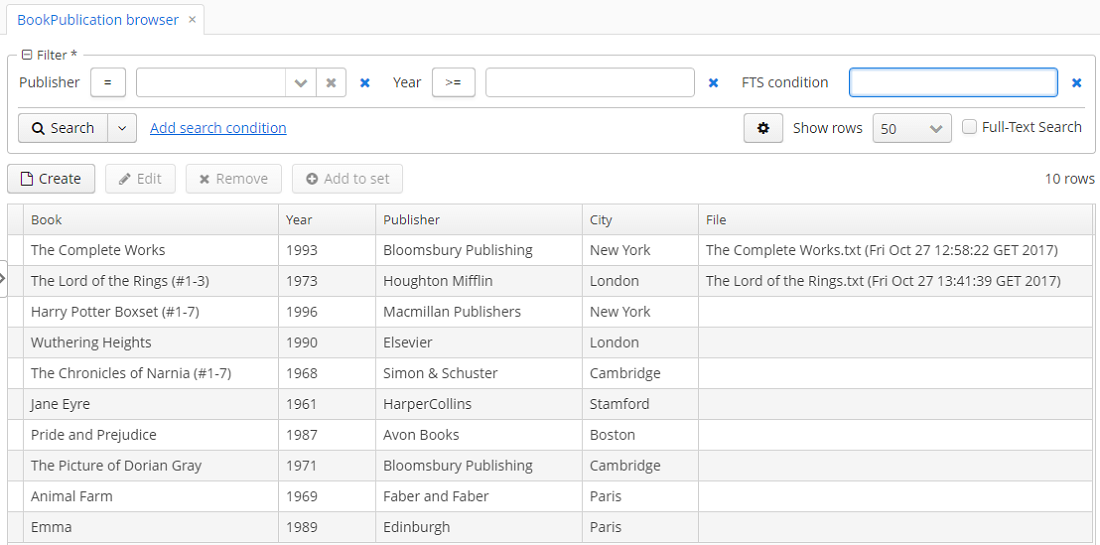
Выбрать условие FTS condition можно в окне выбора условий фильтра.
3.5.2.1.19. Form
Компонент Form предназначен для совместного отображения и редактирования нескольких атрибутов сущности. Он представляет собой простой контейнер, схожий с GridLayout, и может содержать любое количество колонок с полями. Тип полей задаётся декларативно в XML-дескрипторе экрана, заголовки полей располагаются слева от поля. Главное отличие от GridLayout состоит в том, что Form позволяет привязать все вложенные поля к единому data container.
Form используется вместо FieldGroup по умолчанию в стандартных экранах редактирования сущности начиная с версии фреймворка 7.0.
XML-имя компонента: form
Пример описания группы полей в XML-дескрипторе экрана:
<data>
<instance id="orderDc" class="com.company.sales.entity.Order" view="order-edit">
<loader/>
</instance>
</data>
<layout>
<form id="form" dataContainer="orderDc">
<dateField property="date"/>
<textField property="amount" description="Total amount"/>
<pickerField property="customer"/>
<field id="statusField" property="status"/>
</form>
</layout>В данном примере компонент form отображает атрибуты сущности Order, загруженной в контейнер данных orderDc. Вложенные в form элементы определяют визуальные компоненты, связанные с атрибутами сущности. Заголовки полей будут созданы автоматически на основе локализованных имен атрибутов сущности. Вложенные компоненты могут иметь любые собственные атрибуты, такие как description, показанный в примере.
Кроме конкретных визуальных компонентов, в форме можно объявлять обобщенные поля с помощью элемента field. Фреймворк выберет подходящий визуальный компонент на основе соответствующего полю атрибута сущности и имеющихся стратегий генерации компонентов. Элемент field может иметь общие атрибуты, такие как description, contextHelpText и т.д.
Для того, чтобы инжектировать некоторый вложенный компонент в контроллер экрана, у него должен быть указан атрибут id. Компонент будет инжектирован с его конкретным типом, например TextField. Если же инжектируется обобщенное поле, заданное элементом field, то его типом будет интерфейс Field, который является суперклассом всех визуальных компонентов, которые могут быть отображены в форме.
Компонент form поддерживает атрибуты colspan и rowspan. Эти атрибуты задают, сколько колонок и строк будет занимать данный вложенный компонент. Например, так можно растянуть поле Field 1 на две колонки:
<form>
<column width="250px">
<textField caption="Field 1" colspan="2" width="100%"/>
<textField caption="Field 2"/>
</column>
<column width="250px">
<textField caption="Field 3"/>
</column>
</form>В результате компоненты будут располагаться следующим образом:

Аналогично, поле Field 1 можно растянуть на две строки:
<form>
<column width="250px">
<textField caption="Field 1" rowspan="2" height="100%"/>
</column>
<column width="250px">
<textField caption="Field 2"/>
<textField caption="Field 3"/>
</column>
</form>В результате компоненты будут располагаться следующим образом:

Атрибуты form:
-
childrenCaptionWidth– позволяет задать фиксированную ширину заголовков всех вложенных колонок и их дочерних полей. Значение-1устанавливает ширину по содержимому (AUTO), то есть по суммарной ширине вложенных компонентов.
-
childrenCaptionAlignment– определяет выравнивание заголовков дочерних компонентов во всех вложенных колонках. Принимает два значения:LEFTиRIGHT. Значение по умолчанию –LEFT. Применяется только в том случае, если атрибут captionPosition имеет значениеLEFT.
-
captionPosition- задаёт положение заголовков полей:TOPилиLEFT.
-
dataContainer- указывает data container для вложенных полей.
Элементы form:
-
column– необязательный элемент, позволяющий располагать поля в несколько колонок. Для этого вложенные элементы должны находиться не непосредственно внутриform, а внутри своегоcolumn. Например:<form id="form" dataContainer="orderDc"> <column width="250px"> <dateField property="date"/> <textField property="amount"/> </column> <column width="400px"> <pickerField property="customer"/> <textArea property="info"/> </column> </form>В данном случае поля будут расположены в две колонки, причём в первой колонке все поля будут шириной
250px, а во второй -400px.Атрибуты
column:-
id– необязательный идентификатор колонки, позволяющий ссылаться на нее в случае расширении экрана.
-
width– задает ширину полей данной колонки. По умолчанию ширина полей -200px. В данном атрибуте ширина может быть задана как в пикселах, так и в процентах от общего размера колонки по горизонтали.
-
childrenCaptionWidth– позволяет задать фиксированную ширину заголовков всех дочерних полей. Значение-1устанавливает ширину по содержимому (AUTO).
-
childrenCaptionAlignment– определяет выравнивание заголовков вложенных полей. Принимает два значения:LEFTиRIGHT. Значение по умолчанию –LEFT. Применяется только в том случае, если атрибут captionPosition имеет значениеLEFT.
-
Методы интерфейса Form:
-
add()- позволяет добавлять одно или несколько полей вFormпрограммно. В качестве параметра принимает экземплярComponent, также можно указать позицию поля, передав индексы колонки и строки с помощью атрибутовcolumnиrow. Кроме того, перегруженный метод принимает параметры rowspan и colspan.Компоненты, добавляемые программно, не привязываются к контейнеру данных
Formавтоматически, поэтому для связывания с данными нужно использовать методsetValueSource()добавляемого компонента.Например, если в XML задана форма с полем
name:<data> <instance id="customerDc" class="com.company.demo.entity.Customer"> <loader/> </instance> </data> <layout> <form id="form" dataContainer="customerDc"> <column> <textField id="nameField" property="name"/> </column> </form> </layout>То можно добавить поле
emailпрограммно в контроллере экрана следующим образом:@Inject private UiComponents uiComponents; @Inject private InstanceContainer<Customer> customerDc; @Inject private Form form; @Subscribe private void onInit(InitEvent event) { TextField<String> emailField = uiComponents.create(TextField.TYPE_STRING); emailField.setCaption("Email"); emailField.setWidthFull(); emailField.setValueSource(new ContainerValueSource<>(customerDc, "email")); form.add(emailField); }
-
setChildrenCaptionAlignment(CaptionAlignment alignment)– задаёт выравнивание заголовков дочерних компонентов во всех столбцах. -
setChildrenCaptionAlignment(int column, CaptionAlignment alignment)– задаёт выравнивание заголовков дочерних компонентов для заданного столбца.
- Атрибуты form
-
align - box.expandRatio - caption - captionAsHtml - captionPosition - childrenCaptionAlignment - childrenCaptionWidth - colspan - contextHelpText - contextHelpTextHtmlEnabled - css - dataContainer - description - descriptionAsHtml - editable - enable - height - htmlSanitizerEnabled - icon - id - responsive - rowspan - stylename - visible - width
- Атрибуты column
-
childrenCaptionAlignment - childrenCaptionWidth - id - width
- API
3.5.2.1.20. GroupTable
Компонент GroupTable - это таблица с возможностью динамической группировки по любому полю. Для того чтобы сгруппировать таблицу по какой-либо колонке, нужно в заголовке таблицы перетащить эту колонку в позицию слева от элемента  . Сгруппированные значения можно разворачивать и сворачивать с помощью кнопок
. Сгруппированные значения можно разворачивать и сворачивать с помощью кнопок  /
/ .
.
XML-имя компонента: groupTable.
Для GroupTable должен быть указан data container с типом CollectionContainer. В противном случае группировка работать не будет.
Пример использования:
<data>
<collection id="ordersDc"
class="com.company.sales.entity.Order"
view="order-with-customer">
<loader id="ordersDl">
<query>
<![CDATA[select e from sales_Order e]]>
</query>
</loader>
</collection>
</data>
<layout>
<groupTable id="ordersTable"
width="100%"
dataContainer="ordersDc">
<columns>
<group>
<column id="date"/>
</group>
<column id="customer"/>
<column id="amount"/>
</columns>
<rowsCount/>
</groupTable>
</layout>group − необязательный элемент, может в единственном экземпляре находиться внутри columns. Содержит набор элементов column, по которым будет выполняться первоначальная группировка при открытии экрана.
В приведенном ниже примере мы будем использовать атрибут includeAll элемента columns совместно с элементом group.
<groupTable id="groupTable"
width="100%"
height="100%"
dataContainer="customersDc">
<columns includeAll="true">
<group>
<column id="address"/>
</group>
<column id="name"
sortable="false"/>
</columns>
</groupTable>Таким образом, для столбца name задаётся специфический атрибут, а GroupTable группируется по столбцу address.
Элемент column может содержать атрибут groupAllowed с булевым значением. С помощью этого атрибута можно запретить пользователю группировать таблицу по данной колонке.
При включенном атрибуте aggregatable таблица отображает результаты агрегации по всем строкам в дополнительной строке вверху, а также результаты агрегации по группам. Отображение агрегации по всем строкам можно отключить, установив false в атрибуте showTotalAggregation.
При включенном атрибуте multiselect клик по строке группировки с зажатой клавишей Ctrl разворачивает группу (если была свёрнута) и применяет выделение ко всем строкам этой группы. При этом, если вся группа выделена, Ctrl+click не снимает выделение со всей группы. Вы по-прежнему можете снять выделение с отдельных строк, пользуясь стандартным поведением клавиши Ctrl.
-
Методы интерфейса
GroupTable: -
-
groupByColumns()- применяет группировку по заданным колонкам.В примере ниже таблица будет сгруппирована сначала по колонке
department, а затем - по колонкеcity:groupTable.groupByColumns("department", "city");
-
ungroupByColumns()- снимает группировку по заданным колонкам.Следующий пример снимет группировку по
department, однако группировка по колонкеcityиз предыдущего примера будет сохранена:groupTable.ungroupByColumns("department");
-
ungroup()- снимает группировку по всем колонкам.
-
Метод
setAggregationDistributionProvider()аналогичен одноименному методу для компонентаTableс той лишь разницей, что при создании провайдера используется объектGroupAggregationDistributionContext<V>, содержащий дополнительно:-
GroupInfo groupInfo– объект с информацией о строке группировки: свойствах колонок, по которым была проведена группировка и их значениях.
-
-
Метод
getAggregationResults()возвращает мэп с результатами агрегации по указанному объекту GroupInfo, где ключи в мэп − идентификаторы столбцов таблицы, а значения − значения агрегации.
-
Метод
setStyleProvider()позволяет задать стиль отображения ячеек таблицы. ДляGroupTableданный метод будет приниматьGroupTable.GroupStyleProvider, который расширяетTable.StyleProvider.GroupStyleProviderимеет специальный метод для стилизации сгрупированных строк с GroupInfo в качестве принимаего параметра. Он будет вызываться для каждой сгруппированной строки вGroupTable.Пример задания стилей:
@Inject private GroupTable<Customer> customerTable; @Subscribe public void onInit(InitEvent event) { customerTable.setStyleProvider(new GroupTable.GroupStyleProvider<Customer>() { @SuppressWarnings("unchecked") @Override public String getStyleName(GroupInfo info) { CustomerGrade grade = (CustomerGrade) info.getPropertyValue(info.getProperty()); switch (grade) { case PREMIUM: return "premium-grade"; case HIGH: return "high-grade"; case STANDARD: return "standard-grade"; } return null; } @Override public String getStyleName(Customer customer, @Nullable String property) { if (Boolean.TRUE.equals(customer.getActive())) { return "active-customer"; } return null; } }); }Далее нужно определить стили в теме приложения. Подробная информация о создании темы находится в Создание темы приложения. Для веб-клиента новые стили определяются в файле
styles.scss. Имена стилей, заданные в контроллере, образуют CSS-селекторы. Например:.active-customer { font-weight: bold; } .premium-grade { background-color: red; color: white; } .high-grade { background-color: green; color: white; } .standard-grade { background-color: blue; color: white; }
-
В остальном функциональность GroupTable аналогична простой таблице Table.
- Атрибуты groupTable
-
align - aggregatable - aggregationStyle - caption - captionAsHtml - columnControlVisible - contextHelpText - contextHelpTextHtmlEnabled - contextMenuEnabled - css - dataContainer - description - descriptionAsHtml - editable - emptyStateLinkMessage - emptyStateMessage - enable - box.expandRatio - height - htmlSanitizerEnabled - id - metaClass - multiLineCells - multiselect - presentations - reorderingAllowed - settingsEnabled - showTotalAggregation - sortable - stylename - tabIndex - textSelectionEnabled - visible - width
- Элементы groupTable
-
actions - buttonsPanel - columns - rows - rowsCount
- Атрибуты columns
- Элементы columns
- Атрибуты column
-
align - caption - captionProperty - collapsed - dateFormat - editable - expandRatio - groupAllowed - id - link - linkInvoke - linkScreen - linkScreenOpenType - maxTextLength - optionsContainer - resolution - sort - sortable - visible - width
- Элементы column
- Атрибуты aggregation
- API
-
addColumnCollapseListener - addSelectionListener - getAggregationResults - groupByColumns - setAggregationDistributionProvider - setClickListener - setEmptyStateLinkClickHandler - setItemDescriptionProvider - setStyleProvider - ungroup - ungroupByColumns
3.5.2.1.21. Image
Компонент Image предназначен для отображения графического содержимого из различных источников. Компонент можно привязать к источнику данных или сконфигурировать программно.
|
Руководство Working with Images in CUBA applications демонстрирует, как использовать изображения в приложениях. |
XML имя компонента: image.
Компонент Image может отображать значение атрибута сущности с типом FileDescriptor или byte[]. Для этого используются атрибуты dataContainer и property, например:
<image id="image" dataContainer="employeeDс" property="avatar"/>В данном случае компонент отображает атрибут avatar сущности Employee, находящейся в контейнере данных employeeDс.
Помимо источников данных, компонент Image может использовать в качестве источника содержимого различные типы ресурсов. Тип ресурса можно указать декларативно с помощью элементов image, перечисленных ниже:
-
classpath- ресурс, расположенный в classpath.<image> <classpath path="com/company/sample/web/screens/myPic.jpg"/> </image>
-
file- файл с изображением.<image> <file path="D:\sample\modules\web\web\VAADIN\images\myImage.jpg"/> </image>
-
relativePath- относительный путь к файлу в каталоге приложения.<image> <relativePath path="VAADIN/images/myImage.jpg"/> </image>
-
theme- ресурс из темы приложения, например:VAADIN/themes/customTheme/some/path/image.png.<image> <theme path="com.company.sample/myPic.jpg"/> </image>
-
url- ресурс, загружаемый по URL.<image> <url url="https://www.cuba-platform.com/sites/all/themes/cuba_adaptive/img/lori.png"/> </image>
Атрибуты image:
-
scaleMode- устанавливает режим масштабирования изображения. Доступны следующие режимы:-
FILL- изображение масштабируется, чтобы заполнить всю область компонента: используется вся ширина и высота компонента. -
CONTAIN- изображение подстраивается под размер компонента с сохранением пропорций, уменьшаясь или растягиваясь по меньшей стороне компонента. -
COVER- изображение масштабируется так, чтобы заполнить всю область компонента, сохраняя при этом соотношения сторон. Если пропорции изображения не совпадают с пропорциями компонента, то изображение будет обрезано по размеру. -
SCALE_DOWN- изображение изменяет размер, сравнивая разницу междуNONEиCONTAIN, для того, чтобы найти наименьший конкретный размер объекта. -
NONE- изображение сохранит свой исходный размер, размер компонента будет равен размеру изображения.
-
-
alternateText- устанавливает альтернативный текст на случай, если ресурс недоступен или не задан.<image id="image" alternateText="logo"/>
Параметры ресурсов image:
-
bufferSize- размер буфера, используемого для загрузки этого ресурса, в байтах.<image> <file bufferSize="1024" path="C:/img.png"/> </image>
-
cacheTime- время хранения объекта в кэше в миллисекундах.<image> <file cacheTime="2400" path="C:/img.png"/> </image>
-
mimeType- MIME-тип ресурса.<image> <url url="https://avatars3.githubusercontent.com/u/17548514?v=4&s=200" mimeType="image/png"/> </image>
Для программного управления компонентом Image следует использовать следующие методы:
-
setValueSource()- устанавливает для изображения контейнер данных и его атрибут. Поддерживаются только атрибуты типовFileDescriptorиbyte[].Программное указание контейнера данных позволяет, к примеру, отображать изображения в ячейках таблицы:
frameworksTable.addGeneratedColumn("image", entity -> { Image image = uiComponents.create(Image.NAME); image.setValueSource(new ContainerValueSource<>(frameworksTable.getInstanceContainer(entity), "image")); image.setHeight("100px"); return image; });
-
setSource()- устанавливает источник изображения. Метод принимает тип ресурса и возвращает объект ресурса, который может быть сконфигурирован далее. Для каждого типа ресурсов есть свои методы, например,setPath()дляThemeResourceилиsetStreamSupplier()дляStreamResource:Image image = uiComponents.create(Image.NAME); image.setSource(ThemeResource.class) .setPath("images/image.png");или
image.setSource(StreamResource.class) .setStreamSupplier(() -> new FileDataProvider(fileDescriptor).provide()) .setBufferSize(1024);Можно использовать следующие типы ресурсов, реализующие интерфейс
Resource, или расширить их:-
ClasspathResource- для изображений, хранимых в classpath. Этот ресурс также можно использовать декларативно с помощью элементаclasspathкомпонентаimage. -
FileDescriptorResource- для изображений, получаемых изFileStorage. -
FileResource- для изображений, хранимых в файловой системе. Этот ресурс также можно использовать декларативно с помощью элементаfileкомпонентаimage. -
RelativePathResource- для изображений, хранимых в каталоге приложения. Этот ресурс также можно использовать декларативно с помощью элементаrelativePathкомпонентаimage. -
StreamResource- для изображений, получаемых из потока. -
ThemeResource- для изображений темы, например,VAADIN/themes/yourtheme/some/path/image.png. Этот ресурс также можно использовать декларативно с помощью элементаthemeкомпонентаimage. -
UrlResource- для изображений, загружаемых по указанному URL. Этот ресурс также можно использовать декларативно с помощью элементаurlкомпонентаimage.
-
-
createResource()- создаёт ресурс изображения указанного типа. Созданный объект может быть позже передан в методsetSource().FileDescriptorResource resource = image.createResource(FileDescriptorResource.class) .setFileDescriptor(avatar); image.setSource(resource);
-
addClickListener()- добавляет слушатель для отслеживания кликов по области изображения.image.addClickListener(clickEvent -> { if (clickEvent.isDoubleClick()) notifications.create() .withCaption("Double clicked") .show(); });
-
addSourceChangeListener()- добавляет слушатель для отслеживания изменений источника изображения.
- Атрибуты image
-
align - alternateText - caption - captionAsHtml - colspan - contextHelpText - contextHelpTextHtmlEnabled - css - dataContainer - description - descriptionAsHtml - editable - enable - box.expandRatio - height - htmlSanitizerEnabled - icon - id - property - required - requiredMessage - responsive - rowspan - scaleMode - stylename - stylename - visible - width
- Атрибуты ресурсов image
- Элементы image
-
classpath - file - relativePath - theme - url
- API
-
addClickListener - addSourceChangeListener - createResource - setScaleMode - setSource - setValueSource
3.5.2.1.22. Label
Надпись (Label) − текстовый компонент, отображающий статический текст либо значение атрибута сущности.
XML-имя компонента: label
Пример задания надписи с текстом, взятым из пакета локализованных сообщений:
<label value="msg://orders"/>Атрибут value предназначен для задания текста надписи.
В веб-клиенте текст, содержащийся в атрибуте value, будет разбит на несколько строк, если по длине он превысит значение атрибута width. Поэтому для отображения многострочной надписи, достаточно указать абсолютное значение атрибута width. Если текст надписи слишком длинный, а значение атрибута width не определено, то текст будет урезан.
<label value="Label, which should be split into multiple lines"
width="200px"/>Параметры надписи можно задать в контроллере экрана. Для этого необходимо задать компоненту идентификатор, по которому получить ссылку на него в контроллере:
<label id="dynamicLabel"/>@Inject
private Label dynamicLabel;
@Subscribe
protected void onInit(InitEvent event) {
dynamicLabel.setValue("Some value");
}Компонент Label может отображать значение атрибута сущности. Для этого используются атрибуты dataContainer и property. Например:
<data>
<instance id="customerDc" class="com.company.sales.entity.Customer" view="_local">
<loader/>
</instance>
</data>
<layout>
<label dataContainer="customerDc" property="name"/>
</layout>В данном случае компонент отображает атрибут name сущности Customer, находящейся в контейнере данных customerDc.
Атрибут htmlEnabled указывает, каким образом будет рассматриваться значение атрибута value: при htmlEnabled="true" как HTML-код, иначе как строка.
Атрибут htmlSanitizerEnabled разрешает или запрещает санитизацию HTML. Если атрибуты htmlEnabled и htmlSanitizerEnabled установлены в true, то значение атрибута value будет санитизировано.
protected static final String UNSAFE_HTML = "<i>Jackdaws </i><u>love</u> <font size=\"javascript:alert(1)\" " +
"color=\"moccasin\">my</font> " +
"<font size=\"7\">big</font> <sup>sphinx</sup> " +
"<font face=\"Verdana\">of</font> <span style=\"background-color: " +
"red;\">quartz</span><svg/onload=alert(\"XSS\")>";
@Inject
private Label<String> label;
@Subscribe
public void onInit(InitEvent event) {
label.setHtmlEnabled(true);
label.setHtmlSanitizerEnabled(true);
label.setValue(UNSAFE_HTML);
}Значение атрибута htmlSanitizerEnabled имеет приоритет над значением глобального свойства cuba.web.htmlSanitizerEnabled.
- Стили компонента Label
-
В веб-клиенте с темой, основанной на Halo, к компоненту
Labelможно применить заданные стили. Стили задаются в XML-дексрипторе или контроллере экрана с помощью атрибутаstylename:<label value="Label to be styled" stylename="colored"/>Чтобы применить стиль программно, выберите одну из констант класса
HaloThemeс префиксом компонентаLABEL_:label.setStyleName(HaloTheme.LABEL_COLORED);-
bold- жирный шрифт. Подходит для выделения важных текстовых элементов UI.
-
colored- цветной текст.
-
failure- стиль сообщения об ошибке. Добавляет рамку вокруг компонента и значок рядом с текстом. Используется как уведомление рядом с другим компонентом.
-
h1- стиль основных заголовков приложения.
-
h2- стиль заголовков разделов приложения.
-
h3- стиль подзаголовков.
-
h4- стиль подзаголовков.
-
light- облегченный шрифт. Подходит для выделения второстепенных текстовых элементов UI.
-
no-margin- убирает отступы заголовков.
-
spinner- стиль спиннера. Используйте для пустых компонентовLabel, чтобы создать спиннер.
-
success- стиль сообщения об успешном выполнении. Добавляет рамку вокруг компонента и значок рядом с текстом. Используется как уведомление рядом с другим компонентом.
-
- Атрибуты label
-
align - css - dataContainer - description - descriptionAsHtml - enable - box.expandRatio - height - htmlEnabled - htmlSanitizerEnabled - icon - id - property - stylename - value - visible - width
- Элементы label
- Предопределенные стили label
-
bold - colored - failure - h1 - h2 - h3 - h4 - huge - large - light - no-margin - small - spinner - success - tiny
- API
3.5.2.1.23. Link
Ссылка (Link) − компонент-гиперссылка, позволяющая открывать внешние веб-ресурсы.
XML-имя компонента: link
Пример XML-описания компонента link:
<link caption="Link" url="https://www.cuba-platform.com" target="_blank"/>Атрибуты link:
-
url- адрес ресурса.
-
target- для веб-клиента задает способ открытия страницы, аналогичен атрибутуtargetHTML-тега<a>.
-
rel- необязательный атрибут, определяющий отношения между текущим документом и документом, на который ведет ссылка. Он соответствует атрибутуrelHTML-тега<a>.Значение по умолчанию
"noopener noreferrer".-
noopener- указывает, что открываемая страница не должна иметь доступа к родительской вкладке, иными словами, он устанавливает дляwindow.openerзначениеnull. -
noreferrerуказывает, что при открытии ссылки не будут переданы HTTP-заголовки.
-
- Атрибуты link
-
align - caption - captionAsHtml - css - description - descriptionAsHtml - enable - box.expandRatio - htmlSanitizerEnabled - icon - id - rel - stylename - url - target - visible - width
3.5.2.1.24. LinkButton
Кнопка-ссылка (LinkButton) − кнопка, выглядящая как гиперссылка.
XML-имя компонента: linkButton
Кнопка-ссылка может содержать текст или значок (или и то и другое). На рисунке ниже отражены разные виды кнопок.
По умолчанию заголовок кнопки-ссылки разбивается на несколько строк, если по длине он превышает значение атрибута width. Поэтому для отображения многострочного заголовка достаточно указать абсолютное значение атрибута width. Если текст заголовка слишком длинный, а значение атрибута width не определено, то текст будет урезан.
Чтобы отобразить заголовок кнопки-ссылки в одной строке, пользователь может изменить поведение по умолчанию:
-
Создать расширение темы или новую тему.
-
Определить переменную SCSS
$cuba-link-button-caption-wrap:$cuba-link-button-caption-wrap: false
Кнопка-ссылка отличается от обычной кнопки Button только своим внешним видом. Все свойства и поведение идентичны описанным для Button.
Пример XML-описания кнопки-ссылки, вызывающей метод someMethod() контроллера, с надписью (атрибут caption), всплывающей подсказкой (атрибут description) и значком (атрибут icon):
<linkButton id="linkButton"
caption="msg://linkButton"
description="Press me"
icon="SAVE"
invoke="someMethod"/>- Атрибуты linkButton
-
action - align - caption - captionAsHtml - css - description - descriptionAsHtml - enable - box.expandRatio - htmlSanitizerEnabled - icon - id - invoke - stylename - visible - width
3.5.2.1.25. LookupField
Компонент для выбора значения из выпадающего списка. Выпадающий список реализует фильтрацию значений по мере ввода пользователя и постраничный вывод доступных значений.
XML-имя компонента: lookupField.
-
Простейший вариант использования
LookupField- выбор значения перечисления (enum) для атрибута сущности. Например, сущностьRoleимеет атрибутtypeтипаRoleType, который является перечислением. Тогда для редактирования этого атрибута можно использоватьLookupFieldследующим образом:<data> <instance id="roleDc" class="com.haulmont.cuba.security.entity.Role" view="_local"> <loader/> </instance> </data> <layout expand="editActions" spacing="true"> <lookupField dataContainer="roleDc" property="type"/> </layout>Как видно из примера, в экране описывается data container
roleDcдля сущностиRole. В компонентеlookupFieldв атрибуте dataContainer указывается ссылка на источник данных, а в атрибуте property − название атрибута сущности, значение которого должно быть отображено. В данном случае атрибут является перечислением, и в выпадающем списке будут отображены локализованные названия всех значений этого перечисления.
-
Аналогично можно использовать
LookupFieldдля выбора экземпляра связанной сущности. Для формирования списка опций используется атрибут optionsContainer:<data> <instance id="carDc" class="com.haulmont.sample.core.entity.Car" view="carEdit"> <loader/> </instance> <collection id="colorsDc" class="com.haulmont.sample.core.entity.Color" view="_minimal"> <loader id="colorsDl"> <query> <![CDATA[select e from sample_Color e]]> </query> </loader> </collection> </data> <layout> <lookupField dataContainer="carDc" property="color" optionsContainer="colorsDc"/> </layout>В данном случае компонент отобразит имена экземпляров сущности
Color, находящихся в коллекции данныхcolorsDs, а выбранное значение подставится в атрибутcolorсущностиCar, находящейся в контейнереcarDs.С помощью атрибута captionProperty можно указать, какой атрибут сущности использовать вместо имени экземпляра для строковых названий опций.
-
Метод
setOptionCaptionProvider()позволяет задать заголовки для строковых названий опций, отображаемых компонентомLookupField:lookupField.setOptionCaptionProvider((item) -> item.getLocalizedName()); -
Список опций компонента может быть задан произвольно с помощью методов
setOptionsList(),setOptionsMap()иsetOptionsEnum(), либо с помощью XML-атрибутаoptionsContainer.-
Метод
setOptionsList()позволяет программно задать список опций компонента. Для этого объявляем компонент в XML-дескрипторе:<lookupField id="numberOfSeatsField" dataContainer="modelDc" property="numberOfSeats"/>Затем инжектируем компонент в контроллер и в методе
onInit()задаем ему список опций:@Inject protected LookupField<Integer> numberOfSeatsField; @Subscribe public void onInit(InitEvent event) { List<Integer> list = new ArrayList<>(); list.add(2); list.add(4); list.add(5); list.add(7); numberOfSeatsField.setOptionsList(list); }В выпадающем списке компонента отобразятся числа 2, 4, 5, 7. Выбранное число подставится в атрибут
numberOfSeatsсущности, находящейся в контейнере данныхmodelDс.
-
Метод
setOptionsMap()позволяет задать строковые названия и значения опций по отдельности. Например, для описанного в XML-дескрипторе компонентаnumberOfSeatsFieldв методеonInit()контроллера задаем мэп опций:@Inject protected LookupField<Integer> numberOfSeatsField; @Subscribe public void onInit(InitEvent event) { Map<String, Integer> map = new LinkedHashMap<>(); map.put("two", 2); map.put("four", 4); map.put("five", 5); map.put("seven", 7); numberOfSeatsField.setOptionsMap(map); }В выпадающем списке компонента отобразятся строки
two,four,five,seven. Однако значением компонента будет число, соответствующее выбранной строке. Оно и подставится в атрибутnumberOfSeatsсущности, находящейся в контейнере данныхmodelDс.
-
setOptionsEnum()принимает в качестве параметра класс перечисления. Выпадающий список будет содержать локализованные названия значений перечисления, значением компонента будет являться выбранное значение перечисления.
-
-
setPopupWidth()позволяет установить ширину выпадающего списка, которая передается в метод в виде строки. Используя относительное значение (например,"50%"), можно установить ширину выпадающего списка относительно шириныLookupField. По умолчанию эта ширина имеет значениеnull, поэтому ширина выпадающего списка может быть больше ширины компонента, для того чтобы соответствовать содержимому всех отображаемых элементов. Установив значение"100%", ширина выпадающего списка будет равна ширинеLookupField.
-
setOptionStyleProvider()позволяет задать отдельные стили для различных значений в выпадающем списке:lookupField.setOptionStyleProvider(entity -> { User user = (User) entity; switch (user.getGroup().getName()) { case "Company": return "company"; case "Premium": return "premium"; default: return "company"; } });
-
Каждый элемент выпадающего списка может иметь значок слева. Чтобы установить значки, используйте метод
setOptionIconProvider():lookupField.setOptionIconProvider(entity -> { if (entity.getType() == LegalStatus.LEGAL) return "icons/icon-office.png"; return "icons/icon-user.png"; });
При использовании значков в формате SVG необходимо явно указывать их размеры, чтобы избежать наложения:
<svg version="1.1" id="Capa_1" xmlns="http://www.w3.org/2000/svg" xmlns:xlink="http://www.w3.org/1999/xlink" xml:space="preserve" style="enable-background:new 0 0 55 55;" viewBox="0 0 55 55" height="25px" width="25px">
-
Метод
setOptionImageProvider()позволяет задать изображения для опций, отображаемых компонентомLookupField. Этот метод задает функцию, которая принимает один из типов ресурсов.@Inject private LookupField<Customer> lookupField; @Inject private Image imageResource; @Subscribe private void onInit(InitEvent event) { lookupField.setOptionImageProvider(e -> imageResource.createResource(ThemeResource.class).setPath("icons/radio.svg")); } -
Если у компонента
LookupFieldне установлен атрибут required, и если связанный атрибут сущности не объявлен как обязательный, то в списке опций компонента присутствует пустая строка, при выборе которой компонент возвращает значениеnull. Атрибут nullName позволяет задать строку, отображаемую в этом случае вместо пустой. Пример использования:<lookupField dataContainer="carDc" property="colour" optionsContainer="colorsDs" nullName="(none)"/>В данном случае вместо пустой строки отобразится строка
(none), при выборе которой в связанный атрибут сущности подставится значениеnull.При программном задании списка опций методом
setOptionsList()можно одну из опций передать в методsetNullOption(). Тогда при ее выборе пользователем значением компонента будетnull.- Фильтрация опций LookupField:
-
-
С помощью атрибута
filterModeможно задать тип фильтрации опций при вводе пользователя:-
NO− нет фильтрации. -
STARTS_WITH− по началу фразы. -
CONTAINS− по любому вхождению (используется по умолчанию).
-
-
Метод
setFilterPredicate()позволяет настроить способ фильтрации. Предикат проверяет, совпадает ли введённая пользователем строка со заголовком элемента в списке, к примеру:BiFunction<String, String, Boolean> predicate = String::contains; lookupField.setFilterPredicate((itemCaption, searchString) -> predicate.apply(itemCaption.toLowerCase(), searchString));Функциональный интерфейс
FilterPredicateсодержит методtest, который позволяет реализовать более сложную логику фильтрации опций, например, игнорировать специальные символы или надстрочные знаки:lookupField.setFilterPredicate((itemCaption, searchString) -> StringUtils.replaceChars(itemCaption, "ÉÈËÏÎ", "EEEII") .toLowerCase() .contains(searchString));
-
-
Компонент
LookupFieldспособен обрабатывать ввод пользователя при отсутствии подходящей опции в списке. Для этого используется методsetNewOptionHandler(). Например:@Inject private Metadata metadata; @Inject private LookupField<Color> colorField; @Inject private CollectionContainer<Color> colorsDc; @Subscribe protected void onInit(InitEvent event) { colorField.setNewOptionHandler(caption -> { Color color = metadata.create(Color.class); color.setName(caption); colorsDc.getMutableItems() .add(color); colorField.setValue(color); }); }Обработчик новых опций вызывается, если пользователь ввел некоторое значение, не совпадающее ни с одной из опций, и нажал Enter. В данном случае в обработчике создается новый экземпляр сущности
Color, его атрибутnameустанавливается в значение, введенное пользователем, этот экземпляр добавляется в источник данных опций и выбирается в компоненте.Вместо метода
setNewOptionHandler()для обработки ввода пользователя можно использовать XML-атрибутnewOptionHandlerс указанным в нем методом контроллера. Данный метод должен иметь два параметра - первый типаLookupField, второй типаString. В них будут переданы соответственно экземпляр компонента и введенное пользователем значение. АтрибутnewOptionAllowedиспользуется, чтобы разрешить добавление новых опций.
-
XML-атрибут
nullOptionVisibleустанавливает видимость элемента со значением null в списке опций. Может работать только если атрибут required имеет значениеfalse.
-
XML-атрибут
textInputAllowedиспользуется для отключения возможности фильтрации опций с клавиатуры. Это бывает удобно для коротких списков. Значение по умолчанию -true.
-
XML-атрибут
pageLengthпозволяет переопределить количество опций на одной странице выпадающего списка, заданное свойством приложения cuba.gui.lookupFieldPageLength. -
В веб-клиенте с темой, основанной на Halo, к компоненту
LookupFieldможно применить предопределенные стили. Стили задаются в XML-дексрипторе или контроллере экрана с помощью атрибутаstylename:<lookupField id="lookupField" stylename="borderless"/>Чтобы применить стиль программно, выберите одну из констант класса
HaloThemeс префиксом компонентаLOOKUPFIELD_:lookupField.setStyleName(HaloTheme.LOOKUPFIELD_BORDERLESS);Стили компонента LookupField:
-
align-center- выравнивание текста по центру области.
-
align-right- выравнивание текста по правому краю области.
-
borderless- удаляет рамку и фон текстовой области.
-
- Атрибуты lookupField
-
align - caption - captionAsHtml - captionProperty - contextHelpText - contextHelpTextHtmlEnabled - css - dataContainer - description - descriptionAsHtml - editable - enable - box.expandRatio - filterMode - height - htmlSanitizerEnabled - icon - id - inputPrompt - newOptionAllowed - newOptionHandler - nullName - nullOptionVisible - optionsContainer - optionsEnum - pageLength - property - required - requiredMessage - stylename - tabIndex - textInputAllowed - visible - width
- Элементы lookupField
- Предопределенные стили lookupField
-
align-right - align-center - borderless - huge - large - small - tiny
- API
-
addValueChangeListener - commit - discard - isModified - setContextHelpIconClickHandler - setFilterPredicate - setOptionCaptionProvider - setOptionImageProvider - setOptionsEnum - setOptionsList - setOptionsMap - setOptionsStyleProvider - setPopupWidth
3.5.2.1.26. LookupPickerField
Компонент LookupPickerField позволяет отображать экземпляр сущности в текстовом поле, выбирать экземпляр в выпадающем списке и выполнять действия нажатием на кнопки справа.
XML-имя компонента: lookupPickerField.
LookupPickerField является по сути гибридом LookupField и PickerField, поэтому все описанное для этих интерфейсов верно и для него. Исключением является список действий по умолчанию, добавляемых при определении компонента в XML: для LookupPickerField это действия lookup  и
и open  .
.
Пример использования LookupPickerField для выбора значения ссылочного атрибута color сущности Car:
<data>
<instance id="carDc" class="com.haulmont.sample.core.entity.Car" view="carEdit">
<loader/>
</instance>
<collection id="colorsDc" class="com.haulmont.sample.core.entity.Color" view="_minimal">
<loader id="colorsDl">
<query>
<![CDATA[select e from sample_Color e]]>
</query>
</loader>
</collection>
</data>
<layout>
<lookupPickerField dataContainer="carDc" property="color" optionsContainer="colorsDc"/>
</layout>- Атрибуты lookupPickerField
-
align - caption - captionAsHtml - captionProperty - contextHelpText - contextHelpTextHtmlEnabled - css - dataContainer - description - descriptionAsHtml - editable - enable - box.expandRatio - filterMode - height - htmlSanitizerEnabled - icon - id - inputPrompt - metaClass - newOptionAllowed - newOptionHandler - nullName - optionsContainer - pageLength - property - required - requiredMessage - stylename - tabIndex - visible - width
- Элементы lookupPickerField
- Предопределённые стили lookupPickerField
- API
-
addValueChangeListener - commit - discard - isModified - setContextHelpIconClickHandler - setOptionCaptionProvider - setOptionImageProvider - setOptionsStyleProvider - setPopupWidth
3.5.2.1.27. MaskedField
Текстовое поле, в которое данные вводятся в определенном формате. MaskedField удобно использовать, например, для ввода телефонных номеров.
XML-имя компонента: maskedField.
Компонент MaskedField реализован только для блока Web Client.
MaskedField в основном повторяет функциональность TextField, за исключением того, что ему нельзя установить datatype. То есть MaskedField предназначен для работы только с текстом и строковыми атрибутами сущностей. MaskedField имеет следующие специфические атрибуты:
-
mask- задает маску для поля. Чтобы задать маску, используются следующие символы:-
#- цифра -
U- буква верхнего регистра -
L- буква нижнего регистра -
?- буква -
А- буква или цифра -
*- любой символ -
H- hex символ в верхнем регистре -
h- hex символ в нижнем регистре -
~- знак + или -
-
-
valueMode- определяет формат возвращаемого значения (с маской, или без) и может принимать значениеmaskedилиclear.
Пример текстового поля с маской для ввода номеров телефонов:
<maskedField id="phoneNumberField" mask="(###)###-##-##" valueMode="masked"/>
<button id="showPhoneNumberBtn" caption="msg://showPhoneNumberBtn"/>@Inject
private MaskedField phoneNumberField;
@Inject
private Notifications notifications;
@Subscribe("showPhoneNumberBtn")
protected void onShowPhoneNumberBtnClick(Button.ClickEvent event) {
notifications.create()
.withCaption((String) phoneNumberField.getValue())
.withType(Notifications.NotificationType.HUMANIZED)
.show();
}

- Атрибуты maskedField
-
align - caption - captionAsHtml - contextHelpText - contextHelpTextHtmlEnabled - css - dataContainer - description - descriptionAsHtml - editable - enable - box.expandRatio - height - htmlSanitizerEnabled - icon - id - mask - maxLength - property - required - requiredMessage - stylename - tabIndex - trim - valueMode - visible - width
- Элементы maskedField
- API
-
addEnterPressListener - addValueChangeListener - setContextHelpIconClickHandler
3.5.2.1.28. OptionsGroup
Компонент, который обеспечивает выбор из списка опций, используя группу переключателей для выбора единственного значения или группу флажков для выбора нескольких значений.
XML-имя компонента: optionsGroup.
-
Простейший вариант использования
OptionsGroup− выбор значения перечисления (enum) для атрибута сущности. Например, сущностьCustomerимеет атрибутgradeтипаCustomerGrade, который является перечислением. Тогда для редактирования этого атрибута можно использоватьOptionsGroupследующим образом:<data> <instance id="customerDc" class="com.company.app.entity.Customer" view="_local"> <loader/> </instance> </data> <layout> <optionsGroup id="gradeField" property="grade" dataContainer="customerDc"/> </layout>Как видно из примера, в экране описывается data container
customerDcдля сущностиCustomer. В компонентеoptionsGroupв атрибуте dataContainer указывается ссылка на источник данных, а в атрибуте property − название атрибута сущности, значение которого должно быть отображено.В результате компонент примет следующий вид:

-
Список опций компонента может быть задан произвольно с помощью методов
setOptionsList(),setOptionsMap()иsetOptionsEnum(), либо с помощью XML-атрибутовoptionsContainer,optionsEnum.
-
Метод
setOptionsList()позволяет программно задать список опций компонента. Для этого объявляем компонент в XML-дескрипторе:<optionsGroup id="optionsGroupWithList"/>Затем инжектируем компонент в контроллер и в методе
onInit()задаем ему список опций:@Inject private OptionsGroup<Integer, Integer> optionsGroupWithList; @Subscribe protected void onInit(InitEvent event) { List<Integer> list = new ArrayList<>(); list.add(2); list.add(4); list.add(5); list.add(7); optionsGroupWithList.setOptionsList(list); }Компонент примет следующий вид:

При этом метод
getValue()компонента в зависимости от выбранной опции будет возвращатьIntegerзначения 2,4,5,7.
-
Метод
setOptionsMap()позволяет задать строковые названия и значения опций по отдельности. Например, для описанного в XML-дескрипторе компонентаoptionsGroupWithMapв методеonInit()контроллера задаем мэп опций:@Inject private OptionsGroup<Integer, Integer> optionsGroupWithMap; @Subscribe protected void onInit(InitEvent event) { Map<String, Object> map = new LinkedHashMap<>(); map.put("two", 2); map.put("four", 4); map.put("five", 5); map.put("seven", 7); optionsGroupWithMap.setOptionsMap(map); }Компонент примет следующий вид:
При этом метод
getValue()компонента в зависимости от выбранной опции будет возвращатьIntegerзначения 2,4,5,7, а не строки, отображаемые на экране.
-
setOptionsEnum()принимает в качестве параметра класс перечисления. Список опций будет состоять из локализованных названий значений перечисления, значением компонента будет являться выбранное значение перечисления. -
Компонент может брать список опций из источника данных. Для этого используется атрибут optionsContainer. Например:
<data> <collection id="coloursDc" class="com.haulmont.app.entity.Colour" view="_local"> <loader id="coloursLoader"> <query> <![CDATA[select c from app_Colour c]]> </query> </loader> </collection> </data> <layout> <optionsGroup id="coloursField" optionsContainer="coloursDc"/> </layout>В данном случае компонент
coloursFieldотобразит имена экземпляров сущностиColour, находящихся в контейнере данныхcoloursDc, а его методgetValue()вернет выбранный экземпляр сущности.С помощью атрибута captionProperty можно указать, какой атрибут сущности использовать вместо имени экземпляра для строковых названий опций.
-
С помощью атрибута
multiselectможно переключитьOptionsGroupв режим множественного выбора. Еслиmultiselectвключен, то компонент отображается как группа независимых флажков, а значением компонента является список выбранных опций.Например, создадим в XML-дескрипторе экрана компонент:
<optionsGroup id="roleTypesField" multiselect="true"/>И в контроллере зададим для него список опций - значения перечисления
RoleType:@Inject protected OptionsGroup roleTypesField; @Subscribe protected void onInit(InitEvent event) { roleTypesField.setOptionsList(Arrays.asList(RoleType.values())); }Компонент примет следующий вид:
В данном случае метод
getValue()компонента вернет объект типаjava.util.List, содержащий значенияRoleType.READONLYиRoleType.DENYING.Этот пример иллюстрирует также способность компонента
OptionsGroupавтоматически отображать локализованные значения перечислений, входящих в модель данных приложения.Чтобы программно задать выбор некоторых значений
OptionsGroup, нужно передать список значений в форматеjava.util.Listв методsetValue():optionsGroup.setValue(Arrays.asList(RoleType.STANDARD, RoleType.ADMIN));
-
Атрибут
orientationзадает расположение элементов группы. По умолчанию элементы располагаются по вертикали. Значениеhorizontalзадает горизонтальное расположение.
Внешний вид компонента OptionsGroup можно настроить с помощью переменных SCSS с префиксом $cuba-optiongroup-*. Эти переменные можно изменить в визуальном редакторе после расширения темы или создания новой темы.
- Атрибуты optionsGroup
-
align - box.expandRatio - caption - captionAsHtml - captionProperty - colspan - contextHelpText - contextHelpTextHtmlEnabled - css - dataContainer - description - descriptionAsHtml - editable - enable - height - htmlSanitizerEnabled - icon - id - multiselect - optionsContainer - optionsEnum - orientation - property - required - requiredMessage - responsive - rowspan - stylename - tabIndex - visible - width
- Элементы optionsGroup
- API
-
addValueChangeListener - setContextHelpIconClickHandler - setOptionCaptionProvider - setOptionsEnum - setOptionsList - setOptionsMap
3.5.2.1.29. OptionsList
OptionsList представляет собой вариацию компонента OptionsGroup с представлением опций в виде вертикального прокручиваемого списка. Если включена возможность множественного выбора, элементы могут быть выбраны с удерживанием клавиши Ctrl при клике или диапазона при удерживании клавиши Shift.
XML-имя компонента: optionsList.
Компонент OptionsList реализован для блока Web Client.
По умолчанию компонент OptionsList отображает первый пустой элемент в списке опций. Пустой элемент можно скрыть с помощью атрибута nullOptionVisible, установив ему значение false.
С помощью метода addDoubleClickListener() можно добавить слушатель, реагирующий на события двойных кликов по названиям опций компонента – DoubleClickEvent.
optionsList.addDoubleClickListener(doubleClickEvent ->
notifications.create()
.withCaption("Double clicked")
.show());С той же целью вы можете подписаться на событие в контроллере экрана, например:
@Subscribe("optionsList")
private void onOptionsListDoubleClick(OptionsList.DoubleClickEvent event) {
notifications.create()
.withCaption("Double clicked")
.show();
}Единственная разница в API между OptionsList и OptionsGroup заключается в том, что OptionsList не имеет атрибута orientation.
- Атрибуты optionsList
-
align - caption - captionAsHtml - captionProperty - contextHelpText - contextHelpTextHtmlEnabled - css - dataContainer - description - descriptionAsHtml - editable - enable - box.expandRatio - height - htmlSanitizerEnabled - icon - id - multiselect - nullOptionVisible - optionsContainer - optionsEnum - property - required - requiredMessage - stylename - tabIndex - visible - width
- Элементы optionsList
- API
-
addDoubleClickListener - addValueChangeListener - setContextHelpIconClickHandler - setOptionCaptionProvider
3.5.2.1.30. PasswordField
Текстовое поле, которое вместо символов, введенных пользователем, отображает эхо-символы.
XML-имя компонента: passwordField.
PasswordField в основном аналогичен компоненту TextField, за исключением того, что ему нельзя установить datatype. То есть PasswordField предназначен для работы только с текстом и строковыми атрибутами сущностей.
Пример использования:
<passwordField id="passwordField" caption="msg://name"/>
<button id="showPasswordBtn" caption="msg://buttonsName"/>@Inject
private PasswordField passwordField;
@Inject
private Notifications notifications;
@Subscribe("showPasswordBtn")
protected void onShowPasswordBtnClick(Button.ClickEvent event) {
notifications.create()
.withCaption(passwordField.getValue())
.show();
}
Атрибут autocomplete позволяет включить сохранение паролей в веб браузере. По умолчанию отключено.
Атрибут capsLockIndicator принимает id компонента CapsLockIndicator, который отображает состояние клавиши Caps Lock при вводе пароля. Состояние Caps Lock отслеживается только тогда, когда поле passwordField находится в фокусе. Когда поле теряет фокус, статус Caps Lock автоматически становится "off".
Пример:
<passwordField id="passwordField"
capsLockIndicator="capsLockIndicator"/>
<capsLockIndicator id="capsLockIndicator"
align="MIDDLE_CENTER"
capsLockOffMessage="Caps Lock is OFF"
capsLockOnMessage="Caps Lock is ON"/>- Атрибуты passwordField
-
align - autocomplete - capsLockIndicator - caption - captionAsHtml - contextHelpText - contextHelpTextHtmlEnabled - css - dataContainer - description - descriptionAsHtml - editable - enable - box.expandRatio - height - htmlSanitizerEnabled - icon - id - maxLength - property - required - requiredMessage - stylename - tabIndex - visible - width
- Элементы passwordField
- API
3.5.2.1.31. PickerField
PickerField позволяет отображать экземпляр сущности в текстовом поле и выполнять действия нажатием на кнопки справа.

XML-имя компонента: pickerField.
-
Как правило,
PickerFieldиспользуется для работы со ссылочными атрибутами сущностей. При этом компоненту достаточно указать атрибуты dataContainer и property:<data> <instance id="carDc" class="com.haulmont.sample.core.entity.Car" view="carEdit"> <loader/> </instance> </data> <layout> <pickerField dataContainer="carDc" property="color"/> </layout>Как видно из примера, в экране описывается контейнер данных
carDcдля некоторой сущностиCar, имеющей атрибутcolor. В элементеpickerFieldв атрибутеdataContainerуказывается ссылка на контейнер, а в атрибутеproperty− название атрибута сущности, значение которого должно быть отображено в компоненте. Атрибут сущности должен являться ссылкой на другую сущность, в приведенном примере этоColor.
-
Для
PickerFieldможно определить произвольное количество действий, отображаемых кнопками справа.Это можно сделать как в XML-дескрипторе с помощью вложенного элемента
actions, так и программно в контроллере методомaddAction().-
Существует набор стандартных действий для
PickerField:picker_lookup,picker_clear,picker_open. Они выполняют соответственно выбор связанной сущности, очистку поля и открытие экрана редактирования выбранной связанной сущности. Для стандартных действий в XML нужно определить идентификатор действия и его тип с помощью атрибутаtype.Если при объявлении компонента никаких действий в элементе
actionsне задано, загрузчик XML определит для него действияlookupиclear. Чтобы добавить к действиям по умолчанию, например, действиеopen, нужно определить элементactionsследующим образом:<pickerField dataContainer="carDc" property="color"> <actions> <action id="lookup" type="picker_lookup"/> <action id="open" type="picker_open"/> <action id="clear" type="picker_clear"/> </actions> </pickerField>Элемент
actionне дополняет, а переопределяет набор стандартных действий, поэтому необходимо указывать идентификаторы всех требуемых действий. Компонент примет следующий вид:
Используйте метод
addAction()для программного задания стандартных действий. Если компонент определен в XML-дескрипторе без вложенного элементаactions, то достаточно добавить недостающие действия:@Inject protected PickerField<Color> colorField; @Subscribe protected void onInit(InitEvent event) { colorField.addAction(actions.create(OpenAction.class)); }Если же компонент создается в контроллере, то никаких действий по умолчанию он не получает, и необходимо добавить все нужные действия явно:
@Inject private InstanceContainer<Car> carDc; @Inject private UiComponents uiComponents; @Inject private Actions actions; @Subscribe protected void onInit(InitEvent event) { PickerField<Color> colorField = uiComponents.create(PickerField.NAME); colorField.setValueSource(new ContainerValueSource<>(carDc, "color")); colorField.addAction(actions.create(LookupAction.class)); colorField.addAction(actions.create(OpenAction.class)); colorField.addAction(actions.create(ClearAction.class)); getWindow().add(colorField); }Поведение стандартных действий можно кастомизировать, если подписаться на событие
ActionPerformedEventи предоставить собственную реализацию действия. Например, так можно задать специфический экран выбора:@Inject private ScreenBuilders screenBuilders; @Inject private PickerField<Color> pickerField; @Subscribe("pickerField.lookup") protected void onPickerFieldLookupActionPerformed(Action.ActionPerformedEvent event) { screenBuilders.lookup(pickerField) .withScreenClass(CustomColorBrowser.class) .build() .show(); }Подробнее см. раздел Открытие экранов
-
Произвольные действия в XML-дескрипторе также определяются во вложенном элементе
actions, а логика действий описывается в соответствующем событии, например:<pickerField dataContainer="orderDc" property="customer"> <actions> <action id="lookup"/> <action id="show" icon="PICKERFIELD_OPEN" caption="Show"/> </actions> </pickerField>@Inject private PickerField<Customer> pickerField; @Subscribe("pickerField.show") protected void onPickerFieldShowActionPerformed(Action.ActionPerformedEvent event) { CustomerEdit customerEdit = screenBuilders.editor(pickerField) .withScreenClass(CustomerEdit.class) .build(); customerEdit.setDiscount(true); customerEdit.show(); }Декларативное и программное создание действий подробно описано в разделе Действия. Интерфейс Action.
-
-
Компонент
PickerFieldможно использовать без непосредственной привязки к данным, то есть без указания dataContainer и property. В этом случае для указания типа сущности, с которой должен работатьPickerField, используется атрибутmetaClass. Например:<pickerField id="colorField" metaClass="sample_Color"/>Экземпляр выбранной сущности можно получить, инжектировав компонент в контроллер и вызвав его метод
getValue().Для правильной работы компонента
PickerFieldнеобходима либо установка атрибутаmetaClass, либо одновременная установка атрибутов dataContainer и property. -
В компоненте
PickerFieldможно использовать горячие клавиши: см. Горячие клавиши.
-
Компонент
PickerFieldможет иметь значок слева. Ниже приведен пример использования функции в методеsetOptionIconProvider()контроллера экрана. Значок"cancel"должен быть установлен, когда значение поля равноnull; в противном случае должен быть установлен значок"chain".@Inject private PickerField<Customer> pickerField; protected String generateIcon(Customer customer) { return (customer!= null) ? "icons/chain.png" : "icons/cancel.png"; } @Subscribe private void onInit(InitEvent event) { pickerField.setOptionIconProvider(this::generateIcon); }
- Атрибуты pickerField
-
align - caption - captionAsHtml - captionProperty - contextHelpText - contextHelpTextHtmlEnabled - css - dataContainer - description - descriptionAsHtml - editable - enable - box.expandRatio - height - htmlSanitizerEnabled - icon - id - metaClass - property - required - requiredMessage - stylename - tabIndex - visible - width
- Элементы pickerField
- API
-
addAction - addValueChangeListener - commit - discard - isModified - setContextHelpIconClickHandler - setOptionCaptionProvider - setOptionIconProvider
3.5.2.1.32. PopupButton
Кнопка с выпадающим меню. Меню может содержать список действий или отображать собственное содержимое.
XML-имя компонента: popupButton.
Кнопка PopupButton может содержать текст, заданный с помощью атрибута caption, или значок (или и то, и другое). Всплывающую подсказку можно задать с помощью атрибута description. На рисунке ниже отражены разные виды кнопок:
Элементы popupButton:
-
actions- определяет выпадающий список действий.Отображаются только следующие свойства действий:
caption,enable,visible. Свойстваdescription,shortcutигнорируются. Обработка свойстваiconзависит от свойства приложения cuba.gui.showIconsForPopupMenuActions и от атрибутаshowActionIconsкомпонента. Последний имеет приоритет.Пример кнопки с выпадающим списком, содержащим два действия:
<popupButton id="popupButton" caption="msg://popupButton" description="Press me"> <actions> <action id="popupAction1" caption="msg://action1"/> <action id="popupAction2" caption="msg://action2"/> </actions> </popupButton>Действия для
popupButtonможно как создать с нуля, так и использовать действия, уже созданные для какого-либо элемента в данном экране, например:<popupButton id="popupButton"> <actions> <action id="ordersTable.create"/> <action id="ordersTable.edit"/> <action id="ordersTable.remove"/> </actions> </popupButton>
-
popup- позволяет создать собственное содержимое всплывающего меню. Если оно задано, элементactionsигнорируется.Пример кнопки с собственным содержимым:
<popupButton id="popupButton" caption="Settings" align="MIDDLE_CENTER" icon="font-icon:GEARS" closePopupOnOutsideClick="true" popupOpenDirection="BOTTOM_CENTER"> <popup> <vbox width="250px" height="AUTO" spacing="true" margin="true"> <label value="Settings" align="MIDDLE_CENTER" stylename="h2"/> <progressBar caption="Progress" width="100%"/> <textField caption="New title" width="100%"/> <lookupField caption="Status" optionsEnum="com.haulmont.cuba.core.global.SendingStatus" width="100%"/> <hbox spacing="true"> <button caption="Save" icon="SAVE"/> <button caption="Reset" icon="REMOVE"/> </hbox> </vbox> </popup> </popupButton>
Атрибуты popupButton:
-
autoClose- определяет, должно ли всплывающее меню закрываться автоматически после вызова действия.
-
closePopupOnOutsideClick- если установлено значениеtrue, щелчок по области за пределами всплывающего меню закрывает его. Это не относится к щелчкам по самой кнопке компонента.
-
popupOpenDirection- задаёт направление открытия всплывающего окна. Возможные значения:-
BOTTOM_LEFT, -
BOTTOM_RIGHT, -
BOTTOM_CENTER.
-
-
showActionIcons- разрешает отображение значков для кнопок действий.
-
togglePopupVisibilityOnClick- определяет, должны ли последовательные щелчки по кнопке компонента изменять видимость всплывающего меню.
Методы интерфейса PopupButton:
-
addPopupVisibilityListener()- добавляет компоненту слушатель для отслеживания событий изменения видимости компонента.popupButton.addPopupVisibilityListener(popupVisibilityEvent -> notifications.create() .withCaption("Popup visibility changed") .show());Также изменения видимости
PopupButtonможно отслеживать, подписавшись на соответствующее событие в контроллере экрана:@Subscribe("popupButton") protected void onPopupButtonPopupVisibility(PopupButton.PopupVisibilityEvent event) { notifications.create() .withCaption("Popup visibility changed") .show(); }
Внешний вид компонента PopupButton можно настроить с помощью переменных SCSS с префиксом $cuba-popupbutton-*. Эти переменные можно изменить в визуальном редакторе после расширения темы или создания новой темы.
- Атрибуты popupButton
-
align - autoClose - caption - captionAsHtml - closePopupOnOutsideClick - css - description - descriptionAsHtml - enable - box.expandRatio - htmlSanitizerEnabled - icon - id - menuWidth - popupOpenDirection - showActionIcons - stylename - tabIndex - togglePopupVisibilityOnClick - visible - width
- Элементы popupButton
- API
3.5.2.1.33. PopupView
PopupView представляет собой компонент, позволяющий открывать popup с контейнером. Контейнер может открываться по клику на минимизированное значение или программно. Он может быть закрыт отведением курсора или по клику вне контейнера.
Обычный PopupView со скрытым и видимым popup-ом:

Рисунок 12. Popup скрыт
Рисунок 13. Popup открыт
Компонент реализован для блока Web Client.
Пример использования PopupView, где минимизированное значение получено из пакета локализации:
<popupView id="popupView"
minimizedValue="msg://minimizedValue"
caption="PopupView caption">
<vbox width="60px" height="40px">
<label value="Content" align="MIDDLE_CENTER"/>
</vbox>
</popupView>Содержимое popup-а должно быть контейнером, например BoxLayout.
Методы PopupView:
-
setPopupVisible()позволяет открывать и закрывать popup программно.@Inject private PopupView popupView; @Subscribe protected void onInit(InitEvent event) { popupView.setMinimizedValue("Hello world!"); } -
setMinimizedValue()позволяет программно менять минимизированное значение.@Inject private PopupView popupView; @Override public void init(Map<String, Object> params) { popupView.setMinimizedValue("Hello world!"); }
-
addPopupVisibilityListener(PopupVisibilityListener listener)позволяет отслеживать изменения видимости popup.@Inject private PopupView popupView; @Inject private Notifications notifications; @Subscribe protected void onInit(InitEvent event) { popupView.addPopupVisibilityListener(popupVisibilityEvent -> notifications.create() .withCaption(popupVisibilityEvent.isPopupVisible() ? "The popup is visible" : "The popup is hidden") .withType(Notifications.NotificationType.HUMANIZED) .show() ); }
-
Компонент
PopupViewпредоставляет методы для установки положения popup на экране. Значенияtopиleftопределяют положение верхнего левого угла popup. Положение можно установить с помощью стандартных значений либо задать произвольные. Доступны следующие стандартные значения:-
TOP_RIGHT -
TOP_LEFT -
TOP_CENTER -
MIDDLE_RIGHT -
MIDDLE_LEFT -
MIDDLE_CENTER -
BOTTOM_RIGHT -
BOTTOM_LEFT -
BOTTOM_CENTERСтандартное значение
DEFAULTрасполагает popup в середине минимизированного значения.Методы для установки положения popup:
-
void setPopupPosition(int top, int left)- устанавливает значенияtopиleft. -
void setPopupPositionTop(int top)- устанавливает значениеtop. -
void setPopupPositionLeft(int left)- устанавливает значениеleft. -
void setPopupPosition(PopupPosition position)- использует одно из стандартных значений для установки положения.@Inject private PopupView popupView; @Subscribe public void onInit(InitEvent event) { popupView.setPopupPosition(PopupView.PopupPosition.BOTTOM_CENTER); }Если положение popup установлено с помощью стандартных значений, то значения
leftиtopбудут сброшены и наоборот.
-
-
Если положение установлено с использованием стандартных значений, то popup будет незначительно сдвинут от границ экрана. Вы можете переопределить сдвиг с помощью переменных SCSS
$popup-horizontal-marginи$popup-vertical-margin. -
Для получения значений положения popup определены следующие методы:
-
int getPopupPositionTop()- возвращает значениеtop. -
int getPopupPositionLeft()- возвращает значениеleft. -
PopupPosition getPopupPosition()- возвращает null, если положение popup было задано без использования стандартных значений.
-
Атрибуты PopupView:
-
minimizedValueопределяет текст минимизированного значения. В тексте разрешено использовать теги HTML.
-
Если атрибуту
hideOnMouseOutустановлено значениеfalse, popup будет закрываться по клику вне popup.
- Атрибуты popupView
-
caption - captionAsHtml - contextHelpText - contextHelpTextHtmlEnabled - css - description - descriptionAsHtml - box.expandRatio - height - hideOnMouseOut - htmlSanitizerEnabled - icon - id - minimizedValue - stylename - visible - width
- API
3.5.2.1.34. ProgressBar
Компонент ProgressBar служит для отображения хода выполнения некоторого длительного процесса.

XML-имя компонента: progressBar
Пример использования компонента совместно с механизмом фоновых задач:
<progressBar id="progressBar" width="100%"/>@Inject
private ProgressBar progressBar;
@Inject
private BackgroundWorker backgroundWorker;
private static final int ITERATIONS = 5;
@Subscribe
protected void onInit(InitEvent event){
BackgroundTask<Integer, Void> task = new BackgroundTask<Integer, Void>(300, getWindow()) {
@Override
public Void run(TaskLifeCycle<Integer> taskLifeCycle) throws Exception{
for(int i = 1; i <= ITERATIONS; i++) {
TimeUnit.SECONDS.sleep(2); (1)
taskLifeCycle.publish(i);
}
return null;
}
@Override
public void progress(List<Integer> changes){
double lastValue = changes.get(changes.size() - 1);
progressBar.setValue((lastValue / ITERATIONS));
}
};
BackgroundTaskHandler taskHandler = backgroundWorker.handle(task);
taskHandler.execute();
}| 1 | некая задача, требующая времени |
Здесь в методе BackgroundTask.progress(), выполняемом в UI-потоке, компоненту ProgressBar устанавливается текущее значение. Значением компонента должно быть число типа double от 0.0 до 1.0.
Изменения значения компонента ProgressBar можно отслеживать с помощью слушателя ValueChangeListener. Источник события ValueChangeEvent можно отследить с помощью метода isUserOriginated().
Если выполняемый процесс не может передавать информацию о прогрессе, то с помощью атрибута indeterminate можно задать отображение неопределенного состояния индикатора. Если значение атрибута равно true, то индикатор отображает неопределенное состояние. По умолчанию false. Например:
<progressBar id="progressBar" width="100%" indeterminate="true"/>По умолчанию неопределённый индикатор представляет собой горизонтальную полосу. Чтобы отобразить ProgressBar в виде крутящегося колесика, установите атрибут stylename="indeterminate-circle".
Чтобы изменить форму индикатора на точку, перемещающуюся по полосе, вместо растущей полосы, используйте стиль point:
progressBar.setStyleName(HaloTheme.PROGRESSBAR_POINT);- Атрибуты progressBar
-
align - caption - captionAsHtml - contextHelpText - contextHelpTextHtmlEnabled - css - description - descriptionAsHtml - enable - box.expandRatio - height - htmlSanitizerEnabled - id - indeterminate - stylename - visible - width
- Предопределенные стили progressBar
- API
3.5.2.1.35. RadioButtonGroup
Компонент, который обеспечивает выбор единственного значения из списка опций, используя группу переключателей.
XML-имя компонента: radioButtonGroup.
Компонент RadioButtonGroup реализован для блока Web Client.
Список опций для компонента можно указать с помощью методов setOptions(), setOptionsList(), setOptionsMap() и setOptionsEnum(), а также атрибута optionsContainer.
-
Простейший вариант использования
RadioButtonGroup- выбор значения перечисления (enumeration). К примеру, сущностьRoleимеет атрибутtypeтипаRoleType, который является перечислением. Тогда для отображения этого атрибута можно использоватьRadioButtonGroupследующим образом, с помощью атрибутаoptionsEnum:<radioButtonGroup optionsEnum="com.haulmont.cuba.security.entity.RoleType" property="type"/>Метод
setOptionsEnum()принимает в качестве параметра класс перечисления. Список опций будет состоять из локализованных названий значений перечисления, значением компонента будет являться выбранное значение перечисления.radioButtonGroup.setOptionsEnum(RoleType.class);Того же результата можно достигнуть, используя метод
setOptions(), который позволяет работать со всеми типами опций:radioButtonGroup.setOptions(new EnumOptions<>(RoleType.class));
-
setOptionsList()позволяет программно задать список опций компонента. Для этого объявляем компонент в XML-дескрипторе:<radioButtonGroup id="radioButtonGroup"/>Затем инжектируем компонент в контроллер и задаем ему список опций:
@Inject private RadioButtonGroup<Integer> radioButtonGroup; @Subscribe protected void onInit(InitEvent event) { List<Integer> list = new ArrayList<>(); list.add(2); list.add(4); list.add(5); list.add(7); radioButtonGroup.setOptionsList(list); }Компонент примет следующий вид:

При этом метод
getValue()компонента в зависимости от выбранной опции будет возвращатьIntegerзначения 2, 4, 5, 7.
-
setOptionsMap()позволяет задать строковые названия и значения опций по отдельности. Например, для инжектированного в контролллер экрана компонентаradioButtonGroupзадаём мэп опций:@Inject private RadioButtonGroup<Integer> radioButtonGroup; @Subscribe protected void onInit(InitEvent event) { Map<String, Integer> map = new LinkedHashMap<>(); map.put("two", 2); map.put("four", 4); map.put("five", 5); map.put("seven", 7); radioButtonGroup.setOptionsMap(map); }Компонент примет следующий вид:

При этом метод
getValue()компонента в зависимости от выбранной опции будет возвращатьIntegerзначения 2, 4, 5, 7, а не строки, отображаемые на экране.
-
Компонент может принимать список опций из data container. Для этого используется атрибут
optionsContainer. Например:<data> <collection id="employeesCt" class="com.company.demo.entity.Employee" view="_minimal"> <loader> <query><![CDATA[select e from demo_Employee e]]></query> </loader> </collection> </data> <layout> <radioButtonGroup optionsContainer="employeesCt"/> </layout>В данном случае компонент
radioButtonGroupотобразит имена экземпляров сущностиEmployee, находящихся в контейнереemployeesCt, а его методgetValue()вернёт выбранный экземпляр сущности.
С помощью атрибута captionProperty можно указать, какой атрибут сущности использовать вместо имени экземпляра для строковых названий опций.
Программно можно задать options container для компонента с помощью метода
setOptions()интерфейсаRadioButtonGroup:@Inject private RadioButtonGroup<Employee> radioButtonGroup; @Inject private CollectionContainer<Employee> employeesCt; @Subscribe protected void onInit(InitEvent event) { radioButtonGroup.setOptions(new ContainerOptions<>(employeesCt)); }
OptionDescriptionProvider используется для генерации всплывающих подсказок. Для создания подсказок вы можете использовать как метод setOptionDescriptionProvider(), так и аннотацию @Install:
@Inject
private RadioButtonGroup<Product> radioButtonGroup;
@Subscribe
public void onInit(InitEvent event) {
radioButtonGroup.setOptionDescriptionProvider(product -> "Price: " + product.getPrice());
}@Install(to = "radioButtonGroup", subject = "optionDescriptionProvider")
private String radioButtonGroupOptionDescriptionProvider(Experience experience) {
switch (experience) {
case HIGH:
return "Senior";
case COMMON:
return "Middle";
default:
return "Junior";
}
}Атрибут orientation задаёт расположение элементов группы. По умолчанию элементы располагаются по вертикали. Значение horizontal задаёт горизонтальное расположение.
- Атрибуты RadioButtonGroup
-
align - box.expandRatio - caption - captionAsHtml - captionProperty - colspan - contextHelpText - contextHelpTextHtmlEnabled - css - dataContainer - description - descriptionAsHtml - editable - enable - height - htmlSanitizerEnabled - icon - id - optionsContainer - optionsEnum - orientation - property - required - requiredMessage - responsive - rowspan - stylename - tabIndex - visible - width
- API
-
addValueChangeListener - setContextHelpIconClickHandler - setOptionCaptionProvider - setOptionDescriptionProvider - setOptions - setOptionsEnum - setOptionsList - setOptionsMap
3.5.2.1.36. RelatedEntities
RelatedEntities - компонент в виде кнопки с выпадающим списком, при нажатии показывающим список классов, связанных с сущностью, экземпляры которой отображаются в таблице. Пользователь выбирает интересующий его класс сущности, после чего открывается новый браузер с экземплярами данной сущности, связанными с выбранными экземплярами в начальной таблице.
XML-имя компонента: relatedEntities
При отборе связанных сущностей для отображения учитываются разрешения пользователя на открытие экранов, чтение сущностей и чтение атрибутов.
По умолчанию для выбранного в списке класса сущности открывается браузер сущности, определенный по соглашениям ({entity_name}.browse, {entity_name}.lookup). Опционально, экран можно явно задать в компоненте.
В открытом браузере динамически создается фильтр, который выбирает связанные с выбранными сущностями записи.
Пример описания компонента в XML-дескрипторе экрана:
<table id="invoiceTable"
multiselect="true"
width="100%">
<actions>
<action id="create"/>
<action id="edit"/>
<action id="remove"/>
</actions>
<buttonsPanel id="buttonsPanel">
<button id="createBtn"
action="invoiceTable.create"/>
<button id="editBtn"
action="invoiceTable.edit"/>
<button id="removeBtn"
action="invoiceTable.remove"/>
<relatedEntities for="invoiceTable"
openType="NEW_TAB">
<property name="invoiceItems"
screen="sales_InvoiceItem.lookup"
filterCaption="msg://invoiceItems"/>
</relatedEntities>
</buttonsPanel>
. . .
</table>Атрибут for является обязательным. В нем указывается идентификатор таблицы.
Атрибут openType="NEW_TAB" устанавливает режим открытия браузера (новая вкладка). По умолчанию браузер открывается в текущей вкладке.
Элемент property позволяет явно задать связанную сущность, которая будет отображаться в выпадающем списке.
Атрибуты property:
-
name- имя атрибута текущей сущности, ссылающегося на связанную сущность
-
screen- идентификатор браузера, открывающегося при выборе сущности в списке
-
filterCaption- имя динамически формируемого фильтра
Атрибут exclude позволяет исключить определенные связанные сущности из числа отображаемых. В качестве значения указывается регулярное выражение, отбирающее ссылочные атрибуты текущей сущности для исключения.
В платформе есть API для открытия экранов связанных сущностей без использования компонента RelatedEntities: интерфейс RelatedEntitiesAPI и его реализация RelatedEntitiesBean. Логика задаётся методом openRelatedScreen(), который принимает коллекцию сущностей с одной стороны отношения, MetaClass отдельной сущности из этой коллекции и поле, являющееся ссылкой на связанные сущности.
<button id="related"
caption="Related customer"/>@UiController("sales_Order.browse")
@UiDescriptor("order-browse.xml")
@LookupComponent("ordersTable")
@LoadDataBeforeShow
public class OrderBrowse extends StandardLookup<Order> {
@Inject
private RelatedEntitiesAPI relatedEntitiesAPI;
@Inject
private GroupTable<Order> ordersTable;
@Subscribe("related")
protected void onRelatedClick(Button.ClickEvent event) {
relatedEntitiesAPI.openRelatedScreen(ordersTable.getSelected(), Order.class, "customer");
}
}По умолчанию метод открывает стандартный экран просмотра списка. Дополнительно можно указать параметр RelatedScreenDescriptor, если требуется открыть экран, отличный от стандартного, или открыть его с параметрами. RelatedScreenDescriptor - это простой Java-объект, хранящий идентификатор экрана (String), тип его открытия (WindowManager.OpenType), заголовок фильтра (String) и параметры экрана (Map<String, Object>).
relatedEntitiesAPI.openRelatedScreen(ordersTable.getSelected(),
Order.class, "customer",
new RelatedEntitiesAPI.RelatedScreenDescriptor("sales_Customer.lookup", WindowManager.OpenType.DIALOG));- Атрибуты relatedEntities
-
align - caption - captionAsHtml - css - description - descriptionAsHtml - enable - exclude - box.expandRatio - for - htmlSanitizerEnabled - icon - id - openType - stylename - tabIndex - visible - width
- Атрибуты property
-
caption - filterCaption - name - screen
3.5.2.1.37. ResizableTextArea
ResizableTextArea − многострочное текстовое поле для редактирования текста с возможностью изменять размер.
XML-имя компонента: resizableTextArea.
ResizableTextArea в основном повторяет функциональность TextArea и имеет следующие специфические атрибуты:
-
resizableDirection– задаёт возможность изменения размера области и его направление.<resizableTextArea id="textArea" resizableDirection="BOTH"/>
Доступны следующие режимы изменения размера:
-
BOTH− компонент может изменять размер в обоих направлениях. РежимBOTHиспользуется по умолчанию. Режим не будет работать, если задан размер компонента в процентах. -
NONE− компонент не может изменять размер. -
VERTICAL− компонент может изменять размер только по вертикали. Режим не будет работать, если задана высота компонента в процентах. -
HORIZONTAL− компонент может изменять размер только по горизонтали. Режим не будет работать, если задана ширина компонента в процентах.
События изменения размеров области можно отслеживать с помощью слушателя
ResizeListener, например:resizableTextArea.addResizeListener(resizeEvent -> notifications.create() .withCaption("Resized") .show()); -
- Атрибуты resizableTextArea
-
align - caption - captionAsHtml - caseConversion - cols - contextHelpText - contextHelpTextHtmlEnabled - css - dataContainer - datatype - description - descriptionAsHtml - editable - enable - box.expandRatio - height - htmlSanitizerEnabled - icon - id - inputPrompt - maxLength - property - required - requiredMessage - responsive - rows - settingsEnabled - stylename - tabIndex - textChangeEventMode - textChangeTimeout - trim - visible - width - wordWrap
- Предопределенные стили resizableTextArea
-
align-center - align-right - borderless - huge - large - small - tiny
- API
-
addResizeListener - addTextChangeListener - addValueChangeListener - addValidator - applySettings - commit - discard - isModified - saveSettings - setContextHelpIconClickHandler
3.5.2.1.38. RichTextArea
Текстовая область для отображения и ввода форматированного текста.
XML-имя компонента: richTextArea
Компонент RichTextArea реализован только для блока Web Client.
RichTextArea в основном повторяет функциональность TextField, за исключением того, что ему нельзя установить datatype. То есть RichTextArea предназначен для работы только с текстом и строковыми атрибутами сущностей.
RichTextArea также используется для ввода и вывода HTML-строк. Если атрибут htmlSanitizerEnabled установлен в true, то значение RichTextArea будет санитизировано.
protected static final String UNSAFE_HTML = "<i>Jackdaws </i><u>love</u> <font size=\"javascript:alert(1)\" " +
"color=\"moccasin\">my</font> " +
"<font size=\"7\">big</font> <sup>sphinx</sup> " +
"<font face=\"Verdana\">of</font> <span style=\"background-color: " +
"red;\">quartz</span><svg/onload=alert(\"XSS\")>";
@Inject
private RichTextArea richTextArea;
@Subscribe
public void onInit(InitEvent event) {
richTextAreasetHtmlSanitizerEnabled(true);
richTextArea.setValue(UNSAFE_HTML);
}Значение атрибута htmlSanitizerEnabled имеет приоритет над значением глобального свойства cuba.web.htmlSanitizerEnabled.
- Атрибуты richTextArea
-
align - caption - captionAsHtml - contextHelpText - contextHelpTextHtmlEnabled - css - dataContainer - description - descriptionAsHtml - editable - enable - box.expandRatio - height - htmlSanitizerEnabled - icon - id - property - required - requiredMessage - stylename - tabIndex - visible - width
- API
3.5.2.1.39. SearchPickerField
Компонент SearchPickerField служит для поиска экземпляров сущностей по вводимой пользователем строке. Пользователю достаточно ввести несколько символов и нажать клавишу Enter. Если поиск дал несколько совпадений, найденные значения отображаются в виде выпадающего списка. Если же критерию поиска соответствует только один экземпляр, он сразу становится значением компонента. SearchPickerField позволяет также выполнять действия нажатием на кнопки справа.
|
|
XML-имя компонента: searchPickerField.
-
Для работы компонента
SearchPickerFieldнеобходимо создать collectionDatasource, и задать в нем запрос, содержащий условия поиска. Условие обязательно должно содержать параметр с именемcustom$searchString- именно в него компонент передает введенную пользователем подстроку при нажатии Enter. Источник данных с условием поиска должен быть указан в атрибуте optionsDatasource компонента. Например:<dsContext> <datasource id="carDs" class="com.company.sample.entity.Car" view="_local"/> <collectionDatasource id="colorsDs" class="com.company.sample.entity.Color" view="_local"> <query> select c from sample_Color c where c.name like :(?i)custom$searchString </query> </collectionDatasource> </dsContext> <layout> <searchPickerField datasource="carDs" property="color" optionsDatasource="colorsDs"/> </layout>В данном случае компонент будет искать экземпляры сущности
Colourпо вхождению подстроки в ее атрибутname. Префикс(?i)служит для регистро-независимого поиска (см. Поиск подстроки без учета регистра). Выбранное значение подставится в атрибутcolourсущностиCar, находящейся в источнике данныхcarDs.Атрибут
escapeValueForLikeсо значениемtrueпозволяет искать значения, содержащие специальные символы%,\и_при помощи like. Чтобы использоватьescapeValueForLike = true, необходимо добавить в запрос источника данных escape-значение:select c from ref_Colour c where c.name like :(?i)custom$searchString or c.description like :(?i)custom$searchString escape '\'Атрибут
escapeValueForLikeработает со всеми типами базы данных, кроме HSQLDB.
-
С помощью атрибута
minSearchStringLengthможно задать минимальное количество символов, которое должен ввести пользователь для поиска значения. -
В контроллере экрана для компонента можно реализовать методы, вызываемые в двух случаях:
-
если количество введенных символов меньше значения атрибута
minSearchStringLength. -
если поиск введенных пользователем символов не дал результатов.
Пример реализации методов для вывода на экран сообщений:
@Inject private Notifications notifications; @Inject private SearchPickerField colorField; @Subscribe protected void onInit(InitEvent event) { colorField.setSearchNotifications(new SearchField.SearchNotifications() { @Override public void notFoundSuggestions(String filterString) { notifications.create() .withCaption("No colors found for search string: " + filterString) .withType(Notifications.NotificationType.TRAY) .show(); } @Override public void needMinSearchStringLength(String filterString, int minSearchStringLength) { notifications.create() .withCaption("Minimum length of search string is " + minSearchStringLength) .withType(Notifications.NotificationType.TRAY) .show(); } }); }
-
-
SearchPickerFieldреализует интерфейсы LookupField и PickerField, поэтому все описанное для этих интерфейсов в части работы с сущностями верно и для него. Исключением является список действий по умолчанию, добавляемых при определении компонента в XML: дляSearchPickerFieldэто действияlookup и open.
- Атрибуты searchPickerField
-
align - caption - captionAsHtml - captionProperty - contextHelpText - contextHelpTextHtmlEnabled - css - datasource - description - descriptionAsHtml - editable - enable - box.expandRatio - filterMode - height - htmlSanitizerEnabled - icon - id - inputPrompt - metaClass - minSearchStringLength - newOptionAllowed - newOptionHandler - nullName - optionsDatasource - property - required - requiredMessage - stylename - tabIndex - visible - width
- Элементы searchPickerField
- Предопределённые стили searchPickerField
- API
-
addValueChangeListener - setContextHelpIconClickHandler - setOptionCaptionProvider - setOptionImageProvider - setPopupWidth
3.5.2.1.40. SideMenu
Компонент SideMenu позволяет создать боковое главное меню в главном окне приложения, управлять элементами меню, добавлять значки и ярлыки и применять стили.
Его также можно использовать в экранах приложения как обычный визуальный компонент.

XML-имя компонента: sideMenu.
Пример описания компонента в XML-дескрипторе экрана:
<sideMenu id="sideMenu"
width="100%"
selectOnClick="true"/>CUBA Studio предоставляет готовый шаблон главного экрана с реализацией компонента sideMenu и готовыми стилями боковой панели:
<layout>
<hbox id="horizontalWrap"
expand="workArea"
height="100%"
stylename="c-sidemenu-layout"
width="100%">
<vbox id="sideMenuPanel"
expand="sideMenu"
height="100%"
margin="false,false,true,false"
spacing="true"
stylename="c-sidemenu-panel"
width="250px">
<hbox id="appTitleBox"
spacing="true"
stylename="c-sidemenu-title"
width="100%">
<label id="appTitleLabel"
align="MIDDLE_CENTER"
value="mainMsg://application.logoLabel"/>
</hbox>
<embedded id="logoImage"
align="MIDDLE_CENTER"
stylename="c-app-icon"
type="IMAGE"/>
<hbox id="userInfoBox"
align="MIDDLE_CENTER"
expand="userIndicator"
margin="true"
spacing="true"
width="100%">
<userIndicator id="userIndicator"
align="MIDDLE_CENTER"/>
<newWindowButton id="newWindowButton"
description="mainMsg://newWindowBtnDescription"
icon="app/images/new-window.png"/>
<logoutButton id="logoutButton"
description="mainMsg://logoutBtnDescription"
icon="app/images/exit.png"/>
</hbox>
<sideMenu id="sideMenu"
width="100%"/>
<ftsField id="ftsField"
width="100%"/>
</vbox>
<workArea id="workArea"
height="100%">
<initialLayout margin="true"
spacing="true">
<label id="welcomeLabel"
align="MIDDLE_CENTER"
stylename="c-welcome-text"
value="mainMsg://application.welcomeText"/>
</initialLayout>
</workArea>
</hbox>
</layout>Атрибуты sideMenu:
-
selectOnClick- установка атрибута вtrueподсвечивает выделение элемента меню после его выбора кликом мыши. По умолчаниюfalse.
Методы интерфейса SideMenu:
-
createMenuItem- создаёт новый объект элемента меню, но не добавляет его к меню. Идентификаторidдолжен быть уникальным в области всего меню.
-
addMenuItem- добавляет элемент к меню.
-
removeMenuItem- удаляет элемент из списка элементов меню. -
getMenuItem- возвращает объект элемента меню по его идентификатору. -
hasMenuItems- возвращаетtrue, если в меню есть вложенные элементы.
Компонент SideMenu предназначен для отображения элементов меню. Чтобы создать элемент меню, используется API компонента MenuItem в контроллере экрана. Методы, перечисленные ниже, можно использовать для динамического обновления элементов меню, реализуя бизнес-логику приложения. Пример программного создания элемента меню:
SideMenu.MenuItem item = sideMenu.createMenuItem("special");
item.setCaption("Daily offer");
item.setBadgeText("New");
item.setIconFromSet(CubaIcon.GIFT);
sideMenu.addMenuItem(item,0);
Методы интерфейса MenuItem:
-
setCaption- устанавливает заголовок элемента меню.
-
setCaptionAsHtml- разрешает/запрещает использование HTML-заголовков.
-
setBadgeText- устанавливает текст ярлыка элемента меню. Ярлыки представляют собой небольшие виджеты справа от элемента меню, к примеру:int count = 5; SideMenu.MenuItem item = sideMenu.createMenuItem("count"); item.setCaption("Messages"); item.setBadgeText(count + " new"); item.setIconFromSet(CubaIcon.ENVELOPE); sideMenu.addMenuItem(item,0);
Текст ярлыка можно обновлять автоматически с помощью компонента Timer:
public void updateCounters(Timer source) { sideMenu.getMenuItemNN("sales") .setBadgeText(String.valueOf(LocalTime.MIDNIGHT.minusSeconds(timerCounter-source.getDelay()))); timerCounter++; }
-
setIcon- устанавливает значок элемента меню.
-
setCommand- используется для описания действия, которое должно быть выполнено при выборе этого элемента меню кликом мыши.
-
addChildItem/removeChildItem- добавляет/удаляет элементы меню в подгруппу корневого элемента.
-
setExpanded- раскрывает или сворачивает подгруппы меню по умолчанию.
-
setStyleName- устанавливает один или более пользовательских стилей для компонента, заменяя все ранее заданные стили. Имена стилей при перечислении отделаются пробелами. Имя стиля должно быть названием существующего CSS-класса.Стандартный шаблон главного экрана с
sideMenuстилизован несколькими предопределёнными стилями:c-sidemenu-layout,c-sidemenu-panelиc-sidemenu-title. Стиль бокового меню по умолчаниюc-sidemenuподдерживается в темахHalo,Hoverи их расширениях.
-
setTestId- устанавливает значениеcuba-idдля тестирования UI.
Внешний вид компонента SideMenu можно настроить с помощью переменных SCSS с префиксами $cuba-sidemenu-* и $cuba-responsive-sidemenu-*. Эти переменные можно изменить в визуальном редакторе после расширения темы или создания новой темы.
- Атрибуты sideMenu
-
align - caption - css - description - enable - height - icon - id - selectOnClick - stylename - tabIndex - visible - width
- Атрибуты ftsfield
-
align - caption - description - enable - height - icon - id - stylename - visible - width
- API sideMenu
- API menuItem
-
addChildItem - removeChildItem - setBadgeText - setCaption - setCaptionAsHtml - setCommand - setExpanded - setIcon - setStyleName - setTestId
3.5.2.1.41. Slider
Компонент Slider представляет собой горизонтальную или вертикальную полосу с ползунком. Перетаскивая ползунок с помощью мыши, можно установить числовое значение в заданном диапазоне. Во время перетаскивания отображается числовое значение.

XML-имя компонента: slider.
Тип данных по умолчанию double. С помощью атрибута datatype могут быть установлены другие числовые типы данных: int, long и decimal. Тип данных задается декларативно в XML-дескрипторе или с помощью API в контроллере экрана.
Для создания слайдера, связанного с данными, необходимо использовать атрибуты dataContainer и property. В таком случае тип данных слайдера определяется из атрибута сущности, указанного в параметре property.
В примере для слайдера будет установлен тип данных, соответствующий типу данных атрибута amount сущности Order.
<data>
<instance id="orderDc" class="com.company.sales.entity.Order" view="_local">
<loader/>
</instance>
</data>
<layout>
<slider dataContainer="orderDc" property="amount"/>
</layout>Атрибуты компонента slider:
-
max- максимальное значение диапазона, по умолчанию 100.
-
min- минимальное значение диапазона, по умолчанию 0.
-
resolution- количество знаков после запятой дляdecimal, по умолчанию 0.
-
orientation- горизонтальное или вертикальное расположение слайдера, по умолчанию горизонтальное.
-
updateValueOnClick- если установленоtrue, то установить ползунок в нужное значение можно кликнув по полосе. Значение по умолчаниюfalse.
В примере указан вертикально расположенный компонент slider с типом данных integer и диапазоном значений от 2 до 20.
<slider id="slider"
orientation="vertical"
datatype="int"
min="2"
max="20"/>Значение слайдера может быть получено с помощью метода getValue() и установлено с помощью метода setValue().
Изменение значения слайдера, так же как и любого другого компонента, реализующего интерфейс Field, можно отслеживать с помощью слушателя ValueChangeListener, подписавшись на соответствующее событие.
В примере ниже значение слайдера при каждом изменении записывается в текстовое поле.
@Inject
private TextField<Integer> textField;
@Subscribe("slider")
private void onSliderValueChange(HasValue.ValueChangeEvent<Integer> event) {
textField.setValue(event.getValue());
}- Attributes of slider
-
align - caption - captionAsHtml - colspan - contextHelpText - contextHelpTextHtmlEnabled - css - dataContainer - datatype - description - descriptionAsHtml - enable - box.expandRatio - height - htmlSanitizerEnabled - icon - id - max - min - orientation - property - requiredMessage - resolution - responsive - required - rowspan - stylename - updateValueOnClick - visible - width
- API
3.5.2.1.42. SourceCodeEditor
SourceCodeEditor - компонент для отображения и ввода исходного кода. Он представляет собой многострочное текстовое поле с возможностью подсветки кода и отображения полей печати и номеров строк.
XML-имя компонента: sourceCodeEditor.
Компонент SourceCodeEditor реализован для блока Web Client.
SourceCodeEditor в основном повторяет функциональность TextField и имеет следующие специфические атрибуты:
-
если
handleTabKeyимеет значениеtrue, нажатие на кнопку Tab на клавиатуре добавляет отступ текущей строки, если значение равноfalse, нажатие перемещает курсор или фокус на следующую позицию табуляции. Данный атрибут необходимо установить во время инициализации экрана, он не может быть изменён во время работы.
Следующие свойства можно легко изменять в работающем приложении:
-
highlightActiveLineиспользуется для подсветки текущей строки, на которой находится курсор.
-
атрибут
modeпредоставляет список языков, для которых поддерживается подсветка синтаксиса. Этот список задан в перечисленииModeинтерфейсаSourceCodeEditorи включает в себя следующие языки: Java, HTML, XML, Groovy, SQL, JavaScript, Properties и Text без подсветки.
-
printMarginопределяет, отображать или скрыть линию края печати в текстовом поле.
-
showGutterиспользуется для отображения или скрытия левой панели с номерами строк.
Ниже приведён пример компонента SourceCodeEditor с динамически настраиваемыми атрибутами.
XML-дескриптор:
<hbox spacing="true">
<checkBox id="highlightActiveLineCheck" align="BOTTOM_LEFT" caption="Highlight Active Line"/>
<checkBox id="printMarginCheck" align="BOTTOM_LEFT" caption="Print Margin"/>
<checkBox id="showGutterCheck" align="BOTTOM_LEFT" caption="Show Gutter"/>
<lookupField id="modeField" align="BOTTOM_LEFT" caption="Mode" required="true"/>
</hbox>
<sourceCodeEditor id="simpleCodeEditor" width="100%"/>Контроллер:
@Inject
private CheckBox highlightActiveLineCheck;
@Inject
private LookupField<HighlightMode> modeField;
@Inject
private CheckBox printMarginCheck;
@Inject
private CheckBox showGutterCheck;
@Inject
private SourceCodeEditor simpleCodeEditor;
@Subscribe
protected void onInit(InitEvent event) {
highlightActiveLineCheck.setValue(simpleCodeEditor.isHighlightActiveLine());
highlightActiveLineCheck.addValueChangeListener(e ->
simpleCodeEditor.setHighlightActiveLine(Boolean.TRUE.equals(e.getValue())));
printMarginCheck.setValue(simpleCodeEditor.isShowPrintMargin());
printMarginCheck.addValueChangeListener(e ->
simpleCodeEditor.setShowPrintMargin(Boolean.TRUE.equals(e.getValue())));
showGutterCheck.setValue(simpleCodeEditor.isShowGutter());
showGutterCheck.addValueChangeListener(e ->
simpleCodeEditor.setShowGutter(Boolean.TRUE.equals(e.getValue())));
Map<String, HighlightMode> modes = new HashMap<>();
for (HighlightMode mode : SourceCodeEditor.Mode.values()) {
modes.put(mode.toString(), mode);
}
modeField.setOptionsMap(modes);
modeField.setValue(HighlightMode.TEXT);
modeField.addValueChangeListener(e ->
simpleCodeEditor.setMode(e.getValue()));
}Результат выполения кода:
Компонент SourceCodeEditor также поддерживает автодополнение кода, определяемое с помощью класса Suggester. Чтобы подключить автодополнение, необходимо переопределить и вызвать метод setSuggester, например:
@Inject
protected DataGrid<User> usersGrid;
@Inject
private SourceCodeEditor suggesterCodeEditor;
@Inject
private CollectionContainer<User> usersDc;
@Inject
private CollectionLoader<User> usersDl;
@Subscribe
protected void onInit(InitEvent event) {
suggesterCodeEditor.setSuggester((source, text, cursorPosition) -> {
List<Suggestion> suggestions = new ArrayList<>();
usersDl.load();
for (User user : usersDc.getItems()) {
suggestions.add(new Suggestion(source, user.getLogin(), user.getName(), null, -1, -1));
}
return suggestions;
});
}Результат:
Список автодополнения появляется по нажатию Ctrl+Space или после ввода точки. Для отключения автодополнения после ввода точки необходимо установить значение атрибута suggestOnDot в false. Значение по умолчанию true.
<sourceCodeEditor id="simpleCodeEditor" width="100%" suggestOnDot="false"/>Внешний вид компонента SourceCodeEditor можно настроить с помощью переменных SCSS с префиксом $cuba-sourcecodeeditor-*. Эти переменные можно изменить в визуальном редакторе после расширения темы или создания новой темы.
- Атрибуты sourceCodeEditor
-
align - caption - captionAsHtml - colspan - contextHelpText - contextHelpTextHtmlEnabled - css - dataContainer - description - descriptionAsHtml - editable - enable - box.expandRatio - handleTabKey - height - highlightActiveLine - htmlSanitizerEnabled - icon - id - mode - printMargin - property - required - requiredMessage - rowspan - suggestOnDot - showGutter - stylename - tabIndex - visible - width
- API
3.5.2.1.43. SuggestionField
Компонент SuggestionField предназначен для поиска экземпляров сущности по строке, вводимой пользователем. Он отличается от SuggestionPickerField тем, что может возвращать любые типы значений, например, сущности, строки или перечисления, а также не имеет кнопок для действий. Список опций загружается асинхронно в соответствии с логикой, задаваемой разработчиком на стороне сервера.
XML-имя компонента: suggestionField.
Компонент реализован для блока Web Client.
Атрибуты suggestionField:
-
asyncSearchDelayMs- устанавливает задержку между последним нажатием клавиши и асинхронным поиском.
-
minSearchStringLength- устанавливает минимальную длину строки для начала поиска.
-
popupWidth- устанавливает ширину всплывающей подсказки.Возможные значения:
-
auto- ширина поля подсказки равна максимальной ширине текста подсказки, -
parent- ширина поля подсказки равна ширине основного компонента, -
абсолютное (например,
"170px") или относительное (например,"50%") значение.
-
-
suggestionsLimit- устанавливает ограничение количества выводимых подсказок.
Элементы suggestionField:
-
query- необязательный элемент, позволяющий задать запрос для выбора предлагаемых значений. Элементquery, в свою очередь, имеет следующие атрибуты:-
entityClass(обязательный атрибут) - полное квалифицированное имя класса сущности.
-
view- дополнительный атрибут, задающий представление, с которым будет загружена сущность.
-
escapeValueForLike- позволяет разрешить поиск по значениям, содержащим специальные символы:%,\, и т.д. По умолчаниюfalse,
-
searchStringFormat- строка Groovy, что позволяет использовать в запросе валидные Groovy-выражения.
<suggestionField id="suggestionField" captionProperty="login"> <query entityClass="com.haulmont.cuba.security.entity.User" escapeValueForLike="true" view="user.edit" searchStringFormat="%$searchString%"> select e from sec$User e where e.login like :searchString escape '\' </query> </suggestionField>Если элемент
queryне задан, то список опций должен быть предоставлен объектом типаSearchExecutor, созданным программно (см. ниже). -
Как правило, для компонента достаточно установить SearchExecutor. SearchExecutor - это функциональный интерфейс, содержащий один метод: List<E> search(String searchString, Map<String, Object> searchParams):
suggestionField.setSearchExecutor((searchString, searchParams) -> {
return Arrays.asList(entity1, entity2, ...);
});SearchExecutor может возвращать любые типы значений, например, сущности, строки или перечисления.
-
Сущности:
customersDs.refresh();
List<Customer> customers = new ArrayList<>(customersDs.getItems());
suggestionField.setSearchExecutor((searchString, searchParams) ->
customers.stream()
.filter(customer -> StringUtils.containsIgnoreCase(customer.getName(), searchString))
.collect(Collectors.toList()));-
Строки:
List<String> strings = Arrays.asList("Red", "Green", "Blue", "Cyan", "Magenta", "Yellow");
stringSuggestionField.setSearchExecutor((searchString, searchParams) ->
strings.stream()
.filter(str -> StringUtils.containsIgnoreCase(str, searchString))
.collect(Collectors.toList()));-
Перечисления:
List<SendingStatus> enums = Arrays.asList(SendingStatus.values());
enumSuggestionField.setSearchExecutor((searchString, searchParams) ->
enums.stream()
.map(sendingStatus -> messages.getMessage(sendingStatus))
.filter(str -> StringUtils.containsIgnoreCase(str, searchString))
.collect(Collectors.toList()));-
Класс
OptionWrapperиспользуется тогда, когда необходимо отделить значение любого типа от его строкового представления:
List<OptionWrapper> wrappers = Arrays.asList(
new OptionWrapper("One", 1),
new OptionWrapper("Two", 2),
new OptionWrapper("Three", 3);
suggestionField.setSearchExecutor((searchString, searchParams) ->
wrappers.stream()
.filter(optionWrapper -> StringUtils.containsIgnoreCase(optionWrapper.getCaption(), searchString))
.collect(Collectors.toList()));|
Метод |
Параметр searchString может быть использован для фильтрации кандидатов по строке, введенной пользователем. Чтобы искать по значениям, содержащим специальные символы, используйте метод escapeForLike():
suggestionField.setSearchExecutor((searchString, searchParams) -> {
searchString = QueryUtils.escapeForLike(searchString);
return dataManager.loadList(LoadContext.create(Customer.class).setQuery(
LoadContext.createQuery("select c from sample_Customer c where c.name like :name order by c.name escape '\\'")
.setParameter("name", "%" + searchString + "%")));
});-
OptionsStyleProviderпозволяет задать отдельные стили для различных значений подсказок, отображаемых компонентомsuggestionField:suggestionField.setOptionsStyleProvider((field, item) -> { User user = (User) item; switch (user.getGroup().getName()) { case "Company": return "company"; case "Premium": return "premium"; default: return "company"; } });
Внешний вид компонента SuggestionField можно настроить с помощью переменных SCSS с префиксом $cuba-suggestionfield-*. Эти переменные можно изменить в визуальном редакторе после расширения темы или создания новой темы.
- Атрибуты suggestionField
-
align - asyncSearchDelayMs - caption - captionAsHtml - captionProperty - colspan - contextHelpText - contextHelpTextHtmlEnabled - css - dataContainer - description - descriptionAsHtml - editable - enable - box.expandRatio - height - htmlSanitizerEnabled - icon - id - inputPrompt - minSearchStringLength - popupWidth - property - required - requiredMessage - responsive - rowspan - stylename - suggestionsLimit - tabIndex - visible - width
- Элементы suggestionField
- Атрибуты query
-
entityClass - escapeValueForLike - searchStringFormat - view
- Предопределенные стили suggestionField
- API
-
addValueChangeListener - setContextHelpIconClickHandler - setOptionCaptionProvider
3.5.2.1.44. SuggestionPickerField
Компонент SuggestionPickerField предназначен для поиска экземпляров сущности по строке, вводимой пользователем. Он отличается от SearchPickerField тем, что обновляет список опций при каждом вводе символа пользователем без необходимости нажимать Enter. Список опций загружается асинхронно в соответствии с логикой, задаваемой разработчиком на стороне сервера.
SuggestionPickerField является также PickerField и может содержать действия, отображаемые кнопками справа.
XML-имя компонента: suggestionPickerField.
Компонент реализован для блока Web Client.
SuggestionPickerField используется для выбора значений ссылочных атрибутов, поэтому для компонента обычно указываются атрибуты dataContainer и property:
<data>
<instance id="orderDc"
class="com.company.sales.entity.Order"
view="order-with-customer">
<loader id="orderDl"/>
</instance>
</data>
<layout>
<suggestionPickerField id="suggestionPickerField"
captionProperty="name"
dataContainer="orderDc"
property="customer"/>
</layout>Атрибуты suggestionPickerField:
-
asyncSearchDelayMs- устанавливает задержку между последним нажатием клавиши и асинхронным поиском.
-
metaClass- указывает ссылку на интерфейс метаданных компонента в случае, если компонент используется без непосредственной привязки к данным, то есть без указания dataContainer и property.
-
minSearchStringLength- устанавливает минимальную длину строки для начала поиска.
-
popupWidth- устанавливает ширину всплывающей подсказки.Возможные значения:
-
auto- ширина поля подсказки равна максимальной ширине текста подсказки, -
parent- ширина поля подсказки равна ширине основного компонента, -
абсолютное (например,
"170px") или относительное (например,"50%") значение.
-
-
suggestionsLimit- устанавливает ограничение количества выводимых подсказок.
|
Внешний вид поля |
Элементы suggestionPickerField:
-
actions- необязательный элемент для описания действий, связанных с компонентом. Кроме описания произвольных действий, поддерживаются следующие стандартные действия PickerField:picker_lookup,picker_clear,picker_open.
- Простой пример использования SuggestionPickerField
-
Как правило, для компонента достаточно установить
SearchExecutor.SearchExecutor- это функциональный интерфейс, содержащий один метод:List<E extends Entity> search(String searchString, Map<String, Object> searchParams):suggestionPickerField.setSearchExecutor((searchString, searchParams) -> { return Arrays.asList(entity1, entity2, ...); });Метод
search()выполняется в фоновом потоке, поэтому он не может обращаться к визуальным компонентам и компонентам данных. Можно использовать DataManager или напрямую вызывать сервисы среднего слоя, или обрабатывать и возвращать данные, предварительно загруженные в экран.Параметр
searchStringможет быть использован для фильтрации кандидатов по строке, введенной пользователем. Чтобы искать по значениям, содержащим специальные символы, используйте методescapeForLike():suggestionPickerField.setSearchExecutor((searchString, searchParams) -> { searchString = QueryUtils.escapeForLike(searchString); return dataManager.load(Customer.class) .query("e.name like ?1 order by e.name escape '\\'", "%" + searchString + "%") .list(); });
- Использование ParametrizedSearchExecutor
-
В примерах выше параметр
searchParamsявляется пустым. Для поиска с параметрами используетсяParametrizedSearchExecutor:suggestionPickerField.setSearchExecutor(new SuggestionField.ParametrizedSearchExecutor<Customer>(){ @Override public Map<String, Object> getParams() { return ParamsMap.of(...); } @Override public List<Customer> search(String searchString, Map<String, Object> searchParams) { return executeSearch(searchString, searchParams); } });
- Использование EnterActionHandler и ArrowDownActionHandler
-
Компонент также может быть использован с обработчиками событий
EnterActionHandlerиArrowDownActionHandler. Эти листнеры срабатывают, когда пользователь нажимает клавиши Enter или Arrow Down при скрытом всплывающем окне для подсказок. Они также представляют собой функциональные интерфейсы с единственным методом с одним параметром -currentSearchString. Вы можете настроить и свои обработчики событий и использовать методshowSuggestions()интерфейсаSuggestionField, который принимает список сущностей, для отображения подсказок:suggestionPickerField.setArrowDownActionHandler(currentSearchString -> { List<Customer> suggestions = findSuggestions(); suggestionPickerField.showSuggestions(suggestions); }); suggestionPickerField.setEnterActionHandler(currentSearchString -> { List<Customer> suggestions = getDefaultSuggestions(); suggestionPickerField.showSuggestions(suggestions); });
- Атрибуты suggestionPickerField
-
align - asyncSearchDelayMs - caption - captionAsHtml - captionProperty - colspan - contextHelpText - contextHelpTextHtmlEnabled - css - dataContainer - description - descriptionAsHtml - editable - enable - box.expandRatio - height - htmlSanitizerEnabled - icon - id - inputPrompt - metaClass - minSearchStringLength - popupWidth - property - required - requiredMessage - responsive - rowspan - stylename - suggestionsLimit - tabIndex - visible - width
- Элементы suggestionPickerField
- Предопределенные стили suggestionPickerField
- API
-
addValueChangeListener - setContextHelpIconClickHandler - setOptionCaptionProvider - setOptionIconProvider - setOptionsStyleProvider
3.5.2.1.45. Table
В этом разделе:
Компонент Table позволяет выводить информацию в табличном виде, сортировать данные, управлять колонками и заголовками таблицы, вызывать действия для выбранных строк.
XML-имя компонента: table
Пример описания таблицы в XML-дескрипторе экрана:
<data readOnly="true">
<collection id="ordersDc" class="com.company.sales.entity.Order" view="order-with-customer">
<loader id="ordersDl">
<query>
<![CDATA[select e from sales_Order e]]>
</query>
</loader>
</collection>
</data>
<layout>
<table id="ordersTable" dataContainer="ordersDc" width="100%">
<columns>
<column id="date"/>
<column id="amount"/>
<column id="customer"/>
</columns>
<rowsCount/>
</table>
</layout>Здесь в элементе data определен контейнер данных, который выбирает сущности Order с помощью JPQL запроса select o from sales_Order o order by o.date. Для компонента table указывается используемый контейнер данных, а в элементе columns - какие атрибуты сущности, содержащейся в контейнере, использовать в качестве колонок.
Если вы хотите указать источник данных для таблицы программно в контроллере экрана, используйте атрибут metaClass вместо декларативного указания значения dataContainer в XML.
Элементы table
-
rows- обязательный элемент в случае, если для привязывания таблицы к данным используется атрибут datasource.Для строк можно настроить отображение заголовков - задать каждой строке свой значок в дополнительной колонке слева. Для этого в контроллере экрана необходимо реализовать интерфейс
ListComponent.IconProviderи установить его таблице:@Inject private Table<Customer> table; @Subscribe protected void onInit(InitEvent event) { table.setIconProvider(new ListComponent.IconProvider<Customer>() { @Nullable @Override public String getItemIcon(Customer entity) { CustomerGrade grade = entity.getGrade(); switch (grade) { case PREMIUM: return "icons/premium_grade.png"; case HIGH: return "icons/high_grade.png"; case MEDIUM: return "icons/medium_grade.png"; default: return null; } } }); }
-
columns- элемент, определяющий набор колонок таблицы. Если не задан, то столбцы таблицы будут автоматически определены из атрибутов представления, используемого при загрузке данных из контейнера данных. Элементcolumnsимеет следующие атрибуты:-
includeAll– загружает все атрибуты представления, используемого при загрузке данных из контейнера данных.В приведенном ниже примере мы покажем все атрибуты из представления, используемого в
customersDc. Если представление содержит системные свойства, они также будут показаны.<table id="table" width="100%" height="100%" dataContainer="customersDc"> <columns includeAll="true"/> </table>Если представление сущности содержит ссылочный атрибут, этот атрибут выводится в соответствии с его шаблоном @NamePattern. Если вы хотите показать какой-то конкретный атрибут, он должен быть определен в представлении, а также в элементе
column:<columns includeAll="true"> <column id="address.street"/> </columns>Если представление не указано, атрибут
includeAllзагрузит все атрибуты из данной сущности и ее предков.
-
exclude– разделенный запятыми список атрибутов, которые не должны быть загружены в таблицу.В приведенном ниже примере мы покажем все атрибуты, за исключением атрибутов
nameиorder:<table id="table" width="100%" height="100%" dataContainer="customersDc"> <columns includeAll="true" exclude="name, order"/> </table>
Каждая колонка описывается во вложенном элементе
columnсо следующими атрибутами:-
id− обязательный атрибут, содержит название атрибута сущности, выводимого в колонке. Может быть как непосредственным атрибутом сущности, находящейся в контейнере, так и атрибутом связанной сущности - переход по графу объектов обозначается точкой. Например:<columns> <column id="date"/> <column id="customer"/> <column id="customer.name"/> <column id="customer.address.country"/> </columns>
-
caption− необязательный атрибут, содержит заголовок колонки. Если не задан, будет отображено локализованное название атрибута сущности.
-
captionAsHtml− необязательный атрибут, определяющий возможность использовать HTML-теги в заголовке колонки. По умолчаниюfalse.<column id="name" caption="msg://role.name" captionAsHtml="true"/>role.name=<em>Name</em>
-
collapsed− необязательный атрибут, при указанииtrueколонка будет изначально скрыта. Пользователь может управлять отображением колонок с помощью меню, доступного по кнопке в правой верхней части таблицы, если атрибут
в правой верхней части таблицы, если атрибут columnControlVisibleтаблицы неfalse. По умолчаниюcollapsedимеет значениеfalse.
-
expandRatio− необязательный атрибут, определяющий относительную длину для каждой колонки. Принимает значение большее или равное 0. Если хотя бы одной колонке установлено значение атрибутаexpandRatio, все неявные значения игнорируются и учитываются только явно присвоенные значения. Если вы одновременно установите атрибуты width иexpandRatio, это вызовет ошибку в приложении.
-
width− необязательный атрибут, отвечает за изначальную ширину колонки. Может принимать только числовые значения в пикселах.
-
align- необязательный атрибут, устанавливает выравнивание текста в ячейках данной колонки. Возможные значения:LEFT,RIGHT,CENTER. По умолчаниюLEFT.
-
editable− необязательный атрибут, разрешает/запрещает редактирование данной колонки в редактируемой таблице. Чтобы колонка была редактируемой, атрибут editable всей таблицы также должен быть установлен вtrue. Динамическое изменение значения этого атрибута не поддерживается.
-
sortable− необязательный атрибут, позволяющий запретить сортировку колонки. Вступает в действие, если атрибут sortable всей таблицы установлен вtrue(что имеет место по умолчанию).
-
sort− необязательный атрибут, позволяющий задать начальную сортировку таблицы по указанной колонке в соответствии с направлением сортировки. Возможные значения:-
ASCENDING– сортировка по возрастанию (например, A-Z, 1..9). -
DESCENDING– сортировка по убыванию (например, Z-A, 9..1).
<columns> <column property="name" sort="DESCENDING"/> </columns> -
Обратите внимание: если значение атрибута settingsEnabled установлено в
true, таблица сортируется в соответствии с настройками пользователя.В одно и то же время таблица может быть сортирована только по одной колонке. Таким образом, приведенный ниже пример:
<columns> <column property="name" sort="DESCENDING"/> <column property="parent" sort="ASCENDING"/> </columns>вызовет исключение.
Если одновременно для колонки установить атрибуты
sortиsortable="false", это также вызовет исключение.-
maxTextLength- необязательный атрибут, позволяет ограничивать количество символов в ячейке. При этом если разница между фактическим и допустимым количеством символов не превышает порог в 10 символов, "лишние" символы не скрываются. Для просмотра полной записи надо кликнуть на ее видимую часть. Пример колонки с ограничением в 10 символов:
-
link- установка атрибута вtrueпозволяет отобразить в ячейке таблицы ссылку на экран просмотра экземпляра сущности (поддерживается только для Web Client). Атрибутlink="true") может указываться и для колонок примитивных типов: в этом случае, при нажатии на ссылку будет открываться редактор основной сущности таблицы. Такой подход может применяться для упрощения навигации - пользователи смогут открывать редактор одним кликом по некоторому ключевому атрибуту.
-
linkScreen- позволяет указать идентификатор экрана, который будет открыт по нажатию на ссылку, включенную свойствомlink.
-
linkScreenOpenType- задает режим открытия экрана (THIS_TAB,NEW_TABилиDIALOG).
-
linkInvoke- позволяет заменить открытие окна на вызов метода контроллера.@Inject private Notifications notifications; public void linkedMethod(Entity item, String columnId) { Customer customer = (Customer) item; notifications.create() .withCaption(customer.getName()) .show(); }
-
captionProperty- имя атрибута сущности, который должен быть отображен в колонке вместо указанного в id. Например, если имеется связанная сущностьPriorityс атрибутамиnameиorderNo, можно определить следующую колонку:<column id="priority.orderNo" captionProperty="priority.name" caption="msg://priority" />В этом случае в колонке будет отображаться название приоритета, а сортировка колонки будет осуществляться по атрибуту
orderNo.
-
необязательный атрибут
generatorсодержит ссылку на метод в контроллере экрана, который создает визуальный компонент для отображения содержимого ячейки:<columns> <column id="name"/> <column id="imageFile" generator="generateImageFileCell"/> </columns>public Component generateImageFileCell(Employee entity){ Image image = uiComponents.create(Image.NAME); image.setSource(FileDescriptorResource.class).setFileDescriptor(entity.getImageFile()); return image; }Он может быть использован вместо передачи реализации
Table.ColumnGeneratorв метод addGeneratedColumn(). -
Элемент
columnможет содержать вложенный элемент formatter для представления значения атрибута в виде, отличном от стандартного для данного Datatype:<column id="date"> <formatter class="com.haulmont.cuba.gui.components.formatters.DateFormatter" format="yyyy-MM-dd HH:mm:ss" useUserTimezone="true"/> </column>
-
-
rowsCount− необязательный элемент, создающий для таблицы компонентRowsCount, который позволяет загружать в таблицу данные постранично. Размер страницы задается путем ограничения количества записей в контейнере методомsetMaxResults()loader'а. Как правило, это делает связанный с загрузчиком данных таблицы компонент Filter, однако при отсутствии универсального фильтра можно вызвать этот метод и напрямую из контроллера экрана.Компонент
RowsCountможет также отобразить общее число записей, возвращаемых текущим запросом в контейнере данных, без извлечения этих записей. По клику пользователя на знак "?" вызываетсяcom.haulmont.cuba.core.global.DataManager#getCount, что приводит к выполнению в БД запроса с такими же, как у текущего запроса условиями, но с агрегатной функциейCOUNT(*)вместо результатов. Полученное число отображается вместо знака "?".Атрибут
autoLoadкомпонентаRowsCount, установленный в значениеtrue, позволяет автоматически загружать общее число записей. Его можно установить в XML-дескрипторе:<rowsCount autoLoad="true"/>Также включить или отключить автоматическую загрузку количества записей можно с помощью API в контроллере экрана:
boolean autoLoadEnabled = rowsCount.getAutoLoad(); rowsCount.setAutoLoad(false);
-
actions− необязательный элемент для описания действий, связанных с таблицей. Кроме описания произвольных действий, поддерживаются следующие стандартные действия, определенные в пакетеcom.haulmont.cuba.gui.actions.list:create,edit,remove,refresh,add,exclude,excel.
Атрибуты table
-
Атрибут
emptyStateMessageпозволяет задать сообщение в тех случаях, когда нет загруженных данных, установлены нулевые значения или контейнер данных пуст. Данный атрибут часто используется совместно с атрибутом emptyStateLinkMessage. Сообщение может содержать информацию о том, какие данные должна содержать таблица. Например:<table id="table" emptyStateMessage="No data added to the table" ... width="100%">Атрибут
emptyStateMessageподдерживает загрузку сообщений из пакета сообщений. Если вы не хотите отображать сообщение, просто не указывайте этот атрибут.
-
Атрибут
emptyStateLinkMessageпозволяет задать сообщение в виде гиперссылки в тех случаях, когда нет загруженных данных, установлены нулевые значения или контейнер данных пуст. Данный атрибут часто используется совместно с атрибутом emptyStateMessage. Сообщение должно описывать действие, которое необходимо выполнить для заполнения таблицы. Например:<table id="table" emptyStateMessage="No data added to the table" emptyStateLinkMessage="Add data (Ctrl+\)" ... width="100%">
Атрибут
emptyStateLinkMessageподдерживает загрузку сообщений из пакета сообщений. Если вы не хотите отображать сообщение, просто не указывайте этот атрибут.Чтобы обработать событие перехода по ссылке, используйте метод setEmptyStateLinkClickHandler или подпишитесь на соответствующее событие в контроллере экрана:
@Install(to = "customersTable", subject = "emptyStateLinkClickHandler") private void customersTableEmptyStateLinkClickHandler(Table.EmptyStateClickEvent<Customer> emptyStateClickEvent) { screenBuilders.editor(emptyStateClickEvent.getSource()) .newEntity() .show(); }
-
Атрибут
multiselectпозволяет задать режим множественного выделения строк в таблице. Еслиmultiselectравенtrue, то пользователь может выделить несколько строк с помощью клавиатуры или мыши, удерживая клавиши Ctrl или Shift. По умолчанию режим множественного выделения отключен.
-
Атрибут
sortableразрешает или запрещает сортировку в таблице. По умолчанию имеет значениеtrue. Если сортировка разрешена, то при нажатии на название колонки справа от названия появляется значок /
/ . Сортировку некоторой отдельной колонки можно запретить с помощью атрибута sortable этой колонки.
. Сортировку некоторой отдельной колонки можно запретить с помощью атрибута sortable этой колонки.При включенной с помощью элемента
rowsCount(см. выше) страничной загрузке таблицы сортировка производится разными способами в зависимости от того, умещаются ли все записи на одной странице. Если умещаются, то сортировка производится в памяти, без обращений к БД. Если же страниц больше одной, то сортировка производится на базе данных путем отправки нового запроса с соответствующимORDER BY.Колонка таблицы может ссылаться на локальный атрибут или на связанную сущность. Например:
<table id="ordersTable" dataContainer="ordersDc"> <columns> <column id="customer.name"/> <!-- the 'name' attribute of the 'Customer' entity --> <column id="contract"/> <!-- the 'Contract' entity --> </columns> </table>В последнем случае, сортировка на базе данных производится по атрибутам, указанным в аннотации
@NamePatternсвязанной сущности. Если у связанной сущности нет такой аннотации, то сортировка производится в памяти только в пределах текущей страницы.Если колонка таблицы ссылается на неперсистентный атрибут, то сортировка на базе данных производится по атрибутам, указанным в параметре
related()аннотации@MetaProperty. Если такой параметр не указан, то сортировка производится в памяти только в пределах текущей страницы.Если таблица соединена со вложенным property container, который содержит коллекцию связанных сущностей, то для того, чтобы таблицу можно было сортировать, атрибут-коллекция должен быть упорядоченного типа (
ListилиLinkedHashSet). Если атрибут имеет типSet, то атрибутsortableне оказывает влияния и пользователи не смогут сортировать таблицу.Если необходимо, можно создать собственную реализацию сортировки.
-
Атрибут
presentationsуправляет механизмом представлений. Значение по умолчанию равноfalse. Когда значение атрибута равноtrue, то в верхнем правом углу таблицы появляется значок . Механизм представлений реализован только для блока Web Client.
. Механизм представлений реализован только для блока Web Client.
-
Установка атрибута
columnControlVisibleвfalseзапрещает пользователю скрывать колонки с помощью меню, выпадающего при нажатии на кнопку в правой части шапки таблицы. Флажками в меню отмечаются отображаемые в данный момент колонки. Существуют дополнительные пункты меню:-
Select all− показать все колонки таблицы; -
Deselect all− спрятать все колонки, кроме первой. Первая колонка не скрывается для правильного отображения таблицы.
-
-
Установка атрибута
reorderingAllowedвfalseзапрещает пользователю менять местами колонки, перетаскивая их с помощью мыши.
-
Установка атрибута
columnHeaderVisibleвfalseскрывает заголовок таблицы.
-
При установленном в
falseатрибутеshowSelectionтекущая строка не имеет выделения.
-
Атрибут
contextMenuEnabledразрешает или запрещает показывать контекстное меню. По умолчанию атрибут имеет значениеtrue. В контекстном меню отображаются действия таблицы (если они есть), и пункт Системная информация, содержащий информацию о выбранной сущности (если у пользователя есть разрешениеcuba.gui.showInfo).
-
Если атрибуту
multiLineCellsтаблицы присвоить значениеtrue, то ячейки, содержащие текст с переносами строк, будут отображать его в несколько строк. В таком режиме в веб-клиенте для правильной работы полосы прокрутки все строки текущей страницы таблицы будут загружены веб-браузером сразу, без ленивой загрузки видимой части таблицы. По умолчанию атрибут имеет значениеfalse.
-
Атрибут
aggregatableвключает режим агрегации строк таблицы. Поддерживаются следующие операции:-
SUM- сумма -
AVG- среднее значение -
COUNT- количество -
MIN- минимальное значение -
MAX- максимальное значение
Для агрегируемых колонок необходимо указать элемент
aggregationс атрибутомtype, задающим функцию агрегации. По умолчанию в агрегируемых колонках поддерживаются только числовые типы данных, такие какInteger,Double,LongиBigDecimal. Агрегированные значения столбцов выводятся в дополнительной строке вверху таблицы. Пример описания таблицы с агрегацией:<table id="itemsTable" aggregatable="true" dataContainer="itemsDc"> <columns> <column id="product"/> <column id="quantity"/> <column id="amount"> <aggregation type="SUM"/> </column> </columns> </table>Элемент
aggregationможет содержать атрибутeditable. Установка атрибута в значениеtrueсовместно с использованием метода setAggregationDistributionProvider() позволяет реализовать функциональность распределения значения агрегируемой ячейки между строками таблицы.Элемент
aggregationможет также содержать атрибутstrategyClass, указывающий класс, реализующий интерфейсAggregationStrategy(см. ниже пример установки стратегии агрегации программно).Атрибут
valueDescriptionзадает текст всплывающей подсказки, отображаемой при наведении курсора мыши по агрегированному значению. Для операций, перечисленных выше (SUM,AVG,COUNT,MIN,MAX), всплывающие подсказки уже есть по умолчанию.Для отображения агрегированного значения в виде, отличном от стандартного для данного Datatype, для него можно указать Formatter:
<column id="amount"> <aggregation type="SUM"> <formatter class="com.company.sample.MyFormatter"/> </aggregation> </column>Атрибут
aggregationStyleпозволяет задать положение строки агрегации:TOPилиBOTTOM. По умолчанию используетсяTOP.В дополнение к операциям, перечисленным выше, можно задать собственную стратегию агрегации путем создания класса, реализующего интерфейс
AggregationStrategy, и передачи его методуsetAggregation()классаTable.Columnв составе экземпляраAggregationInfo. Например:public class TimeEntryAggregation implements AggregationStrategy<List<TimeEntry>, String> { @Override public String aggregate(Collection<List<TimeEntry>> propertyValues) { HoursAndMinutes total = new HoursAndMinutes(); for (List<TimeEntry> list : propertyValues) { for (TimeEntry timeEntry : list) { total.add(HoursAndMinutes.fromTimeEntry(timeEntry)); } } return StringFormatHelper.getTotalDayAggregationString(total); } @Override public Class<String> getResultClass() { return String.class; } }AggregationInfo info = new AggregationInfo(); info.setPropertyPath(metaPropertyPath); info.setStrategy(new TimeEntryAggregation()); Table.Column column = weeklyReportsTable.getColumn(columnId); column.setAggregation(info); -
-
Атрибут
editableпозволяет перевести таблицу в режим in-place редактирования ячеек. В этом режиме в колонках, имеющих атрибутeditable = true, отображаются компоненты для редактирования значений атрибутов сущности, находящейся в источнике данных.Тип компонента для каждой редактируемой колонки выбирается автоматически на основании типа атрибута сущности. Например, для строковых и числовых атрибутов используется TextField, для
Date- DateField, для перечислений - LookupField, для ссылок на другие сущности - PickerField.Для редактируемой колонки типа
Dateможно дополнительно указать атрибутыdateFormatилиresolutionаналогично описанным для DateField.Для редактируемой колонки, отображающей связанную сущность, можно дополнительно указать атрибуты optionsContainer и captionProperty. При указании
optionsContainerвместо PickerField используется компонент LookupField.Произвольно настроить отображение ячеек, в том числе для редактирования содержимого, можно с помощью метода
Table.addGeneratedColumn()- см. ниже.
-
В веб-клиенте с темой, основанной на Halo, атрибут
stylenameпозволяет применять к таблице предопределенные стилиTable. Стили задаются в XML-дексрипторе или контроллере экрана с помощью атрибутаstylename:<table id="table" dataContainer="itemsDc" stylename="no-stripes"> <columns> <column id="product"/> <column id="quantity"/> </columns> </table>Чтобы применить стиль программно, выберите одну из констант класса
HaloThemeс префиксом компонентаTABLE_:table.setStyleName(HaloTheme.TABLE_NO_STRIPES);- Стили компонента Table
-
borderless- удаляет внешнюю рамку таблицы.
-
compact- уменьшает отступы внутри ячеек таблицы.
-
no-header- скрывает заголовки таблицы.
-
no-horizontal-lines- удаляет горизонтальные строковые разделители.
-
no-stripes- отключает чередование цветов строк таблицы.
-
no-vertical-lines- удаляет вертикальные разделители столбцов.
-
small- уменьшает размер шрифта и отступы внутри ячеек таблицы.
Методы интерфейса Table
-
метод
addColumnCollapsedListener() позволяет отслеживать видимость колонок таблицы с помощью интерфейса слушателяColumnCollapsedListener.
-
getSelected(),getSingleSelected()- возвращают экземпляры сущностей, соответствующие выделенным в таблице строкам. Коллекцию можно получить вызовом методаgetSelected(). Если ничего не выбрано, возвращается пустой набор. Еслиmultiselectотключен, удобно пользоваться методомgetSingleSelected(), возвращающим одну выбранную сущность илиnull, если ничего не выбрано.
-
addSelectionListener()- позволяет отслеживать выделение строк таблицы, например:customersTable.addSelectionListener(customerSelectionEvent -> notifications.create() .withCaption("You selected " + customerSelectionEvent.getSelected().size() + " customers") .show());Также отслеживание изменений можно реализовать, подписавшись на соответствующее событие:
@Subscribe("customersTable") protected void onCustomersTableSelection(Table.SelectionEvent<Customer> event) { notifications.create() .withCaption("You selected " + customerSelectionEvent.getSelected().size() + " customers") .show(); }Источник события
SelectionEventможно отследить с помощью метода isUserOriginated().
-
Метод
addGeneratedColumn()позволяет задать собственное представление данных в колонке. Он принимает два параметра: идентификатор колонки и реализацию интерфейсаTable.ColumnGenerator. Идентификатор может совпадать с одним из идентификаторов, указанных для колонок таблицы в XML-дескрипторе - в этом случае новая колонка вставляется вместо заданной в XML. Если идентификатор не совпадает ни с одной колонкой, создается новая справа.Метод
generateCell()интерфейсаTable.ColumnGeneratorвызывается таблицей для каждой строки, и в него передается экземпляр сущности, отображаемой в данной строке. МетодgenerateCell()должен вернуть визуальный компонент, который и будет отображаться в ячейке.Пример использования:
@Inject private GroupTable<Car> carsTable; @Inject private CollectionContainer<Car> carsDc; @Inject private CollectionContainer<Color> colorsDc; @Inject private UiComponents uiComponents; @Inject private Actions actions; @Subscribe protected void onInit(InitEvent event) { carsTable.addGeneratedColumn("color", entity -> { LookupPickerField<Color> field = uiComponents.create(LookupPickerField.NAME); field.setValueSource(new ContainerValueSource<>(carsTable.getInstanceContainer(entity), "color")); field.setOptions(new ContainerOptions<>(colorsDc)); field.addAction(actions.create(LookupAction.class)); field.addAction(actions.create(OpenAction.class)); return field; }); }В данном случае в ячейках колонки
colorтаблицы отображается компонент LookupPickerField. Компонент будет сохранять свое значение в атрибутcolorсущности, экземпляр которой отображается в данной строке.Метод
getInstanceContainer(), возвращающий контейнер с текущим экземпляром сущности, должен использоваться только в data binding компонентов, создаваемых при генерации ячеек таблицы.Если в ячейке необходимо отобразить просто динамически сформированный текст, вместо компонента Label используйте класс
Table.PlainTextCell. Это упростит отрисовку и сделает таблицу быстрее.Если в метод
addGeneratedColumn()передан идентификатор колонки, не объявленной в XML-дескрипторе, то может понадобиться установить заголовок новой колонки следующим образом:carsTable.getColumn("colour").setCaption("Colour");Существует также более декларативный подход, использующий XML-атрибут generator.
-
Метод
requestFocus()позволяет установить фокус на определенное поле конкретной записи. Принимает два параметра: экземпляр сущности, определяющий строку и идентификатор колонки. Пример программной установки фокуса:table.requestFocus(item, "count");
-
Метод
scrollTo()позволяет программно прокрутить таблицу до нужной записи. Метод принимает экземпляр сущности, определяющий нужную строку в таблице.Пример использования метода:
table.scrollTo(item);
-
Метод
setCellClickListener()может избавить от необходимости добавлять генерируемые колонки с компонентами, если нужно нарисовать что-либо в ячейках и получать оповещения когда пользователь кликает на эти ячейки. Имплементация классаCellClickListener, передаваемая в данный метод, получает текущий экземпляр сущности и идентификатор колонки. Содержимое ячеек будет завернуто в элементspanсо стилемcuba-table-clickable-cell, который можно использовать для задания отображения ячеек.Пример использования
CellClickListener:@Inject private Table<Customer> customersTable; @Inject private Notifications notifications; @Subscribe protected void onInit(InitEvent event) { customersTable.setCellClickListener("name", customerCellClickEvent -> notifications.create() .withCaption(customerCellClickEvent.getItem().getName()) .show()); }
-
С помощью метода
setAggregationDistributionProvider()можно задать провайдерAggregationDistributionProvider, определяющий правила распределения агрегированного значения между ячейками таблицы. Если пользователь вводит значение в агрегированную ячейку, оно распределяется по составляющим ячейкам в соответствии с кастомным алгоритмом. Алгоритм может учитывать и существующие значения ячеек. Поддерживается только для стиля агрегацииTOP. Для того чтобы сделать агрегированные ячейки редактируемыми, используйте атрибут editable элементаaggregation.При создании провайдера используется объект
AggregationDistributionContext<E>, который содержит данные, необходимые для распределения агрегируемого значения:-
Column column− колонка, в которой произошло изменение значения в общей или групповой агрегации; -
Object value− новое значение агрегации; -
Collection<E> scope− коллекция сущностей, на которые повлияет изменение значения агрегации; -
boolean isTotalAggregationуказывает, в какой агрегации произошли изменения: в общей или групповой.В качестве примера рассмотрим таблицу, представляющую бюджет. Пользователь создает категории бюджета и задает для каждой из них проценты, в соответствии с которыми должна распределяться сумма дохода. Далее в агрегируемой ячейке указывается общая сумма дохода, после чего происходит распределение по категориям.
Пример описания в дескрипторе:
<table id="budgetItemsTable" width="100%" dataContainer="budgetItemsDc" aggregatable="true" editable="true" showTotalAggregation="true"> ... <columns> <column id="category"/> <column id="percent"/> <column id="sum"> <aggregation editable="true" type="SUM"/> </column> </columns> ... </table>Реализация в контроллере:
budgetItemsTable.setAggregationDistributionProvider(context -> { Collection<BudgetItem> scope = context.getScope(); if (scope.isEmpty()) { return; } double value = context.getValue() != null ? ((double) context.getValue()) : 0; for (BudgetItem budgetItem : scope) { budgetItem.setSum(value / 100 * budgetItem.getPercent()); } });
-
-
Метод
getAggregationResults()возвращает мэп с результатами агрегации, где ключи в мэп − идентификаторы столбцов таблицы, а значения − значения агрегации.
-
Метод
setStyleProvider()позволяет задать стиль отображения ячеек таблицы. Параметром метода должна быть реализация интерфейсаTable.StyleProvider. МетодgetStyleName()этого интерфейса вызывается таблицей отдельно для каждой строки и для каждой ячейки. Если метод вызван для строки, то первый параметр содержит экземпляр сущности, отображаемый этой строкой, а второй параметрnull. Если же метод вызван для ячейки, то второй параметр содержит имя атрибута, отображаемого этой ячейкой.Пример задания стилей:
@Inject protected Table customersTable; @Subscribe protected void onInit(InitEvent event) { customersTable.setStyleProvider((customer, property) -> { if (property == null) { // style for row if (hasComplaints(customer)) { return "unsatisfied-customer"; } } else if (property.equals("grade")) { // style for column "grade" switch (customer.getGrade()) { case PREMIUM: return "premium-grade"; case HIGH: return "high-grade"; case MEDIUM: return "medium-grade"; default: return null; } } return null; }); }Далее нужно определить заданные для строк и ячеек стили в теме приложения. Подробная информация о создании темы находится в Создание темы приложения. Для веб-клиента новые стили определяются в файле
styles.scss. Имена стилей, заданные в контроллере, совместно с префиксами, обозначающими строку или колонку таблицы, образуют CSS-селекторы. Например:.v-table-row.unsatisfied-customer { font-weight: bold; } .v-table-cell-content.premium-grade { background-color: red; } .v-table-cell-content.high-grade { background-color: green; } .v-table-cell-content.medium-grade { background-color: blue; }
-
Метод
addPrintable()позволяет задать специфическое представление данных колонки при выводе в XLS-файл, осуществляемом стандартным действиемexcelили напрямую с помощью классаExcelExporter. Метод принимает идентификатор колонки и реализацию интерфейсаTable.Printableдля нее. Например:ordersTable.addPrintable("customer", new Table.Printable<Customer, String>() { @Override public String getValue(Customer customer) { return "Name: " + customer.getName; } });Метод
getValue()интерфейсаTable.Printableдолжен возвращать данные, которые будут находиться в ячейке таблицы. Это может быть не только строка - метод может возвращать значения других типов, например, числовые данные или даты, и они будут представлены в XLS-файле соответствующим образом.Если форматированный вывод в XLS необходим для генерируемой колонки, нужно использовать реализацию интерфейса
Table.PrintableColumnGenerator, передавая ее методуaddGeneratedColumn(). Значение для вывода в ячейку XLS-документа задается в методеgetValue()этого интерфейса:ordersTable.addGeneratedColumn("product", new Table.PrintableColumnGenerator<Order, String>() { @Override public Component generateCell(Order entity) { Label label = uiComponents.create(Label.NAME); Product product = order.getProduct(); label.setValue(product.getName() + ", " + product.getCost()); return label; } @Override public String getValue(Order entity) { Product product = order.getProduct(); return product.getName() + ", " + product.getCost(); } });Если генерируемой колонке тем или иным способом не задано представления
Printable, то в случае, если колонке соответствует атрибут сущности, будет выведено его значение, в противном случае не будет выведено ничего.
-
Метод
setItemClickAction()позволяет задать действие, выполняемое при двойном клике на строке таблицы. Если такое действие не задано, при двойном клике таблица пытается найти среди своих действий подходящее в следующем порядке:-
Действие, назначенное на клавишу Enter посредством свойства
shortcut. -
Действие с именем
edit. -
Действие с именем
view.Если такое действие найдено и имеет свойство
enabled = true, оно выполняется.
-
-
Метод
setEnterPressAction()позволяет задать действие, выполняемое при нажатии клавиши Enter. Если такое действие не задано, таблица пытается найти среди своих действий подходящее в следующем порядке:-
Действие, назначенное методом
setItemClickAction(). -
Действие, назначенное на клавишу Enter посредством свойства
shortcut. -
Действие с именем
edit. -
Действие с именем
view.
Если такое действие найдено и имеет свойство
enabled = true, оно выполняется. -
-
setEmptyStateLinkClickHandlerпозволяет задать обработчик, который будет вызван после нажатия на гиперссылку в сообщении, установленном в атрибуте emptyStateLinkMessage:@Subscribe public void onInit(InitEvent event) { customersTable.setEmptyStateLinkClickHandler(emptyStateClickEvent -> screenBuilders.editor(emptyStateClickEvent.getSource()) .newEntity() .show()); }
-
Метод
setItemDescriptionProviderзадает провайдер, служащий для генерации всплывающих подсказок для ячеек таблицы.В приведенном ниже примере мы покажем использование метода
setItemDescriptionProviderдля таблицыdepartmentsTable. СущностьDepartmentимеет три атрибута:name,active,parentDept.@Inject private Table<Department> departmentsTable; @Subscribe public void onInit(InitEvent event) { departmentsTable.setItemDescriptionProvider(((department, property) -> { if (property == null) { (1) if (department.getParentDept() == null) { return "Parent Department"; } } else if (property.equals("active")) { (2) return department.getActive() ? "Active department" : "Inactive department"; } return null; })); }1 – описание для строки. 2 – описание для колонки "active".
Внешний вид компонента Table можно настроить с помощью переменных SCSS с префиксом $cuba-table-*. Эти переменные можно изменить в визуальном редакторе после расширения темы или создания новой темы.
- Атрибуты table
-
align - aggregatable - aggregationStyle - caption - captionAsHtml - columnControlVisible - columnHeaderVisible - contextHelpText - contextHelpTextHtmlEnabled - contextMenuEnabled - css - dataContainer - description - descriptionAsHtml - editable - emptyStateLinkMessage - emptyStateMessage - enable - box.expandRatio - height - htmlSanitizerEnabled - id - metaClass - multiLineCells - multiselect - presentations - reorderingAllowed - settingsEnabled - showSelection - sortable - stylename - tabIndex - textSelectionEnabled - visible - width
- Элементы table
-
actions - buttonsPanel - columns - rows - rowsCount
- Атрибуты columns
- Атрибуты column
-
align - caption - captionAsHtml - captionProperty - collapsed - dateFormat - editable - expandRatio - generator - id - link - linkInvoke - linkScreen - linkScreenOpenType - maxTextLength - optionsContainer - resolution - sort - sortable - visible - width
- Элементы column
- Атрибуты aggregation
- Предопределенные стили table
-
borderless - compact - no-header - no-horizontal-lines - no-stripes - no-vertical-lines - small
- API
-
addGeneratedColumn - addPrintable - addColumnCollapseListener - addSelectionListener - applySettings - generateCell - getAggregationResults - getSelected - requestFocus - saveSettings - scrollTo - setAggregationDistributionProvider - setClickListener - setEmptyStateLinkClickHandler - setEnterPressAction - setItemClickAction - setItemDescriptionProvider - setStyleProvider
3.5.2.1.46. TextArea
Текстовая область − многострочное текстовое поле для редактирования текста.
XML-имя компонента: textArea
TextArea в основном повторяет функциональность TextField и имеет следующие специфические атрибуты:
-
colsиrowsзадают количество строк и столбцов текста:<textArea id="textArea" cols="20" rows="5" caption="msg://name"/>Значения
widthиheightимеют приоритет над значениямиcolsиrows.
-
wordWrap- установите данный атрибут вfalse, чтобы отключить перенос строк по словам.Компонент
TextAreaподдерживает слушательTextChangeListener, определённый в родительском интерфейсеTextInputField. События изменения текста обрабатываются асинхронно после ввода, не блокируя сам ввод.textArea.addTextChangeListener(event -> { int length = event.getText().length(); textAreaLabel.setValue(length + " of " + textArea.getMaxLength()); });
-
Атрибут
textChangeEventModeзадаёт режим передачи изменений на сервер для вызова события на серверной стороне. В платформе реализовано 3 режима передачи:-
LAZY(по умолчанию) - событие вызывается во время паузы в наборе текста. Продолжительность паузы задаётся с помощью методаsetTextChangeTimeout()или атрибута textChangeTimeout. Событие изменения текста обрабатывается принудительно перед возможным событиемValueChangeEvent, даже если пользователь не выдержал паузу в наборе текста. -
TIMEOUT- событие вызывается после периода ожидания. В случае ввода нескольких изменений за один период, на сервер отсылается событие со всеми изменениями, включая последнее. Продолжительность периода ожидания задаётся с помощью методаsetTextChangeTimeout()или атрибута textChangeTimeout.В случае, если
ValueChangeEventможет случиться до истечения периода ожидания, событиеTextChangeEventобрабатывается до его истечения, при условии, что набранный текст был изменён после предыдущегоTextChangeEvent. -
EAGER- событие вызывается незамедлительно после каждого изменения текста, то есть после каждого нажатия клавиш. Запросы отправляются по отдельности и обрабатываются последовательно один за другим. Тем не менее асинхронная передача событий изменения на сервер позволяет не блокировать дальнейший ввод текста.
-
-
textChangeTimeoutопределяет продолжительность паузы при наборе текста или период ожидания, когда режим передачи измененийLAZYилиTIMEOUT.- Стили компонента TextArea
-
В веб-клиенте с темой, основанной на Halo, к компоненту
TextAreaможно применить предопределенные стили. Стили задаются в XML-дексрипторе или контроллере экрана с помощью атрибутаstylename:<textArea id="textArea" stylename="borderless"/>Чтобы применить стиль программно, выберите одну из констант класса
HaloThemeс префиксом компонентаTEXTAREA_:textArea.setStyleName(HaloTheme.TEXTAREA_BORDERLESS);-
align-center- выравнивание текста по центру области.
-
align-right- выравнивание текста по правому краю области.
-
borderless- удаляет рамку и фон текстовой области.
-
- Атрибуты textArea
-
align - caption - captionAsHtml - caseConversion - cols - contextHelpText - contextHelpTextHtmlEnabled - conversionErrorMessage - css - dataContainer - datatype - description - descriptionAsHtml - editable - enable - box.expandRatio - height - htmlSanitizerEnabled - icon - id - inputPrompt - maxLength - property - required - requiredMessage - responsive - rows - settingsEnabled - stylename - tabIndex - textChangeEventMode - textChangeTimeout - trim - visible - width - wordWrap
- Предопределенные стили textArea
-
align-center - align-right - borderless - huge - large - small - tiny
- API
-
addTextChangeListener - addValueChangeListener - addValidator - commit - discard - isModified - setContextHelpIconClickHandler
3.5.2.1.47. TextField
Поле для редактирования текста. Может использоваться как для работы с атрибутами сущностей, так и для ввода и отображения произвольной текстовой информации.
XML-имя компонента: textField
-
Пример текстового поля с заголовком, взятым из пакета локализованных сообщений:
<textField id="nameField" caption="msg://name"/>На рисунке ниже показан вид простого текстового поля.

-
В веб-клиенте с темой, основанной на Halo, к компоненту
TextFieldможно применить предопределенные стили. Стили задаются в XML-дексрипторе или контроллере экрана с помощью атрибутаstylename:<textField id="textField" stylename="borderless"/>Чтобы применить стиль программно, выберите одну из констант класса
HaloThemeс префиксом компонентаTEXTFIELD_:textField.setStyleName(HaloTheme.TEXTFIELD_INLINE_ICON);Стили компонента TextField:
-
align-center- выравние текста по центру поля.
-
align-right- выравнивание текста по правому краю поля.
-
borderless- удаляет рамку и фон текстового поля.
-
inline-icon- расположение значка внутри текстового поля.
Компонент TextField поддерживает автоматическую конвертацию регистра. Атрибут
caseConvertionможет принимать следующие значения:-
UPPER- верхний регистр, -
LOWER- нижний регистр, -
NONE- конвертация отключена (значение по умолчанию). Используйте это значение для поддержки клавиатурного ввода с использованием IME, к примеру, для японского, корейского и китайского языков.
-
-
Для создания текстового поля, связанного с данными, необходимо использовать атрибуты dataContainer и property.
<data> <instance id="customerDc" class="com.company.sales.entity.Customer" view="_local"> <loader/> </instance> </data> <layout> <textField dataContainer="customerDc" property="name" caption="msg://name"/> </layout>Как видно из примера, в экране описывается контейнер данных
customerDsдля некоторой сущностиПокупатель (Customer), имеющей атрибутname. В компоненте текстового поля в атрибуте dataContainer указывается ссылка на контейнер, а в атрибуте property − название атрибута сущности, значение которого должно быть отображено в текстовом поле.
-
Если поле не связано с атрибутом сущности (то есть не указан контейнер данных и название атрибута), то можно указать тип данных с помощью атрибута
datatype. Тип данных используется для форматирования значения поля. В качестве значения атрибута может быть указано любое имя типа данных, зарегистрированного в метаданных приложения – см. Datatype. Как правило, вTextFieldиспользуются следующие типы данных:-
decimal -
double -
int -
long
Если для поля указан атрибут
datatype, при вводе некорректного значения появляется стандартное сообщение об ошибке конвертации.В качестве примера рассмотрим текстовое поле с типом данных
Integer.<textField id="integerField" datatype="int" caption="msg://integerFieldName"/>Если в таком поле ввести значение, которое невозможно интерпретировать как целое число, то при потере фокуса полем будет выведено стандартное сообщение об ошибке.
Стандартные сообщения об ошибках конвертации задаются в главном пакете локализованных сообщений и имеют следующий шаблон:
databinding.conversion.error.<type>, например:databinding.conversion.error.int = Must be Integer -
-
Вы можете определять пользовательские сообщения об ошибках конвертации декларативно, используя атрибут
conversionErrorMessageв XML-дескрипторе:<textField conversionErrorMessage="This field can work only with Integers" datatype="int"/>или программно в контроллере экрана:
textField.setConversionErrorMessage("This field can work only with Integers"); -
Текстовому полю может быть назначен валидатор - класс, реализующий интерфейс
Field.Validator. Валидатор позволяет дополнительно кdatatypeограничить вводимую пользователем информацию. Например, для создания поля ввода положительных целых чисел нужно создать класс валидатора:public class PositiveIntegerValidator implements Field.Validator { @Override public void validate(Object value) throws ValidationException { Integer i = (Integer) value; if (i <= 0) throw new ValidationException("Value must be positive"); } }и задать его для текстового поля с типом данных
intв элементе validator:<textField id="integerField" datatype="int"> <validator class="com.sample.sales.gui.PositiveIntegerValidator"/> </textField>В отличие от проверки вводимой строки на соответствие типу данных, валидация срабатывает не сразу при потере полем фокуса, а только при вызове у поля метода
validate(). Это означает, что поле (и связанный с ним атрибут сущности) может некоторое время содержать значение, не удовлетворяющее условиям валидации (в приведенном примере неположительное число). Это не является проблемой, так как обычно поля редактирования с валидацией располагаются в экране редактирования, а он автоматически вызывает валидацию всех своих полей перед коммитом. Если же поле находится не в экране редактирования, то необходимо вызывать методvalidate()поля в контроллере явно.
-
Компонент
TextFieldподдерживает слушательTextChangeListener, определённый в родительском интерфейсеTextInputField. События изменения текста обрабатываются асинхронно после ввода, не блокируя сам ввод.textField.addTextChangeListener(event -> { int length = event.getText().length(); textFieldLabel.setValue(length + " of " + textField.getMaxLength()); }); textField.setTextChangeEventMode(TextInputField.TextChangeEventMode.LAZY);
-
Параметром
TextChangeEventModeзадаётся режим передачи изменений на сервер для вызова события на серверной стороне. В платформе реализовано 3 режима передачи:-
LAZY(по умолчанию) - событие вызывается во время паузы в наборе текста. Продолжительность паузы можно задать с помощью методаsetInputEventTimeout(). Событие изменения текста обрабатывается принудительно перед возможным событиемValueChangeEvent, даже если пользователь не выдержал паузу в наборе текста. -
TIMEOUT- событие вызывается после периода ожидания. В случае ввода нескольких изменений за один период, на сервер отсылается событие со всеми изменениями, включая последнее. Продолжительность периода ожидания можно задать с помощью методаsetInputEventTimeout().В случае, если
ValueChangeEventможет случиться до истечения периода ожидания, событиеTextChangeEventобрабатывается до его истечения, при условии, что набранный текст был изменён после предыдущегоTextChangeEvent. -
EAGER- событие вызывается незамедлительно после каждого изменения текста, то есть после каждого нажатия клавиш. Запросы отправляются по отдельности и обрабатываются последовательно один за другим. Тем не менее, асинхронная передача событий изменения на сервер позволяет не блокировать дальнейший ввод текста. -
BLUR- событие вызывается, когда текстовое поле теряет фокус.
-
-
EnterPressListenerпозволяет указать действие, которое должно быть выполнено по нажатию клавиши Enter:textField.addEnterPressListener(enterPressEvent -> notifications.create() .withCaption("Enter pressed") .show());
-
ValueChangeListenerпозволяет обрабатывать изменения значения в текстовом поле, когда пользователь уже закончил ввод, т.е. после нажатия клавиши Enter или при потере компонентом фокуса. В слушатель передается объект события типаValueChangeEvent, который имеет следующие методы:-
getPrevValue()возвращает значение компонента до изменения. -
getValue()возвращает текущее значение компонента.textField.addValueChangeListener(stringValueChangeEvent -> notifications.create() .withCaption("Before: " + stringValueChangeEvent.getPrevValue() + ". After: " + stringValueChangeEvent.getValue()) .show());Источник события
ValueChangeEventможно отследить с помощью метода isUserOriginated().
-
-
Если текстовое поле связано с атрибутом сущности (через
dataContainerиproperty), и если для атрибута сущности в JPA-аннотации@Columnуказан параметрlength, тоTextFieldбудет соответственно ограничивать максимальную длину вводимого текста.Если текстовое поле не связано с атрибутом, либо для него не определено значение
length, либо это значение нужно переопределить, то для ограничения максимальной длины вводимого текста можно использовать атрибутmaxLength. Значение "-1" означает отсутствие ограничения. Например:<textField id="shortTextField" maxLength="10"/>
-
По умолчанию текстовое поле отсекает пробелы в начале и конце введенной строки. То есть если пользователь ввел строку " aaa bbb " то значением поля, возвращаемым методом
getValue()и сохраняемым в связанный атрибут сущности, будет строка "aaa bbb". Для того, чтобы отключить отсечение пробелов, используйте атрибутtrimсо значениемfalse.Следует иметь в виду, что отсечение пробелов работает только при вводе нового значения. Если в значении связанного атрибута уже присутствуют пробелы, они будут отображаться, пока пользователь не изменит значение поля.
-
Текстовое поле всегда вместо введенной пустой строки возвращает
null. Соответственно, при включенном атрибутеtrimстрока, состоящая из одних пробелов также превратится вnull. -
Метод
setCursorPosition()используется для установки позиции курсора в указанный индекс (начинается с 0). После вызова метода поле принимает фокус ввода.
- Атрибуты textField
-
align - caption - captionAsHtml - caseConversion - contextHelpText - contextHelpTextHtmlEnabled - conversionErrorMessage - css - dataContainer - datatype - description - descriptionAsHtml - editable - enable - box.expandRatio - height - htmlSanitizerEnabled - icon - id - inputPrompt - maxLength - property - required - requiredMessage - stylename - tabIndex - trim - visible - width
- Элементы textField
- Предопределенные стили textField
-
align-center - align-right - borderless - huge - inline-icon - large - small - tiny
- API
-
addEnterPressListener - addTextChangeListener - addValueChangeListener - commit - discard - isModified - setContextHelpIconClickHandler
3.5.2.1.48. TimeField
Поле для отображения и ввода времени.
XML-имя компонента: timeField.
-
Для создания поля времени, связанного с данными, необходимо использовать атрибуты dataContainer и property:
<data> <instance id="orderDc" class="com.company.sales.entity.Order" view="_local"> <loader/> </instance> </data> <layout> <timeField dataContainer="orderDc" property="deliveryTime"/> </layout>Как видно из примера, в экране описывается контейнер данных
orderDcдля некоторой сущности Заказ (Order), имеющей атрибутdeliveryTime. В компоненте ввода времени в атрибутеdataContainerуказывается ссылка на контейнер, а в атрибутеproperty− название атрибута сущности, значение которого должно быть отображено в поле.Связанный атрибут сущности должен быть типа
java.util.Dateилиjava.sql.Time. -
Формат отображения времени определяется типом данных
timeи задается в главном пакете локализованных сообщений в ключеtimeFormat.
-
Если поле не связано с атрибутом сущности (то есть не указан контейнер данных и название атрибута), то можно указать тип данных с помощью атрибута
datatype. ВTimeFieldиспользуются следующие типы данных:-
localTime -
offsetTime -
time
-
-
Формат отображения времени можно также задать в атрибуте
timeFormatкомпонента. Это может быть как сама строка формата, так и ключ в пакете сообщений (с префиксомmsg://).
-
Независимо от упомянутого выше формата отображением секунд можно управлять с помощью атрибута
showSeconds. По умолчанию секунды отображаются, если формат содержит символыss.<timeField dataContainer="orderDc" property="createTs" showSeconds="true"/>
- Атрибуты timeField
-
align - caption - captionAsHtml - contextHelpText - contextHelpTextHtmlEnabled - css - dataContainer - datatype - description - descriptionAsHtml - editable - enable - box.expandRatio - height - htmlSanitizerEnabled - icon - id - property - required - requiredMessage - showSeconds - stylename - tabIndex - timeFormat - visible - width
- Элементы timeField
- API
-
addValueChangeListener - commit - discard - isModified - setContextHelpIconClickHandler
3.5.2.1.49. TokenList
Компонент TokenList представляет собой упрощенный вариант работы со списком сущностей: названия экземпляров располагаются в вертикальном или горизонтальном списке, добавление производится из выпадающего списка, удаление - с помощью кнопок, расположенных рядом с каждым экземпляром.
XML-имя компонента: tokenList
Пример описания компонента TokenList в XML-дескрипторе экрана:
<data>
<instance id="orderDc" class="com.company.sales.entity.Order" view="order-edit">
<loader/>
<collection id="productsDc" property="products"/>
</instance>
<collection id="allProductsDc" class="com.company.sales.entity.Product" view="_minimal">
<loader id="allProductsDl">
<query><![CDATA[select e from sales_Product e order by e.name]]></query>
</loader>
</collection>
</data>
<layout>
<tokenList id="productsList" dataContainer="orderDc" property="products" inline="true" width="500px">
<lookup optionsContainer="allProductsDc"/>
</tokenList>
</layout>Здесь в элементе data определен вложенный контейнер данных productsDc, содержащий коллекцию входящих в состав заказа продуктов. Кроме того, определен контейнер allProductsDc, содержащий коллекцию всех продуктов, имеющихся в базе данных. Компонент TokenList с идентификатором productsList отображает содержимое контейнера productsDc, а также позволяет изменять эту коллекцию, добавляя в него экземпляры из контейнера allProductsDc.
Атрибуты tokenList:
-
position- задает позиционирование раскрывающегося списка. Атрибут может принимать два значения:TOP,BOTTOM. По умолчаниюTOP.
-
Атрибут
inlineзадает отображение списка выбранных значений: вертикально или горизонтально. Значениеtrueсоответствует горизонтальному расположению, значениеfalse− вертикальному. Так выглядит компонент с горизонтальным расположением значений:
-
simple- значениеtrueпозволяет убрать компонент выбора, оставляя только кнопку добавления и очистки списка. При нажатии на кнопку добавления Add сразу показывается экран списка экземпляров сущности, тип которой задан контейнером данных. Идентификатор экрана выбора определяется по правилам, описанным для стандартного действияLookupActionдляPickerField. Кнопка очистки списка Clear удаляет все элементы из контейнера данных компонентаTokenList.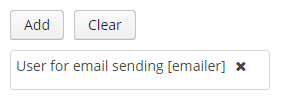
-
clearEnabled- значениеfalseпозволяет скрыть кнопку очистки Clear.
Элементы tokenList:
-
lookup− описатель компонента выбора значений.Атрибуты элемента
lookup:-
Атрибут
lookupзадает возможность выбора значений через экран выбора сущностей: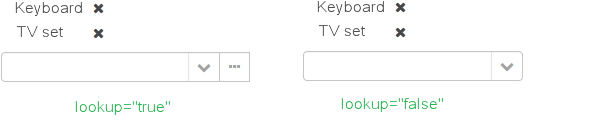
-
inputPrompt- текстовая подсказка, которая отображается в поле выбора. Если подсказка не задана, поле будет пустым.<tokenList id="linesList" dataContainer="orderItemsDс" property="items" width="320px"> <lookup optionsContainer="allItemsDс" inputPrompt="Choose an item"/> </tokenList>
-
Атрибут
lookupScreenзадает идентификатор экрана для выбора значений в режимеlookup="true". Если данный атрибут не задан, то идентификатор экрана выбора определяется по правилам, описанным для стандартного действияcom.haulmont.cuba.gui.actions.picker.LookupAction. -
Атрибут
openTypeможно задать способ открытия экрана выбора, аналогично описанному для стандартного действияcom.haulmont.cuba.gui.actions.picker.LookupAction. По умолчанию -THIS_TAB.
-
Если значение атрибута
multiselectустановлено вtrue, то в экране выбора сущностей будет установлен режим множественного выбора. Каждый экран, в котором предполагается изменять режим выбора, должен реализовать интерфейсcom.haulmont.cuba.gui.screen.MultiSelectLookupScreen. КлассStandardLookupреализует этот интерфейс по умолчанию. Если вам нужно предоставить пользовательскую реализацию, переопределите методsetLookupComponentMultiSelect, например:public class ProductsList extends StandardLookup { @Inject private GroupTable<Product> productsTable; @Override public void setLookupComponentMultiSelect(boolean multiSelect) { productsTable.setMultiSelect(multiSelect); } }
-
Компонент может принимать список опций из data container: для этого используется атрибут optionsContainer. Кроме этого, список опций для компонента можно указать с помощью методов setOptions(), setOptionsList() и setOptionsMap(). В этом случае атрибут <lookup> в дескрипторе экрана можно оставить пустым.
-
setOptionsList()позволяет программно задать список опций компонента. Для этого объявляем компонент в XML-дескрипторе:<tokenList id="tokenList" dataContainer="orderDc" property="items" width="320px"> <lookup/> </tokenList>Затем инжектируем компонент в контроллер и задаем ему список опций:
@Inject private TokenList<OrderItem> tokenList; @Inject private CollectionContainer<OrderItem> allItemsDc; @Subscribe public void onAfterShow(AfterShowEvent event) { tokenList.setOptionsList(allItemsDc.getItems()); }Того же результата можно достигнуть, используя метод
setOptions(), который позволяет работать со всеми типами опций:@Inject private TokenList<OrderItem> tokenList; @Inject private CollectionContainer<OrderItem> allItemsDc; @Subscribe public void onAfterShow(AfterShowEvent event) { tokenList.setOptions(new ContainerOptions<>(allItemsDc)); }
Компонент TokenList способен обрабатывать ввод пользователя при отсутствии подходящей опции в списке. Обработчик новых опций вызывается, если пользователь ввел некоторое значение, не совпадающее ни с одной из опций, и нажал Enter.
Существует два способа использовать newOptionHandler:
-
Декларативно, используя аннотацию
@Installв контроллере экрана:@Inject private CollectionContainer<Tag> tagsDc; @Inject private Metadata metadata; @Install(to = "tokenList", subject = "newOptionHandler") private void tokenListNewOptionHandler(String string) { Tag newTag = metadata.create(Tag.class); newTag.setName(string); tagsDc.getMutableItems().add(newTag); } -
Программно с помощью метода
setNewOptionHandler():@Inject private CollectionContainer<Tag> tagsDc; @Inject private Metadata metadata; @Inject private TokenList<Tag> tokenList; @Subscribe public void onInit(InitEvent event) { tokenList.setNewOptionHandler(string -> { Tag newTag = metadata.create(Tag.class); newTag.setName(string); tagsDc.getMutableItems().add(newTag); }); }
Слушатели tokenList:
-
ItemClickListenerпозволяет отслеживать клики по элементамtokenList. -
ValueChangeListenerотслеживает изменения значения`tokenList`, так же как и любого другого компонента, реализующего интерфейсField. Источник событияValueChangeEventможно отследить с помощью метода isUserOriginated().
- Атрибуты tokenList
-
align - caption - captionAsHtml - captionProperty - clearEnabled - contextHelpText - contextHelpTextHtmlEnabled - css - dataContainer - description - descriptionAsHtml - editable - enable - box.expandRatio - height - htmlSanitizerEnabled - icon - id - inline - position - simple - stylename - tabIndex - visible - width
- Элементы tokenList
- Атрибуты lookup
-
captionProperty - filterMode - inputPrompt - lookup - lookupScreen - multiselect - openType - optionsContainer
- Атрибуты button
- API
-
addValueChangeListener - setContextHelpIconClickHandler - setItemClickListener - setNewOptionHandler - setOptionCaptionProvider
3.5.2.1.50. Tree
Компонент Tree предназначен для отображения иерархической структуры, представленной сущностями, содержащими ссылки на самих себя.

