- @PrimaryKeyJoinColumn
-
Is used in the case of
JOINEDinheritance strategy to specify a foreign key column for the entity which refers to the primary key of the ancestor entity.Parameters:
-
name– the name of the foreign key column of the entity -
referencedColumnName– the name of primary key column of the ancestor entity
Example:
@PrimaryKeyJoinColumn(name = "CARD_ID", referencedColumnName = "ID") -
A newer version is available at the documentation home.
Preface
This manual provides the reference information for the CUBA platform and covers the most important topics of developing business applications with it.
Knowledge of the following technologies is required to use the platform:
-
Java Standard Edition
-
Relational databases (SQL, DDL)
Additionally, knowledge of the following technologies and frameworks will be helpful to get a deeper understanding of the platform:
This manual and other documentation related to the CUBA platform can be found at www.cuba-platform.com/manual. Video materials and presentations that can help you to understand the platform are available at www.cuba-platform.com/tutorials. You can also check out online demo applications at www.cuba-platform.com/online-demo.
If you have any suggestions for improvement of this Manual, please contact support at www.cuba-platform.com/support. When reporting errors in the documentation, please indicate the chapter and surrounding text to point the error.
1. Introduction
This chapter provides information about the CUBA platform features and requirements.
1.1. Overview
CUBA platform is an ideal tool for development teams working on line-of-business applications, typically having extensive data model, hundreds of screens and complex business logic.
Based on a mainstream technology stack, CUBA platform brings unparalleled productivity by utilizing a rich set of ready to use data-aware components, extensive scaffolding, visual interface designer and hot deploy.
Open architecture allows a developer to customize any part of the framework, providing high levels of control and flexibility. Developers have the freedom to use popular Java IDEs and have full access to the source code.
CUBA applications fit seamlessly into the corporate IT environment, supporting major databases and application servers, as well as popular aPaaS clouds. Streamlined clustered deployment ensures scalability and failover, while a generic REST API enables easy integration with other systems.
1.2. Technical Requirements
Minimum requirements for development using CUBA platform:
-
Memory – 4 GB
-
Hard drive space – 5 GB
-
Operating system: Microsoft Windows, Linux or macOS
1.3. Release Notes
CUBA platform changelog is available at http://files.cuba-platform.com/cuba/release-notes/6.5
2. Installation and Setup
Minimum software requirements are as follows:
-
Java SE Development Kit (JDK) 8. It is recommended that you use Oracle Java HotSpot VM.
In order to build and run projects outside Studio, you need to set the path to the JDK root directory in the
JAVA_HOMEenvironment variable, e.g.C:\Program Files\Java\jdk1.8.0_60. On Windows, you can do this at Computer → Properties → Advanced System Settings → Advanced → Environment variables. The value of the variable should be added to the System variables list. -
Java IDE: IntelliJ IDEA 13+ or Eclipse 4.3+. We recommend using IntelliJ IDEA (Community or Ultimate).
In the most basic scenario, the built-in HyperSQL (http://hsqldb.org) can be used as the database server. This is sufficient for exploring the platform capabilities and application prototyping. For building production applications, it is recommended to install and use one of the full-featured DBMS supported by the platform, like PostgreSQL for instance.
The web interface of the platform-based applications supports all popular browsers, including Google Chrome, Mozilla Firefox, Safari, Opera 15+, Internet Explorer 9+, Microsoft Edge.
|
Warning
|
Please make sure your environment does not contain |
2.1. CUBA Studio Installation
- Prerequisites
-
-
Make sure that Java SE Development Kit (JDK) 8 is installed by running the following command in the console:
java -versionThe command should return the Java version, e.g.
1.8.0_60. -
If you connect to the internet via a proxy server, some Java system properties must be passed to the JVM running Studio and Gradle. These properties are explained here: http://docs.oracle.com/javase/8/docs/technotes/guides/net/proxies.html (see properties for HTTP and HTTPS protocols).
It is recommended to set these properties system-wide in the
JAVA_OPTSenvironment variable. The Studio launch script passesJAVA_OPTSto the Java executable.
-
- Fresh installation of CUBA Studio
-
-
Download an appropriate installer or ZIP archive from https://www.cuba-platform.com/download.
-
Run the installer or unzip the archive to a local directory, e.g.
c:/work/studio -
Launch the installed application or open the command line, go to
bindirectory and runstudio -
In the CUBA Studio Server window, enter the following parameters:
-
Java home − JDK installation to be used for building and running projects. If you have set the
JAVA_HOMEenvironment variable as described in the beginning of this chapter, it will appear in this field. Otherwise, Studio will try to find your Java installation itself. -
Advanced button opens a dialog that allows you to enter a path to Gradle home directory. Leave it empty; in this case, the required Gradle distribution will be downloaded automatically.
If you want to use a local Gradle distribution, enter the path to the respective directory. For project build system to work correctly, Gradle 3.1 is required.
-
Server port − CUBA Studio server port (the default port is 8111).
-
IDE port − IDE plugin listening port (the default port is 48561).
-
Repository − binary artifacts repository URL and authentication parameters.
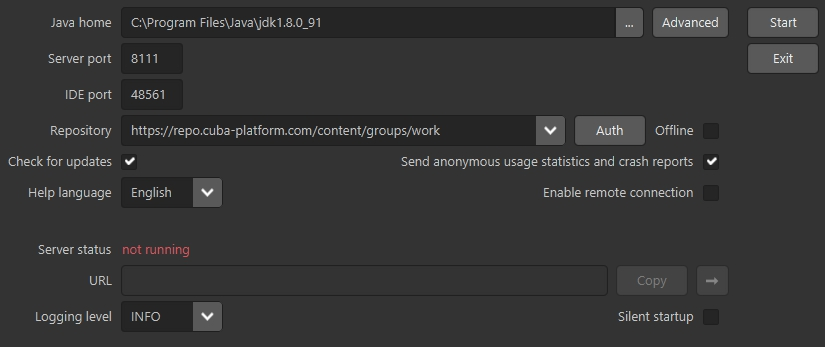
The following options are also available:
-
Check for updates - check for new versions on every start.
-
Help language - built-in help language.
-
Offline - enable working with projects without an Internet connection, provided that all the required libraries have been previously downloaded from the repository.
-
Send anonymous statistics and crash reports - enable Studio to send error statistics to developers.
-
Enable remote connection - by default, it is assumed that Studio runs on localhost. Select this checkbox if you need to connect to this Studio instance from a remote host.
-
Silent startup - if selected, the Studio server starts in tray and opens UI in default browser automatically. This option is available only for Windows and macOS.
-
-
Click Start to run the Studio server.
The server will download, run, and connect to the Gradle daemon. This may take a significant amount of time on first startup; on subsequent launches, this will take just a few seconds.
After that, the web server will be started, and the URL of the Studio interface will appear in the URL field. By clicking →, you can open the address in your default web browser; by clicking Copy you can copy the address to the clipboard.
-
Open the specified address in the web browser.
-
In the Studio web interface, click Create new to create a new project, or Import to add an existing one to the Recent list.
-
Once the project is opened, the Studio will download the source code of the platform components and save it to the local folder. Before building the project, it is recommended to wait until the download is finished and make sure that the background task indicator in the bottom left corner has faded out.
-
- Updating CUBA Studio
-
If you are updating Studio to a newer bug-fix version (e.g. from 6.5.0 to 6.5.1), install it to the existing folder, e.g. on Windows it would be
C:\Program Files (x86)\CUBA Studio 6.5. When installing a new minor or major version, use a separate folder, e.g.CUBA Studio 6.6.If installed from Windows EXE installer or ZIP archive, Studio supports auto-update on newer bug-fix releases. Update files are saved in the
~/.haulmont/studio/updatefolder. In case of any problems with the new version, you can remove the update files and Studio will revert to the version installed manually.Auto-update does not work for minor and major releases and if Studio was installed from macOS DMG. In this case, you should download new installer and run it manually.
2.2. IDE Integration
Take the following steps to integrate Studio with IntelliJ IDEA or Eclipse:
-
Open or create a new project in the Studio.
-
Switch to Project properties section and click Edit. Select the required Java IDE by checking IntelliJ IDEA or Eclipse.
-
Select Build > Create or update <IDE> project files in the Studio menu. The corresponding files will be created in the project directory.
-
For IntelliJ IDEA integration:
-
Run IntelliJ IDEA 13+ and install CUBA Framework Integration plugin, from the plugin repository: File > Settings > Plugins > Browse Repositories.
-
-
For Eclipse integration:
-
Run Eclipse 4.3+, open Help > Install New Software, add
http://files.cuba-platform.com/eclipse-update-siterepository and install the CUBA Plugin. -
In the CUBA section of the Window > Preferences menu, check Studio Integration Enabled, and click OK.
-
Please note that IDE: on port 48561 label has appeared in the bottom left corner of the Studio. Now the corresponding source code files will be opened in IDE when you click IDE buttons in the Studio.
3. Quick Start
This section describes the process of creating an application using CUBA Studio. Similar information is provided in the videos available at www.cuba-platform.com/quickstart.
Make sure that the necessary software is already installed and set up on your computer, see Installation and Setup.
Key stages of our application development:
-
Data model development including creation of entities describing application domain and corresponding database tables.
-
Development of the user interface screens enabling to create, view, update and delete data model entities.
3.1. Application Details
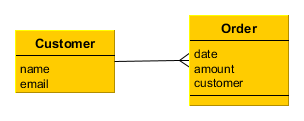
The application should maintain information about the customers and their orders.
A customer has the following attributes:
-
Name
-
Email
Order attributes:
-
Reference to a customer
-
Date
-
Amount
The application UI should contain:
-
Customers browser screen;
-
Customer editor screen, containing as well the list of this customer’s orders;
-
General orders browser screen;
-
Order editor screen.
The application should support user interface in English and Russian.
3.2. Creating a Project
-
Start CUBA Studio and open its web interface (See CUBA Studio Installation).
-
Click Create new.
-
Specify the name of the new project in the Project name field of the New project window – for example,
sales. The name should contain only Latin letters, numbers and underscores. Think carefully on the project name at this stage, as changing it later on will require complex manual intervention. -
The following fields below will be automatically populated:
-
Project path – the path to the new project directory. You can select the directory manually by clicking the … button next to the field. The Select folder window will appear with the list of folders n your hard drive. You can select one of those, or create a new directory by clicking the + button.
-
Project namespace – the namespace which will be used as a prefix for entity names and database tables. The namespace can consist of Latin letters only and should be as short as possible. For example, if the project name is
sales_2, the namespace can besalesorsal. -
Root package − the root package of Java classes. It can be adjusted later, but the classes generated at project creation will not be moved.
-
Platform version – the platform version used in the project. The platform artifacts will be automatically downloaded from the repository on project build.
-
-
Click OK. Empty project will be created in the specified
salesdirectory and the main Studio window will open. -
Assemble the project: select option Build > Assemble project in the Studio main menu. At this stage all required libraries will be downloaded and project artifacts will be assembled in
buildsubdirectories of the modules. -
Create the database on the local HyperSQL server: select option Run > Create database in the menu. The database name is the same as project namespace by default.
-
Select Run > Deploy menu option. Tomcat server with the deployed application will be installed in the project
deploysubdirectory. -
Select Run > Start application server option. The link next to the Web application caption in the status panel will become available in a few seconds so you will be able to open the application directly from Studio.
The username and password are
admin/admin.The running application contains two main menu items (Administration and Help), as well as security and administration subsystems functionality.
3.3. Creating Entities
Let us create the Customer entity class.
-
Go to the DATA MODEL tab in the navigation section and click New → Entity. The New entity dialog window will appear.
-
Enter the name of the entity class –
Customer– in the Class name field.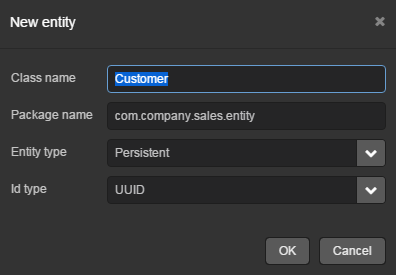
-
Click OK. The entity designer page will be displayed in the workspace.
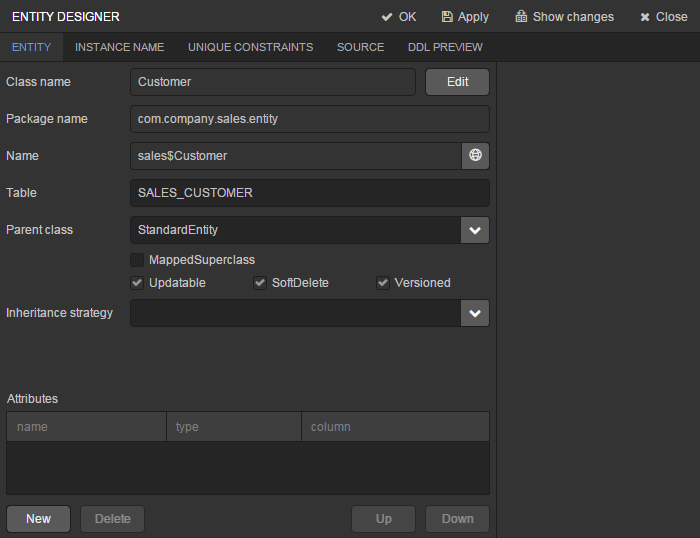
-
The entity name and the database table name will be automatically generated in the Name and the Table fields respectively.
-
Leave the existing value –
StandardEntity- in the Parent class field. -
Leave the Inheritance strategy field blank.
-
Click
 button next to the Name to open the Localized message window. Specify localization for the entity name for the available languages in it.
button next to the Name to open the Localized message window. Specify localization for the entity name for the available languages in it.
Next, let us create entity attributes. To do this, click the New button below the Attributes table.
-
Create attribute window will appear. Enter the name of the entity attribute −
name, in the Name field. SelectDATATYPEvalue in the Attribute type list, specifyStringattribute type in the Type field and then set the length of the text attribute to 100 characters in the Length field. Check the Mandatory box. The name of the database table column will be automatically generated in the Column field.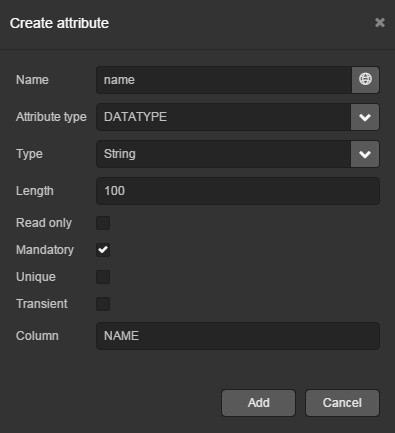
Now click
button next to the attribute name to open the Localized message window. Localize the attribute name in the available languages.Click Add to add the attribute.
-
emailattribute is created in the same way but the value in Length field should be set to50.
After creating the attributes, go to the Instance name tab in the entity designer to specify Name pattern. Select the name attribute in the Available attributes list and move it to the Name pattern attributes list by clicking the button with the right arrow on it.
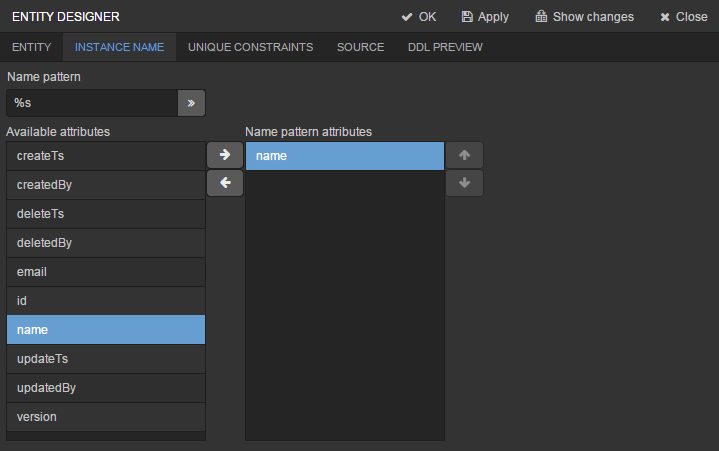
Customer entity creation is now complete. Click OK in the top panel to save the changes and close the page.
Let us create the Order entity. Click New entity option on the Entities tab. Enter the Class name − Order. The entity should have the following attributes:
-
Name −
customer, Attribute type −ASSOCIATION, Type −Customer, Cardinality −MANY_TO_ONE. -
Name −
date, Attribute type −DATATYPE, Type −Date. Check Mandatory box fordateattribute. -
Name −
amount, Attribute type −DATATYPE, Type −BigDecimal.
Specify localized caption for each of the attributes by clicking the button next to the attribute name.
3.4. Creating Database Tables
It is sufficient to click Generate DB scripts button in Entities tab on the navigation panel to create database tables. After that, Database scripts page will open. Both incremental DB update scripts from the current state (Update scripts) and initial DB creation scripts (Init tables, Init constraints, Init data) will be generated on this page.
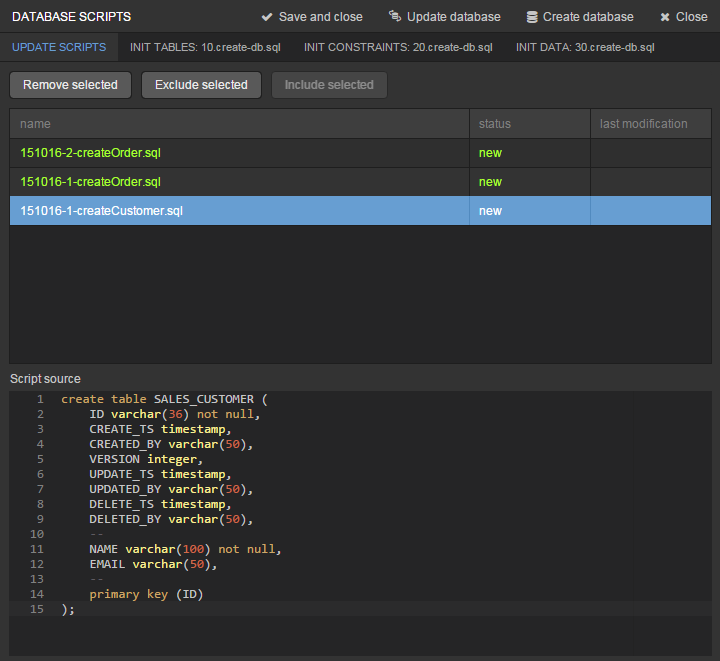
Click Save and close button to save the generated scripts. To run update scripts, stop the running application using the Run > Stop application server command, then select Run > Update database.
3.5. Creating User Interface Screens
Now we will create screens for customers and orders data management.
3.5.1. Screens for Customer
Select Customer entity in the DATA MODEL tab on the navigation panel to create standard screens for viewing and editing Customers. Click New → Generic UI screen at the top of the section. After that, the template browser page will appear.
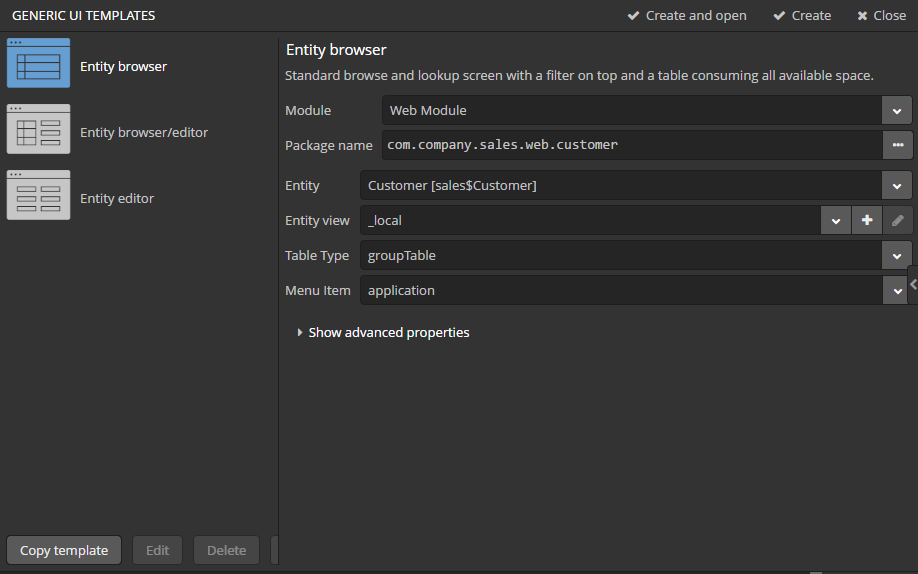
All fields in this dialog are already populated with default values, there is no need to change them. Click the Create button.
Next, select the Entity Editor template and click Create again.
customer-edit.xml and customer-browse.xml items will appear in Web Module on GENERIC UI tab of the navigation panel.
You can specify localized captions for the screens. For this, select a screen and click Edit to open the screen designer page. Go to the Properties tab. Click the button next to the Caption field and specify screen names in different locales. Alternatively, you can open messages.properties item located in the screens package and edit browseCaption and editCaption messages for available locales.
3.5.2. Order Screens
Order entity has the following distinction: since one of the attributes is the Order.customer reference attribute, you should define a view including this attribute (standard _local view does not include reference attributes).
Go to the DATA MODEL tab on the navigation panel, select the Order entity and click the New → View button. View designer page will open. Enter order-with-customer as the view name, click on customer attribute and select _minimal view for the Customer entity in the panel on the right.
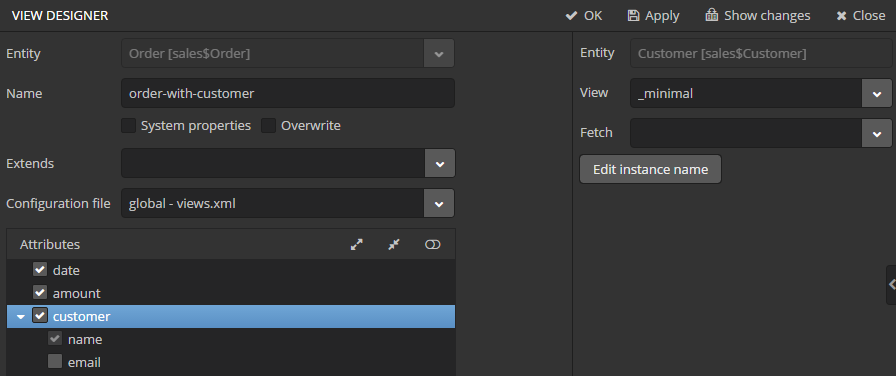
Click OK in the top panel.
After that, select the Order entity and click New → Generic UI screen. Select order-with-customer in the View fields in the browser template of the GENERIC UI TEMPLATES page and click Create. Repeat the same for the editor screen template.
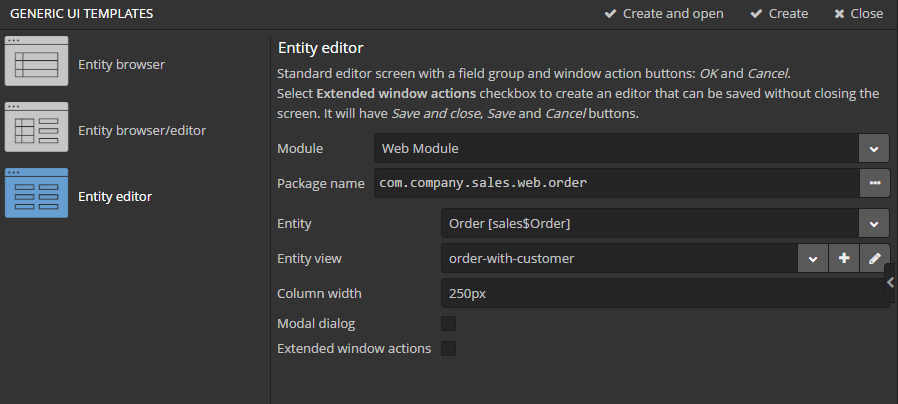
order-edit.xml and order-browse.xml items will appear in the Web Module on the GENERIC UI tab of the navigation panel.
You can specify localized captions for the Order screens as described above for the Customer screens.
3.5.3. Application Menu
At the moment of their creation, the screens were added to the application menu item of the default application menu. Let us rename it. Switch to the Main menu tab on the navigation panel and click Edit. The Menu designer page will open. Select the application menu item to edit its properties.
Enter the new value of the menu identifier − shop − in the Id field, then click the Caption edit button and set localized names of the menu item.
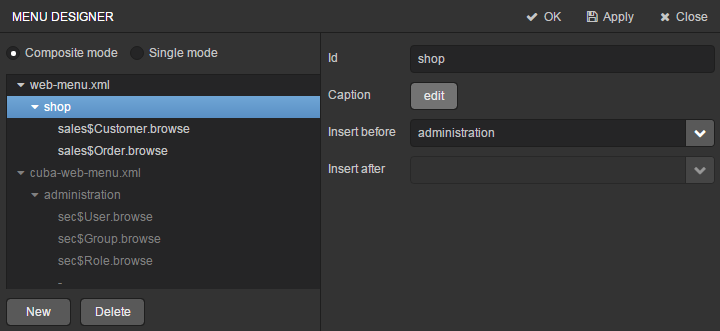
After editing the menu, click OK in the top panel.
3.5.4. Customer Editor With a List of Orders
Do the following to display the list of Orders in the Customers edit screen:
-
Go to the GENERIC UI tab on the navigation panel. Choose
customer-edit.xmlscreen and click Edit. -
Go to the Datasources tab on the screen designer page and click New.
-
Select the newly created data source in the list. Its attributes will appear in the right part of the page.
-
Specify
collectionDatasourcein the Type field. -
Select
com.sample.sales.entity.Orderentity in the Entity list. -
The data source identifier −
ordersDs- will be automatically generated in Id field. -
Select
_localview in the View list. -
Enter the following query in the Query field:
select o from sales$Order o where o.customer.id = :ds$customerDs order by o.dateThe query contains orders selection criterion with
ds$customerDsparameter. The parameter value named likeds${datasource_name}will contain id of the entity selected indatasource_namedatasource at the moment, in this case it is the id of the Customer being edited.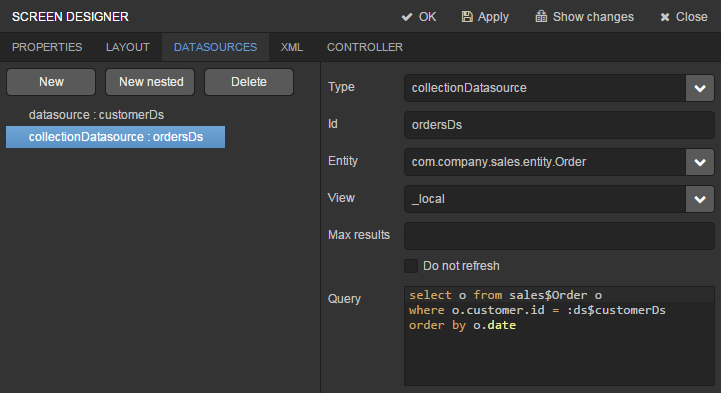
-
Click Apply to save the changes.
-
Next go to the Layout tab in the screen designer and find the
Labelcomponent in the components palette. Drag this component to the screen components hierarchy panel and place it betweenfieldGroupandwindowActions. Go to the Properties tab in the properties panel. Entermsg://ordersin the value field. Click the button next to the value field and define label values in available languages.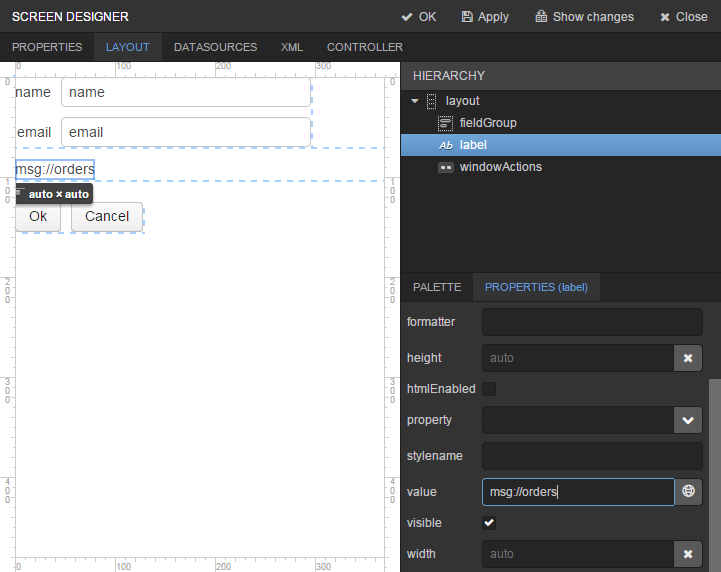
|
Tip
|
If the application is not intended to be used in multiple languages, the value in the value field can be entered straight in the required language. |
-
Drag
Tablefrom the components palette to components hierarchy panel and place it betweenlabelandwindowActions. Select this component in the hierarchy and specify table size in properties on the Layout tab: set100%in the width field and200pxin the height field.Go to the Properties tab. Set
ordersTablevalue as id, chooseorderDsfrom the list of available datasources.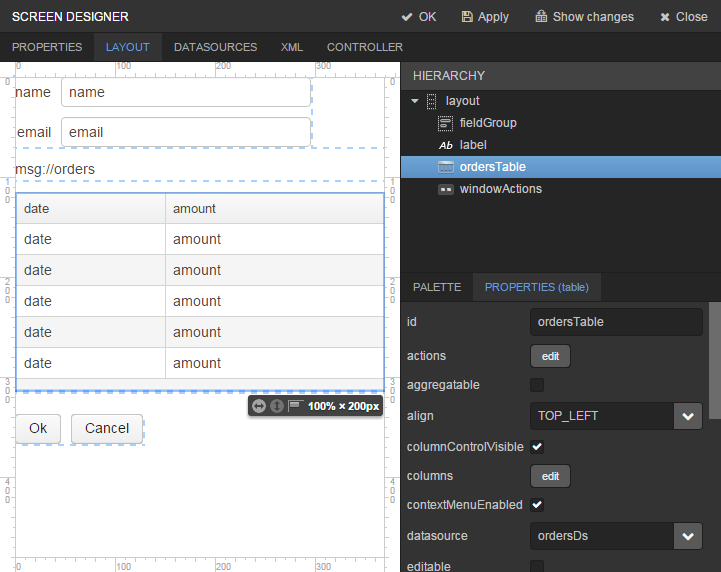
-
Click OK in the top panel to save the changes in the screen.
3.6. Running the Application
Now let us see how the created screens look in the actual application. Select Run > Restart application server.
Log in selecting English language in the login window. Open the Sales > Customers menu item:
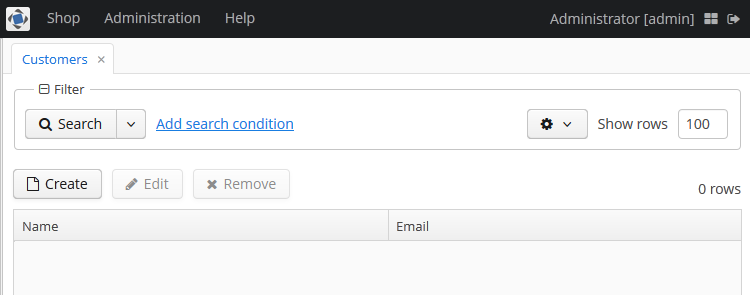
Figure 1. The Customers browser
Click Create:
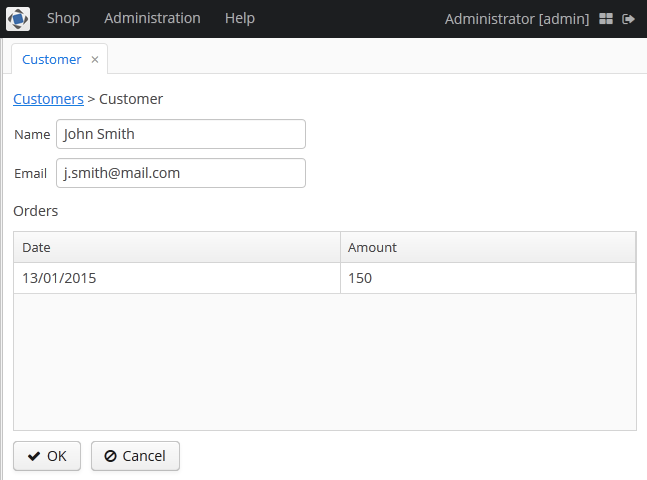
Figure 2. The Customer editor screen
Open the Sales > Orders menu item:
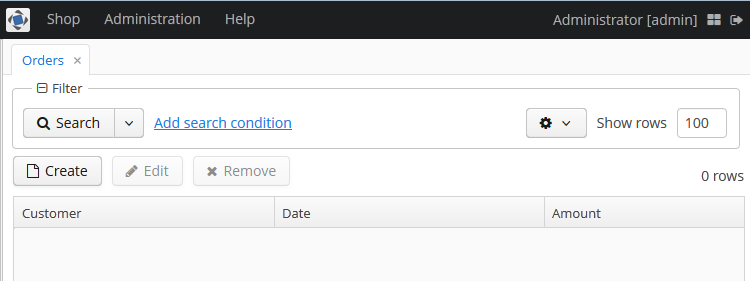
Figure 3. The Orders browser
Click Create:
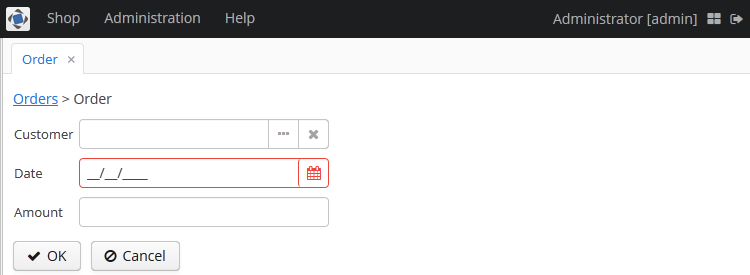
Figure 4. The Order editor
4. The Framework
This chapter contains detailed description of the platform architecture, components and mechanisms.
4.1. Architecture
This section covers the architecture of CUBA applications in different perspectives: by tiers, blocks, modules and components.
4.1.1. Application Tiers and Blocks
The platform enables building applications according to the classic three-tier pattern: client tier, middleware, database. The tier indicates the degree of "remoteness" from the stored data.
Further on, mainly middleware and client tiers will be described, therefore the words "all tiers" will refer to these tiers only.
Each tier enables creating one or more application blocks. A block is a separate executable program interacting with other blocks in the application. CUBA platform tools enable creation of blocks in the form of web or desktop applications.
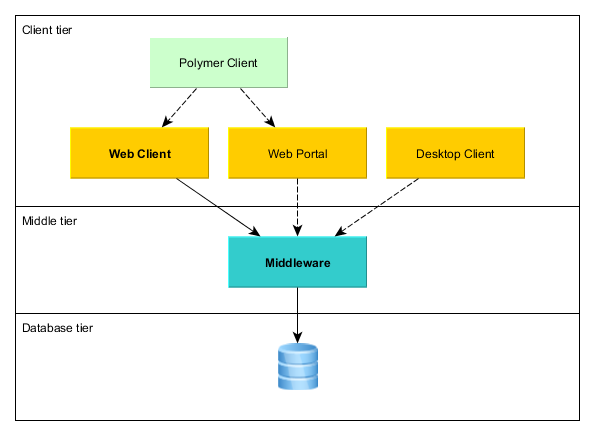
Figure 5. Application Tiers and Blocks
- Middleware
-
The middle tier contains core business logic of the application and provides access to the database. It is represented by a separate web application running on Java EE Web Profile standard container. See Middleware Components.
- Web Client
-
A main block of the client tier. It contains the interface designed primarily for internal users. It is represented by a separate web application running on Java EE Web Profile standard container. The user interface is implemented on the base of Vaadin framework. See Generic User Interface.
- Desktop Client
-
An additional block of the client tier. It contains the interface designed primarily for internal users. It is represented by a desktop Java application; the user interface is implemented on the base of Java Swing framework. See Generic User Interface.
- Web Portal
-
An additional block of the client tier. It can contain an interface for external users and entry points for integration with mobile devices and third-party applications. It is represented by a separate web application running on Java EE Web Profile standard container. The user interface is implemented on the base of Spring MVC framework. See Portal Components.
- Polymer Client
-
An optional client designed for external users and written in pure JavaScript. It is based on Google Polymer framework and communicates with the middleware via REST API running either in Web Client or in Web Portal blocks. See Polymer User Interface.
Middleware is the mandatory block for any application. User interface can be implemented by one or several blocks, such as Web Client and Polymer Client.
All of the Java-based client blocks interact with the middle tier uniformly via HTTP protocol enabling to deploy the middle tier arbitrarily, behind firewall as well. In the simplest case when the middle tier and the web client are deployed on the same server local interaction between them can bypass the network stack for better performance.
4.1.2. Application Modules
A module is the smallest structural part of CUBA application. It is a single module of application project and the corresponding JAR file with executable code.
Standard modules:
-
global – includes entity classes, service interfaces, and other classes common for all tiers. It is used in all application blocks.
-
core – implements services and all other components of the middle tier. It is used only in Middleware.
-
gui – common components of the generic user interface. It is used in Web Client and Desktop Client.
-
web – the implementation of the generic user interface based on Vaadin and other specific web client classes. It is used in Web Client block.
-
desktop – an optional module – implementation of generic user interface based on Java Swing, as well as other specific desktop client classes. It is used in Desktop Client block.
-
portal – an optional module – implementation of Web portal based on Spring MVC.
-
polymer-client – an optional module – implementation of Polymer User Interface in JavaScript.
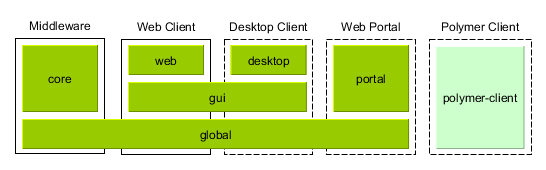
Figure 6. Application Modules
4.1.3. Application Components
The functionality of the platform is divided into several application components (aka base projects):
-
cuba – the main component containing all of the functionality described in this manual.
-
reports – reports generating subsystem.
-
fts – full-text search subsystem.
-
charts – subsystem for displaying charts and maps.
-
bpm – the mechanism of business processes execution according to the BPMN 2.0 standard.
An application always project depends on one ore more application components. It means that the application uses the component as a library and includes its functionality.
Any CUBA application depends on the cuba component. Other platform components are optional and can be included to the application only if needed. All optional components depend on cuba and can also contain dependencies between each other.
Below is a diagramm showing dependencies between the platform application components. Solid lines demonstrate mandatory dependencies, dashed lines mean optional ones.
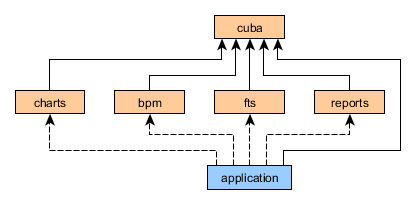
Any CUBA application can, in turn, be used as a component of another application. It enables decomposition of large projects to a set of functional modules, which can be developed independently. You can also create a set of custom application components in your organization and use them in multiple projects, effectively creating your own higher-level platform on top of CUBA. Below is an example of a possible structure of dependencies between application components.
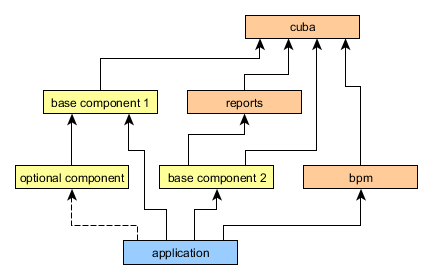
In order to be used as a component, an application project should contain an app-component.xml descriptor and a special entry in the manifest of the global module JAR. CUBA Studio allows you to generate the descriptor and manifest entry for the current project automatically.
See step-by-step guide to working with a custom application component in the Using Application Components section.
4.1.4. Application Structure
The above-listed architectural principles are directly reflected in the composition of assembled application. Let us consider the example of a simple application sales, which has two blocks – Middleware and Web Client; and includes functionality of the two application components - cuba and reports.
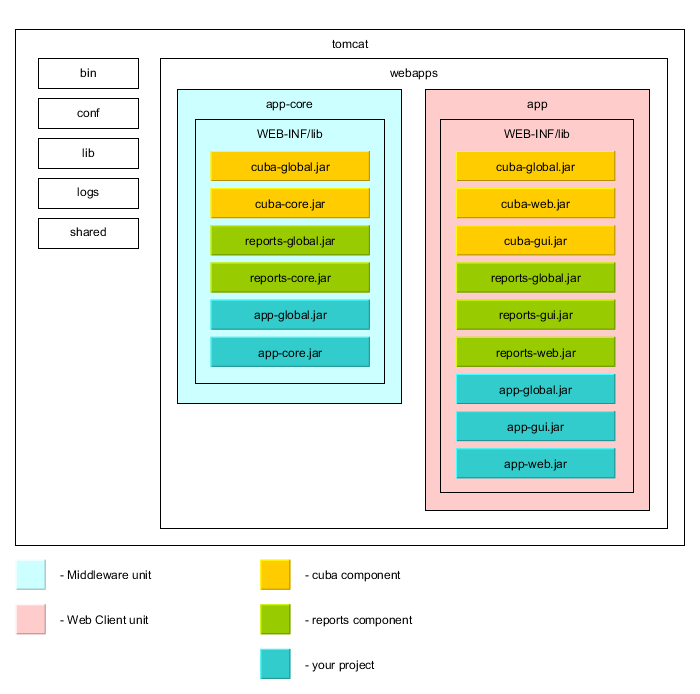
Figure 7. The structure of a simple application
The figure demonstrates the contents of several directories of the Tomcat server with a deployed application sales in it.
The Middleware block is represented by the app-core web application, the Web Client block – by the app web application. The executable code of the web applications can be found in directories WEB-INF/lib in sets of JAR files. Each JAR (artifact) is a result of assembly of one of the application or a component modules.
For instance, the contents of JAR files of the web application in middle tier app-core is determined by the facts that the Middleware block includes global and core modules, and the application uses cuba and reports components.
4.2. Common Components
This chapter covers platform components, which are common for all tiers of the application.
4.2.1. Data Model
Data model entities are divided into two categories:
-
Persistent – instances of such entities are stored in the database tables.
-
Non-persistent – instances exist only in memory.
The entities are characterized by their attributes. An attribute corresponds to a field and a pair of access methods (get / set) of the field. If the setter is omitted, the attribute becomes read only.
Persistent entities may include attributes that are not stored in the database. For non-persistent attribute the field is optional, creation of access methods will be sufficent.
The entity class should meet the following requirements:
-
Be inherited from one of the base classes provided by the platform (see below).
-
Have a set of fields and access methods corresponding to the entity attributes.
-
The class and its fields (or access methods if the attribute has no corresponding field) must be annotated in a definite way for correct operation of the ORM (in case of a persistent entity) and metadata frameworks.
-
To support potential entity extension, fields should be declared with the
protectedmodifier instead ofprivate.
The following attribute types of entities are supported:
-
java.lang.String -
java.lang.Boolean -
java.lang.Integer -
java.lang.Long -
java.lang.Double -
java.math.BigDecimal -
java.util.Date -
java.sql.Date -
java.sql.Time -
java.util.UUID -
byte[] -
enum -
entity
Base entity classes (see below) override equals() and hashCode() methods to check entity instances equivalence by comparing their identifiers. I.e., instances are considered equal, if their identifiers are equal.
4.2.1.1. Base Entity Classes
The base entity classes and interfaces are described in detail in this section.
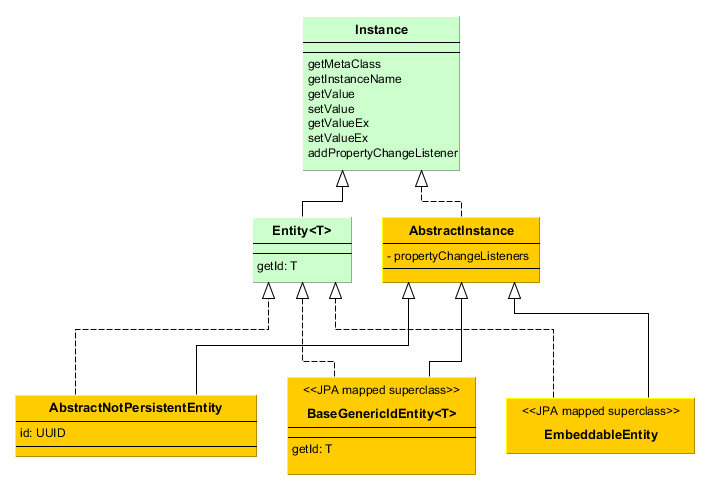
-
Instance– declares the basic methods for working with objects of application domain:-
getting references to the object meta-class;
-
generating the instance name;
-
reading/writing attribute values by name;
-
adding listeners receiving notifications about attribute changes.
-
-
Entity– extendsInstancewith entity identifier; at the same timeEntitydoes not define the type of the identifier leaving this option to descendants. -
AbstractInstance– implements the logic of working with attribute change listeners.WarningAbstractInstancestores the listeners inWeakReference, and if there are no external references to the added listener, it will be immediately destroyed by garbage collector. Normally, attribute change listeners are visual components and UI datasources that are always referenced by other objects, so there is no problem with listeners dropout. However, if a listener is created by application code and no objects refer to it in a natural way, it is necessary to save it in a certain object field apart from just adding it toInstance. -
AbstractNotPersistentEntity– base class of non-persistent entities. -
BaseGenericIdEntity– base class of persistent entities. It implementsEntitybut does not specify the type of the identifier (i.e. the primary key) of the entity. -
EmbeddableEntity- base class of embeddable persistent entities.
Below we consider base classes recommended for inheriting your entities from.
- StandardEntity
-
Inherit from
StandardEntityif you want a standard set of features: the primary key of UUID type, the instances have information on who and when created and modified them, require optimistic locking and soft deletion.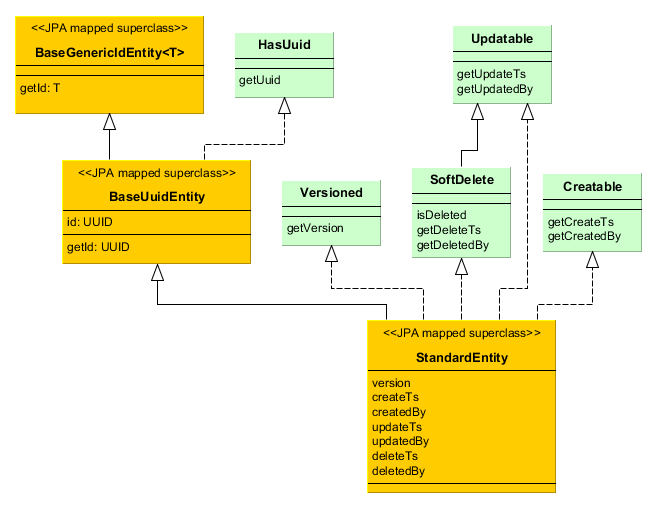
-
HasUuid– interface for entities having a globally unique identifier. -
Versioned– interface for entities supporting optimistic locking. -
Creatable– interface for entities that keep the information about when and by whom the instance was created. -
Updatable– interface for entities that keep the information about when and by whom the instance was last changed. -
SoftDelete– interface for entities supporting soft deletion.
