Предисловие
Данный документ является руководством по применению подсистемы полнотекстового поиска (full text search, FTS) платформы CUBA.
Целевая аудитория
Руководство предназначено для разработчиков, создающих приложения на платформе CUBA с возможностью полнотекстового поиска. Предполагается, что читатель ознакомлен с Руководством по разработке приложений.
Дополнительные материалы
Настоящее Руководство, а также другая документация по платформе CUBA доступны по адресу https://www.cuba-platform.ru/documentation.
Подсистема полнотекстового поиска CUBA основана на фреймворке Apache Lucene, поэтому знакомство с его устройством будет полезным. Смотрите http://lucene.apache.org/core.
Обратная связь
Если у Вас имеются предложения по улучшению данного руководства, мы будем рады принять ваши pull request’ы и issues в исходниках документации на GitHub. Если вы увидели ошибку или несоответствие в документе, пожалуйста, форкните репозиторий и исправьте проблему. Заранее спасибо!
1. Обзор подсистемы FTS
Полнотекстовый поиск (full-text search, FTS) платформы CUBA предоставляет возможность неструктурированного поиска по значениям атрибутов сущностей и по содержимому загруженных файлов.
Особенностью реализации полнотекстового поиска CUBA является его ориентация на использование в бизнес-приложениях со сложными моделями данных. В частности, в результатах поиска отображаются не только сущности, напрямую содержащие в некотором атрибуте искомую строку, но и связанные сущности, при отображении которых используется этот атрибут. Например, если сущность Order (заказ) содержит ссылку на Customer (покупателя), и строка поиска содержит название покупателя, то в результатах поиска будет отображен и найденный покупатель, и заказ, на него ссылающийся. Это поведение логично для пользователя, который обычно видит название покупателя в экране редактирования заказа.
Результаты поиска фильтруются с учетом ограничений, накладываемых подсистемой безопасности фреймворка. То есть, если группа доступа текущего пользователя не разрешает загрузку некоторых экземпляров сущностей, они не будут отображаться в результатах поиска.
Подсистема полнотекстового поиска содержит два взаимосвязанных механизма: индексирование и собственно поиск.
1.1. Индексирование
Если в приложении подключен компонент fts и включено свойство fts.enabled, то при каждом сохранении в базу данных сущности, подлежащей индексированию, ее идентификатор записывается в очередь на индексацию – таблицу SYS_FTS_QUEUE.
Чтобы процесс индексирования запускался автоматически в фоновом режиме, необходимо создать и активировать назначенное задание. Отдельный асинхронный процесс периодически извлекает идентификаторы изменившихся сущностей из очереди, загружает экземпляры сущностей и индексирует их. Индексация производится с помощью библиотеки Apache Lucene. Документ Lucene содержит следующие поля:
-
Имя сущности и идентификатор экземпляра.
-
Поле
all– конкатенация индексируемых атрибутов сущности, но только локальных и типаFileDescriptor. Если атрибут имеет типFileDescriptor, то индексируется содержимое соответствующего файла. Локальные атрибуты бывают одного из следующих типов: строка, число, дата, перечисление. -
Поле
links– конкатенация идентификаторов сущностей, которые содержатся в ссылочных индексируемых атрибутах.
Под индексируемыми атрибутами понимаются атрибуты данной сущности и, возможно, связанных с ней сущностей, объявленные в дескрипторе FTS.
Индекс хранится в файловой системе, по умолчанию в подкаталоге ftsindex рабочего каталога приложения (задаваемого свойством cuba.dataDir), в стандартном варианте развертывания это tomcat/work/app-core/ftsindex. Расположение индекса можно изменить с помощью свойства fts.indexDir.
1.2. Поиск
Поиск ведется по следующим правилам:
-
если искомая строка обрамлена кавычками, то ищется соответствующая фраза – набор таких же слов в том же порядке, игнорируя знаки пунктуации;
-
если искомая строка начинается с символа "*", то производится поиск по вхождению строки в любой части слова индексированных данных;
-
в противном случае поиск производится по совпадению искомой строки с началом слов индексированных данных.