XML-имя компонента: tree
Пример описания компонента Tree в XML-дескрипторе экрана:
<data readOnly="true">
<collection id="departmentsDc" class="com.company.sales.entity.Department" view="department-view">
<loader id="departmentsDl">
<query>
<![CDATA[select e from sales_Department e]]>
</query>
</loader>
</collection>
</data>
<layout>
<tree id="departmentsTree" dataContainer="departmentsDc" hierarchyProperty="parentDept"/>
</layout>В атрибуте dataContainer должен быть указан контейнер данных с типом CollectionContainer, а в атрибуте hierarchyProperty нужно указать имя атрибута сущности, являющегося ссылкой на саму себя.
В атрибуте captionProperty можно задать имя свойства сущности, отображаемого в дереве. Если этот атрибут не определен, то будет отображаться имя экземпляра сущности.
Атрибут contentMode определяет, как должны отображаться заголовки элементов дерева. Поддерживаются следующие режимы отображения:
-
TEXT- текстовые значения отображаются как простой текст. -
PREFORMATTED- текстовые значения отображаются в виде предварительно отформатированного текста. В этом режиме переводы строки сохраняются при отображении на экране. -
HTML- текстовые значения интерпретируются и отображаются в формате HTML. При использовании этого режима следует соблюдать осторожность, чтобы избежать проблем с XSS.
Метод setItemCaptionProvider() задает функцию, которая обеспечивает простановку имени атрибута сущности в качестве заголовка для каждого элемента дерева.
Атрибуты выбора Tree:
-
Атрибут
multiselectпозволяет задать режим множественного выделения элементов дерева. Еслиmultiselectравенtrue, то пользователь может выделить несколько элементов с помощью клавиатуры или мыши, удерживая клавиши Ctrl или Shift. По умолчанию режим множественного выделения отключен.
-
selectionMode- определяет режим выделения строк. Поддерживаются следующие режимы:-
SINGLE- единичный выбор строки. -
MULTI- множественный выбор строк как в таблице. -
NONE- выбор строк отключен.
Выделение строк можно отслеживать с помощью слушателя
SelectionListener. Источник события выделения можно отследить с помощью метода isUserOriginated().Атрибут
selectionModeимеет приоритет над устаревшимmultiselect. -
Метод setItemClickAction() позволяет задать действие, которое будет выполнено при двойном клике по узлу дерева.
Каждый элемент дерева может иметь значок слева. Создайте реализацию интерфейса ListComponent.IconProvider в контроллере экрана и установите ее для компонента Tree:
@Inject
private Tree<Department> tree;
@Subscribe
protected void onInit(InitEvent event) {
tree.setIconProvider(department -> {
if (department.getParentDept() == null) {
return "icons/root.png";
}
return "icons/leaf.png";
});
}Вы можете подписаться на события разворачивания и сворачивания элементов дерева следующим образом:
@Subscribe("tree")
public void onTreeExpand(Tree.ExpandEvent<Task> event) {
notifications.create()
.withCaption("Expanded: " + event.getExpandedItem().getName())
.show();
}
@Subscribe("tree")
public void onTreeCollapse(Tree.CollapseEvent<Task> event) {
notifications.create()
.withCaption("Collapsed: " + event.getCollapsedItem().getName())
.show();
}Для компонента Tree можно установить DescriptionProvider, с помощью которого отображается HTML в том случае, если задан режим ContentMode.HTML. Результат выполнения провайдера будет санитизирован, если для компонента Tree атрибут htmlSanitizerEnabled установлен в значение true.
Значение атрибута htmlSanitizerEnabled имеет приоритет над значением глобального свойства cuba.web.htmlSanitizerEnabled.
В старых экранах компонент Tree может быть связан с данными через источник данных вместо более удобного контейнера. В этом случае необходимо определить вложенный элемент treechildren, который должен содержать ссылку на источник данных с типом hierarchicalDatasource в значении атрибута datasource. Определение hierarchicalDatasource должно включать атрибут hierarchyProperty - имя атрибута сущности, являющегося ссылкой на саму себя.
- Атрибуты tree
-
caption - captionAsHtml - captionProperty - contentMode - contextHelpText - contextHelpTextHtmlEnabled - css - dataContainer - description - descriptionAsHtml - enable - box.expandRatio - height - htmlSanitizerEnabled - id - multiselect - showOrphans - stylename - tabIndex - visible - width
- Элементы tree
- Атрибуты treechildren
- API
-
addCollapseListener - addExpandListener - setDescriptionProvider - setDetailsGenerator - setItemCaptionProvider
3.5.2.1.51. TreeDataGrid
TreeDataGrid, подобно компоненту DataGrid, позволяет выводить информацию в виде таблицы, а также позволяет отображать иерархические данные и более эффективно управлять строками и колонками таблицы за счёт отложенной загрузки данных при прокрутке.
Компонент TreeDataGrid предназначен для работы с сущностями, которые содержат ссылки на самих себя. Это могут быть, например, файловая система или организационная структура предприятия.
XML-имя компонента: treeDataGrid.
Компонент реализован для блока Web Client.
Для TreeDataGrid кроме атрибута dataContainer, задающего data container для загрузки данных в таблицу, необходимо определить атрибут hierarchyProperty – имя атрибута сущности, являющегося ссылкой на саму себя.
Пример описания таблицы в XML-дескрипторе экрана:
<data readOnly="true">
<collection id="departmentsDc" class="com.company.sales.entity.Department" view="department-view">
<loader id="departmentsDl">
<query>
<![CDATA[select e from sales_Department e]]>
</query>
</loader>
</collection>
</data>
<layout>
<treeDataGrid id="treeDataGrid" dataContainer="departmentsDc" hierarchyProperty="parentDept">
<columns>
<column id="name" property="name"/>
<column id="parentDept" property="parentDept"/>
</columns>
</treeDataGrid>
</layout>За исключением атрибута hierarchyProperty, функциональность TreeDataGrid аналогична таблице DataGrid.
- Атрибуты treeDataGrid
-
aggregatable - aggregationPosition - align - caption - captionAsHtml - colspan - columnResizeMode - columnsCollapsingAllowed - contextMenuEnabled - css - dataContainer - description - descriptionAsHtml - editorBuffered - editorCancelCaption - editorEnabled - editorSaveCaption - emptyStateLinkMessage - emptyStateMessage - enable - box.expandRatio - frozenColumnCount - headerVisible - height - hierarchyProperty - htmlSanitizerEnabled - icon - id - metaClass - reorderingAllowed - responsive - rowspan - selectionMode - settingsEnabled - showOrphans - sortable - stylename - tabIndex - textSelectionEnabled - visible - width
- Элементы treeDataGrid
-
actions - buttonsPanel - columns - rowsCount
- Атрибуты columns
- Атрибуты column
-
caption - collapsed - collapsible - collapsingToggleCaption - editable - expandRatio - id - maximumWidth - minimumWidth - property - resizable - sort - sortable - width
- Элементы column
-
aggregation - checkBoxRenderer - componentRenderer - dateRenderer - formatter - iconRenderer - htmlRenderer - localDateRenderer - localDateTimeRenderer - numberRenderer - progressBarRenderer - textRenderer
- Атрибуты aggregation
- API
-
addGeneratedColumn - applySettings - createRenderer - edit - getAggregationResults - saveSettings - getColumns - setDescriptionProvider - addCellStyleProvider - setConverter - setDetailsGenerator - setEmptyStateLinkClickHandler - setEnterPressAction - setItemClickAction - setRenderer - setRowDescriptionProvider - addRowStyleProvider - sort
- Слушатели treeDataGrid
-
ColumnCollapsingChangeListener - ColumnReorderListener - ColumnResizeListener - ContextClickListener - EditorCloseListener - EditorOpenListener - EditorPostCommitListener - EditorPreCommitListener - ItemClickListener - SelectionListener - SortListener
- Предопределенные стили
-
borderless - no-horizontal-lines - no-vertical-lines - no-stripes
3.5.2.1.52. TreeTable
Компонент TreeTable − иерархическая таблица, отображающая в первой колонке древовидную структуру. Предназначена для работы с сущностями, которые содержат ссылки на самих себя. Это могут быть например, файловая система или организационная структура предприятия.
XML-имя компонента: treeTable
В атрибуте dataContainer компонента treeTable должен быть указан контейнер данных с типом CollectionContainer, а в атрибуте hierarchyProperty нужно указать имя атрибута сущности, являющегося ссылкой на саму себя.
Пример описания таблицы в XML-дескрипторе экрана:
<data readOnly="true">
<collection id="departmentsDc" class="com.company.sales.entity.Department" view="_local">
<loader id="departmentsDl">
<query>
<![CDATA[select e from sales_Department e]]>
</query>
</loader>
</collection>
</data>
<layout>
<treeTable id="departmentsTable" dataContainer="departmentsDc" hierarchyProperty="parentDept" width="100%">
<columns>
<column id="name"/>
<column id="active"/>
</columns>
</treeTable>
</layout>Функциональность TreeTable аналогична простой таблице Table.
- Атрибуты treeTable
-
align - aggregatable - aggregationStyle - caption - captionAsHtml - columnControlVisible - contextHelpText - contextHelpTextHtmlEnabled - contextMenuEnabled - css - dataContainer - description - descriptionAsHtml - editable - emptyStateLinkMessage - emptyStateMessage - enable - box.expandRatio - height - htmlSanitizerEnabled - id - metaClass - multiLineCells - multiselect - presentations - reorderingAllowed - settingsEnabled - showOrphans - sortable - stylename - tabIndex - textSelectionEnabled - visible - width
- Элементы treeTable
-
actions - buttonsPanel - columns - rows - rowsCount
- Атрибуты columns
- Атрибуты column
-
align - caption - captionProperty - collapsed - dateFormat - editable - expandRatio - id - link - linkInvoke - linkScreen - linkScreenOpenType - maxTextLength - optionsContainer - resolution - sort - sortable - visible - width
- Элементы column
- Атрибуты aggregation
- API
-
addColumnCollapseListener - addSelectionListener - getAggregationResults - setAggregationDistributionProvider - setClickListener - setEmptyStateLinkClickHandler - setItemDescriptionProvider
3.5.2.1.53. TwinColumn
Компонент TwinColumn представляет собой сдвоенный список для множественного выбора опций. В левом списке содержатся доступные невыбранные значения, в правом списке содержатся выбранные значения. Пользователь выбирает значения, перенося их из левого в правый список и обратно с помощью двойного клика или соответствующих кнопок. Для каждого значения можно задать уникальный стиль отображения и значок.
XML-имя компонента: twinColumn
Компонент реализован только для блока Web Client.
Пример использования компонента twinColumn для выбора экземпляров сущности:
<data>
<instance id="orderDc" class="com.company.sales.entity.Order" view="order-edit">
<loader id="orderDl"/>
</instance>
<collection id="allProductsDc" class="com.company.sales.entity.Product" view="_minimal">
<loader>
<query>
<![CDATA[select e from sales_Product e]]>
</query>
</loader>
</collection>
</data>
<layout>
<twinColumn id="twinColumn"
dataContainer="orderDc"
property="products"
optionsContainer="allProductsDc"/>
</layout>В данном случае компонент twinColumn отобразит имена экземпляров сущности Product, находящихся в контейнере данных allProductsDc, а его метод getValue() вернет коллекцию выбранных экземпляров сущности.
Атрибут addAllBtnEnabled задает отображение кнопок, позволяющих перемещать между списками все опции сразу.
Атрибут columns используется для задания количества символов в строке, а атрибут rows − для задания количества строк текста в каждом списке.
Атрибут reorderable указывает, должен ли меняться порядок опций в списке после выбора. По умолчанию имеет значение true. В таком случае опции будут переупорядочены после выбора в соответствие с порядком элементов в источнике данных. Если значение атрибута равно false, опции будут добавлены в том порядке, в котором они были выбраны.
Атрибуты leftColumnCaption и rightColumnCaption используются для назначения заголовков списков.
Для задания внешнего вида опций можно реализовать интерфейс TwinColumn.StyleProvider и возвращать название стиля и путь к значку в зависимости от конкретного экземпляра сущности, отображаемого в компоненте.
Список опций компонента TwinColumn может быть задан произвольно с помощью методов setOptionsList(), setOptionsMap() и setOptionsEnum(), аналогично описанному для компонента CheckBoxGroup.
- Атрибуты twinColumn
-
align - addAllBtnEnabled - caption - captionAsHtml - captionProperty - columns - contextHelpText - contextHelpTextHtmlEnabled - css - dataContainer - description - descriptionAsHtml - editable - enable - box.expandRatio - height - htmlSanitizerEnabled - icon - id - leftColumnCaption - optionsContainer - property - reorderable - required - requiredMessage - rightColumnCaption - rows - stylename - tabIndex - visible - width
- Элементы twinColumn
- API
-
addValueChangeListener - setContextHelpIconClickHandler - setOptionCaptionProvider
3.5.2.2. Контейнеры
3.5.2.2.1. Accordion
Контейнер Accordion - это вертикальный контейнер со сворачиваемыми вкладками, который позволяет легко скрывать и отображать большой объем контента. Accordion реализован для блока Web Client.
XML-имя компонента: accordion. Пример описания аккордеона в XML-дескрипторе экрана:
<accordion id="accordion" height="100%">
<tab id="tabStamford" caption="msg://tabStamford" margin="true" spacing="true">
<label value="msg://sampleStamford"/>
</tab>
<tab id="tabBoston" caption="msg://tabBoston" margin="true" spacing="true">
<label value="msg://sampleBoston"/>
</tab>
<tab id="tabLondon" caption="msg://tabLondon" margin="true" spacing="true">
<label value="msg://sampleLondon"/>
</tab>
</accordion>Компонент accordion должен иметь вложенные элементы tab, описывающие вкладки. Каждая вкладка является контейнером с вертикальным расположением компонентов, аналогичным vbox. Контейнер аккордеон может быть использован при нехватке места на странице приложения, или же если название вкладки слишком длинное для отображения в TabSheet. Аккордеон предоставляет анимацию плавного перехода.
Атрибуты элемента tab:
-
id– идентификатор вкладки. Следует отметить, что вкладка не является компонентом, и данный идентификатор используется только в рамкахAccordionдля работы с ней из кода контроллера.. -
caption – заголовок вкладки.
-
icon - указывает на местоположение значка в каталоге темы или его имя в используемом наборе значков. Подробную информацию о том, где следует располагать файлы значков, можно прочитать в разделе Значки.
-
lazy– задает отложенную загрузку содержимого вкладки.При открытии экрана
lazy-вкладки не загружают свое содержимое, что приводит к созданию меньшего количества компонентов в памяти. Компоненты вкладки загружаются только в тот момент, когда пользователь выбирает данную вкладку. Кроме того, если наlazy-вкладке расположены визуальные компоненты, связанные с контейнером данных, имеющим загрузчик, то этот загрузчик также не запускается. В результате экран открывается быстрее, а данные загружаются только в тот момент, когда пользователь действительно хочет их увидеть, выбирая данную вкладку.Следует иметь в виду, что компоненты, расположенные на
lazy-вкладке, не существуют в момент открытия экрана. Поэтому их нельзя инжектировать в контроллер, и нельзя получить вызовомgetComponent()в методеinit()контроллера. Обратиться к компонентамlazy-вкладки можно только после того, как пользователь на нее переключился. Этот момент можно отловить с помощью слушателяAccordion.SelectedTabChangeListener, например:@Inject private Accordion accordion; private boolean tabInitialized; @Subscribe protected void onInit(InitEvent event) { accordion.addSelectedTabChangeListener(selectedTabChangeEvent -> { if ("tabCambridge".equals(selectedTabChangeEvent.getSelectedTab().getName())) { initCambridgeTab(); } }); } private void initCambridgeTab() { if (tabInitialized) { return; } tabInitialized = true; (1) }1 Здесь можно разместить код инициализации вкладки. Используйте метод getComponentNN("comp_id")для полученияlazy-компонентов.По умолчанию вкладки не являются
lazy, а значит, загружают свое содержимое в момент открытия экрана. -
В веб-клиенте с темой, основанной на Halo, атрибут
stylenameпозволяет установить для компонентаaccordionстильborderless, который удаляет рамку и фон контейнера:accordion.setStyleName(HaloTheme.ACCORDION_BORDERLESS);
Вкладка компонента accordion может содержать любой другой визуальный контейнер, такой как таблица, сетка и т.д.:
<accordion id="accordion" height="100%" width="100%" enable="true">
<tab id="tabNY" caption="msg://tabNY" margin="true" spacing="true">
<table id="nYTable" width="100%">
<columns>
<column id="borough"/>
<column id="county"/>
<column id="population"/>
<column id="square"/>
</columns>
<rows datasource="newYorkDs"/>
</table>
</tab>
</accordion>
- Атрибуты accordion
-
caption - captionAsHtml - colspan - contextHelpText - contextHelpTextHtmlEnabled - css - description - descriptionAsHtml - enable - box.expandRatio - height - htmlSanitizerEnabled - id - rowspan - stylename - tabCaptionsAsHtml - tabIndex - visible - width
- Атрибуты tab
-
caption - description - enable - expand - icon - id - lazy - margin - spacing - stylename - visible
- API
-
add - addSelectedTabChangeListener - getComponent - getComponentNN - getComponents - getOwnComponent - getOwnComponents - remove - removeAll
3.5.2.2.2. BoxLayout
BoxLayout представляет собой контейнер с последовательным размещением компонентов.
Существует три типа BoxLayout, определяемых именем XML-элемента:
-
hbox− горизонтальное расположение компонентов.
<hbox spacing="true" margin="true"> <dateField dataContainer="orderDc" property="date"/> <lookupField dataContainer="orderDc" property="customer" optionsContainer="customersDc"/> <textField dataContainer="orderDc" property="amount"/> </hbox>
-
vbox− вертикальное расположение компонентов.vboxимеет 100% ширину по умолчанию.
<vbox spacing="true" margin="true"> <dateField dataContainer="orderDc" property="date"/> <lookupField dataContainer="orderDc" property="customer" optionsContainer="customersDc"/> <textField dataContainer="orderDc" property="amount"/> </vbox>
-
flowBox− горизонтальное расположение компонентов с переносом вниз. При недостатке места по горизонтали непомещающиеся компоненты будут перенесены "на следующую строку" (поведение аналогично SwingFlowLayout).
<flowBox spacing="true" margin="true"> <dateField dataContainer="orderDc" property="date"/> <lookupField dataContainer="orderDc" property="customer" optionsContainer="customersDc"/> <textField dataContainer="orderDc" property="amount"/> </flowBox>
В веб-клиенте с темой, основанной на Halo, BoxLayout может быть использован для создания сложных составных компонентов. Атрибут stylename со значением card или well в сочетании с атрибутом stylename="v-panel-caption" вложенного контейнера задают компоненту внешний вид Vaadin Panel.
-
стиль
cardпридаёт контейнеру вид карточки. -
wellделает карточку "утопленной" с затемнением фона.
<vbox stylename="well"
height="200px"
width="300px"
expand="message"
spacing="true">
<hbox stylename="v-panel-caption"
width="100%">
<label value="Widget caption"/>
<button align="MIDDLE_RIGHT"
icon="font-icon:EXPAND"
stylename="borderless-colored"/>
</hbox>
<textArea id="message"
inputPrompt="Enter your message here..."
width="280"
align="MIDDLE_CENTER"/>
<button caption="Send message"
width="100%"/>
</vbox>Метод getComponent() позволяет получить дочерний компонент BoxLayout по его индексу:
Button button = (Button) hbox.getComponent(0);В компоненте BoxLayout можно использовать горячие клавиши. Задать сочетание клавиш и вызываемое действие можно с помощью метода addShortcutAction():
flowBox.addShortcutAction(new ShortcutAction("SHIFT-A", shortcutTriggeredEvent ->
notifications.create()
.withCaption("SHIFT-A action")
.show()
));- Атрибуты hbox, vbox, flowBox
-
align - caption - captionAsHtml - contextHelpText - contextHelpTextHtmlEnabled - css - description - descriptionAsHtml - enable - expand - box.expandRatio - height - htmlSanitizerEnabled - id - margin - spacing - stylename - visible - width
- API
-
add - addLayoutClickListener - addShortcutAction - getComponent - getComponentNN - getComponents - getMargin - getOwnComponent - getOwnComponents - indexOf - remove - removeAll - setMargin - setSpacing
3.5.2.2.3. ButtonsPanel
ButtonsPanel - контейнер, унифицирующий использование и размещение компонентов (чаще всего кнопок) для управления данными в таблице.

XML-имя компонента: buttonsPanel.
Пример описания ButtonsPanel в XML-дескрипторе экрана:
<table id="customersTable" dataContainer="customersDc" width="100%">
<actions>
<action id="create" type="create"/>
<action id="edit" type="edit"/>
<action id="remove" type="remove"/>
<action id="excel" type="excel"/>
</actions>
<columns>
<column id="name"/>
<column id="email"/>
</columns>
<rowsCount/>
<buttonsPanel id="buttonsPanel" alwaysVisible="true">
<button id="createBtn" action="customersTable.create"/>
<button id="editBtn" action="customersTable.edit"/>
<button id="removeBtn" action="customersTable.remove"/>
<button id="excelBtn" action="customersTable.excel"/>
</buttonsPanel>
</table>Элемент buttonsPanel можно разместить как внутри table, так и в произвольном месте экрана.
Если buttonsPanel находится внутри table, то она комбинируется с компонентом rowsCount таблицы, тем самым оптимально расходуя место по вертикали. Кроме того, в этом случае при открытии экрана выбора методом Frame.openLookup() (например, из компонента PickerField) панель кнопок скрывается.
|
Значение атрибута |
Атрибут alwaysVisible служит для отключения скрытия панели в экране выбора при его открытии методом Frame.openLookup(). Если значение атрибута равно true, то панель с кнопками не скрывается. По умолчанию значение атрибута равно false.
По умолчанию кнопки в компоненте buttonsPanel расположены горизонтально с переносом вниз. При недостатке места по горизонтали кнопки, которые не помещаются, будут перенесены на следующую строку.
Для того чтобы кнопки не переносились на следующую строку, пользователь может изменить поведение по умолчанию:
-
Создать расширение темы или новую тему.
-
Определить переменную SCSS
$cuba-buttonspanel-flow:$cuba-buttonspanel-flow: false
События щелчка по области компонента buttonsPanel можно отслеживать с помощью интерфейса LayoutClickListener.
В компоненте ButtonsPanel можно использовать горячие клавиши. Задать сочетание клавиш и вызываемое действие можно с помощью метода addShortcutAction():
buttonsPanel.addShortcutAction(new ShortcutAction("SHIFT-A", shortcutTriggeredEvent ->
notifications.create()
.withCaption("SHIFT-A action")
.show()
));- Атрибуты buttonsPanel
-
align - alwaysVisible - caption - captionAsHtml - contextHelpText - contextHelpTextHtmlEnabled - css - description - descriptionAsHtml - enable - box.expandRatio - height - htmlSanitizerEnabled - id - stylename - visible - width
- API
3.5.2.2.4. CssLayout
Контейнер CssLayout позволяет управлять размещением и стилизацией своих компонентов с помощью CSS.
XML-имя компонента: cssLayout.
Ниже приведен пример использования cssLayout в простом responsive экране.
Отображение компонентов на широком дисплее:
Отображение компонентов на узком дисплее:
XML-дескриптор экрана:
<cssLayout responsive="true" stylename="responsive-container" width="100%">
<vbox margin="true" spacing="true" stylename="group-panel">
<textField caption="Field One" width="100%"/>
<textField caption="Field Two" width="100%"/>
<button caption="Button"/>
</vbox>
<vbox margin="true" spacing="true" stylename="group-panel">
<textField caption="Field Three" width="100%"/>
<textField caption="Field Four" width="100%"/>
<button caption="Button"/>
</vbox>
</cssLayout>Содержимое файла modules/web/themes/halo/halo-ext.scss (в разделе Расширение существующей темы приведена информация о том как создать этот файл):
/* Define your theme modifications inside next mixin */
@mixin halo-ext {
@include halo;
.responsive-container {
&[width-range~="0-900px"] {
.group-panel {
width: 100% !important;
}
}
&[width-range~="901px-"] {
.group-panel {
width: 50% !important;
}
}
}
}-
Атрибут
stylenameпозволяет применять стили к компонентуCssLayoutв XML-дескрипторе или контроллере экрана.-
стиль
v-component-groupиспользуется для склеивания компонентов, т.е. группировки без отступов между ними:<cssLayout stylename="v-component-group"> <textField inputPrompt="Search..."/> <button caption="OK"/> </cssLayout>
-
стиль
wellделает контейнер "утопленным" с затемнением фона. -
стиль
cardпридаёт контейнеру вид карточки. В сочетании со стилемv-panel-caption, установленным для любого вложенного контейнера, он позволяет создавать сложные составные контейнеры, например:<cssLayout height="300px" stylename="card" width="300px"> <hbox stylename="v-panel-caption" width="100%"> <label value="Widget caption"/> <button align="MIDDLE_RIGHT" icon="font-icon:EXPAND" stylename="borderless-colored"/> </hbox> <vbox height="100%"> <label value="Panel content"/> </vbox> </cssLayout>Результат:
-
- Атрибуты cssLayout
-
caption - captionAsHtml - contextHelpText - contextHelpTextHtmlEnabled - description - descriptionAsHtml - enable - css - box.expandRatio - height - htmlSanitizerEnabled - id - responsive - stylename - visible - width
- API
-
add - addShortcutAction - addLayoutClickListener - getComponent - getComponentNN - getComponents - getOwnComponent - getOwnComponents - indexOf - remove - removeAll
3.5.2.2.5. Frame
Элемент frame предназначен для включения в экран фреймов.
Атрибуты:
-
src− путь к XML-дескриптору фрейма.
-
screen- идентификатор фрейма в screens.xml (если фрейм зарегистрирован).
Должен быть указан один из этих атрибутов. Если указано оба, фрейм будет загружен из явно указанного в src файла.
- Атрибуты frame
-
align - caption - captionAsHtml - css - description - descriptionAsHtml - box.expandRatio - height - htmlSanitizerEnabled - id - screen - src - stylename - visible - width
- API
-
add - getComponent - getComponentNN - getComponents - getMargin - getOwnComponent - getOwnComponents - indexOf - remove - removeAll - setMargin - setSpacing
3.5.2.2.6. GridLayout
GridLayout - контейнер, располагающий компоненты по сетке.

XML-имя компонента: grid.
Пример использования контейнера:
<grid spacing="true">
<columns count="4"/>
<rows>
<row>
<label value="Date" align="MIDDLE_LEFT"/>
<dateField dataContainer="orderDc" property="date"/>
<label value="Customer" align="MIDDLE_LEFT"/>
<lookupField dataContainer="orderDc" property="customer" optionsContainer="customersDc"/>
</row>
<row>
<label value="Amount" align="MIDDLE_LEFT"/>
<textField dataContainer="orderDc" property="amount"/>
</row>
</rows>
</grid>Элементы grid:
-
columns- обязательный элемент, описывает колонки сетки. Должен либо иметь атрибутcount, либо вложенные элементыcolumnдля каждой колонки.В простейшем случае достаточно задать число колонок в атрибуте
count. Тогда, если ширина всего контейнера явно задана в пикселах или процентах, незанятое место будет распределяться между колонками равными долями.Для распределения незанятого места неравными долями необходимо определить для каждой колонки элемент
columnи задать для него атрибутflex.Пример сетки, в которой вторая и четвертая колонки занимают все лишнее место по горизонтали, причем четвертая колонка забирает себе в три раза больше лишнего места:
<grid spacing="true" width="100%"> <columns> <column/> <column flex="1"/> <column/> <column flex="3"/> </columns> <rows> <row> <label value="Date"/> <dateField dataContainer="orderDc" property="date" width="100%"/> <label value="Customer"/> <lookupField dataContainer="orderDc" property="customer" optionsContainer="customersDc" width="100%"/> </row> <row> <label value="Amount"/> <textField dataContainer="orderDc" property="amount" width="100%"/> </row> </rows> </grid>Если атрибут
flexне указан, или указано значение 0, то ширина данной колонки будет установлена по содержимому, если хотя бы одна другая колонка имеет ненулевойflex. В приведенном примере первая и третья колонки получат ширину по максимальной длине текста надписей.Для того, чтобы лишнее место вообще образовалось, необходимо установить всему контейнеру ширину в пикселах или процентах. В противном случае ширина колонок будет рассчитана по ширине содержимого, и атрибут
flexне будет иметь никакого эффекта.
-
rows− обязательный элемент, содержит последовательность строк. Каждая строка определяется в своем элементеrow.Элемент
rowможет содержать атрибутflex, аналогичный описанному дляcolumn, но влияющий на распределение лишнего места по вертикали при заданной общей высоте сетки.Элемент
rowдолжен содержать элементы компонентов, отображаемых в ячейках данной строки сетки. Число компонентов в одной строке не должно превышать заданного количества колонок, но может быть меньше.
Любой компонент, находящийся в контейнере grid, может иметь атрибуты colspan и rowspan. Эти атрибуты задают соответственно сколько колонок и строк будет занимать данный компонент. Например, так можно растянуть поле Field3 на три колонки:
<grid spacing="true">
<columns count="4"/>
<rows>
<row>
<label value="Name 1"/>
<textField/>
<label value="Name 2"/>
<textField/>
</row>
<row>
<label value="Name 3"/>
<textField colspan="3" width="100%"/>
</row>
</rows>
</grid>В результате компоненты будут располагаться следующим образом:

События щелчка по области компонента GridLayout можно отслеживать с помощью интерфейса LayoutClickListener.
Метод getComponent() позволяет получить дочерний компонент GridLayout по индексам его колонки и строки:
Button button = (Button) gridLayout.getComponent(0,1);В компоненте GridLayout можно использовать горячие клавиши. Задать сочетание клавиш и вызываемое действие можно с помощью метода addShortcutAction():
grid.addShortcutAction(new ShortcutAction("SHIFT-A", shortcutTriggeredEvent ->
notifications.create()
.withCaption("SHIFT-A action")
.show()
));- Атрибуты grid
-
align - caption - captionAsHtml - contextHelpText - contextHelpTextHtmlEnabled - css - description - descriptionAsHtml - enable - box.expandRatio - height - htmlSanitizerEnabled - id - margin - spacing - stylename - visible - width
- Элементы grid
- Атрибуты columns
- Атрибуты column
- Атрибуты row
- API
-
add - addShortcutAction - addLayoutClickListener - getComponent - getComponentNN - getComponents - getMargin - getOwnComponent - getOwnComponents - remove - removeAll - setMargin - setSpacing
3.5.2.2.7. GroupBoxLayout
GroupBoxLayout - контейнер, позволяющий выделить рамкой содержащиеся в нем компоненты, и задать им общий заголовок. Кроме того, он умеет сворачивать свое содержимое.
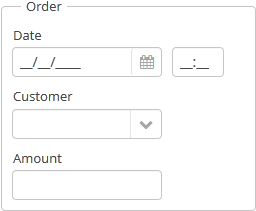
XML-имя компонента: groupBox.
Пример описание контейнера в XML-дескрипторе экрана:
<groupBox caption="Order">
<dateField dataContainer="orderDc" property="date" caption="Date"/>
<lookupField dataContainer="orderDc" property="customer" optionsContainer="customersDc" caption="Customer"/>
<textField dataContainer="orderDc" property="amount" caption="Amount"/>
</groupBox>Атрибуты groupBox:
-
caption- заголовок группы.
-
orientation- задает направление расположения вложенных компонентов −horizontalилиvertical. По умолчаниюvertical.
-
collapsable− значениеtrueпозволяет пользователю скрывать содержимое компонента с помощью значков/.
-
collapsed− если указано значениеtrue, то содержимое компонента будет свернуто сразу после открытия экрана. Используется совместно сcollapsable="true".Пример свернутого
GroupBox:
Изменения состояния компонента
groupBox(сворачивание и разворачивание) можно отслеживать с помощью интерфейсаExpandedStateChangeListener.
-
outerMargin- устанавливает внешние поля вокруг границыgroupBox. Если указано значениеtrue, внешние поля будут добавлены ко всем сторонам компонента. Чтобы задать внешние поля индивидуально, укажите значенияtrueилиfalseдля каждой стороныgroupBox:<groupBox outerMargin="true, false, true, false">Если атрибут
showAsPanelустановлен вtrue,outerMarginигнорируется.
-
showAsPanel– если указано значениеtrue, то компонент будет выглядеть как Vaadin Panel. Значение по умолчанию -false.
Контейнер groupBox по умолчанию имеет ширину 100% аналогично vbox.
В веб-клиенте к компоненту groupBox можно применить предопределенные стили. Стили задаются в XML-дексрипторе или контроллере экрана с помощью атрибута stylename. Чтобы применить стиль программно, выберите одну из констант класса HaloTheme с префиксом компонента LAYOUT_ или GROUPBOX_. Следующие стили должны использоваться совместно с атрибутом showAsPanel, имеющим значение true:
-
стиль
borderlessудаляет рамку и фон контейнераgroupBox:groupBox.setShowAsPanel(true); groupBox.setStyleName(HaloTheme.GROUPBOX_PANEL_BORDERLESS);
-
стиль
wellделает контейнер "утопленным" с затемнением фона:<groupBox caption="Well-styled groupBox" showAsPanel="true" stylename="well" width="300px" height="200px"/>
Существует дополнительный предопределенный стиль контейнера groupBox - light. Этот стиль можно задать с помощью атрибута stylename. Groupbox со стилем light имеет только верхнюю границу, как показано на рисунке ниже.
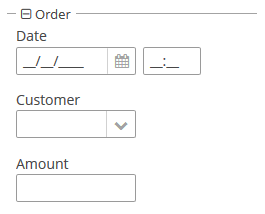
В компоненте Groupbox можно использовать горячие клавиши. Задать сочетание клавиш и вызываемое действие можно с помощью метода addShortcutAction():
groupBox.addShortcutAction(new ShortcutAction("SHIFT-A", shortcutTriggeredEvent ->
notifications.create()
.withCaption("SHIFT-A action")
.show()
));- Атрибуты groupBox
-
align - caption - captionAsHtml - collapsable - collapsed - contextHelpText - contextHelpTextHtmlEnabled - css - description - descriptionAsHtml - expand - box.expandRatio - height - htmlSanitizerEnabled - id - orientation - outerMargin - settingsEnabled - spacing - stylename - width
- Предопределенные стили groupBox
-
borderless - light - well
- API
-
add - addExpandedStateChangeListener - addShortcutAction - applySettings - getComponent - getComponentNN - getComponents - getOwnComponent - getOwnComponents - indexOf - remove - removeAll - saveSettings - setOuterMargin - setSpacing
3.5.2.2.8. HtmlBoxLayout
HtmlBoxLayout позволяет определять расположение компонентов в HTML-шаблоне, который включается в тему.
|
Не используйте |
XML-имя компонента: htmlBox.
Ниже приведен пример использования htmlBox в простом экране.
XML-дескриптор экрана:
<htmlBox align="TOP_CENTER"
template="sample"
width="500px">
<label id="logo"
value="Subscribe"
stylename="logo"/>
<textField id="email"
width="100%"
inputPrompt="email@test.test"/>
<button id="submit"
width="100%"
invoke="showMessage"
caption="Subscribe"/>
</htmlBox>Атрибуты htmlBox:
-
Атрибут
templateзадает имя HTML-файла, находящегося в подкаталогеlayoutsтемы. Перед созданием шаблона необходимо создать расширение темы или новую тему.Например, если вы используете тему Halo и хотите назвать шаблон
my_template, укажитеmy_templateв атрибуте и разместите шаблон в файлеmodules/web/themes/halo/layouts/my_template.html.Содержимое шаблона
modules/web/themes/halo/layouts/sample.html:<div location="logo" class="logo"></div> <table class="component-container"> <tr> <td> <div location="email" class="email"></div> </td> <td> <div location="submit" class="submit"></div> </td> </tr> </table>Шаблон должен содержать элементы
<div>с атрибутамиlocation. В этих элементах будут отображаться компоненты CUBA, определенные в XML дескрипторе с соответствующими идентификаторами.Содержимое файла
modules/web/themes/halo/com.company.application/halo-ext.scss(в разделе Расширение существующей темы приведена информация о том как создать этот файл):@mixin com_company_application-halo-ext { .email { width: 390px; } .submit { width: 100px; } .logo { font-size: 96px; text-transform: uppercase; margin-top: 50px; } .component-container { display: inline-block; vertical-align: top; width: 100%; } }
-
Атрибут
templateContentsзадаёт непосредственно содержимое шаблона, который будет использован для отображения данного контейнера.Пример использования атрибута:
<htmlBox height="256px" width="400px"> <templateContents> <![CDATA[ <table align="center" cellspacing="10" style="width: 100%; height: 100%; color: #fff; padding: 20px; background: #31629E repeat-x"> <tr> <td colspan="2"><h1 style="margin-top: 0;">Login</h1> <td> </tr> <tr> <td align="right">User name:</td> <td> <div location="username"></div> </td> </tr> <tr> <td align="right">Password:</td> <td> <div location="password"></div> </td> </tr> <tr> <td align="right" colspan="2"> <div location="okbutton" style="padding: 10px;"></div> </td> </tr> <tr> <td colspan="2" style="padding: 7px; background-color: #4172AE"><span style="font-family: FontAwesome; margin-right: 5px;"></span> This information is in the layout. <td> </tr> </table> ]]> </templateContents> <textField id="username" width="100%"/> <textField id="password" width="100%"/> <button id="okbutton" caption="Login"/> </htmlBox>
-
Атрибут
htmlSanitizerEnabledразрешает или запрещает санитизацию HTML. Если атрибутhtmlSanitizerEnabledустановлен в значениеtrue, содержимое компонентаHtmlBoxLayoutбудет санитизировано.Пример использования в контроллере:
protected static final String UNSAFE_HTML = "<i>Jackdaws </i><u>love</u> <font size=\"javascript:alert(1)\" " + "color=\"moccasin\">my</font> " + "<font size=\"7\">big</font> <sup>sphinx</sup> " + "<font face=\"Verdana\">of</font> <span style=\"background-color: " + "red;\">quartz</span><svg/onload=alert(\"XSS\")>"; @Inject private HtmlBoxLayout htmlBox; @Subscribe public void onInit(InitEvent event) { htmlBox.setHtmlSanitizerEnabled(true); htmlBox.setTemplateContents(UNSAFE_HTML); }Значение атрибута
htmlSanitizerEnabledимеет приоритет над значением глобального свойства cuba.web.htmlSanitizerEnabled.
- Атрибуты htmlBox
-
align - caption - captionAsHtml - contextHelpText - contextHelpTextHtmlEnabled - css - description - descriptionAsHtml - enable - box.expandRatio - height - htmlSanitizerEnabled - id - stylename - template - templateContents - visible - width
- API
-
add - getComponent - getComponentNN - getComponents - getOwnComponent - getOwnComponents - remove - removeAll
3.5.2.2.9. Layout
layout - это корневой элемент компоновки экрана. Является сам по себе контейнером с вертикальным расположением компонентов, аналогичным vbox.
Атрибуты layout:
-
spacing - устанавливает наличие отступов между компонентами внутри контейнера.
-
margin - устанавливает наличие отступа между внешними границами и содержимым контейнера.
-
expand - задает компонент внутри контейнера, который необходимо расширить на все доступное пространство в направлении размещения компонентов.
-
responsive - определяет, должен ли контейнер реагировать на изменения размеров доступной области.
-
stylename - атрибут, задающий имя стиля контейнера.
-
height - устанавливает высоту контейнера.
-
width - устанавливает ширину контейнера.
-
maxHeight- устанавливает максимальную высоту CSS для элементаlayoutэкрана. Например,"640px","100%".
-
minHeight- устанавливает минимальную высоту CSS для элементаlayoutэкрана. Например,"640px","auto".
-
maxWidth- yстанавливает максимальную ширину CSS для элементаlayoutэкрана. Например,"640px","100%".
-
minWidth- устанавливает минимальную ширину CSS для элементаlayoutэкрана. Например,"640px","auto".
Пример использования:
<layout minWidth="600px"
minHeight="200px">
<textArea width="800px"/>
</layout>
Рисунок 14. Полноразмерный компонент textArea внутри элемента layout
Рисунок 15. Если размер окна меньше заданных минимальных размеров, в окне появляются полосы прокрутки
Эти атрибуты работают и в диалоговых окнах:
<dialogMode forceDialog="true"
width="500"
height="250"/>
<layout minWidth="600px"
minHeight="200px">
<textArea width="250px"/>
</layout>
Рисунок 16. Если размер диалогового окна меньше заданных минимальных размеров, в окне появляются полосы прокрутки
3.5.2.2.10. ScrollBoxLayout
ScrollBoxLayout − контейнер, который позволяет прокручивать свое содержимое.
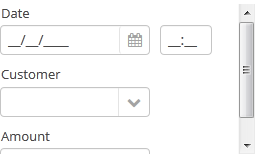
XML-имя компонента: scrollBox
Пример описание контейнера с прокруткой в XML-дескрипторе экрана:
<groupBox caption="Order" width="300" height="170">
<scrollBox width="100%" height="100%" spacing="true" margin="true">
<dateField dataContainer="orderDc" property="date" caption="Date"/>
<lookupField dataContainer="orderDc" property="customer" optionsContainer="customersDc" caption="Customer"/>
<textField dataContainer="orderDc" property="amount" caption="Amount"/>
</scrollBox>
</groupBox>-
С помощью атрибута
orientationможно задавать направление расположения вложенных компонентов −horizontalилиvertical. По умолчаниюvertical.
-
Атрибут
scrollBarsпозволяет настраивать полосы прокрутки. Может принимать значенияhorizontal,vertical- для прокрутки по горизонтали и вертикали соответственно,both- для прокрутки во всех направлениях. Установка значенияnoneзапрещает прокрутку в любом направлении.
-
contentHeight- устанавливает высоту содержимого контейнера.
-
contentWidth- устанавливает ширину содержимого контейнера.
-
contentMaxHeight- устанавливает максимальную высоту CSS для содержимого контейнера. Например,"640px","100%".
-
contentMinHeight- устанавливает минимальную высоту CSS для содержимого контейнера. Например,"640px","auto".
-
contentMaxWidth- устанавливает максимальную ширину CSS для содержимого контейнера. Например,"640px","100%".
-
contentMinWidth- устанавливает минимальную ширину CSS для содержимого контейнера. Например,"640px","auto".
<layout>
<scrollBox contentMinWidth="600px"
contentMinHeight="200px"
height="100%"
width="100%">
<textArea height="150px"
width="800px"/>
</scrollBox>
</layout>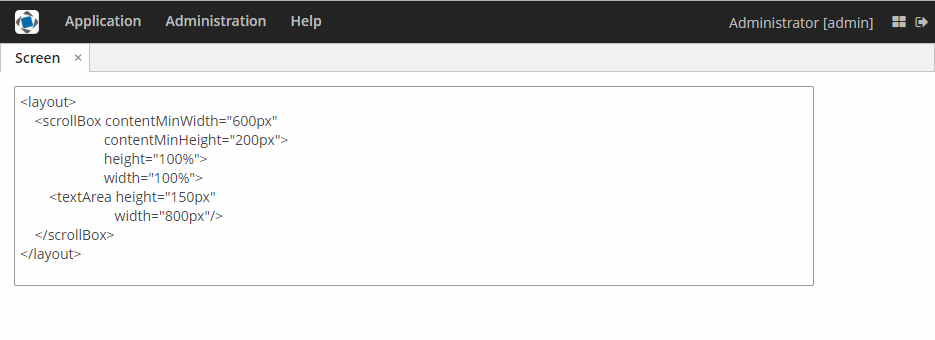
Рисунок 17. Полноразмерный scrollBox с компонентом textArea внутри
Рисунок 18. При уменьшении размера окна появляется полоса прокрутки, чтобы сохранить ширину вложенного компонента
|
Рекомендуется указывать ширину и высоту содержимого Нельзя устанавливать |
В компоненте ScrollBox можно использовать горячие клавиши. Задать сочетание клавиш и вызываемое действие можно с помощью метода addShortcutAction():
scrollBox.addShortcutAction(new ShortcutAction("SHIFT-A", shortcutTriggeredEvent ->
notifications.create()
.withCaption("SHIFT-A action")
.show()
));- Атрибуты scrollBox
-
align - caption - captionAsHtml - contextHelpText - contextHelpTextHtmlEnabled - css - description - descriptionAsHtml - box.expandRatio - height - htmlSanitizerEnabled - id - margin - orientation - scrollBars - spacing - stylename - width
- API
-
add - addShortcutAction - getComponent - getComponentNN - getComponents - getMargin - getOwnComponent - getOwnComponents - indexOf - remove - removeAll - setMargin - setSpacing
3.5.2.2.11. SplitPanel
SplitPanel − контейнер, разбитый на две области, размер которых по горизонтали либо вертикали можно менять путем перемещения разделителя.

XML-имя компонента: split.
Пример описания панели с разделителем в XML-дескрипторе экрана:
<split orientation="horizontal" pos="30" width="100%" height="100%">
<vbox margin="true" spacing="true">
<dateField dataContainer="orderDc" property="date" caption="Date"/>
<lookupField dataContainer="orderDc" property="customer" optionsContainer="customersDc" caption="Customer"/>
</vbox>
<vbox margin="true" spacing="true">
<textField dataContainer="orderDc" property="amount" caption="Amount"/>
</vbox>
</split>Внутри контейнера split обязательно должны находиться два вложенных контейнера или компонента, которые и будут расположены по обе стороны разделителя.
Атрибуты split:
-
dockable- управляет видимостью кнопки сворачиванияSplitPanel, значение по умолчаниюfalse.
Сворачивание доступно только для горизонтального контейнера
SplitPanel.
-
dockMode- задаёт направление сворачивания. Возможные значения:LEFTиRIGHT.<split orientation="horizontal" dockable="true" dockMode="RIGHT"> ... </split>
-
minSplitPosition,maxSplitPosition- определяют диапазон допустимых значений позиции разделителя. Могут быть установлены в пикселях или в процентах.Например, вы можете запретить перетаскивать сплиттер вне диапазона между 100 и 300 пикселями с левой стороны компонента:
<split id="splitPanel" maxSplitPosition="300px" minSplitPosition="100px" width="100%" height="100%"> <vbox margin="true" spacing="true"> <button caption="Button 1"/> <button caption="Button 2"/> </vbox> <vbox margin="true" spacing="true"> <button caption="Button 4"/> <button caption="Button 5"/> </vbox> </split>Если вы хотите установить диапазон программно, вы должны указать единицу измерения с помощью
Component.UNITS_PIXELSилиComponent.UNITS_PERCENTAGEsplitPanel.setMinSplitPosition(100, Component.UNITS_PIXELS); splitPanel.setMaxSplitPosition(300, Component.UNITS_PIXELS);
-
orientation- задает ориентацию расположения компонентов.horizontal- вложенные компоненты располагаются горизонтально,vertical- вертикально.
-
pos- целое число, определяющее процентное соотношение размера первой области по отношению ко второй. Например,pos="30"означает соотношение областей 30/70. По умолчанию соотношение областей составляет 50/50.
-
reversePosition- указывает, что атрибутposсодержит позицию разделителя, отсчитанную с обратной стороны компонента.
-
Если атрибут
lockedустановлен вtrue, то пользователи не смогут изменить положение разделителя.
-
Атрибут
stylenameсо значениемlargeувеличивает толщину разделителя.split.setStyleName(HaloTheme.SPLITPANEL_LARGE);
Методы SplitPanel:
-
Позицию разделителя можно получить с помощью метода
getSplitPosition().
-
События изменения положения разделителя можно отлеживать
PositionUpdateListener. Источник событияSplitPositionChangeEventможно отследить с помощью метода isUserOriginated(). -
Если нужно получить единицу измерения позиции разделителя, используйте метод
getSplitPositionUnit(). Он возвращаетComponent.UNITS_PIXELSилиComponent.UNITS_PERCENTAGE. -
isSplitPositionReversed()возвращаетtrueв случае, если позиция отсчитывается с обратной стороны компонента.
-
С помощью методов
getMinSplitPosition()иgetMaxSplitPosition()можно получить текущую минимальную или максимальную позицию разделителя соответственно.
-
С помощью методов
getMinSplitPositionSizeUnit()иgetMaxSplitPositionSizeUnit()можно получить единицу измерения минимальной или максимальной позиции разделителя соответственно. Возможные единицы измерения:Component.UNITS_PIXELSиComponent.UNITS_PERCENTAGE.
Внешний вид компонента SplitPanel можно настроить с помощью переменных SCSS с префиксом $cuba-splitpanel-*. Эти переменные можно изменить в визуальном редакторе после расширения темы или создания новой темы.
- Атрибуты split
-
align - caption - captionAsHtml - contextHelpText - contextHelpTextHtmlEnabled - css - description - descriptionAsHtml - dockable - dockMode - box.expandRatio - height - htmlSanitizerEnabled - id - locked - minSplitPosition - maxSplitPosition - orientation - pos - reversePosition - settingsEnabled - stylename - width
- API
-
add - addPositionUpdateListener - applySettings - getComponent - getComponentNN - getComponents - getMaxSplitPosition - getMaxSplitPositionSizeUnit - getMinSplitPosition - getMinSplitPositionSizeUnit - getOwnComponent - getOwnComponents - remove - removeAll - saveSettings
3.5.2.2.12. TabSheet
Контейнер TabSheet - это панель с вкладками (tabs). В один момент времени отображается содержимое только одной вкладки.
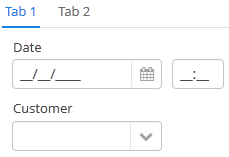
XML-имя компонента: tabSheet.
Пример описания панели с вкладками в XML-дескрипторе экрана:
<tabSheet>
<tab id="mainTab" caption="Tab1" margin="true" spacing="true">
<dateField dataContainer="orderDc" property="date" caption="Date"/>
<lookupField dataContainer="orderDc" property="customer" optionsContainer="customersDc" caption="Customer"/>
</tab>
<tab id="additionalTab" caption="Tab2" margin="true" spacing="true">
<textField dataContainer="orderDc" property="amount" caption="Amount"/>
</tab>
</tabSheet>Атрибут description контейнера tabSheet задаёт текст подсказки, отображаемой при наведении курсора мыши или клике в области вкладок контейнера.
Компонент tabSheet должен иметь вложенные элементы tab, описывающие вкладки. Каждая вкладка является контейнером с вертикальным расположением компонентов, аналогичным vbox.
Атрибуты элемента tab:
-
id- идентификатор вкладки. Следует отметить, что вкладка не является компонентом, и данный идентификатор используется только в рамкахTabSheetдля работы с ней из кода контроллера. -
caption - заголовок вкладки.
-
description - текст подсказки, отображаемой при наведении курсора мыши или клике на конкретную вкладку.
-
closable- определяет, будет ли отображаться кнопка x для закрытия вкладки. Значение по умолчанию -false. -
icon - указывает на местоположение значка в каталоге темы или его имя в используемом наборе значков. Применяется только для блока Web Client. Подробную информацию о том, где следует располагать файлы значков, можно прочитать в разделе Значки.
-
lazy- задает отложенную загрузку содержимого вкладки.При открытии экрана lazy-вкладки не загружают свое содержимое, что приводит к созданию меньшего количества компонентов в памяти. Компоненты вкладки загружаются только в тот момент, когда пользователь выбирает данную вкладку. Кроме того, если на
lazy-вкладке расположены визуальные компоненты, связанные с контейнером данных, имеющим загрузчик, то этот загрузчик также не запускается. В результате экран открывается быстрее, а данные загружаются только в тот момент, когда пользователь действительно хочет их увидеть, выбирая данную вкладку.Следует иметь в виду, что компоненты, расположенные на lazy-вкладке, не существуют в момент открытия экрана. Поэтому их нельзя инжектировать в контроллер, и нельзя получить вызовом
getComponent()в методеinit()контроллера. Обратиться к компонентамlazy-вкладки можно только после того, как пользователь на нее переключился. Этот момент можно отловить с помощью слушателяTabSheet.SelectedTabChangeListener, например:@Inject private TabSheet tabSheet; private boolean detailsInitialized, historyInitialized; @Subscribe protected void onInit(InitEvent event) { tabSheet.addSelectedTabChangeListener(selectedTabChangeEvent -> { if ("detailsTab".equals(selectedTabChangeEvent.getSelectedTab().getName())) { initDetails(); } else if ("historyTab".equals(selectedTabChangeEvent.getSelectedTab().getName())) { initHistory(); } }); } private void initDetails() { if (detailsInitialized) { return; } detailsInitialized = true; (1) } private void initHistory() { if (historyInitialized) { return; } historyInitialized = true; (2) }По умолчанию вкладки не являются
lazy, а значит, загружают свое содержимое в момент открытия экрана.Источник события
SelectedTabChangeEventможно отследить с помощью метода isUserOriginated().- Стили TabSheet
-
В веб-клиенте с темой, основанной на Halo, к контейнеру
TabSheetможно применить предопределенные стили. Стили задаются в XML-дексрипторе или контроллере экрана с помощью атрибутаstylename:<tabSheet stylename="framed"> <tab id="mainTab" caption="Framed tab"/> </tabSheet>Чтобы применить стиль программно, выберите одну из констант класса
HaloThemeс префиксом компонентаTABSHEET_:tabSheet.setStyleName(HaloTheme.TABSHEET_COMPACT_TABBAR);-
centered-tabs- центрирует вкладки на панели. Подходит для страниц, где все вкладки целиком помещаются на панели (т.е. нет прокрутки вкладок).
-
compact-tabbar- уменьшает отступы вокруг вкладок.
-
equal-width-tabs- задаёт всем вкладкам на панели равный размер (т.е. expand ratio == 1 для всех вкладок). Заголовки вкладок будут обрезаны, если они не поместятся на вкладку целиком. Прокрутка вкладок в этом случае не работает (будут видны одновременно все вкладки).
-
framed- добавляет рамку как вокруг всего контейнера целиком, так и вокруг каждой вкладки на панели.
-
icons-on-top- располагает значок вкладки над её заголовком (по умолчанию значки располагаются слева от заголовка).
-
only-selected-closeable- только выделенная вкладка имеет кнопку закрытия. Стиль не запрещает программного закрытия вкладок, а только скрывает кнопку от пользователя.
-
padded-tabbar- добавляет небольшие отступы вокруг вкладок на панели, так что они не касаются границ контейнера.
-
Внешний вид компонента TabSheet можно настроить с помощью переменных SCSS с префиксом $cuba-tabsheet-*. Эти переменные можно изменить в визуальном редакторе после расширения темы или создания новой темы.
- Атрибуты tabSheet
-
caption - captionAsHtml - contextHelpText - contextHelpTextHtmlEnabled - css - height - htmlSanitizerEnabled - id - description - descriptionAsHtml - box.expandRatio - stylename - tabCaptionsAsHtml - tabIndex - tabsVisible - visible - width
- Атрибуты tab
-
caption - closable - description - enable - expand - margin - icon - id - lazy - spacing - stylename - visible
- Предопределенные стили tabSheet
-
centered-tabs - compact-tabbar - equal-width-tabs - framed - framed - only-selected-closeable - padded-tabbar
- API
-
add - addSelectedTabChangeListener - getComponent - getComponentNN - getComponents - getOwnComponent - getOwnComponents - remove - removeAll
3.5.2.3. Правила компоновки экранов
В данном разделе объясняется, как правильно располагать визуальные компоненты и контейнеры на экранах UI.
3.5.2.3.1. Позиционирование компонентов
- Виды размеров
-
Размеры компонента, т.е. его ширина и высота, могут быть заданы следующих видов:
-
По содержимому -
AUTO -
Фиксированные (в пикселах) -
10px -
Относительные (в процентах) -
100%
-
- Размер по содержимому
-
Компонент займет столько места, сколько нужно его содержимому.
Примеры:
-
Компонент Label выбирает такой размер по размеру текста.
-
Контейнеры выбирают размер по сумме размеров всех расположенных в контейнере компонентов.
XML<label width=”AUTO”/>Javalabel.setWidth(Component.AUTO_SIZE);Компоненты с размером по содержимому будут подстраивать размер во время компоновки экрана и при изменении размера содержимого.

-
- Фиксированный размер
-
Фиксированные размеры не предполагают изменения размера компонента во время исполнения.
XML<vbox width=”320px” height=”240px”/>Javavbox.setWidth(”320px”);
- Относительные размеры
-
Относительные размеры указывают, какой процент доступного компоненту места будет использован.
XML<label width=”100%”/>Javalabel.setWidth(”50%”);Компонент с относительными размерами будет реагировать на изменение доступного места и изменять свой реальный размер на экране.
- Особенности контейнеров
-
По умолчанию контейнеры без установленного атрибута expand выделяют для всех вложенных компонентов одинаковое количество места. Исключения: flowBox и htmlBox.
Пример контейнера с одинаковой высотой компонентов по умолчанию:
<layout> <button caption="Button"/> <button caption="Button"/> </layout>
Компоненты и контейнеры при создании имеют высоту и ширину по содержимому. Некоторые контейнеры имеют другие значения высоты и ширины по умолчанию:
Контейнер Ширина Высота 100%
AUTO
100%
AUTO
100%
AUTO
Корневой элемент компоновки layout является вертикальным контейнером (
VBox) и имеет 100% ширину и высоту 100%. В режиме диалога высота корневого элемента может бытьAUTO.Вкладка компонента TabSheet (
tab) является контейнеромVBox.Компонент
GroupBoxсодержитVBoxилиHBoxв зависимости от значения свойства orientation.Пример контейнера с высотой по содержимому:
<layout> <vbox> <button caption="Button"/> <button caption="Button"/> </vbox> </layout>
Пример контейнера с относительными размерами компонентов:
<layout spacing="true"> <groupBox caption="GroupBox" height="100%"/> <button caption="Button"/> </layout>
Здесь
layout, так же какvboxилиhbox, выделяет равные части всем вложенным компонентам, а дляgroupBoxуказана высота 100%. Кроме того,groupBoxимеет 100% ширину по умолчанию, поэтому он занимает все доступное ему пространство.
- Особенности компонентов
-
Для Table и Tree рекомендуется задавать абсолютную или относительную высоту, иначе таблица/дерево может неограниченно вырасти при большом количестве строк/узлов.
Контейнер ScrollBox должен обязательно иметь заданные высоту и ширину (не
AUTO). ВнутриScrollBoxнельзя использовать 100% размеры в направлении, для которого необходима полоса прокрутки.Ниже приведены примеры правильного использования
ScrollBoxс вертикальной и горизонтальной прокруткой. Если требуются обе полосы прокрутки, компоненты должны иметь и ширину, и высоту (AUTOили абсолютные значения).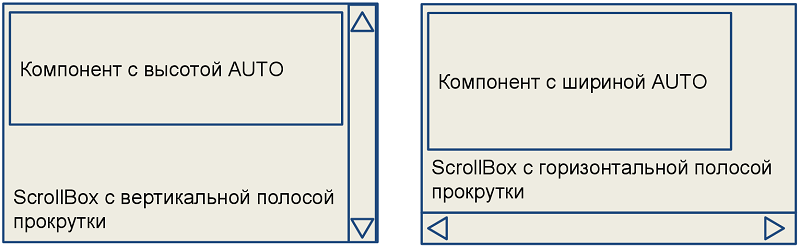
- Опция expand
-
Атрибут expand контейнера позволяет указать, какому из компонентов предоставить максимальное доступное место.
Компоненту, указанному в
expand, будет выставлен размер 100% в направлении роста контейнера (VBox— по вертикали,HBox— по горизонтали). При изменении размера контейнера изменять размер будет именно этот компонент.<vbox expand="bigBox"> <vbox id="bigBox"/> <label value="Label"/> </vbox>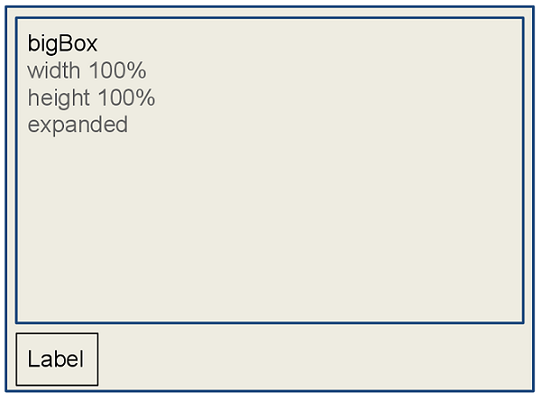
expandработает по направлению роста контейнера, например:<layout spacing="true" expand="groupBox"> <groupBox id="groupBox" caption="GroupBox" width="200px"/> <button caption="Button"/> </layout>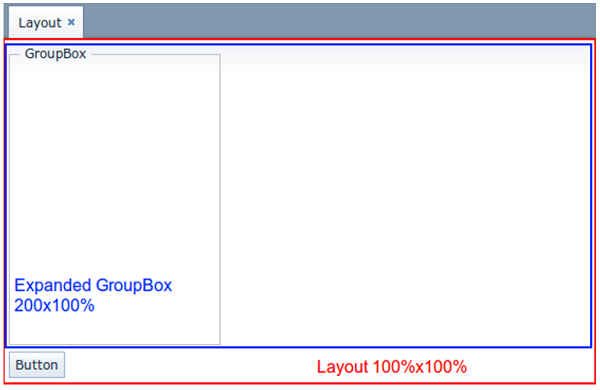
В следующем примере используется вспомогательный элемент Label - spacer. Для него применяется
expand, поэтому он занимает всё оставшееся в контейнере место.<layout expand="spacer"> <textField caption="Number"/> <dateField caption="Date"/> <label id="spacer"/> <hbox spacing="true"> <button caption="OK"/> <button caption="Cancel"/> </hbox> </layout>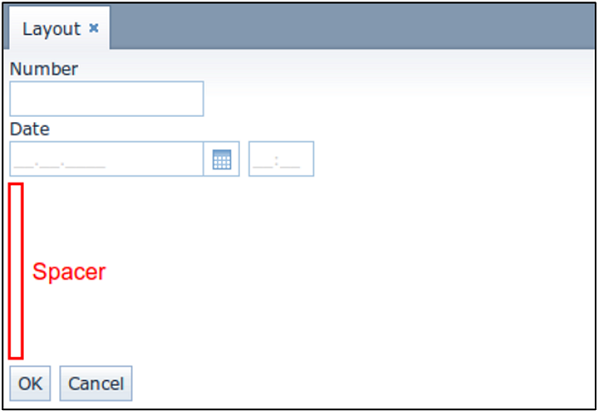
3.5.2.3.2. Отступы
- Отступ от границ контейнера (margin)
-
Атрибут margin позволяет задать отступ вложенных компонентов от края контейнера.
Если задан
margin="true", то отступ применяется для всех сторон контейнера.<layout> <vbox margin="true" height="100%"> <groupBox caption="Group" height="100%"/> </vbox> <groupBox caption="Group" height="100%"/> </layout>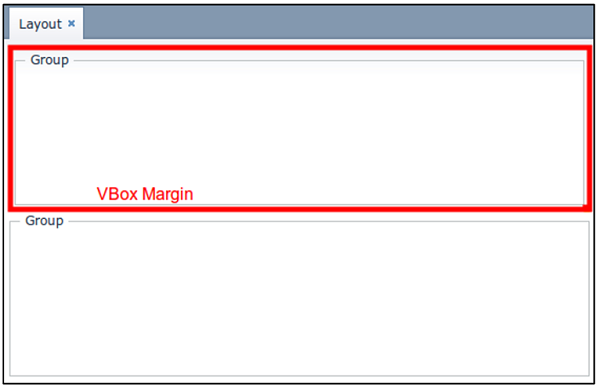
Можно также задать отступ для каждой из сторон отдельно (в порядке Верхний, Правый, Нижний, Левый). Пример использования только верхнего и нижнего отступа:
<vbox margin="true,false,true,false">
- Отступ между компонентами контейнера (spacing)
-
Атрибут spacing указывает, использовать ли отступ между вложенными компонентами по направлению роста контейнера.

Не используйте
marginдля эмуляцииspacing. Spacing работает правильно в случаях, когда часть компонентов контейнера становится невидимой.<layout spacing="true"> <button caption="Button"/> <button caption="Button"/> <button caption="Button"/> <button caption="Button"/> </layout>
3.5.2.3.3. Выравнивание
- Выравнивание компонентов в контейнере
-
Для выравнивания компонентов в контейнере воспользуйтесь атрибутом align.
Пример расположения надписи по центру контейнера:
<vbox height="100%"> <label align="MIDDLE_CENTER" value="Label"/> </vbox>
Компонент, для которого задан
align, не должен иметь размер "100%" в направлении выравнивания. В контейнере должно быть доступное для компонента место, по размеру большее чем сам компонент. Именно в этом пространстве будет выровнен компонент.Пример выравнивания в доступном пространстве:
<layout> <groupBox height="100%" caption="Group"/> <label align="MIDDLE_CENTER" value="Label"/> </layout>
3.5.2.3.4. Типовые ошибки компоновки
- Ошибка №1. Указание относительных размеров для компонента в контейнере с размерами по содержимому
-
Пример неправильной компоновки c явным относительным размером:

В этом примере для надписи задана высота 100%. При этом у контейнера
VBoxпо умолчанию используется высотаAUTO, то есть по содержимому.Пример неправильной компоновки c
expand:
Expand неявно задаёт относительную высоту 100% для
label, что, как и в примере выше, неверно. В таких случаях экран может выглядеть некорректно, часть компонентов может пропадать или иметь нулевые размеры. При возникновении проблем с компоновкой в первую очередь проверьте правильность указания относительных размеров.
- Ошибка №2. Вложенные в ScrollBox компоненты имеют 100% размеры
-
Пример неправильной компоновки:

При возникновении таких ошибок полосы прокрутки в
ScrollBoxне будут появляться при превышении вложенными компонентами размеров области прокрутки.
- Ошибка №3. Выравнивание для компонентов при отсутствии доступного места
-
Пример неправильной компоновки:

В этом примере
HBoxимеет размеры по содержимому, поэтому заданное для надписи выравнивание не оказывает никакого эффекта.
3.5.2.4. Разное
В данном разделе рассматриваются различные элементы универсального пользовательского интерфейса, имеющие отношение к визуальным компонентам.
3.5.2.4.1. UiComponents
UiComponents это фабрика, которая позволяет создавать UI-компоненты по имени, классу или токену типа.
Если вы создаете компонент, работающий с данными, используйте токен типа для получения компонента, параметризованного нужным типом данных. Для простых типов и компонентов Label, TextField или DateField, можно использовать токены-константы, такие как TextField.TYPE_INTEGER. Для компонентов, работающих с сущностями модели данных, такими как PickerField, LookupField или Table, используйте статический метод of() для получения токена нужного типа. Для других компонентов и контейнеров используйте класс компонента в качестве аргумента метода create().
Пример использования:
@Inject
private UiComponents uiComponents;
@Subscribe
protected void onInit(InitEvent event) {
// components working with simple data types
Label<String> label = uiComponents.create(Label.TYPE_STRING);
TextField<Integer> amountField = uiComponents.create(TextField.TYPE_INTEGER);
LookupField<String> stringLookupField = uiComponents.create(LookupField.TYPE_STRING);
// components working with entities
LookupField<Customer> customerLookupField = uiComponents.create(LookupField.of(Customer.class));
PickerField<Customer> pickerField = uiComponents.create(PickerField.of(Customer.class));
Table<OrderLine> table = uiComponents.create(Table.of(OrderLine.class));
// other components and containers
Button okButton = uiComponents.create(Button.class);
VBoxLayout vBox = uiComponents.create(VBoxLayout.class);
// ...
}3.5.2.4.2. Formatter
Formatter предназначен для преобразования некоторого значения в строку.
В XML-дескрипторе экрана formatter для компонента может быть задан во вложенном элементе formatter. Элемент имеет единственный атрибут:
-
class− имя класса, реализующего интерфейсcom.haulmont.cuba.gui.components.Formatter
Если конструктор класса formatter принимает параметр типа org.dom4j.Element, то ему будет передан элемент XML, описывающий данный formatter. Это можно использовать для параметризации экземпляра formatter’а, например, строкой форматирования. В частности, имеющиеся в платформе классы DateFormatter и NumberFormatter могут брать строку форматирования из атрибута format. Пример использования:
<column id="date">
<formatter class="com.haulmont.cuba.gui.components.formatters.DateFormatter" format="yyyy-MM-dd HH:mm:ss"/>
</column>Кроме того, класс DateFormatter распознает также атрибут type, который может принимать значения DATE или DATETIME. В этом случае форматирование производится с помощью механизма Datatype по строке формата dateFormat или dateTimeFormat соответственно. Например:
<column id="endDate">
<formatter class="com.haulmont.cuba.gui.components.formatters.DateFormatter" type="DATE"/>
</column>По умолчанию, DateFormatter отображает дату и время в часовом поясе сервера. Чтобы учитывать часовой пояс текущего пользователя, установите значение true для атрибута useUserTimezone элемента formatter.
|
Если formatter реализован внутренним классом, то он должен быть объявлен с модификатором
|
Formatter можно назначить компоненту не только в XML-дескрипторе экрана, но и программно, передавая экземпляр formatter’а в метод setFormatter() компонента.
Пример объявления собственного formatter’а и использования его для форматирования значения колонки таблицы:
public class CurrencyFormatter implements Function<BigDecimal, String> {
@Override
public String apply(BigDecimal bigDecimal) {
return NumberFormat.getCurrencyInstance(Locale.getDefault()).format(bigDecimal);
}
}@Inject
private GroupTable<Order> ordersTable;
@Subscribe
public void onInit(InitEvent event) {
Function currencyFormatter = new CurrencyFormatter();
ordersTable.getColumn("totalPrice").setFormatter(currencyFormatter);
}3.5.2.4.3. Presentations
Механизм представлений позволяет пользователям системы управлять настройками отображения таблиц.
Пользователи могут:
-
Сохранять представления под уникальными именами. Настройки таблицы автоматически сохраняются в активном представлении.
-
Редактировать и удалять представления.
-
Переключаться между представлениями.
-
Задавать представление по умолчанию, которое будет применяться при открытии экрана.
-
Создавать глобальные представления, доступные всем пользователям системы. Для создания, изменения и удаления глобальных представлений пользователь должен иметь разрешение
cuba.gui.presentations.global.
Представления доступны в компонентах, реализующих интерфейс com.haulmont.cuba.gui.components.Component.HasPresentations. В платформе такими компонентами являются:
3.5.2.4.4. Validator
Валидатор предназначен для проверки значения, введенного в визуальном компоненте.
|
Следует отличать валидацию от проверки типа данных. Если для некоторого компонента, например TextField, задан тип, отличный от строкового (это происходит при связывании с атрибутом сущности или назначении Валидация же срабатывает не сразу при вводе или потере компонентом фокуса, а только при вызове у компонента метода |
Фреймворк уже содержит несколько реализаций наиболее часто используемых валидаторов, которые можно применять в проектах:
В XML-дескрипторе экрана такие валидаторы для компонента задаются во вложенном элементе validators.
Валидатор можно установить с помощью интерфейса CUBA Studio. Пример добавления валидатора к компоненту TextField:
Каждый валидатор является Prototype бином, и если вы хотите использовать валидаторы из Java-кода, вы можете загрузить их с помощью BeanLocator.
Некоторые валидаторы используют Groovy в сообщении об ошибке. Это означает, что в сообщение об ошибке можно передать параметры (например, $value). Эти параметры учитывают языковую локаль пользователя.
В качестве валидатора можно использовать кастомный Java-класс, реализующий интерфейс Consumer.
В XML-дескрипторе экрана кастомный валидатор для компонента задается во вложенном элементе validator.
|
Если валидатор реализован внутренним классом, то он должен быть объявлен с модификатором |
Валидатор-класс можно назначить компоненту не только в XML-дескрипторе экрана, но и программно, передавая экземпляр валидатора в метод addValidator() компонента.
Пример создания класса валидатора почтового индекса:
public class ZipValidator implements Consumer<String> {
@Override
public void accept(String s) throws ValidationException {
if (s != null && s.length() != 6)
throw new ValidationException("Zip must be of 6 characters length");
}
}Использование валидатора почтового индекса для текстового поля TextField:
<textField id="zipField" property="zip">
<validator class="com.company.sample.web.ZipValidator"/>
</textField>Пример программного задания валидатора:
zipField.addValidator(value -> {
if (value != null && value.length() != 6)
throw new ValidationException("Zip must be of 6 characters length");
});Ниже мы рассмотрим предопределенные валидаторы.
- DecimalMaxValidator
-
Проверяет, что значение меньше или равно указанному максимальному значению. Поддерживаемые типы:
BigDecimal,BigInteger,Long,IntegerиString, представляющий значениеBigDecimalс текущей локалью.Валидатор имеет следующие атрибуты:
-
value− максимальное значение (обязательный атрибут); -
inclusive− если атрибут установлен вtrue, вводимое значение должно быть меньше или равно указанному максимальному значению. Значение по умолчанию −true; -
message− сообщение, выводимое пользователю в случае ошибки валидации. Это сообщение может содержать переменные$valueи$maxдля форматированного вывода.
Ключи сообщения по умолчанию:
-
validation.constraints.decimalMaxInclusive -
validation.constraints.decimalMax
Использование в XML-дескрипторе:
<textField id="numberField" property="numberProperty"> <validators> <decimalMax value="1000" inclusive="false" message="Value '$value' cannot be greater than `$max`"/> </validators> </textField>Использование в Java коде:
DecimalMaxValidator maxValidator = beanLocator.getPrototype(DecimalMaxValidator.NAME, new BigDecimal(1000)); numberField.addValidator(maxValidator); -
- DecimalMinValidator
-
Проверяет, что значение больше или равно указанному минимальному значению. Поддерживаемые типы:
BigDecimal,BigInteger,Long,IntegerиString, представляющий значениеBigDecimalс текущей локалью.Валидатор имеет следующие атрибуты:
-
value− минимальное значение (обязательный атрибут); -
inclusive− если атрибут установлен вtrue, вводимое значение должно быть больше или равно указанному минимальному значению. Значение по умолчанию −true; -
message− сообщение, выводимое пользователю в случае ошибки валидации. Это сообщение может содержать переменные$valueи$minдля форматированного вывода.
Ключи сообщения по умолчанию:
-
validation.constraints.decimalMinInclusive -
validation.constraints.decimalMin
Использование в XML-дескрипторе:
<textField id="numberField" property="numberProperty"> <validators> <decimalMin value="100" inclusive="false" message="Value '$value' cannot be less than `$min`"/> </validators> </textField>Использование в Java коде:
DecimalMinValidator minValidator = beanLocator.getPrototype(DecimalMinValidator.NAME, new BigDecimal(100)); numberField.addValidator(minValidator); -
- DigitsValidator
-
Проверяет, что значение − это число в пределах обозначенного диапазона. Поддерживаемые типы:
BigDecimal,BigInteger,Long,IntegerиString, представляющий значениеBigDecimalс текущей локалью.Валидатор имеет следующие атрибуты:
-
integer− количество цифр в целочисленной части (обязательный атрибут); -
fraction− количество цифр в дробной части (обязательный атрибут); -
message− сообщение, выводимое пользователю в случае ошибки валидации. Это сообщение может содержать переменные$value,$integerи$fractionдля форматированного вывода.
Ключи сообщения по умолчанию:
-
validation.constraints.digits
Использование в XML-дескрипторе:
<textField id="numberField" property="numberProperty"> <validators> <digits integer="3" fraction="2" message="Value '$value' is out of bounds ($integer digits are expected in integer part and $fraction in fractional part)"/> </validators> </textField>Использование в Java коде:
DigitsValidator digitsValidator = beanLocator.getPrototype(DigitsValidator.NAME, 3, 2); numberField.addValidator(digitsValidator); -
- DoubleMaxValidator
-
Проверяет, что значение меньше или равно указанному максимальному значению. Поддерживаемые типы:
DoubleиString, представляющий значениеDoubleс текущей локалью.Валидатор имеет следующие атрибуты:
-
value− максимальное значение (обязательный атрибут); -
inclusive− если атрибут установлен вtrue, вводимое значение должно быть меньше или равно указанному максимальному значению. Значение по умолчанию −true; -
message− сообщение, выводимое пользователю в случае ошибки валидации. Это сообщение может содержать переменные$valueи$maxдля форматированного вывода.
Ключи сообщения по умолчанию:
-
validation.constraints.decimalMaxInclusive -
validation.constraints.decimalMax
Использование в XML-дескрипторе:
<textField id="numberField" property="numberProperty"> <validators> <doubleMax value="1000" inclusive="false" message="Value '$value' cannot be greater than `$max`"/> </validators> </textField>Использование в Java коде:
DoubleMaxValidator maxValidator = beanLocator.getPrototype(DoubleMaxValidator.NAME, new Double(1000)); numberField.addValidator(maxValidator); -
- DoubleMinValidator
-
Проверяет, что значение больше или равно указанному минимальному значению. Поддерживаемые типы:
DoubleиString, представляющий значениеDoubleс текущей локалью.Валидатор имеет следующие атрибуты:
-
value− минимальное значение (обязательный атрибут); -
inclusive− если атрибут установлен вtrue, вводимое значение должно быть больше или равно указанному минимальному значению. Значение по умолчанию −true; -
message− сообщение, выводимое пользователю в случае ошибки валидации. Это сообщение может содержать переменные$valueи$minдля форматированного вывода.
Ключи сообщения по умолчанию:
-
validation.constraints.decimalMinInclusive -
validation.constraints.decimalMin
Использование в XML-дескрипторе:
<textField id="numberField" property="numberProperty"> <validators> <doubleMin value="100" inclusive="false" message="Value '$value' cannot be less than `$min`"/> </validators> </textField>Использование в Java коде:
DoubleMinValidator minValidator = beanLocator.getPrototype(DoubleMinValidator.NAME, new Double(100)); numberField.addValidator(minValidator); -
- FutureOrPresentValidator
-
Проверяет, что дата или время находится в будущем или настоящем. Валидатор не использует Groovy, поэтому нет параметров, которые вы можете передать в сообщение об ошибке. Поддерживаемые типы:
java.util.Date,LocalDate,LocalDateTime,LocalTime,OffsetDateTime,OffsetTime.Валидатор имеет следующие атрибуты:
-
checkSeconds− если установлено значениеtrue, валидатор сравнивает дату или время с секундами и наносекундами. Значение по умолчанию −false; -
message− сообщение, выводимое пользователю в случае ошибки валидации.
Ключи сообщения по умолчанию:
-
validation.constraints.futureOrPresent
Использование в XML-дескрипторе:
<dateField id="dateTimePropertyField" property="dateTimeProperty"> <validators> <futureOrPresent checkSeconds="true"/> </validators> </dateField>Использование в Java коде:
FutureOrPresentValidator futureOrPresentValidator = beanLocator.getPrototype(FutureOrPresentValidator.NAME); dateField.addValidator(futureOrPresentValidator); -
- FutureValidator
-
Проверяет, что дата или время находится в будущем. Валидатор не использует Groovy, поэтому нет параметров, которые вы можете передать в сообщение об ошибке. Поддерживаемые типы:
java.util.Date,LocalDate,LocalDateTime,LocalTime,OffsetDateTime,OffsetTime.Валидатор имеет следующие атрибуты:
-
checkSeconds− если установлено значениеtrue, валидатор сравнивает дату или время с секундами и наносекундами. Значение по умолчанию −false; -
message− сообщение, выводимое пользователю в случае ошибки валидации.
Ключи сообщения по умолчанию:
-
validation.constraints.future
Использование в XML-дескрипторе:
<timeField id="localTimeField" property="localTimeProperty" showSeconds="true"> <validators> <future checkSeconds="true"/> </validators> </timeField>Использование в Java коде:
FutureValidator futureValidator = beanLocator.getPrototype(FutureValidator.NAME); timeField.addValidator(futureValidator); -
- MaxValidator
-
Проверяет, что значение меньше или равно указанному максимальному значению. Поддерживаемые типы:
BigDecimal,BigInteger,Long,Integer.Валидатор имеет следующие атрибуты:
-
value− максимальное значение (обязательный атрибут); -
message− сообщение, выводимое пользователю в случае ошибки валидации. Это сообщение может содержать переменные$valueи$maxдля форматированного вывода.
Ключи сообщения по умолчанию:
-
validation.constraints.max
Использование в XML-дескрипторе:
<textField id="numberField" property="numberProperty"> <validators> <max value="20500" message="Value '$value' must be less than or equal to '$max'"/> </validators> </textField>Использование в Java коде:
MaxValidator maxValidator = beanLocator.getPrototype(MaxValidator.NAME, 20500); numberField.addValidator(maxValidator); -
- MinValidator
-
Проверяет, что значение больше или равно указанному минимальному значению. Поддерживаемые типы:
BigDecimal,BigInteger,Long,Integer.Валидатор имеет следующие атрибуты:
-
value− минимальное значение (обязательный атрибут); -
message− сообщение, выводимое пользователю в случае ошибки валидации. Это сообщение может содержать переменные$valueи$minдля форматированного вывода.
Ключи сообщения по умолчанию:
-
validation.constraints.min
Использование в XML-дескрипторе:
<textField id="numberField" property="numberProperty"> <validators> <min value="30" message="Value '$value' must be greater than or equal to '$min'"/> </validators> </textField>Использование в Java коде:
MinValidator minValidator = beanLocator.getPrototype(MinValidator.NAME, 30); numberField.addValidator(minValidator); -
- NegativeOrZeroValidator
-
Проверяет, что значение меньше или равно 0. Поддерживаемые типы:
BigDecimal,BigInteger,Long,Integer,Double,Float.Валидатор имеет следующие атрибуты:
-
message− сообщение, выводимое пользователю в случае ошибки валидации. Это сообщение может содержать переменную$valueдля форматированного вывода. Обратите внимание, чтоFloatне имеет своего собственного типа данных и не будет отформатирован с пользовательской локалью.
Ключи сообщения по умолчанию:
-
validation.constraints.negativeOrZero
Использование в XML-дескрипторе:
<textField id="numberField" property="numberProperty"> <validators> <negativeOrZero message="Value '$value' must be less than or equal to 0"/> </validators> </textField>Использование в Java коде:
NegativeOrZeroValidator negativeOrZeroValidator = beanLocator.getPrototype(NegativeOrZeroValidator.NAME); numberField.addValidator(negativeOrZeroValidator); -
- NegativeValidator
-
Проверяет, что значение строго меньше 0. Поддерживаемые типы:
BigDecimal,BigInteger,Long,Integer,Double,Float.Валидатор имеет следующие атрибуты:
-
message− сообщение, выводимое пользователю в случае ошибки валидации. Это сообщение может содержать переменную$valueдля форматированного вывода. Обратите внимание, чтоFloatне имеет своего собственного типа данных и не будет отформатирован с пользовательской локалью.
Ключи сообщения по умолчанию:
-
validation.constraints.negative
Использование в XML-дескрипторе:
<textField id="numberField" property="numberProperty"> <validators> <negative message="Value '$value' should be less than 0"/> </validators> </textField>Использование в Java коде:
NegativeValidator negativeValidator = beanLocator.getPrototype(NegativeValidator.NAME); numberField.addValidator(negativeValidator); -
- NotBlankValidator
-
Проверяет, что значение содержит по крайней мере один символ без пробела. Валидатор не использует Groovy, поэтому нет параметров, которые вы можете передать в сообщение об ошибке. Поддерживаемый тип:
String.Валидатор имеет следующие атрибуты:
-
message− сообщение, выводимое пользователю в случае ошибки валидации.
Ключи сообщения по умолчанию:
-
validation.constraints.notBlank
Использование в XML-дескрипторе:
<textField id="textField" property="textProperty"> <validators> <notBlank message="Value must contain at least one non-whitespace character"/> </validators> </textField>Использование в Java коде:
NotBlankValidator notBlankValidator = beanLocator.getPrototype(NotBlankValidator.NAME); textField.addValidator(notBlankValidator); -
- NotEmptyValidator
-
Проверяет, что значение не пустое и не
null. Поддерживаемые типы:CollectionиString.Валидатор имеет следующие атрибуты:
-
message− сообщение, выводимое пользователю в случае ошибки валидации. Это сообщение может содержать переменную$value(только типаString) для форматированного вывода.
Ключи сообщения по умолчанию:
-
validation.constraints.notEmpty
Использование в XML-дескрипторе:
<textField id="textField" property="textProperty"> <validators> <notEmpty/> </validators> </textField>Использование в Java коде:
NotEmptyValidator notEmptyValidator = beanLocator.getPrototype(NotEmptyValidator.NAME); textField.addValidator(notEmptyValidator); -
- NotNullValidator
-
Проверяет, что значение не
null. Валидатор не использует Groovy, поэтому нет параметров, которые вы можете передать в сообщение об ошибке.Валидатор имеет следующие атрибуты:
-
message− сообщение, выводимое пользователю в случае ошибки валидации.
Ключи сообщения по умолчанию:
-
validation.constraints.notNull
Использование в XML-дескрипторе:
<textField id="numberField" property="numberProperty"> <validators> <notNull/> </validators> </textField>Использование в Java коде:
NotNullValidator notNullValidator = beanLocator.getPrototype(NotNullValidator.NAME); numberField.addValidator(notNullValidator); -
- PastOrPresentValidator
-
Проверяет, что дата или время находится в прошлом или настоящем. Валидатор не использует Groovy, поэтому нет параметров, которые вы можете передать в сообщение об ошибке. Поддерживаемые типы:
java.util.Date,LocalDate,LocalDateTime,LocalTime,OffsetDateTime,OffsetTime.Валидатор имеет следующие атрибуты:
-
checkSeconds− если установлено значениеtrue, валидатор сравнивает дату или время с секундами и наносекундами. Значение по умолчанию −false; -
message− сообщение, выводимое пользователю в случае ошибки валидации.
Ключи сообщения по умолчанию:
-
validation.constraints.pastOrPresent
Использование в XML-дескрипторе:
<dateField id="dateTimeField" property="dateTimeProperty"> <validators> <pastOrPresent/> </validators> </dateField>Использование в Java коде:
PastOrPresentValidator pastOrPresentValidator = beanLocator.getPrototype(PastOrPresentValidator.NAME); numberField.addValidator(pastOrPresentValidator); -
- PastValidator
-
Проверяет, что дата или время находится в прошлом. Валидатор не использует Groovy, поэтому нет параметров, которые вы можете передать в сообщение об ошибке. Поддерживаемые типы:
java.util.Date,LocalDate,LocalDateTime,LocalTime,OffsetDateTime,OffsetTime.Валидатор имеет следующие атрибуты:
-
checkSeconds− если установлено значениеtrue, валидатор сравнивает дату или время с секундами и наносекундами. Значение по умолчанию −false; -
message− сообщение, выводимое пользователю в случае ошибки валидации.
Ключи сообщения по умолчанию:
-
validation.constraints.past
Использование в XML-дескрипторе:
<dateField id="dateTimeField" property="dateTimeProperty"> <validators> <pastOrPresent/> </validators> </dateField>Использование в Java коде:
PastOrPresentValidator pastOrPresentValidator = beanLocator.getPrototype(PastOrPresentValidator.NAME); numberField.addValidator(pastOrPresentValidator); -
- PositiveOrZeroValidator
-
Проверяет, что значение больше или равно 0. Поддерживаемые типы:
BigDecimal,BigInteger,Long,Integer,Double,Float.Валидатор имеет следующие атрибуты:
-
message− сообщение, выводимое пользователю в случае ошибки валидации. Это сообщение может содержать переменную$valueдля форматированного вывода. Обратите внимание, чтоFloatне имеет своего собственного типа данных и не будет отформатирован с пользовательской локалью.
Ключи сообщения по умолчанию:
-
validation.constraints.positiveOrZero
Использование в XML-дескрипторе:
<textField id="numberField" property="numberProperty"> <validators> <positiveOrZero message="Value '$value' should be greater than or equal to '0'"/> </validators> </textField>Использование в Java коде:
PositiveOrZeroValidator positiveOrZeroValidator = beanLocator.getPrototype(PositiveOrZeroValidator.NAME); numberField.addValidator(positiveOrZeroValidator); -
- PositiveValidator
-
Проверяет, что значение строго больше 0. Поддерживаемые типы:
BigDecimal,BigInteger,Long,Integer,Double,Float.Валидатор имеет следующие атрибуты:
-
message− сообщение, выводимое пользователю в случае ошибки валидации. Это сообщение может содержать переменную$valueдля форматированного вывода. Обратите внимание, чтоFloatне имеет своего собственного типа данных и не будет отформатирован с пользовательской локалью.
Ключи сообщения по умолчанию:
-
validation.constraints.positive
Использование в XML-дескрипторе:
<textField id="numberField" property="numberProperty"> <validators> <positive message="Value '$value' should be greater than '0'"/> </validators> </textField>Использование в Java коде:
PositiveValidator positiveValidator = beanLocator.getPrototype(PositiveValidator.NAME); numberField.addValidator(positiveValidator); -
- RegexpValidator
-
Проверяет, что строковое значение соответствует указанному регулярному выражению. Поддерживаемый тип:
String.Валидатор имеет следующие атрибуты:
-
regexp− регулярное выражение для проверки соответствия (обязательный атрибут); -
message− сообщение, выводимое пользователю в случае ошибки валидации. Это сообщение может содержать переменную$valueдля форматированного вывода.
Ключи сообщения по умолчанию:
-
validation.constraints.regexp
Использование в XML-дескрипторе:
<textField id="textField" property="textProperty"> <validators> <regexp regexp="[a-z]*"/> </validators> </textField>Использование в Java коде:
RegexpValidator regexpValidator = beanLocator.getPrototype(RegexpValidator.NAME, "[a-z]*"); textField.addValidator(regexpValidator); -
- SizeValidator
-
Проверяет, что значение находится в определенном диапазоне. Поддерживаемые типы:
CollectionandString.Валидатор имеет следующие атрибуты:
-
min− минимальное значение (включительно), не может быть меньше 0. Значение по умолчанию − 0; -
max− максимальное значение (включительно), не может быть меньше 0. Значение по умолчанию −Integer.MAX_VALUE; -
message− сообщение, выводимое пользователю в случае ошибки валидации. Это сообщение может содержать переменные$value(только для типаString),$min,$maxдля форматированного вывода.
Ключи сообщения по умолчанию:
-
validation.constraints.collectionSizeRange -
validation.constraints.sizeRange
Использование в XML-дескрипторе:
<textField id="textField" property="textProperty"> <validators> <size min="2" max="10" message="Value '$value' should be between '$min' and '$max'"/> </validators> </textField> <twinColumn id="twinColumn"> <validators> <size min="2" max="4" message="Collection size must be between $min and $max"/> </validators> </twinColumn>Использование в Java коде:
SizeValidator sizeValidator = beanLocator.getPrototype(SizeValidator.NAME); textField.addValidator(sizeValidator); -
3.5.2.5. API компонентов
- Доступно для всех визуальных компонентов
-
-
unwrap()- возвращает экземпляр компонента для текущего типа клиента (компонент Vaadin или Swing). Можно использовать в клиентском модуле для доступа к API базового компонента, см. раздел Работа с компонентами Vaadin.com.vaadin.ui.TextField vTextField = textField.unwrap(com.vaadin.ui.TextField.class); -
unwrapComposition()- возвращает экземпляр самого внешнего контейнера для текущего типа клиента. Можно использовать в клиентском модуле для доступа к API базового компонента.
-
- Buffered
-
-
commit()- обновляет источник данных, сохраняя все изменения, внесённые после последнего коммита.
-
discard()- отменяет все изменения, внесённые после последнего коммита. Значение компонента обновляется из источника данных.
-
isModified()- возвращаетtrue, если значение компонента изменилось с момента последнего обновления из источника данных.
if (textArea.isModified()) { textArea.commit(); }Доступно для компонентов:
-
- Collapsable
-
-
addExpandedStateChangeListener()- добавляет слушатель, реализующий интерфейсExpandedStateChangeListener, для отслеживания событий сворачивания/разворачивания компонента.@Subscribe("groupBox") protected void onGroupBoxExpandedStateChange(Collapsable.ExpandedStateChangeEvent event) { notifications.create() .withCaption("Expanded: " + groupBox.isExpanded()) .show(); }
Доступно для компонентов:
-
- ComponentContainer
-
-
add()- добавляет дочерний компонент в контейнер.
-
remove()- удаляет дочерний компонент из контейнера.
-
removeAll()- удаляет все дочерние компоненты из контейнера.
-
getOwnComponent()- возвращает компонент, вложенный непосредственно в этот контейнер.
-
getComponent()- возвращает компонент, находящийся где-либо внутри дерева компонентов в этом контейнере.
-
getComponentNN()- возвращает компонент, находящийся где-либо внутри дерева компонентов в этом контейнере, и выбрасывает исключение, если компонент не найден.
-
getOwnComponents()- возвращает список всех компонентов, вложенных непосредственно в этот контейнер.
-
getComponents()- возвращает список всех компонентов, находящихся где-либо внутри дерева компонентов в этом контейнере.
Доступно для компонентов:
Accordion - BoxLayout - CssLayout - FieldGroup - Form - Frame - GridLayout - GroupBoxLayout - HtmlBoxLayout - ScrollBoxLayout - SplitPanel - TabSheet
-
- OrderedContainer
-
-
indexOf()- возвращает индекс компонента внутри упорядоченного контейнера.
Доступно для компонентов:
BoxLayout - CssLayout - Frame - GroupBoxLayout - ScrollBoxLayout -
-
- HasContextHelp
-
-
setContextHelpText()- задаёт текст контекстной подсказки для компонента, см. атрибут contextHelpText. -
setContextHelpTextHtmlEnabled()- указывает, может ли текст контекстной подсказки быть обработан как HTML, см.атрибут contextHelpTextHtmlEnabled. -
setContextHelpIconClickHandler()- добавляет слушатель кликов по значку контекстной подсказки. Слушатель имеет приоритет над текстом подсказки, таким образом, контекстная подсказка с текстом не будет отображаться, если также установлен слушатель кликов по значку подсказки.
textArea.setContextHelpIconClickHandler(contextHelpIconClickEvent -> dialogs.createMessageDialog() .withCaption("Title") .withMessage("Message body") .withType(Dialogs.MessageType.CONFIRMATION) .show() );Доступно для большинства компонентов:
Accordion - BoxLayout - BrowserFrame - ButtonsPanel - Calendar - CheckBox - CheckBoxGroup - ColorPicker - CssLayout - CurrencyField - DataGrid - DateField - DatePicker - Embedded - FieldGroup - FileUploadField - Filter - Form - GridLayout - GroupBoxLayout - GroupTable - HtmlBoxLayout - Image - JavaScriptComponent - Label - LookupField - LookupPickerField - MaskedField - OptionsGroup - OptionsList - PasswordField - PickerField - PopupView - ProgressBar - RadioButtonGroup - RichTextArea - ScrollBoxLayout - SearchPickerField - Slider - SourceCodeEditor - SplitPanel - SuggestionField - SuggestionPickerField - Table - TabSheet - TextArea - TextField - TimeField - TokenList - Tree - TreeDataGrid - TreeTable - TwinColumn
-
- HasSettings
-
-
applySettings()- восстанавливает последние пользовательские настройки для этого компонента. -
saveSettings()- сохраняет текущие пользовательские настройки для этого компонента.
Доступно для компонентов:
DataGrid - Filter - GroupBoxLayout - SplitPanel - Table - TextArea
-
- HasUserOriginated
-
-
isUserOriginated()- предоставляет информацию о происхождении события. Возвращаетtrue, если событие было вызвано пользователем на стороне клиента, илиfalse, если событие было вызвано программно на стороне сервера.Пример использования:
@Subscribe("customersTable") protected void onCustomersTableSelection(Table.SelectionEvent<Customer> event) { if (event.isUserOriginated()) notifications.create() .withCaption("You selected " + event.getSelected().size() + " customers") .show(); }
Метод
isUserOriginated()доступен для следующих событий:-
CollapseEventкомпонентов TreeDataGrid, Tree, -
ColumnCollapsingChangeEventкомпонента DataGrid, -
ColumnReorderEventкомпонента DataGrid, -
ColumnResizeEventкомпонента DataGrid, -
ExpandedStateChangeEventкомпонентов Filter и GroupBoxLayout (см. Collapsable), -
ExpandEventкомпонентов TreeDataGrid, Tree, -
SelectedTabChangeEventкомпонента TabSheet, -
SelectionEventкомпонента DataGrid, -
SelectionEventкомпонента Table, -
SortEventкомпонента DataGrid, -
SplitPositionChangeEventкомпонента SplitPanel, -
ValueChangeEventкомпонентов, реализующих интерфейсHasValue(см. ValueChangeListener).
-
- HasValue
-
-
addValueChangeListener()- добавляет слушатель, реализующий интерфейсValueChangeListener, для отслеживания изменения значения компонента.@Inject private TextField<String> textField; @Inject private Notifications notifications; @Subscribe protected void onInit(InitEvent event) { textField.addValueChangeListener(stringValueChangeEvent -> notifications.create() .withCaption("Before: " + stringValueChangeEvent.getPrevValue() + ". After: " + stringValueChangeEvent.getValue()) .show()); }С той же целью вы можете подписаться на событие изменения значения конкретного компонента в контроллере экрана, к примеру:
@Subscribe("textField") protected void onTextFieldValueChange(HasValue.ValueChangeEvent<String> event) { notifications.create() .withCaption("Before: " + event.getPrevValue() + ". After: " + event.getValue()) .show(); }
См. также UserOriginated.
Доступно для компонентов:
CheckBox - CheckBoxGroup - ColorPicker - CurrencyField - DateField - DatePicker - FileUploadField - Label - LookupField - LookupPickerField - MaskedField - OptionsGroup - OptionsList - PasswordField - PickerField - ProgressBar - RadioButtonGroup - RichTextArea - SearchPickerField - Slider - SourceCodeEditor - SuggestionField - SuggestionPickerField - TextArea - TextField - TimeField - TokenList - TwinColumn -
-
- LayoutClickNotifier
-
-
addLayoutClickListener()- добавляет слушатель, реализующий интерфейсLayoutClickListener, для отслеживания кликов по области компонента.vbox.addLayoutClickListener(layoutClickEvent -> notifications.create() .withCaption("Clicked") .show());С той же целью вы можете подписаться на событие клика по конкретному компоненту, к примеру:
@Subscribe("vbox") protected void onVboxLayoutClick(LayoutClickNotifier.LayoutClickEvent event) { notifications.create() .withCaption("Clicked") .show(); }
Доступно для компонентов:
-
- HasMargin
-
-
setMargin()- устанавливает компоненту внешние поля.-
Добавление внешних полей со всех сторон компонента:
vbox.setMargin(true); -
Добавление внешних полей только в верхней и нижней части компонента:
vbox.setMargin(true, false, true, false); -
Создание объекта конфигурации
MarginInfo:vbox.setMargin(new MarginInfo(true, false, false, true));
-
-
getMargin()- возвращает конфигурацию внешних полей в виде экземпляраMarginInfo.
Доступно для компонентов:
BoxLayout - Filter - Frame - GridLayout - ScrollBoxLayout
-
- HasOuterMargin
-
-
setOuterMargin()- устанавливает внешние поля вокруг границы компонента.-
Добавление внешних полей со всех сторон компонента:
groupBox.setOuterMargin(true); -
Добавление внешних полей только в верхней и нижней части компонента:
groupBox.setOuterMargin(true, false, true, false); -
Создание объекта конфигурации
MarginInfo:groupBox.setOuterMargin(new MarginInfo(true, false, false, true));
-
-
getOuterMargin()- возвращает конфигурацию внешних полей в виде экземпляраMarginInfo.
Доступно для компонентов:
-
- HasSpacing
-
-
setSpacing()- добавляет внутренние поля между компонентом и вложенными в него компонентами.vbox.setSpacing(true);
Доступно для компонентов:
-
- ShortcutNotifier
-
-
addShortcutAction()- добавляет действие, вызываемое при нажатии определённого сочетания клавиш.cssLayout.addShortcutAction(new ShortcutAction("SHIFT-A", shortcutTriggeredEvent -> notifications.create() .withCaption("SHIFT-A action") .show()));
Доступно для компонентов:
-
3.5.2.6. XML-атрибуты компонентов
- align
-
Атрибут, задающий расположение компонента относительно вышестоящего контейнера. Возможные значения:
-
TOP_RIGHT -
TOP_LEFT -
TOP_CENTER -
MIDDLE_RIGHT -
MIDDLE_LEFT -
MIDDLE_CENTER -
BOTTOM_RIGHT -
BOTTOM_LEFT -
BOTTOM_CENTER
-
- box.expandRatio
-
В контейнерах vbox и hbox компоненты размещаются в слотах. Атрибут
box.expandRatioопределяет относительную длину для каждого слота. Принимает значение большее или равное 0.<hbox width="500px" expand="button1" spacing="true"> <button id="button1" box.expandRatio="1"/> <button id="button2" width="100%" box.expandRatio="3"/> <button id="button3" width="100%" box.expandRatio="2"/> </hbox>Если для компонента указать
box.expandRatio=1, а его высота или ширина (в зависимости от типа контейнера) составляет 100%, компонент будет расширен на всё доступное пространство в направлении размещения компонентов.По умолчанию слоты для компонентов, в зависимости от типа контейнера, имеют одинаковую высоту или ширину (т.е.
box.expandRatio=1). Если хотя бы одному компоненту установлено иное значение, все неявные значения игнорируются и учитываются только явно присвоенные значения.См. также атрибут expand.
- caption
-
Атрибут, устанавливающий заголовок для визуального компонента.
Значением атрибута должна быть либо строка сообщения, либо ключ в пакете сообщений. В случае ключа значение должно начинаться с префикса
msg://Способы задания ключа:
-
Короткий ключ − при этом сообщение ищется в пакете, заданном для данного экрана:
caption="msg://infoFieldCaption" -
Полный ключ, с заданием пакета:
caption="msg://com.company.sample.gui.screen/infoFieldCaption"
-
- captionAsHtml
-
Определяет, разрешена ли HTML-разметка в заголовке компонента. Если выбрано значение
true, заголовки отображаются в браузере как HTML, при этом ответственность за безопасность используемого HTML-кода несёт сам разработчик. Если выбрано значениеfalse, содержимое заголовка отображается как обычный текст.Возможные значения −
true,false. По умолчаниюfalse.
- captionProperty
-
Задает имя атрибута сущности, отображаемого компонентом. Используется только для сущностей, находящихся в источнике данных (например заданном для LookupField свойством optionsDatasource).
Если
captionPropertyне задан, будет отображаться имя экземпляра.
- colspan
-
Указывает, сколько колонок сетки должен занять компонент (по умолчанию 1).
Данный атрибут может быть назначен любому компоненту, находящемуся непосредственно внутри контейнера GridLayout.
- contextHelpText
-
Атрибут, задающий текст контекстной подсказки для компонента. Если установлено значение, рядом с полем будет отображаться специальный значок ?. Если поле имеет отдельный заголовок, то есть, установлены атрибуты caption или icon, значок подсказки будет отображаться рядом с заголовком, в противном случае - рядом с самим полем:
В web-клиенте подсказка отображается при наведении курсора мыши на значок ?.
<textField id="textField" contextHelpText="msg://contextHelp"/>
- contextHelpTextHtmlEnabled
-
Указывает, может ли текст контекстной подсказки быть обработан как HTML.
<textField id="textField" description="Description" contextHelpText="<p><h1>Lorem ipsum dolor</h1> sit amet, <b>consectetur</b> adipiscing elit.</p><p>Donec a lobortis nisl.</p>" contextHelpTextHtmlEnabled="true"/>
Возможные значения −
true,false.
- css
-
Позволяет декларативно указывать CSS-свойства для визуальных UI. Может использоваться совместно с атрибутом stylename, см. пример ниже.
Описание компонента в XML:<cssLayout css="display: grid; grid-gap: 10px; grid-template-columns: 33% 33% 33%" stylename="demo" width="100%" height="100%"> <label value="A" css="grid-column: 1 / 3; grid-row: 1"/> <label value="B" css="grid-column: 3; grid-row: 1 / 3;"/> <label value="C" css="grid-column: 1; grid-row: 2;"/> <label value="D" css="grid-column: 2; grid-row: 2;"/> </cssLayout>Дополнительный CSS:.demo > .v-label { display: block; background-color: #444; color: #fff; border-radius: 5px; padding: 20px; font-size: 150%; }
- dataContainer
-
Предназначен для задания data container, описанного в секции
dataXML-дескриптора экрана.При указании атрибута
dataContainerдля компонента необходимо также задать атрибут property.
- dataLoader
-
Предназначен для задания data loader, описанного в секции
dataXML-дескриптора экрана для data container.
- datasource
-
Предназначен для задания источника данных, описанного в секции
dsContextXML-дескриптора экрана.При указании атрибута
datasourceдля компонента, реализующего интерфейсDatasourceComponent, необходимо также задать атрибут property.
- datatype
-
Предназначен для задания типа данных, если поле не связано с атрибутом сущности (то есть не указан контейнер данных и название атрибута). В качестве значения атрибута указывается имя типа данных, зарегистрированного в метаданных приложения − см. Datatype.
Атрибут используется для компонентов TextField, DateField, DatePicker, TimeField, Slider.
- description
-
Атрибут, задающий текст подсказки для компонента, отображаемой при наведении курсора мыши или клике в области компонента.
- descriptionAsHtml
-
Определяет, разрешена ли HTML-разметка в описании компонента. Если выбрано значение
true, заголовки отображаются в браузере как HTML, при этом ответственность за безопасность используемого HTML-кода несёт сам разработчик. Если выбрано значениеfalse, содержимое заголовка отображается как обычный текст.Возможные значения −
true,false. По умолчаниюfalse.
- editable
-
Атрибут, указывающий на возможность редактирования содержимого компонента (не путать с enable).
Возможные значения −
true,false. По умолчаниюtrue.На возможность редактирования содержимого для компонента, связанного с данными (наследника
DatasourceComponentилиListComponent), влияет также подсистема безопасности. Если по данным подсистемы безопасности данный компонент должен быть недоступен для редактирования, значение атрибутаeditableне принимается во внимание.
- enable
-
Атрибут компонента, устанавливающий его состояние: доступен, недоступен.
Если компонент недоступен, то он не принимает фокус ввода. Недоступность контейнера приводит к тому, что все его компоненты также становятся недоступными. Возможные значения −
true,false. По умолчанию все компоненты доступны.
- expand
-
Атрибут контейнера для управления его внутренней компоновкой.
Задает компонент внутри контейнера, который необходимо расширить на все доступное пространство в направлении размещения компонентов. Для контейнера с вертикальным размещением устанавливает компоненту 100% высоту, для контейнера с горизонтальным размещением - 100% ширину. Кроме того, при изменении размера контейнера изменять размер будет именно этот компонент.
См.также box.expandRatio.
- height
-
Атрибут, устанавливающий высоту компонента. Высота может быть задана в пикселях либо в процентах от высоты вышестоящего контейнера. Например:
100px,100%,50. Если единица измерения не указана, подразумевается высота в пикселях.Установка значения в
%означает, что компонент по высоте займет соответствующую часть пространства, предоставляемого контейнером более высокого уровня.При выборе значения
AUTOили-1pxдля компонента устанавливается высота по умолчанию, для контейнера высота определяется по содержимому, то есть суммарной высотой вложенных компонентов.
- htmlSanitizerEnabled
-
Определяет, доступна ли HTML-санитизация для содержимого компонента (атрибуты caption, description, contextHelpText). Если атрибут
htmlSanitizerEnabledустановлен в значениеtrue, а также соответствующие атрибуты (captionAsHtml, descriptionAsHtml, contextHelpTextHtmlEnabled) установлены в значениеtrue, значение атрибутовcaption,descriptionиcontextHelpTextбудет санитизировано.protected static final String UNSAFE_HTML = "<i>Jackdaws </i><u>love</u> <font size=\"javascript:alert(1)\" " + "color=\"moccasin\">my</font> " + "<font size=\"7\">big</font> <sup>sphinx</sup> " + "<font face=\"Verdana\">of</font> <span style=\"background-color: " + "red;\">quartz</span><svg/onload=alert(\"XSS\")>"; @Inject private TextField<String> textFieldOn; @Inject private TextField<String> textFieldOff; @Subscribe public void onInit(InitEvent event) { textFieldOn.setCaption(UNSAFE_HTML); textFieldOn.setCaptionAsHtml(true); textFieldOn.setHtmlSanitizerEnabled(true); (1) textFieldOff.setCaption(UNSAFE_HTML); textFieldOff.setCaptionAsHtml(true); textFieldOff.setHtmlSanitizerEnabled(false); (2) }1 – TextFieldсодержит в себе безопасный HTML в качестве заголовка.2 – TextFieldсодержит в себе небезопасный HTML в качестве заголовка.Значение атрибута
htmlSanitizerEnabledимеет приоритет над значением глобального свойства cuba.web.htmlSanitizerEnabled.
- icon
-
Атрибут, устанавливающий значок для визуального компонента.
Значением атрибута должен быть путь к файлу значка относительно каталога темы:
icon="icons/create.png"либо его имя в используемом наборе значков:
icon="CREATE_ACTION"Если значок должен быть выбран в зависимости от языка пользователя, можно указать путь к нему в пакете сообщений, а в атрибуте
icon− ключ сообщения, например:icon="msg://addIcon"В веб-клиенте с темой Halo (или производной от нее) вместо файлов можно использовать элементы шрифта Font Awesome. Для этого достаточно указать константу из класса
com.vaadin.server.FontAwesomeс префиксомfont-icon:например:icon="font-icon:BOOK"Подробнее об использовании значков можно прочитать в разделе Значки.
- id
-
Идентификатор компонента.
Рекомендуется формировать значение по правилам Java-идентификаторов и использовать camelСase, например,
userGrid,filterPanel.Может быть указан для любого компонента и должен быть уникальным в пределах экрана.
- inputPrompt
-
Атрибут
inputPromptзадает строку, отображаемую в поле, если его значение равноnull.<suggestionField inputPrompt="Let's search something!"/>Атрибут используется для компонентов TextField, LookupField, LookupPickerField, SearchPickerField, SuggestionPickerField только в веб-клиенте.
- margin
-
Атрибут
marginустанавливает наличие отступа между внешними границами и содержимым контейнера.Может иметь два вида значений:
-
margin="true"− установить отступ со всех сторон сразу -
margin="true,false,true,false"− установить отступ только сверху и снизу (формат значения "сверху,справа,снизу,слева")
По умолчанию отступы отсутствуют.
-
- metaClass
-
Задает тип колонок таблицы в случае, если не задано значение атрибутов dataContainer или datasource. Определение атрибута
metaClassв XML эквивалентно заданию пустых значений для табличных компонентов DataGrid, GroupTable, Table, TreeDataGrid и TreeTable. Таким образом, вы можете указать данные для компонента программно в контроллере экрана.<table id="table" metaClass="sec$User"> <actions> <action id="refresh" type="refresh"/> </actions> </table>
- nullName
-
Идентификатор опции, выбор которой будет равносилен установке значения в
null.Атрибут используется для компонентов LookupField, LookupPickerField, SearchPickerField.
Пример для компонента LookupField, установка значения атрибута в XML-дескрипторе:
<lookupField datasource="orderDs" property="customer" nullName="(none)" optionsDatasource="customersDs" width="200px"/>Пример для компонента LookupField, установка значения атрибута в контроллере:
<lookupField id="customerLookupField" optionsDatasource="customersDs" width="200px" datasource="orderDs" property="customer"/>customerLookupField.setNullOption("<null>");
- openType
-
Задает режим открытия связанного экрана. Соответствует перечислению
WindowManager.OpenTypeсо значениямиNEW_TAB,THIS_TAB,NEW_WINDOW,DIALOG. По умолчаниюTHIS_TAB.
- optionsContainer
-
Задает имя контейнера data container, используемого для формирования списка опций.
Совместно с
optionsContainerможет использоваться атрибут captionProperty.
- optionsDatasource
-
Задает имя источника данных, используемого для формирования списка опций.
Совместно с
optionsDatasourceможет использоваться атрибут captionProperty.
- optionsEnum
-
Задаёт полное имя класса перечисления, используемого для формирования списка опций.
- property
-
Атрибут компонента, реализующего интерфейс
DatasourceComponent.Предназначен для задания имени атрибута сущности, значение которого будет отображаться или редактироваться данным визуальным компонентом.
Используется всегда совместно с атрибутом datasource.
- required
-
Атрибут визуального компонента, реализующего интерфейс
Field. Указывает, что в данное поле обязательно должно быть введено значение.Возможные значения атрибута −
true,false. По умолчаниюfalse.Совместно с
requiredможет использоваться атрибут requiredMessage.
- requiredMessage
- responsive
-
Определяет, должен ли компонент реагировать на изменения размеров доступной области. Реакцию можно задать с помощью стилей.
Возможные значения атрибута −
true,false. По умолчаниюfalse.
- rowspan
-
Указывает, сколько строк сетки должен занять компонент (по умолчанию 1).
Данный атрибут может быть назначен любому компоненту, находящемуся непосредственно внутри контейнера GridLayout.
- settingsEnabled
-
Определяет, нужно ли сохранять пользовательские настройки отображения компонента. Настройки сохраняются только для компонентов, имеющих id.
Возможные значения атрибута −
true,false. По умолчаниюtrue.
- showOrphans
-
Атрибут
showOrphansиспользуется для управления видимостью сиротских записей древовидных компонентов, то есть записей, родители которых недоступны в текущем наборе данных. Если атрибутshowOrphansимеет значениеfalse, компонент не отображает сиротские записи. Если атрибутshowOrphansимеет значениеtrue, компонент ведет себя как и раньше, то есть сиротские записи отображаются на верхнем уровне в виде корневых записей.Значение по умолчанию:
true.Сокрытие сиротских записей выглядит как естественный выбор при использовании фильтров. Однако это не помогает при постраничном отображении (некоторые страницы будут пустыми или наполовину заполненными), поэтому при использовании древовидных компонентов постраничное отображение следует отключить:
-
Установите значение атрибута useMaxResults у фильтра в значение
false; -
Удалите элемент rowsCount из таблиц.
Этот атрибут используется для компонентов Tree, TreeDataGrid, TreeTable.
-
- spacing
-
Атрибут
spacingустанавливает наличие отступов между компонентами внутри контейнера.Возможные значения −
true,false.По умолчанию отступы отсутствуют.
- stylename
-
Атрибут, задающий имя стиля компонента. Подробнее см. Темы приложения.
В теме
haloопределено несколько стандартных стилей для компонентов:-
huge- устанавливает размер поля 160% от его размера по умолчанию.
-
large- устанавливает размер поля 120% от его размера по умолчанию.
-
small- устанавливает размер поля 85% от его размера по умолчанию.
-
tiny- устанавливает размер поля 75% от его размера по умолчанию.
-
- tabCaptionsAsHtml
-
Определяет, разрешена ли HTML-разметка в заголовках вкладок. Если выбрано значение
true, заголовки отображаются в браузере как HTML, при этом ответственность за безопасность используемого HTML-кода несёт сам разработчик. Если выбрано значениеfalse, содержимое заголовка отображается как обычный текст.Возможные значения −
true,false. По умолчаниюfalse.
- tabIndex
-
Определяет, может ли компонент принимать фокус, и задаёт относительный порядок перехода фокуса между компонентами экрана.
Может принимать положительное или отрицательное целочисленное значение:
-
отрицательное значениеозначает, что компонент может принимать фокус, но будет пропущен при последовательном перемещении фокуса с клавиатуры; -
0означает, что компонент может принимать фокус, в том числе и при его перемещении с клавиатуры, но его относительный порядковый номер будет совпадать с его расположением на экране относительно других компонентов. -
положительное значениеозначает, что компонент может принимать фокус, в том числе и при его перемещении с клавиатуры. Относительный порядковый номер компонента будет совпадать со значением атрибута: фокус будет перемещаться от меньшего значенияtabIndexк большему. Если для нескольких компонентов установлено одинаковое значениеtabIndex, порядок их фокуса будет совпадать с их расположением на экране относительно друг друга.
-
- tabsVisible
-
Определяет, должна ли область выбора вкладок отображаться в UI.
Возможные значения −
true,false. По умолчаниюtrue.
- textSelectionEnabled
-
Определяет, разрешено ли выделение текста в ячейках таблицы.
Возможные значения атрибута −
true,false. По умолчаниюfalse.
- visible
-
Атрибут, устанавливающий видимость компонента. Возможные значения −
true,false.Если контейнер невидим, не видны и все его компоненты. По умолчанию все компоненты видимы.
- width
-
Атрибут, устанавливающий ширину компонента.
Значение может быть задано в пикселях или в процентах от ширины вышестоящего контейнера. Например:
100px,100%,50. Если единица измерения не указана, подразумевается ширина в пикселях. Простановка значения в%означает, что компонент по ширине займет соответствующую часть пространства, предоставляемого контейнером более высокого уровня.При выборе значения
AUTOили-1pxдля компонента устанавливается ширина по умолчанию, для контейнера ширина определяется по содержимому, то есть суммарной шириной вложенных компонентов.
3.5.3. Компоненты данных
Компоненты данных представляют собой невизуальные элементы экрана, которые обеспечивают загрузку данных со среднего слоя, связь данных с визуальными компонентами и отправку измененных экземпляров обратно на Middleware. В платформе имеются следующие типы компонентов данных:
-
Контейнеры - тонкий слой между сущностями и визуальными компонентами, связанными с данными (data-aware). Разные типы контейнеров могут хранить один экземпляр или коллекцию экземпляров сущностей.
-
Загрузчики загружают данные из Middleware в контейнеры.
-
DataContext отслеживает изменения сущностей и сохраняет измененные экземпляры на Middleware по запросу.
Обычно компоненты данных задаются в XML-дескрипторе экрана внутри элемента <data>. Их можно инжектировать в контроллер экрана так же, как и визуальные компоненты:
@Inject
private CollectionLoader<Customer> customersDl;
private String customerName;
@Subscribe
protected void onBeforeShow(BeforeShowEvent event) {
customersDl.setParameter("name", customerName)
customersDl.load();
}Компоненты данных конкретного экрана регистрируются в объекте ScreenData, который связан с контроллером экрана и доступен с помощью метода getScreenData() экрана. Этот объект полезен в прикладном коде, когда необходимо загрузить все данные экрана, к примеру:
@Subscribe
protected void onBeforeShow(BeforeShowEvent event) {
getScreenData().loadAll();
}|
Обратите внимание, что экраны загружают данные автоматически, если контроллер экрана снабжен аннотацией |
3.5.3.1. Контейнеры данных
Контейнеры данных образуют тонкий слой между визуальными компонентами и моделью данных приложения. Они могут хранить один экземпляр или коллекцию экземпляров сущностей, предоставлять информацию о мета-классе сущности, её представлении и выбранном экземпляре коллекции, а также регистрировать слушатели для различных событий экрана.

Рисунок 19. Интерфейсы контейнеров данных
3.5.3.1.1. InstanceContainer
Интерфейс InstanceContainer - корневой элемент иерархии контейнеров. Он предназначен для работы с единственным экземпляром сущности и содержит следующие методы:
-
setItem()- устанавливает экземпляр сущности для контейнера. -
getItem()- возвращает экземпляр, содержащийся в контейнере. Если контейнер пуст, метод выбрасывает исключение. Используйте этот метод, если вы уверены, что экземпляр был установлен, тогда вам не придётся проверять полученное значение экземпляра на null. -
getItemOrNull()- возвращает экземпляр, содержащийся в контейнере. Если контейнер пуст, метод возвращает null. Всегда проверяйте полученное значение на null перед его использованием. -
getEntityMetaClass()- возвращает мета-класс сущности, которая может храниться в этом контейнере. -
setView()- устанавливает представление, с которым сущности должны загружаться в этот контейнер. Обратите внимание, что контейнеры сами по себе не загружают данные, поэтому данный атрибут просто обозначает желаемое представление для загрузчика, соединенного с данным контейнером. -
getView()- возвращает представление, с которым сущности должны загружаться в этот контейнер.
- События InstanceContainer
-
Интерфейс
InstanceContainerпозволяет регистрировать слушатели для следующих событий.-
ItemPropertyChangeEventвызывается, если изменилось значение какого-либо атрибута сущности, находящейся в данный момент в контейнере. Пример подписки на событие для контейнера, объявленного в XML с идентификаторомcustomerDc:@Subscribe(id = "customerDc", target = Target.DATA_CONTAINER) private void onCustomerDcItemPropertyChange( InstanceContainer.ItemPropertyChangeEvent<Customer> event) { Customer customer = event.getItem(); String changedProperty = event.getProperty(); Object currentValue = event.getValue(); Object previousValue = event.getPrevValue(); // ... } -
ItemChangeEventвызывается при смене выбранного экземпляра (или null), установленного для данного контейнера. Пример подписки на событие для контейнера, объявленного в XML с идентификаторомcustomerDc:@Subscribe(id = "customerDc", target = Target.DATA_CONTAINER) private void onCustomerDcItemChange(InstanceContainer.ItemChangeEvent<Customer> event) { Customer customer = event.getItem(); Customer previouslySelectedCustomer = event.getPrevItem(); // ... }
-
3.5.3.1.2. CollectionContainer
Интерфейс CollectionContainer предназначен для работы с коллекцией экземпляров сущности. Это потомок InstanceContainer, в котором дополнительно определены следующие методы:
-
setItems()- устанавливает коллекцию экземпляров сущности для контейнера. -
getItems()- возвращает неизменяемый список сущностей, хранимых в контейнере. Используйте этот метод для обхода коллекции, получения потока данных или экземпляра сущности по его позиции в списке. Если требуется получить экземпляр сущности по его идентификатору, используйте методgetItem(entityId). Например:@Inject private CollectionContainer<Customer> customersDc; private Optional<Customer> findByName(String name) { return customersDc.getItems().stream() .filter(customer -> Objects.equals(customer.getName(), name)) .findFirst(); } -
getMutableItems()- возвращает изменяемый список сущностей, хранимых в контейнере. Все изменения списка, вызванные методамиadd(),addAll(),remove(),removeAll(),set(),clear(), публикуют событиеCollectionChangeEvent. Визуальные компоненты, подписанные на это событие, будут обновлены автоматически. Например:@Inject private CollectionContainer<Customer> customersDc; private void createCustomer() { Customer customer = metadata.create(Customer.class); customer.setName("Homer Simpson"); customersDc.getMutableItems().add(customer); }Используйте метод
getMutableItems()только тогда, когда необходимо изменить коллекцию. В остальных случаях предпочтительнее использоватьgetItems(). -
setItem()- устанавливает текущий экземпляр сущности для контейнера. Если передан не null, переданный экземпляр должен уже иметься в коллекции, чтобы быть выбранным. Метод публикует событиеItemChangeEvent.Нужно учитывать, что визуальные компоненты, такие как Table, не отслеживают событие
ItemChangeEvent, публикуемое контейнером. Поэтому, если вам нужно выбрать строку в таблице, используйте методsetSelected()вместо методаsetItem()контейнера, содержащего коллекцию. Текущий экземпляр контейнера также будет изменен, так как контейнер отслеживает события компонента. Пример:@Inject private CollectionContainer<Customer> customersDc; @Inject private GroupTable<Customer> customersTable; private void selectFirstRow() { customersTable.setSelected(customersDc.getItems().get(0)); } -
getItem()- переопределяет аналогичный метод родительского интерфейсаInstanceContainerи возвращает текущий экземпляр. Если текущий экземпляр не задан, метод выбрасывает исключение. Используйте этот метод, если вы уверены, что для контейнера задан текущий экземпляр, в этом случае не требуется проверка возвращаемого значения на null. -
getItemOrNull()- переопределяет аналогичный метод родительского интерфейсаInstanceContainerи возвращает текущий экземпляр. Если текущий экземпляр не задан, метод возвращает null. Всегда проверяйте полученное значение на null перед использованием. -
getItemIndex(entityId)- возвращает позицию сущности с данным идентификатором в списке, возвращаемом методамиgetItems()иgetMutableItems(). Этот метод принимаетObject, поэтому вы можете передать как id сущности, так и экземпляр сущности целиком. Реализация контейнера поддерживает отображение идентификаторов на индексы, поэтому метод работает быстро даже с большими списками. -
getItem(entityId)- возвращает экземпляр сущности из коллекции по её идентификатору. Это ускоренный метод, который сначала получает позицию экземпляра с помощьюgetItemIndex(entityId), а затем возвращает экземпляр из списка, используя методgetItems().get(index). Метод выбрасывает исключение, если экземпляр с переданным id отсутствует в коллекции. -
getItemOrNull(entityId)- то же, что иgetItem(entityId), но возвращает null, если экземпляр с данным id отсутствует в коллекции. Всегда проверяйте полученное значение на null перед использованием. -
containsItem(entityId)- возвращает true, если экземпляр с данным id есть в коллекции. Это упрощённый метод, в котором на самом деле используетсяgetItemIndex(entityId). -
replaceItem(entity)- если экземпляр с тем же id есть в коллекции, он заменяется переданным экземпляром. Если таковой экземпляр отсутствует, переданный экземпляр будет добавлен к списку. Метод публикует событиеCollectionChangeEventс типомSET_ITEMилиADD_ITEMS, в зависимости от операции. -
setSorter()- задаёт для контейнера переданный сортировщик. Стандартной реализацией интерфейсаSorterявляетсяCollectionContainerSorter. Платформа задаёт его автоматически, если для контейнера определён загрузчик, однако можно создать и собственную реализацию, если необходимо. -
getSorter()- возвращает текущий сортировщик данного контейнера.
- События CollectionContainer
-
В дополнение к событиям InstanceContainer, интерфейс
CollectionContainerпозволяет зарегистрировать слушатели для событияCollectionChangeEvent, которое вызывается при изменении коллекции сущностей, то есть при добавлении, удалении или замене элементов коллекции. Пример подписки на событие для контейнера, объявленного в XML с идентификаторомcustomersDc:@Subscribe(id = "customersDc", target = Target.DATA_CONTAINER) private void onCustomersDcCollectionChange( CollectionContainer.CollectionChangeEvent<Customer> event) { CollectionChangeType changeType = event.getChangeType(); (1) Collection<? extends Customer> changes = event.getChanges(); (2) // ... }1 - тип изменения: REFRESH, ADD_ITEMS, REMOVE_ITEMS, SET_ITEM. 2 - коллекция сущностей, которые были добавлены или удалены из контейнера. Если тип изменения - REFRESH, то фреймворк не может определить, какие элементы были добавлены или удалены, поэтому данная коллекция пустая.
3.5.3.1.3. Контейнеры свойств
Контейнеры InstancePropertyContainer и CollectionPropertyContainer предназначены для работы с единичными экземплярами и коллекциями экземпляров сущностей, которые являются атрибутами других сущностей. К примеру, если у сущности Order имеется атрибут orderLines, который представляет собой коллекцию экземпляров сущности OrderLine, для привязывания атрибута orderLines к таблице можно использовать контейнер CollectionPropertyContainer.
Контейнеры свойств (property containers) реализуют интерфейс Nested, в котором определены методы получения родительского контейнера и имя его дочернего атрибута, чтобы привязать к нему контейнер свойства. В примере с сущностями Order и OrderLine родительским контейнером будет тот, в котором хранится экземпляр Order.
InstancePropertyContainer работает напрямую с атрибутом родительской сущности. Это значит, что при вызове метода setItem() значение будет установлено для атрибута соответствующей родительской сущности, и будет вызван слушатель её события ItemPropertyChangeEvent.
CollectionPropertyContainer содержит копию родительской коллекции. Ниже описаны его методы:
-
getMutableItems()возвращает изменяемый список сущностей, и изменения списка отражаются на базовом свойстве. То есть, если вы удалите элемент из этого списка, базовый атрибут будет изменён, а для родительского контейнера будет вызван слушательItemPropertyChangeEvent. -
getDisconnectedItems()возвращает изменяемый список сущностей, но изменения списка не отражаются на базовом свойстве. То есть, если вы удалите элемент из этого списка, базовый атрибут останется неизменным. -
setItems()устанавливает коллекцию экземпляров сущностей для контейнера и его базового свойства. СлушательItemPropertyChangeEventвызывается для родительского контейнера. -
setDisconnectedItems()устанавливает коллекцию экземпляров сущностей для контейнера, но базовый исходный атрибут останется неизменным.
Методы getDisconnectedItems() и setDisconnectedItems() можно использовать для временного изменения отображения коллекции в UI, например, для фильтрации таблицы:
@Inject
private CollectionPropertyContainer<OrderLine> orderLinesDc;
private void filterByProduct(String product) {
List<OrderLine> filtered = getEditedEntity().getOrderLines().stream()
.filter(orderLine -> orderLine.getProduct().equals(product))
.collect(Collectors.toList());
orderLinesDc.setDisconnectedItems(filtered);
}
private void resetFilter() {
orderLinesDc.setDisconnectedItems(getEditedEntity().getOrderLines());
}3.5.3.1.4. Контейнеры KeyValue
Контейнеры KeyValueContainer и KeyValueCollectionContainer предназначены для работы с сущностями типа KeyValueEntity. Такая сущность может содержать произвольный набор атрибутов, задаваемый во время работы приложения.
Контейнеры KeyValue содержат следующие специфичные методы:
-
addProperty()- так как контейнер может содержать сущности с произвольным количеством атрибутов, с помощью данного метода необходимо указать, какие атрибуты ожидаются. Он принимает имя атрибута и его тип в виде Datatype или Java-класса. В последнем случае класс должен быть либо сущностью, либо классом, поддерживаемым одним из типов данных (datatypes). -
setIdName()- опциональный метод, позволяющий назначить один из атрибутов идентификатором сущности. Это означает, что экземплярыKeyValueEntity, содержащиеся в данном контейнере, будут иметь идентификаторы, получаемые из данного атрибута. В противном случае, экземплярыKeyValueEntityполучают случайно сгенерированные UUIDs. -
getEntityMetaClass()возвращает динамическую реализацию интерфейсаMetaClass, которая представляет текущую схему экземпляровKeyValueEntity, заданную вызовами методаaddProperty().
KeyValueContainer и KeyValueCollectionContainer могут быть заданы декларативно в XML-дескрипторе элементами keyValueInstance и keyValueCollection.
XML-описание контейнеров KeyValue должно содержать элемент properties, который задает атрибуты KeyValueEntity. Порядок вложенных элементов property должен соответствовать порядку колонок в результирующем наборе, возвращаемом запросом. Например, в следующем определении атрибут customer получит значение из колонки o.customer, а атрибут sum из колонки sum(o.amount):
<data readOnly="true">
<keyValueCollection id="salesDc">
<loader id="salesDl">
<query>
<![CDATA[select o.customer, sum(o.amount) from sales_Order o group by o.customer]]>
</query>
</loader>
<properties>
<property name="customer" class="com.company.sales.entity.Customer"/>
<property name="sum" datatype="decimal"/>
</properties>
</keyValueCollection>
</data>Контейнеры KeyValue предназначены только для чтения данных, так как сущность KeyValueEntity является неперсистентной и не может быть сохранена стандартным механизмом работы с БД.
3.5.3.2. Загрузчики данных
Загрузчики, или loaders, предназначены для загрузки данных со среднего слоя в контейнеры данных.
Интерфейсы загрузчиков немного отличаются в зависимости от типа контейнера, с которым они работают:
-
InstanceLoaderзагружает единственный экземпляр сущности в контейнерInstanceContainerпо идентификатору сущности или с помощью JPQL-запроса. -
CollectionLoaderзагружает коллекцию сущностей вCollectionContainerс помощью JPQL-запроса. Для этого загрузчика можно настроить пагинацию, сортировку и другие дополнительные параметры. -
KeyValueCollectionLoaderзагружает коллекцию экземпляровKeyValueEntityв контейнерKeyValueCollectionContainer. Кроме параметров, доступных дляCollectionLoader, вы также можете указать имя хранилища данных.
В XML-дескрипторах экрана загрузчики объявляются с помощью элемента <loader>, тип загрузчика будет определяться типом контейнера, в который он вложен.
Использование загрузчиков необязательно, так как вы можете загружать данные с помощью DataManager или собственного сервиса и самостоятельно добавлять их в контейнеры, однако загрузчики облегчают этот процесс для экранов, описываемых декларативно, особенно в случае компонента Filter. Обычно загрузчик коллекций получает запрос JPQL из XML-дескриптора экрана, а параметры запроса - из компонента Filter, затем создаёт объект LoadContext и вызывает DataManager для загрузки сущностей. В итоге, XML-дескриптор выглядит подобным образом:
<data>
<collection id="customersDc" class="com.company.sample.entity.Customer" view="_local">
<loader id="customersDl">
<query>
select e from sample_Customer e
</query>
</loader>
</collection>
</data>
<layout>
<filter id="filter" applyTo="customersTable" dataLoader="customersDl">
<properties include=".*"/>
</filter>
<!-- ... -->
</layout>Дополнительные параметры для XML-элемента loader можно указать с помощью атрибутов cacheable, softDeletion и т.д.
В экране редактора сущности XML-элемент loader обычно пуст, так как для загрузки единственного экземпляра сущности требуется её идентификатор, который устанавливается программно классом StandardEditor:
<data>
<instance id="customerDc" class="com.company.sample.entity.Customer" view="_local">
<loader/>
</instance>
</data>Загрузчики могут делегировать непосредственно загрузку данных отдельной функции, переданной с помощью метода setLoadDelegate() либо декларативно с помощью аннотации @Install в контроллере экрана, например:
@Inject
private DataManager dataManager;
@Install(to = "customersDl", target = Target.DATA_LOADER)
protected List<Customer> customersDlLoadDelegate(LoadContext<Customer> loadContext) {
return dataManager.loadList(loadContext);
}В данном примере метод customersDlLoadDelegate() используется загрузчиком customersDl для получения списка экземпляров сущности Customer. Метод принимает LoadContext, который будет создан загрузчиком на основе его параметров: запрос, фильтр (при наличии) и т.д. В этом примере загрузка осуществляется через интерфейс DataManager, который функционально повторяет стандартную реализацию загрузчика, однако вы можете использовать собственный сервис или же выполнить пост-обработку загруженных сущностей.
Загрузчики посылают события PreLoadEvent и PostLoadEvent, которые можно использовать для выполнения некоторой логики до или после загрузки:
@Subscribe(id = "customersDl", target = Target.DATA_LOADER)
private void onCustomersDlPreLoad(CollectionLoader.PreLoadEvent<Customer> event) {
// do something before loading
}
@Subscribe(id = "customersDl", target = Target.DATA_LOADER)
private void onCustomersDlPostLoad(CollectionLoader.PostLoadEvent<Customer> event) {
// do something after loading
}Загрузчики также можно создавать и настраивать программно, к примеру:
@Inject
private DataComponents dataComponents;
private void createCustomerLoader(CollectionContainer<Customer> container) {
CollectionLoader<Customer> loader = dataComponents.createCollectionLoader();
loader.setQuery("select e from sample_Customer e");
loader.setContainer(container);
loader.setDataContext(getScreenData().getDataContext());
}Если для загрузчика установлен DataContext (как всегда бывает в случае, если загрузчик задан в XML-дескрипторе), все загруженные сущности будут автоматически помещены в data context.
- Условия запросов
-
Иногда необходимо изменить запрос загрузчика данных во время выполнения программы для того, чтобы отфильтровать загружаемые данные на уровне БД. Простейший способ фильтрации в зависимости от параметров, вводимых пользователем - это подключить к загрузчику UI-компонент Filter.
Вместо использования универсального фильтра, или в дополнение к нему, для запроса в загрузчике можно задать набор условий. Условие представляет собой набор фрагментов запросов с параметрами. Эти фрагменты будут добавлены в результирующий запрос, только если все параметры, используемые во фрагментах, заданы для запроса. Условия обрабатываются на уровне хранилищ данных, поэтому они могут содержать фрагменты различных языков запросов, поддерживаемых хранилищами. Фреймворк предоставляет возможность описывать условия на языке JPQL.
Рассмотрим создание условий для фильтрации сущности
Customerпо двум ее атрибутам: строковомуnameи булевскомуstatus.Условия запроса для загрузчика могут быть заданы либо декларативно в XML-элементе
<condition>, либо программно методомsetCondition(). Ниже приведен пример описания условий в XML:<window xmlns="http://schemas.haulmont.com/cuba/screen/window.xsd" xmlns:c="http://schemas.haulmont.com/cuba/screen/jpql_condition.xsd" (1) caption="Customers browser" focusComponent="customersTable"> <data> <collection id="customersDc" class="com.company.demo.entity.Customer" view="_local"> <loader id="customersDl"> <query><![CDATA[select e from demo_Customer e]]> <condition> (2) <and> (3) <c:jpql> (4) <c:where>e.name like :name</c:where> </c:jpql> <c:jpql> <c:where>e.status = :status</c:where> </c:jpql> </and> </condition> </query> </loader> </collection> </data>1 - добавьте namespace для JPQL-условий 2 - добавьте элемент conditionвнутриquery3 - если необходимо задать более одного условия, добавьте элемент andилиor4 - задайте JPQL-условие с опциональным элементом joinи обязательнымwhereПредположим, что в экране имеется два UI-компонента для ввода параметров условий: текстовое поле
nameFilterFieldи флажокstatusFilterField. Для того, чтобы обновить данные, когда пользователь изменяет значения в этих компонентах, добавим следующие подписки на события в контроллере экрана:@Inject private CollectionLoader<Customer> customersDl; @Subscribe("nameFilterField") private void onNameFilterFieldValueChange(HasValue.ValueChangeEvent<String> event) { if (event.getValue() != null) { customersDl.setParameter("name", "(?i)%" + event.getValue() + "%"); (1) } else { customersDl.removeParameter("name"); } customersDl.load(); } @Subscribe("statusFilterField") private void onStatusFilterFieldValueChange(HasValue.ValueChangeEvent<Boolean> event) { if (event.getValue()) { customersDl.setParameter("status", true); } else { customersDl.removeParameter("status"); } customersDl.load(); }1 - обратите внимание, что здесь используется Поиск подстроки без учета регистра обеспечиваемый ORM Как было упомянуто выше, условие включается в запрос только когда его параметры установлены. Поэтому результирующий запрос, выполняемый БД, будет зависеть от того, что введено в UI-компонентах:
Значение введено только в nameFilterFieldselect e from demo_Customer e where e.name like :nameЗначение введено только в statusFilterFieldselect e from demo_Customer e where e.status = :statusЗначение введено и в nameFilterField и в statusFilterFieldselect e from demo_Customer e where (e.name like :name) and (e.status = :status)
3.5.3.3. DataContext
Интерфейс DataContext позволяет отслеживать изменения в сущностях, загружаемых на клиентский уровень. Отслеживаемые сущности помечаются как "грязные" при любом изменении их атрибутов, и DataContext сохраняет грязные экземпляры на Middleware при вызове его метода commit().
Внутри DataContext сущность с некоторым идентификатором будет представлена как единственный объект, вне зависимости от того, где и сколько раз она использована в графах других объектов.
Чтобы сущность отслеживалась, её необходимо поместить в DataContext с помощью метода merge(). Если контекст не содержит экземпляра сущности с таким же идентификатором, то контекст создает новый экземпляр и копирует в него состояние переданного. Если контекст уже содержит экземпляр сущности с таким же идентификатором, он копирует в имеющегося состояние переданного и возвращает. Данный механизм позволяет всегда иметь в контексте не более одного экземпляра сущности с конкретным идентификатором.
При помещении сущности в контекст методом merge весь граф объектов с корнем в данной сущности также помещается в контекст. То есть все связанные сущности, включая коллекции, становятся отслеживаемыми.
|
Главный принцип использования метода |
Пример помещения сущности в DataContext:
@Inject
private DataContext dataContext;
private void loadCustomer(Id<Customer, UUID> customerId) {
Customer customer = dataManager.load(customerId).one();
Customer trackedCustomer = dataContext.merge(customer);
customersDc.getMutableItems().add(trackedCustomer);
}Для одного экрана и всех его вложенных фрагментов может существовать только один экземпляр DataContext. Он создаётся автоматически, если в XML-дескрипторе экрана существует элемент <data>.
Элемент <data> может содержать атрибут readOnly="true", в этом случае будет использована специальная "no-op"-реализация, в которой не будут отслеживаться изменения в сущностях и, следовательно, улучшится быстродействие экрана. Экраны просмотра списков, автоматически создаваемые в Studio, по умолчанию имеют read-only data context, поэтому если вам нужно отслеживать изменения и сохранять грязные сущности в браузере, удалите XML-атрибут readOnly="true".
- Получение DataContext
-
DataContextэкрана можно получить в его контроллере используя инжекцию:@Inject private DataContext dataContext;Если имеется ссылка на некоторый экран, то получить его
DataContextможно с помощью классаUiControllerUtils:DataContext dataContext = UiControllerUtils.getScreenData(screenOrFrame).getDataContext();UI-компонента может получить
DataContextтекущего экрана следующим образом:DataContext dataContext = UiControllerUtils.getScreenData(getFrame().getFrameOwner()).getDataContext();
- Родительский DataContext
-
Сущности
DataContextмогут образовывать отношения предок-потомок. Если у экземпляраDataContextесть родительский контекст, он будет сохранять измененные сущности в своего предка вместо того, чтобы сразу отправлять их на Middleware. Эта особенности позволяет редактировать композитные сущности, где дочерние сущности должны сохраняться только вместе с родительской. Если атрибут сущности снабжён аннотацией @Composition, фреймворк автоматически установит родительский контекст для экрана редактирования этого атрибута, чтобы изменённая сущность атрибута могла быть сохранена только вместе с основной сущностью.Подобное поведение можно легко настроить вручную для любой сущности или экрана.
Если вы программно открываете экран редактирования сущности, который должен сохранять изменения в data context текущего экрана, используйте метод
withParentDataContext()builder’а:@Inject private ScreenBuilders screenBuilders; @Inject private DataContext dataContext; private void editFooWithCurrentDataContextAsParent() { FooEdit fooEdit = screenBuilders.editor(Foo.class, this) .withScreenClass(FooEdit.class) .withParentDataContext(dataContext) .build(); fooEdit.show(); }Если вы открываете простой экран с помощью бина
Screens, определите в нём сеттер, принимающий data context родительского экрана:public class FooScreen extends Screen { @Inject private DataContext dataContext; public void setParentDataContext(DataContext parentDataContext) { dataContext.setParent(parentDataContext); } }Этот метод вы сможете использовать при создании экрана:
@Inject private Screens screens; @Inject private DataContext dataContext; private void openFooScreenWithCurrentDataContextAsParent() { FooScreen fooScreen = screens.create(FooScreen.class); fooScreen.setParentDataContext(dataContext); fooScreen.show(); }Убедитесь, что для родительского data context не задан атрибут
readOnly="true". В противном случае при попытке использовать его как предка другого контекста будет выброшено исключение.
3.5.3.4. Использование компонентов данных
В данном разделе рассмотрены практические примеры работы с компонентами данных.
3.5.3.4.1. Декларативное создание компонентов данных
Самый простой способ создать компоненты данных - это определить их в XML-дескрипторе экрана внутри элемента <data>.
Рассмотрим для примера модель данных, содержащую сущности Customer, Order и OrderLine. Дескриптор экрана редактирования сущности Order может иметь следующее определение:
<data> (1)
<instance id="orderDc" class="com.company.sales.entity.Order"> (2)
<view extends="_local"> (3)
<property name="lines" view="_minimal">
<property name="product" view="_local"/>
<property name="quantity"/>
</property>
<property name="customer" view="_minimal"/>
</view>
<loader/> (4)
<collection id="linesDc" property="lines"/> (5)
</instance>
<collection id="customersDc" class="com.company.sales.entity.Customer" view="_minimal"> (6)
<loader> (7)
<query><![CDATA[select e from sales_Customer e]]></query>
</loader>
</collection>
</data>В этом случае будут созданы следующие компоненты данных:
| 1 | - Экземпляр DataContext. |
| 2 | - Контейнер InstanceContainer для сущности Order. |
| 3 | - Встроенное описание представления экземпляра сущности, находящегося в контейнере. Встроенные представления могут расширять общие (заданные в views.xml). |
| 4 | - InstanceLoader загружающий экземпляры сущности Order. |
| 5 | - Контейнер CollectionPropertyContainer для сущности OrderLines. Этот контейнер привязан к атрибуту-коллекции Order.lines. |
| 6 | - Контейнер CollectionContainer для сущности Customer. Атрибут view может указывать на общее представление. |
| 7 | - CollectionLoader, загружающий экземпляры сущности Customer по определённому запросу. |
Контейнеры данных используются в визуальных компонентах следующим образом:
<layout>
<dateField dataContainer="orderDc" property="date"/> (1)
<form id="form" dataContainer="orderDc"> (2)
<column>
<textField property="amount"/>
<lookupPickerField id="customerField" property="customer"
optionsContainer="customersDc"/> (3)
</column>
</form>
<table dataContainer="linesDc"> (4)
<columns>
<column id="product"/>
<column id="quantity"/>
</columns>
</table>| 1 | Отдельные поля имеют атрибуты dataContainer и property. |
| 2 | Элемент form распространяет свой dataContainer на все вложенные поля, поэтому они требуют только указания атрибута property. |
| 3 | Поля выбора имеют атрибут optionsContainer. |
| 4 | У таблиц есть только атрибут dataContainer. |
3.5.3.4.2. Программное создание компонентов данных
Компоненты данных можно создавать и использовать программно.
В следующем примере мы создадим экран редактирования с тем же данными и визуальными компонентами, которые мы определяли декларативно в предыдущем примере, на чистой Java без XML-дескриптора.
package com.company.sales.web.order;
import com.company.sales.entity.Customer;
import com.company.sales.entity.Order;
import com.company.sales.entity.OrderLine;
import com.haulmont.cuba.core.global.View;
import com.haulmont.cuba.gui.UiComponents;
import com.haulmont.cuba.gui.components.*;
import com.haulmont.cuba.gui.components.data.options.ContainerOptions;
import com.haulmont.cuba.gui.components.data.table.ContainerTableItems;
import com.haulmont.cuba.gui.components.data.value.ContainerValueSource;
import com.haulmont.cuba.gui.model.*;
import com.haulmont.cuba.gui.screen.PrimaryEditorScreen;
import com.haulmont.cuba.gui.screen.StandardEditor;
import com.haulmont.cuba.gui.screen.Subscribe;
import com.haulmont.cuba.gui.screen.UiController;
import javax.inject.Inject;
import java.sql.Date;
@UiController("sales_Order.edit")
public class OrderEdit extends StandardEditor<Order> {
@Inject
private DataComponents dataComponents; (1)
@Inject
private UiComponents uiComponents;
private InstanceContainer<Order> orderDc;
private CollectionPropertyContainer<OrderLine> linesDc;
private CollectionContainer<Customer> customersDc;
private InstanceLoader<Order> orderDl;
private CollectionLoader<Customer> customersDl;
@Subscribe
protected void onInit(InitEvent event) {
createDataComponents();
createUiComponents();
}
private void createDataComponents() {
DataContext dataContext = dataComponents.createDataContext();
getScreenData().setDataContext(dataContext); (2)
orderDc = dataComponents.createInstanceContainer(Order.class);
orderDl = dataComponents.createInstanceLoader();
orderDl.setContainer(orderDc); (3)
orderDl.setDataContext(dataContext); (4)
orderDl.setView("order-edit");
linesDc = dataComponents.createCollectionContainer(
OrderLine.class, orderDc, "lines"); (5)
customersDc = dataComponents.createCollectionContainer(Customer.class);
customersDl = dataComponents.createCollectionLoader();
customersDl.setContainer(customersDc);
customersDl.setDataContext(dataContext);
customersDl.setQuery("select e from sales_Customer e"); (6)
customersDl.setView(View.MINIMAL);
}
private void createUiComponents() {
DateField<Date> dateField = uiComponents.create(DateField.TYPE_DATE);
getWindow().add(dateField);
dateField.setValueSource(new ContainerValueSource<>(orderDc, "date")); (7)
Form form = uiComponents.create(Form.class);
getWindow().add(form);
LookupPickerField<Customer> customerField = uiComponents.create(LookupField.of(Customer.class));
form.add(customerField);
customerField.setValueSource(new ContainerValueSource<>(orderDc, "customer"));
customerField.setOptions(new ContainerOptions<>(customersDc)); (8)
TextField<Integer> amountField = uiComponents.create(TextField.TYPE_INTEGER);
amountField.setValueSource(new ContainerValueSource<>(orderDc, "amount"));
Table<OrderLine> table = uiComponents.create(Table.of(OrderLine.class));
getWindow().add(table);
getWindow().expand(table);
table.setItems(new ContainerTableItems<>(linesDc)); (9)
Button okButton = uiComponents.create(Button.class);
okButton.setAction(getWindow().getActionNN(WINDOW_COMMIT_AND_CLOSE));
getWindow().add(okButton);
Button cancelButton = uiComponents.create(Button.class);
cancelButton.setAction(getWindow().getActionNN(WINDOW_CLOSE));
getWindow().add(cancelButton);
}
@Override
protected InstanceContainer<Order> getEditedEntityContainer() { (10)
return orderDc;
}
@Subscribe
protected void onBeforeShow(BeforeShowEvent event) { (11)
orderDl.load();
customersDl.load();
}
}| 1 | DataComponents - это фабрика для создания компонентов данных. |
| 2 | Регистрируем в экране экземпляр DataContext, чтобы обеспечить работу стандартного действия commit. |
| 3 | Загрузчик orderDl загружает данные в контейнер orderDc. |
| 4 | Загрузчик orderDl помещает загруженные сущности в data context для отслеживания изменений. |
| 5 | linesDc создаётся как контейнер свойства. |
| 6 | Определяем запрос для загрузчика customersDl. |
| 7 | ContainerValueSource используется для связи одиночных полей с контейнерами данных. |
| 8 | ContainerOptions предоставляет список опций для полей выбора. |
| 9 | ContainerTableItems используется для связи таблиц с контейнерами. |
| 10 | Переопределяем getEditedEntityContainer(), чтобы указать контейнер, вместо аннотации @EditedEntityContainer. |
| 11 | Загружаем данные перед отображением экрана. Идентификатор редактируемой сущности будет автоматически передан в загрузчик orderDl. |
3.5.3.4.3. Зависимости между компонентами данных
Иногда требуется загружать и отображать данные, которые зависят от других данных в том же экране. К примеру, на скриншоте ниже таблица слева отображает список заказов, а таблица справа - список строк выбранного заказа. Список справа обновляется каждый раз, когда меняется выбранный заказ в таблице слева.