-
- BaseUuidEntity
-
Inherit from
BaseUuidEntityif you want an entity with the primary key of UUID type but you don’t need all features ofStandardEntity. You can implement some of the interfacesCreatable,Versioned, etc. in your concrete entity class.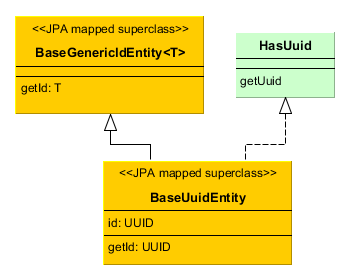
- BaseLongIdEntity
-
Inherit from
BaseLongIdEntityorBaseIntegerIdEntityif you want an entity with the primary key of theLongorIntegertype. You can implement some of the interfacesCreatable,Versioned, etc. in your concrete entity class. ImplementingHasUuidis highly recommended, as it enables some optimizations and allows you to identify your instances uniquely in a distributed environment.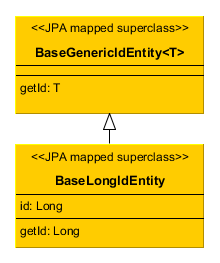
- BaseStringIdEntity
-
Inherit from
BaseStringIdEntityif you want an entity with the primary key of theStringtype. You can implement some of the interfacesCreatable,Versioned, etc. in your concrete entity class. ImplementingHasUuidis highly recommended, as it enables some optimizations and allows you to identify your instances uniquely in a distributed environment. The concrete entity class must have a string field annotated with the@IdJPA annotation.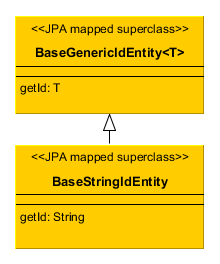
- BaseIdentityIdEntity
-
Inherit from
BaseIdentityIdEntityif you need to map the entity to a table with IDENTITY primary key. You can implement some of the interfacesCreatable,Versioned, etc. in your concrete entity class. ImplementingHasUuidis highly recommended, as it enables some optimizations and allows you to identify your instances uniquely in a distributed environment. Theidattribute of the entity (i.e. getId/setId methods) will be of typeIdProxywhich is designed to substitute the real identifier until it is generated by the database on insert.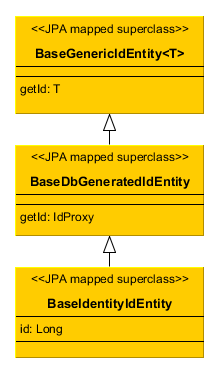
- BaseGenericIdEntity
-
Inherit from
BaseGenericIdEntitydirectly if you need to map the entity to a table with a composite key. In this case, the concrete entity class must have a field of the embeddable type representing the key, annotated with the@EmbeddedIdJPA annotation.
4.2.1.2. Entity Annotations
This section describes all annotations of entity classes and attributes supported by the platform.
Annotations from the javax.persistence package are required for JPA, annotations from com.haulmont.* packages are designed for metadata management and other mechanisms of the platform.
In this manual, if an annotation is identified by a simple class name, it refers to a platform class, located in one of the com.haulmont.* packages.
4.2.1.2.1. Class Annotations
- @Embeddable
-
Defines an embedded entity stored in the same table as the owning entity.
@MetaClass annotation should be used to specify the entity name.
- @EnableRestore
-
Indicates that the entity instances are available for recovery after soft deletion on the
core$Entity.restorescreen available through the Administration > Data Recovery main menu item.
- @Entity
-
Declares a class to be a data model entity.
Parameters:
-
name– the name of the entity, must begin with a prefix, separated by a$sign. It is recommended to use a short name of the project as a prefix to form a separate namespace.
Example:
@Entity(name = "sales$Customer") -
- @Extends
-
Indicates that the entity is an extension and it should be used everywhere instead of the base entity. See Functionality Extension.
- @DiscriminatorColumn
-
Is used for defining a database column responsible for the distinction of entity types in the cases of
SINGLE_TABLEandJOINEDinheritance strategies.Parameters:
-
name– the discriminator column name -
discriminatorType– the discriminator column type
Example:
@DiscriminatorColumn(name = "TYPE", discriminatorType = DiscriminatorType.INTEGER) -
- @DiscriminatorValue
-
Defines the discriminator column value for this entity.
Example:
@DiscriminatorValue("0")
- @Inheritance
-
Defines the inheritance strategy to be used for an entity class hierarchy. It is specified on the entity class that is the root of the entity class hierarchy.
Parameters:
-
strategy– inheritance strategy,SINGLE_TABLEby default
-
- @Listeners
-
Defines the list of listeners intended for reaction to the entity instance lifecycle events on the middle tier.
The annotation value should be a string or an array of strings containing bean names of the listeners. See Entity Listeners.
Examples:
@Listeners("sample_UserEntityListener")@Listeners({"sample_FooListener","sample_BarListener"})
- @MappedSuperclass
Defines that the class is an ancestor for some entities and its attributes must be used as part of descendant entities. Such class is not associated with any particular database table.
- @MetaClass
-
Is used for declaring non-persistent or embedded entity (meaning that
@javax.persistence.Entityannotation cannot be applied)Parameters:
-
name– the entity name, must begin with a prefix, separated by a$sign. It is recommended to use a short name of the project as prefix to form a separate namespace.
Example:
@MetaClass(name = "sales$Customer") -
- @NamePattern
-
Determines the way of getting the name of the instance returned by the
Instance.getInstanceName()method.The annotation value should be a string in the
{0}|{1}format, where:-
{0}– formatting string according to theString.format()rules, or this object method name with the prefix#. The method should returnStringand should have no parameters. -
{1}– a list of field names separated by commas, corresponding to{0}format. If the method is used in{0}, the list of fields is still required as it forms the_minimalview.
Examples:
@NamePattern("%s|name")@NamePattern("#getCaption|login,name") -
- @PostConstruct
-
This annotation can be specified for a method. Such method will be invoked right after the entity instance is created by the Metadata.create() method. This is convenient when instance initialization requires invocation of managed beans. For example, see Entity Fields Initialization.
- @SystemLevel
-
Indicates that the entity is system only and should not be available for selection in various lists of entities, such as generic filter parameter types or dynamic attribute type.
- @Table
-
Defines database table for the given entity.
Parameters:
-
name– the table name
Example:
@Table(name = "SALES_CUSTOMER") -
- @TrackEditScreenHistory
-
Indicates that editor screens opening history will be recorded with the ability to display it on the
sec$ScreenHistory.browsescreen available through the Help > History main menu item.
4.2.1.2.2. Attribute Annotations
Attribute annotations should be set for the corresponding fields, with the following exception: if there is a need to declare read-only, non-persistent attribute foo, it is sufficient to create getFoo() method and annotate it with @MetaProperty.
- @Column
-
Defines DB column for storing attribute values.
Parameters:
-
name– the column name. -
length– (optional parameter,255by default) – the length of the column. It is also used for metadata generation and ultimately, can limit the maximum length of the input text in visual components bound to this attribute. Add the@Lobannotation to remove restriction on the attribute length. -
nullable– (optional parameter,trueby default) – determines if an attribute can containnullvalue. Whennullable = falseJPA ensures that the field has a value when saved. In addition, visual components working with the attribute can request the user to enter a value.
-
- @Composition
-
Indicates that the relationship is a composition, which is a stronger variant of the association. Essentially this means that the related entity should only exist as a part of the owning entity, i.e. be created and deleted together with it.
For example, a list of items in an order (
Orderclass contains a collection ofIteminstances):@OneToMany(mappedBy = "order") @Composition protected List<Item> items;Choosing
@Compositionannotation as the relationship type enables making use of a special commit mode for datasources in edit screens. In this mode, the changes to related instances are only stored when the master entity is committed. See Editing Composite Entities for details.
- @Embedded
-
Defines a reference attribute of embeddable type. The referenced entity should have
@Embeddableannotation.Example:
@Embedded protected Address address;
- @EmbeddedParameters
-
By default, ORM does not create an instance of embedded entity if all its attributes are null in the database. You can use the
@EmbeddedParametersannotation to specify a different behavior when an instance is always non-null, for example:@Embedded @EmbeddedParameters(nullAllowed = false) protected Address address;
- @Id
-
See javax.persistence.Id.
Indicates that the attribute is the entity primary key. Typically, this annotation is set on the field of a base class, such as BaseUuidEntity. Using this annotation for a specific entity class is required only in case of inheritance from the
BaseStringIdEntitybase class (i.e. creating an entity with a string primary key).
- @IgnoreUserTimeZone
-
Makes the platform to ignore the user’s time zone (if it is set for the current session) for an attribute of the timestamp type (annotated with
@javax.persistence.Temporal.TIMESTAMP).
- @JoinColumn
-
Defines DB column that determines the relationship between entities. Presence of this annotation indicates the owning side of the association.
Parameters:
-
name– the column name
Example:
@ManyToOne(fetch = FetchType.LAZY) @JoinColumn(name = "CUSTOMER_ID") protected Customer customer; -
- @JoinTable
-
Defines a join table on the owning side of
@ManyToManyrelationship.Parameters:
-
name– the join table name -
joinColumns–@JoinColumnelement in the join table corresponding to primary key of the owning side of the relationship (the one containing@JoinTableannotation) -
inverseJoinColumns–@JoinColumnelement in the join table corresponding to primary key of the non-owning side of the relationship.
Example of the
customersattribute of theGroupclass on the owning side of the relationship:@ManyToMany @JoinTable(name = "SALES_CUSTOMER_GROUP_LINK", joinColumns = @JoinColumn(name = "GROUP_ID"), inverseJoinColumns = @JoinColumn(name = "CUSTOMER_ID")) protected Set<Customer> customers;Example of the
groupsattribute of theCustomerclass on non-owning side of the same relationship:@ManyToMany(mappedBy = "customers") protected Set<Group> groups; -
- @Lob
-
Indicates that the attribute does not have any length restrictions. This annotation is used together with the
@Columnannotation. If@Lobis set, the default or explicitly defined length in@Columnis ignored.Example:
@Column(name = "DESCRIPTION") @Lob private String description;
- @LocalizedValue
-
Determines a method for retrieving a localized value for an attribute, using MessageTools`.getLocValue()` method.
Parameters:
-
messagePack– explicit indication of the package, from which a localized message will be taken, for example,com.haulmont.cuba.core.entity. -
messagePackExpr– expression defining the path to the attribute, containing a package name from which the localized message should be taken (for example,proc.messagesPack). The path starts from the attribute of the current entity.
The annotation in the example below indicates that localized message for the
stateattribute value should be taken from the package name defined in themessagesPackattribute of theprocentity.@Column(name = "STATE") @LocalizedValue(messagePackExpr = "proc.messagesPack") protected String state; @ManyToOne(fetch = FetchType.LAZY) @JoinColumn(name = "PROC_ID") protected Proc proc; -
- @Lookup
-
Defines the lookup type settings for the reference attributes.
Parameters:
-
type- the default value isSCREEN, so a reference is selected from a lookup screen. TheDROPDOWNvalue enables to select the reference from a drop-down list. If the lookup type is set toDROPDOWN, Studio will generate options datasource when scaffolding editor screen. Thus, the Lookup type parameter should be set before generation of an entity editor screen. Besides, the Filter component will allow a user to select parameter of this type from a drop-down list instead of lookup screen. -
actions- defines the actions to be used in a PickerField component inside the FieldGroup by default. Possible values:lookup,clear,open.
@Lookup(type = LookupType.DROPDOWN, actions = {"open"}) @ManyToOne(fetch = FetchType.LAZY) @JoinColumn(name = "CUSTOMER_ID") protected Customer customer; -
- @ManyToMany
-
Defines a collection attribute with many-to-many relationship type.
Many-to-many relationship always has an owning side and can also have inverse, non-owning side. The owning side should be marked with additional
@JoinTableannotation, and the non-owning side – withmappedByparameter.Parameters:
-
mappedBy– the field of the referenced entity, which owns the relationship. It must only be set on the non-owning side of the relationship. -
targetEntity– the type of referenced entity. This parameter is optional if the collection is declared using Java generics. -
fetch– (optional parameter,LAZYby default) – determines whether JPA will eagerly fetch the collection of referenced entities. This parameter should always remainLAZY, since retrieval of referenced entities in CUBA-application is determined dynamically by the views mechanism.
-
- @ManyToOne
-
Defines a reference attribute with many-to-one relationship type.
Parameters:
-
fetch– (EAGERby default) parameter that determines whether JPA will eagerly fetch the referenced entity. This parameter should always be set toLAZY, since retrieval of referenced entity in CUBA-application is determined dynamically by the views mechanism. -
optional– (optional parameter,trueby default) – indicates whether the attribute can containnullvalue. Ifoptional = falseJPA ensures the existence of reference when the entity is saved. In addition, the visual components working with this attribute can request the user to enter a value.
For example, several
Orderinstances refer to the sameCustomerinstance. In this case theOrder.customerattribute should have the following annotations:@ManyToOne(fetch = FetchType.LAZY) @JoinColumn(name = "CUSTOMER_ID") protected Customer customer; -
- @MetaProperty
-
Indicates that metadata should include the annotated attribute. This annotation can be set for a field or for a getter method, if there is no corresponding field.
This annotation is not required for the fields already containing the following annotations from
javax.persistencepackage:@Column,@OneToOne,@OneToMany,@ManyToOne,@ManyToMany,@Embedded. Such fields are included in metadata automatically. Thus,@MetaPropertyis mainly used for defining non-persistent attributes of the entities.Parameters (optional):
-
mandatory- determines whether the attribute can containnullvalue. Ifmandatory = true, visual components working with this attribute can request the user to enter a value. -
datatype- explicitly defines a datatype that overrides a datatype inferred from the attribute Java type. -
related- defines the array of related persistent attributes to be fetched from the database when this property is included in a view.
Field example:
@Transient @MetaProperty protected String token;Method example:
@MetaProperty public String getLocValue() { if (!StringUtils.isEmpty(messagesPack)) { return AppBeans.get(Messsages.class).getMessage(messagesPack, value); } else { return value; } } -
- @OnDelete
-
Determines related entities handling policy in case of soft deletion of the entity, containing the attribute. See Soft Deletion.
Example:
@OneToMany(mappedBy = "group") @OnDelete(DeletePolicy.CASCADE) private Set<Constraint> constraints;
- @OnDeleteInverse
-
Determines related entities handling policy in case of soft deletion of the entity from the inverse side of the relationship. See Soft Deletion.
Example:
@ManyToOne @JoinColumn(name = "DRIVER_ID") @OnDeleteInverse(DeletePolicy.DENY) private Driver driver;
- @OneToMany
-
Defines a collection attribute with one-to-many relationship type.
Parameters:
-
mappedBy– the field of the referenced entity, which owns the relationship. -
targetEntity– the type of referenced entity. This parameter is optional if the collection is declared using Java generics. -
fetch– (optional parameter,LAZYby default) – determines whether JPA will eagerly fetch the collection of referenced entities. This parameter should always remainLAZY, since retrieval of referenced entities in CUBA-application is determined dynamically by the views mechanism.
For example, several
Iteminstances refer to the sameOrderinstance using@ManyToOnefieldItem.order. In this case theOrderclass can contain a collection ofIteminstances:@OneToMany(mappedBy = "order") protected Set<Item> items; -
- @OneToOne
-
Defines a reference attribute with one-to-one relationship type.
Parameters:
-
fetch– (EAGERby default) determines whether JPA will eagerly fetch the referenced entity. This parameter should be set toLAZY, since retrieval of referenced entities in CUBA-application is determined dynamically by the views mechanism. -
mappedBy– the field of the referenced entity, which owns the relationship. It must only be set on the non-owning side of the relationship. -
optional– (optional parameter,trueby default) – indicates whether the attribute can containnullvalue. Ifoptional = falseJPA ensures the existence of reference when the entity is saved. In addition, the visual components working with this attribute can request the user to enter a value.
Example of owning side of the relationship in the
Driverclass:@OneToOne(fetch = FetchType.LAZY) @JoinColumn(name = "CALLSIGN_ID") protected DriverCallsign callsign;Example of non-owning side of the relationship in the
DriverCallsignclass:@OneToOne(fetch = FetchType.LAZY, mappedBy = "callsign") protected Driver driver; -
- @OrderBy
-
Determines the order of elements in a collection attribute at the point when the association is retrieved from the database. This annotation should be specified for ordered Java collections such as
ListorLinkedHashSetto get a predictable sequence of elements.Parameters:
-
value– string, determines the order in the format:
orderby_list::= orderby_item [,orderby_item]* orderby_item::= property_or_field_name [ASC | DESC]Example:
@OneToMany(mappedBy = "user") @OrderBy("createTs") protected List<UserRole> userRoles; -
- @Temporal
-
Specifies the type of the stored value for
java.util.Dateattribute: date, time or date+time.Parameters:
-
value– the type of the stored value:DATE,TIME,TIMESTAMP
Example:
@Column(name = "START_DATE") @Temporal(TemporalType.DATE) protected Date startDate; -
- @Transient
-
Indicates that field is not stored in the database, meaning it is non-persistent.
The fields supported by JPA types (See http://docs.oracle.com/javaee/7/api/javax/persistence/Basic.html) are persistent by default, that is why
@Transientannotation is mandatory for non-persistent attribute of such type.@MetaProperty annotation is required if
@Transientattribute should be included in metadata.
- @Version
-
Indicates that the annotated field stores a version for optimistic locking support.
Such field is required when an entity class implements the
Versionedinterface (StandardEntitybase class already contains such field).Example:
@Version @Column(name = "VERSION") private Integer version;
4.2.1.3. Enum Attributes
The standard use of JPA for enum attributes involves an integer database field containing a value obtained from the ordinal() method. This approach may lead to the following issues with extending a system in production:
-
An entity instance cannot be loaded, if the value of the enum in the database does not equal to any
ordinalvalue. -
It is impossible to add a new value between the existing ones, which is important when sorting by enumeration value (order by).
CUBA-style approach to solving these problems is to detach the value stored in the database from ordinal value of the enumeration. In order to do this, the field of the entity should be declared with the type, stored in the database (Integer or String), while the access methods (getter / setter) should be created with the actual enumeration type.
Example:
@Entity(name = "sales$Customer")
@Table(name = "SALES_CUSTOMER")
public class Customer extends StandardEntity {
@Column(name = "GRADE")
protected Integer grade;
public CustomerGrade getGrade() {
return grade == null ? null : CustomerGrade.fromId(grade);
}
public void setGrade(CustomerGrade grade) {
this.grade = grade == null ? null : grade.getId();
}
...
}In this case, the enumeration class can look like this:
public enum CustomerGrade implements EnumClass<Integer> {
PREMIUM(10),
HIGH(20),
MEDIUM(30);
private Integer id;
CustomerGrade(Integer id) {
this.id = id;
}
@Override
public Integer getId() {
return id;
}
public static CustomerGrade fromId(Integer id) {
for (CustomerGrade grade : CustomerGrade.values()) {
if (grade.getId().equals(id))
return grade;
}
return null;
}
}For correct reflection in metadata, the enumeration class must implement the EnumClass interface.
As the examples show, grade attribute corresponds to the Integer type value stored in the database, which is specified by the id field of CustomerGrade enumeration, namely 10, 20 or 30. At the same time, the application code and metadata framework use CustomerGrade enum through access methods, which perform the actual conversion.
A call to getGrade() method will simply return null, if the value in the database does not correspond to any of the enumeration values. In order to add a new value, for example, HIGHER, between HIGH and PREMIUM, it is sufficient to add new enumeration value with id = 15, which ensures that sorting by Customer.grade field remains correct.
The Integer field type provides the ordered list of constants and enables sorting in JPQL and SQL queries (>, <, >=, ⇐, order by), not to mention the negligible issue of database space and performance. On the other hand, Integer values are not self-explanatory in query results, that complicates debugging and using raw data from the database or in serialized formats. In this regard, the String type is more convenient.
Enumerations can be created in CUBA Studio on the DATA MODEL tab (New → Enumeration). To be used as an entity attribute, choose ENUM in the Attribute type field of the attribute editor and select the Enumeration class in the Type field. Enumeration values can be associated with localized names that will be displayed in the user interface of the application.
4.2.1.4. Soft Deletion
CUBA platform supports soft deletion mode, when the records are not deleted from the database, but instead, marked in a special way, so that they become inaccessible for common use. Later, these records can be either completely removed from the database using some kind of scheduled procedure or restored.
Soft deletion mechanism is transparent for an application developer, the only requirement is for entity class to implement SoftDelete interface. The platform will adjust data operations automatically.
Soft deletion mode offers the following benefits:
-
Significantly reduces the risk of data loss caused by incorrect user actions.
-
Enables making certain records inaccessible instantly even if there are references to them.
Using Orders-Customers data model as an example, let’s assume that a certain customer has made several orders but we need to make the customer instance inaccessible for users. This is impossible with traditional hard deletion, as deletion of a customer instance requires either deletion of all related orders or setting to null all references to the customer (meaning data loss). After soft deletion, the customer instance becomes unavailable for search and modification; however, a user can see the name of the customer in the order editor, as deletion attribute is purposely ignored when the related entities are fetched.
The standard behavior above can be modified with related entities processing policy.
The deleted entity instances can be manually restored on the Restore Deleted Entities screen available from the Administration menu of an application. This functionality is designed only for application administrators supposed to have all permissions to all entities, and should be used carefully, so it is recommended to deny access to this screen for simple users.
The negative impact of soft deletion is increase in database size and likely need for additional cleanup procedures.
4.2.1.4.1. Use of Soft Deletion
To support soft deletion, the entity class should implement SoftDelete interface, and the corresponding database table should contain the following columns:
-
DELETE_TS– when the record was deleted. -
DELETED_BY– the login of the user who deleted the record.
The default behavior for instances implementing SoftDelete interface, is that soft deleted entities are not returned by queries or search by id. If required, this behavior can by dynamically turned off using the following methods:
-
Calling
setSoftDeletion(false)for the current EntityManager instance. -
Calling
setSoftDeletion(false)forLoadContextobject when requesting data via DataManager. -
On the datasource level – calling
CollectionDatasource.setSoftDeletion(false)or settingsoftDeletion="false"attribute ofcollectionDatasourceelement in the screen’s XML-descriptor.
In soft deletion mode, the platform automatically filters out the deleted instances when loading by identifier and when using JPQL queries, as well as the deleted elements of the related entities in collection attributes. However, related entities in single-value (*ToOne) attributes are loaded, regardless of whether the related instance was deleted or not.
4.2.1.4.2. Related Entities Processing Policy
The platform offers a mechanism for managing related entities when deleting, which is largely similar to ON DELETE rules for database foreign keys. This mechanism works on the middle tier and uses @OnDelete, @OnDeleteInverse annotations on entity attributes.
@OnDelete annotation is processed when the entity in which this annotation is found is deleted, but not the one pointed to by this annotation (this is the main difference from cascade deletion at the database level).
@OnDeleteInverse annotation is processed when the entity which it points to is deleted (which is similar to cascade deletion at foreign key level in the database). This annotation is useful when the object being deleted has no attribute that can be checked before deletion. Typically, the object being checked has a reference to the object being deleted, and this is the attribute that should be annotated with @OnDeleteInverse.
Annotation value can be:
-
DeletePolicy.DENY– prohibits entity deletion, if the annotated attribute is notnullor not an empty collection. -
DeletePolicy.CASCADE– cascade deletion of the annotated attribute. -
DeletePolicy.UNLINK– disconnect the link with the annotated attribute. It is reasonable to disconnect the link only in the owner side of the association – the one with@JoinColumnannotation in the entity class.
Examples:
-
Prohibit deletion of entity with references:
DeletePolicyExceptionwill be thrown if you try to deleteCustomerinstance, which is referred to by at least oneOrder.Order.java@ManyToOne(fetch = FetchType.LAZY) @JoinColumn(name = "CUSTOMER_ID") @OnDeleteInverse(DeletePolicy.DENY) protected Customer customer;Customer.java@OneToMany(mappedBy = "customer") protected List<Order> orders;Messages in the exception window can be localized in the main message pack. Use the following keys:
-
deletePolicy.caption- notification caption. -
deletePolicy.references.message- notification message. -
deletePolicy.caption.Customer- notification caption for concrete entity. -
deletePolicy.references.message.Customer- notification message for concrete entity.
-
-
Cascade deletion of related collection elements: deletion of
Roleinstance causes allPermissioninstances to be deleted as well.Role.java@OneToMany(mappedBy = "role") @OnDelete(DeletePolicy.CASCADE) protected Set<Permission> permissions;Permission.java@ManyToOne(fetch = FetchType.LAZY) @JoinColumn(name = "ROLE_ID") protected Role role; -
Disconnect the links with related collection elements: deletion of
Roleinstance leads to setting to null references to thisRolefor allPermissioninstances included in the collection.Role.java@OneToMany(mappedBy = "role") protected Set<Permission> permissions;Permission.java@ManyToOne(fetch = FetchType.LAZY) @JoinColumn(name = "ROLE_ID") @OnDeleteInverse(DeletePolicy.UNLINK) protected Role role;
Implementation notes:
-
Related entities policy is processed on Middleware when saving entities to the database.
-
Be careful when using
@OnDeleteInversetogether withCASCADEandUNLINKpolicies. During this process, all instances of the related objects are fetched from the database, modified and then saved.For example, if
@OnDeleteInverse(CASCADE)policy is set onJob.customerattribute in aCustomer–Jobassociation with many jobs to one customer, if you set@OnDeleteInverse(CASCADE)policy onJob.customerattribute, all jobs will be retrieved and modified when deleting a Customer instance. This may overload the application server or the database.On the other hand, using
@OnDeleteInverse(DENY)is safe, as it only involves counting the number of the related objects. If there are more than0, an exception is thrown. This makes use of@OnDeleteInverse(DENY)suitable forJob.customerattribute. -
The
UNLINKpolicy for one-to-many and many-to-many collection attributes is not supported:UnsupportedOperationExceptionwill be thrown if you try to delete an entity instance on the owner side of the association. For example, the following delete policy will not work:Owner.java@JoinTable(name = "SAMPLE_OWNER_SUBORDINATE_LINK", joinColumns = @JoinColumn(name = "OWNER_ID"), inverseJoinColumns = @JoinColumn(name = "SUBORDINATE_ID")) @OnDelete(DeletePolicy.UNLINK) @ManyToMany protected List<Subordinate> subordinate;
4.2.1.4.3. Unique Constraints at Database Level
In order to apply unique constraints for certain value in the soft deletion mode, at least one non-deleted record with this value and an arbitrary number of deleted records with the same value may exist in database.
This logic can be implemented in a specific way for each database server type:
-
If database server supports partial indexes (e.g. PostgreSQL), unique restrictions can be achieved as follows:
create unique index IDX_SEC_USER_UNIQ_LOGIN on SEC_USER (LOGIN_LC) where DELETE_TS is null -
If database server does not support partial indexes (e.g. Microsoft SQL Server 2005), DELETE_TS field can be included in the unique index:
create unique index IDX_SEC_USER_UNIQ_LOGIN on SEC_USER (LOGIN_LC, DELETE_TS)
4.2.2. Metadata Framework
Metadata framework is used to support efficient work with data model in CUBA-applications. The framework:
-
provides API for obtaining information about entities, their attributes and relations between the entities; it is also used for traversing object graphs;
-
serves as a specialized and more convenient alternative for Java Reflection API;
-
controls permitted data types and relationships between entities;
-
enables implementation of universal mechanisms for operations with data.
4.2.2.1. Metadata Interfaces
Let us consider the basic metadata interfaces.
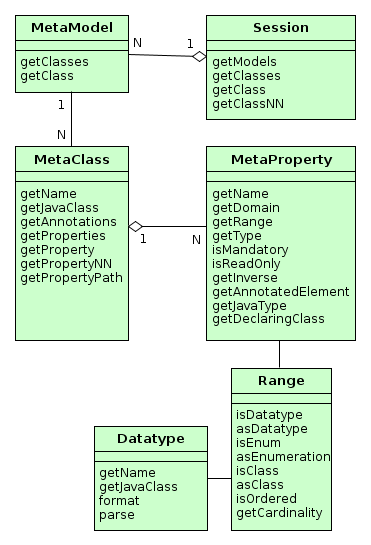
Figure 8. Metadata Framework Interfaces
-
Session -
Entry point of the metadata framework. Enables obtaining
MetaClassinstances by name and by the corresponding Java class. Note the difference in methods:getClass()methods can returnnullwhilegetClassNN()(Non Null) methods cannot.Sessionobject can be obtained using the Metadata infrastructure interface.Example:
@Inject
protected Metadata metadata;
...
Session session = metadata.getSession();
MetaClass metaClass1 = session.getClassNN("sec$User");
MetaClass metaClass2 = session.getClassNN(User.class);
assert metaClass1 == metaClass2;-
MetaModel -
Rarely used interface intended to group meta-classes.
Meta-classes are grouped by the root name of Java project package specified in metadata.xml file.
-
MetaClass -
Entity class metadata interface.
MetaClassis always associated with the Java class which it represents.Basic methods:
-
getName()– entity name, according to convention the first part of the name before$sign is the namespace code, for example,sales$Customer. -
getProperties()– the list of meta-properties (MetaProperty). -
getProperty(),getPropertyNN()– methods return meta-properties by name. If there is no attribute with provided name, the first method returnsnull, and the second throws an exception.Example:
MetaClass userClass = session.getClassNN(User.class); MetaProperty groupProperty = userClass.getPropertyNN("group"); -
getPropertyPath()– allows you to navigate by references. This method accepts string parameter – path in the format of dot-separated attribute names. The returnedMetaPropertyPathobject enables accessing the required (the last in the path) attribute by invokinggetMetaProperty()method.Example:
MetaClass userClass = session.getClassNN(User.class); MetaProperty groupNameProp = userClass.getPropertyPath("group.name").getMetaProperty(); assert groupNameProp.getDomain().getName().equals("sec$Group"); -
getJavaClass()– entity class, corresponding to thisMetaClass. -
getAnnotations()– collection of meta-annotations.
-
-
MetaProperty -
Entity attribute metadata interface.
Basic methods:
-
getName()– property name, corresponds to entity attribute name. -
getDomain()– meta-class, owning this property.
-
-
getType()- the property type:-
simple type:
DATATYPE -
enumeration:
ENUM -
reference type of two kinds:
-
ASSOCIATION− simple reference to another entity. For example, Order-Customer relationship is an association. -
COMPOSITION− reference to the entity, having no consistent value without the owning entity.COMPOSITIONis considered to be a "closer" relationship thanASSOCIATION. For example, the relationship between Order and its Items is aCOMPOSITION, as the Item cannot exist without the Order to which it belongs.The type of
ASSOCIATIONorCOMPOSITIONreference attributes affects entity edit mode: in the first case the related entity is persisted to the database independently, in the second case – only together with the owning entity. See Editing Composite Entities for details.
-
-
-
getRange()–Rangeinterface providing detailed description of the attribute type. -
isMandatory()– indicates a mandatory attribute. For instance, it is used by visual components to signal a user that value is mandatory. -
isReadOnly()– indicates a read-only attribute. -
getInverse()– for reference-type attribute, returns the meta-property from the other side of the association, if such exists. -
getAnnotatedElement()– field (java.lang.reflect.Field) or method (java.lang.reflect.Method), corresponding to the entity attribute. -
getJavaType()– Java class of the entity attribute. It can either be the type of corresponding field or the type of the value returned by corresponding method. -
getDeclaringClass()– Java class containing this attribute.-
Range -
Interface describing entity attribute type in detail.
Basic methods:
-
-
isDatatype()– returnstruefor simple type attribute. -
asDatatype()– returns Datatype for simple type attribute. -
isEnum()– returnstruefor enumeration type attribute. -
asEnumeration()– returns Enumeration for enumeration type attribute. -
isClass()– returnstruefor reference attribute ofASSOCIATIONorCOMPOSITIONtype. -
asClass()– returns metaclass of associated entity for a reference attribute. -
isOrdered()– returnstrueif the attribute is represented by an ordered collection (for exampleList). -
getCardinality()– relation kind of the reference attribute:ONE_TO_ONE,MANY_TO_ONE,ONE_TO_MANY,MANY_TO_MANY.
4.2.2.2. Metadata Building
The main source for metadata structure generation are annotated entity classes.
Entity class will be present in the metadata in the following cases:
-
Persistent entity class is annotated by
@Entity,@Embeddable,@MappedSuperclassand is located within the root package specified in metadata.xml. -
Non-persistent entity class is annotated by
@MetaClassand is located within the root package specified inmetadata.xml.
All entities inside same root package are put into the same MetaModel instance, which is given the name of this package. Entities within the same MetaModel can contain arbitrary references to each other. References between entities from different meta-models can be created in the order of declaration of metadata.xml files in cuba.metadataConfig property.
Entity attribute will be present in metadata if:
-
A class field is annotated by
@Column,@OneToOne,@OneToMany,@ManyToOne,@ManyToMany,@Embedded. -
A class field or an access method (getter) is annotated by
@MetaProperty.
Metaclass and metaproperty parameters are determined on the base of the listed annotations parameters as well as field types and class methods. Besides, if an attribute does not have write access method (setter), it becomes immutable (read only).
4.2.2.3. Datatype
Datatype interface describes a valid data type for an entity attribute if it is not a reference.
Datatypes are registered in the Datatypes class, which loads and initializes Datatype implementation classes in the following way:
-
Default
Datatypesimplementations are loaded from the/com/haulmont/chile/core/datatypes/datatypes.xmlclasspath resource. -
metadata.xml files from application components and from the project itself are scanned for the
datatypeselement and if it is found, customDatatypeimplementations are loaded. See an example of a custom datatype below. -
For backward compatibility, the platform searches for the
datatypes.xmlfile inCLASSPATHroot, and if it is found, defaultDatatypeimplementations are loaded from it instead of the resource mentioned above.
Datatype instance can be obtained in two ways:
-
For an entity attribute – from the corresponding meta-property using
getRange().asDatatype()call. -
Using
Datatypes.get()static method by passing to it the name of theDatatypeimplementation or Java class it was created for.
Datatypes are associated with entity attributes during application start according to the following rules:
-
If
@MetaPropertyannotation is defined on the field or method having a non-emptydatatypevalue, the attribute is associated with theDatatypeinstance with the given name.For instance, if the entity attribute is declared as in the example below, it will be associated with a custom type –
GeoCoordinateDatatype:@MetaProperty(datatype = GeoCoordinateDatatype.NAME) @Column(name = "LATITUDE") private Double latitude; -
In most cases, explicit specification is omitted, and the attribute is associated with the
Datatypeinstance from repository, which is returned byDatatypes.get(Class)by supplied field or method type.In the example below,
latitudeattribute will get a standardDoubleDatatypetype registered in the/com/haulmont/chile/core/datatypes/datatypes.xmlresource:@Column(name = "LATITUDE") private Double latitude;
Basic methods of Datatype interfaces:
-
getName()– returns the unique name of the implementation. -
format()– converts the passed value into a string. -
parse()– transforms a string into the value of corresponding type.
Datatype determines two sets of methods for formatting and parsing: considering and not considering locale. Conversion considering locale is applied everywhere in user interface, ignoring locale – in system mechanisms, for example, serialization in REST API.
Parsing formats ignoring locale are specified in the above mentioned datatypes.xml resource or in the datatypes element of the metadata.xml file.
The parsing formats considering locale are provided in the main messages pack, in the strings with the following keys:
-
numberDecimalSeparator– specifies decimal separator for numeric types. -
numberGroupingSeparator– defines separator between digits groups for numeric types (e.g. when space is used as separator, number will be formatted as 1 000 000). -
integerFormat– format forIntegerandLongtypes. -
doubleFormat– format forDoubletype. -
decimalFormat– format for `BigDecimal `type. -
dateTimeFormat– format forjava.util.Datetype. -
dateFormat– format forjava.sql.Datetype. -
timeFormat– format forjava.sql.Timetype. -
trueString– string corresponding toBoolean.TRUE. -
falseString– string corresponding toBoolean.FALSE.
All the listed formats are specified in the main message pack of CUBA application component by default, and can be overridden in the similar files of the application project.
4.2.2.3.1. Example of Data Formatting in UI
Let us consider the way Order.date attribute is displayed in orders browser table.
order-browse.xml
<table id="ordersTable">
...
<columns>
<column id="date"/>
...date attribute in Order class is defined using "date" type:
@Column(name = "DATE", nullable = false)
@Temporal(TemporalType.DATE)
private Date date;If the current user is logged in with the Russian locale, the following string is retrieved from the main message pack on the client tier:
dateFormat=dd.MM.yyyyThe result: date "6th August 2012 " is converted into a string "06.08.2012" which is displayed in the table cell.
4.2.2.3.2. Examples of Date and Number Formatting in the Application Code
If you need to format or parse values of BigDecimal, Integer, Long, Double, Boolean or Date types depending on the current user locale, use the DatatypeFormatter bean. For example:
@Inject
private DatatypeFormatter formatter;
...
String localDate = formatter.formatDate(dateField.getValue());Below are examples of using Datatype methods directly.
-
Date formatting example
@Inject protected UserSessionSource userSessionSource; ... Date date = ...; String dateStr = Datatypes.getNN(Date.class).format(date, userSessionSource.getLocale()); -
Example of formatting of numeric values with high accuracy (up to 5 decimal places) in Web Client:
/com/sample/sales/web/messages_ru.propertiescoordinateFormat = #,##0.00000SomeClass.java@Inject protected Messages messages; @Inject protected UserSessionSource userSessionSource; ... String coordinateFormat = messages.getMainMessage("coordinateFormat"); FormatStrings formatStrings = Datatypes.getFormatStrings(userSessionSource.getLocale()); NumberFormat format = new DecimalFormat(coordinateFormat, formatStrings.getFormatSymbols()); String formattedValue = format.format(value);
4.2.2.3.3. Example of a Custom Datatype
Let us consider the implementation of a custom GeoCoordinateDatatype, intended for the attributes storing geographical coordinates.
First, create the following class in the global module:
package com.company.sample;
import com.haulmont.chile.core.datatypes.Datatypes;
import com.haulmont.chile.core.datatypes.FormatStrings;
import com.haulmont.chile.core.datatypes.impl.DoubleDatatype;
import org.apache.commons.lang.StringUtils;
import org.dom4j.Element;
import java.text.DecimalFormat;
import java.text.NumberFormat;
import java.text.ParseException;
import java.util.Locale;
public class GeoCoordinateDatatype extends DoubleDatatype {
// This field is required for Studio even if you don't use it in code
public static final String NAME = "geocoordinate";
// The format is the same for all locales but may differ in decimal points
public static final String FORMAT = "#0.000000";
public GeoCoordinateDatatype(Element element) {
super(element);
}
@Override
public String getName() {
return NAME;
}
@Override
public String format(Object value, Locale locale) {
if (value == null)
return "";
FormatStrings formatStrings = Datatypes.getFormatStrings(locale);
if (formatStrings == null)
return format(value);
NumberFormat format = new DecimalFormat(FORMAT, formatStrings.getFormatSymbols());
return format.format(value);
}
@Override
public Double parse(String value, Locale locale) throws ParseException {
if (StringUtils.isBlank(value))
return null;
FormatStrings formatStrings = Datatypes.getFormatStrings(locale);
if (formatStrings == null)
return parse(value);
NumberFormat format = new DecimalFormat(FORMAT, formatStrings.getFormatSymbols());
return parse(value, format).doubleValue();
}
}Then add the datatypes element to the metadata.xml of your project:
<metadata xmlns="http://schemas.haulmont.com/cuba/metadata.xsd">
<datatypes>
<datatype class="com.company.sample.GeoCoordinateDatatype"
format="#0.000000" decimalSeparator="." groupingSeparator=""/>
</datatypes>
<!-- ... -->
</metadata>In the datatype element, you can also specify the sqlType attribute containing an SQL type of your database suitable for storing values of the new type. This SQL type will be used by CUBA Studio when it generates database scripts. Studio can automatically determine an SQL type for the following Java types:
-
java.lang.Boolean -
java.lang.Integer -
java.lang.Long -
java.math.BigDecimal -
java.lang.Double -
java.lang.String -
java.util.Date -
java.util.UUID -
byte[]
If you have specified one of the listed Java types in the javaType attribute, the sqlType attribute can be omitted.
Finally, specify the new datatype for the required attributes (the new data type will also be available in the Studio entity attribute editor):
@MetaProperty(datatype = GeoCoordinateDatatype.NAME)
@Column(name = "LATITUDE")
private Double latitude;After the above listed operations are completed, the latitude attribute will be displayed in the desired format throughout the application.
4.2.2.4. Meta-Annotations
Entity meta-annotations are a set of key/value pairs providing additional information about entities.
Meta-annotations are accessed using meta-class getAnnotations() method.
The sources of meta-annotations are:
-
@OnDelete,@OnDeleteInverse,@Extendsannotations. These annotations cause creation of special meta-annotations for describing relations between entities. -
Extendable meta-annotations marked with
@MetaAnnotation. These annotations are converted to meta-annotations with a key corresponding to the full name of Java class of the annotation and a value which is a map of annotation attributes. For example,@TrackEditScreenHistoryannotation will have a value which is a map with a single entry:value → true. The platform provides the following annotations of this kind:@NamePattern,@SystemLevel,@EnableRestore,@TrackEditScreenHistory. In your application or application components, you can create your own annotation classes and mark them with@MetaAnnotationannotation. -
Optional: entity meta-annotations can also be defined in metadata.xml files. If a meta-annotation in XML has the same name as the meta-annotation created by Java entity class annotation, then it will override the latter.
The example below shows how to override meta-annotations in
metadata.xml:<metadata xmlns="http://schemas.haulmont.com/cuba/metadata.xsd"> <!-- ... --> <annotations> <entity class="com.company.customers.entity.Customer"> <annotation name="com.haulmont.cuba.core.entity.annotation.TrackEditScreenHistory"> <attribute name="value" value="true" datatype="boolean"/> </annotation> <property name="name"> <annotation name="length" value="200"/> </property> <property name="customerGroup"> <annotation name="com.haulmont.cuba.core.entity.annotation.Lookup"> <attribute name="type" class="com.haulmont.cuba.core.entity.annotation.LookupType" value="DROPDOWN"/> <attribute name="actions" datatype="string"> <value>lookup</value> <value>open</value> </attribute> </annotation> </property> </entity> <entity class="com.company.customers.entity.CustomerGroup"> <annotation name="com.haulmont.cuba.core.entity.annotation.EnableRestore"> <attribute name="value" value="false" datatype="boolean"/> </annotation> </entity> </annotations> </metadata>
4.2.3. Views
When retrieving entities from the database, we often face the question: how to ensure loading of related entities to the desired depth?
For example, you need to display the date and amount together with the Customer name in the Orders browser, which means that you need to fetch the related Customer instance. And for the Order editor screen, you need to fetch the collection of Items, in addition to that each Item should contain a related Product instance to display its name.
Lazy loading can not help in most cases because data processing is usually performed not in the transaction where the entities were loaded but, for example, on the client tier in UI. At the same time, it is unacceptable to apply eager fetching using entity annotations as it leads to constant retrieval of the entire graph of related entities which can be very large.
Another similar problem is the requirement to limit the set of local entity attributes of the loaded graph: for example, some entity can have 50 attributes, including BLOB, but only 10 attributes need to be displayed on the screen. In this case, why should we download 40 remaining attributes from the database, then serialize them and transfer to the client when it does not need them at the moment?
Views mechanism resolves these issues by retrieving from the database and transmitting to the client entity graphs limited by depth and by attributes. A view is a descriptor of the object graph required for a certain UI screen or data-processing operation.
Views processing is performed in the following way:
-
All relations in the data model are declared with lazy fetching property (
fetch = FetchType.LAZY. See Entity Annotations). -
In the data loading process, the calling code provides required view together with JPQL query or entity identifier.
-
The so-called FetchGroup is produced on the base of the view – this is a special feature of EclipseLink framework lying in the base of the ORM layer. FetchGroup affects the generation of SQL queries to the database: both the list of returned fields and joins with other tables containing related entities.
Figure 9. View Classes
A view is determined by an instance of the View class, where:
-
entityClass– the entity class, for which the view is defined. In other words, it is the "root" of the loaded entities tree. -
name– the name of the view. It should be eithernullor a unique name within all views for the entity. -
properties– collection ofViewPropertyinstances corresponding to the entity attributes that should be loaded. -
includeSystemProperties– if set, system attributes (defined by basic interfaces of persistent entities, such asBaseEntityandUpdatable) are automatically included in the view.
ViewProperty class has the following properties:
-
name– the name of the entity attribute. -
view– for reference attributes, specifies the view which which will be used to load the related entity. -
fetch- for reference attributes, specifies how to fetch the related entity from the database. It corresponds to theFetchModeenum and can have one of the following values:-
AUTO- the platform will choose an optimal mode depending on the relation type. -
UNDEFINED- fetching will be performed according to JPA rules, which effectively means loading by a separate select. -
JOIN- fetching in the same select by joining with referenced table. -
BATCH- queries of related objects will be optimized in batches. See more here.
If the
fetchattribute is not specified, theAUTOmode is applied. If the reference represents a cacheable entity,UNDEFINEDwill be used regardless of the value specified in the view. -
|
Tip
|
Regardless of the attributes defined in the view, the following attributes are always loaded:
|
|
Warning
|
An attempt to get or set a value for a not loaded attribute (not included into a view) raises an exception. You can check whether the attribute was loaded using the |
4.2.3.1. Views Creation
A view can be created in two possible ways:
-
Programmatically – by creating a
Viewinstance, for example:View view = new View(Order.class) .addProperty("date") .addProperty("amount") .addProperty("customer", new View(Customer.class) .addProperty("name") );Typically, this way can be appropriate for creating views that are used in a single piece of business logic.
-
Declaratively – by creating an XML descriptor and deploying it to
ViewRepository.Viewinstances are created and cached when the XML descriptor is deployed. Further on, the required view can be retrieved in any part of the application code by a call toViewRepositoryproviding the entity class and the view name.
Let us consider in details the declarative way for creation and working with views.
ViewRepository is a Spring bean, accessible to all application blocks. The reference to ViewRepository can be obtained using injection or through the Metadata infrastructure interface. ViewRepository.getView() methods are used to retrieve view instances from the repository. deployViews() methods from AbstractViewRepository basic implementation are used to deploy XML descriptors to the repository.
Two views named _local and _minimal are available in the views repository for each entity by default:
-
_localcontains all local entity attributes. -
_minimalcontains the attributes which are included to the name of the entity instance and specified in the @NamePattern annotation. If the@NamePatternannotation is not specified at the entity, this view does not contain any attributes.
The detailed structure of view XML descriptors is explained here.
The example below shows a view descriptor for the Order entity which provides loading of all local attributes, associated Customer and the Items collection:
<view class="com.sample.sales.entity.Order"
name="orderWithCustomer"
extends="_local">
<property name="customer" view="_minimal"/>
<property name="items" view="itemInOrder"/>
</view>The recommended way of grouping and deployment of view descriptors is as follows:
-
Create views.xml file in the
srcroot of the global module and place all view descriptors that should be globally accessible (i.e. on all application tiers) into it. -
Register this file in the [cuba.viewsConfig] application property of all blocks, i.e. in
app.propertiesof the core module,web-app.propertiesof the web module, etc. This will ensure automatic deployment of the views upon application startup into the repository. -
If there are views which are used only in one application block, they can be specified in the similar file of this block, for example,
web-views.xml, and registered in [cuba.viewsConfig] property of this block only.If the repository contains a view with certain name for some entity, an attempt to deploy another view with this name for the same entity will be ignored. If you need to replace the existing view in the repository with a new one and guarantee its deployment, specify
overwrite = "true"attribute for it.
|
Tip
|
It is recommended to give descriptive names to the views. For example, not just "browse", but "customerBrowse". It simplifies the search of views in XML descriptors. |
4.2.4. Managed Beans
Managed Beans are program components intended for implementation of the application’s business logic. "Managed" in this case means that the instance creation and dependency management is handled by the container, which is the main part of the Spring framework.
|
Tip
|
Managed Bean is a singleton by default, i.e., only one instance of such class exists in each application block. If a singleton bean contains mutable data in fields (in other words, has a state), it is necessary to synchronize access to such data. |
4.2.4.1. Creating a Bean
To create a managed bean, add the @org.springframework.stereotype.Component annotation to the Java class. For example:
package com.sample.sales.core;
import com.sample.sales.entity.Order;
import org.springframework.stereotype.Component;
@Component(OrderWorker.NAME)
public class OrderWorker {
public static final String NAME = "sales_OrderWorker";
public void calculateTotals(Order order) {
}
}It is recommended to assign a unique name to the bean in the {project_name}_{class_name} form and to define it in the NAME constant.
|
Tip
|
The |
The managed bean class should be placed inside the package tree with the root specified in the context:component-scan element of the spring.xml file. In this case, the spring.xml file contains the element:
<context:component-scan base-package="com.sample.sales"/>which means that the search for annotated beans for this application block will be performed starting with the com.sample.sales package.
Managed beans can be created on any tier, because the Spring Framework container is used in all standard blocks of the application.