Для русского и английского языка поиск производится с учетом морфологии.
Алгоритм поиска состоит из двух этапов:
-
Сначала искомая строка ищется в поле
allдокументов Lucene. Найденные сущности добавляются в список результатов. -
Если что-то найдено на первом этапе, то идентификаторы найденных сущностей ищутся в поле
linksдокументов Lucene. Найденные на втором этапе сущности также добавляются в список результатов.
|
Warning
|
Если строка поиска состоит из нескольких слов (и не обрамлена кавычками), то будет произведен поиск всех слов по отдельности по условию ИЛИ. То есть в результаты поиска попадут сущности, содержащие хотя бы одно из введенных слов. |
1.3. Пример индексирования и поиска
Рассмотрим приведенный выше простейший пример со связанными сущностями Order и Customer.
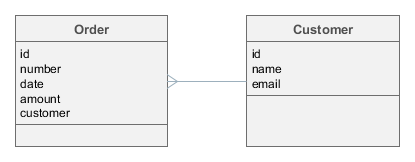
Если все атрибуты объектов являются индексируемыми, при индексации двух связанных экземпляров Order и Customer будут созданы два документа Lucene примерно следующего содержания:
id: Order.id = "b671dbfc-c431-4586-adcc-fe8b84ca9617"
all: Order.number + Order.date + Order.amount = "001^2013-11-14^1000"
links: Customer.id = "f18e32bb-32c7-477a-980f-06e9cc4e7f40"id: Customer.id = "f18e32bb-32c7-477a-980f-06e9cc4e7f40"
all: Customer.name + Customer.email = "John Doe^john.doe@mail.com"Теперь предположим, что ищется строка "john":
-
Сначала производится поиск в полях
allвсех документов. Будет найденCustomerи добавлен в результаты поиска. -
Затем будет произведен поиск идентификатора найденного покупателя в полях
linksвсех документов. Будет найденOrder, и он также будет добавлен в результаты поиска.
2. Установка
Для добавления аддона в проект выполните следующие действия:
-
Кликните дважды Add-ons в дереве проекта CUBA.
-
Перейдите на вкладку Marketplace и найдите аддон Full Text Search.
-
Кликните Install и затем Apply & Close.
-
Кликните Continue в появившемся диалоговом окне.
Аддон, соответствующий используемой версии платформы, будет добавлен в проект.
3. Быстрый старт
В данной главе мы рассмотрим применение подсистемы полнотекстового поиска в тестовом приложении Библиотека, исходный код которого доступен на GitHub.
Разобьем задачу на следующие этапы:
-
Подключим функциональность поиска к проекту, настроим вызов процесса индексирования и убедимся в его работоспособности.
-
Настроим конфигурационный файл FTS для работы с сущностями модели данных примера Библиотека.
-
Для иллюстрации возможностей поиска по загруженным файлам используем сущность
BookPublicationи функциональность загрузки файлов, описанную в разделе Хранилище файлов в Руководстве по разработке приложений.
3.1. Настройка проекта
-
Загрузите и распакуйте исходный репозиторий приложения Библиотека или клонируйте проект, используя git:
git clone https://github.com/cuba-platform/sample-library-cuba7
-
Откройте проект Library, как описано в разделе Открытие существующего проекта Руководства пользователя CUBA Studio.
-
Добавьте в проект аддон, как это описано в разделе Установка.
-
Создайте базу данных на локальном сервере HyperSQL. Выберите пункт меню CUBA → Create database.
-
Запустите приложение: кликните на кнопку
 рядом с выбранной конфигурацией
рядом с выбранной конфигурацией CUBA Applicationв главной панели инструментов. Ссылка на локальный сервер в секции Runs at… позволит перейти к приложению непосредственно из Studio. -
Откройте приложение Библиотека.