Рисунок 20. Зависимые таблицы
В нашем примере сущность Order содержит атрибут orderLines, который является коллекцией с отношением one-to-many. Самый простой способ реализации экрана - загружать список заказов с представлением, содержащим атрибут orderLines, и использовать property container для работы со списком зависимых строк. Затем мы связываем левую таблицу с родительским контейнером, а правую - с контейнером свойства.
Однако этот подход может иметь последствия для производительности, ведь мы загружаем все строки для всех заказов из левой таблицы, несмотря на то, что в один момент времени отображаются строки только для одного выбранного заказа. При этом чем длиннее список заказов, тем больше ненужных данных будет загружено, и вероятность того, что пользователь захочет просмотреть все строки, очень мала. Поэтому мы рекомендуем использовать контейнеры свойств и расширенные представления только тогда, когда нужно загрузить единственный экземпляр родительской сущности: например, в экране редактирования одного заказа.
Кроме того, родительская сущность может не иметь прямого атрибута, указывающего на зависимую сущности. В этом случае подход с использованием контейнера свойств совсем не подходит.
Наилучшей практикой организации отношений между данными в экране является использование запросов с параметрами. Зависимый загрузчик содержит запрос с параметром, который связывает данные с родительским контейнером, и когда меняется текущий экземпляр в родительском контейнере, мы передаём его в качестве параметра и вызываем зависимый загрузчик.
Рассмотрим пример экрана, в котором есть две зависимых пары контейнер/загрузчик и привязанные к ним таблицы для отображения данных.
<window xmlns="http://schemas.haulmont.com/cuba/screen/window.xsd">
<data>
<collection id="ordersDc" (1)
class="com.company.sales.entity.Order" view="order-with-customer">
<loader id="ordersDl">
<query>select e from sales_Order e></query>
</loader>
</collection>
<collection id="orderLinesDc" (2)
class="com.company.sales.entity.OrderLine" view="_local">
<loader id="orderLinesDl">
<query>select e from sales_OrderLine e where e.order = :order</query>
</loader>
</collection>
</data>
<layout>
<hbox id="mainBox" width="100%" height="100%" spacing="true">
<table id="ordersTable" width="100%" height="100%"
dataContainer="ordersDc"> (3)
<columns>
<column id="customer"/>
<column id="date"/>
<column id="amount"/>
</columns>
<rows/>
</table>
<table id="orderLinesTable" width="100%" height="100%"
dataContainer="orderLinesDc"> (4)
<columns>
<column id="product"/>
<column id="quantity"/>
</columns>
<rows/>
</table>
</hbox>
</layout>
</window>| 1 | Родительский контейнер и загрузчик. |
| 2 | Дочерний контейнер и загрузчик. |
| 3 | Основная таблица. |
| 4 | Зависимая таблица. |
package com.company.sales.web.order;
import com.company.sales.entity.Order;
import com.company.sales.entity.OrderLine;
import com.haulmont.cuba.gui.model.CollectionLoader;
import com.haulmont.cuba.gui.model.InstanceContainer;
import com.haulmont.cuba.gui.screen.*;
import javax.inject.Inject;
@UiController("order-list")
@UiDescriptor("order-list.xml")
@LookupComponent("ordersTable")
public class OrderList extends StandardLookup<Order> { (1)
@Inject
private CollectionLoader<Order> ordersDl;
@Inject
private CollectionLoader<OrderLine> orderLinesDl;
@Subscribe
protected void onBeforeShow(BeforeShowEvent event) {
ordersDl.load(); (2)
}
@Subscribe(id = "ordersDc", target = Target.DATA_CONTAINER)
protected void onOrdersDcItemChange(InstanceContainer.ItemChangeEvent<Order> event) {
orderLinesDl.setParameter("order", event.getItem()); (3)
orderLinesDl.load();
}
}| 1 | Класс контроллера экрана не содержит аннотации @LoadDataBeforeShow, поэтому загрузчики не будут вызваны автоматически. |
| 2 | Родительский загрузчик вызывается обработчиком BeforeShowEvent. |
| 3 | В обработчике родительского контейнера ItemChangeEvent передаём параметр в зависимый загрузчик и вызываем его. |
|
Фасет DataLoadCoordinator позволяет устанавливать связи между компонентами данных декларативно без написания кода на Java. |
3.5.3.4.4. Использование параметров экрана в загрузчиках
Часто бывает необходимо загружать данные в экране в зависимости от параметров, переданных в этот экран. В данном разделе приведен пример экрана, принимающего параметр и использующего его для фильтрации загружаемых данных.
Предположим, имеются две сущности: Country и City. У сущности City есть атрибут country, который является ссылкой на Country. Экран со списком городов принимает экземпляр страны и отображает города только этой страны.
Рассмотрим XML-дескриптор экрана со списком городов. Его загрузчик содержит параметр:
<collection id="citiesDc"
class="com.company.demo.entity.City"
view="_local">
<loader id="citiesDl">
<query>
<![CDATA[select e from demo_City e where e.country = :country]]>
</query>
</loader>
</collection>Контроллер экрана городов содержит публичный метод-setter для параметра и использует этот параметр в обработчике BeforeShowEvent. Обратите внимание, что на классе экрана нет аннотации @LoadDataBeforeShow, так как загрузка вызывается явно:
@UiController("demo_City.browse")
@UiDescriptor("city-browse.xml")
@LookupComponent("citiesTable")
public class CityBrowse extends StandardLookup<City> {
@Inject
private CollectionLoader<City> citiesDl;
private Country country;
public void setCountry(Country country) {
this.country = country;
}
@Subscribe
private void onBeforeShow(BeforeShowEvent event) {
if (country == null)
throw new IllegalStateException("country parameter is null");
citiesDl.setParameter("country", country);
citiesDl.load();
}
}Экран городов можно вызвать из другого экрана, передавая параметр, как показано ниже:
@Inject
private ScreenBuilders screenBuilders;
private void showCitiesOfCountry(Country country) {
CityBrowse cityBrowse = screenBuilders.screen(this)
.withScreenClass(CityBrowse.class)
.build();
cityBrowse.setCountry(country);
cityBrowse.show();
}3.5.3.4.5. Специализированная сортировка
Сортировка таблиц по атрибутам сущности в UI производится объектом типа CollectionContainerSorter, который устанавливается для CollectionContainer. Стандартная реализация сортирует данные в памяти, если загруженный список умещается на одну страницу, или посылает запрос с соответствующим "order by" в базу данных. Выражение "order by" формируется бином JpqlSortExpressionProvider среднего слоя.
Некоторые атрибуты могут потребовать специальной реализации сортировки. Ниже рассматривается простой пример: предположим, в сущности Foo есть атрибут number типа String, но на самом деле атрибут хранит только числовые значения. Поэтому необходимо иметь порядок сортировки для чисел: 1, 2, 3, 10, 11. Стандартный механизм сортировки в данном случае выдаст порядок 1, 10, 11, 2, 3.
Сначала создайте наследника класса CollectionContainerSorter в модуле web для сортировки в памяти:
package com.company.demo.web;
import com.company.demo.entity.Foo;
import com.haulmont.chile.core.model.MetaClass;
import com.haulmont.chile.core.model.MetaPropertyPath;
import com.haulmont.cuba.core.entity.Entity;
import com.haulmont.cuba.core.global.Sort;
import com.haulmont.cuba.gui.model.BaseCollectionLoader;
import com.haulmont.cuba.gui.model.CollectionContainer;
import com.haulmont.cuba.gui.model.impl.CollectionContainerSorter;
import com.haulmont.cuba.gui.model.impl.EntityValuesComparator;
import javax.annotation.Nullable;
import java.util.Comparator;
import java.util.Objects;
public class CustomCollectionContainerSorter extends CollectionContainerSorter {
public CustomCollectionContainerSorter(CollectionContainer container,
@Nullable BaseCollectionLoader loader) {
super(container, loader);
}
@Override
protected Comparator<? extends Entity> createComparator(Sort sort, MetaClass metaClass) {
MetaPropertyPath metaPropertyPath = Objects.requireNonNull(
metaClass.getPropertyPath(sort.getOrders().get(0).getProperty()));
if (metaPropertyPath.getMetaClass().getJavaClass().equals(Foo.class)
&& "number".equals(metaPropertyPath.toPathString())) {
boolean isAsc = sort.getOrders().get(0).getDirection() == Sort.Direction.ASC;
return Comparator.comparing(
(Foo e) -> e.getNumber() == null ? null : Integer.valueOf(e.getNumber()),
EntityValuesComparator.asc(isAsc));
}
return super.createComparator(sort, metaClass);
}
}Если специализированная сортировка нужна только в некоторых экранах, CustomCollectionContainerSorter можно инстанциировать прямо в экране:
public class FooBrowse extends StandardLookup<Foo> {
@Inject
private CollectionContainer<Foo> fooDc;
@Inject
private CollectionLoader<Foo> fooDl;
@Subscribe
private void onInit(InitEvent event) {
CustomCollectionContainerSorter sorter = new CustomCollectionContainerSorter(fooDc, fooDl);
fooDc.setSorter(sorter);
}
}Если же специализированная сортировка должна являться глобальной, то создайте собственную фабрику, которая будет инстанциировать сортировщик для всей системы:
package com.company.demo.web;
import com.haulmont.cuba.gui.model.*;
import javax.annotation.Nullable;
public class CustomSorterFactory extends SorterFactory {
@Override
public Sorter createCollectionContainerSorter(CollectionContainer container,
@Nullable BaseCollectionLoader loader) {
return new CustomCollectionContainerSorter(container, loader);
}
}Зарегистрируйте фабрику в web-spring.xml для того, чтобы переопределить стандартную фабрику:
<bean id="cuba_SorterFactory" class="com.company.demo.web.CustomSorterFactory"/>Теперь создайте собственную реализацию JpqlSortExpressionProvider в модуле core для сортировки на уровне БД:
package com.company.demo.core;
import com.company.demo.entity.Foo;
import com.haulmont.chile.core.model.MetaPropertyPath;
import com.haulmont.cuba.core.app.DefaultJpqlSortExpressionProvider;
public class CustomSortExpressionProvider extends DefaultJpqlSortExpressionProvider {
@Override
public String getDatatypeSortExpression(MetaPropertyPath metaPropertyPath, boolean sortDirectionAsc) {
if (metaPropertyPath.getMetaClass().getJavaClass().equals(Foo.class)
&& "number".equals(metaPropertyPath.toPathString())) {
return String.format("CAST({E}.%s BIGINT)", metaPropertyPath.toString());
}
return String.format("{E}.%s", metaPropertyPath.toString());
}
}Зарегистрируйте класс в spring.xml для того, чтобы переопределить стандартную реализацию поставщика выражений:
<bean id="cuba_JpqlSortExpressionProvider" class="com.company.demo.core.CustomSortExpressionProvider"/>3.5.4. Фасеты
Фасеты - это элементы экрана, которые не добавляются в компоновку экрана, в отличие от визуальных компонентов. Вместо этого они добавляют дополнительное поведение к экрану или одному из его компонентов.
Экран может содержать фасеты в элементе facets XML-дескриптора. Фреймворк предоставляет следующие фасеты:
В приложении или аддоне можно создать собственные фасеты. Для этого необходимо выполнить следующие шаги:
-
Создайте интерфейс, расширяющий
com.haulmont.cuba.gui.components.Facet. -
Создайте класс реализации на основе
com.haulmont.cuba.web.gui.WebAbstractFacet. -
Создайте Spring бин реализующий интерфейс
com.haulmont.cuba.gui.xml.FacetProvider, параметризованный типом компонента. -
Создайте XSD для использования компонента в XML-дескрипторах экранов.
-
Опционально, пометьте интерфейс фасета и его методы специальными аннотациями, чтобы добавить поддержку вашего фасета в CUBA Studio.
Классы ClipboardTrigger, WebClipboardTrigger и ClipboardTriggerFacetProvider фреймворка могут служить хорошим примером создания фасета.
3.5.4.1. Timer
Таймер − это фасет, позволяющий выполнять некоторый код контроллера экрана через определенные промежутки времени. Срабатывание таймера происходит в потоке обработки событий пользовательского интерфейса, что позволяет обновлять экран без каких-либо ограничений. Таймер прекращает работу при закрытии экрана, для которого он был создан.
Основной способ создания таймеров - декларативно в XML-дескрипторе экрана в элементе facets.
Для описания таймера используется элемент timer.
-
Атрибут
delayявляется обязательным атрибутом, в нем задается интервал срабатывания таймера в миллисекундах. -
autostart- необязательный атрибут, при установке которого вtrueтаймер стартует сразу после открытия экрана. По умолчаниюfalse, что означает что для старта таймера необходимо вызвать его методstart(). -
repeating− необязательный атрибут, включает многократное срабатывание таймера. Если значение атрибута равноtrue, то таймер выполняется циклически, через равные промежутки времени, заданные в атрибутеdelay. В противном случае таймер выполняется один раз черезdelayмиллисекунд после старта таймера.
Для выполнения некоторого кода по таймеру, создайте подписку на событие TimerActionEvent в контроллере экрана.
Пример объявления таймера и подписки на него в контроллере:
<window xmlns="http://schemas.haulmont.com/cuba/screen/window.xsd" ...>
<facets>
<timer id="myTimer" delay="3000" autostart="true" repeating="true"/>
</facets>@Inject
private Notifications notifications;
@Subscribe("myTimer")
private void onTimer(Timer.TimerActionEvent event) {
notifications.create(Notifications.NotificationType.TRAY)
.withCaption("on timer")
.show();
}Таймер можно инжектировать в поле контроллера, либо получить методом Window.getFacet(). Управлять активностью таймера можно с помощью его методов start() и stop(). Для уже активного таймера вызов start() игнорируется. После остановки таймера методом stop() его можно снова запустить методом start().
Пример определения таймера в XML дескрипторе и использования листенеров в контроллере:
<window xmlns="http://schemas.haulmont.com/cuba/screen/window.xsd" ...>
<facets>
<timer id="helloTimer" delay="5000"/>
<facets>@Inject
private Timer helloTimer;
@Inject
private Notifications notifications;
@Subscribe("helloTimer")
protected void onHelloTimerTimerAction(Timer.TimerActionEvent event) { (1)
notifications.create()
.withCaption("Hello")
.show();
}
@Subscribe("helloTimer")
protected void onHelloTimerTimerStop(Timer.TimerStopEvent event) { (2)
notifications.create()
.withCaption("Timer is stopped")
.show();
}
@Subscribe
protected void onInit(InitEvent event) { (3)
helloTimer.start();
}| 1 | обработчик выполнения таймера |
| 2 | остановка таймера |
| 3 | запуск таймера при инициализации экрана |
Таймер можно также создавать в коде контроллера, при этом необходимо явно добавить таймер к экрану с помощью метода addFacet(), к примеру:
@Inject
private Notifications notifications;
@Inject
private Facets facets;
@Subscribe
protected void onInit(InitEvent event) {
Timer helloTimer = facets.create(Timer.class);
getWindow().addFacet(helloTimer); (1)
helloTimer.setId("helloTimer"); (2)
helloTimer.setDelay(5000);
helloTimer.setRepeating(true);
helloTimer.addTimerActionListener(e -> { (3)
notifications.create()
.withCaption("Hello")
.show();
});
helloTimer.addTimerStopListener(e -> { (4)
notifications.create()
.withCaption("Timer is stopped")
.show();
});
helloTimer.start(); (5)
}| 1 | добавление таймера к экрану |
| 2 | установка параметров таймера |
| 3 | добавление обработчика выполнения |
| 4 | добавление слушателя остановки таймера |
| 5 | запуск таймера |
3.5.4.2. ClipboardTrigger
ClipboardTrigger это фасет, позволяющий копировать текст из поля ввода в буфер обмена. Он задается в элементе facets XML-дескриптора экрана и имеет следующие атрибуты:
-
input- идентификатор текстового поля. Ожидается подклассTextInputField:TextField,TextAreaи т.д. -
button- идентификатор кнопки (компонентButton), по нажатию на которую производится копирование.
Например:
<window xmlns="http://schemas.haulmont.com/cuba/screen/window.xsd" ...>
<facets>
<clipboardTrigger id="clipper" button="clipBtn" input="textArea"/>
</facets>
<layout expand="textArea" spacing="true">
<textArea id="textArea" width="100%"/>
<button id="clipBtn" caption="Clip text"/>
</layout>
</window>@Inject
private Notifications notifications;
@Subscribe("clipBtn")
private void onClipBtnClick(Button.ClickEvent event) {
notifications.create().withCaption("Copied to clipboard").show();
}3.5.4.3. DataLoadCoordinator
Фасет DataLoadCoordinator предназначен для декларативного связывания загрузчиков данных с контейнерами данных, визуальными компонентами и событиями экрана. Он может работать в двух режимах:
-
В автоматическом режиме компонент полагается на имена параметров, имеющие специальные префиксы. Префикс указывает, какой компонент является источником значения параметра и событий его изменения. Если у загрузчика нет параметров в тексте запроса (при этом параметры могут быть в условиях), то он срабатывает по событию BeforeShowEvent в
Screenили по событию AttachEvent вScreenFragment.По умолчанию используется префикс
container_для контейнеров данных иcomponent_для визуальных компонентов. -
В ручном режиме связи указываются в XML-разметке компонента или через его API.
Возможен также полуавтоматический режим, при котором некоторые связи задаются явно, а остальные конфигурируются автоматически.
При использовании DataLoadCoordinator в экране, аннотация @LoadDataBeforeShow на контроллере экрана не оказывает эффекта: загрузка данных полностью управляется компонентом DataLoadCoordinator и кастомными обработчиками событий, если они определены.
Ниже приведены примеры использования компонента.
-
Автоматическая конфигурация. Атрибут
autoустановлен вtrue.<window xmlns="http://schemas.haulmont.com/cuba/screen/window.xsd" xmlns:c="http://schemas.haulmont.com/cuba/screen/jpql_condition.xsd" ...> <data readOnly="true"> <collection id="ownersDc" class="com.company.demo.entity.Owner" view="owner-view"> <loader id="ownersDl"> <query> <![CDATA[select e from demo_Owner e]]> (1) <condition> <and> <c:jpql> <c:where>e.category = :component_categoryFilterField</c:where> (2) </c:jpql> <c:jpql> <c:where>e.name like :component_nameFilterField</c:where> (3) </c:jpql> </and> </condition> </query> </loader> </collection> <collection id="petsDc" class="com.company.demo.entity.Pet"> <loader id="petsDl"> <query><![CDATA[select e from demo_Pet e where e.owner = :container_ownersDc]]></query> (4) </loader> </collection> </data> <facets> <dataLoadCoordinator auto="true"/> </facets> <layout> <pickerField id="categoryFilterField" metaClass="demo_OwnerCategory"/> <textField id="nameFilterField"/>1 - в запросе нет параметров, поэтому загрузчик ownersDlсработает на событие экранаBeforeShowEvent.2 - загрузчик ownersDlтакже сработает на изменение значения компонентаcategoryFilterField.3 - загрузчик ownersDlтакже сработает на изменение значения компонентаnameFilterField. Так как условие использует операторlike, значение будет автоматически завернуто в '(?i)% %' для того, чтобы обеспечить нечувствительный к регистру поиск.4 - загрузчик petsDlсработает при смене выбранной сущности в контейнереownersDc. -
Ручная конфигурация. Атрибут
autoотсутствует или установлен вfalse, вложенные элементы определяют, когда должны сработать загрузчики.<window xmlns="http://schemas.haulmont.com/cuba/screen/window.xsd" xmlns:c="http://schemas.haulmont.com/cuba/screen/jpql_condition.xsd" ...> <data readOnly="true"> <collection id="ownersDc" class="com.company.demo.entity.Owner" view="owner-view"> <loader id="ownersDl"> <query> <![CDATA[select e from demo_Owner e]]> <condition> <and> <c:jpql> <c:where>e.category = :category</c:where> </c:jpql> <c:jpql> <c:where>e.name like :name</c:where> </c:jpql> </and> </condition> </query> </loader> </collection> <collection id="petsDc" class="com.company.demo.entity.Pet"> <loader id="petsDl"> <query><![CDATA[select e from demo_Pet e where e.owner = :owner]]></query> </loader> </collection> </data> <facets> <dataLoadCoordinator> <refresh loader="ownersDl" onScreenEvent="Init"/> (1) <refresh loader="ownersDl" param="category" onComponentValueChanged="categoryFilterField"/> (2) <refresh loader="ownersDl" param="name" onComponentValueChanged="nameFilterField" likeClause="CASE_INSENSITIVE"/> (3) <refresh loader="petsDl" param="owner" onContainerItemChanged="ownersDc"/> (4) </dataLoadCoordinator> </facets> <layout> <pickerField id="categoryFilterField" metaClass="demo_OwnerCategory"/> <textField id="nameFilterField"/>1 - загрузчик ownersDlсработает на событие экранаInitEvent.2 - загрузчик ownersDlтакже сработает на изменение значения компонентаcategoryFilterField.3 - загрузчик ownersDlтакже сработает на изменение значения компонентаnameFilterField. АтрибутlikeClauseприводит к заворачиванию значения в '(?i)% %' для того, чтобы обеспечить нечувствительный к регистру поиск.4 - загрузчик petsDlсработает при смене выбранной сущности в контейнереownersDc. -
Полуавтоматическая конфигурация. Когда атрибут
autoустановлен вtrueи объявлены некоторые вручную сконфигурированные связи, компонент автоматически сконфигурирует все загрузчики, для которых не указано ни одной связи вручную.<window xmlns="http://schemas.haulmont.com/cuba/screen/window.xsd" ...> <data readOnly="true"> <collection id="ownersDc" class="com.company.demo.entity.Owner" view="owner-view"> <loader id="ownersDl"> <query> <![CDATA[select e from demo_Owner e]]> </query> </loader> </collection> <collection id="petsDc" class="com.company.demo.entity.Pet"> <loader id="petsDl"> <query><![CDATA[select e from demo_Pet e where e.owner = :container_ownersDc]]></query> (1) </loader> </collection> </data> <facets> <dataLoadCoordinator auto="true"> <refresh loader="ownersDl" onScreenEvent="Init"/> (2) </dataLoadCoordinator> </facets>1 - загрузчик petsDlсконфигурирован автоматически и сработает при смене выбранной сущности в контейнереownersDc.2 - загрузчик ownersDlсконфигурирован вручную и сработает на событие экранаInitEvent.
3.5.4.4. NotificationFacet
NotificationFacet – это фасет, который обеспечивает возможность предварительной настройки уведомлений. Декларативное описание уведомления заменяет существующий метод Notifications.create(). NotificationFacet определяется в элементе facets XML-дескриптора экрана.
XML-имя компонента: notification.
Пример использования:
<facets>
<notification id="notification"
caption="msg://notificationFacet"
description="msg://notificationDescription"
type="TRAY"/>
</facets>Экран, настроенный с помощью NotificationFacet, может быть показан явно с помощью метода show():
@Inject
protected NotificationFacet notification;
public void showNotification() {
notification.show();
}notification имеет следующие атрибуты:
-
атрибут
onActionсодержит идентификатор действия, после выполнения которого будет показано уведомление.<actions> <action id="notificationAction"/> </actions> <facets> <notification id="notification" caption="msg://notificationFacet" onAction="notificationAction" type="TRAY"/> </facets>
-
атрибут
onButtonсодержит идентификатор кнопки, после нажатия на которую будет показано уведомление.<facets> <notification id="notification" caption="msg://notificationFacet" onButton="notificationBtn" type="TRAY"/> </facets> <layout> <button id="notificationBtn" caption="Show notification"/> </layout>
-
Если атрибут contentMode установлен в
true, вы можете сделать доступной HTML санитизацию для содержимого уведомления, используя атрибутhtmlSanitizerEnabled.<facets> <notification id="notificationFacetOn" caption="NotificationFacet with Sanitizer" contentMode="HTML" htmlSanitizerEnabled="true" onButton="showNotificationFacetOnBtn" type="TRAY"/> <notification id="notificationFacetOff" caption="NotificationFacet without Sanitizer" contentMode="HTML" htmlSanitizerEnabled="false" onButton="showNotificationFacetOffBtn" type="TRAY"/> </facets>Значение атрибута
htmlSanitizerEnabledимеет приоритет над значением глобального свойства cuba.web.htmlSanitizerEnabled.
- Атрибуты notification
-
caption - contentMode - delay - description - htmlSanitizerEnabled - id - onAction - onButton - position - stylename - type
3.5.4.5. MessageDialogFacet
MessageDialogFacet – это фасет, который обеспечивает возможность предварительной настройки Message Dialog. Декларативное описание диалога с сообщением заменяет существующий метод Dialogs.createMessageDialog(). MessageDialogFacet определяется в элементе facets XML-дескриптора экрана.
XML-имя компонента: messageDialog.
Пример использования:
<facets>
<messageDialog id="messageDialog"
caption="msg://msgDialogFacet"
message="msg://msgDialogDemo"
modal="true"
closeOnClickOutside="true"/>
</facets>Экран, настроенный с помощью MessageDialogFacet, может быть показан явно с помощью метода show():
@Inject
protected MessageDialogFacet messageDialog;
@Subscribe("showDialog")
public void onShowDialogClick(Button.ClickEvent event) {
messageDialog.show();
}Кроме того, фасет может быть подписан на действие (см. атрибут onAction) или кнопку (см. атрибут onButton) по идентификатору:
<actions>
<action id="dialogAction"/>
</actions>
<facets>
<messageDialog id="messageDialog"
caption="msg://msgDialogFacet"
message="msg://msgDialogDemo"
onAction="dialogAction"/>
</facets>- Атрибуты messageDialog
-
caption - closeOnClickOutside - contentMode - height - htmlSanitizerEnabled - id - maximized - message - modal - onAction - onButton - stylename - width
3.5.4.6. OptionDialogFacet
OptionDialogFacet – это фасет, который обеспечивает возможность предварительной настройки Option Dialog. Декларативное описание диалога выбора заменяет существующий метод Dialogs.createOptionDialog(). OptionDialogFacet определяется в элементе facets XML-дескриптора экрана.
XML-имя компонента: optionDialog.
Пример использования:
<facets>
<optionDialog id="optionDialog"
caption="msg://optionDialogCaption"
message="msg://optionDialogMsg"
onAction="dialogAction">
<actions>
<action id="ok"
caption="msg://optDialogOk"
icon="CHECK"
primary="true"/>
<action id="cancel"
caption="msg://optDialogCancel"
icon="BAN"/>
</actions>
</optionDialog>
</facets>Экран, настроенный с помощью OptionDialogFacet, может быть показан явно с помощью метода show():
@Inject
protected OptionDialogFacet optionDialog;
@Subscribe("showDialog")
public void onShowDialogClick(Button.ClickEvent event) {
optionDialog.show();
}Кроме того, фасет может быть подписан на действие (см. атрибут onAction) или кнопку (см. атрибут onButton) по идентификатору.
Диалог выбора содержит элемент actions, который представляет собой список диалоговых действий.
Чтобы реализовать кастомную логику для диалогового действия, нужно создать соответствующий метод-обработчик в контроллере:
@Inject
protected OptionDialogFacet optionDialog;
@Inject
protected Notifications notifications;
@Install(to = "optionDialog.ok", subject = "actionHandler") (1)
protected void onDialogOkAction(DialogActionPerformedEvent<OptionDialogFacet> event) {
String actionId = event.getDialogAction().getId();
notifications.create(Notifications.NotificationType.TRAY)
.withCaption("Dialog action performed: " + actionId)
.show();
}
@Install(to = "optionDialog.cancel", subject = "actionHandler") (2)
protected void onDialogCancelAction(DialogActionPerformedEvent<OptionDialogFacet> event) {
String actionId = event.getDialogAction().getId();
notifications.create(Notifications.NotificationType.TRAY)
.withCaption("Dialog action performed: " + actionId)
.show();
}| 1 | - обработчик, вызываемый при нажатии на кнопку OK в диалоге выбора. |
| 2 | - обработчик, вызываемый при нажатии на кнопку Cancel в диалоге выбора. |
3.5.4.7. InputDialogFacet
InputDialogFacet – это фасет, который обеспечивает возможность предварительной настройки Input Dialog. Декларативное описание диалога ввода заменяет существующий метод Dialogs.createInputDialog(). InputDialogFacet определяется в элементе facets XML-дескриптора экрана.
XML-имя компонента: inputDialog.
Пример использования:
<facets>
<inputDialog id="inputDialogFacet"
caption="msg://inputDialog"
onAction="dialogAction">
<parameters>
<booleanParameter id="boolParam"
caption="msg://boolParam"
defaultValue="true"
required="true"/>
<intParameter id="intParam"
caption="msg://intParam"
required="true"/>
<entityParameter id="userParam"
caption="msg://userParam"
entityClass="com.haulmont.cuba.security.entity.User"
required="true"/>
</parameters>
</inputDialog>
</facets>Экран, настроенный с помощью InputDialogFacet, может быть показан явно с помощью метода show():
@Inject
protected InputDialogFacet inputDialog;
@Subscribe("showDialog")
public void onShowDialogClick(Button.ClickEvent event) {
inputDialog.show();
}Кроме того, фасет может быть подписан на действие (см. атрибут onAction) или кнопку (см. атрибут onButton) по идентификатору.
В дополнение к атрибутам, описанным для OptionDialogFacet, диалог ввода имеет атрибут defaultActions, который определяет набор предопределенных действий для использования в диалоговом окне. Стандартные значения:
-
OK -
OK_CANCEL -
YES_NO -
YES_NO_CANCEL
Значение по умолчанию – OK_CANCEL.
элементы inputDialog:
-
элемент
actionsпредставляет собой список диалоговых действий.
-
элемент
parametersможет содержать следующие параметры:-
stringParameter -
booleanParameter -
intParameter -
doubleParameter -
longParameter -
bigDecimalParameter -
dateParameter -
timeParameter -
dateTimeParameter -
entityParameter -
enumParameter
-
Чтобы реализовать кастомную логику для диалогового действия, нужно создать соответствующий метод-обработчик в контроллере.
Для обработки результатов, полученных в диалоге ввода, нужно создать соответствующий делегат:
@Install(to = "inputDialogFacet", subject = "dialogResultHandler")
public void handleDialogResults(InputDialog.InputDialogResult dialogResult) {
String closeActionType = dialogResult.getCloseActionType().name();
String values = dialogResult.getValues().entrySet()
.stream()
.map(entry -> String.format("%s = %s", entry.getKey(), entry.getValue()))
.collect(Collectors.joining(", "));
notifications.create(Notifications.NotificationType.HUMANIZED)
.withCaption("InputDialog Result Handler")
.withDescription("Close Action: " + closeActionType +
". Values: " + values)
.show();
}3.5.4.8. ScreenFacet
ScreenFacet – это фасет, который обеспечивает возможность предварительной настройки открытия экранов и передачи параметров в экраны. Диалоговое описание экрана заменяет существующий метод ScreenBuilders.screen(). ScreenFacet определяется в элементе facets XML-дескриптора экрана.
XML-имя компонента: screen.
Пример использования:
<facets>
<screen id="testScreen"
screenId="sample_TestScreen"
onButton="openTestScreen">
<properties>
<property name="num" value="42"/>
</properties>
</screen>
</facets>Экран, настроенный с помощью ScreenFacet, может быть показан явно с помощью метода show():
@Inject
protected ScreenFacet testScreen;
@Subscribe("showDialog")
public void onShowDialogClick(Button.ClickEvent event) {
testScreen.show();
}Кроме того, фасет может быть подписан на действие (см. атрибут onAction) или кнопку (см. атрибут onButton) по идентификатору.
screen имеет следующие атрибуты:
-
screenId– задаёт идентификатор открываемого экрана.
-
screenClass– задаёт Java-класс контроллера открываемого экрана.
-
openMode– режим открытия экрана, задаваемый значением перечисленияOpenMode:NEW_TAB,DIALOG,NEW_WINDOW,ROOT,THIS_TAB. Значением по умолчанию являетсяNEW_TAB.
ScreenFacet может содержать элемент properties, представляющий собой список параметров, которые будут переданы в открываемый экран через публичные setter-методы контроллера. См. также Передача параметров в экраны.
3.5.4.9. EditorScreenFacet
EditorScreenFacet – это фасет, который обеспечивает возможность предварительной настройки экрана редактирования. Декларативное описание экрана редактирования заменяет существующий метод ScreenBuilders.editor(). EditorScreenFacet определяется в элементе facets XML-дескриптора экрана.
XML-имя компонента: editorScreen.
Пример использования:
<facets>
<editorScreen id="userEditor"
openMode="DIALOG"
editMode="CREATE"
entityClass="com.haulmont.cuba.security.entity.User"
onAction="action"/>
</facets>Экран, настроенный с помощью EditorScreenFacet, может быть показан явно с помощью метода show():
@Inject
protected EditorScreenFacet userEditor;
@Subscribe("showDialog")
public void onShowDialogClick(Button.ClickEvent event) {
userEditor.show();
}Кроме того, фасет может быть подписан на действие (см. атрибут onAction) или кнопку (см. атрибут onButton) по идентификатору.
editorScreen имеет следующие атрибуты:
-
addFirst– определяет, будет ли новый элемент добавлен в начало или в конец коллекции. Влияет только на самостоятельные контейнеры; для вложенных контейнеров новые элементы всегда добавляются в конец.
-
container– устанавливает CollectionContainer. Контейнер обновляется после коммита экрана. Если контейнер является вложенным, фреймворк автоматически инициализирует ссылку на родительскую сущность и настраивает контекст данных для редактирования композиций.
-
editMode– задает режим редактирования экрана, задаваемый значением перечисленияEditMode:CREATE(для создания нового экземпляра сущности) илиEDIT(для редактирования существующего).
-
entityClass– полное имя класса сущности.
-
field– задает идентификатор компонента PickerField. Если это поле задано, фреймворк устанавливает закоммиченную сущность в качестве значения поля после успешного коммита экрана редактирования.
-
listComponent– задает идентификатор компонента списка. Компонент используется для получения контейнера, если он не установлен. Обычно компонент списка представляет собой таблицу или DataGrid, отображающую список сущностей.
- Атрибуты editorScreen
-
addFirst - container - editMode - entityClass - field - id - listComponent onAction - onButton - openMode - screenClass - screenId
- Элементы editorScreen
3.5.4.10. LookupScreenFacet
LookupScreenFacet – это фасет, который обеспечивает возможность предварительной настройки экрана выбора сущности. Декларативное описание экрана выбора сущности заменяет существующий метод ScreenBuilders.lookup(). LookupScreenFacet определяется в элементе facets XML-дескриптора экрана.
XML-имя компонента: lookupScreen.
Пример использования:
<lookupScreen id="userLookup"
openMode="DIALOG"
entityClass="com.haulmont.cuba.security.entity.User"
listComponent="usersTable"
field="pickerField"
container="userDc"
onAction="lookupAction"/>Экран, настроенный с помощью LookupScreenFacet, может быть показан явно с помощью метода show():
@Inject
protected LookupScreenFacet userLookup;
@Subscribe("showDialog")
public void onShowDialogClick(Button.ClickEvent event) {
userLookup.show();
}Кроме того, фасет может быть подписан на действие (см. атрибут onAction) или кнопку (см. атрибут onButton) по идентификатору.
- Атрибуты lookupScreen
-
container - entityClass - field - id - listComponent - onAction - onButton - openMode - screenClass - screenId
- Элементы lookupScreen
3.5.5. Действия. Интерфейс Action
Action − интерфейс, абстрагирующий действие (другими словами, некоторую функцию) от визуального компонента. Он особенно полезен в случаях, когда одно и то же действие может быть вызвано из разных визуальных компонентов. Данный интерфейс задает некоторые общие свойства действий, такие как заголовок, горячая клавиша, признаки доступности и видимости, и другими.
Действия могут быть объявлены декларативно, либо программно путем наследования от класса BaseAction. Кроме того, существует набор предоставляемых фреймворком стандартных действий, применимых для работы с таблицами и компонентами выбора.
Визуальные компоненты, связанные с действием, могут быть двух типов:
-
Визуальный компонент, содержащий одно действие, реализует интерфейс
Component.ActionOwner. Это Button и LinkButton.Связь компонента с действием осуществляется путем вызова метода
ActionOwner.setAction()компонента. В этот момент компонент заменяет свои свойства на соответствующие свойства действия (подробнее см. описание компонентов). -
Визуальный компонент, содержащий несколько действий, реализует интерфейс
Component.ActionsHolder. ЭтоWindow,Frame, Table и ее наследники, Tree, PopupButton, PickerField, LookupPickerField.Действия добавляются компоненту вызовом метода
ActionsHolder.addAction(). Реализация этого метода в компоненте проверяет, нет ли уже в нем действия с таким же идентификатором. Если есть, то имеющееся действие будет заменено на новое переданное. Поэтому можно, например, декларировать стандартное действие в дескрипторе экрана, а затем в контроллере создать новое с переопределенными методами и добавить компоненту.
3.5.5.1. Декларативное создание действий
В XML-дескрипторе экрана для любого компонента, реализующего интерфейс Component.ActionsHolder, в том числе для всего экрана или фрейма, может быть задан набор действий. Делается это в элементе actions, который содержит вложенные элементы action.
Элемент action может иметь следующие атрибуты:
-
id− идентификатор, должен быть уникален в рамках данного компонентаActionsHolder. -
type- задает тип действия. Если данный атрибут установлен, фреймворк находит класс, имеющий аннотацию@ActionTypeс таким же значением, и использует его для инстанциирования действия. Если тип не задан, фреймворк создает экземпляр класса BaseAction. Раздел Стандартные действия описывает типы действий, предоставляемые фреймворком, раздел Собственные типы действий объясняет, как создавать собственные типы действий. -
caption- название действия. -
description- описание действия. -
enable- признак доступности действия (true/false). -
icon- значок действия.
-
primary- атрибут, определяющий подсветку кнопок, обеспечивающих выполнение этого действия (true/false). Если выбраноtrue, для подсветки будет использован особый стиль.В теме
hoverподсветка доступна по умолчанию; для её активации в темеhaloустановите значениеtrueдля переменной стиля$cuba-highlight-primary-action.Следующие действия являются
primaryпо умолчанию, если не установлено иное:createу табличных компонентов иlookupSelectActionв экранах выбора.
-
shortcut- комбинация клавиш для вызова.Комбинации можно жёстко задавать в XML-дескрипторе. Возможные модификаторы -
ALT,CTRL,SHIFT- отделяются символом "-". Например:<action id="create" shortcut="ALT-N"/>Для большей гибкости можно использовать готовые псевдонимы комбинаций из списка ниже, к примеру:
<action id="edit" shortcut="${TABLE_EDIT_SHORTCUT}"/>-
TABLE_EDIT_SHORTCUT -
COMMIT_SHORTCUT -
CLOSE_SHORTCUT -
FILTER_APPLY_SHORTCUT -
FILTER_SELECT_SHORTCUT -
NEXT_TAB_SHORTCUT -
PREVIOUS_TAB_SHORTCUT -
PICKER_LOOKUP_SHORTCUT -
PICKER_OPEN_SHORTCUT -
PICKER_CLEAR_SHORTCUT
Кроме того, есть возможность задавать комбинацию с помощью полного имени интерфейса
Configи имени метода, возвращающего нужную комбинацию:<action id="remove" shortcut="${com.haulmont.cuba.client.ClientConfig#getTableRemoveShortcut}"/> -
-
visible- признак видимости действия (true/false).
Рассмотрим примеры декларативного объявления действий.
-
Объявление действий на уровне экрана:
<window> <actions> <action id="sayHello" caption="msg://sayHello" shortcut="ALT-T"/> </actions> <layout> <button action="sayHello"/> </layout> </window>// controller @Inject private Notifications notifications; @Subscribe("sayHello") protected void onSayHelloActionPerformed(Action.ActionPerformedEvent event) { notifications.create() .withCaption("Hello") .withType(Notifications.NotificationType.HUMANIZED) .show(); }Здесь объявляется действие с идентификатором
sayHelloи названием из пакета сообщений. С этим действием связывается кнопка, заголовок которой будет установлен в название действия. Контроллер экрана подписан на событие действияActionPerformedEvent, так что методonSayHelloActionPerformed()будет вызван при нажатии на кнопку, а также при нажатии комбинации клавиш ALT-T.
|
Обратите внимание, что действия, объявленные на уровне экрана, не обновляют своё состояние. Это значит, если действие имеет установленный |
-
Объявление действий для PopupButton:
<popupButton id="sayBtn" caption="Say"> <actions> <action id="hello" caption="Say Hello"/> <action id="goodbye" caption="Say Goodbye"/> </actions> </popupButton>// controller @Inject private Notifications notifications; private void showNotification(String message) { notifications.create() .withCaption(message) .withType(NotificationType.HUMANIZED) .show(); } @Subscribe("sayBtn.hello") private void onSayBtnHelloActionPerformed(Action.ActionPerformedEvent event) { notifications.create() .withCaption("Hello") .show(); } @Subscribe("sayBtn.goodbye") private void onSayBtnGoodbyeActionPerformed(Action.ActionPerformedEvent event) { notifications.create() .withCaption("Hello") .show(); } -
Объявление действий для Table:
<groupTable id="customersTable" width="100%" dataContainer="customersDc"> <actions> <action id="create" type="create"/> <action id="edit" type="edit"/> <action id="remove" type="remove"/> <action id="copy" caption="Copy" icon="COPY" trackSelection="true"/> </actions> <columns> <!-- --> </columns> <rowsCount/> <buttonsPanel alwaysVisible="true"> <!-- --> <button action="customersTable.copy"/> </buttonsPanel> </groupTable>// controller @Subscribe("customersTable.copy") protected void onCustomersTableCopyActionPerformed(Action.ActionPerformedEvent event) { // ... }Здесь помимо стандартных действий таблицы
create,editиremoveобъявлено действиеcopy. Для этого действия указан также атрибутtrackSelection="true", в результате чего действие и связанная с ним кнопка становятся недоступными, если в таблице не выбрана ни одна строка. Это удобно, если действие предназначено для выполнения над текущей выбранной строкой таблицы. -
Объявление действий для PickerField:
<pickerField id="userPickerField" dataContainer="customerDc" property="user"> <actions> <action id="lookup" type="picker_lookup"/> <action id="show" description="Show user" icon="USER"/> </actions> </pickerField>// controller @Subscribe("userPickerField.show") protected void onUserPickerFieldShowActionPerformed(Action.ActionPerformedEvent event) { // }В данном примере для компонента
PickerFieldобъявлено стандартное действиеpicker_lookupи дополнительное действиеshow. Так как в кнопкахPickerField, отображающих действия, используются значки, а не надписи, атрибутcaptionявно установлен в пустую строку, иначе названием действия и заголовком кнопки стал бы идентификатор действия. Атрибутdescriptionпозволяет отображать всплывающую подсказку при наведении мыши на кнопку действия.
Ссылки на любые декларативно объявленные действия можно получить в контроллере экрана либо непосредственно путем инжекции, либо из компонентов, реализующих интерфейс Component.ActionsHolder. Это может понадобиться для программной установки свойств действия. Например:
@Named("customersTable.copy")
private Action customersTableCopy;
@Inject
private PickerField<User> userPickerField;
@Subscribe
protected void onBeforeShow(BeforeShowEvent event) {
customersTableCopy.setEnabled(false);
userPickerField.getActionNN("show").setEnabled(false);
}3.5.5.2. Стандартные действия
Стандартные действия, предлагаемые платформой, предназначены для решения типовых задач, таких как вызов экрана редактирования для сущности, выбранной в таблице. Стандартные действия объявляются в XML-дескрипторе экрана с указанием их типа в атрибуте type.
Существует два вида стандартных действий:
-
Действия с коллекцией сущностей, отображаемой в таблице или дереве. Это CreateAction, EditAction, ViewAction, RemoveAction, AddAction, ExcludeAction, RefreshAction, ExcelAction, BulkEditAction.
Когда действие с коллекцией добавлено в таблицу или дерево, оно может быть вызвано из контекстного меню данного компонента или с помощью предустановленной горячей клавиши. Обычно для вызова действия используется также кнопка, добавленная в панель кнопок.
<groupTable id="customersTable"> <actions> <action id="create" type="create"/> ... <buttonsPanel> <button id="createBtn" action="customersTable.create"/> ...
-
Действия поля выбора экземпляра сущности. Это LookupAction, OpenAction, OpenCompositionAction, ClearAction.
Когда такое действие добавляется в компонент, оно автоматически отображается кнопкой внутри поля.
<pickerField id="customerField"> <actions> <action id="lookup" type="picker_lookup"/> ...
Каждое стандартное действие реализуется классом, аннотированным @ActionType("<some_type>"). Класс задает свойства и поведение действия по умолчанию.
Для переопределения общих свойств действий можно задать XML-атрибуты элемента action, такие как caption, icon, shortcut и др., например:
<action id="create" type="create" caption="Create customer" icon="USER_PLUS"/>Начиная с CUBA 7.2 стандартные действия имеют дополнительные свойства, которые можно устанавливать в XML, или используя сеттеры в Java. В XML дополнительные свойства конфигурируются во вложенном элементе <properties>, где каждый элемент <property> соответствует сеттеру, имеющемуся в классе данного действия:
<action id="create" type="create">
<properties>
<property name="openMode" value="DIALOG"/>
<property name="screenClass" value="com.company.demo.web.CustomerEdit"/>
</properties>
</action>То же самое можно сделать в контроллере на Java:
@Named("customersTable.create")
private CreateAction createAction;
@Subscribe
public void onInit(InitEvent event) {
createAction.setOpenMode(OpenMode.DIALOG);
createAction.setScreenClass(CustomerEdit.class);
}Если сеттер принимает функциональный интерфейс, то в контроллере можно создать соответствующий метод-обработчик. Например, CreateAction имеет метод setAfterCommitHandler(Consumer), который используется для установки обработчика, вызываемого после коммита созданной сущности. Тогда обработчик можно задать следующим образом:
@Install(to = "customersTable.create", subject = "afterCommitHandler")
protected void customersTableCreateAfterCommitHandler(Customer entity) {
System.out.println("Created " + entity);
}Во всех действиях имеется обработчик enabledRule, который позволяет управлять состоянием "enabled" действия в зависимости от некоторых условий. В примере ниже данный обработчик запрещает RemoveAction для некоторых сущностей:
@Inject
private GroupTable<Customer> customersTable;
@Install(to = "customersTable.remove", subject = "enabledRule")
private boolean customersTableRemoveEnabledRule() {
Set<Customer> customers = customersTable.getSelected();
return canBeRemoved(customers);
}В следующих разделах приведено детальное описание действий, предоставляемых фреймворком. В разделе Собственные типы действий объясняется, как создать собственные типы действий или переопределить существующие.
3.5.5.2.1. AddAction
AddAction - действие с коллекцией, предназначенное для добавления существующих экземпляров сущности из экрана выбора в контейнер данных. Например, оно используется для заполнения many-to-many коллекций.
Действие реализовано классом com.haulmont.cuba.gui.actions.list.AddAction и объявляется в XML с помощью атрибута type="add". Общие свойства действий можно конфигурировать с помощью атрибутов элемента action, подробнее см. раздел Декларативное создание действий. Ниже рассматриваются параметры, специфичные для класса AddAction.
Следующие параметры можно установить и в XML и в Java:
-
openMode- режим открытия экрана выбора, задаваемый значением перечисленияOpenMode:NEW_TAB,DIALOG, и т.д. По умолчанию AddAction открывает экран выбора в режимеTHIS_TAB. -
screenId- строковый идентификатор экрана выбора. По умолчанию AddAction использует экран, аннотированный@PrimaryLookupScreen, или имеющий идентификатор вида<entity_name>.lookupили<entity_name>.browse, напримерdemo_Customer.browse. -
screenClass- класс Java экрана выбора. Данный параметр имеет более высокий приоритет, чемscreenId.
Например, если необходимо открыть определенный экран выбора в режиме диалога, действие можно сконфигурировать в XML следующим образом:
<action id="add" type="add">
<properties>
<property name="openMode" value="DIALOG"/>
<property name="screenClass" value="com.company.sales.web.customer.CustomerBrowse"/>
</properties>
</action>В качестве альтернативы, действие можно инжектировать в контроллер экрана и сконфигурировать, используя сеттеры:
@Named("customersTable.add")
private AddAction customersTableAdd;
@Subscribe
public void onInit(InitEvent event) {
customersTableAdd.setOpenMode(OpenMode.DIALOG);
customersTableAdd.setScreenClass(CustomerBrowse.class);
}Далее рассматриваются параметры, которые можно сконфигурировать только программно в Java. Для генерации корректно аннотированных методов для этих параметров используйте закладку Handlers окна инструментов Component Inspector в Studio.
-
screenOptionsSupplier- обработчик, возвращающий объектScreenOptionsдля передачи в открываемый экран выбора. Например:@Install(to = "customersTable.add", subject = "screenOptionsSupplier") private ScreenOptions customersTableAddScreenOptionsSupplier() { return new MapScreenOptions(ParamsMap.of("someParameter", 10)); }Возвращаемый объект
ScreenOptionsбудет доступен вInitEventоткрываемого экрана. -
screenConfigurer- обработчик, принимающий экран выбора для его конфигурирования перед открытием. Например:@Install(to = "customersTable.add", subject = "screenConfigurer") private void customersTableAddScreenConfigurer(Screen screen) { ((CustomerBrowse) screen).setSomeParameter(10); }Конфигуратор экрана вступает в действие, когда экран уже инициализирован, но еще не показан, то есть после
InitEventиAfterInitEvent, и доBeforeShowEvent. -
selectValidator- обработчик, вызываемый когда пользователь нажимает Select в экране выбора. Он принимает объект, содержащий выбранные сущности. Данный обработчик можно использовать для проверки выбора по каким-либо критериям. Обработчик должен вернутьtrueдля того, чтобы процесс был продолжен и экран выбора закрылся. Например:@Install(to = "customersTable.add", subject = "selectValidator") private boolean customersTableAddSelectValidator(LookupScreen.ValidationContext<Customer> validationContext) { boolean valid = checkCustomers(validationContext.getSelectedItems()); if (!valid) { notifications.create().withCaption("Selection is not valid").show(); } return valid; } -
transformation- обработчик, вызываемый после того, как сущности выбраны и провалидированы в экране выбора. Он принимает коллекцию выбранных сущностей и может быть использован для того, чтобы преобразовать содержимое коллекции перед добавлением сущностей в контейнер данных. Например:@Install(to = "customersTable.add", subject = "transformation") private Collection<Customer> customersTableAddTransformation(Collection<Customer> collection) { return reloadCustomers(collection); } -
afterCloseHandler- обработчик, вызываемый после закрытия экрана выбора. ПринимаетAfterCloseEvent. Например:@Install(to = "customersTable.add", subject = "afterCloseHandler") private void customersTableAddAfterCloseHandler(AfterCloseEvent event) { if (event.closedWith(StandardOutcome.SELECT)) { System.out.println("Selected"); } }
Для того, чтобы произвести какие-либо проверки, или взаимодействовать с пользователем перед выполнением действия, необходимо подписаться на событие ActionPerformedEvent действия и в нужный момент вызвать метод execute(). Действие будет вызвано со всеми параметрами, которые были для него заданы. В примере ниже перед выполнением действия отображается диалог подтверждения:
@Named("customersTable.add")
private AddAction customersTableAdd;
@Subscribe("customersTable.add")
public void onCustomersTableAdd(Action.ActionPerformedEvent event) {
dialogs.createOptionDialog()
.withCaption("Please confirm")
.withMessage("Do you really want to add a customer?")
.withActions(
new DialogAction(DialogAction.Type.YES)
.withHandler(e -> customersTableAdd.execute()), // execute action
new DialogAction(DialogAction.Type.NO)
)
.show();
}Можно также подписаться на ActionPerformedEvent, и вместо вызова метода execute() действия, использовать для открытия экрана выбора ScreenBuilders API напрямую. По сути, в этом случае все специфичные параметры действия игнорируются, и действуют только общие параметры: caption, icon, и т.д. Например:
@Inject
private ScreenBuilders screenBuilders;
@Inject
private Table<Customer> customersTable;
@Subscribe("customersTable.add")
public void onCustomersTableAdd(Action.ActionPerformedEvent event) {
screenBuilders.lookup(customersTable)
.withOpenMode(OpenMode.DIALOG)
.withScreenClass(CustomerBrowse.class)
.withSelectValidator(customerValidationContext -> {
boolean valid = checkCustomers(customerValidationContext.getSelectedItems());
if (!valid) {
notifications.create().withCaption("Selection is not valid").show();
}
return valid;
})
.build()
.show();
}3.5.5.2.2. BulkEditAction
BulkEditAction - действие с коллекцией, предназначенное для изменения значений атрибутов сразу нескольких выбранных экземпляров сущностей. Оно открывает специальный экран, в котором пользователь может ввести желаемые значения атрибутов. После этого, действие обновляет выбранные сущности в базе данных и в контейнере данных UI-компонента.
Действие реализовано классом com.haulmont.cuba.gui.actions.list.BulkEditAction и объявляется в XML с помощью атрибута type="bulkEdit". Общие свойства действий можно конфигурировать с помощью атрибутов элемента action, подробнее см. раздел Декларативное создание действий. Ниже рассматриваются параметры, специфичные для класса BulkEditAction.
-
openMode- режим открытия экрана задания значений атрибутов, задаваемый значением перечисленияOpenMode:NEW_TAB,DIALOG, и т.д. По умолчанию, экран открывается в режимеDIALOG. -
columnsMode- количество колонок в экране, задаваемое значением перечисленияColumnsMode. По умолчаниюTWO_COLUMNS. -
exclude- регулярное выражение для исключения некоторых атрибутов сущности из экрана. -
includeProperties- список атрибутов сущности, которые должны быть показаны в экране. Данный список имеет более высокий приоритет чем выражениеexclude. -
loadDynamicAttributes- отображать ли динамические атрибуты в экране. По умолчанию true. -
useConfirmDialog- отображать ли диалог подтверждения перед применением изменений. По умолчанию true.
Например:
<action id="bulkEdit" type="bulkEdit">
<properties>
<property name="openMode" value="THIS_TAB"/>
<property name="includeProperties" value="name,email"/>
<property name="columnsMode" value="ONE_COLUMN"/>
</properties>
</action>В качестве альтернативы, действие можно инжектировать в контроллер экрана и сконфигурировать, используя сеттеры:
@Named("customersTable.bulkEdit")
private BulkEditAction customersTableBulkEdit;
@Subscribe
public void onInit(InitEvent event) {
customersTableBulkEdit.setOpenMode(OpenMode.THIS_TAB);
customersTableBulkEdit.setIncludeProperties(Arrays.asList("name", "email"));
customersTableBulkEdit.setColumnsMode(ColumnsMode.ONE_COLUMN);
}Далее рассматриваются параметры, которые можно сконфигурировать только программно в Java. Для генерации корректно аннотированных методов для этих параметров используйте закладку Handlers окна инструментов Component Inspector в Studio.
-
fieldSorter- обработчик, принимающий список объектовMetaProperty, соответствующих атрибутам сущности, и возвращающий мэп этих объектов на желаемую позицию в экране. Например:@Install(to = "customersTable.bulkEdit", subject = "fieldSorter") private Map<MetaProperty, Integer> customersTableBulkEditFieldSorter(List<MetaProperty> properties) { Map<MetaProperty, Integer> result = new HashMap<>(); for (MetaProperty property : properties) { switch (property.getName()) { case "name": result.put(property, 0); break; case "email": result.put(property, 1); break; default: } } return result; }
Для того, чтобы произвести какие-либо проверки, или взаимодействовать с пользователем перед выполнением действия, необходимо подписаться на событие ActionPerformedEvent действия и в нужный момент вызвать метод execute(). Действие будет вызвано со всеми параметрами, которые были для него заданы. В примере ниже перед выполнением действия отображается кастомный диалог подтверждения:
@Named("customersTable.bulkEdit")
private BulkEditAction customersTableBulkEdit;
@Subscribe("customersTable.bulkEdit")
public void onCustomersTableBulkEdit(Action.ActionPerformedEvent event) {
dialogs.createOptionDialog()
.withCaption("Please confirm")
.withMessage("Are you sure you want to edit the selected entities?")
.withActions(
new DialogAction(DialogAction.Type.YES)
.withHandler(e -> customersTableBulkEdit.execute()), // execute action
new DialogAction(DialogAction.Type.NO)
)
.show();
}Можно также подписаться на ActionPerformedEvent, и вместо вызова метода execute() действия, использовать BulkEditors API напрямую. По сути, в этом случае все специфичные параметры действия игнорируются, и действуют только общие параметры: caption, icon, и т.д. Например:
@Inject
private BulkEditors bulkEditors;
@Inject
private GroupTable<Customer> customersTable;
@Subscribe("customersTable.bulkEdit")
public void onCustomersTableBulkEdit(Action.ActionPerformedEvent event) {
bulkEditors.builder(metadata.getClassNN(Customer.class), customersTable.getSelected(), this)
.withListComponent(customersTable)
.withColumnsMode(ColumnsMode.ONE_COLUMN)
.withIncludeProperties(Arrays.asList("name", "email"))
.create()
.show();
}Внешний вид экрана задания значений атрибутов можно настроить с помощью переменных SCSS с префиксом $c-bulk-editor-*. Эти переменные можно изменить в визуальном редакторе после расширения темы или создания новой темы.
3.5.5.2.3. ClearAction
ClearAction - действие поля выбора сущности, предназначенное для очистки значения поля. Если поле связано с атрибутом, являющимся one-to-one composition, то экземпляр сущности, отображаемый в поле, будет удален при коммите DataContext (если экран является редактором сущности, это происходит при нажатии пользователем на OK).
Действие реализовано классом com.haulmont.cuba.gui.actions.picker.ClearAction и объявляется в XML с помощью атрибута type="picker_clear". Общие свойства действий можно конфигурировать с помощью атрибутов элемента action, подробнее см. раздел Декларативное создание действий.
Для того, чтобы произвести какие-либо проверки, или взаимодействовать с пользователем перед выполнением действия, необходимо подписаться на событие ActionPerformedEvent действия и в нужный момент вызвать метод execute(). В примере ниже перед выполнением действия отображается диалог подтверждения:
@Named("customerField.clear")
private ClearAction customerFieldClear;
@Subscribe("customerField.clear")
public void onCustomerFieldClear(Action.ActionPerformedEvent event) {
dialogs.createOptionDialog()
.withCaption("Please confirm")
.withMessage("Do you really want to clear the field?")
.withActions(
new DialogAction(DialogAction.Type.YES)
.withHandler(e -> customerFieldClear.execute()), // execute action
new DialogAction(DialogAction.Type.NO)
)
.show();
}3.5.5.2.4. CreateAction
CreateAction - действие с коллекцией, предназначенное для создания новых экземпляров сущности. Оно создает новый экземпляр и открывает экран редактирования сущности с этим экземпляром. После того, как экземпляр сохранен в базу данных экраном редактирования, действие добавляет его в контейнер данных UI-компонента.
Действие реализовано классом com.haulmont.cuba.gui.actions.list.CreateAction и объявляется в XML с помощью атрибута type="create". Общие свойства действий можно конфигурировать с помощью атрибутов элемента action, подробнее см. раздел Декларативное создание действий. Ниже рассматриваются параметры, специфичные для класса CreateAction.
Следующие параметры можно установить и в XML и в Java:
-
openMode- режим открытия экрана редактирования, задаваемый значением перечисленияOpenMode:NEW_TAB,DIALOG, и т.д. По умолчанию экран открывается в режимеTHIS_TAB. -
screenId- строковый идентификатор экрана редактирования. По умолчанию используется экран, аннотированный@PrimaryEditorScreen, или имеющий идентификатор вида<entity_name>.edit, напримерdemo_Customer.edit. -
screenClass- класс Java экрана редактирования. Данный параметр имеет более высокий приоритет, чемscreenId.
Например, если необходимо открыть определенный экран редактирования в режиме диалога, действие можно сконфигурировать в XML следующим образом:
<action id="create" type="create">
<properties>
<property name="openMode" value="DIALOG"/>
<property name="screenClass" value="com.company.sales.web.customer.CustomerEdit"/>
</properties>
</action>В качестве альтернативы, действие можно инжектировать в контроллер экрана и сконфигурировать, используя сеттеры:
@Named("customersTable.create")
private CreateAction customersTableCreate;
@Subscribe
public void onInit(InitEvent event) {
customersTableCreate.setOpenMode(OpenMode.DIALOG);
customersTableCreate.setScreenClass(CustomerEdit.class);
}Далее рассматриваются параметры, которые можно сконфигурировать только программно в Java. Для генерации корректно аннотированных методов для этих параметров используйте закладку Handlers окна инструментов Component Inspector в Studio.
-
screenOptionsSupplier- обработчик, возвращающий объектScreenOptionsдля передачи в открываемый экран редактирования. Например:@Install(to = "customersTable.create", subject = "screenOptionsSupplier") protected ScreenOptions customersTableCreateScreenOptionsSupplier() { return new MapScreenOptions(ParamsMap.of("someParameter", 10)); }Возвращаемый объект
ScreenOptionsбудет доступен вInitEventоткрываемого экрана. -
screenConfigurer- обработчик, принимающий экран редактирования для его конфигурирования перед открытием. Например:@Install(to = "customersTable.create", subject = "screenConfigurer") protected void customersTableCreateScreenConfigurer(Screen editorScreen) { ((CustomerEdit) editorScreen).setSomeParameter(10); }Конфигуратор экрана вступает в действие, когда экран уже инициализирован, но еще не показан, то есть после
InitEventиAfterInitEvent, и доBeforeShowEvent. -
newEntitySupplier- обработчик, возвращающий новый экземпляр сущности для отображения в экране редактирования. Например:@Install(to = "customersTable.create", subject = "newEntitySupplier") protected Customer customersTableCreateNewEntitySupplier() { Customer customer = metadata.create(Customer.class); customer.setName("a customer"); return customer; } -
initializer- обработчик, принимающий новый экземпляр для его инициализации перед отображением в экране редактирования. Например:@Install(to = "customersTable.create", subject = "initializer") protected void customersTableCreateInitializer(Customer entity) { entity.setName("a customer"); } -
afterCommitHandler- обработчик, вызываемый после коммита созданного экземпляра сущности в экране редактирования. Принимает созданный и сохраненный в БД экземпляр сущности. Например:@Install(to = "customersTable.create", subject = "afterCommitHandler") protected void customersTableCreateAfterCommitHandler(Customer entity) { System.out.println("Created " + entity); } -
afterCloseHandler- обработчик, вызываемый после закрытия экрана редактирования. ПринимаетAfterCloseEvent. Например:@Install(to = "customersTable.create", subject = "afterCloseHandler") protected void customersTableCreateAfterCloseHandler(AfterCloseEvent event) { if (event.closedWith(StandardOutcome.COMMIT)) { System.out.println("Committed"); } }
Для того, чтобы произвести какие-либо проверки, или взаимодействовать с пользователем перед выполнением действия, необходимо подписаться на событие ActionPerformedEvent действия и в нужный момент вызвать метод execute(). Действие будет вызвано со всеми параметрами, которые были для него заданы. В примере ниже перед выполнением действия отображается диалог подтверждения:
@Named("customersTable.create")
private CreateAction customersTableCreate;
@Subscribe("customersTable.create")
public void onCustomersTableCreate(Action.ActionPerformedEvent event) {
dialogs.createOptionDialog()
.withCaption("Please confirm")
.withMessage("Do you really want to create new customer?")
.withActions(
new DialogAction(DialogAction.Type.YES)
.withHandler(e -> customersTableCreate.execute()), // execute action
new DialogAction(DialogAction.Type.NO)
)
.show();
}Можно также подписаться на ActionPerformedEvent, и вместо вызова метода execute() действия, использовать для открытия экрана редактирования ScreenBuilders API напрямую. По сути, в этом случае все специфичные параметры действия игнорируются, и действуют только общие параметры: caption, icon, и т.д. Например:
@Inject
private ScreenBuilders screenBuilders;
@Subscribe("customersTable.create")
public void onCustomersTableCreate(Action.ActionPerformedEvent event) {
screenBuilders.editor(customersTable)
.newEntity()
.withOpenMode(OpenMode.DIALOG)
.withScreenClass(CustomerEdit.class)
.withAfterCloseListener(afterScreenCloseEvent -> {
if (afterScreenCloseEvent.closedWith(StandardOutcome.COMMIT)) {
Customer committedCustomer = (afterScreenCloseEvent.getScreen()).getEditedEntity();
System.out.println("Created " + committedCustomer);
}
})
.build()
.show();
}3.5.5.2.5. EditAction
EditAction - действие с коллекцией, предназначенное для редактирования экземпляров сущности. Оно открывает экран редактирования с экземпляром сущности, выбранным в UI-компоненте. После того, как экземпляр сохранен в базу данных экраном редактирования, действие обновляет его в контейнере данных UI-компонента.
Действие реализовано классом com.haulmont.cuba.gui.actions.list.EditAction и объявляется в XML с помощью атрибута type="edit". Общие свойства действий можно конфигурировать с помощью атрибутов элемента action, подробнее см. раздел Декларативное создание действий. Ниже рассматриваются параметры, специфичные для класса EditAction.
Следующие параметры можно установить и в XML и в Java:
-
openMode- режим открытия экрана редактирования, задаваемый значением перечисленияOpenMode:NEW_TAB,DIALOG, и т.д. По умолчанию экран открывается в режимеTHIS_TAB. -
screenId- строковый идентификатор экрана редактирования. По умолчанию используется экран, аннотированный@PrimaryEditorScreen, или имеющий идентификатор вида<entity_name>.edit, напримерdemo_Customer.edit. -
screenClass- класс Java экрана редактирования. Данный параметр имеет более высокий приоритет, чемscreenId.
Например, если необходимо открыть определенный экран редактирования в режиме диалога, действие можно сконфигурировать в XML следующим образом:
<action id="edit" type="edit">
<properties>
<property name="openMode" value="DIALOG"/>
<property name="screenClass" value="com.company.sales.web.customer.CustomerEdit"/>
</properties>
</action>В качестве альтернативы, действие можно инжектировать в контроллер экрана и сконфигурировать, используя сеттеры:
@Named("customersTable.edit")
private EditAction customersTableEdit;
@Subscribe
public void onInit(InitEvent event) {
customersTableEdit.setOpenMode(OpenMode.DIALOG);
customersTableEdit.setScreenClass(CustomerEdit.class);
}Далее рассматриваются параметры, которые можно сконфигурировать только программно в Java. Для генерации корректно аннотированных методов для этих параметров используйте закладку Handlers окна инструментов Component Inspector в Studio.
-
screenOptionsSupplier- обработчик, возвращающий объектScreenOptionsдля передачи в открываемый экран редактирования. Например:@Install(to = "customersTable.edit", subject = "screenOptionsSupplier") protected ScreenOptions customersTableEditScreenOptionsSupplier() { return new MapScreenOptions(ParamsMap.of("someParameter", 10)); }Возвращаемый объект
ScreenOptionsбудет доступен вInitEventоткрываемого экрана. -
screenConfigurer- обработчик, принимающий экран редактирования для его конфигурирования перед открытием. Например:@Install(to = "customersTable.edit", subject = "screenConfigurer") protected void customersTableEditScreenConfigurer(Screen editorScreen) { ((CustomerEdit) editorScreen).setSomeParameter(10); }Конфигуратор экрана вступает в действие, когда экран уже инициализирован, но еще не показан, то есть после
InitEventиAfterInitEvent, и доBeforeShowEvent. -
afterCommitHandler- обработчик, вызываемый после коммита редактируемого экземпляра сущности в экране редактирования. Принимает сохраненный в БД экземпляр сущности. Например:@Install(to = "customersTable.edit", subject = "afterCommitHandler") protected void customersTableEditAfterCommitHandler(Customer entity) { System.out.println("Updated " + entity); } -
afterCloseHandler- обработчик, вызываемый после закрытия экрана редактирования. ПринимаетAfterCloseEvent. Например:@Install(to = "customersTable.edit", subject = "afterCloseHandler") protected void customersTableEditAfterCloseHandler(AfterCloseEvent event) { if (event.closedWith(StandardOutcome.COMMIT)) { System.out.println("Committed"); } }
Для того, чтобы произвести какие-либо проверки, или взаимодействовать с пользователем перед выполнением действия, необходимо подписаться на событие ActionPerformedEvent действия и в нужный момент вызвать метод execute(). Действие будет вызвано со всеми параметрами, которые были для него заданы. В примере ниже перед выполнением действия отображается диалог подтверждения:
@Named("customersTable.edit")
private EditAction customersTableEdit;
@Subscribe("customersTable.edit")
public void onCustomersTableEdit(Action.ActionPerformedEvent event) {
dialogs.createOptionDialog()
.withCaption("Please confirm")
.withMessage("Do you really want to edit the customer?")
.withActions(
new DialogAction(DialogAction.Type.YES)
.withHandler(e -> customersTableEdit.execute()), // execute action
new DialogAction(DialogAction.Type.NO)
)
.show();
}Можно также подписаться на ActionPerformedEvent, и вместо вызова метода execute() действия, использовать для открытия экрана редактирования ScreenBuilders API напрямую. По сути, в этом случае все специфичные параметры действия игнорируются, и действуют только общие параметры: caption, icon, и т.д. Например:
@Inject
private ScreenBuilders screenBuilders;
@Subscribe("customersTable.edit")
public void onCustomersTableEdit(Action.ActionPerformedEvent event) {
screenBuilders.editor(customersTable)
.withOpenMode(OpenMode.DIALOG)
.withScreenClass(CustomerEdit.class)
.withAfterCloseListener(afterScreenCloseEvent -> {
if (afterScreenCloseEvent.closedWith(StandardOutcome.COMMIT)) {
Customer committedCustomer = (afterScreenCloseEvent.getScreen()).getEditedEntity();
System.out.println("Updated " + committedCustomer);
}
})
.build()
.show();
}3.5.5.2.6. ExcelAction
ExcelAction - действие с коллекцией, предназначенное для экспорта содержимого таблицы в файл XLS.
Если в таблице есть выделенные строки, то действие предлагает пользователю выбор: экспортировать только выделенные строки, или все содержимое. Заголовок и сообщение диалога выбора можно переопределить в проекте путем добавления в главный пакет сообщений с ключами actions.exportSelectedTitle и actions.exportSelectedCaption.
Действие реализовано классом com.haulmont.cuba.gui.actions.list.ExcelAction и объявляется в XML с помощью атрибута type="excel". Общие свойства действий можно конфигурировать с помощью атрибутов элемента action, подробнее см. раздел Декларативное создание действий. Ниже рассматриваются параметры, специфичные для класса ExcelAction.
-
fileName- имя файла экспорта. Если не задано, то генерируется автоматически на основе имени сущности. -
exportAggregation- экспортировать ли строки агрегации, если они существуют в таблице. По умолчанию true.
Например:
<action id="excel" type="excel">
<properties>
<property name="fileName" value="customers"/>
<property name="exportAggregation" value="false"/>
</properties>
</action>В качестве альтернативы, действие можно инжектировать в контроллер экрана и сконфигурировать, используя сеттеры:
@Named("customersTable.excel")
private ExcelAction customersTableExcel;
@Subscribe
public void onInit(InitEvent event) {
customersTableExcel.setFileName("customers");
customersTableExcel.setExportAggregation(false);
}Для того, чтобы произвести какие-либо проверки, или взаимодействовать с пользователем перед выполнением действия, необходимо подписаться на событие ActionPerformedEvent действия и в нужный момент вызвать метод execute(). В примере ниже перед выполнением действия отображается диалог подтверждения:
@Named("customersTable.excel")
private ExcelAction customersTableExcel;
@Subscribe("customersTable.excel")
public void onCustomersTableExcel(Action.ActionPerformedEvent event) {
dialogs.createOptionDialog()
.withCaption("Please confirm")
.withMessage("Are you sure you want to print the content to XLS?")
.withActions(
new DialogAction(DialogAction.Type.YES)
.withHandler(e -> customersTableExcel.execute()), // execute action
new DialogAction(DialogAction.Type.NO)
)
.show();
}Можно также подписаться на ActionPerformedEvent, и вместо вызова метода execute() действия, использовать класс ExcelExporter напрямую.
3.5.5.2.7. ExcludeAction
ExcludeAction - действие с коллекцией, предназначенное для удаления экземпляров сущности из контейнера данных в UI. В отличие от RemoveAction, ExcludeAction не удаляет сущности из базы данных, что требуется, например, при работе с many-to-many коллекциями.
Действие реализовано классом com.haulmont.cuba.gui.actions.list.ExcludeAction и объявляется в XML с помощью атрибута type="exclude". Общие свойства действий можно конфигурировать с помощью атрибутов элемента action, подробнее см. раздел Декларативное создание действий. Ниже рассматриваются параметры, специфичные для класса ExcludeAction.
Следующие параметры можно установить и в XML и в Java:
-
confirmation- булевское значение, указывающее, отображать ли диалог подтверждения перед удалением. По умолчанию true. -
confirmationMessage- сообщение диалога подтверждения. По умолчанию, берется из главного пакета сообщений по ключуdialogs.Confirmation.Remove. -
confirmationTitle- заголовок диалога подтверждения. По умолчанию, берется из главного пакета сообщений по ключуdialogs.Confirmationkey.
Например, если необходимо задать определенное сообщение диалога подтверждения, можно сконфигурировать действие в XML:
<action id="exclude" type="exclude">
<properties>
<property name="confirmation" value="true"/>
<property name="confirmationTitle" value="Removing customer..."/>
<property name="confirmationMessage" value="Do you really want to remove the customer from the list?"/>
</properties>
</action>В качестве альтернативы, действие можно инжектировать в контроллер экрана и сконфигурировать, используя сеттеры:
@Named("customersTable.exclude")
private ExcludeAction customersTableExclude;
@Subscribe
public void onInit(InitEvent event) {
customersTableExclude.setConfirmation(true);
customersTableExclude.setConfirmationTitle("Removing customer...");
customersTableExclude.setConfirmationMessage("Do you really want to remove the customer from the list?");
}Далее рассматриваются параметры, которые можно сконфигурировать только программно в Java. Для генерации корректно аннотированных методов для этих параметров используйте закладку Handlers окна инструментов Component Inspector в Studio.
-
afterActionPerformedHandler- обработчик, вызываемый после того, как выбранные сущности удалены. Принимает объект события, который можно использовать для получения выбранных для удаления экземпляров. Например:@Install(to = "customersTable.exclude", subject = "afterActionPerformedHandler") private void customersTableExcludeAfterActionPerformedHandler(RemoveOperation.AfterActionPerformedEvent<Customer> event) { System.out.println("Removed " + event.getItems()); } -
actionCancelledHandler- обработчик, вызываемый если операция удаления отменена пользователем в диалоге подтверждения. Принимает объект события, который можно использовать для получения выбранных для удаления экземпляров. Например:@Install(to = "customersTable.exclude", subject = "actionCancelledHandler") private void customersTableExcludeActionCancelledHandler(RemoveOperation.ActionCancelledEvent<Customer> event) { System.out.println("Cancelled"); }
Для того, чтобы произвести какие-либо проверки, или взаимодействовать с пользователем перед выполнением действия, необходимо подписаться на событие ActionPerformedEvent действия и в нужный момент вызвать метод execute(). Действие будет вызвано со всеми параметрами, которые были для него заданы. В примере ниже перед выполнением действия отображается кастомный диалог подтверждения:
@Named("customersTable.exclude")
private ExcludeAction customersTableExclude;
@Subscribe("customersTable.exclude")
public void onCustomersTableExclude(Action.ActionPerformedEvent event) {
customersTableExclude.setConfirmation(false);
dialogs.createOptionDialog()
.withCaption("My fancy confirm dialog")
.withMessage("Do you really want to remove the customer from the list?")
.withActions(
new DialogAction(DialogAction.Type.YES)
.withHandler(e -> customersTableExclude.execute()), // execute action
new DialogAction(DialogAction.Type.NO)
)
.show();
}Можно также подписаться на ActionPerformedEvent, и вместо вызова метода execute() действия, использовать RemoveOperation API напрямую. По сути, в этом случае все специфичные параметры действия игнорируются, и действуют только общие параметры: caption, icon, и т.д. Например:
@Inject
private RemoveOperation removeOperation;
@Subscribe("customersTable.exclude")
public void onCustomersTableExclude(Action.ActionPerformedEvent event) {
removeOperation.builder(customersTable)
.withConfirmationMessage("Do you really want to remove the customer from the list?")
.withConfirmationTitle("Removing customer...")
.exclude();
}3.5.5.2.8. LookupAction
LookupAction - действие поля выбора сущности, предназначенное для установки экземпляра сущности в поле из экрана выбора.
Действие реализовано классом com.haulmont.cuba.gui.actions.picker.LookupAction и объявляется в XML с помощью атрибута type="picker_lookup". Общие свойства действий можно конфигурировать с помощью атрибутов элемента action, подробнее см. раздел Декларативное создание действий. Ниже рассматриваются параметры, специфичные для класса LookupAction.
Следующие параметры можно установить и в XML и в Java:
-
openMode- режим открытия экрана выбора, задаваемый значением перечисленияOpenMode:NEW_TAB,DIALOG, и т.д. По умолчанию экран открывается в режимеTHIS_TAB. -
screenId- строковый идентификатор экрана выбора. По умолчанию используется экран, аннотированный@PrimaryLookupScreen, или имеющий идентификатор вида<entity_name>.lookupили<entity_name>.browse, напримерdemo_Customer.browse. -
screenClass- класс Java экрана выбора. Данный параметр имеет более высокий приоритет, чемscreenId.
Например, если необходимо открыть определенный экран выбора в режиме диалога, действие можно сконфигурировать в XML следующим образом:
<action id="lookup" type="picker_lookup">
<properties>
<property name="openMode" value="DIALOG"/>
<property name="screenClass" value="com.company.sales.web.customer.CustomerBrowse"/>
</properties>
</action>В качестве альтернативы, действие можно инжектировать в контроллер экрана и сконфигурировать, используя сеттеры:
@Named("customerField.lookup")
private LookupAction customerFieldLookup;
@Subscribe
public void onInit(InitEvent event) {
customerFieldLookup.setOpenMode(OpenMode.DIALOG);
customerFieldLookup.setScreenClass(CustomerBrowse.class);
}Далее рассматриваются параметры, которые можно сконфигурировать только программно в Java. Для генерации корректно аннотированных методов для этих параметров используйте закладку Handlers окна инструментов Component Inspector в Studio.
-
screenOptionsSupplier- обработчик, возвращающий объектScreenOptionsдля передачи в открываемый экран выбора. Например:@Install(to = "customersTable.add", subject = "screenOptionsSupplier") private ScreenOptions customersTableAddScreenOptionsSupplier() { return new MapScreenOptions(ParamsMap.of("someParameter", 10)); }Возвращаемый объект
ScreenOptionsбудет доступен вInitEventоткрываемого экрана. -
screenConfigurer- обработчик, принимающий экран выбора для его конфигурирования перед открытием. Например:@Install(to = "customersTable.add", subject = "screenConfigurer") private void customersTableAddScreenConfigurer(Screen screen) { ((CustomerBrowse) screen).setSomeParameter(10); }Конфигуратор экрана вступает в действие, когда экран уже инициализирован, но еще не показан, то есть после
InitEventиAfterInitEvent, и доBeforeShowEvent. -
selectValidator- обработчик, вызываемый когда пользователь нажимает Select в экране выбора. Он принимает объект, содержащий коллекцию выбранных сущностей. Первый элемент коллекции будет установлен в поле. Данный обработчик можно использовать для проверки выбора по каким-либо критериям. Обработчик должен вернутьtrueдля того, чтобы процесс был продолжен и экран выбора закрылся. Например:@Install(to = "customerField.lookup", subject = "selectValidator") private boolean customerFieldLookupSelectValidator(LookupScreen.ValidationContext<Customer> validationContext) { boolean valid = validationContext.getSelectedItems().size() == 1; if (!valid) { notifications.create().withCaption("Select a single customer").show(); } return valid; } -
transformation- обработчик, вызываемый после того, как сущности выбраны и провалидированы в экране выбора. Он принимает коллекцию выбранных сущностей и может быть использован для того, чтобы преобразовать содержимое коллекции перед установкой сущности в поле. Например:@Install(to = "customerField.lookup", subject = "transformation") private Collection<Customer> customerFieldLookupTransformation(Collection<Customer> collection) { return reloadCustomers(collection); } -
afterCloseHandler- обработчик, вызываемый после закрытия экрана выбора. ПринимаетAfterCloseEvent. Например:@Install(to = "customerField.lookup", subject = "afterCloseHandler") private void customerFieldLookupAfterCloseHandler(AfterCloseEvent event) { if (event.closedWith(StandardOutcome.SELECT)) { System.out.println("Selected"); } }
Для того, чтобы произвести какие-либо проверки, или взаимодействовать с пользователем перед выполнением действия, необходимо подписаться на событие ActionPerformedEvent действия и в нужный момент вызвать метод execute(). Действие будет вызвано со всеми параметрами, которые были для него заданы. В примере ниже перед выполнением действия отображается диалог подтверждения:
@Named("customerField.lookup")
private LookupAction customerFieldLookup;
@Subscribe("customerField.lookup")
public void onCustomerFieldLookup(Action.ActionPerformedEvent event) {
dialogs.createOptionDialog()
.withCaption("Please confirm")
.withMessage("Do you really want to select a customer?")
.withActions(
new DialogAction(DialogAction.Type.YES)
.withHandler(e -> customerFieldLookup.execute()), // execute action
new DialogAction(DialogAction.Type.NO)
)
.show();
}Можно также подписаться на ActionPerformedEvent, и вместо вызова метода execute() действия, использовать для открытия экрана выбора ScreenBuilders API напрямую. По сути, в этом случае все специфичные параметры действия игнорируются, и действуют только общие параметры: caption, icon, и т.д. Например:
@Inject
private ScreenBuilders screenBuilders;
@Inject
private LookupPickerField<Customer> customerField;
@Subscribe("customerField.lookup")
public void onCustomerFieldLookup(Action.ActionPerformedEvent event) {
screenBuilders.lookup(customerField)
.withOpenMode(OpenMode.DIALOG)
.withScreenClass(CustomerBrowse.class)
.withSelectValidator(customerValidationContext -> {
boolean valid = customerValidationContext.getSelectedItems().size() == 1;
if (!valid) {
notifications.create().withCaption("Select a single customer").show();
}
return valid;
})
.build()
.show();
}3.5.5.2.9. OpenAction
OpenAction - действие поля выбора сущности, предназначенное для открытия экрана редактирования для выбранного в поле в данный момент экземпляра сущности.
Действие реализовано классом com.haulmont.cuba.gui.actions.picker.OpenAction и объявляется в XML с помощью атрибута type="picker_open". Общие свойства действий можно конфигурировать с помощью атрибутов элемента action, подробнее см. раздел Декларативное создание действий. Ниже рассматриваются параметры, специфичные для класса OpenAction.
Следующие параметры можно установить и в XML и в Java:
-
openMode- режим открытия экрана редактирования, задаваемый значением перечисленияOpenMode:NEW_TAB,DIALOG, и т.д. По умолчанию экран открывается в режимеTHIS_TAB. -
screenId- строковый идентификатор экрана редактирования. По умолчанию используется экран, аннотированный@PrimaryEditorScreen, или имеющий идентификатор вида<entity_name>.edit, напримерdemo_Customer.edit. -
screenClass- класс Java экрана редактирования. Данный параметр имеет более высокий приоритет, чемscreenId.
Например, если необходимо открыть определенный экран редактирования в режиме диалога, действие можно сконфигурировать в XML следующим образом:
<action id="open" type="picker_open">
<properties>
<property name="openMode" value="DIALOG"/>
<property name="screenClass" value="com.company.sales.web.customer.CustomerEdit"/>
</properties>
</action>В качестве альтернативы, действие можно инжектировать в контроллер экрана и сконфигурировать, используя сеттеры:
@Named("customerField.open")
private OpenAction customerFieldOpen;
@Subscribe
public void onInit(InitEvent event) {
customerFieldOpen.setOpenMode(OpenMode.DIALOG);
customerFieldOpen.setScreenClass(CustomerEdit.class);
}Далее рассматриваются параметры, которые можно сконфигурировать только программно в Java. Для генерации корректно аннотированных методов для этих параметров используйте закладку Handlers окна инструментов Component Inspector в Studio.
-
screenOptionsSupplier- обработчик, возвращающий объектScreenOptionsдля передачи в открываемый экран редактирования. Например:@Install(to = "customerField.open", subject = "screenOptionsSupplier") private ScreenOptions customerFieldOpenScreenOptionsSupplier() { return new MapScreenOptions(ParamsMap.of("someParameter", 10)); }Возвращаемый объект
ScreenOptionsбудет доступен вInitEventоткрываемого экрана. -
screenConfigurer- обработчик, принимающий экран редактирования для его конфигурирования перед открытием. Например:@Install(to = "customerField.open", subject = "screenConfigurer") private void customerFieldOpenScreenConfigurer(Screen screen) { ((CustomerEdit) screen).setSomeParameter(10); }Конфигуратор экрана вступает в действие, когда экран уже инициализирован, но еще не показан, то есть после
InitEventиAfterInitEvent, и доBeforeShowEvent. -
afterCloseHandler- обработчик, вызываемый после закрытия экрана редактирования. ПринимаетAfterCloseEvent. Например:@Install(to = "customerField.open", subject = "afterCloseHandler") private void customerFieldOpenAfterCloseHandler(AfterCloseEvent event) { System.out.println("Closed with " + event.getCloseAction()); }
Для того, чтобы произвести какие-либо проверки, или взаимодействовать с пользователем перед выполнением действия, необходимо подписаться на событие ActionPerformedEvent действия и в нужный момент вызвать метод execute(). Действие будет вызвано со всеми параметрами, которые были для него заданы. В примере ниже перед выполнением действия отображается диалог подтверждения:
@Named("customerField.open")
private OpenAction customerFieldOpen;
@Subscribe("customerField.open")
public void onCustomerFieldOpen(Action.ActionPerformedEvent event) {
dialogs.createOptionDialog()
.withCaption("Please confirm")
.withMessage("Do you really want to open the customer?")
.withActions(
new DialogAction(DialogAction.Type.YES)
.withHandler(e -> customerFieldOpen.execute()), // execute action
new DialogAction(DialogAction.Type.NO)
)
.show();
}Можно также подписаться на ActionPerformedEvent, и вместо вызова метода execute() действия, использовать для открытия экрана редактирования ScreenBuilders API напрямую. По сути, в этом случае все специфичные параметры действия игнорируются, и действуют только общие параметры: caption, icon, и т.д. Например:
@Inject
private ScreenBuilders screenBuilders;
@Inject
private LookupPickerField<Customer> customerField;
@Subscribe("customerField.open")
public void onCustomerFieldOpen(Action.ActionPerformedEvent event) {
screenBuilders.editor(customerField)
.withOpenMode(OpenMode.DIALOG)
.withScreenClass(CustomerEdit.class)
.build()
.show();
}3.5.5.2.10. OpenCompositionAction
OpenCompositionAction - действие поля выбора сущности, предназначенное для открытия экрана редактирования для выбранного в поле в данный момент экземпляра сущности, являющегося one-to-one composition. Если в данный момент связанного экземпляра нет (т.е. поле пустое), то создается новый экземпляр, который сохраняется впоследствии экраном редактирования.
Действие реализовано классом com.haulmont.cuba.gui.actions.picker.OpenCompositionAction и объявляется в XML с помощью атрибута type="picker_open_composition". Параметры действия идентичны параметрам OpenAction.
3.5.5.2.11. RefreshAction
RefreshAction - действие с коллекцией, предназначенное для перезагрузки контейнера данных, используемого таблицей или деревом.
Действие реализовано классом com.haulmont.cuba.gui.actions.list.RefreshAction и объявляется в XML с помощью атрибута type="refresh". Общие свойства действий можно конфигурировать с помощью атрибутов элемента action, подробнее см. раздел Декларативное создание действий.
Для того, чтобы произвести какие-либо проверки, или взаимодействовать с пользователем перед выполнением действия, необходимо подписаться на событие ActionPerformedEvent действия и в нужный момент вызвать метод execute(). В примере ниже перед выполнением действия отображается диалог подтверждения:
@Named("customersTable.refresh")
private RefreshAction customersTableRefresh;
@Subscribe("customersTable.refresh")
public void onCustomersTableRefresh(Action.ActionPerformedEvent event) {
dialogs.createOptionDialog()
.withCaption("Please confirm")
.withMessage("Are you sure you want to refresh the list?")
.withActions(
new DialogAction(DialogAction.Type.YES)
.withHandler(e -> customersTableRefresh.execute()), // execute action
new DialogAction(DialogAction.Type.NO)
)
.show();
}Можно также подписаться на ActionPerformedEvent, и вместо вызова метода execute() действия, запустить нужный загрузчик напрямую. Например:
@Inject
private CollectionLoader<Customer> customersDl;
@Subscribe("customersTable.refresh")
public void onCustomersTableRefresh(Action.ActionPerformedEvent event) {
customersDl.load();
}3.5.5.2.12. RemoveAction
RemoveAction - действие с коллекцией, предназначенное для удаления экземпляров сущности из базы данных и из контейнера данных в UI.
Действие реализовано классом com.haulmont.cuba.gui.actions.list.RemoveAction и объявляется в XML с помощью атрибута type="remove". Общие свойства действий можно конфигурировать с помощью атрибутов элемента action, подробнее см. раздел Декларативное создание действий. Ниже рассматриваются параметры, специфичные для класса RemoveAction.
Следующие параметры можно установить и в XML и в Java:
-
confirmation- булевское значение, указывающее, отображать ли диалог подтверждения перед удалением. По умолчанию true. -
confirmationMessage- сообщение диалога подтверждения. По умолчанию, берется из главного пакета сообщений по ключуdialogs.Confirmation.Remove. -
confirmationTitle- заголовок диалога подтверждения. По умолчанию, берется из главного пакета сообщений по ключуdialogs.Confirmationkey.
Например, если необходимо задать определенное сообщение диалога подтверждения, можно сконфигурировать действие в XML:
<action id="remove" type="remove">
<properties>
<property name="confirmation" value="true"/>
<property name="confirmationTitle" value="Removing customer..."/>
<property name="confirmationMessage" value="Do you really want to remove the customer?"/>
</properties>
</action>В качестве альтернативы, действие можно инжектировать в контроллер экрана и сконфигурировать, используя сеттеры:
@Named("customersTable.remove")
private RemoveAction customersTableRemove;
@Subscribe
public void onInit(InitEvent event) {
customersTableRemove.setConfirmation(true);
customersTableRemove.setConfirmationTitle("Removing customer...");
customersTableRemove.setConfirmationMessage("Do you really want to remove the customer?");
}Далее рассматриваются параметры, которые можно сконфигурировать только программно в Java. Для генерации корректно аннотированных методов для этих параметров используйте закладку Handlers окна инструментов Component Inspector в Studio.
-
afterActionPerformedHandler- обработчик, вызываемый после того, как выбранные сущности удалены. Принимает объект события, который можно использовать для получения выбранных для удаления экземпляров. Например:@Install(to = "customersTable.remove", subject = "afterActionPerformedHandler") protected void customersTableRemoveAfterActionPerformedHandler(RemoveOperation.AfterActionPerformedEvent<Customer> event) { System.out.println("Removed " + event.getItems()); } -
actionCancelledHandler- обработчик, вызываемый если операция удаления отменена пользователем в диалоге подтверждения. Принимает объект события, который можно использовать для получения выбранных для удаления экземпляров. Например:@Install(to = "customersTable.remove", subject = "actionCancelledHandler") protected void customersTableRemoveActionCancelledHandler(RemoveOperation.ActionCancelledEvent<Customer> event) { System.out.println("Cancelled"); }
Для того, чтобы произвести какие-либо проверки, или взаимодействовать с пользователем перед выполнением действия, необходимо подписаться на событие ActionPerformedEvent действия и в нужный момент вызвать метод execute(). Действие будет вызвано со всеми параметрами, которые были для него заданы. В примере ниже перед выполнением действия отображается кастомный диалог подтверждения:
@Named("customersTable.remove")
private RemoveAction customersTableRemove;
@Subscribe("customersTable.remove")
public void onCustomersTableRemove(Action.ActionPerformedEvent event) {
customersTableRemove.setConfirmation(false);
dialogs.createOptionDialog()
.withCaption("My fancy confirm dialog")
.withMessage("Do you really want to remove the customer?")
.withActions(
new DialogAction(DialogAction.Type.YES)
.withHandler(e -> customersTableRemove.execute()), // execute action
new DialogAction(DialogAction.Type.NO)
)
.show();
}Можно также подписаться на ActionPerformedEvent, и вместо вызова метода execute() действия, использовать RemoveOperation API напрямую. По сути, в этом случае все специфичные параметры действия игнорируются, и действуют только общие параметры: caption, icon, и т.д. Например:
@Inject
private RemoveOperation removeOperation;
@Subscribe("customersTable.remove")
public void onCustomersTableRemove(Action.ActionPerformedEvent event) {
removeOperation.builder(customersTable)
.withConfirmationTitle("Removing customer...")
.withConfirmationMessage("Do you really want to remove the customer?")
.remove();
}3.5.5.2.13. ViewAction
ViewAction - действие с коллекцией, предназначенное для просмотра и редактирования экземпляров сущности. Оно открывает экран редактирования таким же образом, как EditAction, но делает все поля ввода нередактируемыми и запрещает действия, реализующие интерфейс Action.DisabledWhenScreenReadOnly. Если необходимо дать пользователю возможность переключить экран в режим редактирования, добавьте в экран кнопку и свяжите ее с предопределенным действием enableEditing:
<hbox id="editActions" spacing="true">
<button action="windowCommitAndClose"/>
<button action="windowClose"/>
<button action="enableEditing"/> <!-- this button is shown only when the screen is in read-only mode -->
</hbox>Заголовок действия enableEditing можно переопределить в главном пакете сообщений, используя ключ actions.EnableEditing, или непосредственно в экране путем указания атрибута caption у соответствующей кнопки.
Действие реализовано классом com.haulmont.cuba.gui.actions.list.ViewAction и объявляется в XML с помощью атрибута type="view". Общие свойства действий можно конфигурировать с помощью атрибутов элемента action, подробнее см. раздел Декларативное создание действий. Ниже рассматриваются параметры, специфичные для класса ViewAction.
Следующие параметры можно установить и в XML и в Java:
-
openMode- режим открытия экрана редактирования, задаваемый значением перечисленияOpenMode:NEW_TAB,DIALOG, и т.д. По умолчанию экран открывается в режимеTHIS_TAB. -
screenId- строковый идентификатор экрана редактирования. По умолчанию используется экран, аннотированный@PrimaryEditorScreen, или имеющий идентификатор вида<entity_name>.edit, напримерdemo_Customer.edit. -
screenClass- класс Java экрана редактирования. Данный параметр имеет более высокий приоритет, чемscreenId.
Например, если необходимо открыть определенный экран редактирования в режиме диалога, действие можно сконфигурировать в XML следующим образом:
<action id="view" type="view">
<properties>
<property name="openMode" value="DIALOG"/>
<property name="screenClass" value="com.company.sales.web.customer.CustomerEdit"/>
</properties>
</action>В качестве альтернативы, действие можно инжектировать в контроллер экрана и сконфигурировать, используя сеттеры:
@Named("customersTable.view")
private ViewAction customersTableView;
@Subscribe
public void onInit(InitEvent event) {
customersTableView.setOpenMode(OpenMode.DIALOG);
customersTableView.setScreenClass(CustomerEdit.class);
}Далее рассматриваются параметры, которые можно сконфигурировать только программно в Java. Для генерации корректно аннотированных методов для этих параметров используйте закладку Handlers окна инструментов Component Inspector в Studio.
-
screenOptionsSupplier- обработчик, возвращающий объектScreenOptionsдля передачи в открываемый экран редактирования. Например:@Install(to = "customersTable.view", subject = "screenOptionsSupplier") protected ScreenOptions customersTableViewScreenOptionsSupplier() { return new MapScreenOptions(ParamsMap.of("someParameter", 10)); }Возвращаемый объект
ScreenOptionsбудет доступен вInitEventоткрываемого экрана. -
screenConfigurer- обработчик, принимающий экран редактирования для его конфигурирования перед открытием. Например:@Install(to = "customersTable.view", subject = "screenConfigurer") protected void customersTableViewScreenConfigurer(Screen editorScreen) { ((CustomerEdit) editorScreen).setSomeParameter(10); }Конфигуратор экрана вступает в действие, когда экран уже инициализирован, но еще не показан, то есть после
InitEventиAfterInitEvent, и доBeforeShowEvent. -
afterCommitHandler- обработчик, вызываемый после коммита редактируемого экземпляра сущности в экране редактирования, если пользователь переключил экран в режим редактирования используя действиеenableEditing, упомянутое выше. Принимает сохраненный в БД экземпляр сущности. Например:@Install(to = "customersTable.view", subject = "afterCommitHandler") protected void customersTableViewAfterCommitHandler(Customer entity) { System.out.println("Updated " + entity); } -
afterCloseHandler- обработчик, вызываемый после закрытия экрана редактирования. ПринимаетAfterCloseEvent. Например:@Install(to = "customersTable.view", subject = "afterCloseHandler") protected void customersTableViewAfterCloseHandler(AfterCloseEvent event) { if (event.closedWith(StandardOutcome.COMMIT)) { System.out.println("Enabled editing and then committed"); } }
Для того, чтобы произвести какие-либо проверки, или взаимодействовать с пользователем перед выполнением действия, необходимо подписаться на событие ActionPerformedEvent действия и в нужный момент вызвать метод execute(). Действие будет вызвано со всеми параметрами, которые были для него заданы. В примере ниже перед выполнением действия отображается диалог подтверждения:
@Named("customersTable.view")
private ViewAction customersTableView;
@Subscribe("customersTable.view")
public void onCustomersTableView(Action.ActionPerformedEvent event) {
dialogs.createOptionDialog()
.withCaption("Please confirm")
.withMessage("Do you really want to view the customer?")
.withActions(
new DialogAction(DialogAction.Type.YES)
.withHandler(e -> customersTableView.execute()), // execute action
new DialogAction(DialogAction.Type.NO)
)
.show();
}Можно также подписаться на ActionPerformedEvent, и вместо вызова метода execute() действия, использовать для открытия экрана редактирования ScreenBuilders API напрямую. По сути, в этом случае все специфичные параметры действия игнорируются, и действуют только общие параметры: caption, icon, и т.д. Например:
@Inject
private ScreenBuilders screenBuilders;
@Subscribe("customersTable.view")
public void onCustomersTableView(Action.ActionPerformedEvent event) {
CustomerEdit customerEdit = screenBuilders.editor(customersTable)
.withOpenMode(OpenMode.DIALOG)
.withScreenClass(CustomerEdit.class)
.withAfterCloseListener(afterScreenCloseEvent -> {
if (afterScreenCloseEvent.closedWith(StandardOutcome.COMMIT)) {
Customer committedCustomer = (afterScreenCloseEvent.getScreen()).getEditedEntity();
System.out.println("Updated " + committedCustomer);
}
})
.build();
customerEdit.setReadOnly(true);
customerEdit.show();
}3.5.5.3. Собственные типы действий
В проекте можно создать собственные типы действий или переопределить существующие стандартные типы.
Предположим, что вы хотите создать действие, которое бы показывало имя экземпляра текущей сущности, выбранной в таблице, и использовать это действие в различных экранах, указывая только его тип. Чтобы это сделать, необходимо выполнить следующие шаги:
-
Создайте для действия отдельный класс с аннотацией
@ActionType, в которой укажите желаемое имя типа:package com.company.sample.web.actions; import com.haulmont.cuba.core.entity.Entity; import com.haulmont.cuba.core.global.MetadataTools; import com.haulmont.cuba.gui.ComponentsHelper; import com.haulmont.cuba.gui.Notifications; import com.haulmont.cuba.gui.components.ActionType; import com.haulmont.cuba.gui.components.Component; import com.haulmont.cuba.gui.components.actions.ItemTrackingAction; import javax.inject.Inject; @ActionType("showSelected") public class ShowSelectedAction extends ItemTrackingAction { @Inject private MetadataTools metadataTools; public ShowSelectedAction(String id) { super(id); setCaption("Show Selected"); } @Override public void actionPerform(Component component) { Entity selected = getTarget().getSingleSelected(); if (selected != null) { Notifications notifications = ComponentsHelper.getScreenContext(target).getNotifications(); notifications.create() .withType(Notifications.NotificationType.TRAY) .withCaption(metadataTools.getInstanceName(selected)) .show(); } } } -
В файле
web-spring.xmlдобавьте элемент<gui:actions>, и в его атрибутеbase-packagesукажите пакет, в котором нужно искать ваши аннотированные действия:<beans ... xmlns:gui="http://schemas.haulmont.com/cuba/spring/cuba-gui.xsd"> <!-- ... --> <gui:actions base-packages="com.company.sample.web.actions"/> </beans> -
Теперь вы можете использовать действие в дескрипторах экрана, просто указывая его тип:
<groupTable id="customersTable"> <actions> <action id="show" type="showSelected"/> </actions> <columns> <!-- ... --> </columns> <buttonsPanel> <button action="customersTable.show"/> </buttonsPanel> </groupTable>
|
Если вы хотите переопределить существующий тип действия, просто зарегистрируйте свое новое действие с таким же типом. |
- Поддержка в CUBA Studio и редактируемые свойства для собственных действий
Собственные типы действий, реализованные в вашем проекте, могут быть встроены в интерфейс дизайнера экранов CUBA Studio. Дизайнер экранов предоставляет следующую поддержку для собственных типов действий:
-
Возможность выбрать тип действия в списке стандартных действий во время добавления нового действия в экран из палитры или при выполнении +Add → Action в таблице.
-
Быстрая навигация из места использования действия к классу действия по нажатию Ctrl + B или Ctrl-клику мыши, когда курсор находится на типе действия в дескрипторе экрана (например на атрибуте
showSelectedв XML-фрагменте<action id="sel" type="showSelected">). -
Редактирование определенных пользователем свойств действия в панели Component Inspector.
-
Генерация обработчиков событий и делегирующих методов, объявленных в классе действия для кастомизации его логики.
-
Поддержка параметризации генерик-типом. Генерик-тип определяется как класс сущности, используемый в таблице (компонент-владелец действия).
Аннотация @com.haulmont.cuba.gui.meta.StudioAction используется для пометки собственного класса действия, содержащего дополнительные свойства, определенные пользователем. Собственные действия нужно помечать этой аннотацией, однако в данный момент Studio не использует дополнительных атрибутов аннотации @StudioAction.
Аннотация @com.haulmont.cuba.gui.meta.StudioPropertiesItem используется, чтобы пометить setter-метод свойства действия как редактируемое свойство. Такие свойства будут отображаться и редактироваться в панели Component Inspector дизайнера экранов. Аннотация имеет следующие атрибуты:
-
name- название атрибута, который будет сохраняться в XML. Если не установлено, то название будет определено по именованию setter-метода. -
type- тип свойства. Используется панелью Inspector, чтобы создать подходящий компонент ввода, предоставляющий подсказки и базовую валидацию. Описания всех типов свойств приведены здесь. -
caption- подпись свойства, отображается в панели Inspector. -
description- дополнительное описание свойства, отображается в панели Inspector как всплывающая подсказка по наведению мыши. -
category- категория свойства в панели Inspector (на данный момент еще не используется дизайнером экранов). -
required- обязательность свойства. Если свойство обязательное, то панель Inspector не позволит ввести для него пустое значение. -
defaultValue- значение свойства по умолчанию, т.е. значение, которое неявно используется действием, если соответствующий XML атрибут отсутствует. Значение по умолчанию не будет записываться в XML. -
options- список вариантов для свойства действия, например для типа свойстваENUMERATION.
Заметьте, что для свойств действий поддерживается только ограниченный набор Java типов:
-
Примитивные типы:
String,Boolean,Byte,Short,Integer,Long,Float,Double. -
Перечисления.
-
java.lang.Class. -
java.util.List- список, состоящий из элементов, чьи типы указаны выше. Панель Inspector не имеет точно подходящего компонента для этого Java класса, поэтому этот тип должен вводиться как обычная строка, и помечаться какPropertyType.STRING.
Примеры:
private String contentType = "PLAIN";
private Class<? extends Screen> dialogClass;
private List<Integer> columnNumbers = new ArrayList<>();
@StudioPropertiesItem(name = "ctype", type = PropertyType.ENUMERATION, description = "Email content type", (1)
defaultValue = "PLAIN", options = {"PLAIN", "HTML"}
)
public void setContentType(String contentType) {
this.contentType = contentType;
}
@StudioPropertiesItem(type = PropertyType.SCREEN_CLASS_NAME, required = true) (2)
public void setDialogClass(Class<? extends Screen> dialogClass) {
this.dialogClass = dialogClass;
}
@StudioPropertiesItem(type = PropertyType.STRING) (3)
public void setColumnNumbers(List<Integer> columnNumbers) {
this.columnNumbers = columnNumbers;
}| 1 | - строковое свойство с ограниченным набором вариантов ввода и значением по умолчанию. |
| 2 | - обязательное свойство с набором вариантов - списком классов экранов, определенных в проекте. |
| 3 | - список целых чисел. Тип свойства установлен как STRING, т.к. панель Inspector не содержит подходящего компонента ввода. |
Также Studio предоставляет поддержку для событий и делегирующих методов в собственных действиях - такую же, как и для встроенных UI компонентов. Для объявления слушателя события или делегирующего метода в классе действия не требуется никаких дополнительных аннотаций. Пример их объявления приведен ниже.
- Пример настраиваемого действия: SendByEmailAction
Этот пример демонстрирует:
-
объявление и аннотирование класса собственного действия.
-
аннотирование редактируемых параметров действия.
-
объявление собственного класса события, производимого действием, и его обработчика.
-
объявление делегирующих методов.
Действие SendByEmailAction реализует посылку email о сущности, выбранной в таблице, которой принадлежит действие. Это действие реализовано как полностью конфигурируемое, большая часть его внутренней логики может быть изменена с помощью редактируемых свойств, делегирующих методов и событий.
Исходный код действия:
@StudioAction(category = "List Actions", description = "Sends selected entity by email") (1)
@ActionType("sendByEmail") (2)
public class SendByEmailAction<E extends Entity> extends ItemTrackingAction { (3)
private final MetadataTools metadataTools;
private final EmailService emailService;
private String recipientAddress = "admin@example.com";
private Function<E, String> bodyGenerator;
private Function<E, List<EmailAttachment>> attachmentProvider;
public SendByEmailAction(String id) {
super(id);
setCaption("Send by email");
emailService = AppBeans.get(EmailService.NAME);
metadataTools = AppBeans.get(MetadataTools.NAME);
}
@StudioPropertiesItem(required = true, defaultValue = "admin@example.com") (4)
public void setRecipientAddress(String recipientAddress) {
this.recipientAddress = recipientAddress;
}
public Subscription addEmailSentListener(Consumer<EmailSentEvent> listener) { (5)
return getEventHub().subscribe(EmailSentEvent.class, listener);
}
public void setBodyGenerator(Function<E, String> bodyGenerator) { (6)
this.bodyGenerator = bodyGenerator;
}
public void setAttachmentProvider(Function<E, List<EmailAttachment>> attachmentProvider) { (7)
this.attachmentProvider = attachmentProvider;
}
@Override
public void actionPerform(Component component) {
if (recipientAddress == null || bodyGenerator == null) {
throw new IllegalStateException("Required parameters are not set");
}
E selected = (E) getTarget().getSingleSelected();
if (selected == null) {
return;
}
String caption = "Entity " + metadataTools.getInstanceName(selected) + " info";
String body = bodyGenerator.apply(selected); (8)
List<EmailAttachment> attachments = attachmentProvider != null ? attachmentProvider.apply(selected) (9)
: new ArrayList<>();
EmailInfo info = EmailInfoBuilder.create()
.setAddresses(recipientAddress)
.setCaption(caption)
.setBody(body)
.setBodyContentType(EmailInfo.TEXT_CONTENT_TYPE)
.setAttachments(attachments.toArray(new EmailAttachment[0]))
.build();
emailService.sendEmailAsync(info); (10)
EmailSentEvent event = new EmailSentEvent(this, info);
eventHub.publish(EmailSentEvent.class, event); (11)
}
public static class EmailSentEvent extends EventObject { (12)
private final EmailInfo emailInfo;
public EmailSentEvent(SendByEmailAction origin, EmailInfo emailInfo) {
super(origin);
this.emailInfo = emailInfo;
}
public EmailInfo getEmailInfo() {
return emailInfo;
}
}
}| 1 | - класс действия помечен аннотацией @StudioAction. |
| 2 | - id действия устанавливается аннотацией @ActionType. |
| 3 | - класс действия параметризован типом E - это тип сущности, которая отображается компонентом таблицы. |
| 4 | - адрес получателя email выставлен как редактируемое свойство действия. |
| 5 | - метод, регистрирующий слушатель для события EmailSentEvent. Этот метод определяется Studio как объявление обработчика события в действии. |
| 6 | - метод, устанавливающий объект Function, этот объект используется для делегирования (контроллеру экрана) логики составления тела письма. Этот метод определяется Studio как объявление делегирующего метода. |
| 7 | - объявление другого делегирующего метода - на этот раз он используется для делегирования логики создания вложений к письму. Заметьте, что оба делегирующих метода используют параметр E генерик-типа. |
| 8 | - обязательный делегирующий метод (реализованный в контроллере экрана) вызывается для составления текста письма. |
| 9 | - если установлен, необязательный делегирующий метод вызывается для генерации вложений к письму. |
| 10 | - здесь собственно и посылается email. |
| 11 | - событие EmailSentEvent публикуется после успешной посылки письма. Если контроллер экрана был подписан на это событие, то будет вызван соответствующий обработчик. |
| 12 | - объявление класса события. Обратите внимание, что в класс события можно добавить поля и таким образом передавать в логику обработки события дополнительные данные. |
Если реализовать класс как показано выше, то Studio отобразит новое собственное действие вместе со стандартными действиями в диалоге создания действия:
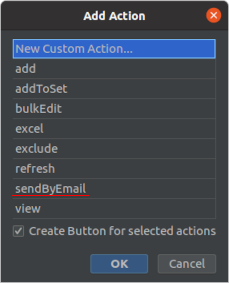
Когда действие добавлено в дескриптор экрана, вы можете выбрать его и редактировать его свойства в панели Component Inspector:
Когда свойство собственного действия изменяется в панели Inspector, оно записывается в дескриптор экрана следующим образом:
<action id="sendByEmail" type="sendByEmail">
<properties>
<property name="recipientAddress" value="peter@example.com"/>
</properties>
</action>Обработчики событий и делегирующие методы действия также отображаются и доступны для генерации в панели Component Inspector:
Пример сгенерированной логики с реализованными обработчиками события и делегирующими методами выглядит следующим образом:
@UiController("sales_Customer.browse")
@UiDescriptor("customer-browse.xml")
@LookupComponent("customersTable")
@LoadDataBeforeShow
public class CustomerBrowse extends StandardLookup<Customer> {
@Inject
private Notifications notifications;
@Named("customersTable.sendByEmail")
private SendByEmailAction<Customer> customersTableSendByEmail; (1)
@Subscribe("customersTable.sendByEmail")
public void onCustomersTableSendByEmailEmailSent(SendByEmailAction.EmailSentEvent event) { (2)
notifications.create(Notifications.NotificationType.HUMANIZED)
.withCaption("Email sent")
.show();
}
@Install(to = "customersTable.sendByEmail", subject = "bodyGenerator")
private String customersTableSendByEmailBodyGenerator(Customer customer) { (3)
return "Hello, " + customer.getName();
}
@Install(to = "customersTable.sendByEmail", subject = "attachmentProvider")
private List<EmailAttachment> customersTableSendByEmailAttachmentProvider(Customer customer) { (4)
return Collections.emptyList();
}
}| 1 | - при инжекции действия используется корректный параметр типа. |
| 2 | - реализация обработчика события. |
| 3 | - реализация делегирующего метода bodyGenerator. Параметр типа Customer подставлен в сигнатуру метода. |
| 4 | - реализация делегирующего метода attachmentProvider. |
3.5.5.4. BaseAction
BaseAction - базовый класс реализации действий. От него рекомендуется наследовать собственные нестандартные действия, если возможностей декларативного создания действий не хватает.
При создании конкретного класса действия необходимо определить метод actionPerform() и передать в конструктор BaseAction идентификатор действия. Можно также переопределить любые методы получения свойств действия: getCaption(), getDescription(), getIcon(), getShortcut(), isEnabled(), isVisible(), isPrimary(). Стандартные реализации этих методов возвращают значения, установленные соответствующими set-методами. Исключение составляет метод getCaption(): если название действия явно не установлено методом setCaption(), то он обращается в пакет локализованных сообщений с именем, соответствующим пакету класса действия, и возвращает сообщение с ключом, равным идентификатору действия. Если сообщения с таким ключом нет, то возвращается сам ключ, то есть идентификатор действия.
В качестве альтернативы переопределению методов можно использовать fluent interface для установки свойств и lambda expression для предоставления кода обработки действия: см. методы withXYZ().
BaseAction может изменять свои свойства enabled и visible в соответствии с разрешениями пользователя и текущим контекстом.
BaseAction видим (visible), если:
-
метод
setVisible(false)не вызывался; -
для действия не установлено UI разрешение
hide.
Действие разрешено (enabled), если:
-
метод
setEnabled(false)не вызывался; -
для действия не установлено UI разрешений
hideилиread-only; -
метод
isPermitted()возвращает true; -
метод
isApplicable()возвращает true.
Примеры использования:
-
Действие кнопки:
@Inject private Notifications notifications; @Inject private Button helloBtn; @Subscribe protected void onInit(InitEvent event) { helloBtn.setAction(new BaseAction("hello") { @Override public boolean isPrimary() { return true; } @Override public void actionPerform(Component component) { notifications.create() .withCaption("Hello!") .withType(Notifications.NotificationType.TRAY) .show(); } }); // OR helloBtn.setAction(new BaseAction("hello") .withPrimary(true) .withHandler(e -> notifications.create() .withCaption("Hello!") .withType(Notifications.NotificationType.TRAY) .show())); }В данном случае кнопка
helloBtnполучит в качестве заголовка строку, находящуюся в пакете сообщений с ключомhello. Для того, чтобы получить название кнопки каким-либо иным способом, можно переопределить методgetCaption()действия. -
Действие кнопки программно создаваемого PickerField:
@Inject private UiComponents uiComponents; @Inject private Notifications notifications; @Inject private MessageBundle messageBundle; @Inject private HBoxLayout box; @Subscribe protected void onInit(InitEvent event) { PickerField pickerField = uiComponents.create(PickerField.NAME); pickerField.addAction(new BaseAction("hello") { @Override public String getCaption() { return null; } @Override public String getDescription() { return messageBundle.getMessage("helloDescription"); } @Override public String getIcon() { return "icons/hello.png"; } @Override public void actionPerform(Component component) { notifications.create() .withCaption("Hello!") .withType(Notifications.NotificationType.TRAY) .show(); } }); // OR pickerField.addAction(new BaseAction("hello") .withCaption(null) .withDescription(messageBundle.getMessage("helloDescription")) .withIcon("icons/ok.png") .withHandler(e -> notifications.create() .withCaption("Hello!") .withType(Notifications.NotificationType.TRAY) .show())); box.add(pickerField); }Здесь анонимный класс-наследник
BaseActionиспользуется для задания действия кнопки поля выбора. Заголовок кнопки не отображается, вместо него используется значок и описание, всплывающее при наведении курсора мыши. -
Действие таблицы:
@Inject private Notifications notifications; @Inject private Table<Customer> table; @Inject private Security security; @Subscribe protected void onInit(InitEvent event) { table.addAction(new HelloAction()); } private class HelloAction extends BaseAction { public HelloAction() { super("hello"); } @Override public void actionPerform(Component component) { notifications.create() .withCaption("Hello " + table.getSingleSelected()) .withType(Notifications.NotificationType.TRAY) .show(); } @Override protected boolean isPermitted() { return security.isSpecificPermitted("myapp.allow-greeting"); } @Override public boolean isApplicable() { return table != null && table.getSelected().size() == 1; } }Здесь объявлен класс
HelloAction, экземпляр которого добавляется в список действий таблицы. Действие разрешено пользователям, имеющим специфическое разрешениеmyapp.allow-greeting, и только когда выбрана одна строка таблицы. Последнее условие реализуется с помощью свойстваtargetдействия, которое автоматически устанавливается когда действие добавляется вListComponent(TableилиTree). -
Если необходимо действие, которое доступно, когда выделены одна или более строк таблицы, удобно воспользоваться наследником
BaseAction- классомItemTrackingAction, который добавляет стандартную реализацию методаisApplicable():@Inject private Table table; @Inject private Notifications notifications; @Subscribe protected void onInit(InitEvent event) { table.addAction(new ItemTrackingAction("hello") { @Override public void actionPerform(Component component) { notifications.create() .withCaption("Hello " + table.getSelected().iterator().next()) .withType(Notifications.NotificationType.TRAY) .show(); } }); }
3.5.6. Диалоговые окна
Интерфейс Dialogs предназначен для отображения стандартных диалоговых окон. Его методы createMessageDialog(), createOptionDialog() и createInputDialog() являются точками входа в fluent API, позволяющий конструировать и отображать диалоги.
Внешний вид диалоговых окон можно настроить с помощью переменных SCSS с префиксом $cuba-window-modal-*. Эти переменные можно изменить в визуальном редакторе после расширения темы или создания новой темы.
- Message Dialog
-
В примере ниже диалог отображает сообщение при нажатии кнопки:
@Inject private Dialogs dialogs; @Subscribe("showDialogBtn") protected void onShowDialogBtnClick(Button.ClickEvent event) { dialogs.createMessageDialog().withCaption("Information").withMessage("Message").show(); }С помощью метода
withMessage()можно передавать текст сообщения.В тексте можно использовать символы
\nдля перевода строк. Для отображения HTML необходимо передатьContentMode.HTMLв методwithContentMode(). При использовании HTML обязательно экранируйте данные, полученные из БД, во избежание инжекции вредоносного кода.Вы можете передать значение
trueв методwithHtmlSanitizer(), чтобы сделать доступной HTML санитизацию для содержимого диалога. Также в этом случае параметрContentMode.HTMLдолжен быть передан в методwithContentMode().protected static final String UNSAFE_HTML = "<i>Jackdaws </i><u>love</u> <font size=\"javascript:alert(1)\" " + "color=\"moccasin\">my</font> " + "<font size=\"7\">big</font> <sup>sphinx</sup> " + "<font face=\"Verdana\">of</font> <span style=\"background-color: " + "red;\">quartz</span><svg/onload=alert(\"XSS\")>"; @Inject private Dialogs dialogs; @Subscribe("showMessageDialogOnBtn") public void onShowMessageDialogOnBtnClick(Button.ClickEvent event) { dialogs.createMessageDialog() .withCaption("MessageDialog with Sanitizer") .withMessage(UNSAFE_HTML) .withContentMode(ContentMode.HTML) .withHtmlSanitizer(true) .show(); } @Subscribe("showMessageDialogOffBtn") public void onShowMessageDialogOffBtnClick(Button.ClickEvent event) { dialogs.createMessageDialog() .withCaption("MessageDialog without Sanitizer") .withMessage(UNSAFE_HTML) .withContentMode(ContentMode.HTML) .withHtmlSanitizer(false) .show(); }Значение, переданное в метод
withHtmlSanitizer(), имеет приоритет над значением глобального свойства cuba.web.htmlSanitizerEnabled.Следующие методы позволяют изменить параметры отображения и поведения диалога:
-
withModal()– если переданоfalse, диалог отображается как немодальный, что позволяет пользователю взаимодействовать с другими частями приложения.
-
withCloseOnClickOutside()– если переданоtrueи диалог модальный, то пользователь может закрыть диалог, щелкнув на любой части окна приложения вне диалога.
-
withMaximized()– если переданоtrue, диалог будет развёрнут во весь экран.
-
withWidth(),withHeight()позволяют указать желаемую геометрию диалога.
Например:
@Inject private Dialogs dialogs; @Subscribe("showDialogBtn") protected void onShowDialogBtnClick(Button.ClickEvent event) { dialogs.createMessageDialog() .withCaption("Information") .withMessage("<i>Message<i/>") .withContentMode(ContentMode.HTML) .withCloseOnClickOutside(true) .withWidth("100px") .withHeight("300px") .show(); } -
- Option Dialog
-
Диалог выбора отображает некоторое сообщение и набор кнопок для выбора пользователем. При конструировании данного диалога необходимо передать в метод
withActions()массив действий, для каждого из которых в диалоге создается кнопка. Например:@Inject private Dialogs dialogs; @Subscribe("showDialogBtn") protected void onShowDialogBtnClick(Button.ClickEvent event) { dialogs.createOptionDialog() .withCaption("Confirm") .withMessage("Are you sure?") .withActions( new DialogAction(DialogAction.Type.YES, Action.Status.PRIMARY).withHandler(e -> { doSomething(); }), new DialogAction(DialogAction.Type.NO) ) .show(); }При нажатии на кнопку диалог закрывается и вызывается метод
actionPerform()соответствующего действия.В качестве кнопок со стандартными названиями и значками удобно использовать анонимные классы, унаследованные от
DialogAction. Поддерживаются пять видов действий, определяемых перечислениемDialogAction.Type:OK,CANCEL,YES,NO,CLOSE. Названия соответствующих кнопок извлекаются из главного пакета локализованных сообщений.Второй параметр конструктора
DialogActionиспользуется для задания визуального стиля кнопки, к которой привязано данное действие. СтатусStatus.PRIMARYподсвечивает кнопку и задаёт ей выделение по умолчанию, что обеспечивается стилемc-primary-action. Если для диалога задано несколько действий сStatus.PRIMARY, то фокус и стиль получает только кнопка первого такого действия в списке.
- Input Dialog
-
Диалог ввода - это мощный инструмент, позволяющий конструировать формы ввода с помощью API, который часто может избавить от необходимости создавать экраны для тривиального ввода данных. Он позволяет вводить значения разнообразных типов, валидировать их и предоставлять различные действия для выбора пользователем.
Рассмотрим несколько примеров.
-
Диалог ввода с параметрами стандартных типов и стандартными действиями OK/Cancel:
@Inject private Dialogs dialogs; @Subscribe("showDialogBtn") private void onShowDialogBtnClick(Button.ClickEvent event) { dialogs.createInputDialog(this) .withCaption("Enter some values") .withParameters( InputParameter.stringParameter("name") .withCaption("Name").withRequired(true), (1) InputParameter.doubleParameter("quantity") .withCaption("Quantity").withDefaultValue(1.0), (2) InputParameter.entityParameter("customer", Customer.class) .withCaption("Customer"), (3) InputParameter.enumParameter("status", Status.class) .withCaption("Status") (4) ) .withActions(DialogActions.OK_CANCEL) (5) .withCloseListener(closeEvent -> { if (closeEvent.closedWith(DialogOutcome.OK)) { (6) String name = closeEvent.getValue("name"); (7) Double quantity = closeEvent.getValue("quantity"); Optional<Customer> customer = closeEvent.getOptional("customer"); (8) Status status = closeEvent.getValue("status"); // process entered values... } }) .show(); }1 - задает строковый обязательный параметр. 2 - задает числовой параметр со значением по умолчанию. 3 - задает параметр типа сущность. 4 - задает параметр типа перечисление. 5 - задает набор действий, представляемых кнопками внизу диалога. 6 - в слушателе на закрытие можно определить, какое действие было выбрано пользователем. 7 - событие закрытия содержит введенные значения, которые можно получить по идентификаторам параметров. 8 - можно получить значение, завернутое в Optional. -
Диалог ввода с нестандартным параметром:
@Inject private Dialogs dialogs; @Inject private UiComponents uiComponents; @Subscribe("showDialogBtn") private void onShowDialogBtnClick(Button.ClickEvent event) { dialogs.createInputDialog(this) .withCaption("Enter some values") .withParameters( InputParameter.stringParameter("name").withCaption("Name"), InputParameter.parameter("customer") (1) .withField(() -> { LookupField<Customer> field = uiComponents.create( LookupField.of(Customer.class)); field.setOptionsList(dataManager.load(Customer.class).list()); field.setCaption("Customer"); (2) field.setWidthFull(); return field; }) ) .withActions(DialogActions.OK_CANCEL) .withCloseListener(closeEvent -> { if (closeEvent.closedWith(DialogOutcome.OK)) { String name = closeEvent.getValue("name"); Customer customer = closeEvent.getValue("customer"); (3) // process entered values... } }) .show(); }1 - задает нестандартный параметр. 2 - заголовок нестандартного параметра задается в создаваемом компоненте. 3 - значение нестандартного параметра получается таким же способом, как и стандартного. -
Диалог ввода с нестандартными действиями:
@Inject private Dialogs dialogs; @Subscribe("showDialogBtn") private void onShowDialogBtnClick(Button.ClickEvent event) { dialogs.createInputDialog(this) .withCaption("Enter some values") .withParameters( InputParameter.stringParameter("name").withCaption("Name") ) .withActions( (1) InputDialogAction.action("confirm") .withCaption("Confirm") .withPrimary(true) .withHandler(actionEvent -> { InputDialog dialog = actionEvent.getInputDialog(); String name = dialog.getValue("name"); (2) dialog.closeWithDefaultAction(); (3) // process entered values... }), InputDialogAction.action("refuse") .withCaption("Refuse") .withValidationRequired(false) .withHandler(actionEvent -> actionEvent.getInputDialog().closeWithDefaultAction()) ) .show(); }1 - метод withActions()может принимать массив кастомных действий.2 - в обработчике действия можно получить значение параметра из объекта диалога. 3 - кастомное действие не закрывает диалог само, поэтому это надо сделать в какой-то момент явно. -
Диалог ввода с валидатором:
@Inject private Dialogs dialogs; @Subscribe("showDialogBtn") private void onShowDialogBtnClick(Button.ClickEvent event) { dialogs.createInputDialog(this) .withCaption("Enter some values") .withParameters( InputParameter.stringParameter("name").withCaption("Name"), InputParameter.entityParameter("customer", Customer.class).withCaption("Customer") ) .withValidator(context -> { (1) String name = context.getValue("name"); (2) Customer customer = context.getValue("customer"); if (Strings.isNullOrEmpty(name) && customer == null) { return ValidationErrors.of("Enter name or select a customer"); } return ValidationErrors.none(); }) .withActions(DialogActions.OK_CANCEL) .withCloseListener(closeEvent -> { if (closeEvent.closedWith(DialogOutcome.OK)) { String name = closeEvent.getValue("name"); Customer customer = closeEvent.getValue("customer"); // process entered values... } }) .show(); }1 - кастомный валидатор в данном примере необходим для того, чтобы обеспечить ввод как минимум одного параметра из двух. 2 - значения параметров в валидаторе можно получить через объект контекста. -
Диалог ввода с параметром типа
FileDescriptor:@Inject private Dialogs dialogs; @Subscribe("showDialogBtn") public void onShowDialogBtnClick(Button.ClickEvent event) { dialogs.createInputDialog(this) .withCaption("Select the file") .withParameters( InputParameter.fileParameter("fileField") (1) .withCaption("File")) .withCloseListener(closeEvent -> { if (closeEvent.closedWith(DialogOutcome.OK)) { FileDescriptor fileDescriptor = closeEvent.getValue("fileField"); (2) } }) .show(); }1 - задает параметр типа FileDescriptor.2 - событие закрытия содержит введенное значение, которое можно получить по идентификатору параметра.
-
3.5.7. Уведомления
Уведомления представляют собой небольшие окна, всплывающие в центре или в углу главного окна приложения. Они могут исчезать автоматически, или когда пользователь щелкает по экрану или нажимает Esc.
Для того чтобы показать уведомление, необходимо инжектировать в контроллер экрана интерфейс Notifications и воспользоваться его fluent API. В примере ниже уведомление показывается, когда пользователь щелкает по кнопке:
@Inject
private Notifications notifications;
@Subscribe("sayHelloBtn")
protected void onSayHelloBtnClick(Button.ClickEvent event) {
notifications.create().withCaption("Hello!").show();
}Уведомление может иметь дополнительное описание, которое показывается под заголовком более мелким шрифтом:
@Inject
private Notifications notifications;
@Subscribe("sayHelloBtn")
protected void onSayHelloBtnClick(Button.ClickEvent event) {
notifications.create().withCaption("Greeting").withDescription("Hello World!").show();
}Уведомления могут быть следующих типов:
-
TRAY– уведомление показывается в правом нижнем углу приложения и исчезает автоматически. -
HUMANIZED– стандартное уведомление в центре экрана, исчезает автоматически. -
WARNING– предупреждение. Исчезает при щелчке по экрану. -
ERROR– уведомление об ошибке. Исчезает при щелчке по экрану.
Тип по умолчанию – HUMANIZED. Другой тип можно указать в параметре метода create():
@Inject
private Notifications notifications;
@Subscribe("sayHelloBtn")
protected void onSayHelloBtnClick(Button.ClickEvent event) {
notifications.create(Notifications.NotificationType.TRAY).withCaption("Hello World!").show();
}В тексте можно использовать символы \n для перевода строк. Для отображения HTML необходимо указать соответствующий параметр в методе withContentMode():
@Inject
private Notifications notifications;
@Subscribe("sayHelloBtn")
protected void onSayHelloBtnClick(Button.ClickEvent event) {
notifications.create()
.withContentMode(ContentMode.HTML)
.withCaption("<i>Hello World!</i>")
.show();
}При использовании HTML обязательно экранируйте данные, полученные из БД, во избежание инжекции вредоносного кода.
Вы можете передать значение true в метод withHtmlSanitizer(), чтобы сделать доступной HTML санитизацию для текстового содержимого уведомления. Также в этом случае параметр ContentMode.HTML должен быть передан в метод withContentMode().
protected static final String UNSAFE_HTML = "<i>Jackdaws </i><u>love</u> <font size=\"javascript:alert(1)\" " +
"color=\"moccasin\">my</font> " +
"<font size=\"7\">big</font> <sup>sphinx</sup> " +
"<font face=\"Verdana\">of</font> <span style=\"background-color: " +
"red;\">quartz</span><svg/onload=alert(\"XSS\")>";
@Inject
private Notifications notifications;
@Subscribe("showNotificationOnBtn")
public void onShowNotificationOnBtnClick(Button.ClickEvent event) {
notifications.create()
.withCaption("Notification with Sanitizer")
.withDescription(UNSAFE_HTML)
.withContentMode(ContentMode.HTML)
.withHtmlSanitizer(true)
.show();
}
@Subscribe("showNotificationOffBtn")
public void onShowNotificationOffBtnClick(Button.ClickEvent event) {
notifications.create()
.withCaption("Notification without Sanitizer")
.withDescription(UNSAFE_HTML)
.withContentMode(ContentMode.HTML)
.withHtmlSanitizer(false)
.show();
}Значение, переданное в метод withHtmlSanitizer(), имеет приоритет над значением глобального свойства cuba.web.htmlSanitizerEnabled.
Вы можете установить положение окна уведомления, используя метод withPosition(). Стандартные значения:
-
TOP_RIGHT -
TOP_LEFT -
TOP_CENTER -
MIDDLE_RIGHT -
MIDDLE_LEFT -
MIDDLE_CENTER -
BOTTOM_RIGHT -
BOTTOM_LEFT -
BOTTOM_CENTER
Также вы можете установить задержку в миллисекундах до исчезновения уведомления, используя метод withHideDelayMs(). Значение -1 используется для того, чтобы потребовать от пользователя щелкнуть сообщение.
3.5.8. Фоновые задачи
Механизм фоновых задач предназначен для асинхронного выполнения длительных операций на клиентском уровне без заморозки пользовательского интерфейса.
Использование фоновых задач:
-
Задача описывается как наследник абстрактного класса
BackgroundTask. В конструктор задачи необходимо передать ссылку на контроллер экрана, с которым будет связана задача, и значение таймаута ее выполнения.Если экран указан, то при его закрытии пользователем активная задача будет прервана. Кроме того, задача будет автоматически прервана по истечении указанного таймаута.
Собственно действия, выполняемые задачей, реализуются в методе run().
-
Создается объект управления задачей −
BackgroundTaskHandler. Для этого экземпляр задачи необходимо передать методуhandle()бинаBackgroundWorker. Ссылку наBackgroundWorkerможно получить инжекцией в контроллер экрана, либо статическим методом классаAppBeans. -
Выполняется запуск задачи.
|
Метод |
Пример:
@Inject
protected BackgroundWorker backgroundWorker;
@Override
public void init(Map<String, Object> params) {
// Create task with 10 sec timeout and this screen as owner
BackgroundTask<Integer, Void> task = new BackgroundTask<Integer, Void>(10, this) {
@Override
public Void run(TaskLifeCycle<Integer> taskLifeCycle) throws Exception {
// Do something in background thread
for (int i = 0; i < 5; i++) {
TimeUnit.SECONDS.sleep(1); // time consuming computations
taskLifeCycle.publish(i); // publish current progress to show it in progress() method
}
return null;
}
@Override
public void canceled() {
// Do something in UI thread if the task is canceled
}
@Override
public void done(Void result) {
// Do something in UI thread when the task is done
}
@Override
public void progress(List<Integer> changes) {
// Show current progress in UI thread
}
};
// Get task handler object and run the task
BackgroundTaskHandler taskHandler = backgroundWorker.handle(task);
taskHandler.execute();
}Подробная информация о назначении методов приведена в JavaDocs классов BackgroundTask, TaskLifeCycle, BackgroundTaskHandler.
Ниже приведены моменты, на которые следует обратить внимание:
-
BackgroundTask<T, V>− параметризованный класс:-
T− тип объектов, показывающих прогресс задачи. Объекты этого типа передаются в методprogress()задачи при вызовеTaskLifeCycle.publish()в рабочем потоке. -
V− тип результата задачи, он передается в методdone(). Его также можно получить вызовом методаBackgroundTaskHandler.getResult(), что приведет к ожиданию завершения задачи.
-
-
Метод
canceled()вызывается только в случае управляемой отмены задачи, то есть при вызовеcancel()уTaskHandler. -
Метод
handleTimeoutException()вызывается при истечении таймаута задачи. Если окно, в котором выполняется задача, закрывается, то задача останавливается без оповещения.
-
Метод
run()задачи должен поддерживать возможность прерывания извне. Для этого в долгих процессах желательно периодически проверять флагTaskLifeCycle.isInterrupted(), и соответственно завершать выполнение. Кроме того, нельзя тихо проглатывать исключениеInterruptedException(или вообще все исключения). Вместо этого нужно либо вообще не перехватывать его, либо выполнять корректный выход из метода.-
Метод
isCancelled()возвращаетtrue, если задача была прервана вызовом методаcancel().public String run(TaskLifeCycle<Integer> taskLifeCycle) { for (int i = 0; i < 9_000_000; i++) { if (taskLifeCycle.isCancelled()) { log.info(" >>> Task was cancelled"); break; } else { log.info(" >>> Task is working: iteration #" + i); } } return "Done"; }
-
-
Объекты
BackgroundTaskне имеют состояния. Если при реализации конкретного класса задачи не заводить полей для хранения промежуточных данных, то можно запускать несколько параллельно работающих процессов, используя единственный экземпляр задачи. -
Объект
BackgroundHandlerможно запускать (т.е. вызывать его методexecute()) всего один раз. Если требуется частый перезапуск задачи, то используйте классBackgroundTaskWrapper. -
Для показа пользователю модального окна с прогрессом и кнопкой Отмена используйте классы
BackgroundWorkWindowилиBackgroundWorkProgressWindowс набором статических методов.Для окна можно задать режим отображения прогресса и разрешить или запретить отмену фоновой задачи. -
Если внутри потока задачи необходимо использовать некоторые значения визуальных компонентов, то нужно реализовать их получение в методе
getParams(), который выполняется в потоке UI один раз при запуске задачи. В методе run() эти параметры будут доступны через методgetParams()объектаTaskLifeCycle. -
При возникновении исключительных ситуаций в потоке UI вызывается метод
BackgroundTask.handleException(), в котором можно отобразить ошибку. -
На выполнение фоновых задач влияют свойства приложения cuba.backgroundWorker.maxActiveTasksCount и cuba.backgroundWorker.timeoutCheckInterval.
|
В блоке Web Client фоновые задачи используют технологию HTTP push, предоставляемую фреймворком Vaadin. См. https://vaadin.com/wiki/-/wiki/Main/Working+around+push+issues для получения информации о настройке веб-серверов для использования данной технологии. |
|
Если вы не используете фоновую задачу, но хотите изменять состояние UI-компонентов из не-UI потока, воспользуйтесь методами интерфейса |
3.5.8.1. Примеры использования фоновых задач
- Отображение выполнения и управление фоновой задачей с помощью BackgroundWorkProgressWindow
-
Часто при запуске фоновых задач появляется необходимость отображения простого UI:
-
показать пользователю, что запрошенное действие находится в процессе выполнения,
-
дать пользователю возможность прервать запрошенное долгое действие,
-
показать процент выполнения, если его можно определить.
Для реализации этих потребностей платформа предоставляет вспомогательные классы
BackgroundWorkWindowиBackgroundWorkProgressWindow. Эти классы содержат статические методы, позволяющие связать фоновую задачу с модальным диалогом, отображающим заголовок, описание, индикатор прогресса и возможно кнопкуОтмена. Разница между этими двумя классами в том, чтоBackgroundWorkProgressWindowиспользует определённый индикатор прогресса, и оно должно использоваться только если задача может оценить процент своего выполнения. КлассBackgroundWorkWindowследует использовать для задач, где нельзя оценить прогресс выполнения.В качестве примера рассмотрим следующую задачу по разработке:
-
Некоторый экран содержит таблицу, отображающую список студентов, с включенным множественным выделением.
-
По нажатию кнопки система должна послать письма-напоминания выбранным студентам, без блокировки UI и с возможностью прервать действие.
Пример реализации:
import com.haulmont.cuba.gui.backgroundwork.BackgroundWorkProgressWindow; public class StudentBrowse extends StandardLookup<Student> { @Inject private Table<Student> studentsTable; @Inject private EmailService emailService; @Subscribe("studentsTable.sendEmail") public void onStudentsTableSendEmail(Action.ActionPerformedEvent event) { Set<Student> selected = studentsTable.getSelected(); if (selected.isEmpty()) { return; } BackgroundTask<Integer, Void> task = new EmailTask(selected); BackgroundWorkProgressWindow.show(task, (1) "Sending reminder emails", "Please wait while emails are being sent", selected.size(), true, true (2) ); } private class EmailTask extends BackgroundTask<Integer, Void> { (3) private Set<Student> students; (4) public EmailTask(Set<Student> students) { super(10, TimeUnit.MINUTES, StudentBrowse.this); (5) this.students = students; } @Override public Void run(TaskLifeCycle<Integer> taskLifeCycle) throws Exception { int i = 0; for (Student student : students) { if (taskLifeCycle.isCancelled()) { (6) break; } emailService.sendEmail(student.getEmail(), "Reminder", "Don't forget, the exam is tomorrow", EmailInfo.TEXT_CONTENT_TYPE); i++; taskLifeCycle.publish(i); (7) } return null; } } }1 - запустить задачу и показать модальное окно с прогрессом 2 - установить опции диалога: "размер" индикатора прогресса, пользователь может прервать задачу, показывать прогресс в процентах 3 - прогресс задачи измеряется в Integer(число обработанных элементов таблицы), а тип результата -Void, потому что эта задача не производит результата4 - выбранные элементы таблицы сохраняются в переменную, которая инициализируется в конструкторе задачи. Это необходимо, потому что метод run()исполняется в фоновом потоке и не может обращаться к UI компонентам.5 - установить таймаут равный 10 минутам 6 - периодически проверяется isCancelled(), чтобы задача сразу завершилась после того, как пользователь нажмет кнопкуCancel7 - обновить индикатор прогресса после каждого посланного письма -
- Периодическое фоновое обновление данных экрана с использованием Timer и BackgroundTaskWrapper
-
BackgroundTaskWrapper- это вспомогательный класс, тонкая обертка вокругBackgroundWorker. Он предоставляет простое API для случаев, когда фоновые задачи одного и того же вида запускаются, перезапускаются и отменяются много раз.В качестве примера использования рассмотрим следующую задачу по разработке:
-
Имеется экран мониторинга очередей, в котором нужно отображать и автоматически обновлять какие-то табличные данные.
-
Данные загружаются медленно, и поэтому их нужно загружать в фоне.
-
Нужно отображать на экране время последнего обновления.
-
Данные ограничены простым фильтром (флажок checkbox).
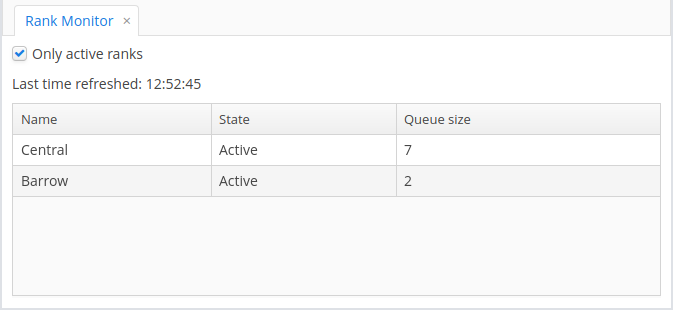
-
Если обновить данные по каким-то причинам не получилось, то экран должен оповестить об этом пользователя:
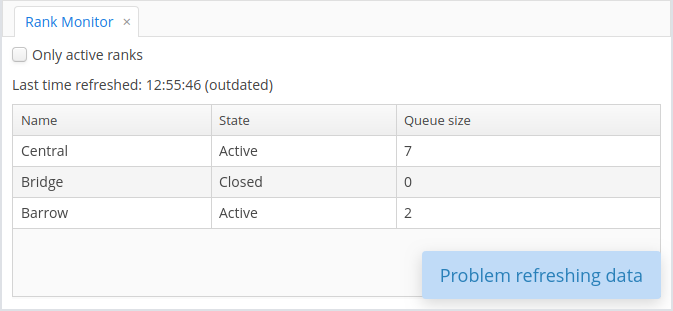
Пример реализации:
@UiController("playground_RankMonitor") @UiDescriptor("rank-monitor.xml") public class RankMonitor extends Screen { @Inject private Notifications notifications; @Inject private Label<String> refreshTimeLabel; @Inject private CollectionContainer<Rank> ranksDc; @Inject private RankService rankService; @Inject private CheckBox onlyActiveBox; @Inject private Logger log; @Inject private TimeSource timeSource; @Inject private Timer refreshTimer; private BackgroundTaskWrapper<Void, List<Rank>> refreshTaskWrapper = new BackgroundTaskWrapper<>(); (1) @Subscribe public void onBeforeShow(BeforeShowEvent event) { refreshTimer.setDelay(5000); refreshTimer.setRepeating(true); refreshTimer.start(); } @Subscribe("onlyActiveBox") public void onOnlyActiveBoxValueChange(HasValue.ValueChangeEvent<Boolean> event) { refreshTaskWrapper.restart(new RefreshScreenTask()); (2) } @Subscribe("refreshTimer") public void onRefreshTimerTimerAction(Timer.TimerActionEvent event) { refreshTaskWrapper.restart(new RefreshScreenTask()); (3) } public class RefreshScreenTask extends BackgroundTask<Void, List<Rank>> { (4) private boolean onlyActive; (5) protected RefreshScreenTask() { super(30, TimeUnit.SECONDS, RankMonitor.this); onlyActive = onlyActiveBox.getValue(); } @Override public List<Rank> run(TaskLifeCycle<Void> taskLifeCycle) throws Exception { List<Rank> data = rankService.loadActiveRanks(onlyActive); (6) return data; } @Override public void done(List<Rank> result) { (7) List<Rank> mutableItems = ranksDc.getMutableItems(); mutableItems.clear(); mutableItems.addAll(result); String hhmmss = new SimpleDateFormat("HH:mm:ss").format(timeSource.currentTimestamp()); refreshTimeLabel.setValue("Last time refreshed: " + hhmmss); } @Override public boolean handleTimeoutException() { (8) displayRefreshProblem(); return true; } @Override public boolean handleException(Exception ex) { (9) log.debug("Auto-refresh error", ex); displayRefreshProblem(); return true; } private void displayRefreshProblem() { if (!refreshTimeLabel.getValue().endsWith("(outdated)")) { refreshTimeLabel.setValue(refreshTimeLabel.getValue() + " (outdated)"); } notifications.create(Notifications.NotificationType.TRAY) .withCaption("Problem refreshing data") .withHideDelayMs(10_000) .show(); } } }1 - создать экземпляр BackgroundTaskWrapperчерез конструктор без параметров; для каждой итерации будет передан новый экземпляр задачи2 - немедленно запустить фоновое обновление данных после смены состояния флажка 3 - каждое срабатывание таймера запускает фоновое обновление данных 4 - задача не публикует ход прогресса, поэтому тип прогресса Void; задача производит результат с типомList<Rank>5 - состояние флажка сохраняется в переменную, которая инициализируется в конструкторе задачи. Это необходимо, потому что метод run()выполняется в фоновом потоке и не может обращаться к UI компонентам.6 - вызов пользовательского сервиса для загрузки данных (это долгое действие и исполняется в фоновом потоке) 7 - применить успешно полученный результат к компонентам экрана 8 - обновить UI в особом случае, если загрузка данных не выполнилась за время таймаута: показать уведомление в углу экрана 9 - проинформировать пользователя, показав уведомление, если загрузка данных завершилась исключением -
3.5.9. Темы приложения
Тема служит для управления визуальным представлением приложения.
Тема веб-приложения состоит из файлов SCSS и других ресурсов, в том числе файлов изображений.
Платформа предоставляет несколько стандартных тем, которые "из коробки" доступны для использования в проекте. Расширение темы позволяет модифицировать существующую тему на уровне проекта. Вы также можете создавать свои собственные темы, которые будут доступны наряду со стандартными.
Если требуется использовать тему в нескольких проектах, ее можно включить в компонент приложения, или создать JAR с темой для повторного использования.
3.5.9.1. Использование существующих тем
Платформа включает в себя три готовые темы: Hover, Halo и Havana. Приложение будет по умолчанию использовать ту из них, которая указана в свойстве приложения cuba.web.theme.
Пользователь может выбрать другую доступную тему в стандартном экране Help → Settings. Если вы не хотите, чтобы пользователи имели возможность сами выбирать тему, зарегистрируйте экран settings в файле web-screens.xml проекта с параметром changeThemeEnabled = false:
<screen id="settings" template="/com/haulmont/cuba/web/app/ui/core/settings/settings-window.xml">
<param name="changeThemeEnabled" value="false"/>
</screen>3.5.9.2. Расширение существующей темы
Существующая в платформе тема может быть изменена в проекте приложения. В измененной теме можно сделать следующее:
-
Изменить изображения для фирменного стиля.
-
Добавить изображения для использования в визуальных компонентах.
-
Создать новые стили и использовать их в атрибутах stylename визуальных компонентов. Для этого требуется знание CSS.
-
Изменить существующие в платформе стили компонентов.
-
Изменить общие параметры, такие как цвет фона, отступы, промежутки и т.д.
- Структура темы и скрипты сборки
-
Тема описывается в файлах SCSS. Для изменения (расширения) темы в проекте необходимо создать специальную файловую структуру в модуле web.
Это удобно сделать с помощью CUBA Studio: В главном меню нажмите CUBA > Advanced > Manage themes > Create theme extension. В диалоговом окне выберите тему, которую вы хотите расширить. Другой способ - использовать команду
themeв CUBA CLI.В результате в проекте будет создана следующая структура каталогов (для расширения темы Halo):
themes/ halo/ branding/ app-icon-login.png app-icon-menu.png com.company.application/ app-component.scss halo-ext.scss halo-ext-defaults.scss favicon.ico styles.scssКроме того, скрипт сборки build.gradle будет дополнен задачей
buildScssThemes, автоматически запускаемой при сборке модуля web. Опциональная задача deployThemes может быть использована для быстрого применения изменений в темах на работающем приложении.Если ваше приложение включает в себя компонент с расширением темы и вы хотите применить это расширение ко всему приложению, в этом случае необходимо создать расширение темы и для базового проекта. Подробнее о наследовании тем смотрите в разделе Наследование тем из компонентов приложения.
- Изменение фирменного стиля
-
Можно настроить некоторые параметры фирменного стиля (branding): значки и заголовки окна логина и главного окна, значок вебсайта
favicon.ico.Для использования собственных изображений, замените соответствующие файлы в каталоге
modules/web/themes/halo/branding.Чтобы задать заголовки главного окна, окна логина и текст приглашения окна логина, измените их в главном пакете сообщений модуля web (то есть в файле
modules/web/<root_package>/web/messages.propertiesи его вариантах для разных локалей). Использование пакетов сообщений дает возможность использовать разные файлы изображений для разных локалей пользователей. Пример содержимого файлаmessages.properties:application.caption = MyApp application.logoImage = branding/myapp-menu.png loginWindow.caption = MyApp Login loginWindow.welcomeLabel = Welcome to MyApp! loginWindow.logoImage = branding/myapp-login.pngПуть к
favicon.icoуказывать не нужно, он должен обязательно находится в корне каталога с именем темы.
- Добавление шрифтов
-
В приложение можно добавить собственные шрифты. Для добавления семейства шрифтов импортируйте его в первой строке файла
styles.scss, например:@import url(http://fonts.googleapis.com/css?family=Roboto);
- Создание новых стилей
-
Рассмотрим пример установки желтого цвета фона для поля, отображающего название заказчика.
В XML-дескрипторе экрана определите компонент form:
<form id="form" dataContainer="customerDc"> <column width="250px"> <textField id="nameField" property="name" stylename="name-field"/> <textField id="address" property="address"/> </column> </form>В атрибуте stylename задайте имя стиля.
В файле
halo-ext.scssдобавьте определение нового стиля в mixinhalo-ext:@mixin com_company_application-halo-ext { .name-field { background-color: lightyellow; } }После пересборки проекта поля будут выглядеть следующим образом:
- Изменение существующих стилей компонентов
-
Для изменения параметров стиля существующих компонентов необходимо добавить соответствующий код CSS в mixin
halo-extфайлаhalo-ext.scss. Например, для того, чтобы пункты главного меню отображались жирным шрифтом, содержимое файлаhalo-ext.scssдолжно быть следующим:@mixin com_company_application-halo-ext { .v-menubar-menuitem-caption { font-weight: bold; } }
- Изменение общих параметров
-
Темы содержат переменные SCSS, которые управляют цветом фона, размерами компонентов, отступами и пр.
Рассмотрим пример расширения темы Halo, так как она основана на теме Valo фреймворка Vaadin, и предоставляет максимальные возможности адаптации.
Файл
themes/halo/halo-ext-defaults.scssпредназначен для размещения в нем переменных темы. Большинство переменных Halo соответствует описанным в документации по Valo, ниже приведены основные:$v-background-color: #fafafa; /* component background colour */ $v-app-background-color: #e7ebf2; /* application background colour */ $v-panel-background-color: #fff; /* panel background colour */ $v-focus-color: #3b5998; /* focused element colour */ $v-error-indicator-color: #ed473b; /* empty required fields colour */ $v-line-height: 1.35; /* line height */ $v-font-size: 14px; /* font size */ $v-font-weight: 400; /* font weight */ $v-unit-size: 30px; /* base theme size, defines the height for buttons, fields and other elements */ $v-font-size--h1: 24px; /* h1-style Label size */ $v-font-size--h2: 20px; /* h2-style Label size */ $v-font-size--h3: 16px; /* h3-style Label size */ /* margins for containers */ $v-layout-margin-top: 10px; $v-layout-margin-left: 10px; $v-layout-margin-right: 10px; $v-layout-margin-bottom: 10px; /* spacing between components in a container (if enabled) */ $v-layout-spacing-vertical: 10px; $v-layout-spacing-horizontal: 10px; /* whether filter search button should have "friendly" style*/ $cuba-filter-friendly-search-button: true; /* whether button that has primary action or marked as primary itself should be highlighted*/ $cuba-highlight-primary-action: false; /* basic table and datagrid settings */ $v-table-row-height: 30px; $v-table-header-font-size: 13px; $v-table-cell-padding-horizontal: 7px; $v-grid-row-height $v-grid-row-selected-background-color $v-grid-cell-padding-horizontal /* input field focus style */ $v-focus-style: inset 0px 0px 5px 1px rgba($v-focus-color, 0.5); /* required fields focus style */ $v-error-focus-style: inset 0px 0px 5px 1px rgba($v-error-indicator-color, 0.5); /* animation for elements is enabled by default */ $v-animations-enabled: true; /* popup window animation is disabled by default */ $v-window-animations-enabled: false; /* inverse header is controlled by cuba.web.useInverseHeader property */ $v-support-inverse-menu: true; /* show "required" indicators for components */ $v-show-required-indicators: false !default;Пример содержимого файла
halo-ext-defaults.scssдля темы с темным фоном и немного уменьшенными отступами:$v-background-color: #444D50; $v-font-size--h1: 22px; $v-font-size--h2: 18px; $v-font-size--h3: 16px; $v-layout-margin-top: 8px; $v-layout-margin-left: 8px; $v-layout-margin-right: 8px; $v-layout-margin-bottom: 8px; $v-layout-spacing-vertical: 8px; $v-layout-spacing-horizontal: 8px; $v-table-row-height: 25px; $v-table-header-font-size: 13px; $v-table-cell-padding-horizontal: 5px; $v-support-inverse-menu: false;В следующем примере набор переменных делает тему Halo похожей на старую тему Havana, удаленную из фреймворка версии 7:
$cuba-menubar-background-color: #315379; $cuba-menubar-border-color: #315379; $v-table-row-height: 25px; $v-selection-color: rgb(77, 122, 178); $v-table-header-font-size: 12px; $v-textfield-border: 1px solid #A5C4E0; $v-selection-item-selection-color: #4D7AB2; $v-app-background-color: #E3EAF1; $v-font-size: 12px; $v-font-weight: 400; $v-unit-size: 25px; $v-border-radius: 0px; $v-border: 1px solid #9BB3D3 !default; $v-font-family: Verdana,tahoma,arial,geneva,helvetica,sans-serif,"Trebuchet MS"; $v-panel-background-color: #ffffff; $v-background-color: #ffffff; $cuba-menubar-menuitem-text-color: #ffffff; $cuba-app-menubar-padding-top: 8px; $cuba-app-menubar-padding-bottom: 8px; $cuba-menubar-text-color: #ffffff; $cuba-menubar-submenu-padding: 1px;
- Изменение заголовка приложения
-
Тема Halo поддерживает свойство приложения cuba.web.useInverseHeader, управляющее цветом заголовка приложения. По умолчанию это свойство установлено в
true, что задает темный (инверсный) заголовок. В проекте можно не изменяя темы сделать заголовок светлым, установив данное свойство вfalse.
3.5.9.3. Создание новой темы
В проекте можно создать одну или несколько новых тем и дать возможность пользователям выбирать среди них подходящую. Создание новой темы позволяет также переопределять переменные файла *-theme.properties, задающие некоторые параметры, требуемые на стороне сервера:
-
Размеры диалоговых окон по умолчанию.
-
Ширина полей ввода по умолчанию.
-
Размеры некоторых компонентов (Filter, FileMultiUploadField).
-
Соответствие между именами значков и именами констант перечисления
com.vaadin.server.FontAwesomeдля использования элементов шрифта Font Awesome в стандартных действиях и экранах платформы при включенном свойстве cuba.web.useFontIcons.
Новые темы можно легко создавать в CUBA Studio, а также в CUBA CLI или вручную. Рассмотрим все три способа создания новой темы на примере темы Hover Dark.
- Создание новой темы в CUBA Studio:
-
-
В главном меню нажмите CUBA > Advanced > Manage themes > Create custom theme. Введите имя новой темы: hover-dark. Выберите hover в выпадающем списке Base theme.
Требуемая структура файлов темы будет автоматически создана в модуле web. Модуль
webThemesModuleи его конфигурация будут автоматически добавлены в скриптыsettings.gradleи build.gradle. Сгенерированная задача сборкиdeployThemesпозволит применять изменения в теме без перезапуска сервера приложения.
-
- Создание темы вручную:
-
-
Создайте следующую файловую структуру в модуле web проекта:
web/ src/ themes/ hover-dark/ branding/ app-icon-login.png app-icon-menu.png com.haulmont.cuba/ app-component.scss favicon.ico hover-dark.scss hover-dark-defaults.scss styles.scss -
Содержимое файла
app-component.scss:@import "../hover-dark"; @mixin com_haulmont_cuba { @include hover-dark; } -
Содержимое файла
hover-dark.scss:@import "../hover/hover"; @mixin hover-dark { @include hover; } -
Содержимое файла
styles.scss:@import "hover-dark-defaults"; @import "hover-dark"; .hover-dark { @include hover-dark; } -
Создайте файл свойств
hover-dark-theme.propertiesв подкаталоге web модуля web:@include=com/haulmont/cuba/hover-theme.properties -
Добавьте модуль
webThemesModuleв файлsettings.gradle:include(":${modulePrefix}-global", ":${modulePrefix}-core", ":${modulePrefix}-web", ":${modulePrefix}-web-themes") //... project(":${modulePrefix}-web-themes").projectDir = new File(settingsDir, 'modules/web/themes') -
Добавьте конфигурацию модуля
webThemesModuleв файл build.gradle:def webThemesModule = project(":${modulePrefix}-web-themes") configure(webThemesModule) { apply(plugin: 'java') apply(plugin: 'maven') apply(plugin: 'cuba') appModuleType = 'web-themes' buildDir = file('../build/scss-themes') sourceSets { main { java { srcDir '.' } resources { srcDir '.' } } } } -
Наконец, создайте задачу gradle
deployThemesв файлеbuild.gradle, чтобы изменения в файлах темы применялись без перезапуска сервера приложения:configure(webModule) { // . . . task buildScssThemes(type: CubaWebScssThemeCreation) task deployThemes(type: CubaDeployThemeTask, dependsOn: buildScssThemes) assemble.dependsOn buildScssThemes }
-
- Создание темы с помощью CUBA CLI:
-
-
Выполните команду
theme, далее выберите тему hover.Файловая структура с расширением выбранной темы будет создана в модуле web проекта.
-
Модифицируйте сгенерированную файловую структуру и содержимое файлов, чтобы они соответствовали примерам выше.
-
Создайте файл
hover-dark-theme.propertiesв подкаталоге web модуля web:@include=com/haulmont/cuba/hover-theme.properties
Задачи сборки темы в файлах
build.gradleиsettings.gradleбудут созданы автоматически через CLI. -
См. также Создание темы Facebook.
- Изменение server-side параметров темы
-
В теме Halo по умолчанию (при включенном свойстве приложения cuba.web.useFontIcons) значки стандартных действий и экранов платформы загружаются из шрифта Font Awesome. В этом случае можно заменить стандартный значок, задав в файле
<your_theme>-theme.propertiesнужное соответствие между именем значка и именем элемента шрифта. Например, чтобы использовать значок "плюс" для действияcreateв новой теме Facebook, содержимое файлаweb/src/facebook-theme.propertiesдолжно быть следующим:@include=com/haulmont/cuba/halo-theme.properties cuba.web.icons.create.png = font-icon:PLUSФрагмент стандартного экрана списка пользователей в теме Facebook и с измененным значком действия
create:
3.5.9.3.1. Создание темы Hover Dark
В этой главе мы рассмотрим создание тёмной вариации стандартной темы Hover - Hover Dark. Пример приложения, в котором использована эта тема, доступен на GitHub.
-
Создайте новую тему hover-dark в вашем проекте, следуя инструкциям из раздела Создание новой темы.
Требуемая структура файлов темы будет автоматически создана в модуле web. Модуль
webThemesModuleи его конфигурация будут автоматически добавлены в скриптыsettings.gradleи build.gradle. -
Переопределите стандартные значения переменных темы в файле
hover-dark-defaults.scss; иными словами, замените содержимое файла следующим:@import "../hover/hover-defaults"; $v-app-background-color: #262626; $v-background-color: lighten($v-app-background-color, 12%); $v-border: 1px solid (v-tint 0.8); $font-color: valo-font-color($v-background-color, 0.85); $v-button-font-color: $font-color; $v-font-color: $font-color; $v-link-font-color: lighten($v-focus-color, 15%); $v-link-text-decoration: none; $v-textfield-background-color: $v-background-color; $cuba-hover-color: #75a4c1; $cuba-maintabsheet-tabcontainer-background-color: $v-app-background-color; $cuba-menubar-background-color: lighten($v-app-background-color, 4%); $cuba-tabsheet-tab-caption-selected-color: $v-font-color; $cuba-window-modal-header-background: $v-background-color; $cuba-menubar-menuitem-border-radius: 0; -
С помощью свойства cuba.themeConfig вы можете настроить видимость конкретных тем в меню приложения:
cuba.themeConfig = com/haulmont/cuba/hover-theme.properties /com/company/demo/web/hover-dark-theme.properties
В результате, в приложении будут доступны две темы - стандартная тема Hover и её тёмная вариация.
3.5.9.3.2. Создание темы Facebook
Рассмотрим пример создания на основе Halo новой темы Facebook, напоминающей интерфейс сайта известной социальной сети.
-
В главном меню Studio нажмите CUBA > Advanced > Manage themes > Create custom theme. В диалоговом окне введите имя новой темы -
facebook, выберитеhaloбазовой темой и нажмите Create. В проекте будет создана структура новой темы:themes/ facebook/ branding/ app-icon-login.png app-icon-menu.png com.haulmont.cuba/ app-component.scss // cuba app-component include facebook.scss // main theme file facebook-defaults.scss // main theme variables favicon.ico styles.scss // entry point of SCSS build procedureФайл
styles.scssсодержит список ваших тем:@import "facebook-defaults"; @import "facebook"; .facebook { @include facebook; }Содержимое файла
facebook.scss:@import "../halo/halo"; @mixin facebook { @include halo; }Содержимое файла
app-component.scssиз каталогаcom.haulmont.cuba:@import "../facebook"; @mixin com_haulmont_cuba { @include facebook; } -
Теперь отредактируйте переменные темы в файле
facebook-defaults.scss. Это можно сделать в Studio, нажав CUBA > Advanced > Manage themes > Edit Facebook theme variables:@import "../halo/halo-defaults"; $v-background-color: #fafafa; $v-app-background-color: #e7ebf2; $v-panel-background-color: #fff; $v-focus-color: #3b5998; $v-border-radius: 0; $v-textfield-border-radius: 0; $v-font-family: Helvetica, Arial, 'lucida grande', tahoma, verdana, arial, sans-serif; $v-font-size: 14px; $v-font-color: #37404E; $v-font-weight: 400; $v-link-text-decoration: none; $v-shadow: 0 1px 0 (v-shade 0.2); $v-bevel: inset 0 1px 0 v-tint; $v-unit-size: 30px; $v-gradient: v-linear 12%; $v-overlay-shadow: 0 3px 8px v-shade, 0 0 0 1px (v-shade 0.7); $v-shadow-opacity: 20%; $v-selection-overlay-padding-horizontal: 0; $v-selection-overlay-padding-vertical: 6px; $v-selection-item-border-radius: 0; $v-line-height: 1.35; $v-font-size: 14px; $v-font-weight: 400; $v-unit-size: 25px; $v-font-size--h1: 22px; $v-font-size--h2: 18px; $v-font-size--h3: 16px; $v-layout-margin-top: 8px; $v-layout-margin-left: 8px; $v-layout-margin-right: 8px; $v-layout-margin-bottom: 8px; $v-layout-spacing-vertical: 8px; $v-layout-spacing-horizontal: 8px; $v-table-row-height: 25px; $v-table-header-font-size: 13px; $v-table-cell-padding-horizontal: 5px; $v-focus-style: inset 0px 0px 1px 1px rgba($v-focus-color, 0.5); $v-error-focus-style: inset 0px 0px 1px 1px rgba($v-error-indicator-color, 0.5); -
При необходимости, в файле
facebook-theme.propertiesв подкаталогеsrcмодуля web можно переопределять server-side переменные темы, заданные в файлеhalo-theme.propertiesплатформы. -
Новая тема была автоматически добавлена в файл
web-app.properties:cuba.web.theme = facebook cuba.themeConfig = com/haulmont/cuba/halo-theme.properties /com/company/application/web/facebook-theme.propertiesСвойство приложения cuba.themeConfig определяет, какие темы будут доступны в меню приложения Settings.
-
Пересоберите приложение и запустите сервер. Теперь при первом входе пользователь увидит приложение в теме Facebook, и в окне Help → Settings сможет выбирать между темами Facebook, Halo и Havana.
3.5.9.4. Наследование тем из компонентов приложения
Если ваш проект включает в себя компонент с новой темой, вы можете настроить использование этой темы во всём проекте.
Чтобы использовать тему из компонента без изменений, просто добавьте её в свойство приложения cuba.themeConfig:
cuba.web.theme = {theme-name}
cuba.themeConfig = com/haulmont/cuba/hover-theme.properties /com/company/{app-component-name}/web/{theme-name}-theme.propertiesОднако, чтобы переопределить некоторые переменные из родительской темы, сначала необходимо создать расширение темы в основном проекте.
В этом примере мы вновь используем тему facebook из предыдущего примера.
-
Создайте тему
facebookдля компонента приложения, следуя инструкции из раздела Создание новой темы. -
Установите компонент, используя меню Studio, как описано в разделе Пример создания и использования компонента.
-
Расширьте тему
haloв проекте, в котором используется ваш компонент. -
В IDE переименуйте все вхождения
haloв каталогеthemes, включая имена файлов, вfacebook. В итоге у вас должна получиться следующая структура:themes/ facebook/ branding/ app-icon-login.png app-icon-menu.png com.company.application/ app-component.scss facebook-ext.scss facebook-ext-defaults.scss favicon.ico styles.scss -
Файл
app-component.scssгруппирует модификации темы в конкретном компоненте приложения. В процессе сборки SCSS плагин Gradle автоматически находит компоненты и включает их в генерируемый файлmodules/web/build/themes-tmp/VAADIN/themes/{theme-name}/app-components.scss.По умолчанию переменные темы из
{theme-name}-ext-defaultsне наследуются в проект. Чтобы изменить это поведение, вручную добавьте включение в файлapp-component.scss:@import "facebook-ext"; @import "facebook-ext-defaults"; @mixin com_company_application { @include com_company_application-facebook-ext; }На этом этапе тема
facebookуже импортирована в проект из компонента приложения. -
Теперь вы можете использовать файлы
facebook-ext.scssиfacebook-ext-defaults.scssиз пакетаcom.company.application, чтобы переопределить переменные темы компонента и модифицировать её для конкретного проекта. -
Добавьте свойства приложения в файл
web-app.properties, чтобы сделать темуfacebookдоступной в меню приложения Settings. Используйте относительный путь для ссылки на файлfacebook-theme.properties.cuba.web.theme = facebook cuba.themeConfig = com/haulmont/cuba/hover-theme.properties /com/company/{app-component-name}/web/facebook-theme.properties
|
Если при сборке тем возникли проблемы, проверьте каталог |
3.5.9.5. Повторное использование тем
Любую тему можно создать и использовать отдельно от компонента приложения. Для создания темы, которую можно использовать повторно, необходимо создать с нуля отдельный Java-проект и собрать его в единый JAR-файл. Ниже приведена инструкция, как подготовить тему facebook из предыдущих примеров для многократного использования.
-
Создайте в IDE новый Java-проект, содержащий файлы SCSS и свойства темы, со следующей структурой:
halo-facebook/ src/ //sources root halo-facebook/ com.haulmont.cuba/ app-component.scss halo-facebook.scss halo-facebook-defaults.scss halo-facebook-theme.properties styles.scssЭтот проект также доступен на GitHub.
-
Содержание скрипта
build.gradle:allprojects { group = 'com.haulmont.theme' version = '0.1' } apply(plugin: 'java') apply(plugin: 'maven') sourceSets { main { java { srcDir 'src' } resources { srcDir 'src' } } } -
Содержание файла
settings.gradle:rootProject.name = 'halo-facebook' -
Содержание файла
app-component.scss:@import "../halo-facebook"; @mixin com_haulmont_cuba { @include halo-facebook; } -
Содержание файла
halo-facebook.scss:@import "../@import "../"; @mixin halo-facebook { @include halo; } -
Содержание файла
halo-facebook-defaults.scss:@import "../halo/halo-defaults"; $v-background-color: #fafafa; $v-app-background-color: #e7ebf2; $v-panel-background-color: #fff; $v-focus-color: #3b5998; $v-border-radius: 0; $v-textfield-border-radius: 0; $v-font-family: Helvetica, Arial, 'lucida grande', tahoma, verdana, arial, sans-serif; $v-font-size: 14px; $v-font-color: #37404E; $v-font-weight: 400; $v-link-text-decoration: none; $v-shadow: 0 1px 0 (v-shade 0.2); $v-bevel: inset 0 1px 0 v-tint; $v-unit-size: 30px; $v-gradient: v-linear 12%; $v-overlay-shadow: 0 3px 8px v-shade, 0 0 0 1px (v-shade 0.7); $v-shadow-opacity: 20%; $v-selection-overlay-padding-horizontal: 0; $v-selection-overlay-padding-vertical: 6px; $v-selection-item-border-radius: 0; $v-line-height: 1.35; $v-font-size: 14px; $v-font-weight: 400; $v-unit-size: 25px; $v-font-size--h1: 22px; $v-font-size--h2: 18px; $v-font-size--h3: 16px; $v-layout-margin-top: 8px; $v-layout-margin-left: 8px; $v-layout-margin-right: 8px; $v-layout-margin-bottom: 8px; $v-layout-spacing-vertical: 8px; $v-layout-spacing-horizontal: 8px; $v-table-row-height: 25px; $v-table-header-font-size: 13px; $v-table-cell-padding-horizontal: 5px; $v-focus-style: inset 0px 0px 1px 1px rgba($v-focus-color, 0.5); $v-error-focus-style: inset 0px 0px 1px 1px rgba($v-error-indicator-color, 0.5); $v-show-required-indicators: true; -
Содержание файла
halo-facebook-theme.properties:@include=com/haulmont/cuba/halo-theme.properties
-
-
Соберите и установите проект с помощью задачи Gradle:
gradle assemble install -
Теперь добавьте эту тему в свой CUBA-проект в качестве зависимости Maven в двух конфигурациях: themes и compile, добавив в
build.gradleследующие строки:configure(webModule) { //... dependencies { provided(servletApi) compile(guiModule) compile('com.haulmont.theme:halo-facebook:0.1') themes('com.haulmont.theme:halo-facebook:0.1') } //... }Если вы установили тему локально, не забудьте добавить локальный репозиторий Maven к списку используемых в проекте репозиториев в окне Studio Project Properties.
-
Чтобы унаследовать тему и добавить модификации для конкретного проекта, необходимо сначала расширить эту тему. Расширьте тему
haloи переименуйте каталогthemes/haloвthemes/halo-facebook:themes/ halo-facebook/ branding/ app-icon-login.png app-icon-menu.png com.company.application/ app-component.scss halo-ext.scss halo-ext-defaults.scss favicon.ico styles.scss -
Внесите следующие изменения в файл
styles.scss:@import "halo-facebook-defaults"; @import "com.company.application/halo-ext-defaults"; @import "app-components"; @import "com.company.application/halo-ext"; .halo-facebook { // include auto-generated app components SCSS @include app_components; @include com_company_application-halo-ext; } -
Последним шагом будет добавление ссылки на
halo-facebook-theme.propertiesв файлеweb-app.properties:cuba.themeConfig = com/haulmont/cuba/hover-theme.properties /halo-facebook/halo-facebook-theme.properties
Теперь тема halo-facebook будет доступна в меню приложения Help > Settings. Вы также можете установить тему по умолчанию, используя свойство приложения cuba.web.theme.
3.5.10. Значки
В расширенную тему можно также добавить файлы значков для использования в свойствах icon действий и визуальных компонентов, например Button.
Например, чтобы добавить в расширение темы Halo значок, достаточно в описанный в разделе Расширение существующей темы каталог modules/web/themes/halo добавить файл значка (желательно в некоторый подкаталог):
themes/
halo/
icons/
cool-icon.pngВ следующих разделах рассматривается использование значков в визуальных компонентах и добавление значков из произвольных библиотек шрифтов.
3.5.10.1. Наборы значков
Наборы значков (icon sets) позволяют отвязать использование значков в визуальных компонентах от конкретных путей к изображениям в теме или констант элементов шрифтов. Кроме того, они упрощают переопределение значков, используемых в UI, унаследованном от компонентов приложения.
Наборы значков - это перечисления (enumerations), каждый элемент которых соответствует некоторому значку. Класс перечисления должен реализовывать интерфейс Icons.Icon с единственным параметром - строкой, задающей источник получения значка, например, font-icon:CHECK или icons/myawesomeicon.png. Для получения источника значка следует использовать бин платформы Icons.
Наборы значков следует создавать в модуле web или gui приложения. Имена элементов перечисления в наборе должны соответствовать регулярному выражению [A-Z]_, то есть содержать только заглавные буквы и нижнее подчёркивание.
Пример набора значков:
public enum MyIcon implements Icons.Icon {
COOL_ICON("icons/cool-icon.png"), (1)
OK("icons/my-ok.png"); (2)
protected String source;
MyIcon(String source) {
this.source = source;
}
@Override
public String source() {
return source;
}
@Override
public String iconName() {
return name();
}
}| 1 | - добавление нового значка, |
| 2 | - переопределение стандартного значка CUBA. |
Наборы значков необходимо зарегистрировать в свойстве приложения cuba.iconsConfig, например:
web-app.properties
cuba.iconsConfig = +com.company.demo.gui.icons.MyIcon|
Чтобы наборы значков из компонента приложения были доступны в проекте, необходимо добавить данное свойство приложения в дескриптор компонента. |
Теперь вы можете использовать значки из созданного набора, декларативно указывая имя соответствующего элемента enum в XML-дескрипторе:
<button icon="COOL_ICON"/>или программно в контроллере экрана:
button.setIconFromSet(MyIcon.COOL_ICON);Используя специальные префиксы, вы можете декларативно использовать значки из разных источников:
-
theme- значок из темы приложения, например,web/themes/halo/awesomeFolder/superIcon.png:<button icon="theme:awesomeFolder/superIcon.png"/> -
file- файл с изображением:<button icon="file:D:/superIcon.png"/> -
classpath- значок, расположенный в classpath, например,com/company/demo/web/superIcon.png<button icon="classpath:/com/company/demo/web/superIcon.png"/>
В платформе доступен уже готовый набор значков - CubaIcon. Он включает в себя практически все значки из библиотеки FontAwesome, а также собственные значки CUBA. Значки из этого набора по умолчанию можно выбрать в редакторе Studio:
3.5.10.2. Добавление значков из других библиотек шрифтов
Для более тонкой настройки расширенной темы можно создать значки, встроенные в шрифты, либо использовать готовые внешние библиотеки значков.
-
Создайте в модуле web класс
enum, реализующий интерфейсcom.vaadin.server.FontIcon, в который поместите новые значки:import com.vaadin.server.FontIcon; import com.vaadin.server.GenericFontIcon; public enum IcoMoon implements FontIcon { HEADPHONES(0XE900), SPINNER(0XE905); public static final String FONT_FAMILY = "IcoMoon"; private int codepoint; IcoMoon(int codepoint) { this.codepoint = codepoint; } @Override public String getFontFamily() { return FONT_FAMILY; } @Override public int getCodepoint() { return codepoint; } @Override public String getHtml() { return GenericFontIcon.getHtml(FONT_FAMILY, codepoint); } @Override public String getMIMEType() { throw new UnsupportedOperationException(FontIcon.class.getSimpleName() + " should not be used where a MIME type is needed."); } public static IcoMoon fromCodepoint(final int codepoint) { for (IcoMoon f : values()) { if (f.getCodepoint() == codepoint) { return f; } } throw new IllegalArgumentException("Codepoint " + codepoint + " not found in IcoMoon"); } } -
Добавьте новые стили и файлы шрифта в расширение темы. Рекомендуется создать отдельную папку
fontsв главном каталоге расширения темы, например,modules/web/themes/halo/com.company.demo/fonts. Поместите в неё стили и файлы шрифтов в своих собственных подпапках, например,fonts/icomoon.Файлы шрифта включают в себя набор следующих расширений:
-
.eot, -
.svg, -
.ttf, -
.woff.Использованный в этом примере набор шрифтов
icomoonиз открытой библиотеки представлен в виде 4 файлов:icomoon.eot,icomoon.svg,icomoon.ttf,icomoon.woff, которые используются совместно.
-
-
Создайте файл стилей, в который включите
@font-faceи CSS класс со стилем для значка. Ниже представлен пример файлаicomoon.scss, где имя классаIcoMoonсоответствует значению, возвращаемому методомFontIcon#getFontFamily:@mixin icomoon-style { /* use !important to prevent issues with browser extensions that change fonts */ font-family: 'icomoon' !important; speak: none; font-style: normal; font-weight: normal; font-variant: normal; text-transform: none; line-height: 1; /* Better Font Rendering =========== */ -webkit-font-smoothing: antialiased; -moz-osx-font-smoothing: grayscale; } @font-face { font-family: 'icomoon'; src:url('icomoon.eot?hwgbks'); src:url('icomoon.eot?hwgbks#iefix') format('embedded-opentype'), url('icomoon.ttf?hwgbks') format('truetype'), url('icomoon.woff?hwgbks') format('woff'), url('icomoon.svg?hwgbks#icomoon') format('svg'); font-weight: normal; font-style: normal; } .IcoMoon { @include icomoon-style; } -
Подключите файл стилей шрифта в
halo-ext.scssили другой файл расширения данной темы:@import "fonts/icomoon/icomoon"; -
Затем создайте новый набор значков, то есть enum, реализующий интерфейс
Icons.Icon:import com.haulmont.cuba.gui.icons.Icons; public enum IcoMoonIcon implements Icons.Icon { HEADPHONES("ico-moon:HEADPHONES"), SPINNER("ico-moon:SPINNER"); protected String source; IcoMoonIcon(String source) { this.source = source; } @Override public String source() { return source; } @Override public String iconName() { return name(); } } -
Создайте новый
IconProvider.Для работы с наборами значков в платформе есть механизм, основанный на использовании
IconProviderиIconResolver.IconProvider- это интерфейс-маркер, доступный только в веб-модуле, который предоставляет доступ к ресурсу (com.vaadin.server.Resource) по переданному пути.Бин
IconResolverпроходится по всем бинам, реализующимIconProvider, в поисках того, кто может предоставить ресурс к данному значку.Чтобы использовать этот механизм, необходимо создать собственную реализацию
IconProvider, например, так:import com.haulmont.cuba.web.gui.icons.IconProvider; import com.vaadin.server.Resource; import org.slf4j.Logger; import org.slf4j.LoggerFactory; import org.springframework.stereotype.Component; @Order(10) @Component public class IcoMoonIconProvider implements IconProvider { private final Logger log = LoggerFactory.getLogger(IcoMoonIconProvider.class); @Override public Resource getIconResource(String iconPath) { Resource resource = null; iconPath = iconPath.split(":")[1]; try { resource = ((Resource) IcoMoon.class .getDeclaredField(iconPath) .get(null)); } catch (IllegalAccessException | NoSuchFieldException e) { log.warn("There is no icon with name {} in the FontAwesome icon set", iconPath); } return resource; } @Override public boolean canProvide(String iconPath) { return iconPath.startsWith("ico-moon:"); } }Здесь мы явно назначаем порядок для этого бина аннотацией
@Order. -
Далее нужно зарегистрировать набор значков в файле свойств приложения:
cuba.iconsConfig = +com.company.demo.gui.icons.IcoMoonIcon
Теперь вы можете использовать значки по прямой ссылке на класс и элемент enum в XML-дескрипторе экрана:
<button caption="Headphones" icon="ico-moon:HEADPHONES"/>или в контроллере Java:
spinnerBtn.setIconFromSet(IcoMoonIcon.SPINNER);В результате, новые значки добавились к кнопкам:
- Переопределение значков с помощью наборов
-
Механизм наборов значков позволяет переопределять некоторые значки из других наборов. Для этого необходимо создать и зарегистрировать новый набор значков (enumeration) с теми же именами значков (options), но с другими путями (
source). В примере ниже создан новый наборMyIcon, в котором переопределены стандартные значки из набораCubaIcon.-
Стандартный набор:
public enum CubaIcon implements Icons.Icon { OK("font-icon:CHECK"), CANCEL("font-icon:BAN"), ... } -
Новый набор:
public enum MyIcon implements Icons.Icon { OK("icons/my-custom-ok.png"), ... } -
Регистрация нового набора в
web-app.properties:cuba.iconsConfig = +com.company.demo.gui.icons.MyIcon
Теперь вместо стандартного значка OK будет использовано новое изображение:
Icons icons = AppBeans.get(Icons.NAME); button.setIcon(icons.getIcon(CubaIcon.OK))При необходимости игнорировать переопределение и использовать стандартные значки, просто используйте путь к значку вместо имени элемента перечисления:
<button caption="Created" icon="icons/create.png"/>или
button.setIcon(CubaIcon.CREATE_ACTION.source()); -
3.5.11. Атрибуты DOM и CSS
Платформа CUBA предоставляет специальный API для HTML-атрибутов, позволяющий устанавливать DOM и CSS атрибуты для визуальных компонентов.
DOM/CSS атрибуты можно установить программно с помощью бина HtmlAttributes и следующих его методов:
-
setDomAttribute(Component component, String attributeName, String value)– устанавливает DOM-атрибут для самого верхнего элемента UI-компонента. -
setCssProperty(Component component, String propertyName, String value)– устанавливает CSS-свойство для самого верхнего элемента UI-компонента. -
setDomAttribute(Component component, String querySelector, String attributeName, String value)– устанавливает DOM-атрибут для всех вложенных элементов UI-компонента, соответствующих заданному селектору запроса. -
getDomAttribute(Component component, String querySelector, String attributeName)– получает значение DOM-атрибута, заданное ранее с помощьюHtmlAttributes. Не отражает реальное значение из DOM. -
removeDomAttribute(Component component, String querySelector, String attributeName)– удаляет DOM-атрибут для всех вложенных элементов UI-компонента, соответствующих заданному селектору запроса. -
setCssProperty(Component component, String querySelector, String propertyName, String value)– задает значение CSS-свойства для всех вложенных элементов UI-компонента, соответствующих заданному селектору запроса. -
getCssProperty(Component component, String querySelector, String propertyName)– получает значение CSS-свойства, заданное ранее с помощьюHtmlAttributes. Не отражает реальное значение из DOM. -
removeCssProperty(Component component, String querySelector, String propertyName)– очищает значение CSS-свойства для всех вложенных элементов UI-компонента, соответствующих заданному селектору запроса. -
applyCss(Component component, String querySelector, String css)– задает значение CSS-свойства из строки CSS.
Описанные выше методы принимают следующие параметры:
-
component– идентификатор компонента. -
querySelector– строка, содержащая один или несколько селекторов для сопоставления. Эта строка должна быть валидной строкой селектора CSS. -
attributeName– имя DOM-атрибута (например,title). -
propertyName– имя CSS-свойства (например,border-color). -
value– значение атрибута.
Имена наиболее часто используемых DOM-атрибутов и CSS-свойств доступны как константы класса HtmlAttributes, однако вы можете использовать и свои собственные имена атрибутов.
|
Будет ли атрибут работать с конкретным компонентом, зависит от этого компонента. Некоторые визуальные компоненты могут скрыто использовать те же атрибуты для своих собственных нужд, поэтому приведённые выше методы в определенных случаях могут не работать. |
Чтобы использовать бин HtmlAttributes, его нужно инжектировать в контроллер экрана, например:
XML descriptor
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<window xmlns="http://schemas.haulmont.com/cuba/screen/window.xsd"
caption="Demo"
messagesPack="com.company.demo.web">
<layout>
<button id="demoButton"
caption="msg://demoButton"
width="33%"/>
</layout>
</window>
Screen controller
import com.haulmont.cuba.gui.components.Button;
import com.haulmont.cuba.gui.components.HtmlAttributes;
import com.haulmont.cuba.gui.screen.Screen;
import com.haulmont.cuba.gui.screen.Subscribe;
import com.haulmont.cuba.gui.screen.UiController;
import com.haulmont.cuba.gui.screen.UiDescriptor;
import javax.inject.Inject;
@UiController("demo_DemoScreen")
@UiDescriptor("demo-screen.xml")
public class DemoScreen extends Screen {
@Inject
private Button demoButton;
@Inject
protected HtmlAttributes html;
@Subscribe
private void onBeforeShow(BeforeShowEvent event) {
html.setDomAttribute(demoButton, HtmlAttributes.DOM.TITLE, "Hello!");
html.setCssProperty(demoButton, HtmlAttributes.CSS.BACKGROUND_COLOR, "red");
html.setCssProperty(demoButton, HtmlAttributes.CSS.BACKGROUND_IMAGE, "none");
html.setCssProperty(demoButton, HtmlAttributes.CSS.BOX_SHADOW, "none");
html.setCssProperty(demoButton, HtmlAttributes.CSS.BORDER_COLOR, "red");
html.setCssProperty(demoButton, "color", "white");
html.setCssProperty(demoButton, HtmlAttributes.CSS.MAX_WIDTH, "400px");
}
}3.5.12. Горячие клавиши
В данном разделе приведена информация обо всех горячих клавишах (shortcuts), которые используются по умолчанию в универсальном пользовательском интерфейсе приложения. Все перечисленные ниже свойства приложения принадлежат интерфейсу ClientConfig и используются в блоке Web Client.
-
Главное окно приложения.
-
CTRL-SHIFT-PAGE_DOWN - переход на следующую вкладку. Настраивается свойством приложения
cuba.gui.nextTabShortcut. -
CTRL-SHIFT-PAGE_UP - переход на предыдущую вкладку. Настраивается свойством приложения
cuba.gui.previousTabShortcut.
-
-
Панель папок. Чтобы использовать в папках горячие клавиши, свойство cuba.web.foldersPaneEnabled должно иметь значение
true.-
ENTER – открыть выделенную папку.
-
SPACE - выделить/снять выделение с папки, находящейся в фокусе.
-
ARROW UP, ARROW DOWN - выбрать папку.
-
ARROW LEFT, ARROW RIGHT - свернуть/развернуть папку, содержащую вложенные папки, или переместить фокус на уровень выше.
-
-
Экраны.
-
ESCAPE - закрыть текущий экран. Настраивается свойством приложения
cuba.gui.closeShortcut. -
CTRL-ENTER - закрыть текущий экран редактирования с сохранением изменений. Настраивается свойством приложения
cuba.gui.commitShortcut.
-
-
Стандартные действия компонента-списка (Table, GroupTable, TreeTable, Tree). Кроме указанных свойств приложения горячая клавиша для конкретного экземпляра действия может быть установлена его методом
setShortcut().-
CTRL-\ - вызов действия CreateAction. Настраивается свойством приложения
cuba.gui.tableShortcut.insert. -
CTRL-ALT-\ - вызов действия AddAction. Настраивается свойством приложения
cuba.gui.tableShortcut.add. -
ENTER - вызов действия EditAction. Настраивается свойством приложения
cuba.gui.tableShortcut.edit. -
CTRL-DELETE - вызов действий RemoveAction и ExcludeAction. Настраивается свойством приложения
cuba.gui.tableShortcut.remove.
-
-
Выпадающие списки (LookupField, LookupPickerField).
-
SHIFT-DELETE – очистить значение.
-
-
Стандартные действия поля выбора (PickerField, LookupPickerField, SearchPickerField). Кроме указанных свойств приложения горячая клавиша для конкретного экземпляра действия может быть установлена его методом
setShortcut().-
CTRL-ALT-L - вызов действия LookupAction. Настраивается свойством приложения
cuba.gui.pickerShortcut.lookup. -
CTRL-ALT-O - вызов действия OpenAction. Настраивается свойством приложения
cuba.gui.pickerShortcut.open. -
CTRL-ALT-C - вызов действия ClearAction. Настраивается свойством приложения
cuba.gui.pickerShortcut.clear.В полях выбора кроме вышеперечисленных горячих клавиш поддерживается вызов действий сочетанием CTRL-ALT-1, CTRL-ALT-2 и так далее по количеству действий. То есть при нажатии сочетания клавиш CTRL-ALT-1 произойдет вызов действия, которое описано первым в списке действий, при нажатии сочетания клавиш CTRL-ALT-2 − вызов второго действия и так далее. Сочетание CTRL-ALT можно заменить другим, указав его в свойстве приложения
cuba.gui.pickerShortcut.modifiers.
-
-
Компонент Filter.
-
SHIFT-BACKSPACE – открыть список выбора фильтров. Настраивается свойством приложения
cuba.gui.filterSelectShortcut. -
SHIFT-ENTER - применить выбранный фильтр. Настраивается свойством приложения
cuba.gui.filterApplyShortcut.
-
3.5.13. Навигация и история просмотров URL
Механизм навигации и истории просмотров URL фреймворка CUBA предоставляет функциональность, которая важна для многих веб-приложений. Механизм состоит из следующих частей:
-
История – обработка нажатия на кнопку Back браузера. Кнопка Forward не поддерживается из-за невозможности воспроизвести все условия открытия экрана.
-
Маршруты и навигация – регистрация и обработка маршрутов к экранам приложения.
-
API маршрутизации – набор методов, позволяющих отобразить текущее состояние экрана на URL.
Фрагмент – это последняя часть URL после символа "#". Эта часть используется для обозначение маршрута.
В качестве примера рассмотрим следующий URL:
host:port/app/#main/42/orders/edit?id=17
В этом URL main/42/orders/edit?id=17 представляет собой фрагмент, который состоит из следующих частей:
-
main– маршрут до корневого экрана (главного экрана приложения); -
42– метка состояния, которая используется внутренними элементами механизма навигации; -
orders/edit– маршрут вложенного экрана; -
?id=17– часть с параметрами.
Все открытые экраны отображают свои маршруты на текущий URL. Например, если экран просмотра пользователей открыт и активен в данный момент, URL приложения выглядит следующим образом:
http://localhost:8080/app/#main/0/usersЕсли экран не имеет зарегистрированного маршрута, к фрагменту URL добавляется только метка состояния. Например:
http://localhost:8080/app/#main/42Для экранов редактирования идентификатор редактируемой сущности добавляется к адресу в качестве параметра, если экран имеет зарегистрированный маршрут. Например,
http://localhost:8080/app/#main/1/users/edit?id=27zy3tj6f47p2e3m4w58vdca9yИдентификаторы типа UUID кодируются как Base32 Crockford Encoding, все остальные типы используются как есть.
Когда пользователь не выполнил вход в приложение, но при этом запрошен маршрут некоторого экрана, используется параметр переадресации. Предположим, в адресной строке введен маршрут app/#main/orders. Когда приложение загружается, и отображается экран входа в систему, адрес будет изменен на: app/#login?redirectTo=orders. После входа в систему откроется экран, соответствующий маршруту orders.
Если запрошенный маршрут не существует, приложение показывает пустой экран с надписью "Не найдено".
Механизм навигации и истории просмотров URL доступен по умолчанию. Свойство приложения cuba.web.urlHandlingMode позволяет отключить этот механизм, используя значение NONE, или вернуться к старому механизму работы с кнопкой Back браузера, используя значение BACK_ONLY.
3.5.13.1. Обработка изменений URL
Фреймворк автоматически реагирует на изменения URL приложения: производится попытка распознать запрошенный маршрут и выполнить навигацию по истории или открыть экран, зарегистрированный для этого маршрута.
Когда экран открыт по маршруту с параметрами, фреймворк отправляет событие UrlParamsChangedEvent контроллеру экрана перед тем, как экран будет показан. То же самое происходит при изменении параметров URL во время открытия экрана. Вы можете подписаться на это событие для обработки начальных параметров и их изменений. Например, можно загрузить данные или скрыть/показать компоненты пользовательского интерфейса экрана в зависимости от параметров URL.
Пример подписки на событие в контроллере экрана:
@Subscribe
protected void onUrlParamsChanged(UrlParamsChangedEvent event) {
// handle
}Смотрите полный пример использования UrlParamsChangedEvent ниже.
3.5.13.2. API маршрутизации
В этом разделе описываются ключевые понятия API маршрутизации.
- Регистрация маршрута
-
Для регистрации маршрута экрана добавьте аннотацию
@Routeк контроллеру экрана, например:@Route("my-screen") public class MyScreen extends Screen { }Аннотация имеет три параметра:
-
path(илиvalue) – собственно маршрут; -
parentPrefixиспользуется для сжатия маршрутов (смотрите ниже). -
root– это свойство типаboolean, позволяющее указать, зарегистрирован ли маршрут для корневого экрана (например, экран входа в систему или главный экран). Значение по умолчанию –false.Если вы хотите создать корневой экран с маршрутом, отличным от
login, и сделать его доступным по ссылке без входа в систему, вы должны разрешить его просмотр анонимным пользователям. В противном случае при вводе URL вида/app/#your_root_screenпользователь будет перенаправлен на/app/#loginвместо открытия вашего корневого экрана.-
Добавьте
cuba.web.allowAnonymousAccess = trueв файлweb-app.properties. -
Разрешите просмотр созданного экрана для анонимных пользователей: запустите приложение, перейдите в Администрирование > Роли и создайте новую роль с доступом к вашему экрану. Затем назначьте созданную роль пользователю anonymous.
-
Если вам нужно определить маршрут для устаревшего экрана, добавьте атрибут
route(и необязательноrouteParentPrefix, эквивалентный параметруparentPrefix, иrootRoute, эквивалентный параметруroot) к элементу экрана в файле screens.xml, например:<screen id="myScreen" template="..." route="my-screen" /> -
- Сжатие маршрута
-
Эта функция предназначена для того, чтобы URL был понятным и читаемым при открытии нескольких экранов с маршрутами, имеющими одинаковые части.
Предположим, что у нас есть экраны браузера и редактора для сущности
Order:@Route("orders") public class OrderBrowser extends StandardLookup<Order> { } @Route("orders/edit") public class OrderEditor extends StandardEditor<Order> { }Сжатие URL используется, чтобы избежать повторения маршрута
ordersв URL, когда экран редактора открывается сразу после браузера. Просто укажите повторяющуюся часть в параметреparentPrefixаннотации@Routeна экране редактора:@Route("orders") public class OrderBrowser extends StandardLookup<Order> { } @Route(value = "orders/edit", parentPrefix = "orders") public class OrderEditor extends StandardEditor<Order> { }Теперь, когда редактор открыт в той же вкладке, что и браузер, полученный адрес будет похож на
app/#main/0/orders/edit?id=…
- Отображение состояния пользовательского интерфейса на URL
-
Бин
UrlRoutingпозволяет изменять текущий URL приложения в соответствии с текущим экраном и некоторыми параметрами. Он имеет следующие методы:-
pushState()– изменяет адрес и отправляет новую запись истории браузера; -
replaceState()– заменяет адрес без добавления новой записи истории браузера; -
getState()– возвращает текущее состояние как объектNavigationState.
Методы
pushState()/replaceState()принимают текущий контроллер экрана и дополнительный мэп параметров.Смотрите пример использования
UrlRoutingв разделе ниже. -
3.5.13.3. Использование механизма навигации и истории просмотров URL
Этот раздел содержит примеры использования механизма навигации и истории просмотров URL.
Предположим, у нас есть сущность Task и экран TaskInfo с информацией о выбранной задаче.
Контроллер экрана TaskInfo содержит аннотацию @Route для указания маршрута к экрану:
package com.company.demo.web.navigation;
import com.haulmont.cuba.gui.Route;
import com.haulmont.cuba.gui.screen.Screen;
import com.haulmont.cuba.gui.screen.UiController;
import com.haulmont.cuba.gui.screen.UiDescriptor;
@Route("task-info")
@UiController("demo_TaskInfoScreen")
@UiDescriptor("task-info.xml")
public class TaskInfoScreen extends Screen {
}В результате пользователь может открыть экран, введя http://localhost:8080/app/#main/task-info в адресной строке:
Когда экран открыт, адрес также содержит метку состояния.
- Отображение состояния на URL
-
Предположим, на экране
TaskInfoотображается информация об одной задаче и присутствует элемент управления для переключения задач. Вы можете отобразить просматриваемую задачу в адресной строке, чтобы иметь возможность скопировать URL, а затем открыть экран для этой конкретной задачи, вставив URL в адресную строку.Следующий код реализует отображение выбранной задачи на URL:
package com.company.demo.web.navigation; import com.company.demo.entity.Task; import com.google.common.collect.ImmutableMap; import com.haulmont.cuba.gui.Route; import com.haulmont.cuba.gui.UrlRouting; import com.haulmont.cuba.gui.components.Button; import com.haulmont.cuba.gui.components.LookupField; import com.haulmont.cuba.gui.screen.*; import com.haulmont.cuba.web.sys.navigation.UrlIdSerializer; import javax.inject.Inject; @Route("task-info") @UiController("demo_TaskInfoScreen") @UiDescriptor("task-info.xml") @LoadDataBeforeShow public class TaskInfoScreen extends Screen { @Inject private LookupField<Task> taskField; @Inject private UrlRouting urlRouting; @Subscribe("selectBtn") protected void onSelectBtnClick(Button.ClickEvent event) { Task task = taskField.getValue(); (1) if (task == null) { urlRouting.replaceState(this); (2) return; } String serializedTaskId = UrlIdSerializer.serializeId(task.getId()); (3) urlRouting.replaceState(this, ImmutableMap.of("task_id", serializedTaskId)); (4) } }1 - получить текущую задачу из LookupField2 - удалить параметры URL, если задача не выбрана 3 - сериализовать идентификатор задачи с помощью вспомогательного класса UrlIdSerializer4 - заменить текущее состояние URL новым, содержащим в качестве параметра сериализованный идентификатор задачи. В результате URL приложения изменяется, когда пользователь выбирает задачу и нажимает кнопку Select Task:
- UrlParamsChangedEvent
-
Теперь давайте выполним последнее требование: когда пользователь вводит URL с маршрутом и параметром
task_id, приложение должно показать экран с соответствующей выбранной задачей. Ниже приведен полный код контроллера экрана.package com.company.demo.web.navigation; import com.company.demo.entity.Task; import com.google.common.collect.ImmutableMap; import com.haulmont.cuba.core.global.DataManager; import com.haulmont.cuba.gui.Route; import com.haulmont.cuba.gui.UrlRouting; import com.haulmont.cuba.gui.components.Button; import com.haulmont.cuba.gui.components.LookupField; import com.haulmont.cuba.gui.navigation.UrlParamsChangedEvent; import com.haulmont.cuba.gui.screen.*; import com.haulmont.cuba.web.sys.navigation.UrlIdSerializer; import javax.inject.Inject; import java.util.UUID; @Route("task-info") @UiController("demo_TaskInfoScreen") @UiDescriptor("task-info.xml") @LoadDataBeforeShow public class TaskInfoScreen extends Screen { @Inject private LookupField<Task> taskField; @Inject private UrlRouting urlRouting; @Inject private DataManager dataManager; @Subscribe protected void onUrlParamsChanged(UrlParamsChangedEvent event) { String serializedTaskId = event.getParams().get("task_id"); (1) UUID taskId = (UUID) UrlIdSerializer.deserializeId(UUID.class, serializedTaskId); (2) taskField.setValue(dataManager.load(Task.class).id(taskId).one()); (3) } @Subscribe("selectBtn") protected void onSelectBtnClick(Button.ClickEvent event) { Task task = taskField.getValue(); if (task == null) { urlRouting.replaceState(this); return; } String serializedTaskId = UrlIdSerializer.serializeId(task.getId()); urlRouting.replaceState(this, ImmutableMap.of("task_id", serializedTaskId)); } }1 - получить значение параметра из UrlParamsChangedEvent2 - десериализовать идентификатор задачи 3 - загрузить экземпляр задачи и установить его в поле LookupField
3.5.13.4. Генератор маршрутов URL
Иногда необходимо получить правильный URL некоторого экрана приложения, который можно отправить по электронной почте или показать пользователю. Самый простой способ создать его – использовать генератор маршрутов URL.
Генератор маршрутов URL предоставляет API для генерации ссылок на экран редактирования сущности или на экран, определенный его идентификатором или классом. Ссылка также может содержать параметры URL, которые позволяют отобразить внутреннее состояние экрана на URL, чтобы использовать его позже.
В бине UrlRouting реализован метод getRouteGenerator(), позволяющий получить экземпляр RouteGenerator. RouteGenerator имеет следующие методы:
-
getRoute(String screenId)– возвращает маршрут для экрана с заданнымscreenId, например:String route = urlRouting.getRouteGenerator().getRoute("demo_Customer.browse");Результирующий URL выглядит следующим образом:
route = "http://host:port/context/#main/customers" -
getRoute(Class<? extends Screen> screenClass)– генерирует маршрут для экрана с заданнымscreenClass, например:String route = urlRouting.getRouteGenerator().getRoute(CustomerBrowse.class);Результирующий URL выглядит следующим образом:
route = "http://host:port/context/#main/customers" -
getEditorRoute(Entity entity)– генерирует маршрут к дефолтному экрану редактирования заданной сущности, например:Customer сustomer = customersTable.getSingleSelected(); String route = urlRouting.getRouteGenerator().getEditorRoute(сustomer);Результирующий URL выглядит следующим образом:
route = "http://localhost:8080/app/#main/customers/edit?id=5jqtc3pwzx6g6mq1vv5gkyjn0s" -
getEditorRoute(Entity entity, Class<? extends Screen> screenClass)– генерирует маршрут для экрана редактирования с заданнымиscreenClassиentity. -
getRoute(Class<? extends Screen> screenClass, Map<String, String> urlParams)– генерирует маршрут для экрана с заданнымиscreenClassиurlParams.
- Пример использования генератора маршрутов URL
-
Предположим, что у нас есть сущность
Customerсо стандартными экранами, для которых зарегистрированы маршруты. Добавим на экран браузера кнопку, которая генерирует ссылку на экран редактирования выбранной сущности:
@Inject
private UrlRouting urlRouting;
@Inject
private GroupTable<Customer> customersTable;
@Inject
private Dialogs dialogs;
@Subscribe("getLinkButton")
public void onGetLinkButtonClick(Button.ClickEvent event) {
Customer selectedCustomer = customersTable.getSingleSelected();
if (selectedCustomer != null) {
String routeToSelectedRole = urlRouting.getRouteGenerator()
.getEditorRoute(selectedCustomer);
dialogs.createMessageDialog()
.withCaption("Generated route")
.withMessage(routeToSelectedRole)
.withWidth("710")
.show();
}
}Результирующий маршрут выглядит следующим образом:

3.5.14. Композитные компоненты
Композитный компонент – это компонент, состоящий из других компонентов. Так же как фрагменты экранов, композитные компоненты позволяют переиспользовать некоторую компоновку и логику презентации. Композитные компоненты рекомендуется использовать в следующих случаях:
-
Функциональность компонента может быть реализована комбинацией существующих компонентов универсального пользовательского интерфейса. Если вам требуются какие-либо нестандартные возможности, создавайте собственный компонент путем оборачивания компонента Vaadin или библиотеки JavaScript, или используйте Универсальный JavaScriptComponent.
-
Компонент относительно прост и не загружает/сохраняет данные самостоятельно. В противном случае рассмотрите возможность создания фрагмента экранов.
Класс композитного компонента должен расширять базовый класс CompositeComponent. Композитный компонент должен иметь единственный компонент в качестве корня внутреннего дерева компонентов. Корневой компонент можно получить методом CompositeComponent.getComposition().
Внутренние компоненты удобно определять декларативно в XML. В этом случае класс компонента должен иметь аннотацию @CompositeDescriptor, задающую путь к дескриптору компоновки. Если значение аннотации не начинается с символа /, файл дескриптора загружается из файла, находящегося в том же пакете, что и класс компонента.
|
Обратите внимание, что идентификаторы внутренних компонентов должны быть уникальны в экране во избежание противоречий в слушателях и при инжектировании. Используйте идентификаторы с префиксами, например |
Альтернативой является создание дерева внутренних компонентов программно, в обработчике события CreateEvent.
CreateEvent посылается фреймворком, когда он заканчивает инициализацию компонента. В этот момент, если компонент использует XML-дескриптор, он загружен, и метод getComposition() возвращает корневой внутренний компонент. Данное событие можно использовать как для дополнительной инициализации компонента, так и для создания внутренних компонентов без XML.
Ниже описывается пошаговое создание компонента Stepper, предназначенного для редактирования целочисленного значения в поле ввода и нажатием на кнопки вверх/вниз рядом с полем.
Далее предполагается, что проект имеет базовый пакет com/company/demo.
- Дескриптор компоновки компонента
-
Создайте XML-дескриптор компоновки в файле
com/company/demo/web/components/stepper/stepper-component.xmlмодуляweb:<composite xmlns="http://schemas.haulmont.com/cuba/screen/composite.xsd"> (1) <hbox id="rootBox" width="100%" expand="valueField"> (2) <textField id="valueField"/> (3) <button id="upBtn" icon="font-icon:CHEVRON_UP"/> <button id="downBtn" icon="font-icon:CHEVRON_DOWN"/> </hbox> </composite>1 - XSD определяет возможное содержимое дескриптора 2 - единственный корневой компонент 3 - любое количество вложенных компонентов
- Класс имплементации компонента
-
Создайте класс имплементации компонента в том же пакете:
package com.company.demo.web.components.stepper; import com.haulmont.bali.events.Subscription; import com.haulmont.cuba.gui.components.*; import com.haulmont.cuba.gui.components.data.ValueSource; import com.haulmont.cuba.web.gui.components.*; import java.util.Collection; import java.util.function.Consumer; @CompositeDescriptor("stepper-component.xml") (1) public class StepperField extends CompositeComponent<HBoxLayout> (2) implements Field<Integer>, (3) CompositeWithCaption, (4) CompositeWithHtmlCaption, CompositeWithHtmlDescription, CompositeWithIcon, CompositeWithContextHelp { public static final String NAME = "stepperField"; (5) private TextField<Integer> valueField; (6) private Button upBtn; private Button downBtn; private int step = 1; (7) public StepperField() { addCreateListener(this::onCreate); (8) } private void onCreate(CreateEvent createEvent) { valueField = getInnerComponent("valueField"); upBtn = getInnerComponent("upBtn"); downBtn = getInnerComponent("downBtn"); upBtn.addClickListener(clickEvent -> updateValue(step)); downBtn.addClickListener(clickEvent -> updateValue(-step)); } private void updateValue(int delta) { Integer value = getValue(); setValue(value != null ? value + delta : delta); } public int getStep() { return step; } public void setStep(int step) { this.step = step; } @Override public boolean isRequired() { (9) return valueField.isRequired(); } @Override public void setRequired(boolean required) { valueField.setRequired(required); getComposition().setRequiredIndicatorVisible(required); } @Override public String getRequiredMessage() { return valueField.getRequiredMessage(); } @Override public void setRequiredMessage(String msg) { valueField.setRequiredMessage(msg); } @Override public void addValidator(Consumer<? super Integer> validator) { valueField.addValidator(validator); } @Override public void removeValidator(Consumer<Integer> validator) { valueField.removeValidator(validator); } @Override public Collection<Consumer<Integer>> getValidators() { return valueField.getValidators(); } @Override public boolean isEditable() { return valueField.isEditable(); } @Override public void setEditable(boolean editable) { valueField.setEditable(editable); upBtn.setEnabled(editable); downBtn.setEnabled(editable); } @Override public Integer getValue() { return valueField.getValue(); } @Override public void setValue(Integer value) { valueField.setValue(value); } @Override public Subscription addValueChangeListener(Consumer<ValueChangeEvent<Integer>> listener) { return valueField.addValueChangeListener(listener); } @Override public void removeValueChangeListener(Consumer<ValueChangeEvent<Integer>> listener) { valueField.removeValueChangeListener(listener); } @Override public boolean isValid() { return valueField.isValid(); } @Override public void validate() throws ValidationException { valueField.validate(); } @Override public void setValueSource(ValueSource<Integer> valueSource) { valueField.setValueSource(valueSource); getComposition().setRequiredIndicatorVisible(valueField.isRequired()); } @Override public ValueSource<Integer> getValueSource() { return valueField.getValueSource(); } }1 - аннотация @CompositeDescriptorуказывает путь к дескриптору компоновки компонента, который находится в том же пакете что и класс.2 - класс компонента наследуется от CompositeComponent, параметризованного типом корневого компонента.3 - компонент реализует интерфейс Field<Integer>, так как он предназначен для отображения и редактирования целочисленных значений.4 - набор интерфейсов с дефолтными методами для реализации стандартной функциональности Generic UI компонента. 5 - имя компонента, используемое для регистрации в файле ui-component.xml(см. ниже).6 - поля, содержащие ссылки на внутренние компоненты. 7 - свойство компонента, задающее значение изменения при нажатии на кнопки вверх/вниз. Свойство имеет публичные getter/setter методы и может быть назначено в XML экрана. 8 - инициализация компонента производится в слушателе события CreateEvent.
- Загрузчик компонента
-
Создайте загрузчик компонента для того, чтобы компонент можно было использовать в XML-дескрипторах экранов:
package com.company.demo.web.components.stepper; import com.google.common.base.Strings; import com.haulmont.cuba.gui.xml.layout.loaders.AbstractFieldLoader; public class StepperFieldLoader extends AbstractFieldLoader<StepperField> { (1) @Override public void createComponent() { resultComponent = factory.create(StepperField.NAME); (2) loadId(resultComponent, element); } @Override public void loadComponent() { super.loadComponent(); String incrementStr = element.attributeValue("step"); (3) if (!Strings.isNullOrEmpty(incrementStr)) { resultComponent.setStep(Integer.parseInt(incrementStr)); } } }1 - загрузчик должен наследоваться от класса AbstractComponentLoader, параметризованного типом компонента. В нашем случае, так как компонент реализует интерфейсField, необходимо воспользоваться более специфичным базовым классомAbstractFieldLoader.2 - создание компонента по его имени. 3 - загрузка свойства stepиз XML, если оно указано.
- Регистрация компонента
-
Для регистрации компонента и его загрузчика во фреймворке, создайте файл
com/company/demo/ui-component.xmlв модулеweb:<?xml version="1.0" encoding="UTF-8" standalone="no"?> <components xmlns="http://schemas.haulmont.com/cuba/components.xsd"> <component> <name>stepperField</name> <componentLoader>com.company.demo.web.components.stepper.StepperFieldLoader</componentLoader> <class>com.company.demo.web.components.stepper.StepperField</class> </component> </components>Добавьте следующее свойство в
com/company/demo/web-app.properties:cuba.web.componentsConfig = +com/company/demo/ui-component.xmlТеперь фреймворк сможет распознать новый компонент в XML-дескрипторах экранов приложения.
Если приложение, в котором создан композитный компонент, оформлено в виде компонента приложения - требуется повторно создать его дескриптор.
- XSD компонента
-
XSD требуется для использования компонента в XML-дескрипторах экранов. Определите ее в файле
com/company/demo/ui-component.xsdмодуляweb:<?xml version="1.0" encoding="UTF-8" standalone="no"?> <xs:schema xmlns="http://schemas.company.com/demo/0.1/ui-component.xsd" attributeFormDefault="unqualified" elementFormDefault="qualified" targetNamespace="http://schemas.company.com/demo/0.1/ui-component.xsd" xmlns:xs="http://www.w3.org/2001/XMLSchema" xmlns:layout="http://schemas.haulmont.com/cuba/screen/layout.xsd"> <xs:element name="stepperField"> <xs:complexType> <xs:complexContent> <xs:extension base="layout:baseFieldComponent"> (1) <xs:attribute name="step" type="xs:integer"/> (2) </xs:extension> </xs:complexContent> </xs:complexType> </xs:element> </xs:schema>1 - наследование всех базовых свойств поля. 2 - определение атрибута для свойства stepкомпонента.
- Использование компонента
-
Пример использования созданного компонента в экране приложения:
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<window xmlns="http://schemas.haulmont.com/cuba/screen/window.xsd"
xmlns:app="http://schemas.company.com/demo/0.1/ui-component.xsd" (1)
caption="msg://caption"
messagesPack="com.company.demo.web.components.sample">
<data>
<instance id="fooDc" class="com.company.demo.entity.Foo" view="_local">
<loader/>
</instance>
</data>
<layout>
<form id="form" dataContainer="fooDc">
<column width="250px">
<textField id="nameField" property="name"/>
<app:stepperField id="ageField" property="limit" step="10"/> (2)
</column>
</form>
</layout>
</window>| 1 | - namespace ссылается на XSD компонента. |
| 2 | - композитный компонент, соединенный с некоторым атрибутом limit сущности. |
- Собственный стиль
-
Теперь давайте добавим собственные стили для улучшения визуального представления компонента.
Сначала измените корневой компонент на CssLayout и назначьте стили внутренним компонентам. Кроме стилей, определенных в проекте (см. ниже), здесь используются следующие предопределенные стили: v-component-group, icon-only.
<composite xmlns="http://schemas.haulmont.com/cuba/screen/composite.xsd"> <cssLayout id="rootBox" width="100%" stylename="v-component-group stepper-field"> <textField id="valueField"/> <button id="upBtn" icon="font-icon:CHEVRON_UP" stylename="stepper-btn icon-only"/> <button id="downBtn" icon="font-icon:CHEVRON_DOWN" stylename="stepper-btn icon-only"/> </cssLayout> </composite>Измените класс компонента соответственно:
@CompositeDescriptor("stepper-component.xml") public class StepperField extends CompositeComponent<CssLayout> implements ...Сгенерируйте расширение темы в проекте (см. здесь как это сделать в Studio) и добавьте следующий код в файл
modules/web/themes/hover/com.company.demo/hover-ext.scss:@mixin com_company_demo-hover-ext { .stepper-field { display: flex; .stepper-btn { width: $v-unit-size; min-width: $v-unit-size; } } }Перезапустите сервер приложения и откройте экран с компонентом. Форма, содержащая наш композитный компонент Stepper, должна выглядеть так:

3.5.15. Подключаемые фабрики компонентов
Механизм подключаемых фабрик компонентов расширяет процедуру генерации компонентов и позволяет создавать различные поля редактирования в Form, Table и DataGrid. Это означает, что компоненты приложения или сам ваш проект могут предоставлять собственные стратегии, которые будут создавать нестандартные компоненты и/или поддерживать кастомные типы данных.
Точкой входа в данный механизм является метод UiComponentsGenerator.generate(ComponentGenerationContext). Он работает следующим образом:
-
Пытается найти все реализации интерфейса
ComponentGenerationStrategy. Если как минимум одна реализация существует:-
Обходит все реализации в соответствии с интерфейсом
org.springframework.core.Ordered. -
Возвращается первый созданный не нулевой компонент.
-
Реализации интерфейса ComponentGenerationStrategy используются при создании UI компонентов. Проект может содержать любое количество таких стратегий.
ComponentGenerationContext - класс, содержащий следующую информацию, которая может быть использована при создании компонента:
-
metaClass- задает сущность, для которой создается компонент. -
property- задает атрибут сущности, для которой создается компонент. -
datasource- источник данных, который может быть связан с компонентом. -
optionsDatasource- источник данных, который может быть связан с компонентом для показа опций. -
valueSource- источник данных, который может быть связан с компонентом. -
options- источник данных, который может быть связан с компонентом для показа опций. -
xmlDescriptor- XML дескриптор с дополнительной информацией, в случае, если компонент описан в XML дескрипторе. -
componentClass- класс компонента для которого должен быть создан компонент (например,Table,Form,DataGrid).
В платформе существуют две стандартных реализации ComponentGenerationStrategy:
-
DefaultComponentGenerationStrategy- используется для создания компонентов в соответствии с переданнымComponentGenerationContext. Имеет значение order равноеComponentGenerationStrategy.LOWEST_PLATFORM_PRECEDENCE(1000). -
DataGridEditorComponentGenerationStrategy- используется для создания компонентов для DataGrid Editor в соответствии с переданнымComponentGenerationContext. Имеет значение order равноеComponentGenerationStrategy.HIGHEST_PLATFORM_PRECEDENCE + 30(130).
Пример ниже показывает, как заменить стандартную генерацию поля в компоненте Form для определенного атрибута некоторой сущности.
import com.company.sales.entity.Order;
import com.haulmont.chile.core.model.MetaClass;
import com.haulmont.cuba.core.global.Metadata;
import com.haulmont.cuba.gui.UiComponents;
import com.haulmont.cuba.gui.components.*;
import com.haulmont.cuba.gui.components.data.ValueSource;
import org.springframework.core.Ordered;
import javax.annotation.Nullable;
import javax.inject.Inject;
import java.sql.Date;
@org.springframework.stereotype.Component(SalesComponentGenerationStrategy.NAME)
public class SalesComponentGenerationStrategy implements ComponentGenerationStrategy, Ordered {
public static final String NAME = "sales_SalesComponentGenerationStrategy";
@Inject
private UiComponents uiComponents;
@Inject
private Metadata metadata;
@Nullable
@Override
public Component createComponent(ComponentGenerationContext context) {
String property = context.getProperty();
MetaClass orderMetaClass = metadata.getClassNN(Order.class);
// Check the specific field of the Order entity
// and that the component is created for the Form component
if (orderMetaClass.equals(context.getMetaClass())
&& "date".equals(property)
&& context.getComponentClass() != null
&& Form.class.isAssignableFrom(context.getComponentClass())) {
DatePicker<Date> datePicker = uiComponents.create(DatePicker.TYPE_DATE);
ValueSource valueSource = context.getValueSource();
if (valueSource != null) {
//noinspection unchecked
datePicker.setValueSource(valueSource);
}
return datePicker;
}
return null;
}
@Override
public int getOrder() {
return 50;
}
}Пример ниже показывает, как определить ComponentGenerationStrategy для специализированного datatype.
import com.company.colordatatype.datatypes.ColorDatatype;
import com.haulmont.chile.core.datatypes.Datatype;
import com.haulmont.chile.core.model.MetaClass;
import com.haulmont.chile.core.model.MetaPropertyPath;
import com.haulmont.chile.core.model.Range;
import com.haulmont.cuba.core.app.dynamicattributes.DynamicAttributesUtils;
import com.haulmont.cuba.gui.UiComponents;
import com.haulmont.cuba.gui.components.ColorPicker;
import com.haulmont.cuba.gui.components.Component;
import com.haulmont.cuba.gui.components.ComponentGenerationContext;
import com.haulmont.cuba.gui.components.ComponentGenerationStrategy;
import com.haulmont.cuba.gui.components.data.ValueSource;
import org.springframework.core.annotation.Order;
import javax.annotation.Nullable;
import javax.inject.Inject;
@Order(100)
@org.springframework.stereotype.Component(ColorComponentGenerationStrategy.NAME)
public class ColorComponentGenerationStrategy implements ComponentGenerationStrategy {
public static final String NAME = "colordatatype_ColorComponentGenerationStrategy";
@Inject
private UiComponents uiComponents;
@Nullable
@Override
public Component createComponent(ComponentGenerationContext context) {
String property = context.getProperty();
MetaPropertyPath mpp = resolveMetaPropertyPath(context.getMetaClass(), property);
if (mpp != null) {
Range mppRange = mpp.getRange();
if (mppRange.isDatatype()
&& ((Datatype) mppRange.asDatatype()) instanceof ColorDatatype) {
ColorPicker colorPicker = uiComponents.create(ColorPicker.class);
colorPicker.setDefaultCaptionEnabled(true);
ValueSource valueSource = context.getValueSource();
if (valueSource != null) {
//noinspection unchecked
colorPicker.setValueSource(valueSource);
}
return colorPicker;
}
}
return null;
}
protected MetaPropertyPath resolveMetaPropertyPath(MetaClass metaClass, String property) {
MetaPropertyPath mpp = metaClass.getPropertyPath(property);
if (mpp == null && DynamicAttributesUtils.isDynamicAttribute(property)) {
mpp = DynamicAttributesUtils.getMetaPropertyPath(metaClass, property);
}
return mpp;
}
}3.5.16. Работа с компонентами Vaadin
Для работы непосредственно с компонентами Vaadin, реализующими интерфейсы библиотеки визуальных компонентов в блоке Web Client, воспользуйтесь следующими методами интерфейса Component:
-
unwrap()- получить Vaadin-компонент для данного CUBA-компонента. -
unwrapComposition()- получить Vaadin-компонент, который является наиболее внешним контейнером в реализации данного CUBA-компонента. Для простых компонентов, например Button, этот метод возвращает тот же объект, что иunwrap()-com.vaadin.ui.Button. Для сложных компонентов, например Table,unwrap()вернет соответствующий объектcom.vaadin.ui.Table, аunwrapComposition()- объектcom.vaadin.ui.VerticalLayout, который содержит таблицу вместе с описанными вместе с ней ButtonsPanel иRowsCount.
Методы принимают класс компонента, который нужно вернуть, например:
com.vaadin.ui.TextField vTextField = textField.unwrap(com.vaadin.ui.TextField.class);Можно также использовать статические методы unwrap() и getComposition() класса WebComponentsHelper, передавая в них CUBA-компонент.
Следует иметь в виду, что если экран расположен в модуле gui проекта, то в его контроллере можно работать только с обобщенными интерфейсами CUBA-компонентов. Чтобы использовать unwrap(), нужно либо расположить весь экран в модуле web, либо воспользоваться механизмом компаньонов контроллеров.
3.5.17. Собственные визуальные компоненты
В данном разделе содержится обзор различных способов создания собственных визуальных компонентов в CUBA-приложениях. Практическое руководство по использованию этих подходов содержится в разделе Создание собственных визуальных компонентов.
|
Прежде чем создавать новый компонент на основе какой-либо низкоуровневой технологии, рассмотрите возможность создания композитного компонента на основе уже имеющихся компонентов универсального пользовательского интерфейса. |
Новый визуальный компонент может быть создан с помощью следующих технологий:
-
На основе Vaadin add-on.
Это простейший способ, требующий следующих шагов:
-
Добавить в build.gradle зависимость от артефакта аддона.
-
Создать в проекте модуль web-toolkit. Данный модуль содержит файл виджетсета GWT и позволяет создавать клиентские части визуальных компонентов.
-
Подключить виджетсет аддона в виджетсет проекта.
-
Если требуется адаптировать внешний вид компонента к теме приложения, создать расширение темы и задать для компонента нужный CSS.
См. пример в разделе Подключение аддона Vaadin.
-
-
Как обертка библиотеки на JavaScript.
Данный метод рекомендуется, если у вас уже есть подходящий компонент, написанный на JavaScript. Чтобы использовать его в приложении, требуется следующее:
-
Создать в модуле web серверный компонент Vaadin. Серверный компонент определяет API для серверного кода, методы доступа, слушатели событий и т.д. Серверный компонент должен быть унаследован от класса
AbstractJavaScriptComponent. Модуль web-toolkit для интеграции JavaScript-компонента не требуется. -
Создать JavaScript-коннектор. Коннектор - это функция, которая инициализирует JavaScript-компонент и ответственна за взаимодействие между JavaScript и server-side кодом.
-
Создать класс состояния. Публичные поля данного класса определяют, какие данные посылаются сервером клиенту. Класс состояния должен быть унаследован от
JavaScriptComponentState.
См. пример в разделе Подключение JavaScript библиотеки.
-
-
В виде нового компонента GWT.
Данный метод рекомендуется для создания полностью новых визуальных компонентов. Он требует следующих шагов:
-
Создать в проекте модуль web-toolkit.
-
Создать класс клиентского виджета GWT.
-
Создать серверный компонент Vaadin.
-
Создать класс состояния, определяющий данные, посылаемые сервером клиенту.
-
Создать класс коннектора, который соединяет клиентский код с серверным компонентом.
-
Создать интерфейс RPC, который определяет серверный API, вызываемый клиентом.
См. пример в разделе Создание GWT компонента.
-
Степень интегрированности визуального компонента в платформу можно разделить на три уровня:
-
На первом уровне новый компонент становится доступным как нативный компонент Vaadin. Прикладной разработчик может использовать его в контроллерах экранов приложения напрямую: создать экземпляр и добавить его в нативный контейнер. Методы создания компонентов, описанные выше, предоставляют именно этот уровень интеграции.
-
На втором уровне новый компонент интегрируется в универсальный пользовательский интерфейс платформы. В этом случае, с точки зрения прикладного разработчика, компонент выглядит так же как и стандартный компонент из библиотеки визуальных компонентов. Разработчик может определить компонент в XML-дескрипторе экрана или создать его с помощью
UiComponentsв контроллере. См. пример в разделе Подключение аддона Vaadin с интеграцией в Generic UI. -
На третьем уровне новый компонент доступен в палитре компонентов WYSIWYG-дизайнера экранов Studio. См. пример в разделе Поддержка собственных визуальных компонентов и фасетов в CUBA Studio.
3.5.17.1. Использование ресурсов WebJar
Данный метод позволяет использовать различные JavaScript-библиотеки, упакованные в JAR-файлы и развёрнутые в Maven Central. Для подключения библиотеки к приложению требуется следующее:
-
Добавить зависимость в метод
compileмодуля web:compile 'org.webjars.bower:jrcarousel:1.0.0' -
Создать в проекте модуль web-toolkit.
-
Создать класс клиентского виджета GWT и реализовать в нём
nativeJSNI метод для создания компонента. -
Создать класс серверного компонента с аннотацией
@WebJarResource.Аннотация может использоваться только с наследниками
ClientConnector(которые обычно являются классами компонентов UI в модуле web-toolkit).Значение аннотации
@WebJarResource, или определение ресурса, можно указать в одном из двух форматов:-
<webjar_name>:<sub_path>, например:@WebJarResource("pivottable:plugins/c3/c3.min.css") -
<webjar_name>/<resource_version>/<webjar_resource>, например:@WebJarResource("jquery-ui/1.12.1/jquery-ui.min.js")
Оно может содержать одно или более строковых определений ресурсов WebJar:
@WebJarResource({ "jquery-ui:jquery-ui.min.js", "jquery-fileupload:jquery-fileupload.min.js", "jquery-fileupload:jquery-fileupload.min.js" }) public class CubaFileUpload extends CubaAbstractUploadComponent { ... }Указывать версию WebJar не нужно, так как согласно стратегии управления версиями Maven будет автоматически использован WebJar с самым большим номером версии.
Дополнительно можно указать путь к каталогу внутри
VAADIN/webjars/, из которого должны подгружаться статические ресурсы. В такой каталог вы можете сами помещать новые версии ресурсов, и они будут автоматически переопределять используемые WebJar. Для указания каталога используйте свойствоoverridePathаннотации@WebJarResource, к примеру:@WebJarResource(value = "pivottable:plugins/c3/c3.min.css", overridePath = "pivottable") -
-
Добавить новый компонент к экрану.
3.5.17.2. Универсальный JavaScriptComponent
JavaScriptComponent - это простой компонент пользовательского интерфейса, который представляет собой универсальную обёртку для использования любой готовой библиотеки JavaScript в приложении на базе CUBA напрямую, без необходимости подключать компонент Vaadin.
Компонент можно использовать в XML-дескрипторе экрана, декларативно настраивать динамические свойства и зависимости JavaScript.
XML-имя компонента: jsComponent.
- Определение зависимостей
-
Вы можете задать для компонента несколько зависимостей (
jsиcss). Каждая зависимость должна соответствовать одному из следующих источников:-
Ресурс WebJar - начинается с
webjar:// -
Файл, расположенный в локальном каталоге VAADIN - начинается с
vaadin://
Пример добавления зависимостей:
jsComponent.addDependencies( "webjar://leaflet.js", "http://code.jquery.com/jquery-3.4.1.min.js" ); jsComponent.addDependency( "http://api.map.baidu.com/getscript?v=2.0", DependencyType.JAVASCRIPT ); -
- Функция инициализации
-
Для компонента необходимо задать функцию инициализации. Имя этой функции будет использовано JavaScript-коннектором для поиска точки входа (подробнее о коннекторах см. ниже).
В пределах окна имя функции инициализации должно быть уникальным.
Имя функции можно передать в компонент с помощью метода
setInitFunctionName():jsComponent.setInitFunctionName("com_company_demo_web_screens_Sandbox"); - Определение JavaScript-коннектора
-
Чтобы использовать компонент
JavaScriptComponentдля подключения библиотеки JavaScript, вам необходимо создать JavaScript-коннектор - функцию, которая будет инициализировать компонент JavaScript и управлять коммуникацией между сервером и кодом JavaScript.Из функции коннектора доступны следующие методы:
-
this.getElement()возвращает HTML DOM элемент компонента. -
this.getState()возвращает распределенный объект состояния с текущим состоянием компонента как синхронизируемый объект с серверной стороны.
-
- Возможности компонента
-
Ниже перечислены возможности компонента
JavaScriptComponent, которые позволяют следующее:-
Задать объект состояния, который можно использовать в коннекторе на стороне клиента и который будет доступен в поле
dataсостояния компонента, к примеру:MyState state = new MyState(); state.minValue = 0; state.maxValue = 100; jsComponent.setState(state); -
Зарегистрировать функцию, которая может быть вызвана из кода JavaScript по указанному имени, например:
jsComponent.addFunction("valueChanged", callbackEvent -> { JsonArray arguments = callbackEvent.getArguments(); notifications.create() .withCaption(StringUtils.join(arguments, ", ")) .show(); });this.valueChanged(values); -
Вызвать именованную функцию, которую JavaScript-коннектор добавил к объекту-обёртке коннектора.
jsComponent.callFunction("showNotification ");this.showNotification = function () { alert("TEST"); };
-
- Пример использования JavaScriptComponent
-
В этом разделе описан пример интеграции сторонней JavaScript-библиотеки в приложение CUBA. В качестве примера мы взяли библиотеку Quill Rich Text Editor, доступную по адресу https://quilljs.com/. Чтобы использовать Quill в своём проекте, необходимо выполнить шаги, описанные ниже.
-
Добавьте следующую зависимость к модулю web:
compile('org.webjars.npm:quill:1.3.6') -
Создайте файл
quill-connector.jsв каталоге проектаweb/VAADIN/quillв модуле web. -
Добавьте в этот файл код реализации коннектора:
com_company_demo_web_screens_Sandbox = function () { var connector = this; var element = connector.getElement(); element.innerHTML = "<div id=\"editor\">" + "<p>Hello World!</p>" + "<p>Some initial <strong>bold</strong> text</p>" + "<p><br></p>" + "</div>"; connector.onStateChange = function () { var state = connector.getState(); var data = state.data; var quill = new Quill('#editor', data.options); // Subscribe on textChange event quill.on('text-change', function (delta, oldDelta, source) { if (source === 'user') { connector.valueChanged(quill.getText(), quill.getContents()); } }); } }; -
Создайте экран с описанием компонента
jsComponent:<jsComponent id="quill" initFunctionName="com_company_demo_web_screens_Sandbox" height="200px" width="400"> <dependencies> <dependency path="webjar://quill:dist/quill.js"/> <dependency path="webjar://quill:dist/quill.snow.css"/> <dependency path="vaadin://quill/quill-connector.js"/> </dependencies> </jsComponent> -
Контроллер этого экрана включает в себя следующую реализацию:
@UiController("demo_Sandbox") @UiDescriptor("sandbox.xml") public class Sandbox extends Screen { @Inject private JavaScriptComponent quill; @Inject private Notifications notifications; @Subscribe protected void onInit(InitEvent event) { QuillState state = new QuillState(); state.options = ParamsMap.of("theme", "snow", "placeholder", "Compose an epic..."); quill.setState(state); quill.addFunction("valueChanged", javaScriptCallbackEvent -> { String value = javaScriptCallbackEvent.getArguments().getString(0); notifications.create() .withCaption(value) .withPosition(Notifications.Position.BOTTOM_RIGHT) .show(); }); } class QuillState { public Map<String, Object> options; } }
Как результат, мы видим компонент Quill Rich Text Editor на экране приложения:
Другой пример интеграции сторонней JavaScript-библиотеки смотрите в разделе Подключение JavaScript библиотеки.
-
3.5.17.3. ScreenDependencyUtils
Вспомогательный класс ScreenDependencyUtils предоставляет простой способ добавления зависимостей. CSS, JavaScript или HTML-зависимости могут быть добавлены к определенному экрану или фрагменту и должны быть получены из следующих источников:
-
Ресурс WebJar - начинается с
webjar:// -
Файл, расположенный в локальном каталоге VAADIN - начинается с
vaadin:// -
Веб-источник - начинается с
http://orhttps://
Для добавления и получения зависимостей используются следующие методы:
-
setScreenDependencies- устанавливает список зависимостей. -
addScreenDependencies- добавляет список зависимостей. -
addScreenDependency- добавляет зависимость. -
List<ClientDependency> getScreenDependencies- возвращает список ранее добавленных зависимостей.
В примере CSS-файл добавляется к экрану входа в систему:
protected void loadStyles() {
ScreenDependencyUtils.addScreenDependency(this,
"vaadin://brand-login-screen/login.css", Dependency.Type.STYLESHEET);
}В результате на HTML-страницу будет добавлен следующий импорт:
<link rel="stylesheet" type="text/css" href="http://localhost:8080/app/VAADIN/brand-login-screen/login.css">Добавленный CSS-файл применяется только к экрану входа в систему:
3.5.17.4. Создание собственных визуальных компонентов
В разделе Собственные визуальные компоненты был приведен обзор методов расширения набора стандартных визуальных компонентов в проекте. У вас есть следующие варианты:
-
Подключение аддона Vaadin. Много сторонних компонентов Vaadin распространяются в виде дополнений (add-on). Библиотека аддонов находится по адресу https://vaadin.com/directory.
-
Подключение компонента, написанного на JavaScript. Vaadin дает возможность создавать серверные компоненты, использующие JavaScript-библиотеку.
-
Создание собственного компонента Vaadin с клиентской частью, написанной на GWT.
Далее вы можете интегрировать получившийся компонент Vaadin в универсальный пользовательский интерфейс CUBA, чтобы иметь возможность использовать его декларативно в XML-дескрипторах экранов и привязывать к контейнерам данных.
Финальным шагом интеграции является поддержка нового компонента в WYSIWYG редакторе экранов Studio.
Далее в этом разделе приводятся примеры создания новых визуальных компонентов каждым из описанных выше способов. Интеграция в Generic UI одинакова для всех трех способов, поэтому она описана только для примера с подключением аддона Vaadin.
3.5.17.4.1. Подключение аддона Vaadin
Рассмотрим пример использования компонента Stepper, доступного по адресу http://vaadin.com/addon/stepper. Данный компонент позволяет пошагово изменять значение текстового поля с помощью клавиатуры, колесика мыши и встроенных кнопок вверх/вниз.
Создайте новый проект в CUBA Studio и назовите его addon-demo.
Для подключения аддона Vaadin проект должен иметь модуль web-toolkit. Его удобно создать с помощью CUBA Studio: В главном меню нажмите CUBA > Advanced > Manage modules > Create 'web-toolkit' Module.
Затем, добавьте зависимости аддона:
-
В build.gradle, для модуля web, добавьте зависимость от аддона, который содержит компонент:
configure(webModule) { ... dependencies { ... compile("org.vaadin.addons:stepper:2.4.0") } -
В файле
AppWidgetSet.gwt.xmlмодуля web-toolkit укажите, что виджетсет проекта наследуется от виджетсета аддона:<module> <inherits name="com.haulmont.cuba.web.widgets.WidgetSet" /> <inherits name="org.vaadin.risto.stepper.StepperWidgetset" /> <set-property name="user.agent" value="safari" /> </module>Для более быстрой сборки виджетов на время разработки вы можете установить свойство
user.agent. В данном примере набор виджетов будет собираться только для браузеров, основанных на WebKit: Chrome, Safari, и т.д.
Компонент из аддона Vaadin подключен. Далее мы покажем как использовать его в экранах проекта.
-
Создаем новую сущность
Customerс двумя полями:-
nameтипа String -
scoreтипа Integer
-
-
Сгенерируем для новой сущности стандартные экраны. В диалоге генерации стандартных экранов убедитесь что значение поля Module -
Module: 'app-web_main'(это поле отображается только, если к проекту подключен модуль gui). Экраны, использующие компоненты Vaadin напрямую, должны располагаться в модуле web.На самом деле экран может располагаться и в модуле gui, но тогда код, работающий с Vaadin компонентом, должен быть вынесен в отдельный компаньон.
-
Далее добавим компонент
stepperна экран.В XML-дескрипторе экрана редактирования
customer-edit.xmlзаменим полеscoreкомпонентомhBox, который будет использоваться в качестве контейнера для Vaadin компонента.<?xml version="1.0" encoding="UTF-8" standalone="no"?> <window xmlns="http://schemas.haulmont.com/cuba/screen/window.xsd" caption="msg://editorCaption" focusComponent="form" messagesPack="com.company.demo.web.customer"> <data> <instance id="customerDc" class="com.company.demo.entity.Customer" view="_local"> <loader/> </instance> </data> <dialogMode height="600" width="800"/> <layout expand="editActions" spacing="true"> <form id="form" dataContainer="customerDc"> <column width="250px"> <textField id="nameField" property="name"/> <!-- A box that will be used as a container for a Vaadin component --> <hbox id="scoreBox" caption="msg://com.company.demo.entity/Customer.score" height="100%" width="100%"/> </column> </form> <hbox id="editActions" spacing="true"> <button action="windowCommitAndClose"/> <button action="windowClose"/> </hbox> </layout> </window>В контроллер экрана редактирования
CustomerEdit.javaдобавим следующий код:package com.company.demo.web.customer; import com.company.demo.entity.Customer; import com.haulmont.cuba.gui.components.HBoxLayout; import com.haulmont.cuba.gui.screen.*; import com.vaadin.ui.Layout; import org.vaadin.risto.stepper.IntStepper; import javax.inject.Inject; @UiController("demo_Customer.edit") @UiDescriptor("customer-edit.xml") @EditedEntityContainer("customerDc") @LoadDataBeforeShow public class CustomerEdit extends StandardEditor<Customer> { @Inject private HBoxLayout scoreBox; private IntStepper stepper = new IntStepper(); @Subscribe protected void onInit(InitEvent event) { scoreBox.unwrap(Layout.class) .addComponent(stepper); stepper.setSizeFull(); stepper.addValueChangeListener(valueChangeEvent -> getEditedEntity().setScore(valueChangeEvent.getValue())); } @Subscribe protected void onInitEntity(InitEntityEvent<Customer> event) { event.getEntity().setScore(0); } @Subscribe protected void onBeforeShow(BeforeShowEvent event) { stepper.setValue(getEditedEntity().getScore()); } }Здесь в методе
onInit()производится инициализация компонента, подключенного из аддона, затем, с помощью методаunwrap, извлекается ссылка на Vaadin-контейнер, и в этот контейнер добавляется наш новый компонент.Для связи компонента с данными, во-первых, в методе
onBeforeShow()ему устанавливается текущее значение из редактируемогоCustomer, а во-вторых, добавляется слушатель на изменение значения, который обновляет соответствующий атрибут сущности при изменении значения пользователем. -
Для адаптации внешнего вида компонента создадим в проекте расширение темы. Это удобно сделать с помощью CUBA Studio: В главном меню нажмите CUBA > Advanced > Manage themes > Create theme extension. Другой способ - использовать команду
extend-themeв CUBA CLI. В списке тем для расширения выберемhoverи нажмем кнопку Create. Затем откроем файлthemes/hover/com.company.demo/hover-ext.scssмодуля web, и добавим в него следующий код:/* Define your theme modifications inside next mixin */ @mixin com_company_demo-hover-ext { /* Basic styles for stepper inner text box */ .stepper input[type="text"] { @include box-defaults; @include valo-textfield-style; &:focus { @include valo-textfield-focus-style; } } } -
Запускаем сервер приложения. Экран редактирования должен выглядеть следующим образом:
3.5.17.4.2. Подключение аддона Vaadin с интеграцией в Generic UI
В предыдущем разделе мы подключили в проект сторонний компонент Stepper. В данном разделе мы интегрируем его в универсальный пользовательский интерфейс CUBA, что даст разработчикам возможность использовать компонент декларативно в XML-дескрипторах экранов и связывать его с сущностями через Компоненты данных.
Чтобы интегрировать Stepper в Generic UI, необходимо создать следующие файлы:
-
Stepper- интерфейс компонента в подкаталоге gui модуля web. -
WebStepper- реализация компонента в подкаталоге gui модуля web. -
StepperLoader- XML-загрузчик компонента в подкаталоге gui модуля web. -
ui-component.xsd- описатель схемы XML для нового компонента. Если файл уже существует, то информацию о новом компоненте следует добавить в существующий файл.-
cuba-ui-component.xml- файл регистрации загрузчика нового компонента в модуле web. Если файл уже существует, то информацию о новом компоненте следует добавить в существующий файл.
-
Откройте проект в IDE.
Создадим требуемые файлы и внесем в них необходимые изменения.
-
Создайте интерфейс
Stepperв подкаталоге gui модуля web. Замените его содержимое на следующий код:package com.company.demo.web.gui.components; import com.haulmont.cuba.gui.components.Field; // note that Stepper should extend Field public interface Stepper extends Field<Integer> { String NAME = "stepper"; boolean isManualInputAllowed(); void setManualInputAllowed(boolean value); boolean isMouseWheelEnabled(); void setMouseWheelEnabled(boolean value); int getStepAmount(); void setStepAmount(int amount); int getMaxValue(); void setMaxValue(int maxValue); int getMinValue(); void setMinValue(int minValue); }В качестве базового для нашего компонента выбран интерфейс
Field. Это позволяет осуществить связь с данными (data binding), то есть отображать и редактировать значение некоторого атрибута сущности. -
Создайте класс
WebStepper- реализации компонента в подкаталоге gui модуля web. Замените содержимое класса следующим кодом:package com.company.demo.web.gui.components; import com.haulmont.cuba.web.gui.components.WebV8AbstractField; import org.vaadin.risto.stepper.IntStepper; // note that WebStepper should extend WebV8AbstractField public class WebStepper extends WebV8AbstractField<IntStepper, Integer, Integer> implements Stepper { public WebStepper() { this.component = createComponent(); attachValueChangeListener(component); } private IntStepper createComponent() { return new IntStepper(); } @Override public boolean isManualInputAllowed() { return component.isManualInputAllowed(); } @Override public void setManualInputAllowed(boolean value) { component.setManualInputAllowed(value); } @Override public boolean isMouseWheelEnabled() { return component.isMouseWheelEnabled(); } @Override public void setMouseWheelEnabled(boolean value) { component.setMouseWheelEnabled(value); } @Override public int getStepAmount() { return component.getStepAmount(); } @Override public void setStepAmount(int amount) { component.setStepAmount(amount); } @Override public int getMaxValue() { return component.getMaxValue(); } @Override public void setMaxValue(int maxValue) { component.setMaxValue(maxValue); } @Override public int getMinValue() { return component.getMinValue(); } @Override public void setMinValue(int minValue) { component.setMinValue(minValue); } }В качестве базового класса выбран
WebV8AbstractField, который реализует логику интерфейсаField. -
StepperLoaderв модуле web загружает компонент из его представления в XML.package com.company.demo.web.gui.xml.layout.loaders; import com.company.demo.web.gui.components.Stepper; import com.haulmont.cuba.gui.xml.layout.loaders.AbstractFieldLoader; public class StepperLoader extends AbstractFieldLoader<Stepper> { @Override public void createComponent() { resultComponent = factory.create(Stepper.class); loadId(resultComponent, element); } @Override public void loadComponent() { super.loadComponent(); String manualInput = element.attributeValue("manualInput"); if (manualInput != null) { resultComponent.setManualInputAllowed(Boolean.parseBoolean(manualInput)); } String mouseWheel = element.attributeValue("mouseWheel"); if (mouseWheel != null) { resultComponent.setMouseWheelEnabled(Boolean.parseBoolean(mouseWheel)); } String stepAmount = element.attributeValue("stepAmount"); if (stepAmount != null) { resultComponent.setStepAmount(Integer.parseInt(stepAmount)); } String maxValue = element.attributeValue("maxValue"); if (maxValue != null) { resultComponent.setMaxValue(Integer.parseInt(maxValue)); } String minValue = element.attributeValue("minValue"); if (minValue != null) { resultComponent.setMinValue(Integer.parseInt(minValue)); } } }Логика загрузки базовых свойств компонента
Fieldсосредоточена в классеAbstractFieldLoader. Нам достаточно загрузить только специфические свойстваStepper. -
В файле
cuba-ui-component.xml, расположенном в корне модуля web, регистрируется новый компонент и его загрузчик. Замените содержимое файла следующим кодом:<?xml version="1.0" encoding="UTF-8" standalone="no"?> <components xmlns="http://schemas.haulmont.com/cuba/components.xsd"> <component> <name>stepper</name> <componentLoader>com.company.demo.web.gui.xml.layout.loaders.StepperLoader</componentLoader> <class>com.company.demo.web.gui.components.WebStepper</class> </component> </components> -
Файл
ui-component.xsd, расположенный в корне модуля web, это описатель XML схемы новых компонентов проекта. Добавьте элементstepperи описание его атрибутов.<?xml version="1.0" encoding="UTF-8" standalone="no"?> <xs:schema xmlns="http://schemas.company.com/agd/0.1/ui-component.xsd" elementFormDefault="qualified" targetNamespace="http://schemas.company.com/agd/0.1/ui-component.xsd" xmlns:xs="http://www.w3.org/2001/XMLSchema"> <xs:element name="stepper"> <xs:complexType> <xs:attribute name="id" type="xs:string"/> <xs:attribute name="caption" type="xs:string"/> <xs:attribute name="height" type="xs:string"/> <xs:attribute name="width" type="xs:string"/> <xs:attribute name="dataContainer" type="xs:string"/> <xs:attribute name="property" type="xs:string"/> <xs:attribute name="manualInput" type="xs:boolean"/> <xs:attribute name="mouseWheel" type="xs:boolean"/> <xs:attribute name="stepAmount" type="xs:int"/> <xs:attribute name="maxValue" type="xs:int"/> <xs:attribute name="minValue" type="xs:int"/> </xs:complexType> </xs:element> </xs:schema>
Далее рассмотрим, как добавить новый компонент на экран.
-
Либо удалите изменения, сделанные в предыдущем разделе, либо сгенерируйте для сущности стандартные экраны.
-
Далее добавим компонент
stepperна экран. Вы можете добавить его как декларативно, так и программно. Рассмотрим оба способа.-
Декларативное использование компонента в XML-декскрипторе.
-
Откройте файл
customer-edit.xml. -
Объявите новое пространство имен
xmlns:app="http://schemas.company.com/agd/0.1/ui-component.xsd" -
Удалите поле
scoreизform. -
Добавьте компонент
stepperна экран.
В результате XML-дескриптор редактора должен выглядеть так:
<?xml version="1.0" encoding="UTF-8" standalone="no"?> <window xmlns="http://schemas.haulmont.com/cuba/screen/window.xsd" xmlns:app="http://schemas.company.com/agd/0.1/ui-component.xsd" caption="msg://editorCaption" focusComponent="form" messagesPack="com.company.demo.web.customer"> <data> <instance id="customerDc" class="com.company.demo.entity.Customer" view="_local"> <loader/> </instance> </data> <dialogMode height="600" width="800"/> <layout expand="editActions" spacing="true"> <form id="form" dataContainer="customerDc"> <column width="250px"> <textField id="nameField" property="name"/> <app:stepper id="stepper" dataContainer="customerDc" property="score" minValue="0" maxValue="20"/> </column> </form> <hbox id="editActions" spacing="true"> <button action="windowCommitAndClose"/> <button action="windowClose"/> </hbox> </layout> </window>В данном примере компонент
stepperподсоединен к атрибутуscoreсущностиCustomer, экземпляр которой находится в источнике данныхcustomerDc. -
-
Программное создание в контроллере Java.
<?xml version="1.0" encoding="UTF-8" standalone="no"?> <window xmlns="http://schemas.haulmont.com/cuba/screen/window.xsd" caption="msg://editorCaption" focusComponent="form" messagesPack="com.company.demo.web.customer"> <data> <instance id="customerDc" class="com.company.demo.entity.Customer" view="_local"> <loader/> </instance> </data> <dialogMode height="600" width="800"/> <layout expand="editActions" spacing="true"> <form id="form" dataContainer="customerDc"> <column width="250px"> <textField id="nameField" property="name"/> </column> </form> <hbox id="editActions" spacing="true"> <button action="windowCommitAndClose"/> <button action="windowClose"/> </hbox> </layout> </window>package com.company.demo.web.customer; import com.company.demo.entity.Customer; import com.company.demo.web.gui.components.Stepper; import com.haulmont.cuba.gui.UiComponents; import com.haulmont.cuba.gui.components.Form; import com.haulmont.cuba.gui.components.data.value.ContainerValueSource; import com.haulmont.cuba.gui.model.InstanceContainer; import com.haulmont.cuba.gui.screen.*; import javax.inject.Inject; @UiController("demo_Customer.edit") @UiDescriptor("customer-edit.xml") @EditedEntityContainer("customerDc") @LoadDataBeforeShow public class CustomerEdit extends StandardEditor<Customer> { @Inject private Form form; @Inject private InstanceContainer<Customer> customerDc; @Inject private UiComponents uiComponents; @Subscribe protected void onInit(InitEvent event) { Stepper stepper = uiComponents.create(Stepper.NAME); stepper.setValueSource(new ContainerValueSource<>(customerDc, "score")); stepper.setCaption("Score"); stepper.setWidthFull(); stepper.setMinValue(0); stepper.setMaxValue(20); form.add(stepper); } @Subscribe protected void onInitEntity(InitEntityEvent<Customer> event) { event.getEntity().setScore(0); } }
-
-
Запускаем сервер приложения. Экран редактирования должен выглядеть следующим образом:
3.5.17.4.3. Подключение JavaScript библиотеки
В платформе CUBA реализован компонент Slider, позволяющий получить числовое значение в заданном диапазоне. Для ваших задач может понадобиться подобный компонент с двумя ползунками, определяющими диапазон значений. Поэтому в данном примере мы подключим компонент Slider из библиотеки jQuery UI.
Создайте новый проект в CUBA Studio и назовите его jscomponent.
Чтобы создать Slider компонент, необходимо создать следующие файлы:
-
SliderServerComponent- интегрированный с JavaScript компонент Vaadin. -
SliderState- класс состояния компонента Vaadin. -
slider-connector.js- JavaScript коннектор для компонента Vaadin
Процесс интеграции компонента в универсальный интерфейс аналогичен описанному в разделе Подключение аддона Vaadin с интеграцией в Generic UI, поэтому рассматривать его здесь мы не будем.
Создадим требуемые файлы в подкаталоге toolkit/ui/slider модуля web и внесем в них необходимые изменения.
-
Класс состояния
SliderStateопределяет, какие данные будут пересылаться между сервером и клиентом. В нашем случае мы будем пересылать информацию о минимальном и максимальном возможном значении и выбранных значениях слайдера.package com.company.jscomponent.web.toolkit.ui.slider; import com.vaadin.shared.ui.JavaScriptComponentState; public class SliderState extends JavaScriptComponentState { public double[] values; public double minValue; public double maxValue; } -
Серверный компонент Vaadin
SliderServerComponent.package com.company.jscomponent.web.toolkit.ui.slider; import com.haulmont.cuba.web.widgets.WebJarResource; import com.vaadin.annotations.JavaScript; import com.vaadin.ui.AbstractJavaScriptComponent; import elemental.json.JsonArray; @WebJarResource({"jquery:jquery.min.js", "jquery-ui:jquery-ui.min.js", "jquery-ui:jquery-ui.css"}) @JavaScript({"slider-connector.js"}) public class SliderServerComponent extends AbstractJavaScriptComponent { public interface ValueChangeListener { void valueChanged(double[] newValue); } private ValueChangeListener listener; public SliderServerComponent() { addFunction("valueChanged", arguments -> { JsonArray array = arguments.getArray(0); double[] values = new double[2]; values[0] = array.getNumber(0); values[1] = array.getNumber(1); getState(false).values = values; listener.valueChanged(values); }); } public void setValue(double[] value) { getState().values = value; } public double[] getValue() { return getState().values; } public double getMinValue() { return getState().minValue; } public void setMinValue(double minValue) { getState().minValue = minValue; } public double getMaxValue() { return getState().maxValue; } public void setMaxValue(double maxValue) { getState().maxValue = maxValue; } @Override protected SliderState getState() { return (SliderState) super.getState(); } @Override public SliderState getState(boolean markAsDirty) { return (SliderState) super.getState(markAsDirty); } public ValueChangeListener getListener() { return listener; } public void setListener(ValueChangeListener listener) { this.listener = listener; } }Серверный компонент Vaadin определяет набор геттеров и сеттеров для работы с состоянием слайдера, а также интерфейс слушателя изменения значений. Класс компонента должен быть унаследован от
AbstractJavaScriptComponent.Метод
addFunction()в конструкторе класса объявляет обработчик RPC-вызова функцииvalueChanged()с клиента.Аннотации
@JavaScriptи@WebJarResourceуказывают на файлы, которые должны быть загружены на веб-страницу. В нашем примере это JavaScript файлы библиотеки jQuery UI, а также файл со стилями для jQuery UI, расположенные в WebJar ресурсе, и файл коннектора, расположенный в одном Java-пакете с серверным компонентом. -
JavaScript коннектор
slider-connector.js.com_company_jscomponent_web_toolkit_ui_slider_SliderServerComponent = function() { var connector = this; var element = connector.getElement(); $(element).html("<div/>"); $(element).css("padding", "5px 0px"); var slider = $("div", element).slider({ range: true, slide: function(event, ui) { connector.valueChanged(ui.values); } }); connector.onStateChange = function() { var state = connector.getState(); slider.slider("values", state.values); slider.slider("option", "min", state.minValue); slider.slider("option", "max", state.maxValue); $(element).width(state.width); } }Коннектор представляет собой функцию, которая при загрузке веб-страницы проинициализирует JavaScript компонент. Имя функции должно соответствовать полному имени класса серверного компонента, где точки в имени пакета заменены на символ подчеркивания.
Vaadin добавляет ряд полезных методов в функцию коннектора. Например,
this.getElement()возвращает HTML DOM элемент компонента,this.getState()возвращает объект-состояние.В нашем примере коннектор делает следующее:
-
Инициализирует компонент
sliderиз библиотеки jQuery UI. При изменении положения одного из ползунков будет вызвана функцияslide(). Мы видим, что она в свою очередь вызывает методvalueChanged()коннектора.valueChanged()- это метод, который мы объявили на стороне сервера в классеSliderServerComponent. -
Объявляет функцию
onStateChange(). Она будет вызываться при изменении объекта-состояния на стороне сервера.
-
Для демонстрации работы компонента создадим сущность Product с тремя атрибутами:
-
nameтипа String -
minDiscountтипа Double -
maxDiscountтипа Double
Затем сгенерируем стандартные экраны для данной сущности. Обратите внимание, что мы используем не универсальный компонент платформы, а "нативный" компонент Vaadin. Следовательно, экраны должны располагаться в модуле Web, а не в GUI - укажите это в окне генерации стандартных экранов.
В редакторе сущности мы хотим устанавливать минимальное и максимальное значение скидки с помощью компонента slider, который мы только что создали.
Перейдите к файлу product-edit.xml. Поля minDiscount и maxDiscount сделайте нередактируемыми, добавив к соответствующим элементам атрибут editable="false". Затем добавьте компонент hbox, который будет использоваться в качестве контейнера для Vaadin компонента.
В результате XML-дескриптор экрана редактирования должен выглядеть следующим образом:
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<window xmlns="http://schemas.haulmont.com/cuba/screen/window.xsd"
caption="msg://editorCaption"
focusComponent="form"
messagesPack="com.company.jscomponent.web.product">
<data>
<instance id="productDc"
class="com.company.jscomponent.entity.Product"
view="_local">
<loader/>
</instance>
</data>
<dialogMode height="600"
width="800"/>
<layout expand="editActions" spacing="true">
<form id="form" dataContainer="productDc">
<column width="250px">
<textField id="nameField" property="name"/>
<textField id="minDiscountField" property="minDiscount" editable="false"/>
<textField id="maxDiscountField" property="maxDiscount" editable="false"/>
<hbox id="sliderBox" width="100%"/>
</column>
</form>
<hbox id="editActions" spacing="true">
<button action="windowCommitAndClose"/>
<button action="windowClose"/>
</hbox>
</layout>
</window>Перейдите к файлу ProductEdit.java. Замените его содержимое следующим кодом:
package com.company.jscomponent.web.product;
import com.company.jscomponent.entity.Product;
import com.company.jscomponent.web.toolkit.ui.slider.SliderServerComponent;
import com.haulmont.cuba.gui.components.HBoxLayout;
import com.haulmont.cuba.gui.screen.*;
import com.vaadin.ui.Layout;
import javax.inject.Inject;
@UiController("jscomponent_Product.edit")
@UiDescriptor("product-edit.xml")
@EditedEntityContainer("productDc")
@LoadDataBeforeShow
public class ProductEdit extends StandardEditor<Product> {
@Inject
private HBoxLayout sliderBox;
@Subscribe
protected void onInitEntity(InitEntityEvent<Product> event) {
event.getEntity().setMinDiscount(15.0);
event.getEntity().setMaxDiscount(70.0);
}
@Subscribe
protected void onBeforeShow(BeforeShowEvent event) {
SliderServerComponent slider = new SliderServerComponent();
slider.setValue(new double[]{
getEditedEntity().getMinDiscount(),
getEditedEntity().getMaxDiscount()
});
slider.setMinValue(0);
slider.setMaxValue(100);
slider.setWidth("250px");
slider.setListener(newValue -> {
getEditedEntity().setMinDiscount(newValue[0]);
getEditedEntity().setMaxDiscount(newValue[1]);
});
sliderBox.unwrap(Layout.class).addComponent(slider);
}
}В методе onInitEntity() мы проставляем начальные значения скидок для нового продукта.
В методе onBeforeShow() инициализируем компонент слайдера. Для компонента слайдера мы проставляем текущие значения, максимальное и минимальное значения, а также объявляем слушатель изменений значений. При движении ползунка мы будем проставлять новые значения скидок в соответствующие поля редактируемой сущности.
Запустите проект и откройте экран редактирования продукта. Изменение положения ползунка на слайдере должно изменять значение в соответствующем текстовом поле.
3.5.17.4.4. Создание GWT компонента
В данном примере мы рассмотрим создание простого GWT-компонента - поля рейтинга в виде 5 звезд, а также использование его в экранах приложения.

Создадим новый проект в CUBA Studio. Имя проекта - ratingsample.
Создайте модуль web-toolkit. Его удобно создать с помощью CUBA Studio: В главном меню нажмите CUBA > Advanced > Manage modules > Create 'web-toolkit' Module.
Чтобы создать GWT компонент, необходимо создать следующие файлы:
-
RatingFieldWidget.java- виджет GWT в модуле web-toolkit. -
RatingFieldServerComponent.java- класс компонента Vaadin. -
RatingFieldState.java- класс состояния компонента. -
RatingFieldConnector.java- коннектор, связывающий клиентский код с серверным компонентом. -
RatingFieldServerRpc.java- класс, определяющий API сервера для клиентской части.
Создадим требуемые файлы и внесем в них необходимые изменения.
-
Создайте в модуле web-toolkit класс
RatingFieldWidget. Замените содержимое файла на следующий код:package com.company.ratingsample.web.toolkit.ui.client.ratingfield; import com.google.gwt.dom.client.DivElement; import com.google.gwt.dom.client.SpanElement; import com.google.gwt.dom.client.Style.Display; import com.google.gwt.user.client.DOM; import com.google.gwt.user.client.Event; import com.google.gwt.user.client.ui.FocusWidget; import java.util.ArrayList; import java.util.List; public class RatingFieldWidget extends FocusWidget { private static final String CLASSNAME = "ratingfield"; // API for handle clicks public interface StarClickListener { void starClicked(int value); } protected List<SpanElement> stars = new ArrayList<>(5); protected StarClickListener listener; protected int value = 0; public RatingFieldWidget() { DivElement container = DOM.createDiv().cast(); container.getStyle().setDisplay(Display.INLINE_BLOCK); for (int i = 0; i < 5; i++) { SpanElement star = DOM.createSpan().cast(); // add star element to the container DOM.insertChild(container, star, i); // subscribe on ONCLICK event DOM.sinkEvents(star, Event.ONCLICK); stars.add(star); } setElement(container); setStylePrimaryName(CLASSNAME); } // main method for handling events in GWT widgets @Override public void onBrowserEvent(Event event) { super.onBrowserEvent(event); switch (event.getTypeInt()) { // react on ONCLICK event case Event.ONCLICK: SpanElement element = event.getEventTarget().cast(); // if click was on the star int index = stars.indexOf(element); if (index >= 0) { int value = index + 1; // set internal value setValue(value); // notify listeners if (listener != null) { listener.starClicked(value); } } break; } } @Override public void setStylePrimaryName(String style) { super.setStylePrimaryName(style); for (SpanElement star : stars) { star.setClassName(style + "-star"); } updateStarsStyle(this.value); } // let application code change the state public void setValue(int value) { this.value = value; updateStarsStyle(value); } // refresh visual representation private void updateStarsStyle(int value) { for (SpanElement star : stars) { star.removeClassName(getStylePrimaryName() + "-star-selected"); } for (int i = 0; i < value; i++) { stars.get(i).addClassName(getStylePrimaryName() + "-star-selected"); } } }Виджет представляет собой клиентский класс, отвечающий за отображение компонента в веб-браузере и реакцию на события. Он определяет интерфейсы для работы с серверной частью. В нашем случае это метод
setValue()и интерфейсStarClickListener. -
Класс компонента Vaadin
RatingFieldServerComponent. Он определяет API для серверного кода, различные get/set методы, слушатели событий и подключение источников данных. Прикладные разработчики используют в своём коде методы этого класса.package com.company.ratingsample.web.toolkit.ui; import com.company.ratingsample.web.toolkit.ui.client.ratingfield.RatingFieldServerRpc; import com.company.ratingsample.web.toolkit.ui.client.ratingfield.RatingFieldState; import com.vaadin.ui.AbstractField; // the field will have a value with integer type public class RatingFieldServerComponent extends AbstractField<Integer> { public RatingFieldServerComponent() { // register an interface implementation that will be invoked on a request from the client registerRpc((RatingFieldServerRpc) value -> setValue(value, true)); } @Override protected void doSetValue(Integer value) { if (value == null) { value = 0; } getState().value = value; } @Override public Integer getValue() { return getState().value; } // define own state class @Override protected RatingFieldState getState() { return (RatingFieldState) super.getState(); } @Override protected RatingFieldState getState(boolean markAsDirty) { return (RatingFieldState) super.getState(markAsDirty); } } -
Класс состояния
RatingFieldStateотвечает за то, какие данные будут пересылаться между клиентом и сервером. В нём определяются публичные поля, которые будут автоматически сериализованы на сервере и десериализованы на клиенте.package com.company.ratingsample.web.toolkit.ui.client.ratingfield; import com.vaadin.shared.AbstractFieldState; public class RatingFieldState extends AbstractFieldState { { // change the main style name of the component primaryStyleName = "ratingfield"; } // define a field for the value public int value = 0; } -
Интерфейс
RatingFieldServerRpc— определяет API сервера для клиентской части, его методы могут вызываться с клиента при помощи механизма удалённого вызова процедур, встроенного в Vaadin. Этот интерфейс мы реализуем в самом компоненте, в данном случае просто вызываем методsetValue()нашего поля.package com.company.ratingsample.web.toolkit.ui.client.ratingfield; import com.vaadin.shared.communication.ServerRpc; public interface RatingFieldServerRpc extends ServerRpc { //method will be invoked in the client code void starClicked(int value); } -
Создайте в модуле web-toolkit класс
RatingFieldConnector. Коннектор связывает клиентский код с серверной частью.package com.company.ratingsample.web.toolkit.ui.client.ratingfield; import com.company.ratingsample.web.toolkit.ui.RatingFieldServerComponent; import com.vaadin.client.communication.StateChangeEvent; import com.vaadin.client.ui.AbstractFieldConnector; import com.vaadin.shared.ui.Connect; // link the connector with the server implementation of RatingField // extend AbstractField connector @Connect(RatingFieldServerComponent.class) public class RatingFieldConnector extends AbstractFieldConnector { // we will use a RatingFieldWidget widget @Override public RatingFieldWidget getWidget() { RatingFieldWidget widget = (RatingFieldWidget) super.getWidget(); if (widget.listener == null) { widget.listener = value -> getRpcProxy(RatingFieldServerRpc.class).starClicked(value); } return widget; } // our state class is RatingFieldState @Override public RatingFieldState getState() { return (RatingFieldState) super.getState(); } // react on server state change @Override public void onStateChanged(StateChangeEvent stateChangeEvent) { super.onStateChanged(stateChangeEvent); // refresh the widget if the value on server has changed if (stateChangeEvent.hasPropertyChanged("value")) { getWidget().setValue(getState().value); } } }
Код виджета RatingFieldWidget не определяет внешний вид компонента, кроме назначения имён стилей ключевым элементам. Для того, чтобы определить внешний вид нашего компонента, создадим файлы стилей. Это удобно сделать с помощью CUBA Studio: В главном меню нажмите CUBA > Advanced > Manage themes > Create theme extension. Другой способ - использовать команду extend-theme в CUBA CLI. В списке тем для расширения выберем hover и нажмем кнопку Create. Эта тема использует вместо значков глифы шрифта FontAwesome, чем мы и воспользуемся.
Стили каждого компонента принято выделять в отдельный файл componentname.scss в каталоге components/componentname в формате примеси SCSS. В каталоге themes/hover/com.company.ratingsample модуля web создадим структуру вложенных каталогов: components/ratingfield. Затем внутри ratingfield создадим файл ratingfield.scss:
@mixin ratingfield($primary-stylename: ratingfield) {
.#{$primary-stylename}-star {
font-family: FontAwesome;
font-size: $v-font-size--h2;
padding-right: round($v-unit-size/4);
cursor: pointer;
&:after {
content: '\f006'; // 'fa-star-o'
}
}
.#{$primary-stylename}-star-selected {
&:after {
content: '\f005'; // 'fa-star'
}
}
.#{$primary-stylename} .#{$primary-stylename}-star:last-child {
padding-right: 0;
}
.#{$primary-stylename}.v-disabled .#{$primary-stylename}-star {
cursor: default;
}
}Подключим этот файл в главном файле темы hover-ext.scss:
@import "components/ratingfield/ratingfield";
@mixin com_company_ratingsample-hover-ext {
@include ratingfield;
}Для демонстрации работы компонента создадим новый экран в модуле web.
Назовите экран rating-screen.
Перейдем к редактированию экрана rating-screen.xml в IDE. Нам понадобится контейнер для нашего компонента, объявим его в XML экрана:
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<window xmlns="http://schemas.haulmont.com/cuba/screen/window.xsd"
caption="msg://caption"
messagesPack="com.company.ratingsample.web.screens.rating">
<layout expand="container">
<vbox id="container">
<!-- we'll add vaadin component here-->
</vbox>
</layout>
</window>Откроем класс контроллера экрана RatingScreen.java и добавим код размещения нашего компонента на экране:
package com.company.ratingsample.web.screens.rating;
import com.company.ratingsample.web.toolkit.ui.RatingFieldServerComponent;
import com.haulmont.cuba.gui.components.VBoxLayout;
import com.haulmont.cuba.gui.screen.Screen;
import com.haulmont.cuba.gui.screen.Subscribe;
import com.haulmont.cuba.gui.screen.UiController;
import com.haulmont.cuba.gui.screen.UiDescriptor;
import com.vaadin.ui.Layout;
import javax.inject.Inject;
@UiController("ratingsample_RatingScreen")
@UiDescriptor("rating-screen.xml")
public class RatingScreen extends Screen {
@Inject
private VBoxLayout container;
@Subscribe
protected void onInit(InitEvent event) {
RatingFieldServerComponent field = new RatingFieldServerComponent();
field.setCaption("Rate this!");
container.unwrap(Layout.class).addComponent(field);
}
}На рисунке ниже показана завершенная структура проекта:
Запускаем сервер приложения и смотрим на результат.
3.5.17.4.5. Поддержка собственных визуальных компонентов и фасетов в CUBA Studio
Дизайнер экранов в CUBA Studio позволяет разработчикам встроить собственный UI компонент (или фасет), реализованный в аддоне или в проекте, добавляя особые аннотации метаданных к определению компонента.
|
Собственные UI компоненты и фасеты поддерживаются в CUBA Studio начиная с версии Studio |
Поддержка UI компонента в дизайнере экранов включает в себя следующие возможности:
-
Отображение компонента в панели Palette.
-
Генерация XML кода для компонента, когда он добавляется из палитры (Palette). Автоматическое добавление импорта пространства имен XSD, если это указано в объявлении компонента.
-
Отображение иконки, соответствующей добавленному компоненту, в панели Hierarchy.
-
Отображение и редактирование свойств компонента в панели Inspector. Генерация атрибутов XML тегов при изменении свойств компонента.
-
Показ подсказок для значений свойств.
-
Валидация значений свойств.
-
Инжекция компонента в контроллер экрана.
-
Генерация обработчиков событий и делегирующих методов, объявленных компонентом.
-
Отображение заглушки компонента в панели Layout Preview.
-
Переход к web-документации, если ссылка предоставлена разработчиком.
- Предварительные условия
Нужно понимать, что результат работы дизайнера экранов - это сгенерированный XML код в дескрипторе экрана. Однако, чтобы собственный компонент или фасет был успешно загружен из XML в экран работающего приложения, в вашем проекте также должны быть реализованы следующие элементы кода:
-
Создан класс интерфейса компонента или фасета.
-
Для компонентов - реализован загрузчик компонента. Для фасетов - создан провайдер фасета, это Spring бин, реализующий интерфейс
com.haulmont.cuba.gui.xml.FacetProvider, параметризованный классом фасета. -
Компонент и его загрузчик зарегистрированы в файле
cuba-ui-component.xml. -
Необязательно: определена XML схема, описывающая структуру и ограничения на описание компонента (фасета) в дескрипторе экрана.
Эти шаги описаны в секции Подключение аддона Vaadin с интеграцией в Generic UI.
- Демо-проект Stepper
Полностью реализованный пример собственного UI компонента с аннотациями метаданных можно найти в проекте-примере интеграции Vaadin аддона Stepper. Его исходный код находится здесь: https://github.com/cuba-labs/vaadin-stepper-addon-integration.
Файлы, на которые следует обратить внимание:
-
Аннотации UI метаданных добавлены к интерфейсу компонента:
com.company.demo.web.gui.components.Stepper. -
Иконки компонента для палитры (
stepper.svgиstepper_dark.svg) расположены в каталогеmodules/web/src/com/company/demo/web/gui/components/icons. -
Дескриптор экрана
customer-edit.xmlиспользует компонентstepperв вёрстке.
import com.haulmont.cuba.gui.meta.*;
@StudioComponent(category = "Samples",
unsupportedProperties = {"description", "icon", "responsive"},
xmlns = "http://schemas.company.com/demo/0.1/ui-component.xsd",
xmlnsAlias = "app",
icon = "com/company/demo/web/gui/components/icons/stepper.svg",
canvasBehaviour = CanvasBehaviour.INPUT_FIELD)
@StudioProperties(properties = {
@StudioProperty(name = "dataContainer", type = PropertyType.DATACONTAINER_REF),
@StudioProperty(name = "property", type = PropertyType.PROPERTY_PATH_REF, options = "int"),
}, groups = @PropertiesGroup(
properties = {"dataContainer", "property"}, constraint = PropertiesConstraint.ALL_OR_NOTHING
))
public interface Stepper extends Field<Integer> {
@StudioProperty(name = "manualInput", type = PropertyType.BOOLEAN, defaultValue = "true")
void setManualInputAllowed(boolean value);
boolean isManualInputAllowed();
// ...
}Открыв файл customer-edit.xml в дизайнере экранов, вы увидите, как компонент встроен в панели дизайнера.
Панель Component Palette содержит элемент Stepper:
Панель Component Hierarchy отображает компонент рядом с другими компонентами в дереве:
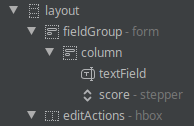
Панель Component Inspector отображает и позволяет редактировать свойства компонента:
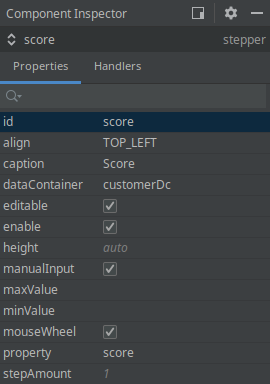
Наконец, панель предпросмотра вёрстки отображает компонент в виде текстового поля:
Теперь давайте перейдем к аннотациям и атрибутам, которые нужно добавить к интерфейсу компонента, чтобы добиться такой интеграции.
- Список аннотаций метаданных
Все аннотации UI метаданных и связанные классы расположены в пакете com.haulmont.cuba.gui.meta. Аннотации UI метаданных поддерживаются для следующих типов UI элементов:
-
Визуальные компоненты - помечаются как
@StudioComponent. -
Фасеты - помечаются как
@StudioFacet. -
Действия - помечаются как
@StudioAction. Аннотации для действий описаны в секции Собственные типы действий.
Доступны следующие аннотации:
-
@StudioComponent- указывает, что UI компонент, чей интерфейс проаннотирован, должен быть доступен в дизайнере экранов. Предоставляет атрибуты, необходимые для панелей дизайнера экранов. Проаннотированный интерфейс должен быть потомком интерфейсаcom.haulmont.cuba.gui.components.Component. -
@StudioFacet- указывает, что фасет, чей интерфейс проаннотирован, должен быть доступен в дизайнере экранов. Предоставляет необходимые атрибуты для панелей дизайнера экранов. Проаннотированный интерфейс должен быть потомком интерфейсаcom.haulmont.cuba.gui.components.Facet. Фасет должен иметь связанный бинFacetProvider, определенный в проекте. -
@StudioProperty- указывает, что проаннотированный метод-setter нужно показать в панели Inspector как свойство UI компонента или фасета. -
@StudioProperties- определяет дополнительные свойства и группы свойств для UI компонента или фасета. Можно использовать, чтобы определить дополнительные свойства, не относящиеся к setter-методам свойств компонента, а также чтобы переопределить унаследованные свойства или чтобы провалидировать связанные по смыслу пары свойств. -
@PropertiesGroup- определяет группу свойств: список связанных свойств, которые должны быть определены только одновременно, или наоборот - взаимно исключают друг друга. -
@StudioElementsGroup- указывает, что проаннотированный метод-setter нужно показать в дизайнере экранов как вложенную группу под-элементов UI компонента или фасета, например колонки, действия или список динамических свойств. -
@StudioElement- указывает, что проаннотированный класс или интерфейс должен быть доступен в дизайнере экранов как часть UI компонента или фасета, например колонка, действие или динамическое свойство. -
@StudioEmbedded- используется для случаев, когда набор свойств компонента выделен в отдельный POJO. -
@StudioCollection- объявляет метаданные для вложенной группы под-элементов, которые должны быть поддержаны в дизайнере экранов, например колонки, действия, поля.
- Объявление UI компонента
Чтобы объявить, что UI компонент должен появиться в дизайнере экранов, нужно пометить его интерфейс аннотацией com.haulmont.cuba.gui.meta.StudioComponent.
@StudioComponent(caption = "GridLayout", xmlElement = "bgrid", category = "Containers")
private interface BGridLayout extends BLayout {
// ...
}Аннотация @StudioComponent имеет следующие атрибуты:
-
caption- подпись компонента, отображаемая в панели Palette. -
description- описание компонента, отображаемое в панели Palette как всплывающая подсказка при наведении мыши. -
category- категория в панели Palette (Containers, Components и т.д.), куда компонент будет помещён. -
icon- путь к файлу иконки компонента, используемой в панелях Palette и Hierarchy, в формате SVG или PNG, относительно корня модуля, в котором расположен компонент. Иконка компонента может иметь два варианта: для светлой и тёмной тем IDE. Имя файла тёмного варианта иконки определяется добавлением постфикса_darkк имени файла иконки, например:stepper.svgиstepper_dark.svg. -
xmlElement- название XML тега, которое будет вставляться в XML дескриптор экрана, когда компонент добавляется в экран. -
xmlns- пространство имён XML, требуемое для компонента. Когда компонент добавляется в экран, Studio автоматически добавляет импорт пространства имён к корневому элементу дескриптора экрана. -
xmlnsAlias- алиас пространства имён XML, требуемый для компонента. Например если алиас пространства имён -track, а название XML тега - этоgoogleTracker, то компонент будет добавлен в экран как тег<track:googleTracker/>. -
defaultProperty- имя свойства компонента по умолчанию, оно будет автоматически выбрано в панели Inspector, когда компонент выбирается в вёрстке. -
unsupportedProperties- список свойств, которые унаследованы от родительских интерфейсов компонента, но на самом деле не поддерживаются компонентом. Эти свойства будут скрыты в панели Inspector. -
canvasBehavior- определяет то, как UI компонент будет выглядеть на панели layout preview. Возможные варианты:-
COMPONENT- компонент отображается на предпросмотре как простой прямоугольник с иконкой. -
INPUT_FIELD- компонент отображается на предпросмотре как текстовое поле. -
CONTAINER- компонент отображается на предпросмотре как контейнер.
-
-
canvasIcon- путь к файлу иконки, отображаемой на предпросмотре как заполнитель, если атрибутcanvasBehaviourимеет значениеCOMPONENT. Файл иконки должен быть в формате SVG или PNG. Если это значение не указано, то будет использоваться атрибутicon. -
canvasIconSize- размер иконки, отображаемой на предпросмотре как заполнитель. Возможные значения:-
SMALL- небольшая иконка. -
LARGE- большая иконка, и под ней отображаетсяidкомпонента.
-
-
containerType- вид расположения контейнера (вертикальный, горизонтальный или flow), если атрибутcanvasBehaviourимеет значениеCONTAINER. -
documentationURL- URL, указывающий на страницу документации для UI компонента. Используется действием CUBA Documentation в дизайнере экранов. Если путь к документации зависит от версии библиотеки, то используйте%VERSION%как заместитель. Он будет заменён минорной версией (например1.2) библиотеки, содержащей UI компонент.
- Определение фасета
Чтобы указать, что собственный фасет должен быть доступен в дизайнере экранов, нужно пометить его интерфейс аннотацией com.haulmont.cuba.gui.meta.StudioFacet.
|
Чтобы фасет появился в дизайнере экранов, в проекте нужно создать связанную с ним реализацию FacetProvider. |
FacetProvider - это Spring бин, реализующий интерфейс com.haulmont.cuba.gui.xml.FacetProvider, и параметризованный классом интерфейса фасета. Используйте класс платформы com.haulmont.cuba.web.gui.facets.ClipboardTriggerFacetProvider как пример.
Атрибуты аннотации @StudioFacet совпадают с атрибутами аннотации @StudioComponent, описанными в предыдущей секции.
Пример:
@StudioFacet(
xmlElement = "clipboardTrigger",
category = "Facets",
icon = "icon/clipboardTrigger.svg",
documentationURL = "https://doc.cuba-platform.com/manual-%VERSION%/gui_ClipboardTrigger.html"
)
public interface ClipboardTrigger extends Facet {
@StudioProperty(type = PropertyType.COMPONENT_REF, options = "com.haulmont.cuba.gui.components.TextInputField")
void setInput(TextInputField<?> input);
@StudioProperty(type = PropertyType.COMPONENT_REF, options = "com.haulmont.cuba.gui.components.Button")
void setButton(Button button);
// ...
}- Стандартные свойства компонентов
Свойства компонентов объявляются с помощью двух аннотаций:
-
@StudioProperty- указывает, что проаннотированный метод (setter, setXxx) должен быть показан в панели Inspector как свойство компонента. -
@StudioProperties- объявляет на интерфейсе компонента дополнительные свойства и группы свойств компонента, не связанные с setter-методами.
Пример:
@StudioComponent(caption = "RichTextArea")
@StudioProperties(properties = {
@StudioProperty(name = "css", type = PropertyType.CSS_BLOCK)
})
interface RichTextArea extends Component {
@StudioProperty(type = PropertyType.CSS_CLASSNAME_LIST)
void setStylename(String stylename);
@StudioProperty(type = PropertyType.SIZE, defaultValue = "auto")
void setWidth(String width);
@StudioProperty(type = PropertyType.SIZE, defaultValue = "auto")
void setHeight(String height);
@StudioProperty(type = PropertyType.LOCALIZED_STRING)
void setContextHelpText(String contextHelpText);
@StudioProperty(type = PropertyType.LOCALIZED_STRING)
void setDescription(String description);
@StudioProperty
@Min(-1)
void setTabIndex(int tabIndex);
}Метод-setter может быть проаннотирован как @StudioProperty без указания каких-либо атрибутов. В этом случае:
-
имя и подпись свойства будут выведены из имени метода.
-
тип свойства будет определен по типу параметра setter-метода.
Аннотация @StudioProperty имеет следующие атрибуты:
-
name- название свойства. -
type- определяет вид содержимого, которое хранится в свойстве, например это может быть строка, имя сущности или ссылка на другой компонент в том же экране. Поддерживаемые типы свойств описаны ниже. -
caption- подпись свойства, отображаемая в панели Inspector. -
description- дополнительное описание свойства, которое будет отображаться в панели Inspector как всплывающая подсказка при наведении мыши. -
category- категория свойств в панели Inspector (в данный момент ещё не используется дизайнером экранов Studio) -
required- свойство является обязательным, дизайнер экранов не позволит ввести пустое значение данного свойства. -
defaultValue- указывает значение свойства, которое используется компонентом неявно в том случае, если соответствующий XML атрибут не указан. Данное значение, если его ввести, будет удалено из XML кода. -
options- контекстно зависимый список вариантов для свойства компонента:-
Для типа
ENUMERATION- список вариантов перечисления. -
Для типа
BEAN_REF- список разрешенных базовых классов для Spring бина. -
Для типа
COMPONENT_REF- список разрешенных базовых классов (интерфейсов) для компонента. -
Для типа
PROPERTY_PATH_REF- список разрешенных типов атрибута сущности. Используйте зарегистрированные имена встроенных типов данных для примитивных атрибутов илиto_oneиto_manyдля атрибутов-ассоциаций.
-
-
xmlAttribute- название XML-атрибута, если не указано, то будет использоваться значение изname. -
xmlElement- название XML-элемента. Если использовать этот атрибут, то вы можете продекларировать свойство компонента, которое будет записываться в под-тег основного XML-тега компонента, см. ниже. -
typeParameter- указывает имя генерик-параметра типа компонента, который предоставляется этим свойством компонента. См. описание ниже.
- Типы свойств компонента
Поддерживаются следующие типы свойств (com.haulmont.cuba.gui.meta.PropertyType):
-
INTEGER,LONG,FLOAT,DOUBLE,STRING,BOOLEAN,CHARACTER- примитивные типы. -
DATE- дата в форматеYYYY-MM-DD. -
DATE_TIME- дата и время в форматеYYYY-MM-DD hh:mm:ss. -
TIME- время в форматеhh:mm:ss. -
ENUMERATION- перечислимый тип. Список вариантов перечисления предоставляется атрибутом аннотацииoptions. -
COMPONENT_ID- идентификатор компонента, под-элемента или действия. Значение должно быть корректным идентификатором Java. -
ICON_ID- путь к файлу иконки или ID иконки из иконок, предопределенных в CUBA или определенных в проекте. -
SIZE- значение размера, например ширина или высота. -
LOCALIZED_STRING- локализованное сообщение, представленное строковым значением или ключом сообщения с префиксомmsg://илиmainMsg://. -
JPA_QUERY- строка запроса на языке JPA QL. -
ENTITY_NAME- имя сущности (указанное в атрибуте аннотацииjavax.persistence.Entity#name), определенной в проекте. -
ENTITY_CLASS- полное имя класса сущности, определенной в проекте. -
JAVA_CLASS_NAME- полное имя произвольного Java-класса. -
CSS_CLASSNAME_LIST- список CSS-классов, разделенных пробелом. -
CSS_BLOCK- строка CSS свойств. -
BEAN_REF- ID бина Spring, определенного в проекте. Список разрешенных базовых классов, от которых Spring бин должен быть унаследован, можно указать в атрибутеoptionsданной аннотации. -
COMPONENT_REF- ID компонента, определенного в данном экране. Список разрешенных базовых классов, от которых компонент должен быть унаследован, можно указать в атрибутеoptionsданной аннотации. -
DATASOURCE_REF- ID источника данных, определенного в экране (устаревшее API). -
COLLECTION_DATASOURCE_REF- ID источника данных-коллекции, определенного в экране (устаревшее API). -
DATALOADER_REF- ID загрузчика данных, определенного в экране. -
DATACONTAINER_REF- ID контейнера данных, определенного в экране. -
COLLECTION_DATACONTAINER_REF- ID контейнера коллекции данных, определенного в экране. -
PROPERTY_REF- имя атрибута сущности. Список типов данных атрибута можно ограничить, указав атрибутoptionsданной аннотации. Чтобы для данного свойства отображались подсказки, свойство компонента должно быть связано с другим свойством компонента, определяющим контейнер данных или источник данных, с помощью группы свойств. -
PROPERTY_PATH_REF- имя атрибута сущности или список вложенных атрибутов, разделенных точкой, напримерuser.group.name. Список типов данных атрибута можно ограничить, указав атрибутoptionsданной аннотации. Чтобы для данного свойства отображались подсказки, свойство компонента должно быть связано с другим свойством компонента, определяющим контейнер данных или источник данных, с помощью группы свойств. -
DATATYPE_ID- ID типа данных CUBA, напримерstringилиdecimal. -
SHORTCUT- комбинация клавиш, напримерCTRL-SHIFT-U. -
SCREEN_CLASS- полное имя класса контроллера экрана, определенного в проекте. -
SCREEN_ID- ID экрана, определенного в проекте. -
SCREEN_OPEN_MODE- режим открытия экрана.
- Валидация свойств компонента
Панель Inspector поддерживает валидацию свойств компонента с помощью ограниченного набора аннотаций BeanValidation:
-
@Min,@Max,@DecimalMin,@DecimalMax. -
@Negative,@Positive,@PosizitiveOrZero,@NegativeOrZero. -
@NotBlank,@NotEmpty. -
@Digits. -
@Pattern. -
@Size,@Length. -
@URL.
Пример:
@StudioProperty(type = PropertyType.INTEGER)
@Positive
void setStepAmount(int amount);
int getStepAmount();Если пользователь пытается ввести некорректное значение, то отображается следующее сообщение об ошибке:
- Аннотация @StudioProperties и группы свойств
Метаданные, определенные аннотацией @StudioProperty, могут быть переопределены аннотацией @StudioProperties, определенной на интерфейсе компонента.
Аннотация @StudioProperties может иметь несколько объявлений групп в атрибуте groups - с помощью аннотации @PropertiesGroup. Каждая группа определяет группу свойств, тип этой группы определяется атрибутом @PropertiesGroup#constraint:
-
ONE_OF- свойства взаимно исключают друг друга, не могут быть указаны одновременно. -
ALL_OR_NOTHING- список семантически связанных свойств, которые должны использоваться только вместе, одновременно.
Важное применение группы свойств - это указание пары атрибутов dataContainer и property для компонентов, которые могут быть привязаны к контейнеру данных. Эти свойства обязаны быть включены в группу вида ALL_OR_NOTHING. Вот пример компонента с подобной группой свойств:
@StudioComponent(
caption = "RichTextField",
category = "Fields",
canvasBehaviour = CanvasBehaviour.INPUT_FIELD)
@StudioProperties(properties = {
@StudioProperty(name = "dataContainer", type = PropertyType.DATACONTAINER_REF),
@StudioProperty(name = "property", type = PropertyType.PROPERTY_PATH_REF, options = "string")
}, groups = @PropertiesGroup(
properties = {"dataContainer", "property"}, constraint = PropertiesConstraint.ALL_OR_NOTHING
))
interface RichTextField extends Component {
// ...
}- Объявление метаданных под-элемента с помощью @StudioCollection
Составные компоненты, такие как table, pickerField или графики - определяются в дескрипторе экрана как несколько вложенных XML тегов. Под-теги представляют собой части компонента, и они загружаются в экран загрузчиком ComponentLoader родительского компонента. Имеются два варианта, как определить метаданные для под-элементов:
-
С помощью
@StudioCollection- метаданные под-элементов можно указать прямо в интерфейсе компонента. -
С помощью
@StudioElementGroupи@StudioElement- метаданные под-элементов указываются на отдельных классах, которые отображают собой XML под-теги.
Аннотация com.haulmont.cuba.gui.meta.StudioCollection имеет следующие атрибуты:
-
xmlElement- название XML тега для коллекции. -
itemXmlElement- название XML тега для элемента коллекции. -
documentationURL- URL, указывающий на страницу документации для элемента. Используется действием CUBA Documentation в дизайнере экранов. Если путь к документации зависит от версии библиотеки, то используйте%VERSION%как заместитель. Он будет заменён минорной версией (например1.2) библиотеки, содержащей UI компонент. -
itemProperties- список аннотаций@StudioProperty, определяющих свойства элемента.
Ниже представлен пример.
Желаемая структура XML в дескрипторе экрана:
<layout>
<langPicker>
<options>
<option caption="msg://lang.english" code="en" flagIcon="icons/english.png"/>
<option caption="msg://lang.french" code="fr" flagIcon="icons/french.png"/>
</options>
</langPicker>
</layout>Класс компонента с объявлением @StudioCollection:
@StudioComponent(xmlElement = "langPicker", category = "Samples")
public interface LanguagePicker extends Field<Locale> {
@StudioCollection(xmlElement = "options", itemXmlElement = "option",
itemProperties = {
@StudioProperty(name = "caption", type = PropertyType.LOCALIZED_STRING, required = true),
@StudioProperty(name = "code", type = PropertyType.STRING),
@StudioProperty(name = "flagIcon", type = PropertyType.ICON_ID)
})
void setOptions(List<LanguageOption> options);
List<LanguageOption> getOptions();
}Панель Inspector для главного элемента компонента дополнительно отображает кнопку Add → {название элемента}, которая добавляет под-элемент в XML:
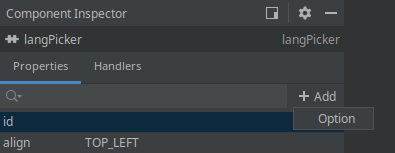
Если под-элемент выбран в верстке экрана, то панель Inspector отображает его свойства, указанные в аннотации StudioCollection:
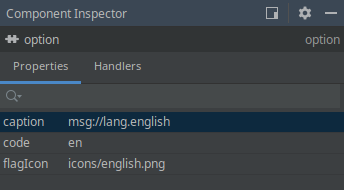
- Определение метаданных под-элементов с помощью @StudioElementGroup и @StudioElement
Аннотация @StudioElementGroup используется для пометки setter-метода в интерфейсе компонента. Она дает указание для Studio, что метаданные под-элементов нужно искать в классе, который используется как параметр setter-метода.
@StudioElementsGroup(xmlElement = "subElementGroupTagName")
void setSubElements(List<ComponentSubElement> subElements);Аннотация @StudioElementGroup имеет следующие атрибуты:
-
xmlElement- название XML тега группы под-элементов. -
icon- путь к иконке, используемой в панелях Palette и Hierarchy для группы под-элементов, в формате SVG или PNG, относительно корня модуля. -
documentationURL- URL, указывающий на страницу документации для группы под-элементов. Используется действием CUBA Documentation в дизайнере экранов. Если путь к документации зависит от версии библиотеки, то используйте%VERSION%как заместитель. Он будет заменён минорной версией (например1.2) библиотеки, содержащей UI компонент.
Аннотация @StudioElement помечает класс, который соответствует под-элементу компонента. Доступные атрибуты для XML тега, соответствующего данному элементу, объявляются с помощью аннотаций @StudioProperty и @StudioProperties.
@StudioElement(xmlElement = "subElement", caption = "Sub Element")
public interface SubElement {
@StudioProperty
void setElementProperty(String elementProperty);
// ...
}Атрибуты аннотации @StudioElement похожи на атрибуты аннотации @StudioComponent:
-
xmlElement- название XML тега под-элемента. -
caption- подпись элемента, отображается в панели Inspector. -
description- дополнительное описание для элемента, отображается в панели Inspector как всплывающая подсказка при наведении мыши. -
icon- путь к иконке под-элемента, отображаемой в панелях Palette и Hierarchy, формат SVG или PNG, относительно корня модуля. -
xmlns- пространство имён XML, требуемое для элемента. Когда элемент добавляется в экран, Studio автоматически добавляет импорт пространства имён к корневому элементу дескриптора экрана. -
xmlnsAlias- алиас пространства имён XML, требуемый для элемента. Например если алиас пространства имён -map, а название XML тега - этоlayer, то элемент будет добавлен в экран как тег<map:layer/>. -
defaultProperty- имя свойства элемента по умолчанию, оно будет автоматически выбрано в панели Inspector, когда элемент выбирается в вёрстке. -
unsupportedProperties- список свойств, которые унаследованы от родительских интерфейсов элемента, но на самом деле им не поддерживаются. Эти свойства будут скрыты в панели Inspector. -
documentationURL- URL, указывающий на страницу документации для элемента. Используется действием CUBA Documentation в дизайнере экранов. Если путь к документации зависит от версии библиотеки, то используйте%VERSION%как заместитель. Он будет заменён минорной версией (например1.2) библиотеки, содержащей UI компонент.
Ниже представлен пример.
Это желаемая структура XML в дескрипторе экрана:
<layout>
<serialChart backgroundColor="#ffffff" caption="Weekly Stats">
<graphs>
<graph colorProperty="color" valueProperty="price"/>
<graph colorProperty="costColor" valueProperty="cost"/>
</graphs>
</serialChart>
</layout>Класс компонента с определением @StudioElementsGroup:
@StudioComponent(xmlElement = "serialChart", category = "Samples")
public interface SerialChart extends Component {
@StudioProperty
void setCaption(String caption);
String getCaption();
@StudioProperty(type = PropertyType.STRING)
void setBackgroundColor(Color backgroundColor);
Color getBackgroundColor();
@StudioElementsGroup(xmlElement = "graphs")
void setGraphs(List<ChartGraph> graphs);
List<ChartGraph> getGraphs();
}Класс под-элемента, проаннотированный как @StudioElement:
@StudioElement(xmlElement = "graph", caption = "Graph")
public interface ChartGraph {
@StudioProperty(type = PropertyType.PROPERTY_PATH_REF)
void setValueProperty(String valueProperty);
String getValueProperty();
@StudioProperty(type = PropertyType.PROPERTY_PATH_REF)
void setColorProperty(String colorProperty);
String getColorProperty();
}Панель Inspector для главного элемента компонента дополнительно отображает кнопку Add → {подпись элемента}, которая добавляет новый под-элемент в XML:
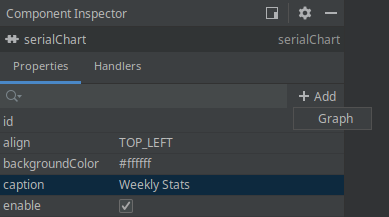
Если под-элемент выбран в верстке, то панель Inspector отображает его свойства, объявленные в классе под-элемента:
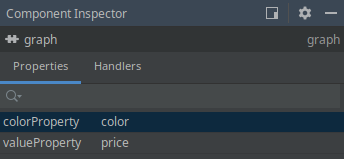
- Объявление атрибутов под-тега
Существует возможность задавать некоторые из свойств компонента не в главном теге, а единственном под-теге главного XML тега в дескрипторе экрана. В качестве примера рассмотрим следующий вариант XML верстки компонента:
<myChart>
<scrollBar color="white" position="TOP"/>
</myChart>Здесь scrollBar - это часть главного компонента myChart, а не самостоятельный компонент, и мы хотим объявить метаданные атрибутов в главном интерфейсе компонента.
Аннотации метаданных для атрибутов под-тега можно объявить прямо в интерфейсе компонента при помощи атрибута xmlElement аннотации @StudioProperty. Этот атрибут определяет название под-тега. Объявление компонента будет выглядеть следующим образом:
@StudioComponent(xmlElement = "myChart", category = "Samples")
public interface MyChart extends Component {
@StudioProperty(name = "position", caption = "scrollbar position",
xmlElement = "scrollBar", xmlAttribute = "position",
type = PropertyType.ENUMERATION, options = {"TOP", "BOTTOM"})
void setScrollBarPosition(String scrollBarPosition);
String getScrollBarPosition();
@StudioProperty(name = "color", caption = "scrollbar color",
xmlElement = "scrollBar", xmlAttribute = "color")
void setScrollBarColor(String scrollBarColor);
String getScrollBarColor();
}- Вынесение атрибутов основного тега в POJO с помощью @StudioEmbedded
Существуют случаи, когда возникает потребность вынести часть свойств компонента в отдельный POJO (plain old Java object, обыкновенный Java-класс с геттерами и сеттерами). В то же время в схеме XML вынесенные свойства указываются как атрибуты основного XML тега компонента. В этом случае можно применить аннотацию @StudioEmbedded. Метод-setter, который принимает POJO-объект, нужно пометить как @StudioEmbedded, чтобы объявить, что этот POJO содержит объявления дополнительных свойств компонента.
Аннотация com.haulmont.cuba.gui.meta.StudioEmbedded не имеет атрибутов.
Пример представлен ниже.
Желаемая структура XML, обратите внимание, что все атрибуты указаны для главного XML тега компонента:
<layout>
<richTextField textColor="blue" editable="false" id="rtf"/>
</layout>POJO-класс с проаннотированными свойствами:
public class FormattingOptions {
private String textColor = "black";
private boolean foldComments = true;
@StudioProperty(defaultValue = "black", description = "Main text color")
public void setTextColor(String textColor) {
this.textColor = textColor;
}
@StudioProperty(defaultValue = "true")
public void setFoldComments(boolean foldComments) {
this.foldComments = foldComments;
}
}Интерфейс компонента:
@StudioComponent(category = "Samples",
unsupportedProperties = {"icon", "responsive"},
description = "Text field with html support")
public interface RichTextField extends Field<String> {
@StudioEmbedded
void setFormattingOptions(FormattingOptions formattingOptions);
FormattingOptions getFormattingOptions(FormattingOptions formattingOptions);
}Панель Inspector показывает вынесенные свойства в общем списке:
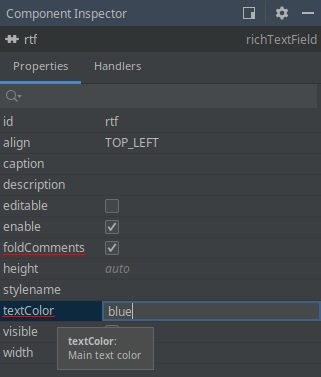
- Поддержка обработчиков событий и делегирующих методов
Studio предоставляет такую же поддержку для событий и делегирующих методов в пользовательских UI компонентах и фасетах, как и для встроенных UI компонентов. При объявлении слушателя события или делегирующего метода в интерфейсе компонента не требуется никаких дополнительных аннотаций.
Пример компонента, объявляющего обработчик события и свой собственный класс события:
@StudioComponent(category = "Samples")
public interface LazyTreeTable extends Component {
// ...
Subscription addNodeExpandListener(Consumer<NodeExpandEvent> listener);
class NodeExpandEvent extends EventObject {
private final Object nodeId;
public NodeExpandEvent(LazyTreeTable source, Object nodeId) {
super(source);
this.nodeId = nodeId;
}
public Object getNodeId() {
return nodeId;
}
}
}Объявленный обработчик события становится доступным в панели Inspector:
Реализация обработчика события, сгенерированная Studio в контроллере экрана, будет иметь вид:
@UiController("demo_Dashboard")
@UiDescriptor("dashboard.xml")
public class Dashboard extends Screen {
// ...
@Subscribe("regionTable")
public void onRegionTableNodeExpand(LazyTreeTable.NodeExpandEvent event) {
}
}Следующий пример демонстрирует, как объявить делегирующие методы в фасете, который параметризован генерик-типом:
@StudioFacet
public interface LookupScreenFacet<E extends Entity> extends Facet {
// ...
void setSelectHandler(Consumer<Collection<E>> selectHandler);
void setOptionsProvider(Supplier<ScreenOptions> optionsProvider);
void setTransformation(Function<Collection<E>, Collection<E>> transformation);
@StudioProperty(type = PropertyType.COMPONENT_REF, typeParameter = "E",
options = "com.haulmont.cuba.gui.components.ListComponent")
void setListComponent(ListComponent<E> listComponent);
}- Поддержка параметров генерик-типов
Studio поддерживает параметризацию интерфейса компонента генерик-типом. Параметр может быть классом сущности, классом экрана или произвольным Java классом. Параметр типа используется тогда, когда компонент инжектируется в контроллер экрана, или когда генерируются заглушки реализации делегирующих методов.
Studio выводит генерик-тип, используемый конкретным компонентом, глядя на свойства компонента, присвоенные ему в XML верстке. Свойство компонента может указать генерик-тип прямо или опосредованно. Например компонент table отображает список сущностей и параметризуется классом сущности. Чтобы определить используемый в конкретном случае тип сущности, Studio смотрит на атрибут dataContainer, а затем на определение контейнера коллекции данных. Если все атрибуты присвоены, тогда класс сущности, используемый контейнером данных, и берется как значение генерик-типа для данного компонента table.
Параметр typeParameter аннотации @StudioProperty указывает имя параметра типа для UI компонента или фасета, который предоставляется данным свойством компонента. Значение генерик-типа может быть предоставлено свойствами следующих типов:
-
PropertyType.JAVA_CLASS_NAME- используется указанный класс. -
PropertyType.ENTITY_CLASS- используется указанный класс сущности. -
PropertyType.SCREEN_CLASS_NAME- указывается указанный класс экрана. -
PropertyType.DATACONTAINER_REF,PropertyType.COLLECTION_DATACONTAINER_REF- используется класс сущности указанного контейнера данных. -
PropertyType.DATASOURCE_REF,PropertyType.COLLECTION_DATASOURCE_REF- используется класс сущности указанного источника данных. -
PropertyType.COMPONENT_REF- используется класс сущности, к которому привязано данное поле ввода (класс определяется через привязанный контейнер данных или источник данных).
Ниже приведен пример.
Интерфейс UI компонента, который отображает список сущностей, поставляемый контейнером коллекции данных:
@StudioComponent(category = "Samples")
public interface MyTable<E extends Entity> extends Component { (1)
@StudioProperty(type = PropertyType.COLLECTION_DATACONTAINER_REF,
typeParameter = "E") (2)
void setContainer(CollectionContainer<E> container);
void setStyleProvider(@Nullable Function<? super E, String> styleProvider); (3)
}| 1 | - интерфейс компонента параметризован параметром E, который представляет класс сущности элементов, отображаемых в таблице. |
| 2 | - указав на свойстве типа COLLECTION_DATACONTAINER_REF атрибут аннотации typeParameter, можно дать указание для Studio, чтобы реально используемый тип сущности выводился на основании привязанного к компоненту контейнера данных. |
| 3 | - генерик-тип компонента также используется делегирующим методом, который компонент экспортирует для пользователей. |
Чтобы Studio автоматически выводила генерик-тип, используемый компонентом, этот компонент должен быть связан с контейнером данных в дескрипторе экрана:
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<window xmlns="http://schemas.haulmont.com/cuba/screen/window.xsd"
caption="msg://dashboard.caption"
messagesPack="com.company.demo.web.screens">
<data>
<collection id="regionsDc" class="com.company.demo.entity.Region">
<!-- ... -->
</collection>
</data>
<layout>
<myTable id="regionTable" container="regionsDc"/>
</layout>
</window>Тогда Studio будет генерировать подобный код в контроллере экрана:
@UiController("demo_Dashboard")
@UiDescriptor("dashboard.xml")
public class Dashboard extends Screen {
@Inject
private MyTable<Region> regionTable; (1)
@Install(to = "regionTable", subject = "styleProvider")
private String regionTableStyleProvider(Region region) { (2)
return "bold-text";
}
}| 1 | - компонент инжектируется в контроллер экрана с корректным генерик-типом. |
| 2 | - ожидаемый генерик-тип используется и в сигнатуре делегирующего метода. |
3.5.18. Инфраструктура Generic UI
В данном разделе рассмотрены основные классы инфраструктуры Generic UI, которые могут быть расширены в приложении.

Рисунок 21. Классы инфраструктуры Generic UI
-
AppUI- класс, унаследованный отcom.vaadin.ui.UI. Экземпляр данного класса соответствует одной открытой вкладке веб браузера. Содержит ссылку на реализацию интерфейсаRootWindow- это может быть либо окно логина, либо главное окно приложения, в зависимости от состояния подключения. Ссылку наAppUIможно получить вызовом статического методаAppUI.getCurrent().Для кастомизации функциональности
AppUIв проекте, создайте класс, расширяющийAppUIв модуле web и зарегистрируйте его в web-spring.xml с идентификаторомcuba_AppUIиprototypescope, например:<bean id="cuba_AppUI" class="com.company.sample.web.MyAppUI" scope="prototype"/> -
Connection- интерфейс, обеспечивающий функциональность подключения к среднему слою и хранящий пользовательскую сессию UserSession. Стандартной реализацией этого интерфейса является классConnectionImpl.Для кастомизации функциональности
Connectionв проекте, создайте класс, расширяющийConnectionImplв модуле web и зарегистрируйте его в web-spring.xml с идентификаторомcuba_Connectionиvaadinscope, например:<bean id="cuba_Connection" class="com.company.sample.web.MyConnection" scope="vaadin"/> -
ExceptionHandlers- содержит коллекцию обработчиков исключений клиентского уровня. -
Appпозволяет получить ссылки наConnection,ExceptionHandlersи другие объекты инфраструктуры. ЭкземплярAppсуществует в единственном экземпляре для данной HTTP-сессии пользователя. Ссылку наAppможно получить вызовом статического методаApp.getInstance().Если необходимо кастомизировать функциональность
Appв проекте, создайте класс, расширяющийDefaultAppв модуле web и зарегистрируйте его в web-spring.xml с идентификаторомcuba_Appиvaadinscope, например:<bean name="cuba_App" class="com.company.sample.web.MyApp" scope="vaadin"/>
3.5.19. Процесс входа в Web Client
В данном разделе описывается, как работает аутентификация на веб-клиент и как расширить ее в проекте. Для информации об аутентификации на среднем слое см. Вход в систему.
|
Руководство Anonymous Access & Social Login содержит пример настройки публичного доступа к некоторым экранам приложения, а также реализации пользовательского входа в приложение с помощью учетной записи Google, Facebook или GitHub. |
Реализация логина в Web Client включает следующие механизмы:
-
Connectionреализованный классомConnectionImpl. -
Реализации интерфейса
LoginProvider. -
Реализации интерфейса
HttpRequestFilter.
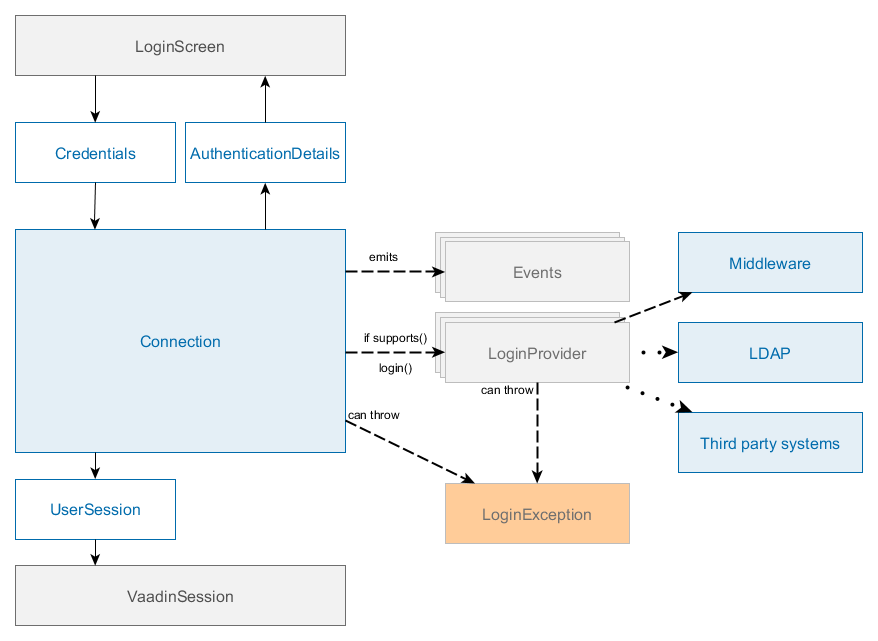
Рисунок 22. Механизмы логина в Web Client
Основной интерфейс подсистемы входа в Web Client - Connection, включающий следующие основные методы:
-
login() - аутентифицирует пользователя, создаёт пользовательскую сессию и изменяет состояние соединения.
-
logout() - выполняет выход из системы.
-
substituteUser() - замещает пользователя в текущей сессии. Этот метод создаёт новый объект UserSession, но с тем же ID.
-
getSession() - возвращает текущую сессию.
После успешного входа Connection устанавливает объект UserSession в атрибут VaadinSession и устанавливает SecurityContext. Объект Connection связан с VaadinSession, поэтому вы не можете использовать его из фоновых потоков, при попытке вызова login/logout из фонового потока выбрасывается исключение IllegalConcurrentAccessException.
Обычно, логин выполняется из экрана LoginScreen, который поддерживает вход при помощи логина/пароля и токена "запомнить меня".
Реализация Connection по умолчанию - ConnectionImpl, который делегирует логин цепочке объектов LoginProvider. Интерфейс LoginProvider предназначен для реализации модулей входа, которые могут обрабатывать специфичные реализации интерфейса Credentials, также этот интерфейс включает метод supports(), позволяющий проверить поддерживает ли модули определённый тип Credentials.