4.2.4.2. Using the Bean
A reference to the bean can be obtained through injection or through the AppBeans class. As an example of using the bean, let us look at the implementation of the OrderService bean that delegates the execution to the OrderWorker bean:
package com.sample.sales.core;
import com.haulmont.cuba.core.Persistence;
import com.sample.sales.entity.Order;
import org.springframework.stereotype.Service;
import org.springframework.transaction.annotation.Transactional;
import javax.inject.Inject;
@Service(OrderService.NAME)
public class OrderServiceBean implements OrderService {
@Inject
protected Persistence persistence;
@Inject
protected OrderWorker orderWorker;
@Transactional
@Override
public BigDecimal calculateTotals(Order order) {
Order entity = persistence.getEntityManager().merge(order);
orderWorker.calculateTotals(entity);
}
}In this example, the service starts a transaction, merges the detached entity obtained from the client level into the persistent context, and passes the control to the OrderWorker bean, which contains the main business logic.
4.2.5. JMX Beans
Sometimes, it is necessary to give system administrator an ability to view and change the state of some managed bean at runtime. In such case, it is recommended to create a JMX bean – a program component having the JMX interface. JMX bean is usually a wrapper delegating calls to the managed bean which actually maintains state: cache, configuration data or statistics.
Figure 10. JMX Bean Class Diagram
As you can see from the diagram, the JMX bean consists of the interface and the implementation class. The class should be a managed bean, i.e., should have the @Component annotation and unique name. The interface of the JMX bean is registered in spring.xml in a special way to create the JMX interface in the current JVM.
Calls to all JMX bean interface methods are intercepted using Spring AOP by the MBeanInterceptor interceptor class, which sets the correct ClassLoader in the current thread and enables logging of unhandled exceptions.
|
Warning
|
The JMX bean interface name must conform to the following format: |
JMX-interface can be utilized by external tools, such as jconsole or jvisualvm. In addition, the Web Client platform block includes the JMX console, which provides the basic tools to view the status and call the methods of the JMX beans.
4.2.5.1. Creating a JMX Bean
The following example shows how to create a JMX bean.
-
JMX bean interface:
package com.sample.sales.core; import org.springframework.jmx.export.annotation.*; @ManagedResource(description = "Performs operations on Orders") public interface OrdersMBean { @ManagedOperation(description = "Recalculates an order amount") @ManagedOperationParameters({@ManagedOperationParameter(name = "orderId", description = "")}) String calculateTotals(String orderId); }The interface and its methods may contain annotations to specify the description of the JMX bean and its operations. This description will be displayed in all tools that work with this JMX interface, thereby helping the system administrator.
Since the JMX tools support a limited set of data types, it is desirable to use
Stringas the type for the parameters and result of the method and perform the conversion inside the method, if necessary. Alongside withString, the following parameter types are supported:boolean,double,float,int,long,Boolean,Integer. -
The JMX bean class:
package com.sample.sales.core; import com.haulmont.cuba.core.*; import com.haulmont.cuba.core.app.*; import com.sample.sales.entity.Order; import org.apache.commons.lang.exception.ExceptionUtils; import org.springframework.stereotype.Component; import javax.inject.Inject; import java.util.UUID; @Component("sales_OrdersMBean") public class Orders implements OrdersMBean { @Inject protected OrderWorker orderWorker; @Inject protected Persistence persistence; @Authenticated @Override public String calculateTotals(String orderId) { try { try (Transaction tx = persistence.createTransaction()) { Order entity = persistence.getEntityManager().find(Order.class, UUID.fromString(orderId)); orderWorker.calculateTotals(entity); tx.commit(); }; return "Done"; } catch (Throwable e) { return ExceptionUtils.getStackTrace(e); } } }The
@Componentannotation defines the class as a managed bean with thesales_OrdersMBeanname. The name is specified directly in the annotation and not in the constant, since access to the JMX bean from Java code is not required.Lets overview the implementation of the
calculateTotals()method.-
The method has the
@Authenticatedannotation, i.e., system authentication is performed on method entry in the absence of the user session. -
The method’s body is wrapped in the try/catch block, so that, if successful, the method returns "Done", and in case of error – the stack trace of the exception as string.
In this case, all exceptions are handled and therefore do not get logged automatically, because they never fall through to
MBeanInterceptor. If logging of exceptions is required, the call of the logger should be added in thecatchsection. -
The method starts the transaction, loads the
Orderentity instance by identifier, and passes control to theOrderWorkerbean for processing.
-
-
The registration of the JMX bean in
spring.xml:<bean id="sales_MBeanExporter" lazy-init="false" class="com.haulmont.cuba.core.sys.jmx.MBeanExporter"> <property name="beans"> <map> <entry key="${cuba.webContextName}.sales:type=Orders" value-ref="sales_OrdersMBean"/> </map> </property> </bean>
All JMX beans of a project are declared in one MBeanExporter instance in the map/entry elements of the beans property. The key is JMX ObjectName, the value – the bean’s name specified in the @Component annotation. ObjectName begins with the name of the web application, because several web applications, which export the same JMX interfaces, can be deployed into one application server instance (i.e., into one JVM).
4.2.5.2. The Platform JMX Beans
This section describes some of the JMX beans available in the platform.
4.2.5.2.1. CachingFacadeMBean
CachingFacadeMBean provides methods to clear various caches in the Middleware and Web Client blocks.
JMX ObjectName: app-core.cuba:type=CachingFacade and app.cuba:type=CachingFacade
4.2.5.2.2. ConfigStorageMBean
ConfigStorageMBean enables viewing and setting values of the application properties in the Middleware, Web Client and Web Portal blocks.
This interface has separate sets of operations for working with properties stored in files (*AppProperties) and stored in the database (*DbProperties). These operations show only the properties explicitly set in the storage. It means that if you have a configuration interface defining a property and its default value, but you did not set the value in the database (or a file), these methods will not show the property and its current value.
Please note that the changes to property values stored in files are not persistent, and are valid only until restart of the application block.
Unlike the operations described above, the getConfigValue() operation returns exactly the same value as the corresponding method of the configuration interface invoked in the application code.
JMX ObjectName:
-
app-core.cuba:type=ConfigStorage -
app.cuba:type=ConfigStorage -
app-portal.cuba:type=ConfigStorage
4.2.5.2.3. EmailerMBean
EmailerMBean enables viewing the current values of the email sending parameters, and sending test messages.
JMX ObjectName: app-core.cuba:type=Emailer
4.2.5.2.4. PersistenceManagerMBean
PersistenceManagerMBean provides the following abilities:
-
Managing entity statistics mechanism.
-
Viewing new DB update scripts using the
findUpdateDatabaseScripts()method. Triggering DB update with theupdateDatabase()method. -
Executing arbitrary JPQL queries in the Middleware context by using
jpqlLoadList(),jpqlExecuteUpdate()methods.
JMX ObjectName: app-core.cuba:type=PersistenceManager
4.2.5.2.5. ScriptingManagerMBean
ScriptingManagerMBean is the JMX facade for the Scripting infrastructure interface.
JMX ObjectName: app-core.cuba:type=ScriptingManager
JMX attributes:
-
RootPath– absolute path to the configuration directory of the Middleware block, in which this bean was started.
JMX operations:
-
runGroovyScript()– executes a Groovy script in the Middleware context and returns the result. The following variables are passed to the script:-
persistenceof the Persistence type. -
metadataof the Metadata type. -
configurationof the Configuration type. -
dataManagerof the DataManager type.The result type should be of the String type to be displayed in the JMX interface. Otherwise, the method is similar to the Scripting.runGroovyScript() method.
The example script for creating a set of test users is shown below:
import com.haulmont.cuba.core.* import com.haulmont.cuba.core.global.* import com.haulmont.cuba.security.entity.* PasswordEncryption passwordEncryption = AppBeans.get(PasswordEncryption.class) Transaction tx = persistence.createTransaction() try { EntityManager em = persistence.getEntityManager() Group group = em.getReference(Group.class, UUID.fromString('0fa2b1a5-1d68-4d69-9fbd-dff348347f93')) for (i in (1..250)) { User user = new User() user.setGroup(group) user.setLogin("user_${i.toString().padLeft(3, '0')}") user.setName(user.login) user.setPassword(passwordEncryption.getPasswordHash(user.id, '1')); em.persist(user) } tx.commit() } finally { tx.end() }
-
4.2.5.2.6. ServerInfoMBean
ServerInfoMBean provides the general information about this Middleware block: the build number, build date and the server id.
JMX ObjectName: app-core.cuba:type=ServerInfo
4.2.6. Infrastructure Interfaces
Infrastructure interfaces provide access to frequently used functionality of the platform. Most of them are located in the global module and can be used both on the middle and client tiers. However, some of them (Persistence, for example) are accessible only for Middleware code.
Infrastructure interfaces are implemented by Spring Framework beans, so they can be injected into any other managed components (managed beans, Middleware services, generic user interface screen controllers).
Also, like any other beans, infrastructure interfaces can be obtained using static methods of AppBeans class, and can be used in non-managed components (POJO, helper classes etc.).
4.2.6.1. Configuration
The interface helps to obtain references to configuration interfaces.
Examples:
// field injection
@Inject
protected Configuration configuration;
...
String tempDir = configuration.getConfig(GlobalConfig.class).getTempDir();// setter injection
protected GlobalConfig globalConfig;
@Inject
public void setConfiguration(Configuration configuration) {
this.globalConfig = configuration.getConfig(GlobalConfig.class);
}// location
String tempDir = AppBeans.get(Configuration.class).getConfig(GlobalConfig.class).getTempDir();4.2.6.2. Messages
Messages interface provides methods to get localized message strings.
Let’s consider interface methods in detail.
-
getMessage()– returns the localized message by key, pack name and required locale. There are several modifications of this method with different sets of parameters. If locale is not specified in the method parameter, the current user locale is used.Examples:
@Inject protected Messages messages; ... String message1 = messages.getMessage(getClass(), "someMessage"); String message2 = messages.getMessage("com.abc.sales.web.customer", "someMessage"); String message3 = messages.getMessage(RoleType.STANDARD); -
formatMessage()– retrieves a localized message by key, pack name and required locale, then uses it to format the input parameters. The format is defined according toString.format()method rules. There are several modifications of this method with different sets of parameters. If locale is not specified in the method parameter, the current user locale is used.Example:
String formattedValue = messages.formatMessage(getClass(), "someFormat", someValue); -
getMainMessage()– returns the localized message from the main message pack of the application block.Example:
protected Messages messages = AppBeans.get(Messages.class); ... messages.getMainMessage("actions.Ok"); -
getMainMessagePack()– returns the name of the main message pack of the application block.Example:
String formattedValue = messages.formatMessage(messages.getMainMessagePack(), "someFormat", someValue); -
getTools()– returnsMessageToolsinterface instance (see below).
4.2.6.2.1. MessageTools
MessageTools interface is a managed bean containing additional methods for working with localized messages. You can access MessageTools interface either using Messages.getTools() method, or as any other bean – by means of injection or through AppBeans class.
MessageTools methods:
-
loadString()– returns a localized message, specified by reference inmsg://{messagePack}/{key}formatReference components:
-
msg://– mandatory prefix. -
{messagePack}– optional name of the message pack. If it is not specified, it is assumed that the pack name is passed toloadString()as a separate parameter. -
{key}– message key in the pack.
Examples of the message references:
msg://someMessage msg://com.abc.sales.web.customer/someMessage -
-
getEntityCaption()– returns the localized entity name. -
getPropertyCaption()– returns the localized name of an entity attribute. -
hasPropertyCaption()– checks whether the entity attribute was given a localized name. -
getLocValue()– returns the localized value of the entity attribute based on @LocalizedValue annotation. -
getMessageRef()– forms a message reference for meta-property which can be used to retrieve the localized name of the entity attribute. -
getDefaultLocale()– returns default application locale, which is the first one listed in cuba.availableLocales application property. -
useLocaleLanguageOnly()– returnstrue, if for all locales supported by the application (defined incuba.availableLocalesproperty) only the language parameter is specified, without country and variant. This method is used by platform mechanisms which need to find the most appropriate supported locale when locale info is received from the external sources such as operation system or HTTP request. -
trimLocale()– deletes from the passed locale everything except language, ifuseLocaleLanguageOnly()method returnstrue.
You can override MessageTools to extend the set of its methods in your application. Below are the examples of working with the extended interface:
MyMessageTools tools = messages.getTools();
tools.foo();((MyMessageTools) messages.getTools()).foo();4.2.6.3. Metadata
Metadata interface provides access to metadata session and view repository.
Interface methods:
-
getSession()– returns the metadata session instance. -
getViewRepository()– returns the view repository instance. -
getExtendedEntities()– returnsExtendedEntitiesinstance, intended for working with the extended entities. See more in Extending an Entity. -
create()– creates an entity instance, taking into account potential extension. See more in Extending an Entity. -
getTools()– returnsMetadataToolsinterface instance (see below).
4.2.6.3.1. MetadataTools
MetadataTools is a managed bean, containing additional methods for working with metadata. You can access MetadataTools interface by either using Metadata.getTools() method, or as any other bean – by means of injection or through AppBeans class.
`MetadataTools `methods:
-
getAllPersistentMetaClasses()– returns the collection of persistent entities meta-classes. -
getAllEmbeddableMetaClasses()– returns the collection of embeddable entities meta-classes. -
getAllEnums()– returns the collection of enumeration classes used as entity attributes types. -
format()– formats the passed value according to data type of the given meta-property. -
isSystem()– checks if a meta-property is system, i.e. specified in one of the basic entity interfaces. -
isPersistent()– checks if a meta-property is persistent, i.e. stored in the database. -
isTransient()– checks if a meta-property or an arbitrary attribute is non-persistent. -
isEmbedded()– checks if a meta-property is an embedded object. -
isAnnotationPresent()– checks if an annotation is present on the class or on one of its ancestors. -
getNamePatternProperties()– returns collection of meta-properties of attributes included in the instance name, returned byInstance.getInstanceName()method. See @NamePattern.
You can override MetadataTools bean in your application to extend the set of its methods. The examples of working with the extended interface:
MyMetadataTools tools = metadata.getTools();
tools.foo();((MyMetadataTools) metadata.getTools()).foo();4.2.6.4. Resources
Resources interface maintains resources loading according to the following rules:
-
If the provided location is a URL, the resource is downloaded from this URL;
-
If the provided location begins with
classpath:prefix, the resource is downloaded from classpath; -
If the location is not a URL and it does not begin with
classpath:, then:-
The file is searched in the configuration folder of application using the provided location as relative pathname. If the file is found, the resource is downloaded from it;
-
If the resource is not found at the previous steps, it is downloaded from classpath.
-
In practice, explicit identification of URL or classpath: prefix is rarely used, so resources are usually downloaded either from the configuration folder or from classpath. The resource in the configuration folder overrides the classpath resource with the same name.
Resources methods:
-
getResourceAsStream()– returnsInputStreamfor the provided resource, ornull, if the resource is not found. The stream should be closed after it had been used, for example:@Inject protected Resources resources; ... InputStream stream = null; try { stream = resources.getResourceAsStream(resourceLocation); ... } finally { IOUtils.closeQuietly(stream); }You can also use "try with resources":
try (InputStream stream = resources.getResourceAsStream(resourceLocation)) { ... } -
getResourceAsString()– returns the indicated resource content as string, ornull, if the resource is not found.
4.2.6.5. Scripting
Scripting interface is used to compile and load Java and Groovy classes dynamically (i.e. at runtime) as well as to execute Groovy scripts and expressions.
Scripting methods:
-
evaluateGroovy()– executes the Groovy expression and returns its result.cuba.groovyEvaluatorImport application property is used to define the common set of the imported classes inserted into each executed expression. By default, all standard application blocks import PersistenceHelper class.
The compiled expressions are cached, and this considerably speeds up repeated execution.
Example:
@Inject protected Scripting scripting; ... Integer intResult = scripting.evaluateGroovy("2 + 2", new Binding()); Binding binding = new Binding(); binding.setVariable("instance", new User()); Boolean boolResult = scripting.evaluateGroovy("return PersistenceHelper.isNew(instance)", binding);
-
runGroovyScript()– executes Groovy script and returns its result.The script should be located either in application configuration folder or in classpath (the current
Scriptingimplementation supports classpath resources within JAR files only). A script in the configuration folder overrides the script in classpath with the same name.The path to the script is constructed using separators
/. The separator is not required in the beginning of the path.Example:
@Inject protected Scripting scripting; ... Binding binding = new Binding(); binding.setVariable("itemId", itemId); BigDecimal amount = scripting.runGroovyScript("com/abc/sales/CalculatePrice.groovy", binding); -
loadClass()– loads Java or Groovy class using the following steps:-
If the class is already loaded, it will be returned.
-
The Groovy source code (file
*.groovy) is searched in the configuration folder. If it is found, it will be compiled and the class will be returned. -
The Java source code (file
*.java) is searched in the configuration folder. If it is found, it will be compiled and the class will be returned. -
The compiled class is searched in classpath. If it is found, it will be loaded and returned.
-
If nothing is found,
nullwill be returned.
The files in configuration folder containing Java and Groovy source code can be modified at runtime. On the next
loadClass()call the corresponding class will be recompiled and the new one will be returned, with the following restrictions:-
The type of the source code must not be changed from Groovy to Java;
-
If Groovy source code was once compiled, the deletion of the source code file will not lead to loading of another class from classpath. Instead of this, the class compiled from the removed source code will still be returned.
Example:
@Inject protected Scripting scripting; ... Class calculatorClass = scripting.loadClass("com.abc.sales.PriceCalculator"); -
-
getClassLoader()– returnsClassLoader, which is able to work according to the rules forloadClass()method described above.
Cache of the compiled classes can be cleaned at runtime using CachingFacadeMBean JMX bean.
See also ScriptingManagerMBean.
4.2.6.6. Security
This interface provides authorization – checking user access rights to different objects in the system. Most of the interface methods delegate to the corresponding methods of current UserSession object, but before this they search for an original meta-class of the entity, which is important for projects with extensions. Besides methods duplicating UserSession functionality, this interface contains isEntityAttrReadPermitted() and isEntityAttrUpdatePermitted() methods that check attribute path availability with respect to availability of all attributes and entities included in the path.
The Security interface is recommended to use everywhere instead of direct calling of the UserSession.isXYXPermitted() methods.
See more in User Authentication.
4.2.6.7. TimeSource
TimeSource interface provides the current time. Using new Date() and similar methods in the application code is not recommended.
Examples:
@Inject
protected TimeSource timeSource;
...
Date date = timeSource.currentTimestamp();long startTime = AppBeans.get(TimeSource.class).currentTimeMillis();4.2.6.8. UserSessionSource
The interface is used to obtain current user session object. See more in User Authentication.
4.2.6.9. UuidSource
The interface is used to obtain UUID values, including those used for entity identifiers. Using UUID.randomUUID() in the application code is not recommended.
To call from a static context, you can use the UuidProvider class, which also has an additional fromString() method that works faster than the standard UUID.fromString() method.
4.2.6.10. DataManager
DataManager interface provides CRUD functionality on both middle and client tiers. It is a universal tool for loading entity graphs from the database and saving changed detached entity instances.
DataManager always starts a new transaction and commits it on operation completion, thus returning entities in the detached state.
DataManager always applies security restrictions on entity operations and attributes when invoked from a client, and ignores them by default when invoked from middleware code. If you want to check these restrictions when using DataManager in your middleware code, obtain a wrapper via DataManager.secure() method and call its methods. Alternatively, you can set the cuba.dataManagerChecksSecurityOnMiddleware application property to turn on security check for the whole application. Note that access group constraints (row-level security) are always applied regardless of whether DataManager is called from the client or middle tier.
DataManager methods are listed below:
-
load(),loadList()– loads a graph of entities according to the parameters of theLoadContextobject passed to it.LoadContextmust include either a JPQL query or an entity identifier. If both are defined, the query is used, and the identifier is ignored. The rules for queries creation are similar to those described in Executing JPQL Queries . The difference is that the query inLoadContextmay only use named parameters; positional parameters are not supported.load()andloadList()methods check user permissionEntityOp.READfor the entity being loaded. Additionally, loading entities from DB is subject for access group constraints.Examples of loading entities in the screen controller:
@Inject private DataManager dataManager; private Book loadBookById(UUID bookId) { LoadContext<Book> loadContext = LoadContext.create(Book.class) .setId(bookId).setView("book.edit"); return dataManager.load(loadContext); } private List<BookPublication> loadBookPublications(UUID bookId) { LoadContext<BookPublication> loadContext = LoadContext.create(BookPublication.class) .setQuery(LoadContext.createQuery("select p from library$BookPublication p where p.book.id = :bookId") .setParameter("bookId", bookId)) .setView("bookPublication.full"); return dataManager.loadList(loadContext); } -
loadValues()- loads a list of key-value pairs. The method acceptsValueLoadContextwhich defines a query for scalar values and a list of keys. The returned list contains instances ofKeyValueEntity. For example:ValueLoadContext context = ValueLoadContext.create() .setQuery(ValueLoadContext.createQuery( "select o.customer, sum(o.amount) from demo$Order o " + "where o.date >= :date group by o.customer") .setParameter("date", orderDate)) .addProperty("customer") .addProperty("sum"); List<KeyValueEntity> list = dataManager.loadValues(context); -
getCount()- returns a number of records for a query passed to the method. When possible, the standard implementation inRdbmsStoreexecutesselect count()query with the same conditions as in the original query for maximum performance. -
commit()– saves a set of entities passed inCommitContextto the database. Collections of entities for updating and deletion must be specified separately.The method returns the set of entity instances returned by EntityManager.merge(); essentially these are fresh instances just updated in DB. Further work should be performed with these returned instances to prevent data loss or optimistic locking. You can ensure that required attributes are present in the returned entities by setting a view for each saved instance using
CommitContext.getViews()map.This method checks user permissions
EntityOp.UPDATEfor the updated entities andEntityOp.DELETEfor the deleted ones.Examples for saving a collection of entities:
@Inject private DataManager dataManager; private void saveBookInstances(List<BookInstance> toSave, List<BookInstance> toDelete) { CommitContext commitContext = new CommitContext(toSave, toDelete); dataManager.commit(commitContext); } private Set<Entity> saveAndReturnBookInstances(List<BookInstance> toSave, View view) { CommitContext commitContext = new CommitContext(); for (BookInstance bookInstance : toSave) { commitContext.addInstanceToCommit(bookInstance, view); } return dataManager.commit(commitContext); } -
reload()- convenience methods to reload a specified instance from the database with the required view. They delegate toload()method. -
remove()- removes a specified instance from the database. Delegates tocommit()method.
While loading data, DataManager may also implement additional functionality described below.
|
Tip
|
See DataManager vs. EntityManager for information on differences between DataManager and EntityManager. |
4.2.6.10.1. Queries with distinct
If a screen contains a table with paging, and JPQL that is used to load data can be modified at run time as a result of applying a generic filter or access group constraints, the following can happen when distinct operator is omitted in JPQL queries:
-
If a collection is joined at the database level, the loaded dataset will contain duplicate rows.
-
On client level, the duplicates disappear in the datasource as they are added to a map (
java.util.Map). -
In case of paged table, a page may show fewer lines than requested, while the total number of lines exceeds requested.
Thus, we recommend including distinct in JPQL queries, which ensures the absence of duplicates in the dataset returned from the database. However, certain DB servers (PostgreSQL in particular) have performance problems when executing SQL queries with distinct if the number of returned records is large (more than 10000).
To solve this, the platform contains a mechanism to operate correctly without distinct at SQL level. This mechanism is enabled by cuba.inMemoryDistinct application property. When activated, it does the following:
-
The JPQL query should still include
select distinct. -
DataManagercutsdistinctout of the JPQL query before sending it to ORM. -
After the data page is loaded by
DataManager, it deletes the duplicates and runs additional queries to DB in order to retrieve the necessary number of rows which are then returned to the client.
4.2.6.10.2. Sequential Queries
DataManager can select data from the results of previous requests. This capability is used by the generic filter for sequential application of filters.
The mechanism works as follows:
-
If a
LoadContextwith defined attributesprevQueriesandqueryKeyis provided,DataManagerexecutes the previous query and saves identifiers of retrieved entities in theSYS_QUERY_RESULTtable (corresponding tosys$QueryResultentity), separating the sets of records by user sessions and the query session keyqueryKey. -
The current query is modified to be combined with the results of the previous one, so that the resulting data complies with the conditions of both queries combined by AND.
-
The process may be further repeated. In this case the gradually reduced set of previous results is deleted from the
SYS_QUERY_RESULTtable and refilled again.
The SYS_QUERY_RESULT table should be periodically cleaned of all unnecessary query results left by terminated user sessions. This is done by the deleteForInactiveSessions() method of the QueryResultsManagerAPI bean. In an application with enabled cuba.allowQueryFromSelected property this method should be called by scheduled tasks, for example:
<task:scheduled-tasks scheduler="scheduler">
<task:scheduled ref="cuba_QueryResultsManager" method="deleteForInactiveSessions" fixed-rate="600000"/>
</task:scheduled-tasks>4.2.7. PersistenceHelper
A helper class for obtaining the information on persistent entities. Unlike the Persistence and PersistenceTools beans, this class is available on all tiers.
The PersistenceHelper bean has the following methods:
-
isLoaded()- determines if an attribute is loaded from the database. The attribute is loaded if it is included into a view, or if it is a local attribute and a view was not provided to the loading mechanism (EntityManager or DataManager). Only immediate attributes of the entity are supported. -
isNew()– determines if the passed instance is newly created, i.e., in the New state. Also returnstrueif this instance is actually in Managed state but newly-persisted in the current transaction, or if it is not a persistent entity. -
isManaged()- determines if the passed instance is Managed, i.e. attached to a persistence context. -
isDetached()– determines if the passed instance is in the Detached state. Also returnstrue, if this instance is not a persistent entity. -
isSoftDeleted()– determines if the passed entity class supports the soft deletion. -
getEntityName()– returns the name of the entity specified in the @Entity annotation.
4.2.8. AppContext
AppContext is a system class, which stores references to certain common components for each application block in its static fields:
-
ApplicationContextof Spring Framework. -
Set of application properties loaded from
app.propertiesfiles. -
ThreadLocalvariable, storing SecurityContext instances. -
Collection of application lifecycle listeners (
AppContext.Listener).
When the application is started, AppContext is initialized using loader classes, specific for each application block:
-
Middleware loader –
AppContextLoader -
Web Client loader –
WebAppContextLoader -
Web Portal loader –
PortalAppContextLoader -
Desktop Client loader –
DesktopAppContextLoader
AppContext can be used in the application code for the following tasks:
-
Registering listeners, triggered after full initialization and before termination of the application, for example:
AppContext.addListener(new AppContext.Listener() { @Override public void applicationStarted() { System.out.println("Application is ready"); } @Override public void applicationStopped() { System.out.println("Application is closing"); } });At the moment of
applicationStarted()call:-
All the beans are fully initialized and their
@PostConstructmethods are executed. -
Static
AppBeans.get()methods can be used for obtaining beans. -
The
AppContext.isStarted()method returnstrue. -
The
AppContext.isReady()method returnsfalse. -
If cuba.automaticDatabaseUpdate application property is enabled, all database update scripts are successfully executed (in the Middleware block).
At the moment of
applicationStopped()call:-
All the beans are operational and can be obtained via
AppBeans.get()methods. -
AppContext.isStarted()method returnsfalse. -
The
AppContext.isReady()method returnsfalse.
A real example of using
AppContext.Listenercan be found in Running Code at Application Start. -
-
Getting the application property values, stored in
app.propertiesfiles in case they are not available through configuration interfaces. -
Passing
SecurityContextto new execution threads, see User Authentication.
4.2.9. Application Properties
Application properties represent named values of different types, which determine various aspects of application configuration and functionality. The platform uses application properties extensively, and you can also employ them to configure application-specific features.
Platform application properties can be classified by intended purpose as follows:
-
Configuration parameters – specify sets of configuration files and certain user interface parameters, i.e. determine the application functionality. Values of configuration parameters are usually defined for the application project at development time.
For example: cuba.springContextConfig.
-
Deployment parameters – describe various URLs to connect application blocks, DBMS type, security settings etc. Values of deployment parameters are usually depend on the environment where the application instance is installed.
For example: cuba.connectionUrlList, cuba.dbmsType, cuba.userSessionExpirationTimeoutSec.
-
Runtime parameters – audit settings, email sending parameters etc. Values of these properties can be changed when needed at the application run time even without restart.
For example: cuba.entityLog.enabled, cuba.email.smtpHost.
- Setting Application Properties
-
Values of application properties can be set in the database, in the property files, or via Java system properties. Besides, a value set in a file overrides the value with the same name from the database. A value set as a Java system property overrides both values from files and from the database.
Some properties do not support setting values in the database for the following reason: their values are needed when the database is not accessible to the application code yet. These are configuration and deployment parameters mentioned above. So you can only define them in property files or via Java system properties. Runtime parameters can always be set in the database (and possibly be overridden by values in files or system properties).
Typically, an application property is used in one or several application blocks. For example, cuba.persistenceConfig is used only in Middleware, cuba.web.appWindowMode is used in Web Client, while cuba.springContextConfig is used in all blocks. It means that if you need to set some value to a property, you should do it in all blocks that use this property. Properties stored in the database are automatically available to all blocks, so you set them just in one place (in the database table) regardless of what blocks use them. Moreover, there is a standard UI screen to manage properties of this type: see Administration > Application Properties. Properties stored in files should be set separately in the respective files of the blocks.
TipWhen you need to set a value to a platform property, find this property in the documentation. If the documentation states that the property is stored in the database, use the Administration > Application Properties screen to set its value. Otherwise, find out what blocks use the property and define it in the
app.propertiesfiles of these blocks. For example, if the documentation states that the property is used in all blocks, and your application consists of Middleware and Web Client, you should define the property in theapp.propertiesfile of the core module and in theweb-app.propertiesfile of the web module. Deployment parameters can also be set outside of project files in the configuration directory. See Storing Properties in Files for details.
- Additive Properties
-
Properties representing configuration parameters can be additive. Additive properties get their values from all components used in the application. This allows platform mechanisms to configure your application depending on the properties provided by application components. For example, cuba.persistenceConfig is an additive property. In your project, it specifies a
persistence.xmlfile defining your project’s data model. But due to the fact that the real property value will include alsopersistence.xmlfiles of the application components, the whole data model of your application will include also entities defined in the components.Additive properties are stored in files and usually have the plus sign in the beginning of values, indicating that the property value will be assembled from application components at runtime. If you omit
+for an additive property, its value will be obtained only from the current project. It can be useful if you don’t want to inherit some configuration from components, for example, when you define a menu structure.
- Programmatic Access to Application Properties
-
You can access application properties in your code using the following mechanisms:
-
Configuration interfaces. If you define application properties as annotated methods of a configuration interface, the application code will have typed access to the properties. Configuration interfaces allow you to define and access properties of all types of storage: database, files and system properties.
-
The
getProperty()method of the AppContext class. If you set a property in a file or as a Java system property, you can read its value using this method. This approach has the following drawbacks:-
Properties stored in the database are not supported.
-
Unlike invoking an interface method, you have to provide the property name as String.
-
Unlike getting a result of a specific type, you can only get the property value as String.
-
-
4.2.9.1. Storing Properties in Files
Properties that determine configuration and deployment parameters are specified in special property files named according to the *app.properties pattern. Each application block contains a set of such files, including files from cuba application component. The set of property files is defined as follows:
-
For web application blocks (Middleware, Web Client, Web Portal) the set of property files is specified in the
appPropertiesConfigparameter of web.xml. -
For the Desktop Client block the standard way to specify the set of property files is to override the
getDefaultAppPropertiesConfig()method in an application class inherited fromcom.haulmont.cuba.desktop.App.
For example, the set of property files of the Middleware block is specified in the web/WEB-INF/web.xml file of the core module and looks as follows:
<context-param>
<param-name>appPropertiesConfig</param-name>
<param-value>
classpath:cuba-app.properties
classpath:com/company/sample/app.properties
file:${catalina.home}/conf/app-core/local.app.properties
</param-value>
</context-param>The classpath: prefix means that the corresponding file can be found in the Java classpath, while file: prefix means that it should be loaded from the file system. Java system properties can be used: in this example, catalina.home is the Tomcat installation path.
An order in which files are declared is important because the values, specified in each subsequent file override the values of the properties with the same name, specified in the preceding files. This allows you to override platform properties in the application.
The last file in the above set is local.app.properties. It can be used to override application properties upon deployment. If the file does not exist, it is silently ignored. You can create this file on the application server and define all properties specific to the environment in it. As a result, the settings will be separated from the application, and you will be able to update the application without fear of losing the specific configuration information. The Using Tomcat in Production section contains an example of using the local.app.properties file.
For Desktop Client, JVM command line arguments serve as an equivalent of local.app.properties. In this block, the properties loader treats all the arguments containing "=" sign as a key/value pair and uses them to replace corresponding application properties specified in app.properties files.
|
Tip
|
Use the following rules when create
|
4.2.9.2. Storing Properties in the Database
Application properties that represent runtime parameters are stored in the SYS_CONFIG database table.
Such properties have the following distinctive features:
-
As the property value is stored in the database, it is defined in a single location, regardless of what application blocks use it.
-
The value can be changed and saved at runtime in the following ways:
-
Using the Administration > Application Properties screen.
-
Using the ConfigStorageMBean JMX bean.
-
If the configuration interface has a setter method, you can set the property value in the application code.
-
-
Property value can be overridden for a particular application block in its
*app.propertiesfile or via Java system property with the same name.
It is important to mention, that access to properties stored in the database on the client side leads to Middleware requests. This is less efficient than retrieving properties from local *app.properties files. To reduce the number of requests, the client caches properties for the lifetime of configuration interface implementation instance. Thus, if you need to access the properties of a configuration interface from some UI screen for several times, it is recommended to get the reference to this interface upon screen initialization and save it to a screen controller field for further access.
4.2.9.3. Configuration Interfaces
The configuration interfaces mechanism enables working with application properties using Java interface methods, providing the following benefits:
-
Typed access – application code works with actual data types (String, Boolean, Integer etc.).
-
Instead of string property identifiers, the application code uses interface methods, which are checked by the compiler and you can use code completion when working in an IDE.
Example of reading the transaction timeout value in the Middleware block:
@Inject
private ServerConfig serverConfig;
public void doSomething() {
int timeout = serverConfig.getDefaultQueryTimeoutSec();
...
}If injection is impossible, the configuration interface reference can be obtained via the Configuration infrastructure interface:
int timeout = AppBeans.get(Configuration.class)
.getConfig(ServerConfig.class)
.getDefaultQueryTimeoutSec();|
Warning
|
Configuration interfaces are not regular Spring managed beans. They can only be obtained through explicit interface injection or via |
4.2.9.3.1. Using Configuration Interfaces
To create a configuration interface in your application, do the following:
-
Create an interface inherited from
com.haulmont.cuba.core.config.Config(not to be confused with the entity classcom.haulmont.cuba.core.entity.Config). -
Add
@Sourceannotation to specify where the property values should be stored:-
SourceType.SYSTEM– values will be taken from the system properties of the given JVM using theSystem.getProperty()method. -
SourceType.APP– values will be taken from*app.propertiesfiles. -
SourceType.DATABASE– values will be taken from the database.
-
-
Create property access methods (getters / setters). If you are not going to change the property value from the application code, do not create setter. A getter return type defines the property type. Possible property types are described below.
-
Add
@Propertyannotation defining the property name to the getter. -
You can optionally set
@Sourceannotation for a particular property if its source differs from the interface source.
Example:
@Source(type = SourceType.DATABASE)
public interface SalesConfig extends Config {
@Property("sales.companyName")
String getCompanyName();
}Do not create any implementation classes because the platform will create a required proxy automatically when you inject the configuration interface or obtain it through Configuration.
4.2.9.3.2. Property Types
The following property types are supported in the platform out-of-the-box:
-
String, primitive types and their object wrappers (boolean,Boolean,int,Integer, etc.) -
enum. The property value is stored in a file or in the database as the value name of the enumeration.If the enum implements the
EnumClassinterface and has the staticfromId()method for getting a value by an identifier, you can specify that the enum identifier should be stored instead of value with the@EnumStoreannotation. For example:@Property("myapp.defaultCustomerGrade") @DefaultInteger(10) @EnumStore(EnumStoreMode.ID) CustomerGrade getDefaultCustomerGrade(); @EnumStore(EnumStoreMode.ID) void setDefaultCustomerGrade(CustomerGrade grade); -
Persistent entity classes. When accessing a property of the entity type, the instance defined by the property value is loaded from the database.
To support arbitrary types, use TypeStringify and TypeFactory classes to convert the value to/from a string and specify these classes for the property with @Stringify and @Factory annotations.
Let us consider this process using the UUID type as an example.
-
Create class
com.haulmont.cuba.core.config.type.UuidTypeFactoryinherited fromcom.haulmont.cuba.core.config.type.TypeFactoryand implement the following method in it:public Object build(String string) { if (string == null) { return null; } return UUID.fromString(string); } -
There is no need to create
TypeStringifyastoString()method is sufficient in this case. -
Annotate the property in the configuration interface:
@Factory(factory = UuidTypeFactory.class) UUID getUuidProp(); void setUuidProp(UUID value);
The platform provides TypeFactory implementations for the following types:
-
UUID–UuidTypeFactory, as described above. -
java.util.Date–DateFactory. Date value must be specified inyyyy-MM-dd HH:mm:ss.SSSformat, for example:cuba.test.dateProp = 2013-12-12 00:00:00.000 -
List<Integer>(the list of integers) –IntegerListTypeFactory. The property value must be specified in the form of numbers, separated by spaces, for example:cuba.test.integerListProp = 1 2 3 -
List<String>(the list of strings) –StringListTypeFactory. The property value must be specified as a list of strings separated by "|" sign, for example:cuba.test.stringListProp = aaa|bbb|ccc
4.2.9.3.3. Default Values
You can specify default values for properties defined by configuration interfaces. These values will be returned instead of null if the property is not set in the storage location – the database or *app.properties files.
A default value can be specified as a string using the @Default annotation, or as a specific type using other annotations from com.haulmont.cuba.core.config.defaults package:
@Property("cuba.email.adminAddress")
@Default("address@company.com")
String getAdminAddress();
@Property("cuba.email.delayCallCount")
@Default("2")
int getDelayCallCount();
@Property("cuba.email.defaultSendingAttemptsCount")
@DefaultInt(10)
int getDefaultSendingAttemptsCount();
@Property("cuba.test.dateProp")
@Default("2013-12-12 00:00:00.000")
@Factory(factory = DateFactory.class)
Date getDateProp();
@Property("cuba.test.integerList")
@Default("1 2 3")
@Factory(factory = IntegerListTypeFactory.class)
List<Integer> getIntegerList();
@Property("cuba.test.stringList")
@Default("aaa|bbb|ccc")
@Factory(factory = StringListTypeFactory.class)
List<String> getStringList();A default value for an entity is a string of the {entity_name}-{id}-{optional_view_name} format, for example:
@Default("sec$User-98e5e66c-3ac9-11e2-94c1-3860770d7eaf-browse")
User getAdminUser();
@Default("sec$Role-a294aef0-3ac9-11e2-9433-3860770d7eaf")
Role getAdminRole();4.2.10. Messages Localization
Applications based on CUBA platform support messages localization, which means that all user interface elements can be displayed in the language, selected by user.
Language selection options are determined by the combination of cuba.localeSelectVisible and cuba.availableLocales application properties.
This section describes the localization mechanism and rules of localized messages creation. For information about obtaining messages see Getting Localized Messages.
4.2.10.1. Message Packs
A message pack is a set of property files with the names in messages{_XX}.properties format located in a single Java package. XX suffix indicates the language of the messages in this file and corresponds to the language code in Locale.getLanguage(). It is also possible to use other Locale attributes, for example, country. In this case the message pack file will look like messages{_XX_YY}.properties. One of the files in the pack can have no language suffix – it is the default file. The name of the message pack corresponds to the name of the Java package, which contains the pack files.
Let us consider the following example:
/com/abc/sales/gui/customer/messages.properties
/com/abc/sales/gui/customer/messages_fr.properties
/com/abc/sales/gui/customer/messages_ru.propertiesThis pack consists of 3 files – one for Russian, one for French and a default file. The name of the pack is com.abc.sales.gui.customer.
Message files contain key/value pairs, where the key is the message identifier referenced by the application code, and the value is the message itself in the language of the file. The rules for matching pairs are similar to those of java.util.Properties property files with the following specifics:
-
File encoding –
UTF-8only. -
Including other message packs is supported using
@includekey. Several packs can be included using comma-separated list. In this case, if some message key is found in both the current and the included pack, the message from the current pack will be used. Example of including packs:@include=com.haulmont.cuba.web, com.abc.sales.web someMessage=Some Message ...
Messages are retrieved from the packs using Messages interface methods according to the following rules:
-
At first step the search is performed in the application configuration directory.
-
messages_XX.propertiesfile is searched in the directory specified by the message pack name, whereXXis the code of the required language. -
If there is no such file, default
messages.propertiesfile is searched in the same directory. -
If either the required language file or the default file is found, it is loaded together with all
@includefiles, and the key message is searched in it. -
If the file is not found or it does not contain the proper key, the directory is changed to the parent one and the search procedure is repeated. The search continues until the root of the configuration directory is reached.
-
-
If the message is not found in the configuration directory, the search is performed in classpath according to the same algorithm.
-
If the message is found, it is cached and returned. If not, the fact that the message is not present is cached as well and the key which was passed for search is returned. Thus, the complex search procedure is only performed once and further on the result is loaded from the local cache of the application block.
|
Tip
|
It is recommended to organize message packs as follows:
|
4.2.10.2. Main Message Pack
Each standard application block should have its own main message pack. For the client tier blocks the main message pack contains main menu entries and common UI elements names (for example, names of OK and Cancel buttons). The main pack also determines Datatype transformation formats for all application blocks, including Middleware.
cuba.mainMessagePack application property is used to specify the main message pack. The property value can be either a single pack or list of packs separated by spaces. For example:
cuba.mainMessagePack=com.haulmont.cuba.web com.abc.sales.webIn this case the messages in the second pack of the list will override those from the first pack. Thus, the messages defined in the application components packs can be overridden in the application project.
4.2.10.3. Entity and Attributes Names Localization
To display localized names of the entities and attributes in UI, create special message packs in the Java packages containing the entities. Use the following format in message files:
-
Key of the entity name – simple class name (without package).
-
Key of the attribute name – simple class name, then the name of the attribute separated by period.
The example of default English localization of com.abc.sales.entity.Customer entity – /com/abc/sales/entity/messages.properties file:
Customer=Customer
Customer.name=Name
Customer.email=Email
Order=Order
Order.customer=Customer
Order.date=Date
Order.amount=AmountSuch message packs are usually used implicitly by the framework, for example, by Table and FieldGroup visual components. Besides, you can obtain the names of the entities and attributes using the following methods:
-
Programmatically – by MessageTools
getEntityCaption(),getPropertyCaption()methods; -
In XML screen descriptor – by reference to the message according to MessageTools.loadString() rules:
msg://{entity_package}/{key}, for example:caption="msg://com.abc.sales.entity/Customer.name"
4.2.10.4. Enum Localization
To localize the enumeration names and values, add messages with the following keys to the message pack located in the Java package of the enumeration class:
-
Enumeration name key – simple class name (without package);
-
Value key – simple class name, then the value name separated by period.
For example, for enum
package com.abc.sales;
public enum CustomerGrade {
PREMIUM,
HIGH,
STANDARD
}default English localization file /com/abc/sales/messages.properties should contain the following lines:
CustomerGrade=Customer Grade
CustomerGrade.PREMIUM=Premium
CustomerGrade.HIGH=High
CustomerGrade.STANDARD=StandardLocalized enum values are automatically used by different visual components such as LookupField. You can obtain localized enum value programmatically: use getMessage() method of the Messages interface and simply pass the enum instance to it.
4.2.11. User Authentication
This section describes some access control aspects from the developer’s point of view. For complete information on configuring user data access restrictions, see Security Subsystem.
4.2.11.1. UserSession
User session is the main element of access control mechanism of CUBA applications. It is represented by the UserSession object, which is associated with the currently authenticated user and contains information about user rights. The UserSession object can be obtained in any application block using the UserSessionSource infrastructure interface.
The UserSession object is created on Middleware during LoginService.login() method execution after the user is authenticated using a name and a password. The object is then cached in the Middleware block and returned to the client tier. When running in cluster, the session object is replicated to all cluster members. The client tier also stores the session object after receiving it, associating it with the active user in one way or another (for example, storing it in HTTP session). Further on, all Middleware invocations on behalf of this user are accompanied by passing the session identifier (of UUID type). This process does not need any special support in the application code, as the session identifier is passed automatically, regardless of the signature of invoked methods. Processing of client invocations in the Middleware starts from retrieving session from the cache using the obtained identifier. Then the session is associated with the request execution thread. The session object is deleted from the cache when the LoginService.logout() method is called or when the timeout defined by cuba.userSessionExpirationTimeoutSec application property expires.
Thus the session identifier created when the user logs into the system is used for user authentication during each Middleware invocation.
The UserSession object also contains methods for current user authorization – validation of the rights to system objects: isScreenPermitted(), isEntityOpPermitted(), isEntityAttrPermitted(), isSpecificPermitted(). However, it is recommended to use the Security infrastructure interface for programmatic authorization.
The UserSession object can contain named attributes of arbitrary serializable type. The attributes are set by setAttribute() method and returned by getAttribute() method. The latter is also able to return the following session parameters, as if they were attributes:
-
userId– ID of the currently registered or substituted user; -
userLogin– login of the currently registered or substituted user in lowercase.
The session attributes are replicated in the Middleware cluster, same as the other user session data.
4.2.11.2. Login
Standard user login process:
-
The user enters his username and password.
-
Application client block hashes the password using
getPlainHash()method ofPasswordEncryptionbean and invokesLoginService.login()Middleware method passing the user login and password hash to it. -
LoginServicedelegates execution to theLoginWorkerbean, which loadsUserobject by the entered login, hashes the obtained password hash again using user identifier as salt and compares the obtained hash to the password hash stored in the DB. In case of mismatch,LoginExceptionis thrown. -
If the authentication is successful, all the access parameters of the user (roles list, rights, restrictions and session attributes) are loaded to the created UserSession instance.
Password hashing algorithm is implemented by the EncryptionModule type bean and is specified in cuba.passwordEncryptionModule application property. SHA-1 is used by default.
The platform has a mechanism for the protection against password brute force cracking. The protection is enabled by the cuba.bruteForceProtection.enabled application property on Middleware. If the protection is enabled then the combination of user login and IP address is blocked for a time interval in case of multiple unsuccessful login attempts. A maximum number of login attempts for the combination of user login and IP address is defined by the cuba.bruteForceProtection.maxLoginAttemptsNumber application property (default value is 5). Blocking interval in seconds is defined by the cuba.bruteForceProtection.blockIntervalSec application property (default value is 60).
It is possible that the user password (actually, password hash) is not stored in the database, but is verified by external means, for example, by means of integration with LDAP. In this case the authentication is in fact performed by the client block, while the Middleware "trusts" the client by creating the session based on user login only, without the password, using LoginService.loginTrusted() method. This method requires satisfying the following conditions:
-
The client block has to pass the so-called trusted password, specified in the cuba.trustedClientPassword Middleware and client block application property.
-
IP address of the client block has to be in the list specified in the cuba.trustedClientPermittedIpList application property.
Login to the system is also required for scheduled automatic processes as well as for connecting to the Middleware beans using JMX interface. Formally, these actions are considered administrative and they do not require authentication as long as no entities are changed in the database. When an entity is persisted to the database, the process requires login of the user who is making the change so that the login of the user responsible for the changes is stored.
An additional benefit from login to the system for an automatic process or for JMX call is that the server log output is displayed with the current user login if the user session is set to the execution thread. This simplifies searching messages created by specific process during log parsing.
System access for the processes within Middleware is done using LoginWorker.loginSystem() call passing the login (without password) of the user on whose behalf the process will be executed. As result, UserSession object will be created and cached in the corresponding Middleware block but it will not be replicated in the cluster.
See more about processes authentication inside Middleware in System Authentication.
4.2.11.3. SecurityContext
SecurityContext class instance stores information about the user session for the current execution thread. It is created and passed to AppContext.setSecurityContext() method in the following moments:
-
For the Web Client and Web Portal blocks – at the beginning of processing of each HTTP request from the user browser.
-
For the Middleware block – at the beginning of processing of each request from the client tier and from CUBA Scheduled Tasks.
-
For the Desktop Client block – once after the user login, as the desktop application is running in single user mode.