Логин и пароль пользователя −
admin/admin. -
Для того, чтобы включить функциональность полнотекстового поиска, в главном меню приложения откройте Administration → Application properties, найдите и откройте список
ftsв таблице свойств, двойным щелчком откройте атрибут fts.enabled и выберите true в поле Current value.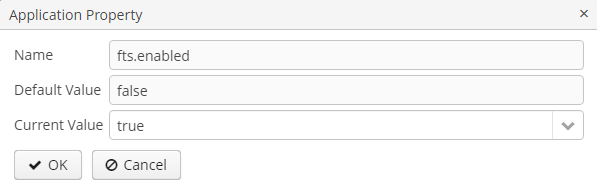
После выполнения вышеописанных действий функциональность полнотекстового поиска подключена к приложению и готова к работе. Если выйти из системы и снова выполнить логин, в правой части верхней панели главного окна приложения появится поле поиска. Кроме того, полнотекстовый поиск может использоваться в UI-компоненте Filter.
Однако поиск не будет давать результатов, так как никакие данные еще не проиндексированы.
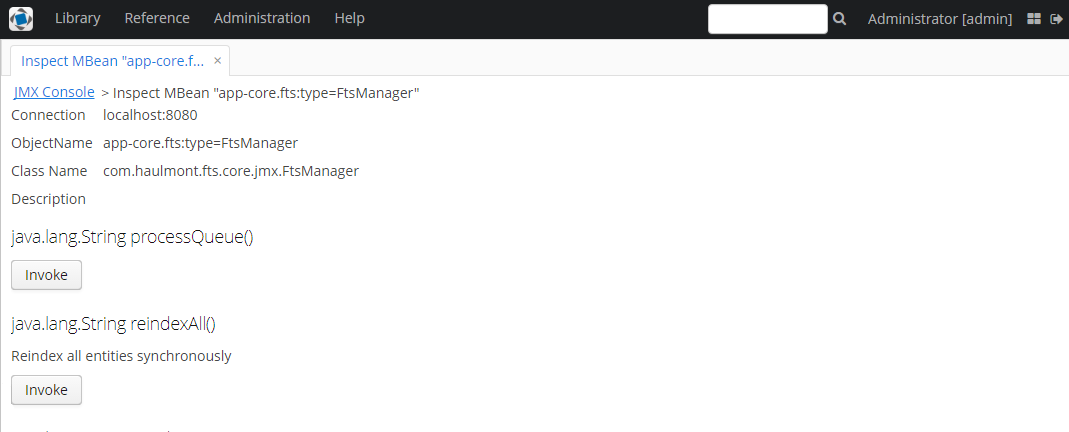
Для однократного запуска индексации текущего состояния базы данных (а точнее, сущностей, описанных в конфигурационном файле FTS по умолчанию), откройте в главном меню Administration → JMX Console, найдите JMX-бин app-core.fts:type=FtsManager и вызовите последовательно сначала метод reindexAll(), а затем processEntireQueue().
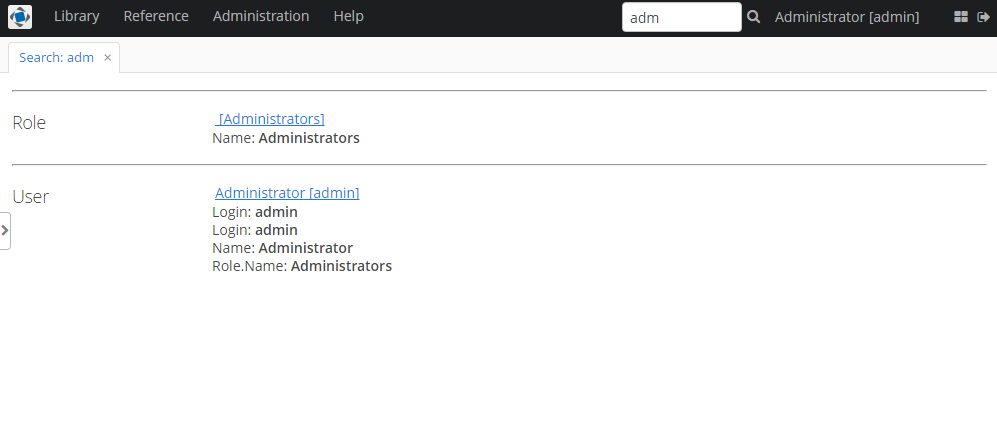
После этого поиск, например, строки "adm" должен выдавать следующие результаты:
3.2. Настройка вызова процесса индексирования
Для периодического вызова процесса индексирования удобно воспользоваться механизмом назначенных заданий фреймворка CUBA.