Рисунок 23. Стандартный процесс входа в Web Client
Стандартный процесс входа:
-
Пользователь вводит свой логин и пароль.
-
Web Client создаёт объект
LoginPasswordCredentials, передав логи и пароль в его конструктор, и вызывает методConnection.login()с этими данными для входа. -
Connectionиспользует цепочку объектовLoginProvider. Существует стандартный модуль входаLoginPasswordLoginProvider, который работает с аутентификационными данными типаLoginPasswordCredentials. В зависимости от значения свойства cuba.checkPasswordOnClient, он либо вызываетAuthenticationService.login(Credentials)передавая логин и пароль пользователя, либо загружает сущностьUserпо логину, проверяет пароль на соответствие загруженному хэшу, и выполняет вход как доверенный клиент используяTrustedClientCredentialsи cuba.trustedClientPassword. -
Если вход выполнен успешно, то объект
AuthenticationDetailsс активной сессией UserSession возвращается вConnection. -
Connectionсоздаёт специальный класс-обёрткуClientUserSessionи устанавливает его в атрибутVaadinSession. -
Connectionсоздаёт экземплярSecurityContextи устанавливает его вAppContext. -
Connectionпубликует событиеStateChangeEvent, стандартный обработчик которого обновляет UI и инициализируетMainScreen.
Все реализации LoginProvider должны:
-
Аутентифицировать пользователя при помощи переданного объекта
Credentials. -
Создать и запустить новую пользовательскую сессию при помощи
AuthenticationServiceили вернуть существующий объект активной сессии (например, для пользователя anonymous). -
Вернуть данные аутентификации или null если объект
Credentialsне может быть обработан, например, если модуль входа отключен или не сконфигурирован. -
Выбросить исключение
LoginExceptionв случае некорректных данныхCredentialsили пробросить вызывающему коду исключениеLoginException, полученное от среднего слоя,.
HttpRequestFilter - маркерный интерфейс для бинов, которые будут автоматически добавлены в цепочку фильтров приложения в качестве HTTP фильтра: https://docs.oracle.com/javaee/6/api/javax/servlet/Filter.html. Вы можете использовать такой фильтр для реализации дополнительной аутентификации, пре- и пост-обработки запроса и ответа.
Вы можете реализовать такой Filter если создадите компонент Spring Framework и реализуете интерфейс HttpRequestFilter:
@Component
public class CustomHttpFilter implements HttpRequestFilter {
@Override
public void init(FilterConfig filterConfig) throws ServletException {
}
@Override
public void doFilter(ServletRequest request, ServletResponse response,
FilterChain chain)
throws IOException, ServletException {
// delegate to the next filter/servlet
chain.doFilter(request, response);
}
@Override
public void destroy() {
}
}Обратите внимание, что минимальная реализация должна делегировать исполнение объекту FilterChain, в противном случае ваше приложение будет неработоспособно. По умолчанию фильтры добавленные как бины HttpRequestFilter не будут получать запросы к каталогу VAADIN и другим путям, указанным в свойстве приложения cuba.web.cubaHttpFilterBypassUrls.
- Встроенные провайдеры входа
-
Платформа включает следующие реализации интерфейса
LoginProvider:-
AnonymousLoginProvider- предоставляет анонимный вход для пользователей, не выполнивших вход в систему. -
LoginPasswordLoginProvider- делегирует логин сервисуAuthenticationService, передаваяLoginPasswordCredentials. -
RememberMeLoginProvider- делегирует логин сервисуAuthenticationService, передаваяRememberMeCredentials. -
LdapLoginProvider- принимаетLoginPasswordCredentials, выполняет аутентификацию при помощи LDAP и делегирует логин сервисуAuthenticationService, передаваяTrustedClientCredentials. -
ExternalUserLoginProvider- принимаетExternalUserCredentialsи делегирует логин сервисуAuthenticationService, передаваяTrustedClientCredentials. Тем самым позволяет выполнить вход от имени любого пользователя по его логину.
Все реализации создают активную сессию при помощи
AuthenticationService.login().Вы можете переопределить любой из провайдеров входа при помощи механизмов Spring Framework.
-
- События
-
Стандартная реализация
Connection-ConnectionImplпубликует следующие события во время процедуры входа:-
BeforeLoginEvent/AfterLoginEvent -
LoginFailureEvent -
UserConnectedEvent/UserDisconnectedEvent -
UserSessionStartedEvent/UserSessionFinishedEvent -
UserSessionSubstitutedEvent
Обработчики событий
BeforeLoginEventиLoginFailureEventмогут выбросить исключениеLoginExceptionчтобы прервать процесс входа или переопределить оригинальную причину ошибки входа.Например, при помощи обработчика
BeforeLoginEventвы можете разрешить вход в Web Client только для пользователей, логин которых включает домен компании.@Component public class BeforeLoginEventListener { @Order(10) @EventListener protected void onBeforeLogin(BeforeLoginEvent event) throws LoginException { if (event.getCredentials() instanceof LoginPasswordCredentials) { LoginPasswordCredentials loginPassword = (LoginPasswordCredentials) event.getCredentials(); if (loginPassword.getLogin() != null && !loginPassword.getLogin().contains("@company")) { throw new LoginException( "Only users from @company are allowed to login"); } } } }Дополнительно, стандартный класс приложения -
DefaultAppпубликует следующие события:-
AppInitializedEvent- публикуется после инициализации объектаApp, выполняется один раз для одной HTTP сессии. -
AppStartedEvent- публикуется во время обработки первого HTTP запроса кAppперед инициализацией анонимного входа. Обработчики события могут выполнить вход при помощиConnection, связанного сApp. -
AppLoggedInEvent- публикуется после инициализации UIAppсразу после того, как выполнен вход в приложение. -
AppLoggedOutEvent- публикуется после инициализации UIAppсразу после того, как выполнен выход из приложения. -
SessionHeartbeatEvent- публикуется во время запросовheartbeatот веб-браузера пользователя.
Событие
AppStartedEventможет использоваться для реализации прозрачного входа и SSO со сторонними системами, такими как Jasig CAS. Обычно, используется вместе с дополнительной реализациейHttpRequestFilter, которая должна собрать и предоставить дополнительные аутентификационные данные из HTTP запроса.Допустим, что система должна автоматически выполнять вход для пользователей, у которых есть специальный файл cookie -
PROMO_USER.@Order(10) @Component public class AppStartedEventListener implements ApplicationListener<AppStartedEvent> { private static final String PROMO_USER_COOKIE = "PROMO_USER"; @Inject private Logger log; @Override public void onApplicationEvent(AppStartedEvent event) { String promoUserLogin = event.getApp().getCookieValue(PROMO_USER_COOKIE); if (promoUserLogin != null) { Connection connection = event.getApp().getConnection(); if (!connection.isAuthenticated()) { try { connection.login(new ExternalUserCredentials(promoUserLogin)); } catch (LoginException e) { log.warn("Unable to login promo user {}: {}", promoUserLogin, e.getMessage()); } finally { event.getApp().removeCookie(PROMO_USER_COOKIE); } } } } }Так, если веб-браузер хранит файл cookie
PROMO_USER, и пользователь откроет приложение, будет выполнен вход от имени пользователя, указанного вpromoUserLogin.Если вы хотите выполнить дополнительные действия после входа в приложение и инициализации UI вы можете реализовать обработчик события
AppLoggedInEvent. Обратите внимание, что вы должны проверить, аутентифицирован ли пользователь или нет в обработчиках события, поскольку все события публикуются и для пользователяanonymous, даже если пользователь не аутентифицирован. -
- События жизненного цикла веб-сессии
-
Фреймворк посылает следующие события, касающиеся жизненного цикла HTTP-сессии:
-
WebSessionInitializedEvent- публикуется после инициализации HTTP сессии. -
WebSessionDestroyedEvent- публикуется после завершения HTTP сессии.
Эти события могут использоваться для выполнения некоторой системной логики. Обратите внимание, что в потоке, обрабатывающем событие отсутствует
SecurityContext. -
- Точки расширения
-
Вы можете расширить механизм входа, используя следующие точки расширения:
-
Connection- заменить существующийConnectionImpl. -
HttpRequestFilter- реализовать дополнительныйHttpRequestFilter. -
LoginProviderimplementations - реализовать новый или заменить существующий бинLoginProvider. -
Events - реализовать обработчик одного из доступных событий.
Вы можете заменить существующие бины, используя механизмы Spring Framework, например, зарегистрировав новый бин в конфигурационном файле Spring XML модуля web.
<bean id="cuba_LoginPasswordLoginProvider" class="com.company.demo.web.CustomLoginProvider"/> -
3.5.20. Анонимный доступ к экранам
По умолчанию для анонимной (неаутентифицированной) сессии доступен только экран логина. Путем расширения стандартного экрана логина в приложении можно добавить на него любую информацию или даже добавить компонент WorkArea и открывать в нем любые экраны системы, если на них есть права у анонимного пользователя. Однако как только пользователь войдет в систему, все экраны, открытые в анонимном режиме, будут закрыты.
Иногда бывает необходимо предоставить некоторые экраны приложения вне зависимости от того, аутентифицирован пользователь в системе или нет. Рассмотрим следующие требования:
-
Когда пользователь открывает приложение, он видит экран Welcome.
-
В приложении есть экран Info с некоторой общедоступной информацией. Данный экран должен отображаться в окне верхнего уровня, то есть без главного меню и других компонентов главного окна.
-
Пользователь может открыть экран Info из экрана Welcome, либо вводом URL в веб-браузере.
-
Находясь в экране Welcome, пользователь может перейти к экрану логина и продолжить работать в системе как аутентифицированный пользователь.
Ниже описаны шаги реализации данных требований.
-
Создайте экран Info и добавьте его контроллеру аннотацию
@Routeдля того, чтобы иметь возможность открывать его по ссылке:<?xml version="1.0" encoding="UTF-8" standalone="no"?> <window xmlns="http://schemas.haulmont.com/cuba/screen/window.xsd" caption="msg://caption" messagesPack="com.company.demo.web.info"> <layout margin="true"> <label value="Info" stylename="h1"/> </layout> </window>package com.company.demo.web.info; import com.haulmont.cuba.gui.Route; import com.haulmont.cuba.gui.screen.*; @UiController("demo_InfoScreen") @UiDescriptor("info-screen.xml") @Route(path = "info") (1) public class InfoScreen extends Screen { }1 - задает адрес экрана. Если экран открыт в окне верхнего уровня (в корне), его адрес будет вида http://localhost:8080/app/#info. -
Для реализации экрана Welcome создайте расширение стандартного главного экрана в проекте. Используйте один из шаблонов Main screen … мастера создания экрана в Studio, а затем добавьте нужные компоненты в элемент
initialLayout, например:<?xml version="1.0" encoding="UTF-8" standalone="no"?> <window xmlns="http://schemas.haulmont.com/cuba/screen/window.xsd" xmlns:ext="http://schemas.haulmont.com/cuba/window-ext.xsd" extends="/com/haulmont/cuba/web/app/main/main-screen.xml"> <layout> <hbox id="horizontalWrap"> <workArea id="workArea"> <initialLayout> <label id="welcomeLab" stylename="h1" value="Welcome!"/> <button id="openInfoBtn" caption="Go to Info screen"/> </initialLayout> </workArea> </hbox> </layout> </window>package com.company.demo.web.main; import com.company.demo.web.info.InfoScreen; import com.haulmont.cuba.gui.Screens; import com.haulmont.cuba.gui.components.Button; import com.haulmont.cuba.gui.screen.*; import com.haulmont.cuba.web.app.main.MainScreen; import javax.inject.Inject; @UiController("main") @UiDescriptor("ext-main-screen.xml") public class ExtMainScreen extends MainScreen { @Inject private Screens screens; @Subscribe("openInfoBtn") private void onOpenInfoBtnClick(Button.ClickEvent event) { screens.create(InfoScreen.class, OpenMode.ROOT).show(); (1) } }1 - создание экрана InfoScreenи открытие его в окне верхнего уровня (в режиме корня) в ответ на нажатие пользователем кнопки. -
Для того, чтобы экран Welcome открывался вместо экрана логина когда пользователь открывает приложение, добавьте следующие свойства в файл
web-app.properties:cuba.web.initialScreenId = main cuba.web.allowAnonymousAccess = true -
Разрешите экран Info для анонимных пользователей: запустите приложение, перейдите в Administration > Roles, создайте роль Anonymous в редакторе ролей и дайте ей доступ на экран Info. Назначьте пользователю anonymous только что созданную роль.
В результате, когда пользователи открывают приложение, они видят экран Welcome:
Пользователи могут открыть экран Info без аутентификации, либо нажать кнопку логина для входа в защищенную часть системы.
3.5.21. Уведомление об устаревшем браузере
Если версия браузера не поддерживается приложением, пользователь увидит стандартную страницу с уведомлением об этом, предложением обновить браузер и списком рекомендуемых браузеров.
Работа с приложением будет невозможна до тех пор, пока пользователь не обновит браузер.
Рисунок 24. Страница с уведомлением
Можно изменить или локализовать текст содержимого стандартной страницы. Для этого используйте следующие ключи в главном пакете сообщений модуля web:
-
unsupportedPage.captionMessage– заголовок уведомления; -
unsupportedPage.descriptionMessage– описание уведомления; -
unsupportedPage.browserListCaption– заголовок списка браузеров; -
unsupportedPage.chromeMessage– сообщение для браузера Chrome; -
unsupportedPage.firefoxMessage– сообщение для браузера Firefox; -
unsupportedPage.safariMessage– сообщение для браузера Safari; -
unsupportedPage.operaMessage– сообщение для браузера Opera; -
unsupportedPage.edgeMessage– сообщение для браузера Edge; -
unsupportedPage.explorerMessage– сообщение для браузера Explorer.
Вы можете использовать пользовательский шаблон для страницы уведомления:
-
Создайте новый файл шаблона
*.html. -
Определите путь до нового шаблона в свойстве
cuba.web.unsupportedPagePathфайлаweb-app.properties:cuba.web.unsupportedPagePath = /com/company/sample/web/sys/unsupported-page-template.html
3.5.22. Открытие внешних ссылок
WebBrowserTools - это служебный бин для открытия внешних URL адресов. В то время как компонент BrowserFrame открывает встроенные веб-страницы внутри приложения, WebBrowserTools позволяет открывать внешние ссылки во вкладке браузера пользователя.
WebBrowserTools представляет собой функциональный интерфейс, содержащий единственный метод: void showWebPage(String url, @Nullable Map<String, Object> params).
@Inject
private WebBrowserTools webBrowserTools;
@Subscribe("button")
public void onButtonClick(Button.ClickEvent event) {
webBrowserTools.showWebPage("https://cuba-platform.com", ParamsMap.of("_target", "blank"));
}Метод showWebPage() может принимать дополнительные параметры:
-
target- строковое значение параметраtargetдля вызоваwindow.openна стороне клиента. Рассматриваются такие значения, как"_blank","_self","_top","_parent". Если параметр не указан, по умолчанию используется"_blank". -
width- целочисленное значение ширины окна браузера в пикселях. -
height- целочисленное значение высоты окна браузера в пикселях. -
border- строковое значение для стиля границ окна браузера. Может принимать следующие значения:"DEFAULT","MINIMAL","NONE".
|
К примеру, если вы хотите открывать некий URL прямо из меню приложения, вам нужно создать класс, реализующий Более детально о классе |
3.5.23. Открытие статических ресурсов в браузере
Статические ресурсы можно загрузить и открыть в браузере с помощью URL без аутентификации, REST или FileDescriptor. Для этого нужно расположить файлы в локальном каталоге проекта: /modules/web/web/VAADIN, и после этого ресурсы будут доступны по адресу http://localhost:8080/app/VAADIN/{fileName}, например:
http://localhost:8080/app/VAADIN/customers_list.txt3.5.24. Событие обновления веб-страницы
UIRefreshEvent - это application event, посылаемый при каждом обновлении веб-страницы. Это событие является UiEvent, поэтому оно может обрабатываться только слушателями событий контроллеров экранов.
@UiController("extMainScreen")
@UiDescriptor("ext-main-screen.xml")
public class ExtMainScreen extends MainScreen {
@Inject
private Notifications notifications;
@EventListener
protected void onPageRefresh(UIRefreshEvent event) {
notifications.create()
.withCaption("Page is refreshed " + event.getTimestamp())
.show();
}
}3.6. GUI Legacy API
3.6.1. Экраны (устаревшее)
|
Это устаревший API. Новый API, доступный начиная с v.7.0, описан в разделе Экраны. |
Экран универсального пользовательского интерфейса состоит из XML-дескриптора и класса контроллера. Дескриптор содержит ссылку на класс контроллера.
Для того чтобы экран можно было вызывать из главного меню или из Java кода (например, из контроллера другого экрана), XML-дескриптор должен быть зарегистрирован в файле screens.xml проекта. Экран, который должен быть открыт по умолчанию после входа в систему, можно задать с помощью свойства приложения cuba.web.defaultScreenId.
Главное меню приложения формируется на основе файлов menu.xml.
3.6.1.1. Типы экранов
|
Это устаревший API. Новый API, доступный начиная с v.7.0, описан в разделе Контроллер экрана. |
В данном разделе рассматриваются основные типы экранов:
3.6.1.1.1. Фрейм
|
Это устаревший API. Новый API, доступный начиная с v.7.0, описан в разделе Контроллер экрана. |
Фреймы представляют собой части экранов, которые применяются для декомпозиции и многократного использования. Для подключения фрейма в XML экрана используется элемент frame.
Контроллер фрейма должен быть унаследован от класса AbstractFrame.
|
Фрейм можно создать в Studio с помощью шаблона Blank frame. |
Правила взаимодействия экрана и вложенного в него фрейма:
-
Из экрана обращаться к компонентам фрейма можно через точку:
frame_id.component_id -
Из контроллера фрейма получить компонент экрана можно обычным вызовом
getComponent(component_id), но только в том случае, если компонент с таким именем не объявлен в самом фрейме. То есть компоненты фрейма маскируют компоненты экрана. -
Из фрейма получить источник данных экрана можно простым вызовом
getDsContext().get(ds_id)или инжекцией, либо в запросеds$ds_id, но только в том случае, если источник данных с таким именем не объявлен в самом фрейме (аналогично компонентам). -
Из экрана получить источник данных фрейма можно только через итерацию по
getDsContext().getChildren()
При коммите экрана вызывается также коммит измененных источников данных всех вложенных фреймов.
3.6.1.1.2. Простой экран
|
Это устаревший API. Новый API, доступный начиная с v.7.0, описан в разделе Контроллер экрана. |
Простой экран предназначен для отображения и редактирования произвольной информации, в том числе отдельных экземпляров и списков сущностей. Данный тип экрана имеет только базовую функциональность, позволяющую отобразить его в главном окне системы и работать с источниками данных.
Контроллер простого экрана должен быть унаследован от класса AbstractWindow.
|
Простой экран можно создать в Studio с помощью шаблона Blank screen. |
3.6.1.1.3. Экран выбора
|
Это устаревший API. Новый API, доступный начиная с v.7.0, описан в разделе Контроллер экрана. |
Экран выбора (lookup) предназначен для выбора и возврата экземпляров и списков сущностей. Стандартное действие LookupAction в таких визуальных компонентах, как PickerField и LookupPickerField, вызывает экраны выбора для поиска связанных сущностей.
При вызове экрана выбора методом openLookup() отображается панель с кнопками для выбора. Когда пользователь выбирает один или несколько экземпляров, экран вызывает переданный ему обработчик, тем самым возвращая вызывающему коду результаты выбора. При вызове методом openWindow() или, например, из главного меню, панель с кнопками выбора не отображается, что превращает экран выбора в простой экран.
Контроллер экрана выбора должен быть унаследован от класса AbstractLookup. В XML экрана в атрибуте lookupComponent должен быть указан компонент (например, Table), из которого будет взят экземпляр сущности при выборе.
|
Экран выбора для сущности можно создать в Studio с помощью шаблонов Entity browser или Entity combined screen. |
По умолчанию, действие LookupAction использует экран, зарегистрированный в файле screens.xml с идентификатором вида {имя_сущности}.lookup или {имя_сущности}.browse, например, sales$Customer.lookup. Поэтому при использовании вышеупомянутых компонентов убедитесь, что такой экран создан. Studio регистрирует browse-экраны с идентификаторами вида {имя_сущности}.browse, поэтому они автоматически вызываются в качестве экранов выбора.
- Настройка вида и поведения экрана выбора
-
-
Для того, чтобы заменить панель выбора (кнопки Select и Cancel) для всех экранов выбора в проекте, создайте фрейм и зарегистрируйте его с идентификатором
lookupWindowActions. Стандартный фрейм расположен в файле/com/haulmont/cuba/gui/lookup-window.actions.xml. Новый фрейм должен содержать кнопку, связанную с действиемlookupSelectAction(которое автоматически добавляется в экран, когда он открывается как экран выбора). -
Чтобы заменить панель выбора в некотором экране, создайте в нем кнопку, связанную с действием
lookupSelectAction. В этом случае стандартный фрейм не будет показан. Например:<layout expand="table"> <hbox> <button id="selectBtn" caption="Select item" action="lookupSelectAction"/> </hbox> <!-- ... --> </layout> -
Чтобы заменить стандартное действие выбора своим, просто добавьте его в контроллере:
@Override public void init(Map<String, Object> params) { addAction(new SelectAction(this) { @Override protected Collection getSelectedItems(LookupComponent lookupComponent) { Set<MyEntity> selected = new HashSet<>(); // ... return selected; } }); }В качестве базового класса используйте
com.haulmont.cuba.gui.components.SelectAction, переопределив требуемые методы.
-
3.6.1.1.4. Экран редактирования
|
Это устаревший API. Новый API, доступный начиная с v.7.0, описан в разделе Контроллер экрана. |
Экран редактирования предназначен для отображения и редактирования экземпляра сущности. Поддерживает функциональность установки редактируемого экземпляра и действия по коммиту изменений в базу данных. Экран редактирования должен вызываться методом openEditor() с передачей экземпляра сущности.
Стандартные действия CreateAction и EditAction открывают экран, зарегистрированный в файле screens.xml с идентификатором вида {имя_сущности}.edit, например, sales$Customer.edit.
Контроллер экрана редактирования должен быть унаследован от класса AbstractEditor.
|
Экран редактирования для сущности можно создать в Studio с помощью шаблона Entity editor. |
В XML экрана в атрибуте datasource указывается источник данных, в который проставляется редактируемый экземпляр сущности. Для отображения действий, выполняющих коммит или отмену изменений, в XML можно использовать следующие стандартные фреймы с кнопками:
-
editWindowActions(файлcom/haulmont/cuba/gui/edit-window.actions.xml) - содержит кнопки OK и Cancel -
extendedEditWindowActions(файлcom/haulmont/cuba/gui/extended-edit-window.actions.xml) - содержит кнопки OK & Close, OK и Cancel
В экране редактирования неявно создаются следующие действия:
-
windowCommitAndClose(соответствует константеWindow.Editor.WINDOW_COMMIT_AND_CLOSE) - действие, выполняющее коммит изменений в базу данных и закрывающее экран. Создается при наличии в экране визуального компонента с идентификаторомwindowCommitAndClose, в частности, при использовании вышеописанного стандартного фреймаextendedEditWindowActionsотображается кнопкой OK & Close. -
windowCommit(соответствует константеWindow.Editor.WINDOW_COMMIT) - действие, выполняющее коммит изменений в базу данных. При отсутствии действияwindowCommitAndCloseпосле коммита закрывает экран. Создается всегда, и при наличии в экране вышеописанных стандартных фреймов отображается кнопкой OK. -
windowClose(соответствует константеWindow.Editor.WINDOW_CLOSE) - действие, закрывающее экран без коммита изменений. Создается всегда, и при наличии в экране вышеописанных стандартных фреймов отображается кнопкой Cancel.
Таким образом, если в экран добавлен фрейм editWindowActions, то кнопка OK коммитит изменения и закрывает экран, а кнопка Cancel - закрывает без коммита. Если же добавлен фрейм extendedEditWindowActions, то кнопка OK только коммитит изменения, оставляя экран открытым, кнопка OK & Close коммитит и закрывает экран, кнопка Cancel - закрывает без коммита.
Вместо стандартных фреймов для отображения действий можно использовать произвольные компоненты, например, LinkButton.
3.6.1.1.5. Комбинированный экран
|
Это устаревший API. Новый API, доступный начиная с v.7.0, описан в разделе Контроллер экрана. |
Комбинированный экран позволяет отобразить список сущностей слева и форму редактирования выбранного экземпляра справа. Таким образом, это комбинация экранов выбора и редактирования.
Контроллер экрана редактирования должен быть унаследован от класса EntityCombinedScreen.
|
Комбинированный экран для сущности можно создать в Studio с помощью шаблона Entity combined screen. |
3.6.1.2. XML-дескриптор
|
Это устаревший API. Новый API, доступный начиная с v.7.0, описан в разделе XML-дескриптор экрана. |
XML-дескриптор - это файл формата XML, описывающий источники данных и расположение визуальных компонентов экрана.
Схема XML доступна по адресу http://schemas.haulmont.com/cuba/7.2/window.xsd.
Рассмотрим структуру дескриптора.
window − корневой элемент.
Атрибуты window:
-
class− имя класса контроллера -
messagesPack− пакет сообщений данного экрана, который будет использован при получении локализованных строк без указания пакета из XML-дескриптора и из контроллера методомgetMessage() -
caption− заголовок экрана, может содержать ссылку на сообщение из вышеуказанного пакета, например,caption="msg://caption" -
focusComponent− идентификатор компонента, который получит фокус ввода при отображении экрана -
lookupComponent- обязательный для экрана выбора атрибут, задающий идентификатор визуального компонента, из которого будет выбран экземпляр сущности. Поддерживаются компоненты следующих типов (и их наследников):-
Table -
Tree -
LookupField -
PickerField -
OptionsGroup
-
-
datasource- обязательный для экрана редактирования атрибут, задающий идентификатор источника данных, в который будет проставлен экземпляр редактируемой сущности.
Элементы window:
-
metadataContext− элемент для инициализации представлений (views), необходимых данному экрану. Предпочтительным является определение всех представлений в одном общем файле views.xml, так как все описатели представлений разворачиваются в один общий репозиторий, и при рассредоточении описателей по разным файлам трудно обеспечить уникальность имен. -
dsContext− определяет источники данных данного экрана. -
dialogMode- определяет параметры геометрии и поведения экрана при открытии его в виде диалогового окна.Атрибуты
dialogMode:-
closeable- определяет наличие в диалоговом окне кнопки закрытия. Возможные значения:true,false. -
closeOnClickOutside- определяет возможность закрыть окно кликом по окружающей области, если диалог открыт в модальном режиме. Возможные значения:true,false. -
forceDialog- указывает, что экран должен всегда открываться в режиме диалога, независимо от того, какойWindowManager.OpenTypeбыл выбран в вызывающем коде. Возможные значения:true,false. -
height- устанавливает высоту диалогового окна. -
maximized- если выбрано значениеtrue, диалог будет развёрнут во весь экран. Возможные значения:true,false. -
modal- устанавливает модальный режим диалогового окна. Возможные значения:true,false. -
positionX- задаёт положение левого верхнего угла диалога по осиx. -
positionY- задаёт положение левого верхнего угла диалога по осиy. -
resizable- определяет возможность пользователя изменять размеры диалога. Возможные значения:true,false. -
width- устанавливает ширину диалогового окна.
Пример использования
dialogMode:<dialogMode height="600" width="800" positionX="200" positionY="200" forceDialog="true" closeOnClickOutside="false" resizable="true"/> -
-
actions- определяет список действий данного экрана. -
timers- определяет список таймеров данного экрана. -
companions- определяет список классов-компаньонов данного контроллераЭлементы
companions:-
web- задает компаньон, реализованный в модуле web -
desktop- задает компаньон, реализованный в модуле desktopКаждый из этих элементов содержит атрибут
class, задающий класс компаньона.
-
-
layout − корневой элемент компоновки экрана. Является сам по себе контейнером с вертикальным расположением компонентов.
3.6.1.3. Контроллер экрана
|
Это устаревший API. Новый API, доступный начиная с v.7.0, описан в разделе Контроллер экрана. |
Контроллер экрана - это Java или Groovy класс, связанный с XML-дескриптором, и содержащий логику инициализации и обработки событий экрана.
Контроллер должен быть унаследован от одного из следующих базовых классов:
-
AbstractFrame − предназначен для реализации фреймов.
-
AbstractWindow − предназначен для реализации простых экранов.
-
AbstractLookup − предназначен для реализации экранов выбора.
-
AbstractEditor − предназначен для реализации экранов редактирования.
|
Если экрану не нужна никакая дополнительная логика, то в качестве контроллера можно использовать сам базовый класс |
Класс контроллера должен быть зарегистрирован в XML-дескрипторе экрана в атрибуте class корневого элемента window.
Рисунок 25. Базовые классы контроллеров
3.6.1.3.1. AbstractFrame
|
Это устаревший API. Новый API, доступный начиная с v.7.0, описан в разделе Контроллер экрана. |
AbstractFrame является корнем иерархии классов контроллеров. Рассмотрим его основные методы:
-
init()- вызывается фреймворком после создания всего дерева компонентов, описанного XML-дескриптором, но до отображения экрана.В метод
init()из вызывающего кода передается мэп параметров, которые могут быть использованы внутри контроллера. Эти параметры могут быть переданы как из кода контроллера вызывающего экрана (в методеopenWindow(),openLookup()илиopenEditor()), так и установлены в файле регистрации экранов screens.xml.Метод
init()следует имплементировать при необходимости инициализации компонентов экрана, например:@Inject private Table someTable; @Override public void init(Map<String, Object> params) { someTable.addGeneratedColumn("someColumn", new Table.ColumnGenerator<Colour>() { @Override public Component generateCell(Colour entity) { ... } }); }
-
openFrame()- загрузить фрейм по идентификатору, зарегистрированному в screens.xml, и, если в метод передан компонент-контейнер, отобразить его внутри контейнера. Возвращается контроллер фрейма. Например:@Inject private BoxLayout container; @Override public void init(Map<String, Object> params) { SomeFrame frame = openFrame(container, "someFrame"); frame.setHeight("100%"); frame.someInitMethod(); }Контейнер не обязательно сразу передавать в метод
openFrame(), вместо этого можно загрузить фрейм, а затем добавить его в нужный контейнер:@Inject private BoxLayout container; @Override public void init(Map<String, Object> params) { SomeFrame frame = openFrame(null, "someFrame"); frame.setHeight("100%"); frame.someInitMethod(); container.add(frame); }
-
openWindow(),openLookup(),openEditor()- открыть соответственно простой экран, экран выбора или редактирования. Методы возвращают контроллер созданного экрана.При открытии экрана в режиме диалога метод
openWindow()может быть вызван с параметрами, к примеру:@Override public void actionPerform(Component component) { openWindow("sec$User.browse", WindowManager.OpenType.DIALOG.width(800).height(300).closeable(true).resizable(true).modal(false)); }Эти параметры будут учитываться, если они не конфликтуют с более приоритетными параметрами самого вызываемого экрана. Последние могут быть заданы в методе getDialogOptions() контроллера экрана или в XML-дескрипторе этого экрана:
<dialogMode forceDialog="true" width="300" height="200" closeable="true" modal="true" closeOnClickOutside="true"/>Для выполнения действий после закрытия вызываемого экрана необходимо добавить слушатель типа
CloseListener, например:CustomerEdit editor = openEditor("sales$Customer.edit", customer, WindowManager.OpenType.THIS_TAB); editor.addCloseListener((String actionId) -> { // do something });CloseWithCommitListenerможно использовать в случае, если необходимо реагировать только при закрытии экрана действием с именемWindow.COMMIT_ACTION_ID(то есть кнопкой OK), например:CustomerEdit editor = openEditor("sales$Customer.edit", customer, WindowManager.OpenType.THIS_TAB); editor.addCloseWithCommitListener(() -> { // do something });
-
showMessageDialog()- отобразить диалоговое окно с сообщением.
-
showOptionDialog()- отобразить диалоговое окно с сообщением и возможностью выбора пользователем некоторых действий. Действия задаются массивом объектов типа Action, которые в диалоге отображаются посредством соответствующих кнопок.Для отображения стандартных кнопок типа OK, Cancel и других рекомендуется использовать объекты типа
DialogAction, например:showOptionDialog("PLease confirm", "Are you sure?", MessageType.CONFIRMATION, new Action[] { new DialogAction(DialogAction.Type.YES) { @Override public void actionPerform(Component component) { // do something } }, new DialogAction(DialogAction.Type.NO) });
-
showNotification()- отобразить всплывающее окно с сообщением.
-
showWebPage()- открыть указанную веб-страницу в браузере.
3.6.1.3.2. AbstractWindow
|
Это устаревший API. Новый API, доступный начиная с v.7.0, описан в разделе Контроллер экрана. |
AbstractWindow является наследником AbstractFrame, и определяет следующие собственные методы:
-
getDialogOptions()- получить объектDialogOptionsдля управления геометрией и поведением экрана когда он открывается в режиме диалога (WindowManager.OpenType.DIALOG). Эти параметры могут быть заданы при инициализации экрана, а также могут изменяться на лету.Установка ширины и высоты:
@Override public void init(Map<String, Object> params) { getDialogOptions().setWidth("480px").setHeight("320px"); }Установка положения диалога на экране:
getDialogOptions() .setPositionX(100) .setPositionY(100);Возможность закрыть диалог кликом по окружающей области:
getDialogOptions().setModal(true).setCloseOnClickOutside(true);Указание того, что диалог должен быть немодальным и с изменяемыми размерами:
@Override public void init(Map<String, Object> params) { getDialogOptions().setModal(false).setResizable(true); }Указание того, что диалог должен быть развёрнут во весь экран:
getDialogOptions().setMaximized(true);Указание того, что экран должен всегда открываться в режиме диалога, независимо от того, какой
WindowManager.OpenTypeбыл выбран в вызывающем коде:@Override public void init(Map<String, Object> params) { getDialogOptions().setForceDialog(true); }
-
setContentSwitchMode()- определяет режим переключения вкладок главного TabSheet для вкладки, содержащей данное окно: скрывать содержимое или полностью выгружать его.Доступны следующие режимы:
-
DEFAULT- режим переключения определяется режимом главного TabSheet, установленном в свойстве приложения cuba.web.managedMainTabSheetMode. -
HIDE- содержимое вкладки должно быть только скрыто, независимо от режима главного TabSheet. -
UNLOAD- содержимое вкладки должно быть выгружено, независимо от режима главного TabSheet.
-
-
saveSettings()- сохраняет настройки экрана для текущего пользователя в базе данных при закрытии экрана.К примеру, на экране имеется чекбокс showPanel, управляющий отображением некой панели. Мы переопределяем метод
saveSettings(): создаём в нём XML-элемент для этого чекбокса, добавляем ему атрибутshowPanel, содержащий текущее значение чекбокса, а затем сохраняем элементsettingsв XML-файл для текущего пользователя в базе данных.@Inject private CheckBox showPanel; @Override public void saveSettings() { boolean showPanelValue = showPanel.getValue(); Element xmlDescriptor = getSettings().get(showPanel.getId()); xmlDescriptor.addAttribute("showPanel", String.valueOf(showPanelValue)); super.saveSettings(); }
-
applySettings()- восстанавливает настройки экрана для текущего пользователя из базы данных при открытии экрана.Переопределим метод для восстановления настроек из предыдущего примера. Получаем XML-элемент чекбокса, проверяем, что нужный нам атрибут
showPanelне равенnull, а затем восстанавливаем для чекбокса предыдущее сохранённое значение:@Override public void applySettings(Settings settings) { super.applySettings(settings); Element xmlDescriptor = settings.get(showPanel.getId()); if (xmlDescriptor.attribute("showPanel") != null) { showPanel.setValue(Boolean.parseBoolean(xmlDescriptor.attributeValue("showPanel"))); } }Другой пример управления настройками экрана можно увидеть на стандартном экране Server Log в меню Administration приложения CUBA, который автоматически сохраняет и восстанавливает последние открытые пользователем лог-файлы.
-
ready()- шаблонный метод, который можно имплементировать в контроллере для перехвата момента открытия экрана. Методready()вызывается фреймворком после методаinit()непосредственно перед показом экрана в главном окне приложения.
-
validateAll()- валидация экрана. Реализация по умолчанию вызывает методvalidate()у всех компонентов экрана, реализующих интерфейсComponent.Validatable, накапливает информацию об исключениях, и если таковые имеются, выводит соответствующее сообщение и возвращаетfalse, иначе возвращаетtrue.Данный метод следует переопределять только в том случае, если необходимо полностью заменить стандартную процедуру валидации экрана. Если же нужно только дополнить ее, достаточно определить специальный шаблонный метод
postValidate().
-
postValidate()- шаблонный метод, который можно имплементировать в контроллере для дополнительной валидации экрана. Получаемый методом объектValidationErrorsиспользуется для добавления информации об ошибках валидации, которая будет отображена совместно с ошибками стандартной валидации. Например:private Pattern pattern = Pattern.compile("\\d"); @Override protected void postValidate(ValidationErrors errors) { if (getItem().getAddress().getCity() != null) { if (pattern.matcher(getItem().getAddress().getCity()).find()) { errors.add("City name can't contain digits"); } } }
-
showValidationErrors()- метод, который отображает сообщение об ошибках валидации экрана. Чтобы изменить поведение стандартных сообщений, метод можно переопределить. Тип уведомления определяется свойством приложения cuba.gui.validationNotificationType.@Override public void showValidationErrors(ValidationErrors errors) { super.showValidationErrors(errors); }
-
close()- закрыть данный экран.Метод принимает строковое значение, передаваемое далее в шаблонный метод
preClose()и слушателямCloseListener. Таким образом, заинтересованный код может получить информацию о причине закрытия экрана от кода, инициирующего закрытие. В частности, в экранах редактирования сущностей при закрытии экрана после коммита изменений рекомендуется использовать константуWindow.COMMIT_ACTION_ID, без коммита изменений - константуWindow.CLOSE_ACTION_ID.Если какой-либо из источников данных содержит несохраненные изменения, перед закрытием экрана будет выдано диалоговое окно с соответствующим предупреждением. Тип предупреждения можно выбрать с помощью свойства приложения cuba.gui.useSaveConfirmation.
Вариант метода
close()с параметромforce = trueзакрывает экран без вызоваpreClose()и без предупреждения, независимо от наличия несохраненных изменений.Метод
close()возвращаетtrue, если экран был успешно закрыт, иfalse- если закрытие было прервано.
-
preClose()- шаблонный метод, который можно имплементировать в контроллере для перехвата момента закрытия экрана. Метод получает строковое значение, указанное инициатором закрытия при вызове методаclose().Если метод
preClose()возвращаетfalse, то процесс закрытия экрана прерывается.
-
addBeforeCloseWithCloseButtonListener()- добавляет слушатель, который отслеживает закрытие окна одним из следующих способов: кнопка закрытия окна, панель breadcrumbs или действия для закрытия вкладокTabSheet(Close, Close All, Close Others). Чтобы предотвратить случайное закрытие окна пользователем, можно вызвать методpreventWindowClose()событияBeforeCloseEvent:addBeforeCloseWithCloseButtonListener(BeforeCloseEvent::preventWindowClose);
-
addBeforeCloseWithShortcutListener- добавляет слушатель, который отслеживает закрытие окна горячими клавишами (например, нажатиемEsc). Чтобы предотвратить случайное закрытие окна пользователем, можно вызвать методpreventWindowClose()событияBeforeCloseEvent:addBeforeCloseWithShortcutListener(BeforeCloseEvent::preventWindowClose);
3.6.1.3.3. AbstractLookup
|
Это устаревший API. Новый API, доступный начиная с v.7.0, описан в разделе Контроллер экрана. |
AbstractLookup базовый класс контроллеров экранов выбора, является наследником AbstractWindow, и определяет следующие собственные методы:
-
setLookupComponent()- установить компонент, из которого будет производиться выбор экземпляров сущности.Как правило, компонент выбора устанавливается в XML-дескрипторе экрана, и вызывать данный метод в прикладном коде нет необходимости.
-
setLookupValidator()- установить для экрана объект типаWindow.Lookup.Validator, методvalidate()которого вызывается фреймворком перед тем как вернуть выбранные экземпляры сущностей. Еслиvalidate()возвращаетfalse, процесс выбора и закрытия экрана прерывается.По умолчанию валидатор не установлен.
3.6.1.3.4. AbstractEditor
|
Это устаревший API. Новый API, доступный начиная с v.7.0, описан в разделе Контроллер экрана. |
AbstractEditor − базовый класс контроллеров экранов редактирования, является наследником AbstractWindow.
При создании конкретного класса контроллера рекомендуется параметризовать AbstractEditor типом редактируемой сущности. При этом методы getItem() и initNewItem() будут работать с конкретным типом сущности и прикладному коду не потребуется дополнительных приведений типов. Например:
public class CustomerEdit extends AbstractEditor<Customer> {
@Override
protected void initNewItem(Customer item) {
...AbstractEditor определяет следующие собственные методы:
-
getItem()- возвращает экземпляр редактируемой сущности, установленный в главном источнике данных экрана (т.е. указанном в атрибутеdatasourceкорневого элемента XML-дескриптора).Если редактируется не новый экземпляр, то в момент открытия экрана он перезагружается из базы данных с необходимым представлением, указанным для главного источника данных.
Изменения, вносимые в экземпляр, возвращаемый
getItem(), отражаются на состоянии источника данных, и будут отправлены на Middleware при коммите экрана.Следует иметь в виду, что
getItem()возвращает значение только после инициализации экрана методомsetItem(). До этого момента, например, в методахinit()иinitNewItem(), данный метод возвращаетnull.Однако в методе
init()экземпляр сущности, переданный вopenEditor(), можно получить из параметров следующим образом:@Override public void init(Map<String, Object> params) { Customer item = WindowParams.ITEM.getEntity(params); // do something }В метод
initNewItem()экземпляр передается явно и нужного типа.В обоих случаях полученный экземпляр сущности, если он не новый, будет впоследствии перезагружен, и вносить в него изменения или сохранять в поле для последующего использования не имеет смысла.
-
setItem()- вызывается фреймворком при открытии экрана методомopenEditor()для установки редактируемого экземпляра сущности в главном источнике данных. В момент вызова созданы все компоненты и источники данных экрана, и отработал методinit()контроллера.Для инициализации экрана редактирования вместо переопределения
setItem()рекомендуется имплементировать специальные шаблонные методыinitNewItem()иpostInit().
-
initNewItem()- шаблонный метод, вызываемый фреймворком перед установкой редактируемого экземпляра сущности в главном источнике данных.Метод
initNewItem()вызывается только для нового, только что созданного экземпляра сущности. Если редактируется detached экземпляр, метод не вызывается.Данный метод можно имплементировать в контроллере при необходимости инициализации нового экземпляра сущности перед его установкой в источник данных, например:
@Inject private UserSession userSession; @Override protected void initNewItem(Complaint item) { item.setOpenedBy(userSession.getUser()); item.setStatus(ComplaintStatus.OPENED); }Более сложный пример использования
initNewItem()приведен в разделе рецептов разработки.
-
postInit()- шаблонный метод, вызываемый фреймворком сразу после установки редактируемого экземпляра сущности в главном источнике данных. Во время выполнения данного метода можно вызыватьgetItem(), который будет возвращать новый или перезагруженный при инициализации экрана экземпляр сущности.Данный метод можно имплементировать в контроллере для окончательной инициализации экрана, например:
@Inject private EntityStates entityStates; @Inject protected EntityDiffViewer diffFrame; @Override protected void postInit() { if (!entityStates.isNew(getItem())) { diffFrame.loadVersions(getItem()); } }
-
commit()- валидировать экран и отправить изменения через DataSupplier на Middleware.Если используется вариант метода с параметром
validate = false, то валидация перед коммитом не производится.Данный метод не рекомендуется переопределять, лучше использовать специальные шаблонные методы
postValidate(),preCommit()иpostCommit().
-
commitAndClose()- валидировать экран, отправить изменения на Middleware и закрыть экран. В методpreClose()и зарегистрированным слушателямCloseListenerбудет передано значение константыWindow.COMMIT_ACTION_ID.Данный метод не рекомендуется переопределять, лучше использовать специальные шаблонные методы
postValidate(),preCommit()иpostCommit().
-
preCommit()- шаблонный метод, вызываемый фреймворком в процессе коммита изменений, после того как валидация завершена успешно и перед отправкой данных на Middleware.Данный метод можно имплементировать в контроллере. Если метод возвращает
false, процесс коммита (и закрытия экрана, если был вызванcommitAndClose()), прерывается. Например:@Override protected boolean preCommit() { if (somethingWentWrong) { notifications.create() .withCaption("Something went wrong") .withType(Notifications.NotificationType.WARNING) .show(); return false; } return true; }
-
postCommit()- шаблонный метод, вызываемый фреймворком на финальной стадии коммита изменений. Параметры метода:-
committed- установлен вtrue, если в экране действительно были изменения, и они отправлены на Middleware; -
close- установлен вtrue, если экран после коммита будет закрыт.Реализация метода по умолчанию, если экран не закрывается, отображает сообщение об успешном коммите изменений и вызывает метод
postInit().Данный метод можно переопределить в контроллере для выполнения некоторых действий после успешного коммита, например:
@Inject private Datasource<Driver> driverDs; @Inject private EntitySnapshotService entitySnapshotService; @Override protected boolean postCommit(boolean committed, boolean close) { if (committed) { entitySnapshotService.createSnapshot(driverDs.getItem(), driverDs.getView()); } return super.postCommit(committed, close); }
-
Далее приведены диаграммы последовательностей инициализации и различных вариантов коммита экрана редактирования.