In the first two cases, SecurityContext is removed from the execution thread when the request execution is finished.
If you create a new execution thread from the application code, pass the current SecurityContext instance to it as in the example below:
final SecurityContext securityContext = AppContext.getSecurityContext();
executor.submit(new Runnable() {
public void run() {
AppContext.setSecurityContext(securityContext);
// business logic here
}
});The same can be done using SecurityContextAwareRunnable or SecurityContextAwareCallable wrappers, for example:
executor.submit(new SecurityContextAwareRunnable<>(() -> {
// business logic here
}));Future<String> future = executor.submit(new SecurityContextAwareCallable<>(() -> {
// business logic here
return some_string;
}));4.2.12. Exceptions Handling
This section describes various aspects of working with exceptions in CUBA applications.
4.2.12.1. Exception Classes
The following rules should be followed when creating your own exception classes:
-
If the exception is part of business logic and requires some non-trivial actions to handle it, the exception class should be made checked (inherited from
Exception). Such exceptions are handled by the invoking code. -
If the exception indicates an error and assumes interruption of execution and a simple action like displaying the error information to the user, its class should be unchecked (inherited from
RuntimeException). Such exceptions are processed by special handler classes registered in the client blocks of the application. -
If the exception is thrown and processed in the same block, its class should be declared in corresponding module. If the exception is thrown on Middleware and processed on the client tier, the exception class should be declared in the global module.
The platform contains a special unchecked exception class SilentException. It can be used to interrupt execution without showing any messages to the user or writing them to the log. SilentException is declared in the global module, and therefore is accessible both in Middleware and client blocks.
4.2.12.2. Passing Middleware Exceptions
If an exception is thrown on Middleware as a result of handling a client request, the execution terminates and the exception object is returned to the client. The object usually includes the chain of underlying exceptions. This chain can contain classes which are inaccessible for the client tier (for example, JDBC driver exceptions). For this reason, instead of sending this chain to the client we send its representation inside a specially created RemoteException object.
The information about the causing exceptions is stored as a list of RemoteException.Cause objects. Each Cause object always contains an exception class name and its message. Moreover, if the exception class is "supported by client", Cause stores the exception object as well. This enables passing information to the client in the exception fields.
Exception class should be annotated by @SupportedByClient if its objects should be passed to the client tier as Java objects. For example:
@SupportedByClient
public class WorkflowException extends RuntimeException {
...Thus, when an exception is thrown on Middleware and it is not annotated by @SupportedByClient the calling client code will receive RemoteException containing original exception information in a string form. If the source exception is annotated by @SupportedByClient, the caller will receive it directly. This enables handling the exceptions declared by Middleware services in the application code in the traditional way – using try/catch blocks.
Bear in mind that if you need the exception supported by client to be passed on the client as an object, it should not contain any unsupported exceptions in its getCause() chain. Therefore, if you create an exception instance on Middleware and want to pass it to the client, specify cause parameter only if you are sure that it contains the exceptions known to the client.
ServiceInterceptor class is a service interceptor which packs the exception objects before passing them to the client tier. Besides, it performs exceptions logging. All information about the exception including full stack trace is logged by default. If it is not desirable, add @Logging annotation to the exception class and specify the logging level:
-
FULL– full information, including stacktrace (default). -
BRIEF– exception class name and message only. -
NONE– no output.
For example:
@SupportedByClient
@Logging(Logging.Type.BRIEF)
public class FinancialTransactionException extends Exception {
...4.2.12.3. Client-Level Exception Handlers
Unhandled exceptions in Web Client and Desktop Client blocks thrown on the client tier or passed from Middleware, are passed to the special handlers mechanism. This mechanism is implemented in the gui module and available for both blocks.
The handler should be a managed bean implementing the GenericExceptionHandler interface, handle processing in its handle() method and return true, or immediately return false, if this handler is not able to handle the passed exception. This behaviour enables creating a "chain of responsibility" for handlers.
It is recommended to inherit your handlers from the AbstractGenericExceptionHandler base class, which is able to disassemble the exceptions chain (including ones packed inside RemoteException) and handle specific exception types. Exception types supported by this handler are defined by passing strings array to the base constructor from the handler constructor. Each string of the array should contain one full class name of the handled exception, for example:
@Component("cuba_EntityAccessExceptionHandler")
public class EntityAccessExceptionHandler extends AbstractGenericExceptionHandler {
public EntityAccessExceptionHandler() {
super(EntityAccessException.class.getName());
}
...If the exception class is not accessible on the client side, specify its name with the string literal:
@Component("cuba_OptimisticExceptionHandler")
public class OptimisticExceptionHandler extends AbstractGenericExceptionHandler implements Ordered {
public OptimisticExceptionHandler() {
super("javax.persistence.OptimisticLockException");
}
...In the case of using AbstractGenericExceptionHandler as a base class, the processing logic is located in doHandle() method and looks as follows:
@Override
protected void doHandle(String className, String message, @Nullable Throwable throwable, WindowManager windowManager) {
String msg = messages.getMainMessage("zeroBalance.message");
windowManager.showNotification(msg, IFrame.NotificationType.ERROR);
}If the name of the exception class is insufficient to make a decision whether this handler can be applied to the exception, canHandle() method should be defined. This method accepts also the text of the exception. If the handler is applicable for this exception, the method must return true. For example:
@Component("cuba_NumericOverflowExceptionHandler")
public class NumericOverflowExceptionHandler extends AbstractGenericExceptionHandler {
public NumericOverflowExceptionHandler() {
super(EclipseLinkException.class.getName());
}
@Override
protected boolean canHandle(String className, String message, @Nullable Throwable throwable) {
return StringUtils.containsIgnoreCase(message, "Numeric field overflow");
}
...WindowManager provides a method for showing an exception with its stack trace: showExceptionDialog(). The method has the following parameters:
-
throwable-Throwableinstance. -
caption- dialog caption. It is an optional parameter, if not set, the default caption is used. -
message- dialog message. It is an optional parameter, if not set, the default caption is used.
An example of using the method in an exception handler:
@Override
protected void doHandle(String className, String message, @Nullable Throwable throwable, WindowManager windowManager) {
if (throwable != null)
windowManager.showExceptionDialog(throwable, "Exception is thrown", message);
else
windowManager.showNotification(message, IFrame.NotificationType.ERROR);
}4.2.13. Bean Validation
Bean validation is an optional mechanism that provides uniform validation of data on the middleware, in Generic UI and REST API. It is based on the JSR 349 - Bean Validation 1.1 and its reference implementation: Hibernate Validator.
4.2.13.1. Defining Constraints
You can define constraints using annotations of the javax.validation.constraints package or custom annotations. The annotations can be set on an entity or POJO class declaration, field or getter, and on a middleware service method.
Example of using standard validation annotations on entity fields:
@Table(name = "DEMO_CUSTOMER")
@Entity(name = "demo$Customer")
public class Customer extends StandardEntity {
@Size(min = 3) // length of value must be longer then 3 characters
@Column(name = "NAME", nullable = false)
protected String name;
@Min(1) // minimum value
@Max(5) // maximum value
@Column(name = "GRADE", nullable = false)
protected Integer grade;
@Pattern(regexp = "\\S+@\\S+") // value must conform to the pattern
@Column(name = "EMAIL")
protected String email;
//...
}Example of using a custom class-level annotation (see below):
@CheckTaskFeasibility(groups = {Default.class, UiCrossFieldChecks.class}) // custom validation annotation
@Table(name = "DEMO_TASK")
@Entity(name = "demo$Task")
public class Task extends StandardEntity {
//...
}Example of validation of a service method parameters and return value:
public interface TaskService {
String NAME = "demo_TaskService";
@Validated // indicates that the method should be validated
@NotNull
String completeTask(@Size(min = 5) String comment, @NotNull Task task);
}- Constraint Groups
-
Constraint groups enable applying only a subset of all defined constraints depending on the application logic. For example, you may want to force a user to enter a value for an entity attribute, but at the same time to have an ability to set this attribute to null by some internal mechanism. In order to do it, you should specify the
groupsattribute on the constraint annotation. Then the constraint will take effect only when the same group is passed to the validation mechanism.The platform passes to the validation mechanism the following constraint groups:
-
RestApiChecks- when validating in REST API. -
ServiceParametersChecks- when validating service parameters. -
ServiceResultChecks- when validating service return values. -
UiComponentChecks- when validating individual UI fields. -
UiCrossFieldChecks- when validating class-level constraints on entity editor commit. -
javax.validation.groups.Default- this group is always passed except on the UI editor commit.
-
- Validation Messages
-
Constraints can have messages to be displayed to users.
Messages can be set directly in the validation annotations, for example:
@Pattern(regexp = "\\S+@\\S+", message = "Invalid format") @Column(name = "EMAIL") protected String email;You can also place the message in a localized messages pack and use the following format to specify the message in an annotation:
{msg://message_pack/message_key}. For example:@Pattern(regexp = "\\S+@\\S+", message = "{msg://com.company.demo.entity/Customer.email.validationMsg}") @Column(name = "EMAIL") protected String email;Messages can contain parameters and expressions. Parameters are enclosed in
{}and represent either localized messages or annotation parameters, e.g.{min},{max},{value}. Expressions are enclosed in${}and can include the validated value variablevalidatedValue, annotation parameters likevalueormin, and JSR-341 (EL 3.0) expressions. For example:@Pattern(regexp = "\\S+@\\S+", message = "Invalid email: ${validatedValue}, pattern: {regexp}") @Column(name = "EMAIL") protected String email;Localized message values can also contain parameters and expressions.
- Custom Constraints
-
You can create you own domain-specific constraints with programmatic or declarative validation.
In order to create a constraint with programmatic validation, do the following:
-
Create an annotation in the global module of your project and annotate it with
@Constraint. The annotation must containmessage,groupsandpayloadattributes:@Target({ ElementType.TYPE }) @Retention(RUNTIME) @Constraint(validatedBy = TaskFeasibilityValidator.class) public @interface CheckTaskFeasibility { String message() default "{msg://com.company.demo.entity/CheckTaskFeasibility.message}"; Class<?>[] groups() default {}; Class<? extends Payload>[] payload() default {}; } -
Create a validator class in the global module of your project:
public class TaskFeasibilityValidator implements ConstraintValidator<CheckTaskFeasibility, Task> { @Override public void initialize(CheckTaskFeasibility constraintAnnotation) { } @Override public boolean isValid(Task value, ConstraintValidatorContext context) { Date now = AppBeans.get(TimeSource.class).currentTimestamp(); return !(value.getDueDate().before(DateUtils.addDays(now, 3)) && value.getProgress() < 90); } } -
Use the annotation:
@CheckTaskFeasibility(groups = UiCrossFieldChecks.class) @Table(name = "DEMO_TASK") @Entity(name = "demo$Task") public class Task extends StandardEntity { @Future @Temporal(TemporalType.DATE) @Column(name = "DUE_DATE") protected Date dueDate; @Min(0) @Max(100) @Column(name = "PROGRESS", nullable = false) protected Integer progress; //... }
You can also create custom constraints using a composition of existing ones, for example:
@NotNull @Size(min = 2, max = 14) @Pattern(regexp = "\\d+") @Target({METHOD, FIELD, ANNOTATION_TYPE}) @Retention(RUNTIME) @Constraint(validatedBy = {}) public @interface ValidProductCode { String message() default "{msg://om.company.demo.entity/ValidProductCode.message}"; Class<?>[] groups() default {}; Class<? extends Payload>[] payload() default {}; }When using a composite constraint, the resulting set of constraint violations will contain separate entries for each enclosed constraint. If you want to return a single violation, annotate the annotation class with
@ReportAsSingleViolation. -
4.2.13.2. Running Validation
- Validation in UI
-
Generic UI components connected to a datasource get an instance of
BeanValidatorto check the field value. The validator is invoked from theComponent.Validatable.validate()method implemented by the visual component and can throw theCompositeValidationExceptionexception that contains the set of violations.The standard validator can be removed or initialized with a different constraint group:
public class Screen extends AbstractWindow { @Inject private TextField field1; @Inject private TextField field2; public void init(Map<String, Object> params) { // Completely remove bean validation from the UI component field1.getValidators().stream() .filter(validator -> validator instanceof BeanValidator) .forEach(textField::removeValidator); // Here validators will check only constraints with explicitly set UiComponentChecks group, because // the Default group will not be passed field2.getValidators().stream() .filter(validator -> validator instanceof BeanValidator) .forEach(validator -> { ((BeanValidator) validator).setValidationGroups(new Class[] {UiComponentChecks.class}); }); } }By default,
BeanValidatorhas bothDefaultandUiComponentChecksgroups.If an entity attribute is annotated with
@NotNullwithout constraint groups, it will be marked as mandatory in metadata and UI components working with this attribute through a datasource will haverequired = true.The DateField and DatePicker components automatically set their
rangeStartandrangeEndproperties by the@Pastand@Futureannotations, but without considering time.Editor screens perform validation against class-level constraints on commit if the constraint includes the
UiCrossFieldChecksgroup and if all attribute-level checks are passed. You can turn off the validation of this kind using thecrossFieldValidateproperty of the screen in the screen XML descriptor or in the controller:<window xmlns="http://schemas.haulmont.com/cuba/window.xsd" caption="msg://editorCaption" class="com.company.demo.web.task.TaskEdit" datasource="taskDs" crossFieldValidate="false"> <!-- ... --> </window>public class TaskEdit extends AbstractEditor<Task> { @Override public void init(Map<String, Object> params) { setCrossFieldValidate(false); } }
- Validation in Middleware Services
-
Middleware services perform validation of parameters and results if a method has annotation
@Validatedin the service interface. For example:public interface TaskService { String NAME = "demo_TaskService"; @Validated @NotNull String completeTask(@Size(min = 5) String comment, @NotNull Task task); }The
@Validatedannotation can specify constraint groups to apply a certain set of constraints. If no groups are specified, the following are used by default:-
DefaultandServiceParametersChecks- for method parameters -
DefaultandServiceResultChecks- for method return value
The
MethodParametersValidationExceptionandMethodResultValidationExceptionexceptions are thrown on validation errors.If you perform some custom programmatic validation in a service, use
CustomValidationExceptionto inform clients about validation errors in the same format as the standard bean validation does. It can be particularly relevant for REST API clients. -
- Validation in REST API
-
Universal REST API automatically performs bean validation for create and update actions. Validation errors are returned to the client in the following way:
-
MethodResultValidationExceptionandValidationExceptioncause500 Server errorHTTP status -
MethodParametersValidationException,ConstraintViolationExceptionandCustomValidationExceptioncause400 Bad requestHTTP status -
Response body with
Content-Type: application/jsonwill contain a list of objects withmessage,messageTemplate,pathandinvalidValueproperties, for example:[ { "message": "Invalid email: aaa", "messageTemplate": "{msg://com.company.demo.entity/Customer.email.validationMsg}", "path": "email", "invalidValue": "aaa" } ]-
pathindicates a path to the invalid attribute in the validated object graph -
messageTemplatecontains a string which is defined in themessageannotation attribute -
messagecontains an actual value of the validation message -
invalidValueis returned only if its type is one of the following:String,Date,Number,Enum,UUID.
-
-
- Programmatic Validation
-
You can perform bean validation programmatically using the
BeanValidationinfrastructure interface, available on both middleware and client tier. It is used to obtain ajavax.validation.Validatorimplementation which runs validation. The result of validation is a set ofConstraintViolationobjects. For example:@Inject private BeanValidation beanValidation; public void save(Foo foo) { Validator validator = beanValidation.getValidator(); Set<ConstraintViolation<Foo>> violations = validator.validate(foo); // ... }
4.3. Database Components
This section provides information on how to configure the application for working with particular DBMS. It also describes a script-based mechanism, which enables creating a new database and keeping it up-to-date throughout the entire cycle of the development and operation of the application.
Database components belong to the Middleware block; other blocks of the application do not have direct access to the database.
Some additional information on working with the database is provided in the Working with Databases section.
4.3.1. DBMS Types
The type of the DBMS used in the application is defined by the cuba.dbmsType and (optionally) cuba.dbmsVersion application properties. These properties affect various platform mechanisms depending on the database type.
The application connects to the database through the javax.sql.DataSource which is extracted from JNDI by the name specified in the cuba.dataSourceJndiName application property (java:comp/env/jdbc/CubaDS by default). Configuration of the data source for standard deployment is defined in the context.xml file of the core module. The data source should use a proper JDBC driver for the selected DBMS.
The platform supports the following types of DBMS "out of the box":
| cuba.dbmsType | cuba.dbmsVersion | |
|---|---|---|
HSQLDB |
hsql |
|
PostgreSQL 8.4+ |
postgres |
|
Microsoft SQL Server 2005, 2008 |
mssql |
|
Microsoft SQL Server 2012+ |
mssql |
2012 |
Oracle Database 11g+ |
oracle |
|
MySQL 5.6+ |
mysql |
The table below describes the recommended mapping of data types between entity attributes in Java and table columns in different DBMS. CUBA Studio automatically chooses these types when generates scripts to create and update the database. The operation of all platform mechanisms is guaranteed when you use these types.
| Java | HSQL | PostgreSQL | MS SQL Server | Oracle | MySQL |
|---|---|---|---|---|---|
UUID |
varchar(36) |
uuid |
uniqueidentifier |
varchar2(32) |
varchar(32) |
Date |
timestamp |
timestamp |
datetime |
timestamp |
datetime(3) |
java.sql.Date |
timestamp |
date |
datetime |
date |
date |
java.sql.Time |
timestamp |
time |
datetime |
timestamp |
time(3) |
BigDecimal |
decimal(p, s) |
decimal(p, s) |
decimal(p, s) |
number(p, s) |
decimal(p, s) |
Double |
double precision |
double precision |
double precision |
float |
double precision |
Long |
bigint |
bigint |
bigint |
number(19) |
bigint |
Integer |
integer |
integer |
integer |
integer |
integer |
Boolean |
boolean |
boolean |
tinyint |
char(1) |
boolean |
String (limited) |
varchar(n) |
varchar(n) |
varchar(n) |
varchar2(n) |
varchar(n) |
String (unlimited) |
longvarchar |
text |
varchar(max) |
clob |
longtext |
byte[] |
longvarbinary |
bytea |
image |
blob |
longblob |
Usually, the whole work to convert the data between the database and the Java code is performed by the ORM layer in conjunction with the appropriate JDBC driver. This means that no manual conversion is required when working with the data using the EntityManager methods and JPQL queries; you should simply use Java types listed in the left column of the table.
When using native SQL through EntityManager.createNativeQuery() or through QueryRunner, some types in the Java code will be different from those mentioned above, depending on DBMS used. In particular, this applies to attributes of the UUID - type – only the PostgreSQL driver returns values of corresponding columns using this type; other servers return String. To abstract application code from the database type, it is recommended to convert parameter types and query results using the DbTypeConverter interface.
4.3.1.1. Support for Other DBMSs
In the application project, you can use any DBMS supported by the ORM framework (EclipseLink). Follow the steps below:
-
Specify the type of database in the form of an arbitrary code in the cuba.dbmsType property. The code must be different from those used in the platform:
hsql,postgres,mssql,oracle. -
Implement the
DbmsFeatures,SequenceSupport,DbTypeConverterinterfaces by classes with the following names:TypeDbmsFeatures,TypeSequenceSupport, andTypeDbTypeConverter, respectively, whereTypeis the DBMS type code. The package of the implementation class must be the same as of the interface. -
Create database init and update scripts in the directories marked with the DBMS type code. Init scripts must create all database objects required by the platform entities (you can copy them from the existing
10-cuba, etc. directories and modify for your database). -
To create and update the database by Gradle tasks, you need to specify the additional parameters for these tasks in
build.gradle:task createDb(dependsOn: assemble, type: CubaDbCreation) { dbms = 'my' // DBMS code driver = 'net.my.jdbc.Driver' // JDBC driver class dbUrl = 'jdbc:my:myserver://192.168.47.45/mydb' // Database URL masterUrl = 'jdbc:my:myserver://192.168.47.45/master' // URL of a master DB to connect to for creating the application DB dropDbSql = 'drop database mydb;' // Drop database statement createDbSql = 'create database mydb;' // Create database statement timeStampType = 'datetime' // Date and time datatype - needed for SYS_DB_CHANGELOG table creation dbUser = 'sa' dbPassword = 'saPass1' } task updateDb(dependsOn: assemble, type: CubaDbUpdate) { dbms = 'my' // DBMS code driver = 'net.my.jdbc.Driver' // JDBC driver class dbUrl = 'jdbc:my:myserver://192.168.47.45/mydb' // Database URL dbUser = 'sa' dbPassword = 'saPass1' }
4.3.1.2. DBMS Version
In addition to cuba.dbmsType application property, there is an optional cuba.dbmsVersion property. It affects the choice of interface implementations for DbmsFeatures, SequenceSupport, DbTypeConverter, and the search for database init and update scripts.
The name of the implementation class of the integration interface is constructed as follows: TypeVersionName. Here, Type is the value of the cuba.dbmsType property (capitalized), Version is the value of cuba.dbmsVersion, and Name is the interface name. The package of the class must correspond to that of the interface. If a class with the same name is not available, an attempt is made to find a class with the name without version: TypeName. If such class does not exist either, an exception is thrown.
For example, the com.haulmont.cuba.core.sys.persistence.Mssql2012SequenceSupport class is defined in the platform. This class will take effect if the following properties are specified in the project:
cuba.dbmsType = mssql
cuba.dbmsVersion = 2012The search for database init and update scripts prioritizes the type-version directory over the type directory. This means that the scripts in the type-version directory replace the scripts with the same name in the type directory. The type-version directory can also contain some scripts with unique names; they will be added to the common set of scripts for execution, too. Script sorting is performed by path, starting with the first subdirectory of the type or type-version directory, i.e. regardless of the directory where the script is located (versioned or not).
For example, the init script for Microsoft SQL Server versions below and above 2012 should look as follows:
modules/core/db/init/
mssql/
10.create-db.sql
20.create-db.sql
30.create-db.sql
mssql-2012/
10.create-db.sql4.3.2. Scripts to Create and Update the Database
A CUBA-application project always contains two sets of scripts:
-
Scripts to create the database, intended for the creation of the database from scratch. They contain a set of the DDL and DML operators, which create an empty database schema that is fully consistent with the current state of the data model of the application. These scripts can also fill the database with the necessary initialization data.
-
Scripts to update the database, intended for bringing the database structure to the current state of the data model from any of the previous states.
When changing the data model, it is necessary to reproduce the corresponding change of the database schema in create and update scripts. For example, when adding the address attribute to the Customer entity, it is necessary to:
-
Change the table creation script:
create table SALES_CUSTOMER ( ID varchar(36) not null, CREATE_TS timestamp, CREATED_BY varchar(50), NAME varchar(100), ADDRESS varchar(200), -- added column primary key (ID) ) -
Add an update script, which modifies the same table:
alter table SALES_CUSTOMER add ADDRESS varchar(200)
The create scripts are located in the /db/init directory of the core module. For each type of DBMS supported by the application, a separate set of scripts is created and located in the subdirectory specified in cuba.dbmsType application property, for example /db/init/postgres. Create scripts names should have the following format {optional_prefix}create-db.sql.
The update scripts are located in the /db/update directory of the core module. For each type of DBMS supported by the application, a separate set of scripts is created and located in the subdirectory specified in cuba.dbmsType application property, for example, /db/update/postgres.
The update scripts can be of two types: with the *.sql or *.groovy extension. The primary way to update the database is with SQL scripts. Groovy scripts are only executed by the server mechanism to launch database scripts, therefore they are mainly used at the production stage, in cases when migration or import of the data that cannot be implemented in pure SQL.
The update scripts should have names, which form the correct sequence of their execution when sorted in the alphabetical order (usually, it is a chronological sequence of their creation). Therefore, when creating such scripts manually, it is recommended to specify the name of the update scripts in the following format: {yymmdd}-{description}.sql, where yy is a year, mm is a month, dd is a day, and description is a short description of the script. For example, 121003-addCodeToCategoryAttribute.sql. Studio also adheres to this format when generating scripts automatically.
In order to be executed by the updateDb task, the groovy scripts should have .upgrade.groovy extension and the same naming logic. Post update actions are not allowed in that scripts, while the same ds (access to datasource) and log (access to logging) variables are used for the data binding. The execution of groovy scripts can be disabled by setting executeGroovy = false in the updateDb task of build.gradle.
It is possible to group update scripts into subdirectories, however the path to the script with the subdirectory should not break the chronological sequence. For example, subdirectories can be created by using year, or by year and month.
In a deployed application, the scripts to create and update the database are located in a special database script directory, that is set by the cuba.dbDir application property.
4.3.2.1. The Structure of SQL Scripts
Create and update SQL scripts are text files with a set of DDL and DML commands separated by the "^" character. The "^" character is used, so that the ";" separator can be applied as part of complex commands; for example, when creating functions or triggers. The script execution mechanism splits the input file into separate commands using the "^" separator and executes each command in a separate transaction. This means that, if necessary, it is possible to group several single statements (e.g., insert), separated by semicolons and ensure that they execute in a single transaction.
|
Tip
|
The "^" delimiter can be escaped by doubling it. For example, if you want to pass |
An example of the update SQL script:
create table LIBRARY_COUNTRY (
ID varchar(36) not null,
CREATE_TS time,
CREATED_BY varchar(50),
NAME varchar(100) not null,
primary key (ID)
)^
alter table LIBRARY_TOWN add column COUNTRY_ID varchar(36) ^
alter table LIBRARY_TOWN add constraint FK_LIBRARY_TOWN_COUNTRY_ID foreign key (COUNTRY_ID) references LIBRARY_COUNTRY(ID)^
create index IDX_LIBRARY_TOWN_COUNTRY on LIBRARY_TOWN (COUNTRY_ID)^4.3.2.2. The Structure of Groovy scripts
Groovy update scripts have the following structure:
-
The main part, which contains the code executed before the start of the application context. In this section, you can use any Java, Groovy and the Middleware application block classes. However, it should be kept in mind that no beans, infrastructure interfaces and other application objects have yet been instantiated and it is impossible to use them.
The main part is primarily designed to update the database schema, as usually done with ordinary SQL scripts.
-
The PostUpdate part – a set of closures, which will be executed after the start of the application context and once the update process is finished. Inside these closures, it is possible to use any Middleware objects.
In this part of the script, it is convenient to perform data import as it is possible to use the Persistence interface and data model objects.
The execution mechanism passes the following variables to the Groovy scripts:
-
ds– instance ofjavax.sql.DataSourcefor the application database; -
log– instance oforg.apache.commons.logging.Logto output messages in the server log; -
postUpdate– object that contains theadd(Closure closure)method to add PostUpdate closures described above.
|
Warning
|
Groovy scripts are executed only by the server mechanism to launch database scripts. |
An example of the Groovy update script:
import com.haulmont.cuba.core.Persistence
import com.haulmont.cuba.core.global.AppBeans
import com.haulmont.refapp.core.entity.Colour
import groovy.sql.Sql
log.info('Executing actions in update phase')
Sql sql = new Sql(ds)
sql.execute """ alter table MY_COLOR add DESCRIPTION varchar(100); """
// Add post update action
postUpdate.add({
log.info('Executing post update action using fully functioning server')
def p = AppBeans.get(Persistence.class)
def tr = p.createTransaction()
try {
def em = p.getEntityManager()
Colour c = new Colour()
c.name = 'yellow'
c.description = 'a description'
em.persist(c)
tr.commit()
} finally {
tr.end()
}
})4.3.3. The Execution of Database Scripts by Gradle Tasks
This mechanism is generally used by application developers for updating their own database instance. The execution of scripts essentially comes down to running a special Gradle task from build.gradle build script. This can be done from the command line or via the Studio interface.
To run scripts to create the database, the createDb task is used. In Studio, it corresponds to the Run → Create database command in main menu. When this task is started, the following occurs:
-
Scripts of the application components and
db/**/*.sqlscripts of the core module of the current project are built in themodules/core/build/dbdirectory. Sets of scripts for application components are located in subdirectories with numeric prefixes. The prefixes are used to provide the alphabetical order of the execution of scripts according to the dependencies between components. -
If the database exists, it is completely erased. A new empty database is created.
-
All creation scripts from
modules/core/build/db/init/**/*create-db.sqlsubdirectory are executed sequentially in the alphabetical order, and their names along with the path relative to the db directory are registered in the SYS_DB_CHANGELOG table. -
Similarly, in the SYS_DB_CHANGELOG table, all currently available
modules/core/build/db/update/**/*.sqlupdate scripts are registered. This is required for applying the future incremental updates to the database.
To run scripts to update the database, the updateDb task is used. In Studio, it corresponds to the Run → Update database command in main menu. When this task is started, the following occurs:
-
The scripts are built in the same way as for the
createDbcommand described above. -
The execution mechanism checks, whether all creation scripts of application components have been run (by checking the
SYS_DB_CHANGELOGtable). If not, the application component creation scripts are executed and registered in theSYS_DB_CHANGELOGtable. -
A search is performed in
modules/core/build/db/update/**directories, for update scripts which are not registered in theSYS_DB_CHANGELOGtable, i.e., not previously executed. -
All scripts found in the previous step are executed sequentially in the alphabetical order, and their names along with the path relative to the
dbdirectory are registered in theSYS_DB_CHANGELOGtable.
4.3.4. The Execution of Database Scripts by the Server
The mechanism to execute database scripts by the server is used for bringing the DB up to date at the start of the application server and is activated during the initialization of the Middleware block. Obviously, the application should have been built and deployed on the server – production or developer’s Tomcat instance.
Depending on the conditions described below, this mechanism either executes create or update scripts, i.e., it can initialize the DB from scratch and update it. However, unlike the Gradle createDb task described in the previous section, the database must exist to be initialized – the server does not create the DB automatically but only executes scripts on it.
The mechanism to execute scripts by the server works as follows:
-
The scripts are extracted from the database scripts directory, defined by the cuba.dbDir application property, which by default is set to
tomcat/webapps/app-core/WEB-INF/db. -
If the DB does not have the
SEC_USERtable, the database is considered empty and the full initialization is run using the create scripts. After executing the initialization scripts, their names are stored in theSYS_DB_CHANGELOGtable. The names of all available update scripts are stored in the same table, without their execution. -
If the DB has the
SEC_USERtable but does not have theSYS_DB_CHANGELOGtable (this is the case when the described mechanism is launched for the first time on the existing production DB), no scripts are executed. Instead, theSYS_DB_CHANGELOGtable is created and the names of all currently available create and update scripts are stored. -
If the DB has both the
SEC_USERandSYS_DB_CHANGELOGtables, the update scripts whose names were not previously stored in theSYS_DB_CHANGELOGtable are executed and their names are stored in theSYS_DB_CHANGELOGtable. The sequence of scripts execution is determined by two factors: the priority of the application component (see database scripts directory:10-cuba,20-bpm, …) and the name of the script file (taking into account the subdirectories of theupdatedirectory) in the alphabetical order.Before the execution of update scripts, the check is performed, whether all creation scripts of application components have been run (by checking the
SYS_DB_CHANGELOGtable). If the database is not initialized for use of some application component, its creation scripts are executed.
The mechanism to execute the scripts on server startup is enabled by the cuba.automaticDatabaseUpdate application property.
In already running application, the script execution mechanism can be launched using the app-core.cuba:type=PersistenceManager JMX bean by calling its updateDatabase() method with the update parameter. Obviously it is only possible to update already existing DB as it is impossible to log in to the system to run a method of the JMX bean with an empty DB. Please note, that an unrecoverable error will occur, if part of the data model no longer corresponding to the outdated DB schema is initialized during Middleware startup or user login. That is why the automatic update of the DB on the server startup before initializing the data model is only universal.
The JMX app-core.cuba:type=PersistenceManager bean has one more method related to the DB update mechanism: findUpdateDatabaseScripts(). It returns a list of new update scripts available in the directory and not registered in the DB (not yet executed).
Recommendations for usage of the server DB update mechanism can be found in Creating and Updating the Database in Production.
4.4. Middleware Components
The following figure shows the main components of the CUBA application middle tier.
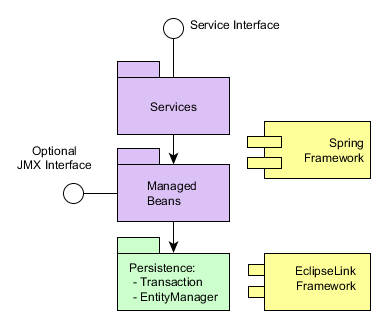
Figure 11. Components of the Middle Tier
Services are container-managed components that form the application boundary and provide the interface to the client tier. Services may contain the business logic themselves or delegate the execution to managed beans.
Managed beans are container-managed components that contain the business logic of the application. They are called by services, other beans or via the optional JMX interface.
Persistence is the infrastructure interface to access the data storage functionality: ORM and transactions management.
4.4.1. Services
Services form the layer that defines a set of Middleware operations available to the client tier. In other words, a service is an entry point to the Middleware business logic. In a service, you can manage transactions, check user permissions, work with the database or delegate execution to other managed beans of the middle tier.
Below is a class diagram which shows the components of a service:
The service interface is located in the global module and is available for both middle and client tiers. At runtime, a proxy is created for the service interface on the client tier. The proxy provides invocation of service bean methods using Spring HTTP Invoker mechanism.
The service implementation bean is located in the core module and is available on the middle tier only.
ServiceInterceptor is called automatically for any service method using Spring AOP. It checks the availability of the user session for the current thread, and transforms and logs exceptions if the service is called from the client tier.
4.4.1.1. Creating a Service
The name of service interface should end with Service, the names of implementation class – with ServiceBean.
The following steps are required for creating a service:
-
Create the service interface in the global module, as the service interface must be available at all tiers), and specify the service name in it. It is recommended to specify the name in the following format:
{project_name}_{interface_name}. For example:package com.sample.sales.core; import com.sample.sales.entity.Order; public interface OrderService { String NAME = "sales_OrderService"; void calculateTotals(Order order); } -
Create the service class in the core module and add the
@org.springframework.stereotype.Serviceannotation to it with the name specified in the interface:package com.sample.sales.core; import com.sample.sales.entity.Order; import org.springframework.stereotype.Service; @Service(OrderService.NAME) public class OrderServiceBean implements OrderService { @Override public void calculateTotals(Order order) { } }
The service class, being a managed bean, should be placed inside the package tree with the root specified in the context:component-scan element of the spring.xml file. In this case, the spring.xml file contains the element:
<context:component-scan base-package="com.sample.sales"/>which means that the search for annotated beans for this application block will be performed starting with the com.sample.sales package.
If different services or other Middleware components require calling the same business logic, it should be extracted and encapsulated inside an appropriate managed bean. For example:
// service interface
public interface SalesService {
String NAME = "sample_SalesService";
BigDecimal calculateSales(UUID customerId);
}// service implementation
@Service(SalesService.NAME)
public class SalesServiceBean implements SalesService {
@Inject
private SalesCalculator salesCalculator;
@Transactional
@Override
public BigDecimal calculateSales(UUID customerId) {
return salesCalculator.calculateSales(customerId);
}
}// managed bean encapsulating business logic
@Component
public class SalesCalculator {
@Inject
private Persistence persistence;
public BigDecimal calculateSales(UUID customerId) {
Query query = persistence.getEntityManager().createQuery(
"select sum(o.amount) from sample$Order o where o.customer.id = :customerId");
query.setParameter("customerId", customerId);
return (BigDecimal) query.getFirstResult();
}
}4.4.1.2. Using a Service
In order to call a service, the corresponding proxy object should be created in the client block of the application. There is a special factory that creates service proxies: for the Web Client block, it is WebRemoteProxyBeanCreator, for Web Portal – PortalRemoteProxyBeanCreator, for Desktop Client – RemoteProxyBeanCreator.
The proxy object factory is configured in spring.xml of the corresponding client block and contains service names and interfaces.
For example, to call the sales_OrderService service from the web client in the sales application, add the following code into the web-spring.xml file of the web module:
<bean id="sales_proxyCreator" class="com.haulmont.cuba.web.sys.remoting.WebRemoteProxyBeanCreator">
<property name="serverSelector" ref="cuba_ServerSelector"/>
<property name="remoteServices">
<map>
<entry key="sales_OrderService" value="com.sample.sales.core.OrderService"/>
</map>
</property>
</bean>All imported services should be declared in the single remoteServices property in the map/entry elements.
|
Tip
|
CUBA Studio automatically registers services in all client blocks of the project. |
From the application code perspective, the service’s proxy object at the client level is a standard Spring bean and can be obtained either by injection or through AppBeans class. For example:
@Inject
private OrderService orderService;
public void calculateTotals() {
orderService.calculateTotals(order);
}or
public void calculateTotals() {
AppBeans.get(OrderService.class).calculateTotals(order);
}4.4.1.3. DataService
DataService provides a facade for calling DataManager middleware implementation from the client tier. The usage of DataService interface in the application code is not recommended. Instead, use DataManager directly on both middle and client tiers.
4.4.2. Data Stores
A usual way of working with data in CUBA applications is manipulating entities - either declaratively through datasources and data-aware visual components, or programmatically via DataManager or EntityManager. The entities are mapped to data in a data store, which is usually a relational database. An application can connect to multiple data stores so its data model will contain entities mapped to data located in different databases.
An entity can belong only to a single data store. You can display entities from different data stores on a single UI screen, and DataManager will ensure they will be dispatched to appropriate data stores on save. Depending on the entity type, DataManager selects a registered data store represented by an implementation of the DataStore interface and delegates loading and saving entities to it. When you control transactions in your code and work with entities via EntityManager, you have to specify explicitly what data store to use. See the Persistence interface methods and @Transactional annotation parameters for details.
The platform contains a single implementation of the DataStore interface called RdbmsStore. It is designed to work with relational databases through the ORM layer. You can implement DataStore in your project to provide integration, for example, with a non-relational database or an external system having REST interface.
In any CUBA application, there is always the main data store which contains system and security entities and where the users log in. When we mention a database in this manual, we always mean the main data store if not explicitly stated otherwise. The main data store must be a relational database connected through a JDBC data source. The main data source is located in JNDI and should have a name specified in the cuba.dataSourceJndiName application property, which is jdbc/CubaDS by default.
Additional data store names should be specified in the cuba.additionalStores application property. If the additional store is RdbmsStore, you should provide the following properties for it:
-
cuba.dataSourceJndiName_{store_name}- JNDI name of the corresponding JDBC data source. -
cuba.dbmsType_{store_name}- type of the data store DBMS. -
cuba.persistenceConfig_{store_name}- location of the data storepersistence.xmlfile.
If you implement the DataStore interface in your project, specify the name of the implementation bean in the cuba.storeImpl_{store_name} application property.
For example, if you need to work with two additional data stores: db1 (a PostgreSQL database) and mem1 (an in-memory storage implemented by some project bean), specify the following application properties in the app.properties file of your core module:
cuba.additionalStores = db1, mem1
cuba.dataSourceJndiName_db1 = jdbc/db1
cuba.dbmsType_db1 = postgres
cuba.persistenceConfig_db1 = com/company/sample/db1-persistence.xml
cuba.storeImpl_mem1 = sample_InMemoryStoreThe cuba.additionalStores and cuba.persistenceConfig_db1 properties should also be specified in the property files of all used application blocks (web-app.properties, portal-app.properties, etc.).
|
Tip
|
CUBA Studio allows you to set up additional data stores on the Project properties > Advanced tab. It automatically creates all required application properties and JDBC data sources, as well as maintains additional |
- References between entities from different data stores
-
DataManager can automatically maintain TO-ONE references between entities from different data stores, if they are properly defined. For example, consider the case when you have
Orderentity in the main data store andCustomerentity in an additional data store, and you want to have a reference fromOrdertoCustomer. Then do the following:-
In the
Orderentity, define an attribute with the type of theCustomeridentifier. The attribute should be annotated with@SystemLevelto exclude it from various lists available to users, like attributes in Filter:@SystemLevel @Column(name = "CUSTOMER_ID") private Long customerId; -
In the
Orderentity, define a non-persistent reference toCustomerand specify thecustomerIdattribute as "related":@Transient @MetaProperty(related = "customerId") private Customer customer; -
Include non-persistent
customerattribute to appropriate views.
After that, when you load
Orderwith a view includingcustomerattribute,DataManagerautomatically loads relatedCustomerfrom the additional data store. The loading of collections is optimized for performance: after loading a list of orders, the loading of references from the additional data store is done in batches. The size of the batch is defined by the cuba.crossDataStoreReferenceLoadingBatchSize application property.When you commit an entity graph which includes
OrderwithCustomer,DataManagersaves the instances via correspondingDataStoreimplementations, and then saves the identifier of the customer in the order’scustomerIdattribute.Cross-datastore references are also supported by the Filter component.
TipCUBA Studio automatically maintains the set of attributes for cross-datastore references when you select an entity from a different data store as an association.
-
4.4.3. The Persistence Interface
The Persistence interface is designed to be an entry point to the data storage functionality provided by the ORM layer.
The interface has the following methods:
-
createTransaction(),getTransaction()– obtain the interface for managing transactions. The methods can accept a data store name. If it is not provided, the main data store is assumed. -
callInTransaction(),runInTransaction()- execute an action in a new transaction with or without return value. The methods can accept a data store name. If it is not provided, the main data store is assumed. -
isInTransaction()– checks if there is an active transaction the moment. -
getEntityManager()– returns an EntityManager instance bound to the current transaction. The method can accept a data store name. If it is not provided, the main data store is assumed. -
isSoftDeletion()– allows you to determine if the soft deletion mode is active. -
setSoftDeletion()– enables or disables the soft deletion mode. Setting this property affects all newly createdEntityManagerinstances. Soft deletion is enabled by default. -
getDbTypeConverter()– returns the DbTypeConverter instance for the main database or for an additional data store. -
getDataSource()– returns thejavax.sql.DataSourceinstance for the main database or for an additional data store.WarningFor all
javax.sql.Connectionobjects obtained throughgetDataSource().getConnection()method theclose()method should be called in thefinallysection after using the connection. Otherwise, the connection will not be returned to the pool. Over time, the pool will overflow and the application will not be able to execute database queries. -
getTools()– returns an instance of thePersistenceToolsinterface (see below).
4.4.3.1. PersistenceTools
Managed bean containing helper methods related to data storage functionality. It can be obtained either by calling the Persistence.getTools() method or like any other bean, through injection or the AppBeans class.
The PersistenceTools bean has the following methods:
-
getDirtyFields()– returns a collection of entity attribute names that have been changed since the last load of the instance from the DB. For new instances an empty collection is returned. -
isLoaded()– determines if the specified instance attribute was loaded from the DB. The attribute may not be loaded, if it was not present in the view specified when loading the instance.This method only works for instances in the Managed state.
-
getReferenceId()– returns an ID of the related entity without loading it from the DB.Let us suppose that an
Orderinstance was loaded in the persistent context and it is necessary to get the ID value of theCustomerinstance related to thisOrder. A call to theorder.getCustomer().getId()method will execute the DB query to load theCustomerinstance, which in this case is unnecessary, because the value of the Customer ID is also located in theOrdertable as a foreign key. Whereas the execution ofpersistence.getTools().getReferenceId(order, "customer")will not send any additional queries to the database.
This method works only for instances in the Managed state.
The PersistenceTools bean can be overridden in your application to extend the set of default helper methods. An example of working with the extended interface is shown below:
MyPersistenceTools tools = persistence.getTools();
tools.foo();((MyPersistenceTools) persistence.getTools()).foo();4.4.3.2. DbTypeConverter
The interface containing methods for conversion between data model attribute values and parameters/results of JDBC queries. An object of this interface can be obtained through the Persistence.getDbTypeConverter() method.
The DbTypeConverter interface has the following methods:
-
getJavaObject()– converts the result of the JDBC query into a type suitable for assigning to entity attribute. -
getSqlObject()– converts the value of the entity attribute into a type suitable for assigning to the JDBC query parameter. -
getSqlType()– returns ajava.sql.Typesconstant that corresponds to the passed entity attribute type.
4.4.4. ORM Layer
Object-Relational Mapping is the technology for linking relational database tables to programming language objects.
- Benefits of using ORM
-
-
Enables working with a relational DBMS by means of Java objects manipulation.
-
Simplifies programming by eliminating routine writing of SQL queries.
-
Simplifies programming by letting you load and save entire object graphs with one command.
-
Ensures easy porting of the application to different DBMS.
-
Enables use of a concise object query language – JPQL.
-
- Shortcomings
-
-
Requires understanding of how ORM works.
-
Makes direct optimization of SQL and use of the DBMS specifics difficult.
-
CUBA uses the ORM implementation based on the EclipseLink framework.
4.4.4.1. EntityManager
EntityManager – main ORM interface for working with persistent entities.
Reference to EntityManager may be obtained via the Persistence interface by calling its getEntityManager() method. The retrieved instance of EntityManager is bound to the current transaction, i.e. all calls to getEntityManager() as part of one transaction return one and the same instance of EntityManager. After the end of the transaction using the corresponding EntityManager instance is impossible.
An instance of EntityManager contains a persistence context – a set of instances loaded from the database or newly created. The persistence context is a data cache within a transaction. EntityManager automatically flushes to the database all changes made in its persistence context on the transaction commit or when the EntityManager.flush() method is called.
The EntityManager interface used in CUBA applications mainly copies the standard javax.persistence.EntityManager interface. Let us have a look at its main methods:
-
persist()– adds a new instance of the entity to the persistence context. When the transaction is committed a corresponding record is created in DB using SQLINSERT. -
merge()– copies the state of detached instance to the persistence context the following way: an instance with the same identifier gets loaded from DB and the state of the passed Detached instance is copied into it and then the loaded Managed instance is returned. After that you should work with the returned Managed instance. The state of this entity will be stored in DB using SQLUPDATEon transaction commit. -
remove()– removes an object from the database, or, if soft deletion mode is turned on, setsdeleteTsanddeletedByattributes.If the passed instance is in Detached state,
merge()is performed first. -
find()– loads an entity instance by its identifier.When forming a request to the database the system considers the view which has been passed as a parameter to this method. As a result, the persistence context will contain a graph of objects with all view attributes loaded.
TipUnlike for DataManager, all local attributes are loaded regardless of what is specified in the view. In
EntityManager, the view affects only reference attributes. -
createQuery()– creates aQueryorTypedQueryobject for executing a JPQL query. -
createNativeQuery()– creates aQueryobject to execute an SQL query. -
reload()– reloads the entity instance with the provided view. -
isSoftDeletion()– checks if theEntityManageris in soft deletion mode. -
setSoftDeletion()– sets soft deletion mode for thisEntityManager. -
getConnection()– returns ajava.sql.Connection, which is used by this instance ofEntityManager, and hence by the current transaction. Such connection does not need to be closed, it will be closed automatically when the transaction is complete. -
getDelegate()– returnsjavax.persistence.EntityManagerprovided by the ORM implementation.
Example of using EntityManager in a service:
@Service(SalesService.NAME)
public class SalesServiceBean implements SalesService {
@Inject
private Persistence persistence;
@Override
public BigDecimal calculateSales(UUID customerId) {
BigDecimal result;
// start transaction
try (Transaction tx = persistence.createTransaction()) {
// get EntityManager for the current transaction
EntityManager em = persistence.getEntityManager();
// create and execute Query
Query query = em.createQuery(
"select sum(o.amount) from sample$Order o where o.customer.id = :customerId");
query.setParameter("customerId", customerId);
result = (BigDecimal) query.getFirstResult();
// commit transaction
tx.commit();
}
return result != null ? result : BigDecimal.ZERO;
}
}|
Tip
|
See DataManager vs. EntityManager for information on differences between DataManager and EntityManager. |
4.4.4.2. Entity States
- New
-
An instance which has just been created in memory:
Car car = new Car().A new instance may be passed to
EntityManager.persist()to be stored to the database, in which case it changes its state to Managed. - Managed
-
An instance loaded from the database, or a new one passed to
EntityManager.persist(). Belongs to aEntityManagerinstance, i.e. is contained in its persistence context.Any changes of the instance in Managed state will be saved to the database when the transaction that the
EntityManagerbelongs to is committed. - Detached
-
An instance loaded from the database and detached from its persistence context (as a result of the transaction end or serialization).
The changes applied to a Detached instance will be saved to the database only if this instance becomes Managed by being passed to
EntityManager.merge().
4.4.4.3. Lazy Loading
Lazy loading (loading on demand) enables delayed loading of linked entities, i.e. they get loaded when their properties are accessed for the first time.