Сначала необходимо активировать весь механизм запуска задач. Добавьте в файл app.properties модуля core проекта приложения следующее свойство:
cuba.schedulingActive = trueПерезапустите сервер приложения, войдите в систему пользователем admin, откройте экран JMX Console, найдите и откройте JMX-бин app-core.cuba:type=Scheduling и убедитесь, что атрибут Active имеет значение true.
Далее откройте экран Administration → Scheduled Tasks, нажмите Create и задайте следующие значения атрибутов новой задачи:
-
Defined by: Bean
-
Bean name: cuba_FtsManager
-
Method name: processQueue()
-
Singleton: false
-
Period, sec: 30
Сохраните задачу, выделите ее в таблице и нажмите Activate. С этого момента каждые 30 секунд будет вызываться процесс индексирования измененных сущностей.
|
Tip
|
При работе с кластером серверов приложения, каждый сервер, предоставляющий функциональность поиска, должен поддерживать свою копию индекса. Для этого:
После этого изменения будут ставится в очередь для каждого сервера по отдельности; сервера будут брать из очереди свои собственные записи и обновлять свои индексы. |
|
Warning
|
Автоматическое индексирование не затрагивает сущности, созданные до его запуска. Для постановки таких сущностей в очередь на индексацию воспользуйтесь методами |
3.3. Настройка файла конфигурации
При добавлении базового проекта fts в модуле core создаётся новый файл fts.xml. Проверьте его содержимое и при необходимости отредактируйте, включив в него те сущности, которые должны участвовать в полнотекстовом поиске.
<fts-config>
<entities>
<entity class="com.sample.library.entity.Author">
<include re=".*"/>
</entity>
<entity class="com.sample.library.entity.Book">
<include re=".*"/>
</entity>
<entity class="com.sample.library.entity.BookInstance">
<include re=".*"/>
</entity>
<entity class="com.sample.library.entity.BookPublication">
<include re=".*"/>
</entity>
<entity class="com.sample.library.entity.LibraryDepartment">
<include re=".*"/>
</entity>
<entity class="com.sample.library.entity.LiteratureType">
<include re=".*"/>
</entity>
<entity class="com.sample.library.entity.Publisher">
<include re=".*"/>
</entity>
<entity class="com.sample.library.entity.Town">
<include re=".*"/>
</entity>
</entities>
</fts-config>Это файл конфигурации FTS, в данном случае включающий в индексирование все сущности предметной области со всеми их атрибутами.
Добавьте в файл app.properties модуля core приложения следующее свойство:
cuba.ftsConfig = +com/sample/library/fts.xmlВ результате индексироваться будут и сущности, определенные в платформе в файле com/haulmont/fts/fts.xml, и описанные в файле проекта fts.xml.
Перезапустите сервер приложения. На данном этапе полнотекстовый поиск должен работать по всем сущностям модели приложения, а также по сущностям подсистемы безопасности фреймворка: Role, Group, User.
3.4. Поиск по содержимому загруженных файлов
Теперь добавим функциональность загрузки файлов для каждой публикации и их отображение на экране списка сущности BookPublication.
Для начала внесите изменения в BookPublication. Добавьте новый атрибут file, который будет являться ссылкой на сущность FileDescriptor с отношением много-к-одному. FileDescriptor – это описатель загруженного файла (не путать с java.io.FileDescriptor), позволяющий ссылаться на файл из объектов модели данных.