Рисунок 26. Инициализация экрана редактирования

Рисунок 27. Коммит и закрытие экрана с фреймом editWindowActions

Рисунок 28. Коммит экрана с фреймом extendedEditWindowActions

Рисунок 29. Коммит и закрытие экрана с фреймом extendedEditWindowActions
- API
-
commit() - commitAndClose() - getItem() - initNewItem() - postCommit() - postInit() - preCommit() - setItem()
3.6.1.3.5. EntityCombinedScreen
|
Это устаревший API. Новый API, доступный начиная с v.7.0, описан в разделе Контроллер экрана. |
EntityCombinedScreen − базовый класс контроллеров комбинированных экранов, является наследником AbstractLookup.
Класс EntityCombinedScreen ищет ключевые компоненты экрана, такие как таблица, field group и некоторые другие, по зашитым в код идентификаторам. Если эти компоненты в вашем экране названы по другому, переопределите protected-методы класса и возвращайте из них ваши идентификаторы, чтобы контроллер мог найти нужные компоненты. См. JavaDocs класса для более подробной информации.
3.6.1.3.6. Инжекция зависимостей контроллеров
|
Это устаревший API. Новый API, доступный начиная с v.7.0, описан в разделе Контроллер экрана. |
В контроллерах можно использовать Dependency Injection для получения ссылок на используемые объекты. Для этого нужно объявить либо поле соответствующего типа, либо метод доступа на запись (setter) с соответствующим типом результата, и добавить ему одну из следующих аннотаций:
-
@Inject- простейший вариант, поиск объекта для инжекции будет произведен по типу поля/метода и по имени, эквивалентному имени поля либо имени атрибута (по правилам JavaBeans) для метода -
@Named("someName")- вариант с явным указанием имени искомого объекта
Инжектировать в контроллеры можно следующие объекты:
-
Визуальные компоненты данного экрана, определенные в XML-дескрипторе. Если тип атрибута унаследован от
Component, в текущем экране будет произведен поиск компонента с соответствующим именем. -
Действия, определенные в XML-дескрипторе - см. Действия. Интерфейс Action
-
Источники данных, определенные в XML-дескрипторе. Если тип атрибута унаследован от
Datasource, в текущем экране будет произведен поиск источника данных с соответствующим именем. -
UserSession. Если тип атрибута - UserSession, будет инжектирован объект текущей пользовательской сессии. -
DsContext. Если тип атрибута -DsContext, будет инжектированDsContextтекущего экрана. -
WindowContext. Если тип атрибута -WindowContext, будет инжектированWindowContextтекущего экрана. -
DataSupplier. Если тип атрибута - DataSupplier, будет инжектирован соответствующий экземпляр. -
Любой бин, определенный в контексте данного клиентского блока приложения, в том числе:
-
импортируемые клиентом сервисы Middleware
-
WindowConfig -
ExportDisplay
-
-
Если ничего из вышеперечисленного не подошло и контроллер имеет компаньонов, в случае совпадения типов будет инжектирован компаньон для текущего типа клиента.
С помощью специальной аннотации @WindowParam можно инжектировать в контроллер параметры, передаваемые в мэп метода init(). Аннотация имеет атрибут name, в котором указывается имя параметра (ключ в мэп), и опциональный атрибут required. Если required = true, то при отсутствии в мэп соответствующего параметра в лог выводится сообщение с уровнем WARNING.
Пример инжекции объекта типа Job, передаваемого в метод init() контроллера:
@WindowParam(name = "job", required = true)
protected Job job;3.6.1.3.7. Компаньоны контроллеров
|
Данный раздел не актуален начиная с версии 7.0, так как десктоп-клиент более не поддерживается. Вместо того, чтобы создавать компаньонов, просто разместите экран в модуле web. |
3.6.2. Источники данных (устаревшее)
|
Это устаревший API. Новый API, доступный начиная с v.7.0, описан в разделе Компоненты данных. |
Источники данных обеспечивают работу связанных с данными (data-aware) компонентов.
Визуальные компоненты сами не обращаются к Middleware, а получают экземпляры сущностей из связанных источников данных. При этом один источник данных может обслуживать несколько визуальных компонентов, если им нужен один и тот же экземпляр или набор экземпляров.
Связь визуального компонента и источника данных проявляется в следующем:
-
При изменении пользователем значения в компоненте новое значение проставляется в атрибуте сущности, находящейся в источнике.
-
При изменении атрибута сущности из кода новое значение проставляется и отображается в визуальном компоненте.
-
Для слежения за вводом пользователя можно использовать как слушатель источника данных, так и слушатель значения визуального компонента - они срабатывают друг за другом.
-
При необходимости прочитать или записать значение атрибута сущности в коде предпочтительнее использовать источник данных, а не компонент. Рассмотрим пример чтения атрибута:
@Inject private FieldGroup fieldGroup; @Inject private Datasource<Order> orderDs; @Named("fieldGroup.customer") private PickerField customerField; public void init(Map<String, Object> params){ Customer customer; // Get customer from component: not for common use Component component = fieldGroup.getFieldNN("customer").getComponentNN(); customer = ((HasValue)component).getValue(); // Get customer from component customer = customerField.getValue(); // Get customer from datasource: recommended customer = orderDs.getItem().getCustomer(); }Как видно из примера, работа со значениями атрибутов сущностей через компонент - не самый прямолинейный способ. В первом случае он требует приведения типа и указания поля FieldGroup в виде строки. Второй пример более безопасный и прямой, но он требует знания ещё и типа поля, которое должно быть инжектировано в контроллер. В то же время, получив методом
getItem()из источника данных хранящийся в нем экземпляр, можно напрямую читать и изменять значения его атрибутов.
|
Как правило, визуальный компонент привязывается к атрибуту, непосредственно принадлежащему сущности, находящейся в источнике данных. В приведенном выше примере компонент привязан к атрибуту Можно также привязать компонент к атрибуту связанной сущности, например к |
Источники данных также отслеживают изменения содержащихся в них сущностей, и могут отправлять измененные экземпляры обратно на Middleware для сохранения в базе данных.
Рассмотрим основные интерфейсы источников.
Рисунок 30. Интерфейсы источников данных
-
Datasource − простейший источник данных, предназначенный для работы с одним экземпляром сущности. Экземпляр устанавливается методом
setItem()и доступен черезgetItem().Стандартной реализацией такого источника является класс
DatasourceImpl, который используется, например, как главный источник данных в экранах редактирования сущностей. -
CollectionDatasource − источник данных, предназначенный для работы с коллекцией экземпляров сущности. Коллекция загружается при вызове метода
refresh(), ключи экземпляров доступны через методgetItemIds(). МетодsetItem()устанавливает, аgetItem()возвращает "текущий" экземпляр коллекции, т.е., например, соответствующий выбранной в данный момент строке таблицы.Способ загрузки коллекции сущностей определяется реализацией. Наиболее типичный - загрузка с Middleware через DataManager, при этом для формирования JPQL запроса используются методы
setQuery(),setQueryFilter().Стандартной реализацией такого источника является класс
CollectionDatasourceImpl, который используется в экранах, отображающих списки сущностей.-
GroupDatasource − подвид
CollectionDatasource, предназначенный для работы с компонентом GroupTable.Стандартной реализацией является класс
GroupDatasourceImpl. -
HierarchicalDatasource − подвид
CollectionDatasource, предназначенный для работы с компонентами Tree и TreeTable.Стандартной реализацией является класс
HierarchicalDatasourceImpl.
-
-
NestedDatasource - источник данных, предназначенный для работы с экземплярами, загруженными в атрибуте другой сущности. При этом источник, содержащий сущность-хозяина, доступен методом
getMaster(), а мета-свойство, соответствующее атрибуту хозяина, содержащему экземпляры данного источника, доступно через методgetProperty().Например, в источнике
dsOrderустановлен экземпляр сущностиOrder, содержащий ссылку на экземплярCustomer. Тогда для связи экземпляраCustomerс визуальными компонентами достаточно создатьNestedDatasource, у которого хозяином являетсяdsOrder, а мета-свойство указывает на атрибутOrder.customer.-
PropertyDatasource - подвид
NestedDatasource, предназначенный для работы с одним экземпляром или коллекцией связанных сущностей, не являющихся встроенными (embedded).Стандартные реализации: для работы с одним экземпляром -
PropertyDatasourceImpl, для работы с коллекцией -CollectionPropertyDatasourceImpl,GroupPropertyDatasourceImpl,HierarchicalPropertyDatasourceImpl. Последние реализуют также интерфейсCollectionDatasource, однако некоторые его нерелевантные методы, связанные с загрузкой, например,setQuery(), выбрасываютUnsupportedOperationException. -
EmbeddedDatasource - подвид
NestedDatasource, содержащий экземпляр встроенной сущности.Стандартной реализацией является класс
EmbeddedDatasourceImpl.
-
-
RuntimePropsDatasource − специфический источник, предназначенный для работы с динамическими атрибутами сущностей.
Как правило, источники данных объявляются декларативно в секции dsContext дескриптора экрана.
- Автоматическое обновление CollectionDatasource
-
При открытии экрана, его визуальные компоненты, соединенные с источниками типа
CollectionDatasource, заставляют эти источники загрузить данные. В результате, таблицы отображают данные сразу после открытия экрана, без всякого дополнительного действия пользователя. Если вы хотите предотвратить автоматическую загрузку, то установите параметр экранаDISABLE_AUTO_REFRESHвtrueв методеinit()этого экрана, или передайте его из вызывающего кода. Данный параметр определен в перечисленииWindowParams, поэтому он может быть задан следующим образом:@Override public void init(Map<String, Object> params) { WindowParams.DISABLE_AUTO_REFRESH.set(params, true); }В этом случае, источники данных типа
CollectionDatasourceбудут загружены только когда будет вызван их методrefresh(). Это может быть сделано как кодом приложения, так и в случае, если пользователь нажмет кнопку Search компонента Filter.
3.6.2.1. Создание источников данных
|
Это устаревший API. Новый API, доступный начиная с v.7.0, описан в разделе Компоненты данных. |
Объекты источников данных могут быть созданы как декларативно - путем объявления в XML-дескрипторе экрана, так и программно в контроллере. Обычно используются стандартные реализации интерфейсов источников, однако при необходимости можно создать собственный класс, унаследовав его от стандартного.
3.6.2.1.1. Декларативное создание
|
Это устаревший API. Новый API, доступный начиная с v.7.0, описан в разделе Компоненты данных. |
Как правило, источники данных объявляются декларативно в элементе dsContext дескриптора экрана. В зависимости от взаимного расположения элементов объявлений создаются источники двух разновидностей:
-
если элемент расположен непосредственно в
dsContext, создается обычныйDatasourceилиCollectionDatasource, который содержит независимо загруженную сущность или коллекцию; -
если элемент расположен внутри элемента другого источника, создается
NestedDatasource, при этом внешний источник становится его хозяином.
Пример объявления источников данных:
<dsContext>
<datasource id="carDs" class="com.haulmont.sample.entity.Car" view="carEdit">
<collectionDatasource id="allocationsDs" property="driverAllocations"/>
<collectionDatasource id="repairsDs" property="repairs"/>
</datasource>
<collectionDatasource id="colorsDs" class="com.haulmont.sample.entity.Color" view="_local">
<query>
<![CDATA[select c from sample$Color c order by c.name]]>
</query>
</collectionDatasource>
</dsContext>Здесь источник carDs содержит один экземпляр сущности Car, а вложенные в него allocationsDs и repairsDs содержат коллекции связанных сущностей из атрибутов Car.driverAllocations и Car.repairs соответственно. Экземпляр Car вместе со связанными сущностями проставляется в источник данных извне. Если данный экран является экраном редактирования, то это происходит автоматически при открытии экрана. Источник данных colorsDs содержит коллекцию экземпляров сущности Color, загружаемую самим источником по указанному JPQL-запросу с представлением _local.
Рассмотрим схему XML.
dsContext - корневой элемент.
Элементы dsContext:
-
datasource- определяет источник данных, содержащий единственный экземпляр сущности.Атрибуты:
-
id- идентификатор источника, должен быть уникальным для данногоDsContext. -
class- Java класс сущности, которая будет содержаться в данном источнике -
view- имя представления сущности. Если источник сам загружает экземпляры, то это представление будет использовано при загрузке. В противном случае это представление сигнализирует внешним механизмам о том, как нужно загрузить сущность для данного источника. -
allowCommit- при установке значенияfalseметодisModified()данного источника всегда возвращаетfalse, а методcommit()ничего не делает. Таким образом, изменения содержащихся в источнике сущностей игнорируются. По умолчаниюtrue, т.е. изменения отслеживаются и могут быть сохранены. -
datasourceClass- собственный класс реализации источника данных, если необходим.
-
-
collectionDatasource- определяет источник данных, содержащий коллекцию экземпляров.Атрибуты
collectionDatasource:-
refreshMode- режим обновления источника, по умолчаниюALWAYS. В режимеNEVERпри вызовеrefresh()источник не производит загрузку данных, а только переходит в состояниеDatasource.State.VALID, оповещает слушателей и сортирует имеющиеся в нем экземпляры. РежимNEVERудобен, если необходимо программно заполнитьCollectionDatasourceпредварительно загруженными или созданными сущностями. Например:@Override public void init(Map<String, Object> params) { Set<Customer> entities = (Set<Customer>) params.get("customers"); for (Customer entity : entities) { customersDs.includeItem(entity); } customersDs.refresh(); } -
softDeletion- значениеfalseотключает режим мягкого удаления при загрузке сущностей, т.е. будут загружены также и удаленные экземпляры. По умолчаниюtrue.Элементы
collectionDatasource: -
query- запрос для загрузки сущностей
-
-
groupDatasource- полностью аналогиченcollectionDatasource, но создает реализацию источника данных, пригодную для использования совместно с компонентом GroupTable. -
hierarchicalDatasource- аналогиченcollectionDatasource, и создает реализацию источника данных, пригодную для использования совместно с компонентами Tree и TreeTable.Специфическим атрибутом является
hierarchyProperty, задающий имя атрибута сущности, по которому строится иерархия.
Класс реализации источника выбирается неявно на основе имени элемента XML и, как было сказано выше, взаимного расположения элементов. Однако если необходимо применить нестандартный источник данных, его класс может быть явно указан в атрибуте datasourceClass.
3.6.2.1.2. Программное создание
|
Это устаревший API. Новый API, доступный начиная с v.7.0, описан в разделе Компоненты данных. |
При необходимости создать источник данных в Java коде рекомендуется воспользоваться специальным классом DsBuilder.
Экземпляр DsBuilder параметризуется цепочкой вызовов его методов в стиле текучего (fluent) интерфейса. Если установлены параметры master и property, то в результате будет создан NestedDatasource, в противном случае - Datasource или CollectionDatasource.
Пример:
CollectionDatasource ds = new DsBuilder(getDsContext())
.setJavaClass(Order.class)
.setViewName(View.LOCAL)
.setId("ordersDs")
.buildCollectionDatasource();3.6.2.1.3. Собственные классы реализации
|
Это устаревший API. Новый API, доступный начиная с v.7.0, описан в разделе Компоненты данных. |
Как правило, нестандартная реализация источника данных требуется для изменения процесса загрузки коллекции сущностей. При создании класса такого источника рекомендуется унаследовать его от CustomCollectionDatasource, либо от CustomGroupDatasource или CustomHierarchicalDatasource, и определить метод getEntities().
Пример:
public class MyDatasource extends CustomCollectionDatasource<SomeEntity, UUID> {
private SomeService someService = AppBeans.get(SomeService.NAME);
@Override
protected Collection<SomeEntity> getEntities(Map<String, Object> params) {
return someService.getEntities();
}
}Для создания экземпляра нестандартного источника данных декларативным способом необходимо указать класс в атрибуте datasourceClass элемента XML. При программном создании через DsBuilder класс источника указывается вызовом setDsClass() или в параметре одного из методов build*().
3.6.2.2. Запросы в CollectionDatasourceImpl
|
Это устаревший API. Новый API, доступный начиная с v.7.0, описан в разделе Компоненты данных. |
Класс CollectionDatasourceImpl и его наследники GroupDatasourceImpl, HierarchicalDatasourceImpl являются стандартной реализацией источников данных, работающих с коллекциями независимых экземпляров сущностей. Эти источники загружают данные через DataManager, отправляя на Middleware запрос на языке JPQL. Далее рассматриваются особенности формирования таких запросов.
3.6.2.2.1. Возвращаемые значения
|
Это устаревший API. Новый API, доступный начиная с v.7.0, описан в разделе Компоненты данных. |
Запрос должен возвращать сущности того типа, который указан при создании источника данных. Тип сущности при декларативном создании указывается в атрибуте class элемента XML, при создании через DsBuilder - в методе setJavaClass() или setMetaClass().
Например, запрос источника данных типа Customer может выглядеть следующим образом:
select c from sales$Customer cили
select o.customer from sales$Order oЗапрос не может возвращать агрегированные значения или отдельные атрибуты, например:
select c.id, c.name from sales$Customer c /* неверно - возвращает отдельные поля, а не весь объект Customer */3.6.2.2.2. Параметры запроса
|
Это устаревший API. Новый API, доступный начиная с v.7.0, описан в разделе Компоненты данных. |
JPQL-запрос в источнике данных может содержать параметры нескольких видов. Вид параметра определяется по префиксу имени параметра. Префиксом является часть имени до знака "$". Интерпретация имени после "$" рассматривается ниже.
-
Префикс
ds.Значением параметра являются данные другого источника данных, зарегистрированного в этом же
DsContext. Например:<collectionDatasource id="customersDs" class="com.sample.sales.entity.Customer" view="_local"> <query> <![CDATA[select c from sales$Customer c]]> </query> </collectionDatasource> <collectionDatasource id="ordersDs" class="com.sample.sales.entity.Order" view="_local"> <query> <![CDATA[select o from sales$Order o where o.customer.id = :ds$customersDs]]> </query> </collectionDatasource>В данном случае параметром запроса источника данных
ordersDsбудет текущий экземпляр сущности, находящийся в источнике данныхcustomersDs.При использовании параметров с префиксом
dsмежду источниками данных автоматически создаются зависимости, приводящие к обновлению источника если меняется значение его параметра. В приведенном примере если изменяется выбранный Покупатель, автоматически обновляется список его Заказов.Обратите внимание, что в примере запроса с параметром левой частью оператора сравнения является значение идентификатора
o.customer.id, а правой - экземплярCustomer, содержащийся в источникеcustomersDs. Такое сравнение допустимо, так как при выполнении запроса на Middleware реализация интерфейса Query, присваивая значения параметрам запроса, автоматически подставляет ID сущности вместо переданного экземпляра сущности.В имени параметра после префикса и имени источника может быть также указан путь по графу сущностей к атрибуту, из которого нужно взять значение, например:
<query> <![CDATA[select o from sales$Order o where o.customer.id = :ds$customersDs.id]]> </query>или
<query> <![CDATA[select o from sales$Order o where o.tagName = :ds$customersDs.group.tagName]]> </query>
-
Префикс
custom.Значение параметра будет взято из объекта
Map<String, Object>, переданного в методrefresh()источника данных. Например:<collectionDatasource id="ordersDs" class="com.sample.sales.entity.Order" view="_local"> <query> <![CDATA[select o from sales$Order o where o.number = :custom$number]]> </query> </collectionDatasource>ordersDs.refresh(ParamsMap.of("number", "1"));Приведение экземпляра при необходимости к его идентификатору осуществляется аналогично параметрам с префиксом
ds. Путь по графу сущностей в имени параметра в данном случае не поддерживается.
-
Префикс
param.Значение параметра будет взято из объекта
Map<String, Object>, переданного при открытии экрана в методinit()контроллера. Например:<query> <![CDATA[select e from sales$Order e where e.customer = :param$customer]]> </query>openWindow("sales$Order.lookup", WindowManager.OpenType.DIALOG, ParamsMap.of("customer", customersTable.getSingleSelected()));Приведение экземпляра при необходимости к его идентификатору осуществляется аналогично параметрам с префиксом
ds. Поддерживается путь к атрибуту по графу сущностей в имени параметра.
-
Префикс
component.Значением параметра будет текущее значение визуального компонента, путь к которому указан в имени параметра. Например:
<query> <![CDATA[select o from sales$Order o where o.number = :component$filter.orderNumberField]]> </query>Путь к компоненту должен включать все вложенные фреймы.
Приведение экземпляра при необходимости к его идентификатору аналогично параметрам
ds. Поддерживается путь к атрибуту по графу сущностей в имени параметра как продолжение пути к компоненту.При изменении значения компонента источник данных автоматически не обновляется.
-
Префикс
session.Значением параметра будет значение атрибута пользовательской сессии, указанного в имени параметра.
Значение извлекается методом
UserSession.getAttribute(), поэтому поддерживаются также предопределенные имена атрибутов сессии:-
userId- ID текущего зарегистрированного или замещенного пользователя; -
userLogin- логин текущего зарегистрированного или замещенного пользователя в нижнем регистре.Пример:
<query> <![CDATA[select o from sales$Order o where o.createdBy = :session$userLogin]]> </query>Приведение экземпляра при необходимости к его идентификатору аналогично параметрам
ds. Путь по графу сущностей в имени параметра в данном случае не поддерживается.
-
|
Если значение параметра не найдено по правилам, задаваемым префиксом, для данного параметра устанавливается значение |
3.6.2.2.3. Фильтр запроса
|
Это устаревший API. Новый API, доступный начиная с v.7.0, описан в разделе Компоненты данных. |
Запрос источника данных может быть модифицирован во время работы приложения, в зависимости от вводимых пользователем условий, что позволяет эффективно фильтровать данные на уровне выборки из БД.
Простейший способ обеспечения такой возможности - подключение к источнику данных специального визуального компонента Filter.
Если по какой-то причине применение универсального фильтра нежелательно, можно встроить в текст запроса специальную разметку на XML, позволяющую сформировать итоговый запрос в зависимости от значений, введенных пользователем в произвольные визуальные компоненты экрана.
В таком фильтре могут быть использованы следующие элементы:
-
filter- корневой элемент фильтра. Может непосредственно содержать только одно условие.-
and,or- логические условия, могут содержать любое количество других условий и предложений. -
c- предложение на JPQL, которое добавляется в секциюwhere. Содержит только текст и опционально атрибутjoin, значение которого будет добавлено в соответствующее место запроса, если добавляется данное предложениеwhere.
-
Условия и предложения добавляются в итоговый запрос, только если присутствующие внутри них параметры получили значения, т.е. не равны null.
Пример:
<query>
<![CDATA[select distinct d from app$GeneralDoc d]]>
<filter>
<or>
<and>
<c join=", app$DocRole dr">dr.doc.id = d.id and d.processState = :custom$state</c>
<c>d.barCode like :component$barCodeFilterField</c>
</and>
<c join=", app$DocRole dr">dr.doc.id = d.id and dr.user.id = :custom$initiator</c>
</or>
</filter>
</query>В данном случае если в метод refresh() источника данных переданы параметры state и initiator, а в визуальном компоненте barCodeFilterField установлено некоторое значение, то итоговый запрос примет вид:
select distinct d from app$GeneralDoc d, app$DocRole dr
where
(
(dr.doc.id = d.id and d.processState = :custom$state)
and
(d.barCode like :component$barCodeFilterField)
)
or
(dr.doc.id = d.id and dr.user.id = :custom$initiator)Если же, к примеру, компонент barCodeFilterField пуст, а в refresh() передан только параметр initiator, то запрос получится следующим:
select distinct d from app$GeneralDoc d, app$DocRole dr
where
(dr.doc.id = d.id and dr.user.id = :custom$initiator)3.6.2.2.4. Поиск подстроки без учета регистра
|
Это устаревший API. Новый API, доступный начиная с v.7.0, описан в разделе Компоненты данных. |
В источниках данных можно использовать особенность выполнения JPQL-запросов, описанную для интерфейса Query уровня Middleware: для удобного формирования условия поиска без учета регистра символов и по любой части строки можно использовать префикс (?i). Однако, в связи с тем, что значение параметра обычно передается неявно, имеются следующие отличия:
-
Префикс
(?i)нужно указывать не в значении, а перед именем параметра. -
Значение параметра будет автоматически переведено в нижний регистр.
-
Если в значении параметра отсутствуют символы
%, то они будут добавлены в начало и конец.
Для примера рассмотрим обработку следующего запроса:
select c from sales$Customer c where c.name like :(?i)component$customerNameFieldВ данном случае значение параметра, взятое из компонента customerNameField, будет переведено в нижний регистр и обрамлено символами %, а затем в базе данных будет выполнен SQL запрос с условием вида lower(C.NAME) like ?
Следует иметь в виду, что при таком поиске индекс, созданный в БД по полю NAME, не используется.
3.6.2.3. Value Datasources
|
Это устаревший API. Новый API, доступный начиная с v.7.0, описан в разделе Компоненты данных. |
Value datasources позволяют выполнять запросы, возвращающие скалярные и агрегатные значения. Например, следующим запросом можно загрузить некоторую агрегатную статистику по покупателям:
select o.customer, sum(o.amount) from demo$Order o group by o.customerValue datasources работают с сущностями особого типа: KeyValueEntity. Такая сущность может содержать произвольный набор атрибутов, задаваемый во время работы приложения. Так, в примере выше, экземпляры KeyValueEntity будут содержать два атрибута: первый типа Customer, второй типа BigDecimal.
Реализации value datasources унаследованы от других широко используемых классов источников данных и дополнительно реализуют специфический интерфейс ValueDatasource. На диаграмме ниже изображены реализации value datasources и их базовые классы:
Интерфейс ValueDatasource содержит следующие методы:
-
addProperty()- так как источник данных может содержать произвольный набор атрибутов, с помощью данного метода необходимо указать, какие атрибуты ожидаются. Он принимает имя атрибута и его тип в виде Datatype или Java-класса. В последнем случае класс должен быть либо сущностью, либо классом, поддерживаемым одним из типов данных (datatypes). -
setIdName()- опциональный метод, позволяющий назначить один из атрибутов идентификатором сущности. Это означает, что экземплярыKeyValueEntity, содержащиеся в данном источнике данных, будут иметь идентификаторы, получаемые из данного атрибута. В противном случае, экземплярыKeyValueEntityполучают случайно сгенерированные UUIDs. -
getMetaClass()возвращает динамическую реализацию интерфейсаMetaClass, которая представляет текущую схему экземпляровKeyValueEntity, заданную вызовами методаaddProperty().
Value datasources могут быть заданы декларативно в XML-дескрипторе. Существует три XML-элемента, соответствующих классам реализации:
-
valueCollectionDatasource -
valueGroupDatasource -
valueHierarchicalDatasource
XML описание value datasource должно содержать элемент properties, который задает атрибуты KeyValueEntity, содержащихся в источнике данных (см. метод addProperty() выше). Порядок элементов property должен соответствовать порядку колонок в результирующем наборе, возвращаемом запросом. Например, в следующем определении атрибут customer получит значение из колонки o.customer, а атрибут sum из колонки sum(o.amount):
<dsContext>
<valueCollectionDatasource id="salesDs">
<query>
<![CDATA[select o.customer, sum(o.amount) from demo$Order o group by o.customer]]>
</query>
<properties>
<property class="com.company.demo.entity.Customer" name="customer"/>
<property datatype="decimal" name="sum"/>
</properties>
</valueCollectionDatasource>
</dsContext>Value datasources предназначены только для чтения данных, так как сущность KeyValueEntity является неперсистентной и не может быть сохранена стандартным механизмом работы с БД.
Value datasource можно создать как вручную, так и с помощью Studio на вкладке Datasources дизайнера экранов.
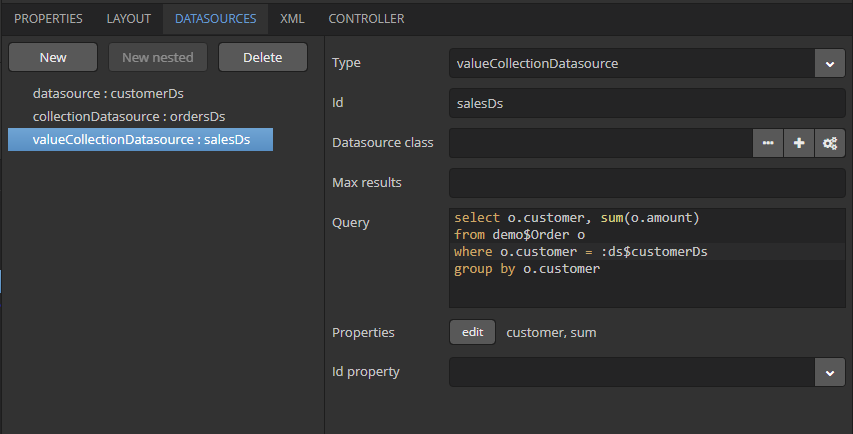
Окно редактирования атрибутов Properties позволяет создать атрибуты источника данных с указанным типом данных и/или Java-класса.
3.6.2.4. Слушатели источников данных
|
Это устаревший API. Новый API, доступный начиная с v.7.0, описан в разделе Компоненты данных. |
Слушатели источников данных (datasource listeners) позволяют получать оповещения об изменении состояния источников данных и экземпляров сущностей, в них находящихся.
Существует четыре типа слушателей. Три из них: ItemPropertyChangeListener, ItemChangeListener и StateChangeListener определены в интерфейсе Datasource и могут быть использованы в любых источниках данных. CollectionChangeListener определен в интерфейсе CollectionDatasource и может быть использован только в источниках данных, работающих с коллекциями сущностей.
По сравнению с ValueChangeListener, слушатели источников данных удобнее для использования с точки зрения контроля над жизненным циклом экрана, поэтому рекомендуется использовать их с компонентами, привязанными к источникам данных.
Пример использования слушателей источников данных:
public class EmployeeBrowse extends AbstractLookup {
private Logger log = LoggerFactory.getLogger(EmployeeBrowse.class);
@Inject
private CollectionDatasource<Employee, UUID> employeesDs;
@Override
public void init(Map<String, Object> params) {
employeesDs.addItemPropertyChangeListener(event -> {
log.info("Property {} of {} has been changed from {} to {}",
event.getProperty(), event.getItem(), event.getPrevValue(), event.getValue());
});
employeesDs.addStateChangeListener(event -> {
log.info("State of {} has been changed from {} to {}",
event.getDs(), event.getPrevState(), event.getState());
});
employeesDs.addItemChangeListener(event -> {
log.info("Datasource {} item has been changed from {} to {}",
event.getDs(), event.getPrevItem(), event.getItem());
});
employeesDs.addCollectionChangeListener(event -> {
log.info("Datasource {} content has been changed due to {}",
event.getDs(), event.getOperation());
});
}
}Интерфейсы слушателей описаны ниже.
-
ItemPropertyChangeListenerдобавляется с помощью методаDatasource.addItemPropertyChangeListener(). Слушатель вызывается, если изменилось значение какого-либо атрибута сущности, находящейся в данный момент в источнике. Через объект события можно получить сам измененный экземпляр, имя измененного атрибута, старое и новое значение.Слушатель
ItemPropertyChangeListenerможно использовать для действий в ответ на изменение пользователем сущности из UI, то есть редактирования полей ввода. -
ItemChangeListenerдобавляется с помощью методаDatasource.addItemChangeListener(). Он вызывается при смене выбранного экземпляра, возвращаемого методомgetItem().Для
Datasourceэто происходит при установке другого экземпляра (илиnull) методомsetItem().Для
CollectionDatasourceданный слушатель вызывается, когда в связанном визуальном компоненте меняется выделенный элемент. Например, это может быть выделенная строка таблицы, элемент дерева, или выделенный элемент выпадающего списка. -
StateChangeListenerдобавляется с помощью методаDatasource.addStateChangeListener(). Он вызывается при изменении состояния источника данных. Источник данных может находиться в одном из трех состояний, соответствующих перечислениюDatasource.State:-
NOT_INITIALIZED- источник только что создан. -
INVALID- создан весь DsContext, к которому относится данный источник. -
VALID- источник данных в рабочем состоянии:Datasourceсодержит экземпляр сущности илиnull,CollectionDatasource- коллекцию экземпляров или пустую коллекцию.Получение оповещения об изменении состояния источника может быть актуально для сложных редакторов, состоящих из нескольких фреймов, где сложно отследить момент проставления редактируемой сущности в источник. В этом случае можно использовать слушатель
StateChangeListenerдля отложенной инициализации некоторых элементов экрана:employeesDs.addStateChangeListener(event -> { if (event.getState() == Datasource.State.VALID) initDataTypeColumn(); });
-
-
CollectionChangeListenerдобавляется с помощью методаCollectionDatasource.addCollectionChangeListener(). Слушатель вызывается при изменении коллекции сущностей, хранящейся в источнике данных. Объект события имеет методgetOperation(), возвращающий значение типаCollectionDatasource.Operation:REFRESH,CLEAR,ADD,REMOVE,UPDATE. Этот тип указывает операцию, которая привела к изменению коллекции.
3.6.2.5. DsContext
|
Это устаревший API. Новый API, доступный начиная с v.7.0, описан в разделе Компоненты данных. |
Все созданные декларативно источники данных регистрируются в объекте DsContext экрана. Ссылку на DsContext можно получить методом getDsContext() контроллера экрана, либо инжекцией в поле класса.
DsContext решает следующие задачи:
-
Позволяет организовать зависимости между источниками данных, когда при навигации по одному источнику (т.е. при изменении "текущего" экземпляра методом
setItem()) обновляется связанный источник. Такие зависимости дают возможность в экранах легко организовывать master-detail связи между визуальными компонентами.Зависимости между источниками организуются с помощью параметров запросов с префиксом
ds$. -
Позволяет собрать все измененные экземпляры сущностей и отправить их на Middleware в одном вызове
DataManager.commit(), т.е. сохранить в базе данных в одной транзакции.В качестве примера предположим, что некоторый экран позволяет редактировать экземпляр сущности
Orderи коллекцию принадлежащих ему экземпляровOrderLine. ЭкземплярOrderнаходится вDatasource, коллекцияOrderLine- во вложенномCollectionDatasource, созданном по атрибутуOrder.lines. Допустим, пользователь изменил какой-то атрибутOrderи создал новый экземплярOrderLine. Тогда при коммите экрана в DataManager будут одновременно отправлены два экземпляра - измененныйOrderи новыйOrderLine. Далее, они вместе попадут в один персистентный контекст и при коммите транзакции сохранятся в БД. Это позволяет не использовать параметров каскадности на уровне ORM и избежать проблем, упомянутых в описании аннотации @OneToMany.В результате коммита
DsContextполучает от Middleware набор сохраненных экземпляров (в случае оптимистической блокировки у них, как минимум, увеличено значение атрибутаversion), и устанавливает эти экземпляры в источниках данных взамен устаревших. Это позволяет сразу после коммита работать со свежими экземплярами без необходимости лишнего обновления источников данных, связанного с запросами к Middleware и базе данных. -
Объявляет два слушателя:
BeforeCommitListenerиAfterCommitListener, позволяющие получать оповещения перед коммитом измененных экземпляров и после него. Перед коммитом можно дополнить коллекцию отправляемых в DataManager на Middleware экземпляров, тем самым обеспечив сохранение в той же транзакции произвольных сущностей. После коммита можно получить коллекцию вернувшихся изDataManagerсохраненных экземпляров.Данный механизм необходим, если некоторые сущности, с которыми работает экран, находятся не под управлением источников данных, а создаются и изменяются непосредственно в коде контроллера. Например, визуальный компонент FileUploadField после загрузки файла создает новый экземпляр сущности
FileDescriptor, который можно сохранить вместе с другими сущностями экрана именно таким способом - добавив вCommitContextв слушателеBeforeCommitListener.В следующем примере новый экземпляр
Customerбудет отправлен на Middleware и сохранен в БД вместе с остальными измененными сущностями экрана при его коммите:protected Customer customer; protected void createNewCustomer() { customer = metadata.create(Customer.class); customer.setName("John Doe"); } @Override public void init(Map<String, Object> params) { getDsContext().addBeforeCommitListener(context -> { if (customer != null) context.getCommitInstances().add(customer); } }
3.6.2.6. DataSupplier
|
Это устаревший API. Новый API, доступный начиная с v.7.0, описан в разделе Компоненты данных. |
DataSupplier - интерфейс, через который источники данных обращаются к Middleware для загрузки и сохранения сущностей. Его стандартная реализация просто делегирует выполнение DataManager. Экран может задать свою реализацию интерфейса DataSupplier в атрибуте dataSupplier элемента window.
Ссылку на DataSupplier можно получить либо инжекцией в контроллер экрана, либо через экземпляры DsContext или Datasource. В обоих случаях возвращается или стандартная, или собственная реализация интерфейса (если таковая определена).
3.6.3. Диалоговые окна и уведомления (устаревшее)
|
Это устаревший API. Новый API, доступный начиная с v.7.0, описан в разделах Диалоговые окна и Уведомления. |
Для вывода сообщений пользователю можно использовать диалоговые окна и уведомления.
Диалоговые окна имеют заголовок с кнопкой закрытия и отображаются всегда в центре главного окна приложения. Уведомления могут отображаться как в центре, так и в углу приложения, и автоматически исчезать.
3.6.3.1. Диалоговые окна
|
Это устаревший API. Новый API, доступный начиная с v.7.0, описан в разделе Диалоговые окна. |
- Диалоги общего назначения
-
Диалоговые окна общего назначения вызываются методами
showMessageDialog()иshowOptionDialog()интерфейсаFrame. Этот интерфейс реализуется контроллером экрана, поэтому данные методы можно вызывать напрямую в коде контроллера.-
showMessageDialog()предназначен для отображения сообщения. Метод принимает следующие параметры:-
title- заголовок диалогового окна. -
message- сообщение. В случае HTML-типа (см. ниже) в сообщении можно использовать теги HTML для форматирования. При использовании HTML обязательно экранируйте данных из БД во избежание code injection в веб-клиенте. В не-HTML сообщениях можно использовать символы\nдля переноса строки. -
messageType- тип сообщения. Возможные типы:-
CONFIRMATION,CONFIRMATION_HTML- диалог подтверждения. -
WARNING,WARNING_HTML- диалог преупреждения.Различие типов сообщений отражается только в пользовательском интерфейсе десктоп-приложений.
Типы сообщений могут быть установлены с параметрами:
-
width- ширина диалога, -
modal- модальность диалога, -
maximized- должен ли диалог быть развёрнут во весь экран, -
closeOnClickOutside- возможность закрыть диалог кликом по любой области за его пределами.Пример вызова диалога:
showMessageDialog("Warning", "Something is wrong", MessageType.WARNING.modal(true).closeOnClickOutside(true));
-
-
-
-
showOptionDialog()предназначен для отображения сообщения и кнопок для выбора пользователем. Метод в дополнение к параметрам, описанным дляshowMessageDialog(), принимает массив или список действий. Для каждого действия в диалоге создается кнопка, при нажатии на которую пользователем диалог закрывается и вызывается методactionPerform()данного действия.В качестве кнопок со стандартными названиями и значками удобно использовать анонимные классы, унаследованные от
DialogAction. Поддерживаются пять видов действий, определяемых перечислениемDialogAction.Type:OK,CANCEL,YES,NO,CLOSE. Названия соответствующих кнопок извлекаются из главного пакета локализованных сообщений.Пример вызова диалога с кнопками Да и Нет и с заголовком и сообщением, взятыми из пакета локализованных сообщений текущего экрана:
showOptionDialog( getMessage("confirmCopy.title"), getMessage("confirmCopy.msg"), MessageType.CONFIRMATION, new Action[] { new DialogAction(DialogAction.Type.YES, Status.PRIMARY).withHandler(e -> copySettings()), new DialogAction(DialogAction.Type.NO, Status.NORMAL) } );Параметр
StatusконструктораDialogActionиспользуется для определения визуального стиля кнопки, к которой привязано данное действие. СтатусStatus.PRIMARYподсвечивает кнопку и задаёт ей выделение по умолчанию. ПараметрStatusможно не использовать, в этом случае используется подсветка кнопок по умолчанию. Если вshowOptionDialogпередано несколько действий сStatus.PRIMARY, то фокус и стиль получает только кнопка первого такого действия в списке.
-
- Диалог загрузки файлов
-
Диалоговое окно
FileUploadDialogпредоставляет базовую функциональность загрузки файлов в промежуточное хранилище. Оно содержит drop zone для перетаскивания файлов извне браузера и кнопку загрузки файла.
Открыть диалог можно с помощью метода
openWindow(), в случае успешной загрузки окно будет закрыто сCOMMIT_ACTION_ID. Закрытие диалога можно отслеживать с помощью слушателейCloseListenerиCloseWithCommitListener. Чтобы получить UUID и имя загруженного файла, используйте методыgetFileId()иgetFileName(). Затем для файла можно, например, создатьFileDescriptor, позволяющий ссылаться на него из объектов модели данных, или реализовать другую логику.FileUploadDialog dialog = (FileUploadDialog) openWindow("fileUploadDialog", OpenType.DIALOG); dialog.addCloseWithCommitListener(() -> { UUID fileId = dialog.getFileId(); String fileName = dialog.getFileName(); FileDescriptor fileDescriptor = fileUploadingAPI.getFileDescriptor(fileId, fileName); // your logic here });
Внешний вид диалогового окна можно настроить с помощью переменных SCSS с префиксом $cuba-window-modal-*. Эти переменные можно изменить в визуальном редакторе после расширения темы или создания новой темы.
3.6.3.2. Уведомления
|
Это устаревший API. Новый API, доступный начиная с v.7.0, описан в разделе Уведомления. |
Уведомления вызываются методом showNotification() интерфейса Frame. Этот интерфейс реализуется контроллером экрана, поэтому данный метод можно вызывать напрямую в коде контроллера.
Метод showNotification() принимает следующие параметры:
-
caption- текст уведомления. В случае HTML-типа (см. ниже) в сообщении можно использовать теги HTML для форматирования. При использовании HTML обязательно экранируйте данных из БД во избежание code injection в веб-клиенте. В не-HTML сообщениях можно использовать символы\nдля переноса строки. -
description- опциональное описание, которое будет отображено нижеcaption. Также можно использовать символы\nили HTML-форматирование. -
type- тип уведомления. Возможные типы:-
TRAY,TRAY_HTML- уведомление показывается в правом нижнем углу приложения и исчезает автоматически. -
HUMANIZED,HUMANIZED_HTML- стандартное уведомление в центре экрана, исчезает автоматически. -
WARNING,WARNING_HTML- предупреждение. Исчезает при клике пользователя. -
ERROR,ERROR_HTML- уведомление об ошибке. Исчезает при клике пользователя.
-
Примеры вызова уведомлений:
showNotification(getMessage("selectBook.text"), NotificationType.HUMANIZED);
showNotification("Validation error", "<b>Date</b> is incorrect", NotificationType.TRAY_HTML);3.6.4. Действия с коллекцией (устаревшее)
|
Это устаревший API. Новый API, доступный начиная с v.7.0, описан в разделе Стандартные действия с коллекцией. |
Для наследников ListComponent (это Table, GroupTable, TreeTable и Tree) набор стандартных действий определен в перечислении ListActionType, классы их реализации находятся в пакете com.haulmont.cuba.gui.components.actions.
Пример использования стандартных действий в таблице:
<table id="usersTable" width="100%">
<actions>
<action id="create"/>
<action id="edit"/>
<action id="remove"/>
<action id="refresh"/>
</actions>
<buttonsPanel>
<button action="usersTable.create"/>
<button action="usersTable.edit"/>
<button action="usersTable.remove"/>
<button action="usersTable.refresh"/>
</buttonsPanel>
<rowsCount/>
<columns>
<column id="login"/>
...
</columns>
<rows datasource="usersDs"/>
</table>Рассмотрим их подробнее.
CreateAction
CreateAction - действие с идентификатором create. Предназначено для создания нового экземпляра сущности и открытия экрана редактирования для этого экземпляра. Если экран редактирования успешно закоммитил новый экземпляр в базу данных, то CreateAction добавляет этот новый экземпляр в источник данных таблицы и делает его выбранным.
В классе CreateAction определены следующие специфические методы:
-
setOpenType()- позволяет задать режим открытия экрана редактирования новой сущности. По умолчанию экран открывается в режимеTHIS_TAB.Так как довольно часто требуется открывать экраны редактирования в другом режиме (как правило,
DIALOG), при декларативном создании действияcreateв элементеactionможно указать атрибутopenTypeс нужным значением. Это избавляет от необходимости получать ссылку на действие в контроллере и программно устанавливать данное свойство. Например:<table id="usersTable"> <actions> <action id="create" openType="DIALOG"/> -
setWindowId()- позволяет задать идентификатор экрана редактирования сущности. По умолчанию используется экран{имя_сущности}.edit, напримерsales$Customer.edit. -
setWindowParams()- позволяет задать параметры экрана редактирования, передаваемые в его методinit(). Далее эти параметры можно использовать напрямую в запросе источника данных через префиксparam$или инжектировать в контроллер экрана с помощью аннотации@WindowParam. -
setWindowParamsSupplier()отличается отsetWindowParams()тем, что позволяет получить значения параметров непосредственно перед вызовом действия. Полученные параметры объединяются с предоставленными черезsetWindowParams()и могут переопределять их. Например:createAction.setWindowParamsSupplier(() -> { Customer customer = metadata.create(Customer.class); customer.setCategory(/* some value dependent on the current state of the screen */); return ParamsMap.of("customer", customer); }); -
setInitialValues()- позволяет задать начальные значения атрибутов создаваемой сущности. Принимает объектMap, в котором ключами являются имена атрибутов, а значениями - значения атрибутов. Например:Map<String, Object> values = new HashMap<>(); values.put("type", CarType.PASSENGER); carCreateAction.setInitialValues(values);Пример использования
setInitialValues()приведен также в разделе рецептов разработки. -
setInitialValuesSupplier()отличается отsetInitialValues()тем, что позволяет получить значения параметров непосредственно перед вызовом действия. Полученные параметры объединяются с предоставленными черезsetInitialValues()и могут переопределять их. Например:carCreateAction.setInitialValuesSupplier(() -> ParamsMap.of("type", /* value depends on the current state of the screen */)); -
setBeforeActionPerformedHandler()позволяет задать обработчик, который будет вызван до выполнения действия. Если метод возвращаетtrue, действие будет выполнено, еслиfalse- отменено. Например:customersTableCreate.setBeforeActionPerformedHandler(() -> { showNotification("The new customer instance will be created"); return isValid(); }); -
afterCommit()- вызывается действием после того, как экран редактирования успешно закоммитил новую сущность и был закрыт. Данный метод не имеет реализации и может быть переопределен в наследниках для реакции на это событие. -
setAfterCommitHandler()- позволяет задать обработчик, который будет вызван после того, как экран редактирования успешно закоммитил новую сущность и был закрыт. Данный обработчик можно использовать вместо переопределения методаafterCommit(), тем самым избавившись от необходимости создания наследника действия. Например:@Named("customersTable.create") private CreateAction customersTableCreate; @Override public void init(Map<String, Object> params) { customersTableCreate.setAfterCommitHandler(new CreateAction.AfterCommitHandler() { @Override public void handle(Entity entity) { showNotification("Committed", NotificationType.HUMANIZED); } }); } -
afterWindowClosed()- вызывается действием в последнюю очередь после закрытия экрана редактирования, независимо от того, была ли закоммичена новая сущность или нет. Данный метод не имеет реализации и может быть переопределен в наследниках для реакции на это событие. -
setAfterWindowClosedHandler()- позволяет задать обработчик, который будет вызван после закрытия экрана редактирования, независимо от того, была ли закоммичена новая сущность или нет. Данный обработчик можно использовать вместо переопределения методаafterWindowClosed(), тем самым избавившись от необходимости создания наследника действия.
EditAction
EditAction - действие с идентификатором edit. Открывает экран редактирования для выбранного экземпляра сущности. Если экран редактирования успешно закоммитил экземпляр в базу данных, то EditAction обновляет этот экземпляр в источнике данных таблицы.
В классе EditAction определены следующие специфические методы:
-
setOpenType()- позволяет задать режим открытия экрана редактирования сущности. По умолчанию экран открывается в режимеTHIS_TAB.Так как довольно часто требуется открывать экраны редактирования в другом режиме (как правило,
DIALOG), при декларативном создании действияeditв элементеactionможно указать атрибутopenTypeс нужным значением. Это избавляет от необходимости получать ссылку на действие в контроллере и программно устанавливать данное свойство. Например:<table id="usersTable"> <actions> <action id="edit" openType="DIALOG"/> -
setWindowId()- позволяет задать идентификатор экрана редактирования сущности. По умолчанию используется экран{имя_сущности}.edit, напримерsales$Customer.edit. -
setWindowParams()- позволяет задать параметры экрана редактирования, передаваемые в его методinit(). Далее эти параметры можно использовать напрямую в запросе источника данных через префиксparam$или инжектировать в контроллер экрана с помощью аннотации@WindowParam. -
setWindowParamsSupplier()отличается отsetWindowParams()тем, что позволяет получить значения параметров непосредственно перед вызовом действия. Полученные параметры объединяются с предоставленными черезsetWindowParams()и могут переопределять их. Например:customersTableEdit.setWindowParamsSupplier(() -> ParamsMap.of("category", /* some value dependent on the current state of the screen */)); -
setBeforeActionPerformedHandler()позволяет задать обработчик, который будет вызван до выполнения действия. Если метод возвращаетtrue, действие будет выполнено, еслиfalse- отменено. Например:customersTableEdit.setBeforeActionPerformedHandler(() -> { showNotification("The customer instance will be edited"); return isValid(); }); -
afterCommit()- вызывается действием после того, как экран редактирования успешно закоммитил сущность и был закрыт. Данный метод не имеет реализации и может быть переопределен в наследниках для реакции на это событие. -
setAfterCommitHandler()- позволяет задать обработчик, который будет вызван после того, как экран редактирования успешно закоммитил новую сущность и был закрыт. Данный обработчик можно использовать вместо переопределения методаafterCommit(), тем самым избавившись от необходимости создания наследника действия. Например:@Named("customersTable.edit") private EditAction customersTableEdit; @Override public void init(Map<String, Object> params) { customersTableEdit.setAfterCommitHandler(new EditAction.AfterCommitHandler() { @Override public void handle(Entity entity) { showNotification("Committed", NotificationType.HUMANIZED); } }); } -
afterWindowClosed()- вызывается действием в последнюю очередь после закрытия экрана редактирования, независимо от того, была ли закоммичена редактируемая сущность. Данный метод не имеет реализации и может быть переопределен в наследниках для реакции на это событие. -
setAfterWindowClosedHandler()- позволяет задать обработчик, который будет вызван после закрытия экрана редактирования, независимо от того, была ли закоммичена новая сущность или нет. Данный обработчик можно использовать вместо переопределения методаafterWindowClosed(), тем самым избавившись от необходимости создания наследника действия. -
getBulkEditorIntegration()позволяет настроить массовое редактирование строк таблицы, для этого атрибутmultiselectтаблицы должен иметь значениеtrue. Компонент BulkEditor будет открыт, если при вызовеEditActionв таблице выделено более одной строки.Возвращаемый экземпляр
BulkEditorIntegrationможно изменить с помощью следующих методов:-
setOpenType(), -
setExcludePropertiesRegex(), -
setFieldValidators(), -
setModelValidators(), -
setAfterEditCloseHandler().
@Named("clientsTable.edit") private EditAction clientsTableEdit; @Override public void init(Map<String, Object> params) { super.init(params); clientsTableEdit.getBulkEditorIntegration() .setEnabled(true) .setOpenType(WindowManager.OpenType.DIALOG); } -
RemoveAction
RemoveAction - действие с идентификатором remove. Предназначено для удаления выбранного экземпляра сущности.
В классе RemoveAction определены следующие специфические методы:
-
setAutocommit()- позволяет управлять моментом удаления сущности из базы данных. По умолчанию после срабатывания действия и удаления сущности из источника данных у источника вызывается методcommit(), в результате чего сущность удаляется из базы данных. Cвойствоautocommitможно установить вfalseлибо методомsetAutocommit(), либо соответствующим параметром конструктора. В результате после удаления сущности из источника данных для подтверждения удаления потребуется явно вызвать методcommit()источника данных.Значение
autocommitне влияет на работу источников данных в режимеDatasource.CommitMode.PARENT, то есть тех, которые обеспечивают редактирование композиционных сущностей. -
setConfirmationMessage()- позволяет задать текст сообщения в диалоге подтверждения удаления. -
setConfirmationTitle()- позволяет задать заголовок диалога подтверждения удаления. -
setBeforeActionPerformedHandler()позволяет задать обработчик, который будет вызван до выполнения действия. Если метод возвращаетtrue, действие будет выполнено, еслиfalse- отменено. Например:customersTableRemove.setBeforeActionPerformedHandler(() -> { showNotification("The customer instance will be removed"); return isValid(); }); -
afterRemove()- вызывается действием после успешного удаления сущности. Данный метод не имеет реализации и может быть переопределен в наследниках для реакции на это событие. -
setAfterRemoveHandler()позволяет задать обработчик, который будет вызван после успешного удаления сущности. Данный обработчик можно использовать вместо переопределения методаafterWindowClosed(), тем самым избавившись от необходимости создания наследника действия. Например:@Named("customersTable.remove") private RemoveAction customersTableRemove; @Override public void init(Map<String, Object> params) { customersTableRemove.setAfterRemoveHandler(new RemoveAction.AfterRemoveHandler() { @Override public void handle(Set removedItems) { showNotification("Removed", NotificationType.HUMANIZED); } }); }
RefreshAction
RefreshAction - действие с идентификатором refresh. Предназначено для обновления (перезагрузки) коллекции сущностей. При срабатывании вызывает метод refresh() источника данных, с которым связан компонент.
В классе RefreshAction определены следующие специфические методы:
-
setRefreshParams()- позволяет задать параметры, передаваемые в методCollectionDatasource.refresh(), для использования внутри запроса. По умолчанию никакие параметры не передаются. -
setRefreshParamsSupplier()отличается отsetRefreshParams()тем, что позволяет получить значения параметров непосредственно перед вызовом действия. Полученные параметры объединяются с предоставленными черезsetRefreshParams()и могут переопределять их. Например:customersTableRefresh.setRefreshParamsSupplier(() -> ParamsMap.of("number", /* some value dependent on the current state of the screen */));
AddAction
AddAction - действие с идентификатором add. Предназначено для выбора существующего экземпляра сущности и добавления его в коллекцию. При срабатывании открывает экран выбора сущностей.
В классе AddAction определены следующие специфические методы:
-
setOpenType()- позволяет задать режим открытия экрана выбора сущности. По умолчанию экран открывается в режимеTHIS_TAB.Так как довольно часто требуется открывать экраны выбора в другом режиме (как правило,
DIALOG), при декларативном создании действияaddв элементеactionможно указать атрибутopenTypeс нужным значением. Это избавляет от необходимости получать ссылку на действие в контроллере и программно устанавливать данное свойство. Например:<table id="usersTable"> <actions> <action id="add" openType="DIALOG"/> -
setWindowId()- позволяет задать идентификатор экрана выбора сущности. По умолчанию используется экран{имя_сущности}.lookup, напримерsales$Customer.lookup. Если такого экрана не существует, то делается попытка открыть экран{имя_сущности}.browse, напримерsales$Customer.browse. -
setWindowParams()- позволяет задать параметры экрана выбора, передаваемые в его методinit(). Далее эти параметры можно использовать напрямую в запросе источника данных через префиксparam$или инжектировать в контроллер экрана с помощью аннотации@WindowParam. -
setWindowParamsSupplier()отличается отsetWindowParams()тем, что позволяет получить значения параметров непосредственно перед вызовом действия. Полученные параметры объединяются с предоставленными черезsetWindowParams()и могут переопределять их. Например:tableAdd.setWindowParamsSupplier(() -> ParamsMap.of("customer", getItem())); -
setHandler()- позволяет задать объект, реализующий интерфейсWindow.Lookup.Handler, передаваемый в экран выбора. По умолчанию используется объект классаAddAction.DefaultHandler. -
setBeforeActionPerformedHandler()позволяет задать обработчик, который будет вызван до выполнения действия. Если метод возвращаетtrue, действие будет выполнено, еслиfalse- отменено. Например:customersTableAdd.setBeforeActionPerformedHandler(() -> { notifications.create() .withCaption("The new customer will be added") .show(); return isValid(); });
ExcludeAction
ExcludeAction - действие с идентификатором exclude. Позволяет исключать экземпляры сущности из коллекции, не удаляя их из базы данных. Класс данного действия является наследником RemoveAction, однако при срабатывании вызывает у CollectionDatasource не removeItem(), а excludeItem(). Кроме того, для вложенных источников данных ExcludeAction разрывает связь с родительской сущностью, поэтому с помощью данного действия можно организовать редактирование ассоциации one-to-many.
В классе ExcludeAction в дополнение к RemoveAction определены следующие специфические методы:
-
setConfirm()- показывать ли диалог подтверждения удаления. Это свойство можно также установить через конструктор действия. По умолчанию установлено вfalse. -
setBeforeActionPerformedHandler()позволяет задать обработчик, который будет вызван до выполнения действия. Если метод возвращаетtrue, действие будет выполнено, еслиfalse- отменено. Например:customersTableExclude.setBeforeActionPerformedHandler(() -> { showNotification("The selected customer will be excluded"); return isValid(); });
ExcelAction
ExcelAction - действие с идентификатором excel. Предназначено для экспорта данных таблицы в формат XLS и выгрузки соответствующего файла. Данное действие можно связать только с компонентами Table, GroupTable и TreeTable.
При программном создании действия можно задать параметр конструктора display, передав реализацию интерфейса ExportDisplay для выгрузки файла. По умолчанию используется стандартная реализация.
В классе ExcelAction определены следующие специфические методы:
-
setFileName()- позволяет задать имя выгружаемого файла Excel без расширения. -
getFileName()- возвращает имя выгружаемого файла Excel без расширения. -
setBeforeActionPerformedHandler()позволяет задать обработчик, который будет вызван до выполнения действия. Если метод возвращаетtrue, действие будет выполнено, еслиfalse- отменено. Например:customersTableExcel.setBeforeActionPerformedHandler(() -> { showNotification("The selected data will ve downloaded as an XLS file"); return isValid(); });
3.6.5. Действия поля выбора (устаревшее)
|
Это устаревший API. Новый API, доступный начиная с v.7.0, описан в разделе Стандартные действия поля выбора. |
Для компонентов PickerField, LookupPickerField и SearchPickerField набор стандартных действий определен в перечислении PickerField.ActionType. Реализации являются внутренними классами интерфейса PickerField.
Пример использования стандартных действий в компоненте выбора:
<searchPickerField optionsDatasource="coloursDs"
datasource="carDs" property="colour">
<actions>
<action id="clear"/>
<action id="lookup"/>
<action id="open"/>
</actions>
</searchPickerField>LookupAction
LookupAction - действие с идентификатором lookup. Предназначено для выбора экземпляра сущности и установки его в качестве значения компонента. При срабатывании открывает экран выбора сущностей.
В классе LookupAction определены следующие специфические методы:
-
setLookupScreenOpenType()- позволяет задать режим открытия экрана выбора сущности. По умолчанию экран открывается в режимеTHIS_TAB. -
setLookupScreen()- позволяет задать идентификатор экрана выбора сущности. По умолчанию используется экран{имя_сущности}.lookup, напримерsales$Customer.lookup. Если такого экрана не существует, то делается попытка открыть экран{имя_сущности}.browse, напримерsales$Customer.browse. -
setLookupScreenParams()- позволяет задать параметры экрана выбора, передаваемые в его методinit(). -
afterSelect()- вызывается действием после того, как выбранный экземпляр установлен в качестве значения компонента. Данный метод не имеет реализации и может быть переопределен в наследниках для реакции на это событие. -
afterCloseLookup()- вызывается действием в последнюю очередь после закрытия экрана выбора, независимо от того, был сделан выбор или нет. Данный метод не имеет реализации и может быть переопределен в наследниках для реакции на это событие.
ClearAction
ClearAction - действие с идентификатором clear. Предназначено для очистки (то есть установки в null) текущего значения компонента.
OpenAction
OpenAction - действие с идентификатором open. Предназначено для открытия экрана редактирования экземпляра сущности, являющегося текущим значением компонента.
В классе OpenAction определены следующие специфические методы:
-
setEditScreenOpenType()- позволяет задать режим открытия экрана редактирования сущности. По умолчанию экран открывается в режимеTHIS_TAB. -
setEditScreen()- позволяет задать идентификатор экрана редактирования сущности. По умолчанию используется экран{имя_сущности}.edit, напримерsales$Customer.edit. -
setEditScreenParams()- позволяет задать параметры экрана редактирования, передаваемые в его методinit(). -
afterWindowClosed()- вызывается действием после закрытия экрана редактирования. Данный метод не имеет реализации и может быть переопределен в наследниках для реакции на это событие.
3.6.6. screens.xml (устаревшее)
|
Экраны, написанные на новом API версии 7.0 не требуют регистрации. Они обнаруживаются по аннотации |
Файлы данного типа используются в блоке Web Client для регистрации XML-дескрипторов экранов.
Схема XML доступна по адресу http://schemas.haulmont.com/cuba/7.2/screens.xsd.
Расположение файла задается в свойстве приложения cuba.windowConfig. При создании нового проекта в Studio, она создает файл web-screens.xml в корневом пакете модуля web, например modules/web/src/com/company/sample/web-screens.xml.
Рассмотрим структуру файла.
screen-config - корневой элемент. Он содержит следующие элементы:
-
screen- описатель экранаАтрибуты
screen:-
id- идентификатор экрана, по которому он доступен в программном коде (например, в методахFrame.openWindow()и т.п.) и в menu.xml. -
template- путь к файлу XML-дескриптора экрана. Загрузка производится по правилам интерфейса Resources. -
class- если атрибутtemplateне указан, в данном атрибуте нужно указать имя класса, реализующего либоCallable, либоRunnable.В случае
Callableметодcall()должен возвращать экземпляр созданногоWindow, который будет возвращен вызывающему коду как результатWindowManager.openWindow(). Класс может содержать конструктор с параметрами для передачи ему строковых значений, заданных вложенным элементомparam(см. ниже). -
agent- если для одногоidзарегистрировано несколько шаблонов, данный атрибут используется для определения, какой шаблон выбрать. Существует три стандартных типа агентов:DESKTOP,TABLET,PHONE. Они позволяют выбрать экран в зависимости от текущего устройства и параметров дисплея пользователя. Подробнее см. Screen Agent. -
multipleOpen- опциональный атрибут, задающий возможность многократного открытия экрана. Если равенfalseили не задан, и в главном окне уже открыт экран с данным идентификатором, то вместо открытия нового экземпляра экрана отобразится имеющийся. Значениеtrueпозволяет открывать произвольное количество одинаковых экранов.
Элементы
screen:-
param- задает параметр экрана, передаваемый в мэп методаinit()контроллера. Параметры, передаваемые из вызывающего кода в методыopenWindow(), переопределяют одноименные параметры, заданные вscreens.xml.Атрибуты
param:-
name- имя параметра -
value- значение параметра. Строкиtrueиfalseавтоматически преобразуются в значения типаBoolean.
-
-
-
include- включение другого файла типаscreens.xmlАтрибуты
include:-
file- путь к файлу по правилам интерфейса Resources
-
Пример файла screens.xml:
<screen-config xmlns="http://schemas.haulmont.com/cuba/screens.xsd">
<screen id="sales$Customer.lookup" template="/com/sample/sales/gui/customer/customer-browse.xml"/>
<screen id="sales$Customer.edit" template="/com/sample/sales/gui/customer/customer-edit.xml"/>
<screen id="sales$Order.lookup" template="/com/sample/sales/gui/order/order-browse.xml"/>
<screen id="sales$Order.edit" template="/com/sample/sales/gui/order/order-edit.xml"/>
</screen-config>3.7. Фронтенд интерфейс
Фронтенд интерфейс - это блок, являющийся альтернативой универсальному пользовательскому интерфейсу (Generic UI). В то время как универсальный пользовательский интерфейс, как правило, предназначен для внутренних (back-office) пользователей, фронтенд интерфейс ориентирован на внешних пользователей и предоставляет больше возможностей для кастомизации внешнего вида. Фронтенд интерфейс использует хорошо знакомые фронтенд-разработчикам технологии и позволяет легко интегрировать UI-библиотеки и компоненты из обширной экосистемы JavaScript. Однако, разработка фронтенд интерфейса требует более глубокого знания современных фронтенд-технологий.
Фронтенд интерфейс может быть основан на одной из следующих технологий:
-
React
-
React Native
-
Polymer (deprecated)
-
Предпочитаемый вами фреймворк (например, Angular или Vue): для этого вы можете использовать фреймворк-нейтральный TypeScript SDK
Мы предоставляем ряд инструментов и библиотек, которые вы можете использовать для разработки вашего приложения (фронтенд клиента):
- Frontend Generator
-
Frontend Generator - это инструмент автоматической кодогенерации, который может быть использован для ускорения процесса разработки фронтенд клиента. Его можно использовать как самостоятельный инструмент командной строки, либо через CUBA Studio. С его помощью можно сгенерировать стартовое приложение и добавить необходимые элементы, такие как, например, экраны просмотра и редактирования сущностей. Также, с его помощью можно сгенерировать TypeScript SDK.
- Библиотеки компонентов и утилит для React и React Native
-
Мы предоставляем две библиотеки для фронтенд клиентов на базе React и React Native. Они используется в коде, сгенерированном с помощью Frontend Generator, и могут быть использованы самостоятельно. Библиотека CUBA React Core предоставляет базовую функциональность, такую, как работа с сущностями. Эта библиотека используется фронтенд клиентами на базе React и React Native. Библиотека CUBA React UI содержит UI-компоненты. Она использует UI-кит Ant Design и используется клиентами на базе React.
- CUBA REST JS library
-
CUBA REST JS - это библиотека, отвечающая за взаимодействие с универсальным REST API. Фронтенд клиенты используют универсальный REST API для коммуникации со средним слоем. Однако, вам не нужно вручную слать запросы из вашего кода. Если ваш фронтенд клиент использует React или React Native, компоненты CUBA React Core во многих случаях будут сами осуществлять эту коммуникацию, используя CUBA REST JS. Если вы используете другой фреймворк, или вам требуется бо́льшая свобода действий, вы можете использовать CUBA REST JS напрямую.
- TypeScript SDK
-
TypeScript SDK генерируется с помощью Frontend Generator и является описанием сущностей, представлений и фасадов REST-сервисов вашего проекта на языке TypeScript. SDK может использоваться для разработки фронтенд клиента с использованием предпочитаемого вами фреймворка (не поддерживаемого "из коробки") или для разработки BFF (Backend for Frontend) на базе Node.js.
Узнать о том, как использовать эти инструменты для разработки вашего фронтенд клиента, можно в Руководстве по фронтенд интерфейсу.
3.7.1. Создание фронтенд интерфейса в Studio
См. раздел Фронтенд интерфейс в Руководстве пользователя CUBA Studio.
3.7.3. Пользовательский интерфейс на Polymer (Deprecated)
|
Начиная с версии 7.2 платформы, Polymer UI объявлен устаревшим (Deprecated). Используйте React UI. |
3.8. Компоненты портала
В данном руководстве порталом называется клиентский блок, способный решать следующие задачи:
-
предоставлять альтернативный веб-интерфейс, как правило, предназначенный для пользователей за пределами организации;
-
предоставлять интерфейс для интеграции с мобильными приложениями и со сторонними системами.
Конкретное приложение может содержать несколько портальных модулей, предназначенных для различных целей, например, в случае приложения, автоматизирующего бизнес такси, это может быть публичный веб-сайт для клиентов, интеграционный модуль мобильного приложения заказа такси, интеграционный модуль мобильного приложения водителей, и т.д.
Базовый проект cuba платформы содержит в своем составе модуль portal, который является заготовкой для создания порталов в проектах. Он предоставляет базовую функциональность клиентского блока для работы с Middleware. Кроме того, универсальный REST API, включенный в модуль portal в качестве зависимости, запускается по умолчанию.
Рассмотрим основные компоненты, предоставляемые платформой для построения портала.
-
PortalAppContextLoader- загрузчик AppContext, должен быть зарегистрирован в элементеlistenerфайлаweb.xml. -
PortalDispatcherServlet- центральный сервлет, распределяющий запросы по контроллерам Spring MVC, как для веб-интерфейса, так и для REST API. Набор файлов конфигурации контекста Spring определяется свойством приложения cuba.dispatcherSpringContextConfig. Данный сервлет должен быть зарегистрирован вweb.xmlи отображен на корневой URL веб-приложения. -
App- объект, содержащий информацию о текущем HTTP запросе и ссылку на объектConnection. ЭкземплярAppможет быть получен в прикладном коде вызовом статического методаApp.getInstance(). -
Connection- позволяет выполнять логин и логаут пользователя на Middleware. -
PortalSession- специфический для портала объект пользовательской сессии. Возвращается интерфейсом инфраструктуры UserSessionSource, а также статическим методомPortalSessionProvider.getUserSession().Имеет дополнительный метод
isAuthenticated(), возвращающийtrue, если данная сессия принадлежит неанонимному, т.е. явно зарегистрировавшемуся с логином и паролем, пользователю.При первом обращении некоторого пользователя к порталу
SecurityContextHandlerInterceptorсоздает для него (или привязывает уже имеющуюся) анонимную сессию, регистрируясь на Middleware с именем пользователя, указанным в свойстве приложения cuba.portal.anonymousUserLogin. Регистрация производится методом loginTrusted(), поэтому в блоке портала необходимо установить также свойство cuba.trustedClientPassword. Таким образом, любой анонимный пользователь портала может работать с сервисами Middleware с правами пользователяcuba.portal.anonymousUserLogin.Если портал содержит страницу регистрации пользователя с именем и паролем, то после выполнения
Connection.login()при обработке запросовSecurityContextHandlerInterceptorустанавливает в потоке выполнения пользовательскую сессию явно зарегистрированного пользователя, и работа с Middleware происходит от его имени. -
PortalLogoutHandler- обрабатывает навигацию на страницу логаута. Должен быть зарегистрирован в файлеportal-security-spring.xmlпроекта.
3.9. Механизмы платформы
В данной главе рассматриваются различные опциональные возможности, предоставляемые платформой.
3.9.1. Динамические атрибуты
Динамические атрибуты - это дополнительные поля сущности, которые можно добавлять без изменения схемы БД и перезагрузки приложения. Механизм динамических атрибутов предназначен для описания новых свойств сущностей на этапе настройки и эксплуатации системы.
Динамические атрибуты CUBA являются реализацией концепции Entity-Attribute-Value.
Рисунок 31. Диаграмма классов механизма динамических атрибутов
-
Category- определяет категорию объектов, которая содержит описание структуры динамических атрибутов. Каждая категория относится к некоторому типу сущности.Например, имеется сущность типа Автомобиль. Для нее можно определить две категории: Грузовой и Пассажирский. При этом категория Грузовой будет содержать атрибуты Грузоподъемность и Вид кузова, а категория Пассажирский - атрибуты Количество мест и Наличие детского сидения.
-
CategoryAttribute- определяет динамический атрибут, относящийся к некоторой категории. Каждый атрибут описывает одно поле определенного типа. У каждого атрибута имеется обязательное полеКод(code), которое используется в качестве его системного имени.Имяатрибута (name) используется для отображения пользователю. -
CategoryAttributeValue- значение динамического атрибута для конкретного экземпляра сущности. Физически значения динамических атрибутов хранятся в специальной таблицеSYS_ATTR_VALUE. У каждой записи этой таблицы есть ссылка на определенную сущность (колонкаENTITY_ID).
Экземпляр сущности может иметь атрибуты одновременно из всех категорий, связанных с этим типом сущности. Если необходимо, чтобы некоторый экземпляр сущности принадлежал только одной категории с соответствующим набором атрибутов (Автомобиль может быть либо Грузовым, либо Пассажирским), класс сущности должен реализовывать интерфейс Categorized. В этом случае экземпляр сущности будет содержать ссылку на категорию и динамические атрибуты только выбранной категории.
Загрузка и сохранение динамических атрибутов осуществляется в DataManager. Для указания того, что динамические атрибуты должны быть загружены вместе с экземплярами сущностей, используется метод setLoadDynamicAttributes() класса LoadContext и метод dynamicAttributes() fluent API. По умолчанию динамические атрибуты не загружаются. В то же время DataManager всегда сохраняет динамические атрибуты, содержащиеся в экземплярах сущностей, переданных в commit().
Доступ к значениям динамических атрибутов может быть осуществлен через методы getValue() / setValue() любой персистентной сущности, унаследованной от BaseGenericIdEntity. В эти методы необходимо передавать код атрибута с префиксом +, например:
Car entity = dataManager.load(Car.class).id(carId).dynamicAttributes(true).one;
Double capacity = entity.getValue("+loadCapacity");
entity.setValue("+loadCapacity", capacity + 10);
dataManager.commit(entity);На самом деле, прямой доступ к значениям динамических атрибутов в коде приложения нужен крайне редко. Любой динамический атрибут может быть автоматически отображен в любом компоненте Table или Form, связанном с источником данных, содержащим сущность, для которой данный атрибут был создан. Экран редактирования атрибута, рассматриваемый в следующем разделе, позволяет указать, в каких экранах и компонентах отображать атрибут.
Разрешения пользователей на доступ к динамическим атрибутам назначаются в редакторе ролей так же как и для обычных атрибутов. Динамические атрибуты отображаются с префиксом +.
3.9.1.1. Управление динамическими атрибутами
Управление категориями и описаниями атрибутов осуществляется с помощью экрана Administration → Dynamic Attributes. Данный экран отображает список категорий слева и список атрибутов выбранной категории справа.
Для того, чтобы создать динамический атрибут для некоторой сущности, сначала создайте для нее категорию. Флажок Default указывает, что данная категория будет автоматически выбрана для нового экземпляра сущности, если сущность реализует интерфейс Categorized. Если сущность не является Categorized, то значение флажка не используется, и можно завести как одну, так и несколько категорий для сущности - все их атрибуты будут отображаться в соответствии с настройками видимости.
Для того чтобы изменения в атрибутах и настройках видимости вступили в силу, необходимо нажать кнопку Применить изменения на экране со списком категорий. Изменения также можно применить через Administration → JMX Console, вызвав метод clearDynamicAttributesCache() JMX бина app-core.cuba:type=CachingFacade.
Ниже приведен пример экрана редактирования категории:
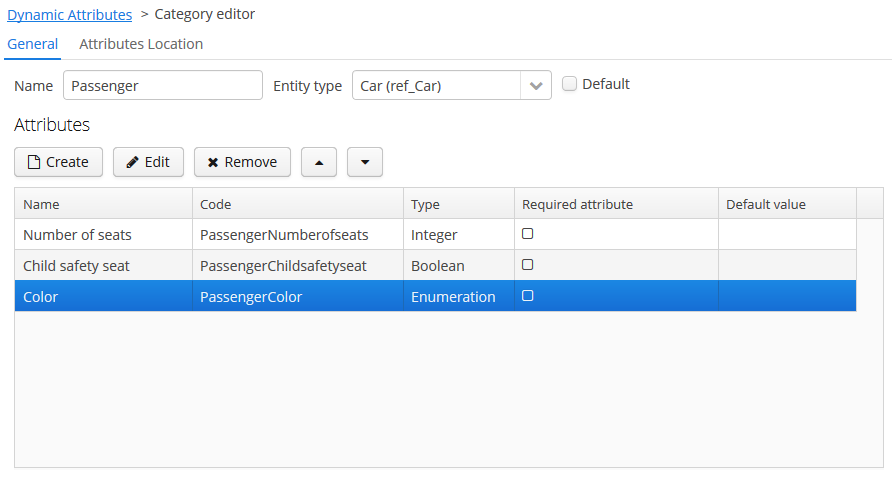
Рисунок 32. Экран редактирования категории
Секция Name localization отображается на экране редактирования категории, если приложение поддерживает более одного языка, и позволяет задать локализованное значение имени категории для каждой доступной локали.
Рисунок 33. Локализация имени категории
На вкладке Attributes Location вы можете настроить расположение каждого динамического атрибута внутри DynamicAttributesPanel.
Рисунок 34. Настройка расположения атрибутов
Укажите количество колонок в выпадающем списке Columns count. Перетащите атрибут из списка атрибутов в нужный столбец и нужную строку. Вы можете добавлять пустые ячейки и менять порядок отображения атрибутов. После внесения изменений нажмите на кнопку Save configuration.
Расположение атрибутов на панели DynamicAttributesPanel в редакторе сущности:
Редактор динамического атрибута позволяет задать имя, системный код, описание, тип значения, значение атрибута по умолчанию и скрипт валидации.
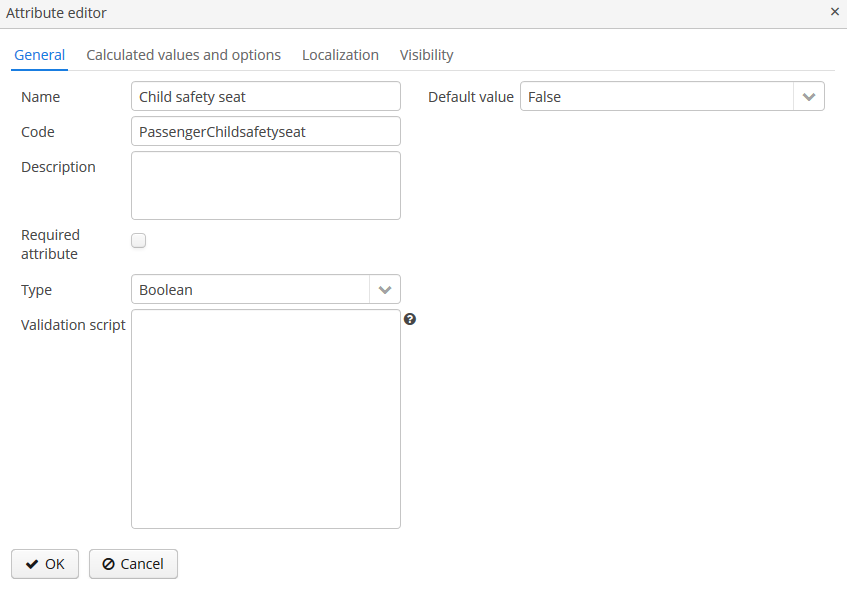
Рисунок 35. Редактор динамического атрибута
Для всех типов значения, кроме Boolean, доступно поле Width, позволяющее задать ширину поля в Form в пикселах или процентах. Если поле Width не заполнено, его значение по умолчанию равно 100%.
Для всех типов значения, кроме Boolean, также доступен чекбокс Is collection. Он позволяет создавать динамические атрибуты выбранного типа со множеством значений.
Для всех числовых типов значений: Double, Fixed-point number, Integer – доступны следующие поля:
-
Minimum value – при вводе значения атрибута просходит проверка, что значение должно быть больше или равно указанному минимальному значению.
-
Maximum value – при вводе значения атрибута просходит проверка, что значение должно быть меньше или равно указанному максимальному значению.
Для типа значения Fixed-point number доступно поле Number format pattern, в котором можно задать паттерн форматирования. Паттерн задается по правилам, описанным в DecimalFormat.
Для всех типов значений есть возможность указать скрипт валидации в поле Validation script для проверки значения, введенного пользователем. Логика валидации задается в скрипте Groovy. В случае неуспешной валидации Groovy скрипт должен вернуть сообщение об ошибке. В противном случае скрипт не должен возвращать ничего или может вернуть null. Проверяемое значение доступно в скрипте в переменной value. Для сообщения об ошибке используется Groovy строка, ключ $value может быть использован в сообщении для формирования результата.
Пример:
if (!value.startsWith("correctValue")) return "the value '\$value' is incorrect"Для типа значения Enumeration множество значений перечисления задаётся в поле Enumeration в редакторе списка.
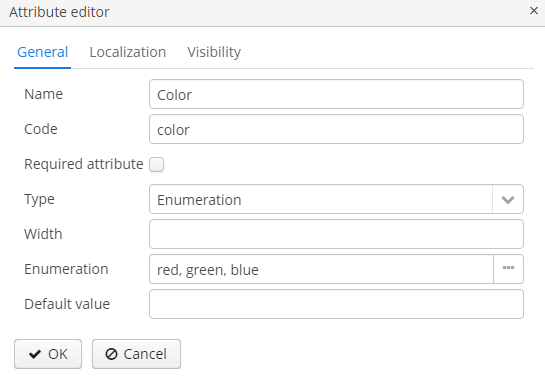
Рисунок 36. Редактор динамического атрибута для типа значений Enumeration
Каждое значение перечисления может быть локализовано на языки, доступные в приложении:
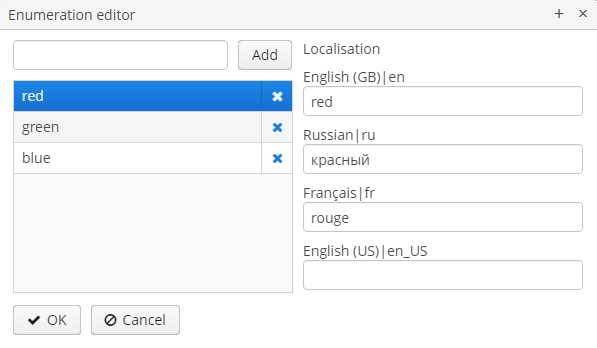
Рисунок 37. Локализация динамического атрибута для типа значений Enumeration
Для типов данных String, Double, Entity, Fixed-point number и Integer доступен чекбокс Lookup field. Если данный чекбокс установлен, то пользователь может выбирать значение атрибута из выпадающего списка. Список допустимых значений можно настроить на вкладке Calculated values and options. Для типа данных Entity настраиваются условия Where и Join.
Рассмотрим вкладку Calculated values and options. В поле Attribute depends on вы можете указать, от каких атрибутов зависит текущий атрибут. При изменении значения одного из этих атрибутов будет пересчитан либо скрипт для вычисления значения атрибута, либо скрипт для вычисления списка возможных значений.
Groovy скрипт для вычисления значения атрибута задается в поле Recalculation value script. Скрипт должен возвращать новое значение параметра. В скрипт передаются следующие переменные:
-
entity– редактируемая сущность; -
dynamicAttributes– мэп, гдеkey– код атрибута,value– значение динамического атрибута.
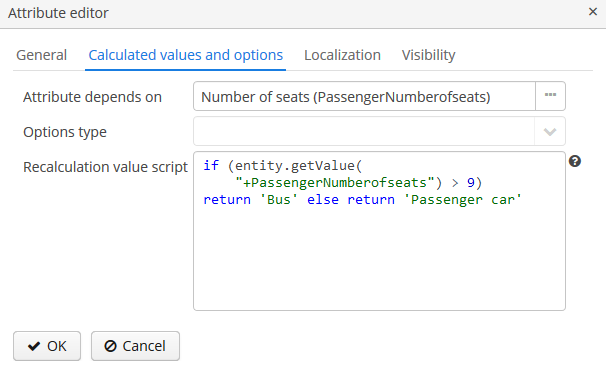
Рисунок 38. Скрипт пересчета значения
Пример скрипта пересчета значения, использующего мэп dynamicAttributes:
if (dynamicAttributes['PassengerNumberofseats'] > 9) return 'Bus' else return 'Passenger car'Скрипт выполняется каждый раз после изменения значения одного из атрибутов, от которых зависит данный атрибут.
Если скрипт задан, то поле ввода для атрибута будет нередактируемым.
Пересчет значения атрибута работает только со следующими UI-компонентами: Form, DynamicAttributesPanel.
Поле Options type определяет тип загрузчика опций и является обязательным для заполнения, если на вкладке General был установлен чекбокс Lookup field. Если чекбокс не был установлен, то поле Options type является недоступным для заполнения.
Доступные типы загрузчика опций: Groovy, SQL, JPQL (только для типа данных Entity).
-
Загрузчик опций Groovy загружает список значений, используя скрипт Groovy. В скрипт передается переменная
entity, по которой можно получить доступ к атрибутам сущности (включая динамические атрибуты). Пример скрипта для атрибута типаString: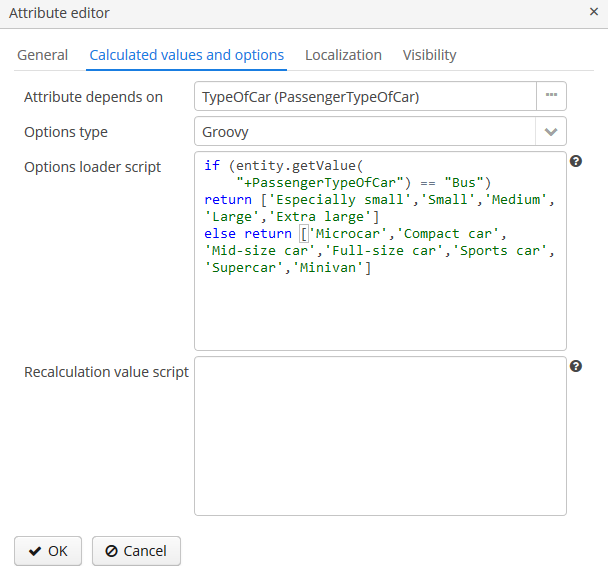 Рисунок 39. Скрипт для загрузчика опций Groovy
Рисунок 39. Скрипт для загрузчика опций Groovy -
Загрузчик опций SQL загружает список значений, используя скрипт SQL. Вы можете получить доступ к идентификатору сущности, используя переменную
${entity}. Чтобы получить доступ к параметрам сущности, используйте конструкцию${entity.<field>}, гдеfield– имя параметра сущности. Для доступа к динамическим атрибутам сущности используется префикс+, например,${entity.+<field>}. Пример скрипта (здесь мы получаем доступ к сущности и динамическому атрибутуCategorytype):select name from DYNAMICATTRIBUTESLOADER_TAG where CUSTOMER_ID = ${entity} and NAME = ${entity.+Categorytype} -
Загрузчик опций JPQL применяется только для динамического атрибута типа
Entity. JPQL условия задаются в полях Join Clause и Where Clause. Кроме того вы можете воспользоваться мастером созданий ограничений (Constraint Wizard). Мастер позволяет визуально задавать JPQL условия. В параметрах JPQL можно использовать переменные{entity}и{entity.<field>}.
Для всех типов значения поддерживается локализация имени атрибута на вкладке Localization:
Рисунок 40. Локализация динамического атрибута
- Видимость атрибутов
-
Динамический атрибут также имеет настройки видимости, описывающие, на каких экранах его нужно отображать. По умолчанию атрибут не отображается нигде.
 Рисунок 41. Настройки видимости динамического атрибута
Рисунок 41. Настройки видимости динамического атрибутаКроме экрана можно также указать компонент, в котором атрибут должен появляться (например, для экранов, где несколько компонентов Form показывают поля одной и той же сущности).
Если атрибут отмечен как видимый на каком-либо экране, он автоматически отобразится во всех формах и таблицах, отображающих объекты данного типа в данном экране.
Доступ к динамическим атрибутам также может быть ограничен через настройки в ролях пользователей. Настройки осуществляются так же, как для обычных атрибутов.
Динамические атрибуты можно добавить в экран вручную. Для этого необходимо добавить атрибут
dynamicAttributes="true"загрузчику сущности и использовать код динамического атрибута с префиксом+при привязке UI-компонентов к данным:<data> <instance id="carDc" class="com.company.app.entity.Car" view="_local"> <loader id="carDl" dynamicAttributes="true"/> </instance> </data> <layout> <form id="form" dataContainer="carDc"> <!--...--> <textField property="+PassengerNumberofseats"/> </form>
3.9.1.2. DynamicAttributesPanel
Если сущность реализует интерфейс com.haulmont.cuba.core.entity.Categorized, то для работы с ее динамическими атрибутами можно использовать компонент DynamicAttributesPanel. Этот компонент позволяет пользователю выбрать для экземпляра сущности некоторую категорию и указать значения динамических атрибутов этой категории.
Для использования DynamicAttributesPanel в экране редактирования необходимо выполнить следующее:
-
Включите атрибут
categoryв представление вашей категоризируемой сущности:<view entity="ref_Car" name="car-view" extends="_local"> <property name="category" view="_minimal"/> </view> -
Объявите контейнер данных в разделе
data:<data> <instance id="carDc" class="com.company.ref.entity.Car" view="car-view"> <loader dynamicAttributes="true"/> </instance> </data>Чтобы загрузить динамические атрибуты сущности, установите для параметра
dynamicAttributesзагрузчика данных значениеtrue. По умолчанию динамические атрибуты не загружаются. -
После этого можно включить в XML-дескриптор экрана визуальный компонент
dynamicAttributesPanel:<dynamicAttributesPanel dataContainer="carDc" cols="2" rows="2" width="AUTO"/>С помощью параметра
colsможно указать количество столбцов для отображения динамических атрибутов. Или использовать параметрrowsдля указания количества строк (в этом случае количество столбцов будет вычисляться автоматически). По умолчанию все атрибуты будут отображаться в одном столбце.На вкладке Attributes Location редактора категорий вы можете более гибко настроить отображение динамических атрибутов. В таком случае значения параметров
colsиrowsбудут игнорироваться.
3.9.2. Отправка email
Платформа предоставляет средства отправки сообщений электронной почты со следующими возможностями:
-
Синхронная или асинхронная отправка. В случае синхронной отправки вызывающий код ожидает, пока сообщение не будет передано на SMTP сервер. При асинхронной отправке сообщение сохраняется в базе данных, и управление немедленно возвращается вызывающему коду. Отправка производится позже путем вызова из назначенного задания.
-
Надежная фиксация факта отправки и ошибок в базе данных, как для синхронной, так и для асинхронной отправки.
-
Пользовательский интерфейс для поиска и просмотра информации о посылаемых сообщениях, включая все атрибуты и содержимое сообщений, а также статус отправки и количество предпринятых попыток.
3.9.2.1. Методы отправки
Для отправки email на Middleware следует использовать бин EmailerAPI, на клиентском уровне - сервис EmailService.
Рассмотрим основные методы этих компонентов:
-
sendEmail()- синхронная отправка сообщения. Вызывающий код блокируется на время отправки сообщения SMTP серверу.Сообщение может быть передано как в виде набора параметров (список адресатов через запятую, тема, содержимое, массив вложений), так и в виде специального объекта
EmailInfo, инкапсулирующего всю эту информацию, плюс позволяющего явно задать адрес отправителя и сформировать тело письма по шаблону FreeMarker.При синхронной отправке может быть сгенерировано исключение
EmailException, несущее в себе информацию о том, по каким адресам отправка не удалась, и соответствующие им сообщения об ошибках.В процессе работы метода для каждого адресата в базе данных создается экземпляр сущности
SendingMessage, который сначала получает статусSendingStatus.SENDING, а после успешной отправки -SendingStatus.SENT. В случае ошибки отправки статус сообщения меняется наSendingStatus.NOTSENT. -
sendEmailAsync()- асинхронная отправка сообщения. Данный метод возвращает список (по числу получателей) экземпляровSendingMessageсо статусомSendingStatus.QUEUE, созданных в базе данных. Собственно отправка производится при последующем вызове методаEmailerAPI.processQueuedEmails(), который необходимо зарегистрировать в механизме назначенных заданий с желаемой периодичностью.
3.9.2.2. Вложения
Объект EmailAttachment - обёртка, хранящая вложение в виде массива байт (поле data), имя файла (поле name), и при необходимости, уникальный для данного сообщения идентификатор вложения (необязательное, но полезное поле contentId).
Идентификатор вложения может быть использован для вставки в сообщение изображений следующим образом:при создании EmailAttachment задаётся уникальный contentId, например, myPic. В теле письма для вставки вложения необходимо в качестве пути использовать запись вида: cid:myPic. Т.е. для вставки изображения нужно указать следующий элемент HTML:
<img src="cid:myPic"/>3.9.2.3. Настройка параметров отправки email
Параметры отправки email могут быть настроены с помощью перечисленных ниже свойств приложения. Все они являются параметрами времени выполнения и хранятся в базе данных, однако могут быть переопределены для конкретного блока Middleware в его файле app.properties.
Все параметры отправки email доступны через конфигурационный интерфейс EmailerConfig.
-
cuba.email.fromAddress- адрес отправителя по умолчанию. Принимается во внимание, если не указан атрибутEmailInfo.from.Значение по умолчанию:
DoNotReply@localhost
-
cuba.email.smtpHost- адрес SMTP сервера.Значение по умолчанию:
test.host
-
cuba.email.smtpPort- порт SMTP сервера.Значение по умолчанию:
25
-
cuba.email.smtpAuthRequired- требуется ли аутентификация на SMTP сервере. Соответствует параметруmail.smtp.auth, передаваемому при создании объектаjavax.mail.Session.Значение по умолчанию:
false
-
cuba.email.smtpSslEnabled- включен ли протоколSSL. Соответствует параметруmail.transport.protocolсо значениемsmtps, передаваемому при создании объектаjavax.mail.Session.Значение по умолчанию:
false
-
cuba.email.smtpStarttlsEnable- задает использование командыSTARTTLSпри аутентификации на SMTP сервере. Соответствует параметруmail.smtp.starttls.enable, передаваемому при создании объектаjavax.mail.Session.Значение по умолчанию:
false
-
cuba.email.smtpUser- имя пользователя для аутентификации на SMTP сервере.
-
cuba.email.smtpPassword- пароль пользователя для аутентификации на SMTP сервере.
-
cuba.email.delayCallCount- используется при асинхронной отправке email из очереди для пропуска нескольких первых вызововEmailManager.queueEmailsToSend()сразу после старта сервера, чтобы снизить нагрузку во время инициализации приложения. Отправка email начнется следующим вызовом.Значение по умолчанию:
2
-
cuba.email.messageQueueCapacity- при асинхронной отправке количество сообщений, читаемое из очереди и отправляемое за один вызовEmailManager.queueEmailsToSend().Значение по умолчанию:
100
-
cuba.email.defaultSendingAttemptsCount- при асинхронной отправке email количество попыток отправки по умолчанию. Принимается во внимание, если при вызовеEmailer.sendEmailAsync()не указан параметрattemptsCount.Значение по умолчанию:
10
-
cuba.email.maxSendingTimeSec- максимальное предполагаемое время в секундах, требуемое для отправки сообщения на SMTP сервер. Используется при асинхронной отправке для оптимизации выборки объектовSendingMessageиз очереди в БД.Значение по умолчанию: 120
-
cuba.email.sendAllToAdmin- указывает, что все сообщения должны отправляться на адресcuba.email.adminAddress, независимо от указанного адреса получателя. Этот параметр рекомендуется использовать во время отладки системы.Значение по умолчанию:
false
-
cuba.email.adminAddress- адрес, на который отправляются все сообщения при включенном свойствеcuba.email.sendAllToAdmin.Значение по умолчанию:
admin@localhost
-
cuba.emailerUserLogin- логин пользователя системы, под которым регистрируется механизм асинхронной отправки email для того, чтобы иметь возможность сохранить информацию в базе данных. Рекомендуется создать отдельного пользователя (напримерemailer) без пароля, чтобы под его именем нельзя было войти через пользовательский интерфейс приложения. Это полезно для поиска в логе сервера сообщений, касаемых отсылки email.Значение по умолчанию:
admin
-
cuba.email.exceptionReportEmailTemplateBody- путь к*.gspфайлу шаблона, описывающему тело письма с отчётом об ошибке.В шаблонах используется синтаксис Groovy
SimpleTemplateEngine, что позволяет использовать блоки кода Groovy прямо в тексте шаблона.-
метод
toHtml()конвертирует строки в HTML-строки с экранированием и заменой специальных символов, -
timestamp- дата и время последней попытки отправки сообщения, -
errorMessage- текст сообщения об ошибке, -
stacktrace- stacktrace ошибки, -
user- ссылка на объект типаUser.
Пример файла шаблона:
<html> <body> <p>${timestamp}</p> <p>${toHtml(errorMessage)}</p> <p>${toHtml(stacktrace)}</p> <p>User login: ${user.getLogin()}</p> </body> </html> -
-
cuba.email.allowutf8- если установлено значениеtrue, разрешает кодировку UTF-8 в заголовках сообщений, например в адресах. Это свойство должно быть установлено только в том случае, если почтовый сервер также поддерживает UTF-8. Свойство связано с параметромmail.mime.allowutf8, который передается при создании объектаjavax.mail.Session.Значение по умолчанию:
false
-
cuba.email.exceptionReportEmailTemplateSubject- путь к*.gspфайлу шаблона, описывающему тему письма с отчётом об ошибке.Пример файла шаблона:
[${systemId}] [${userLogin}] Exception Report
Чтобы использовать свойства из JavaMail API, их необходимо добавить в файл app.properties модуля core. Свойства, начинающиеся с mail.*, используются при создании объекта javax.mail.Session.
Просмотреть текущие значения параметров, а также отправить тестовое сообщение, можно с помощью JMX-бина app-core.cuba:type=Emailer.
3.9.2.4. Отправка email
В данном разделе рассматривается пример использования механизма рассылки email.
Рассмотрим следующую задачу:
-
Имеется сущность
NewsItemи экран ее редактированияNewsItemEdit. -
Сущность
NewsItemимеет следующие атрибуты:date,caption,content. -
Необходимо отсылать электронные письма каждый раз, когда через экран
NewsItemEditсоздается новый экземпляр сущности. Email должен содержатьNewsItem.captionв качестве темы письма, тело письма должно формироваться на основе шаблона, включающегоNewsItem.content.
-
Добавьте следующий код в
NewsItemEdit.java:@UiController("sample_NewsItem.edit") @UiDescriptor("news-item-edit.xml") @EditedEntityContainer("newsItemDc") @LoadDataBeforeShow public class NewsItemEdit extends StandardEditor<NewsItem> { private boolean justCreated; (1) @Inject protected EmailService emailService; @Inject protected Dialogs dialogs; @Subscribe public void onInitEntity(InitEntityEvent<NewsItem> event) { (2) justCreated = true; } @Subscribe(target = Target.DATA_CONTEXT) public void onPostCommit(DataContext.PostCommitEvent event) { (3) if (justCreated) { dialogs.createOptionDialog() (4) .withCaption("Email") .withMessage("Send the news item by email?") .withType(Dialogs.MessageType.CONFIRMATION) .withActions( new DialogAction(DialogAction.Type.YES) { @Override public void actionPerform(Component component) { sendByEmail(); } }, new DialogAction(DialogAction.Type.NO) ) .show(); } } private void sendByEmail() { (5) NewsItem newsItem = getEditedEntity(); EmailInfo emailInfo = EmailInfoBuilder.create() .setAddresses("john.doe@company.com,jane.roe@company.com") (6) .setCaption(newsItem.getCaption()) (7) .setFrom(null) (8) .setTemplatePath("com/company/demo/templates/news_item.txt") (9) .setTemplateParameters(Collections.singletonMap("newsItem", newsItem)) (10) .build(); emailService.sendEmailAsync(emailInfo); } }1 - флаг, указывающий, что в этом редакторе был создан новый экземпляр сущности NewsItem2 - этот метод вызывается при инициализации нового экземпляра сущности 3 - этот метод вызывается после коммита в data context 4 - если новый экземпляр был сохранен в базе данных, попросить пользователя об отправке сообщения по электронной почте 5 - помещает электронное письмо в очередь для асинхронной отправки 6 - получатели 7 - тема 8 - адрес отправителя берется из свойства приложения cuba.email.fromAddress 9 - путь до шаблона 10 - параметры шаблона Как видно, метод
sendByEmail()вызывает сервисEmailServiceи передает ему экземплярEmailInfo, описывающий сообщение. Тело сообщений будет создаваться на основе шаблонаnews_item.txt. -
Создайте шаблон тела письма в файле
news_item.txtв пакетеcom.company.demo.templatesмодуля core:The company news: ${newsItem.content}Это шаблон Freemarker, который использует параметры, переданные в
EmailInfo(в данном случае единственный параметрnewsItem). -
Запустите приложение, откройте браузер сущности
NewsItemи нажмите Create. Откроется экран редактирования сущности. Заполните поля и нажмите OK. Появится диалог подтверждения с вопросом об отсылке email. Нажмите Yes. -
Перейдите в экран Administration > Email History вашего приложения. Вы увидите две записи (по числу получателей) со статусом
Queue. Он означает, что сообщения находятся в очереди и еще не отосланы. -
Для обработки очереди необходимо создать назначенное задание. Перейдите в экран Administration > Scheduled Tasks вашего приложения. Создайте новую задачу и установите ей следующие параметры:
-
Bean Name -
cuba_Emailer -
Method Name -
processQueuedEmails() -
Singleton - да (этот параметр важен только при эксплуатации кластера серверов middleware)
-
Period, sec - 10
Сохраните задачу и нажмите на ней Activate.
Если вы ранее не настраивали выполнение назначенных заданий для данного приложения ранее, то на данном этапе ничего не произойдет - новая задача не начнет выполняться, пока вы не запустите весь механизм назначенных заданий.
-
-
Откройте файл
modules/core/src/app.propertiesи добавьте в него следующее свойство:cuba.schedulingActive = trueПерезапустите сервер приложения. Механизм выполнения заданий теперь активен и вызывает обработку очереди email.
-
Перейдите в экран Administration > Email History. Статус сообщений будет либо
Sent, если они успешно отосланы, либо, что более вероятно,SendingилиQueue, если произошла ошибка отправки. В последнем случае вы можете открыть журнал приложения в файлеbuild/tomcat/logs/app.logи выяснить причину. Механизм отсылки email предпримет несколько (по умолчанию 10) попыток и в случае неудачи переведет сообщения в статусNot sent. -
Наиболее очевидной причиной ошибки отправки является то, что вы не настроили параметры SMTP-сервера. Эти параметры могут быть заданы в базе данных с помощью JMX бина
app-core.cuba:type=Emailerили в свойствах приложения блока middleware. Рассмотрим второй способ. Откройте файлmodules/core/src/app.propertiesи добавьте в него требуемые параметры:cuba.email.fromAddress = do-not-reply@company.com cuba.email.smtpHost = mail.company.comПерезапустите сервер приложения. Перейдите в экран Administration > JMX Console, найдите JMX бин
Emailerи попробуйте послать самому себе тестовое сообщение с помощью операцииsendTestEmail(). -
Теперь механизм отсылки email настроен корректно, однако он не будет отсылать сообщения, уже переведенные в статус
Not sent. Поэтому необходимо создать новый экземплярNewsItemчерез экран редактирования. Сделайте это и понаблюдайте, как статус новых сообщений в экране Email History изменится наSent.
3.9.3. Инспектор сущностей
Инспектор сущностей позволяет работать с любыми объектами предметной области без создания специфических экранов. Инспектор динамически генерирует экраны просмотра списка и редактирования экземпляра выбранной сущности.
Это дает возможность администратору системы просматривать и редактировать данные, которые недоступны в стандартных экранах в силу их дизайна, а на этапе прототипирования создать только модель данных и пункты главного меню, ссылающиеся на инспектор сущностей.
Точкой входа в инспектор является экран com/haulmont/cuba/gui/app/core/entityinspector/entity-inspector-browse.xml.
Если в экран передан параметр entity типа String с именем сущности, то инспектор отобразит список экземпляров этой сущности с возможностью фильтрации, выбора и редактирования экземпляров. Параметр может быть указан при регистрации экрана в screens.xml, например:
screens.xml
<screen id="sales$Product.lookup"
template="/com/haulmont/cuba/gui/app/core/entityinspector/entity-inspector-browse.xml">
<param name="entity"
value="sales$Product"/>
</screen>menu.xml
<item id="sales$Product.lookup"/>Идентификатор экрана вида {имя_сущности}.lookup дает возможность использовать этот экран компонентам PickerField и LookupPickerField в стандартном действии PickerField.LookupAction.
В общем случае данный экран можно вызывать без передачи параметров, тогда в его верхней части отображается поле для выбора сущности. В компоненте cuba экран инспектора зарегистрирован с идентификатором entityInspector.browse, поэтому для его вызова достаточно наличия пункта меню:
<item id="entityInspector.browse"/>- Экспорт и импорт с помощью инспектора сущностей
-
С помощью инспектора сущностей можно экспортировать и импортировать любые простые сущности, в том числе и системные (например, назначенные задания, блокировки).
После выбора типа сущности на экране инспектора появляются действия для экспорта выделенных в списке экземпляров сущности в форматах ZIP или JSON, а также для импорта в систему (с помощью кнопок Export/Import).
Имейте в виду, когда сущность экспортируется c помощью EntityInspector, то ссылочные атрибуты с типом связи one-to-many или many-to-many не экспортируются. Импорт и экспорт с помощью инспектора сущностей работает для простых случаев, если же у вас сложный граф объектов, то лучше делать импорт/экспорт в коде приложения с помощью EntityImportExportService.
3.9.4. Журнал изменений сущностей
Механизм журналирования предназначен для отслеживания изменений атрибутов произвольных сущностей в процессе работы приложения. Измененные значения сохраняются в специальной таблице базы данных, список изменений для конкретного экземпляра сущности может быть отображен в пользовательском интерфейсе.
Данный механизм перехватывает сохранение сущностей в БД на уровне Entity Listeners, т.е. гарантированно отслеживаются все изменения, проходящие через персистентный контекст EntityManager. Непосредственное изменение сущностей в базе данных с помощью SQL, в том числе изнутри системы через NativeQuery и QueryRunner, в журнал не попадает.
Измененные экземпляры сущностей перед сохранением в БД отправляются в методы registerCreate(), registerModify(), registerDelete() бина EntityLogAPI. Параметр auto этих методов позволяет отделить автоматическое журналирование посредством Entity Listeners от ручного вызова этих же методов в прикладном коде. При вызове из Entity Listeners в параметре auto передается true.
Журнал содержит информацию о том, кто и когда изменил данный экземпляр, а также новые значения измененных атрибутов. Записи журнала сохраняются в таблице SEC_ENTITY_LOG базы данных, соответствующей сущности EntityLogItem. Измененные значения атрибутов хранятся в этой же таблице в колонке CHANGES, а при чтении на Middleware преобразуются в экземпляры сущности EntityLogAttr.
3.9.4.1. Настройка журналирования
Простейший способ настройки аудита - воспользоваться экраном приложения Administration > Entity Log > Setup.
Вы также можете настроить аудит путем внесения информации напрямую в БД, если необходимо включить конфигурацию в скрипты инициализации базы данных.
Аудит настраивается при помощи сущностей LoggedEntity и LoggedAttribute (соответствующих таблицам SEC_LOGGED_ENTITY и SEC_LOGGED_ATTR).
LoggedEntity описывает тип сущности, изменения которой необходимо журналировать. Атрибуты LoggedEntity:
-
name(колонка NAME) - тип сущности в виде имени мета-класса, например,sales_Customer. -
auto(колонка AUTO) - нужно ли журналировать изменения при вызовеEntityLogAPIс параметромauto = true(т.е. из Entity Listeners). -
manual(колонка MANUAL) - нужно ли журналировать изменения при вызовеEntityLogAPIс параметромauto = false.
LoggedAttribute описывает журналируемый атрибут сущности и содержит ссылку на LoggedEntity и имя атрибута.
Для настройки журналирования некоторой сущности достаточно внести соответствующие записи в таблицы SEC_LOGGED_ENTITY и SEC_LOGGED_ATTR. Например, для ведения журнала изменений атрибутов name и grade сущности Customer, необходимо выполнить:
insert into SEC_LOGGED_ENTITY (ID, CREATE_TS, CREATED_BY, NAME, AUTO, MANUAL)
values ('25eeb644-e609-11e1-9ada-3860770d7eaf', now(), 'admin', 'sales_Customer', true, true);
insert into SEC_LOGGED_ATTR (ID, CREATE_TS, CREATED_BY, ENTITY_ID, NAME)
values (newid(), now(), 'admin', '25eeb644-e609-11e1-9ada-3860770d7eaf', 'name');
insert into SEC_LOGGED_ATTR (ID, CREATE_TS, CREATED_BY, ENTITY_ID, NAME)
values (newid(), now(), 'admin', '25eeb644-e609-11e1-9ada-3860770d7eaf', 'grade');Механизм журналирования по умолчанию активен. Если вы хотите его отключить, необходимо установить в false атрибут Enabled JMX-бина app-core.cuba:type=EntityLog и вызвать его операцию invalidateCache(). В качестве альтернативы можно установить в false значение свойства приложения cuba.entityLog.enabled и рестартовать сервер.
3.9.4.2. Отображение журнала
Для просмотра журнала изменений некоторого экземпляра сущности достаточно обычным способом загрузить в контейнеры данных экрана коллекцию экземпляров EntityLogItem и ассоциированных с ними EntityLogAttr, и создать визуальные компоненты, связанные с этими контейнерами.
В приведенном ниже примере показан фрагмент XML-дескриптора экрана сущности Customer, который содержит вкладку с содержимым журнала сущности.
Фрагмент XML-дескриптора customer-edit.xml
<data>
<instance id="customerDc"
class="com.company.sample.entity.Customer"
view="customer-view">
<loader id="customerDl"/>
</instance>
<collection id="entitylogsDc"
class="com.haulmont.cuba.security.entity.EntityLogItem"
view="logView" >
<loader id="entityLogItemsDl">
<query><![CDATA[select i from sec$EntityLog i where i.entityRef.entityId = :customer
order by i.eventTs]]>
</query>
</loader>
<collection id="logAttrDc"
property="attributes"/>
</collection>
</data>
<layout>
<tabSheet id="tabSheet">
<tab id="propertyTab">
<!--...-->
</tab>
<tab id="logTab">
<table id="logTable"
dataContainer="entitylogsDc"
width="100%"
height="100%">
<columns>
<column id="eventTs"/>
<column id="user.login"/>
<column id="type"/>
</columns>
</table>
<table id="attrTable"
height="100%"
width="100%"
dataContainer="logAttrDc">
<columns>
<column id="name"/>
<column id="oldValue"/>
<column id="value"/>
</columns>
</table>
</tab>
</tabSheet>
</layout>Теперь рассмотрим контроллер экрана редактирования сущности Customer:
Фрагмент контроллера экрана редактирования
@UiController("sample_Customer.edit")
@UiDescriptor("customer-edit.xml")
@EditedEntityContainer("customerDc")
public class CustomerEdit extends StandardEditor<Customer> {
@Inject
private InstanceLoader<Customer> customerDl;
@Inject
private CollectionLoader<EntityLogItem> entityLogItemsDl;
@Subscribe
private void onBeforeShow(BeforeShowEvent event) { (1)
customerDl.load();
}
@Subscribe(id = "customerDc", target = Target.DATA_CONTAINER)
private void onCustomerDcItemChange(InstanceContainer.ItemChangeEvent<Customer> event) { (2)
entityLogItemsDl.setParameter("customer", event.getItem().getId());
entityLogItemsDl.load();
}
}Обратите внимание, что на классе экрана нет аннотации @LoadDataBeforeShow, так как загрузка вызывается явно.
| 1 | − в методе onBeforeShow загружаются данные перед отображением экрана. |
| 2 | − в обработчике ItemChangeEvent родительского контейнера customerDc передаётся параметр в зависимый загрузчик, и затем загружаются данные. |
3.9.5. Снимки сущностей
Механизм сохранения снимков сущностей, так же как и журнал изменений, предназначен для отслеживания изменений данных в процессе работы приложения. Его отличительными особенностями являются:
-
Сохраняются не изменения некоторых атрибутов одного экземпляра, а состояние (снимок) целого графа сущностей, определяемого заданным представлением.
-
Процесс сохранения снимка вызывается явно из кода клиентского уровня.
-
Платформа предоставляет возможность просмотра и сравнения между собой сохраненных снимков.
3.9.5.1. Сохранение снимков
Для сохранения снимка некоторого графа сущностей достаточно вызвать метод EntitySnapshotService.createSnapshot() и передать ему основную сущность графа и представление, описывающее граф. Снимок создается по загруженной сущности, никаких обращений к базе данных не производится, поэтому снимок в результате содержит не больше полей, чем представление, с которым была загружена основная сущность.
Граф Java объектов преобразуется в XML и сохраняется в базе данных вместе со ссылкой на основную сущность в таблице SYS_ENTITY_SNAPSHOT, соответствующей сущности EntitySnapshot.
Как правило, снимки требуется сохранять после коммита экрана редактирования. Для этого можно использовать подписку на event handler метод onAfterCommitChanges контроллера экрана, например:
public class OrderEdit extends StandardEditor<Order> {
@Inject
InstanceContainer <Order> orderDc;
@Inject
protected EntitySnapshotService entitySnapshotService;
...
@Subscribe
public void onAfterCommitChanges(AfterCommitChangesEvent event) {
entitySnapshotService.createSnapshot(orderDc.getItem(), orderDc.getView());
}
}3.9.5.2. Отображение снимков
Для отображения сохраненных для некоторой сущности снимков можно использовать фрейм com/haulmont/cuba/gui/app/core/entitydiff/diff-view.xml, например:
<frame id="diffFrame"
src="/com/haulmont/cuba/gui/app/core/entitydiff/diff-view.xml"
width="100%"
height="100%"/>В контроллере экрана редактирования необходимо вызвать загрузку снимков во фрейм:
public class CustomerEditor extends AbstractEditor<Customer> {
@Inject
private EntityStates entityStates;
@Inject
protected EntityDiffViewer diffFrame;
...
@Override
protected void postInit() {
if (!entityStates.isNew(getItem())) {
diffFrame.loadVersions(getItem());
}
}
}Фрейм diff-view.xml отображает список сохраненных для данной сущности снимков с возможностью их сравнения. Для каждого снимка указывается пользователь, дата и время сохранения. При выборе из списка некоторого снимка сущности в таблице сравнения показываются изменения данных по сравнению с предыдущим снимком. В первом снимке измененными считаются все атрибуты. Если выбрано два снимка, то в таблицу выводится результат их сравнения.
В таблице сравнения отображаются имена атрибутов и их новые значения, при выборе строки показывается детальная информация по изменениям атрибута в двух снимках. Ссылочные поля выводятся в соответствии с их шаблоном @NamePattern. При сравнении коллекций добавленные и удаленные элементы выделяются цветом (зеленый, красный), а элементы с измененными атрибутами остаются без выделения. Изменение позиций элементов не учитывается.
3.9.6. Статистика сущностей
Механизм статистики сущностей предоставляет данные о текущем количестве экземпляров сущностей в базе данных. Эти данные используются для автоматического принятия решений о выборе способа поиска связанных сущностей и ограничении размера выборок в экранах пользовательского интерфейса.
Статистика хранится в таблице SYS_ENTITY_STATISTICS, соответствующей сущности EntityStatistics. Заполнить статистику можно как вручную, внося соответствующие записи в таблицу, так и автоматически с помощью метода refreshStatistics() JMX-бина PersistenceManagerMBean. При указании в качестве параметра имени сущности статистика будет собрана только для данной сущности, в противном случае - для всех. Сбор статистики может занять значительное время и вызвать нежелательную нагрузку на БД, поэтому выполнять его нужно либо вручную, либо назначенным заданием в подходящее время.
Программный доступ к статистике осуществляется с помощью интерфейса PersistenceManagerAPI на Middleware и PersistenceManagerService на клиентском уровне. Статистика кэшируется в памяти, поэтому если изменения статистики вносятся напрямую в базу данных, для вступления их в силу необходимо перезапустить сервер или вызвать метод PersistenceManagerMBean.flushStatisticsCache().
Рассмотрим атрибуты EntityStatistics и их влияние на поведение системы.
-
name(колонкаNAME) - тип сущности в виде имени мета-класса, например,sales_Customer. -
instanceCount(колонкаINSTANCE_COUNT) - примерное текущее количество экземпляров сущности. -
fetchUI(колонкаFETCH_UI) - размер страницы данных, предлагаемый пользователю при извлечении списков сущностей.Например, компонент Filter устанавливает это число в поле Показывать N строк.
-
maxFetchUI(колонкаMAX_FETCH_UI) - максимальное количество экземпляров сущности, которое может быть извлечено и передано на клиентский уровень.Данный параметр играет роль при отображении списков сущностей в компонентах типа LookupField и LookupPickerField, а также в таблицах без универсального фильтра, то есть когда на связанный загрузчик данных не налагается ограничений методом
CollectionLoader.setMaxResults(). В этом случае сам загрузчик данных ограничивает количество извлекаемых экземпляров значениемmaxFetchUI. -
lookupScreenThreshold(колонкаLOOKUP_SCREEN_THRESHOLD) - порог количества экземпляров сущности, при превышении которого в универсальных механизмах пользовательского интерфейса для поиска связанных сущностей будут использоваться экраны выбора вместо выпадающих списков.В частности, этот параметр принимается во внимание компонентом Filter при выборе параметров фильтрации: до достижения порога используется компонент LookupField, при превышении порога - компонент PickerField. Поэтому, если необходимо заставить фильтр отображать выбор параметра некоторого типа через экран выбора, достаточно внести запись статистики для этой сущности со значением
lookupScreenThresholdменьшим, чемinstanceCount.
JMX-бин PersistenceManagerMBean в атрибутах DefaultFetchUI, DefaultMaxFetchUI, DefaultLookupScreenThreshold позволяет задать значения вышеперечисленных параметров по умолчанию. В результате, если для некоторой сущности статистика отсутствует (что является обычной ситуацией), будет использоваться соответствующий параметр по умолчанию.
Кроме того, JMX-бин PersistenceManagerMBean позволяет ввести данные статистики для конкретной сущности с помощью операции enterStatistics(). Например, для того, чтобы для сущности sales_Customer установить размер страницы данных по умолчанию в 1000, а максимальное количество извлекаемых экземпляров в компонентах LookupField в 30000, следует вызвать операцию enterStatistics() со следующими параметрами:
entityName: sales_Customer
fetchUI: 1000
maxFetchUI: 30000Другой пример: у вас есть фильтр с условием по сущности Customer, и вы хотите использовать экран выбора вместо выпадающего списка при выборе параметра типа Customer. Тогда вызовите метод enterStatistics() со следующими параметрами:
entityName: sales_Customer
instanceCount: 2
lookupScreenThreshold: 1В данном случае реальное число записей Customer в базе данных игнорируется, и явно устанавливается превышение порога.
3.9.7. Экспорт и импорт сущностей в JSON
Платформа предоставляет API для экспортирования и импортирования графов сущностей в формате JSON. Он доступен на Middleware в виде интерфейса EntityImportExportAPI, и на клиентском уровне в виде сервиса EntityImportExportService. Эти интерфейсы имеют одинаковый набор методов, описанный ниже. Реализация экспорта/импорта делегирует выполнение интерфейсу EntitySerializationAPI, который при необходимости может быть использован напрямую.
-
exportEntitiesToJSON()- сериализует коллекцию сущностей в JSON.@Inject private EntityImportExportService entityImportExportService; @Inject private GroupDatasource<Customer, UUID> customersDs; ... String jsonFromDs = entityImportExportService.exportEntitiesToJSON(customersDs.getItems()); -
exportEntitiesToZIP()- сериализует коллекцию сущностей в JSON и упаковывает его в ZIP-архив. В следующем примере упакованный архив сохраняется в хранилище данных с помощью интерфейса FileLoader:@Inject private EntityImportExportService entityImportExportService; @Inject private GroupDatasource<Customer, UUID> customersDs; @Inject private Metadata metadata; @Inject private DataManager dataManager; ... byte[] array = entityImportExportService.exportEntitiesToZIP(customersDs.getItems()); FileDescriptor descriptor = metadata.create(FileDescriptor.class); descriptor.setName("customersDs.zip"); descriptor.setExtension("zip"); descriptor.setSize((long) array.length); descriptor.setCreateDate(new Date()); try { fileLoader.saveStream(descriptor, () -> new ByteArrayInputStream(array)); } catch (FileStorageException e) { throw new RuntimeException(e); } dataManager.commit(descriptor); -
importEntitiesFromJSON()- десериализует граф сущностей из JSON и сохраняет десериализованные сущности согласно правилам, описанным в параметреentityImportView(см. JavaDocs на классEntityImportView). Если некоторой сущности нет в базе данных, она создается, в противном случае атрибуты, переданные вentityImportView, обновляются у сущности, уже имеющейся в базе данных. -
importEntitiesFromZIP()- читает ZIP-архив, содержащий JSON, распаковывает его и обрабатывает аналогично методуimportEntitiesFromJSON().@Inject private EntityImportExportService entityImportExportService; @Inject private FileLoader fileLoader; private FileDescriptor descriptor; ... EntityImportView view = new EntityImportView(Customer.class); view.addLocalProperties(); try { byte[] array = IOUtils.toByteArray(fileLoader.openStream(descriptor)); Collection<Entity> collection = entityImportExportService.importEntitiesFromZIP(array, view); } catch (FileStorageException e) { throw new RuntimeException(e); }
3.9.8. Хранилище файлов
Хранилище файлов обеспечивает загрузку, хранение и выгрузку произвольных файлов, ассоциированных с сущностями системы. Стандартная реализация сохраняет файлы вне основной базы данных, в специальной структуре файловой системы.
Механизм работы с файлами состоит из следующих частей:
-
Сущность
FileDescriptor- описатель загруженного файла (не путать сjava.io.FileDescriptor), позволяющий ссылаться на файл из объектов модели данных. -
Интерфейс
FileStorageAPI- доступ к хранилищу файлов на уровне Middleware. Основные методы:-
saveStream()- сохранить содержимое файла, переданное вInputStream, по данным указанногоFileDescriptor. -
openStream()- вернуть содержимое файла, указанного объектомFileDescriptor, в виде открытогоInputStream.
-
-
Класс
FileUploadController- контроллер Spring MVC, позволяющий отправлять файлы с клиентского уровня на Middleware посредством HTTP POST запросов. -
Класс
FileDownloadController- контроллер Spring MVC, позволяющий получать файлы с Middleware на клиентский уровень посредством HTTP GET запросов. -
Визуальные компоненты FileUpload и FileMultiUpload - позволяют загрузить файлы с компьютера пользователя на клиентский уровень приложения, и затем организовать их передачу на Middleware.
-
Интерфейс
FileUploadingAPI- промежуточное хранилище загружаемых файлов на клиентском уровне. Используется вышеупомянутыми компонентами для загрузки файлов на клиентский уровень. В прикладном коде используется методputFileIntoStorage(), перемещающий файл в постоянное хранилище на Middleware. -
FileLoader- интерфейс для работы с хранилищем файлов, предоставляющий единый набор методов как на уровне Middleware, так и на клиентском уровне. -
ExportDisplay- интерфейс клиентского уровня, позволяющий выгружать различные ресурсы приложения на компьютер пользователя. Для получения файлов из хранилища можно использовать методshow(), принимающийFileDescriptor. ЭкземплярExportDisplayможно получить либо вызовом статического методаAppConfig.createExportDisplay(), либо инжекцией в класс контроллера.
|
Передача файлов между пользовательским компьютером и хранилищем в обе стороны производится только путем копирования данных между потоками ввода-вывода. Ни на каком уровне приложения файл не оказывается целиком в памяти, поэтому возможна передача файлов практически любых размеров. |
3.9.8.1. Загрузка файлов
Для загрузки файлов с компьютера пользователя в хранилище следует использовать компоненты FileUpload и FileMultiUpload. Примеры использования приведены в описании компонентов.
|
Руководство Working with Images in CUBA applications содержит примеры, демонстрирующие, как загружать изображения. |
Компонент FileUpload также можно использовать в готовом диалоговом окне FileUploadDialog, позволяющем загружать файлы в промежуточное хранилище.
Диалоговое окно FileUploadDialog предоставляет базовую функциональность загрузки файлов в промежуточное хранилище. Оно содержит drop zone для перетаскивания файлов извне браузера и кнопку загрузки файла.
Данный диалог можно использовать следующим образом:
@Inject
private Screens screens;
@Inject
private FileUploadingAPI fileUploadingAPI;
@Inject
private DataManager dataManager;
@Subscribe("showUploadDialogBtn")
protected void onShowUploadDialogBtnClick(Button.ClickEvent event) {
FileUploadDialog dialog = (FileUploadDialog) screens.create("fileUploadDialog", OpenMode.DIALOG);
dialog.addCloseWithCommitListener(() -> {
UUID fileId = dialog.getFileId();
String fileName = dialog.getFileName();
File file = fileUploadingAPI.getFile(fileId); (1)
FileDescriptor fileDescriptor = fileUploadingAPI.getFileDescriptor(fileId, fileName); (2)
try {
fileUploadingAPI.putFileIntoStorage(fileId, fileDescriptor); (3)
dataManager.commit(fileDescriptor); (4)
} catch (FileStorageException e) {
throw new RuntimeException(e);
}
});
screens.show(dialog);
}| 1 | - получение объекта java.io.File, указывающего на файл в файловой системе блока Web Client. Это может потребоваться, если вам нужно как-то обработать файл, а не просто поместить его в хранилище. |
| 2 | - создание сущности FileDescriptor. |
| 3 | - загрузка файла в хранилище среднего слоя. |
| 4 | - сохранение сущности FileDescriptor. |
В случае успешной загрузки диалог закрывается с COMMIT_ACTION_ID, поэтому используйте CloseWithCommitListener для получения результата загрузки. Чтобы получить UUID и имя загруженного файла, используйте методы getFileId() и getFileName(). Затем можно получить сам файл, а также, например, создать FileDescriptor и загрузить файл в хранилище, или реализовать какую-либо другую логику.
Промежуточное хранилище клиентского уровня FileUploadingAPI использует для хранения временных файлов каталог, заданный свойством приложения cuba.tempDir. Временные файлы удаляются автоматически в следующих случаях:
-
Для
FileUploadFieldзадан режимIMMEDIATE. -
Используется метод
FileUploadingAPI.putFileIntoStorage(UUID, FileDescriptor).
В остальных случаях рекомендуется удалить файл, используя метод FileUploadingAPI.deleteFile(UUID).
Временные файлы могут оставаться в промежуточном хранилище в случае сбоев. Для удаления таких файлов служит метод clearTempDirectory() бина cuba_FileUploading. Этот метод периодически (в полночь вторника, четверга и субботы) вызывается шедулером, объявленным в файле cuba-web-spring.xml, и удаляет файлы старше 2-х дней.
3.9.8.2. Выгрузка данных
Для выгрузки файлов на клиентском уровне следует использовать интерфейс ExportDisplay, получив ссылку на него вызовом статического метода AppConfig.createExportDisplay(), либо инжекцией в класс контроллера. Например:
AppConfig.createExportDisplay(this).show(fileDescriptor);Метод show() может принимать дополнительный параметр типа ExportFormat, в котором можно задать тип содержимого и расширение имени файла. Если формат не передан, расширение берется из FileDescriptor, а типом содержимого принимается application/octet-stream.
От расширения имени файла зависит, будет ли файл выгружаться через диалог сохранения или открытия файлов браузера (Content-Disposition = attachment), или браузер попытается отобразить содержимое прямо в своем окне (Content-Disposition = inline). Список расширений файлов, отображаемых в окне браузера, задается свойством приложения cuba.web.viewFileExtensions.
ExportDisplay можно также использовать для выгрузки произвольных данных, если в качестве параметра метода show() передать экземпляр класса ByteArrayDataProvider. Например:
public class SampleScreen extends AbstractWindow {
@Inject
private ExportDisplay exportDisplay;
public void onDownloadBtnClick(Component source) {
String html = "<html><head title='Test'></head><body><h1>Test</h1></body></html>";
byte[] bytes;
try {
bytes = html.getBytes("UTF-8");
} catch (UnsupportedEncodingException e) {
throw new RuntimeException(e);
}
exportDisplay.show(new ByteArrayDataProvider(bytes), "test.html", ExportFormat.HTML);
}
}3.9.8.3. Интерфейс FileLoader
Интерфейс FileLoader предоставляет единый набор методов для работы с файловым хранилищем как на уровне Middleware, так и на клиентском уровне. Загрузка и выгрузка данных осуществляется с помощью потоков:
-
saveStream()– сохраняет содержимое потокаInputStreamв хранилище. -
openStream()– возвращает входной поток для выгрузки содержимого файла из хранилища.
|
И на клиентской и на серверной стороне |
В качестве примера использования FileLoader представим, что нам нужно сохранять текст, введённый пользователем, в текстовый файл и отображать содержимое этого файла в другом поле на том же экране.
Экран содержит два поля textArea. Пользователь вводит текст в первое поле textArea, затем нажимает на кнопку buttonIn, и текст сохраняется в хранилище FileStorage. Второе поле будет отображать содержимое сохраненного файла по нажатию кнопки buttonOut.
Ниже представлен фрагмент XML-дескриптора экрана:
<hbox margin="true"
spacing="true">
<vbox spacing="true">
<textArea id="textAreaIn"/>
<button id="buttonIn"
caption="Save text in file"
invoke="onButtonInClick"/>
</vbox>
<vbox spacing="true">
<textArea id="textAreaOut"
editable="false"/>
<button id="buttonOut"
caption="Show the saved text"
invoke="onButtonOutClick"/>
</vbox>
</hbox>Контроллер экрана содержит два метода, вызываемых при нажатии кнопок под текстовыми полями:
-
В методе
onButtonInClick()мы создаём байтовый массив из ввода в первом текстовом поле. Затем создаём объектFileDescriptorи с помощью его атрибутов указываем имя нового файла, его расширение, размер и дату создания.После этого мы сохраняем новый файл методом
saveStream()интерфейсаFileLoader, передав в него объектFileDescriptorи содержимое файла с поставщикомInputStream. Также делаем коммит объектаFileDescriptorв data store с помощью интерфейсаDataManager. -
В методе
onButtonOutClick()мы получаем содержимое сохранённого файла методомopenStream()интерфейсаFileLoader. Затем отображаем содержимое во втором полеtextArea.
import com.haulmont.cuba.core.entity.FileDescriptor;
import com.haulmont.cuba.core.global.DataManager;
import com.haulmont.cuba.core.global.FileLoader;
import com.haulmont.cuba.core.global.FileStorageException;
import com.haulmont.cuba.core.global.Metadata;
import com.haulmont.cuba.gui.components.AbstractWindow;
import com.haulmont.cuba.gui.components.TextArea;
import com.haulmont.cuba.gui.upload.FileUploadingAPI;
import org.apache.commons.io.IOUtils;
import javax.inject.Inject;
import java.io.ByteArrayInputStream;
import java.io.IOException;
import java.io.InputStream;
import java.util.Date;
public class FileLoaderScreen extends AbstractWindow {
@Inject
private Metadata metadata;
@Inject
private FileLoader fileLoader;
@Inject
private DataManager dataManager;
@Inject
private TextArea textAreaIn;
@Inject
private TextArea textAreaOut;
private FileDescriptor fileDescriptor;
public void onButtonInClick() {
byte[] bytes = textAreaIn.getRawValue().getBytes();
fileDescriptor = metadata.create(FileDescriptor.class);
fileDescriptor.setName("Input.txt");
fileDescriptor.setExtension("txt");
fileDescriptor.setSize((long) bytes.length);
fileDescriptor.setCreateDate(new Date());
try {
fileLoader.saveStream(fileDescriptor, () -> new ByteArrayInputStream(bytes));
} catch (FileStorageException e) {
throw new RuntimeException(e);
}
dataManager.commit(fileDescriptor);
}
public void onButtonOutClick() {
try {
InputStream inputStream = fileLoader.openStream(fileDescriptor);
textAreaOut.setValue(IOUtils.toString(inputStream, StandardCharsets.UTF_8));
} catch (FileStorageException | IOException e) {
throw new RuntimeException(e);
}
}
}
3.9.8.4. Стандартная реализация хранилища
Стандартная реализация хранит файлы в специальной структуре каталогов на одном или нескольких файловых ресурсах.
Корни структуры можно задать в свойстве приложения cuba.fileStorageDir. Формат - список путей через запятую. Например:
cuba.fileStorageDir=/work/sales/filestorage,/mnt/backup/filestorageЕсли данное свойство не задано, хранилище будет создано в подкаталоге filestorage рабочего каталога Middleware. В стандартном варианте развертывания в Tomcat это каталог tomcat/work/app-core/filestorage.
В случае указания нескольких ресурсов хранилище ведет себя следующим образом:
-
Первый каталог в списке является основным, остальные - резервными.
-
Запись сохраняемых файлов производится в основной каталог, а затем файл копируется во все резервные каталоги.
Перед записью проверяется доступность каждого каталога. Если недоступен основной каталог, выбрасывается исключение и запись не производится. Если недоступен какой-то из резервных каталогов, запись все равно производится, в лог выводится сообщение об ошибке.
-
Чтение производится из основного каталога.
При недоступности основного каталога чтение производится из первого резервного каталога, в котором имеется данный файл. В лог выводится сообщение об ошибке.
Файловая структура хранилища организована следующим образом:
-
Имеется три уровня каталогов, соответствующих дате загрузки файла - год, месяц, день.
-
Файл сохраняется в каталоге дня. Именем файла является идентификатор соответствующего объекта
FileDescriptor. Расширение файла - исходное. -
В корне структуры хранилища ведется файл
storage.log, содержащий информацию о том, какой файл, когда и каким пользователем был записан в хранилище. Этот журнал не несет никакой функциональности, но может быть полезен при поиске проблем.
JMX-бин app-core.cuba:type=FileStorage отображает текущий список корней хранилища, а также предоставляет следующие методы для поиска проблем:
-
findOrphanDescriptors()- найти в базе данных все экземплярыFileDescriptor, для которых не имеется соответствующего файла в хранилище. -
findOrphanFiles()- найти файлы в хранилище, для которых не имеется соответствующего экземпляраFileDescriptorв БД.
3.9.8.5. Реализация хранилища Amazon S3 File Storage
Вместо стандартной реализации файлового хранилища можно использовать облачные сервисы. Мы рекомендуем подключать отдельные облачные файловые хранилища при развёртывании приложений в облачных сервисах, так как последние, в большинстве своём, не гарантируют хранения внешних файлов приложения на своих жёстких дисках.
Компонент AWS Filestorage реализует поддержку файлового хранилища Amazon S3 "из коробки". Для поддержки других сервисов вам потребуется реализовать собственную логику загрузки и хранения файлов.
Для использования компонента в приложении необходимо выполнить установку и настройку компонента в соответствии с инструкцией в README.
Файловая структура хранилища организована таким же образом, как и в стандартной реализации хранилища.
3.9.9. Панель папок
Панель папок предназначена для быстрого доступа пользователя к часто используемой информации. Она представляет собой скрываемую панель в левой части главного окна приложения, в которой располагается иерархическая структура, нажатие на элементы которой (папки) приводит к отображению соответствующих экранов системы с определенными параметрами.
На момент написания данного руководства панель папок реализована только для Web Client.
Платформа поддерживает три вида папок: папки приложения, папки поиска и наборы записей.
-
Папки приложения:
-
Открывают экраны с фильтром или без него.
-
Набор папок может зависеть от текущего сеанса пользователя. Видимость конкретной папки определяется путем выполнения скрипта Groovy.
-
Пользователь может создавать или изменять папки приложения, только если у него есть специальное право.
-
В заголовке папки может отображаться текущее количество входящих в папку записей, вычисляемое скриптом Groovy.
-
Заголовки папок приложения обновляются по таймеру, тем самым может изменяться счетчик записей и стиль отображения каждой папки.
-
-
Папки поиска:
-
Открывают экраны с фильтром.
-
Могут быть как локальными - доступными только пользователю, их создавшему, так и глобальными - доступными всем пользователям.
-
Локальные папки может создавать и изменять любой пользователь, глобальные - только имеющий специальное право.
-
-
Наборы:
Папки приложения отображаются в верхней части панели в отдельной иерархии, папки поиска и наборы - в нижней части панели в совместной иерархии. Для включения отображения панели папок необходимо:
-
Установить свойство cuba.web.foldersPaneEnabled в значение
true. -
Расширить главный экран, используя шаблон Main screen with top menu в мастере создания экранов Studio. Этот шаблон включает в себя специальный компонент
FoldersPane.
Каждая папка в панели папок может иметь значок слева. Чтобы включить такую возможность, необходимо установить свойство cuba.web.showFolderIcons в значение true. В таком случае будут использоваться стандартные значки.
Рисунок 42. Папки приложения и поиска со стандартными значками
Чтобы установить другие значки, используйте метод setFolderIconProvider() для компонента FoldersPane. Ниже приведён пример использования функции в методе setFolderIconProvider() в кастомном главном экране. Значок "category" устанавливается для папок приложения; для других папок должен быть установлен значок "tag".
foldersPane.setFolderIconProvider(e -> {
if (e instanceof AppFolder) {
return "icons/category.png";
}
return "icons/tag.png";
});
Рисунок 43. Папки приложения и поиска с кастомными значками
Для восстановления стандартных значков передайте в метод setFolderIconProvider() значение null.
На функционирование панели папок влияют следующие свойства приложения:
3.9.9.1. Папки приложения
Для создания папок приложения пользователь должен иметь специфическое право Создание/изменение папок приложения (код cuba.gui.appFolder.global). Такое право задаётся в экране редактирования роли на вкладке Specific.
Простейшая папка приложения может быть создана из контекстного меню панели папок. Такая папка не связана с экранами системы и предназначена только для группировки других папок в иерархии.
Для создания папки, открывающей некоторый экран с фильтром, необходимо выполнить следующее:
-
Открыть экран и отобрать записи по нужному фильтру.
-
В меню кнопки Фильтр… выбрать команду Сохранить как папку приложения.
-
В окне добавления заполнить атрибуты папки:
-
Наименование папки
-
Заголовок окна - строка, добавляемая к заголовку окна, когда он открывается из папки
-
Родительская папка - определяет место создаваемой папки в иерархии
-
Скрипт видимости - скрипт Groovy, выполняемый в начале сеанса пользователя, и определяющий доступность для него данной папки.
Скрипт должен вернуть булевское значение. Если скрипт не задан, либо возвращает null, папка доступна. Пример:
userSession.currentOrSubstitutedUser.login == 'admin' -
Cкрипт количества записей - скрипт Groovy, выполняемый в начале сеанса пользователя и по таймеру, для вычисления количества записей для данной папки и ее стиля отображения.
Скрипт должен вернуть числовое значение, целая часть которого будет использована в качестве счетчика. Если скрипт не задан, либо возвращает
null, счетчик не будет отображаться. Кроме возвращаемого значения скрипт может установить переменнуюstyle, которая будет использована как имя стиля отображения папки. Пример:def em = persistence.getEntityManager() def q = em.createQuery('select count(o) from sales_Order o') def count = q.getSingleResult() style = count > 0 ? 'emphasized' : null return countДля отображения указанного скриптом стиля тема приложения должна содержать описание этого стиля для элемента
v-tree-nodeвнутриcuba-folders-pane, например:.c-folders-pane .v-tree-node.emphasized { font-weight: bold; } -
Порядковый номер - порядковый номер папки в иерархии.
-
В скриптах доступны следующие переменные, установленные в контексте groovy.lang.Binding:
-
folder- экземпляр сущностиAppFolder- папка, для которой выполняется скрипт -
userSession- экземплярUserSession- текущая пользовательская сессия -
persistence- реализация интерфейса Persistence -
metadata- реализация интерфейса Metadata
При обновлении папок для всех скриптов используется один экземпляр groovy.lang.Binding, поэтому между ними можно передавать переменные для исключения дублирующихся запросов и повышения производительности.
Тексты скриптов могут содержаться либо непосредственно в атрибутах сущности AppFolder, либо в отдельных файлах. В последнем случае атрибут должен содержать путь к файлу скрипта (обязательно с расширением ".groovy") по правилам интерфейса Resources. Таким образом, если содержимое атрибута представляет собой строку, заканчивающуюся на ".groovy", текст скрипта загружается из указанного файла, в противном случае в качестве скрипта используется само содержимое атрибута.
Папки приложения представляют собой экземпляры сущности AppFolder и хранятся в связанных таблицах SYS_FOLDER и SYS_APP_FOLDER.
3.9.9.2. Папки поиска
Папки поиска создаются пользователями аналогично папкам приложения - группирующие папки непосредственно из контекстного меню панели папок, связанные с экранами - из меню кнопки Фильтр… экрана командой Сохранить как папку поиска.
Для создания глобальной папки пользователь должен иметь специфическое право Создание/изменение глобальных папок поиска (код cuba.gui.searchFolder.global). Такое право задаётся в экране редактирования роли на вкладке Specific.
Фильтр папки поиска можно изменить после ее создания - для этого достаточно открыть папку и в экране изменить фильтр Папка: {имя папки}. После сохранения фильтра он будет изменен и в папке тоже.
Папки поиска представляют собой экземпляры сущности SearchFolder и хранятся в связанных таблицах SYS_FOLDER и SEC_SEARCH_FOLDER.
3.9.9.3. Наборы
Для того, чтобы использовать наборы в некотором экране, выполните следующее:
Например:
<layout>
<filter id="customerFilter" dataLoader="customersDl"
applyTo="customersTable"/>
<groupTable id="customersTable" dataContainer="customersDc">
<actions>
<action id="addToSet" type="addToSet"/>
...
</actions>
<buttonsPanel>
<button action="customersTable.addToSet"/>
...
</buttonsPanel>Когда экран отображает некоторый набор, т.е. он открыт щелчком по набору в панели папок, в контекстном меню таблицы автоматически появляются команды Add to current set / Remove from current set. Если таблица содержит внутри себя компонент buttonsPanel (как в приведенном выше примере), команды контекстного меню будут продублированы соответствующими кнопками.
Наборы представляют собой экземпляры сущности SearchFolder и хранятся в связанных таблицах SYS_FOLDER и SEC_SEARCH_FOLDER.
3.9.10. Информация об используемом ПО
Платформа предоставляет средства для регистрации и отображения в пользовательском интерфейсе информации об используемом в приложении стороннем программном обеспечении (credits). Информация включает в себя название, ссылку на веб-сайт и текст лицензии.
Компоненты платформы содержат собственные файлы описаний com/haulmont/cuba/credits.xml, com/haulmont/reports/credits.xml и т.д. В проекте приложения можно создать аналогичный файл и в свойстве приложения cuba.creditsConfig указать этот файл.
Структура файла credits.xml:
-
Элемент
items- перечисление используемых библиотек с указанием текста лицензии либо во вложенном элементеlicense, либо атрибутомlicenseсо ссылкой на текст в секцииlicenses.Cсылаться можно на лицензии, объявленные не только в этом же файле, но и в любом другом файле, объявленном в переменной
cuba.creditsConfigраньше, чем текущий. -
Элемент
licenses- перечисление текстов общеупотребительных лицензий.
Для отображения общего списка используемого ПО предназначен фрейм com/haulmont/cuba/gui/app/core/credits/credits-frame.xml, загружающий информацию из файлов, заданных в свойстве cuba.creditsConfig. Пример использования фрейма в экране:
<dialogMode width="500" height="400"/>
<layout expand="creditsBox">
<groupBox id="creditsBox"
caption="msg://credits"
width="100%">
<frame id="credits"
src="/com/haulmont/cuba/gui/app/core/credits/credits-frame.xml"
width="100%"
height="100%"/>
</groupBox>
</layout>Если экран с фреймом открывается в диалоговом режиме (WindowManager.OpenType.DIALOG), ему необходимо задать высоту, иначе возможна неправильная работа скроллинга. См. элемент dialogMode в примере выше.
3.9.11. Интеграция с MyBatis
Фреймворк MyBatis обладает, по сравнению с ORM и QueryRunner, более широкими возможностями по выполнению SQL и отображению результатов на объекты предметной области.
Для использования MyBatis в проекте необходимо выполнить следующие шаги.
-
Создайте класс-обработчик UUID в корневом пакете модуля core.
import com.haulmont.cuba.core.global.UuidProvider; import org.apache.ibatis.type.JdbcType; import org.apache.ibatis.type.TypeHandler; import java.sql.*; public class UUIDTypeHandler implements TypeHandler { @Override public void setParameter(PreparedStatement ps, int i, Object parameter, JdbcType jdbcType) throws SQLException { ps.setObject(i, parameter, Types.OTHER); } @Override public Object getResult(ResultSet rs, String columnName) throws SQLException { String val = rs.getString(columnName); if (val != null) { return UuidProvider.fromString(val); } else { return null; } } @Override public Object getResult(ResultSet rs, int columnIndex) throws SQLException { String val = rs.getString(columnIndex); if (val != null) { return UuidProvider.fromString(val); } else { return null; } } @Override public Object getResult(CallableStatement cs, int columnIndex) throws SQLException { String val = cs.getString(columnIndex); if (val != null) { return UuidProvider.fromString(val); } else { return null; } } } -
Создайте файл конфигурации
mybatis.xmlв модуле core рядом с файлом spring.xml, указав в нём ссылку на обработчикUUIDTypeHandler:<!DOCTYPE configuration PUBLIC "-//mybatis.org//DTD Config 3.0//EN" "http://mybatis.org/dtd/mybatis-3-config.dtd"> <configuration> <settings> <setting name="lazyLoadingEnabled" value="false"/> </settings> <typeHandlers> <typeHandler javaType="java.util.UUID" handler="com.company.demo.core.UUIDTypeHandler"/> </typeHandlers> </configuration> -
Добавьте следующие бины в файл spring.xml модуля core:
<bean id="sqlSessionFactory" class="org.mybatis.spring.SqlSessionFactoryBean"> <property name="dataSource" ref="cubaDataSource"/> <property name="configLocation" value="com/company/demo/mybatis.xml"/> <property name="mapperLocations" value="com/company/demo/core/sqlmap/*.xml"/> </bean> <bean class="org.mybatis.spring.mapper.MapperScannerConfigurer"> <property name="basePackage" value="com/company/demo.core.dao"/> <property name="sqlSessionFactory" ref="sqlSessionFactory"/> </bean> <bean id="sqlSession" class="org.mybatis.spring.SqlSessionTemplate"> <constructor-arg index="0" ref="sqlSessionFactory" /> </bean>Бин
sqlSessionFactoryсодержит ссылку на созданный ранееmybatis.xml.В параметре
mapperLocationsзадается путь (по правилам интерфейсаResourceLoaderSpring) к файлам отображений MyBatis. -
Наконец, добавьте зависимости MyBatis в секцию модуля
coreв файле build.gradle:compile('org.mybatis:mybatis:3.2.8') compile('org.mybatis:mybatis-spring:1.2.5')
Пример файла отображения для загрузки экземпляра сущности Заказ вместе со связанным Покупателем и коллекцией Пунктов заказа:
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.sample.sales">
<select id="selectOrder" resultMap="orderResultMap">
select
o.ID as order_id,
o.DATE as order_date,
o.AMOUNT as order_amount,
c.ID as customer_id,
c.NAME as customer_name,
c.EMAIL as customer_email,
i.ID as item_id,
i.QUANTITY as item_quantity,
p.ID as product_id,
p.NAME as product_name
from
SALES_ORDER o
left join SALES_CUSTOMER c on c.ID = o.CUSTOMER_ID
left join SALES_ITEM i on i.ORDER_ID = o.id and i.DELETE_TS is null
left join SALES_PRODUCT p on p.ID = i.PRODUCT_ID
where
c.id = #{id}
</select>
<resultMap id="orderResultMap" type="com.sample.sales.entity.Order">
<id property="id" column="order_id"/>
<result property="date" column="order_date"/>
<result property="amount" column="order_amount"/>
<association property="customer" column="customer_id" javaType="com.sample.sales.entity.Customer">
<id property="id" column="customer_id"/>
<result property="name" column="customer_name"/>
<result property="email" column="customer_email"/>
</association>
<collection property="items" ofType="com.sample.sales.entity.Item">
<id property="id" column="item_id"/>
<result property="quantity" column="item_quantity"/>
<association property="product" column="product_id" javaType="com.sample.sales.entity.Product">
<id property="id" column="product_id"/>
<result property="name" column="product_name"/>
</association>
</collection>
</resultMap>
</mapper>Для получения результатов запроса в приведенном выше примере можно использовать следующий код:
try (Transaction tx = persistence.createTransaction()) {
SqlSession sqlSession = AppBeans.get("sqlSession");
Order order = (Order) sqlSession.selectOne("com.sample.sales.selectOrder", orderId);
tx.commit();
}3.9.12. Пессимистичная блокировка
Пессимистичная блокировка сущностей применяется, если велика вероятность одновременного редактирования одного и того же экземпляра, и стандартная оптимистичная блокировка, основанная на версионности сущностей, порождает слишком много коллизий.
Пессимистичная блокировка использует явное блокирование экземпляра сущности при открытии его в экране редактирования. В результате только один пользователь в некоторый момент времени может редактировать данный экземпляр сущности.
Механизм пессимистичной блокировки можно использовать также для управления совместным выполнением произвольных процессов. Причем блокировки являются распределенными, т.к. информация о них реплицируется в кластере Middleware. Подробнее см. JavaDoc интерфейсов LockManagerAPI и LockService.
Режим пессимистичной блокировки может быть задан для любого класса сущности в процессе настройки или эксплуатации системы с помощью экрана Administration > Locks > Setup, либо следующим образом:
-
вставить в таблицу SYS_LOCK_CONFIG запись со следующими значениями полей:
-
ID - произвольный идентификатор типа UUID.
-
NAME - наименование блокируемого объекта. Для сущности это должно быть имя ее мета-класса.
-
TIMEOUT_SEC - таймаут истечения блокировки в секундах.
Например:
insert into sys_lock_config (id, create_ts, name, timeout_sec) values (newid(), current_timestamp, 'sales_Order', 300)
-
-
перезапустить сервер или выполнить метод
reloadConfiguration()JMX-бинаapp-core.cuba:type=LockManager.
Текущее состояние блокировок можно отслеживать через JMX-бин app-core.cuba:type=LockManager, или через специальный экран, доступный в меню Administration > Locks. Экран также позволяет разблокировать любой объект принудительно.
3.9.13. Выполнение SQL с помощью QueryRunner
QueryRunner - класс, предназначенный для выполнения SQL. Его следует использовать вместо JDBC везде, где есть необходимость работы с SQL и нежелательно применение аналогичных средств ORM.
QueryRunner платформы является вариантом Apache DbUtils QueryRunner, усовершенствованным для использования Java Generics.
Пример использования:
QueryRunner runner = new QueryRunner(persistence.getDataSource());
try {
Set<String> scripts = runner.query("select SCRIPT_NAME from SYS_DB_CHANGELOG",
new ResultSetHandler<Set<String>>() {
public Set<String> handle(ResultSet rs) throws SQLException {
Set<String> rows = new HashSet<String>();
while (rs.next()) {
rows.add(rs.getString(1));
}
return rows;
}
});
return scripts;
} catch (SQLException e) {
throw new RuntimeException(e);
}Есть два варианта использования QueryRunner - либо в текущей транзакции, либо в отдельной в режиме autocommit.
-
Для выполнения запроса в текущей транзакции необходимо создать экземпляр
QueryRunnerконструктором без параметров, не передаваяDataSource. После этого нужно вызывать методыquery()илиupdate(), передавая в нихConnection, полученный вызовомEntityManager.getConnection(). После выполнения закрыватьConnectionне нужно, он будет закрыт при коммите транзакции. -
Для выполнения запроса в отдельной транзакции необходимо создать экземпляр
QueryRunnerконструктором с параметромDataSource, получив экземплярDataSourceвызовомPersistence.getDataSource(). После этого нужно вызывать методыquery()илиupdate()без передачи какого-либоConnection, оно будет создано из указанногоDataSourceи затем сразу закрыто.
3.9.14. Выполнение задач по расписанию
Платформа предлагает два способа запуска задач по расписанию:
-
Использование стандартного механизма
TaskSchedulerфреймворка Spring -
Использование собственного механизма выполнения назначенных заданий
3.9.14.1. Spring TaskScheduler
Данный механизм подробно описан в разделе Task Execution and Scheduling руководства Spring Framework.
TaskScheduler можно использовать для запуска методов произвольных бинов Spring в любом блоке приложения - как на Middleware, так и на клиентском уровне.
Пример конфигурации в файле spring.xml:
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:task="http://www.springframework.org/schema/task"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-4.3.xsd http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context-4.3.xsd http://www.springframework.org/schema/task http://www.springframework.org/schema/task/spring-task-4.3.xsd">
<!--...-->
<task:scheduled-tasks scheduler="scheduler">
<task:scheduled ref="sales_Processor" method="someMethod" fixed-rate="60000"/>
<task:scheduled ref="sales_Processor" method="someOtherMethod" cron="0 0 1 * * MON-FRI"/>
</task:scheduled-tasks>
</beans>Здесь объявлены две задачи, запускающие на выполнение методы someMethod() и someOtherMethod() бина sales_Processor. При этом someMethod() запускается с момента старта приложения через фиксированные промежутки времени - 60 сек. Метод someOtherMethod() запускается в соответствии с расписанием, заданным выражением Cron (описание формата таких выражений см. https://docs.spring.io/spring/docs/current/javadoc-api/org/springframework/scheduling/support/CronSequenceGenerator.html).
Собственно запуск задач выполняет бин, заданный в атрибуте scheduler элемента scheduled-tasks. Это бин класса CubaThreadPoolTaskScheduler, который сконфигурирован в модулях core и web компонента cuba (см. cuba-spring.xml, cuba-web-spring.xml). Данный класс содержит специфическую для CUBA функциональность.
Для того чтобы предоставить SecurityContext коду, выполняемому задачами Spring на среднем слое, используйте системную аутентификацию.
3.9.14.2. Назначенные задания CUBA
Механизм назначенных заданий CUBA предназначен для запуска по расписанию методов произвольных бинов Spring в блоке Middleware. Целью данного механизма и отличием его от вышеупомянутого стандартного механизма Spring Framework являются:
-
возможность конфигурирования заданий во время работы приложения без остановки сервера
-
координация выполнения синглтон-заданий в кластере Middleware, в том числе:
-
надежная защита от одновременного выполнения
-
привязка заданий к серверам по приоритетам
-
Под синглтон-заданием понимается задача, которая должна выполняться в некоторый момент времени только на одном сервере. Пример - чтение из очереди и отсылка email.
3.9.14.2.1. Регистрация задания
Задания регистрируются в таблице SYS_SCHEDULED_TASK базы данных, соответствующей сущности ScheduledTask. Для работы с заданиями существуют экраны просмотра и редактирования, доступные через меню Администрирование → Назначенные задания.
Рассмотрим атрибуты задания:
-
Defined by - каким программным объектом реализуется задание. Возможные значения:
-
Bean - задание реализуется методом бина Spring. Дополнительные атрибуты:
-
Bean name - имя бина.
Бин отображается в списке и доступен для выбора, только если он объявлен в модуле core и у него есть интерфейс, содержащий подходящие для вызова из задания методы. Бины без интерфейса не поддерживаются.
-
Method name - метод интерфейса бина для выполнения. Метод должен либо не иметь параметров, либо иметь все параметры типа
String. Тип результата должен быть либоvoid, либоString. В последнем случае результат выполнения будет сохранен в таблице выполнений (см. Log finish ниже). -
Method parameters - параметры выбранного метода. Поддерживаются только параметры типа
String.
-
-
Class - задание представляет собой класс, реализующий интерфейс
java.util.concurrent.Callable. Класс должен иметь открытый конструктор без параметров. Дополнительные атрибуты:-
Class name - имя класса
-
-
Script - задание представляет собой скрипт Groovy. Скрипт выполняется через
Scripting.runGroovyScript(). Дополнительные атрибуты:-
Script name - имя скрипта.
-
-
-
User name - имя пользователя, от имени которого будет выполняться задание. Если не задано, то задание будет выполнено от имени пользователя, указанного в свойстве приложения cuba.jmxUserLogin.
-
Singleton - признак, является ли задание синглтоном, т.е. выполняющимся только на одном сервере системы.
-
Scheduling type - способ планирования задачи:
-
Cron - с помощью Cron-выражения, представляющего собой последовательность из шести полей, разделенных пробелами: секунда, минута, час, день, месяц, день недели. Месяц и день недели могут быть представлены первыми тремя буквами английского названия. Примеры выражений:
-
0 0 * * * * - начало каждого часа каждого дня.
-
*/10 * * * * * - каждые 10 секунд.
-
0 0 8-10 * * * - в 8, 9 и 10 часов каждого дня.
-
0 0/30 8-10 * * * - 8:00, 8:30, 9:00, 9:30 и 10 часов каждого дня.
-
0 0 9-17 * * MON-FRI - каждый час с 9 до 17 по рабочим дням.
-
0 0 0 7 1 ? - каждое Рождество в полночь.
-
-
Period - с помощью интервала между выполнениями.
-
Fixed Delay - задача будет запускаться с указанной в Period задержкой после окончания предыдущего выполнения.
-
-
Period - период или задержка запуска задания в секундах если Scheduling type установлен в Period или Fixed Delay.
-
Start date - дата/время первого запуска для
Scheduling type = Period. Если не установлено, то задание запускается сразу при старте сервера. Если установлено, то задание запускается в моментstartDate + period * N, где N - целое число.Start dateимеет смысл указывать только для "нечастых" заданий - раз в 1 час, 1 сутки и т.п. -
Timeout - время в секундах, по истечении которого считается, что задание закончило выполнение, независимо от того, есть ли информация о завершении задания, или нет. Если timeout не задан явно, он принимается равным 3 часам.
Для Singleton-задач в кластерном деплойменте рекомендуется всегда устанавливать таймаут в реалистичное значение. Если останавливается узел кластера, выполняющий задачу, то при стандартном значении другие узлы кластера будут ждать 3 часа перед тем, как запустить задачу снова.
-
Time frame - в случае заданного
Start dateилиCron expressionопределяет временное окно в секундах, в течение которого будет запущено задание, если времяstartDate + period * Nпрошло. Если Time frame не задано явно, оно принимается равнымperiod / 2.Если
Start dateне указано, тоTime frameне принимается во внимание, т.е. задание будет запущено в любое время после прохождения промежутка времениPeriodпосле предыдущего выполнения задания. -
Start delay - задержка выполнения в секундах после запуска сервера и активации выполнения задач. Используйте данный параметр для тяжелых задач, если вы считаете что они тормозят запуск сервера.
-
Permitted servers - список перечисленных через запятую идентификаторов серверов, на которых возможен запуск данного задания. Если список не задан, то задание может выполняться на любом сервере.
Для синглтон-заданий порядок перечисления серверов указывает их приоритет - первый имеет больший приоритет чем последний. Сервер с большим приоритетом перехватит выполнение синглтона следующим образом: если сервер с большим приоритетом обнаруживает, что предыдущий раз задание было выполнено сервером с меньшим приоритетом, то он запускает задание независимо от того, пройден ли
Periodили нет.
|
Приоритет серверов работает только в случае Scheduling type равного |
-
Log start - признак регистрации факта запуска задания в таблице
SYS_SCHEDULED_EXECUTION, соответствующей сущностиScheduledExecution.Если задание является синглтоном, то в текущей реализации регистрация факта запуска производится в любом случае, независимо от данного признака.
-
Log finish - признак регистрации факта завершения задания в таблице
SYS_SCHEDULED_EXECUTION, соответствующей сущностиScheduledExecution.Если задание является синглтоном, то в текущей реализации регистрация факта завершения производится в любом случае, независимо от данного признака.
-
Description - произвольное текстовое описание задания.
Задание также имеет признак активности, который устанавливается в экране списка заданий. Неактивные задания не запускаются.
3.9.14.2.2. Управление обработкой заданий
-
Для запуска обработки назначенных заданий необходимо установить свойство приложения cuba.schedulingActive в значение
true. Это можно сделать либо в экране Administration > Application Properties, либо с помощью JMX-бинаapp-core.cuba:type=Scheduling(см. атрибутActive). -
Все изменения в заданиях, сделанные через экраны системы, вступают в силу немедленно для всех серверов кластера.
-
Для удаления старой истории выполнения заданий можно использовать метод
removeExecutionHistory()JMX-бинаapp-core.cuba:type=Scheduling. У него имеется два параметра:-
age- время в часах, прошедшее после выполнения задания. -
maxPeriod- максимальный период заданий в часах, выполнения которых надо удалять. Это позволяет удалять только историю "частых" задач, а историю выполняемых, например, раз в сутки и реже, хранить без ограничений.Данный метод можно вызывать автоматически, для этого достаточно создать новое задание и установить для него следующие параметры:
-
Bean name -
cuba_SchedulingMBean -
Method name -
removeExecutionHistory(String age, String maxPeriod) -
Method parameters - например,
age= 72,maxPeriod= 12.
-
-
3.9.14.2.3. Особенности реализации
-
Период вызова обработки заданий (метода
SchedulingAPI.processScheduledTasks()) задается вcuba-spring.xmlи по умолчанию равен 1 сек. Он задает минимальное значение периода запуска задания, которое должно быть в два раза больше, т.е. 2 сек. Уменьшать эти времена не рекомендуется. -
Текущая реализация планировщика основана на синхронизации с помощью блокировки строк в таблице базы данных. Это означает, что при значительной нагрузке БД может не успевать вовремя отвечать планировщику, и необходимо увеличивать период запуска (>1сек), и, соответственно, минимальный период запуска заданий также будет увеличиваться.
-
Синглтон-задания в случае незаданного атрибута Permitted servers выполняются только на мастер-узле кластера (при выполнении прочих условий). Следует иметь в виду, что отдельный сервер вне кластера также является мастером.
-
Задание не запускается, если оно в данный момент не закончило предыдущее выполнение, и не истек указанный Timeout. Для синглтон-заданий в текущей реализации это обеспечивается информацией в базе данных, для не-синглтонов поддерживается таблица статуса выполнения в памяти сервера.
-
Механизм выполнения создает и кэширует пользовательские сессии в соответствии с указанными для заданий User name, либо свойством приложения cuba.jmxUserLogin. Сессия доступна в потоке выполнения запускаемого задания обычным способом - через интерфейс UserSessionSource.
|
Для нормальной работы синглтон-заданий необходима точная синхронизация серверов Middleware по времени! |
3.9.15. Ссылки на экраны
|
В разделе Навигация и история просмотров URL описывается более продвинутая функциональность по отображению URL на экраны приложения. |
Блок Web Client позволяет открывать экраны приложения по команде, переданной в URL. Причем если в данный момент в браузере нет сессии приложения с зарегистрированным пользователем, то сначала будет отображено окно логина, и сразу после успешной регистрации - главное окно приложения с требуемым экраном.
Набор возможных команд указывается в свойстве приложения cuba.web.linkHandlerActions, по умолчанию это команды open и o. При обработке HTTP запроса анализируется последняя часть URL, и если она совпадает с одной из команд, управление передается в соответствующий процессор, который является бином, реализующим интерфейс LinkHandlerProcessor.
Платформа предоставляет процессор, принимающий следующие параметры запроса:
-
screen- имя экрана, указанное в screens.xml, например:http://localhost:8080/app/open?screen=sec$User.browse -
item- экземпляр сущности для передачи в экран редактирования, закодированный по правилам классаEntityLoadInfo, т.е.entityName-instanceIdилиentityName-instanceId-viewName. Примеры:http://localhost:8080/app/open?screen=sec$User.edit&item=sec$User-60885987-1b61-4247-94c7-dff348347f93 http://localhost:8080/app/open?screen=sec$User.edit&item=sec$User-60885987-1b61-4247-94c7-dff348347f93-user.editДля открытия экрана создания нового экземпляра сущности в данном параметре нужно передать строку вида
NEW-entityName:http://localhost:8080/app/open?screen=sec$User.edit&item=NEW-sec$User -
params- параметры экрана, передаваемые в методinit()контроллера. Параметры кодируются в видеname1:value1,name2:value2. Значениями параметров могут быть экземпляры сущностей, в свою очередь закодированные по правилам классаEntityLoadInfo. Примеры:http://localhost:8080/app/open?screen=sales$Customer.lookup¶ms=p1:v1,p2:v2 http://localhost:8080/app/open?screen=sales$Customer.lookup¶ms=p1:sales$Customer-01e37691-1a9b-11de-b900-da881aea47a6
Если вам необходимо добавить обработку специфических команд, выполните следующие шаги:
-
Создайте в модуле web проекта бин, реализующий интерфейс
LinkHandlerProcessor. -
Метод
canHandle()бина должен возвращать true, если текущий URL, параметры которого переданы в объектеExternalLinkContext, должен быть обработан данным бином. -
В методе
handle()выполните необходимые действия.
Ваш бин может опционально реализовывать интерфейс Ordered или содержать аннотацию Order фреймворка Spring. Тогда вы сможете указать позицию вашего бина в цепочке процессоров. Используйте константы HIGHEST_PLATFORM_PRECEDENCE и LOWEST_PLATFORM_PRECEDENCE интерфейса LinkHandlerProcessor чтобы поместить ваш бин до или после процессоров, определенных в платформе. Так, если вы укажете порядок числом, меньшим HIGHEST_PLATFORM_PRECEDENCE, ваш бин будет запрошен раньше, и вы при необходимости сможете переопределить поведение, заданное процессором платформы.
3.9.16. Генерация последовательностей
Данный механизм позволяет генерировать уникальные последовательности чисел через единый API, независимо от используемой СУБД.
Основной частью данного механизма является бин UniqueNumbers с интерфейсом UniqueNumbersAPI, доступный в блоке Middleware. Методы интерфейса:
-
getNextNumber()- получить следующее значение последовательности. Механизм позволяет вести одновременно несколько последовательностей, идентифицируемых простыми строками. Имя последовательности, из которой нужно получить значение, передается в параметреdomain.Последовательности не требуют предварительной инициализации - при первом вызове
getNextNumber()соответствующая последовательность будет создана и вернет значение 1. -
getCurrentNumber()- получить текущее, то есть последнее сгенерированное, значение последовательности. Параметрdomain- имя последовательности. -
setCurrentNumber()- установить текущее значение последовательности. Следующий вызовgetNextNumber()вернет значение, увеличенное на 1.
Пример получения следующего значения последовательности в бине блока Middleware:
@Inject
private UniqueNumbersAPI uniqueNumbers;
private long getNextValue() {
return uniqueNumbers.getNextNumber("mySequence");
}Для получения значений последовательностей в клиентских блоках используется метод getNextNumber() сервиса UniqueNumbersService.
Для управления последовательностями можно использовать JMX-бин app-core.cuba:type=UniqueNumbers с методами, дублирующими методы UniqueNumbersAPI.
Реализация механизма генерации последовательностей зависит от типа используемой СУБД. Поэтому параметрами последовательностей можно также управлять непосредственно в БД, но разными способами.
-
Для HSQL, PostgreSQL, Microsoft SQL Server 2012+ и Oracle каждой последовательности
UniqueNumbersAPIсоответствует последовательность (sequence)SEC_UN_{domain}в базе данных. -
Для Microsoft SQL Server версии ниже 2012 каждой последовательности соответствует таблица
SEC_UN_{domain}с первичным ключом типа IDENTITY. -
Для MySQL последовательности соответствуют строкам в таблице
SYS_SEQUENCE.
3.9.17. Журналирование пользовательских сессий
Механизм журналирования предназначен для отслеживания факта входа пользователей в систему. В журнале администратор системы может найти информацию, кто и когда вошёл в систему и вышел из неё. Механизм основан на отслеживании пользовательских сессий. При каждом создании объекта UserSession в базу данных сохраняется следующая информация:
-
ID сессии пользователя,
-
ID пользователя,
-
последнее действие пользователя (логин / выход / истечение срока сессии / сессия прервана),
-
удаленный IP-адрес, с которого пришёл запрос на вход в систему,
-
тип клиента (web, portal),
-
ID сервера (например,
localhost:8080/app-core), -
дата и время начала сессии,
-
дата и время окончания сессии,
-
информация о клиенте (окружение сессии: операционная система, веб-браузер и т.д.).
По умолчанию записи о пользовательских сессиях не сохраняются. Простейший способ активировать журналирование - воспользоваться кнопкой Enable Logging в экране приложения Administration > User Session Log. В качестве альтернативы можно установить в true значение свойства приложения cuba.UserSessionLogEnabled и перезапустить сервер.
При необходимости можно создать отчёт для сущности sec$SessionLogEntry.
3.10. Расширение функциональности
Платформа позволяет расширять и переопределять свою функциональность в приложениях в следующих аспектах:
-
расширение набора атрибутов сущностей
-
расширение функциональности экранов
-
расширение и переопределение бизнес-логики, сосредоточенной в бинах Spring
Рассмотрим две первые задачи на примере добавления поля Адрес в сущность User подсистемы безопасности платформы.
3.10.1. Расширение сущности
Создадим в проекте приложения класс сущности, унаследованный от com.haulmont.cuba.security.entity.User и добавим в него требуемый атрибут с соответствующими методами доступа:
@Entity(name = "sales_ExtUser")
@Extends(User.class)
public class ExtUser extends User {
@Column(name = "ADDRESS", length = 100)
private String address;
public String getAddress() {
return address;
}
public void setAddress(String address) {
this.address = address;
}
}В аннотации @Entity должно быть указано новое имя сущности. Так как базовая сущность не объявляет стратегию наследования, то по умолчанию это SINGLE_TABLE. Это означает, что унаследованная сущность будет храниться в той же таблице, что и базовая, и аннотация @Table не требуется. Другие аннотации базовой сущности - @NamePattern, @Listeners и прочие - автоматически применяются к расширяющей сущности, но могут быть переопределены в ее классе.
Важным элементом класса новой сущности является аннотация @Extends с базовым классом в качестве параметра. Она позволяет сформировать реестр расширяющих сущностей, и заставить механизмы платформы использовать их повсеместно вместо базовых. Реестр реализуется классом ExtendedEntities, который является бином Spring с именем cuba_ExtendedEntities, и доступен также через интерфейс Metadata.
Добавим локализованное название нового атрибута в пакет com.sample.sales.entity:
messages.properties
ExtUser.address=Addressmessages_ru.properties
ExtUser.address=АдресЗарегистрируем новую сущность в файле persistence.xml проекта:
<class>com.sample.sales.entity.ExtUser</class>Добавим в скрипты создания и обновления базы данных команду модификации соответствующей таблицы:
-- add column for "address" attribute
alter table SEC_USER add column ADDRESS varchar(100)
^
-- add discriminator column required for entity inheritance
alter table SEC_USER add column DTYPE varchar(100)
^
-- set discriminator value for existing records
update SEC_USER set DTYPE = 'sales_ExtUser' where DTYPE is null
^Чтобы использовать новые атрибуты сущности в экранах, создадим представления для новой сущности с теми же именами, что у представлений базовой сущности. Новые представления должны расширять базовые и определять новые атрибуты. Например:
<view class="com.sample.sales.entity.ExtUser"
name="user.browse"
extends="user.browse">
<property name="address"/>
</view>Расширяющее представление включает в себя все атрибуты базового представления. Расширяющее представление не требуется, если базовое расширяет _local и вы добавляете только локальные атрибуты. Поэтому в описываемом случае данный шаг может быть пропущен.
3.10.2. Расширение экранов
Платформа позволяет создавать новые XML-дескрипторы экранов путем наследования от существующих.
Наследование XML выполняется путем указания в корневом элементе window атрибута extends, содержащего путь к базовому дескриптору.
Правила переопределения элементов XML экрана:
-
Если в расширяющем дескрипторе указан некоторый элемент, в базовом дескрипторе будет произведен поиск соответствующего элемента по следующему алгоритму:
-
Если в переопределяющем элементе указан атрибут
id, ищется соответствующий элемент с таким жеid. -
Если поиск дал результат, то найденный элемент переопределяется.
-
Если поиск не дал результата, то определяется, сколько в базовом дескрипторе элементов по данному пути и с данным именем. Если ровно один - он переопределяется.
-
Если поиск не дал результата, и в базовом дескрипторе по данному пути с данным именем нет элементов, либо их больше одного, добавляется новый элемент.
-
-
В переопределяемом либо добавляемом элементе устанавливается текст из расширяющего элемента.
-
В переопределяемый либо добавляемый элемент копируются все атрибуты из расширяющего элемента. При совпадении имени атрибута значение берется из расширяющего элемента.
-
Добавление нового элемента по умолчанию производится в конец списка соседних элементов. Чтобы добавить новый элемент в начало или с произвольным индексом, необходимо выполнить следующее:
-
определить в расширяющем дескрипторе дополнительный namespace:
xmlns:ext="http://schemas.haulmont.com/cuba/window-ext.xsd" -
добавить в расширяющий элемент атрибут
ext:indexс желаемым индексом, например:ext:index="0".
-
Для отладки преобразования дескрипторов можно включить вывод в журнал сервера результирующего XML. Делается это путем указания уровня TRACE для логгера com.haulmont.cuba.gui.xml.XmlInheritanceProcessor в файле конфигурации Logback.
- Расширение устаревших экранов
-
Фреймворк содержит некоторое количества экранов, реализованных на legacy API для обратной совместимости. Ниже рассмотрены примеры расширения экранов сущности
User, входящей в состав подсистемы безопасности.Создайте XML-дескриптор браузера сущности
ExtUser:ext-user-browse.xml<?xml version="1.0" encoding="UTF-8" standalone="no"?> <window xmlns="http://schemas.haulmont.com/cuba/window.xsd" xmlns:ext="http://schemas.haulmont.com/cuba/window-ext.xsd" extends="/com/haulmont/cuba/gui/app/security/user/browse/user-browse.xml"> <layout> <groupTable id="usersTable"> <columns> <column ext:index="2" id="address"/> </columns> </groupTable> </layout> </window>В данном примере дескриптор унаследован от стандартного браузера сущностей
Userфреймворка, и в таблицу добавлена колонкаaddressс индексом2, т.е. отображающаяся послеloginиname.Зарегистрируйте новый экран в screens.xml с теми же идентификаторами, которые использовались для базового экрана. После этого новый экран будет повсеместно вызываться взамен старого.
<screen id="sec$User.browse" template="com/sample/sales/gui/extuser/extuser-browse.xml"/> <screen id="sec$User.lookup" template="com/sample/sales/gui/extuser/extuser-browse.xml"/>Аналогично создайте экран редактирования:
ext-user-edit.xml<?xml version="1.0" encoding="UTF-8" standalone="no"?> <window xmlns="http://schemas.haulmont.com/cuba/window.xsd" xmlns:ext="http://schemas.haulmont.com/cuba/window-ext.xsd" extends="/com/haulmont/cuba/gui/app/security/user/edit/user-edit.xml"> <layout> <groupBox id="propertiesBox"> <grid id="propertiesGrid"> <rows> <row id="propertiesRow"> <fieldGroup id="fieldGroupLeft"> <column> <field ext:index="3" id="address" property="address"/> </column> </fieldGroup> </row> </rows> </grid> </groupBox> </layout> </window>Зарегистрируйте его в
screens.xmlс идентификатором базового экрана:<screen id="sec$User.edit" template="com/sample/sales/gui/extuser/extuser-edit.xml"/>После выполнения описанных выше действий в приложении вместо сущности
Userфреймворка будет использоватьсяExtUserс соответствующими экранами.Контроллер экрана может быть расширен путем создания нового класса, унаследованного от контроллера базового экрана. Имя класса указывается в атрибуте
classкорневого элемента расширяющего XML дескриптора, при этом выполняются обычные правила наследования XML, описанные выше. - Расширение экранов при помощи CUBA Studio
-
В этом примере мы расширим экран для сущности
Customerиз компонента Customer Management, описанного в разделе Пример создания и использования компонента: добавим кнопкуExcelдля таблицы браузера покупателей.-
Создайте новый проект в Studio и подключите к нему компонент Customer Management.
-
Выберите New > Screen в контекстном меню элемента Generic UI в дереве проекта. Затем на вкладке Screen Templates выберите шаблон Extend an existing screen. В списке Extend Screen выберите
customer-browse.xml. Новые файлыext-customer-browse.xmlиExtCustomerBrowse.javaбудут созданы в модуле web. -
Откройте XML-дескриптор
ext-customer-browse.xmlи перейдите на вкладку Designer. В рабочей области будут отображены компоненты родительского экрана. -
Выделите таблицу
customersTableи добавьте новое действиеexcel. -
Добавьте кнопку на панель
buttonsPanel, связанную с действиемcustomersTable.excel.
В итоге дескриптор экрана
ext-customer-browse.xmlна вкладке Text будет выглядеть следующим образом:ext-customer-browse.xml<?xml version="1.0" encoding="UTF-8" standalone="no"?> <window xmlns="http://schemas.haulmont.com/cuba/screen/window.xsd" messagesPack="com.company.sales2.web" extends="com/company/customers/web/customer/customer-browse.xml"> <layout> <groupTable id="customersTable"> <actions> <action id="excel" type="excel"/> </actions> <buttonsPanel id="buttonsPanel"> <button id="excelButton" action="customersTable.excel"/> </buttonsPanel> </groupTable> </layout> </window>Рассмотрим класс контроллера экрана
ExtCustomerBrowse.java.ExtCustomerBrowse.java@UiController("customers_Customer.browse") @UiDescriptor("ext-customer-browse.xml") public class ExtCustomerBrowse extends CustomerBrowse { }Так как идентификатор экрана
customers_Customer.browseсовпадает с идентификатором базового экрана, новый экран будет повсеместно вызываться взамен старого. -
3.10.3. Расширение бизнес-логики
Основная часть бизнес-логики платформы сосредоточена в бинах Spring, что позволяет легко расширить или переопределить ее в приложении.
Для подмены реализации бина достаточно создать свой класс, реализующий интерфейс или расширяющий базовый класс платформы, и зарегистрировать его в spring.xml приложения. Аннотацию @Component в расширяющем классе применять нельзя, переопределение бинов возможно только с помощью конфигурации в XML.
Рассмотрим пример добавления метода в бин PersistenceTools.
Создаем класс с нужным методом:
public class ExtPersistenceTools extends PersistenceTools {
public Entity reloadInSeparateTransaction(final Entity entity, final String... viewNames) {
Entity result = persistence.createTransaction().execute(new Transaction.Callable<Entity>() {
@Override
public Entity call(EntityManager em) {
return em.reload(entity, viewNames);
}
});
return result;
}
}Регистрируем класс в spring.xml модуля core проекта с тем же идентификатором, что и бин платформы:
<bean id="cuba_PersistenceTools" class="com.sample.sales.core.ExtPersistenceTools"/>После этого контекст Spring вместо экземпляра базового класса PersistenceTools будет всегда возвращать ExtPersistenceTools, например:
Persistence persistence;
PersistenceTools tools;
persistence = AppBeans.get(Persistence.class);
tools = persistence.getTools();
assertTrue(tools instanceof ExtPersistenceTools);
tools = AppBeans.get(PersistenceTools.class);
assertTrue(tools instanceof ExtPersistenceTools);
tools = AppBeans.get(PersistenceTools.NAME);
assertTrue(tools instanceof ExtPersistenceTools);Таким же образом можно переопределять логику сервисов, например, из компонентов приложения: для подмены реализации бина нужно создать класс, расширяющий функциональность исходного сервиса. В следующем примере мы создали новый класс NewOrderServiceBean, чтобы переопределить в нём метод из исходного сервиса OrderServiceBean:
public class NewOrderServiceBean extends OrderServiceBean {
@Override
public BigDecimal calculateOrderAmount(Order order) {
BigDecimal total = super.calculateOrderAmount(order);
BigDecimal vatPercent = new BigDecimal(0.18);
return total.multiply(BigDecimal.ONE.add(vatPercent));
}
}Теперь, после регистрации нового класса в spring.xml, новая реализация будет использоваться в приложении вместо исходной, заданной в OrderServiceBean. Обратите внимание, что в определении бина используется идентификатор из компонента приложения и полное имя нового класса:
<bean id="workshop_OrderService" class="com.company.retail.service.NewOrderServiceBean"/>3.10.4. Регистрация сервлетов и фильтров
Чтобы использовать сервлеты и фильтры, настроенные в компоненте приложения, их нужно зарегистрировать программным способом. Обычно сервлеты и фильтры регистрируются в файле web.xml, но файл web.xml компонента не влияет на приложение, поэтому стандартный способ не подходит.
Для динамической регистрации сервлетов и фильтров используется бин ServletRegistrationManager: он гарантирует, что при загрузке каждого сервлета будет использован корректный ClassLoader, и позволяет обращаться к статическим классам, таким как AppContext. Этот бин необходимо использовать для корректной работы компонентов независимо от варианта развёртывания приложения.
Бин ServletRegistrationManager имеет два метода:
-
createServlet()- создаёт сервлет указанного класса. Он загружает класс сервлета с нужным экземпляромClassLoader, который получает из контекста приложения. Таким образом, новый сервлет может использовать статические классы платформы, например,AppContextили бин Messages. -
createFilter()- создаёт фильтр аналогично созданию сервлетов.
Для использования этого бина мы рекомендуем создать в компоненте приложения отдельный бин-инициализатор. Этот бин должен содержать слушатели событий ServletContextInitializedEvent и ServletContextDestroyedEvent.
Пример бина-инициализатора:
@Component
public class WebInitializer {
@Inject
private ServletRegistrationManager servletRegistrationManager;
@EventListener
public void initializeHttpServlet(ServletContextInitializedEvent e) {
Servlet myServlet = servletRegistrationManager.createServlet(
e.getApplicationContext(), "com.demo.comp.MyHttpServlet");
e.getSource().addServlet("my_servlet", myServlet)
.addMapping("/myservlet/*");
}
}Здесь класс WebInitializer содержит только один слушатель, который используется для регистрации HTTP-сервлета из компонента приложения в родительском приложении.
Метод createServlet() принимает контекст приложения, полученный из события ServletContextInitializedEvent, и полное имя класса HTTP-сервлета. Далее мы регистрируем сервлет по его имени (my_servlet) и указываем URL, по которому будет доступен сервлет (/myservlet/). Теперь при подключении этого компонента к другому приложению сервлет MyHttpServlet будет зарегистрирован сразу после инициализации AppContext и ServletContext.
Сервлет регистрируется с маппингом myservlet и будет доступен по адресу /app/myservlet/ или /app-core/myservlet/ в зависимости от контекста приложения.
Более сложный пример использования бина ServletRegistrationManager приведён в разделе Регистрация DispatcherServlet из компонента приложения.
3.10.5. Программная регистрация главных сервлетов и фильтров
Обычно главные сервлеты (CubaApplicationServlet, CubaDispatcherServlet) и фильтры (CubaHttpFilter) регистрируются в конфигурационном файле web.xml блока Web Client:
<servlet>
<servlet-name>app_servlet</servlet-name>
<servlet-class>com.haulmont.cuba.web.sys.CubaApplicationServlet</servlet-class>
<async-supported>true</async-supported>
</servlet>
<servlet>
<servlet-name>dispatcher</servlet-name>
<servlet-class>com.haulmont.cuba.web.sys.CubaDispatcherServlet</servlet-class>
<load-on-startup>1</load-on-startup>
</servlet>
<servlet-mapping>
<servlet-name>dispatcher</servlet-name>
<url-pattern>/dispatch/*</url-pattern>
</servlet-mapping>
<servlet-mapping>
<servlet-name>app_servlet</servlet-name>
<url-pattern>/*</url-pattern>
</servlet-mapping>
<filter>
<filter-name>cuba_filter</filter-name>
<filter-class>com.haulmont.cuba.web.sys.CubaHttpFilter</filter-class>
<async-supported>true</async-supported>
</filter>
<filter-mapping>
<filter-name>cuba_filter</filter-name>
<url-pattern>/*</url-pattern>
</filter-mapping>Но иногда требуется их программная регистрация.
Рассмотрим пример бина, который инициализирует главные сервлеты и фильтры:
@Component(MainServletsInitializer.NAME)
public class MainServletsInitializer {
public static final String NAME = "demo_MainServletsInitializer";
@Inject
protected ServletRegistrationManager servletRegistrationManager;
@EventListener
public void initServlets(ServletContextInitializedEvent event){
initAppServlet(event); (1)
initDispatcherServlet(event); (2)
initCubaFilter(event); (3)
}
protected void initAppServlet(ServletContextInitializedEvent event) {
CubaApplicationServlet cubaServlet = (CubaApplicationServlet) servletRegistrationManager.createServlet(
event.getApplicationContext(),
"com.haulmont.cuba.web.sys.CubaApplicationServlet");
cubaServlet.setClassLoader(Thread.currentThread().getContextClassLoader());
ServletRegistration.Dynamic registration = event.getSource()
.addServlet("app_servlet", cubaServlet); (4)
registration.setLoadOnStartup(0);
registration.setAsyncSupported(true);
registration.addMapping("/*");
JSR356WebsocketInitializer.initAtmosphereForVaadinServlet(registration, event.getSource()); (5)
try {
cubaServlet.init(new AbstractWebAppContextLoader.CubaServletConfig("app_servlet", event.getSource())); (6)
} catch (ServletException e) {
throw new RuntimeException("An error occurred while initializing app_servlet servlet", e);
}
}
protected void initDispatcherServlet(ServletContextInitializedEvent event) {
CubaDispatcherServlet cubaDispatcherServlet = (CubaDispatcherServlet) servletRegistrationManager.createServlet(
event.getApplicationContext(),
"com.haulmont.cuba.web.sys.CubaDispatcherServlet");
try {
cubaDispatcherServlet.init(
new AbstractWebAppContextLoader.CubaServletConfig("dispatcher", event.getSource()));
} catch (ServletException e) {
throw new RuntimeException("An error occurred while initializing dispatcher servlet", e);
}
ServletRegistration.Dynamic cubaDispatcherServletReg = event.getSource()
.addServlet("dispatcher", cubaDispatcherServlet);
cubaDispatcherServletReg.setLoadOnStartup(1);
cubaDispatcherServletReg.addMapping("/dispatch/*");
}
protected void initCubaFilter(ServletContextInitializedEvent event) {
CubaHttpFilter cubaHttpFilter = (CubaHttpFilter) servletRegistrationManager.createFilter(
event.getApplicationContext(),
"com.haulmont.cuba.web.sys.CubaHttpFilter");
FilterRegistration.Dynamic registration = event.getSource()
.addFilter("cuba_filter", cubaHttpFilter);
registration.setAsyncSupported(true);
registration.addMappingForUrlPatterns(EnumSet.of(DispatcherType.REQUEST), true, "/*");
}
}| 1 | - регистрация и инициализация CubaApplicationServlet. |
| 2 | - регистрация и инициализация CubaDispatcherServlet. |
| 3 | - регистрация и инициализация CubaHttpFilter. |
| 4 | - мы должны зарегистрировать сервлет в первую очередь, чтобы инициализировать Atmosphere Framework. |
| 5 | - явная инициализация JSR 356. |
| 6 | - инициализация сервлета. |
Подробнее см. класс SingleAppWebContextLoader.
4. Разработка приложений
Данная глава содержит практическую информацию по созданию приложений на основе платформы.
4.1. Рекомендуемый стиль кода
Форматирование кода
-
Для Java и Groovy кода рекомендуется придерживаться стандартного стиля, описанного в документе Code Conventions for the Java Programming Language. При программировании в IntelliJ IDEA для этого достаточно использовать стиль по умолчанию, а для переформатирования применять сочетание клавиш Ctrl-Alt-L.
Максимальная длина строки − 120 символов. Длина отступа - 4 символа, использование пробелов вместо символов табуляции включено.
-
XML код: длина отступа - 4 символа, использование пробелов вместо символов табуляции включено.
Соглашения по именованию
| Идентификатор | Правило именования | Пример |
|---|---|---|
Java и Groovy классы |
||
Класс контроллера экрана |
UpperCamelCase Контроллер экрана списка сущностей − Контроллер экрана редактирования − |
|
XML дескрипторы экранов |
||
Идентификатор компонента, имена параметров в запросах |
lowerCamelCase, только буквы и цифры |
|
Идентификатор источника данных |
lowerCamelCase, только буквы и цифры, оканчивается на Ds |
|
SQL скрипты |
||
Зарезервированные слова |
lowercase |
|
Таблицы |
UPPER_CASE. Название предваряется именем проекта для формирования пространства имен. В именах таблиц рекомендуется использовать единственное число. |
|
Колонки |
UPPER_CASE |
|
Колонки внешних ключей |
UPPER_CASE. Состоит из имени таблицы, на которую ссылается колонка (без префикса проекта), и суффикса _ID. |
|
Индексы |
UPPER_CASE. Состоит из префикса IDX_, имени таблицы, для которой создается индекс (с префиксом проекта), и имен полей, включенных в индекс. |
|
4.2. Файловая структура проекта
Рассмотрим файловую структуру проекта на примере простого приложения Sales, состоящего из блоков Middleware и Web Client.
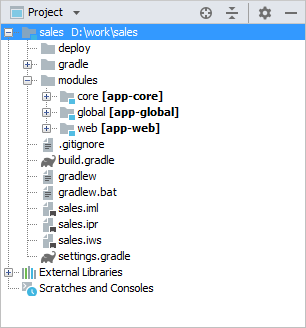
Рисунок 44. Файловая структура проекта
В корне проекта расположены скрипты сборки: build.gradle и settings.gradle.
В каталоге modules расположены подкаталоги модулей проекта по умолчанию − global, core, web.
Модуль global содержит каталог исходных текстов src, в корне которого располагаются конфигурационные файлы metadata.xml, persistence.xml и views.xml. Пакет com.sample.sales.service содержит интерфейсы сервисов Middleware, пакет com.sample.sales.entity - классы сущностей и файлы локализации для них.
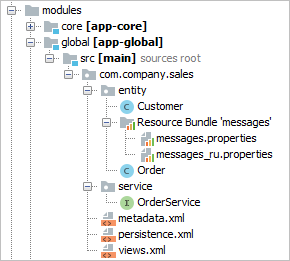
Рисунок 45. Структура модуля global
Модуль core содержит следующие каталоги:
-
db- каталог скриптов миграции базы данных. -
src- каталог исходных текстов, в корне которого расположены файл свойств приложения блока Middleware и конфигурационный файл spring.xml. Пакетcom.samples.sales.serviceсодержит классы среднего слоя: классы реализации сервисов, Spring-бинов и JMX-бинов. -
test- каталог тестовых классов. -
web- каталог с конфигурационными файлами веб-приложения, в которое собирается блок Middleware: context.xml и web.xml.
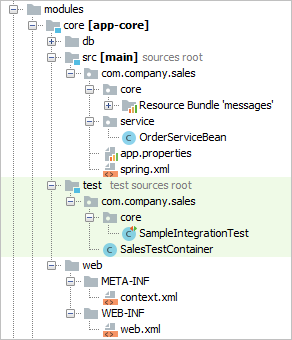
Рисунок 46. Структура модуля core
Модуль web содержит следующие каталоги:
-
src- каталог исходных текстов, в корне которого расположены файл свойств приложения блока Web Client и конфигурационные файлы web-menu.xml, web-permissions.xml, web-screens.xml и web-spring.xml. Пакетcom.samples.sales.webсодержит главный класс блока Web Client (наследникDefaultApp) и главный пакет локализованных сообщений. -
web- каталог с конфигурационными файлами веб-приложения, в которое собирается блок Web Client: context.xml и web.xml.
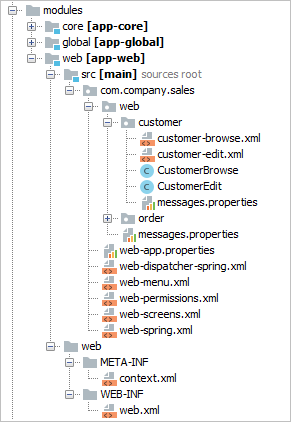
Рисунок 47. Структура модуля web
4.3. Скрипты сборки
Для сборки проектов на основе платформы используется система сборки Gradle. Скрипты сборки представляют собой два файла в корневом каталоге проекта:
-
settings.gradle- задает название и состав модулей проекта -
build.gradle- определяет конфигурацию сборки.
В данном разделе описывается структура скриптов, а также предназначение и параметры задач (tasks) Gradle.
4.3.1. Структура build.gradle
В данном разделе описывается структура и основные элементы скрипта build.gradle.
- buildscript
-
В секции
buildscriptзадается следующее:-
Версия платформы, на которой основан данный проект.
-
Набор репозиториев, из которых будут загружаться зависимости проекта. Настройка доступа к репозиториям описана ниже.
-
Зависимости, используемые системой сборки, включая плагин CUBA для Gradle.
После секции
buildscriptобъявляются несколько переменных, используемых далее в скрипте. -
- cuba
-
Логика сборки, специфичная для CUBA, сосредоточена в Gradle плагине
cuba. Он подключается в корне скрипта и в секцияхconfigureкаждого модуля:apply(plugin: 'cuba')Параметры плагина cuba задаются в секции
cuba:cuba { artifact { group = 'com.company.sales' version = '0.1' isSnapshot = true } tomcat { dir = "$project.rootDir/build/tomcat" } ide { copyright = '...' classComment = '...' vcs = 'Git' } }Рассмотрим доступные параметры:
-
artifact- задает группу и версию собираемых артефактов проекта. Имена артефактов формируются на основе имен модулей, заданных вsettings.gradle.-
group- группа артефактов. -
version- версия артефактов. -