Lazy loading generates more database queries than eager fetching, but it is stretched in time.
-
For example, in case of lazy loading of a list of N instances of entity A, each containing a link to an instance of entity B, will require N+1 requests to DB.
-
In most cases, minimizing the number of requests to the database results in less response time and database load. The platform uses the mechanism of views to achieve this. Using view allows ORM to create only one request to the database with table joining for the above mentioned case.
Lazy loading works only for instances in Managed state, i.e. within the transaction which loaded the instance.
4.4.4.4. Executing JPQL Queries
The Query interface is designed to execute JPQL queries. The reference to it may be obtained from the current EntityManager instance by calling createQuery() method. If the query is supposed to be used to load entities, we recommend calling createQuery() with the result type as a parameter. This will create a TypedQuery instance.
The methods of Query mainly correspond to the methods of the standard JPA javax.persistence.Query interface. Let us have a look at the differences.
-
setParameter()– sets a value to a query parameter. If the value is an entity instance, implicitly converts the instance into its identifier. For example:Customer customer = ...; TypedQuery<Order> query = entityManager.createQuery( "select o from sales$Order o where o.customer.id = ?1", Order.class); query.setParameter(1, customer);Note that the entity is passed as a parameter while comparison in the query is done using identifier.
A variant of the method with
implicitConversions = falsedoes not perform such conversion. -
setView(),addView()– define a view which is used to load data. -
getDelegate()– returns an instance ofjavax.persistence.Query, provided by the ORM implementation.
When a request is executed through Query, changes in the current persistence context are ignored, i.e. the query just runs on the database. If the results are the instances already contained in the persistence context, the query result will contain instances from context and not the ones read from the database. The following test fragment should clarify this:
TypedQuery<User> query;
List<User> list;
query = em.createQuery("select u from sec$User u where u.name = ?1", User.class);
query.setParameter(1, "testUser");
list = query.getResultList();
assertEquals(1, list.size());
User user = list.get(0);
user.setName("newName");
query = em.createQuery("select u from sec$User u where u.name = ?1", User.class);
query.setParameter(1, "testUser");
list = query.getResultList();
assertEquals(1, list.size());
User user1 = list.get(0);
assertTrue(user1 == user);Queries that change data (update, delete) cause flush of the current persistence context to the database prior to execution. In other words, ORM first synchronizes the states of entities in the persistence context and in the database, and only after that runs the modifying query. We recommend to run such queries in an unchanged persistence context in order to prevent implicit actions by ORM, which may have negative impact on performance.
4.4.4.4.1. JPQL Functions
The table below describes the JPQL functions supported and not supported by CUBA Platform.
| Function | Support | Query |
|---|---|---|
Aggregate Functions |
Supported |
|
Not supported: aggregate functions with scalar expression (EclipseLink feature) |
|
|
ALL, ANY, SOME |
Supported |
|
Arithmetic Functions (INDEX, SIZE, ABS, SQRT, MOD) |
Supported |
|
CASE Expressions in UPDATE query |
Supported |
|
Not supported: CASE in UPDATE query |
|
|
Date Functions (CURRENT_DATE, CURRENT_TIME, CURRENT_TIMESTAMP) |
Supported |
|
EclipseLink Functions (CAST, REGEXP, EXTRACT) |
Supported |
|
Entity Type Expression |
Supported: entity type passed as a parameter |
|
Not supported: direct link to an entity type |
|
|
Function Invocation |
Supported: function result in comparison clauses |
|
Not supported: function result as is |
|
|
IN |
Supported |
|
IS EMPTY collection |
Supported |
|
KEY/VALUE |
Not supported |
|
Literals |
Supported |
|
Not supported: date and time literals |
|
|
MEMBER OF |
Supported: fields or query results |
|
Not supported: literals |
|
|
NEW in SELECT |
Not supported |
|
NULLIF/COALESCE |
Supported |
|
NULLS FIRST, NULLS LAST in order by |
Supported |
|
String Functions (CONCAT, SUBSTRING, TRIM, LOWER, UPPER, LENGTH, LOCATE) |
Supported |
|
Not supported: TRIM with trim char |
|
|
Subquery |
Supported |
|
Not supported: path expression instead of entity name in subquery’s FROM |
|
|
TREAT |
Supported |
|
Not supported: TREAT in WHERE clauses |
|
4.4.4.4.2. Case-Insensitive Substring Search
You can use the (?i) prefix in the value of the query parameters to conveniently specify conditions for case insensitive search by any part of the string. For example, look at the query:
select c from sales$Customer c where c.name like :nameIf you pass the string (?i)%doe% as a value of the name parameter, the search will return John Doe, if such record exists in the database, even though the case of symbols is different. This will happen because ORM will run the SQL query with the condition lower(C.NAME) like ?.
It should be kept in mind that such search will not use index on the name field, even if such exists in the database.
4.4.4.4.3. Macros in JPQL
JPQL query text can include macros, which are processed before the query is executed. They are converted into the executable JPQL and can additionally modify the set of query parameters.
The macros solve the following problems:
-
Provide a workaround for the limitation of JPQL which makes it impossible to express the condition of dependency of a given field on current time (i.e. expressions like "current_date -1" do not work).
-
Enable comparing
Timestamptype fields (the date/time fields) with a date.
Let us consider them in more detail:
- @between
-
Has the format
@between(field_name, moment1, moment2, time_unit), where-
field_nameis the name of the compared attribute. -
moment1,moment2– start and end points of the time interval where the value offield_nameshould fall into. Each of the points should be defined by an expression containingnowvariable with an addition or subtraction of an integer number. -
time_unit– defines the unit for time interval added to or subtracted fromnowin the time point expressions and time points rounding precision. May be one of the following:year,month,day,hour,minute,second.
The macro gets converted to the following expression in JPQL:
field_name >= :moment1 and field_name < :moment2Example 1. Customer was created today:
select c from sales$Customer where @between(c.createTs, now, now+1, day)Example 2. Customer was created within the last 10 minutes:
select c from sales$Customer where @between(c.createTs, now-10, now, minute)Example 3. Documents dated within the last 5 work days (for the projects including workflow):
select d from sales$Doc where @between(d.createTs, now-5, now, workday) -
- @today
-
Has the format
@today(field_name)and helps to define a condition checking that the attribute value falls into the current date. Essentially, this is a special case of the@betweenmacro.Example. Customer was created today:
select d from sales$Doc where @today(d.createTs) - @dateEquals
-
Has the format
@dateEquals(field_name, parameter)and allows you to define a condition checking thatfield_namevalue (inTimestampformat) falls into the date passed asparameter.Example:
select d from sales$Doc where @dateEquals(d.createTs, :param) - @dateBefore
-
Has the format
@dateBefore(field_name, parameter) and allows you to define a condition checking thatfield_namevalue (inTimestampformat) is smaller than the date passed asparameter.Example:
select d from sales$Doc where @dateBefore(d.createTs, :param) - @dateAfter
-
Has the format
@dateAfter(field_name, parameter) and allows you to define a condition that the date of thefield_namevalue (inTimestampformat) is more or equal to the date passed asparameter.Example:
select d from sales$Doc where @dateAfter(d.createTs, :param) - @enum
-
Allows you to use a fully qualified enum constant name instead of its database identifier. This simplifies searching for enum usages throughout the application code.
Example:
select r from sec$Role where r.type = @enum(com.haulmont.cuba.security.entity.RoleType.SUPER) order by r.name
4.4.4.5. Running SQL Queries
ORM enables execution of SQL queries returning either the lists of individual fields or entity instances. To do this, create a Query or TypedQuery object by calling one of the EntityManager.createNativeQuery() methods.
If individual columns are selected, the resulting list will include the rows as Object[]. For example:
Query query = persistence.getEntityManager().createNativeQuery(
"select ID, NAME from SALES_CUSTOMER where NAME like ?1");
query.setParameter(1, "%Company%");
List list = query.getResultList();
for (Iterator it = list.iterator(); it.hasNext(); ) {
Object[] row = (Object[]) it.next();
UUID id = (UUID) row[0];
String name = (String) row[1];
}If a single column or aggregate function is selected, the result list will contain these values directly:
Query query = persistence.getEntityManager().createNativeQuery(
"select count(*) from SEC_USER where login = #login");
query.setParameter("login", "admin");
long count = (long) query.getSingleResult();If the resulting entity class is passed to EntityManager.createNativeQuery() along with the query text, TypedQuery is returned, and ORM attempts to map the query results to entity attributes. For example:
TypedQuery<Customer> query = em.createNativeQuery(
"select * from SALES_CUSTOMER where NAME like ?1",
Customer.class);
query.setParameter(1, "%Company%");
List<Customer> list = query.getResultList();Keep in mind when using SQL, that the columns corresponding to entity attributes of UUID type are returned as UUID or as String depending on the DBMS in use:
-
HSQLDB –
String -
PostgreSQL –
UUID -
Microsoft SQL Server –
String -
Oracle –
String -
MySQL –
String
Parameters of this type should also be passed either as UUID or using their string representation, depending on the DBMS. To ensure that your code does not depend on the DBMS specifics, use DbTypeConverter. It provides methods to convert data between Java objects and JDBC parameters and results.
Native queries support positional and named parameters. Positional parameters are marked in the query text with ? followed by the parameter number starting from 1. Named parameters are marked with the number sign (#). See the examples above.
Behavior of SQL queries returning entities and modifying queries (update, delete) in relation to the current persistence context is similar to that of JPQL queries described above.
4.4.4.6. Entity Listeners
Entity Listeners are designed to react to the entity instances lifecycle events on Middleware.
A listener is a class implementing one or several interfaces from the com.haulmont.cuba.core.listener package. The listener will react to events corresponding to the implemented interfaces.
- BeforeDetachEntityListener
-
onBeforeDetach()method is called before the object is detached from EntityManager on transaction commit.This listener can be used for populating non-persistent entity attributes before sending it to the client tier.
- BeforeAttachEntityListener
-
onBeforeAttach()method is called before the object is attached to the persistence context as a result ofEntityManager.merge()operation.This listener can be used, for example, to populate persistent entity attributes before saving it to the database.
- BeforeInsertEntityListener
-
onBeforeInsert()method is called before a record is inserted into the database. All kinds of operations can be performed with the current EntityManager available within this method. - AfterInsertEntityListener
-
onAfterInsert()is called after a record is inserted into database, but before transaction commit. This method does not allow modifications of the current persistence context, however, database modifications can be done using QueryRunner. - BeforeUpdateEntityListener
-
onBeforeUpdate()method is called before a record is updated in the database. All kinds of operations can be performed with the current EntityManager available within this method. - AfterUpdateEntityListener
-
onAfterUpdate()method is called after a record was updated in the database, but before transaction commit. This method does not allow modifications of the current persistence context, however, database modifications can be done using QueryRunner. - BeforeDeleteEntityListener
-
onBeforeDelete()method is called before a record is deleted from the database (in the case of soft deletion – before updating a record). All kinds of operations can be performed with the current EntityManager available within this method. - AfterDeleteEntityListener
-
onAfterDelete()method is called after a record is deleted from the database (in the case of soft deletion – before updating a record), but before transaction commit. This method does not allow modifications of the current persistence context, however, database modifications can be done using QueryRunner.
An entity listener should be a managed bean, so you can use injection. For example:
@Component("sample_MyEntityListener")
public class MyEntityListener implements
BeforeInsertEntityListener<MyEntity>,
BeforeUpdateEntityListener<MyEntity> {
@Inject
protected Metadata metadata;
@Override
public void onBeforeInsert(MyEntity entity, EntityManager entityManager) {
Foo foo = metadata.create(Foo.class);
...
entity.setFoo(foo);
entityManager.persist(foo);
}
@Override
public void onBeforeUpdate(MyEntity entity, EntityManager entityManager) {
Foo foo = entityManager.find(Foo.class, entity.getFoo().getId());
...
}
}An entity listener can be specified for an entity in two ways:
-
Statically – the bean names of listeners are listed in @Listeners annotation on the entity class.
@Entity(...) @Table(...) @Listeners("sample_MyEntityListener") public class MyEntity extends StandardEntity { ... } -
Dynamically – the bean name of the listener is passed to the
addListener()method of theEntityListenerManagerbean. See an example in this section: Running Code at Application Start.
Only one listener instance of a certain type is created for all instances of a particular entity class, therefore listener must not have a state.
If several listeners of the same type (for example from annotations of entity class and its parents and also added dynamically) were declared for an entity, they will be invoked in the following order:
-
For each ancestor, starting from the most distant one, dynamically added listeners are invoked first, followed by statically assigned listeners.
-
Once parent classes are processed, dynamically added listeners for the given class are invoked first, followed by statically assigned.
|
Tip
|
If you need to do some calculations and update attributes of multiple entity instances at once on transaction commit, consider using a transaction listener. |
4.4.5. Transaction Management
This section covers various aspects of transaction management in CUBA applications.
4.4.5.1. Programmatic Transaction Management
Programmatic transaction management is done using the com.haulmont.cuba.core.Transaction interface. A reference to it can be obtained via the createTransaction() or getTransaction() methods of the Persistence infrastructure interface.
The createTransaction() method creates a new transaction and returns the Transaction interface. Subsequent calls of commit(), commitRetaining(), end() methods of this interface control the created transaction. If at the moment of creation there was another transaction, it will be suspended and resumed after the completion of the newly created one.
The getTransaction() method either creates a new transaction or attaches to an existing one. If at the moment of the call there is an active transaction, then the method completes successfully, but subsequent calls of commit(), commitRetaining(), end() have no influence on the existing transaction. However calling end() without a prior call to commit() will mark current transaction as RollbackOnly.
Examples of programmatic transaction management:
@Inject
private Metadata metadata;
@Inject
private Persistence persistence;
...
// try-with-resources style
try (Transaction tx = persistence.createTransaction()) {
Customer customer = metadata.create(Customer.class);
customer.setName("John Smith");
persistence.getEntityManager().persist(customer);
tx.commit();
}
// plain style
Transaction tx = persistence.createTransaction();
try {
Customer customer = metadata.create(Customer.class);
customer.setName("John Smith");
persistence.getEntityManager().persist(customer);
tx.commit();
} finally {
tx.end();
}Transaction interface has also the execute() method accepting an action class or a lambda expression. The action will be performed in the transaction. This enables organizing transaction management in functional style, for example:
UUID customerId = persistence.createTransaction().execute((EntityManager em) -> {
Customer customer = metadata.create(Customer.class);
customer.setName("ABC");
em.persist(customer);
return customer.getId();
});
Customer customer = persistence.createTransaction().execute(em ->
em.find(Customer.class, customerId, "_local"));Keep in mind that execute() method of a given instance of Transaction may be called only once because the transaction ends after the action code is executed.
4.4.5.2. Declarative Transaction Management
Any method of the Middleware managed bean may be annotated with @org.springframework.transaction.annotation.Transactional, which will automatically create a transaction when the method is called. Such method does not require invoking Persistence.createTransaction(), you can immediately get EntityManager and work with it.
@Transactional annotation supports a number of parameters, including:
-
propagation- transaction creation mode. TheREQUIREDvalue corresponds togetTransaction(), theREQUIRES_NEWvalue – tocreateTransaction(). The default value isREQUIRED.@Transactional(propagation = Propagation.REQUIRES_NEW) public void doSomething() { } -
value- data store name. If omitted, the main data store is assumed. For example:@Transactional("db1") public void doSomething() { }
Declarative transaction management allows you to reduce the amount of boilerplate code, but it has the following drawback: transactions are committed outside of the application code, which often complicates debugging because it conceals the moment when changes are sent to the database and the entities become Detached. Additionally, keep in mind that declarative markup will only work if the method is called by the container, i.e. calling a transaction method from another method of the same object will not start a transaction.
With this in mind, we recommend using declarative transaction management only for simple cases like a service method reading a certain object and returning it to the client.
4.4.5.3. Examples of Transactions Interaction
- Rollback of a Nested Transaction
-
If a nested transaction was created via
getTransaction()and rolled back, then commit of the enclosing transaction will be impossible. For example:void methodA() { Transaction tx = persistence.createTransaction(); try { // (1) calling a method creating a nested transaction methodB(); // (4) at this point an exception will be thrown, because transaction // is marked as rollback only tx.commit(); } finally { tx.end(); } } void methodB() { Transaction tx = persistence.getTransaction(); try { // (2) let us assume the exception occurs here tx.commit(); } catch (Exception e) { // (3) handle it and exit return; } finally { tx.end(); } }If the transaction in
methodB()is created withcreateTransaction()instead, then rolling it back will have no influence on the enclosing transaction inmethodA(). - Reading and Modifying Data in a Nested Transaction
-
Let us first have a look at a dependent nested transaction created using
getTransaction():void methodA() { Transaction tx = persistence.createTransaction(); try { EntityManager em = persistence.getEntityManager(); // (1) loading an entity with name == "old name" Employee employee = em.find(Employee.class, id); assertEquals("old name", employee.getName()); // (2) setting new value to the field employee.setName("name A"); // (3) calling a method creating a nested transaction methodB(); // (8) the changes are committed to DB, and // it will contain "name B" tx.commit(); } finally { tx.end(); } } void methodB() { Transaction tx = persistence.getTransaction(); try { // (4) retrieving the same instance of EntityManager as methodA EntityManager em = persistence.getEntityManager(); // (5) loading an entity with the same identifier Employee employee = em.find(Employee.class, id); // (6) the field value is the new one since we are working with the same // persistent context, and there are no calls to DB at all assertEquals("name A", employee.getName()); employee.setName("name B"); // (7) no actual commit is done at this point tx.commit(); } finally { tx.end(); } }Now, let us have a look at the same example with an independent nested transaction created with
createTransaction():void methodA() { Transaction tx = persistence.createTransaction(); try { EntityManager em = persistence.getEntityManager(); // (1) loading an entity with name == "old name" Employee employee = em.find(Employee.class, id); assertEquals("old name", employee.getName()); // (2) setting new value to the field employee.setName("name A"); // (3) calling a method creating a nested transaction methodB(); // (8) an exception occurs due to optimistic locking // and commit will fail tx.commit(); } finally { tx.end(); } } void methodB() { Transaction tx = persistence.createTransaction(); try { // (4) creating a new instance of EntityManager, // as this is a new transaction EntityManager em = persistence.getEntityManager(); // (5) loading an entity with the same identifier Employee employee = em.find(Employee.class, id); // (6) the field value is old because an old instance of the entity // has been loaded from DB assertEquals("old name", employee.getName()); employee.setName("name B"); // (7) the changes are commited to DB, and the value of // "name B" will now be in DB tx.commit(); } finally { tx.end(); } }In the last example, the exception at point (8) will only occur if the entity supports optimistic locking, i.e. if it implements
Versionedinterface.
4.4.5.4. Transaction Parameters
- Transaction Timeout
-
You can set a timeout in seconds for created transaction. When the timeout is exceeded, the transaction is interrupted and rolled back. Transaction timeout effectively limits the maximum duration of a database request.
When transactions are managed programmatically, the timeout is specified by passing
TransactionParamsobject to thePersistence.createTransaction()method. For example:Transaction tx = persistence.createTransaction(new TransactionParams().setTimeout(2));In case of declarative transactions management, use the
timeoutparameter of the@Transactionalannotation:@Transactional(timeout = 2) public void someServiceMethod() { ...The default timeout can be defined using the cuba.defaultQueryTimeoutSec application property.
- Read-only Transactions
-
A transaction can be marked as read-only if it is intended only for reading data from the database. For example, all
loadmethods of DataManager use read-only transactions by default. Read-only transactions yield better performance because the platform does not execute code that handles possible entity modifications.BeforeCommittransaction listeners are not invoked as well.WarningIf the persistence context of a read-only transaction contains modified entities,
IllegalStateExceptionwill be thrown on attempt to commit the transaction. It means that you should mark a transaction as read-only only when you are sure that it doesn’t modify any entity.When transactions are managed programmatically, the read-only sign is specified by passing
TransactionParamsobject to thePersistence.createTransaction()method. For example:Transaction tx = persistence.createTransaction(new TransactionParams().setReadOnly(true));In case of declarative transactions management, use the
readOnlyparameter of the@Transactionalannotation:@Transactional(readOnly = true) public void someServiceMethod() { ...
4.4.5.5. Transaction Listeners
Transaction listeners are designed to react on transaction lifecycle events. Unlike entity listeners, they are not tied to an entity type and invoked for each transaction.
A listener is a managed bean implementing one or both BeforeCommitTransactionListener and AfterCompleteTransactionListener interfaces.
- BeforeCommitTransactionListener
-
beforeCommit()method is called before transaction commit after all entity listeners if the transaction is not read-only. The method accepts a current EntityManager and a collection of entities in the current persistence context.The listener can be used to enforce complex business rules involving multiple entities. In the following example, the
amountattribute of theOrderentity must be calculated based ondiscountvalue located in the order, andpriceandquantityofOrderLineentities constituted the order.@Component("demo_OrdersTransactionListener") public class OrdersTransactionListener implements BeforeCommitTransactionListener { @Inject private PersistenceTools persistenceTools; @Override public void beforeCommit(EntityManager entityManager, Collection<Entity> managedEntities) { // gather all orders affected by changes in the current transaction Set<Order> affectedOrders = new HashSet<>(); for (Entity entity : managedEntities) { // skip not modified entities if (!persistenceTools.isDirty(entity)) continue; if (entity instanceof Order) affectedOrders.add((Order) entity); else if (entity instanceof OrderLine) { Order order = ((OrderLine) entity).getOrder(); // a reference can be detached, so merge it into current persistence context affectedOrders.add(entityManager.merge(order)); } } // calculate amount for each affected order by its lines and discount for (Order order : affectedOrders) { BigDecimal amount = BigDecimal.ZERO; for (OrderLine orderLine : order.getOrderLines()) { if (!orderLine.isDeleted()) { amount = amount.add(orderLine.getPrice().multiply(orderLine.getQuantity())); } } BigDecimal discount = order.getDiscount().divide(BigDecimal.valueOf(100), 2, BigDecimal.ROUND_DOWN); order.setAmount(amount.subtract(amount.multiply(discount))); } } } - AfterCompleteTransactionListener
-
afterComplete()method is called after transaction is completed. The method accepts a parameter indicating whether the transaction was successfully committed and a collection of detached entities contained in the persistence context of the completed transaction.Usage example:
@Component("demo_OrdersTransactionListener") public class OrdersTransactionListener implements AfterCompleteTransactionListener { private Logger log = LoggerFactory.getLogger(OrdersTransactionListener.class); @Override public void afterComplete(boolean committed, Collection<Entity> detachedEntities) { if (!committed) return; for (Entity entity : detachedEntities) { if (entity instanceof Order) { log.info("Order: " + entity); } } } }
4.4.6. Entity and Query Cache
- Entity Cache
-
Entity cache is provided by EclipseLink ORM framework. It stores recently read or written entity instance in memory, which minimizes database access and improves the application performance.
Entity cache is used only when you retrieve entities by ID, so queries by other attributes still run on the database. However, these queries can be simpler and faster if related entities are in cache. For example, if you query for Orders together with related Customers and do not use cache, the SQL query will contain a JOIN for customers table. If Customer entities are cached, the SQL query will select only orders, and related customers will be retrieved from the cache.
In order to turn on entity cache, set the following properties in the app.properties file of your core module:
-
eclipselink.cache.shared.sales$Customer = true- turns on caching ofsales$Customerentity. -
eclipselink.cache.size.sales$Customer = 500- sets cache size forsales$Customerto 500 instances. Default size is 100.
The fact of whether an entity is cached affects the fetch mode chosen by the platform for loading entity graphs. If a reference attribute is a cacheable entity, the fetch mode is always
UNDEFINED, which allows ORM to retrieve the reference from the cache instead of executing queries with JOINs or separate batch queries.The platform provides entity cache coordination in middleware cluster. When a cached entity is updated or deleted on one cluster node, the same cached instance on other nodes (if any) will be invalidated, so the next operation with this instance will read a fresh state from the database.
-
- Query Cache
-
Query cache stores identifiers of entity instances returned by JPQL queries, so it naturally complements the entity cache.
For example, if entity cache is enabled for an entity (say,
sales$Customer), and you execute the queryselect c from sales$Customer c where c.grade = :gradefor the first time, the following happens:-
ORM runs the query on the database.
-
Loaded
Customerinstances are placed to the entity cache. -
A mapping of the query text and parameters to the list of identifiers of the returned instances is placed to the query cache.
When you execute the same query with the same parameters the second time, the platform finds the query in the query cache and loads entity instances from the entity cache by identifiers. No database operations are needed.
Queries are not cached by default. You can specify that a query should be cached on different layers of the application:
-
Using
setCacheable()method of the Query interface when working with EntityManager. -
Using
setCacheable()method of theLoadContext.Queryinterface when working with DataManager. -
Using
setCacheable()method of theCollectionDatasourceinterface orcacheableXML attribute when working with datasources.
WarningUse cacheable queries only if entity cache is enabled for the returned entity. Otherwise on every query entity instances will be fetched from the database by their identifiers one by one.
Query cache is invalidated automatically when ORM performs creation, update or deletion of instances of the corresponding entities. The invalidation works across the middleware cluster.
The
app-core.cuba:type=QueryCacheSupportJMX-bean can be used to monitor the cache state and to evict cached queries manually. For example, if you have modified an instance of thesales$Customerentity directly in the database, you should evict all cached queries for this entity using theevict()operation withsales$Customerargument.The following application properties affect the query cache:
-
4.4.7. System Authentication
When executing user requests, the Middleware program code always has access to the information on the current user via the UserSessionSource interface. This is possible because the corresponding SecurityContext object is automatically set for the current thread when a request is received from the client tier.
However, there are situations when the current thread is not associated with any system user, for example, when calling a bean’s method from the scheduler, or via the JMX interface. In case the bean modifies entities in the database, it will require information on who is making changes, i.e., authentication.
This kind of authentication is called "system authentication" as it requires no user participation – the application middle layer simply creates or uses an existing user session and sets the corresponding SecurityContext object for the current thread.
The following methods can be used to provide the system authentication for a code block:
-
Make use of the
com.haulmont.cuba.security.app.Authenticationbean:@Inject protected Authentication authentication; ... authentication.begin(); try { // authenticated code } finally { authentication.end(); } -
Add the
@Authenticatedannotation to the bean method:@Authenticated public String foo(String value) { // authenticated code }
The second case uses the Authentication bean implicitly, via the AuthenticationInterceptor object, which intercepts calls of all bean methods with the @Authenticated annotation.
In the examples above, the user session will be created on behalf of the user, whose login is specified in the cuba.jmxUserLogin application property. If authentication on behalf of another user is required, pass the login of the desired user to the begin() method of the first variant.
|
Warning
|
If current thread has an active user session assigned at the time of For example, if a bean is in the same JVM as the Web Client block, to which the user is currently connected, the call of the JMX bean method from the Web Client built-in JMX console will be executed on behalf of the currently logged in user, regardless of the system authentication. |
4.5. Generic User Interface
Generic user interface (Generic UI, GUI) subsystem allows you to create UI screens using XML and Java. The screens created using this approach work identically in both standard client blocks: Web Client and Desktop Client.
Figure 12. The Structure of Generic User Interface
Main components of Generic UI screens are marked as green:
-
XML-descriptors – XML files containing information about datasources and screen layout.
-
Controllers – Java classes containing logic for screen initialization and handling of events generated by UI controls.
The code of application screens included in the gui module interacts with visual component interfaces (VCL Interfaces) implemented separately in the web and desktop modules of the cuba application component. For Web Client the implementation is based on the Vaadin framework, for Desktop Client on the Java Swing framework.
Visual Components Library (VCL)contains a large set of ready-to-use components.
Datasources mechanism provides a unified interface that ensures functioning of data-aware visual components.
Client’s infrastructure (Infrastructure) includes main application window, mechanisms for display and interaction of UI screens and means of interaction with the middleware.
4.5.1. Screens
A generic UI screen is defined by an XML-descriptor and a controller class. The descriptor has a link to the controller class.
In order to be able to invoke the screen from the main menu or from Java code (e.g. from controller of a different screen) the XML-descriptor should be registered in the project’s screens.xml file.
The main menu of an application is generated separately for the Web Client and the Desktop Client based on the menu.xml files, located in the project’s web and desktop modules.
4.5.1.1. Screen Types
This section describes the following basic types of screens:
4.5.1.1.1. Frame
Frames are parts of the screen intended for decomposition and reuse.
The frame element of the screen’s XML is used to add a frame to the screen. It defines either path to the frame’s XML descriptor, or its identifier, if the frame is registered in screens.xml.
A frame controller should be derived from the AbstractFrame class.
Rules for interaction between a screen and its enclosed frame are the following:
-
Frame components can be referenced from a screen using a dot:
frame_id.component_id -
List of screen components can be obtained from a frame controller by invoking
getComponent(component_id)method but only if there is no component with the same name in the frame itself. I.e. frame components mask screen components. -
Screen datasource can be obtained from a frame by invoking
getDsContext().get(ds_id)method or injection, or usingds$ds_idin query, but only if the datasource with a matching name is not declared in the frame itself (same as for components). -
From a screen, frame datasource can be obtained only by iterating
getDsContext().getChildren()collection.
Screen commit also causes commits of modified datasources of the frame it uses.
4.5.1.1.2. Simple Screen
Simple screens enable displaying and editing of arbitrary information including individual instances and lists of entities. This screen type has only core functionality to display it in the application’s main window, close it and to work with datasources.
Screen identifier in screens.xml may have an arbitrary format.
The controller of a simple screen should be inherited from the AbstractWindow class.
4.5.1.1.3. Lookup Screen
When a lookup screen is invoked by openLookup() method, it displays a panel at the bottom with the buttons designed to pass an instance of the currently selected entity to the calling code. That is the main difference between lookup and simple screen. When being invoked by openWindow() method or, for example, from the main menu, the panel with the buttons is not displayed.
Lookup screens are recommended to be used to display lists of entities. Visual components intended to display and edit links between entities (such as PickerField, LookupPickerField, SearchPickerField) invoke lookup screens to find related entities.
For standard actions to work correctly, an identifier of a lookup screen in screens.xml should have the format of {entity_name}.lookup, for example, sales$Customer.lookup.
The controller of a lookup screen should be inherited from the AbstractLookup class. The lookupComponent attribute of the screen’s XML should refer to the component (for example Table), from which the selected entity instance should be taken as a result of the lookup.
4.5.1.1.4. Edit Screen
Edit screen is designed to display and edit entity instances. It initializes the instance being edited and supports actions for committing changes to the database. Edit screen should be opened by the openEditor() method passing an entity instance as an argument.
For standard actions to work correctly, an identifier of an edit screen in screens.xml should have the format of {entity_name}.edit, for example, sales$Customer.edit.
Edit screen controller should be inherited from the AbstractEditor class. The datasource attribute of a screen’s XML should refer to a datasource containing the edited entity instance. The following standard button frames in the XML can be used to display actions that commit or cancel changes:
-
editWindowActions(filecom/haulmont/cuba/gui/edit-window.actions.xml) – contains OK and Cancel buttons -
extendedEditWindowActions(filecom/haulmont/cuba/gui/extended-edit-window.actions.xml) – contains OK & Close, OK and Cancel
The following actions are implicitly initialized in the edit screen:
-
windowCommitAndClose(corresponds to theWindow.Editor.WINDOW_COMMIT_AND_CLOSEconstant) – an action committing changes to the database and closing the screen. The action is initialized if the screen has a visual component withwindowCommitAndCloseidentifier. The action is displayed as an OK & Close button when the mentioned above standardextendedEditWindowActionsframe is used. -
windowCommit(corresponds to theWindow.Editor.WINDOW_COMMITconstant) – an action which commits changes to the database. In absence ofwindowCommitAndCloseaction, closes the screen after committing. The action is always displayed as an OK button if the screen has the abovementioned standard frames. -
windowClose(corresponds to theWindow.Editor.WINDOW_CLOSEconstant) – which closes the screen without committing any changes. The action is always initialized. If the screen has the abovementioned standard frames, it is displayed as Cancel button.
Thus, if the screen contains an editWindowActions frame, the OK button commits the changes and closes the screen, and the Cancel button – closes the screen without committing the changes. If the screen contains an extendedEditWindowActions frame, the OK button only commits the changes, OK & Close button commits the changes and closes the screen, and the Cancel button closes the screen without committing the changes.
Instead of standard frames actions can be visualized using arbitrary components, for example, LinkButton.
4.5.1.2. XML-Descriptor
XML-descriptor is a file in XML format describing datasources and screen layout.
XML schema is available at http://schemas.haulmont.com/cuba/6.5/window.xsd.
Descriptor has the following structure:
window − root element.
window attributes:
-
class− name of a controller class. -
messagesPack− a default message pack for the screen. It is used to obtain localized messages in the controller usinggetMessage()method and in the XML descriptor using message key without specifying the pack. -
caption− window caption, can contain a link to a message from the above mentioned pack, for example,caption="msg://credits" -
focusComponent− identifier of a component which should get input focus when the screen is displayed. -
lookupComponent– mandatory attribute for a lookup screen; defines the identifier of a visual component that the entity instance should be selected from. Supports the following types of components (and their subclasses):-
Table -
Tree -
LookupField -
PickerField -
OptionsGroup
-
-
datasource– mandatory attribute for an edit screen which defines the identifier of the datasource containing the edited entity instance.
window elements:
-
metadataContext− the element initializing the views required for the screen. It is recommended to define all views in a single views.xml file, because all view descriptors are deployed into a common repository, so it is difficult to ensure unique names if the descriptors are scattered across multiple files. -
dsContext− defines datasource for the screen. -
actions– defines the list of actions for the screen. -
timers– defines the list of timers for the screen. -
companions– defines the list of companion classes for the screen controller.Elements of
companions:-
web– defines a companion implemented in the web module. -
desktop– defines a companion implemented in the desktop module.
Each of these elements contains
classattribute defining the companion class. -
-
layout− root element of the screen layout, a container with a vertical layout of components, similar to vbox.Attributes of
layout:
4.5.1.3. Screen Controller
Screen controller is a Java or Groovy class, linked to an XML-descriptor and containing screen initialization and event handling logic.
Controller should be inherited from one of the following base classes:
-
AbstractFrame − for implementation of frames.
-
AbstractWindow − for implementation of simple screens.
-
AbstractLookup − for implementation of lookup screens.
-
AbstractEditor − for implementation of edit screens.
|
Tip
|
If a screen does not need additional logic, it can use the base class itself as a controller – |
Controller class should be registered in class attribute of the root element window in a screen’s XML descriptor.
Figure 13. Controller Base Classes
4.5.1.3.1. AbstractFrame
AbstractFrame is the root of the controller classes hierarchy. Below is the description of its main methods:
-
init()is called by the framework after creating components tree described by an XML-descriptor, but before a screen is displayed.init() method accepts a map of parameters that can be used in controller. These parameters can be passed both from the controller of the calling screen (using
openWindow(),openLookup()oropenEditor()methods) or defined in the screen registration file screens.xml.init()method should be implemented if it is necessary to initialize screen components, for example:@Inject private Table someTable; @Override public void init(Map<String, Object> params) { someTable.addGeneratedColumn("someColumn", new Table.ColumnGenerator<Colour>() { @Override public Component generateCell(Colour entity) { ... } }); }
-
openFrame()– loads a frame according to an identifier registered in screens.xml file. If the method receives a container component from the invoking code, the frame is shown within the container. The method returns frame controller. For example:@Inject private BoxLayout container; @Override public void init(Map<String, Object> params) { SomeFrame frame = openFrame(container, "someFrame"); frame.setHeight("100%"); frame.someInitMethod(); }It is not required to pass the container immediately via
openFrame()method, instead it is possible to load the frame first and then add it to the necessary container:@Inject private BoxLayout container; @Override public void init(Map<String, Object> params) { SomeFrame frame = openFrame(null, "someFrame"); frame.setHeight("100%"); frame.someInitMethod(); container.add(frame); }
-
openWindow(),openLookup(),openEditor()– open a simple screen, a lookup screen, or an edit screen respectively. Methods return a controller of the created screen.For the dialog mode, the method
openWindow()can be called with parameters, for example:@Override public void actionPerform(Component component) { openWindow("sec$User.browse", WindowManager.OpenType.DIALOG.width(800).height(300).closeable(true).resizable(true).modal(false)); }These parameters will be considered if they don’t conflict with the higher-priority parameters of the window being opened. The latter can be set either in the getDialogOptions() method of screen controller or in XML descriptor of the screen:
<dialogMode forceDialog="true" width="300" height="200" closeable="true" modal="true"/>CloseListenercan be added in order to perform actions after the invoked screen closes, for example:CustomerEdit editor = openEditor("sales$Customer.edit", customer, WindowManager.OpenType.THIS_TAB); editor.addCloseListener((String actionId) -> { // do something });Use
CloseWithCommitListenerto be notified only when the invoked screen closes by an action with theWindow.COMMIT_ACTION_IDname (i.e. OK button), for example:CustomerEdit editor = openEditor("sales$Customer.edit", customer, WindowManager.OpenType.THIS_TAB); editor.addCloseWithCommitListener(() -> { // do something });
-
showMessageDialog()– shows a dialog box with a message.
-
showOptionDialog()– shows a dialog box with a message and an option for user to invoke certain actions. Actions are defined by an array of Action type items displayed as buttons in the dialog.It is recommended to use
DialogActionobjects for display of standard buttons such as OK, Cancel and other, for example:showOptionDialog("PLease confirm", "Are you sure?", MessageType.CONFIRMATION, new Action[] { new DialogAction(DialogAction.Type.YES) { @Override public void actionPerform(Component component) { // do something } }, new DialogAction(DialogAction.Type.NO); });
-
showNotification()– shows a pop up notification.
-
showWebPage()– opens specified web page in a browser.
4.5.1.3.2. AbstractWindow
AbstractWindow is a subclass of AbstractFrame and defines the following methods:
-
getDialogOptions()– returns aDialogOptionsobject to control geometry and behaviour of the screen when it is opened as a dialog (WindowManager.OpenType.DIALOG). These options can be set when the screen is initialized as well as can be changed at a runtime. See the examples below.Setting the width and height:
@Override public void init(Map<String, Object> params) { getDialogOptions().setWidth(480).setHeight(320); }Making the dialog non-modal and resizable:
@Override public void init(Map<String, Object> params) { getDialogOptions().setModal(false).setResizable(true); }Specifying that the screen should always be opened as a dialog regardless of what
WindowManager.OpenTypewas selected in the calling code:@Override public void init(Map<String, Object> params) { getDialogOptions().setForceDialog(true); }
-
saveSettings()- saves the screen settings of the current user to the database when the screen is closed.For example, the screen contains a checkBox showPanel that manages some panel’s visibility. In the following method we create an XML element for the checkBox, then add an attribute
showPanelcontaining the checkBox value to this element, and finally we save thesettingselement to the XML descriptor for the current user in the database:@Inject private CheckBox showPanel; @Override public void saveSettings() { boolean showPanelValue = showPanel.getValue(); Element xmlDescriptor = getSettings().get(showPanel.getId()); xmlDescriptor.addAttribute("showPanel", String.valueOf(showPanelValue)); super.saveSettings(); }
-
applySettings()- restores settings saved in the database for the current user when the screen is opened.This method can be overridden to restore custom settings. For example, in the method below we get the XML element of the checkBox from the previous example, then we make sure the required attribute is not null, and if it isn’t, we set the restored value to the checkBox:
@Override public void applySettings(Settings settings) { super.applySettings(settings); Element xmlDescriptor = settings.get(showPanel.getId()); if (xmlDescriptor.attribute("showPanel") != null) { showPanel.setValue(Boolean.parseBoolean(xmlDescriptor.attributeValue("showPanel"))); } }Another example of managing settings is the standard Server Log screen from the Administration menu of CUBA application that automatically saves and restores recently opened log files.
-
ready()- a template method that can be implemented in controller to intercept the moment of screen opening. It is invoked when the screen is fully initialized and opened.
-
validateAll()– validates a screen. The default implementation callsvalidate()for all screen components implementing theComponent.Validatableinterface, collects information about exceptions and displays corresponding message. Method returnsfalse, if any exceptions were found; andtrueotherwise.This method should be overridden only if it is required to override screen validation procedure completely. It is sufficient to implement a special template method –
postValidate(), if validation should be just supplemented.
-
postValidate()– a template method that can be implemented in controller for additional screen validation. The method stores validation errors information inValidationErrorsobject which is passed to it. Afterwards this information is displayed together with the errors of standard validation. For example:private Pattern pattern = Pattern.compile("\\d"); @Override protected void postValidate(ValidationErrors errors) { if (getItem().getAddress().getCity() != null) { if (pattern.matcher(getItem().getAddress().getCity()).find()) { errors.add("City name can't contain digits"); } } }
-
close()– closes this screen.The method accepts string value, which is then passed to
preClose()template method and toCloseListenerlisteners. Thus, the information about the reason why the window was closed can be obtained from the code that initiated the closing event. It is recommended to use the following constants for closing edit screens:Window.COMMIT_ACTION_IDafter committing changes,Window.CLOSE_ACTION_ID– without committing changes.If any of the datasources contains unsaved changes, a dialog with a corresponding message will be displayed before the screen is closed. Notification type may be adjusted using the cuba.gui.useSaveConfirmation application property.
A variant of
close()method withforce = trueparameter closes the screen without callingpreClose()and without a notification regardless of any unsaved changes.close()method returnstrue, if the screen is closed successfully, andfalse– if closing procedure was interrupted.
-
preClose()is a template method which can be implemented in a controller to intercept the moment when the window closes. The method receives a string value provided by the closing initiator when invokingclose()method.If the
preClose()method returnsfalse, the window closing process is interrupted.
- API
-
applySettings() - close() - getDialogOptions() - postValidate() - preClose() - ready() - saveSettings() - validateAll()
4.5.1.3.3. AbstractLookup
AbstractLookup is the base class for lookup screen controllers. It is a subclass of AbstractWindow and defines the following own methods:
-
setLookupComponent()– sets the component, which will be used to select entity instances.As a rule, component for selection is defined in screen XML-descriptor and there is no need to call this method in the application code.
-
setLookupValidator()– setsWindow.Lookup.Validatorobject to the screen, whichvalidate()method is invoked by the framework before returning selected entity instances. Ifvalidate()method returnsfalse, the lookup and window closing process is interrupted.By default, the validator is not set.
4.5.1.3.4. AbstractEditor
AbstractEditor is the base class for edit screen controller. It is a subclass of AbstractWindow.
When creating a controller class, it is recommended to parameterize AbstractEditor with the edited entity class. This enables getItem() and initNewItem() methods work with the specified entity type and application code does not need to do additional type conversion. For example:
public class CustomerEdit extends AbstractEditor<Customer> {
@Override
protected void initNewItem(Customer item) {
...AbstractEditor defines the following own methods:
-
getItem()– returns an instance of the entity being edited, which is set in the main datasource of the screen (i.e. specified in thedatasourceattribute of the root element of the XML-descriptor).If the instance being edited is not a new one, screen opening procedure will reload the instance from the database with the required view as set for the main datasource.
Changes made to the instance returned by
getItem(), are reflected in the state of the datasource and will be sent to the Middleware at commit.WarningIt should be considered that
getItem()returns a value only after screen is initialized withsetItem()method. Until this moment, this method returnsnull, for instance when calling from insideinit()orinitNewItem().However, in the
init()method, an instance of an entity passed toopenEditor()can be retrieved from parameters using the following approach:@Override public void init(Map<String, Object> params) { Customer item = WindowParams.ITEM.getEntity(params); // do something }The
initNewItem()method receives an instance as a parameter of the appropriate type.In both cases the obtained entity instance will be reloaded afterwards unless it is a new one. Therefore you should not change it or save it in a field for future use.
-
setItem()– invoked by the framework when a window is opened usingopenEditor()to set the instance being edited to the main datasource. By the moment of invocation all screen components and datasources will have been created and the controller’sinit()method will have been executed.It is recommended to use template methods
initNewItem()andpostInit(), instead of overridingsetItem()in order to initialize a screen.
-
initNewItem()– a template method invoked by the framework before setting the edited entity instance into the main datasource.The
initNewItem()method is called for newly created entity instances only. The method is not called for detached instances. This method can be implemented in the controller, if new entity instances must be initialized before setting them in the datasource. For example:@Inject private UserSession userSession; @Override protected void initNewItem(Complaint item) { item.setOpenedBy(userSession.getUser()); item.setStatus(ComplaintStatus.OPENED); }A more complex example of using the
initNewItem()method can be found in development recipes section.
-
postInit()– a template method invoked by the framework immediately after the edited entity instance is set to the main datasource. In this method,getItem()can be called to return a new entity instance or an instance re-loaded during screen initialization.This method can be implemented in controller for final screen initialization, for example:
@Inject protected EntityDiffViewer diffFrame; @Override protected void postInit() { if (!PersistenceHelper.isNew(getItem())) { diffFrame.loadVersions(getItem()); } }
-
commit()– validates the screen and submits changes to the Middleware via DataSupplier.If a method is used with
validate = false, commit does not perform a validation.It is recommended to use specialized template methods –
postValidate(),preCommit()andpostCommit()instead of overriding this method.
-
commitAndClose()– validates the screen, submits changes to the Middleware and closes the screen. The value of theWindow.COMMIT_ACTION_IDwill be passed to thepreClose()method and registeredCloseListenerlisteners.It is recommended to use specialized template methods –
postValidate(),preCommit()andpostCommit()instead of overriding this method.
-
preCommit()– a template method invoked by the framework during the commit process, after a successful validation, but before the data is submitted to the Middleware.This method can be implemented in controller. If the method returns
false, commit process gets interrupted, as well as window closing process (ifcommitAndClose()was invoked). For example:@Override protected boolean preCommit() { if (somethingWentWrong) { showNotification("Something went wrong", NotificationType.WARNING); return false; } return true; }
-
postCommit()– a template method invoked by the framework at the final stage of committing changes. Method parameters are:-
committed– set totrue, if the screen had changes and they have been submitted to Middleware. -
close– set totrue, if the screen should be closed after the changes are committed.If the screen does not close the default implementation of this method displays a message about successful commit and invokes
postInit().This method can be overridden in controller in order to perform additional actions after successful commit, for example:
@Inject private Datasource<Driver> driverDs; @Inject private EntitySnapshotService entitySnapshotService; @Override protected boolean postCommit(boolean committed, boolean close) { if (committed) { entitySnapshotService.createSnapshot(driverDs.getItem(), driverDs.getView()); } return super.postCommit(committed, close); }
-
The diagrams below show initialization sequence and different ways to commit changes for an edit screen.