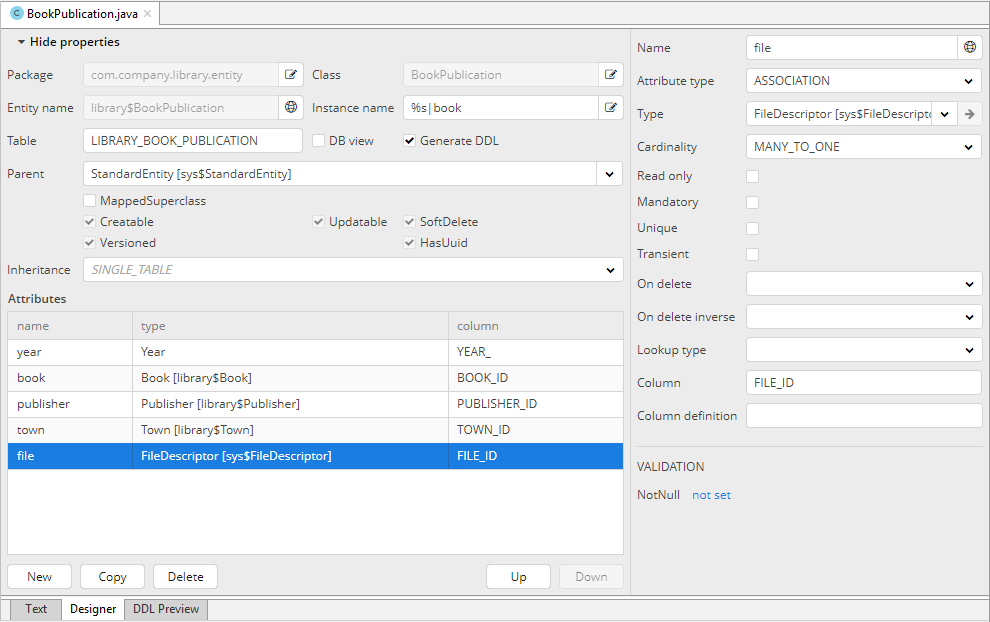
После сохранения изменений добавьте новый атрибут к существующему представлению bookPublication.full. Также следует добавить атрибут на экраны просмотра списка и редактирования сущности BookPublication. Для этого поместите курсор на строку, в которой описан атрибут, и нажмите Alt+Enter. Выберите Add entity attribute to screens и в появившемся окне выберите экраны, на которые нужно добавить новый атрибут.
Сгенерируйте новые скрипты обновления БД, выполните команду обновления базы данных и перезапустите сервер приложения. При пересоздании базы данных полнотекстовый поиск по умолчанию отключается. Снова включите флажок Value для атрибута Enable в экране JMX Console, выполните индексацию всех файлов, выйдите из системы снова выполните логин.
Так как мы добавили новый атрибут, в таблице публикаций на экране списка сущности BookPublication теперь появился новый пустой столбец: File. Чтобы его заполнить, откройте экран редактирования строки таблицы, с помощью нового поля File загрузите текстовый файл в систему и нажмите OK. По умолчанию CUBA поддерживает следующие форматы файлов: RTF, TXT, DOC, DOCX, XLS, XSLX, ODT, ODS и PDF.
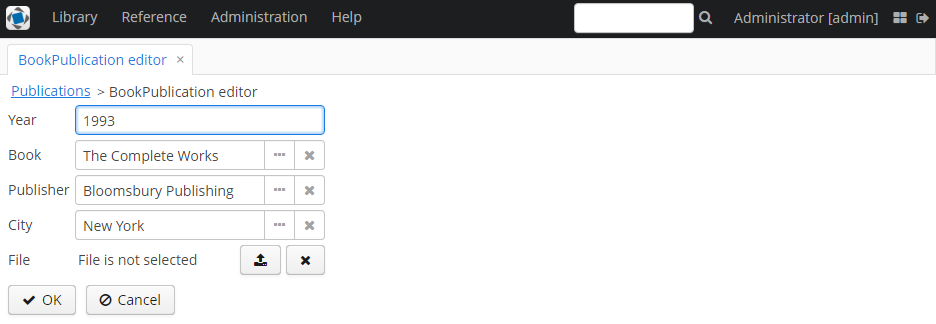
Новые файлы теперь отображаются в таблице. Внешний вид таблицы можно отредактировать.