isSnapshot- если установлено вtrue, то в именах артефактов будет присутствовать суффиксSNAPSHOT.Версию артефактов можно переопределить в командной строке, например:
gradle assemble -Pcuba.artifact.version=1.1.1
-
-
tomcat- задает параметры сервера Tomcat, который используется для быстрого развертывания.-
dir- расположение каталога установки Tomcat. -
port- порт сервера; по умолчанию 8080. -
debugPort- порт для подключения Java отладчика; по умолчанию 8787. -
shutdownPort- порт для передачи командыSHUTDOWN; по умолчанию 8005. -
ajpPort- порт AJP connector; по умолчанию 8009.
-
-
ide- задает некоторые параметры для Studio и IDE.-
vcs- тип используемой в проекте VCS. В данный момент поддерживаются толькоGitиsvn. -
copyright- текст Copyright Notice, вставляемый в начало файлов исходных текстов. -
classComment- текст комментария, который будет расположен над объявлением класса в исходных текстах Java.
-
-
uploadRepository- задает параметры репозитория, в который будут выгружаться собранные артефакты проекта при выполнении задачиuploadArchives.-
url- URL репозитория. По умолчанию используется репозиторий Haulmont. -
user- имя пользователя репозитория. -
password- пароль пользователя репозитория.Параметры репозитория выгрузки артефактов можно передать в командной строке с помощью следующих аргументов:
gradlew uploadArchives -PuploadUrl=http://myrepo.com/content/repositories/snapshots -PuploadUser=me -PuploadPassword=mypassword
-
-
- dependencies
-
Данная секция описывает набор компонентов приложения, используемых в проекте. Зависимости бывают двух типов:
appComponent- для компонентов CUBA иuberJar- для библиотек, которые загружаются перед стартом приложения. Компоненты CUBA указываются координатами артефакта их модуля global. В примере ниже используются три компонента:com.haulmont.cuba(компонент cuba платформы),com.haulmont.reports(премиум-дополнение reports) иcom.company.base(кастомный компонент):dependencies { appComponent("com.haulmont.cuba:cuba-global:$cubaVersion") appComponent("com.haulmont.reports:reports-global:$cubaVersion") appComponent("com.company.base:base-global:0.1-SNAPSHOT") } - configure
-
Секции
configureописывают конфигурацию модулей. Наиболее важная часть конфигурации - описание зависимостей, например:configure(coreModule) { dependencies { // standard dependencies using variables defined in the script above compile(globalModule) provided(servletApi) jdbc(hsql) testRuntime(hsql) // add a custom repository-based dependency compile('com.company.foo:foo:1.0.0') // add a custom file-based dependency compile(files("${rootProject.projectDir}/lib/my-library-0.1.jar")) // add all JAR files in the directory to dependencies compile(fileTree(dir: 'libs', include: ['*.jar'])) }Есть возможность добавлять зависимости через конфигурацию
serverдля модулей core, web и portal (модули, имеющие задачу с типомCubaDeployment). Это имеет смысл в некоторых случаях, например, когда для варианта развёртывания с помощью UberJar обращение к зависимости происходит до старта приложения, а сама зависимость нужна для всех вариантов развёртывания в конкретном модуле. Тогда объявление отдельно на уровне модуля (что нужно, например, для случая развертывания опции WAR) и через конфигурациюuberJarна уровне проекта вызовет ненужное дублирование зависимости для UberJar. Такие зависимости при выполнении задачdeploy,buildWarиbuildUberJarбудут помещаться в серверные библиотеки.Блок
entitiesEnhancingпозволяет описать конфигурацию bytecode enhancement (weaving) классов сущностей. Его нужно объявить как минимум в модуле global, однако можно включить его в конфигурацию каждого модуля по-отдельности.Секции
mainиtestздесь - это наборы исходников проекта и тестов, а необязательный параметрpersistenceConfigпозволяет явно указать набор файлов persistence.xml. Если не установлено, задача будет обрабатывать все персистентные сущности, перечисленные в файлах*persistence.xml, найденных в CLASSPATH.configure(coreModule) { ... entitiesEnhancing { main { enabled = true persistenceConfig = 'custom-persistence.xml' } test { enabled = true persistenceConfig = 'test-persistence.xml' } } }Нестандартные зависимости модулей можно задавать в Studio в экране Project properties > Advanced. См. также контекстную помощь Studio.
|
В случае транзитивных зависимостей и конфликта версий будет использована стандартная стратегия разрешения версий Maven. Согласно этой стратегии, релизные версии имеют приоритет над snapshot-версиями, а более точный числовой квалификатор имеет приоритет над более общим. При прочих равных, строковые квалификаторы приоритизируются в алфавитном порядке. Пример: Иногда необходимо использовать определенную версию некоторой библиотеки, но другая версия той же библиотеки попадает в проект транзитивно из дерева зависимостей. Например, вы можете использовать версию Чтобы использовать желаемую версию, настройте стратегию разрешения Gradle в своем файле В этом блоке кода мы добавили правило, согласно которому версия |
4.3.2. Настройка доступа к репозиторию
- Основной репозиторий
-
При создании нового проекта в CUBA Studio вам необходимо выбрать основной репозиторий, содержащий артефакты платформы. По умолчанию имеется два таких репозитория (может быть больше если установлен приватный репозиторий):
-
https://repo.cuba-platform.com/content/groups/work- репозиторий, расположенный на сервере Haulmont. Он требует передачи общих имени и пароля, которые указываются прямо в скрипте сборки (cuba/cuba123). -
https://dl.bintray.com/cuba-platform/main- репозиторий, находящийся в JFrog Bintray. Он предоставляет анонимный доступ.
Оба репозитория имеют идентичное содержимое для последних версий платформы, но Bintray не содержит снэпшотов. Мы предполагаем, что Bintray является более надежным для доступа из любой точки мира.
В случае Bintray, скрипт сборки сконфигурирован также для использования репозиториев Maven Central, JCenter и Vaadin Add-ons по отдельности.
Хранилище артефактов Bintray, доступное по адресу
https://dl.bintray.com/cuba-platform, вскоре будет закрыто компанией JFrog. Пожалуйста, не используйте репозиторий Bintray в ваших проектах. Предварительный график отключения выглядит следующим образом:-
После 31 марта 2021 года:
-
Новые версии платформы и дополнений больше не будут загружаться в репозиторий Bintray.
-
Новые коммерческие подписки на дополнения больше не будут иметь доступа к старым релизам дополнений, расположенных в репозитории Bintray.
-
-
После 1 февраля 2022 года:
-
Репозиторий Bintray больше не будет доступен. Существующие проекты CUBA, использующие этот репозиторий, не смогут собираться и запускаться.
-
Вместо репозитория Bintray вам следует использовать второй репозиторий
https://repo.cuba-platform.comво всех проектах.Официальное объявление: https://jfrog.com/blog/into-the-sunset-bintray-jcenter-gocenter-and-chartcenter/
-
- Дополнительные репозитории
-
Проект может использовать любые дополнительные репозитории, содержащие компоненты приложения. Они должны быть вручную указаны в
build.gradleпосле основного репозитория, например:repositories { // main repository containing CUBA artifacts maven { url 'https://repo.cuba-platform.com/content/groups/work' credentials { // ... } } // custom repository maven { url 'http://localhost:8081/repository/maven-snapshots' } }
4.3.3. Поддержка Kotlin
При создании нового проекта в Studio, на первой странице мастера нового проекта можно выбрать предпочтительный язык (Java, Kotlin, Java+Groovy). При этом скрипты сборки будут сконфигурированы соответствующим образом.
Если необходимо добавить поддержку Kotlin в существующий проект, внесите следующие изменения в файл build.gradle:
buildscript {
ext.cubaVersion = '7.2.0'
ext.kotlinVersion = '1.3.61' // add this line
// ...
dependencies {
classpath "com.haulmont.gradle:cuba-plugin:$cubaVersion"
classpath "org.jetbrains.kotlin:kotlin-gradle-plugin:$kotlinVersion" // add this line
classpath "org.jetbrains.kotlin:kotlin-stdlib-jdk8:$kotlinVersion" // add this line
}
}
// ...
apply(plugin: 'cuba')
apply(plugin: 'org.jetbrains.kotlin.jvm') // add this line
// ...
configure([globalModule, coreModule, webModule]) {
// ...
apply(plugin: 'cuba')
apply(plugin: 'org.jetbrains.kotlin.jvm') // add this line
dependencies {
compile("org.jetbrains.kotlin:kotlin-stdlib:$kotlinVersion") // add this line
compile("org.jetbrains.kotlin:kotlin-reflect:$kotlinVersion") // add this line
// ...Если для проекта сконфигурирована поддержка Kotlin или Groovy, то в Studio можно выбрать язык, на котором она будет герерировать код. См. Settings/Preferences > Languages & Frameworks > CUBA > Project settings > Scaffolding language.
4.3.4. Задачи сборки
Исполняемыми единицами в Gradle являются задачи (tasks). Они задаются как внутри плагинов, так и в самом скрипте сборки. Рассмотрим специфические для CUBA задачи, параметры которых могут быть сконфигурированы в build.gradle.
4.3.4.1. buildInfo
Задача buildInfo автоматически добавляется в конфигурацию модуля global плагином CUBA для Gradle. Она записывает файл build-info.properties с информацией о приложении в артефакт global (например, app-global-1.0.0.jar). Во время работы приложения, эта информация читается бином BuildInfo и отображается на экране Help > About. Данный бин может также вызываться другими механизмами для получения информации о имени, версии и т.д. приложения.
В проекте можно явно указать следующие параметры задачи:
-
appName- имя приложения. По умолчанию используется имя проекта, заданное вsettings.gradle. -
artifactGroup- группа артефактов, которая по конвенции равна корневому пакету проекта. -
version- версия приложения. По умолчанию используется версия, заданная в свойствеcuba.artifact.version. -
properties- мэп произвольных свойств. По умолчанию пусто.
Пример указания параметров задачи:
configure(globalModule) {
buildInfo {
appName = 'MyApp'
properties = ['prop1': 'val1', 'prop2': 'val2']
}
// ...4.3.4.2. buildUberJar
buildUberJar – задача типа CubaUberJarBuilding, выполняющая сборку приложения и его зависимостей в JAR-файл вместе со встроенным HTTP-сервером Jetty. Можно создать либо один all-in-one JAR, либо несколько по числу блоков приложения, используемых в проекте, например, app-core.jar для Middleware и app.jar для Web Client.
Задача должна быть объявлена в корне скрипта build.gradle. Собранные JAR-файлы находятся в подкаталоге build/distributions проекта. Руководство по запуску собранных JAR-файлов смотрите в разделе Развертывание UberJAR.
|
Эту задачу можно настроить на странице Deployment > UberJAR Settings в Studio. |
Параметры задачи:
-
appProperties- опциональный мэп свойств приложения. Эти свойства будут добавлены в файлыWEB-INF/local.app.propertiesвнутри создаваемых JAR.task buildUberJar(type: CubaUberJarBuilding) { appProperties = ['cuba.automaticDatabaseUpdate' : true] // ... } -
singleJar- если установлен вtrue, то создается единый JAR, включающий все модули проекта (core, web, portal). По умолчаниюfalse.task buildUberJar(type: CubaUberJarBuilding) { singleJar = true // ... } -
webPort- порт встроенного HTTP-сервера для единого (еслиsingleJar=true) или web JAR. Если не установлен, имеет значение8080. Может быть задан во время работы приложения с помощью аргумента командной строки-port. -
corePort- порт встроенного HTTP-сервера для core JAR. Если не установлен, имеет значение8079. Может быть задан во время работы приложения с помощью аргумента командной строки-port. -
portalPort- порт встроенного HTTP-сервера для portal JAR. Если не установлен, имеет значение8081. Может быть задан во время работы приложения с помощью аргумента командной строки-port. -
appName- имя приложения, по умолчаниюapp. Его можно изменить для всего проекта, заполнив поле Module prefix в экране Project Properties в Studio, либо установить его только для задачиbuildUberJar, использовав этот параметр, например:task buildUberJar(type: CubaUberJarBuilding) { appName = 'sales' // ... }После изменения имени приложения на
salesзадача создаст файлыsales-core.jarиsales.jar, и веб-клиент будет доступен по адресуhttp://localhost:8080/sales. Вы также можете изменить веб-контекст (последнюю часть URL после /) во время работы приложения, не изменяя заранее имени приложения, с помощью аргумента командной строки-contextName, или просто переименовав сам JAR файл. -
logbackConfigurationFile- задает относительный путь к файлу, в котором содержится конфигурация логирования.Например:
logbackConfigurationFile = "/modules/global/src/logback.xml" -
useDefaultLogbackConfiguration- пока установлено значениеtrue(по умолчанию), задача будет копировать конфигурацию из её собственного стандартного файлаlogback.xml. -
coreJettyEnvPath- содержит относительный (от корня проекта) путь к файлу, в котором содержатся определения ресурсов JNDI для HTTP-сервера Jetty.task buildUberJar(type: CubaUberJarBuilding) { coreJettyEnvPath = 'modules/core/web/META-INF/jetty-env.xml' // ... } -
webJettyConfPath- относительный путь к файлу, который будет использован в качестве файла конфигурации сервера Jetty для единого JAR (еслиsingleJar=true) или web JAR (еслиsingleJar=false). См. https://www.eclipse.org/jetty/documentation/9.4.x/jetty-xml-config.html. -
coreJettyConfPath- относительный путь к файлу, который будет использован в качестве файла конфигурации сервера Jetty для core JAR (еслиsingleJar=false), -
portalJettyConfPath- относительный путь к файлу, который будет использован в качестве файла конфигурации сервера Jetty для portal JAR (еслиsingleJar=false). -
coreWebXmlPath- относительный путь к файлу, который будет использован в качествеweb.xmlдля веб-приложения модуля core. -
webWebXmlPath- относительный путь к файлу, который будет использован в качествеweb.xmlдля веб-приложения модуля web. -
portalWebXmlPath- относительный путь к файлу, который будет использован в качествеweb.xmlдля веб-приложения модуля portal. -
excludeResources- шаблон файлов ресурсов, которые не должны быть включены в JAR. -
mergeResources- шаблон файлов ресурсов, которые необходимо объединить в JAR. -
webContentExclude- шаблон файлов ресурсов, которые не должны быть включены в web JAR. -
coreProject- проект Gradle, представляющий модуль core (Middleware). Если не установлено, используется стандартный модуль core проекта. -
webProject- проект Gradle, представляющий модуль web (Web Client). Если не установлено, используется стандартный модуль web проекта. -
portalProject- проект Gradle, представляющий модуль portal (Web Portal). Если не установлено, используется стандартный модуль portal проекта. -
frontProject- проект Gradle, представляющий модуль Фронтенд интерфейс. Если не установлено, используется стандартный модуль front проекта.
4.3.4.2.1. Добавление зависимостей
Иногда требуется, чтобы некоторые зависимости загружались до дого, как приложение будет запущено. В этом случае, необходимо объявить эти зависимости на уровне всего проекта, используя конфигурацию uberJar. В качестве примера можно рассмотреть дополнительный logback адаптер. В этом случае, скрипт для сборки будет выглядеть так:
buildscript {
//объявления для скрипта
}
dependencies {
//объявления дополнительных компонентов приложения
uberJar ('net.logstash.logback:logstash-logback-encoder:6.3')
}
//определения модулей, задач и т.д.Когда зависимость объявлена таким образом, то содержимое библиотеки logstash-logback-encoder будет распаковано и помещено в корневой каталог архива uberJar.
4.3.4.3. buildWar
buildWar - задача типа CubaWarBuilding, выполняющая сборку приложения и его зависимостей в WAR-файл. Должна быть объявлена в корне скрипта build.gradle. Собранные WAR-файлы находятся в подкаталоге build/distributions проекта.
|
Эту задачу можно настроить на странице Deployment > WAR Settings в Studio. |
Любое CUBA-приложение состоит как минимум из двух блоков: Middleware и Web Client. Поэтому наиболее естественный способ развертывания приложения это создание двух файлов WAR: один для Middleware, второй для Web Client. Это также позволяет масштабировать приложение при увеличении нагрузки. Однако раздельные WAR-файлы содержат дублированные зависимости, что увеличивает их общий размер. Кроме того, часто расширенные возможности развертывания не нужны и только усложняют процесс. Задача CubaWarBuilding может создавать WAR-файлы обоих типов: один файл на блок или единственный WAR, содержащий оба блока. В последнем случае блоки приложения загружаются в раздельные class loaders внутри одного веб-приложения.
- Создание раздельных WAR-файлов для Middleware и Web Client
-
Для создания двух отдельных WAR-файлов для Middleware и Web Client используйте следующую конфигурацию:
task buildWar(type: CubaWarBuilding) { appProperties = ['cuba.automaticDatabaseUpdate': 'true'] singleWar = false }Параметры задачи:
-
appName- имя приложения. По умолчанию совпадает с Modules prefix, например,app. -
appProperties- опциональный мэп свойств приложения. Эти свойства будут добавлены в файлы/WEB-INF/local.app.propertiesвнутри создаваемых WAR. -
singleWar- должен быть установлен вfalseдля создания раздельных WAR-файлов. -
includeJdbcDriver- включить JDBC драйвер, который используется в проекте. По умолчаниюfalse. -
includeContextXml- включить файлcontext.xml, который используется в проекте. По умолчаниюfalse. -
coreContextXmlPath- относительный путь к файлу, который должен быть использован вместо проектногоcontext.xmlесли параметрincludeContextXmlустановлен вtrue. -
hsqlInProcess- если установлен вtrue, то URL подключения к БД вcontext.xmlбудет изменен на подключение к HSQL в режиме in-process. -
coreProject- проект Gradle, представляющий модуль core (Middleware). Если не установлено, используется стандартный модуль core проекта. -
webProject- проект Gradle, представляющий модуль web (Web Client). Если не установлено, используется стандартный модуль web проекта. -
portalProject- проект Gradle, представляющий модуль portal (Web Portal). Установите данное свойство, если в проекте используется модуль portal. Например,portalProject = project(':app-portal'). -
coreWebXmlPath,webWebXmlPath,portalWebXmlPath- относительный путь к файлу, который будет использован в качествеweb.xmlсоответствующего блока приложения.Пример использования собственных
web.xml:task buildWar(type: CubaWarBuilding) { singleWar = false // ... coreWebXmlPath = 'modules/core/web/WEB-INF/production-web.xml' webWebXmlPath = 'modules/web/web/WEB-INF/production-web.xml' } -
logbackConfigurationFile- задает относительный путь к файлу, в котором содержится конфигурация логирования.Например:
task buildWar(type: CubaWarBuilding) { // ... logbackConfigurationFile = 'etc/war-logback.xml' } -
useDefaultLogbackConfiguration- пока установлено значениеtrue(по умолчанию), задача будет копировать конфигурацию из её собственного стандартного файлаlogback.xml. -
frontBuildDir- имя каталога, в который собирается собирается фронтенд интерфейс. По умолчаниюbuild. Установите данный параметр, если сборка происходит в другой каталог.
-
- Создание единого WAR-файла
-
Для создания единого файла WAR, включающего в себя блоки Middleware и Web Client, используйте следующую конфигурацию:
task buildWar(type: CubaWarBuilding) { webXmlPath = 'modules/web/web/WEB-INF/single-war-web.xml' }Следующие параметры должны быть указаны в дополнение к описанным выше:
-
singleWar- должен быть опущен или установлен вtrue. -
webXmlPath- относительный путь к файлу, который будет использован в качествеweb.xmlединого WAR. Этот файл задает два servlet context listeners, которые загружают блоки приложения:SingleAppCoreServletListenerиSingleAppWebServletListener. Все параметры инициализации передаются через параметры контекста.Пример файла
single-war-web.xml:<?xml version="1.0" encoding="UTF-8"?> <web-app xmlns="http://java.sun.com/xml/ns/javaee" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://java.sun.com/xml/ns/javaee http://java.sun.com/xml/ns/javaee/web-app_3_0.xsd" version="3.0"> <!--Application components--> <context-param> <param-name>appComponents</param-name> <param-value>com.haulmont.cuba</param-value> </context-param> <!-- Web Client parameters --> <context-param> <description>List of app properties files for Web Client</description> <param-name>appPropertiesConfigWeb</param-name> <param-value> classpath:com/company/sample/web-app.properties /WEB-INF/local.app.properties file:${app.home}/local.app.properties </param-value> </context-param> <context-param> <description>Web resources version for correct caching in browser</description> <param-name>webResourcesTs</param-name> <param-value>${webResourcesTs}</param-value> </context-param> <!-- Middleware parameters --> <context-param> <description>List of app properties files for Middleware</description> <param-name>appPropertiesConfigCore</param-name> <param-value> classpath:com/company/sample/app.properties /WEB-INF/local.app.properties file:${app.home}/local.app.properties </param-value> </context-param> <!-- Servlet context listeners that load the application blocks --> <listener> <listener-class> com.vaadin.server.communication.JSR356WebsocketInitializer </listener-class> </listener> <listener> <listener-class> com.haulmont.cuba.core.sys.singleapp.SingleAppCoreServletListener </listener-class> </listener> <listener> <listener-class> com.haulmont.cuba.web.sys.singleapp.SingleAppWebServletListener </listener-class> </listener> </web-app>
Все фильтры и сервлеты при развёртывании в единый WAR-файл необходимо программно зарегистрировать, см. Регистрация сервлетов и фильтров.
Единый WAR файл содержит только модули core и web (Middleware и Web Client). Для развертывания модуля portal используйте раздельные WAR-файлы.
При использовании в проекте модуля front при развёртывании он должен быть доступен по пути
/<appName>/front. Для того чтобы фронтенд-интерфейс корректно работал вsingleWar, необходимо поменять переменную средыPUBLIC_URL=/app/front/при сборке (например, в.env.production.local(см. README)). -
В разделе Развертывание WAR в Jetty содержатся пошаговые инструкции по некоторым вариантам развертывания WAR-файлов.
4.3.4.4. buildWidgetSet
buildWidgetSet - задача типа CubaWidgetSetBuilding, которая собирает кастомный GWT widgetset если в проекте есть модуль web-toolkit. Данный модуль позволяет разрабатывать собственные визуальные компоненты.
Доступные параметры:
-
style- стиль вывода скрипта:OBF,PRETTYилиDETAILED. По умолчаниюOBF. -
logLevel- уровень логирования:ERROR,WARN,INFO,TRACE,DEBUG,SPAM, orALL. По умолчаниюINFO. -
draft- компилировать быстро с минимумом оптимизаций. По умолчаниюfalse.
Пример использования:
task buildWidgetSet(type: CubaWidgetSetBuilding) {
widgetSetClass = 'com.company.sample.web.toolkit.ui.AppWidgetSet'
style = 'PRETTY'
}4.3.4.5. createDb
createDb - задача типа CubaDbCreation, создающая базу данных приложения путем выполнения соответствующих скриптов. Объявляется в модуле core.
Если источник данных сконфигурирован свойствами приложения, то параметры, описанные ниже, автоматически получаются из свойств приложения, поэтому определение задачи может быть пустым:
task createDb(dependsOn: assemble, description: 'Creates local database', type: CubaDbCreation) {
}Следующие параметры могут быть заданы явно:
-
storeName- имя дополнительного хранилища данных. Если не указано, то задача выполняет скрипты основного хранилища. -
dbms- тип СУБД, задаваемый в виде строкиhsql,postgres,mssql, илиoracle. -
dbName- имя базы данных. -
dbUser- имя пользователя СУБД. -
dbPassword- пароль пользователя СУБД. -
host- хост и, опционально, порт СУБД в форматеhost[:port]. Если не задан, используетсяlocalhost. -
connectionParams- опциональная строка параметров которая будет добавлена в конец URL подключения. -
masterUrl- URL для подключения при создании БД. Если не задан, используется значение по умолчанию, зависящее от типа СУБД и параметраhost. -
dropDbSql- команда SQL для удаления БД. Если не задана, используется значение по умолчанию, зависящее от типа СУБД. -
createDbSql- команда SQL для создания БД. Если не задана, используется значение по умолчанию, зависящее от типа СУБД. -
driverClasspath- список JAR файлов, содержащих JDBC драйвер. Элементы списка разделяются символом ":" на Linux и символом ";" на Windows. Если не задан, используются зависимости, входящие в конфигурациюjdbcданного модуля. Явное заданиеdriverClasspathактуально при использовании Oracle, т.к. его JDBC драйвер не присутствует в зависимостях. -
oracleSystemPassword- при использовании Oracle пароль пользователя SYSTEM.Пример для PostgreSQL:
task createDb(dependsOn: assemble, description: 'Creates local database', type: CubaDbCreation) { dbms = 'postgres' dbName = 'sales' dbUser = 'cuba' dbPassword = 'cuba' }Пример для MS SQL Server:
task createDb(dependsOn: assemble, description: 'Creates local database', type: CubaDbCreation) { dbms = 'mssql' dbName = 'sales' dbUser = 'sa' dbPassword = 'saPass1' connectionParams = ';instance=myinstance' }Пример для Oracle:
task createDb(dependsOn: assemble, description: 'Creates database', type: CubaDbCreation) { dbms = 'oracle' host = '192.168.1.10' dbName = 'orcl' dbUser = 'sales' dbPassword = 'sales' oracleSystemPassword = 'manager' driverClasspath = "$tomcatDir/lib/ojdbc6.jar" }
4.3.4.6. debugWidgetSet
debugWidgetSet - задача типа CubaWidgetSetDebug, которая запускает GWT Code Server для отладки виджетов в веб-браузере.
Пример использования:
task debugWidgetSet(type: CubaWidgetSetDebug) {
widgetSetClass = 'com.company.sample.web.toolkit.ui.AppWidgetSet'
}Убедитесь, что кофигурация runtime модуля web-toolkit содержит зависимость от библиотеки Servlet API:
configure(webToolkitModule) {
dependencies {
runtime(servletApi)
}
...См. Отладка виджетов в веб-браузере для получения информации о том как отлаживать код в веб-браузере.
4.3.4.7. deploy
deploy - задача типа CubaDeployment, выполняющая быстрое развертывание модуля в Tomcat. Объявляется в модулях core, web, portal. Параметры:
-
appName- имя веб-приложения, которое будет создано из модуля. Фактически это имя подкаталога внутриtomcat/webapps. -
jarNames- список имен JAR файлов (без версии), получающихся в результате сборки модуля, которые надо поместить в каталогWEB-INF/libвеб-приложения. Все остальные артефакты модуля и зависимостей будут записаны вtomcat/shared/lib.
Например:
task deploy(dependsOn: assemble, type: CubaDeployment) {
appName = 'app-core'
jarNames = ['cuba-global', 'cuba-core', 'app-global', 'app-core']
}4.3.4.8. deployThemes
deployThemes - задача типа CubaDeployThemeTask, выполняющая сборку и развертывание определенных в проекте тем в запущенное веб-приложение, развернутое задачей deploy. Изменения в темах применяются без рестарта сервера.
Например:
task deployThemes(type: CubaDeployThemeTask, dependsOn: buildScssThemes) {
}4.3.4.9. deployWar
deployWar - задача типа CubaJelasticDeploy, выполняющая развёртывание WAR-файла на сервер Jelastic.
Пример использования:
task deployWar(type: CubaJelasticDeploy, dependsOn: buildWar) {
email = '<your@email.address>'
password = '<your password>'
context = '<app contex>'
environment = '<environment name or ID>'
hostUrl = '<Host API url>'
}Параметры задачи:
-
appName- имя приложения. По умолчанию совпадает с Modules prefix, например,app. -
email- логин учётной записи сервера Jelastic. -
password- пароль учётной записи сервера Jelastic. -
context- контекст приложения. Значение по умолчанию:ROOT. -
environment- окружение, в которое будет развернут WAR. Можно указать как имя, так и ID окружения. -
hostUrl- URL-адрес API хостинга. Обычно этоapp.jelastic.<host name>. -
srcDir- директория, в которой находится WAR. По умолчанию это"${project.buildDir}/distributions/war".
4.3.4.10. restart
restart - задача, выполняющая остановку, быстрое развертывание и старт локального сервера Tomcat.
4.3.4.11. setupTomcat
setupTomcat - задача типа CubaSetupTomcat, выполняющая установку и инициализацию локального сервера Tomcat для последующего быстрого развертывания приложения. Эта задача автоматически добавляется в проект при подключении плагина сборки cuba, поэтому объявлять ее в build.gradle не нужно. Каталог установки Tomcat задается свойством tomcat.dir секции cuba. По умолчанию это подкаталог build/tomcat проекта.
4.3.4.12. start
start - задача типа CubaStartTomcat, выполняющая запуск локального сервера Tomcat, установленного задачей setupTomcat. Эта задача автоматически добавляется в проект при подключении плагина cuba, поэтому объявлять ее в build.gradle не нужно.
4.3.4.13. startDb
startDb - задача типа CubaHsqlStart, выполняющая запуск локального сервера HSQLDB. Параметры:
-
dbName- имя базы данных, по умолчаниюcubadb. -
dbDataDir- каталог, в котором размещена база данных, по умолчанию подкаталогdeploy/hsqldbпроекта. -
dbPort- порт сервера, по умолчанию 9001.
Например:
task startDb(type: CubaHsqlStart) {
dbName = 'sales'
}4.3.4.14. stop
stop - задача типа CubaStopTomcat, выполняющая остановку локального сервера Tomcat, установленного задачей setupTomcat. Эта задача автоматически добавляется в проект при подключении плагина cuba, поэтому объявлять ее в build.gradle не нужно.
4.3.4.15. stopDb
stopDb - задача типа CubaHsqlStop, выполняющая остановку локального сервера HSQLDB. Параметры аналогичны задаче startDb.
4.3.4.16. tomcat
tomcat – задача типа Exec, выполняющая запуск локального сервера Tomcat в текущем окне терминала, которое остаётся открытым даже в случае ошибок при старте. Это упрощает диагностику ошибок запуска Tomcat, например, связанных с версией Java.
4.3.4.17. updateDb
updateDb - задача типа CubaDbUpdate, обновляющая базу данных приложения путем выполнения соответствующих скриптов. Аналогична задаче createDb, за исключением отсутствия параметров dropDbSql и createDbSql.
Если источник данных сконфигурирован свойствами приложения, то параметры, описанные ниже, автоматически получаются из свойств приложения, поэтому определение задачи может быть пустым:
task updateDb(dependsOn: assembleDbScripts, description: 'Updates local database', type: CubaDbUpdate) {
}Для задачи можно явно установить параметры, описанные для createDb (кроме dropDbSql и createDbSql).
4.3.4.18. zipProject
zipProject - задача типа CubaZipProject, создающая ZIP-архив проекта. Архив не будет содержать проектные файлы IDE, результаты сборки и сервер Tomcat. Однако база данных HSQL включается в архив (если присутствует в подкаталоге build).
Эта задача автоматически добавляется в проект при подключении плагина сборки cuba, поэтому объявлять ее в build.gradle не нужно.
4.3.5. Запуск задач сборки
Задачи (tasks) Gradle, описанные в скриптах сборки, запускаются на исполнение следующими способами:
-
Если работа с проектом ведется с помощью CUBA Studio, то многие команды, которые запускаются из главного меню CUBA, делегируют выполнение задачам Gradle: это все команды пункта Build Tasks, команды Start/Stop/Restart Application Server и Create/Update Database.
-
С помощью исполняемого скрипта
gradlew(Gradle wrapper), включенного в проект. -
С помощью установленного вручную Gradle версии 5.6.4. В этом случае используется исполняемый файл
gradle, находящийся в подкаталогеbinустановленного Gradle.
Например, чтобы выполнить компиляцию Java файлов и сборку JAR файлов артефактов проекта, необходимо запустить следующую команду:
Windows:
gradlew assemble
Linux & macOS:
./gradlew assemble|
Если ваш проект использует премиум-дополнения, и вы запускаете сборку вне Studio, необходимо передать в Gradle имя и пароль доступа к премиум-репозиторию. См. раздел выше для получения подробной информации. |
Рассмотрим типичные задачи сборки в обычном порядке их использования.
-
assemble- выполнить компиляцию Java файлов и сборку JAR файлов артефактов проекта в подкаталогахbuildмодулей. -
clean- удалить подкаталогиbuildвсех модулей проекта. -
setupTomcat - установить сервер Tomcat в путь, заданный свойством
cuba.tomcat.dirскриптаbuild.gradle. -
deploy - быстрое развертывание приложения на сервере Tomcat, предварительно установленном задачей
setupTomcat. -
createDb - создание базы данных приложения и выполнение соответствующих скриптов.
-
updateDb - обновление существующей базы данных приложения путем выполнения соответствующих скриптов.
-
start - запуск сервера Tomcat.
-
stop - остановка запущенного сервера Tomcat.
-
restart - последовательное выполнение задач
stop,deploy,start.
4.3.6. Установка приватного репозитория артефактов
В этом разделе рассказывается, как установить приватный Maven репозиторий, чтобы использовать его для хранения артефактов платформы и других зависимостей, вместо публичного репозитория CUBA. Это рекомендуется делать в следующих случаях:
-
У вас нестабильное или слабое интернет-соединение. Несмотря на то что Gradle кэширует артефакты на компьютере разработчика, время от времени все-таки необходимо подключаться к репозиторию артефактов, например, при первом запуске проекта или при переключении на новую версию платформы.
-
У вас ограничен доступ к интернету из-за политики безопасности организации.
-
Вы не собираетесь продлевать подписку на премиум-дополнения, но вы бы хотели продолжить разработку вашего приложения в будущем, используя загруженные версии артефактов.
Процесс установки приватного репозитория состоит из следующих шагов:
-
Разверните локальный менеджер репозиториев, подключенный к интернету.
-
Настройте приватный репозиторий как прокси для публичного репозитория CUBA.
-
Настройте build-скрипт вашего проекта на использование приватного репозитория. Это можно сделать через Studio, либо через правку файла
build.gradle. -
Выполните полную сборку проекта, чтобы все необходимые артефакты закэшировались в приватный репозиторий.
-
Если требуется разрабатывать приложение CUBA в изолированной сети, то установите еще одну копию менеджера репозиториев в изолированной сети и скопируйте в него содержимое кэша из первого репозитория.
4.3.6.1. Установка менеджера репозиториев
В данном руководстве будет рассмотрен пример установки менеджера репозитория Sonatype Nexus OSS.
- В операционной системе Microsoft Windows
-
-
Скачайте на компьютер программу Sonatype Nexus OSS версии 2.x (протестирована версия 2.14.3)
-
Распакуйте архив в папку
c:\nexus-2.14.3-02 -
Измените параметры в файле настроек
c:\nexus-2.14.3-02\conf\nexus.properties-
Вы можете указать сетевой порт, по умолчанию установлен 8081
-
Настройте путь к папке с данными кэша:
замените
nexus-work=${bundleBasedir}/../sonatype-work/nexusна
nexus-work=${bundleBasedir}/nexus/sonatype-work/content
-
-
Перейдите в папку
c:\nexus-2.14.3-02\bin -
Чтобы иметь возможность запускать nexus как службу, установите wrapper (запустите команду с правами Администратора):
nexus.bat install -
Запустите службу nexus.
-
Откройте в браузере адрес
http://localhost:8081/nexusи войдите, используя данные по умолчанию: логинadminи парольadmin123.
-
- С помощью Docker
-
Локальный репозиторий можно также легко установить с помощью Docker. См. инструкции на Docker Hub.
-
Запустите
docker pull sonatype/nexus:ossчтобы загрузить свежий образ. -
Запустите контейнер:
docker run -d -p 8081:8081 --name nexus sonatype/nexus:oss -
Контейнер будет готов к использованию в течение нескольких минут. Его работоспобность можно проверить следующими способами:
-
curl http://localhost:8081/nexus/service/local/status -
Открыть
http://localhost:8081/nexusв веб-браузере.
-
-
Логин
admin, парольadmin123.
-
4.3.6.2. Настройка прокси-репозитория
Щелкните на ссылку Repositories в панели слева.
На открывшейся странице нажмите кнопку Add, затем выберите пункт Proxy Repository. Будет создан новый репозиторий. Заполните обязательные поля на вкладке Configuration:
-
Repository ID:
cuba-work -
Repository Name:
cuba-work -
Provider:
Maven2 -
Remote Storage Location:
https://repo.cuba-platform.com/content/groups/work -
Отключите опцию Auto Blocking Enabled:
false -
Включите опцию Authentication, задайте имя пользователя Username:
cuba, пароль Password:cuba123 -
Нажмите кнопку Save.
Создайте группу репозиториев. В Nexus нажмите кнопку Add, затем выберите Repository Group и проделайте следующие шаги на вкладке Configuration:
-
Введите Group ID:
cuba-group -
Введите Group Name:
cuba-group -
Выберите Provider:
Maven2 -
Перенесите репозиторий cuba-work из Available Repositories в Ordered Group Repositories
-
Нажмите кнопку Save.
Если у вас есть подписка на Премиум-дополнения, то создайте еще один репозиторий со следующими настройками:
-
Repository ID:
cuba-premium -
Repository Name:
cuba-premium -
Provider:
Maven2 -
Remote Storage Location:
https://repo.cuba-platform.com/content/groups/premium -
Отключите опцию Auto Blocking Enabled:
false -
Включите опцию Authentication, используйте первую часть лицензионного ключа (до дефиса) в поле Username и вторую часть ключа (после дефиса) в поле Password
-
Нажмите кнопку Save
-
Нажмите кнопку Refresh
-
Щелкните по репозиторию cuba-group
-
На вкладке Configuration добавьте репозиторий cuba-premium в группу cuba-group следом за репозиторием cuba-work
-
Нажмите кнопку Save.
4.3.6.3. Использование приватного репозитория
Теперь приватный репозиторий готов к работе. Найдите URL группы cuba-group в верхней части экрана, например:
http://localhost:8081/nexus/content/groups/cuba-group
-
Найдите список зарегистрированных репозиториев в Studio. Если вы создаете новый проект, он находится в окне New Project. Для существующего проекта, откройте CUBA > Project Properties.
-
В диалоге создания репозитория, введите URL репозитория и имя/пароль доступа к нему:
admin / admin123. -
После сохранения информации о репозитории, выберите его для использования в проекте путем отметки флажка в списке.
-
Сохраните изменения в свойствах проекта или продолжите мастер создания нового проекта.
Во время первой сборки проекта ваш новый репозиторий скачает артефакты и сохранит их в кэше для дальнейшего использования. Вы можете найти эти файлы в папке c:\nexus-2.14.3-02\sonatype-work.
4.3.6.4. Репозиторий в изолированной сети
Если вам требуется разработка приложения CUBA в сети без доступа к Интернет, то проделайте следующие шаги:
-
Разверните копию менеджера репозиториев в указанной сети.
-
Скопируйте содержимое репозитория из открытой сети в изолированную. Если вы следовали инструкциям выше, то данные находятся в папке
c:\nexus-2.14.3-02\sonatype-work
-
Перезапустите службу nexus.
Если вам нужно добавить артефакты от новой платформы в изолированный репозиторий, вам потребуется вернуться в окружение, подключенное к интернету, затем выполнить сборку проекта через онлайн-репозиторий и скопировать содержимое кэша репозитория в изолированное окружение.
4.4. Создание проекта
Рекомендуемый способ создания нового проекта - использование CUBA Studio. Пример рассмотрен в руководстве Быстрый старт.
Также можно легко создать проект в CUBA CLI:
-
Откройте любой терминал и запустите CUBA CLI.
-
Введите команду
create-app. Работает авто-дополнение по нажатию TAB. -
CLI поможет настроить конфигурацию проекта. Вы можете выбрать свои опции или принять конфигурацию по умолчанию, нажимая ENTER на каждом шаге:
-
Project name – имя проекта. Для тестовых проектов CLI генерирует случайные имена, которые можно выбрать по умолчанию.
-
Project namespace – пространство имен, которое будет использоваться как префикс имен сущностей и таблиц базы данных. Пространство имен может состоять только из латинских букв, и должно быть как можно короче.
-
Platform version – используемая в проекте версия платформы. Артефакты платформы будут автоматически загружены из репозитория при сборке проекта.
-
Root package – корневой пакет Java-классов.
-
Database – тип базы данных SQL.
-
После этого в текущем каталоге будет создан подкаталог с проектом.
После создания проекта вы можете продолжить разрабатывать его в Studio или с помощью CLI и любой IDE.
4.5. Работа с компонентами приложений
Любое CUBA-приложение может быть компонентом другого приложения. Компонент приложения представляет собой по сути full-stack библиотеку, предоставляющую функциональность на всех уровнях - от схемы БД до бизнес-логики и UI.
Компоненты, опубликованные в маркетплейсе CUBA в качестве аддонов, расширяют функциональность фреймворка и могут быть использованы в любом приложении, созданном на платформе.
4.5.1. Использование публичных аддонов
Аддоны, доступные на маркетплейсе CUBA, можно добавить к приложению одним из способов, описанных ниже. Первый и второй способы подразумевают, что в приложении настроен доступ к одному из стандартных репозиториев CUBA. Третий подход применим к аддонам с открытым исходным кодом и не требует подключения к какому-либо удалённому репозиторию.
- Подключение из Studio
-
Если вы используете CUBA Studio 11+, управляйте аддонами в окне CUBA Add-Ons, как это описано в документации по Studio.
Для предыдущих версий CUBA Studio выполните следующие действия:
-
Откройте экран Project properties и на панели App components нажмите на кнопку со знаком плюс рядом с Custom components.
-
Скопируйте координаты аддона из маркетплейса или документации к аддону и вставьте их в поле координат компонента, например:
com.haulmont.addon.cubajm:cuba-jm-global:0.3.1 -
Нажмите OK в диалоговом окне. Studio попытается найти бинарные артефакты аддона в репозитории, используемом в проекте в настоящий момент. Если они найдены, диалоговое окно закроется, и аддон появится в списке собственных компонентов.
-
Сохраните изменения в свойствах проекта нажатием OK.
-
- Добавление вручную
-
-
Откройте файл
build.gradleна редактирование и добавьте координаты аддона в секциюdependencies:dependencies { appComponent("com.haulmont.cuba:cuba-global:$cubaVersion") // your add-ons go here appComponent("com.haulmont.addon.cubajm:cuba-jm-global:0.3.1") } -
Обновите проект Gradle в вашей IDE, например, выбрав пункт CUBA → Re-Import Gradle Project в главном меню Studio, чтобы добавить аддон к окружению проекта.
-
Добавьте в файлы
web.xmlмодулейcoreиwebидентификатор аддона (он совпадает с Maven groupId) в параметр контекстаappComponentsк списку компонентов приложения, разделённому пробелами:<context-param> <param-name>appComponents</param-name> <param-value>com.haulmont.cuba com.haulmont.addon.cubajm</param-value> </context-param>
-
- Сборка из исходников
-
-
Склонируйте репозиторий аддона в локальный каталог и откройте проект аддона в Studio.
-
Выполните команду CUBA > Advanced > Install app component в главном меню Studio, чтобы установить аддон в локальный репозиторий Maven (по умолчанию это каталог
~/.m2). -
Откройте основной проект в Studio и добавьте локальный репозиторий Maven к списку используемых репозиториев в экране настроек проекта Project properties.
-
Добавьте аддон в проект используя диалог CUBA Add-ons в Studio. Подробнее см. Установка аддона по координатам в секции Управление аддонами Руководства пользователя CUBA Studio.
-
Нажмите OK в диалоге и сохраните изменения.
-
|
Если в проекте используется несколько аддонов, имеющих модуль web-toolkit, то в проекте также должен быть модуль web-toolkit. Если его нет, то в приложение загружается только один набор виджетсетов из одного аддона. Таким образом, модуль web-toolkit необходим для интеграции всех виджетсетов из используемых аддонов. |
4.5.2. Создание компонентов приложения
В этом разделе описаны рекомендации по созданию компонентов приложения с целью повторного использования.
- Правила именования
-
-
Имя корневого пакета должно следовать нотации reverse-DNS, например,
com.jupiter.amazingsearch.Имя корневого пакета не должно начинаться с имени любого другого компонента или приложения. К примеру, если корневой пакет вашего приложения
com.jupiter.tickets, вы НЕ можете использовать пакетcom.jupiter.tickets.amazingsearchдля компонента. Это обусловлено тем, что Spring сканирует classpath бинов, начиная с указанного корневого пакета, и это сканирование должно быть уникальным для всех компонентов. -
Пространство имён используется в качестве префикса таблиц в базе данных, поэтому для публичных компонентов оно должно быть составным, к примеру,
jptams, а не простоsearch. Это минимизирует риск совпадения имён между компонентов и конечным приложением. В пространстве имён запрещено использовать нижние подчёркивания и дефисы, только буквы и цифры. -
Значение Module prefix должно повторять пространство имён, но может при этом содержать дефисы, например,
jpt-amsearch. -
Используйте namespace в качестве префикса имён бинов и свойств приложения, например:
@Component("jptams_Finder") @Property("jptams.ignoreCase")
-
- Установка в локальный Maven-репозиторий
-
Чтобы сделать компонент доступным для использования в проектах, расположенных на том же компьютере, установите его в локальный репозиторий Maven, выполнив команду CUBA > Advanced > Install app component в меню Studio. Данная команда просто запускает задачу Gradle
installпосле остановки демонов Gradle.
- Загрузка в удалённый Maven-репозиторий
-
-
Создайте репозиторий, следуя инструкции в разделе Установка приватного репозитория артефактов.
-
Укажите репозиторий и данные для входа в настройках вашего проекта вместо стандартного репозитория CUBA.
-
Откройте файл
build.gradleпроекта компонента на редактирование и добавьте секциюuploadRepositoryв секциюcuba:cuba { //... // repository for uploading your artifacts uploadRepository { url = 'http://repo.company.com/nexus/content/repositories/snapshots' user = 'admin' password = 'admin123' } } -
Откройте проект компонента в Studio.
-
Выполните задачу Gradle
uploadArchivesиз командной строки. Артефакты компонента будут загружены в ваш репозиторий. -
Удалите артефакты проекта из локального Maven-репозитория, чтобы убедиться, что они будут загружены из удалённого репозитория при следующей сборке проекта приложения. Для этого просто удалите папку
.m2/repository/com/companyиз домашнего каталога пользователя. -
Теперь при сборке и запуске приложения, использующего этот компонент, он будет скачиваться из удалённого репозитория.
-
4.5.3. Пример создания и использования компонента
В данном разделе рассматривается пример создания и использования в проекте компонента приложения. Компонент будет предоставлять функциональность "Customer Management" и содержать сущность Customer и соответствующие экраны UI. Приложение будет использовать сущность Customer из компонента в качестве ссылки в собственной сущности Order.
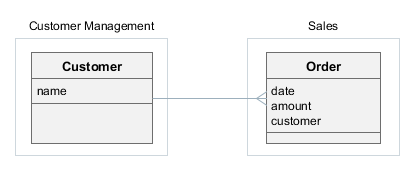
- Создание компонента Customer Management
-
-
Создайте новый проект в Studio и укажите следующие значения в окне New project:
-
Project name –
customers -
Project namespace –
cust -
Root package –
com.company.customers
-
-
Откройте экран Project Properties и установите значение поля Module prefix в
cust. -
Создайте сущность
Customerс атрибутомname.Если компонент содержит персистентные классы, аннотированные
@MappedSuperclass, убедитесь, что в этом же проекте есть их наследники, являющиеся сущностями (т.е. аннотированные@Entity). В противном случае байткод таких базовых классов не будет необходимым образом модифицирован, и они не будут правильно работать в приложениях, использующих компонент. -
Сгенерируйте скрипты БД и создайте стандартные экраны для сущности
Customer:cust_Customer.browseиcust_Customer.edit. -
Перейдите в дизайнер меню и переименуйте пункт меню
application-custвcustomerManagement. Затем в файлеmessages.propertiesглавного пакета сообщений укажите новый заголовок для пункта менюcustomerManagement. -
Сгенерируйте описатель компонента – файл
app-component.xml, выбрав пункт CUBA > Advanced > App Component Descriptor в главном меню Studio. -
Проверьте функциональность Customer Management:
-
Выберите пункт меню CUBA > Create Database.
-
Запустите приложение: кликните на кнопку "debug" рядом с выбранной конфигурацией
CUBA Applicationв главной панели инструментов. -
Откройте
http://localhost:8080/custв веб-браузере.
-
-
Установите компонент приложения в локальный Maven-репозиторий, выбрав пункт главного меню CUBA > Advanced > Install App Component.
-
- Создание приложения Sales
-
-
Создайте новый проект в Studio и укажите следующие значения в окне New project:
-
Project name –
sales -
Project namespace –
sales -
Root package –
com.company.sales
-
-
Откройте экран настроек Project Properties и включите флажок Use local Maven repository.
-
Добавьте компонент в проект как описано в разделе Установка аддона по координатам section of the Руководства пользователя Studio. Используйте Maven-координаты компонента Customer Management, например,
com.company.customers:cust-global:0.1-SNAPSHOT. -
Создайте сущность
Orderс атрибутамиdateиamount. Добавьте атрибутcustomerв виде many-to-one ассоциации с сущностьюCustomer– она должна быть доступна в выпадающем списке Type. -
Сгенерируйте скрипты БД и создайте стандартные экраны для сущности
Order. При создании экранов создайте представлениеorder-with-customer-view, включающее атрибутcustomer, и используйте его в экранах. -
Проверьте функциональность приложения:
-
Выберите пункт меню CUBA > Create Database.
-
Запустите приложение: кликните на кнопку "debug" рядом с выбранной конфигурацией
CUBA Applicationв главной панели инструментов. -
Откройте
http://localhost:8080/appв веб-браузере. Приложение должно содержать два пункта меню верхнего уровня: Customer Management и Application.
-
-
- Модификация компонента Customer Management
-
Предположим, что необходимо изменить функциональность компонента (добавить атрибут в сущность
Customer) и пересобрать приложение для внесения этих изменений.-
Откройте проект
customersв Studio. -
Откройте сущность
Customerна редактирование и добавьте атрибутaddress. Включите этот атрибут в экраны браузера и редактора. -
Сгенерируйте скрипты БД – будет создан новый скрипт обновления с изменением таблицы. Сохраните скрипты.
-
Проверьте изменения в компоненте:
-
Выберите пункт меню CUBA > Update Database.
-
Запустите приложение: кликните на кнопку "debug" рядом с выбранной конфигурацией
CUBA Applicationв главной панели инструментов. -
Откройте
http://localhost:8080/custв веб-браузере.
-
-
Переустановите компонент в локальный Maven-репозиторий, выбрав пункт меню CUBA > Advanced > Install App Component.
-
Переключитесь в проект
salesв Studio. -
Выберите пункт меню CUBA > Build Tasks > Clean.
-
Выберите пункт меню CUBA > Update Database – будет выполнен скрипт обновления из компонента Customer Management.
-
Запустите приложение: кликните на кнопку "debug" рядом с выбранной конфигурацией
CUBA Applicationв главной панели инструментов. -
Откройте
http://localhost:8080/appв веб-браузере – приложение теперь содержит сущностьCustomerи соответствующие экраны с атрибутомaddress.
-
4.5.4. Дополнительные хранилища в компонентах приложения
Если компонент использует дополнительное хранилище данных, то в приложении необходимо определить хранилище с таким же именем и такого же типа. Например, если компонент использует хранилище db1, соединенное с базой данных PostgreSQL, то в приложении также должно быть хранилище с именем db1 типа PostgreSQL.
Если вы используете Studio, то просто создайте дополнительное хранилище как описано в документации Studio. В противном случае, воспользуйтесь рекомендациями раздела Data Stores.
4.5.5. Регистрация DispatcherServlet из компонента приложения
В этом разделе мы рассмотрим, как настроить динамическую регистрацию сервлетов и фильтров, настроенных в компоненте приложения, в родительском приложении. Чтобы избежать дублирования кода в файле конфигурации web.xml, необходимо зарегистрировать сервлеты и фильтры с помощью специального бина ServletRegistrationManager.
Простой пример такой регистрации рассмотрен на примере HTTP-сервлета. Здесь мы рассмотрим более сложный случай: частную реализацию сервлета DispatcherServlet в компоненте приложения. Этот сервлет будет загружать параметры своей конфигурации из файла demo-dispatcher-spring.xml, поэтому, чтобы попробовать этот пример на практике, вы должны создать пустой файл с этим именем в корневом каталоге ресурсов проекта (например, web/src).
public class WebDispatcherServlet extends DispatcherServlet {
private volatile boolean initialized = false;
@Override
public String getContextConfigLocation() {
String configFile = "demo-dispatcher-spring.xml";
File baseDir = new File(AppContext.getProperty("cuba.confDir"));
String[] tokenArray = new StrTokenizer(configFile).getTokenArray();
StringBuilder locations = new StringBuilder();
for (String token : tokenArray) {
String location;
if (ResourceUtils.isUrl(token)) {
location = token;
} else {
if (token.startsWith("/"))
token = token.substring(1);
File file = new File(baseDir, token);
if (file.exists()) {
location = file.toURI().toString();
} else {
location = "classpath:" + token;
}
}
locations.append(location).append(" ");
}
return locations.toString();
}
@Override
protected WebApplicationContext initWebApplicationContext() {
WebApplicationContext wac = findWebApplicationContext();
if (wac == null) {
ApplicationContext parent = AppContext.getApplicationContext();
wac = createWebApplicationContext(parent);
}
onRefresh(wac);
String attrName = getServletContextAttributeName();
getServletContext().setAttribute(attrName, wac);
if (this.logger.isDebugEnabled()) {
this.logger.debug("Published WebApplicationContext of servlet '" + getServletName() +
"' as ServletContext attribute with name [" + attrName + "]");
}
return wac;
}
@Override
public void init(ServletConfig config) throws ServletException {
if (!initialized) {
super.init(config);
initialized = true;
}
}
@Override
protected void service(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
_service(response);
}
@Override
public void service(ServletRequest req, ServletResponse res) throws ServletException, IOException {
_service(res);
}
private void _service(ServletResponse res) throws IOException {
String testMessage = AppContext.getApplicationContext().getBean(Messages.class).getMainMessage("testMessage");
res.getWriter()
.write("WebDispatcherServlet test message: " + testMessage);
}
}Чтобы зарегистрировать DispatcherServlet, вам нужно вручную загрузить класс, создать его экземпляр и проинициализировать его, в противном случае использование разных типов ClassLoader может вызвать проблемы при развёртывании в SingleWAR/SingleUberJAR. Кроме того, собственная реализация DispatcherServlet должна выдерживать двойную инициализацию - сначала вручную, а затем с помощью servlet container.
Пример компонента для инициализации WebDispatcherServlet:
@Component
public class WebInitializer {
private static final String WEB_DISPATCHER_CLASS = "com.demo.comp.web.WebDispatcherServlet";
private static final String WEB_DISPATCHER_NAME = "web_dispatcher_servlet";
private final Logger log = LoggerFactory.getLogger(WebInitializer.class);
@Inject
private ServletRegistrationManager servletRegistrationManager;
@EventListener
public void initialize(ServletContextInitializedEvent e) {
Servlet webDispatcherServlet = servletRegistrationManager.createServlet(e.getApplicationContext(), WEB_DISPATCHER_CLASS);
ServletContext servletContext = e.getSource();
try {
webDispatcherServlet.init(new AbstractWebAppContextLoader.CubaServletConfig(WEB_DISPATCHER_NAME, servletContext));
} catch (ServletException ex) {
throw new RuntimeException("Failed to init WebDispatcherServlet");
}
servletContext.addServlet(WEB_DISPATCHER_NAME, webDispatcherServlet)
.addMapping("/webd/*");
}
}Метод createServlet() инжектированного бина ServletRegistrationManager принимает контекст приложения, полученный из события ServletContextInitializedEvent, и полное имя класса WebDispatcherServlet. Для инициализации сервлета мы передаём экземпляр ServletContext, также полученный из события ServletContextInitializedEvent, и имя сервлета.
Сервлет регистрируется с маппингом webd и будет доступен по адресу /app/webd/ или /app-core/webd/ в зависимости от контекста приложения.
4.6. Использование профилей Spring
Профили Spring позволяют кастомизировать приложение для работы в различном окружении. В зависимости от активного профиля можно инстанциировать различные реализации одного и того же бина, а также присваивать различные значения свойствам приложения.
Если Spring-бин имеет аннотацию @Profile, он будет инстанциирован только если указанный в аннотации профиль соответствует какому-либо активному профилю. В примере ниже SomeDevServiceBean будет использован когда активен профиль dev, а SomeProdServiceBean будет использован когда активен профиль prod:
public interface SomeService {
String NAME = "demo_SomeService";
String hello(String input);
}
@Service(SomeService.NAME)
@Profile("dev")
public class SomeDevServiceBean implements SomeService {
@Override
public String hello(String input) {
return "Service stub: hello " + input;
}
}
@Service(SomeService.NAME)
@Profile("prod")
public class SomeProdServiceBean implements SomeService {
@Override
public String hello(String input) {
return "Real service: hello " + input;
}
}Для того, чтобы определить некоторые специфичные для профиля свойства приложения, создайте файл <profile>-app.properties (или <profile>-web-app.properties для web модуля) в том же пакете, что и основной файл app.properties.
Например, для core модуля:
com/company/demo/app.properties
com/company/demo/prod-app.propertiesДля web модуля:
com/company/demo/web-app.properties
com/company/demo/prod-web-app.propertiesСпецифичный для профиля файл будет загружен сразу после базового файла, поэтому объявленные в нем свойства переопределят свойства, заданные в базовом файле. В примере ниже для профиля prod задаются параметры подключения к некоторой базе данных:
prod-app.properties
cuba.dbmsType = postgres
cuba.dataSourceProvider = application
cuba.dataSource.dbName = my-prod-db
cuba.dataSource.host = my-prod-host
cuba.dataSource.username = cuba
cuba.dataSource.password = cubaСписок активных профилей задается для приложения следующими способами:
-
В servlet context параметре
spring.profiles.activeв файлеweb.xml, например:<web-app ...> <context-param> <param-name>spring.profiles.active</param-name> <param-value>prod</param-value> </context-param> -
В системном свойстве Java
spring.profiles.active. Например, при запуске Uber JAR:java -Dspring.profiles.active=prod -jar app.jar
4.7. Логирование
Для ведения логов в платформе используется фреймворк Logback.
|
Руководство Logging in CUBA Applications показывает, как ведение логов интегрируется, настраивается и просматривается в виде части самого приложения или с помощью внешних инструментов. |
Для вывода в лог используйте SLF4J API, получая логгер по имени текущего класса. Пример создания логгера и вывода в него:
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
public class Foo {
// create logger
private static Logger log = LoggerFactory.getLogger(Foo.class);
private void someMethod() {
// output message with DEBUG level
log.debug("invoked someMethod");
}
}- Конфигурация логирования
-
Конфигурация логирования задается в файле
logback.xml.-
На этапе разработки, данный файл можно найти в каталоге
deploy/app_homeпроекта после выполнения быстрого развертывания. Файлы логов создаются в каталогеdeploy/app_home/logs.Имейте в виду, что каталог
deployне внесен в Git, и может быть удален и пересоздан в любой момент, поэтому изменения, внесенные в файлы этого каталога могут быть легко потеряны.Если вы хотите внести постоянные изменения в конфигурацию логирования, используемую при разработке, создайте файл
etc/logback.xml(его можно скопировать из исходногоdeploy/app_home/logback.xmlи изменить как требуется). Этот файл будет копироваться вdeploy/app_homeкаждый раз, когда вы запускаете приложение в Studio или выполняете задачу Gradledeploy:my_project/ deploy/ app_home/ logback.xml ... etc/ logback.xml - if exists, will be automatically copied to deploy/app_home -
При создании архивов WAR и UberJAR,
logback.xmlможно предоставить с помощью указания относительного пути к нужному файлу в параметреlogbackConfigurationFileзадач buildWar и buildUberJar. Если данный параметр не указан, в WAR/UberJar будет встроена конфигурация логирования по умолчанию.Имейте в виду, что файл
etc/logback.xml, созданный вами для конфигурации этапа разработки, не будет использован по умолчанию для WAR/UberJar, т.е. необходимо указать файл явно:my_project/ etc/ logback.xml war-logback.xmlbuild.gradletask buildWar(type: CubaWarBuilding) { // ... logbackConfigurationFile = 'etc/war-logback.xml' } -
На этапе эксплуатации встроенную в WAR/UberJAR конфигурацию логирования можно переопределить, положив файл
logback.xmlс нужными настройками в домашний каталог приложения.Файл
logback.xmlв домашнем каталоге приложения будет распознан только если системное свойствоapp.homeуказано в командной строке. Это не сработает, если домашний каталог будет установлен автоматически вtomcat/work/app_homeили~/.app_home.
-
- logback.xml structure
-
Рассмотрим структуру файла
logback.xml.-
Элементы
appenderзадают "устройства вывода" логов. Основными аппендерами являютсяFILEиCONSOLE. В параметреlevelэлементаfilterможно задать порог уровня сообщения. По умолчанию порог для файла -DEBUG, для консоли -INFO. Это означает, что в файл выводятся сообщения с уровнямиERROR,WARN,INFO,DEBUG, а в консоль - с уровнямиERROR,WARNиINFO.Для файлового аппендера в элементе
fileзадается путь к файлу лога. -
Элементы
loggerзадают параметры логгеров, через которые производится посылка сообщений из кода программы. Имена логгеров иерархические, то есть например настройки для логгераcom.company.sampleвлияют на логгерыcom.company.sample.core.CustomerServiceBean,com.company.sample.web.CustomerBrowse, если для них явно не заданы собственные настройки.Минимальный уровень указывается в атрибуте
level. Например, если для логгера задан приоритетINFO, то сообщения с уровнямиDEBUGиTRACEвыводиться не будут. Следует иметь в виду, что на вывод сообщения также влияет порог уровня, заданный в аппендере.
Оперативно изменять уровни для логгеров и пороги аппендеров для работающего сервера можно с помощью экрана Administration > Server Log, доступного в веб-клиенте. Сделанные настройки логирования действуют только в текущем сеансе работы сервера и в файл не сохраняются. Этот экран позволяет также просматривать и загружать файлы логов из каталога журналов сервера.
-
- Log message format
-
Платформа автоматически добавляет к сообщениям, выводимым в лог, следующую информацию:
-
приложение - имя веб приложения, развернутого в Tomcat, код которого выводит данное сообщение. Эта информация помогает различить сообщения от разных блоков приложения (Middleware, Web Client), так как они выводятся в один файл.
-
пользователь - логин пользователя приложения, от имени которого в данный момент работает код, выводящий сообщение. Это позволяет в общем логе отслеживать активность конкретных пользователей. Если код, выводящий сообщение, не связан в момент вывода с пользовательской сессией, информация о пользователе не выводится.
Например, следующее сообщение в логе выведено кодом блока Middleware (
app-core), работающим от имени пользователяadmin:16:12:20.498 DEBUG [http-nio-8080-exec-7/app-core/admin] com.haulmont.cuba.core.app.DataManagerBean - loadList: ... -
4.7.1. Полезные логгеры
В данном разделе приведен список логгеров фреймворка, которые могут быть полезны при поиске проблем в приложении.
- eclipselink.sql
-
При установке в
DEBUG, EclipseLink ORM логгирует все SQL-операторы и время их выполнения. Данный логгер уже определен в стандартномlogback.xml, поэтому достаточно только изменить его уровень. Например:<configuration> ... <logger name="eclipselink.sql" level="DEBUG"/>Пример вывода в лог:
2018-09-21 12:48:18.583 DEBUG [http-nio-8080-exec-5/app-core/admin] com.haulmont.cuba.core.app.RdbmsStore - loadList: metaClass=sec$User, view=com.haulmont.cuba.security.entity.User/user.browse, query=select u from sec$User u, max=50 2018-09-21 12:48:18.586 DEBUG [http-nio-8080-exec-5/app-core/admin] eclipselink.sql - <t 891235430, conn 1084868057> SELECT t1.ID AS a1, t1.ACTIVE AS a2, t1.CHANGE_PASSWORD_AT_LOGON AS a3, t1.CREATE_TS AS a4, t1.CREATED_BY AS a5, t1.DELETE_TS AS a6, t1.DELETED_BY AS a7, t1.EMAIL AS a8, t1.FIRST_NAME AS a9, t1.IP_MASK AS a10, t1.LANGUAGE_ AS a11, t1.LAST_NAME AS a12, t1.LOGIN AS a13, t1.LOGIN_LC AS a14, t1.MIDDLE_NAME AS a15, t1.NAME AS a16, t1.PASSWORD AS a17, t1.POSITION_ AS a18, t1.TIME_ZONE AS a19, t1.TIME_ZONE_AUTO AS a20, t1.UPDATE_TS AS a21, t1.UPDATED_BY AS a22, t1.VERSION AS a23, t1.GROUP_ID AS a24, t0.ID AS a25, t0.DELETE_TS AS a26, t0.DELETED_BY AS a27, t0.NAME AS a28, t0.VERSION AS a29 FROM SEC_USER t1 LEFT OUTER JOIN SEC_GROUP t0 ON (t0.ID = t1.GROUP_ID) WHERE (t1.DELETE_TS IS NULL) LIMIT ? OFFSET ? bind => [50, 0] 2018-09-21 12:48:18.587 DEBUG [http-nio-8080-exec-5/app-core/admin] eclipselink.sql - <t 891235430, conn 1084868057> [1 ms] spent - com.haulmont.cuba.core.sys.AbstractWebAppContextLoader
-
При установке в
TRACE, фреймворк логгирует свойства приложения, заданные в файлах и полученные из компонентов приложения во время старта сервера, что может помочь в случае если сервер не запускается нормально.Имейте в виду, что может понадобиться также установить порог
TRACEдля соответствующегоappender, так как обычно они имеют более высокий порог. Например:<configuration> ... <appender name="File" class="ch.qos.logback.core.rolling.RollingFileAppender"> <filter class="ch.qos.logback.classic.filter.ThresholdFilter"> <level>TRACE</level> </filter> ... <logger name="com.haulmont.cuba.core.sys.AbstractWebAppContextLoader" level="TRACE"/>Пример вывода в лог:
2018-09-21 12:38:59.525 TRACE [localhost-startStop-1] com.haulmont.cuba.core.sys.AbstractWebAppContextLoader - AppProperties of the 'core' block: cuba.automaticDatabaseUpdate=true ...
4.7.2. Особенности конфигурации логирования
В данном разделе рассматриваются особенности конфигурации логирования, знание которых может помочь при анализе проблем.
Платформа содержит класс LogbackConfigurator, который встраивается в стандартную процедуру инициализации Logback в качестве имплементации интерфейса Configurator. Этот конфигуратор выполняет следующие шаги при поиске источника конфигурации:
-
Ищет файл
logback.xmlв домашнем каталоге приложения (т.е. в каталоге, указанном системным свойствомapp.home). -
Если не найден, ищет файл
app-logback.xmlв корне classpath. -
Если ничего не найдено, выполняет базовую конфигурацию: вывод в консоль с порогом WARN.
Имейте в виду, что данная процедура выполняется только если в корне classpath нет файла logback.xml.
Задача Gradle setupTomcat создает logback.xml в каталоге deploy/app_home, так что описанная выше процедура инициализации находит его на первом шаге. Это обеспечивает на этапе разработки дефолтную конфигурацию с записью логов в каталог deploy/app_home/logs.
Задача Gradle deploy копирует проектный файл etc/logback.xml (если он существует) в deploy/app_home, так что разработчик может настроить конфигурационный файл в проекте и он будет использован в локальном Tomcat.
Задачи Gradle buildWar и buildUberJar могут создавать файл app-logback.xml в корне classpath (которым является каталог /WEB-INF/classes для WAR и / для UberJAR) из следующих источников:
-
Из файла, указанного в параметре задачи
logbackConfigurationFile. -
Из
logback.xmlвcuba-gradle-plugin, если параметр задачиuseDefaultLogbackConfigurationустановлен в true (это его состояние по умолчанию).
Если logbackConfigurationFile не указан и useDefaultLogbackConfiguration установлен в false, никакая конфигурация логирования в архиве не создается.
Благодаря процедуре инициализации LogbackConfigurator, и при отсутствии в корне classpath файла logback.xml, конфигурация, встроенная в WAR/UberJAR может быть переопределена файлом logback.xml в домашнем каталоге приложения. Это позволяет кастомизировать логирование в среде эксплуатации без необходимости пересборки WAR/UberJAR.
4.8. Отладка
В данном разделе содержится информация об использовании пошаговой отладки CUBA-приложений.
4.8.1. Подключение отладчика
Запустить сервер Tomcat в режиме отладки можно либо выполнением команды сборки
gradle start
либо запуском командного файла bin/debug.* установленного Tomcat.
После этого сервер будет принимать подключения отладчика на порту 8787. Порт можно изменить в файле bin/setenv.* в переменной JPDA_OPTS.
Для пошаговой отладки в Intellij IDEA необходимо в проекте приложения создать новый элемент Run/Debug Configuration типа Remote, и в его поле Port указать 8787.
4.8.2. Простая отладка в веб-браузере
Самый простой способ отладки ошибок на клиентской стороне без использования GWT Super Dev Mode - это использовать конфигурацию отладки внутри модуля web.
-
Добавьте новую конфигурацию внутри блока
webModule:configure(webModule) { configurations { webcontent debug // a new configuration } '''''' } -
Добавьте зависимость для отладчика в блок
dependenciesблокаwebModule:dependencies { provided(servletApi) compile(guiModule) debug("com.haulmont.cuba:cuba-web-toolkit:$cubaVersion:debug@zip") }Если у вас подключено премиум-дополнение charts, используйте зависимость
debug("com.haulmont.charts:charts-web-toolkit:$cubaVersion:debug@zip"). -
Добавьте задачу
deploy.doLastв блок конфигурацииwebModule:task deploy.doLast { project.delete "$cuba.tomcat.dir/webapps/app/VAADIN/widgetsets" project.copy { from zipTree(configurations.debug.singleFile) into "$cuba.tomcat.dir/webapps/app" } }
Сценарии отладки будут развёрнуты в папке $cuba.tomcat.dir/webapps/app/VAADIN/widgetsets/com.haulmont.cuba.web.toolkit.ui.WidgetSet.
4.8.3. Отладка виджетов в веб-браузере
Для отладки виджетов на стороне браузера можно использовать GWT Super Dev Mode.
-
Настройте задачу debugWidgetSet в
build.gradle. -
Разверните приложение и запустите Tomcat.
-
Запустите задачу
debugWidgetSet:gradlew debugWidgetSetGWT Code Server будет перекомпилировать ваш widgetset при изменениях кода виджетов.
-
Откройте страницу
http://localhost:8080/app?debug&superdevmodeв браузере Chrome и подождите, пока widgetset будет построен первый раз. -
Откройте консоль отладки браузера:
-
После изменения Java-кода в модуле
web-toolkitобновляйте страницу в браузере. Widgetset будет инкрементально перестраиваться примерно за 8-10 секунд.
4.9. Тестирование
Приложения CUBA можно тестировать с помощью общеизвестных подходов: модульных тестов, интеграционных тестов и тестов UI.
Модульные тесты хорошо подходят для тестирования логики, инкапсулированной в определенных классах, слабо связанных с инфраструктурой приложения. Для того, чтобы начать писать JUnit-тесты, достаточно создать каталог test в модулях global, core или web вашего проекта. Если вам нужны моки, добавьте зависимость от предпочтительного мок-фреймворка или JMockit, который уже используется в CUBA. Зависимость должна быть добавлена в build.gradle перед JUnit:
configure([globalModule, coreModule, webModule]) {
// ...
dependencies {
testCompile('org.jmockit:jmockit:1.48') (1)
testCompile('org.junit.jupiter:junit-jupiter-api:5.5.2')
testCompile('org.junit.jupiter:junit-jupiter-engine:5.5.2')
testCompile('org.junit.vintage:junit-vintage-engine:5.5.2')
}
// ...
test {
useJUnitPlatform()
jvmArgumentProviders.add(new JmockitAgent(classpath)) (2)
}
}
class JmockitAgent implements CommandLineArgumentProvider { (3)
FileCollection classpath
JmockitAgent(FileCollection classpath) {
this.classpath = classpath
}
Iterable<String> asArguments() {
def path = classpath.find { it.name.contains("jmockit") }.absolutePath
["-javaagent:${path}"]
}
}| 1 | - зависимость от мок-фреймворка |
| 2 | - в случае JMockit при запуске тестов необходимо указать аргумент -javaagent |
| 3 | - класс, который находит JMockit JAR в classpath и формирует требуемое значение -javaagent |
|
См. также руководство Unit Testing in CUBA Applications. |
Интеграционные тесты запускаются в контейнере Spring, поэтому они могут тестировать большинство аспектов приложения, включая взаимодействие с базой данных и экраны UI. В данном разделе рассматривается создание интеграционных тестов на среднем слое и в веб-клиенте.
Для UI-тестов рекомендуется использовать библиотеку Masquerade, которая предоставляет набор полезных абстракций для тестирования CUBA-приложений. См. README и Wiki на GitHub.
4.9.1. Интеграционные тесты Middleware
Интеграционные тесты Middleware выполняются в полнофункциональном контейнере Spring с подключением к базе данных. В тестах такого типа можно выполнять код любого слоя внутри Middleware - от сервисов до ORM.
|
См. также руководство Middleware Integration Testing in CUBA Applications. |
Сразу после создания нового проекта с помощью Studio, в базовом пакете модуля core находятся два класса: тестовый контейнер и пример теста. Класс тестового контейнера запускает контейнер Spring среднего слоя, настроенный для выполнения тестов. Пример теста использует этот контейнер и демонстрирует, как можно тестировать некоторые операции с сущностью.
Рассмотрим сгенерированный класс контейнера и пути его адаптации для нужд проекта.
Класс контейнера должен расширять класс TestContainer, предоставляемый CUBA. В конструкторе класса необходимо выполнить следующее:
-
Добавить в список
appComponentsвсе компоненты приложения (аддоны), используемые в проекте. -
Если необходимо, указать дополнительные файлы свойств приложения в списке
appPropertiesFiles. -
Вызвать метод
autoConfigureDataSource()для инициализации тестового источника данных по информации из свойств приложения или из context.xml.
Сгенерированный тестовый контейнер обеспечивает подключение к той же базе данных, с которой работает приложение. То есть ваши тесты будут выполняться на основном хранилище данных, даже если вы поменяете его тип или то, как задается его JDBC DataSource.
В использовании одной базы данных и для тестов, и для приложения, есть недостаток: данные, введенные вручную в приложении, могут мешать выполнению тестов, и наоборот. Чтобы избежать этого, для тестов можно использовать отдельную БД. Рекомендуется использовать СУБД такого же типа, что и для основной БД, так как в этом случае можно использовать один набор скриптов миграции БД. Ниже приведен пример настройки тестовой базы данных на локальном PostgreSQL.
Во-первых, добавьте задачу создания тестовой БД в build.gradle:
configure(coreModule) {
// ...
task createTestDb(dependsOn: assembleDbScripts, type: CubaDbCreation) {
dbms = 'postgres'
host = 'localhost'
dbName = 'demo_test'
dbUser = 'cuba'
dbPassword = 'cuba'
}Затем создайте файл test-app.properties в базовом пакете корня тестов (например, modules/core/test/com/company/demo/test-app.properties) и укажите свойства подключения к тестовой БД:
cuba.dataSource.host = localhost
cuba.dataSource.dbName = demo_test
cuba.dataSource.username = cuba
cuba.dataSource.password = cubaДобавьте этот файл в список appPropertiesFiles тестового контейнера:
public class DemoTestContainer extends TestContainer {
public DemoTestContainer() {
super();
appComponents = Arrays.asList(
"com.haulmont.cuba"
);
appPropertiesFiles = Arrays.asList(
"com/company/demo/app.properties",
"com/haulmont/cuba/testsupport/test-app.properties",
"com/company/demo/test-app.properties" // your test properties
);
autoConfigureDataSource();
}Перед выполнением тестов создайте тестовую БД путем выполнения задачи:
./gradlew createTestDbТестовый контейнер используется в классах тестов в качестве JUnit 5 extension, указанного с помощью аннотации @RegisterExtension:
package com.company.demo.core;
import com.company.demo.DemoTestContainer;
import com.company.demo.entity.Customer;
import com.haulmont.cuba.core.entity.contracts.Id;
import com.haulmont.cuba.core.global.AppBeans;
import com.haulmont.cuba.core.global.DataManager;
import org.junit.jupiter.api.BeforeAll;
import org.junit.jupiter.api.Test;
import org.junit.jupiter.api.extension.RegisterExtension;
import static org.junit.jupiter.api.Assertions.assertEquals;
public class CustomerTest {
// Using the common singleton instance of the test container which is initialized once for all tests
@RegisterExtension
static DemoTestContainer cont = DemoTestContainer.Common.INSTANCE;
static DataManager dataManager;
@BeforeAll
static void beforeAll() {
// Get a bean from the container
dataManager = AppBeans.get(DataManager.class);
}
@Test
void testCreateLoadRemove() {
Customer customer = cont.metadata().create(Customer.class);
customer.setName("c1");
Customer committedCustomer = dataManager.commit(customer);
assertEquals(customer, committedCustomer);
Customer loadedCustomer = dataManager.load(Id.of(customer)).one();
assertEquals(customer, loadedCustomer);
dataManager.remove(loadedCustomer);
}
}- Полезные методы тестового контейнера
-
Класс
TestContainerсодержит следующие методы, которые можно использовать в коде тестов (см. примерCustomerTestвыше):-
persistence()- возвращает ссылку на интерфейс Persistence. -
metadata()- возвращает ссылку на интерфейс Metadata. -
deleteRecord()- этот набор перегруженных методов предназначен для использования в@Afterметодах для удаления тестовых объектов из БД.
Кроме того, ссылку на любой бин можно получить статическим методом
AppBeans.get(). -
- Логирование
-
Класс
TestContainerнастраивает логирование в соответствие с файломtest-logback.xml, предоставляемым платформой. Данный файл содержится в артефактеcuba-core-tests.Для того, чтобы настроить уровни логирования в своих тестах, необходимо выполнить следующее:
-
Создайте файл
my-test-logback.xmlв каталогеtestмодуляcoreпроекта. Вы можете взять за основу содержимое файлаtest-logback.xml, находящегося внутри артефактаcuba-core-tests. -
Добавьте блок статической инициализации в класс тестового контейнера проекта и укажите местоположение файла конфигурации Logback в системном свойстве
logback.configurationFile:public class DemoTestContainer extends TestContainer { static { System.setProperty("logback.configurationFile", "com/company/demo/my-test-logback.xml"); }
-
- Дополнительные хранилища
-
Если в вашем проекте используются дополнительные хранилища, и если тип дополнительной базы данных отличается от основной, необходимо добавить ее драйвер как
testRuntimeзависимость модуляcoreвbuild.gradle, например:configure(coreModule) { // ... dependencies { // ... testRuntime(hsql) jdbc('org.postgresql:postgresql:9.4.1212') testRuntime('org.postgresql:postgresql:9.4.1212') // add this }
4.9.2. Интеграционные тесты веб-уровня
Интеграционные тесты веб-уровня выполняются в контейнере Spring блока Web Client. Тестовый контейнер работает независимо от среднего слоя, так как фреймворк автоматически создает заглушки (stubs) для всех сервисов. Тестовая инфраструктура состоит из следующих классов, расположенных в пакете com.haulmont.cuba.web.testsupport и его вложенных пакетах:
-
TestContainer- обертка вокруг контейнера Spring для использования в качестве базового класса в проектах. -
TestServiceProxy- предоставляет заглушки по умолчанию для сервисов среднего слоя. Данный класс можно также использовать для регистрации моков сервисов, специфичных для теста: см. статический методmock(). -
DataServiceProxy- заглушка по умолчанию дляDataManager. Содержит реализацию методаcommit(), которая имитирует поведение реального хранилища: делает новые экземпляры сущностей detached, инкрементирует версии, и т.д. Методы загрузки ничего не делают и возвращают null и пустые коллекции. -
TestUiEnvironment- предоставляет набор методов для конфигурирования и полученияTestContainer. Экземпляр данного класса должен быть использован в тестах в качестве JUnit 5 extension. -
TestEntityFactory- фабрика для удобного создания тестовых экземпляров сущностей. Может быть получена изTestContainer.
Несмотря на то, что фреймворк предоставляет дефолтные заглушки для сервисов среднего слоя, в тестах могут понадобится собственные моки сервисов. Для создания моков можно использовать любой мок-фреймворк, просто подключив его в зависимости проекта как описано в разделе выше. Моки сервисов регистрируются с помощью метода TestServiceProxy.mock().
- Пример контейнера для интеграционных тестов веб-уровня
-
Создайте каталог
testв модулеweb. Затем создайте в подходящем пакете данного каталога класс контейнера:package com.company.demo; import com.haulmont.cuba.web.testsupport.TestContainer; import java.util.Arrays; public class DemoWebTestContainer extends TestContainer { public DemoWebTestContainer() { appComponents = Arrays.asList( "com.haulmont.cuba" // add CUBA add-ons and custom app components here ); appPropertiesFiles = Arrays.asList( // List the files defined in your web.xml // in appPropertiesConfig context parameter of the web module "com/company/demo/web-app.properties", // Add this file which is located in CUBA and defines some properties // specifically for test environment. You can replace it with your own // or add another one in the end. "com/haulmont/cuba/web/testsupport/test-web-app.properties" ); } public static class Common extends DemoWebTestContainer { // A common singleton instance of the test container which is initialized once for all tests public static final DemoWebTestContainer.Common INSTANCE = new DemoWebTestContainer.Common(); private static volatile boolean initialized; private Common() { } @Override public void before() throws Throwable { if (!initialized) { super.before(); initialized = true; } setupContext(); } @Override public void after() { cleanupContext(); // never stops - do not call super } } }
- Пример теста экрана UI
-
Ниже приведен пример теста, который проверяет состояние редактируемой в экране сущности после некоторого действия пользователя.
package com.company.demo.customer; import com.company.demo.DemoWebTestContainer; import com.company.demo.entity.Customer; import com.company.demo.web.screens.customer.CustomerEdit; import com.haulmont.cuba.gui.Screens; import com.haulmont.cuba.gui.components.Button; import com.haulmont.cuba.gui.screen.OpenMode; import com.haulmont.cuba.web.app.main.MainScreen; import com.haulmont.cuba.web.testsupport.TestEntityFactory; import com.haulmont.cuba.web.testsupport.TestEntityState; import com.haulmont.cuba.web.testsupport.TestUiEnvironment; import org.junit.jupiter.api.BeforeEach; import org.junit.jupiter.api.Test; import org.junit.jupiter.api.extension.RegisterExtension; import java.util.Collections; import static org.junit.jupiter.api.Assertions.assertEquals; import static org.junit.jupiter.api.Assertions.assertNull; public class CustomerEditInteractionTest { @RegisterExtension TestUiEnvironment environment = new TestUiEnvironment(DemoWebTestContainer.Common.INSTANCE).withUserLogin("admin"); (1) private Customer customer; @BeforeEach public void setUp() throws Exception { TestEntityFactory<Customer> customersFactory = environment.getContainer().getEntityFactory(Customer.class, TestEntityState.NEW); customer = customersFactory.create(Collections.emptyMap()); (2) } @Test public void testGenerateName() { Screens screens = environment.getScreens(); (3) screens.create(MainScreen.class, OpenMode.ROOT).show(); (4) CustomerEdit customerEdit = screens.create(CustomerEdit.class); (5) customerEdit.setEntityToEdit(customer); customerEdit.show(); assertNull(customerEdit.getEditedEntity().getName()); Button generateBtn = (Button) customerEdit.getWindow().getComponent("generateBtn"); (6) customerEdit.onGenerateBtnClick(new Button.ClickEvent(generateBtn)); (7) assertEquals("Generated name", customerEdit.getEditedEntity().getName()); } }1 - создание экземпляра TestUiEnvironmentс разделяемым контейнером и пользователемadminв заглушке пользовательской сессии.2 - создание экземпляра сущности в состоянии new.3 - получение инфраструктурного объекта Screens.4 - открытие главного экрана, который необходим для открытия остальных экранов приложения. 5 - создание, инициализация и открытие экрана редактирования сущности. 6 - получение компонента Button.7 - создание объекта события нажатия кнопки и вызов метода контроллера, который реагирует на это событие.
- Пример теста загрузки данных в экран
-
Ниже приведен пример теста, который проверяет корректность загрузки данных в экране UI.
package com.company.demo.customer; import com.company.demo.DemoWebTestContainer; import com.company.demo.entity.Customer; import com.company.demo.web.screens.customer.CustomerEdit; import com.haulmont.cuba.core.app.DataService; import com.haulmont.cuba.core.entity.Entity; import com.haulmont.cuba.core.global.LoadContext; import com.haulmont.cuba.gui.Screens; import com.haulmont.cuba.gui.model.InstanceContainer; import com.haulmont.cuba.gui.screen.OpenMode; import com.haulmont.cuba.gui.screen.UiControllerUtils; import com.haulmont.cuba.web.app.main.MainScreen; import com.haulmont.cuba.web.testsupport.TestEntityFactory; import com.haulmont.cuba.web.testsupport.TestEntityState; import com.haulmont.cuba.web.testsupport.TestUiEnvironment; import com.haulmont.cuba.web.testsupport.proxy.TestServiceProxy; import mockit.Delegate; import mockit.Expectations; import mockit.Mocked; import org.junit.jupiter.api.AfterEach; import org.junit.jupiter.api.BeforeEach; import org.junit.jupiter.api.Test; import org.junit.jupiter.api.extension.RegisterExtension; import static org.junit.jupiter.api.Assertions.assertEquals; public class CustomerEditLoadDataTest { @RegisterExtension TestUiEnvironment environment = new TestUiEnvironment(DemoWebTestContainer.Common.INSTANCE).withUserLogin("admin"); (1) @Mocked private DataService dataService; (1) private Customer customer; @BeforeEach public void setUp() throws Exception { new Expectations() {{ (2) dataService.load((LoadContext<? extends Entity>) any); result = new Delegate() { Entity load(LoadContext lc) { if ("demo_Customer".equals(lc.getEntityMetaClass())) { return customer; } else return null; } }; }}; TestServiceProxy.mock(DataService.class, dataService); (3) TestEntityFactory<Customer> customersFactory = environment.getContainer().getEntityFactory(Customer.class, TestEntityState.DETACHED); customer = customersFactory.create( "name", "Homer", "email", "homer@simpson.com"); (4) } @AfterEach public void tearDown() throws Exception { TestServiceProxy.clear(); (5) } @Test public void testLoadData() { Screens screens = environment.getScreens(); screens.create(MainScreen.class, OpenMode.ROOT).show(); CustomerEdit customerEdit = screens.create(CustomerEdit.class); customerEdit.setEntityToEdit(customer); customerEdit.show(); InstanceContainer customerDc = UiControllerUtils.getScreenData(customerEdit).getContainer("customerDc"); (6) assertEquals(customer, customerDc.getItem()); } }1 - определение мока с помощью фреймворка JMockit. 2 - задание поведения мока. 3 - регистрация мока. 4 - создание экземпляра сущности в состоянии detached.5 - удаление мока после завершения теста. 6 - получение контейнера данных.
4.10. Hot Deploy
Платформа CUBA поддерживает технологию Hot Deploy, которая позволяет мгновенно отображать сделанные в проекте изменения в работающем приложении без необходимости перезапускать сервер. Принцип работы Hot deploy заключается во временном копировании изменённых ресурсов и исходных файлов Java проекта в конфигурационный каталог приложения, откуда они загружаются и компилируются работающим приложением.
- Как это работает
-
Когда в каком-то файле исходного кода производятся изменения, Studio копирует этот файл в конфигурационный каталог веб-приложения (
tomcat/conf/appилиtomcat/conf/app-core). Ресурсы в конфигурационном каталоге имеют приоритет над ресурсами в JAR-файлах приложения, поэтому работающее приложение загрузит именно эти ресурсы, когда они понадобятся. Если загружается файл исходного кода на Java, то приложение компилирует его на лету и загружает результирующий класс.Кроме того, Studio посылает приложению специальные сигналы для того чтобы заставить его очистить кэши и перезагрузить измененные ресурсы. Это кэш локализованных сообщений и конфигурации представлений, зарегистрированных экранов и меню.
При перезагрузке сервера приложения все файлы в конфигурационном каталоге удаляются, и JAR-файлы содержат последние версии вашего кода.
- Какие изменения применяются через hot deploy
-
-
Дескрипторы и контроллеры экранов (включая статические методы), расположенные в модулях web и gui.
-
Реализации сервисов среднего слоя, расположенные в модуле core.
-
Шаблоны портала.
Изменения в прочих классах и бинах UI и среднего слоя, включая их статические методы, могут применяться на лету только тогда, когда изменяется ещё хотя бы один файл экрана или реализации сервиса, который их используют.
Причина такого поведения в том, что перезагрузка классов вызывается только по сигналу: для контроллера экрана это переоткрытие этого экрана пользователем, а для сервисов Studio генерирует особый файл-триггер, который будет распознан сервером и использован для перезагрузки конкретного класса сервиса и всех его зависимостей.
-
- Какие изменения не применяются через hot deploy
-
-
Любые классы в модуле global, включая интерфейсы сервисов среднего слоя, сущности, entity listeners и т.д.
-
- Использование hot deploy в Studio
-
Настройки Hot deploy можно изменить в Studio: нажмите CUBA > Settings в главном меню и выберите элемент CUBA > Project settings.
-
Щелкните ссылку Hot Deploy Settings чтобы сконфигурировать отображение между каталогами исходного кода и каталогами Tomcat.
-
Флажок Instant hot deploy позволяет отключить автоматический hot deploy для текущего проекта.
Если мгновенный hot deploy отключен, применение изменений можно вызвать вручную командой главного меню CUBA > Build Tasks > Hot Deploy To Configuration Directory.
-
4.11. Устранение проблем
В этой секции предлагаются решения различных проблем, случающихся при разработке CUBA приложений.
4.11.1. Сборка виджетсета под Windows
При сборке проектов, включающих модуль web-toolkit и собственный GWT виджетсет под ОС Windows в некоторых случаях вы можете встретить следующее сообщение об ошибке в консольном окне Run:
Execution failed for task ':app-web-toolkit:buildWidgetSet'. > A problem occurred starting process 'command 'C:\Program Files\AdoptOpenJDK\jdk-8.0.242.08-hotspot\bin\java.exe'' * Try: Run with --stacktrace option to get the stack trace. Run with --info or --debug option to get more log output. Run with --scan to get full insights.
Это сообщение не показывает точную причину проблемы. Откройте терминал (например окно инструментов Terminal в IntelliJ IDEA или CUBA Studio) и запустите команду с опцией --stacktrace в каталоге проекта (подправьте имя модуля, если префикс модуля в вашем проекте отличается от значения по умолчанию app):
gradlew :app-web-toolkit:buildWidgetSet --stacktrace
Вы получите вывод с ошибкой, заканчивающийся как показано ниже:
...
Caused by: java.io.IOException: Cannot run program "C:\Program Files\AdoptOpenJDK\jdk-8.0.242.08-hotspot\bin\java.exe" (in directory "C:\projects\proj\modules\web-toolkit"): CreateProcess error=206, The filename or extension is too long
at net.rubygrapefruit.platform.internal.DefaultProcessLauncher.start(DefaultProcessLauncher.java:25)
... 8 more
Caused by: java.io.IOException: CreateProcess error=206, The filename or extension is too long
... 9 more
Если сообщение об ошибке содержит "CreateProcess error=206" - это означает, что вы встретили известное ограничение Windows - невозможность запустить процесс со строкой запуска более чем 32K символов.
К сожалению, нет возможности как-то автоматически обойти эту проблему. Возможные решения для ошибки "The filename or extension is too long" следующие:
-
Сменить операционную систему, используемую для разработки (на MacOS или Linux).
-
Обновить проект на использование Gradle 6 или более новой версии, изменив свойство
distributionUrlв проектном файлеgradle\wrapper\gradle.properties. Gradle 6 избегает упомянутой ошибки, т.к. в нем изменен способ, которым параметры запуска передаются во внешние команды. Нужно иметь в виду, что платформа CUBA использует по умолчанию и была протестирована с Gradle 5.6.4, поэтому после изменения версии Gradle вам может потребоваться подправить скрипты сборки в проекте. -
Сократить строку запуска задачи buildWidgetSet, чтобы уменьшить ее длину ниже предела в 32K.
- Сокращение строки запуска buildWidgetSet
Проделайте следующие меры, чтобы сократить строку запуска buildWidgetSet:
-
Переместите ваш проект в каталог с коротким путем от корня диска, например
C:\proj\. -
Переместите и переименуйте домашнюю директорию Gradle, чтобы она имела настолько короткое имя, насколько возможно. Подробности ниже.
-
Исключите транзитивные зависимости модуля
app-web-toolkit, которые не являются обязательными для сборки виджетсета. Подробности ниже.
- Определение длины строки запуска команды buildWidgetSet
Чтобы определить реальную длину строки запуска Java процесса, который собирает виджетсет, запустите следующую команду в терминале:
gradlew -i :app-web-toolkit:buildWidgetSet --stacktrace > build.log
Затем откройте созданный файл build.log в текстовом редакторе и найдите следующий фрагмент в конце файла:
GWT Compiler args: [...] JVM Args: [...] Starting process 'command 'C:\...\bin\java.exe''. Working directory: ... Command: C:\...\java.exe <ТЫСЯЧИ СИМВОЛОВ> com.company.project.web.toolkit.ui.AppWidgetSet
Строка "Starting process …" как раз содержит все аргументы строки запуска, поэтому ее длина близка к реальной длине строки запуска, которую требуется сократить.
- Изменение пути к домашней папке Gradle
Прочитать больше о домашней папке Gradle можно на сайте Gradle.
-
Выберите новое имя домашнего каталога Gradle. Рекомендуется каталог с именем из одной буквы, расположенный в корне диска, например
C:\g\. -
Откройте стандартный диалог операционной системы "Переменные среды" и добавьте новую переменную среды с именем
GRADLE_USER_HOMEи новым именем домашнего каталога как значением:C:\g -
Откройте домашнюю папку вашего пользователя в Проводнике:
C:\users\%myusername%. -
Выберите каталог
.gradle. Переместите его на новое место и переименуйте:C:\users\%myusername%\.gradleстановитсяC:\g -
Перезапустите IntelliJ IDEA или CUBA Studio, чтобы применить изменения переменных среды.
- Исключение транзитивных зависимостей модуля app-web-toolkit
Сначала потребуется определить транзитивные зависимости модуля app-web-toolkit. Выполните следующую команду в терминале:
gradlew :app-web-toolkit:dependencies > deps.log
Затем откройте созданный файл deps.log в текстовом редакторе. Вам нужна compile группа представленных там зависимостей.
Откройте файл build.gradle и модифицируйте секцию configure(webToolkitModule) {. Добавьте исключения зависимостей, как представлено на примере ниже:
configure(webToolkitModule) {
configurations.compile {
// зависимости - библиотеки, которые не требуются для сборки виджетсета
exclude group: 'org.springframework'
exclude group: 'org.springframework.security.oauth'
exclude group: 'org.eclipse.persistence'
exclude group: 'org.codehaus.groovy'
exclude group: 'org.apache.ant'
exclude group: 'org.eclipse.jetty'
exclude group: 'com.esotericsoftware'
exclude group: 'com.googlecode.owasp-java-html-sanitizer'
exclude group: 'net.sourceforge.htmlunit'
// зависимости - аддоны, которые не содержат web-компонентов или виджетсет
// и поэтому не требуются для сборки виджетсета
exclude group: 'com.haulmont.addon.restapi'
exclude group: 'com.haulmont.reports'
exclude group: 'com.haulmont.addon.admintools'
exclude group: 'com.haulmont.addon.search'
exclude group: 'com.haulmont.addon.emailtemplates'
exclude group: 'de.diedavids.cuba.metadataextensions'
exclude group: 'de.diedavids.cuba.instantlauncher'
}
// ...
}
Представленный выше пример можно использовать как образец. Но в вашем конкретном проекте может потребоваться исключить дополнительные библиотеки или аддоны.
Продолжайте исключать дополнительные библиотеки, пока длина строки запуска команды buildWidgetSet (которая определяется по детальному журналу, как описано выше) не сократится до менее чем 32000 символов.
5. Развертывание приложений
В данной главе рассматриваются различные аспекты развертывания и эксплуатации CUBA-приложений.
На диаграмме ниже приведена возможная структура развернутого приложения. В приведенном варианте приложение обеспечивает отсутствие единой точки отказа, балансировку нагрузки и подключение различных типов клиентов.
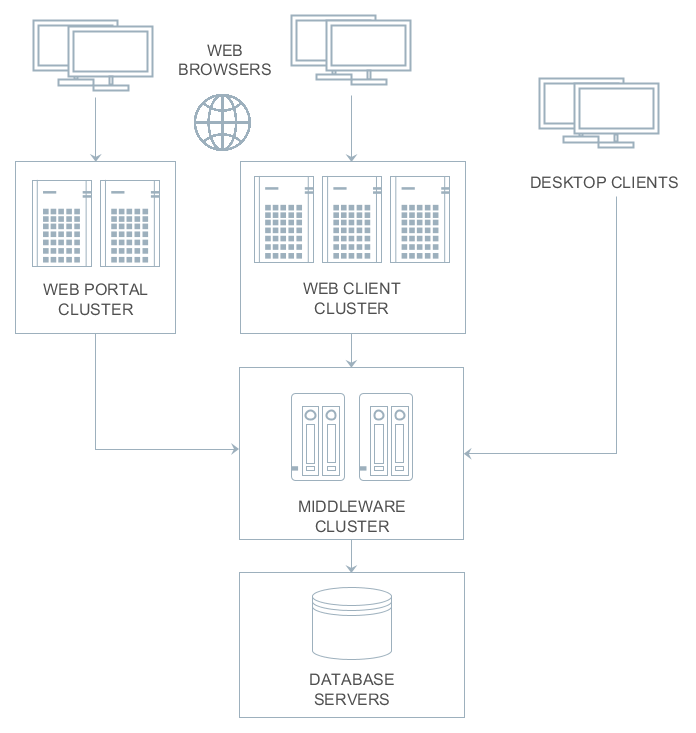
В простейшем случае, однако, приложение может быть установлено на одном компьютере, содержащем, в том числе, и базу данных. Различные варианты развертывания в зависимости от нагрузки и требований к отказоустойчивости подробно рассмотрены в Масштабирование приложения.
5.1. Домашний каталог приложения
Домашний каталог - это каталог файловой системы, в котором CUBA-приложение создает временные файлы, и где можно расположить конфигурационные файлы local.app.properties и logback.xml. Большинство каталогов приложения, описанных ниже расположены в домашнем каталоге. Файловое хранилище также использует по умолчанию подкаталог домашнего каталога.
Так как CUBA приложение создает разные файлы (временные файлы, файлы журналов и др.) в домашнем каталоге, то этот каталог должен быть доступен для записи для пользователя, под которым приложение запущено.
Фреймворк получает путь к домашнему каталогу из системного свойства Java app.home.
|
Рекомендуется задавать это свойство явно, используя аргумент командной строки |
- Явное указание домашнего каталога
При запуске UberJAR - укажите путь к домашнему каталогу в аргументе командной строки -D, например:
java -Dapp.home=/opt/app_home -jar app.jar
При развертывании WAR-файла - установите app.home в аргументе командной строки -D в соответствующем скрипте запуска сервера приложения, либо другим специфичным для сервера способом. Например, в Tomcat создайте файл bin/setenv.sh следующего содержания:
CATALINA_OPTS="-Dapp.home=\"$CATALINA_BASE/work/app_home\" -Xmx512m -Dfile.encoding=UTF-8"
Если используется развертывание в Tomcat Windows Service, расположите каждое свойство на отдельной строке в поле Java Options окна настроек службы.
- Автоопределение домашнего каталога
Если системное свойство app.home не указано в командной строке, оно устанавливается автоматически в соответствии со следующими правилами:
-
Если приложение стартует как UberJAR, домашним каталогом становится текущий рабочий каталог процесса.
-
Если установлено системное свойство
catalina.base(т.е. приложение работает на Tomcat), домашний каталог устанавливается в${catalina.base}/work/app_home. -
В противном случае, домашний каталог устанавливается в подкаталог
.app_homeдомашнего каталога пользователя.
|
Варианты 2 и 3 имеют следующий недостаток: процедура инициализации Logback вступает в действие до того, как свойство |
При использовании быстрого развертывания на этапе разработки, начиная с CUBA 7.2 домашний каталог приложения устанавливается в каталог проекта deploy/app_home. Если ваш проект использует более старую версию платформы, каталоги приложения располагаются внутри подкаталогов conf и work Tomcat.
5.2. Каталоги приложения
В данном разделе описываются каталоги файловой системы, используемые различными блоками приложения во время выполнения.
5.2.1. Конфигурационный каталог
Каталог конфигурации предназначен для размещения ресурсов, дополняющих и переопределяющих конфигурацию, пользовательский интерфейс и бизнес-логику после развертывания приложения. Переопределение обеспечивается механизмом загрузки интерфейса инфраструктуры Resources, который сначала выполняет поиск в конфигурационном каталоге, а потом в classpath, так что одноименные ресурсы в конфигурационном каталоге имеют приоритет над расположенными в JAR-файлах и каталогах классов.
Конфигурационный каталог может содержать следующие типы ресурсов:
-
Конфигурационные файлы metadata.xml, persistence.xml, views.xml, remoting-spring.xml.
-
XML-дескрипторы экранов UI.
-
Контроллеры экранов UI в виде исходных текстов Java или Groovy.
-
Скрипты или классы Groovy, а также исходные тексты классов Java, используемые приложением через интерфейс Scripting.
Расположение конфигурационного каталога определяется свойством приложения cuba.confDir. По умолчанию, конфигурационный каталог размещается внутри домашнего каталога приложения.
5.2.2. Рабочий каталог
Рабочий каталог используется приложением для хранения файлов данных и конфигурации.
Например, подкаталог filestorage рабочего каталога по умолчанию используется хранилищем загруженных файлов. Кроме того, блок Middleware на старте сохраняет в рабочем каталоге сгенерированные файлы persistence.xml и orm.xml.
Расположение рабочего каталога определяется свойством приложения cuba.dataDir. По умолчанию, рабочий каталог размещается внутри домашнего каталога приложения.
5.2.3. Каталог журналов
Расположение и содержимое файлов журналов определяются конфигурацией фреймворка Logback, находящейся в файле logback.xml. См. раздел Логирование для получения подробной информации.
Расположение файлов логов обычно указывают относительно домашнего каталога приложения, например:
<configuration debug="false">
<property name="logDir" value="${app.home}/logs"/>
<!-- ... -->Установите свойство приложения cuba.logDir в тот же каталог, который задается в logback.xml. Это позволит администраторам системы просматривать и загружать логи в экране Administration > Server Log.
5.2.4. Временный каталог
Данный каталог может быть использован для создания произвольных временных файлов во время выполнения приложения. Путь к временному каталогу определяется свойством приложения cuba.tempDir. По умолчанию, временный каталог размещается внутри домашнего каталога приложения.
5.2.5. Каталог скриптов базы данных
В данном каталоге развернутого блока Middleware хранится набор SQL скриптов создания и обновления БД.
Структура каталога скриптов повторяет описанную в разделе Скрипты миграции БД, но имеет один дополнительный верхний уровень, разделяющий скрипты используемых компонентов и самого приложения. Нумерация каталогов верхнего уровня определяется во время сборки проекта.
Расположение каталога скриптов БД определяется свойством приложения cuba.dbDir. В варианте быстрого развертывания в Tomcat это подкаталог WEB-INF/db каталога веб-приложения среднего слоя: tomcat/webapps/app-core/WEB-INF/db. Для других вариантов развертывания скрипты размещаются в каталоге /WEB-INF/db внутри WAR или UberJAR.
5.3. Варианты развертывания
В данном разделе рассматриваются различные варианты развертывания CUBA-приложений.
5.3.1. Быстрое развертывание
Быстрое развертывание используется по умолчанию при разработке приложения, так как обеспечивает минимальное время сборки, установки и старта приложения. Данный вариант может также использоваться и для эксплуатации приложения.
Быстрое развертывание производится, когда вы запускаете приложение в Studio или выбираете в главном меню команду CUBA > Build Tasks > Deploy. При этом Studio запускает задачу deploy, объявленную для модулей core и web в файле build.gradle. Перед первым выполнением deploy выполняется также задача setupTomcat, которая устанавливает и инициализирует локальный сервер Tomcat. Данные задачи можно также выполнить и вне Studio.
|
Пожалуйста, убедитесь, что ваше окружение не содержит переменных |
В результате быстрого развертывания в каталоге deploy проекта создается следующая структура (перечислены только важные каталоги и файлы):
deploy/
app_home/
app/
conf/
temp/
work/
app-core/
conf/
temp/
work/
logs/
app.log
local.app.properties
logback.xml
tomcat/
bin/
setenv.bat, setenv.sh
startup.bat, startup.sh
debug.bat, debug.sh
shutdown.bat, shutdown.sh
conf/
catalina.properties
server.xml
logging.properties
Catalina/
localhost/
lib/
hsqldb-2.4.1.jar
logs/
shared/
lib/
webapps/
app/
app-core/-
deploy/app_home- домашний каталог приложения.-
app/conf,app-core/conf- конфигурационные каталоги приложений веб-клиента и среднего слоя.
-
-
app/temp,app-core/temp- временные каталоги приложений веб-клиента и среднего слоя. -
app/work,app-core/work- рабочие каталоги приложений веб-клиента и среднего слоя. -
logs- каталог журналов приложений. Основной лог-файл приложений -app.log.-
local.app.properties- файл, в котором можно задавать свойства приложения для данного варианта развертывания. -
logback.xml- конфигурация логирования.
-
-
deploy/tomcat- каталог локального Tomcat.-
bin- каталог, содержащий скрипты запуска и остановки сервера Tomcat:-
setenv.bat,setenv.sh- скрипты установки переменных окружения. Эти скрипты следует использовать для установки параметров памяти JVM, настройки доступа по JMX, параметров подключения отладчика.Если вы столкнулись с медленной загрузкой Tomcat под Linux, установленной на виртуальной машине (VPS), попробуйте настроить JVM на использование источника неблокирующей энтропии в файле
setenv.sh:CATALINA_OPTS="$CATALINA_OPTS -Djava.security.egd=file:/dev/./urandom" -
startup.bat,startup.sh- скрипты запуска Tomcat. Сервер стартует в отдельном консольном окне в Windows и в фоне в Unix-like операционных системах.Для запуска сервера в текущем консольном окне вместо
startup.*используйте команды> catalina.bat run$ ./catalina.sh run -
debug.bat,debug.sh- скрипты, аналогичныеstartup.*, однако запускающие Tomcat с возможностью подключения отладчика. Именно эти скрипты запускаются при выполнении задачи start скрипта сборки. -
shutdown.bat,shutdown.sh- скрипты остановки Tomcat.
-
-
conf- каталог, содержащий файлы конфигурации Tomcat и развернутых в нем приложений.-
catalina.properties- свойства Tomcat. Для загрузки общих библиотек из каталогаshared/lib(см. ниже) данный файл должен содержать строку:shared.loader=${catalina.home}/shared/lib/*.jar -
server.xml- описатель конфигурации Tomcat. В этом файле можно изменить порты сервера. -
logging.properties- описатель конфигурации логирования самого сервера Tomcat. -
Catalina/localhost- в этом каталоге можно разместить дескрипторы развертывания приложений context.xml. Дескрипторы, расположенные в данном каталоге имеют приоритет над дескрипторами в каталогахMETA-INFсамих приложений, что часто бывает удобно при эксплуатации системы. Например, в таком дескрипторе на уровне сервера можно указать параметры подключения к базе данных, отличные от указанных в самом приложении.Дескриптор развертывания на уровне сервера должен иметь имя приложения и расширение
.xml. То есть для создания такого дескриптора, например, для приложенияapp-core, необходимо скопировать содержимое файлаwebapps/app-core/META-INF/context.xmlв файлconf/Catalina/localhost/app-core.xml.
-
-
lib- каталог библиотек, загружаемых в common classloader сервера. Эти библиотеки доступны как самому серверу, так и всем развернутым в нем веб-приложениям. В частности, в данном каталоге должны располагаться JDBC-драйверы используемых баз данных (hsqldb-XYZ.jar,postgresql-XYZ.jarи т.д.) -
logs- каталог логов сервера. -
shared/lib- каталог библиотек, доступных всем развернутым приложениям. Классы этих библиотек загружаются в специальный shared classloader сервера. Использование shared classloader задается в файлеconf/catalina.propertiesкак описано выше.Задачи deploy файла сборки копируют в этот каталог все библиотеки, не перечисленные в параметре
jarNames, то есть не специфичные для данного приложения. -
webapps- каталог веб-приложений. Каждое приложение располагается в собственном подкаталоге в формате exploded WAR.Задачи deploy файла сборки создают подкаталоги приложений с именами, указанными в параметрах
appName, и кроме прочего копируют в их подкаталогиWEB-INF/libбиблиотеки, перечисленные в параметреjarNames.
-
Пути устанновки локального Tomcat и домашнего каталога приложения можно задать в свойствах cuba.tomcat.dir и cuba.appHome в файле build.gradle, например:
cuba {
// ...
tomcat {
dir = "$project.rootDir/some_path/tomcat"
}
appHome = "$project.rootDir/some_path/app_home"
}5.3.1.1. Использование Tomcat при эксплуатации приложения
Процедура быстрого развертывания по умолчанию создает веб приложения app и app-core, работающие на локальном инстансе Tomcat на порту 8080. Это означает, что веб-клиент доступен по адресу http://localhost:8080/app.
Вы можете использовать этот экземпляр Tomcat для эксплуатации приложения, просто скопировав каталоги tomcat и app_home на сервер. Пользователь, запускающий Tomcat, должен иметь права на чтение и запись в этих каталогах.
После этого необходимо установить имя хоста сервера в app_home/local.app.properties:
cuba.webHostName = myserver
cuba.webAppUrl = http://myserver:8080/appКроме того, необходимо настроить подключение к production базе данных. Это можно сделать в файле context.xml веб-приложения (tomcat/webapps/app-core/META-INF/context.xml), или скопировать этот файл в tomcat/conf/Catalina/localhost/app-core.xml как описано в предыдущем разделе, чтобы разделить настройки соединения с БД для разработки и эксплуатации.
Базу данных для production можно создать из бэкапа той базы, которая использовалась при разработке, либо настроить автоматическое создание и обновление БД. См. Создание и обновление БД при эксплуатации приложения.
5.3.2. Развертывание WAR в Jetty
Рассмотрим пример сборки WAR-файлов и их развертывания на сервере Jetty.
Мы будем использовать следующую структуру каталогов:
-
C:\work\jetty-home\- дистрибутив Jetty; -
C:\work\jetty-base\- директория конфигурации Jetty, в ней хранятся конфигурационные файлы Jetty, дополнительные библиотеки и веб-приложения. -
C:\work\app_home\- домашний каталог CUBA приложения.-
Используйте диалог Дерево проектов CUBA > Project > Deployment > WAR Settings в Studio или вручную добавьте в конец build.gradle задачу сборки buildWar:
task buildWar(type: CubaWarBuilding) { appProperties = ['cuba.automaticDatabaseUpdate': 'true'] singleWar = false }В данном случае собирается два WAR-файла, отдельно для блоков Middleware и Web Client.
-
Запустите сборку, выбрав
buildWarчерез командную строку (подразумевается что Gradle wrapper создан заранее):gradlew buildWarВ результате в подкаталоге
build\distributions\warпроекта будут созданы файлыapp-core.warиapp.war. -
Создайте домашний каталог приложения на сервере, например,
c:\work\app_home. -
Скопируйте файл
logback.xmlиз локального сервера Tomcat (под-каталог проектаdeploy/tomcat/conf) в домашний каталог приложения (c:\work\app_home) и отредактируйте свойствоlogDirв этом файле:<property name="logDir" value="${app.home}/logs"/> -
Загрузите и установите сервер Jetty, например в каталог
c:\work\jetty-home. Данный пример тестировался на версииjetty-distribution-9.4.22.v20191022.zip. -
Создайте каталог
c:\work\jetty-base, откройте в нем командную строку и выполните:java -jar c:\work\jetty-home\start.jar --add-to-start=http,jndi,deploy,plus,ext,resources -
Создайте файл
c:\work\jetty-base\app-jetty.xml, содержащий определение пула соединений к базе данных. Содержимое файла для БД PostgreSQL должно основываться на следующем шаблоне:<?xml version="1.0"?> <!DOCTYPE Configure PUBLIC "-" "http://www.eclipse.org/jetty/configure_9_0.dtd"> <Configure id="wac" class="org.eclipse.jetty.webapp.WebAppContext"> <New id="CubaDS" class="org.eclipse.jetty.plus.jndi.Resource"> <Arg/> <Arg>jdbc/CubaDS</Arg> <Arg> <New class="org.apache.commons.dbcp2.BasicDataSource"> <Set name="driverClassName">org.postgresql.Driver</Set> <Set name="url">jdbc:postgresql://localhost/db_name</Set> <Set name="username">username</Set> <Set name="password">password</Set> <Set name="maxIdle">2</Set> <Set name="maxTotal">20</Set> <Set name="maxWaitMillis">5000</Set> </New> </Arg> </New> </Configure>Файл
app-jetty.xmlдля MS SQL должен соответствовать следующему шаблону:<?xml version="1.0"?> <!DOCTYPE Configure PUBLIC "-" "http://www.eclipse.org/jetty/configure_9_0.dtd"> <Configure id="wac" class="org.eclipse.jetty.webapp.WebAppContext"> <New id="CubaDS" class="org.eclipse.jetty.plus.jndi.Resource"> <Arg/> <Arg>jdbc/CubaDS</Arg> <Arg> <New class="org.apache.commons.dbcp2.BasicDataSource"> <Set name="driverClassName">com.microsoft.sqlserver.jdbc.SQLServerDriver</Set> <Set name="url">jdbc:sqlserver://server_name;databaseName=db_name</Set> <Set name="username">username</Set> <Set name="password">password</Set> <Set name="maxIdle">2</Set> <Set name="maxTotal">20</Set> <Set name="maxWaitMillis">5000</Set> </New> </Arg> </New> </Configure> -
Скачайте следующие JAR-файлы, необходимые для функционирования пула соединений к БД и скопируйте их в папку
c:\work\jetty-base\lib\ext. Два из них можно взять из проектного под-каталогаdeploy\tomcat\shared\lib:commons-pool2-2.6.2.jar commons-dbcp2-2.7.0.jar commons-logging-1.2.jar -
Скопируйте файл
start.iniиз дистрибутива Jetty в каталогc:\work\jetty-base. Добавьте следующий текст в начало файлаc:\work\jetty-base\start.ini:--exec -Xdebug -agentlib:jdwp=transport=dt_socket,address=8787,server=y,suspend=n -Dapp.home=c:\work\app_home -Dlogback.configurationFile=c:\work\app_home\logback.xml app-jetty.xml -
Скопируйте JDBC-драйвер используемой базы данных в каталог
c:\work\jetty-base\lib\ext. Файл драйвера можно взять из каталогаdeploy\tomcat\libпроекта. В случае PostgreSQL это файлpostgresql-42.2.5.jar. -
Скопируйте файлы WAR в каталог
c:\work\jetty-base\webapps. -
Откройте командную строку в каталоге
c:\work\jetty-baseи выполните:java -jar c:\work\jetty-home\start.jar -
Откройте
http://localhost:8080/appв веб-браузере.
-
5.3.3. Развертывание WAR в WildFly
WAR-файлы с приложением CUBA можно разворачивать на сервере WildFly. Рассмотрим пример сборки WAR-файлов для приложения, использующего PostgreSQL, и их развертывания на сервере WildFly версии 18.0.1 под Windows.
-
Откройте файл
build.gradleна редактирование и добавьте зависимость для модуля global в секциюdependencies:runtime 'org.reactivestreams:reactive-streams:1.0.1' -
Соберите приложение и выполните CUBA > Build Tasks > Deploy, чтобы получить локальную инсталляцию Tomcat, в которой будут все необходимые зависимости для приложения.
-
Подготовьте домашний каталог приложения:
-
Создайте каталог, который будет полностью доступен процессу сервера WildFly, например,
C:\Users\UserName\app_home. -
Скопируйте файл
logback.xmlизtomcat/confв этот каталог и отредактируйте в нём свойствоlogDirследующим образом:
<property name="logDir" value="${app.home}/logs"/> -
-
Настройте конфигурацию сервера WildFly:
-
Установите WildFly, например, в каталог
C:\wildfly. -
Отредактируйте файл
\wildfly\bin\standalone.conf.bat, добавив в конец следующую строку:
set "JAVA_OPTS=%JAVA_OPTS% -Dapp.home=%USERPROFILE%/app_home -Dlogback.configurationFile=%USERPROFILE%/app_home/logback.xml"Здесь мы задаём системное свойство
app.home, содержащее домашний каталог приложения, и указываем, где находится конфигурационный файлlogback.xml. Вместо переменной%USERPROFILE%можно использовать абсолютный путь.-
Сравните версии Hibernate Validator в WildFly и приложении CUBA. Если платформа использует более свежую версию, замените файл
\wildfly\modules\system\layers\base\org\hibernate\validator\main\hibernate-validator-x.y.z-sometext.jarболее новым файлом из каталогаtomcat\shared\lib, например,hibernate-validator-6.1.1.Final.jar. -
Обновите номер версии указанного JAR-файла в файле
\wildfly\modules\system\layers\base\org\hibernate\validator\main\module.xml. -
Зарегистрируйте драйвер PostgreSQL в WildFly, скопировав файл
postgresql-42.2.5.jarиз каталогаtomcat\libв\wildfly\standalone\deployments. -
Настройте логирование WildFly: отредактируйте файл
\wildfly\standalone\configuration\standalone.xml, добавив две строки в блок<subsystem xmlns="urn:jboss:domain:logging:{version}":<subsystem xmlns="urn:jboss:domain:logging:8.0"> <add-logging-api-dependencies value="false"/> <use-deployment-logging-config value="false"/> . . . </subsystem>
-
-
Создайте JDBC Datasource:
-
Запустите WildFly, выполнив
standalone.bat. -
Откройте консоль администратора по адресу
http://localhost:9990. При первом входе потребуется создать пользователя и задать пароль. -
Перейдите в раздел Configuration - Subsystems - Datasources and Drivers - Datasources и добавьте источник данных для вашего приложения:
Name: Cuba JNDI Name: java:/jdbc/CubaDS JDBC Driver: postgresql-42.2.5.jar Driver Module Name: org.postgresql Driver Class Name: org.postgresql.Driver Connection URL: URL вашей БД Username: имя пользователя БД Password: пароль БДДрайвер JDBC будет доступен в списке обнаруженных драйверов, если вы скопировали файл
postgresql-x.y.z.jarна предыдущем шаге.Выполните проверку соединения, нажав кнопку Test connection.
-
Активируйте источник данных.
-
Как вариант, вы можете также создать JDBC Datasource используя утилиту командной строки
bin/jboss-cli.bat:[disconnected /] connect [standalone@localhost:9990 /] data-source add --name=Cuba --jndi-name="java:/jdbc/CubaDS" --driver-name=postgresql-42.2.5.jar --user-name=dblogin --password=dbpassword --connection-url="jdbc:postgresql://dbhost/dbname" [standalone@localhost:9990 /] quit
-
-
Соберите приложение:
-
Откройте диалог: дерево проектов CUBA > Project > Deployment > WAR Settings в Studio.
-
Включите флаг Build WAR.
-
Сохраните настройки.
-
Откройте файл build.gradle в IDE и добавьте свойство
doAfterдля копирования дескриптора развертывания WildFly в задачу buildWar:task buildWar(type: CubaWarBuilding) { appProperties = ['cuba.automaticDatabaseUpdate' : true] singleWar = false doAfter = { copy { from 'jboss-deployment-structure.xml' into "${project.buildDir}/tmp/buildWar/core/war/META-INF/" } copy { from 'jboss-deployment-structure.xml' into "${project.buildDir}/tmp/buildWar/web/war/META-INF/" } } }Для конфигурации singleWAR задача будет отличаться:
task buildWar(type: CubaWarBuilding) { webXmlPath = 'modules/web/web/WEB-INF/single-war-web.xml' appProperties = ['cuba.automaticDatabaseUpdate' : true] doAfter = { copy { from 'jboss-deployment-structure.xml' into "${project.buildDir}/tmp/buildWar/META-INF/" } } }Если ваш проект также содержит модуль Polymer, нужно добавить в файл
single-war-web.xmlследующую конфигурацию:<servlet> <servlet-name>default</servlet-name> <init-param> <param-name>resolve-against-context-root</param-name> <param-value>true</param-value> </init-param> </servlet> -
В корневом каталоге проекта создайте файл
jboss-deployment-structure.xmlи добавьте в него дескриптор развертывания WildFly:
<?xml version="1.0" encoding="UTF-8"?> <jboss-deployment-structure xmlns="urn:jboss:deployment-structure:1.0"> <deployment> <exclusions> <module name="org.apache.commons.logging" /> <module name="org.apache.log4j" /> <module name="org.jboss.logging" /> <module name="org.jboss.logging.jul-to-slf4j-stub" /> <module name="org.jboss.logmanager" /> <module name="org.jboss.logmanager.log4j" /> <module name="org.slf4j" /> <module name="org.slf4j.impl" /> <module name="org.slf4j.jcl-over-slf4j" /> </exclusions> </deployment> </jboss-deployment-structure>-
Запустите сборку WAR-файлов с помощью задачи
buildWar.
-
-
Скопируйте файлы
app-core.warиapp.warиз каталогаbuild\distributions\warв каталог WildFly\wildfly\standalone\deployments. -
Перезапустите WildFly.
-
Приложение будет доступно по адресу
http://localhost:8080/app. Логи записываются в домашний каталог приложения:C:\Users\UserName\app_home\logs.
5.3.4. Развертывание WAR в Tomcat Windows Service
-
Откройте диалог в Studio: дерево проектов CUBA > Project > Deployment > WAR Settings, или просто вручную добавьте задачу buildWar в конец скрипта сборки build.gradle.:
task buildWar(type: CubaWarBuilding) { singleWar = true includeContextXml = true includeJdbcDriver = true appProperties = ['cuba.automaticDatabaseUpdate': true] }Если параметры сервера отличаются от параметров локального Tomcat, используемого для быстрого развертывания, укажите соответствующие свойства приложения. Например, если конечный сервер запущен на порту 9999 и вы используете сборку раздельных WAR файлов, то определение задачи должно выглядеть следующим образом:
task buildWar(type: CubaWarBuilding) { singleWar = false includeContextXml = true includeJdbcDriver = true appProperties = [ 'cuba.automaticDatabaseUpdate': true, 'cuba.webPort': 9999, 'cuba.connectionUrlList': 'http://localhost:9999/app-core' ] }Вы можете указать отдельный файл проекта
war-context.xmlдля указания настроек подключения к базе данных, или предоставить этот файл позже на сервере:task buildWar(type: CubaWarBuilding) { singleWar = true includeContextXml = true includeJdbcDriver = true appProperties = ['cuba.automaticDatabaseUpdate': true] coreContextXmlPath = 'modules/core/web/META-INF/war-context.xml' } -
Запустите задачу
buildWar. В результате, файлapp.war(или несколько файлов, если вы настроили сборку раздельных WAR) будет собран в каталогеbuild/distributionsвашего проекта.gradlew buildWar -
Скачайте и установите Tomcat 9 Windows Service Installer с официального сайта Apache Tomcat.
-
После завершения установки, перейдите в подкаталог
binустановленного сервера и запуститеtomcat9w.exeот имени администратора, чтобы поменять настройки службы Tomcat:-
На вкладке Java установите параметр Maximum memory pool 1024MB.
-
Укажите для Tomcat использовать кодировку UTF-8, добавив строку
-Dfile.encoding=UTF-8в поле Java Options. -
Укажите домашний каталог приложения, добавив строку
-Dapp.home=c:/app_homeв поле Java Options.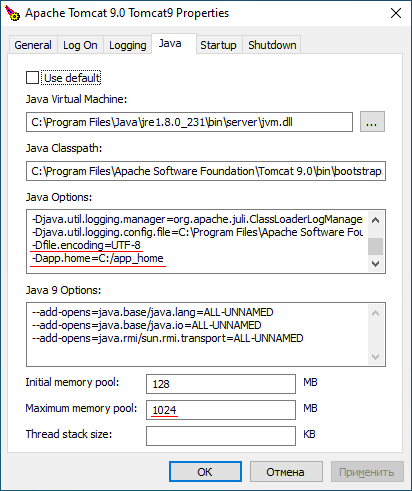
-
-
Если вы хотите предоставить параметры подключения к БД через локальный файл на сервере, создайте файл в подкаталоге
conf/Catalina/localhostкаталога Tomcat. Название файла зависит от названия WAR-сборки, напримерapp.xmlдля single WAR, илиapp-core.xml, если собираются раздельные WAR-файлы. Скопируйте содержимоеcontext.xmlв этот файл. -
При использовании настроек по умолчанию, все журнальные сообщения приложения попадают в файл
logs/tomcat9-stdout.log. У вас есть два варианта, как кастомизировать настройки журналов:-
Создать файл конфигурации logback в вашем проекте. Укажите путь к этому файлу в параметре
logbackConfigurationFileзадачи buildWar (вручную или с помощью диалога Studio WAR Settings). -
Создать файл с настройками журналирования на конечном сервере.
Скопируйте файл
logback.xmlиз локального Tomcat (под-папкаdeploy/tomcat/confпроекта) в домашний каталог приложения и поменяйте свойствоlogDirв этом файле:<property name="logDir" value="${app.home}/logs"/>Добавьте следующую строчку в поле Java Options окна настроек Windows-службы Tomcat 9, чтобы указать путь к настройкам журналирования:
-Dlogback.configurationFile=C:/app_home/logback.xml
-
-
Скопируйте сгенерированный WAR файл(-ы) в подкаталог
webappsсервера Tomcat. -
Перезапустите службу Tomcat.
-
Откройте
http://localhost:8080/appв браузере.
5.3.5. Развертывание WAR в Tomcat Linux Service
Инструкция ниже разработана и проверена для Ubuntu 18.04, для пакетов tomcat9 и tomcat8.
-
Откройте диалог в Studio: дерево проектов CUBA > Project > Deployment > WAR Settings, или просто вручную добавьте задачу buildWar в конец скрипта сборки build.gradle. Вы можете указать отдельный файл проекта
war-context.xmlдля указания настроек подключения к базе данных, или предоставить этот файл позже на сервере:task buildWar(type: CubaWarBuilding) { singleWar = true includeContextXml = true includeJdbcDriver = true appProperties = ['cuba.automaticDatabaseUpdate': true] webXmlPath = 'modules/web/web/WEB-INF/single-war-web.xml' coreContextXmlPath = 'modules/core/web/META-INF/war-context.xml' }Если параметры конечного сервера отличаются от тех, что установлены на локальном Tomcat, используемом для быстрого развертывания, укажите соответствующие свойства приложения. Например, если конечный сервер запущен на порту 9999 и вы используете сборку раздельных WAR файлов, то определение задачи должно выглядеть следующим образом:
task buildWar(type: CubaWarBuilding) { singleWar = false includeContextXml = true includeJdbcDriver = true appProperties = [ 'cuba.automaticDatabaseUpdate': true, 'cuba.webPort': 9999, 'cuba.connectionUrlList': 'http://localhost:9999/app-core' ] } -
Запустите Gradle задачу
buildWar. В результате, файлapp.war(или несколько файлов, если вы настроили сборку раздельных WAR) будет собран в каталогеbuild/distributionsвашего проекта.gradlew buildWar -
Установите пакет Tomcat 9:
sudo apt install tomcat9 -
Скопируйте сборку
app.warв каталог/var/lib/tomcat9/webappsсервера. Вы также можете удалить каталог/var/lib/tomcat9/webapps/ROOTс примером веб-приложения, если он существует.Служба Tomcat 9 по умолчанию работает от пользователя
tomcat. Владелец каталогаwebapps- такжеtomcat. -
Создайте домашний каталог приложения, например
/opt/app_homeи сделайте пользователя, под которым работает Tomcat (tomcat), владельцем этого каталога:sudo mkdir /opt/app_home sudo chown tomcat:tomcat /opt/app_home -
Сервис Tomcat 9 (в отличие от предыдущих версий Debian-пакета Tomcat) работает в "песочнице" systemd и имеет ограниченный доступ к файловой системе. Дополнительную информацию об этом см. в файле
/usr/share/doc/tomcat9/README.Debian. Необходимо поменять настройки systemd, чтобы разрешить сервису Tomcat доступ на запись к домашнему каталогу приложения:-
Создайте файл
override.confв каталоге/etc/systemd/system/tomcat9.service.d/sudo mkdir /etc/systemd/system/tomcat9.service.d/ sudo nano /etc/systemd/system/tomcat9.service.d/override.conf -
Содержимое файла
override.conf:[Service] ReadWritePaths=/opt/app_home/ -
Обновите конфигурацию systemd, выполнив:
sudo systemctl daemon-reload
-
-
Создайте конфигурационный файл
/usr/share/tomcat9/bin/setenv.shсо следующим содержимым:CATALINA_OPTS="$CATALINA_OPTS -Xmx1024m" CATALINA_OPTS="$CATALINA_OPTS -Dapp.home=/opt/app_home"Если вы наблюдаете медленный запуск Tomcat, установленного на виртуальной машине (VPS), добавьте дополнительную строчку в скрипт
setenv.sh:CATALINA_OPTS="$CATALINA_OPTS -Djava.security.egd=file:/dev/./urandom" -
Если вы хотите предоставить параметры подключения к БД через локальный файл на сервере, создайте файл в каталоге
/var/lib/tomcat9/conf/Catalina/localhost/. Название файла зависит от названия WAR-сборки, напримерapp.xmlдля single WAR, илиapp-core.xml, если собираются раздельные WAR-файлы. Скопируйте содержимоеcontext.xmlв этот файл. -
При использовании настроек по умолчанию, все журнальные сообщения приложения попадают в системный журнал
/var/log/syslog. У вас есть два варианта, как кастомизировать настройки журналов:-
Создать файл конфигурации logback в вашем проекте. Укажите путь к этому файлу в параметре
logbackConfigurationFileзадачи buildWar (вручную или с помощью диалога Studio WAR Settings). -
Создать файл с настройками журналирования на конечном сервере.
Скопируйте файл
logback.xmlиз локального Tomcat (под-папкаdeploy/tomcat/confпроекта) в домашний каталог приложения и поменяйте свойствоlogDirв этом файле:<property name="logDir" value="${app.home}/logs"/>Добавьте следующую строчку в скрипт
setenv.sh, чтобы указать путь к настройкам журналирования:CATALINA_OPTS="$CATALINA_OPTS -Dlogback.configurationFile=/opt/app_home/logback.xml"
-
-
Перезапустите службу Tomcat:
sudo systemctl restart tomcat9 -
Откройте
http://localhost:8080/appв вашем веб-браузере.
- Изменения в случае использования пакета tomcat8
-
CUBA поддерживает развертывание и в Tomcat 9, и в Tomcat 8.5. Примите во внимание следующие различия процедуры развертывания приложения в Tomcat 8.5:
-
Tomcat 8.5 предоставляется пакетом
tomcat8 -
Имя пользователя -
tomcat8 -
Base каталог Tomcat -
/var/lib/tomcat8 -
Home каталог Tomcat -
/usr/share/tomcat8 -
Сервис Tomcat не использует "песочницу" systemd, поэтому нет необходимости менять настройки systemd.
-
Стандартные потоки вывода и ошибок пишутся в файл
/var/lib/tomcat8/logs/catalina.out.
-
- Решение проблем интеграции аддона Reporting с LibreOffice при использовании пакета tomcat9
-
При развертывании приложения через пакет tomcat9 и использовании интеграции аддона Reporting с LibreOffice вы можете столкнуться с проблемами запуска процессов LibreOffice. Ошибку можно диагностировать по этому сообщению в журнале:
2019-12-04 09:52:37.015 DEBUG [OOServer: ERR] com.haulmont.yarg.formatters.impl.doc.connector.OOServer - ERR: (process:10403): dconf-CRITICAL **: 09:52:37.014: unable to create directory '/.cache/dconf': Read-only file system. dconf will not work properly.Эта ошибка вызывана тем, что домашний каталог пользователя
tomcatуказывает на каталог, недоступный для записи. Это можно исправить, поменяв домашнюю папку пользователяtomcatна значение/var/lib/tomcat9/work:# проблемное значение echo ~tomcat / # исправить sudo systemctl stop tomcat9 sudo usermod -d /var/lib/tomcat9/work tomcat sudo systemctl start tomcat9
5.3.6. Развертывание UberJAR
UberJAR - это простейший способ запустить приложение CUBA в режиме эксплуатации. Вы собираете единый all-in-one JAR-файл с помощью задачи Gradle buildUberJar (см. также вкладку Deployment > UberJAR Settings в Studio) и запускаете приложение из командной строки, используя команду java:
java -jar app.jarВсе параметры приложения определяются во время сборки, но могут быть переопределены при запуске (см. ниже). Порт веб-приложения по умолчанию - 8080, и оно доступно по адресу http://host:8080/app. Если в проекте есть Polymer UI, он будет доступен по умолчанию по адресу http://host:8080/app-front.
Можно также собрать отдельные JAR-файлы для Middleware и Web Client и запустить их аналогично:
java -jar app-core.jar java -jar app.jar
Порт веб-клиента по умолчанию - 8080, он будет подключаться к middleware, использующему localhost:8079. Таким образом, выполнив эти две команды в двух разных терминалах Windows, вы сможете подключиться к веб-клиенту приложения по адресу http://localhost:8080/app.
Вы можете изменить параметры, определяемые во время сборки, передав свойства приложения через системные свойства Java. Кроме того, порты, имена контекстов и пути к конфигурационным файлам можно передавать в качестве аргументов командной строки.
- Аргументы командной строки
-
-
port- задаёт порт, на котором будет работать встроенный HTTP-сервер. Например:java -jar app.jar -port 9090Следует учесть, что при указании порта для блока core необходимо также задать свойство приложения cuba.connectionUrlList для клиентских блоков, указав соответствующий адрес Middleware:
java -jar app-core.jar -port 7070 java -Dcuba.connectionUrlList=http://localhost:7070/app-core -jar app.jar -
contextName- имя веб-контекста для данного блока приложения. Например, чтобы получить доступ к веб-клиенту по адресуhttp://localhost:8080/sales, выполните следующую команду:java -jar app.jar -contextName salesЧтобы подключиться к веб-клиенту по адресу
http://localhost:8080, выполните команду:java -jar app.jar -contextName / -
frontContextName- имя веб-контекста для Polymer UI (имеет смысл для единого, web или portal JAR файлов).
UberJAR не работает корректно с аргументами
frontContextName,contextNameдля фронтенд клиентов на базе React.-
portalContextName- имя веб-контекста для модуля portal, работающего в едином JAR. -
jettyEnvPath- путь к файлу окружения Jetty, который переопределяет настройки, заданные внутри JAR параметром сборкиcoreJettyEnvPath. Может быть как абсолютным путём, так и относительным рабочего каталога. -
jettyConfPath- путь к файлу конфигурации сервера Jetty, который переопределяет настройки, заданные внутри JAR параметром сборкиwebJettyConfPath/coreJettyConfPath/portalJettyConfPath. Может быть как абсолютным путём, так и относительным рабочего каталога.
-
- Домашний каталог приложения
-
По умолчанию домашним каталогом является рабочий каталог приложения. Это означает, что каталоги приложения будут созданы в каталоге, из которого приложение запущено. Домашний каталог может быть также указан в системном свойстве
app.home. Например, чтобы иметь домашний каталог в/opt/app_home, необходимо указать следующее в командной строке:java -Dapp.home=/opt/app_home -jar app.jar - Логирование
-
Если необходимо изменить настройки логирования, заданные внутри JAR, то можно передать системное свойство Java
logback.configurationFileс URL для загрузки внешнего конфигурационного файла, например:java -Dlogback.configurationFile=file:./logback.xml -jar app.jarЗдесь подразумевается, что файл
logback.xmlрасположен в папке, из которой запускается приложение.Для правильного задания каталога логов убедитесь, что свойство
logDirвlogback.xmlуказывает на подкаталогlogsдомашнего каталога приложения:<configuration debug="false"> <property name="logDir" value="${app.home}/logs"/> <!-- ... --> - Задание свойств приложения на этапе развертывания
-
Возможен вариант задания свойств приложения уже в среде развертывания. Таким образом могут указываться значения, недоступные на момент сборки (например по соображениям безопасности).
Свойства приложения могут быть заданы в файле
local.app.properties, через переменные окружения ОС или системные свойства Java, переданные в командной строке.Файл
local.app.propertiesдолжен находиться в домашнем каталоге приложения. Им является текущий рабочий каталог, если вы не задали иной путь в аргументе командной строки-Dapp.home=some_path. Например:local.app.propertiescuba.web.loginDialogDefaultUser = <disabled> cuba.web.loginDialogDefaultPassword = <disabled>Если используются переменнные окружения ОС, то можно задавать имя свойства в верхнем регистре и с точками замененными на подчеркивания:
export CUBA_WEB_LOGINDIALOGDEFAULTUSER="<disabled>" export CUBA_WEB_LOGINDIALOGDEFAULTPASSWORD="<disabled>"Системные свойства Java должны быть указаны в командной строке (имейте в виду, что они будут видны в менеджерах задач и в выводе команды
ps):java -Dcuba.web.loginDialogDefaultUser=<disabled> -Dcuba.web.loginDialogDefaultPassword=<disabled> -jar app.jarПеременнные окружения ОС переопределяют значения, заданные в файлах
app.properties, системные свойства Java переопределяют и переменные окружения, и файлы. - Остановка приложения
-
Корректно остановить приложение можно следующими способами:
-
Нажав Ctrl+C в окне терминала, в котором работает приложение.
-
Выполнив
kill <PID>в Unix-like системе. -
Послав ключ (последовательность символов) остановки на порт, указанный в командной строке запущенного приложения. Следующие аргументы командной строки имеют отношение к остановке:
-
stopPort- порт прослушивания и посылки ключа остановки. -
stopKey- ключ остановки. Если не указан, используетсяSHUTDOWN. -
stop- остановить другой процесс отсылкой ключа.
-
Например:
# Start application 1 and listen to SHUTDOWN key on port 9090 java -jar app.jar -stopPort 9090 # Start application 2 and listen to MYKEY key on port 9090 java -jar app.jar -stopPort 9090 -stopKey MYKEY # Shutdown application 1 java -jar app.jar -stop -stopPort 9090 # Shutdown application 2 java -jar app.jar -stop -stopPort 9090 -stopKey MYKEY -
5.3.6.1. Настройка HTTPS для UberJAR
Ниже приведен пример настройки HTTPS с самоподписанным сертификатом для развертывания UberJAR.
-
Сгенерируйте ключи и сертификаты, используя встроенную JDK-утилиту
Java Keytool:keytool -keystore keystore.jks -alias jetty -genkey -keyalg RSA -
В корневом каталоге проекта создайте файл конфигурации SSL
jetty.xml:<Configure id="Server" class="org.eclipse.jetty.server.Server"> <Call name="addConnector"> <Arg> <New class="org.eclipse.jetty.server.ServerConnector"> <Arg name="server"> <Ref refid="Server"/> </Arg> <Set name="port">8090</Set> </New> </Arg> </Call> <Call name="addConnector"> <Arg> <New class="org.eclipse.jetty.server.ServerConnector"> <Arg name="server"> <Ref refid="Server"/> </Arg> <Arg> <New class="org.eclipse.jetty.util.ssl.SslContextFactory"> <Set name="keyStorePath">keystore.jks</Set> <Set name="keyStorePassword">password</Set> <Set name="keyManagerPassword">password</Set> <Set name="trustStorePath">keystore.jks</Set> <Set name="trustStorePassword">password</Set> </New> </Arg> <Set name="port">8443</Set> </New> </Arg> </Call> </Configure>Удостоверьтесь, что значения свойств
keyStorePassword,keyManagerPasswordиtrustStorePasswordсовпадают с паролями, установленными вKeytool. -
Включите файл
jetty.xmlв конфигурацию задачи сборки:task buildUberJar(type: CubaUberJarBuilding) { singleJar = true coreJettyEnvPath = 'modules/core/web/META-INF/jetty-env.xml' appProperties = ['cuba.automaticDatabaseUpdate' : true] webJettyConfPath = 'jetty.xml' } -
Соберите Uber JAR, следуя инструкции, описанной в разделе Развертывание UberJAR.
-
Поместите файл
keystore.jksв папку с JAR-файлами собранного приложения и запустите Uber JAR.Теперь приложение доступно по адресу
https://localhost:8443/app.
5.3.7. Развертывание с помощью Docker
Данный раздел описывает развертывание приложения CUBA в Docker-контейнерах.
Мы возьмем проект Sales, мигрируем его на базу данных PostgreSQL, и соберем UberJAR для запуска в контейнере. В принципе, приложение, собранное в виде WAR-файла также можно использовать в контейнере с сервером Tomcat, но это требует несколько больше конфигурирования, поэтому для целей демонстрации мы ограничимся вариантом UberJAR.
- Конфигурирование и сборка UberJAR
-
Клонируйте проект из https://github.com/cuba-platform/sample-sales-cuba7 и откройте его в CUBA Studio.
Сначала смените тип базы данных на PostgreSQL:
-
Выберите CUBA > Main Data Store Settings… в главном меню.
-
Выберите PostgreSQL в поле Database type и нажмите OK.
-
Выберите CUBA > Generate Database Scripts в главном меню. Studio откроет диалог Database Scripts со сгенерированными скриптами. Нажмите Save and close.
-
Выберите CUBA > Create Database в главном меню. Studio создаст базу данных
salesна локальном сервере PostgreSQL.
Теперь сконфигурируйте задачу Gradle для сборки UberJAR.
-
Выберите пункт CUBA > Deployment > Edit UberJAR Settings главного меню.
-
Отметьте флажки Build Uber JAR и Single Uber JAR.
-
Нажмите Generate рядом с полем Logback configuration file.
-
Нажмите Configure рядом с полем Custom data store configuration.
-
Проверьте, что URL в группе Database Properties начинаетсяс префикса
jdbc:postgresql://. Установите хостpostgresвместоlocalhostв первом текстовом поле URL. Это необходимо для работы с базой данных, работающей в отдельном контейнере, который описан ниже. -
Нажмите OK. Studio добавит задачу buildUberJar в файл
build.gradle. -
Откройте сгенерированный файл
etc/uber-jar-logback.xmlили другой файл, используемый как конфигурация Logback, и убедитесь, что свойствоlogDirимеет следующее значение:<property name="logDir" value="${app.home}/logs"/>Кроме того, убедитесь что конфигурация Logback ограничивает уровень логгера
org.eclipse.jettyкак минимум доINFO. Если такого логгера в файле не задано, то добавьте его:<logger name="org.eclipse.jetty" level="INFO"/>
Запустите задачу сборки JAR-файла через главное меню: CUBA → Deployment → Build UberJAR, или выполнив следующую команду в терминале:
./gradlew buildUberJar -
- Создание Docker-образа
-
Теперь создадим файл
Dockerfileи соберем образ с нашим приложением.-
Создайте каталог
docker-imageв корне проекта. -
Скопируйте JAR-файл из
build/distributions/uberJarв этот каталог. -
Создайте файл
Dockerfileсо следующими инструкциями:FROM openjdk:8 COPY . /opt/sales CMD java -Dapp.home=/opt/sales-home -jar /opt/sales/app.jar
Системное свойство Java
app.homeзадает домашний каталог приложения, в котором хранятся логи приложения и другие файлы, создаваемые приложением. После запуска контейнера мы сможем отобразить данный каталог на каталог хост-компьютера для доступа к логам и другим данным, в том числе файлам, загружаемым в FileStorage.Теперь соберем образ:
-
Откройте терминал в корневом каталоге проекта.
-
Запустите команду сборки, передавая имя образа в опции
-t, и каталог, в котором находится файлDockerfile:docker build -t sales docker-image
Проверьте, что образ
salesотображается при выполнении командыdocker images. -
- Запуск контейнеров приложения и базы данных
-
Приложение готово к запуску в контейнере, но нам необходима база данных PostgreSQL, работающая также в контейнере. Для управления двумя контейнерами - одним с приложением и другим с базой данных, мы будем использовать Docker Compose.
Создайте в корне проекта файл
docker-compose.ymlсо следующим содержимым:version: '2' services: postgres: image: postgres:12 environment: - POSTGRES_DB=sales - POSTGRES_USER=cuba - POSTGRES_PASSWORD=cuba ports: - "5433:5432" web: depends_on: - postgres image: sales volumes: - /Users/me/sales-home:/opt/sales-home ports: - "8080:8080"Обратите внимание на следующие части данного файла:
-
Секция
volumesотображает путь/opt/sales-homeвнутри контейнера, являющийся домашним каталогом приложения, на путь/Users/me/sales-homeхост-компьютера. Это означает, что логи приложения будут доступны в каталоге/Users/me/sales-home/logsхост-компьютера. -
Внутренний порт контейнера 5432, на котором работает PostgreSQL, отображен на порт 5433 хост-компьютера для избежания конфликта с сервером PostgreSQL, работающим на хосте. Используя этот порт, вы можете обращаться к базе данных извне, например, чтобы сделать бэкап:
pg_dump -Fc -h localhost -p 5433 -d sales -U cuba > /Users/me/sales.backup
-
Контейнер приложения выставляет порт 8080, так что UI приложения будет доступен по адресу
http://localhost:8080/appна хост-компьютере.
Для запуска приложения и базы данных откройте терминал в каталоге, содержащем файл
docker-compose.ymlи запустите команду:docker-compose up -
5.3.8. Развертывание в облаке Jelastic
Рассмотрим пример сборки и развёртывания приложения в облаке Jelastic.
|
В данный момент развёртывание в облаке возможно для проектов, использующих в качестве сервера базы данных PostgreSQL или HSQL. |
-
Создайте бесплатную тестовую учётную запись в облаке Jelastic с помощью веб-браузера.
-
Создайте новое окружение, в которое будет развёрнут WAR:
-
Кликните New Environment.
-
В открывшемся окне задайте настройки: окружение должно иметь Java 8, Tomcat 8 и PostgreSQL 9.1+ (если в проекте используется база данных PostgreSQL). В поле Environment Name задайте уникальное имя окружения и нажмите на кнопку Create.
-
Если в созданном окружении был использован PostgreSQL, вы получите email с информацией о подключении к БД. Перейдите в административный веб-интерфейс по ссылке в письме, полученном после создания окружения, и создайте пустую базу данных. Выбранное имя базы данных должно быть указано позже в
context.xml.
-
-
Соберите единый Single WAR файл, используя CUBA Studio:
-
Выберите пункт главного меню CUBA > Deployment > WAR Settings.
-
Включите флажок Build WAR.
-
Введите значение
..в поле Application home directory: -
Включите флажки Include JDBC driver и Include Tomcat’s context.xml.
-
Если ваш проект использует базу данных PostgreSQL, нажмите на кнопку Generate рядом с полем Custom context.xml path. Укажите пользователя, пароль, хост и имя базы данных, созданной ранее в веб-интерфейсе Jelastic.
-
Установите флажок Single WAR for Middleware and Web Client.
-
Нажмите на кнопку Generate рядом с полем Custom web.xml path. Studio сгенерирует специальный
web.xmlдля единого WAR, содержащего блоки Middleware и Web Client.
-
Добавьте свойство
cuba.logDirв окне App properties:appProperties = ['cuba.automaticDatabaseUpdate': true, 'cuba.logDir': '${catalina.base}/logs'] -
Нажмите на кнопку OK. В конец файла build.gradle добавилась задача сборки buildWar:
task buildWar(type: CubaWarBuilding) { includeJdbcDriver = true includeContextXml = true appProperties = ['cuba.automaticDatabaseUpdate': true, 'cuba.logDir' : '${catalina.base}/logs'] webXmlPath = 'modules/web/web/WEB-INF/single-war-web.xml' coreContextXmlPath = 'modules/core/web/META-INF/war-context.xml' } -
Если ваш проект использует HSQL, откройте задачу
buildWarв файлеbuild.gradleи добавьте свойствоhsqlInProcess = true, чтобы запустить встроенный сервер HSQL при развертывании WAR файла. Убедитесь, что свойствоcoreContextXmlPathне задано.task buildWar(type: CubaWarBuilding) { appProperties = ['cuba.automaticDatabaseUpdate': true, 'cuba.logDir': '${catalina.base}/logs'] includeContextXml = true webXmlPath = 'modules/web/web/WEB-INF/single-war-web.xml' includeJdbcDriver = true hsqlInProcess = true } -
Запустите сборку, выбрав
buildWarчерез командную строку:gradlew buildWarВ результате в подкаталоге
build\distributions\warпроекта будет создан файлapp.war.
-
-
Для развертывания WAR-файла в Jelastic используйте задачу Gradle deployWar:
task deployWar(type: CubaJelasticDeploy, dependsOn: buildWar){ email = **** password = **** hostUrl = 'app.j.layershift.co.uk' environment = 'my-env-1' } -
По завершению процесса развёртывания CUBA-приложение будет доступно в облаке Jelastic. Чтобы его открыть, воспользуйтесь URL вида
<environment>.<hostUrl>в браузере.Например:
http://my-env-1.j.layershift.co.ukВы также можете открыть приложение с помощью кнопки Open in Browser, расположенной на панели окружений в Jelastic.
5.3.9. Развёртывание в облаке Bluemix
С помощью CUBA Studio можно легко развернуть приложение в облаке IBM® Bluemix®.
|
Развёртывание в облаке Bluemix в настоящее время рекомендуется только для проектов, использующих базу данных PostgreSQL. HSQLDB доступна только с опцией in-process, таким образом, база данных будет пересоздаваться каждый раз при перезапуске облачного приложения, соответственно, пользовательские данные будут потеряны. |
-
Создайте учётную запись в сервисе Bluemix. Также скачайте и установите следующее программное обеспечение:
-
Bluemix CLI: http://clis.ng.bluemix.net/ui/home.html
-
Cloud Foundry CLI: https://github.com/cloudfoundry/cli/releases
-
После установки убедитесь, что команды
bluemixиcfработают в командной строке. При необходимости добавьте путь к исполняемым файлам\IBM\Bluemix\binв переменную средыPATH.
-
-
Создайте новое пространство (Space) в облаке Bluemix, задайте ему любое имя. В дальнейшем вы можете поместить несколько приложений в одно пространство.
-
Добавьте к созданному пространству сервер приложений Tomcat: Create App → CloudFoundry Apps → Tomcat.
-
Задайте имя приложения. Имя должно быть уникальным, так как на его основе строится URL, по которому WEB-приложение будет доступно впоследствии.
-
Чтобы добавить к пространству подходящий сервис базы данных, нажмите Create service в панели управления пространством и выберите ElephantSQL.
-
Откройте панель управления приложением (ранее созданный Tomcat) и подключите сервис базы данных к приложению. Нажмите Connect Existing. Чтобы изменения вступили в силу, система предлагает обновить (restage) приложение. На данном этапе в этом нет необходимости: сервер Tomcat будет обновлен позже при развертывании CUBA-приложения.
-
После подключения сервиса базы данных к приложению параметры подключения к СУБД будут доступны по кнопке View Credentials. Также параметры подключения к СУБД сохраняются в переменной среды
VCAP_SERVICESоблачного приложения и доступны по командеcf env. Созданная БД доступна глобально, управлять базой данных можно по указанному URL. -
Настройте CUBA-проект на базу данных PostgreSQL (на СУБД, аналогичную той которую Вы используете в облаке Bluemix).
-
Создайте скрипты базы данных и запустите локальный сервер Tomcat. Убедитесь, что приложение работоспособно.
-
Создайте WAR-файл, при помощи которого приложение будет равзернуто в сервер Tomcat.
-
В секции Deployment откройте окно *WAR Settings.
-
При помощи чекбоксов выберите все доступные опции: для корректного развертывания в облаке необходим единый Single WAR файл с помещёнными в него драйвером базы данных и конфигурационным файлом
context.xml.
-
Нажмите кнопку Generate рядом с полем Custom context.XML. В появившемся диалоге укажите параметры подключения к базе данных - сервису в облаке Bluemix.
Используйте параметры из строки
uriсервиса, как в примере ниже:{ "elephantsql": [ { "credentials": { "uri": "postgres://ixbtsvsq:F_KyeQjpEdpQfd4n0KpEFCYyzKAbN1W9@qdjjtnkv.db.elephantsql.com:5432/ixbtsvsq", "max_conns": "5" } } ] }Database user:
ldwpelplDatabase password:
eFwXx6lNFLheO5maP9iRbS77Sk1VGO_TDatabase URL:
echo-01.db.elephantsql.com:5432Database name:
ldwpelpl -
Нажмите кнопку Generate для создания собственного файла
web.xml, необходимого для единого WAR-файла. -
Сохраните настройки. Создайте WAR-файл, выполнив команду Gradle
buildWarили из командной строки.
В результате, в папке проекта
build/distributions/war/появился файлapp.war.
-
-
В корневом каталоге прокекта вручную создайте файл
manifest.ymlсо следующим содержимым:applications: - path: build/distributions/war/app.war memory: 1G instances: 1 domain: eu-gb.mybluemix.net name: myluckycuba host: myluckycuba disk_quota: 1024M buildpack: java_buildpack env: JBP_CONFIG_TOMCAT: '{tomcat: { version: 8.0.+ }}' JBP_CONFIG_OPEN_JDK_JRE: '{jre: { version: 1.8.0_+ }}'где
-
path- относительный путь к сгенерированному WAR-файлу. -
memory: по умолчанию серверу Tomcat выделяется лимит памяти в 1G. При необходимости вы можете уменьшить или увеличить объём выделенной памяти, эта настройка также доступна через WEB-интерфейс Bluemix. Учтите, что количество памяти, выделенной приложению, влияет на стоимость облачного размещения. -
name- имя сервера приложения Tomcat, созданного в облаке. -
host: идентично имени приложения. -
env: этим параметром задаются переменные среды. В нашем случае переменными среды задаются версии Tomcat и Java, необходимые для правильного функционирования CUBA-приложения.
-
-
В комадной строке перейдите в корневой каталог проекта CUBA.
cd your_project_directory -
Создайте подключение к Bluemix.
bluemix api https://api.ng.bluemix.net -
Зайдите в Вашу учетную запись Bluemix.
cf login -
Разверните созданный WAR в облачный Tomcat.
cf pushКоманда
pushиспользует параметры, указанные в конфигурационном файлеmanifest.yml. -
Посмотреть логи сервера Tomcat можно на вкладке Logs панели управления приложением в WEB-интерфейсе Bluemix, а также в командной строке при помощи команды
cf logs cuba-app --recent -
По завершению процесса развёртывания CUBA-приложение будет доступно в облаке Bluemix. Чтобы его открыть, воспользуйтесь URL
host.domainв браузере. Этот URL будет отображаться в поле ROUTE таблицы ваших приложений Cloud Foundry Apps.
5.3.10. Развертывание в облаке Heroku
Данный раздел описывает порядок развертывания приложения CUBA в облаке Heroku®.
|
Это руководство охватывает процесс развертывания проекта с использованием базы данных PostgreSQL. |
5.3.10.1. Развертывание WAR-файла в Heroku
- Учетная запись Heroku
-
Создайте учетную запись в Heroku с помощью веб-браузера, будет достаточно бесплатного аккаунта
hobby-dev. Затем войдите в аккаунт и создайте новое приложение с помощью кнопки New в верхней части страницы.Задайте уникальное имя приложения (либо оставьте поле пустым, чтобы имя назначилось автоматически) и выберите подходящее геоположение сервера. Вы зарегистрировали приложение, например
morning-beach-4895, это будет название приложения Heroku.Сначала вас переадресует на вкладку Deploy. Выберите там метод развертывания Heroku Git.
- Командная строка Heroku (CLI)
-
-
Установите на компьютер программное обеспечение Heroku CLI.
-
Перейдите в папку проекта CUBA. В дальнейшем для этой папки будет использоваться переменная
$PROJECT_FOLDER. -
Откройте командную строку в
$PROJECT_FOLDERи наберите команду:heroku login -
По запросу введите логин и пароль для Heroku. Начиная с текущего момента от вас больше не потребуется вводить логин и пароль для команд heroku.
-
Установите плагин Heroku CLI deployment plugin:
heroku plugins:install heroku-cli-deploy
-
- База данных PostgreSQL
-
С помощью браузера пройдите на страницу Heroku data
Вы можете использовать существующую базу Postgres или создать новую. Далее описываются шаги по созданию новой БД.
-
Найдите на странице блок Heroku Postgres и нажмите кнопку Create one
-
На следующем экране нажмите кнопку Install Heroku Postgr…
-
Далее подключите базу к приложению Heroku, выбрав подходящую из выпадающего списка
-
Далее выберите тарифный план (например, бесплатный
hobby-dev)
Как вариант, вы можете установить PostgreSQL с помощью Heroku CLI:
heroku addons:create heroku-postgresql:hobby-dev --app morning-beach-4895Здесь
morning-beach-4895это название вашего приложения Heroku.Теперь вы можете увидеть новую БД на вкладке Resources. База соединена с приложением Heroku. Чтобы получить детали для подключения к сервису БД, перейдите на страницу Datasource вашей БД в Heroku, опуститесь вниз до секции Administration и нажмите кнопку View credentials.
Host compute.amazonaws.com Database d2tk User nmmd Port 5432 Password 9c05 URI postgres://nmmd:9c05@compute.amazonaws.com:5432/d2tk -
- Настройки проекта перед развертыванием
-
-
Мы предполагаем, что в проекте CUBA вы используете базу данных Postgres.
-
Откройте проект в CUBA Studio, перейдите к пункту дерева проекта CUBA → Deployment, откройте диалог WAR Settings и затем отредактируйте настройки, как описано ниже.
-
Включите Build WAR
-
Задайте точку '.' в качестве домашнего каталога приложения в поле Application home directory
-
Включите Include JDBC driver
-
Включите Include Tomcat’s context.xml
-
Нажмите кнопку Generate, находящуюся справа от поля Custom context.xml path. Во всплывающем окне заполните параметры подключения к БД
-
Откройте сгенерированный файл
modules/core/web/META-INF/war-context.xmlи проверьте детали подключения:<Context> <!-- Database connection --> <Resource name="jdbc/CubaDS" type="javax.sql.DataSource" maxTotal="20" maxIdle="2" maxWaitMillis="5000" driverClassName="org.postgresql.Driver" url="jdbc:postgresql://compute.amazonaws.com/d2tk" username="nmmd" password="9c05"/> <!-- ... --> </Context> -
Отметьте галочкой Single WAR for Middleware and Web Client
-
Нажмите кнопку Generate справа от поля Custom web.xml path
-
Скопируйте код, приведенный ниже, в поле App properties:
[ 'cuba.automaticDatabaseUpdate' : true ] -
Сохраните настройки и дождитесь обновления проекта Gradle.
-
-
- Сборка WAR-файла
-
Соберите WAR-файл, сделав двойной клик по появившемуся элементу Build WAR дерева проектов или выполнив Gradle команду
buildWarв терминале:gradlew buildWar - Настройка приложения
-
-
Загрузите JAR-файл Tomcat Webapp Runner из репозитория https://mvnrepository.com/artifact/com.github.jsimone/webapp-runner. Версия Webapp Runner должна соответствовать используемой версии Tomcat. К примеру, Webapp Runner версии 8.5.11.3 подходит для Tomcat версии 8.5.11. Переименуйте JAR-файл в
webapp-runner.jarи поместите его в корень проекта$PROJECT_FOLDER. -
Загрузите JAR-файл Tomcat DBCP из репозитория https://mvnrepository.com/artifact/org.apache.tomcat/tomcat-dbcp. Используйте версию, соответствующую вашему Tomcat, например 8.5.11. Создайте папку
$PROJECT_FOLDER/libs, переименуйте JAR-файл вtomcat-dbcp.jarи поместите его в папку$PROJECT_FOLDER/libs. -
Создайте файл с названием
Procfileв$PROJECT_FOLDER. Файл должен содержать следующий текст:web: java $JAVA_OPTS -cp webapp-runner.jar:libs/* webapp.runner.launch.Main --enable-naming --port $PORT build/distributions/war/app.war
-
- Настройка Git
-
Откройте командную строку в папке
$PROJECT_FOLDERи запустите команды, указанные ниже:git init heroku git:remote -a morning-beach-4895 git add . git commit -am "Initial commit" - Развертывание приложения
-
Откройте командную строку в папке
$PROJECT_FOLDERи запустите команды, указанные ниже:Для *nix:
heroku jar:deploy webapp-runner.jar --includes libs/tomcat-dbcp.jar:build/distributions/war/app.war --app morning-beach-4895Для Windows:
heroku jar:deploy webapp-runner.jar --includes libs\tomcat-dbcp.jar;build\distributions\war\app.war --app morning-beach-4895Откройте вкладку Resources в панели управления Heroku. Должна появиться новая запись Dyno с командой из вашего
Procfile:
Приложение в данный момент разворачивается. Вы можете отслеживать процесс по логам.
- Мониторинг логов
-
Дождитесь сообщения в командной строке
https://morning-beach-4895.herokuapp.com/ deployed to Heroku.Чтобы отслеживать данные в логах, запустите в командной строке из любой папки следующую команду:
heroku logs --tail --morning-beach-4895
После завершения процесса развертывания ваше приложение будет доступно в браузере по ссылке https://morning-beach-4895.herokuapp.com
Вы также можете открыть приложение с помощью кнопки Open app, расположенной на панели Heroku.
5.3.10.2. Развертывание из GitHub в Heroku
Данное руководство описывает процесс настройки сборки и развертывания проекта, размещенного на GitHub.
- Учетная запись Heroku
-
Создайте учетную запись в Heroku с помощью веб-браузера, будет достаточно бесплатного аккаунта
hobby-dev. Затем войдите в аккаунт и создайте новое приложение с помощью кнопки New в верхней части страницы.Задайте уникальное имя приложения (либо оставьте поле пустым, чтобы имя назначилось автоматически) и выберите подходящее геоположение сервера. Вы зарегистрировали приложение, например
space-sheep-02453, это будет название приложения Heroku.Сначала вас переадресует на вкладку Deploy. Выберите там метод развертывания GitHub. Следуйте инструкциям на экране, чтобы авторизоваться в учетную запись GitHub. Нажмите кнопку Search, чтобы вывести список доступных репозиториев GitHub вашей учетной записи, затем подключите желаемый репозиторий к проекту CUBA. Когда приложение Heroku подсоединено к GitHub, то вам доступна функция автоматического развертывания приложения Automatic Deploys. Это позволяет развертывать приложение в Heroku автоматически при каждом событии
git push. В этом руководстве данная опция включена. - Командная строка Heroku (CLI)
-
-
Установите на компьютер программное обеспечение Heroku CLI
-
Откройте командную строку в любой папке вашего компьютера и наберите команду:
heroku login -
По запросу введите логин и пароль для Heroku. Начиная с текущего момента от вас больше не потребуется вводить логин и пароль для команд heroku.
-
- База данных PostgreSQL
-
-
Откройте панель Heroku в веб-браузере
-
Перейдите на вкладку Resources
-
Нажмите кнопку Find more add-ons, чтобы найти дополнения для подключения СУБД
-
Найдите блок Heroku Postgres и нажмите его. Проследуйте инструкциям на экране, нажмите кнопки Login to install / Install Heroku Postgres для установки дополнения.
Как вариант, вы можете установить PostgreSQL с помощью Heroku CLI, где
space-sheep-02453- это имя вашего Heroku приложения:heroku addons:create heroku-postgresql:hobby-dev --app space-sheep-02453Теперь вы можете увидеть новую БД на вкладке Resources. База соединена с приложением Heroku. Чтобы получить детали для подключения к сервису БД, перейдите на страницу Datasource вашей БД в Heroku, опуститесь вниз до секции Administration и нажмите кнопку View credentials.
Host compute.amazonaws.com Database zodt User artd Port 5432 Password 367f URI postgres://artd:367f@compute.amazonaws.com:5432/zodt -
- Настройки проекта перед развертыванием
-
-
Перейдите в папку проекта CUBA (
$PROJECT_FOLDER) на вашем компьютере -
Скопируйте содержимое файла
modules/core/web/META-INF/context.xmlвmodules/core/web/META-INF/heroku-context.xml -
Впишите в файл
heroku-context.xmlактуальные данные для подключения в БД (см. пример ниже):<Context> <Resource driverClassName="org.postgresql.Driver" maxIdle="2" maxTotal="20" maxWaitMillis="5000" name="jdbc/CubaDS" password="367f" type="javax.sql.DataSource" url="jdbc:postgresql://compute.amazonaws.com/zodt" username="artd"/> <Manager pathname=""/> </Context>
-
- Настройка сборки
-
Добавьте следующую задачу Gradle в ваш файл
$PROJECT_FOLDER/build.gradletask stage(dependsOn: ['setupTomcat', ':app-core:deploy', ':app-web:deploy']) { doLast { // replace context.xml with heroku-context.xml def src = new File('modules/core/web/META-INF/heroku-context.xml') def dst = new File('deploy/tomcat/webapps/app-core/META-INF/context.xml') dst.delete() dst << src.text // change port from 8080 to heroku $PORT def file = new File('deploy/tomcat/conf/server.xml') file.text = file.text.replace('8080', '${port.http}') // add local.app.properties for core application def coreConfDir = new File('deploy/tomcat/conf/app-core/') coreConfDir.mkdirs() def coreProperties = new File(coreConfDir, 'local.app.properties') coreProperties.text = ''' cuba.automaticDatabaseUpdate = true ''' // rename deploy/tomcat/webapps/app to deploy/tomcat/webapps/ROOT def rootFolder = new File('deploy/tomcat/webapps/ROOT') if (rootFolder.exists()) { rootFolder.deleteDir() } def webAppDir = new File('deploy/tomcat/webapps/app') webAppDir.renameTo( new File(rootFolder.path) ) // add local.app.properties for web application def webConfDir = new File('deploy/tomcat/conf/ROOT/') webConfDir.mkdirs() def webProperties = new File(webConfDir, 'local.app.properties') webProperties.text = ''' cuba.webContextName = / ''' } } - Procfile
-
Команда, которая запускает приложение в Heroku, передается через специальный файл
Procfile. Создайте файл с названиемProcfileв папке$PROJECT_FOLDER, содержащий следующий текст:web: cd ./deploy/tomcat/bin && export 'JAVA_OPTS=-Dport.http=$PORT' && ./catalina.sh runЭто передает значение переменной среды JAVA_OPTS в Tomcat, который в свою очередь запускает скрипт Catalina.
- Премиум дополнения
-
Если ваш проект использует премиальные дополнения CUBA, то укажите дополнительные переменные в приложении Heroku.
-
Откройте панель Heroku в браузере
-
Перейдите на вкладку Settings
-
Разверните секцию Config Variables, нажав кнопку Reveal Config Vars
-
Добавьте новые переменные Config Vars, используя части вашего лицензионного ключа (разделенные дефисом) как username и password:
CUBA_PREMIUIM_USER | username CUBA_PREMIUM_PASSWORD | password -
- Gradle wrapper
-
Проект CUBA использует Gradle wrapper (gradlew). Чтобы иметь возможность работать с командой
gradlew, заранее создайте Gradle wrapper, использовав команду меню Build > Create or update Gradle wrapper.-
Создайте файл
system.propertiesв папке$PROJECT_FOLDERследующего содержания (пример соответствует локально установленной версии JDK 1.8.0_121):java.runtime.version=1.8.0_121 -
Убедитесь, что файлы
Procfile,system.properties,gradlew,gradlew.batиgradleне включены в.gitignore -
Добавьте эти файлы в репозиторий и выполните коммит:
git add gradlew gradlew.bat gradle/* system.properties Procfile git commit -am "Added Gradle wrapper and Procfile" -
- Развертывание приложения
-
Как только вы выполните Push изменений в GitHub, то Heroku начнет разворачивать приложение.
git pushКонтроль процесса развертывания осуществляется в панели Heroku на вкладке Activity. Перейдите по ссылке View build log, чтобы отслеживать лог.
После завершения процесса развертывания ваше приложение будет доступно в браузере по ссылке
https://space-sheep-02453.herokuapp.com/Вы также можете открыть приложение с помощью кнопки Open app, расположенной на панели Heroku.
- Мониторинг логов
-
Чтобы отслеживать данные в логах, запустите в командной строке следующую команду:
heroku logs --tail --app space-sheep-02453Логи Tomcat также доступны в веб-приложении: Menu > Administration > Server Log
5.3.10.3. Развертывание контейнера в Heroku
Настройте и соберите Uber JAR как описано в разделе Развертывание с помощью Docker. Создайте аккаунт в Heroku и установите Heroku CLI. Более детально эти действия описаны в разделе Развертывание WAR-файла в Heroku.
Создайте приложение с уникальным именем и подключите к нему базу данных (в примере подключается PostgreSQL с бесплатным тарифным планом hobby-dev) с помощью Heroku CLI:
heroku create cuba-sales-docker --addons heroku-postgresql:hobby-devПосле создания базы данных нужно указать детали для подключения к сервису БД в файле jetty-env.xml.
-
Откройте https://dashboard.heroku.com.
-
Выберите проект, откройте вкладку Resources и выберите базу данных.
-
В новом окне перейдите на вкладку Settings и нажмите на кнопку View Credentials.
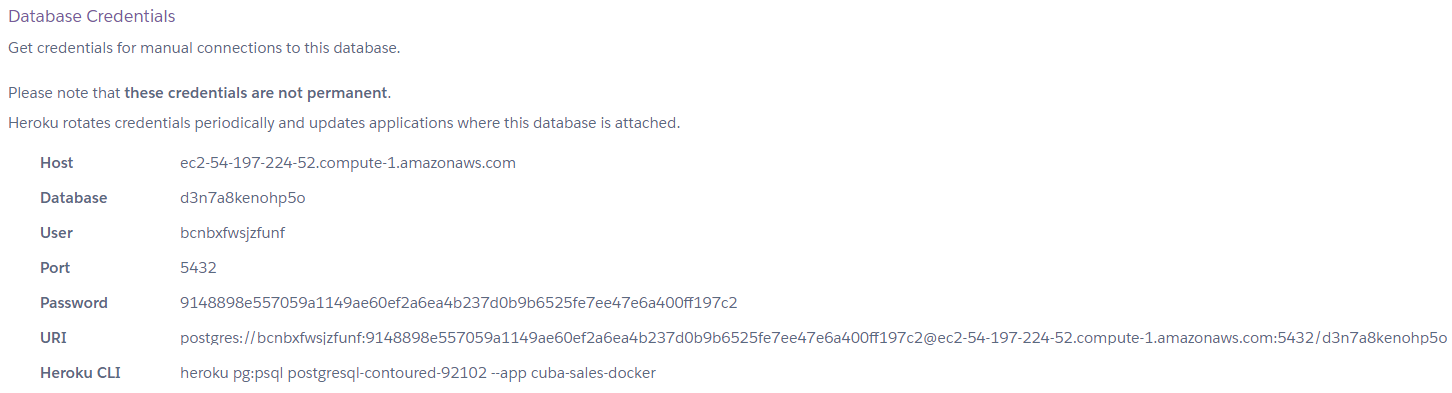
Откройте проект в IDE, откройте файл jetty-env.xml. Необходимо поменять URL (имя хоста и базы данных), имя пользователя и пароль. Для этого нужно скопировать данные, указанные на сайте, в файл.
<?xml version="1.0"?>
<!DOCTYPE Configure PUBLIC "-" "http://www.eclipse.org/jetty/configure_9_0.dtd">
<Configure id='wac' class="org.eclipse.jetty.webapp.WebAppContext">
<New id="CubaDS" class="org.eclipse.jetty.plus.jndi.Resource">
<Arg/>
<Arg>jdbc/CubaDS</Arg>
<Arg>
<New class="org.apache.commons.dbcp2.BasicDataSource">
<Set name="driverClassName">org.postgresql.Driver</Set>
<Set name="url">jdbc:postgresql://<Host>/<Database></Set>
<Set name="username"><User></Set>
<Set name="password"><Password></Set>
<Set name="maxIdle">2</Set>
<Set name="maxTotal">20</Set>
<Set name="maxWaitMillis">5000</Set>
</New>
</Arg>
</New>
</Configure>Соберите монолитный Uber JAR-файл с помощью команды Gradle:
gradle buldUberJarТакже необходимо внести изменения в Dockerfile. Прежде всего нужно ограничить объем памяти, потребляемой приложением. Затем нужно получить порт приложения из Heroku и добавить его к образу.
Файл Dockerfile будет выглядеть следующим образом:
### Dockerfile
FROM openjdk:8
COPY . /usr/src/cuba-sales
CMD java -Xmx512m -Dapp.home=/usr/src/cuba-sales/home -jar /usr/src/cuba-sales/app.jar -port $PORTОткройте командную строку в папке $PROJECT_FOLDER и запустите команды, указанные ниже:
git init
heroku git:remote -a cuba-sales-docker
git add .
git commit -am "Initial commit"После этого нужно зайти в репозиторий контейнеров, это место для хранения образов в Heroku.
heroku container:loginТеперь можно создать образ и загрузить его в репозиторий контейнеров.
heroku container:push webЗдесь web — тип процесса приложения. При запуске этой команды Heroku по умолчанию создает образ с помощью Dockerfile в текущем каталоге, а затем загружает его в Heroku.
После завершения процесса развертывания ваше приложение будет доступно в браузере по ссылке https://cuba-sales-docker.herokuapp.com/app
Вы также можете открыть приложение с помощью кнопки Open app, расположенной на панели Heroku.
Третий способ открыть запущенное приложение — использовать следующую команду (необходимо добавить app контекст к ссылке, т.е. https://cuba-sales-docker.herokuapp.com/app):
heroku open5.4. Конфигурация прокси для Tomcat
Для задач интеграции может потребоваться прокси-сервер. В этом разделе описывается конфигурация HTTP-сервера Nginx в качестве прокси для приложения на платформе CUBA.
|
Если вы настраиваете прокси, то не забудьте задать значение в параметре cuba.webAppUrl. |
- Настройка Tomcat
-
В случаях, когда Tomcat используется за прокси-сервером - его тоже нужно донастроить. Это необходимо, чтобы Tomcat мог обработать заголовки от прокси-сервера.
Сначала добавьте в конфигурационный файл Tomcat
conf/server.xmlследующий код:<Valve className="org.apache.catalina.valves.RemoteIpValve" remoteIpHeader="X-Forwarded-For" requestAttributesEnabled="true" internalProxies="127\.0\.0\.1"/>Есть еще одна настройка, которую вы можете поменять в файле
conf/server.xml- это атрибутpatternэлементаAccessLogValve. Добавьте%{x-forwarded-for}iв атрибутpattern, чтобы в Tomcat access log записывались и IP-адреса прокси-серверов, и изначальный IP-адрес источника запроса.<Valve className="org.apache.catalina.valves.AccessLogValve" ... pattern="%h %{x-forwarded-for}i %l %u %t "%r" %s %b" />Затем перезапустите Tomcat:
sudo service tomcat8 restart- NGINX
-
Для Nginx предлагается 2 конфигурации проксирования, описанные ниже. Примеры подготовлены и проверены на Ubuntu 18.04.
К примеру, ваше веб-приложение работает по ссылке
http://localhost:8080/app.Установите Nginx:
sudo apt-get install nginxОткройте в браузере ссылку
http://localhostи убедитесь, что стартовая страница Nginx работает.Теперь вы можете удалить символьную ссылку на тестовый сайт Nginx:
rm /etc/nginx/sites-enabled/default
Далее сконфигурируйте прокси одной из выбранных схем:
- Прямое проксирование
-
В этом случае все запросы обрабатывает прокси, прозрачно перенаправляя их в приложение.
Создайте конфигурационный файл Nginx
/etc/nginx/sites-enabled/direct_proxy:server { listen 80; server_name localhost; location /app/ { proxy_set_header Host $host; proxy_set_header X-Forwarded-Server $host; proxy_set_header X-Forwarded-Proto $scheme; # Required to send real client IP to application server proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header X-Real-IP $remote_addr; # Optional timeouts proxy_read_timeout 3600; proxy_connect_timeout 240; proxy_http_version 1.1; # Required for WebSocket: proxy_set_header Upgrade $http_upgrade; proxy_set_header Connection "upgrade"; proxy_pass http://127.0.0.1:8080/app/; } }и перезапустите Nginx:
sudo service nginx restartВы можете открыть свой сайт по ссылке
http://localhost/app.
- Проксирование с перенаправлением
-
В этом примере описано, как изменить путь к приложению в URL с
/appна/, как если бы приложение было развёрнуто в корневом контексте (аналог/ROOT). Это позволит вам обращаться к приложению по адресуhttp://localhost.Создайте конфигурационный файл Nginx
/etc/nginx/sites-enabled/direct_proxy:server { listen 80; server_name localhost; location / { proxy_set_header Host $host; proxy_set_header X-Forwarded-Server $host; proxy_set_header X-Forwarded-Proto $scheme; # Required to send real client IP to application server proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header X-Real-IP $remote_addr; # Optional timeouts proxy_read_timeout 3600; proxy_connect_timeout 240; proxy_http_version 1.1; # Required for WebSocket: proxy_set_header Upgrade $http_upgrade; proxy_set_header Connection "upgrade"; proxy_pass http://127.0.0.1:8080/app/; # Required for folder redirect proxy_cookie_path /app /; proxy_set_header Cookie $http_cookie; proxy_redirect http://localhost/app/ http://localhost/; } }и перезапустите Nginx
sudo service nginx restartВаше приложение доступно по ссылке
http://localhost.
|
Обратите внимание, что похожие инструкции развертывания прокси справедливы для конфигураций Jetty, WildFly и др. Вам может понадобиться дополнительно настроить эти сервера. |
5.5. Конфигурация прокси для Uber JAR
В этой части рассказывается, как настроить HTTP-сервер Nginx в качестве прокси для приложения CUBA Uber JAR.
- NGINX
Для Nginx предлагается 2 конфигурации проксирования, описанных ниже. Все примеры подготовлены и проверены на Ubuntu 16.04.
-
Прямое проксирование
-
Проксирование с перенаправлением
К примеру, ваше веб-приложение работает по ссылке http://localhost:8080/app.
|
Приложение Uber JAR использует сервер Jetty версии 9.2. Jetty внутри JAR следует сконфигурировать таким образом, чтобы он обрабатывал заголовки Nginx. |
- Настройка Jetty
-
-
Настройка внутри JAR
Сначала создайте конфигурационный файл
jetty.xmlв корне проекта и вставьте в него следующий код:<?xml version="1.0" encoding="utf-8"?> <!DOCTYPE Configure PUBLIC "-//Jetty//Configure//EN" "http://www.eclipse.org/jetty/configure_9_0.dtd"> <Configure id="Server" class="org.eclipse.jetty.server.Server"> <New id="httpConfig" class="org.eclipse.jetty.server.HttpConfiguration"> <Set name="outputBufferSize">32768</Set> <Set name="requestHeaderSize">8192</Set> <Set name="responseHeaderSize">8192</Set> <Call name="addCustomizer"> <Arg> <New class="org.eclipse.jetty.server.ForwardedRequestCustomizer"/> </Arg> </Call> </New> <Call name="addConnector"> <Arg> <New class="org.eclipse.jetty.server.ServerConnector"> <Arg name="server"> <Ref refid="Server"/> </Arg> <Arg name="factories"> <Array type="org.eclipse.jetty.server.ConnectionFactory"> <Item> <New class="org.eclipse.jetty.server.HttpConnectionFactory"> <Arg name="config"> <Ref refid="httpConfig"/> </Arg> </New> </Item> </Array> </Arg> <Set name="port">8080</Set> </New> </Arg> </Call> </Configure>Добавьте свойство
webJettyConfPathв задачуbuildUberJarвашего файлаbuild.gradle:task buildUberJar(type: CubaUberJarBuilding) { singleJar = true coreJettyEnvPath = 'modules/core/web/META-INF/jetty-env.xml' appProperties = ['cuba.automaticDatabaseUpdate' : true] webJettyConfPath = 'jetty.xml' }Вы можете использовать Studio, чтобы сгенерировать
jetty-env.xml, для этого пройдите в Project Properties > Deployment > далее на вкладку UberJAR Settings. Или используйте пример ниже:<?xml version="1.0"?> <!DOCTYPE Configure PUBLIC "-" "http://www.eclipse.org/jetty/configure_9_0.dtd"> <Configure id='wac' class="org.eclipse.jetty.webapp.WebAppContext"> <New id="CubaDS" class="org.eclipse.jetty.plus.jndi.Resource"> <Arg/> <Arg>jdbc/CubaDS</Arg> <Arg> <New class="org.apache.commons.dbcp2.BasicDataSource"> <Set name="driverClassName">org.postgresql.Driver</Set> <Set name="url">jdbc:postgresql://<Host>/<Database></Set> <Set name="username"><User></Set> <Set name="password"><Password></Set> <Set name="maxIdle">2</Set> <Set name="maxTotal">20</Set> <Set name="maxWaitMillis">5000</Set> </New> </Arg> </New> </Configure>Соберите Uber JAR, используя следующую команду:
gradlew buildUberJarВаше приложение будет расположено в папке
build/distributions/uberJar, имя по умолчанию:app.jar.Запустите приложение:
java -jar app.jarЗатем установите и настройте Nginx, как описано в секции Tomcat.
В зависимости от выбранной схемы проксирования, ваш сайт будет доступен по одной из ссылок:
http://localhost/appилиhttp://localhost. -
Настройка с помощью внешнего файла
Используйте тот же самый конфигурационный файл
jetty.xmlв корне проекта, как описано выше, но не изменяйтеbuild.gradle.Соберите Uber JAR, используя следующую команду:
gradlew buildUberJarВаше приложение будет расположено в папке
build/distributions/uberJar, имя по умолчанию:app.jar.Запустите приложение с параметром
-jettyConfPath:java -jar app.jar -jettyConfPath jetty.xmlЗатем установите и настройте Nginx, как описано в секции Tomcat.
В зависимости от выбранной схемы проксирования и настроек в
jetty.xml, ваш сайт будет доступен по одной из ссылок:http://localhost/appилиhttp://localhost.
-
5.6. Масштабирование приложения
В данном разделе рассмотрены способы масштабирования CUBA-приложения, состоящего из блоков Middleware и Web Client, при возрастании нагрузки и ужесточении требований к отказоустойчивости.
|
Этап 1. Оба блока развернуты на одном сервере приложения. Это простейший вариант, реализуемый стандартной процедурой быстрого развертывания. В данном случае обеспечивается максимальная производительность передачи данных между блоками Web Client и Middleware, так как при включенном свойстве приложения cuba.useLocalServiceInvocation сервисы Middleware вызываются в обход сетевого стека. |
|
|
Этап 2. Блоки Middleware и Web Client развернуты на отдельных серверах приложения. Данный вариант позволяет распределить нагрузку между двумя серверами приложения и более оптимально использовать ресурсы серверов. Кроме того, в этом случае нагрузка от веб-пользователей меньше сказывается на выполнении других процессов. Под другими процессами здесь понимается обслуживание средним слоем других типов клиентов, выполнение задач по расписанию и, возможно, интеграционные задачи. Требования к ресурсам серверов:
В этом и более сложных вариантах развертывания в блоке Web Client свойство приложения cuba.useLocalServiceInvocation должно быть установлено в false, а свойство cuba.connectionUrlList должно содержать URL блока Middleware. |
|
Этап 3. Кластер серверов Web Client работает с одним сервером Middleware. Данный вариант применяется, когда вследствие большого количества одновременно подключенных пользователей требования к памяти для блока Web Client превышают возможности одной JVM. В этом случае запускается кластер (два или более) серверов Web Client, и подключение пользователей производится через Load Balancer. Все серверы Web Client работают с одним сервером Middleware. Дублирование серверов Web Client автоматически обеспечивает отказоустойчивость на этом уровне. Однако, так как репликация HTTP-сессий не поддерживается, при незапланированном отключении одного из серверов Web Client все пользователи, подключенные к нему, вынуждены будут выполнить новый логин в приложение. Load Balancer должен поддерживать sticky sessions, чтобы все запросы пользователя отсылались на один и тот же узел Web Client. Настройка данного варианта развертывания описана в Настройка кластера Web Client. |
|
Этап 4. Кластер серверов Web Client работает с кластером серверов Middleware. Это максимальный вариант развертывания, обеспечивающий отказоустойчивость и балансировку нагрузки для Middleware и Web Client. Подключение пользователей к серверам Web Client производится через Load Balancer, который должен поддерживать sticky sessions (аналогично этапу 3). Серверы WebClient работают с кластером серверов Middleware. Для этого им не требуется дополнительный Load Balancer - достаточно определить список URL серверов Middleware в свойстве cuba.connectionUrlList. Можно также использовать дополнение для интеграции с Apache ZooKeeper для динамического обнаружения серверов среднего слоя. В кластере серверов Middleware организуется взаимодействие для обмена информацией о пользовательских сессиях, блокировках и пр. При этом обеспечивается полная отказоустойчивость блока Middleware - при отключении одного из серверов выполнение запросов от клиентских блоков продолжается на доступном сервере прозрачно для пользователей. Настройка данного варианта развертывания описана в Настройка кластера Middleware. |
|
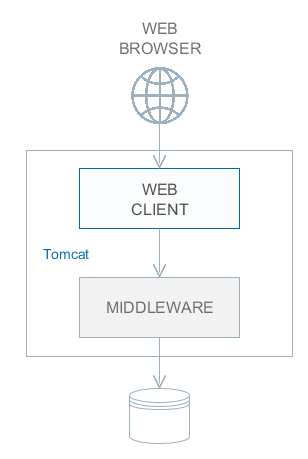
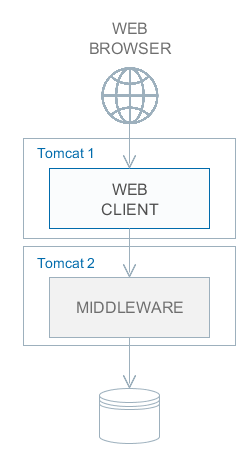
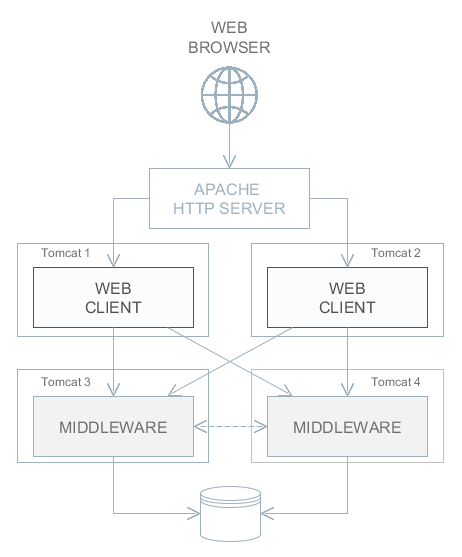
5.6.1. Настройка кластера Web Client
В данном разделе рассматривается следующая конфигурация развертывания:
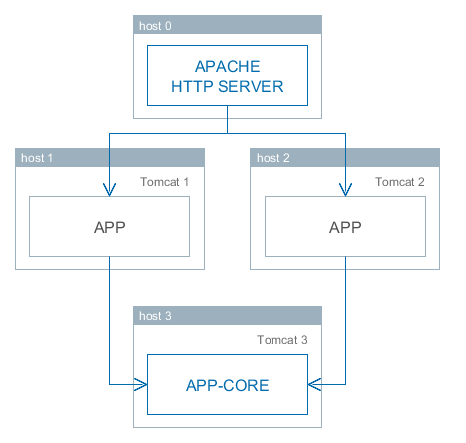
Здесь на серверах host1 и host2 блок установлены инстансы Tomcat с веб-приложением app, реализующим блок Web Client. Пользователи обращаются к балансировщику нагрузки по адресу http://host0/app, который перенаправляет запрос этим серверам. На сервере host3 установлен Tomcat с веб-приложением app-core, реализующим блок Middleware.
|
Состояние Generic UI и UserSession находятся на одном узле Web Client - на том, который выполнял логин данного пользователя. Поэтому балансировщик нагрузки должен поддерживать sticky sessions (или session affinity) для того, чтобы все запросы от пользователя отсылались на один и тот же узел Web Client. |
5.6.1.1. Установка и настройка Load Balancer
Рассмотрим процесс установки балансировщика нагрузки на базе Apache HTTP Server для операционной системы Ubuntu 14.04.
-
Выполните установку Apache HTTP Server и его модуля mod_jk:
$ sudo apt-get install apache2 libapache2-mod-jk -
Замените содержимое файла
/etc/libapache2-mod-jk/workers.propertiesна следующее:workers.tomcat_home= workers.java_home= ps=/ worker.list=tomcat1,tomcat2,loadbalancer,jkstatus worker.tomcat1.port=8009 worker.tomcat1.host=host1 worker.tomcat1.type=ajp13 worker.tomcat1.connection_pool_timeout=600 worker.tomcat1.lbfactor=1 worker.tomcat2.port=8009 worker.tomcat2.host=host2 worker.tomcat2.type=ajp13 worker.tomcat2.connection_pool_timeout=600 worker.tomcat2.lbfactor=1 worker.loadbalancer.type=lb worker.loadbalancer.balance_workers=tomcat1,tomcat2 worker.jkstatus.type=status -
Добавьте в файл
/etc/apache2/sites-available/000-default.confследующее:<VirtualHost *:80> ... <Location /jkmanager> JkMount jkstatus Order deny,allow Allow from all </Location> JkMount /jkmanager/* jkstatus JkMount /app loadbalancer JkMount /app/* loadbalancer </VirtualHost> -
Перезапустите сервис Apache HTTP:
$ sudo service apache2 restart
5.6.1.2. Настройка серверов Web Client
|
В примерах ниже пути к конфигурационным файлам приводятся для варианта Быстрое развертывание. |
На серверах Tomcat 1 и Tomcat 2 необходимо произвести следующие настройки:
-
В файлах
tomcat/conf/server.xmlдобавить параметрjvmRoute, эквивалентный имени worker, заданному в настройках балансировщика нагрузки -tomcat1иtomcat2:<Server port="8005" shutdown="SHUTDOWN"> ... <Service name="Catalina"> ... <Engine name="Catalina" defaultHost="localhost" jvmRoute="tomcat1"> ... </Engine> </Service> </Server> -
Задать следующие свойства приложения в файлах
app_home/local.app.properties:cuba.useLocalServiceInvocation = false cuba.connectionUrlList = http://host3:8080/app-core cuba.webHostName = host1 cuba.webPort = 8080Параметры cuba.webHostName и cuba.webPort не обязательны для работы кластера WebClient, но позволяют проще идентифицировать сервера в других механизмах платформы, например в консоли JMX. Кроме того, в экране User Sessions в атрибуте Client Info отображается сформированный из этих параметров идентификатор блока Web Client, на котором работает данный пользователь.
5.6.2. Настройка кластера Middleware
В данном разделе рассматривается следующая конфигурация развертывания:
Здесь на серверах host1 и host2 блок установлены инстансы Tomcat с веб-приложением app, реализующим блок Web Client. Настройка кластера этих серверов рассмотрена в предыдущем разделе. На серверах host3 и host4 установлены инстансы Tomcat с веб-приложением app-core, реализующим блок Middleware. Между ними настроено взаимодействие для обмена информацией о пользовательских сессиях и блокировках, сброса кэшей и др.
|
В примерах ниже пути к конфигурационным файлам приводятся для варианта Быстрое развертывание. |
5.6.2.1. Настройка обращения к кластеру Middleware
Для того, чтобы клиентские блоки могли работать с несколькими серверами Middleware, достаточно указать список URL этих серверов в свойстве приложения cuba.connectionUrlList. Это можно сделать в файле app_home/local.app.properties:
cuba.useLocalServiceInvocation = false
cuba.connectionUrlList = http://host3:8080/app-core,http://host4:8080/app-core
cuba.webHostName = host1
cuba.webPort = 8080Сервер среднего слоя выбирается в случайном порядке в момент первого обращения для данной пользовательской сессии, и фиксируется на все время жизни сессии ("sticky session"). Запросы от анонимной сессии и без сессии не фиксируются и выполняются на серверах выбираемых в случайном порядке.
Алгоритм выбора сервера предоставляется бином cuba_ServerSorter, который по умолчанию реализован классом RandomServerSorter. В проекте можно реализовать собственный алгоритм выбора.
5.6.2.2. Настройка взаимодействия серверов Middleware
Сервера Middleware могут поддерживать общие списки пользовательских сессий и других объектов, а также координировать сброс кэшей. Для этого достаточно на каждом их них включить свойство приложения cuba.cluster.enabled. Пример файла app_home/local.app.properties:
cuba.cluster.enabled = true
cuba.webHostName = host3
cuba.webPort = 8080
cuba.webContextName = app-coreДля серверов Middleware обязательно нужно указать правильные значения свойств cuba.webHostName и cuba.webPort для формирования уникального Server Id.
Механизм взаимодействия основан на библиотеке JGroups. Платформа содержит два конфигурационных файла для JGroups:
-
jgroups.xml- стек протоколов, основанный на UDP, пригодный для работы в локальной сети с разрешенными широковещательными сообщениями. Данная конфигурация используется по умолчанию. -
jgroups_tcp.xml- стек протоколов, основанный на TCP, пригодный для работы в любой сети. Он требует явного указания адресов узлов кластера в параметрахTCP.bind_addrиTCPPING.initial_hosts. Для использования данной конфигурации настройте свойство приложения cuba.cluster.jgroupsConfig.Если между серверами middleware имеется firewall, не забудьте настроить на нем доступные порты в соответствии с выбранными настройками
JGroups.
Для настройки параметров JGroups для вашего окружения скопируйте подходящий файл jgroups.xml из корня архива cuba-core-<version>.jar в корень модуля core вашего проекта (в каталог src) или в каталог tomcat/conf/app-core, и настройте его нужным образом.
Программный интерфейс для взаимодействия в кластере Middleware обеспечивает бин ClusterManagerAPI. Его можно использовать в приложении - см. JavaDocs и примеры использования в коде платформы.
- Синхронная репликация пользовательских сессий
По умолчанию все сообщения JGroups отправляются в кластер асинхронно. Это означает, что код Middleware возвращает ответ клиентскому слою раньше того момента, когда кластерное сообщение будет получено другими узлами кластера.
Подобное поведение улучшает время ответа системы, однако оно может вызвать проблемы с балансировщиками запросов между клиентским слоем и Middleware, использующими стратегию round-robin (такими как NGINX или Kubernetes). А именно: запрос на вход в систему (логин) с веб-клиента возвращается раньше, чем новая пользовательская сессия полностью реплицирована другим узлам кластера. Последующий вызов сервиса среднего слоя с веб-клиента может быть направлен стратегией round-robin на другой узел среднего слоя, где этот вызов упадет с ошибкой NoUserSessionException, поскольку этот узел кластера еще не получил новую пользовательскую сессию.
Чтобы избежать ошибок NoUserSessionException при использовании round-robin балансировщика с кластером Middleware, новые пользовательские сессии, создаваемые при логине в систему, должны реплицироваться синхронно. Установите следующие свойства в файле app.properties (или app_home/local.app.properties на конечном сервере):
cuba.syncNewUserSessionReplication = true
# также если вы используете аддон REST API
cuba.rest.syncTokenReplication = true5.6.2.3. Использование ZooKeeper для координации кластера
Существует компонент приложения, обеспечивающий динамическое обнаружение серверов middleware для коммуникации между блоками middleware и для запросов с клиентских блоков. Он основан на интеграции с Apache ZooKeeper - централизованным сервисом для работы с конфигурационной информацией. Если данный компонент включен в проект, при запуске блоков приложения необходимо указывать только один статический адрес - адрес ZooKeeper. При этом сервера middleware публикуют свои адреса в каталоге ZooKeeper, а механизм обнаружения запрашивает ZooKeeper для получения адресов доступных серверов. Если сервер middleware останавливается, его адрес автоматически исключается из каталога (немедленно или по истечении таймаута).
5.6.3. Server Id
Server Id служит для надежной идентификации серверов в кластере Middleware. Идентификатор имеет вид host:port/context, например:
tezis.haulmont.com:80/app-core192.168.44.55:8080/app-coreИдентификатор формируется на основе параметров конфигурации cuba.webHostName, cuba.webPort, cuba.webContextName, поэтому крайне важно корректно указать эти параметры для блока Middleware, работающего в кластере.
Server Id может быть получен c помощью бина ServerInfoAPI или через JMX-интерфейс ServerInfoMBean.
5.7. Использование инструментов JMX
В данном разделе рассмотрены различные аспекты использования инструментов Java Management Extensions в CUBA-приложениях.
5.7.1. Встроенная JMX консоль
Модуль Web Client базового проекта cuba платформы содержит средство просмотра и редактирования JMX объектов. Точкой входа в этот инструмент является экран com/haulmont/cuba/web/app/ui/jmxcontrol/browse/display-mbeans.xml, зарегистрированный под идентификатором jmxConsole и в стандартном меню доступный через пункт Администрирование → Консоль JMX.
Без дополнительной настройки консоль отображает все JMX объекты, зарегистрированные в JVM, на которой работает блок Web Client, к которому в данный момент подключен пользователь. Соответственно, в простейшем случае развертывания всех блоков приложения в одном экземпляре веб-контейнера консоль имеет доступ к JMX бинам всех уровней, а также к JMX объектам самой JVM и веб-контейнера.
Имена бинов приложения имеют префикс, соответствующий имени веб-приложения, их содержащего. Например, бин app-core.cuba:type=CachingFacade загружен веб-приложением app-core, реализующим блок Middleware, а бин app.cuba:type=CachingFacade загружен веб-приложением app, реализующим блок Web Client.
Рисунок 48. JMX консоль
Консоль JMX может также работать с JMX объектами произвольной удаленной JVM. Это актуально в случае развертывания блоков приложения на нескольких экземплярах веб-контейнера, например, отдельно Web Client и Middleware.
Для подключения к удаленной JVM необходимо в поле Соединение JMX консоли выбрать созданное ранее соединение, либо вызвать экран создания нового соединения:
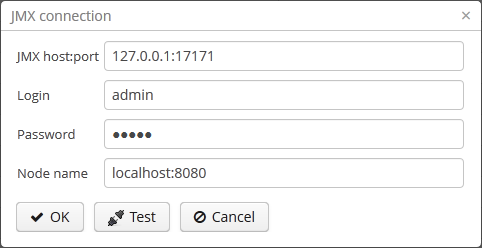
Рисунок 49. Редактирование JMX соединения
Для соединения указывается JMX хост и порт, логин и пароль. Имеется также поле Имя узла, которое заполняется автоматически, если по указанному адресу обнаружен какой-либо блок CUBA-приложения. В этом случае значением этого поля становится комбинация свойств cuba.webHostName и cuba.webPort данного блока, что позволяет идентифицировать содержащий его сервер. Если подключение произведено к постороннему JMX интерфейсу, то поле Имя узла будет иметь значение "Unknown JMX interface". Значение данного поля можно произвольно изменять.
Для подключения удаленной JVM она должна быть соответствующим образом настроена - см. ниже.
5.7.2. Настройка удаленного доступа к JMX
В данном разделе рассматривается настройка запуска сервера Tomcat, необходимая для удаленного подключения к нему инструментов JMX.
5.7.2.1. Tomcat JMX под Windows
-
Отредактировать файл
bin/setenv.batследующим образом:set CATALINA_OPTS=%CATALINA_OPTS% ^ -Dcom.sun.management.jmxremote ^ -Djava.rmi.server.hostname=192.168.10.10 ^ -Dcom.sun.management.jmxremote.ssl=false ^ -Dcom.sun.management.jmxremote.port=7777 ^ -Dcom.sun.management.jmxremote.authenticate=true ^ -Dcom.sun.management.jmxremote.password.file=../conf/jmxremote.password ^ -Dcom.sun.management.jmxremote.access.file=../conf/jmxremote.accessЗдесь в параметре
java.rmi.server.hostnameнеобходимо указать реальный IP адрес или DNS имя компьютера, на котором запущен сервер, в параметреcom.sun.management.jmxremote.port- порт для подключения инструментов JMX. -
Отредактировать файл
conf/jmxremote.access. Он должен содержать имена пользователей, которые будут подключаться к JMX, и их уровень доступа. Например:admin readwrite -
Отредактировать файл
conf/jmxremote.password. Он должен содержать пароли пользователей JMX, например:admin admin -
Файл паролей должен иметь разрешение на чтение только для пользователя, от имени которого работает сервер Tomcat. Настроить права можно следующим образом:
-
Открыть командную строку и перейти в каталог
conf. -
Выполнить команду:
cacls jmxremote.password /P "domain_name\user_name":Rгде
domain_name\user_name- домен и имя пользователя. -
После выполнения данной команды файл в Проводнике будет отмечен изображением замка.
-
-
Если Tomcat установлен как служба Windows, то для службы должен быть задан вход в систему с учетной записью, имеющей права на файл
jmxremote.password. Кроме того, следует иметь в виду, что в этом случае файлbin/setenv.batне используется, и соответствующие параметры запуска JVM должны быть заданы в приложении, настраивающем службу.
5.7.2.2. Tomcat JMX под Linux
-
Отредактировать файл
bin/setenv.shследующим образом:CATALINA_OPTS="$CATALINA_OPTS -Dcom.sun.management.jmxremote \ -Djava.rmi.server.hostname=192.168.10.10 \ -Dcom.sun.management.jmxremote.port=7777 \ -Dcom.sun.management.jmxremote.ssl=false \ -Dcom.sun.management.jmxremote.authenticate=true" CATALINA_OPTS="$CATALINA_OPTS -Dcom.sun.management.jmxremote.password.file=../conf/jmxremote.password -Dcom.sun.management.jmxremote.access.file=../conf/jmxremote.access"Здесь в параметре