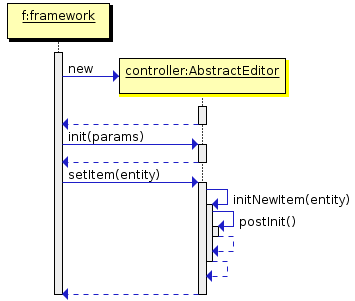
Figure 14. Edit Screen Initialization
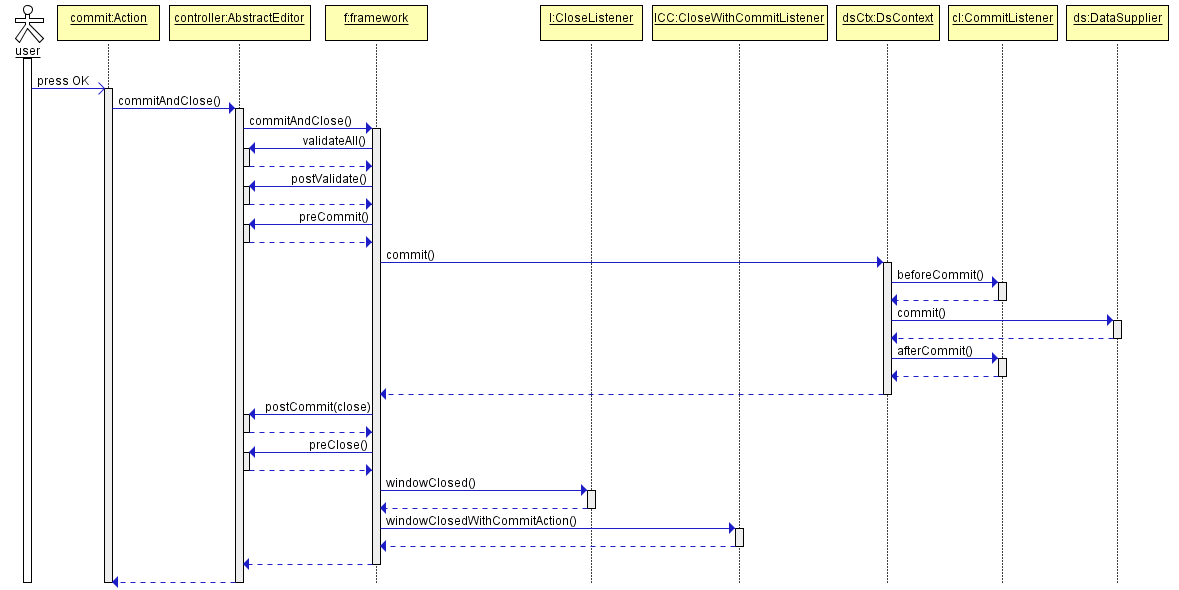
Figure 15. Committing And Closing a Window With an editWindowActions Frame
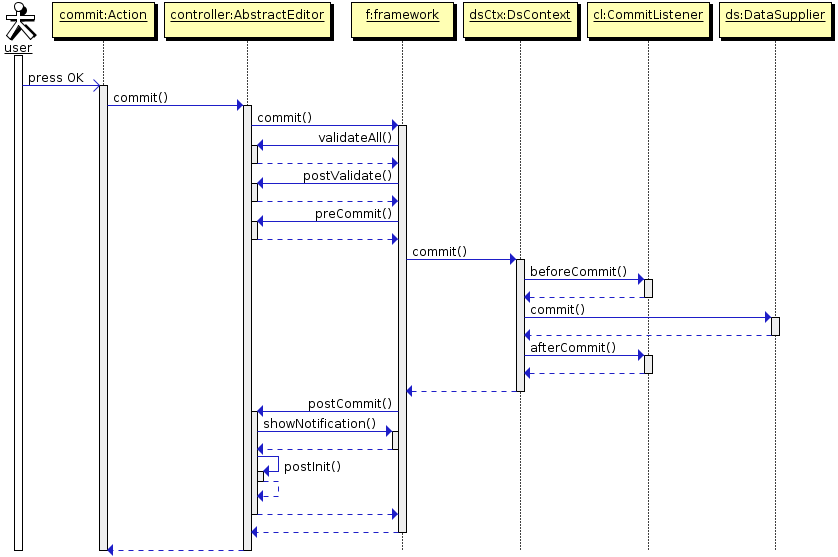
Figure 16. Committing a Screen With an extendedEditWindowActions Frame
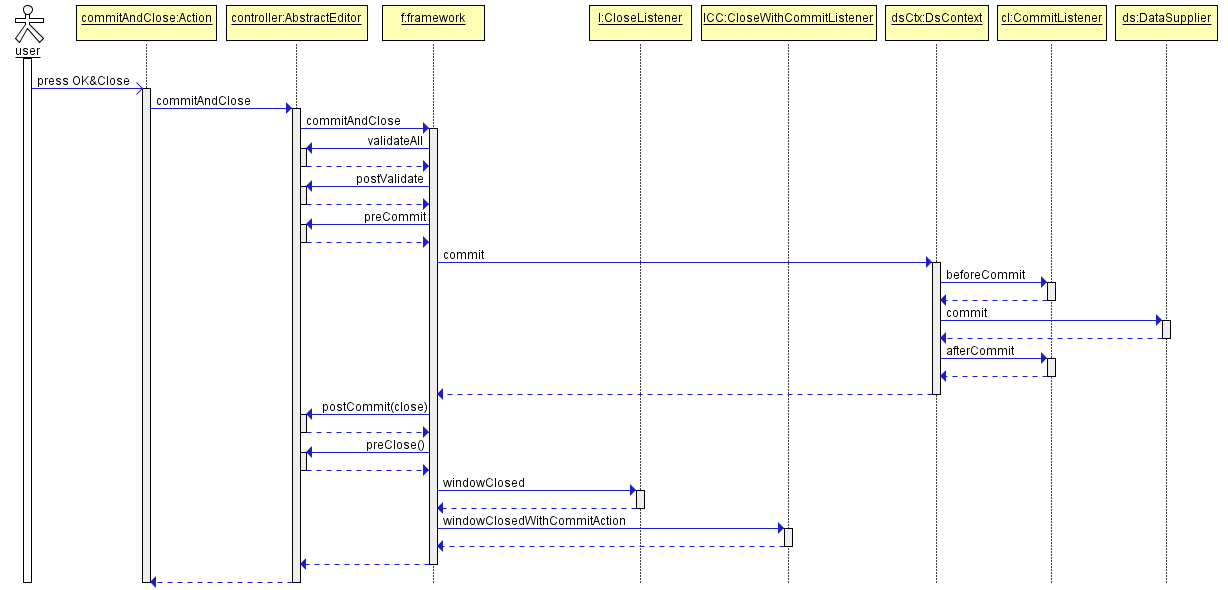
Figure 17. Committing a Screen With an extendedEditWindowActions Frame
- API
-
commit() - commitAndClose() - getItem() - initNewItem() - postCommit() - postInit() - preCommit() - setItem()
4.5.1.3.5. Controller Dependency Injection
Dependency Injection in controllers can be used to acquire references to utilized objects. For this purpose it is required to declare either a field of the corresponding type or a write access method (setter) with an appropriate parameter type and with one of the following annotations:
-
@Inject– the simplest option, where an object for injection will be found according to the field/method type and the name of the field or attribute corresponding to the method according to JavaBeans rules. -
@Named("someName")– explicitly defines the name of the target object.
The following objects can be injected into controllers:
-
This screen’s visual components defined in the XML-descriptor. If the attribute type is derived from
Component, the system will search for a component with the corresponding name within the current screen. -
Actions defined in the XML-descriptor – see Actions. The Action Interface.
-
Datasources defined in the XML-descriptor. If the attribute type is derived from
Datasource, the system will search for a datasource with the corresponding name in the current screen. -
UserSession. If the attribute type is UserSession, the system will inject an object of the current user session. -
DsContext. If the attribute type isDsContext, the system will inject theDsContextof the current screen. -
WindowContext. If the attribute type isWindowContext, the system will inject theWindowContextof the current screen. -
DataSupplier. If the attribute type is DataSupplier, the corresponding instance will be injected. -
Any bean defined in the context of a given client block, including:
-
Middleware services imported by Client
-
ComponentsFactory -
WindowConfig -
ExportDisplay
-
-
If nothing of the mentioned above is appropriate and the controller has companions, a companion for the current client type will be injected, if the types match.
It is possible to inject parameters passed in a map to the init() method into the controller using @WindowParam annotation. The annotation has the name attribute which contains the parameter name (a key in the map) and an optional required attribute. If required = true and the map does not contain the corresponding parameter a WARNING message is added to the log.
An example of the injection of a Job entity passed to the controller’s init() method:
@WindowParam(name = "job", required = true)
protected Job job;4.5.1.3.6. Controller Companions
Controller base classes are located in the gui module of the cuba application component and do not contain references to the implementation of visual component classes (Swing or Vaadin). This allows you to use them in both types of clients.
At the same time concrete controller classes can be created in gui, web or desktop modules, depending on screen specifics and client blocks used in the project. If a controller is common for all client types but additional functionality is required for different client types, it can be implemented in so-called companion classes.
Companion class is located in client module of the corresponding client type (web or desktop) and implements an interface defined in the controller that uses the companion class. A companion class should be defined in the companions element of the screen XML-descriptor. Controller can retrieve a reference to the companion instance using injection or by invoking getCompanion(), and then pass control to the companion instance when appropriate, e.g. for extended initialization of visual components in a way specific to a given client type.
For example, on some screen, you need to initialize a table differently for web and desktop clients. Then in the screen controller located in gui module, define a companion interface and delegate the table initialization to it:
public class CustomerBrowse extends AbstractLookup {
public interface Companion {
void initTable(Table<Customer> table);
}
@Inject
protected Table<Customer> table;
@Inject
protected Companion companion;
@Override
public void init(Map<String, Object> params) {
if (companion != null) {
companion.initTable(table);
}
}
}Create companion implementations in web and desktop modules:
public class WebCustomerBrowseCompanion implements CustomerBrowse.Companion {
@Override
public void initTable(Table<Customer> table) {
com.vaadin.ui.Table webTable = (com.vaadin.ui.Table) WebComponentsHelper.unwrap(table);
// do something specific to Vaadin table
}
}public class DesktopCustomerBrowseCompanion implements CustomerBrowse.Companion {
@Override
public void initTable(Table<Customer> table) {
javax.swing.JTable desktopTable = (javax.swing.JTable) DesktopComponentsHelper.unwrap(table);
// do something specific to Swing table
}
}And register the implementation classes in the screen XML descriptor:
<window ...
class="com.company.sample.gui.customers.CustomerBrowse">
<companions>
<web class="com.company.sample.web.customers.WebCustomerBrowseCompanion"/>
<desktop class="com.company.sample.desktop.customers.DesktopCustomerBrowseCompanion"/>
</companions>
<dsContext>...</dsContext>
<layout>...</layout>
</window>The companion classes are located in web and desktop modules, therefore you can use WebComponentsHelper.unwrap() and DesktopComponentsHelper.unwrap() to get references to Vaadin and Swing components implementing the table.
4.5.1.4. Screen Agent
Screen agent enables choosing a screen template according to the current device and display parameters. For example, you can create two screens with different layouts (and possibly different functionality), and register them in screens.xml with the same identifier. Then at runtime, the platform will choose a screen that better conforms to the display from which the user accesses the application.
There are three predefined screen agents in the platform: DESKTOP, TABLET, PHONE. They are defined by the following classes respectively: DesktopScreenAgent, TabletScreenAgent, PhoneScreenAgent. You can define your own agents by creating managed beans implementing the ScreenAgent interface.
A screen agent is specified for a screen in the screens.xml file. The value of the agent attribute should be either one of the predefined constants listed above or a name of the custom bean implementing ScreenAgent.
In Studio, an agent is specified on the Properties tab of the screen designer page.
4.5.2. Visual Components Library
4.5.2.1. Components
Menu |
|
|
|
|
|
Buttons |
|
|
|
|
|
|
|
Text |
|
|
|
Text inputs |
|
|
|
|
|
|
|
|
|
|
|
|
|
Date inputs |
|
|
|
|
|
|
|
Selects |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Uploads |
|
|
|
Tables and trees |
|
|
|
|
|
|
|
|
|
|
|
Others |
|
|
|
|
|
|
|
|
|
|
|
|







4.5.2.1.1. AppMenu
AppMenu component provides means of customizing the main menu in the main window layout and managing menu items dynamically.

CUBA Studio provides the screen template for main window based on the standard mainWindow screen provided by the platform. This template extends the AppMainWindow class and provides direct access to the AppMenu instance:
public class ExtAppMainWindow extends AppMainWindow {
@Override
public void init(Map<String, Object> params) {
super.init(params);
AppMenu.MenuItem item = mainMenu.createMenuItem("shop", "Shop");
AppMenu.MenuItem subItem = mainMenu.createMenuItem("customer", "Customers", null, menuItem -> {
showNotification("Customers menu item clicked", NotificationType.HUMANIZED);
});
item.addChildItem(subItem);
mainMenu.addMenuItem(item, 0);
}
}Methods of the AppMenu interface:
-
addMenuItem()- adds menu item to the end of root items list or to specified position in the root items list.
-
createMenuItem()- the factory method that creates new menu item. Does not add item to the menu.idmust be unique for whole menu.
-
createSeparator()- creates menu separator. -
getMenuItem()/getMenuItemNN()- returns the item from the menu tree by itsid. -
getMenuItems()- returns the list of root menu items. -
hasMenuItems()- returnstrueif the menu has items.
Methods of the MenuItem interface:
-
addChildItem() / removeChildItem()- adds/removes the menu item to the end or to the specified position of children list. -
getCaption()- returns the String caption of the menu item. -
getChildren()- returns the list of child items.
-
setCommand()- sets item command, or the action to be performed on this menu item click. -
setDescription()- sets the String description of the menu item, displayed as a popup tip. -
setIcon()- sets the item’s icon. -
getId()- returns the menu item id. -
getMenu()- returns the menu item owner. -
setStylename()- sets one or more user-defined style names of the component, replacing any previous user-defined styles. Multiple styles can be specified as a space-separated list of style names. The style names must be valid CSS class names. -
hasChildren()- returnstrueif the menu item has child items. -
isSeparator()- returnstrueif the item is a separator. -
setVisible()- manages visibility of the menu item.
- API
4.5.2.1.2. Button
A button performs an action when a user clicks on it.
Component’s XML-name: button
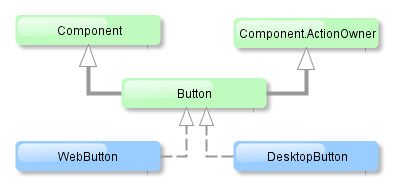
Button component is implemented for both Web and Desktop clients.
Buttons can contain a caption, an icon, or both. The figure below shows different button types.
An example of a button with a tooltip and a caption retrieved from a localized message pack:
<button id="textButton" caption="msg://someAction" description="Press me"/>The button’s caption is set using the caption attribute, the tooltip – using the description attribute.
If the disableOnClick attribute is set to true the button will be automatically disabled when clicked, typically to prevent (accidental) extra clicks on a button. You can later return the button to the enabled state by invoking the setEnabled(true) method.
The icon attribute defines icon location in theme catalog. Detailed information on recommended icon placement is available in Themes.
Example of creating a button with an icon:
<button id="iconButton" caption="" icon="icons/save.png"/>The button’s main function is to perform an action on a click. Controller method that should be invoked after a click can be defined using invoke attribute. The attribute value should contain name of the controller method satisfying the following conditions:
-
The method should be
public. -
The method should return
void. -
The method should not have any arguments, or should have a single argument of
Componenttype. If the method has aComponentargument, then an instance of the invoking button will be passed in it.
Below is the example of a button invoking someMethod:
<button invoke="someMethod" caption="msg://someButton"/>A method named someMethod should be defined in the screen controller:
public void someMethod() {
//some actions
}The invoke attribute is ignored if action attribute is set. The action attribute contains the name of action corresponding to the button.
Example of a button with an action:
<actions>
<action id="someAction" caption="msg://someAction"/>
</actions>
<layout>
<button action="someAction"/>Any action present in the component implementing Component.ActionsHolder interface can be assigned to a button. This applies to Table, GroupTable, TreeTable, Tree. The way of adding actions (declaratively in the XML descriptor or programmatically in the controller) is irrelevant. In any case, for using an action, the name of the component and the identifier of the required action must be specified in the action attribute, separated by dot. For instance, in the next example the create action of the coloursTable table is assigned to a button:
<button action="coloursTable.create"/>Button actions can also be created programmatically in the screen controller by deriving them from BaseAction class.
If an Action instance is defined for a Button, the button will take the following properties from it: caption, description, icon, enable, visible. caption and description properties will be imported from Action only if they are not set in the Button itself. All other listed Action properties have priority over the Button properties. If Action properties are changed after the Action is set for a Button, then Button properties also change accordingly, i.e. the button listens to the changes in Action properties. In this case, the caption and description properties will change even if they was initially assigned to the button itself.
- Button styles
-
In Web Client with a Halo-based theme, you can set predefined styles to the Button component using the
stylenameattribute either in the XML descriptor or in the screen controller:<button id="button" caption="Friendly button" stylename="friendly"/>When setting a style programmatically, select one of the
HaloThemeclass constants with theBUTTON_prefix:button.setStyleName(HaloTheme.BUTTON_FRIENDLY);
- Attributes of button
-
action - align - caption - description - disableOnClick - enable - icon - id - invoke - stylename - tabIndex - visible - width
- Predefined styles of button
-
borderless - borderless-colored - danger - friendly - icon-align-right - icon-align-top - icon-only - primary - quiet
4.5.2.1.3. BulkEditor
BulkEditor is a component that enables changing attribute values for several entity instances at once. The component is a button, usually added to a table or a tree, which opens the entity bulk editor on click.
XML-name of the component: bulkEditor
The component is implemented for Web Client and Desktop Client.
To enable the use of BulkEditor, the table or tree must have the multiselect attribute set to "true".
The entity editor is automatically generated based on the defined view (containing the fields of this entity, including references) and the user permissions. System attributes are not displayed in the editor either.
Entity attributes in the editor are sorted alphabetically. By default, the fields are empty. At screen commit, non-empty attribute values defined in the editor, are set for all the entity instances.
The editor also enables removing a specific field value for all the instances by setting it to null. In order to do this, click  button next to the field. After that, the field will become non-editable. The field can be unlocked by clicking the same button again.
button next to the field. After that, the field will become non-editable. The field can be unlocked by clicking the same button again.
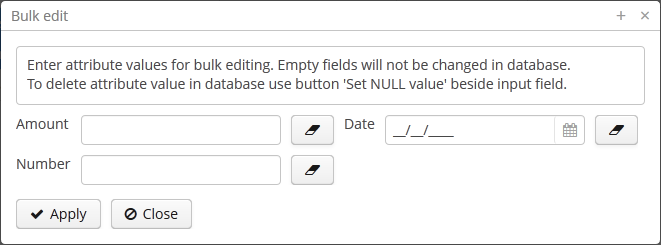
Example of bulkEditor use in a table:
<table id="invoiceTable"
multiselect="true"
width="100%">
<actions>
<!-- ... -->
</actions>
<buttonsPanel>
<!-- ... -->
<bulkEditor for="invoiceTable"
exclude="customer"/>
</buttonsPanel>The for attribute is required. It contains the identifier of a table or a tree; in this case, it is the invoiceTable.
The exclude attribute can contain a regular expression to exclude some fields explicitly from the list of attributes available for editing. For example: date|customer
4.5.2.1.4. Calendar
The Calendar component is intended to organize and display calendar events.

XML-name of the component: calendar.
The component is implemented for Web Client.
An example of component definition in an XML-descriptor of a screen:
<calendar id="calendar"
captionProperty="caption"
startDate="2016-10-01"
endDate="2016-10-31"
height="100%"
width="100%"/>The view mode is determined from the date range of the calendar, defined by the start date and the end date. The default view is the weekly view, it is used for ranges up to seven days a week. For a single-day view use the range within one date. Calendar will be shown in a monthly view when the date range is over than one week (seven days) long.
Navigation buttons to page the calendar one week forward or backward are hidden by default. To show them on a weekly view, use the attribute navigationButtonsVisible:
<calendar width="100%"
height="100%"
navigationButtonsVisible="true"/>
Attributes of calendar:
-
endDate- the end date for the calendar’s range.
-
endDateProperty- the name of an entity attribute that contains the end date.
-
descriptionProperty- the name of an entity attribute that contains the event description.
-
isAllDayProperty- the name of an entity attribute that determines if the event is all day long.
-
startDate- the start date for the calendar’s range.
-
startDateProperty- the name of an entity attribute that contains the start date.
-
stylenameProperty- the name of an entity attribute that contains the event style name.
-
timeFormat- time format: 12H or 24H.
To display events in the calendar cells, you can add the events directly to the Calendar object using the addEvent() method or use the CalendarEventProvider interface. An example of direct event adding:
@Inject
private Calendar calendar;
public void generateEvent(String caption, String description, Date start, Date end, boolean isAllDay, String stylename) {
SimpleCalendarEvent calendarEvent = new SimpleCalendarEvent();
calendarEvent.setCaption(caption);
calendarEvent.setDescription(description);
calendarEvent.setStart(start);
calendarEvent.setEnd(end);
calendarEvent.setAllDay(isAllDay);
calendarEvent.setStyleName(stylename);
calendar.getEventProvider().addEvent(calendarEvent);
}There are two data providers available: ListCalendarEventProvider (created by default) and EntityCalendarEventProvider.
ListCalendarEventProvider is filled by addEvent() method that gets a CalendarEvent object as a parameter:
@Inject
private Calendar calendar;
public void addEvents() {
ListCalendarEventProvider listCalendarEventProvider = new ListCalendarEventProvider();
calendar.setEventProvider(listCalendarEventProvider);
listCalendarEventProvider.addEvent(generateEvent("Training", "Student training", "2016-10-17 09:00", "2016-10-17 14:00", false, "event-blue"));
listCalendarEventProvider.addEvent(generateEvent("Development", "Platform development", "2016-10-17 15:00", "2016-10-17 18:00", false, "event-red"));
listCalendarEventProvider.addEvent(generateEvent("Party", "Party with friends", "2016-10-22 13:00", "2016-10-22 18:00", false, "event-yellow"));
}
private SimpleCalendarEvent generateEvent(String caption, String description, String start, String end, Boolean allDay, String style) {
SimpleCalendarEvent calendarEvent = new SimpleCalendarEvent();
SimpleDateFormat df = new SimpleDateFormat("yyyy-MM-dd HH:mm");
calendarEvent.setCaption(caption);
calendarEvent.setDescription(description);
calendarEvent.setStart(df.parse(start));
calendarEvent.setEnd(df.parse(end));
calendarEvent.setAllDay(allDay);
calendarEvent.setStyleName(style);
return calendarEvent;
}EntityCalendarEventProvider is filled with data directly from an entity fields. To be used for the EntityCalendarEventProvider, an entity should at least have attributes for the event start date (DateTime type), event end date (DateTime type) and event caption (String type).
In the example below we will assume that the datasource entity has all required attributes: eventCaption, eventDescription, eventStartDate, eventEndDate, eventStylename, and will set their names as values for calendar attributes:
<calendar id="calendar"
datasource="calendarEventsDs"
width="100%"
height="100%"
startDate="2016-10-01"
endDate="2016-10-31"
captionProperty="eventCaption"
descriptionProperty="eventDescription"
startDateProperty="eventStartDate"
endDateProperty="eventEndDate"
stylenameProperty="eventStylename"/>The Calendar component supports several event listeners for user interaction with its elements, such as date and week captions, date/time range selections, event dragging and event resizing. Navigation buttons used to scroll forward and backward in time are also listened by the server. Below is the list of default listeners:
-
addDateClickListener(CalendarDateClickListener listener);- adds listener for date clicks:calendar.addDateClickListener( calendarDateClickEvent -> showNotification(String.format("Date clicked: %s", calendarDateClickEvent.getDate().toString()), NotificationType.HUMANIZED));
-
addWeekClickListener()- adds listener for week number clicks.
-
addEventClickListener()- adds listener for calendar event clicks.
-
addEventResizeListener()- adds listener for event size changing.
-
addEventMoveListener()- adds listener for event drag and drop.
-
addForwardClickListener()- adds listener for calendar forward scrolling.
-
addBackwardClickListener()- adds listener for calendar backward scrolling.
-
addRangeSelectListener()- adds listener for calendar range selection.
Calendar events can be styled with CSS. To configure a style, create the style name and set the parameters in the .scss-file. For example, let’s configure the background color of an event:
.v-calendar-event.event-green {
background-color: #c8f4c9;
color: #00e026;
}Then use the setStyleName method of the event:
calendarEvent.setStyleName("event-green");As a result, the event’s background is green:
In order to change the names of days and months in the Calendar component, use the setDayNames() and setMonthNames() methods, passing a map with the new values to them:
Map<DayOfWeek, String> days = new HashMap<>(7);
days.put(DayOfWeek.MONDAY,"Heavens and earth");
days.put(DayOfWeek.TUESDAY,"Sky");
days.put(DayOfWeek.WEDNESDAY,"Dry land");
days.put(DayOfWeek.THURSDAY,"Stars");
days.put(DayOfWeek.FRIDAY,"Fish and birds");
days.put(DayOfWeek.SATURDAY,"Animals and man");
days.put(DayOfWeek.SUNDAY,"Rest");
calendar.setDayNames(days);- Attributes of calendar
-
caption - captionProperty - colspan - datasource - description - descriptionProperty - endDateProperty - endDate - height - icon - id - isAllDayProperty - rowspan - startDate - startDateProperty - stylename - stylenameProperty - timeFormat - visible - width
- API
- Listeners of calendar
-
CalendarBackwardClickListener - CalendarDateClickListener - CalendarEventClickListener - CalendarEventMoveListener - CalendarEventResizeListener - CalendarForwardClickListener - CalendarRangeSelectListener - CalendarWeekClickListener
4.5.2.1.5. CheckBox
CheckBox is a component with two states: selected or deselected.

Component’s XML-name: checkBox.
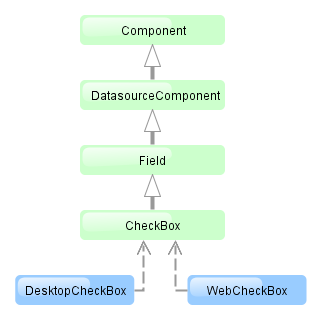
CheckBox component is implemented for Web Client and Desktop Client.
An example of a checkbox with a label retrieved from a localized messages pack:
<checkBox id="accessField" caption="msg://accessFieldCaption"/>Selecting / deselecting of the checkbox changes its value: Boolean.TRUE or Boolean.FALSE. The value can be retrieved using getValue() method and set using setValue(). Submitting null using setValue() will change the value to Boolean.FALSE and uncheck the checkbox.
Changes of the checkbox value, as well as of any other components implementing the Field interface, can be tracked using a ValueChangeListener. For example:
@Inject
private CheckBox accessField;
@Override
public void init(Map<String, Object> params) {
accessField.addValueChangeListener(event -> {
if (Boolean.TRUE.equals(event.getValue())) {
showNotification("set", NotificationType.HUMANIZED);
} else {
showNotification("not set", NotificationType.HUMANIZED);
}
});
}The datasource and property attributes should be used to create a checkbox associated with data.
<dsContext>
<datasource id="customerDs" class="com.sample.sales.entity.Customer" view="_local"/>
</dsContext>
<layout>
<checkBox datasource="customerDs" property="active"/>According to the example the screen includes the description of customerDs data source for a Customer entity with active attribute. The datasource attribute of the checkBox component should contain a reference to a data source; the property attribute should contain the name of an entity attribute which value should be displayed in the checkbox. The attribute should have Boolean type. If the attribute value is null the checkbox is deselected.
4.5.2.1.6. ColorPicker
ColorPicker is a field that allows a user to preview and select a color. Component returns a hexadecimal (HEX) value of the color as a string.
An example of a color picker with a caption retrieved from the localized messages pack:
<colorPicker id="colorPicker" caption="msg://colorPickerCaption"/>The figure below shows an example of the color picker with the popup closed.
To create a color picker connected to data, use datasource and property attributes.
<dsContext>
<datasource id="carsDs" class="com.sample.sales.entity.Cars" view="_local"/>
</dsContext>
<layout>
<colorPicker id="colorPicker" datasource="carsDs" property="color"/>Attributes of сolorPicker:
-
defaultCaptionEnabled- if set totrueandbuttonCaptionis not set, displays HEX value as a button caption.
-
historyVisible- determines the visibility of history of recently picked colors in the popup window.
You can determine visibility of the popup tabs using the following attributes:
-
rgbVisible- determines the visibility of the RGB tab. -
hsvVisible- determines the visibility of the HSV tab. -
swatchesVisible- determines the visibility of the swatches tab.
By default, only the RGB tab is visible.
Also, if you want to redefine the labels in popup, you can use caption attributes:
-
popupCaption- caption of the popup window. -
confirmButtonCaption- caption of the confirm button. -
cancelButtonCaption- caption of the cancel button. -
swatchesTabCaption- swatches tab caption. -
lookupAllCaption- caption of lookup item for all colors. -
lookupRedCaption- caption of lookup item for red color. -
lookupGreenCaption- caption of lookup item for green color. -
lookupBlueCaption- caption of lookup item for blue color.
getValue() method of the component returns a string, containing a HEX code of the selected color.
Changes of the color picker value, as well as of any other components implementing the Field interface, can be tracked using a ValueChangeListener.
- Attributes of colorPicker
-
align - buttonCaption - cancelButtonCaption - caption - confirmButtonCaption - datasource - defaultCaptionEnabled - editable - height - historyVisible - hsvVisible - icon - id - lookupAllCaption - lookupBlueCaption - lookupGreenCaption - lookupRedCaption - popupCaption - rgbVisible - required - stylename - swatchesTabCaption - swatchesVisible - tabIndex - visible - width
- Listeners of colorPicker
4.5.2.1.7. DataGrid
DataGrid, similarly to the Table component, is designed to display and sort tabular data, and provides means to manipulate rows and columns with greater performance due to lazy loading of data while scrolling.
XML name of the component: dataGrid.
The component is implemented for Web Client.
An example of component definition in an XML-descriptor of a screen:
<dsContext>
<collectionDatasource id="ordersDs"
class="com.sample.sales.entity.Order"
view="orderWithCustomer">
<query>
select o from sales$Order o order by o.date
</query>
</collectionDatasource>
</dsContext>
<dataGrid id="ordersDataGrid"
datasource="ordersDs"
height="100%"
width="100%">
<columns>
<column id="date" property="date"/>
<column id="customerName" property="customer.name"/>
<column id="amount" property="amount"/>
</columns>
</dataGrid>In the example above the id attribute is a column identifier, and the property is the name of the entity attribute from the data source that populates the column with data.
dataGrid elements:
-
columns- mandatory element that defines theDataGridcolumns set. Each column is described in the nestedcolumnelement with the following attributes:-
id- an optional attribute with the column identifier. If not set, the string with thepropertyvalue will be used as the column identifier. In this case setting thepropertyvalue is mandatory, otherwise theGuiDevelopmentExceptionexception will be thrown. Theidattribute is still mandatory for the columns created in the screen controller.
-
property- contains the entity attribute’s name. Can be either an attribute of the entity from the data source or a linked entity – object graph traversal is indicated with a dot. For example:<columns> <column id="date" property="date"/> <column id="customer" property="customer"/> <column id="customerName" property="customer.name"/> <column id="customerCountry" property="customer.address.country"/> </columns> -
caption- an optional attribute containing the column caption. If not specified, a localized attribute name will be displayed.
-
expandRatio- sets the column width ratio. By default, all columns have equal width (i.e.expandRatio = 1). If another value is set for at least one column, all implicit values are ignored, and only set values are considered.
-
collapsible- defines whether a user can hide or show columns using the sidebar menu in the top right ofDataGrid. The default value istrue
-
collapsed- an optional attribute; hides the column by default when set totrue. The default value isfalse.
-
collapsingToggleCaption- sets the column’s caption in the sidebar menu. By default its value isnull, in this case the caption remains the same as the column’s caption.
-
resizable- defines whether a user can change the column’s size.
-
sortable- an optional attribute to disable sorting of the column. Takes effect if the wholeDataGridhassortableattribute set totrue(which is by default). -
width- an optional attribute controlling default column width. May contain only numeric values in pixels.
-
minimumWidth- sets the minimal column width in pixels.
-
maximumWidth- sets the maximal column width in pixels.
The
columnelement may contain a nested formatter element that allows you to represent the attribute value in a format different from the standard for this DataType:<column id="date"> <formatter class="com.haulmont.cuba.gui.components.formatters.DateFormatter" format="yyyy-MM-dd HH:mm:ss"/> </column> -
-
actions- optional element to define actions forDataGrid. Besides custom actions, the standard actions from theListActionTypeenumeration are also supported: create, edit, remove, refresh, add, exclude.
-
rowsCount- optional element that creates aRowsCountcomponent for theDataGrid.RowsCountenables pagination of data, the page size is set by limitation of records in the data source with the help ofCollectionDatasource.setMaxResults()method from the screen controller. Another way to do this is to use a universalFiltercomponent bound with the same data source as theDataGrid.
The RowsCount component can also display the total number of records returned by current data request without loading these records. When a user clicks the "?" button, it calls the AbstractCollectionDatasource.getCount() method that passes to the database a request with the same parameters as current but with COUNT(*) aggregation function instead of getting results. The returned number is displayed in place of "?" symbol.
dataGrid attributes:
-
columnResizeMode- sets the mode of columns resizing by user. Two modes are supported:-
AMINATED- the columns size follows the mouse when dragging (default mode). -
SIMPLE- the columns size is changed after the dragging is finished.
The column size changes can be tracked with
ColumnResizeListener. -
-
columnsCollapsingAllowed- defines whether a user can hide columns in the sidebar menu. Displayed columns are checked in the menu. When a column name is checked/unchecked, the value ofcollapsedattribute of each column is updated. When set tofalse, thecollapsedattribute of any column cannot be set totrue.The column collapsing changes can be tracked with
ColumnCollapsingChangeListener.
-
contextMenuEnabled- enables turning on and off the context menu. Default value istrue.The right mouse clicks on the
DataGridcan be tracked withContextClickListener.
-
editorBuffered- sets the buffered editor mode. The default mode is buffered (true).
-
editorCancelCaption- sets the caption on the cancel button in theDataGrideditor.
-
editorEnabled- enables the item inline editor UI. Default value isfalse.
-
editorSaveCaption- sets the caption on the save button in theDataGridinline editor.
-
frozenColumnCount- sets the number of fixedDataGridcolumns. The0value means that no columns will be fixed except the predefined column with checkboxes for multiple choice if the multiselect mode is used. The-1value makes even multiselect column not fixed.
-
headerVisible- defines if theDataGridheader is visible. The default value istrue.
-
reorderingAllowed- defines whether a user can change the columns order by dragging them with a mouse. The default value istrue.The column order changes can be tracked with
ColumnReorderListener.
-
selectionMode- sets the rows selection mode. There are 4 predefined selection modes:-
SINGLE- single record selection. -
MULTI- multiple selection as in any table. -
MULTI_CHECK- multiple selection using the embedded column with checkboxes. -
NONE- selection is disabled.Rows selection events can be tracked by
SelectionListener.
-
-
sortable- enables or disables theDataGridsorting. The default value istrue. When the sorting is enabled, the click on the column name will display the sorting icon to the right of che column caption. Sorting of any specific column can be disabled by this column’ssortableattribute.The
DataGridsorting events can be tracked bySortListener.
-
textSelectionEnabled- enables or disables text selection in theDataGrid cells. The default value isfalse.
Methods of the DataGrid interface:
-
getColumns()- returns the current set ofDataGridcolumns in their current display order. -
getSelected(),getSingleSelected()- return instances of the entities corresponding to the selected rows of the table. A collection can be obtained by invoking getSelected(). If nothing is selected, the application returns an empty set. IfSelectionMode.SINGLEis set, it is more convenient to use getSingleSelected() method returning one selected entity or null, if nothing is selected. -
getVisibleColumns()- returns the current set of visibleDataGridcolumns in their current display order.
-
scrollTo()- method allows you to scroll theDataGridto the specified row. It takes an entity instance identifying the row as a parameter. Besides the entity instance, an overridden method can take aScrollDestinationparameter with the following possible values:-
ANY- scroll as little as possible to show the required record. -
START- scroll to place the required record in the beginning of theDataGridvisible area. -
MIDDLE- scroll to place the required record in the centre of theDataGridvisible area. -
END- scroll to place the required record in the end of theDataGridvisible area.
-
-
scrollToStart()andscrollToEnd()- scroll theDataGridto the top and to the end respectively.
-
setCellStyleProvider()- enables setting theDataGridcell display style.
-
setRowStyleProvider()- enables setting theDataGridrow display style.
-
setEnterPressAction()- method allows you to define an action executed when Enter is pressed. If such action is not defined, the table will attempt to find an appropriate one in the list of its actions in the following order:-
The action defined by the
setItemClickAction()method. -
The action assigned to the Enter key by the
shortcutproperty. -
The
editaction. -
The
viewaction.
If such action is found, and has
enabled = trueproperty, the action is executed. -
-
setItemClickAction()- method allows you to define an action that will be performed when a table row is double-clicked. If such action is not defined, the table will attempt to find an appropriate one in the list of its actions in the following order:-
The action assigned to the Enter key by the
shortcutproperty. -
The
editaction. -
The
viewaction.
If such action is found, and has
enabled = trueproperty, the action is executed.Item click events can be tracked with
ItemClickListener. -
-
sort()- sorts the data for the specified column in the sort direction chosen from 2 values of theSortDirectionenum:-
ASCENDING- ascending (e.g. A-Z, 1..9) sort order. -
DESCENDING- descending (e.g. Z-A, 9..1) sort order.
-
-
setCellDescriptionProvider()methods allows to set theCellDescriptionProviderinstance for generating optional descriptions (tooltips) for individual DataGrid cells. The description may contain HTML markup.customersDataGrid.setRowDescriptionProvider(Instance::getInstanceName);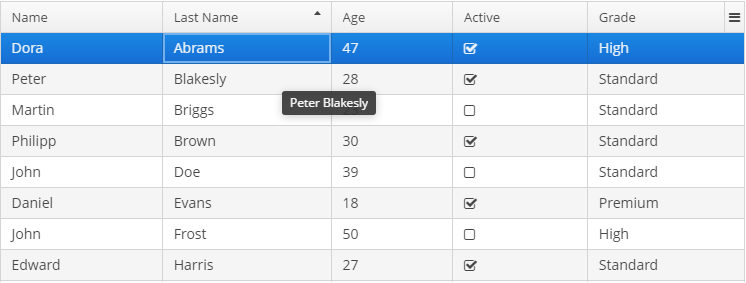
-
setRowDescriptionProvider()sets theRowDescriptionProviderinstance for generating optional descriptions (tooltips) for DataGrid rows. If aCellDescriptionProvideris also set, the row description generated by provider is used for cells for which the cell description provider returns null.customersDataGrid.setCellDescriptionProvider((entity,columnId)->{ if ("name".equals(columnId)||"lastName".equals(columnId)){ return null; } String description="<strong>"+ messages.getTools().getPropertyCaption(entity.getMetaClass(),columnId)+ ": </strong>"; if ("grade".equals(columnId)){ description += messages.getMessage(entity.getGrade()); } else if ("active".equals(columnId)){ description += getMessage(entity.getActive() ? "trueString":"falseString"); } else { description += entity.getValue(columnId); } return description; });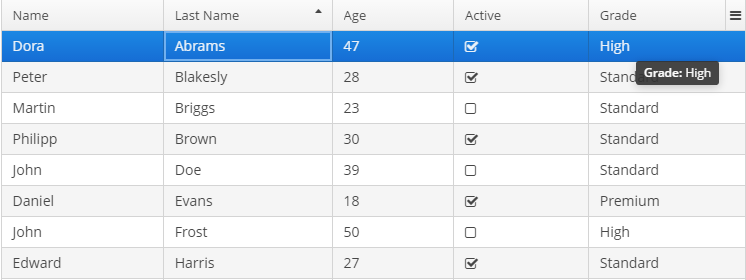
Usage of DataGrid inline editor:
The DataGrid component has an API for inline editing of records in the cells. When an item is being edited, the inline edit UI with default save and cancel buttons is displayed.
Methods of inline editor API:
-
getEditedItemId()- returns theidof the item that is currently being edited. -
isEditorActive()- returns whether an item is currently being edited in the editor.
-
editItem()- opens the editor interface for the provided item. Scrolls the grid to bring the item to view if it is not already visible.
You can add and remove listeners to the editor using the following methods:
-
addEditorPreCommitListener(),removeEditorPreCommitListener()-DataGrideditor pre commit listener.
-
addEditorPostCommitListener(),removeEditorPostCommitListener()-DataGrideditor post commit listener.
-
addEditorCloseListener(),removeEditorCloseListener()-DataGrideditor close listener.
The changes are committed to the datasource only. The logic to save these changes in the database should be added separately.
The editor field can be customized with the help of ColumnEditorFieldGenerator interface. Apply the setEditorFieldGenerator() to a column in order to set a custom component for editing this column:
ordersGrid.getColumnNN("amount").setEditorFieldGenerator((datasource, property) -> {
LookupField lookupField = componentsFactory.createComponent(LookupField.class);
lookupField.setDatasource(datasource, property);
lookupField.setOptionsList(Arrays.asList(BigDecimal.ZERO, BigDecimal.ONE, BigDecimal.TEN));
return lookupField;
});The result:
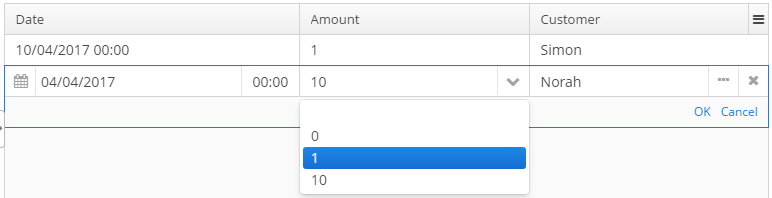
Usage of the ColumnGenerator interface:
DataGrd enables adding generated columns with the help of the methods:
-
addGeneratedColumn(String columnId, ColumnGenerator generator) -
addGeneratedColumn(String columnId, ColumnGenerator generator, int index)
ColumnGenerator is a special interface that defines the generated, or calculated, column:
-
value of each column’s row,
-
the type of value - common for the whole column.
Below is an example of generating a column that displays users' login in the upper case:
@Override
public void init(Map<String, Object> params){
DataGrid.Column column = usersGrid.addGeneratedColumn("loginUpperCase",new DataGrid.ColumnGenerator<User, String>(){
@Override
public String getValue(DataGrid.ColumnGeneratorEvent<User> event){
return event.getItem().getLogin().toUpperCase();
}
@Override
public Class<String> getType(){
return String.class;
}
},1);
column.setCaption("Login Upper Case");
}The result:

ColumnGeneratorEvent, passed in the getValue method, contains information on the entity, displayed in the current DataGrid row, and the column propertyId.
By default, the generated column is added to the end of the table. There are two possible ways to manage the column’s position: either using an index in the code or adding a column in advance in the XML descriptor and pass its id to the addGeneratedColumn method.
Usage of renderers:
The way the data is displayed in columns can be customized by means of renderers. For example, to display icons as pictures in the cells, the path to an icon can be used together with the ImageRenderer class:
@Override
public void init(Map<String, Object> params){
DataGrid.Column avatar = usersGrid.addGeneratedColumn("userAvatar", new DataGrid.ColumnGenerator<User, String>() {
@Override
public String getValue(DataGrid.ColumnGeneratorEvent<User> event) {
return "icons/user.png";
}
@Override
public Class<String> getType() {
return String.class;
}
}, 0);
avatar.setCaption("Avatar");
avatar.setRenderer(usersGrid.createRenderer(DataGrid.ImageRenderer.class));
}The result:

The WebComponentRenderer interface allows you to display components of different web components types in the DataGrid cells. This interface is implemented only in the Web Module. Below is an example of creating a column with the LookupField component:
import com.haulmont.cuba.core.global.Configuration;
import com.haulmont.cuba.core.global.GlobalConfig;
import com.haulmont.cuba.gui.components.AbstractWindow;
import com.haulmont.cuba.gui.components.Component;
import com.haulmont.cuba.gui.components.DataGrid;
import com.haulmont.cuba.gui.components.LookupField;
import com.haulmont.cuba.gui.xml.layout.ComponentsFactory;
import com.haulmont.cuba.security.entity.User;
import com.haulmont.cuba.web.gui.components.renderers.WebComponentRenderer;
import javax.inject.Inject;
import java.util.Locale;
import java.util.Map;
import java.util.TreeMap;
public class Users extends AbstractWindow {
@Inject
private ComponentsFactory componentsFactory;
@Inject
private Configuration configuration;
@Inject
private DataGrid<User> usersGrid;
@Override
public void init(Map<String, Object> params) {
Map<String, Locale> locales = configuration.getConfig(GlobalConfig.class).getAvailableLocales();
Map<String, Object> options = new TreeMap<>();
for (Map.Entry<String, Locale> entry : locales.entrySet()) {
options.put(entry.getKey(), messages.getTools().localeToString(entry.getValue()));
}
DataGrid.Column column = usersGrid.addGeneratedColumn("language",
new DataGrid.ColumnGenerator<User, Component>() {
@Override
public Component getValue(DataGrid.ColumnGeneratorEvent<User> event) {
LookupField component = componentsFactory.createComponent(LookupField.class);
component.setOptionsMap(options);
component.setWidth("100%");
User user = event.getItem();
component.setValue(user.getLanguage());
component.addValueChangeListener(e -> user.setLanguage((String) e.getValue()));
return component;
}
@Override
public Class<Component> getType() {
return Component.class;
}
});
column.setRenderer(new WebComponentRenderer());
}
}The result:
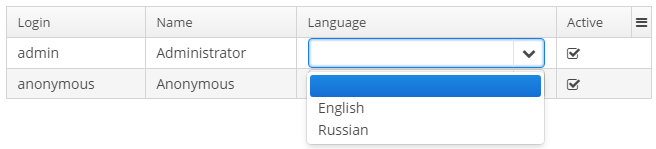
When the field type does not match the data type that can be processed by a renderer, one can use the converters to match data types of the model and the view. For example, to display a boolean value as an icon, it would be handy to use the HtmlRenderer to display HTML layout and a converter, which will convert a boolean value to the layout for icons' display.
@Override
public void init(Map<String, Object> params){
DataGrid.Column hasEmail = usersGrid.addGeneratedColumn("hasEmail", new DataGrid.ColumnGenerator<User, Boolean>() {
@Override
public Boolean getValue(DataGrid.ColumnGeneratorEvent<User> event) {
return StringUtils.isNotEmpty(event.getItem().getEmail());
}
@Override
public Class<Boolean> getType() {
return Boolean.class;
}
});
hasEmail.setCaption("Has Email");
hasEmail.setRenderer(usersGrid.createRenderer(DataGrid.HtmlRenderer.class));
hasEmail.setConverter(new DataGrid.Converter<String, Boolean>() {
@Override
public Boolean convertToModel(String value, Class<? extends Boolean> targetType, Locale locale) {
return null;
}
@Override
public String convertToPresentation(Boolean value, Class<? extends String> targetType, Locale locale) {
return BooleanUtils.isTrue(value)
? FontAwesome.CHECK_SQUARE_O.getHtml()
: FontAwesome.SQUARE_O.getHtml();
}
@Override
public Class<Boolean> getModelType() {
return Boolean.class;
}
@Override
public Class<String> getPresentationType() {
return String.class;
}
});
}The result:

The renderers can be created in two ways:
-
passing a renderer interface to the fabric method of the
DataGridinterface. Suits for GUI and Web modules. -
directly creating a renderer implementation for the corresponding module:
dataGrid.createRenderer(DataGrid.ImageRenderer.class) → new WebImageRenderer()For the moment this way is suitable only for the Web module.
The list of renderers supported by the Platform:
-
TextRenderer- displays plain text. -
HtmlRenderer- displays HTML layout. -
ProgressBarRenderer- displaysdoublevalues between 0 and 1 as aProgressBarcomponent. -
DateRenderer- displays dates in the defined format. -
NumberRenderer- displays numbers in the defined format. -
ButtonRenderer- displays string values as a button caption. -
ImageRenderer- uses the path to an image to display the image. -
CheckBoxRenderer- displays boolean values as a checkbox icon.
Header and Footer:
HeaderRow and FooterRow interfaces are used to represent header and footer cells respectively. They can be a merged cell for multiple columns.
The following methods of DataGrid allow to create and manage the DataGrid header and footer:
-
appendHeaderRow(),appendFooterRow()- adds a new row at the bottom of the header/footer section. -
prependHeaderRow(),prependFooterRow()- adds a new row at the top of the header/footer section. -
addHeaderRowAt(),addFooterRowAt()- inserts a new row at the given position to the header/footer section. Shifts the row currently at that position and any subsequent rows down incrementing their indices. -
removeHeaderRow(),removeFooterRow()- removes the given row from the header/footer section. -
getHeaderRowCount(),getFooterRowCount()- gets the row count for the header/footer section. -
setDefaultHeaderRow()- sets the default row of the header. The default row is a special header row providing a user interface for sorting columns.
HeaderCell and FooterCell interfaces provide means of customization of static DataGrid cells:
-
setStyleName()- sets a custom style name for this cell. -
getCellType()- returns the type of content stored in this cell. There are 3 types ofDataGridStaticCellTypeenumeration available:-
TEXT -
HTML -
COMPONENT
-
-
getComponent(),getHtml(),getText()- returns the content displayed in this cell depending on its type.
Below is an example of DataGrid the header, that contains merged cells, and the footer displaying calculated values.