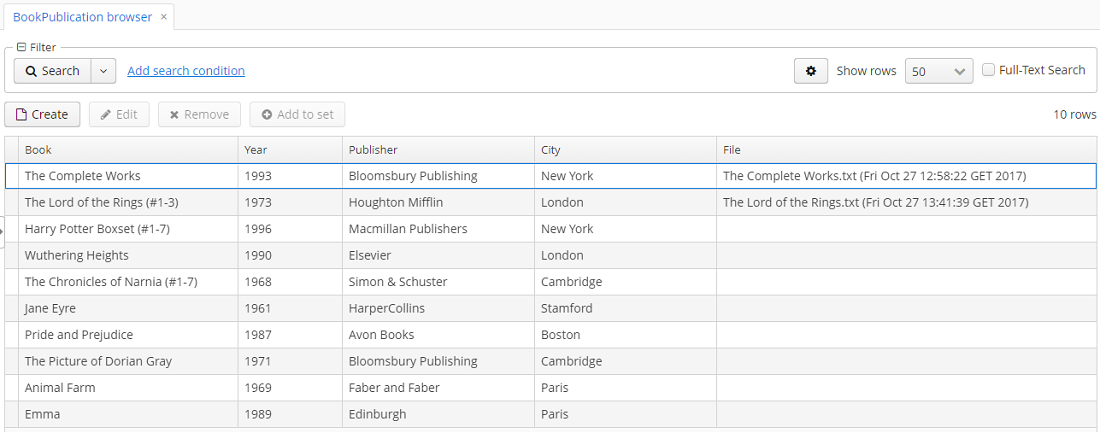
Чтобы переиндексировать имеющиеся в базе данных сущности и файлы в соответствии с новой конфигурацией поиска, откройте в экране JMX Console JMX-бин app-core.fts:type=FtsManager и вызовите последовательно сначала метод reindexAll(), а затем processQueue(). Все вновь добавляемые и изменяемые данные будут индексироваться автоматически, с задержкой, определяемой интервалом вызова назначенного задания, т.е. не более 30 секунд.
В результате полнотекстовый поиск будет выводить все результаты, включая вхождения в содержимом загруженных файлов.
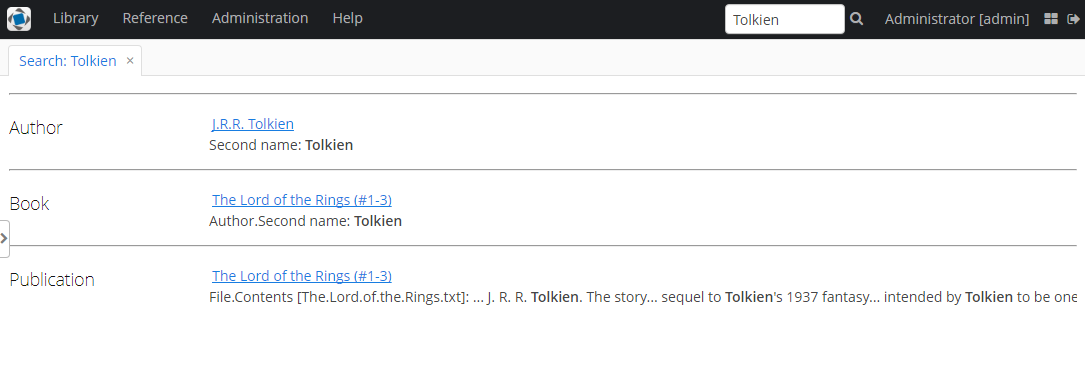
Более подробную информацию о FileStorageAPI и FileDescriptor ищите в соответствующих разделах основного руководства.
3.5. Запуск и настройка переиндексации сущностей
Если полнотекстовый поиск был подключен в момент, когда в систему уже внесены какие-либо данные, то эти данные нужно проиндексировать. Добавление записей в очередь на индексацию осуществляется с помощью методов JMX-бина app-core.fts:type=FtsManager. Удобный способ вызвать метод JMX-бина – воспользоваться экраном JMX Console пункта меню Администрирование.