java.rmi.server.hostnameнеобходимо указать реальный IP адрес или DNS имя компьютера, на котором запущен сервер, в параметреcom.sun.management.jmxremote.port- порт для подключения инструментов JMX. -
Отредактировать файл
conf/jmxremote.access. Он должен содержать имена пользователей, которые будут подключаться к JMX, и их уровень доступа. Например:admin readwrite -
Отредактировать файл
conf/jmxremote.password. Он должен содержать пароли пользователей JMX, например:admin admin -
Файл паролей должен иметь разрешение на чтение только для пользователя, от имени которого работает сервер Tomcat. Настроить права для текущего пользователя можно следующим образом:
-
Открыть командную строку и перейти в каталог
conf. -
Выполнить команду:
chmod go-rwx jmxremote.password
-
5.8. Настройка server push
Приложения CUBA используют технологию server push в механизме фоновых задач. Это может потребовать дополнительной настройки сервера приложения и прокси-сервера (если таковой используется).
По умолчанию server push использует протокол WebSocket. Следующие свойства приложения влияют на функциональность server push платформы:
Информация ниже взята из статьи с веб-сайта Vaadin - Configuring push for your environment.
- Chrome показывает ERR_INCOMPLETE_CHUNKED_ENCODING
-
Это совершенно нормально и означает, что (long-polling) push-соединение было прервано третьей стороной. Обычно это происходит, когда между браузером и сервером имеется прокси-сервер, а прокси-сервер имеет настроенный тайм-аут и отключает соединение, когда тайм-аут достигнут. После этого браузер должен повторно подключиться к серверу.
- Tomcat 8 + Websockets
-
java.lang.ClassNotFoundException: org.eclipse.jetty.websocket.WebSocketFactory$AcceptorЭто означает, что где то в classpath развернут Jetty. Atmosphere путается и использует реализацию Websocket от Jetty сервера вместо Tomcat. Одной из распространенных причин этого является то, что Вы случайно развернули
vaadin-client-compiler, у которого Jetty есть в качестве зависимости (требуется, например, для SuperDevMode).
- Glassfish 4 + Streaming
-
Чтобы Streaming режим работал в Glassfish 4, необходимо включить опцию comet.
Для этого установите
(Configurations → server-config → Network Config → Protocols → http-listener-1 → HTTP → Comet Support)или используйте
asadmin set server-config.network-config.protocols.protocol.http-listener-1.http.comet-support-enabled="true"
- Glassfish 4 + Websockets
-
Если Вы используете Glassfish 4.0, то для избежания проблем Вам необходимо обновиться на версию Glassfish 4.1.
- Weblogic 12 + Websockets
-
Используйте WebLogic 12.1.3 или новее. По умолчанию, WebLogic 12 имеет 30 сек. таймаут для websocket соединений. Чтобы избежать постоянных повторных соединений, вы можете установить параметр
weblogic.websocket.tyrus.session-max-idle-timeoutлибо в значение-1(т.е. без таймаута), либо в большее чем30000(значение в миллисекундах).
- JBoss EAP 6.4 + Websockets
-
JBoss EAP 6.4 включает поддержку websockets, но по умолчанию они отключены. Чтобы включить websockets, Вам необходимо переключить JBoss в режим использования NIO-коннектора, запустив:
$ bin/jboss-cli.sh --connectзатем выполнив следующие команды:
batch /subsystem=web/connector=http/:write-attribute(name=protocol,value=org.apache.coyote.http11.Http11NioProtocol) run-batch :reloadЧтобы включить websockets, необходимо добавить WEB-INF/jboss-web.xml в Ваш war-файл со следующим содержанием:
<jboss-web version="7.2" xmlns="http://www.jboss.com/xml/ns/javaee" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.jboss.com/xml/ns/javaee schema/jboss-web_7_2.xsd"> <enable-websockets>true</enable-websockets> </jboss-web>
- Duplicate resource
-
Если логи сервера содержат
Duplicate resource xyz-abc-def-ghi-jkl. Could be caused by a dead connection not detected by your server. Replacing the old one with the fresh oneЭто указывает на то, что сначала браузер подключился к серверу и использовал данный идентификатор для push-соединения. Позже браузер (возможно, тот же самый) снова подключился с использованием того же идентификатора, но сервер считает, что старое соединение с браузером все еще активно. Сервер закрывает старое соединение и регистрирует предупреждение.
Это происходит из-за того, что между браузером и сервером существует прокси-сервер, а прокси-сервер настроен так, чтобы убивать открытые соединения после определенного таймаута бездействия (данные не отправляются до того, как сервер выдает команду push). Из-за того, как работает TCP/IP, сервер не знает, что соединение было убито и продолжает думать, что старый клиент подключен, и все в порядке.
У вас есть несколько вариантов, чтобы избежать этой проблемы:
-
Если вы контролируете прокси-сервер, настройте его не закрывать push-соединения (подключения к URL-адресу
/PUSH). -
Если Вы знаете какой таймаут задан на прокси-сервере, установить таймаут для push в приложении немного меньше. Тогда сервер будет завершать неактивное соединение до того, как сработает таймаут прокси-сервера.
-
Установить параметр
cuba.web.pushLongPollingв значениеtrueчтобы включить long polling вместо websocket. -
Используйте параметр
cuba.web.pushLongPollingSuspendTimeoutMs, чтобы установить таймаут push в миллисекундах.
-
-
- Использование Proxy
-
Если пользователи подключаются к серверу приложения через прокси, не поддерживающий WebSocket, рекомендуется установить свойство
cuba.web.pushLongPollingвtrueи увеличить таймаут запроса на прокси до 10 минут или больше.Ниже приведен пример конфигурации веб-сервера Nginx для использования WebSocket:
location / { proxy_set_header X-Forwarded-Host $host; proxy_set_header X-Forwarded-Server $host; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_read_timeout 3600; proxy_connect_timeout 240; proxy_set_header Host $host; proxy_set_header X-RealIP $remote_addr; proxy_pass http://127.0.0.1:8080/; proxy_set_header X-Forwarded-Proto $scheme; proxy_set_header Upgrade $http_upgrade; proxy_set_header Connection "upgrade"; }
5.9. Health check URL
Каждый блок приложения, развернутый как веб-приложение, предоставляет URL для проверки своего состояния. HTTP GET запрос на этот URL возвращает ok если блок готов к работе.
Пути URL для различных блоков перечислены ниже:
-
Middleware:
/remoting/health -
Web Client:
/dispatch/health -
Web Portal:
/rest/health(требует подключения аддона REST API)
То есть для приложения с именем app, развернутого на localhost:8080, адреса будут следующими:
-
http://localhost:8080/app-core/remoting/health -
http://localhost:8080/app/dispatch/health -
http://localhost:8080/app-portal/rest/health
Ответ ok можно заменить на произвольный текст с помощью свойства приложения cuba.healthCheckResponse.
Контроллеры проверки посылают события типа HealthCheckEvent. Следовательно, вы можете добавить собственную логику проверки работоспособности приложения. В примере на GitHub, бин web-уровня реагирует на события проверки и вызывает сервис среднего слоя, который в свою очередь выполняет операцию на базе данных.
5.10. Создание и обновление БД при эксплуатации приложения
В данном разделе рассматриваются способы создания и обновления базы данных на этапе развертывания и эксплуатации приложения. Для знакомства с устройством и правилами создания скриптов БД см. Скрипты создания и обновления БД.
5.10.1. Использование механизма выполнения скриптов БД сервером
Механизм выполнения скриптов БД сервером можно использовать как для первичной инициализации базы данных, так и для ее последующего обновления в процессе развития приложения и изменения схемы данных.
Чтобы инициализировать новую базу данных, нужно выполнить следующее:
-
Включите свойство приложения cuba.automaticDatabaseUpdate, добавив следующую строку в файл local.app.properties, расположенный в домашнем каталоге приложения (если оно не задано в
app.propertiesпроекта):cuba.automaticDatabaseUpdate = trueВ случае быстрого развертывания в Tomcat этот файл находится в каталоге
tomcat/conf/app-core. Если файл не существует, создайте его. -
Создайте пустую базу данных, соответствующую заданному источнику данных.
-
Запустите сервер приложения, содержащий блок Middleware. На старте приложения БД будет проинициализирована и сразу же готова к работе.
В дальнейшем при каждом старте сервера приложения механизм выполнения скриптов будет сравнивать набор скриптов, находящийся в каталоге скриптов базы данных, со списком выполненных скриптов, зарегистрированным в БД. При появлении в каталоге новых скриптов они будут выполнены и также зарегистрированы. Таким образом, достаточно в каждую новую версию приложения включать скрипты обновления, и при рестарте сервера приложения база данных будет приводиться в актуальное состояние.
При эксплуатации механизма выполнения скриптов на старте сервера следует иметь в виду следующее:
-
При любой ошибке выполнения скрипта блок Middleware прерывает инициализацию и становится неработоспособным. Клиентские блоки выдают сообщения о невозможности подключения к Middleware.
Для выяснения причин сбоя необходимо открыть файл лога
app.logв каталоге журналов сервера и найти сообщения о выполнении SQL от логгераcom.haulmont.cuba.core.sys.DbUpdaterEngine, и, возможно, последующие сообщения об ошибках. -
Скрипты обновления, а также отделенные символом "^" команды DDL и SQL внутри скриптов выполняются в отдельных транзакциях. Поэтому при возникновении ошибки при обновлении существует большая вероятность того, что часть скриптов, или даже отдельных команд последнего скрипта, выполнилась и зафиксирована в БД.
В связи с этим рекомендуется непосредственно перед запуском сервера с новой версией приложения делать резервное сохранение БД. Тогда после устранения причины ошибки достаточно восстановить БД и запустить автоматический процесс вновь.
Если бэкап БД отсутствует, то после устранения причины ошибки необходимо выяснить, какая часть вызвавшего ошибку скрипта выполнилась и закоммичена. Если скрипт не выполнился целиком, то можно сразу снова запускать автоматический процесс. Если же часть команд до ошибочной была отделена символом "^", выполнялась в отдельной транзакции и была закоммичена, то необходимо выполнить оставшуюся часть команд, а затем зарегистрировать данный скрипт в
SYS_DB_CHANGELOGвручную. После этого можно стартовать сервер, механизм автоматического обновления продолжит работу со следующего невыполненного скрипта.CUBA Studio генерирует скрипты обновления с символом ";" в качестве разделителями для всех типов БД, кроме Oracle. Если команды скрипта разделены точками с запятой, они выполняются в одной транзакции, и в случае ошибки скрипт откатывается целиком. Тем самым обеспечивается постоянное соответствие между структурой БД и списком выполненных скриптов обновления.
5.10.2. Инициализация и обновление БД из командной строки
Скрипты создания и обновления БД могут быть запущены из командной строки с помощью класса com.haulmont.cuba.core.sys.utils.DbUpdaterUtil, входящего в состав блока Middleware платформы. При запуске должны быть переданы следующие аргументы:
-
dbType– тип СУБД, возможные значения: postgres, mssql, oracle, mysql. -
dbVersion– версия СУБД (необязательный аргумент). -
dbDriver- имя класса JDBC-драйвера (необязательный аргумент). Если не передан, имя класса драйвера определяется исходя изdbType. -
dbUser- имя пользователя БД. -
dbPassword- пароль пользователя БД. -
dbUrl- URL для подключения к БД. Для выполнения первичной инициализации указанная база данных должна быть пустой, никакой предварительной очистки ее не производится. -
scriptsDir- абсолютный путь к каталогу, содержащему скрипты в стандартной структуре. Как правило, используется каталог скриптов базы данных, поставляемый с приложением. -
одна из возможных команд:
-
create- выполнить инициализацию базы данных. -
check- отобразить список невыполненных скриптов обновления. -
update- выполнить обновление базы данных.
-
Пример скрипта для Linux, запускающего DbUpdaterUtil:
#!/bin/sh
DB_URL="jdbc:postgresql://localhost/mydb"
APP_CORE_DIR="./../webapps/app-core"
WEBLIB="$APP_CORE_DIR/WEB-INF/lib"
SCRIPTS="$APP_CORE_DIR/WEB-INF/db"
TOMCAT="./../lib"
SHARED="./../shared/lib"
CLASSPATH=""
for jar in `ls "$TOMCAT/"`
do
CLASSPATH="$TOMCAT/$jar:$CLASSPATH"
done
for jar in `ls "$WEBLIB/"`
do
CLASSPATH="$WEBLIB/$jar:$CLASSPATH"
done
for jar in `ls "$SHARED/"`
do
CLASSPATH="$SHARED/$jar:$CLASSPATH"
done
java -cp $CLASSPATH com.haulmont.cuba.core.sys.utils.DbUpdaterUtil \
-dbType postgres -dbUrl $DB_URL \
-dbUser $1 -dbPassword $2 \
-scriptsDir $SCRIPTS \
-$3Данный скрипт рассчитан на работу с БД с именем mydb, расположенной на локальном сервере PostgreSQL. Скрипт должен быть расположен в каталоге bin сервера Tomcat, и запускаться с параметрами {имя пользователя}, {пароль}, {команда}, например:
./dbupdate.sh cuba cuba123 updateХод выполнения скриптов отображается в консоли. При возникновении ошибок обновления следует поступать так же, как описано в предыдущем разделе для механизма автоматического обновления.
|
При обновлении БД из командной строки имеющиеся Groovy-скрипты запускаются, но реально отрабатывает только их основная часть. По причине отсутствия контекста сервера PostUpdate-часть игнорируется с выдачей в консоль соответствующего сообщения. |
6. Подсистема безопасности
CUBA включает в себя продуманную подсистему безопасности, предназначенную для решения общих проблем бизнес-приложений:
-
Аутентификация с использованием встроенного репозитория пользователей, LDAP, SSO или социальных сетей.
-
Основанный на ролях контроль доступа для модели данных (операции и атрибуты сущностей), экранов UI и произвольных именованных разрешений. Например, John Doe может просматривать документы, но не может создавать, изменять и удалять их. Кроме того, он видит все атрибуты документов, кроме суммы.
-
Контроль доступа на уровне строк - возможность ограничить доступ к определенным экземплярам сущности. Например, John Doe видит только те документы, которые были созданы в его отделе.
6.1. Безопасность веб-приложения
Защищены ли CUBA приложения?
Фреймворк CUBA следует лучшим практикам безопасности и предоставляет автоматическую защиту от большинства самых распространённых уязвимостей веб-приложений. Архитектура платформы реализует безопасную модель программирования, позволяя вам сконцентрироваться на бизнес задачах и логике приложений.
- 1. Состояние и валидация данных UI
-
Web Client - серверное приложение, в котором всё состояние вашего приложения, бизнес- и UI-логика расположены на сервере. В отличие от фронтенд-фреймворков, исполняющих код UI в веб-браузере, веб-клиент никогда не открывает серверные структуры данных для клиентской части, где уязвимости могут быть использованы злонамеренным кодом. Валидация данных всегда выполняется на сервере, гарантируя, что злонамеренные пользователи не смогут её обойти, то же самое применимо и к валидации данных в универсальном REST API.
- 2. Межсайтовый скриптинг (Cross-Site Scripting / XSS)
-
Веб-клиент имеет встроенную защиту от атак межсайтового скриптинга (XSS). Все выводимые данные автоматически преобразуются в HTML-формат перед тем как они будут показаны в веб-браузере.
- 3. Межсайтовая подделка запроса (Cross-Site Request Forgery / CSRF)
-
Все запросы между сервером и клиентом включают CSRF токен, специфичный для пользовательской сессии. Фреймворк Vaadin обеспечивает всё взаимодействие между сервером и клиентом, поэтому вам не потребуется добавлять CSRF токен к каждому запросу вручную.
- 4. Веб-сервисы
-
Все сетевые вызовы в веб-клиенте проходят через один веб-сервис, используемый для вызова удалённых процедур (RPC) из клиентской части UI компонентов. Приложения не открывают доступ к своей бизнес-логике в виде веб-сервисов, поэтому пользователям доступно меньшее количество точек входа для возможных атак.
Универсальный REST API автоматически применяет разрешения ролей и все ограничения (constraints) как для пользователей системы, выполнивших вход, так и при анонимном доступе.
- 5. SQL Инъекции
-
Платформа использует слой ORM на базе EclipseLink, реализующую защиту от SQL инъекций. Параметры SQL запросов всегда передаются в JDBC в виде массива параметров и не подставляются в SQL запросы в виде строк.
6.2. Компоненты подсистемы безопасности
Основные компоненты подсистемы безопасности CUBA приведены на следующей диаграмме.
Рисунок 50. Диаграмма компонентов подсистемы безопасности
Рассмотрим их более подробно.
Security management screens - имеющиеся в платформе экраны, с помощью которых администратором системы осуществляется настройка прав доступа пользователей.
Login screen − окно входа в систему. В этом окне производится аутентификация пользователя по имени учетной записи и паролю. В базе данных вместо пароля, в целях его безопасности, хранится хэш.
После входа пользователя в систему создается объект UserSession − пользовательская сессия. Это центральный элемент обеспечения безопасности, объект, ассоциированный с аутентифицированным в данный момент в системе пользователем и содержащий информацию о правах доступа пользователя к данным.
Процесс входа пользователя в систему подробно описан в разделе Вход в систему.
Roles − роли пользователей. Роль - это объект системы, задающий набор разрешений. Пользователь может иметь несколько ролей.
Access Groups - группы доступа пользователей. Группы представляют собой иерархическую структуру, каждый элемент которой задает набор ограничений (Constraints), позволяющих контролировать доступ на уровне отдельных экземпляров (строк таблицы) некоторой сущности.
6.2.1. Окно входа в систему
Окно входа в систему (Login screen) предназначено для регистрации пользователя путем ввода логина и пароля. Логин не чувствителен к регистру вводимых символов.
Управлять отображением флажка Remember Me в веб-клиенте можно с помощью свойства приложения cuba.web.rememberMeEnabled. Стандартное окно входа содержит также выпадающий список поддерживаемых системой языков. Отображение списка и его содержимое определяются комбинацией свойств приложения cuba.localeSelectVisible и cuba.availableLocales.
Смотрите также свойства приложения cuba.web.loginDialogDefaultUser, cuba.web.loginDialogDefaultPassword и cuba.web.loginDialogPoweredByLinkVisible.
В веб-клиенте стандартное окно логина можно кастомизировать или полностью заменить в проекте, используя CUBA Studio. Выберите New > Screen в контекстном меню элемента Generic UI в дереве проекта. Затем на вкладке Screen Templates выберите шаблон Login screen или Login screen with branding image. Новые файлы дескриптора и контроллера экрана логина будут созданы в модуле Web. Идентификатор нового экрана будет автоматически использован в качестве значения свойства приложения cuba.web.loginScreenId. Смотрите также Корневые экраны.
В платформе имеется механизм защиты от взлома пароля методом перебора, смотрите свойство приложения cuba.bruteForceProtection.enabled.
Для более глубокой кастомизации процесса аутентификации, смотрите разделы Вход в систему и Процесс входа в Web Client.
Внешний вид окна входа в систему можно настроить с помощью переменных SCSS с префиксом $cuba-login-*. Эти переменные можно изменить в визуальном редакторе после расширения темы или создания новой темы.
6.2.2. Пользователи
Для каждого пользователя системы создается соответствующий экземпляр сущности sec$User. Он содержит уникальный логин, хэш пароля, ссылку на группу доступа, список ролей и другие атрибуты. Управление пользователями осуществляется с помощью экрана Administration → Users:
Помимо стандартных действий создания, изменения и удаления записей имеются следующие:
-
Copy - быстрое создание нового пользователя на основе выбранного. Новый пользователь будет иметь такую же группу доступа и набор ролей. И то и другое можно изменить в появляющемся экране редактирования нового пользователя.
-
Copy settings - позволяет скопировать выбранным пользователям настройки интерфейса, сделанные каким-либо другим пользователем. Настройки интерфейса включают в себя представления таблиц, положение разделителей контейнеров SplitPanel, наборы фильтров и папок поиска.
-
Change password - позволяет администратору системы задать новый пароль выбранному пользователю.
-
Reset passwords - позволяет произвести следующие действия над выбранными пользователями:
-
Если в появляющемся окне Reset passwords for selected users не включать флажок Generate new passwords, то пользователям будет установлен признак Change password at next logon. При следующем успешном логине пользователя ему будет предложено сменить свой пароль.
Для того, чтобы пользователь мог сменить себе пароль, у него должно быть право на экран
sec$User.changePassword. Имейте это в виду при конфигурировании ролей, особенно если вы назначаете всем пользователям Denying роль. Данный экран можно найти внутри элемента Other screens в редакторе роли. -
Если в окне Reset passwords for selected users включить флажок Generate new passwords, то для выбранных пользователей будут сгенерированы и показаны новые случайные пароли. Список новых паролей можно выгрузить в формат XLS, и например, разослать пользователям. Кроме того, для каждого пользователя будет установлен признак Change password at next logon, что делает сгенерированный пароль одноразовым.
-
Если в дополнение к Generate new passwords включить флажок Send emails with generated passwords, то новые одноразовые пароли не будут показаны администратору, а будут автоматически разосланы соответствующим пользователям на их адреса email. Отправка осуществляется асинхронно, поэтому требуется настройка назначенного задания, упомянутая в разделе Методы отправки.
Шаблоны этих email можно отредактировать. Для этого необходимо создать в модуле core шаблоны по аналогии с reset-password-subject.gsp и reset-password-body.gsp. Для локализации можно добавить соответствующие файлы шаблонов с суффиксами локалей, как это сделано в платформе.
В шаблонах используется синтаксис Groovy
SimpleTemplateEngine, что позволяет использовать блоки кода Groovy прямо в тексте шаблона. Например:Hello <% print (user.active ? user.login : 'user') %> <% if (user.email.endsWith('@company.com')) { %> The password for your account has been reset. Please login with the following temporary password: ${password} and immediately create a new one for the further work. Thank you <% } else {%> Please contact your system administrator for a new password. <%}%>В шаблонах доступны следующие переменные:
user,passwordиpersistence. Вы также можете использовать бины Spring среднего слоя, для этого импортируйте классAppBeansи получите нужный бин с помощью методаAppBeans.get().После переопределения шаблонов в
app.propertiesмодуля core необходимо задать следующие свойства:cuba.security.resetPasswordTemplateBody = <relative path to your file> cuba.security.resetPasswordTemplateSubject = <relative path to your file>Для удобства настройки в production, шаблоны можно разместить или переопределить в конфигурационном каталоге и задать свойства в
local.app.properties.
-
Рассмотрим экран редактирования пользователя:
-
Login - обязательный к заполнению уникальный логин пользователя.
-
Group - группа доступа.
-
Last name, First name, Middle name - части полного имени пользователя.
-
Name - полное имя пользователя. Автоматически формируется на основе вводимых частей (Last, First, Middle) и правила, заданного свойством приложения cuba.user.fullNamePattern. Может быть произвольно изменено вручную.
-
Position - должность.
-
Language - язык интерфейса, устанавливаемый для пользователя, если возможность выбирать язык при входе в систему отключена при помощи свойства приложения cuba.localeSelectVisible.
-
Time Zone – часовой пояс, в соответствии с которым будут отображаться и вводиться значения типа timestamp.
-
Email - адрес email.
-
Active - если данный флаг не установлен, то пользователь не может войти в систему.
-
Permitted IP Mask - маска разрешенных IP-адресов, с которых возможен вход в систему.
Маска представляет собой список адресов через запятую. Поддерживаются как адреса формата IPv4, так и адреса формата IPv6. В первом случае адрес должен состоять из четырех чисел, разделенных точками, при этом любая часть вместо числа может содержать знак "*", что означает "любое число". Адрес в формате IPv6 представляет собой восемь групп по четыре шестнадцатеричные цифры, разделенных двоеточием. Любая группа также может быть заменена знаком "*".
Маска может содержать адреса только одного формата. Наличие адресов формата IPv4 и IPv6 одновременно недопустимо.
Пример:
192.168.*.* -
Roles - список ролей пользователя.
-
Substituted Users - список замещаемых пользователей.
6.2.2.1. Замещение пользователей
Администратор системы может дать возможность пользователю замещать другого пользователя. При этом у замещающего пользователя сессия не меняется, а подменяется набор ролей, ограничений и атрибутов. Все эти параметры текущий пользователь получает от замещаемого пользователя.
|
В прикладном коде для получения текущего пользователя рекомендуется использовать метод В то же время механизмы аудита платформы (атрибуты |
Если пользователь имеет замещаемых пользователей, то в правом верхнем углу главного окна приложения вместо простой надписи с именем текущего пользователя отображается выпадающий список:
При выборе другого пользователя в этом списке все открытые экраны будут закрыты, и произойдет замещение. После этого метод UserSession.getUser() по-прежнему будет возвращать пользователя, выполнившего логин в систему, а метод UserSession.getSubstitutedUser() - замещенного пользователя. Если замещения нет, метод UserSession.getSubstitutedUser() возвращает null.
Управление замещаемыми пользователями производится с помощью таблицы Substituted Users экрана редактирования пользователя. Рассмотрим экран добавления замещаемого пользователя:
-
User - текущий редактируемый пользователь. Он будет замещать другого пользователя.
-
Substituted user - замещаемый пользователь.
-
Start date, End date - необязательный период замещения. Вне периода замещение будет недоступным. Если период не указан, замещение доступно, пока не удалена данная запись таблицы.
6.2.3. Часовой пояс
Все значения даты и времени по умолчанию отображаются в соответствии с часовым поясом сервера. Часовой пояс сервера возвращается методом TimeZone.getDefault() блока приложения. По умолчанию, платформа получает часовой пояс из операционной системы, однако его можно явно задать системным свойством Java user.timezone. Например, чтобы задать часовой пояс по Гринвичу для веб-клиента и Middleware, работающих на сервере Tomcat под Unix, нужно добавить в файл tomcat/bin/setenv.sh следующее свойство:
CATALINA_OPTS="$CATALINA_OPTS -Duser.timezone=GMT"Пользователь может просматривать и редактировать значения типа timestamp в часовых поясах, отличных от часового пояса сервера. Существует два способа управления часовыми поясами пользователя:
-
Администратор может задать часовой пояс в экране редактирования пользователя.
-
Пользователь может задать свой часовой пояс в окне Help → Settings.
В обоих случаях, часовой пояс настраивается при помощи двух полей:
-
Выпадающий список с названиями часовых поясов позволяет явно выбрать часовой пояс.
-
Флажок Auto указывает, что часовой пояс будет получен из текущего окружения (для веб-клиента - из веб-браузера).
Если оба поля пусты, часовые пояса для пользователя не конвертируются. В противном случае, платформа сохраняет часовой пояс в объекте UserSession при логине и использует его для ввода и отображения значений типа timestamp. Значение, возвращаемое методом UserSession.getTimeZone() может также использоваться и в прикладном коде.
Если часовой пояс используется для текущей сессии, его краткое имя и отклонение от времени по Гринвичу отображаются в главном окне приложения рядом с именем текущего пользователя.
|
Преобразование часовых поясов выполняется только для атрибутов типа DateTimeDatatype, то есть, содержащих timestamp. Атрибуты, хранящие только дату ( |
6.2.4. Разрешения
Разрешение определяет право пользователя на какой-либо объект или функциональность системы: экран, операцию над сущностью и так далее. Такие объекты, по отношению к разрешенниям, называются целями.
Разрешения даются пользователям путем назначения им ролей.
|
Пользователь не имеет права на объект, пока соответствующее разрешение не будет дано некоторой ролью. Поэтому пользователи без ролей не имеют никаких прав и не могут иметь доступа к системе через Generic UI и REST API. |
Существуют следующие типы разрешений, различаемые по целям:
- Разрешения на экраны системы (screen permissions)
-
Экран может быть либо разрешен, либо запрещен.
Права на экраны проверяются при построении главного меню системы и при создании экранов методом
create()интерфейсаScreens. Для проверки права на экран в прикладном коде используйте методisScreenPermitted()интерфейса Security. - Разрешения на операцию c сущностью (entity operation permissions)
-
Для каждой сущности можно разрешить операции Create, Read, Update, Delete.
См. также раздел Проверки доступа к данным для получения информации о том, как разрешения на операции c сущностью используются различными механизмами фреймворка. Для проверки права на операцию c сущностью в прикладном коде используйте метод
isEntityOpPermitted()интерфейса Security. - Разрешения на атрибуты сущности (entity attribute permissions)
-
Каждый атрибут каждой сущности может быть разрешен для просмотра или для модификации.
См. также раздел Проверки доступа к данным для получения информации о том, как разрешения на атрибуты сущностей используются различными механизмами фреймворка. Для проверки права на атрибут сущности в прикладном коде используйте метод
isEntityAttrPermitted()интерфейса Security. - Специфические разрешения (specific permissions)
-
Разрешения на произвольную именованную функциональность. Набор специфических разрешений для проекта задается в конфигурационном файле permissions.xml.
Пример использования:
@Inject private Security security; public void calculateBalance() { if (!security.isSpecificPermitted("myapp.calculateBalance")) return; ... } - Разрешения на компоненты экранов (screen component permissions)
-
Разрешения на компоненты экранов позволяют скрывать или переводить в режим "только чтение" любые UI компоненты экрана, даже если они не связаны с сущностями модели данных. Такие разрешения применяются фреймворком после отсылки AfterInitEvent и до BeforeShowEvent.
Разрешения на компоненты экранов отличаются от всех остальных типов разрешений тем, что они только ограничивают права на свои цели. Пока целевой компонент вместе с разрешением "скрыть" или "только чтение" не задан, данный компонент полностью доступен пользователю.
Целевой компонент указывается путем к нему в экране в соответствии со следующими правилами:
-
Если компонент принадлежит экрану, указывается просто идентификатор компонента
id. -
Если компонент принадлежит фрейму, вложенному в экран, то сначала указывается идентификатор фрейма, а затем через точку идентификатор компонента внутри фрейма.
-
Если необходимо установить разрешение для вкладки TabSheet или поля Form, то сначала указывается идентификатор компонента, а затем в квадратных скобках идентификатор соответственно вкладки или поля.
-
Чтобы установить разрешение на действие, необходимо указать идентификатор компонента, содержащего действие, а затем идентификатор действия в угловых скобках. Например:
customersTable<changeGrade>.
-
6.2.5. Роли
Роль объединяет набор разрешений, которые могут быть предоставлены пользователю.
Пользователь может иметь несколько ролей. При этом он получает логическую сумму (ИЛИ) прав на некоторый объект от всех ролей, которые у него есть. Например, если пользователю назначены роли A и B, роль A не дает разрешений на X, роль B разрешает X, то в итоге X будет разрешен.
Роль может давать разрешения на конкретные целевые объекты, а также на целые категории объектов: экраны, операции над сущностями, атрибуты сущностей, специфические разрешения. Например, можно легко дать разрешение Read на все сущности и разрешение View на все их атрибуты.
Разрешения на компоненты экранов являются исключением из правил, описанных выше: они могут быть указаны только на конкретный компонент, и если ни одна роль не определяет разрешения на некоторый компонент, то этот компонент полностью доступен пользователю.
Роль может иметь признак "по умолчанию", что означает, что такая роль будет автоматически назначаться вновь создаваемым пользователям. Это позволяет выдавать некоторый набор разрешений всем пользователям по умолчанию.
- Определение ролей во время разработки
-
Рекомендуемый способ определения роли - создать класс, расширяющий
AnnotatedRoleDefinition, переопределить методы, возвращающие разрешения различных типов, и добавить им аннотации, указывающие, какие разрешения дает данная роль. Класс должен находиться в модулеcore. Например, роль дающая разрешения на сущностьCustomerи ее экраны списка и редактирования может выглядеть следующим образом:@Role(name = "Customers Full Access") public class CustomersFullAccessRole extends AnnotatedRoleDefinition { @EntityAccess(entityClass = Customer.class, operations = {EntityOp.CREATE, EntityOp.READ, EntityOp.UPDATE, EntityOp.DELETE}) @Override public EntityPermissionsContainer entityPermissions() { return super.entityPermissions(); } @EntityAttributeAccess(entityClass = Customer.class, modify = "*") @Override public EntityAttributePermissionsContainer entityAttributePermissions() { return super.entityAttributePermissions(); } @ScreenAccess(screenIds = {"application-demo", "demo_Customer.browse", "demo_Customer.edit"}) @Override public ScreenPermissionsContainer screenPermissions() { return super.screenPermissions(); } }Аннотации могут быть указаны несколько раз. Например, следующая роль дает доступ только на чтение ко всем сущностям и их атрибутам, позволяет модифицировать атрибуты
gradeandcommentsсущностиCustomer, а также позволяет создавать и изменять сущностьOrderи ее атрибуты:@Role(name = "Order Management") public class OrderManagementRole extends AnnotatedRoleDefinition { @EntityAccess(entityName = "*", operations = {EntityOp.READ}) @EntityAccess(entityClass = Order.class, operations = {EntityOp.CREATE, EntityOp.UPDATE}) @Override public EntityPermissionsContainer entityPermissions() { return super.entityPermissions(); } @EntityAttributeAccess(entityName = "*", view = "*") @EntityAttributeAccess(entityClass = Customer.class, modify = {"grade", "comments"}) @EntityAttributeAccess(entityClass = Order.class, modify = "*") @Override public EntityAttributePermissionsContainer entityAttributePermissions() { return super.entityAttributePermissions(); } }Определять роли во время разработки можно только если свойство приложения cuba.security.rolesPolicyVersion установлено в 2, что является значением по умолчанию для проектов, созданных на версии CUBA 7.2 или новее. Если ваш проект мигрирует с предыдущей версии CUBA, см. раздел Предыдущая реализация ролей и разрешений.
- Определение ролей во время работы приложения
-
Фреймворк содержит UI, который позволяет создавать роли в работающем приложении, см. Administration > Roles. Роли, созданные таким образом, можно изменить или удалить. Роли, заданные при разработке приложения, доступны только на чтение.
В верхней части экрана редактирования роли отображаются общие параметры роли, в нижней части - вкладки управления разрешениями.
-
Вкладка Screens - разрешения на экраны системы. Дерево в левой части вкладки отражает структуру главного меню системы. Последним элементом дерева является Other screens, внутри которого сосредоточены экраны, не включенные в главное меню (например, экраны редактирования сущностей).
Флажок Allow all screens разрешает все экраны сразу. Он эквивалентен аннотации
@ScreenAccess(screenIds = "*"). -
Вкладка Entities - разрешения на операции с сущностями. При переходе на данную вкладку изначально включен флажок Assigned only, поэтому в таблице отображаются только сущности, для которых в данной роли уже есть явные разрешения. Поэтому для новой роли таблица пуста. Для установки разрешений снимите флажок Assigned only и нажмите Apply. Список сущностей можно фильтровать, вводя в поле Entity любую часть имени сущности и нажимая Apply. Установив флажок System level, можно выбрать системную сущность, помеченную аннотацией
@SystemLevel. По умолчанию такие сущности не показываются в таблице.Панель Allow all entities предназначена для разрешения операций над всеми сущностями. Ее флажки эквивалентны аннотации
@EntityAccess(entityName = "*", …). -
Вкладка Attributes - разрешения на атрибуты сущностей. В таблице сущностей в колонке Permissions отображается список атрибутов, для которых явно указаны разрешения. Управление списком сущностей аналогично описанному для вкладки Entities.
Панель Allow all attributes предназначена для разрешения просмотра или модификации всех атрибутов всех сущностей. Если необходимо разрешить все атрибуты конкретной сущности, отметьте флажок "*" внизу панели Permissions для этой сущности. То же самое можно сделать используя символ "*" в атрибутах
entityNameиview/modifyаннотации@EntityAttributeAccess. -
Вкладка Specific - разрешения на именованную функциональность. Имена объектов, на которые могут быть назначены специфические разрешения, определяются в конфигурационном файле permissions.xml проекта.
Флажок Allow all specific permissions является эквивалентом аннотации
@SpecificAccess(permissions = "*"). -
Вкладка UI - разрешения на UI-компоненты экранов. Для создания ограничения выберите нужный экран в выпадающем списке Screen, задайте путь к компоненту в поле Component, и нажмите Add. При формировании пути, следуйте правилам, описанным в разделе Разрешения. Для отображения структуры экрана нажмите кнопку Components tree, выберите компонент и выберите Copy id to path в контекстном меню.
-
- Области действия (security scopes)
-
Области действия позволяют назначать одному пользователю различные наборы ролей (и тем самым различные разрешения) в зависимости от клиентской технологии, которую он использует для доступа к приложению. Область действия указывается в атрибуте
securityScopeаннотации@Role, или в поле Security scope экрана редактирования роли, если роль создается во время работы приложения.Ядро фреймворка содержит единственного клиента - Generic UI, поэтому все роли по умолчанию имеют область действия
GENERIC_UI. Все пользователи, входящие в систему через UI приложения получат набор ролей с этим значением области действия.Аддон REST API определяет свою собственную область действия -
REST, поэтому если вы добавите аддон к проекту, вам необходимо сконфигурировать отдельный набор ролей для пользователей, входящих в систему через REST API. Если этого не сделать, пользователи не смогут входить через REST, так как у них не будет разрешенияcuba.restApi.enabled.
- System roles
-
Фреймворк определяет две предустановленные роли для области действия
GENERIC_UI:-
system-minimal- содержит минимальный набор разрешений, необходимый пользователям для работы с Generic UI. Данная роль задается классомMinimalRoleDefinition. Она дает специфическое разрешениеcuba.gui.loginToClient, а также разрешения на некоторый системные сущности и экраны. У ролиsystem-minimalустановлен атрибут "по умолчанию", поэтому она автоматически назначается новым пользователям. -
system-full-access- дает все разрешения на все объекты, тем самым может использоваться для создания администраторов, имеющих полные права на систему. Встроенный пользовательadminпо умолчанию имеет эту роль.
-
6.2.6. Группы доступа
Группы доступа позволяют организовывать пользователей в иерархическую структуру для установки ограничений и для присвоения произвольных атрибутов сессии.
Пользователь может быть причислен только к одной группе, однако он получит список ограничений и атрибутов сессии от всех групп вверх по иерархии.
Группы доступа могут быть заданы в коде приложения или во время выполнения в экране Administration > Access Groups. В первом случае необходимо создать классы, расширяющие AnnotatedAccessGroupDefinition и добавить аннотацию @AccessGroup с указанием родительской группы в атрибуте parent. Классы должны быть расположены в модуле core. Например:
@AccessGroup(name = "Root")
public class RootGroup extends AnnotatedAccessGroupDefinition {
// definitions of constraints and session attributes
}@AccessGroup(name = "Sales", parent = RootGroup.class)
public class Sales extends AnnotatedAccessGroupDefinition {
// definitions of constraints and session attributes
}6.2.6.1. Ограничения
Ограничения (Constraints) позволяют реализовать row-level access control, т.е. контроль доступа на уровне экземпляров сущностей. В отличие от разрешений, которые накладываются на классы сущностей, ограничения накладываются на конкретные экземпляры. Ограничения можно накладывать на чтение, создание, модификацию и удаление сущностей, так что фреймворк будет отфильтровывать некоторые экземпляры или запрещать операции с экземплярами, соответствующими ограничениям. Кроме того, можно задать специальные ограничения, не привязанные к действиям CRUD.
|
Пользователь получает набор ограничений от всех групп начиная со своей и вверх по иерархии. Поэтому чем ниже пользователь в иерархии групп, тем больше у него ограничений. |
Следует отметить, что все ограничения проверяются при операциях с данными, осуществляемых клиентом через стандартный DataManager. В случае несоответствия проверяемой сущности условиям ограничений при создании, модификации или удалении, выбрасывается исключение RowLevelSecurityException. См. также раздел Проверки доступа к данным для получения информации о том, как ограничения доступа к данным используются различными механизмами фреймворка.
Существует два типа проверки ограничений: проверка в базе данных и проверка в памяти.
-
Для ограничений с проверкой в базе данных условия задаются с помощью фрагментов выражений на языке JPQL. Эти фрагменты подставляются в каждый запрос, выбирающий экземпляры данной сущности. Таким образом, сущности, не соответствующие условиям ограничения, отфильтровываются на уровне базы данных. Ограничение с проверкой в базе данных можно задать только на чтение сущностей, и они затрагивают только корневые сущности в загружаемых графах объектов.
-
Для ограничений с проверкой в памяти условия задаются с помощью кода Java (во время разработки), или выражений на Groovy (во время работы приложения). Эти выражения выполняются для каждой сущности проверяемого графа объектов, и если какая-либо сущность не соответствует условиям - она отфильтровывается из графа объектов.
- Задание ограничений во время разработки
-
Ограничения можно описывать в классе, расширяющем
AnnotatedAccessGroupDefinition, который используется для определения группы доступа. Класс должен располагаться в модулеcore. Ниже приведен пример группы доступа, определяющей несколько ограничений для сущностейCustomerиOrder:@AccessGroup(name = "Sales", parent = RootGroup.class) public class SalesGroup extends AnnotatedAccessGroupDefinition { @JpqlConstraint(target = Customer.class, where = "{E}.grade = 'B'") (1) @JpqlConstraint(target = Order.class, where = "{E}.customer.grade = 'B'") (2) @Override public ConstraintsContainer accessConstraints() { return super.accessConstraints(); } @Constraint(operations = {EntityOp.CREATE, EntityOp.READ, EntityOp.UPDATE, EntityOp.DELETE}) (3) public boolean customerConstraints(Customer customer) { return Grade.BRONZE.equals(customer.getGrade()); } @Constraint(operations = {EntityOp.CREATE, EntityOp.READ, EntityOp.UPDATE, EntityOp.DELETE}) (4) public boolean orderConstraints(Order order) { return order.getCustomer() != null && Grade.BRONZE.equals(order.getCustomer().getGrade()); } @Constraint(operations = {EntityOp.UPDATE, EntityOp.DELETE}) (5) public boolean orderUpdateConstraints(Order order) { return order.getAmount().compareTo(new BigDecimal(100)) < 1; } }1 - загружать только покупателей, у которых атрибут gradeравенB(соответствует значению перечисленияGrade.BRONZE).2 - загружать только заказы покупателей, у которых атрибут gradeравенB.3 - ограничение с проверкой в памяти, которое исключает из графа загружаемых объектов все отличные от Grade.BRONZE. 4 - ограничение с проверкой в памяти, которое разрешает работать только с заказами для покупателей с grade == Grade.BRONZE.5 - ограничение с проверкой в памяти, которое разрешает изменять и удалять только заказы с amount < 100.Правила формирования ограничения на JPQL:
-
В качестве алиаса извлекаемой сущности необходимо использовать строку
{E}. При выполнении запросов она будет заменена на реальный алиас, заданный в запросе. -
В параметрах JPQL можно использовать следующие предопределенные константы:
-
session$userLogin− имя учетной записи текущего пользователя (в случае замещения − имя учетной записи замещаемого пользователя). -
session$userId− ID текущего пользователя (в случае замещения − ID замещаемого пользователя). -
session$userGroupId− ID группы текущего пользователя (в случае замещения − ID группы замещаемого пользователя). -
session$XYZ− произвольный атрибут текущей пользовательской сессии, где XYZ − имя атрибута.
-
-
Содержимое атрибута
whereдобавляется в выражениеwhereзапроса по условиюand(И). Само словоwhereписать не нужно, оно будет добавлено автоматически, даже если исходный запрос его не содержал. -
Содержимое атрибута
joinдобавляется в выражениеfromзапроса. Оно должно начинаться с запятой или словjoinилиleft join.
-
- Задание ограничений во время работы приложения
-
Для создания ограничения, выберите в экране Access Groups группу, на которую нужно наложить ограничение, и перейдите на вкладку Constraints. Экран редактирования ограничения содержит мастер Constraint Wizard, который помогает создавать простые JPQL и Groovy условия для атрибутов сущности. Если выбран тип операции Custom, то появляется обязательное поле Code, где нужно указать строку, по которой будет идентифицироваться данное ограничение.
Редактор JPQL в полях Join Clause и Where Clause поддерживает автодополнение имен сущностей и их атрибутов. Для вызова автодополнения нажмите Ctrl+Space. Если вызов произведен после точки, будет выведен список атрибутов сущности, соответствующей контексту, иначе - список всех сущностей модели данных.
В Groovy скрипт ограничения с проверкой в памяти необходимо использовать
{E}в качестве переменной, содержащей проверяемый экземпляр сущности. Кроме того, в скрипт передается переменнаяuserSessionтипаUserSession. В примере ниже приведен скрипт ограничения, проверяющий, что сущность была создана текущим пользователем:{E}.createdBy == userSession.user.loginПри нарушении ограничения пользователю показывается уведомление. Заголовок и текст уведомления для каждого ограничения можно локализовать: см. кнопку Localization на вкладке Constraints экрана Access Groups.
- Проверка ограничений в коде приложения
-
Разработчик может проверить условия ограничений для конкретной сущности с помощью методов интерфейса
Security:-
isPermitted(Entity, ConstraintOperationType)- для проверки ограничений по типу операции. -
isPermitted(Entity, String)- для проверки ограничений по коду ограничия.
Кроме того, существует возможность связать любое действие, унаследованное от класса
ItemTrackingAction, c проверкой ограничений. Для этого в XML-элементеactionследует задать атрибутconstraintOperationType, либо использовать методsetConstraintOperationType()в контроллере экрана. Имейте в виду, что код ограничения будет выполняться на клиентском уровне, поэтому он не должен содержать обращения к классам среднего слоя.Пример:
<table> ... <actions> <action id="create"/> <action id="edit" constraintOperationType="update"/> <action id="remove" constraintOperationType="delete"/> </actions> </table> -
6.2.6.2. Атрибуты сессии
Группа доступа может определять список атрибутов сессии для пользователей, входящих в данную группу. Эти атрибуты можно использовать в коде приложения и при настройке ограничений.
В пользовательскую сессию при входе в систему будут помещены все атрибуты, заданные для группы, в которой находится пользователь, и для всех родительских групп вверх по иерархии. При этом если атрибут встречается в иерархии групп несколько раз, значение он получит от самой верхней группы, то есть переопределение значений атрибутов на нижнем уровне невозможно. При попытке переопределения в журнал сервера будет выведено сообщение с уровнем WARN.
Атрибуты сессии могут быть заданы вместе с ограничениями в классе, используемом для задания группы доступа. Класс должен быть расположен в модуле core. Ниже приведен пример группы доступа, которая определяет атрибут accessLevel со значением 1:
@AccessGroup(name = "Level 1", parent = RootGroup.class)
public class FirstLevelGroup extends AnnotatedAccessGroupDefinition {
@SessionAttribute(name = "accessLevel", value = "1", javaClass = Integer.class)
@Override
public Map<String, Serializable> sessionAttributes() {
return super.sessionAttributes();
}
}Атрибуты сессии могут быть также заданы во время работы приложения с помощью экрана Access Groups: выберите группу и перейдите на вкладку Session Attributes.
Получить атрибут сессии в коде приложения можно с помощью объекта UserSession:
@Inject
private UserSessionSource userSessionSource;
...
Integer accessLevel = userSessionSource.getUserSession().getAttribute("accessLevel");Использовать атрибут в ограничениях можно, указав его в параметре JPQL с префиксом session$:
{E}.accessLevel = :session$accessLevel6.2.7. Экспорт и импорт ролей и групп доступа
Экраны Roles и Access Groups содержат действия для экспорта выделенных в списке ролей/групп доступа в форматах ZIP или JSON, а также для импорта ролей/групп доступа в систему (с помощью кнопок Export/Import).
|
Экспорт и импорт возможен только для ролей и групп доступа, определенных во время работы приложения. |
6.2.8. Предыдущая реализация ролей и разрешений
До CUBA 7.2 метод расчета действующих разрешений был другим:
-
Было два типа разрешений: "разрешить" и "запретить".
-
Если никакая роль не запрещала целевой объект, то он был разрешен.
-
Разрешение могло быть дано либо явно путем указания "allow/deny" для целевого объекта, или ролью определенного типа, например роль "Denying" давала разрешение "deny" всем объектам кроме атрибутов сущностей. Если целевой объект не получал явных разрешений, либо разрешений от типа роли, он был полностью доступен пользователю. В результате, пользователь вообще без ролей имел полные права на систему.
При настройке ролей, рекомендовалось сначала давать обычным пользователям роль "Denying", а затем набор ролей с явными разрешениями. Теперь запрещающая роль не нужна, так как пользователи не имеют никаких прав на объекты, пока соответствующие разрешения не даны им какой-либо ролью.
Кроме того, в предыдущих версиях не было областей действия, так что все роли действовали и на клиентов Generic UI и на клиентов REST API.
Поведение подсистемы безопасности управляется несколькими свойствами приложения, которые имеют значения по умолчанию, соответствующие новому поведению. Если вы мигрировали проект на CUBA 7.2 с предыдущей версии, Studio добавляет свойства, приведенные ниже, для переключения в режим старого поведения и сохранения текущей настройки прав доступа. Если вы хотите воспользоваться новыми возможностями (в частности, настройкой ролей во время разработки) и перенастроить подсистему безопасности, удалите эти свойства.
В модуле core, устанавливаются свойства для предыдущего поведения, использования конфигурационного файла default-permission-values.xml и игнорирования роли system-minimal:
app.properties
cuba.security.rolesPolicyVersion = 1
cuba.security.defaultPermissionValuesConfigEnabled = true
cuba.security.minimalRoleIsDefault = falseЕсли в проекте используется аддон REST API, в модулях web и portal добавляется следующее свойство для того, чтобы установить область действия контроля доступа REST в то же значение, что используется в Generic UI:
web-app.properties
cuba.rest.securityScope = GENERIC_UI
portal-app.properties
cuba.rest.securityScope = GENERIC_UI6.3. Проверки доступа к данным
Таблица ниже поясняет, как разрешения и ограничения доступа к данным используются различными механизмами фреймворка.
Entity Operations |
Entity Attributes |
Read Constraint |
Read Constraint |
Create/Update/Delete |
|
EntityManager |
Нет |
Нет |
Нет |
Нет |
Нет |
DataManager on middle tier |
Нет |
Да |
Нет |
Нет |
|
DataManager.secure on middle tier DataManager on client tier |
Да (3) |
Нет |
Да |
Да |
Да |
Generic UI data-aware components |
Да |
Да |
- (6) |
- (6) |
- (6) |
REST API |
Да |
Да |
Да |
Да |
Да |
REST API |
Да |
Да |
Да |
Да |
- (7) |
REST API |
Да |
Да |
- (8) |
- (8) |
- (8) |
Замечания:
1) Ограничения чтения с проверкой в базе данных влияют только на корневую сущность.
// order is loaded only if it satisfies constraints on the Order entity
Order order = dataManager.load(Order.class).viewProperties("date", "amount", "customer.name").one();
// related customer is loaded regardless of database-checked constraints on Customer entity
assert order.getCustomer() != null;2) Ограничения чтения с проверкой в памяти влияют и на корневую сущность, и на все связанные сущности в загруженном графе.
// order is loaded only if it satisfies constraints on the Order entity
Order order = dataManager.load(Order.class).viewProperties("date", "amount", "customer.name").one();
// related customer is not null only if it satisfies in-memory-checked constraints on Customer entity
if (order.getCustomer() != null) ...3) Разрешения на операцию c сущностью в DataManager проверяются только для корневой сущности.
// loading Order
Order order = dataManager.load(Order.class).viewProperties("date", "amount", "customer.name").one();
// related customer is loaded even if the user has no permission to read the Customer entity
assert order.getCustomer() != null;4) DataManager проверяет разрешения на операцию c сущностью и in-memory ограничения на среднем слое только если свойство приложения cuba.dataManagerChecksSecurityOnMiddleware установлено в true.
5) DataManager проверяет разрешения на атрибуты сущности только если свойство приложения cuba.entityAttributePermissionChecking установлено в true.
6) UI-компоненты не проверяют ограничения сами, но когда данные загружаются стандартным способом, ограничения налагаются в DataManager. В результате, если некоторый экземпляр сущности отфильтрован ограничениями, соответвующий UI-компонент отображается, но он пустой. Кроме того, любое действие, унаследованное от класса ItemTrackingAction, можно связать с ограничением определенного типа, так что действие будет доступным только когда проверка ограничения выполнена успешно.
7) REST-запросы выполняют только чтение данных.
8) Параметры и результаты методов REST-сервисов не проверяются на соответствие ограничениям. Поведение сервиса в отношении ограничений определяется тем, как он читает и сохраняет данные, например, использует ли он DataManager или DataManager.secure().
6.4. Примеры управления доступом
В данном разделе приведены практические рекомендации по настройке доступа пользователей к данным.
6.4.1. Настройка ролей
Рекомендованный способ настройки ролей и разрешений:
-
Создайте роль
Default, отбирающую все права в системе. Проще всего это сделать, установив тип роли Denying или Strictly denying. Последний тип рекомендуется, если используется доступ к данным системы через REST API. См. также раздел Проверки доступа к данным для получения информации о том, когда проверяются разрешения.Включите флажок Default role, чтобы эта роль автоматически назначалась всем новым пользователям.
-
Создайте набор ролей, дающих нужные права различным категориям пользователей. Можно предложить две стратегии создания таких ролей:
-
Крупнозернистые (coarse-grained) роли - каждая роль содержит набор разрешений для всего круга обязанностей пользователя в системе. Например
Sales Manager,Accountant. В этом случае пользователям в дополнение к запрещающейDefaultроли необходимо назначить как правило только одну разрешающую роль. -
Мелкозернистые (fine-grained) роли - каждая роль содержит небольшой набор разрешений для выполнения пользователем некоторой функции в системе. Например
Task Creator,References Editor. В этом случае пользователям в дополнение к запрещающейDefaultроли необходимо назначить несколько разрешающих ролей в соответствии с кругом их обязанностей.
Разумеется, ничто не мешает совмещать обе стратегии.
-
-
Администратору системы можно просто не назначать никаких ролей вообще, тогда у него будут все права на все объекты системы. Пользователя с запрещающими ролями можно сделать администратором, добавив ему роль типа Super.
Доступ к функциональности администрирования
Ниже приведен краткий перечень разрешений, которые необходимо настроить для пользователя с Denying-ролью, чтобы предоставить ему доступ к функциональности из меню Администрирование. К примеру, если вы хотите открыть доступ только к функциональности Entity log, добавьте разрешения, перечисленные в одноименной секции ниже.
Рекомендуется всегда предоставлять доступ к сущности sys$FileDescriptor как минимум на чтение, так она широко используется в различных механизмах платформы: отправка писем, вложения, системные журналы и т.д.
Разрешения, описанные ниже, можно настроить в редакторе сущности Role на соответствующих вкладках: Entity, Screen и Specific.
Кроме того. доступ к системным сущностям по умолчанию можно сконфигурировать с помощью свойства приложения cuba.defaultPermissionValuesConfig.
- Users
-
Сущность User может использоваться и как ссылочный атрибут в модели данных вашего приложения. Чтобы отображать пользователей в выпадающих списках и экранах выбора, достаточно дать разрешение на доступ к самой сущности
sec$User.В случае, если вам требуется создавать и редактировать сущность
Userиз запрещающей роли, вам понадобятся следующие разрешения:-
Entities:
sec$User,sec$Group; (опционально)sec$Role,sec$UserRole,sec$UserSubstitution.
Без разрешения на чтение сущности
sec$UserSubstitutionне будет работать работы механизм user substitution.-
Screens: элемент меню Users,
sec$User.edit,sec$Group.lookup; (опционально)sec$Group.edit,sec$Role.edit,sec$Role.lookup,sec$User.changePassword,sec$User.copySettings,sec$User.newPasswords,sec$User.resetPasswords,sec$UserSubstitution.edit.
-
- Access Groups
-
Создание и управление группами доступа и ограничениями безопасности.
-
Entities:
sec$Group,sec$Constraint,sec$SessionAttribute,sec$LocalizedConstraintMessage. -
Screens: элемент меню Access Groups,
sec$Group.lookup,sec$Group.edit,sec$Constraint.edit,sec$SessionAttribute.edit,sec$LocalizedConstraintMessage.edit.
-
- Dynamic Attributes
-
Доступ к дополнительным неперсистентным атрибутам сущности.
-
Entities:
sys$Category,sys$CategoryAttribute, а также требуемые сущности из вашей модели данных. -
Screens: элемент меню Dynamic Attributes,
sys$Category.edit,sys$CategoryAttribute.edit,dynamicAttributesConditionEditor,dynamicAttributesConditionFrame.
-
- User Sessions
-
Просмотр информации о пользовательских сессиях.
-
Entities:
sec$User,sec$UserSessionEntity. -
Screens: элемент меню User Sessions,
sessionMessageWindow.
-
- Locks
-
Настройка пессимистичной блокировки сущностей.
-
Entities:
sys$LockInfo,sys$LockDescriptor, а также требуемые сущности из вашей модели данных. -
Screens: элемент меню Locks,
sys$LockDescriptor.edit.
-
- External Files
-
Доступ к файловому хранилищу.
-
Entities:
sys$FileDescriptor. -
Screens: элемент меню External Files; (опционально)
sys$FileDescriptor.edit.
-
- Scheduled Tasks
-
Работа с назначенными заданиями.
-
Entities:
sys$ScheduledTask,sys$ScheduledExecution. -
Screens: элемент меню Scheduled Tasks,
sys$ScheduledExecution.browse,sys$ScheduledTask.edit.
-
- Entity Inspector
-
Работа с любыми объектами приложения из динамически создаваемых экранов при помощи entity inspector.
-
Entities: требуемые сущности из вашей модели данных.
-
Screens: элемент меню Entity Inspector,
entityInspector.edit, а также требуемые сущности из вашей модели данных.
-
- Entity Log
-
Отслеживание изменений сущностей на уровне entity listeners.
-
Entities:
sec$EntityLog,sec$User,sec$EntityLogAttr,sec$LoggedAttribute,sec$LoggedEntity, а также требуемые сущности из вашей модели данных. -
Screens: элемент меню Entity Log.
-
- User Session Log
-
Просмотр исторических данных о входе и выходе пользователей из системы, или user sessions.
-
Entities:
sec$SessionLogEntry. -
Screens: элемент меню User Session Log.
-
- Email History
-
Просмотр сообщений электронной почты, отправленных из приложения.
-
Entities:
sys$SendingMessage,sys$SendingAttachment,sys$FileDescriptor(для вложений). -
Screens: элемент меню Email History,
sys$SendingMessage.attachments.
-
- Server Log
-
Просмотр и скачивание журналов приложения.
-
Entities:
sys$FileDescriptor. -
Screens: элемент меню Server Log,
serverLogDownloadOptionsDialog. -
Specific:
Download log files.
-
- Reports
-
Запуск отчётов, см. дополнение Генератор Отчётов.
-
Entities:
report$Report,report$ReportInputParameter,report$ReportGroup. -
Screens:
report$inputParameters,commonLookup,report$Report.run,report$showChart(если содержит шаблон с типом выводаChart).
-
6.4.2. Создание локальных администраторов
Иерархическая структура групп доступа с наследованием ограничений позволяет создавать локальных администраторов и делегировать им создание пользователей и настройку их прав в рамках подразделений организации.
Локальному администратору доступны экраны подсистемы безопасности, однако он видит только пользователей и группы в своей группе доступа и ниже. Он может создавать подгруппы и пользователей и назначать им имеющиеся в системе роли. При этом все создаваемые им пользователи будут иметь как минимум те же ограничения, что и он сам.
Глобальный администратор, находящийся в корневой группе доступа, лишенной ограничений, должен создать роли, которые будут доступны локальным администраторам для назначения пользователям. Сами локальные администраторы не должны иметь прав на создание и изменение ролей.
Рассмотрим следующую структуру групп доступа:
Задача:
-
Пользователи внутри группы
Departmentsдолжны видеть только пользователей своей группы и ниже. -
В каждой из групп
Dept 1,Dept 2, и т.д. должен быть свой локальный администратор, который может создавать пользователей и назначать им имеющиеся роли.
Способ решения задачи:
-
Задать для группы
Departmentsследующие ограничения:-
Для сущности
sec$Group:{E}.id in ( select h.group.id from sec$GroupHierarchy h where h.group.id = :session$userGroupId or h.parent.id = :session$userGroupId )Это ограничение не позволяет пользователям видеть группы выше своей собственной.
-
Для сущности
sec$User:{E}.group.id in ( select h.group.id from sec$GroupHierarchy h where h.group.id = :session$userGroupId or h.parent.id = :session$userGroupId )Это ограничение не позволяет пользователям видеть других пользователей, входящих в группы выше своей собственной.
-
Для сущности
sec$Role(ограничение на Groovy проверяемое в памяти):!['system-full-access', 'Some Role to Hide 1', 'Some Role to Hide 2'].contains({E}.name)Данное ограничение не позволяет пользователям видеть и получать нежелательные роли.
-
-
Создать роль
Department Administratorдля локальных администраторов:-
На вкладке Screens разрешите следующие экраны:
Administration,Users,Access Groups,Roles,sec$Group.edit,sec$Group.lookup,sec$Role.lookup,sec$User.changePassword,sec$User.copySettings,sec$User.edit,sec$User.lookup,sec$User.newPasswords,sec$User.resetPasswords,sec$UserSubstitution.edit. -
На вкладке Entities разрешите все операции для сущностей
sec$Group,sec$User,sec$UserRoleи операцию Read для сущностиsec$Role(для добавления разрешений на объектsec$UserRoleустановите флажок System level). -
На вкладке Attributes разрешите "*" для сущностей
sec$Group,sec$Userиsec$Role.
-
-
Создайте локальных администраторов в группах их отделов как показано на скриншоте выше и назначьте им роль
Department Administrator.
В результате, когда локальный администратор входит в систему, он видит только группу своего отдела и вложенные группы:
Локальному администратору доступно создание новых пользователей и назначение им имеющихся ролей, кроме перечисленных в ограничении.
6.5. Интеграция с LDAP
Интеграция CUBA-приложения c LDAP позволяет решить две задачи:
-
Хранить пароли пользователей и управлять ими централизованно в базе данных LDAP.
-
Для пользователей компьютеров, входящих в домен Windows, выполнять логин в приложение без ввода имени и пароля (то есть организовывать Single Sign-On).
В режиме интеграции с LDAP пользователи по-прежнему должны иметь учетную запись в приложении. Все разрешения и параметры пользователя (кроме пароля) хранятся в БД приложения, LDAP используется только для аутентификации, т.е. проверки имени и пароля. Пароль в приложении для большинства пользователей, за исключением тех, кому требуется стандартная аутентификация (см. ниже), рекомендуется не задавать вообще. Поле пароля в экране редактирования пользователя не является обязательным к заполнению, если свойство cuba.web.requirePasswordForNewUsers установлено в false.
Если логин пользователя перечислен в свойстве приложения cuba.web.standardAuthenticationUsers, то он всегда аутентифицируется обычным способом через хранимый в базе данных приложения хэш пароля. Поэтому если для некоторого пользователя из данного списка пароль в приложении задан, он сможет войти в систему с этим паролем, если в LDAP такого пользователя нет.
Взаимодействие CUBA-приложения с LDAP осуществляется через бин LdapLoginProvider.
Для расширенной интеграции с Active Directory и обеспечения Single Sign-On для пользователей домена Windows можно использовать библиотеку Jespa и соответствующую имплементацию LoginProvider, которая описана в Интеграция с Active Directory с использованием Jespa.
Вы можете реализовать свой механизм входа при помощи интерфейсов LoginProvider, HttpRequestFilter и обработчиков событий, как это описано в разделе Специфика процесса входа в Web Client.
Также вы можете включить LDAP аутентификацию для клиентов REST API: LDAP аутентификация для REST API.
6.5.1. Базовая интеграция с LDAP
Класс LdapLoginProvider используется по умолчанию при включенном свойстве приложения cuba.web.ldap.enabled. В этом случае для аутентификации пользователей используется библиотека Spring LDAP.
Для настройки интеграции используются следующие свойства приложения блока Web Client:
Пример содержимого файла local.app.properties:
cuba.web.ldap.enabled = true
cuba.web.ldap.urls = ldap://192.168.1.1:389
cuba.web.ldap.base = ou=Employees,dc=mycompany,dc=com
cuba.web.ldap.user = cn=System User,ou=Employees,dc=mycompany,dc=com
cuba.web.ldap.password = system_user_passwordСм. также cuba.web.requirePasswordForNewUsers.
В случае интеграции с Active Directory, при создании пользователей в приложении указывайте в качестве логина их sAMAccountName без имени домена.
6.5.2. Интеграция с Active Directory с использованием Jespa
Jespa − библиотека для Java, обеспечивающая расширенную интеграцию между службой каталогов Active Directory и Java-приложениями по протоколу NTLMv2. Подробно о библиотеке см. http://www.ioplex.com.
6.5.2.1. Подключение библиотеки
Загрузите библиотеку с сайта http://www.ioplex.com и разместите JAR в каком-либо репозитории, зарегистрированном в вашем скрипте сборки build.gradle. Это может быть mavenLocal() или репозиторий вашей организации.
В файле build.gradle в секции конфигурации модуля web добавьте зависимости:
configure(webModule) {
...
dependencies {
compile('com.company.thirdparty:jespa:1.1.17') // from a custom repository
compile('jcifs:jcifs:1.3.17') // from Maven Central
...Создайте в модуле web класс реализации интерфейса LoginProvider:
package com.company.jespatest.web;
import com.google.common.collect.ImmutableMap;
import com.haulmont.cuba.core.global.ClientType;
import com.haulmont.cuba.core.global.GlobalConfig;
import com.haulmont.cuba.core.sys.AppContext;
import com.haulmont.cuba.core.sys.ConditionalOnAppProperty;
import com.haulmont.cuba.security.auth.*;
import com.haulmont.cuba.security.global.LoginException;
import com.haulmont.cuba.web.App;
import com.haulmont.cuba.web.Connection;
import com.haulmont.cuba.web.auth.WebAuthConfig;
import com.haulmont.cuba.web.security.ExternalUserCredentials;
import com.haulmont.cuba.web.security.LoginProvider;
import com.haulmont.cuba.web.security.events.AppStartedEvent;
import com.haulmont.cuba.web.sys.RequestContext;
import jespa.http.HttpSecurityService;
import jespa.ntlm.NtlmSecurityProvider;
import jespa.security.PasswordCredential;
import jespa.security.SecurityProviderException;
import org.apache.commons.lang3.StringUtils;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.context.event.EventListener;
import org.springframework.core.Ordered;
import org.springframework.stereotype.Component;
import javax.annotation.Nullable;
import javax.annotation.PostConstruct;
import javax.inject.Inject;
import javax.servlet.*;
import javax.servlet.http.HttpServletRequest;
import java.io.IOException;
import java.io.Serializable;
import java.security.Principal;
import java.util.HashMap;
import java.util.Map;
import static com.haulmont.cuba.web.security.ExternalUserCredentials.EXTERNAL_AUTH_USER_SESSION_ATTRIBUTE;
@ConditionalOnAppProperty(property = "activeDirectory.integrationEnabled", value = "true")
@Component("sample_JespaAuthProvider")
public class JespaAuthProvider extends HttpSecurityService implements LoginProvider, Ordered, Filter {
private static final Logger log = LoggerFactory.getLogger(JespaAuthProvider.class);
@Inject
private GlobalConfig globalConfig;
@Inject
private WebAuthConfig webAuthConfig;
@Inject
private DomainAliasesResolver domainAliasesResolver;
@Inject
private AuthenticationService authenticationService;
private static Map<String, DomainInfo> domains = new HashMap<>();
private static String defaultDomain;
@PostConstruct
public void init() throws ServletException {
initDomains();
Map<String, String> properties = new HashMap<>();
properties.put("jespa.bindstr", getBindStr());
properties.put("jespa.service.acctname", getAcctName());
properties.put("jespa.service.password", getAcctPassword());
properties.put("jespa.account.canonicalForm", "3");
properties.put("jespa.log.path", globalConfig.getLogDir() + "/jespa.log");
properties.put("http.parameter.anonymous.name", "anon");
fillFromSystemProperties(properties);
try {
super.init(JespaAuthProvider.class.getName(), null, properties);
} catch (SecurityProviderException e) {
throw new ServletException(e);
}
}
@Nullable
@Override
public AuthenticationDetails login(Credentials credentials) throws LoginException {
LoginPasswordCredentials lpCredentials = (LoginPasswordCredentials) credentials;
String login = lpCredentials.getLogin();
// parse domain by login
String domain;
int atSignPos = login.indexOf("@");
if (atSignPos >= 0) {
String domainAlias = login.substring(atSignPos + 1);
domain = domainAliasesResolver.getDomainName(domainAlias).toUpperCase();
} else {
int slashPos = login.indexOf('\\');
if (slashPos <= 0) {
throw new LoginException("Invalid name: %s", login);
}
String domainAlias = login.substring(0, slashPos);
domain = domainAliasesResolver.getDomainName(domainAlias).toUpperCase();
}
DomainInfo domainInfo = domains.get(domain);
if (domainInfo == null) {
throw new LoginException("Unknown domain: %s", domain);
}
Map<String, String> securityProviderProps = new HashMap<>();
securityProviderProps.put("bindstr", domainInfo.getBindStr());
securityProviderProps.put("service.acctname", domainInfo.getAcctName());
securityProviderProps.put("service.password", domainInfo.getAcctPassword());
securityProviderProps.put("account.canonicalForm", "3");
fillFromSystemProperties(securityProviderProps);
NtlmSecurityProvider provider = new NtlmSecurityProvider(securityProviderProps);
try {
PasswordCredential credential = new PasswordCredential(login, lpCredentials.getPassword().toCharArray());
provider.authenticate(credential);
} catch (SecurityProviderException e) {
throw new LoginException("Authentication error: %s", e.getMessage());
}
TrustedClientCredentials trustedCredentials = new TrustedClientCredentials(
lpCredentials.getLogin(),
webAuthConfig.getTrustedClientPassword(),
lpCredentials.getLocale(),
lpCredentials.getParams());
trustedCredentials.setClientInfo(lpCredentials.getClientInfo());
trustedCredentials.setClientType(ClientType.WEB);
trustedCredentials.setIpAddress(lpCredentials.getIpAddress());
trustedCredentials.setOverrideLocale(lpCredentials.isOverrideLocale());
trustedCredentials.setSyncNewUserSessionReplication(lpCredentials.isSyncNewUserSessionReplication());
Map<String, Serializable> targetSessionAttributes;
Map<String, Serializable> sessionAttributes = lpCredentials.getSessionAttributes();
if (sessionAttributes != null
&& !sessionAttributes.isEmpty()) {
targetSessionAttributes = new HashMap<>(sessionAttributes);
targetSessionAttributes.put(EXTERNAL_AUTH_USER_SESSION_ATTRIBUTE, true);
} else {
targetSessionAttributes = ImmutableMap.of(EXTERNAL_AUTH_USER_SESSION_ATTRIBUTE, true);
}
trustedCredentials.setSessionAttributes(targetSessionAttributes);
return authenticationService.login(trustedCredentials);
}
@Override
public boolean supports(Class<?> credentialsClass) {
return LoginPasswordCredentials.class.isAssignableFrom(credentialsClass);
}
@Override
public int getOrder() {
return HIGHEST_PLATFORM_PRECEDENCE + 50;
}
@Override
public void destroy() {
}
@Override
public void init(FilterConfig filterConfig) throws ServletException {
}
@EventListener
public void loginOnAppStart(AppStartedEvent appStartedEvent) {
App app = appStartedEvent.getApp();
Connection connection = app.getConnection();
Principal userPrincipal = RequestContext.get().getRequest().getUserPrincipal();
if (userPrincipal != null) {
String login = userPrincipal.getName();
log.debug("Trying to login using jespa principal " + login);
try {
connection.login(new ExternalUserCredentials(login, App.getInstance().getLocale()));
} catch (LoginException e) {
log.trace("Unable to login on start", e);
}
}
}
@Override
public void doFilter(ServletRequest request, ServletResponse response, FilterChain chain)
throws IOException, ServletException {
HttpServletRequest httpServletRequest = (HttpServletRequest) request;
if (httpServletRequest.getHeader("User-Agent") != null) {
String ua = httpServletRequest.getHeader("User-Agent")
.toLowerCase();
boolean windows = ua.contains("windows");
boolean gecko = ua.contains("gecko") && !ua.contains("webkit");
if (!windows && gecko) {
chain.doFilter(request, response);
return;
}
}
super.doFilter(request, response, chain);
}
private void initDomains() {
String domainsStr = AppContext.getProperty("activeDirectory.domains");
if (StringUtils.isEmpty(domainsStr)) {
return;
}
String[] strings = domainsStr.split(";");
for (int i = 0; i < strings.length; i++) {
String domain = strings[i];
domain = domain.trim();
if (StringUtils.isEmpty(domain)) {
continue;
}
String[] parts = domain.split("\\|");
if (parts.length != 4) {
log.error("Invalid ActiveDirectory domain definition: " + domain);
break;
} else {
domains.put(parts[0], new DomainInfo(parts[1], parts[2], parts[3]));
if (i == 0) {
defaultDomain = parts[0];
}
}
}
}
public String getDefaultDomain() {
return defaultDomain != null ? defaultDomain : "";
}
public String getBindStr() {
return getBindStr(getDefaultDomain());
}
public String getBindStr(String domain) {
initDomains();
DomainInfo domainInfo = domains.get(domain);
return domainInfo != null ? domainInfo.getBindStr() : "";
}
public String getAcctName() {
return getAcctName(getDefaultDomain());
}
public String getAcctName(String domain) {
initDomains();
DomainInfo domainInfo = domains.get(domain);
return domainInfo != null ? domainInfo.getAcctName() : "";
}
public String getAcctPassword() {
return getAcctPassword(getDefaultDomain());
}
public String getAcctPassword(String domain) {
initDomains();
DomainInfo domainInfo = domains.get(domain);
return domainInfo != null ? domainInfo.getAcctPassword() : "";
}
public void fillFromSystemProperties(Map<String, String> params) {
for (String name : AppContext.getPropertyNames()) {
if (name.startsWith("jespa.")) {
params.put(name, AppContext.getProperty(name));
}
}
}
public static class DomainInfo {
private final String bindStr;
private final String acctName;
private final String acctPassword;
DomainInfo(String bindStr, String acctName, String acctPassword) {
this.acctName = acctName;
this.acctPassword = acctPassword;
this.bindStr = bindStr;
}
public String getBindStr() {
return bindStr;
}
public String getAcctName() {
return acctName;
}
public String getAcctPassword() {
return acctPassword;
}
}
}Зарегистрируйте LoginProvider как фильтр в modules/web/WEB-INF/web.xml:
<filter>
<filter-name>jespa_Filter</filter-name>
<filter-class>org.springframework.web.filter.DelegatingFilterProxy</filter-class>
<init-param>
<param-name>targetBeanName</param-name>
<param-value>sample_JespaAuthProvider</param-value>
</init-param>
</filter>
<filter-mapping>
<filter-name>jespa_Filter</filter-name>
<url-pattern>/*</url-pattern>
</filter-mapping>
Создайте в модуле web бин, отвечающий за сопоставление доменов и их псевдонимов:
package com.company.sample.web;
import com.haulmont.cuba.core.sys.AppContext;
import org.apache.commons.lang3.StringUtils;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.stereotype.Component;
import java.util.Arrays;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.stream.Collectors;
@Component(DomainAliasesResolver.NAME)
public class DomainAliasesResolver {
public static final String NAME = "sample_DomainAliasesResolver";
private static final Logger log = LoggerFactory.getLogger(DomainAliasesResolver.class);
private Map<String, String> aliases = new HashMap<>();
public DomainAliasesResolver() {
String domainAliases = AppContext.getProperty("activeDirectory.aliases");
if (StringUtils.isEmpty(domainAliases)) {
return;
}
List<String> aliasesPairs = Arrays.stream(StringUtils.split(domainAliases, ';'))
.filter(StringUtils::isNotEmpty)
.collect(Collectors.toList());
for (String aliasDefinition : aliasesPairs) {
String[] aliasParts = StringUtils.split(aliasDefinition, '|');
if (aliasParts == null
|| aliasParts.length != 2
|| StringUtils.isBlank(aliasParts[0])
|| StringUtils.isBlank(aliasParts[1])) {
log.warn("Incorrect domain alias definition: '{}'", aliasDefinition);
} else {
aliases.put(aliasParts[0].toLowerCase(), aliasParts[1]);
}
}
}
public String getDomainName(String alias) {
String alias_lc = alias.toLowerCase();
String domain = aliases.get(alias_lc);
if (domain == null) {
return alias;
}
log.debug("Resolved domain '{}' from alias '{}'", domain, alias);
return domain;
}
}6.5.2.2. Настройка конфигурации
-
Выполнить настройки, описанные в разделе Installation → Step 1: Create the Computer Account for NETLOGON Communication руководства Jespa Operator’s Manual, которое можно загрузить по адресу http://www.ioplex.com/support.html.
-
Задать параметры доменов в local.app.properties в свойстве приложения
activeDirectory.domains. Каждый описатель домена имеет форматdomain_name|full_domain_name|service_account_name|service_account_password. Описатели доменов отделяются друг от друга точкой с запятой.Например:
activeDirectory.domains = MYCOMPANY|mycompany.com|JESPA$@MYCOMPANY.COM|password1;TEST|test.com|JESPA$@TEST.COM|password2 -
Разрешить интеграцию с Active Directory, установив в
local.app.propertiesсвойство приложенияactiveDirectory.integrationEnabled:activeDirectory.integrationEnabled = true -
Задать в
local.app.propertiesдополнительные свойства для библиотеки (см. Jespa Operator’s Manual). Например:jespa.log.level=3Если приложение развернуто на Tomcat, лог-файл Jespa находится в
tomcat/logs. -
Добавить адрес сервера в местную интрасеть в настройках браузера:
-
Для Internet Explorer и Chrome: Свойства обозревателя > Безопасность > Местная интрасеть > Узлы > Дополнительно.
-
Для Firefox:
about:config>network.automatic-ntlm-auth.trusted-uris=http://myapp.mycompany.com.
-
-
Создать в приложении пользователя с доменной учетной записью.
6.6. Single-Sign-On для приложений CUBA
Single-Sign-On (единый вход, SSO) для приложений CUBA позволяет пользователям входить в несколько запущенных приложений, введя единые имя и пароль один раз в течение сессии веб-браузера.
Чтобы настроить SSO в приложении, используйте специальное дополнение IDP. Процесс настройки единого входа с помощью этого дополнения подробно описан в его документации на GitHub.
6.7. Social Login
Вход через социальные сети, или social login, - это разновидность single sign-on, которая позволяет использовать данные для входа в социальные сети, такие как Facebook, Twitter или Google+, для входа в приложения CUBA вместо того, чтобы создавать пользователя в приложении напрямую.
|
Руководство Anonymous Access & Social Login содержит пример настройки публичного доступа к некоторым экранам приложения, а также реализации пользовательского входа в приложение с помощью учетной записи Google, Facebook или GitHub. |
В этом примере мы рассмотрим, как можно войти в приложение, используя аккаунт на Facebook. В Facebook используется механизм авторизации OAuth2, более подробно о его использовании вы можете узнать из документации по Facebook API и Facebook Login Flow: https://developers.facebook.com/docs/facebook-login/manually-build-a-login-flow.
Исходный код проекта из этого примера доступен на GitHub, ниже приведены ключевые моменты реализации social login.
-
Чтобы подключить приложение к Facebook, создайте для него App ID (уникальный идентификатор приложения) и App Secret (своего рода пароль для аутентификации запросов, поступающих от приложения на серверы Facebook). Следуя инструкции, создайте эти значения и затем зарегистрируйте их в файле
app.propertiesв модуле core в свойствах приложенияfacebook.appIdиfacebook.appSecretсоответственно, например:facebook.appId = 123456789101112 facebook.appSecret = 123456789101112abcde131415fghi16Выдайте разрешение email, позволяющее вашему приложению просматривать основной электронный адрес пользователя.
Далее зарегистрируйте URL, который вы указали при регистрации приложения на Facebook, в свойстве приложения cuba.webAppUrl в модулях core и web, например:
cuba.webAppUrl = http://cuba-fb.test:8080/app -
Расширьте окно входа в систему и добавьте кнопку для входа через социальную сеть. Подпишитесь на событие нажатия кнопки: оно будет точкой входа в процедуру social login.
<linkButton id="facebookBtn" align="MIDDLE_CENTER" caption="Facebook" icon="font-icon:FACEBOOK_SQUARE"/> -
Чтобы использовать учётные записи пользователей Facebook в своём приложении, добавьте новое поле к стандартной учётной записи пользователя CUBA. Расширьте сущность
Userи добавьте строковый атрибутfacebookId:@Column(name = "FACEBOOK_ID") protected String facebookId; -
Создайте роль
FacebookAccessRole, дающую право пользователю просматривать экраны помощи, настроек и информации о приложении:@Role(name = "facebook-access") public class FacebookAccessRole extends AnnotatedRoleDefinition { @ScreenAccess(screenIds = { "help", "aboutWindow", "settings", }) @Override public ScreenPermissionsContainer screenPermissions() { return super.screenPermissions(); } } -
Создайте сервис, который будет искать пользователя приложения в базе данных по переданному
facebookId, и если таковой не найден, то создавать его на лету:public interface SocialRegistrationService { String NAME = "demo_SocialRegistrationService"; User findOrRegisterUser(String facebookId, String email, String name); }@Service(SocialRegistrationService.NAME) public class SocialRegistrationServiceBean implements SocialRegistrationService { @Inject private DataManager dataManager; @Inject private Configuration configuration; @Override public User findOrRegisterUser(String facebookId, String email, String name) { User existingUser = dataManager.load(User.class) .query("select u from sec$User u where u.facebookId = :facebookId") .parameter("facebookId", facebookId) .optional() .orElse(null); if (existingUser != null) { return existingUser; } SocialUser user = dataManager.create(SocialUser.class); user.setLogin(email); user.setName(name); user.setGroup(getDefaultGroup()); user.setActive(true); user.setEmail(email); user.setFacebookId(facebookId); UserRole fbUserRole = dataManager.create(UserRole.class); fbUserRole.setRoleName("facebook-access"); fbUserRole.setUser(user); EntitySet eSet = dataManager.commit(user, fbUserRole); return eSet.get(user); } private Group getDefaultGroup() { SocialRegistrationConfig config = configuration.getConfig(SocialRegistrationConfig.class); return dataManager.load(Group.class) .query("select g from sec$Group g where g.id = :defaultGroupId") .parameter("defaultGroupId", config.getDefaultGroupId()) .one(); } } -
Создайте сервис для реализации логики входа. В данном примере это сервис FacebookService, содержащий два метода:
getLoginUrl()иgetUserData().-
getLoginUrl()генерирует URL для входа на основании URL приложения и типа ответа OAuth2 (code, access token или оба; более подробно о параметреresponse_typeсм. в документации Facebook API). Исходный код этого метода можно посмотреть в файле FacebookServiceBean.java. -
getUserData()будет искать пользователя Facebook по параметрам, переданным в URL и в коде, и вернёт данные существующего пользователя или создаст нового. В этом примере из пользовательских данных нам нужныid,nameиemail;idбудет соответствовать атрибутуfacebookId, который мы создали ранее.
-
-
Определите свойство приложения
facebook.fieldsв файлеapp.propertiesмодуля core:facebook.fields = id,name,email -
Вернёмся к событию нажатия кнопки логина через Facebook в контроллере расширенного окна входа. Код контроллера целиком вы можете найти в файле ExtLoginScreen.java.
В этом событии мы добавим к текущей сессии обработчик запроса, затем сохраним текущий URL и перенаправим пользователя на экран авторизации Facebook в браузере:
private RequestHandler facebookCallBackRequestHandler = this::handleFacebookCallBackRequest; private URI redirectUri; @Inject private FacebookService facebookService; @Inject private GlobalConfig globalConfig; @Subscribe("facebookBtn") public void onFacebookBtnClick(Button.ClickEvent event) { VaadinSession.getCurrent() .addRequestHandler(facebookCallBackRequestHandler); this.redirectUri = Page.getCurrent().getLocation(); String loginUrl = facebookService.getLoginUrl(globalConfig.getWebAppUrl(), FacebookService.OAuth2ResponseType.CODE); Page.getCurrent() .setLocation(loginUrl); }В методе
handleFacebookCallBackRequest()будет обработан обратный вызов после формы авторизации Facebook. Во-первых, используем экземплярUIAccessor, чтобы зафиксировать состояние UI, пока будет обрабатываться запрос на вход.Затем с помощью
FacebookServiceполучимemailиidучётной записи Facebook. После этого найдём соответствующего пользователя CUBA по егоfacebookIdили создадим нового на лету.Далее будет совершен вход в приложение, будет создана новая сессия от лица этого пользователя и обновлен UI. Теперь мы можем удалить обработчик обратного вызова Facebook, так как процедура аутентификации закончена.
public boolean handleFacebookCallBackRequest(VaadinSession session, VaadinRequest request, VaadinResponse response) throws IOException { if (request.getParameter("code") != null) { uiAccessor.accessSynchronously(() -> { try { String code = request.getParameter("code"); FacebookService.FacebookUserData userData = facebookService.getUserData(globalConfig.getWebAppUrl(), code); User user = socialRegistrationService.findOrRegisterUser( userData.getId(), userData.getEmail(), userData.getName()); Connection connection = app.getConnection(); Locale defaultLocale = messages.getTools().getDefaultLocale(); connection.login(new ExternalUserCredentials(user.getLogin(), defaultLocale)); } catch (Exception e) { log.error("Unable to login using Facebook", e); } finally { session.removeRequestHandler(facebookCallBackRequestHandler); } }); ((VaadinServletResponse) response).getHttpServletResponse(). sendRedirect(ControllerUtils.getLocationWithoutParams(redirectUri)); return true; } return false; }
Теперь при нажатии кнопки Facebook на экране входа приложение запросит разрешение на использование учётных данных пользователя Facebook, и если разрешение будет получено, пользователь после логина будет перенаправлен на главную страницу приложения.
Вы можете реализовать свой механизм входа при помощи интерфейсов LoginProvider, HttpRequestFilter и обработчиков событий, как это описано в разделе Процесс входа в Web Client.
Приложение A: Конфигурационные файлы
В данном приложении описаны основные конфигурационные файлы, входящие в состав CUBA-приложений.
A.1. app-component.xml
Файл app-component.xml требуется для того, чтобы данное приложение можно было использовать в качестве компонента другого приложения. Файл определяет зависимости от других компонентов, описывает существующие модули приложения, генерируемые артефакты и предоставляемые свойства приложения.
Файл app-component.xml должен располагаться в пакете, указанном в элементе App-Component-Id манифеста JAR модуля global. Данный элемент манифеста позволяет системе сборки находить компоненты проекта, находящиеся в class path в момент сборки. В результате, для подключения некоторого компонента к проекту, достаточно добавить координаты артефакта модуля global компонента в элементе dependencies/appComponent файла build.gradle проекта.
По соглашению, файл app-component.xml располагается в корневом пакете проекта (заданном в metadata.xml), который также равен группе артефактов проекта (заданной в build.gradle):
App-Component-Id == root-package == cuba.artifact.group == e.g. 'com.company.sample'Для генерации файла app-component.xml и элементов манифеста рекомендуется использовать CUBA Studio.
- Подключение зависимостей как appJars:
-
Если компонент содержит сторонние библиотеки, которые вы хотите использовать как артефакты модулей другого приложения (например,
app-comp-coreилиapp-comp-web), так, чтобы они были развёрнуты в каталогеtomcat/webapps/app[-core]/WEB-INF/lib/, эти зависимости необходимо добавить как библиотеки appJar:<module blocks="core" dependsOn="global,jm" name="core"> <artifact appJar="true" name="cuba-jm-core"/> <artifact classifier="db" configuration="dbscripts" ext="zip" name="cuba-jm-core"/> <!-- Specify only the artifact name for your appJar 3rd party library --> <artifact name="javamelody-core" appJar="true" library="true"/> </module>В случае, если вы не планируете использовать проект в качестве компонента других приложений, сторонние зависимости нужно указывать как appJars в задаче deploy файла
build.gradle:configure(coreModule) { //... task deploy(dependsOn: assemble, type: CubaDeployment) { appName = 'app-core' appJars('app-global', 'app-core', 'javamelody-core') } //... }
A.2. context.xml
Файл context.xml является дескриптором развертывания приложения на сервере Apache Tomcat. В развернутом приложении этот файл располагается в подкаталоге META-INF каталога веб-приложения или WAR-файла, например, tomcat/webapps/app-core/META-INF/context.xml. В проекте файлы данного типа находятся в каталогах /web/META-INF модулей core, web, portal.
Основное предназначение файла для блока Middleware - определить JDBC источник данных и поместить его в JNDI под именем, заданным свойством приложения cuba.dataSourceJndiName.
|
Начиная с CUBA 7.2, существует простой способ задания источников данных в свойствах приложения, см. Конфигурирование источника данных в приложении. |
Пример определения источника данных для PostgreSQL:
<Resource
name="jdbc/CubaDS"
type="javax.sql.DataSource"
maxIdle="2"
maxTotal="20"
maxWaitMillis="5000"
driverClassName="org.postgresql.Driver"
username="cuba"
password="cuba"
url="jdbc:postgresql://localhost/sales"/>Пример определения источника данных для Microsoft SQL Server 2005:
<Resource
name="jdbc/CubaDS"
type="javax.sql.DataSource"
maxIdle="2"
maxTotal="20"
maxWaitMillis="5000"
driverClassName="net.sourceforge.jtds.jdbc.Driver"
username="sa"
password="saPass1"
url="jdbc:jtds:sqlserver://localhost/sales"/>Пример определения источника данных для Microsoft SQL Server 2008+:
<Resource
name="jdbc/CubaDS"
type="javax.sql.DataSource"
maxIdle="2"
maxTotal="20"
maxWaitMillis="5000"
driverClassName="net.sourceforge.jtds.jdbc.Driver"
username="sa"
password="saPass1"
url="jdbc:jtds:sqlserver://localhost/sales"/>Пример определения источника данных для Oracle:
<Resource
name="jdbc/CubaDS"
type="javax.sql.DataSource"
maxIdle="2"
maxTotal="20"
maxWaitMillis="5000"
driverClassName="oracle.jdbc.OracleDriver"
username="sales"
password="sales"
url="jdbc:oracle:thin:@//localhost:1521/orcl"/>Пример определения источника данных для MySQL:
<Resource
type="javax.sql.DataSource"
name="jdbc/CubaDS"
maxIdle="2"
maxTotal="20"
maxWaitMillis="5000"
driverClassName="com.mysql.jdbc.Driver"
password="cuba"
username="cuba"
url="jdbc:mysql://localhost/sales?useSSL=false&allowMultiQueries=true"/>Следующая строка отключает сериализацию HTTP-сессий:
<Manager pathname=""/>A.3. default-permission-values.xml
|
Файлы данного типа используются в CUBA до версии 7.2, а также в мигрированных проектах, сохраняющих предыдущий метод расчета действующих разрешений, как описано в разделе Предыдущая реализация ролей и разрешений. |
Разрешения по умолчанию используются тогда, когда ни одна из имеющихся ролей не задаёт разрешения на конкретный экран или функциональность. Разрешения необходимы по большей части для запрещающих ролей: без этого файла пользователь с запрещающей ролью не будет иметь доступа к главному экрану и экранам фильтров.
Данный файл нужно создать в модуле core.
Расположение файла задается в свойстве приложения cuba.defaultPermissionValuesConfig. Если свойство не задано, будет использован файл платформы по умолчанию - cuba-default-permission-values.xml.
Схема XML доступна по адресу http://schemas.haulmont.com/cuba/default-permission-values.xsd.
Рассмотрим структуру файла.
default-permission-values - корневой элемент. Он содержит всего один вложенный элемент - permission.
permission - само разрешение: определяет, на какой тип объектов накладывается разрешение или запрет.
У permission есть три атрибута:
-
target- конкретный объект разрешения. Формат представления объекта зависит от типа разрешения: для экранов это значение ихid, для операций над сущностями -idсущности с типом операции, к примеру,target="sec$Filter:read", и т.д. -
value- значение разрешения. Может иметь значения0или1(запрещен или разрешен соответственно). -
type- тип объекта разрешения:-
10- экран, -
20- операция над сущностью, -
30- атрибут сущности, -
40- специфическое разрешение на произвольную именованную функциональность, -
50- компонент UI.
-
Пример:
<?xml version="1.0" encoding="UTF-8"?>
<default-permission-values xmlns="http://schemas.haulmont.com/cuba/default-permission-values.xsd">
<permission target="dynamicAttributesConditionEditor" value="0" type="10"/>
<permission target="dynamicAttributesConditionFrame" value="0" type="10"/>
<permission target="sec$Filter:read" value="1" type="20"/>
<permission target="cuba.gui.loginToClient" value="1" type="40"/>
</default-permission-values>A.4. dispatcher-spring.xml
Файлы данного типа определяют конфигурацию дополнительного контейнера Spring Framework для клиентских блоков, содержащих контроллеры Spring MVC.
Дополнительный контейнер контроллеров создается таким образом, что основной контейнер (конфигурируемый файлами spring.xml) является родительским по отношению к нему. Это означает, что бины контейнера контроллеров могут обращаться к бинам основного контейнера, а бины основного контейнера "не видят" контейнер контроллеров.
Расположения файла dispatcher-spring.xml задается в свойстве приложения cuba.dispatcherSpringContextConfig.
Модули web и portal платформы уже содержат такие файлы конфигурации: соответственно cuba-dispatcher-spring.xml и cuba-portal-dispatcher-spring.xml.
Если вы создали контроллеры Spring MVC в своем проекте (например, в модуле web), добавьте следующую конфигурацию:
-
Создайте файл
modules/web/src/com/company/sample/web/dispatcher-config.xmlследующего содержания (предполагается что ваши контроллеры находятся в пакетеcom.company.sample.web.controller):<?xml version="1.0" encoding="UTF-8"?> <beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:context="http://www.springframework.org/schema/context" xsi:schemaLocation=" http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-4.2.xsd http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context-4.2.xsd"> <context:annotation-config/> <context:component-scan base-package="com.company.sample.web.controller"/> </beans> -
Включите файл в свойство приложения cuba.dispatcherSpringContextConfig в файле
web-app.properties:cuba.dispatcherSpringContextConfig = +com/company/sample/web/dispatcher-config.xml
Контроллеры, созданные в модуле web, будут доступны по адресам, начинающимся с URL сервлета dispatcher (по умолчанию /dispatch). Например:
http://localhost:8080/app/dispatch/my-controller-endpoint
Контроллеры, созданные в модуле portal, будут доступны в корневом контексте веб-приложения, например:
http://localhost:8080/app-portal/my-controller-endpoint
A.5. menu.xml
Файлы данного типа используются в блоке Web Client для описания структуры главного меню приложения.
Схема XML доступна по адресу http://schemas.haulmont.com/cuba/7.2/menu.xsd.
Расположение файла menu.xml задается в свойстве приложения cuba.menuConfig. При создании нового проекта в Studio, она создает файл web-menu.xml в корневом пакете модуля web, например modules/web/src/com/company/sample/web-menu.xml.
menu-config - корневой XML-элемент файла. Элементы menu-config образуют древовидную структуру, в которой элементы menu представляют собой ветви, а элементы item и separator - листья.
-
Атрибуты элемента
menu:-
id- уникальный идентификатор элемента. -
caption- заголовок элемента меню. Если не задан, заголовок формируется по правилам, описанным ниже. -
description- текст, появляющийся во всплывающей подсказке при наведении курсора мыши. Можно использовать локализованные сообщения из главного пакета сообщений. -
icon- значок для элемента меню. См. icon. -
insertBefore,insertAfter- идентификатор элемента или пункта меню, перед которым или после которого нужно вставить данный элемент. Используется в прикладном проекте для вставки элемента в нужное место меню, определенного в аналогичных файлах компонентов приложения. Разумеется, использование одного из этих атрибутов для конкретного элемента исключает возможность использования второго атрибута для данного элемента. -
stylename- задает имя стиля пункта меню. См. Темы приложения.
-
-
Атрибуты элемента
item:-
id- уникальный идентификатор элемента. Если не определены атрибутыscreen,bean,class, то id используется для указания на экран с таким же id. При выборе пункта меню в главном окне приложения будет открыт соответствующий экран.<item id="sample_Foo.browse"/> -
caption- заголовок элемента меню. Если не задан, заголовок формируется по правилам, описанным ниже.<item id="sample_Foo.browse" caption="mainMsg://fooBrowseCaption"/> -
screen- идентификатор экрана (например,sample_Foo.browse). Может быть использован для включения в меню одного и того же экрана несколько раз. При выборе пункта меню в главном окне приложения будет открыт соответствующий экран.<item id="foo1" screen="sample_Foo.browse"/> <item id="foo2" screen="sample_Foo.browse"/> -
bean- имя бина. Атрибут должен использоваться совместно сbeanMethod. При выборе пункта меню будет вызван метод бина.<item bean="sample_FooProcessor" beanMethod="processFoo"/> -
class- полное имя класса, который реализует интерфейсRunnable,Consumer<Map<String, Object>>, илиMenuItemRunnabl. При выборе пункта меню будет создан экземпляр данного класса и вызван его метод.<item class="com.company.sample.web.FooProcessor"/> -
description- текст, появляющийся во всплывающей подсказке при наведении курсора мыши. Можно использовать локализованные сообщения из главного пакета сообщений.<item id="sample_Foo.browse" description="mainMsg://fooBrowseDescription"/> -
shortcut- горячая клавиша для вызова данного пункта меню. Возможные модификаторы -ALT,CTRL,SHIFT- отделяются символом “-”. Например:shortcut="ALT-C" shortcut="ALT-CTRL-C" shortcut="ALT-CTRL-SHIFT-C"Горячие клавиши можно также задавать в свойствах приложения и использовать в
menu.xmlследующим образом:shortcut="${sales.menu.customer}" -
openType- тип открытия экрана, возможные значения соответствуют перечислениюOpenMode:NEW_TAB,THIS_TAB,DIALOG. По умолчанию -NEW_TAB. -
icon- значок для элемента меню. См. icon. -
insertBefore,insertAfter- идентификатор элемента или пункта меню, перед которым или после которого нужно вставить данный элемент. -
resizable- актуально для типа открытия экранаDIALOG- задает окну возможность изменения размера. Возможные значения:true,false. По умолчанию главное меню не влияет на возможность изменения размера диалоговых окон. -
stylename- задает имя стиля пункта меню. См. Темы приложения.
-
-
Вложенные элементы
item:
Пример файла меню:
<menu-config xmlns="http://schemas.haulmont.com/cuba/menu.xsd">
<menu id="sales" insertBefore="administration">
<item id="sales_Order.lookup"/>
<separator/>
<item id="sales_Customer.lookup" openType="DIALOG"/> (1)
<item screen="sales_CustomerInfo">
<properties>
<property name="stringParam" value="some string"/> (2)
<property name="customerParam" (3)
entityClass="com.company.demo.entity.Customer"
entityId="0118cfbe-b520-797e-98d6-7d54146fd586"/>
</properties>
</item>
<item screen="sales_Customer.edit">
<properties>
<property name="entityToEdit" (4)
entityClass="com.company.demo.entity.Customer"
entityId="0118cfbe-b520-797e-98d6-7d54146fd586"
entityView="_local"/>
</properties>
</item>
</menu>
</menu-config>| 1 | - открыть экран в диалоговом окне. |
| 2 | - вызвать метод setStringParam(), передавая в него some string. |
| 3 | - вызвать метод setCustomerParam(), передавая в него экземпляр сущности загруженный по данному id. |
| 4 | - вызвать метод setEntityToEdit() класса StandardEditor, передавая в него экземпляр сущности загруженный по данному id и представлению. |
menu-config.sales=Sales
menu-config.sales_Customer.lookup=CustomersЕсли атрибут id не задан, имя элемента меню будет составлено из имени класса (если задан атрибут class) или имени бина и его метода (если задан атрибут bean), поэтому для локализации рекомендуется указывать атрибут id.
A.6. metadata.xml
Файлы данного типа используются для регистрации кастомных типов данных и неперсистентных сущностей, и для задания мета-аннотаций.
Схема XML доступна по адресу http://schemas.haulmont.com/cuba/7.2/metadata.xsd.
Расположение файла metadata.xml задается в свойстве приложения cuba.metadataConfig.
Рассмотрим структуру файла.
metadata - корневой элемент.
Элементы metadata:
-
datatypes- опциональный описатель кастомных типов данных.Элементы
datatypes:-
datatype- описатель типа данных. Имеет следующие атрибуты:-
id- идентификатор, используемый для ссылки на данный тип из аннотации @MetaProperty. -
class- задает класс имплементации. -
sqlType- необязательный атрибут, задающий SQL-тип базы данных, подходящий для хранения значений данного типа. SQL-тип используется в Studio при генерации скриптов для БД. Подробнее см. Пример специализированного Datatype.
Элемент
datatypeможет также содержать другие атрибуты, зависящие от конкретного класса реализацииDatatype. -
-
Должен иметь атрибут class, задающий класс реализации. Другие атрибуты опциональны и зависят от реализации. См. Пример специализированного Datatype.
-
metadata-model- описатель метамодели проекта.Атрибуты
metadata-model:-
root-package- корневой пакет проекта.Элементы
metadata-model: -
class- класс неперсистентной сущности.
-
-
annotations- корень элементов присвоения мета-аннотаций сущностей.Элемент
annotationsсодержит список элементовentity, которые определяют сущности, для которых задаются мета-аннотации. Каждый элементentityдолжен содержать атрибутclass, который задает класс сущности, и список элементовannotation.Элемент
annotationопределяет мета-аннотацию. Он имеет атрибутname, соответствующий имени мета-аннотации. Мэп атрибутов мета-аннотации задается списком вложенных элементовattribute.
Пример:
<metadata xmlns="http://schemas.haulmont.com/cuba/metadata.xsd">
<metadata-model root-package="com.sample.sales">
<class>com.sample.sales.entity.SomeNonPersistentEntity</class>
<class>com.sample.sales.entity.OtherNonPersistentEntity</class>
</metadata-model>
<annotations>
<entity class="com.haulmont.cuba.security.entity.User">
<annotation name="com.haulmont.cuba.core.entity.annotation.TrackEditScreenHistory">
<attribute name="value" value="true" datatype="boolean"/>
</annotation>
<annotation name="com.haulmont.cuba.core.entity.annotation.EnableRestore">
<attribute name="value" value="true" datatype="boolean"/>
</annotation>
</entity>
<entity class="com.haulmont.cuba.core.entity.Category">
<annotation name="com.haulmont.cuba.core.entity.annotation.SystemLevel">
<attribute name="value" value="false" datatype="boolean"/>
</annotation>
</entity>
</annotations>
</metadata>A.7. permissions.xml
Файлы данного типа используются в блоке Web Client для регистрации специфических разрешений пользователей.
Расположение файла задается в свойстве приложения cuba.permissionConfig. При создании нового проекта в Studio, она создает файл web-permissions.xml в корневом пакете модуля web, например modules/web/src/com/company/sample/web-permissions.xml.
Схема XML доступна по адресу http://schemas.haulmont.com/cuba/7.2/permissions.xsd.
Рассмотрим структуру файла.
permission-config - корневой элемент.
Элементы permission-config:
-
specific- описатель специфических разрешений.Элементы
specific:-
category- категория разрешений, используется для группировки в экране управления разрешениями роли. Атрибутidиспользуется как ключ для получения локализованного названия категории. -
permission- именованное разрешение. Атрибутidиспользуется для получения значения разрешения методомSecurity.isSpecificPermitted(), а также как ключ для получения локализованного названия разрешения для отображения в экране управления разрешениями роли.
-
Пример:
<permission-config xmlns="http://schemas.haulmont.com/cuba/permissions.xsd">
<specific>
<category id="app">
<permission id="app.payments.exportTransactionsToPdf"/>
<permission id="app.orders.modifyInvoicedOrders"/>
</category>
</specific>
</permission-config>Для того чтобы локализовать названия категорий и специфических разрешений, задайте ключи в главном пакете сообщений:
permission-config.app = Demo application permissions
permission-config.app.payments.exportTransactionsToPdf = Export transactions to pdf
permission-config.app.orders.modifyInvoicedOrders = Modify invoiced ordersA.8. persistence.xml
Файлы данного типа являются стандартными для JPA и используются для регистрации персистентных сущностей и задания параметров функционирования фреймворка ORM.
Расположение файла persistence.xml задается в свойстве приложения cuba.persistenceConfig.
На старте блока Middleware из заданных файлов собирается один persistence.xml и сохраняется в рабочем каталоге приложения. Параметры ORM могут переопределяться каждым следующим файлом списка, поэтому порядок указания файлов важен.
Пример файла:
<persistence xmlns="http://java.sun.com/xml/ns/persistence" version="1.0">
<persistence-unit name="sales" transaction-type="RESOURCE_LOCAL">
<class>com.sample.sales.entity.Customer</class>
<class>com.sample.sales.entity.Order</class>
</persistence-unit>
</persistence>A.9. remoting-spring.xml
Файлы данного типа определяют конфигурацию дополнительного контейнера Spring Framework для блока Middleware, который предназначен для экспорта сервисов и других компонентов среднего слоя, доступных клиентскому уровню (далее контейнер удаленного доступа).
Расположение файла remoting-spring.xml задается в свойстве приложения cuba.remotingSpringContextConfig.
Контейнер удаленного доступа создается таким образом, что основной контейнер (конфигурируемый файлами spring.xml) является родительским по отношению к нему. Это означает, что бины контейнера удаленного доступа могут обращаться к бинам основного контейнера, а бины основного контейнера "не видят" контейнер удаленного доступа.
Основная задача контейнера удаленного доступа - сделать сервисы Middleware доступными клиентскому уровню с помощью механизма Spring HttpInvoker. Для этого в cuba-remoting-spring.xml базового проекта cuba определяется бин servicesExporter типа RemoteServicesBeanCreator, который получает из основного контейнера все классы сервисов и экспортирует их. В дополнение к обычным аннотированным сервисам контейнер удаленного доступа экспортирует некоторые специфические бины, такие как AuthenticationService.
Кроме того, cuba-remoting-spring.xml определяет базовый пакет, начиная с которого производится поиск аннотированных классов контроллеров Spring MVC, используемых для загрузки-выгрузки файлов.
В прикладном проекте определять файл типа remoting-spring.xml необходимо только в том случае, если создаются специфические контроллеры Spring MVC. Сервисы прикладного проекта в любом случае будут импортированы стандартным бином servicesExporter, определенным в компоненте cuba платформы.
A.10. spring.xml
Файлы данного типа определяют конфигурацию основного контейнера Spring Framework для каждого блока приложения.
Расположение файла spring.xml задается в свойстве приложения cuba.springContextConfig.
Основная часть конфигурирования контейнера возложена на аннотации бинов (такие как @Component, @Service, @Inject и др.), поэтому обязательной частью spring.xml в прикладном проекте является только элемент context:component-scan, в котором задается базовый пакет Java, с которого начинается поиск аннотированных классов. Например:
<context:component-scan base-package="com.sample.sales"/>Остальное содержимое зависит от того, для какого блока приложения конфигурируется контейнер: например, для Middleware это регистрация JMX-бинов, для блоков клиентского уровня - импорт сервисов.
A.11. views.xml
Файлы данного типа используются для описания общих представлений, см. Создание представлений.
Схема XML доступна по адресу http://schemas.haulmont.com/cuba/7.2/view.xsd.
views - корневой элемент
Элементы views:
-
view- описательViewАтрибуты
view:-
class- класс сущности. -
entity- имя сущности, напримерsales_Order. Может быть использован вместо атрибутаclass. -
name- имя представления в репозитории, должно быть уникальным в пределах сущности. -
systemProperties- признак включения системных атрибутов сущности (входящих в состав базовых интерфейсов персистентных сущностейBaseEntityиUpdatable). Необязательный атрибут, по умолчаниюtrue. -
overwrite- признак того, что данный описатель должен переопределить представление с таким же классом и именем, уже развернутое в репозитории. Необязательный атрибут, по умолчаниюfalse. -
extends- указывает имя представления той же сущности, от которого нужно унаследовать атрибуты. Порядок следования описателей в файле при этом не важен. Например, при указанииextends="_local"в текущее представление будут включены все локальные атрибуты сущности. Необязательный атрибут.
Элементы
view:-
property- описательViewProperty.
Атрибуты
property:-
name- имя атрибута сущности. -
view- для ссылочного атрибута указывает имя представления, с которым должна загружаться ассоциированная сущность. Порядок следования описателей в файле при этом не важен. -
fetch- для ссылочного атрибута указывает как следует загружать сущность из базы данных. Подробнее см. Представления.
Элементы
property:-
property- описатель атрибута связанной сущности. Таким способом можно определить неименованное представление для связанной сущности прямо внутри текущего описателя (inline).
-
-
include- включение другого файла типа views.xmlАтрибуты
include:-
file- путь к файлу по правилам интерфейса Resources.
-
Пример:
<views xmlns="http://schemas.haulmont.com/cuba/view.xsd">
<view class="com.sample.sales.entity.Order"
name="order-with-customer"
extends="_local">
<property name="customer" view="_minimal"/>
</view>
<view class="com.sample.sales.entity.Item"
name="itemsInOrder">
<property name="quantity"/>
<property name="product" view="_minimal"/>
</view>
<view class="com.sample.sales.entity.Order"
name="order-with-customer-defined-inline"
extends="_local">
<property name="customer">
<property name="name"/>
<property name="email"/>
</property>
</view>
</views>См. также свойство приложения cuba.viewsConfig.
A.12. web.xml
Файл web.xml является стандартным дескриптором веб-приложения Java, и должен быть создан для блоков Middleware, Web Client и Web Portal.
В проекте приложения файлы web.xml располагаются в каталогах web/WEB-INF соответствующих модулей.
-
Рассмотрим содержимое
web.xmlблока Middleware (модуль core проекта):<?xml version="1.0" encoding="UTF-8" standalone="no"?> <web-app xmlns="http://java.sun.com/xml/ns/javaee" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://java.sun.com/xml/ns/javaee http://java.sun.com/xml/ns/javaee/web-app_3_0.xsd" version="3.0"> <!-- Application properties config files --> <context-param> <param-name>appPropertiesConfig</param-name> <param-value> classpath:com/company/sample/app.properties /WEB-INF/local.app.properties "file:${app.home}/local.app.properties" </param-value> </context-param> <!--Application components--> <context-param> <param-name>appComponents</param-name> <param-value>com.haulmont.cuba com.haulmont.reports</param-value> </context-param> <listener> <listener-class>com.haulmont.cuba.core.sys.AppContextLoader</listener-class> </listener> <servlet> <servlet-name>remoting</servlet-name> <servlet-class>com.haulmont.cuba.core.sys.remoting.RemotingServlet</servlet-class> <load-on-startup>1</load-on-startup> </servlet> <servlet-mapping> <servlet-name>remoting</servlet-name> <url-pattern>/remoting/*</url-pattern> </servlet-mapping> </web-app>В элементах
context-paramзадаются инициализирующие параметры объектаServletContextданного веб-приложения. Список компонентов приложения задается в параметреappComponents, список файлов свойств приложения задается в параметреappPropertiesConfig.В элементе
listenerзадается класс слушателя, реализующего интерфейсServletContextListener. В блоке Middleware CUBA-приложения в качестве слушателя должен использоваться классAppContextLoader, выполняющий инициализацию AppContext.Далее следуют определения сервлетов, среди которых обязательным для Middleware является класс
RemotingServlet, связанный с контейнером удаленного доступа (см. remoting-spring.xml). Данный сервлет отображен на URL/remoting/*. -
Рассмотрим содержимое
web.xmlблока Web Client (модуль web проекта):<?xml version="1.0" encoding="UTF-8"?> <web-app xmlns="http://java.sun.com/xml/ns/javaee" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://java.sun.com/xml/ns/javaee http://java.sun.com/xml/ns/javaee/web-app_3_0.xsd" version="3.0"> <!-- Application properties config files --> <context-param> <param-name>appPropertiesConfig</param-name> <param-value> classpath:com/company/demo/web-app.properties /WEB-INF/local.app.properties "file:${app.home}/local.app.properties" </param-value> </context-param> <!--Application components--> <context-param> <param-name>appComponents</param-name> <param-value>com.haulmont.cuba com.haulmont.reports</param-value> </context-param> <listener> <listener-class>com.vaadin.server.communication.JSR356WebsocketInitializer</listener-class> </listener> <listener> <listener-class>com.haulmont.cuba.web.sys.WebAppContextLoader</listener-class> </listener> <servlet> <servlet-name>app_servlet</servlet-name> <servlet-class>com.haulmont.cuba.web.sys.CubaApplicationServlet</servlet-class> <async-supported>true</async-supported> </servlet> <servlet> <servlet-name>dispatcher</servlet-name> <servlet-class>com.haulmont.cuba.web.sys.CubaDispatcherServlet</servlet-class> <load-on-startup>1</load-on-startup> </servlet> <servlet-mapping> <servlet-name>dispatcher</servlet-name> <url-pattern>/dispatch/*</url-pattern> </servlet-mapping> <servlet-mapping> <servlet-name>app_servlet</servlet-name> <url-pattern>/*</url-pattern> </servlet-mapping> <filter> <filter-name>cuba_filter</filter-name> <filter-class>com.haulmont.cuba.web.sys.CubaHttpFilter</filter-class> <async-supported>true</async-supported> </filter> <filter-mapping> <filter-name>cuba_filter</filter-name> <url-pattern>/*</url-pattern> </filter-mapping> </web-app>В элементах
context-paramзаданы списки компонентов приложения и файлов свойств приложения.В качестве
ServletContextListenerв блоке Web Client используется классWebAppContextLoader.JSR356WebsocketInitializerнеобходим для поддержки протокола WebSockets.Сервлет
CubaApplicationServletобеспечивает функционирование универсального пользовательского интерфейса, основанного на фреймворке Vaadin.Сервлет
CubaDispatcherServletинициализирует дополнительный контекст Spring для работы контроллеров Spring MVC. Этот контекст конфигурируется файлом dispatcher-spring.xml.
Приложение B: Свойства приложения
В данном приложении в алфавитном порядке описаны доступные свойства приложения.
- cuba.additionalStores
-
Задает имена дополнительных хранилищ данных, используемых в приложении.
Используется во всех стандартных блоках.
Пример:
cuba.additionalStores = db1, mem1
- cuba.allowQueryFromSelected
-
Разрешает универсальному фильтру использовать режим последовательного наложения фильтров. См. также Последовательная выборка.
Значение по умолчанию:
trueХранится в базе данных.
Интерфейс:
GlobalConfigИспользуется в блоках Web Client и Middleware.
- cuba.anonymousLogin
-
Логин пользователя, от имени которого создается анонимная сессия.
Значение по умолчанию:
anonymousХранится в базе данных.
Интерфейс:
ServerConfigИспользуется в блоке Middleware.
- cuba.automaticDatabaseUpdate
-
Включает режим выполнения скриптов обновления БД сервером на старте приложения.
Начиная с CUBA 7.2 выполнением скриптов можно управлять по отдельности для главного и дополнительных хранилищ. Для главного хранилища используется свойство
cuba.automaticDatabaseUpdate_MAIN, для дополнительных - свойства в форматеcuba.automaticDatabaseUpdate_<store_name>. Конкретные свойства имеют приоритет над общим.Значение по умолчанию:
falseИнтерфейс:
ServerConfigИспользуется в блоке Middleware.
- cuba.availableLocales
-
Список поддерживаемых языков интерфейса.
Формат свойства:
{название_языка1}|{код_языка_1};{название_языка2}|{код_языка_2};…Пример:cuba.availableLocales=French|fr;English|en{название_языка}− это название, которое будет отображаться в списках доступных языков. Например, в окне входа в систему, в экране редактирования пользователя.{код_языка}− соответствует коду, возвращаемому методомLocale.getLanguage(). Используется как суффикс для формирования имен файлов пакетов сообщений. Например,messages_fr.properties.Следует иметь в виду, что язык, который указан первым в списке языков свойства
cuba.availableLocales, будет отображаться первым в списке доступных языков в том случае, если среди языков данного свойства не будет найден текущий язык операционной системы пользователя. Если же язык операционной системы присутствует в списке доступных, то отображаться первым будет он.Значение по умолчанию:
English|en;Russian|ru;French|frИнтерфейс:
GlobalConfigИспользуется во всех стандартных блоках.
- cuba.backgroundWorker.maxActiveTasksCount
-
Максимальное количество активных фоновых задач.
Значение по умолчанию:
100Интерфейс:
WebConfigИспользуется в блоке Web Client.
- cuba.backgroundWorker.timeoutCheckInterval
-
Задает интервал (в миллисекундах) проверки таймаутов фоновых задач.
Значение по умолчанию:
5000Интерфейс:
ClientConfigИспользуется в блоке Web Client.
- cuba.bruteForceProtection.enabled
-
Включает механизм защиты от взлома пароля методом перебора.
Значение по умолчанию:
falseХранится в базе данных.
Интерфейс:
ServerConfigИспользуется в блоке Middleware.
- cuba.bruteForceProtection.blockIntervalSec
-
Задает интервал блокировки пользователя в секундах после превышения максимального числа неуспешных попыток входа, если свойство cuba.bruteForceProtection.enabled включено.
Значение по умолчанию: 60
Хранится в базе данных.
Интерфейс:
ServerConfigИспользуется в блоке Middleware.
- cuba.bruteForceProtection.maxLoginAttemptsNumber
-
Максимальное количество неуспешных попыток входа для пары логин + IP-адрес, если свойство cuba.bruteForceProtection.enabled включено.
Значение по умолчанию: 5
Хранится в базе данных.
Интерфейс:
ServerConfigИспользуется в блоке Middleware.
- cuba.checkConnectionToAdditionalDataStoresOnStartup
-
При установке в true, фреймворк проверяет подключения ко всем дополнительным хранилищам на старте приложения. При ошибке подключения в лог выводится сообщение. Имейте в виду, что проверка может замедлить запуск приложения.
Значение по умолчанию:
falseИспользуется в блоке Middleware.
- cuba.checkPasswordOnClient
-
При установке в false (по умолчанию),
LoginPasswordLoginProviderклиентских блоков пересылает пароль пользователя на средний слой в методAuthenticationService.login()в исходном виде. Это нормально и не требует дополнительных мер если клиентский блок и middleware расположены в одной JVM. Для распределенного варианта развертывания, когда клиентский блок расположен на другом компьютере в сети, соединение с middleware в данном случае должно быть защищено с помощью SSL.При установке в true,
LoginPasswordLoginProviderзагружает экземпляр сущностиUserпо введенному логину и проверяет пароль сам. Если пароль соответствует загруженному хэшу, производится логин с помощью пароля установленного в свойстве cuba.trustedClientPassword. Данный режим избавляет от необходимости устанавливать SSL-соединение между клиентом и средним слоем в доверенной сети, так как пароли пользователей никогда не передаются по сети в открытом виде, передаются только хэши. Однако следует иметь в виду, что открытым передается пароль доверенного клиента, поэтому SSL-соединение все-таки обеспечивает лучшую защищенность.Значение по умолчанию:
falseИнтерфейс:
WebAuthConfig,PortalConfigИспользуется в блоках Web и Portal.
- cuba.cluster.enabled
-
Включает взаимодействие серверов Middleware в кластере. Подробнее см. Настройка взаимодействия серверов Middleware.
Значение по умолчанию:
falseИспользуется в блоке Middleware.
- cuba.cluster.jgroupsConfig
-
Путь к конфигурационному файлу JGroups. Файл загружается с помощью интерфейса Resources, поэтому может быть расположен в classpath или в конфигурационном каталоге.
Пример:
cuba.cluster.jgroupsConfig = my_jgroups_tcp.xmlЗначение по умолчанию:
jgroups.xmlИспользуется в блоке Middleware.
- cuba.cluster.messageSendingQueueCapacity
-
Ограничивает размер очереди сообщений кластера middleware. Если очередь переполняется, новые сообщения отбрасываются.
Значение по умолчанию:
Integer.MAX_VALUEИспользуется в блоке Middleware.
- cuba.cluster.stateTransferTimeout
-
Задаёт таймаут в миллисекундах для получения состояний кластера middleware при запуске.
Значение по умолчанию:
10000Используется в блоке Middleware.
- cuba.confDir
-
Конфигурационный параметр, задающий расположение каталога конфигурации данного блока приложения.
Значение по умолчанию: подкаталог
${app.home}/${cuba.webContextName}/conf, что означает расположение в подкаталоге домашнего каталога приложения.Интерфейс:
GlobalConfigИспользуется во всех стандартных блоках.
- cuba.connectionReadTimeout
-
Задает таймаут подключения клиентского блока к Middleware. Неотрицательное значение передается в метод
setReadTimeout()классаURLConnection.См. также cuba.connectionTimeout.
Значение по умолчанию:
-1Используется в блоках Web Client и Web Portal.
- cuba.connectionTimeout
-
Задает таймаут подключения клиентского блока к Middleware. Неотрицательное значение передается в метод
setConnectTimeout()классаURLConnection.См. также cuba.connectionReadTimeout.
Значение по умолчанию:
-1Используется в блоках Web Client и Web Portal.
- cuba.connectionUrlList
-
Задает список URL для подключения клиентских блоков к серверам Middleware.
Значением свойства должен быть один или несколько разделенных запятой URL вида
http[s]://host[:port]/app-core, гдеhost- имя сервера,port- порт сервера,app-core- имя веб-приложения, реализующего блок Middleware. Например:cuba.connectionUrlList=http://localhost:8080/app-coreВ случае использования кластера серверов Middleware, для обеспечения отказоустойчивости и балансировки нагрузки необходимо перечислить их адреса через запятую:
cuba.connectionUrlList=http://server1:8080/app-core,http://server2:8080/app-coreПодробнее см. Настройка обращения к кластеру Middleware.
См. также свойство cuba.useLocalServiceInvocation.
Интерфейс:
ClientConfigИспользуется в блоках Web Client и Web Portal.
- cuba.creditsConfig
-
Аддитивное свойство, задающее файл
credits.xml, содержащий информацию об используемом программном обеспечении.Файл загружается с помощью интерфейса Resources, поэтому может быть расположен в classpath или в конфигурационном каталоге.
Используется в блоке Web Client.
Пример:
cuba.creditsConfig = +com/company/base/credits.xml
- cuba.crossDataStoreReferenceLoadingBatchSize
-
Размер пакета, применямого в DataManager для загрузки ссылок из другого хранилища.
Значение по умолчанию:
50Хранится в базе данных.
Интерфейс:
ServerConfigИспользуется в блоке Middleware.
- cuba.dataManagerBeanValidation
-
Указывает, что DataManager должен выполнять bean validation при сохранении сущностей.
Значение по умолчанию:
falseХранится в базе данных.
Интерфейс:
ServerConfigИспользуется в блоке Middleware.
- cuba.dataManagerChecksSecurityOnMiddleware
-
Указывает, что DataManager должен проверять разрешения на операции с сущностями и in-memory ограничения, когда вызывается из кода Middleware.
Значение по умолчанию:
falseХранится в базе данных.
Интерфейс:
ServerConfigИспользуется в блоке Middleware.
- cuba.dataSourceJndiName
-
Задает JNDI имя источника данных
javax.sql.DataSource, через который производится обращение к базе данных приложения.Значение по умолчанию:
java:comp/env/jdbc/CubaDSИспользуется в блоке Middleware.
- cuba.dataDir
-
Конфигурационный параметр, задающий расположение рабочего каталога данного блока приложения.
Значение по умолчанию:
${app.home}/${cuba.webContextName}/work, что означает расположение в подкаталоге домашнего каталога приложения.Интерфейс:
GlobalConfigИспользуется во всех стандартных блоках.
- cuba.dbDir
-
Конфигурационный параметр, задающий расположение каталога скриптов базы данных.
Значение по умолчанию для быстрого развертывания в Tomcat:
${catalina.home}/webapps/${cuba.webContextName}/WEB-INF/db, что означает расположение в подкаталогеWEB-INF/dbвеб-приложения в Tomcat.Значение по умолчанию для WAR и UberJAR:
web-inf:db, что означает расположение в подкаталогеWEB-INF/dbвнутри WAR или UberJAR.Интерфейс:
ServerConfigИспользуется в блоке Middleware.
- cuba.dbmsType
-
Задает тип используемой базы данных. Совместно с cuba.dbmsVersion влияет на выбор имплементаций интерфейсов интеграции с СУБД и на поиск скриптов создания и обновления БД.
Подробнее см. Типы СУБД.
Значение по умолчанию:
hsqlИспользуется в блоке Middleware.
- cuba.dbmsVersion
-
Необязательное свойство, задающее версию используемой базы данных. Совместно с cuba.dbmsType влияет на выбор имплементаций интерфейсов интеграции с СУБД и на поиск скриптов создания и обновления БД.
Подробнее см. Типы СУБД.
Значение по умолчанию:
отсутствуетИспользуется в блоке Middleware.
- cuba.defaultPermissionValuesConfig
-
При использовании предыдущей реализации ролей и разрешений, определяет набор файлов, описывающих разрешения пользователя по умолчанию. Разрешения по умолчанию используются тогда, когда ни одна из имеющихся ролей не задаёт разрешения на конкретный экран или функциональность. Разрешения необходимы по большей части для запрещающих ролей, подробнее см. default-permission-values.xml.
Значение по умолчанию:
cuba-default-permission-values.xmlИспользуется в блоке Middleware.
Пример:
cuba.defaultPermissionValuesConfig = +my-default-permission-values.xml
- cuba.defaultQueryTimeoutSec
-
Задает таймаут транзакции по умолчанию.
Значение по умолчанию:
0, означает, что таймаут отсутствует.Хранится в базе данных.
Интерфейс:
ServerConfigИспользуется в блоке Middleware.
- cuba.disableEntityEnhancementCheck
-
Отключает выполняемую на старте приложения проверку, которая убеждается, что для всех сущностей правильно выполнено bytecode enhancement.
Значение по умолчанию:
trueИнтерфейс:
ServerConfigИспользуется в блоке Middleware.
- cuba.disableEscapingLikeForDataStores
-
Содержит список хранилищ данных, для которых запрещён оператор ESCAPE в JPQL-запросах, содержащих LIKE, в фильтрах.
Хранится в базе данных.
Интерфейс:
GlobalConfigИспользуется во всех стандартных блоках.
- cuba.disableOrmXmlGeneration
-
Запрещает автоматическую генерацию файла
orm.xmlдля расширенных сущностей.Значение по умолчанию:
false, означает чтоorm.xmlбудет создан автоматически при наличии расширенных сущностей.Используется в блоке Middleware.
- cuba.dispatcherSpringContextConfig
-
Аддитивное свойство, задающее файл dispatcher-spring.xml в клиентских блоках.
Файл загружается с помощью интерфейса Resources, поэтому может быть расположен в classpath или в конфигурационном каталоге.
Используется в блоках Web Client, Web Portal.
Пример:
cuba.dispatcherSpringContextConfig = +com/company/sample/portal-dispatcher-spring.xml
- cuba.download.directories
-
Задает список каталогов, из которых можно загружать с Middleware файлы через
com.haulmont.cuba.core.controllers.FileDownloadController. Загрузка файлов используется в частности механизмом отображения журналов сервера, доступным через экран Администрирование → Журнал сервера веб-клиента.Список задается через ";".
Значение по умолчанию:
${cuba.tempDir};${cuba.logDir}, означает что файлы можно загружать из временного каталога и каталога логов.Используется в блоке Middleware.
- cuba.email.*
-
Параметры отправки email, подробно описаны в Настройка параметров отправки email.
- cuba.fileStorageDir
-
Задает корни структуры каталогов файлового хранилища. Подробнее см. Стандартная реализация хранилища
Значение по умолчанию:
nullИнтерфейс:
ServerConfigИспользуется в блоке Middleware.
- cuba.enableDeleteStatementInSoftDeleteMode
-
Переключатель для обратной совместимости. При установке в
true, позволяет выполнять оператор JPQLdelete fromдля soft-deleted сущностей при включенном режиме мягкого удаления. Такой оператор трансформируется в SQL, который удаляет экземпляры не помеченные на мягкое удаление. Это неинтуитивное поведение по умолчанию запрещено.Значение по умолчанию:
falseИспользуется в блоке Middleware.
- cuba.enableSessionParamsInQueryFilter
-
Переключатель для обратной совместимости. При установке в
falseусловия в фильтре запросов источника данных и компонента Filter будут применяться только после передачи как минимум одного значения параметра, а параметры сессии работать не будут.Значение по умолчанию:
trueИспользуется в блоке Web Client.
- cuba.entityAttributePermissionChecking
-
При установке в
trueвключает в DataManager проверку разрешений на атрибуты сущностей. Если значением являетсяfalse, права на атрибуты проверяются только в data-aware компонентах Generic UI и в методах REST API.Значение по умолчанию:
falseХранится в базе данных.
Используется в блоке Middleware.
- cuba.entityLog.enabled
-
Активирует механизм журналирования сущностей.
Значение по умолчанию:
trueХранится в базе данных.
Интерфейс:
EntityLogConfigИспользуется в блоке Middleware.
- cuba.groovyEvaluationPoolMaxIdle
-
Задает максимальное число неиспользуемых скомпилированных выражений Groovy в пуле при выполнении метода
Scripting.evaluateGroovy(). Данный параметр рекомендуется увеличивать при потребности в интенсивном исполнении выражений Groovy, например, вследствие большого количества папок приложения.Значение по умолчанию:
8Используется во всех стандартных блоках.
- cuba.groovyEvaluatorImport
-
Задает список классов, импортируемых всеми выполняемыми через Scripting выражениями на Groovy.
Имена классов в списке разделяются запятой или точкой с запятой.
Значение по умолчанию:
com.haulmont.cuba.core.global.PersistenceHelperИспользуется во всех стандартных блоках.
Пример:
cuba.groovyEvaluatorImport=com.haulmont.cuba.core.global.PersistenceHelper,com.abc.sales.CommonUtils
- cuba.gui.genericFilterApplyImmediately
-
Если установлено значение
true, универсальный фильтр работает в режиме немедленного применения, когда каждое изменение параметров фильтра автоматически перезагружает данные. Если установлено значениеfalse, фильтр будет применен только после нажатия кнопки Search. См. также атрибут фильтра applyImmediately.Значение по умолчанию:
trueХранится в базе данных.
Интерфейс:
ClientConfigИспользуется в блоке Web Client.
- cuba.gui.genericFilterChecking
-
Оказывает влияние на поведение компонента Filter.
При установке в
trueпользователь не может применить фильтр, не введя ни одного параметра.Значение по умолчанию:
falseХранится в базе данных.
Интерфейс:
ClientConfigИспользуется в блоке Web Client.
- cuba.gui.genericFilterColumnsCount
-
Определяет количество колонок для размещения условий фильтра.
Значение по умолчанию:
3Хранится в базе данных.
Интерфейс:
ClientConfigИспользуется в блоке Web Client.
- cuba.gui.genericFilterConditionsLocation
-
Определяет положение панели условий фильтра. Доступны два положения:
top(над элементами управления фильтром) иbottom(под элементами управления фильтром).Значение по умолчанию:
topХранится в базе данных.
Интерфейс:
ClientConfigИспользуется в блоке Web Client.
- cuba.gui.genericFilterControlsLayout
-
Задает шаблон расположения элементов компонента Filter. Каждый элемент имеет следующий формат:
[component_name | options-comma-separated], например[pin | no-caption, no-icon].Доступные элементы:
-
filters_popup- кнопка с выпадающим списком фильтров, объединенная с кнопкой Search button. -
filters_lookup- поле с выпадающим списком фильтров. При использовании этого элемента необходимо добавить также элементsearch. -
search- кнопка Search. Не добавляйте, если уже используетсяfilters_popup. -
add_condition- кнопка-ссылка для добавления новых условий. -
spacer- пустое пространство между элементами. -
settings- кнопка с выпадающим списком Settings. Элементы списка кнопки задаются в виде опций (см. ниже). -
max_results- группа компонентов для задания максимального количества извлекаемых записей. -
fts_switch- флажок для переключения в режим полнотекстового поиска.
Следующие действия могут быть опциями элемента
settings:save,save_as,edit,remove,pin,make_default,save_search_folder,save_app_folder,clear_values.Они также могут быть использованы и как независимые элементы компоновки. В этом случае они могут иметь следующие опции:
-
no-icon- если кнопка действия не должна иметь значка. Например:[save | no-icon]. -
no-caption- если кнопка действия не должна иметь заголовка. Например:[pin | no-caption].
Значение по умолчанию:
++[filters_popup] [add_condition] [spacer] \ [settings | save, save_as, edit, remove, make_default, pin, save_search_folder, save_app_folder, clear_values] \ [max_results] [fts_switch]++Хранится в базе данных.
Интерфейс:
ClientConfigИспользуется в блоке Web Client.
-
- cuba.gui.genericFilterManualApplyRequired
-
Оказывает влияние на поведение компонента Filter.
При установке в
trueэкраны, содержащие фильтры, не будут при открытии автоматически запускать соответствующие загрузчики данных до тех пор, пока пользователь не нажмет кнопку Применить фильтра.При открытии экрана списка с помощью папки приложения или папки поиска значение
cuba.gui.genericFilterManualApplyRequiredне учитывается, то есть в этом случае фильтр будет применяться. Фильтр не применится, если значение атрибутаapplyDefaultу папки явно установлено вfalse.Значение по умолчанию:
falseХранится в базе данных.
Интерфейс:
ClientConfigИспользуется в блоке Web Client.
- cuba.gui.genericFilterMaxResultsOptions
-
Задает возможные значения списка Show rows компонента Filter.
Значение NULL указывает, что список должен содержать пустое значение.
Значение по умолчанию:
NULL, 20, 50, 100, 500, 1000, 5000Интерфейс:
ClientConfigХранится в базе данных.
Используется в блоке Web Client.
- cuba.gui.genericFilterPopupListSize
-
Определяет число элементов, отображающихся в выпадающем списке кнопки Search. Если количество фильтров превышает значение, к выпадающему списку добавляется действие Show more…. Действие открывает новое диалоговое окно со списком всех доступных фильтров.
Значение по умолчанию:
10Хранится в базе данных.
Интерфейс:
ClientConfigИспользуется в блоке Web Client.
- cuba.gui.genericFilterPropertiesHierarchyDepth
-
Определят глубину вложенности атрибутов сущности в диалоговом окне "Добавить условие". Например, если значение глубины равно 2, то для условия фильтра вы можете выбрать атрибут
contractor.city.country, если значение 3, тоcontractor.city.country.nameи т.д.Значение по умолчанию:
2Хранится в базе данных.
Интерфейс:
ClientConfigИспользуется в блоке Web Client.
- cuba.gui.genericFilterTrimParamValues
-
Определяет, нужно ли обрезать пробелы в начале и конце строки текстового поиска. Если установлено
false, введённые строки будут использоваться без обрезки.Значение по умолчанию:
trueХранится в базе данных.
Интерфейс:
ClientConfigИспользуется в блоке Web Client.
- cuba.gui.layoutAnalyzerEnabled
-
Позволяет отключить команду анализа компоновки экрана Analyze layout, доступную в контекстном меню вкладок главного окна и в заголовках модальных окон.
Значение по умолчанию:
trueХранится в базе данных.
Интерфейс:
ClientConfigИспользуется в блоке Web Client.
- cuba.gui.lookupFieldPageLength
-
Задает количество опций на одной странице выпадающего списка в компонентах LookupField и LookupPickerField. Может быть переопределено для конкретного экземпляра компонента с помощью XML-атрибута pageLength.
Значение по умолчанию: 10
Хранится в базе данных.
Интерфейс:
ClientConfigИспользуется в блоке Web Client.
- cuba.gui.manualScreenSettingsSaving
-
Если установлено в
true, экраны не будут сохранять свои настройки автоматически при закрытии. В этом режиме пользователь может сохранить или сбросить настройки экрана, используя контекстное меню на вкладке экрана или на заголовке диалогового окна.Значение по умолчанию:
falseХранится в базе данных.
Интерфейс:
ClientConfigИспользуется в блоке Web Client.
- cuba.gui.showIconsForPopupMenuActions
-
Включает отображение значков действий в пунктах контекстного меню Table и PopupButton.
Значение по умолчанию:
falseХранится в базе данных.
Интерфейс:
ClientConfigИспользуется в блоке Web Client.
- cuba.gui.systemInfoScriptsEnabled
-
Разрешает показ SQL-скриптов добавления/изменения/извлечения экземпляра сущности в окне System Information.
Данные скрипты фактически показывают содержимое строк базы данных, хранящих выбранный экземпляр сущности, независимо от настроек безопасности, в которых некоторые атрибуты могут быть запрещены. Поэтому рекомендуется либо отобрать право на
CUBA / Generic UI / System Informationдля всех ролей пользователей, кроме администраторов, либо установить свойствоcuba.gui.systemInfoScriptsEnabledдля всего приложения вfalse.Значение по умолчанию:
trueХранится в базе данных.
Интерфейс:
ClientConfigИспользуется в блоке Web Client.
- cuba.gui.useSaveConfirmation
-
Определяет форму диалога, возникающего при попытке закрытия экрана, имеющего несохраненные изменения в DataContext.
Значение
trueзадает форму с тремя вариантами выбора: сохранить изменения, не сохранять, либо не закрывать экран.Значение
falseзадает форму с двумя вариантами: закрыть экран не сохраняя изменений, либо не закрывать экран.Значение по умолчанию:
trueХранится в базе данных.
Интерфейс:
ClientConfigИспользуется в блоке Web Client.
- cuba.gui.validationNotificationType
-
Задаёт тип уведомления об ошибке валидации стандартного окна.
Значением может быть элемент перечисления
com.haulmont.cuba.gui.components.Frame.NotificationType:-
TRAY- текстовое уведомление в правом нижнем углу, -
TRAY_HTML- уведомление в правом нижнем углу с поддержкой HTML, -
HUMANIZED- стандартное уведомление в центре экрана, -
HUMANIZED_HTML- стандартное уведомление в центре экрана с поддержкой HTML, -
WARNING- текстовое предупреждение, -
WARNING_HTML- предупреждение с поддержкой HTML, -
ERROR- текстовое уведомление об ошибке, -
ERROR_HTML- уведомление об ошибке с поддержкой HTML.
Значение по умолчанию:
TRAY.Интерфейс:
ClientConfigИспользуется в блоке Web Client.
-
- cuba.hasMultipleTableConstraintDependency
-
Позволяет использовать стратегию наследования
JOINEDдля композитных сущностей. Если установлено значениеtrue, платформа обеспечит нужный порядок вставки новых сущностей в базу данных.Значение по умолчанию:
false
- cuba.healthCheckResponse
-
Задает текст, возвращаемый запросом на health check URL.
Значение по умолчанию:
okИнтерфейс:
GlobalConfigИспользуется во всех блоках приложения.
- cuba.httpSessionExpirationTimeoutSec
-
Задает таймаут бездействия HTTP-сессии в секундах.
Значение по умолчанию:
1800Интерфейс:
WebConfigИспользуется в блоке Web Client.
Рекомендуется выставлять параметры cuba.userSessionExpirationTimeoutSec и cuba.httpSessionExpirationTimeoutSec в одинаковое значение.
Не пытайтесь установить таймаут HTTP сессии в
web.xml- он будет проигнорирован.
- cuba.iconsConfig
-
Аддитивное свойство, задающее наборы значков.
Используется в блоке Web Client.
Пример использования:
cuba.iconsConfig = +com.company.demo.web.MyIconSet
- cuba.inMemoryDistinct
-
Включает режим фильтрации дубликатов записей в памяти, вместо
select distinctна уровне базы данных. Используется в DataManager.Значение по умолчанию:
falseХранится в базе данных.
Интерфейс:
ServerConfigИспользуется в блоке Middleware.
- cuba.jmxUserLogin
-
Логин пользователя, под которым выполняется вход в систему при системной аутентификации.
Значение по умолчанию:
adminИспользуется в блоке Middleware.
- cuba.keyForSecurityTokenEncryption
-
Используется в качестве ключа AES-шифрования токена безопасности (security token). Токен посылается внутри экземпляра сущности, когда он загружается со среднего слоя в следующих случаях:
-
Свойство приложения cuba.entityAttributePermissionChecking установлено в true, что означает, что права на атрибуты проверяются на среднем слое (подробнее см. Права доступа в DataManager).
-
Ограничения доступа к сущностям на уровне экземпляров (row-level security constraints) отфильтровали некоторые элементы атрибута-коллекции. В этом случае, токен включается также в JSON, возвращаемый из REST API, см. документацию по REST API.
-
Для сущности настроен динамический контроль доступа к атрибутам сущностей.
Хотя токен не содержит значений никаких атрибутов (только имена атрибутов и идентификаторы отфильтрованных сущностей), рекомендуется изменить значение по умолчанию при развертывании.
Значение по умолчанию:
CUBA.PlatformИнтерфейс:
ServerConfigИспользуется в блоке Middleware.
-
- cuba.numberIdCacheSize
-
Когда в памяти приложения с помощью метода
Metadata.create()создается экземпляр сущности, унаследованной отBaseLongIdEntityилиBaseIntegerIdEntity, ему сразу присваивается идентификатор. Значение идентификатора получается из механизма, который извлекает следующее число из последовательности в базе данных. Для того, чтобы уменьшить количество обращений к среднему слою и к БД, инкремент последовательности устанавливается по умолчанию в 100, что означает что фреймворк на самом деле получает диапазон значений при каждом обращении к БД. Этот диапазон "кэшируется" и механизм выдает значения идентификаторов без обращений к БД, пока не исчерпается диапазон.Данное свойство задает инкремент последовательностей и соответствующий размер кэшированного диапазона в памяти.
Если вы меняете значение данного свойства когда в БД уже хранятся сущности, необходимо также пересоздать имеющиеся последовательности с новым инкрементом (равным
cuba.numberIdCacheSize) и начальными значениями, соответствующими максимальным имеющимся идентификаторам.Не забудьте установить значение свойства на всех блоках, используемых в приложении. Например, если у вас есть Web Client, Portal Client и Middleware, нужно установить одинаковое значение в
web-app.properties,portal-app.propertiesиapp.properties.Значение по умолчанию: 100
Интерфейс:
GlobalConfigИспользуется во всех стандартных блоках.
- cuba.legacyPasswordEncryptionModule
-
То же самое что и cuba.passwordEncryptionModule, но задает имя бина, используемого для хэширования паролей для пользователей, созданных до миграции на версию 7 фреймворка и имеющих пустое поле
SEC_USER.PASSWORD_ENCRYPTION.Значение по умолчанию:
cuba_Sha1EncryptionModuleИспользуется во всех стандартных блоках.
- cuba.localeSelectVisible
-
Включает или отключает возможность пользователя выбирать язык интерфейса при входе в систему.
Если
cuba.localeSelectVisible=false, то локаль пользовательской сессии выбирается следующим образом:-
если для данного экземпляра сущности
Userустановлен атрибутlanguage, то устанавливается локаль для этого языка; -
если язык операционной системы пользователя присутствует в списке доступных (заданных свойством cuba.availableLocales), то выбирается он;
-
в противном случае выбирается язык, заданный первым в свойстве cuba.availableLocales.
Значение по умолчанию:
trueИнтерфейс:
GlobalConfigИспользуется во всех стандартных блоках.
-
- cuba.logDir
-
Конфигурационный параметр, указывающий расположение каталога журналов данного блока приложения.
Значение по умолчанию:
${app.home}/logs, что означает расположение в подкаталогеlogsдомашнего каталога приложения.Интерфейс:
GlobalConfigИспользуется во всех стандартных блоках.
- cuba.mainMessagePack
-
Аддитивное свойство, задающее главный пакет сообщений данного блока приложения.
Значением свойства может быть либо один пакет, либо список пакетов, разделенный пробелами.
Используется во всех стандартных блоках.
Пример:
cuba.mainMessagePack = +com.company.sample.gui com.company.sample.web
- cuba.maxUploadSizeMb
-
Максимальный размер файла в мегабайтах, который может быть загружен с помощью компонентов FileUploadField и FileMultiUploadField.
Значение по умолчанию:
20Хранится в базе данных.
Интерфейс:
ClientConfigИспользуется в блоке Web Client.
- cuba.metadataConfig
-
Аддитивное свойство, задающее файл metadata.xml.
Файл загружается с помощью интерфейса Resources, поэтому может быть расположен в classpath или в конфигурационном каталоге.
Используется в блоках Middleware и Web Client.
Пример:
cuba.metadataConfig = +com/company/sample/metadata.xml
- cuba.passwordEncryptionModule
-
Задает имя бина, используемого для хэширования паролей пользователей. При создании нового пользователя и при смене пароля, значение данного свойства запоминается для данного пользователя в поле
SEC_USER.PASSWORD_ENCRYPTIONбазы данных.См. также cuba.legacyPasswordEncryptionModule.
Значение по умолчанию:
cuba_BCryptEncryptionModuleИспользуется во всех стандартных блоках.
- cuba.passwordPolicyEnabled
-
Определяет, нужно ли применять политику проверки пароля. Если свойство имеет значение
true, то все новые задаваемые пользователями пароли будут проверяться в соответствии со свойством cuba.passwordPolicyRegExp.Значение по умолчанию:
falseХранится в базе данных.
Интерфейс:
ClientConfigИспользуется в блоках клиентского уровня: Web Client, Web Portal.
- cuba.passwordPolicyRegExp
-
В данном свойстве задается регулярное выражение, которое используется в политике проверки пароля.
Значение по умолчанию:
((?=.*\\d)(?=.*\\p{javaLowerCase}) (?=.*\\p{javaUpperCase}).{6,20})Это означает, что в пароль должен содержать от 6 до 20 символов, в нем можно использоваться цифры, символы и буквы латинского алфавита. При этом обязательно в пароле должна быть хотя бы одна цифра, одна буква в нижнем регистре и одна буква в верхнем регистре. Более подробную информацию о синтаксисе регулярных выражений можно найти на сайтах: https://ru.wikipedia.org/wiki/Регулярные_выражения и http://docs.oracle.com/javase/6/docs/api/java/util/regex/Pattern.html
Интерфейс:
ClientConfigХранится в базе данных.
Используется в блоках клиентского уровня: Web Client, Web Portal.
- cuba.performanceLogDisabled
-
Должно быть установлено в true, если необходимо отключить
PerformanceLogInterceptor.Бин
PerformanceLogInterceptorвызывается аннотацией@PerformanceLog, которая используется для классов и методов и обеспечивает логирование информации о каждом вызове метода и длительности его исполнения. Эти логи сохраняются в файлperfstat.log. Если этот вид логов вам не нужен, то из соображений производительности рекомендуем вам отключитьPerformanceLogInterceptor. Чтобы подключить его обратно, удалите это свойство или установите значение вfalse.Значение по умолчанию:
falseИспользуется в блоке Middleware.
- cuba.performanceTestMode
-
Должно быть установлено в true, когда приложение выполняет тесты производительности.
Интерфейс:
GlobalConfigЗначение по умолчанию:
falseИспользуется в блоках Web Client и Middleware.
- cuba.permissionConfig
-
Аддитивное свойство, задающее файл permissions.xml.
Используется в блоке Web Client.
Пример:
cuba.permissionConfig = +com/company/sample/web-permissions.xml
- cuba.persistenceConfig
-
Аддитивное свойство, задающее файл persistence.xml.
Файл загружается с помощью интерфейса Resources, поэтому может быть расположен в classpath или в конфигурационном каталоге.
Используется в блоках Middleware и Web Client.
Пример:
cuba.persistenceConfig = +com/company/sample/persistence.xml
- cuba.portal.anonymousUserLogin
-
Логин пользователя системы, который используется для создания анонимной пользовательской сессии в блоке Web Portal.
Пользователь с таким логином должен быть создан в подсистеме безопасности, и ему должны быть назначены соответствующие права. Пароль пользователя игнорируется, так как анонимная сессия портала создается методом loginTrusted() с передачей пароля, указанного в свойстве cuba.trustedClientPassword.
Интерфейс:
PortalConfigИспользуется в блоке Web Portal.
- cuba.queryCache.enabled
-
При установке в
falseотключает кэш запросов.Значение по умолчанию:
trueИнтерфейс:
QueryCacheConfigИспользуется в блоке Middleware.
- cuba.queryCache.maxSize
-
Максимальное количество записей в кэше запросов. Запись кэша определяется текстом запроса, параметрами запроса, параметрами пейджинга и признаком мягкого удаления.
Когда размер кэша приближается к максимальному, кэш удаляет записи, которые наименее вероятно будут использованы в дальнейшем.
Значение по умолчанию: 100
Интерфейс:
QueryCacheConfigИспользуется в блоке Middleware.
- cuba.rememberMeExpirationTimeoutSec
-
Задает время истекания "remember me" cookies и экземпляров сущности
RememberMeToken.Значение по умолчанию:
30 * 24 * 60 * 60(30 дней)Интерфейс:
GlobalConfigИспользуется в блоках Web Client и Middleware.
- cuba.remotingSpringContextConfig
-
Аддитивное свойство, задающее файл remoting-spring.xml в блоке Middleware.
Файл загружается с помощью интерфейса Resources, поэтому может быть расположен в classpath или в конфигурационном каталоге.
Используется в блоке Middleware.
Пример:
cuba.remotingSpringContextConfig = +com/company/sample/remoting-spring.xml
- cuba.schedulingActive
-
Включает и выключает механизм выполнения назначенных заданий CUBA.
Значение по умолчанию:
falseХранится в базе данных.
Интерфейс:
ServerConfigИспользуется в блоке Middleware.
- cuba.security.defaultPermissionValuesConfigEnabled
-
Для обеспечения обратной совместимости, включает использование конфигурации default-permission-values.xml. Подробнее см. Предыдущая реализация ролей и разрешений.
Значение по умолчанию:
falseИнтерфейс:
ServerConfigИспользуется в блоке Middleware.
- cuba.security.rolesPolicyVersion
-
Для обеспечения обратной совместимости, определяет режим работы ролей подсистемы безопасности. Подробнее см. Предыдущая реализация ролей и разрешений.
Возможные значения:
-
1 - режим до CUBA 7.2: если разрешение не определено, то доступ есть; используются типы ролей.
-
2 - CUBA 7.2 и новее: если разрешение не определено, то доступ отсутствует; единственный тип разрешения - "allow"; поддерживается определение ролей во время разработки приложения.
Значение по умолчанию: 2
Интерфейс:
ServerConfigИспользуется в блоке Middleware.
-
- cuba.serialization.impl
-
Указывает имплементацию интерфейса
Serialization, которая будет использоваться для сериализации объектов при их передаче между блоками приложения. Платформа содержит две имплементации:-
com.haulmont.cuba.core.sys.serialization.StandardSerialization- стандартная Java-сериализация. -
com.haulmont.cuba.core.sys.serialization.KryoSerialization- сериализация на базе фреймворка Kryo.
Значение по умолчанию:
com.haulmont.cuba.core.sys.serialization.StandardSerializationИспользуется во всех стандартных блоках.
-
- cuba.springContextConfig
-
Аддитивное свойство, задающее файл spring.xml в каждом стандартном блоке приложения.
Файл загружается с помощью интерфейса Resources, поэтому может быть расположен в classpath или в конфигурационном каталоге.
Используется во всех стандартных блоках.
Пример:
cuba.springContextConfig = +com/company/sample/spring.xml
- cuba.supportEmail
-
Задает email, на который отправляются отчеты об исключениях из окна стандартного обработчика, и сообщения пользователей из экрана Help → Feedback.
Если данное свойство установлено в пустую строку, кнопка Report в окне обработчика исключений не показывается.
Для успешной отсылки email необходимо настроить параметры, описанные в разделе Настройка параметров отправки email
Значение по умолчанию: пустая строка.
Хранится в базе данных.
Интерфейс:
WebConfigИспользуется в блоке Web Client.
- cuba.syncNewUserSessionReplication
-
Включает синхронную отправку в кластер новых пользовательских сессий после логина в систему. Детальная информация здесь: Синхронная репликация пользовательских сессий.
Значение по умолчанию:
falseИнтерфейс:
ServerConfigИспользуется в блоке Middleware.
- cuba.tempDir
-
Конфигурационный параметр, задающий расположение временного каталога данного блока приложения.
Значение по умолчанию:
${app.home}/${cuba.webContextName}/temp, что означает расположение в подкаталоге домашнего каталога приложения.Интерфейс:
GlobalConfigИспользуется во всех стандартных блоках.
- cuba.testMode
-
Должно быть установлено в true, когда приложение выполняет автоматические UI-тесты.
Интерфейс:
GlobalConfigЗначение по умолчанию:
falseИспользуется в блоках Web Client и Middleware.
- cuba.themeConfig
-
Задает набор файлов
*-theme.properties, в которых описаны переменные тем, такие как размеры диалоговых окон и ширина полей ввода по умолчанию.Значением свойства должен быть список имен файлов, разделенный пробелами. Файлы загружаются по правилам интерфейса Resources.
Значение по умолчанию для Web Client:
com/haulmont/cuba/havana-theme.properties com/haulmont/cuba/halo-theme.properties com/haulmont/cuba/hover-theme.propertiesИспользуется в блоке Web Client.
- cuba.triggerFilesCheck
-
Позволяет отключить обработку триггер-файлов вызова бинов.
Триггер-файл представляет собой файл, помещаемый в подкаталог
triggersвременного каталога данного блока приложения. Имя триггер-файла состоит из двух частей, разделенных точкой. Первая часть соответствует имени бина, вторая - имени вызываемого метода бина, напримерcuba_Messages.clearCache. Обработчик триггер-файлов следит за их появлением, вызывает соответствующие методы и удаляет файлы.В платформе вызов обработчика задан в файле
cuba-web-spring.xml, то есть по умолчанию обработка триггер-файлов производится для блока Web Client. На уровне проекта можно аналогично запустить обработку для других модулей, периодически вызывая метод process() бина cuba_TriggerFilesProcessor.См. также свойство cuba.triggerFilesCheckInterval.
Значение по умолчанию:
trueИспользуется в блоках, для которых настроена обработка, по умолчанию - Web Client.
- cuba.triggerFilesCheckInterval
-
Устанавливает период в миллисекундах обработки триггер-файлов вызова бинов, заданный в файле
cuba-web-spring.xml.См. также свойство cuba.triggerFilesCheck.
Значение по умолчанию:
5000Используется в блоке Web Client.
- cuba.trustedClientPassword
-
Пароль, используемый при создании аутентификационных данных
TrustedClientCredentials. Средний слой может аутентифицировать пользователей, подключающихся через доверенный клиентский блок, без проверки пользовательского пароля.Это свойство используется в случае, если пароли пользователей не хранятся в БД, и реальную аутентификацию выполняет сам клиентский блок, например, путем интеграции с Active Directory.
Интерфейсы:
ServerConfig,WebAuthConfig,PortalConfigИспользуется в блоках: Middleware, Web Client, Web Portal.
- cuba.trustedClientPermittedIpList
-
Список IP адресов, который используется совместно с
TrustedClientCredentialsиTrustedClientService.Значение по умолчанию:
127.0.0.1Интерфейс:
ServerConfigИспользуется в блоке Middleware.
- cuba.uniqueConstraintViolationPattern
-
Регулярное выражение, используемое обработчиком UniqueConstraintViolationHandler, для определения того, что данное исключение произошло по причине нарушения ограничения уникальности в базе данных. Имя индекса, поддерживающего ограничение, будет взято из первой непустой группы выражения. Например:
ERROR: duplicate key value violates unique constraint "(.+)"Данное свойство позволяет настроить реакцию на исключения уникальности в зависимости от используемой версии и локали сервера базы данных.
Значение по умолчанию: возвращается методом
PersistenceManagerService.getUniqueConstraintViolationPattern()для соответствующей СУБД.Может быть определено в базе данных.
Используется во всех клиентских блоках приложения.
- cuba.useCurrentTxForConfigEntityLoad
-
Если значение данного свойства
true, то при загрузке экземпляров сущностей через конфигурационные интерфейсы будет использоваться текущая транзакция (если таковая имеется в данный момент), что может положительно сказаться на производительности. В противном случае всегда создается и завершается новая транзакция и возвращается detached экземпляр.Значение по умолчанию:
falseИспользуется в блоке Middleware.
- cuba.useEntityDataStoreForIdSequence
-
Если данное свойство приложения установлено в true, последовательности для генерации идентификаторов наследников
BaseLongIdEntityиBaseIntegerIdEntityбудут создаваться в хранилище, к которому принадлежит данная сущность. В противном случае они создаются в основной базе данных.Значение по умолчанию:
falseИнтерфейс:
ServerConfigИспользуется в блоке Middleware.
- cuba.useInnerJoinOnClause
-
Указывает что EclipseLink ORM будет использовать для inner joins выражение
JOIN ONвместо условий в выраженииWHERE.Значение по умолчанию:
falseИспользуется в блоке Middleware.
- cuba.useLocalServiceInvocation
-
При установке данного свойства в
trueблоки Web Client и Web Portal вызывают сервисы Middleware в обход сетевого стека, что положительно сказывается на производительности системы. Это возможно в случае быстрого развертывания, единого WAR и единого Uber JAR. В других вариантах развертывания данное свойство необходимо установить вfalse.Значение по умолчанию:
trueИспользуется в блоках Web Client и Web Portal.
- cuba.useReadOnlyTransactionForLoad
-
Указывает, что все методы
loadв DataManager используют read-only транзакции.Значение по умолчанию:
trueХранится в базе данных.
Интерфейс:
ServerConfigИспользуется в блоке Middleware.
- cuba.user.fullNamePattern
-
Задает шаблон формирования полного имени пользователя.
Значение по умолчанию:
{FF| }{LL}Полное имя можно сформировать по шаблону из имени, отчества и фамилии пользователя. В шаблоне используются следующие правила:
-
Фигурными скобками
{}разделяются части шаблона между собой -
Правила формирования шаблона внутри фигурных скобок: один из следующих символов и далее, без пробела, символ ` |`.
LLозначает фамилию пользователя, написанную в полном варианте (Иванов)Lозначает фамилию пользователя, написанную в кратком варианте (И)FFозначает имя пользователя, написанного в полном варианте (Петр)Fозначает фамилию пользователя, написанную в кратком варианте (П)MMозначает отчество пользователя, написанное в полном варианте (Сергеевич)Mозначает отчество пользователя, написанное в кратком варианте (С) -
После символа
|могут идти любые символы, в том числе, и пробел.
Используется в блоке Web Client.
-
- cuba.user.namePattern
-
Задает шаблон отображения имени экземпляра сущности
User(пользователь). Данное имя отображается, в том числе, в правом верхнем углу главного окна системы.Значение по умолчанию:
{1} [{0}]Вместо
{0}подставляется атрибутlogin, вместо{1}- атрибутname.Используется в блоках Middleware и Web Client.
- cuba.userSessionExpirationTimeoutSec
-
Задает таймаут неактивности сессии пользователя в секундах.
Значение по умолчанию:
1800Интерфейс:
ServerConfigИспользуется в блоке Middleware.
Рекомендуется выставлять параметры
cuba.userSessionExpirationTimeoutSecи cuba.httpSessionExpirationTimeoutSec в одинаковое значение.
- cuba.userSessionLogEnabled
-
Активирует механизм журналирования пользовательских сессий.
Значение по умолчанию:
falseХранится в базе данных.
Интерфейс:
GlobalConfig.Используется во всех стандартных блоках.
- cuba.userSessionProviderUrl
-
URL для соединения с блоком Middleware, через который выполняется вход пользователей в систему.
Этот параметр необходимо устанавливать в дополнительных блоках среднего слоя, которые выполняют запросы клиентов, но не содержат общего кэша пользовательских сессий. Тогда в начале выполнения запроса при отсутствии требуемой сессии в локальном кэше данный блок вызовет метод
TrustedClientService.findSession()по указанному URL, и в случае успеха закэширует полученную сессию у себя.Интерфейс:
ServerConfigИспользуется в блоке Middleware.
- cuba.viewsConfig
-
Аддитивное свойство, задающее файл views.xml. См. Представления.
Файл загружается с помощью интерфейса Resources, поэтому может быть расположен в classpath или в конфигурационном каталоге.
Используется во всех стандартных блоках.
Пример:
cuba.viewsConfig = +com/company/sample/views.xml
- cuba.webAppUrl
-
URL, по которому доступен Web Client приложения.
Используется, в частности, для формирования ссылок на экраны приложения извне, а также классом
ScreenHistorySupport.Значение по умолчанию:
http://localhost:8080/appХранится в базе данных.
Интерфейс:
GlobalConfigМожет использоваться во всех стандартных блоках.
- cuba.windowConfig
-
Аддитивное свойство, задающее файл screens.xml.
Файл загружается с помощью интерфейса Resources, поэтому может быть расположен в classpath или в конфигурационном каталоге.
Используется в блоке Web Client.
Пример:
cuba.windowConfig = +com/company/sample/web-screens.xml
- cuba.web.allowAnonymousAccess
-
Разрешает доступ неаутентифицированных пользователей к экранам приложения.
См. раздел Анонимный доступ к экранам.
Значение по умолчанию:
falseИнтерфейс:
WebConfigИспользуется в блоке Web Client.
- cuba.web.allowHandleBrowserHistoryBack
-
Позволяет обрабатывать в приложении нажатия на кнопку Back браузера путем переопределения метода
AppWindow.onHistoryBackPerformed(). Если свойство установлено в true, стандартное поведение браузера заменяется на вызов этого метода.См. Специфика Web Client.
Значение по умолчанию:
trueИнтерфейс:
WebConfigИспользуется в блоке Web Client.
- cuba.web.appFoldersRefreshPeriodSec
-
Период по умолчанию обновления папок приложения в секундах.
Значение по умолчанию:
180Интерфейс:
WebConfigИспользуется в блоке Web Client.
- cuba.web.appWindowMode
-
Задает начальный режим главного окна: с вкладками или одноэкранный (
TABBEDилиSINGLE). В одноэкранном режиме экран, открываемый в режимеNEW_TAB, отображается не в новой вкладке, а полностью заменяет текущий экран.Пользователь впоследствии может задать желаемый режим через экран Help > Settings.
Значение по умолчанию:
TABBEDИнтерфейс:
WebConfigИспользуется в блоке Web Client.
- cuba.web.closeIdleHttpSessions
-
Определяет, может ли веб-клиент закрыть сессию и UI по истечению таймаута сессии после последнего non-heartbeat сообщения.
Значение по умолчанию:
falseИнтерфейс:
WebConfigИспользуется в блоке Web Client.
- cuba.web.componentsConfig
-
Аддитивное свойство, задающее файл конфигурации для компонентов приложения, поставляемых в отдельных JAR-файлах или указанных в дескрипторе
cuba-ui-component.xmlмодуля web.Пример:
cuba.web.componentsConfig =+demo-web-components.xml
- cuba.web.customDeviceWidthForViewport
-
Определяет собственное значение ширины области просмотра (viewport) для HTML-страниц. Влияет на метатег "viewport" HTML-страниц Vaadin.
Значение по умолчанию:
-1Интерфейс:
WebConfigИспользуется в блоке Web Client.
- cuba.web.defaultScreenCanBeClosed
-
Разрешает закрывать окно по умолчанию с помощью кнопки закрытия, контекстного меню TabSheet или нажатием клавиши ESC в случае, если выбран режим главного окна
TABBED.Значение по умолчанию: true
Интерфейс:
WebConfigИспользуется в блоке Web Client.
- cuba.web.defaultScreenId
-
Задаёт экран, который будет открыт по умолчанию после входа в систему для всех пользователей.
Например:
cuba.web.defaultScreenId = sys$SendingMessage.browseИнтерфейс:
WebConfigИспользуется в блоке Web Client.
- cuba.web.foldersPaneDefaultWidth
-
Ширина по умолчанию панели папок в пикселях.
Значение по умолчанию:
200Интерфейс:
WebConfigИспользуется в блоке Web Client.
- cuba.web.foldersPaneEnabled
-
Включает отображение панели папок для экрана и использование горячих клавиш в папках.
Значение по умолчанию:
falseИнтерфейс:
WebConfigИспользуется в блоке Web Client.
- cuba.web.foldersPaneVisibleByDefault
-
Если
true, то при первом входе пользователя в систему панель папок будет отображаться в развернутом состоянии, еслиfalse- то в свернутом.Значение по умолчанию:
falseИнтерфейс:
WebConfigИспользуется в блоке Web Client.
- cuba.web.htmlSanitizerEnabled
-
Задает использование бина
HtmlSanitizerкомпонентами, реализующими интерфейсHasHtmlSanitizer, для предотвращения cross-site scripting (XSS) в HTML-содержимом. Санитизация может быть также включена или выключена в каждом компоненте по отдельности с помощью htmlSanitizerEnabled.Значение по умолчанию:
trueИнтерфейс:
WebConfigИспользуется в блоке Web Client.
- cuba.web.initialScreenId
-
Задает экран, который должен быть открыт для неаутентифицированного пользователя, когда он переходит по адресу приложения. Свойство cuba.web.allowAnonymousAccess при этом должно быть установлено в
true.Интерфейс:
WebConfigИспользуется в блоке Web Client.
- cuba.web.ldap.enabled
-
Включить/выключить интеграцию с LDAP в Web Client.
Например:
cuba.web.ldap.enabled = trueИнтерфейс:
WebLdapConfigИспользуется в блоке Web Client.
- cuba.web.ldap.urls
-
Указывает URL сервера LDAP.
Например:
cuba.web.ldap.urls = ldap://192.168.1.1:389Интерфейс:
WebLdapConfigИспользуется в блоке Web Client.
- cuba.web.ldap.base
-
Указывает base DN поиска имен пользователей.
- Например
cuba.web.ldap.base = ou=Employees,dc=mycompany,dc=comИнтерфейс:
WebLdapConfigИспользуется в блоке Web Client.
- cuba.web.ldap.user
-
Указывает distinguished name системного пользователя, имеющего право на чтение информации из LDAP.
Например:
cuba.web.ldap.user = cn=System User,ou=Employees,dc=mycompany,dc=comИнтерфейс:
WebLdapConfigИспользуется в блоке Web Client.
- cuba.web.ldap.password
-
Пароль системного пользователя, заданного свойством cuba.web.ldap.user.
Например:
cuba.web.ldap.password = system_user_passwordИнтерфейс:
WebLdapConfigИспользуется в блоке Web Client.
- cuba.web.ldap.userLoginField
-
Название атрибута пользователя в LDAP, значение которого соответствует логину пользователя. По умолчанию
sAMAccountName(подходит для Active Directory).Например:
cuba.web.ldap.userLoginField = usernameИнтерфейс:
WebLdapConfigИспользуется в блоке Web Client.
- cuba.web.linkHandlerActions
-
Определяет список команд, передаваемых в URL, для которых вызывается обработка бином
LinkHandler. См. Ссылки на экраны.Элементы списка отделяются символом
|.Значение по умолчанию:
open|oИнтерфейс:
WebConfigИспользуется в блоке Web Client.
- cuba.web.loginDialogDefaultUser
-
Задает имя пользователя по умолчанию. Оно будет автоматически подставляться в экране входа в систему, что удобно в процессе разработки приложения. В режиме эксплуатации приложения в данном свойстве необходимо задать значение
<disabled>.Значение по умолчанию:
adminИнтерфейс:
WebConfigИспользуется в блоке Web Client.
- cuba.web.loginDialogDefaultPassword
-
Задает пароль пользователя по умолчанию. Он будет автоматически подставляться в экране входа в систему, что удобно в процессе разработки приложения. В режиме эксплуатации приложения в данном свойстве необходимо задать значение ` <disabled>`.
Значение по умолчанию:
adminИнтерфейс:
WebConfigИспользуется в блоке Web Client.
- cuba.web.loginDialogPoweredByLinkVisible
-
Установите в
false, чтобы скрыть ссылку "powered by CUBA Platform" на экране входа в систему.Значение по умолчанию:
trueИнтерфейс:
WebConfigИспользуется в блоке Web Client.
- cuba.web.loginScreenId
-
Идентификатор экрана, который должен использоваться в качестве экрана логина приложения.
Значение по умолчанию:
loginИнтерфейс:
WebConfigИспользуется в блоке Web Client.
- cuba.web.mainScreenId
-
Идентификатор экрана, который должен использоваться в качестве главного экрана приложения.
Значение по умолчанию:
mainИнтерфейс:
WebConfigИспользуется в блоке Web Client.
- cuba.web.mainTabSheetMode
-
Определяет, какой компонент будет использован в режиме TABBED главного окна. Может иметь два строковых значения из перечисления
MainTabSheetMode:-
DEFAULT: будет использован компонентCubaTabSheet, который выгружает и загружает вкладку заново при переключении. -
MANAGED: будет использован компонентCubaManagedTabSheet, который не выгружает содержимое вкладки главного TabSheet из памяти веб-браузера.
Значение по умолчанию:
DEFAULT.Интерфейс:
WebConfig.Используется в блоке Web Client.
-
- cuba.web.managedMainTabSheetMode
-
Если свойство cuba.web.mainTabSheetMode установлено в
MANAGED, определяет, как компонент главного окна переключает вкладки главного TabSheet: только скрывает их или выгружает и загружает вкладку заново при переключении.Значение по умолчанию:
HIDE_TABSИнтерфейс:
WebConfigИспользуется в блоке Web Client.
- cuba.web.maxTabCount
-
Задает максимальное количество вкладок с экранами, которые пользователь может открыть в главном окне приложения. Значение
0снимает ограничение.Значение по умолчанию:
20Интерфейс:
WebConfigИспользуется в блоке Web Client.
- cuba.web.pageInitialScale
-
Задаёт значение свойства
initial-scaleHTML-страницы, если задано свойство cuba.web.customDeviceWidthForViewport, либо свойству cuba.web.useDeviceWidthForViewport установлено значениеtrue. Влияет на метатег "viewport" HTML-страниц Vaadin.Значение по умолчанию:
0.8Интерфейс:
WebConfigИспользуется в блоке Web Client.
- cuba.web.productionMode
-
Позволяет полностью запретить консоль разработчика Vaadin в браузере, доступную через добавление
?debugк адресу приложения, тем самым, отключает доступ к возможностям отладки JavaScript и сокращает количество информации о сервере, выдаваемой браузеру.Значение по умолчанию:
falseИнтерфейс:
WebConfigИспользуется в блоке Web Client.
- cuba.web.pushEnabled
-
Позволяет полностью запретить server push. В этом случае механизм фоновых задач не будет работать.
Значение по умолчанию:
trueИнтерфейс:
WebConfigИспользуется в блоке Web Client.
- cuba.web.pushLongPolling
-
Позволяет использовать long polling вместо WebSocket для реализации server push.
Значение по умолчанию:
falseИнтерфейс:
WebConfigИспользуется в блоке Web Client.
- cuba.web.pushLongPollingSuspendTimeoutMs
-
Задает push тайм-аут в миллисекундах, который используется в случае, если включен long polling вместо WebSocket для реализации server push, т.е.
cuba.web.pushLongPolling="true".Значение по умолчанию:
-1Интерфейс:
WebConfigИспользуется в блоке Web Client.
- cuba.web.rememberMeEnabled
-
Управляет отображением флажка Remember Me в стандартном экране входа в систему в веб-клиенте.
Значение по умолчанию:
trueИнтерфейс:
WebConfigИспользуется в блоке Web Client.
- cuba.web.resourcesCacheTime
-
Определяет, нужно ли кэшировать файлы веб-ресурсов. Значение указывается в секундах. Установка значения 0 полностью отключает кэширование. Пример использования:
cuba.web.resourcesCacheTime = 136Значение по умолчанию: 60 * 60 (1 час).
Интерфейс:
WebConfigИспользуется в блоке Web Client.
- cuba.web.webJarResourcesCacheTime
-
Определяет, нужно ли кэшировать файлы ресурсов WebJar. Значение указывается в секундах. Установка значения 0 полностью отключает кэширование. Пример использования:
cuba.web.webJarResourcesCacheTime = 631Значение по умолчанию: 60 * 60 * 24 * 365 (1 год).
Интерфейс:
WebConfigИспользуется в блоке Web Client.
- cuba.web.resourcesRoot
-
Задает расположение каталога, из которого могут быть загружены файлы для вывода на экран компонентом Embedded. Например:
cuba.web.resourcesRoot=${cuba.confDir}/resourcesЗначение по умолчанию:
nullИнтерфейс:
WebConfigИспользуется в блоке Web Client.
- cuba.web.showBreadCrumbs
-
Позволяет скрыть панель breadcrumbs, которая раполагается в верхней части рабочей области главного окна.
Значение по умолчанию:
trueИнтерфейс:
WebConfigИспользуется в блоке Web Client.
- cuba.web.showFolderIcons
-
Задает отображение значков в панели папок. Если включено, то используются следующие файлы каталога темы приложения:
-
icons/app-folder-small.png- для папок приложения -
icons/search-folder-small.png- для папок поиска -
icons/set-small.png- для наборов
Значение по умолчанию:
falseИнтерфейс:
WebConfigИспользуется в блоке Web Client.
-
- cuba.web.requirePasswordForNewUsers
-
Если значение установлено в
true, то пароль является обязательным полем при создании пользователя из Web Client. Рекомендуется устанавливаеть значениеfalse, если в приложении используется LDAP аутентификация.Значение по умолчанию:
trueИнтерфейс:
WebAuthConfigИспользуется в блоке Web Client.
- cuba.web.standardAuthenticationUsers
-
Разделенный запятыми список логинов пользователей, которые могут входить в систему, используя только стандартную аутентификацию. Для этих пользователей внешняя аутентификация (например, LDAP или IDP SSO) запрещена.
Пустой список означает, что все могут использовать внешнюю аутентификацию, если она включена.
Значение по умолчанию:
<empty list>Интерфейс:
WebAuthConfigИспользуется в блоке Web Client.
- cuba.web.table.cacheRate
-
Регулирует кэширование данных компонента Table в браузере. Количество закэшированных строк будет равняться
cacheRateумноженному на pageLength как снизу так и сверху видимой области.Значение по умолчанию:
2Интерфейс:
WebConfigИспользуется в блоке Web Client.
- cuba.web.table.pageLength
-
Устанавливает количество строк, которое загружается с сервера в браузер когда компонент Table отрисовывается первый раз после обновления. См. также cuba.web.table.cacheRate.
Значение по умолчанию:
15Интерфейс:
WebConfigИспользуется в блоке Web Client.
- cuba.web.theme
-
Задает имя темы, используемой по умолчанию в веб-клиенте. См. также свойство cuba.themeConfig.
Значение по умолчанию:
haloИнтерфейс:
WebConfigИспользуется в блоке Web Client.
- cuba.web.uiHeartbeatIntervalSec
-
Задаёт интервал heartbeat-сообщений для UI веб-клиента. По умолчанию будет использовано вычисляемое значение свойства cuba.httpSessionExpirationTimeoutSec / 3.
Значение по умолчанию: таймаут бездействия HTTP-сессии, сек. / 3
Интерфейс:
WebConfigИспользуется в блоке Web Client.
- cuba.web.unsupportedPagePath
-
Определяет путь к HTML-странице, которая отображается, когда приложение не поддерживает текущую версию браузера.
cuba.web.unsupportedPagePath = /com/company/sales/web/sys/unsupported-browser-page.htmlЗначение по умолчанию:
/com/haulmont/cuba/web/sys/unsupported-page-template.html.Интерфейс:
WebConfig.Используется в блоке Web Client.
- cuba.web.urlHandlingMode
-
Определяет, как должны обрабатываться изменения URL.
Возможными значениями являются элементы перечисления
UrlHandlingMode:-
NONE– изменения URL не обрабатываются вообще; -
BACK_ONLY– для обработки изменений используетсяCubaHistoryControl. Это значение заменяет устаревшее свойство cuba.web.allowHandleBrowserHistoryBack; -
URL_ROUTES– изменения обрабатываются механизмом навигации и истории просмотров URL.
Значение по умолчанию:
URL_ROUTES.Интерфейс:
WebConfig. -
- cuba.web.useFontIcons
-
При включенном свойстве для темы halo в качестве значков стандартных действий и экранов платформы используются элементы шрифта Font Awesome вместо файлов изображений.
Соответствие между именем, указанным в свойстве icon действия или визуального компонента, и элементом шрифта, задается в файле
halo-theme.propertiesплатформы. В нем ключи, начинающиеся сcuba.web.iconsсоответствуют именам значков, а их значения - константам перечисленияcom.vaadin.server.FontAwesome. Например, элемент шрифта для значка стандартного действияcreate, задается строкой:cuba.web.icons.create.png = font-icon:FILE_OЗначение по умолчанию:
trueИнтерфейс:
WebConfigИспользуется в блоке Web Client.
- cuba.web.useInverseHeader
-
Для темы Halo или ее наследников управляет цветом заголовка веб-клиента. Если
true, то заголовок темный (инверсный), еслиfalse- заголовок приобретает цвет основного фона приложения.Данное свойство не действует, если в теме установлена переменная
$v-support-inverse-menu: false;Это имеет смысл для темной темы, если пользователю дана возможность переключаться между светлой и темной темой. Тогда в светлой теме заголовок будет инверсным, а в темной основного цвета фона.
Значение по умолчанию:
trueИнтерфейс:
WebConfigИспользуется в блоке Web Client.
- cuba.web.userCanChooseDefaultScreen
-
Определяет, может ли пользователь установить для себя окно по умолчанию. Если
false, поле Default screen в экране Settings будет доступно только для чтения.Значение по умолчанию:
trueИнтерфейс:
WebConfigИспользуется в блоке Web Client.
- cuba.web.useDeviceWidthForViewport
-
Определяет ширину области просмотра (viewport). Если установлено значение
true, за ширину области просмотра будет принята ширина устройства. Данное свойство влияет на метатег "viewport" HTML-страниц Vaadin.Значение по умолчанию:
falseИнтерфейс:
WebConfigИспользуется в блоке Web Client.
- cuba.web.viewFileExtensions
-
Задает список расширений файлов, отображаемых в окне браузера при выгрузке файла через
ExportDisplay.show(). Разделителем элементов списка является символ|.Значение по умолчанию:
htm|html|jpg|png|jpeg|pdfИнтерфейс:
WebConfigИспользуется в блоке Web Client.
- cuba.webContextName
-
Конфигурационный параметр, задающий имя контекста веб-приложения. Как правило, эквивалентен имени каталога или WAR-файла, содержащего данный блок приложения.
Интерфейс:
GlobalConfigИспользуется в блоках Middleware, Web Client, Web Portal.
Например, для блока Middleware, расположенного в каталоге
tomcat/webapps/app-core, и доступного по URLhttp://somehost:8080/app-coreданное свойство должно быть задано следующим образом:cuba.webContextName=app-core
- cuba.webHostName
-
Конфигурационный параметр, задающий имя хоста, на котором запущен данный блок приложения.
Значение по умолчанию:
localhostИнтерфейс:
GlobalConfigИспользуется в блоках Middleware, Web Client, Web Portal.
Например, для блока Middleware, доступного по URL
http://somehost:8080/app-coreданное свойство должно быть задано следующим образом:cuba.webHostName=somehost
- cuba.webPort
-
Конфигурационный параметр, задающий имя порта, на котором запущен данный блок приложения.
Значение по умолчанию:
8080Интерфейс:
GlobalConfigИспользуется в блоках* Middleware*, Web Client, Web Portal.
Например, для блока Middleware, доступного по URL
http://somehost:8080/app-coreданное свойство должно быть задано следующим образом:cuba.webPort=8080
Приложение C: Системные свойства
Системные свойства задаются при запуске JVM с помощью аргумента командной строки -D и могут быть получены или установлены методами getProperty(), setProperty() класса System.
Системные свойства можно использовать для установки или переопределения значений свойств приложения. Например, следующий аргумент командной строки переопределит значение свойства cuba.connectionUrlList, которое обычно задается в файле web-app.properties:
-Dcuba.connectionUrlList=http://somehost:8080/app-core|
Имейте в виду, что системные свойства влияют на всю JVM, то есть все блоки приложения, выполняющиеся на данной JVM, получат одинаковое значение свойства. |
|
Системные свойства кэшируются фреймворком на старте сервера, поэтому ваше приложение не должно полагаться на возможность переопределения свойства приложения с помощью изменения системного свойства во время работы приложения. Если вам абсолютно необходимо сделать это, сбросьте кэш после изменения системного свойства с помощью метода |
Ниже приведены системные свойства, используемые в платформе, но не являющиеся свойствами приложения.
- logback.configurationFile
-
Определяет местонахождение файла конфигурации фреймворка Logback.
Для блоков приложения, работающих на веб-сервере Tomcat, данное системное свойство задается в файлах
tomcat/bin/setenv.batиtomcat/bin/setenv.sh. По умолчанию оно указывает на конфигурационный файлtomcat/conf/logback.xml.
- cuba.unitTestMode
-
Данное системное свойство устанавливается в значение
trueв режиме выполнения интеграционных тестов базовым классомCubaTestCase.Пример использования:
if (!Boolean.valueOf(System.getProperty("cuba.unitTestMode"))) return "Not in test mode";
Приложение D: Удаленные разделы
D.1. Организация бизнес-логики
См. руководство Create business logic in CUBA.
D.2. Бизнес-логика в контроллерах
См. руководство Create business logic in CUBA.
D.3. Использование бинов клиентского уровня
См. руководство Create business logic in CUBA.
D.4. Использование сервисов среднего слоя
См. руководство Create business logic in CUBA.
D.5. Использование Entity Listeners
См. примеры в разделе Entity Listeners.
D.6. Использование JMX-бинов
См. примеры в разделе Создание JMX-бина.
D.7. Запуск кода на старте приложения
См. пример в разделе Регистрация entity listeners.
D.9. Тема в веб-приложениях
См. Темы приложения.
D.10. Переход с темы Havana на полнофункциональную Halo
См. примеры в разделе Изменение общих параметров темы.
D.11. Передача параметров в экран
См. Открытие экранов.
D.12. Возврат значений из экрана
См. Открытие экранов.
D.14. Настройка логирования в десктоп-клиенте
Не актуально начиная с версии 7.0, так как десктопный клиент более не поддерживается.
D.16. Ассоциация Many-to-Many
См. руководство Data Modelling: Many-to-Many Association.
D.17. Прямая ассоциация Many-to-Many
См. руководство Direct Many-to-Many Association.
D.18. Ассоциация Many-to-Many через связующую сущность
См. руководство Indirect Many-to-Many Association with Joining Entity.
D.19. Наследование сущностей
См. руководство Data Modeling: Entity Inheritance.
D.20. Редактирование композитных сущностей
См. руководство Data Modelling: Composition.
D.21. One-to-Many: один уровень вложенности
См. руководство Data Modelling: Composition.
D.22. One-to-Many: два уровня вложенности
См. руководство Data Modelling: Composition.
D.23. One-to-Many: три уровня вложенности
См. руководство Data Modelling: Composition.
D.24. Композиция One-to-One
См. руководство Data Modelling: Composition.
D.25. Композиция One-to-One в одном редакторе
См. руководство Data Modelling: Composition.
D.26. Присвоение начальных значений
См. руководство Initial Values for Entity Instances.
D.27. Инициализация полей сущности
См. руководство Initial Values for Entity Instances.
D.28. Инициализация с помощью CreateAction
См. руководство Initial Values for Entity Instances.
D.29. Использование метода initNewItem
См. руководство Initial Values for Entity Instances.
D.30. Получение локализованных сообщений
См. руководство Localization in CUBA applications.
D.31. Компоновка главного окна приложения
См. Корневые экраны.
D.32. REST API
REST API перенесен в аддон, см. его документацию.
D.33. Работа с базой данных
См. Базы данных.
D.35. Вывод изображений в колонках таблицы
См. руководство Working with Images.
D.36. Загрузка и вывод изображений
См. руководство Working with Images.
D.37. Сборник рецептов
См. Guides.
D.38. Настройка логирования в Tomcat
См. Логирование.
D.39. Стандартные действия с коллекцией
См. Стандартные действия.
D.40. Стандартные действия поля выбора
См. Стандартные действия.
7. Основные определения и понятия
- Артефакт
-
В контексте данного руководства под артефактом понимается файл (обычно JAR или ZIP), содержащий исполняемый или другой код, получившийся в результате сборки проекта. Артефакт имеет версию и имя, соответствующее определённым правилам, и может храниться в репозитории артефактов.
- Базовые проекты
-
То же самое что компоненты приложения. Данный термин был принят в предыдущих версиях платформы и документации.
- БД
-
Реляционная база данных.
- Браузер сущностей
-
Экранная форма, на которой размещается таблица со списком сущностей, а также кнопки создания, редактирования, удаления сущности.
- Внедрение зависимости
-
Известно также как принцип Inversion Of Control (IoC). Механизм для получения ссылок на используемые объекты, при котором объект только декларирует, от каких объектов он зависит, а контейнер создает нужные объекты и инжектирует в зависимый объект.
- Главный пакет сообщений
- Жадная загрузка
-
Загрузка данных подклассов и связанных объектов одновременно с основной запрашиваемой сущностью.
- Загрузка по требованию
- Контейнер
-
Контейнер управляет жизненным циклом и конфигурацией программных объектов. Является базовым компонентом технологии Dependency Injection (или Inversion of Control).
В платформе CUBA используется контейнер Spring Framework.
- Контроллер экрана
-
Javaкласс, содержащий логику инициализации и обработки событий экрана. Связан с XML-дескриптором экрана.См. Контроллер экрана.
- Локальный атрибут
-
Атрибут сущности, не являющийся ссылкой или коллекцией ссылок на другую сущность. Значения всех локальных атрибутов сущности, как правило, хранятся в одной таблице (исключение составляют некоторые стратегии наследования сущностей).
- Пакет локализованных сообщений
-
См. Пакеты сообщений.
- Персистентный контекст
-
Набор экземпляров сущностей, загруженных из базы данных или только что созданных. Персистентный контекст является кэшем данных в рамках текущей транзакции. При коммите транзакции все изменения сущностей в персистентном контексте сохраняются в БД.
См. Entity Manager.
- Представление
-
См. Представления.
- Репозиторий артефактов
-
Сервер, осуществляющий хранение артефактов в определенной структуре. В процессе сборки некоторого проекта из репозитория загружаются артефакты, от которых зависит данный проект.
- Сущность
-
Основной элемент модели данных, см. Модель данных.
- Application Tiers
- Application Properties
-
Свойства приложения − именованные данные различных типов, определяющие всевозможные аспекты конфигурации и функционирования приложения.
- Application Units
- Eager Fetching
-
См. Жадная загрузка.
- EntityManager
-
Программный компонент среднего слоя, служащий для работы с персистентными сущностями.
См. EntityManager
- Groovy
-
Groovy — объектно-ориентированный язык программирования, разработанный для платформы Java как дополнение к языку Java с возможностями Python, Ruby и Smalltalk.
- Interceptor
-
Элемент AOP (Aspect Oriented Programming), позволяющий изменить или расширить обычный вызов метода объекта.
- JMX
-
Java Management Extensions − технология, которая предоставляет инструменты для управления приложениями, объектами системы, устройствами. Определяет стандарт для написания JMX-компонентов − MBeans.
Более подробную информацию можно найти по адресу: http://www.oracle.com/technetwork/java/javase/tech/javamanagement-140525.html
См. также Использование инструментов JMX.
- JPA
-
Java Persistence API - стандартная спецификация технологии объектно-реляционного отображения (ORM). В платформе CUBA используется фреймворк EclipseLink, реализующий эту спецификацию.
- JPQL
-
Независимый от БД объектно-ориентированный язык запросов, определенный как часть спецификации JPA. См. https://en.wikibooks.org/wiki/Java_Persistence/JPQL.
- Lazy loading
- Managed Beans
-
Программные компоненты, управляемые контейнером и содержащие бизнес-логику приложения.
См. Spring-бины.
- MBeans
-
Managed Beans, имеющие JMX-интерфейс. Как правило, имеют внутреннее состояние (например, кэш, конфигурационные данные или статистику), к которому нужно обеспечить доступ через JMX.
- Middleware
-
Средний слой − уровень приложения, содержащий бизнес-логику, работающий с базой данных, и предоставляющий общий интерфейс для верхних (клиентских) уровней приложения.
- Optimistic locking
-
Оптимистичная блокировка - способ управления совместным доступом к данным различными пользователями, при котором предполагается, что возможность одновременного изменения ими одного и того же экземпляра сущности мала. В этом случае блокировка как таковая отсутствует, вместо нее в момент сохранения изменений производится проверка, нет ли в БД более новой версии данных, сохраненной другим пользователем. Если есть, выбрасывается исключение, и текущий пользователь должен снова загрузить данный экземпляр сущности.
- ORM
-
Object-Relational Mapping - объектно-реляционное отображение - технология связывания таблиц реляционной базы данных с объектами языка программирования.
См. Слой ORM.
- Services
-
Сервисы среднего слоя предоставляют интерфейс для вызова бизнес-логики клиентами и образуют границу Middleware. Сервисы могут содержать бизнес-логику внутри себя, либо делегировать выполнение Managed Beans.
См. Сервисы.
- Single Sign-On, SSO
-
Технология, при использовании которой пользователь переходит от одного приложения к другому без повторной аутентификации. Интеграция CUBA-приложения с Active Directory позволяет пользователям Windows входить в приложение без ввода имени и пароля.
- Soft deletion
-
См. Мягкое удаление.
- UI
-
User Interface - пользовательский интерфейс.
- View
-
См. Представления.
- XML-дескриптор
-
Файл в формате XML, содержащий описание компонентов данных и расположения визуальных компонентов экрана.
См. XML-дескриптор.