<dataGrid id="dataGrid"
datasource="countryGrowthDs"
width="100%">
<columns>
<column property="country"/>
<column property="year2014"/>
<column property="year2015"/>
</columns>
</dataGrid>public class DataGridHeaderFooterFrame extends AbstractFrame {
@Inject
private DataGrid<CountryGrowth> dataGrid;
@Inject
private CollectionDatasource<CountryGrowth, UUID> countryGrowthDs;
@Inject
private UserSessionSource userSessionSource;
private DecimalFormat percentFormat;
@Override
public void init(Map<String, Object> params) {
countryGrowthDs.refresh();
initPercentFormat();
initHeader();
initFooter();
initRenderers();
}
private DecimalFormat initPercentFormat() {
percentFormat = (DecimalFormat) NumberFormat.getPercentInstance(userSessionSource.getLocale());
percentFormat.setMultiplier(1);
percentFormat.setMaximumFractionDigits(2);
return percentFormat;
}
private void initRenderers() {
dataGrid.getColumnNN("year2014").setRenderer(new WebNumberRenderer(percentFormat));
dataGrid.getColumnNN("year2015").setRenderer(new WebNumberRenderer(percentFormat));
}
private void initHeader() {
HeaderRow headerRow = dataGrid.prependHeaderRow();
HeaderCell headerCell = headerRow.join("year2014", "year2015");
headerCell.setText("GDP growth");
headerCell.setStyleName("center-bold");
}
private void initFooter() {
FooterRow footerRow = dataGrid.appendFooterRow();
footerRow.getCell("country").setHtml("<strong>" + getMessage("average") + "</strong>");
footerRow.getCell("year2014").setText(percentFormat.format(getAverage("year2014")));
footerRow.getCell("year2015").setText(percentFormat.format(getAverage("year2015")));
}
private double getAverage(String propertyId) {
double average = 0.0;
Collection<CountryGrowth> items = countryGrowthDs.getItems();
for (CountryGrowth countryGrowth : items) {
Double value = countryGrowth.getValue(propertyId);
average += value != null ? value : 0.0;
}
return average / items.size();
}
}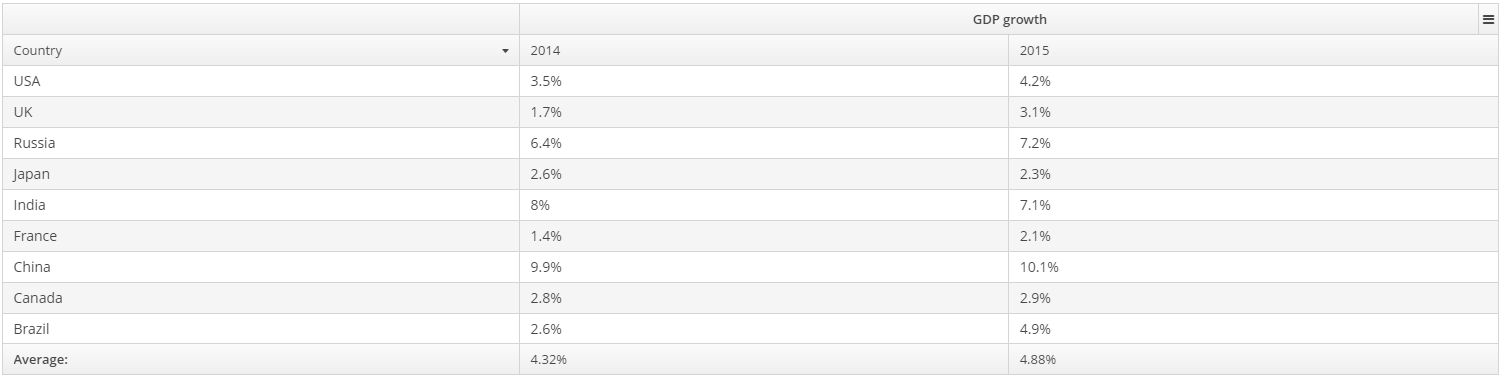
- Attributes of dataGrid
-
align - caption - colspan - columnResizeMode - columnsCollapsingAllowed - contextMenuEnabled - datasource - description - editorBuffered - editorCancelCaption - editorEnabled - editorSaveCaption - enable - frozenColumnCount - headerVisible - height - icon - id - reorderingAllowed - responsive - rowspan - selectionMode - settingsEnabled - sortable - stylename - tabIndex - textSelectionEnabled - visible - width
- Elements of dataGrid
-
actions - buttonsPanel - columns - rowsCount
- Attributes of column
-
caption - collapsed - collapsible - collapsingToggleCaption - editable - expandRatio - id - maximumWidth - minimumWidth - property - resizable - sortable - width
- Elements of column
- API
-
addGeneratedColumn - createRenderer - editItem - getColumns - setCellDescriptionProvider - setCellStyleProvider - setConverter - setEnterPressAction - setItemClickAction - setRenderer - setRowDescriptionProvider - setCellStyleProvider - sort
- Listeners of dataGrid
-
ColumnCollapsingChangeListener - ColumnReorderListener - ColumnResizeListener - ContextClickListener - EditorCloseListener - EditorPostCommitListener - EditorPreCommitListener - ItemClickListener - SelectionListener - SortListener
4.5.2.1.8. DateField
DateField is a field to display and enter date and time. It is an input field, inside which there is a button with a drop-down calendar. To the right, there is a time field.
XML name of the component: dateField.
The DateField component is implemented for Web Client and Desktop Client.
-
To create a date field associated with data, you should use the datasource and property attributes:
<dsContext> <datasource id="orderDs" class="com.sample.sales.entity.Order" view="_local"/> </dsContext> <layout> <dateField datasource="orderDs" property="date"/>In the example above, the screen has the
orderDsdata source for theOrderentity, which has thedateproperty. The reference to the data source is specified in the datasource attribute of thedateFieldcomponent; the name of the entity attribute which value should be displayed in the field is specified in the property attribute. -
If the field is associated with an entity attribute, it will automatically take the appropriate form:
-
If the attribute has the
java.sql.Datetype or the@Temporal(TemporalType.DATE)annotation is specified, the time field will not be displayed. The date format is defined by thedatedatatype and is specified in the main localized message pack in thedateFormatkey. -
Otherwise, the time field with hours and minutes will be displayed. The time format is defined by the
timedatatype and is specified in the main localized message pack in thetimeFormatkey.
-
-
You can change the date and time format using the
dateFormatattribute. An attribute value can be either a format string itself or a key in a message pack (if the value starts withmsg://).The format is defined by rules of the
SimpleDateFormatclass (http://docs.oracle.com/javase/8/docs/api/java/text/SimpleDateFormat.html). If there are noHorhcharacters in the format, the time field will not be displayed.<dateField dateFormat="MM/yy" caption="msg://monthOnlyDateField"/> Warning
WarningDateFieldis primarily intended for quick input by filling placeholders from keyboard. Therefore the component supports only formats with digits and separators. Complex formats with textual representation of weekdays or months will not work.
-
You can specify available dates by using
rangeStartandrangeEndattributes. If a range is set, all dates outside the range will be disabled. You can set range dates in the "yyyy-MM-dd" format in XML or programmatically by using corresponding setters.<dateField id="dateField" rangeStart="2016-08-15" rangeEnd="2016-08-19"/>
-
Changes of the
DateFieldvalue, as well as of any other components implementing theFieldinterface, can be tracked using aValueChangeListener.
-
Date and time accuracy can be defined using a
resolutionattribute. An attribute value should match theDateField.Resolutionenumeration −SEC,MIN,HOUR,DAY,MONTH,YEAR. Default isMIN, i.e., to within a minute.If
resolution="DAY"anddateFormatis not specified, the format will be taken from one specified in the main message pack with thedateFormatkey.If
resolution="MIN"anddateFormatis not specified, the format will be taken from one specified in the main message pack with thedateTimeFormatkey. Below is a field definition for entering a date up to within a month.<dateField resolution="MONTH" caption="msg://monthOnlyDateField"/>
-
DateFieldcan perform timestamp value conversions between server and user time zones if the user’s time zone is set bysetTimeZone()method. The time zone is assigned automatically from the current user session when the component is bound to an entity attribute of the timestamp type. If the component is not bound to such attribute, you can callsetTimeZone()in the screen controller to make theDateFieldperform required conversions..
-
In Web Client with a Halo-based theme, you can set predefined
borderlessstyle name to the DateField component to remove borders and background from the field. This can be done either in the XML descriptor or in the screen controller:<dateField id="dateField" stylename="borderless"/>When setting a style programmatically, select the
HaloThemeclass constant with theDATEFIELD_prefix:dateField.setStyleName(HaloTheme.DATEFIELD_BORDERLESS);
- Attributes of dateField
-
align - caption - datasource - dateFormat - description - editable - enable - height - icon - id - property - stylename - required - rangeEnd - rangeStart - requiredMessage - resolution - tabIndex - visible - width
- Elements of dateField
- Predefined styles of dateField
- Listeners of dateField
4.5.2.1.9. DatePicker
DatePicker is a field to display and choose a date. It has the same view as the drop-down calendar in DateField.
XML name of the component: datePicker.
The DatePicker component is implemented for Web Client.
-
To create a date picker associated with data, you should use the datasource and property attributes:
<dsContext> <datasource id="orderDs" class="com.sample.sales.entity.Order" view="_local"/> </dsContext> <layout> <datePicker id="datePicker" datasource="orderDs" property="date"/>In the example above, the screen has the
orderDsdata source for theOrderentity, which has thedateproperty. The reference to the data source is specified in the datasource attribute of thedatePickercomponent; the name of the entity attribute which value should be displayed in the field is specified in the property attribute.
-
You can specify available dates to select by using
rangeStartandrangeEndattributes. If you set them, all the dates that are outside the range will be disabled.<datePicker id="datePicker" rangeStart="2016-08-15" rangeEnd="2016-08-19"/>
-
Date accuracy can be defined using a
resolutionattribute. An attribute value should match theDatePicker.Resolutionenumeration −DAY,MONTH,YEAR. Default resolution isDAY.<datePicker id="datePicker" resolution="MONTH"/>
<datePicker id="datePicker" resolution="YEAR"/>
- Attributes of datePicker
-
align - caption - datasource - description - editable - enable - height - id - property - rangeEnd - rangeStart - resolution - stylename - tabIndex - visible - width
- Listeners of datePicker
4.5.2.1.10. Embedded
Embedded component is intended for displaying images and embedding arbitrary web pages into the application screens.
XML name of the component: embedded
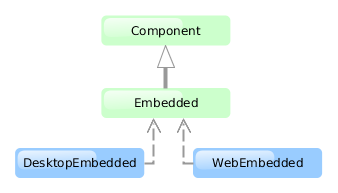
The component is implemented for Web Client and Desktop Client. Desktop Client supports image display only.
Below is an example of using the component to display an image from a file located in FileStorage.
-
Declare the component in an XML screen descriptor:
<groupBox caption="Embedded" spacing="true" height="250px" width="250px" expand="embedded"> <embedded id="embedded" width="100%" align="MIDDLE_CENTER"/> </groupBox> -
In a screen controller, inject the component itself and the
FileStorageServiceinterface. Ininit()method, get theFileDescriptorpassed from the calling code, load the corresponding file in a byte array, create aByteArrayInputStreamfor it, and pass the stream to thesetSource()method of the component:@Inject private Embedded embedded; @Inject private FileStorageService fileStorageService; @Override public void init(Map<String, Object> params) { FileDescriptor imageFile = (FileDescriptor) params.get("imageFile"); byte[] bytes = null; if (imageFile != null) { try { bytes = fileStorageService.loadFile(imageFile); } catch (FileStorageException e) { showNotification("Unable to load image file", NotificationType.HUMANIZED); } } if (bytes != null) { embedded.setSource(imageFile.getName(), new ByteArrayInputStream(bytes)); embedded.setType(Embedded.Type.IMAGE); } else { embedded.setVisible(false); } }
The Embedded component supports several different content types, which are rendered differently in HTML. You can set the content type with the setType() method. Supported types:
-
OBJECT- allows embedding certain file types inside HTML <object> and <embed> elements. -
IMAGE- embeds an image inside a HTML <img> element. -
BROWSER- embeds a browser frame inside a HTML <iframe> element.
In Web Client, the component enables displaying of files located inside VAADIN folder. You can set the resource path relative to the application root, for example:
<embedded id="embedded"
relativeSrc="VAADIN/themes/halo/my-logo.png"/>or
embedded.setRelativeSource("VAADIN/themes/halo/my-logo.png")You can also define a resource files directory in the cuba.web.resourcesRoot application property and specify the name of a file inside this directory with the prefix for the value: file:// , url:// , or theme://:
<embedded id="embedded"
src="file://my-logo.png"/>or
embedded.setSource("my-logo.png")In order to display an external web page, pass its URL to the component:
try {
embedded.setSource(new URL("http://www.cuba-platform.com"));
} catch (MalformedURLException e) {
throw new RuntimeException(e);
}4.5.2.1.11. FieldGroup
FieldGroup is intended for the joint display and editing of multiple entity attributes.
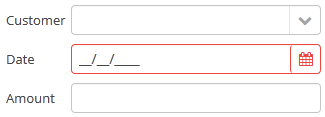
XML-name of the component: fieldGroup
The component is implemented for Web Client and Desktop Client.
Below is an example of defining a group of fields in an XML screen descriptor:
<dsContext>
<datasource id="orderDs"
class="com.sample.sales.entity.Order"
view="order-with-customer">
</datasource>
</dsContext>
<layout>
<fieldGroup id="orderFieldGroup" datasource="orderDs" width="250px">
<field property="date"/>
<field property="customer"/>
<field property="amount"/>
</fieldGroup>
</layout>In the example above, dsContext defines an orderDs data source, which contains a single instance of the Order entity. The data source is specified in the datasource attribute of the fieldGroup component. field elements refer to the entity attributes that need to be displayed in the component.
Elements of fieldGroup:
-
column– optional element that allows you to position fields in multiple columns. For this purpose,fieldelements should be placed not immediately withinfieldGroup, but within acolumn. For example:<fieldGroup id="orderFieldGroup" datasource="orderDs" width="100%"> <column width="250px"> <field property="num"/> <field property="date"/> <field property="amount"/> </column> <column width="400px"> <field property="customer"/> <field property="info"/> </column> </fieldGroup>In this case, fields will be arranged in two columns; the first column will contain all fields with the width of
250px, the second one with the width of400px.Attributes of
column:-
width– specifies the field width of a column. By default, fields have the width of200px. In this attribute, the width can be specified both in pixels and in percentage of the total horizontal width of the column.
-
flex– a number, which indicates the degree of horizontal change in the overall size of the column relative to other columns as a result of changing the entire width offieldGroup. For example, you can specifyflex=1for a column, andflex=3for another one.
-
id– an optional column identifier, which allows you to refer to it in case of screen extension.
-
-
field– the main component element. It defines one field of the component.Custom fields can be included in the
fieldelement as inline XML definition:<fieldGroup> <field id="demo"> <lookupField id="demoField" datasource="userDs" property="group"/> </field> </fieldGroup>Attributes of
field:-
id– required attribute, ifpropertyis not set; otherwise it takes the same value aspropertyby default. Theidattribute should contain an arbitrary unique identifier either of a field with thepropertyattribute set, or a programmatically defined field. In the latter case, thefieldshould have the attributecustom="true"as well (see below).
-
property- required attribute, ifidis not set; it should contain an entity attribute name, which is displayed in the field, for data binding.
-
caption− allows you to specify a field caption. If not specified, an entity attribute localized name will be displayed.
-
visible− allows you to hide the field together with the caption.
-
datasource− allows you to specify a data source for the field, other than specified for the entirefieldGroupcomponent. Thus, attributes of different entities can be displayed in a field group. -
optionsDatasourcespecifies a name of a data source, used to create a list of options. You can specify this attribute for a field connected to a reference entity attribute. By default, the selection of a related entity is made through a lookup screen. IfoptionsDatasourceis specified, you can select the related entity from a drop-down list of options. Actually, specifyingoptionsDatasourcewill lead to the fact that LookupPickerField will be used in the field instead of PickerField.
-
width− allows you to specify the field width excluding caption. By default, the field width will be200px. The width can be specified both in pixels and in percentage of the total horizontal width of the column. To specify the width of all fields simultaneously, you can use thewidthattribute of thecolumnelement described above.
-
custom– if set totrue, it means that a field identifier does not refer to an entity attribute, and a component, which is in the field, will be set programmatically usingsetComponent()method ofFieldGroup(see below).
-
the
generatorattribute is used for declarative creation of custom fields: you can specify the name of the method that returns a custom component for this field:<fieldGroup datasource="productDs"> <column width="250px"> <field property="description" generator="generateDescriptionField"/> </column> </fieldGroup>public Component generateDescriptionField(Datasource datasource, String fieldId) { TextArea textArea = componentsFactory.createComponent(TextArea.class); textArea.setRows(5); textArea.setDatasource(datasource, fieldId); return textArea; }
-
link- if set totrue, enables displaying a link to an entity editor instead of an entity picker field (supported for Web Client only). Such behaviour may be required when the user should be able to view the related entity, but should not change the relationship.
-
linkScreen- contains the identifier of the screen that is opened by clicking the link, enabled in thelinkattribute.
-
linkScreenOpenType- sets the screen opening mode (THIS_TAB,NEW_TABorDIALOG).
-
linkInvoke- contains the controller method to be invoked instead of opening the screen.
The following attributes of
fieldcan be applied depending on the type of the entity attribute displayed in the field:-
If you specify a value of the
maskattribute for a text entity attribute, MaskedField with an appropriate mask will be used instead of TextField. In this case, you can also specify thevalueModeattribute.
-
If you specify a value of the
rowsattribute for a text entity attribute, TextArea with the appropriate number of rows will be used instead of TextField. In this case, you can also specify thecolsattribute. -
For a text entity attribute, you can specify the
maxLengthattribute similarly to one described for TextField. -
For an entity attribute of the
dateordateTimetype, you can specify thedateFormatandresolutionfor the parameterization of the DateField component used in the field. -
For an entity attribute of the
timetype, you can specify theshowSecondsattribute for the parameterization of the TimeField component used in the field.
-
Attributes of fieldGroup:
-
The
borderattribute can be set either tohiddenorvisible. Default ishidden. If set tovisible, thefieldGroupcomponent is highlighted with a border. In the web implementation of the component, displaying a border is done by adding thecuba-fieldgroup-borderCSS class.
-
captionAlignmentattribute defines the position of captions relative to the fields in within theFieldGroup. Two options are available:LEFTandTOP.
-
fieldFactoryBean: declarative fields defined in the XML-descriptor are created with theFieldGroupFieldFactoryinterface. In order to override this factory, use this attribute with the name of your customFieldGroupFieldFactoryimplementation.For the
FieldGroupcreated programmatically, use thesetFieldFactory()method.
Methods of the FieldGroup interface:
-
addFieldenables adding fields to the FieldGroup at runtime. As a parameter it takes aFieldConfiginstance, you can also define the position of the new field by addingcolIndexandrowIndexparameters.
-
bind()method applied to the field aftersetDatasource()triggers the creation of field components.
-
createField()is used to create a FieldGroup element implementingFieldConfiginterface:fieldGroup.addField(fieldGroup.createField("newField"));
-
getComponent()returns a visual component, which is located in a field with the specified identifier. This may be required for additional component parameterization, which is not available through XML attributes offielddescribed above.To obtain a reference to a field component in a screen controller, you can use injection instead of the explicit invocation of
getFieldNN("id").getComponentNN(). To do this, use the@Namedannotation and provide an identifier offieldGroupand a field identifier after a dot.For example, in a field selecting a related entity, you can add an action to open an instance and remove the field cleaning action as follows:
<fieldGroup id="orderFieldGroup" datasource="orderDs"> <field property="date"/> <field property="customer"/> <field property="amount"/> </fieldGroup>@Named("orderFieldGroup.customer") protected PickerField customerField; @Override public void init(Map<String, Object> params) { customerField.addOpenAction(); customerField.removeAction(customerField.getAction(PickerField.ClearAction.NAME)); }To use
getComponent()or to inject field components, you need to know which component type is located in the field. The table below shows the correspondence between entity attribute types and components created for them:Entity attribute type Additional conditions Field component type Related Entity
optionsDatasourceis specifiedEnumeration (
enum)stringmaskis specifiedrowsis specifiedbooleandate,dateTimetimeint,long,double,decimalmaskis specifiedUUIDMaskedField with hex mask
-
removeField()enables removing fields at runtime byid.
-
setComponent()method is used to set your own field view. Can be used together with thecustom="true"attribute of thefieldelement or with the field created programmatically by thecreateField()method (see above). TheFieldConfiginstance can be obtained withgetField()orgetFieldNN()method, then thesetComponent()method is called:@Inject protected FieldGroup fieldGroup; @Inject protected ComponentsFactory componentsFactory; @Override public void init(Map<String, Object> params) { PasswordField passwordField = componentsFactory.createComponent(PasswordField.class); fieldGroup.getFieldNN("password").setComponent(passwordField); }
- Attributes of fieldGroup
-
align - border - caption - captionAlignment - datasource - editable - enable - fieldFactoryBean - id - height - stylename - visible - width
- Attributes of column
- Attributes of field
-
caption - captionProperty - cols - custom - datasource - dateFormat - description - editable - enable - generator - id - link - linkInvoke - linkScreen - linkScreenOpenType - mask - maxLength - optionsDatasource - property - required - requiredMessage - resolution - rows - showSeconds - tabIndex - visible - width
- Elements of field
- API
-
addField - bind - createField - getComponent - removeField - setComponent - setFieldFactory
4.5.2.1.12. FileMultiUploadField
The FileMultiUploadField component allows a user to upload files to the server. The component is a button; when it is clicked, a standard OS file picker window is shown, where the user can select multiple files for upload.
XML name of the component: multiUpload.
The component is implemented for Web Client and Desktop Client.
-
Declare the component in an XML screen descriptor:
<multiUpload id="multiUploadField" caption="msg://upload"/>
-
In the screen controller, inject the component itself, the FileUploadingAPI and DataSupplier interfaces. In the
init()method, add listeners which will react on successful uploads and errors:@Inject private FileMultiUploadField multiUploadField; @Inject private FileUploadingAPI fileUploadingAPI; @Inject private DataSupplier dataSupplier; @Override public void init(Map<String, Object> params) { multiUploadField.addQueueUploadCompleteListener(() -> { for (Map.Entry<UUID, String> entry : multiUploadField.getUploadsMap().entrySet()) { UUID fileId = entry.getKey(); String fileName = entry.getValue(); FileDescriptor fd = fileUploadingAPI.getFileDescriptor(fileId, fileName); // save file to FileStorage try { fileUploadingAPI.putFileIntoStorage(fileId, fd); } catch (FileStorageException e) { new RuntimeException("Error saving file to FileStorage", e); } // save file descriptor to database dataSupplier.commit(fd); } showNotification("Uploaded files: " + multiUploadField.getUploadsMap().values(), NotificationType.HUMANIZED); multiUploadField.clearUploads(); }); multiUploadField.addFileUploadErrorListener(event -> showNotification("File upload error", NotificationType.HUMANIZED)); }The component uploads all selected files to the temporary storage of the client tier and invokes the listener added by the
addQueueUploadCompleteListener()method. In this listener, theFileMultiUploadField.getUploadsMap()method is invoked to obtain a map of temporary storage file identifiers to file names. Then, correspondingFileDescriptorobjects are created by callingFileUploadingAPI.getFileDescriptor()for each map entry.com.haulmont.cuba.core.entity.FileDescriptor(do not confuse withjava.io.FileDescriptor) is a persistent entity, which uniquely identifies an uploaded file and then is used to download the file from the system.Below is the list of listeners available to track the upload process:
-
FileUploadStartListener,
-
FileUploadStartListener,
-
FileUploadFinishListener, -
QueueUploadCompleteListener.
FileUploadingAPI.putFileIntoStorage()method is used to move the uploaded file from the temporary client storage to FileStorage. Parameters of this method are temporary storage file identifier and theFileDescriptorobject.After uploading the file to
FileStorage, theFileDescriptorinstance is saved in a database by invokingDataSupplier.commit(). The saved instance returned by this method can be set to an attribute of an entity related to this file. Here,FileDescriptoris simply stored in the database. The file will be available through the Administration → External Files screen.After processing, the list of files should be cleared by calling the
clearUploads()method in order to prepare for further uploads. -
-
Maximum upload size is determined by the cuba.maxUploadSizeMb application property and is 20MB by default. If a user selects a file of a larger size, a corresponding message will be displayed, and the upload will be interrupted.
-
The
acceptXML attribute (and the correspondingsetAccept()method) can be used to set the file type mask in the file selection dialog. Users still be able to change the mask to "All files" and upload arbitrary files.The value of the attribute should be a comma-separated list of masks. For example:
*.jpg,*.png.
-
The
fileSizeLimitXML attribute (and the correspondingsetFileSizeLimit()method) can be used to set maximum allowed file size in bytes. This limit defines a maximum size for each file.<multiUpload id="multiUploadField" fileSizeLimit="200000"/>
-
The
permittedExtensionsXML attribute (and the correspondingsetPermittedExtensions()method) can be used to set permitted extensions of uploaded files. If the attribute is set, users will not be able to upload files with not permitted extensions.The value of the attribute should be a comma-separated list of extensions with leading dots. For example:
.jpg,.jpeg,.png,.gif.
-
The
dropZoneXML attribute allows you to specify a BoxLayout to be used as a target for drag-and-dropping files from outside of the browser. If the container style is not set, the selected container is highlighted when a user drags files over the container, otherwise the dropZone is not visible.
See Loading and Displaying Images for more complex example of working with uploaded files.
- Attributes of multiUpload
-
accept - align - caption - description - dropZone - enable - fileSizeLimit - height - icon - id - permittedExtensions - stylename - tabIndex - visible - width
- Listeners of multiUpload
-
FileUploadErrorListener - FileUploadFinishListener - FileUploadStartListener - QueueUploadCompleteListener
4.5.2.1.13. FileUploadField
The FileUploadField component allows a user to upload files to the server. The component can contain a caption, a link to uploaded file, and two buttons: for uploading and for clearing the selected file. When the upload button is clicked, a standard OS file picker window is shown, where the user can select a file. In order to upload multiple files, use FileMultiUploadField.
XML name of the component: upload.
The component is implemented for Web Client and Desktop Client.
-
FileUploadFieldis automatically used inside FieldGroup for entity attributes of typeFileDescriptor. In this case, the field looks as shown above and does not require additional configuration. An uploaded file is immediately stored in file storage and the correspondingFileDescriptorinstance is saved to the database. -
You can use the component outside
FieldGroupand connect it to a datasource. For example, here we suppose that thepersonDsdatasource contains an entity with thephotoattribute which is a reference toFileDescriptor:<upload fileStoragePutMode="IMMEDIATE" datasource="personDs" property="photo"/> -
You can also control the saving of file and
FileDescriptorprogrammatically.-
Declare the component in an XML screen descriptor:
<upload id="uploadField" fileStoragePutMode="MANUAL"/>
-
-
In the screen controller, inject the component itself, the FileUploadingAPI and DataSupplier interfaces. In the
init()method, add listeners which will react on successful uploads and errors:@Inject private FileUploadField uploadField; @Inject private FileUploadingAPI fileUploadingAPI; @Inject private DataSupplier dataSupplier; @Override public void init(Map<String, Object> params) { uploadField.addFileUploadSucceedListener(event -> { FileDescriptor fd = uploadField.getFileDescriptor(); try { // save file to FileStorage fileUploadingAPI.putFileIntoStorage(uploadField.getFileId(), fd); } catch (FileStorageException e) { throw new RuntimeException("Error saving file to FileStorage", e); } // save file descriptor to database dataSupplier.commit(fd); showNotification("Uploaded file: " + uploadField.getFileName(), NotificationType.HUMANIZED); }); uploadField.addFileUploadErrorListener(event -> showNotification("File upload error", NotificationType.HUMANIZED)); }The component will upload the file to the temporary storage of the client tier and invoke the listener added by the
addFileUploadSucceedListener()method. In this listener, aFileDescriptorobject is requested from the component.com.haulmont.cuba.core.entity.FileDescriptoris a persistent entity, which uniquely identifies an uploaded file and is used to download the file from the system.FileUploadingAPI.putFileIntoStorage()method is used to move the uploaded file from the temporary client storage to FileStorage. Parameters of this method are temporary storage file identifier and theFileDescriptorobject. Both of these parameters are provided byFileUploadField.After uploading the file to
FileStorage, theFileDescriptorinstance is saved in the database by invokingDataSupplier.commit(). The saved instance returned by this method can be set to an attribute of an entity related to this file. Here,FileDescriptoris simply stored in the database. The file will be available through the Administration → External Files screen.The listener added by the
addFileUploadErrorListener()method will be invoked if an error occurs when uploading a file to the temporary storage of the client tier.Below is the list of listeners available to track the upload process:
-
AfterValueClearListener,
-
BeforeValueClearListener,
-
FileUploadErrorListener,
-
FileUploadFinishListener
-
FileUploadStartListener,
-
FileUploadSucceedListener, -
ValueChangeListener.
-
-
The
fileStoragePutModeXML attribute defines how the file and the correspondingFileDescriptorare stored. In theIMMEDIATEmode it is done right after uploading file to the temporary storage of the client tier. In theMANUALmode, you should do it programmatically in aFileUploadSucceedListener. TheIMMEDIATEmode is selected by default whenFileUploadFieldis used insideFieldGroup. Otherwise, the default mode isMANUAL.
-
The
uploadButtonCaption,uploadButtonIconanduploadButtonDescriptionXML attributes allows you to set the properties of the upload button.
-
The
showClearButtonXML attribute controls whether the clear button is visible. It isfalseby default.
-
The
clearButtonCaption,clearButtonIconandclearButtonDescriptionXML attributes allows you to set the properties of the clear button if it is visible.
-
The
acceptXML attribute (and the correspondingsetAccept()method) can be used to set the file type mask in the file selection dialog. Users still be able to change the mask to "All files" and upload arbitrary files.The value of the attribute should be a comma-separated list of masks. For example:
*.jpg,*.png. -
Maximum upload size is determined by the cuba.maxUploadSizeMb application property and is 20MB by default. If a user selects a file of a larger size, a corresponding message will be displayed, and the upload will be interrupted.
-
The
fileSizeLimitXML attribute (and the correspondingsetFileSizeLimit()method) can be used to set maximum allowed file size specified in bytes.<upload id="uploadField" fileSizeLimit="2000"/>
-
The
permittedExtensionsXML attribute (and the correspondingsetPermittedExtensions()method) can be used to set permitted extensions of uploaded files. If the attribute is set, users will not be able to upload files with not permitted extensions.The value of the attribute should be a comma-separated list of extensions with leading dots. For example:
.jpg,.jpeg,.png,.gif.
-
The
dropZoneXML attribute allows you to specify a BoxLayout to be used as a target for drag-and-dropping files from outside of the browser. The dropZone can cover the whole layout of a dialog window. The selected container is highlighted when a user drags a file over the container, otherwise it is not visible.<layout spacing="true" width="100%"> <vbox id="dropZone" height="AUTO" spacing="true"> <textField id="textField" caption="Title" width="100%"/> <textArea id="textArea" caption="Description" width="100%" rows="5"/> <checkBox caption="Is reference document" width="100%"/> <upload id="upload" dropZone="dropZone" showClearButton="true" showFileName="true"/> </vbox> <hbox spacing="true"> <button caption="mainMsg://actions.Apply"/> <button caption="mainMsg://actions.Cancel"/> </hbox> </layout>
To make a dropZone static and display it permanently, assign the predefined
dropzone-containerstyle to its container. In this case the container should be empty with only thelabelcomponent inside:<layout spacing="true" width="100%"> <textField id="textField" caption="Title" width="100%"/> <checkBox caption="Is reference document" width="100%"/> <upload id="upload" dropZone="dropZone" showClearButton="true" showFileName="true"/> <vbox id="dropZone" height="150px" spacing="true" stylename="dropzone-container"> <label stylename="dropzone-description" value="Drop file here" align="MIDDLE_CENTER"/> </vbox> <hbox spacing="true"> <button caption="mainMsg://actions.Apply"/> <button caption="mainMsg://actions.Cancel"/> </hbox> </layout>
See Loading and Displaying Images for more complex example of working with uploaded files.
- Attributes of upload
-
accept - align - caption - clearButtonCaption - clearButtonDescription - clearButtonIcon - datasource - description - dropZone - editable - enable - fileSizeLimit - fileStoragePutMode - height - icon - id - permittedExtensions - property - showClearButton - stylename - tabIndex - uploadButtonCaption - uploadButtonDescription - uploadButtonIcon - visible - width
- Listeners of upload
-
AfterValueClearListener - BeforeValueClearListener - FileUploadErrorListener - FileUploadFinishListener - FileUploadStartListener - FileUploadSucceedListener - ValueChangeListener
4.5.2.1.14. Filter
The Filter is a versatile tool for filtering lists of entities extracted from a database to display in a tabular form. The component enables quick data filtering by arbitrary conditions, as well as creating filters for repeated use.
Filter should be connected to the collectionDatasource containing a JPQL query. Its logic is based on the modification of this query in accordance with criteria provided by the user. Thus, filtering is done at the database level when the SQL query is executed, and only selected data is loaded to the Middleware and Client tiers.
Using a Filter
A typical filter is shown below:
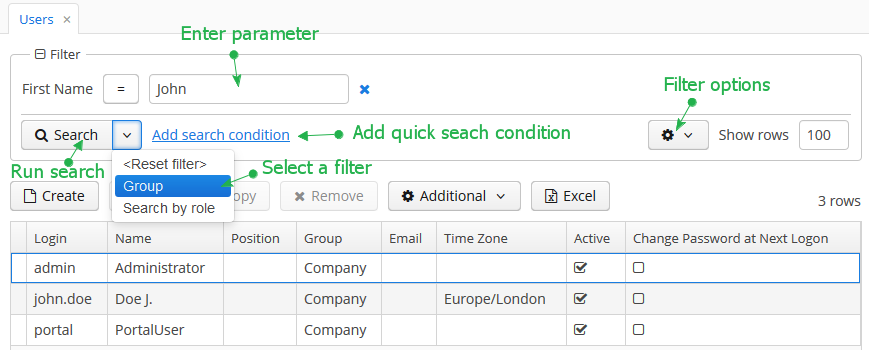
By default, the component is in quick filter mode. This means that a user can add a set of conditions for a one-off data search. After the screen is closed, the conditions will disappear.
To create a quick filter, click Add search condition link. The condition selection screen will be displayed:
Possible condition types are described below:
-
Attributes – attributes of this entity and related entities. Only persistent attributes are displayed. They should also either be explicitly set in the
propertyelement of the filter XML descriptor, or comply with the rules specified in the properties element. -
Custom conditions – conditions specified by developer in the
customelements of the filter XML descriptor. -
Create new… – enables creating a new arbitrary JPQL condition. This option is only available to users having the specific
cuba.gui.filter.customConditionspermission.
Selected conditions are displayed at the top of the filter panel. The  icon will appear next to each condition field, allowing them to be removed from the set.
icon will appear next to each condition field, allowing them to be removed from the set.
Quick filters can be saved for further re-use. In order to save a quick filter, click the filter settings icon, select Save/Save as and provide a new filter name in the popup dialog:
After that, the filter will be saved and will appear in the drop-down menu of the Search button.
The filter settings popup button provides the list of options for filter management:
-
Save – save changes to the current filter.
-
Save as – save the filter under a new name.
-
Edit – open the filter editor (see below).
-
Make default – make the filter default for this screen. The filter will be automatically displayed on the filter panel when the screen is opened.
-
Remove – delete the current filter.
-
Pin applied – use the results of the last search for sequential data filtering (see Applying Filters Sequentially).
-
Save as search folder – create a search folder based on the current filter.
-
Save as application folder – create an application folder based on the current filter. This option is available to users having the specific
cuba.gui.appFolder.globalpermission only.
The Edit option opens the filter editor, allowing advanced configuration of the current filter:
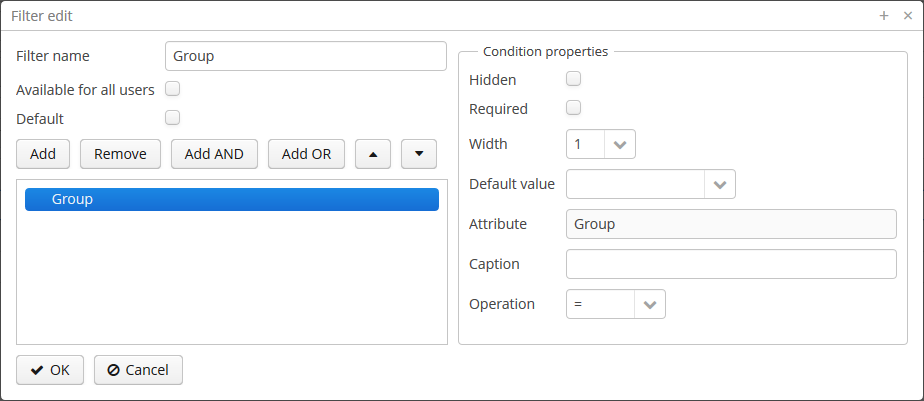
Filter name should be provided in the Name field. This name will be displayed in available filters list for the current screen.
Filter can be made global (i.e., available for all users) using the Available to all users checkbox, or default using the Default checkbox. This operation requires a specific permission called CUBA > Filter > Create/modify global filters.
The filter conditions are contained in the tree. They can be added using the Add button, swapped using  /
/ or removed using the Remove button.
or removed using the Remove button.
AND or OR grouping conditions can be added with the help of the corresponding buttons. All top level conditions (i.e., without explicit grouping) are joined with AND.
Selecting a condition in the tree opens the list of its properties in the right part of the editor.
The conditions can be made hidden or required by means of corresponding checkboxes. The hidden condition parameter is invisible to the user, so it should be provided when the filter is being edited.
Width property enables selecting the width of the parameter field on the filter panel for the current condition. By default, conditions on the filter panel are displayed in three columns. The field width equals to the number of columns it will occupy (1, 2 or 3).
Default parameter value for the current condition can be selected in the Default value field.
A custom caption for filter condition can be provided in the Caption field.
Operation field enables selecting the condition operator. The list of available operators depends on the attribute type.
Filter Component
XML name of the component: filter.
The component is implemented for Web Client and Desktop Client.
An example of component declaration in XML screen descriptor is shown below:
<dsContext>
<collectionDatasource id="carsDs" class="com.company.sample.entity.Car" view="carBrowse">
<query>
select c from ref$Car c order by c.createTs
</query>
</collectionDatasource>
</dsContext>
<layout>
<filter id="carsFilter" datasource="carsDs">
<properties include=".*"/>
</filter>
<table id="carsTable" width="100%">
<columns>
<column id="vin"/>
<column id="model.name"/>
<column id="colour.name"/>
</columns>
<rows datasource="carsDs"/>
</table>
</layout>In the example above, a collectionDatasource is defined in the dsContext. The datasource selects Car entity instances using JPQL query. The datasource which is to be filtered is specified in the filter component’s datasource attribute. Data is displayed using the Table component, which is connected to the same data source.
filter may contain nested elements. They describe conditions available for user selection in Add Condition dialog:
-
properties– multiple entity attributes can be made available for selection. This element has the following attributes:-
include– required attribute. It contains a regular expression, which should match an entity attribute name.
-
exclude– contains a regular expression. If an attribute matches the expression, it will be excluded from previously included (usinginclude).
Example:
<filter id="transactionsFilter" datasource="transactionsDs"> <properties include=".*" exclude="(masterTransaction)|(authCode)"/> </filter>The following entity attributes are ignored when
propertieselement is used:-
Not accessible due to security permissions.
-
Collections (
@OneToMany,@ManyToMany). -
Non-persistent attributes.
-
Attributes that do not have localized names.
-
Attributes annotated with
@SystemLevel. -
Attributes of type
byte[]. -
The
versionattribute.
-
-
property– explicitly includes an entity attribute by name. This element has the following attributes:-
name– required attribute, containing the name of entity attribute to be included. It can be a path (using ".") in the entity graph. For example:<filter id="transactionsFilter" datasource="transactionDs" applyTo="table"> <properties include=".*" exclude="(masterTransaction)|(authCode)"/> <property name="creditCard.maskedPan" caption="msg://EmbeddedCreditCard.maskedPan"/> <property name="creditCard.startDate" caption="msg://EmbeddedCreditCard.startDate"/> </filter>
-
caption– localized entity attribute name displayed in filter conditions. Generally it is a string with themsg://prefix in accordance with MessageTools.loadString() rules.If the
nameattribute is specified as an entity graph path (using ".") , thecaptionattribute is required.
-
paramWhere− specifies the JPQL expression which is used to select the list of condition parameter values if the parameter is a related entity. The{E}placeholder should be used in the expression instead of the alias of the entity being selected.For example, let us assume that
Carhas a reference toModel. Then possible condition parameter values list can be limited toAudimodels only:<filter id="carsFilter" datasource="carsDs"> <property name="model" paramWhere="{E}.manufacturer = 'Audi'"/> </filter>Screen parameters, session attributes and screen components including those showing other parameters can be used in JPQL expression. Query parameters specification rules are described in CollectionDatasourceImpl Queries.
An example of session and screen parameters usage is shown below:
{E}.createdBy = :session$userLogin and {E}.name like :param$groupNameWith the
paramWhereclause, you can introduce dependencies between parameters. For example, let us assume thatManufactureris a separate entity. That isCarhas a reference toModelwhich in turn has a reference toManufacturer. Then you may want to create two conditions for the Cars filter: first to select a Manufacturer and second to select a Model. To restrict the list of models by previously selected manufacturer, add a parameter to theparamWhereexpression:{E}.manufacturer.id = :component$filter.model_manufacturer90062The parameter references a component which displays Manufacturer parameter. You can see the name of the component showing condition parameter by opening context menu on a condition table row in the filter editor:
-
paramView− specifies a view, which will be used to load the list of condition parameter values if the parameter is a related entity. For example,_local. If view is not specified,_minimalview will be used.
-
-
customis an element defining an arbitrary condition. The element content should be a JPQL expression (JPQL Macros can be used), which will be added to the data source query’swhereclause. The{E}placeholder should be used in the expression instead of the alias of the entity being selected. The condition can only have one parameter denoted by "?" if used.A value of custom condition can contain special characters, for example "%" or "_" for "like" operator. If you want to escape these characters, add
escape '<char>'to your condition, for example:{E}.name like ? escape '\'Then if you use
foo\%as a value of the condition parameter, the search will interpret "%" as a character in your name and not as a special character.An example of a filter with arbitrary conditions is shown below:
<filter id="carsFilter" datasource="carsDs"> <properties include=".*"/> <custom name="vin" paramClass="java.lang.String" caption="msg://vin"> {E}.vin like ? </custom> <custom name="colour" paramClass="com.company.sample.entity.Colour" caption="msg://colour" inExpr="true"> ({E}.colour.id in (?)) </custom> <custom name="repair" paramClass="java.lang.String" caption="msg://repair" join="join {E}.repairs cr"> cr.description like ? </custom> <custom name="updateTs" caption="msg://updateTs"> @between({E}.updateTs, now-1, now+1, day) </custom> </filter>customconditions are displayed in the Custom conditions section of the Add condition dialog:
Attributes of
custom:-
name− required attribute, condition name.
-
caption− required attribute, localized condition name. Generally it is a string with themsg://prefix in accordance with MessageTools.loadString() rules.
-
paramClass− Java class of the condition parameter. If the parameter is not specified, this attribute is optional.
-
inExpr− should be set totrue, if the JPQL expression containsin (?)conditions. In this case user will be able to enter several condition parameter values.
-
join− optional attribute. It specifies a string, which will be added to the data source queryfromsection. This can be required to create a complex condition based on an attribute of a related collection.joinorleft joinstatements should be included into the attribute value.For example, let us assume that the
Carentity has arepairsattribute, which is a related entityRepairinstances collection. Then the following condition can be created to filterCarbyRepairentity’sdescriptionattribute:<filter id="carsFilter" datasource="carsDs"> <custom name="repair" caption="msg://repair" paramClass="java.lang.String" join="join {E}.repairs cr"> cr.description like ? </custom> </filter>If the condition above is used, the original data source query
select c from sample$Car c order by c.createTswill be transformed into the following one:
select c from sample$Car c join c.repairs cr where (cr.description like ?) order by c.createTs -
paramWhere− specifies a JPQL expression used to select the list of condition parameter values if the parameter is a related entity. See the description of thepropertyelement’s attribute of the same name. -
paramView− specifies a view, which will be used when a list of condition parameter values are loaded if the parameter is a related entity. See the description of thepropertyelement’s attribute of the same name.
-
filter attributes:
-
editable– if the attribute value isfalse, the Edit option is disabled.
-
manualApplyRequired− defines when the filter will be applied. If the attribute value isfalse, the filter (default or empty) will be applied when the screen is opened. It means that the datasource will be refreshed and linked components (e.g.Table) will display data. If the value istrue, the filter will be applied only after the Search button is clicked.This attribute takes precedence over the cuba.gui.genericFilterManualApplyRequired application property.
-
useMaxResults− limits the page size of entity instances loaded into the data source. It is set totrueby default.If the attribute value is
false, the filter will not show the Show rows field. The number of records in the data source (and displayed in the table accordingly) will be limited only by theMaxFetchUIparameter of the entity statistics, which is set to 10000 by default.If the attribute is not specified or is
true, the Show rows field will be displayed only if the user has specificcuba.gui.filter.maxResultspermission. If thecuba.gui.filter.maxResultspermission is not granted, the filter will force selecting only the first N rows without user to be able to disable it or specify another N. N is defined byFetchUI,DefaultFetchUIparameters. They are obtained from the entity statistics mechanism.A filter shown below has the following parameters:
useMaxResults="true", thecuba.gui.filter.maxResultspermission is denied, andcuba.gui.filter.maxResultsDefaultFetchUI = 2.
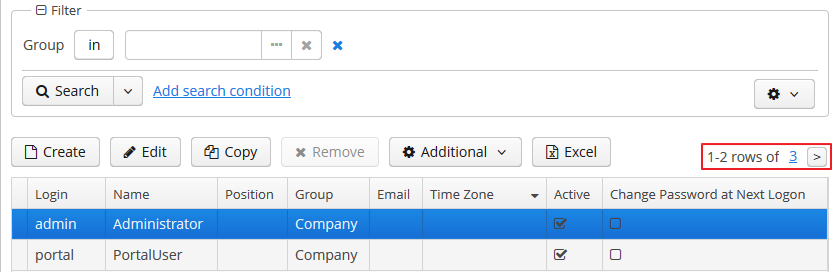
-
textMaxResults- enables using the text field instead of the drop-down list as the Show rows field.falseby default.
-
folderActionsEnabled− if it is set tofalse, the following filter actions will be hidden: Save as Search Folder, Save as Application Folder. By default, the attribute value istrue, and Save as Search Folder, Save as Application Folder are available.
-
applyTo− optional attribute, contains the identifier of a component associated with the filter. It is used when access to related component presentations is required. For example, when saving the filter as a search folder or as an application folder, the presentation that will be applied when browsing this folder can be specified.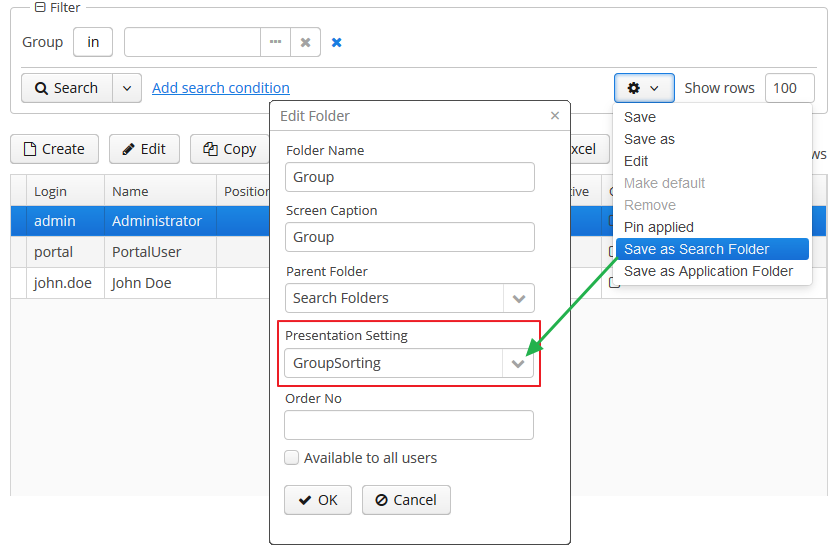
-
caption- enables setting a custom caption for the filter panel.