JMX-бин app-core.fts:type=FtsManager предоставляет два метода для постановки сущностей в очередь на индексацию:
-
reindexAll()– синхронно добавляет все сущности, описанные в файле конфигурации FTS, в очередь на индексацию. При больших объемах данных этот процесс может занять длительное время, и в этом случае рекомендуется воспользоваться методомasyncReindexAll(). -
asyncReindexAll()– сущности добавляются в очередь на индексацию пакетами с помощью методаFtsManager.reindexNextBatch(). Размер пакета задается конфигурационным параметром fts.reindexBatchSize. МетодFtsManager.reindexNextBatch()должен вызываться механизмом назначенных заданий или с помощью планировщика Spring. Пока формирование очереди не завершено, индексация не производится.
Приложение A: Файл конфигурации FTS
Файл конфигурации полнотекстового поиска представляет собой XML-файл, как правило, располагающийся в каталоге src модуля core и содержащий описание индексируемых сущностей и их атрибутов.
Файл конфигурации FTS задается в свойстве приложения cuba.ftsConfig.
Рассмотрим структуру файла.
fts-config – корневой элемент.
Элементы fts-config:
-
entities– список сущностей, подлежащих индексированию и поиску.Элементы
entities:-
entity– описание индексируемой сущности.Атрибуты
entity:-
class– Java класс сущности. -
show– должна ли данная сущность показываться в результатах поиска самостоятельно. Значениеfalseиспользуется для сущностей-связей, которые не интересны пользователю сами по себе, но нужны, например, для связи загруженных файлов и сущностей предметной области. По умолчаниюtrue.
Элементы
entity:-
include– включить атрибут или несколько атрибутов сущности в индекс.Атрибуты
include:-
re– регулярное выражение для отбора атрибутов по имени. -
name– имя атрибута. Может быть путем (через точку) по ссылочным атрибутам. Тип не проверяется, однако если имя является путем, то возможны два случая:-
Конечный атрибут должен быть сущностью (не embeddable), а не простым типом (атрибут простого типа не имеет здесь смысла, он должен индексироваться в своей сущности).
-
Конечный атрибут должен быть простым типом встраиваемой (embeddable) сущности. Например, если индексируемая сущность имеет поле
addressтипаAddress(embeddable сущность), то имя атрибута в файле конфигурации fts должно бытьaddress.cityилиaddress.street, а не простоaddress.
-
-
-
-
-
exclude– исключить ранее включенный атрибут. Возможные атрибуты такие же, как в элементеinclude. -
searchables– Groovy-скрипт для добавления в очередь на индексирование произвольных сущностей, связанных с измененной.Например, когда изменяется (добавляется, удаляется) экземпляр
CardAttachment, мы должны также переиндексировать связанный с ним экземплярCard, так как сам собойCardв очередь не встанет, ибо не менялся.При запуске в скрипт передаются следующие переменные:
-
searchables– список сущностей, который нужно пополнять. -
entity– текущий экземпляр сущности, помещаемый в очередь автоматически.
Пример скрипта:
<entity class="com.haulmont.workflow.core.entity.CardAttachment" show="false"> ... <searchables> searchables.add(entity.card) </searchables> </entity> -
-
searchableIf– Groovy-скрипт для ограничения помещения в очередь некоторых экземпляров индексируемой сущности.Например, может быть, не нужно индексировать старые версии документов.
При запуске в скрипт передается переменная
entity– текущий экземпляр сущности. Скрипт возвращает булевское значение:true, для того чтобы индексировать текущий экземпляр,false, чтобы игнорировать его.Пример скрипта:
<entity class="com.haulmont.docflow.core.entity.Contract"> ... <searchableIf> entity.versionOf == null </searchableIf> </entity>
Пример файла конфигурации FTS:
<fts-config>
<entities>
<entity class="com.sample.library.entity.Author">
<include re=".*"/>
</entity>
<entity class="com.sample.library.entity.Book">
<include re=".*"/>
</entity>
<entity class="com.sample.library.entity.BookInstance">
<include re=".*"/>
</entity>
<entity class="com.sample.library.entity.BookPublication">
<include re=".*"/>
</entity>
<entity class="com.sample.library.entity.Publisher">
<include re=".*"/>
</entity>
<entity class="com.sample.library.entity.EBook">
<include name="publication.book"/>
<include name="attachments.file"/>
</entity>
<entity class="com.haulmont.workflow.core.entity.CardAttachment" show="false">
<include re=".*"/>
<exclude name="card"/>
<searchables>
searchables.add(entity.card)
</searchables>
</entity>
</entities>
</fts-config>Приложение B: Свойства приложения
В данном разделе перечислены свойства приложения, имеющие отношение к подсистеме полнотекстового поиска.
- cuba.ftsConfig
-
Аддитивный конфигурационный параметр, задает файл конфигурации FTS проекта.
Файл загружается с помощью интерфейса
Resources, поэтому может быть расположен в classpath или вконфигурационном каталоге.Используется в блоке Middleware.
Пример:
cuba.ftsConfig = +com/company/sample/fts.xml
- cuba.gui.genericFilterFtsTableTooltipsEnabled
-
Флаг включает генерацию всплывающих сообщений при наведении на строку в комопонентах Table и DataGrid. Всплывающие сообщения содеражат информацию о том, в каком атрибуте сущности было найдено выражение, использованное при полнотекстовом поиске. Генерация таких всплывающих сообщение может занимать значительное время, по умолчанию она отключена.
Интерфейс:
ClientConfigХранится в базе данных.
Значение по умолчанию:
false
- cuba.gui.genericFilterFtsDetailsActionEnabled
-
Флаг включает элемент контекстного меню "Детали полнотекстового поиска" в таблице или дата-гриде в случае, если поиск осуществлялся с помощью универсального фильтра.
Интерфейс:
ClientConfigХранится в базе данных.
Значение по умолчанию:
true
Все свойства, описанные ниже, являются параметрами времени выполнения, хранятся в базе данных и доступны в коде приложения через конфигурационный интерфейс FtsConfig.
- fts.enabled
-
Флаг, разрешающий использование функциональности FTS в проекте.
Значение данного флага может быть оперативно изменено с помощью атрибута Enabled JMX-бина
app-core.fts:type=FtsManager.Значение по умолчанию:
false
- fts.indexDir
-
Абсолютный путь к каталогу для хранения индексных файлов. Если не установлен, используется подкаталог
ftsindexрабочего каталога приложения (задаваемого свойствомcuba.dataDir), в стандартном варианте развертывания этоtomcat/work/app-core/ftsindex.Значение по умолчанию: не установлено
- fts.indexingHosts
-
Список (разделенный символом "|") серверов, которые должны поддерживать поисковый индекс в кластере. Каждый сервер представляется своим Server ID.
Например:
cuba.fts.indexingHosts = host1:8080/app-core|host2:8080/app-coreЗначение по умолчанию: не установлено, что означает, что постановка в очередь и индексирование производятся единственным текущим сервером.
- fts.indexingBatchSize
-
Количество записей, извлекаемое из очереди на индексирование за один вызов метода
processQueue().Данное ограничение актуально для ситуации, когда в очереди на индексацию оказывается сразу очень большое число записей, например, после выполнения метода
reindexAll()JMX-бинаapp-core.fts:type=FtsManager. В этом случае индексация выполняется порциями, что занимает больше времени, но создает ограниченную и предсказуемую нагрузку на сервер.Значение по умолчанию:
300
- fts.reindexBatchSize
-
Количество записей, помещаемое в очередь на индексацию за один вызов метода
reindexNextBatch().Значение по умолчанию:
5000
- fts.maxNumberOfSearchTermsInHitInfo
-
Максимальное количество вхождений искомого слова, которое будет добавлено в hit info для каждого из индексируемых полей сущности. Например, в сущности индексируется поле с типом
FileDescriptor. Если значение свойстваfts.maxNumberOfSearchTermsInHitInfoравно 2, то это значит, что в hit info будет добавлено только 2 первых вхождения искомого слова в файл. То же самое будет со всеми остальными индексируемыми полями сущности.Значение по умолчанию:
1
- fts.maxSearchResults
-
Максимальное количество результатов поиска.
Значение по умолчанию:
100