-
columnsCount- defines the number of columns for conditions on the filter panel. Default value is 3.
-
defaultMode- defines the filter default mode. Possible values aregenericandfts. Whenftsvalue is set then the filter will be opened in the full text search mode (if the entity is indexed). The default value isgeneric.
-
modeSwitchVisible- defines the visibility of the checkbox that switches the filter to the full text search mode. If full text search is unavailable then the checkbox will be invisible despite of the defined value. Possible values aretrueandfalse(trueby default).
Methods of Filter interface:
-
setBorderVisible()- defines if the filter border should be displayed. The default value istrue.
Listeners of Filter:
-
ExpandedStateChangeListener- enables tracking the expanded state changes.
-
FilterEntityChangeListener- is triggered when a filter is selected for the first time on a component initialization or later from the list of saved filters.
- Attributes of filter
-
applyTo - caption - columnsCount - datasource - defaultMode - editable - enable - folderActionsEnabled - id - manualApplyRequired - margin - modeSwitchVisible - settingsEnabled - stylename - textMaxResults - useMaxResults - visible - width
- Elements of filter
-
custom - properties - property
- Attributes of properties
- Attributes of property
-
caption - name - paramView - paramWhere
- Attributes of custom
-
caption - name - inExpr - join - paramClass - paramView - paramWhere
- Listeners of filter
User Permissions
-
To create/change/delete global (available to all users) filters, user must have the
cuba.gui.filter.globalpermission. -
To create/change
customconditions user must have acuba.gui.filter.customConditionspermission. -
To change the maximum number of rows per table page using the Show rows field, user must have the
cuba.gui.filter.maxResultspermission. See also the useMaxResults filter attribute.
For specific permissions configuration information, see Security Subsystem.
External Filter Control Parameters
-
System-wide parameters
The following application properties affect filter behavior:
-
cuba.gui.genericFilterManualApplyRequired − disables automatic applying of the filter (i.e., data loading) when the screen is opened. See also manualApplyRequired filter attribute.
-
cuba.gui.genericFilterChecking − enables the check that at least one condition is filled before applying the filter.
-
cuba.gui.genericFilterControlsLayout − defines an internal layout of the filter controls.
-
cuba.allowQueryFromSelected enables switching off sequential filters application mechanism.
-
cuba.gui.genericFilterColumnsCount - sets the default number of columns for placing conditions on the filter panel. See also columnsCount filter attribute.
-
cuba.gui.genericFilterConditionsLocation - defines the location of the conditions panel.
-
cuba.gui.genericFilterPopupListSize - defines the maximum number of items displayed in the popup list of the Search button.
-
-
Screen invocation parameters
It is possible to specify a filter and its parameters which should be applied when the screen is opened. For this purpose, the filter should be created in advance, stored in the database, and a corresponding record in the
SEC_FILTERtable should have a value in theCODEfield. Screen invocation parameters are set in theweb-menu.xmlconfiguration file.In order to store the filter in the database, the insert script for the filter should be added to the
30.create-db.sqlscript of the entity. To simplify the script creation, find the filter in the Entity Inspector section of the Administration menu, in the filter’s context menu choose System Information, click Script for insert button and copy the script.Then you can adjust the screen to use the filter by default. To specify a filter code, pass to the screen a parameter with the same name as filter component identifier in this screen. Parameter value should be the code of the filter.
To set filter parameter values, pass to the screen parameters with the names equal to parameter names and their values in string format.
An example of main menu item descriptor is shown below. It sets a filter with the
FilterByVINcode to thecarsFiltercomponent of thesample$Car.browsescreen which it opens. It also setsTMAvalue to thecomponent$carsFilter.vin79216condition:<item id="sample$Car.browse"> <param name="carsFilter" value="FilterByVIN"/> <param name="component$carsFilter.vin79216" value="TMA"/> </item>It should be noted that a filter with a defined
CODEfield has some specifics:-
It cannot be edited by users.
-
Name of this filter can be displayed in several languages. To achieve this, specify a string with key equal to the filter code in the application main message pack.
-
Applying Filters Sequentially
If the cuba.allowQueryFromSelected application property is enabled, the last applied filter and the current filtered results can be pinned via the component’s user interface. After that another filter or other parameters of the current filter can be selected and applied to the currently selected records.
This approach helps to achieve two aims:
-
Decompose complex filters, which may lead to better performance as well.
-
Apply filters to the records selected using application or search folders.
Take the following steps to use sequential filters. First, choose and apply one of the filters. Next click the filter settings button and select Pin applied. The filter will be pinned at the top of the filter panel. Then another filter can be applied to the selected records and so on. Any number of filters can be applied sequentially. Filters can also be removed using  button.
button.
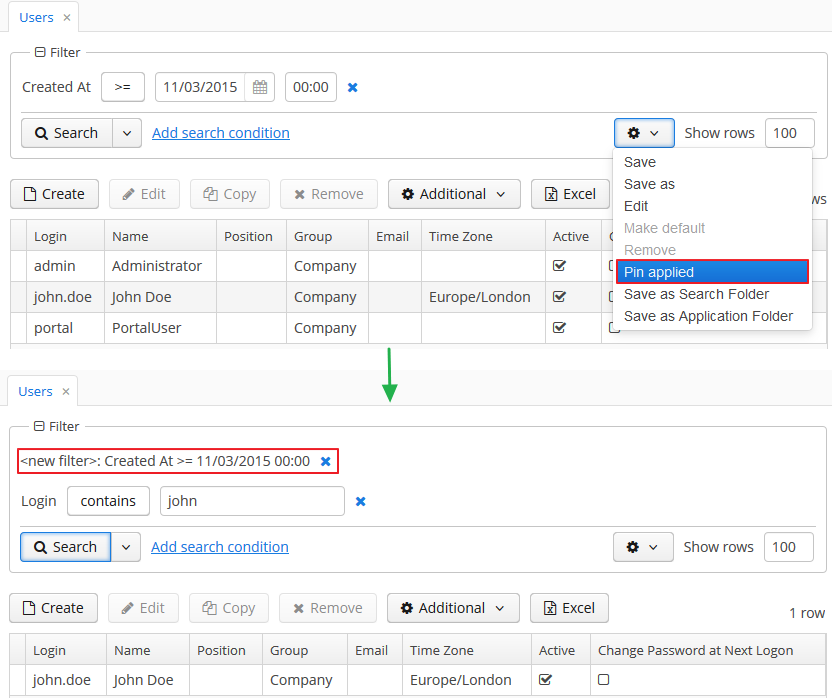
The sequential filters implementation is based on the ability of DataManager to run sequential queries.
API for Working with Filter Parameters
The Filter interface provides methods for reading and writing of filter parameter values in a screen controller:
-
setParamValue(String paramName, Object value) -
getParamValue(String paramName)
paramName - filter parameter name. Parameter name is a part of component name that displays a parameter value. The procedure of getting a component name was described above. Parameter name is placed after the last dot in a component name. For example, if the component name is component$filter.model_manufacturer90062, then the parameter name is model_manufacturer90062.
Note that you cannot use these methods in the init() method of the screen controller, because the filter is not initialized at that moment. A good place to work with filter parameters is the ready() method.
Full-Text Search Mode in Filter
If a filter datasource contains entities that are indexed by the full-text search subsystem (see CUBA Platform. Full Text Search), then a full-text search mode is available in the filter. Use the Full-Text Search checkbox to switch to this mode.
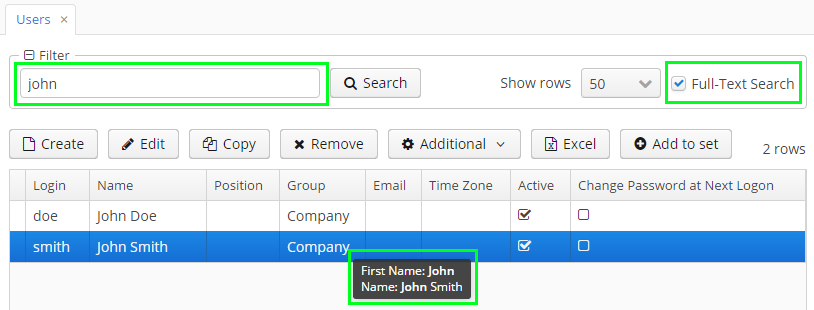
In the full-text search mode, the filter contains only one text field for search criteria, and the search is performed in entity fields indexed by the FTS subsystem.
If a table is defined in the applyTo attribute, then placing the mouse cursor on the table row will display a tooltip with the information what entity attributes satisfy the search criteria.
For hiding the filter mode checkbox, set false value to the modeSwitchVisible filter attribute.
If you want the filter to be opened in the full-text search mode by default, set fts value to the defaultMode filter attribute.
4.5.2.1.15. GroupTable
GroupTable component is a table with an ability to group information dynamically by any field. In order to group a table by a column the required column should be dragged to the left and dropped on the  element of the table header. Grouped values can be expanded and collapsed using
element of the table header. Grouped values can be expanded and collapsed using  /
/ buttons.
buttons.
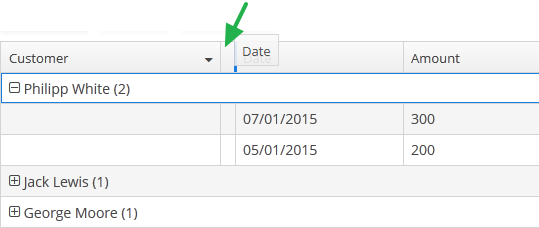
XML name of the component: groupTable.
Component is implemented only for Web Client. In Desktop Client it behaves like a regular table.
groupDatasource must be specified for GroupTable in the datasource attribute of the rows element. Otherwise, grouping will not work. Example:
<dsContext>
<groupDatasource id="ordersDs" class="com.sample.sales.entity.Order"
view="orderWithCustomer">
<query>
select o from sales$Order o order by o.date
</query>
</groupDatasource>
</dsContext>
<layout>
<groupTable id="ordersTable" width="100%">
<columns>
<group>
<column id="date"/>
</group>
<column id="customer.name"/>
<column id="amount"/>
</columns>
<rows datasource="ordersDs"/>
</groupTable>group is an optional element that can be present in a single instance inside columns. It contains a set of column elements, by which grouping will be performed initially when opening a screen.
Each column element can contain the groupAllowed attribute with boolean value. This attribute controls whether a user can group by this column.
If aggregatable attribute is true, the table shows aggregation results for each group and results for all rows in an additional row on the top. If showTotalAggregation attribute is false, results for all rows are not shown.
If multiselect attribute is true, the click to the group row holding down the Ctrl key will expand the group (if collapsed) and set the selection to all rows of this group. The converse is not true: if the whole group is selected, Ctrl+click will not deselect all the group. You still can deselect certain rows using the common Ctrl key behaviour.
The rest of the GroupTable functionality is similar to a simple Table.
- Attributes of groupTable
-
align - aggregatable - aggregationStyle - columnControlVisible - contextMenuEnabled - editable - enable - height - id - multiLineCells - multiselect - presentations - reorderingAllowed - settingsEnabled - showTotalAggregation - sortable - stylename - tabIndex - visible - width
- Elements of groupTable
-
actions - buttonsPanel - columns - rows - rowsCount
- Elements of columns
- Attributes of column
-
align - caption - captionProperty - collapsed - dateFormat - editable - groupAllowed - id - link - linkInvoke - linkScreen - linkScreenOpenType - maxTextLength - optionsDatasource - resolution - sortable - visible - width
- Elements of column
- Attributes of rows
- Listeners of groupTable
4.5.2.1.16. Label
Label is a text component that displays static text or value of an entity attribute.
XML name of the component: label
The Label component is implemented for Web Client and Desktop Client.
Below is an example of setting a label with text taken from the localized message pack:
<label value="msg://orders"/>The value attribute sets text for a label.
In a web client, the text contained in value will be split into multiple lines if its length exceeds the width value. Therefore, to display a multiline label, it is sufficient to specify an absolute value of width. If the label text is too long and the value of width is not specified, the text will be truncated.
<label value="Label, which should be split into multiple lines"
width="200px"/>You can set label parameters in the screen controller. To do this, you should specify a component identifier and get a reference to the component in the controller:
<label id="dynamicLabel"/>@Inject
private Label dynamicLabel;
public void init(Map<String, Object> params) {
dynamicLabel.setValue("Some value");
}The Label component can display value of an entity attribute. For this purpose, datasource and property attributes are used. For example:
<dsContext>
<datasource id="customerDs" class="com.sample.sales.entity.Customer" view="_local"/>
</dsContext>
<layout>
<label datasource="customerDs" property="name"/>In the example above, component displays the name attribute of the Customer entity located in the customerDs data source.
htmlEnabled attribute indicates the way the value attribute will be interpreted: if htmlEnabled="true", the attribute will be treated as HTML code, otherwise as a plain string. Note that the desktop implementation of the screen does not support all HTML tags.
- Label styles
-
In Web Client with a Halo-based theme, you can set predefined styles to the
Labelcomponent using thestylenameattribute either in the XML descriptor or in the screen controller:<label value="Label to be styled" stylename="colored"/>When setting a style programmatically, select one of the
HaloThemeclass constants with theLABEL_prefix:label.setStyleName(HaloTheme.LABEL_COLORED);-
bold- bolder font weight. Suitable for important/prominent UI text.
-
colored- colored text.
-
failure- failure badge style. Adds a border around the label and an icon next to the text. Suitable for UI notifications that need to be used in the direct context of some component.
-
h1- header style for main application headings.
-
h2- header style for different sections in the application.
-
h3- header style for different sub-sections in the application.
-
h4- header style for different sub-sections in the application.
-
light- lighter font weight. Suitable for additional/supplementary UI text.
-
no-margin- removes default margins from the header.
-
spinner- spinner style. Add this style name to an emptyLabelto create a spinner.
-
success- success badge style. Adds a border around the label and an icon next to the text. Suitable for UI notifications that need to be used in the direct context of some component.
-
4.5.2.1.17. Link
Link is a hyperlink, which enables uniform opening of external web resources for the Web and Desktop client.
XML-name of the component: link
An example of XML-description for link:
<link caption="Link" url="https://www.cuba-platform.com" target="_blank"/>link attributes:
-
url– the URL of the web resource.
-
target– sets the web page opening mode for the Web Client, the same as thetargetattribute of the<a>HTML element.
4.5.2.1.18. LinkButton
LinkButton is a button that looks like a hyperlink.
XML name of the component: linkButton
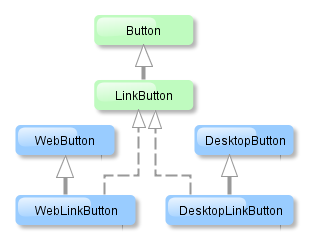
The link button component is implemented for Web Client and Desktop Client.
The link button can contain text or icon (or both). The figure below shows different types of buttons.
The link button differs from regular Button only in its appearance. All properties and behavior are identical to those described for Button.
Below is an example of XML description of a link button that invokes the someMethod() method of a controller. The link button has a caption (the caption attribute), a tooltip (the description attribute) and an icon (the icon attribute):
<linkButton id="linkButton"
caption="msg://linkButton"
description="Press me"
icon="icons/save.png"
invoke="someMethod"/>4.5.2.1.19. LookupField
This is a component to select a value from drop-down list. Drop-down list provides the filtering of values as the user inputs some text, and the pagination of available values.
XML name of the component: lookupField.
The LookupField component is implemented for Web Client and Desktop Client.
-
The simplest case of using
LookupFieldis to select an enumeration value for an entity attribute. For example, aRoleentity has atypeattribute of theRoleTypetype, which is an enumeration. Then you can useLookupFieldto edit this attribute as follows:<dsContext> <datasource id="roleDs" class="com.haulmont.cuba.security.entity.Role" view="_local"/> </dsContext> <layout> <lookupField datasource="roleDs" property="type"/>In the example above, the screen defines
roleDsdata source for theRoleentity. In thelookupFieldcomponent, a link to a data source is specified in the datasource attribute, and a name of an entity attribute is specified in the property attribute. In this case, the entity attribute is an enumeration and the drop-down list will display localized names of all enumeration values. -
Similarly,
LookupFieldcan be used to select an instance of a related entity. optionsDatasource attribute is used to create a list of options:<dsContext> <datasource id="carDs" class="com.company.sample.entity.Car" view="_local"/> <collectionDatasource id="coloursDs" class="com.company.sample.entity.Colour" view="_local"> <query>select c from sample$Colour c</query> </collectionDatasource> </dsContext> <layout> <lookupField datasource="carDs" property="colour" optionsDatasource="coloursDs"/>In this case, the component will display instance names of the
Colourentity located in thecolorsDsdata source, and the selected value will be set into thecolourattribute of theCarentity, which is located in thecarDsdata source.captionProperty attribute defines which entity attribute can be used instead of an instance name for string option names.
-
The list of component options can be specified arbitrarily using the
setOptionsList(),setOptionsMap()andsetOptionsEnum()methods, or using the XMLoptionsDatasourceattribute.
-
setOptionsList()allows you to programmatically specify a list of component options. To do this, declare a component in the XML descriptor:<lookupField id="numberOfSeatsField" datasource="modelDs" property="numberOfSeats"/>Then inject the component into the controller and specify a list of options in the
init()method:@Inject protected LookupField numberOfSeatsField; @Override public void init(Map<String, Object> params) { List<Integer> list = new ArrayList<>(); list.add(2); list.add(4); list.add(5); list.add(7); numberOfSeatsField.setOptionsList(list); }In the component’s drop-down list the values 2, 4, 5 and 7 will be displayed. Selected number will be put into the
numberOfSeatsattribute of an entity located in themodelDsdata source.
-
setOptionsMap()allows you to specify string names and option values separately. For example, in thenumberOfSeatsFieldcomponent in the XML descriptor, specify an option map ininit():@Inject protected LookupField numberOfSeatsField; @Override public void init(Map<String, Object> params) { Map<String, Object> map = new LinkedHashMap<>(); map.put("two", 2); map.put("four", 4); map.put("five", 5); map.put("seven", 7); numberOfSeatsField.setOptionsMap(map); }In the component’s drop-down list,
two,four,five,sevenstrings will be displayed. However, the value of the component will be a number that corresponds to the selected option. It will be put into thenumberOfSeatsattribute of an entity located in themodelDsdata source.
-
setOptionsEnum()takes the class of an enumeration as a parameter. The drop-down list will show localized names of enum values, the value of the component will be an enum value.
-
Each drop-down list component can have an icon on the left. Create an implementation of the
LookupField.OptionIconProviderinterface in the screen controller and set it for thelookupField:lookupField.setOptionIconProvider(new LookupField.OptionIconProvider<Customer>(){ @Override public String getItemIcon(Customer c){ if(c.getType()== LegalStatus.LEGAL) return"icons/icon-office.png"; return"icons/icon-user.png"; } });
-
Using the
filterModeattribute, option filtering type can be defined for the user input:-
NO− no filtering. -
STARTS_WITH− by the beginning of a phrase. -
CONTAINS− by any occurrence (is used by default).
-
-
If the
LookupFieldcomponent is not required and if the related entity attribute is not declared as required, the list of component options has an empty row. If this row is selected, the component returnsnull. The nullName attribute allows you to specify a row to be displayed in this case instead of an empty one. Below is an example:<lookupField datasource="carDs" property="colour" optionsDatasource="coloursDs" nullName="(none)"/>In this case, instead of an empty row,
(none)will be displayed. If this row is selected,nullwill be set to a related entity attribute.If you specify a list of options programmatically using
setOptionsList(), you can pass one of the options intosetNullOption()method. Then, if the user selects it, the component value will benull. -
The
LookupFieldcomponent is able to handle user input if there is no suitable option in the list. In this case,setNewOptionAllowed()andsetNewOptionHandler()are used. For example:@Inject protected LookupField colourField; @Inject protected CollectionDatasource<Colour, UUID> coloursDs; @Override public void init(Map<String, Object> params) { colourField.setNewOptionAllowed(true); colourField.setNewOptionHandler(new LookupField.NewOptionHandler() { @Override public void addNewOption(String caption) { Colour colour = new Colour(); colour.setName(caption); coloursDs.addItem(colour); colourField.setValue(colour); } }); }The
NewOptionHandlerhandler is invoked if the user enters a value that does not coincide with any option and presses Enter. In this case, a newColourentity instance is created in the handler, itsnameattribute is set to the value entered by the user, this instance is added to the options data source and selected in the component.Instead of implementing the
LookupField.NewOptionHandlerinterface for processing user input, the controller method name can be specified in thenewOptionHandlerXML-attribute. This method should have two parameters, one ofLookupFieldtype, and the other ofStringtype. They will be set to the component instance and the value entered by the user, accordingly. ThenewOptionAllowedattribute is used to enable adding new options instead of thesetNewOptionAllowed()method.
-
The
nullOptionVisibleXML attribute sets visibility for the null option in the drop-down list. It allows you to makeLookupFieldnot required but still without the null option.
-
The
textInputAllowedXML attribute can be used to disable filtering options from keyboard. It can be convenient for short lists. The default value istrue.
-
The
pageLengthXML attribute allows you to redefine the number of options on one page of the drop-down list, specified in the cuba.gui.lookupFieldPageLength application property. -
In Web Client with a Halo-based theme, you can set predefined styles to the
LookupFieldcomponent using thestylenameattribute either in the XML descriptor or in the screen controller:<lookupField id="lookupField" stylename="borderless"/>When setting a style programmatically, select one of the
HaloThemeclass constants with theLOOKUPFIELD_prefix:lookupField.setStyleName(HaloTheme.LOOKUPFIELD_BORDERLESS);LookupField styles:
-
align-center- align the text inside the field to center.
-
align-right- align the text inside the field to the right.
-
borderless- removes the border and background from the text field.
-
- Attributes of lookupField
-
align - caption - captionProperty - datasource - description - editable - enable - filterMode - height - icon - id - inputPrompt - newOptionAllowed - newOptionHandler - nullName - nullOptionVisible - optionsDatasource - pageLength - property - required - requiredMessage - stylename - tabIndex - textInputAllowed - visible - width
- Elements of lookupField
- Predefined styles of lookupField
- API
- Listeners of lookupField
4.5.2.1.20. LookupPickerField
The LookupPickerField component enables to display an entity instance in a text field, select an instance in a drop-down list and perform actions by pressing buttons on the right.
XML name of the component: lookupPickerField.
The component is implemented for Web Client and Desktop Client.
In fact, LookupPickerField is a hybrid of LookupField and PickerField. Thus it has the same features except the default list of actions added when determining the component in XML: for LookupPickerField these are lookup  and
and open  actions.
actions.
Below is an example of using LookupPickerField to select a value of the colour reference attribute of the Car entity:
<dsContext>
<datasource id="carDs" class="com.company.sample.entity.Car" view="_local"/>
<collectionDatasource id="coloursDs" class="com.company.sample.entity.Colour" view="_local">
<query>select c from sample$Colour c</query>
</collectionDatasource>
</dsContext>
<layout>
<lookupPickerField datasource="carDs" property="colour" optionsDatasource="coloursDs"/>- Attributes of lookupPickerField
-
align - caption - captionProperty - datasource - description - editable - enable - filterMode - height - icon - id - inputPrompt - metaClass - newOptionAllowed - newOptionHandler - nullName - optionsDatasource - pageLength - property - required - requiredMessage - stylename - tabIndex - visible - width
- Elements of lookupPickerField
- Listeners of lookupPickerField
4.5.2.1.21. MaskedField
This is a text field, in which data is entered in a predefined format. For example, it is convenient to use MaskedField to enter telephone numbers.
XML name of the component: maskedField.
The MaskedField component is implemented for Web Client only.
Basically, MaskedField repeats the functionality of TextField, except that you cannot set datatype for it. So, MaskedField is intended for work only with text and entity attributes of type String. MaskedField has the following specific attributes:
-
mask– sets a mask for the field. To set a mask, use the following characters:-
#– number -
U– uppercase letter -
L– lowercase letter -
?– letter -
А– letter or number -
*– any character -
H– uppercase hex character -
H– lowercase hex character -
~– " +" or "-" character
-
-
valueMode– defines a format of a returned value (with a mask or not) and can take eithermaskedorclear.
Example of a text field with a mask for entering telephone numbers is provided below:
<maskedField id="phoneNumberField" mask="(###)###-##-##" valueMode="masked"/>
<button caption="msg://showPhoneNumberBtn" invoke="showPhoneNumber"/>@Inject
private MaskedField phoneNumberField;
public void showPhoneNumber(){
showNotification((String) phoneNumberField.getValue(), NotificationType.HUMANIZED);
}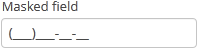

4.5.2.1.22. OptionsGroup
This is a component that allows a user to choose from a list of options. Radio buttons are used to select a single value; a group of checkboxes is used to select multiple values.
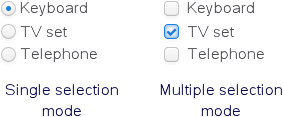
XML name of the component: optionsGroup.
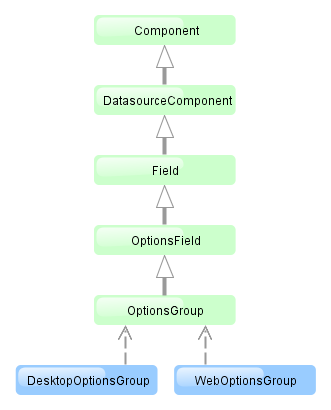
The OptionsGroup component is implemented for Web Client and Desktop Client.
-
The simplest case of using
OptionsGroupis to select an enumeration value for an entity attribute. For example, aRoleentity hastypeattribute of theRoleTypetype, which is an enumeration. Then you can useOptionsGroupto edit this attribute as follows:<dsContext> <datasource id="roleDs" class="com.haulmont.cuba.security.entity.Role" view="_local"/> </dsContext> <layout> <optionsGroup datasource="roleDs" property="type"/>In the example above
roleDsdata source is defined for theRoleentity. In theoptionsGroupcomponent, the link to the data source is specified in the datasource attribute and the name of the entity attribute is set in the property attribute.As a result, the component will be as follows:
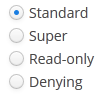
-
The list of component options can be specified arbitrarily using the
setOptionsList(),setOptionsMap()andsetOptionsEnum()methods, or using anoptionsDatasourceattribute.
-
setOptionsList()allows you to specify programmatically a list of component options. To do this, declare a component in the XML descriptor:<optionsGroup id="numberOfSeatsField"/>Then inject the component into the controller and specify a list of options in the
init()method:@Inject protected OptionsGroup numberOfSeatsField; @Override public void init(Map<String, Object> params) { List<Integer> list = new ArrayList<>(); list.add(2); list.add(4); list.add(5); list.add(7); numberOfSeatsField.setOptionsList(list); }The component will be as follows:

Depending on the selected option, the
getValue()method of the component will returnIntegervalues: 2, 4, 5, 7.
-
setOptionsMap()allows you to specify string names and option values separately. For example, we can set the following options map for thenumberOfSeatsFieldcomponent, described the XML descriptor, in theinit()method of the controller:@Inject protected OptionsGroup numberOfSeatsField; @Override public void init(Map<String, Object> params) { Map<String, Object> map = new LinkedHashMap<>(); map.put("two", 2); map.put("four", 4); map.put("five", 5); map.put("seven", 7); numberOfSeatsField.setOptionsMap(map); }The component will be as follows:
Depending on the selected option, the
getValue()method of the component will returnIntegervalues: 2, 4, 5, 7, and not the strings that are displayed on the screen.
-
setOptionsEnum()takes a class of enumeration as a parameter. The options list will consist of localized names of enum values, the value of the component will be an enum value. -
The component can take a list of options from a data source. For this purpose, the optionsDatasource attribute is used. For example:
<dsContext> <collectionDatasource id="coloursDs" class="com.company.sample.entity.Colour" view="_local"> <query>select c from sample$Colour c</query> </collectionDatasource> </dsContext> <layout> <optionsGroup id="coloursField" optionsDatasource="coloursDs"/>In this case, the
coloursFieldcomponent will display instance names of theColourentity, located in thecoloursDsdata source, and itsgetValue()method will return the selected entity instance.With the help of captionProperty attribute entity attribute to be used instead of an instance name for string option names can be defined.
-
multiselectattribute is used to switchOptionsGroupto a multiple choice mode. Ifmultiselectis turned on, the component is displayed as a group of independent checkboxes, and the component value is a list of selected options.For example, if we create the component in the XML screen descriptor:
<optionsGroup id="roleTypesField" multiselect="true"/>and set a list of options for it –
RoleTypeenumeration values:@Inject protected OptionsGroup roleTypesField; @Override public void init(Map<String, Object> params) { roleTypesField.setOptionsList(Arrays.asList(RoleType.values())); }then the component will be as follows:
In this case the
getValue()method of the component will return ajava.util.List, containingRoleType.READONLYandRoleType.DENYINGvalues.The example above also illustrates an ability of the
OptionsGroupcomponent to display localized values of enumerations included in the data model.
-
The
orientationattribute defines the orientation of group elements. By default, elements are arranged vertically. Thehorizontalvalue sets the horizontal orientation.
- Attributes of optionsGroup
-
align - caption - captionProperty - datasource - description - editable - enable - icon - id - multiselect - height - optionsDatasource - orientation - property - required - requiredMessage - stylename - tabIndex - visible - width
- Elements of optionsGroup
- API
- Listeners of optionsGroup
4.5.2.1.23. OptionsList
OptionsList is a variation of the OptionsGroup component which represents the list of options as a vertical scrollable list. If multi-select is enabled, multiple items can be selected by holding the Ctrl key while clicking, or as a range by holding the Shift key.
XML name of the component: optionsList.
The OptionsList component is implemented for Web Client.
By default the OptionsList component displays the first null element in suggestion popup, this can be disabled with the help of nullOptionVisible attribute set to false.
The only difference in API between OptionsList and OptionsGroup is that OptionsList has no orientation attribute.
- Attributes of optionsList
-
align - caption - captionProperty - datasource - description - editable - enable - height - icon - id - multiselect - nullOptionVisible - optionsDatasource - property - required - requiredMessage - stylename - tabIndex - visible - width
- Elements of optionsList
- Listeners of optionsList
4.5.2.1.24. PasswordField
This is a text field that displays echo characters instead of those entered by a user.
XML name of the component: passwordField.
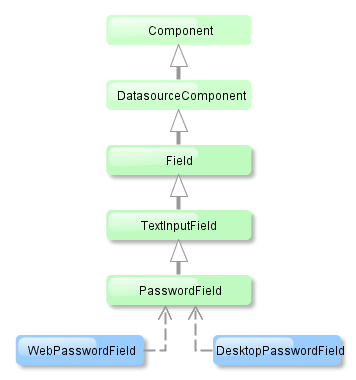
PasswordField is implemented for Web Client and Desktop Client.
Basically, PasswordField is similar to TextField apart from the ability to set datatype. PasswordField is intended to work with text and entity attributes of type String only.
Example:
<passwordField id="passwordField" caption="msg://name"/>
<button caption="msg://buttonsName" invoke="showPassword"/>@Inject
private PasswordField passwordField;
public void showPassword(){
showNotification((String) passwordField.getValue(), NotificationType.HUMANIZED);
}
The autocomplete attribute allows you to enable saving passwords in the web browser. It is disabled by default.
- Attributes of passwordField
-
align - autocomplete - caption - datasource - description - editable - enable - height - icon - id - maxLength - property - required - requiredMessage - stylename - tabIndex - visible - width
- Elements of passwordField
- Listeners of passwordField
4.5.2.1.25. PickerField
PickerField displays an entity instance in a text field and performs actions when a user clicks buttons on the right.

XML name of the component: pickerField.
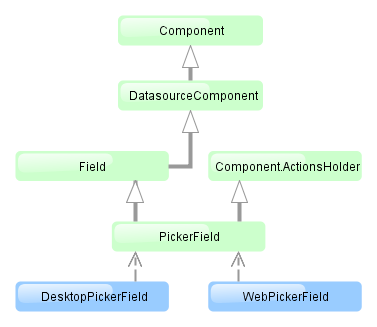
The PickerField component is implemented for Web Client and Desktop Client.
-
As a rule,
PickerFieldis used for working with reference entity attributes. It is sufficient to specify datasource and property attributes for the component:<dsContext> <datasource id="carDs" class="com.company.sample.entity.Car" view="_local"/> </dsContext> <layout> <pickerField datasource="carDs" property="colour"/>In the example above, the screen defines
carDsdata source for aCarentity having thecolourattribute. In thepickerFieldelement, a link to a data source is specified in thedatasourceattribute, and a name of an entity attribute is set in thepropertyattribute. The entity attribute should refer to another entity, in the example above it isColour.
-
For
PickerField, you can define an arbitrary number of actions, displayed as buttons on the right.It can be done either in the XML descriptor using the
actionsnested element, or programmatically in the controller usingaddAction().-
There are standard actions, defined by the
PickerField.ActionType:lookup,clear,open. They perform the selection of a related entity, clearing the field and opening the edit screen for a selected related entity, respectively. When declaring standard actions in XML, you do not have to define any attributes except the identifier. If no actions in theactionselement are defined when declaring the component, the XML loader will definelookupandclearactions for it. To add a default action, for example,open, you need to define theactionselement as follows:<pickerField datasource="carDs" property="colour"> <actions> <action id="lookup"/> <action id="open"/> <action id="clear"/> </actions> </pickerField>The
actionelement does not extend but overrides a set of standard actions. Identifiers of all required actions have to be defined explicitly. The component looks as follows:
Use
addLookupAction(),addOpenAction()andaddClearAction()to set standard actions programmatically. If the component is defined in the XML descriptor withoutactionsnested element, it is sufficient to add missing actions:@Inject protected PickerField colourField; @Override public void init(Map<String, Object> params) { colourField.addOpenAction(); }If the component is created in the controller, it will get no default actions and you need to explicitly add all necessary actions:
@Inject protected ComponentsFactory componentsFactory; @Override public void init(Map<String, Object> params) { PickerField colourField = componentsFactory.createComponent(PickerField.NAME); colourField.setDatasource(carDs, "colour"); colourField.addLookupAction(); colourField.addOpenAction(); colourField.addClearAction(); }You can parameterize standard actions. The XML descriptor has limited abilities to do this: there is only
openTypeattribute, in which you can specify the mode to open a selection screen (forLookupAction) or edit screen (forOpenAction).If you create actions programmatically, you can specify any properties of
PickerField.LookupAction,PickerField.OpenActionandPickerField.ClearActionobjects returned by methods of adding standard actions. For example, you can set a specific lookup screen as follows:PickerField.LookupAction lookupAction = customerField.addLookupAction(); lookupAction.setLookupScreen("customerLookupScreen");For more information, see JavaDocs for standard actions classes.
-
Arbitrary actions in the XML descriptor are also defined in the
actionsnested element, for example:<pickerField datasource="carDs" property="colour"> <actions> <action id="lookup"/> <action id="show" icon="icons/show.png" invoke="showColour" caption=""/> </actions> </pickerField>You can programmatically set an arbitrary action as follows:
@Inject protected PickerField colourField; @Override public void init(Map<String, Object> params) { colourField.addAction(new AbstractAction("show") { @Override public void actionPerform(Component component) { showColour(colourField.getValue()); } @Override public String getCaption() { return ""; } @Override public String getIcon() { return "icons/show.png"; } }); }The declarative and programmatic creation of actions is described in Actions. The Action Interface section.
-
-
PickerFieldcan be used without binding to entities, i.e., without setting datasource and property. In this case,metaClassattribute should be used to specify an entity type forPickerField. For example:<pickerField id="colourField" metaClass="sample$Colour"/>You can get an instance of a selected entity by injecting the component into a controller and invoking its
getValue()method.WarningFor proper operation of the
PickerFieldcomponent you need either set ametaClassattribute, or simultaneously set datasource and property attributes. -
You can use keyboard shortcuts in PickerField, see Keyboard Shortcuts for details.
- Attributes of pickerField
-
align - caption - captionProperty - datasource - description - editable - enable - height - icon - id - metaClass - property - required - requiredMessage - stylename - tabIndex - visible - width
- Elements of pickerField
- API
-
addAction - addClearAction - addLookupAction - addOpenAction - setLookupScreen
- Listeners of pickerField
4.5.2.1.26. PopupButton
This is a button with a drop-down list of actions.
XML name of the component: popupButton.
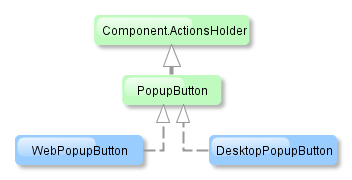
The component is implemented for Web Client and Desktop Client.
PopupButton can contain text or icon (or both). The figure below shows different types of buttons.
Below is an example of a button with a drop-down list containing two actions.
<popupButton id="popupButton" caption="msg://popupButton" description="Press me">
<actions>
<action id="popupAction1" caption="msg://action1" invoke="someAction1"/>
<action id="popupAction2" caption="msg://action2" invoke="someAction2"/>
</actions>
</popupButton>The button has a caption, which is specified using the caption attribute, and a tooltip defined in the description attribute. The drop-down actions list is specified in the actions element. PopupButton displays only the following action properties: caption, enable, visible. The description and shortcut properties are ignored. Handling of the icon property depends on the cuba.gui.showIconsForPopupMenuActions application property and the showActionIcons attribute of the component. The latter has priority.
4.5.2.1.27. PopupView
PopupView is a component that allows you to open a popup with a container. The popup can be opened by clicking on minimized value or programmatically. It can be closed by mouse out or by clicking on outside area.
A typical PopupView with hidden and visible popup is shown below:

Figure 18. Popup hidden
Figure 19. Popup visible
The component is implemented for Web Client.
An example of a PopupView with minimized value retrieved from a localized message pack:
<popupView id="popupView"
minimizedValue="msg://minimizedValue"
caption="PopupView caption">
<vbox width="60px" height="40px">
<label value="Content" align="MIDDLE_CENTER"/>
</vbox>
</popupView>The inner content of the PopupView should be a container, for example BoxLayout.
PopupView methods:
-
setPopupVisible()allows you to open popup window programmatically.@Inject private PopupView popupView; @Override public void init(Map<String, Object> params) { popupView.setPopupVisible(true); } -
setMinimizedValue()allows you to set a minimized value programmatically.@Inject private PopupView popupView; @Override public void init(Map<String, Object> params) { popupView.setMinimizedValue("Hello world!"); }
-
addPopupVisibilityListener(PopupVisibilityListener listener)allows you to listen to the popup window visibility changes.@Inject private PopupView popupView; @Override public void init(Map<String, Object> params) { popupView.addPopupVisibilityListener(event -> showNotification(event.isPopupVisible() ? "The popup is visible" : "The popup is hidden", NotificationType.HUMANIZED)); }
PopupView attributes:
-
minimizedValueattribute defines the text of popup button.
-
If the
hideOnMouseOutattribute is set tofalse, popup container will close after click on outside area.
-
captionAsHtmlattribute allows to use HTML tags in caption of component.
- Attributes of popupView
-
caption - captionAsHtml - description - height - hideOnMouseOut - icon - id - minimizedValue - stylename - visible - width
- Listeners of popupView
4.5.2.1.28. ProgressBar
The ProgressBar component is designed to display the progress of a long process.

XML name of the component: progressBar
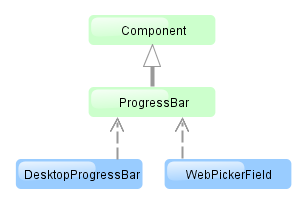
The component is implemented for Web Client and Desktop Client.
Below is an example of the component usage together with the background tasks mechanism:
<progressBar id="progressBar" width="100%"/>@Inject
protected ProgressBar progressBar;
@Inject
protected BackgroundWorker backgroundWorker;
private static final int ITERATIONS = 5;
@Override
public void init(Map<String, Object> params) {
BackgroundTask<Integer, Void> task = new BackgroundTask<Integer, Void>(300, this) {
@Override
public Void run(TaskLifeCycle<Integer> taskLifeCycle) throws Exception {
for (int i = 1; i <= ITERATIONS; i++) {
TimeUnit.SECONDS.sleep(2); // time consuming task
taskLifeCycle.publish(i);
}
return null;
}
@Override
public void progress(List<Integer> changes) {
float lastValue = changes.get(changes.size() - 1);
progressBar.setValue(lastValue / ITERATIONS);
}
};
BackgroundTaskHandler taskHandler = backgroundWorker.handle(task);
taskHandler.execute();
}Here in the BackgroundTask.progress() method, which is executed in UI thread, the ProgressBar component is set to the current value. The component value should be a float number from 0.0 to 1.0.
The changes of the ProgressBar value can be tracked using the ValueChangeListener.
If a running process is unable to send information about the progress, an indeterminate state of the indicator can be displayed. Set the indeterminate to true to show an indeterminate state. Default is false. For example:
<progressBar id="progressBar" width="100%" indeterminate="true"/>By default indeterminate progress bar is displayed as horizontal bar. To make it a spinning wheel instead, set the attribute stylename="indeterminate-circle".
To make the progress bar indicator appear as a dot which progresses over the progress bar track (instead of a growing bar), use the point predefined style:
progressBar.setStyleName(HaloTheme.PROGRESSBAR_POINT);4.5.2.1.29. RelatedEntities
RelatedEntities component is a popup button with a drop-down list of classes related to the entity displayed in a table. Once the user selects the required entity class, a new browser screen is opened, containing the instances of this entity class, related to the entity instances selected in the initial table.
The XML-name of the component: relatedEntities
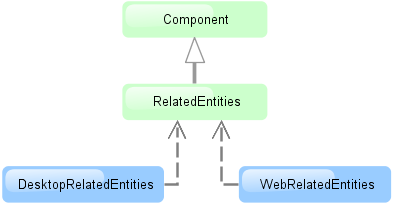
The component is implemented for Web Client and Desktop Client.
Related entities are selected considering the user permissions for entities, entity attributes and screens.
By default, the browser screen for the class selected in the drop-down is defined by convention ({entity_name}.browse,{entity_name}.lookup). Optionally, you can define the screen explicitly in the component.
A filter selecting records related to the selected entities is dynamically created in the browser window.
Example of using the component in screen XML-descriptor:
<table id="invoiceTable"
multiselect="true"
width="100%">
<actions>
<action id="create"/>
<action id="edit"/>
<action id="remove"/>
</actions>
<buttonsPanel id="buttonsPanel">
<button id="createBtn"
action="invoiceTable.create"/>
<button id="editBtn"
action="invoiceTable.edit"/>
<button id="removeBtn"
action="invoiceTable.remove"/>
<relatedEntities for="invoiceTable"
openType="NEW_TAB">
<property name="invoiceItems"
screen="sales$InvoiceItem.lookup"
filterCaption="msg://invoiceItems"/>
</relatedEntities>
</buttonsPanel>The for attribute is required. It contains the table identifier.
The openType="NEW_TAB" attribute sets the opening mode of the lookup windows to new tab. The entity browser is opened in the current tab by default.
The property element enables explicitly defining the related entity displayed in the drop-down.
property attributes:
-
name– the current entity attribute name, referencing the related entity.
-
screen– the identifier of the browser screen that should be opened.
-
filterCaption– the name of the dynamically generated filter.
The exclude attribute enables excluding some of the related entities from the drop-down list. The value of the property is a regular expression matching reference attributes to exclude.
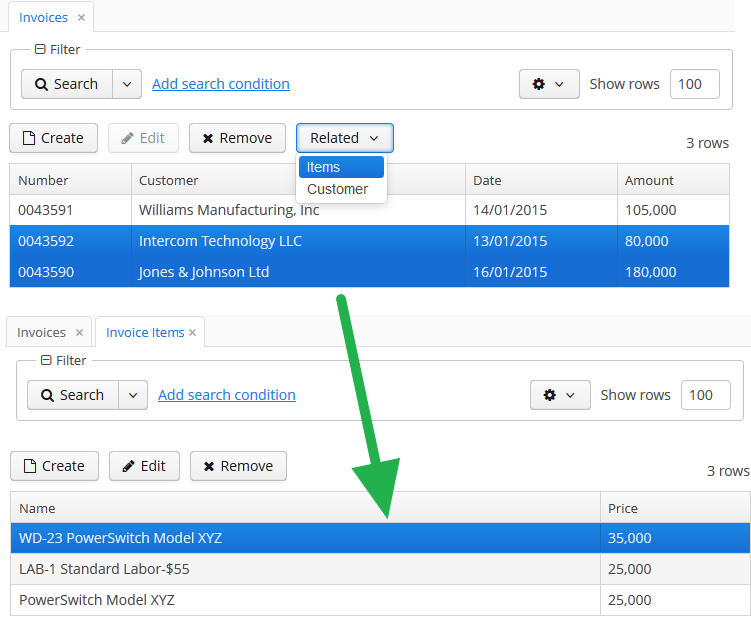
The platform provides an API for opening related entities screens without the RelatedEntities component: the RelatedEntitiesAPI interface and its implementation RelatedEntitiesBean. The logic is defined with the openRelatedScreen() method which takes the collection of entities from one side of relation, MetaClass of single entity from this collection, and a chosen field to find related entities.
<button id="related"
caption="Related customer"
invoke="onRelatedClick"/>import com.company.sales.entity.Order;
import com.haulmont.cuba.gui.components.AbstractLookup;
import com.haulmont.cuba.gui.components.Table;
import com.haulmont.cuba.gui.relatedentities.RelatedEntitiesAPI;
import javax.inject.Inject;
public class OrderBrowse extends AbstractLookup {
@Inject
private RelatedEntitiesAPI relatedEntitiesAPI;
@Inject
private Table<Order> ordersTable;
public void onRelatedClick() {
relatedEntitiesAPI.openRelatedScreen(ordersTable.getSelected(),
Order.class, "customer");
}
}By default, the standard entity browser screen is opened. Optionally you can add a RelatedScreenDescriptor parameter to make the method open another screen or open it with parameters. The RelatedScreenDescriptor is a POJO which can store the screen identifier (String), open type (WindowManager.OpenType), filter caption (String), and screen params (Map<String, Object>).
relatedEntitiesAPI.openRelatedScreen(ordersTable.getSelected(),
Order.class, "customer",
new RelatedScreenDescriptor("sales$Customer.lookup", OpenType.DIALOG));4.5.2.1.30. RichTextArea
This is a text area to display and enter formatted text.
XML name of the component: richTextArea
RichTextArea is implemented only for Web Client.
Basically, RichTextArea mirrors the functionality of TextField, except that you cannot set datatype for it. So, RichTextArea is intended for work only with text and entity attributes of type String.
4.5.2.1.31. SearchPickerField
The SearchPickerField component is used to search for entity instances according to the entered string. A user should enter a few characters and press Enter. If several matches have been found, all of them will be displayed in a drop-down list. If only one instance matches the search query, it immediately becomes a component value. SearchPickerField also enables performing actions by clicking on buttons on the right.
See also SuggestionPickerField.
XML name of the component: searchPickerField.
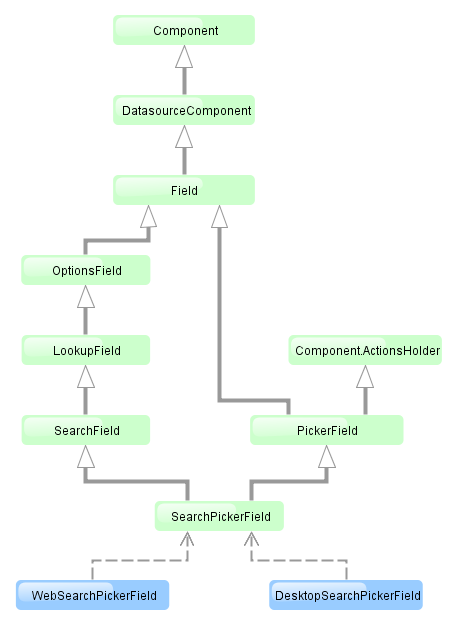
The component is implemented for Web Client and Desktop Client.
-
To use
SearchPickerFieldcomponent, you need to create collectionDatasource and specify a query, which contains corresponding search conditions. Condition must contain a parameter namedcustom$searchString. This parameter will be populated with a substring entered by the user. A data source with a search condition should be defined in the optionsDatasource attribute of the component. For example:<dsContext> <datasource id="carDs" class="com.company.sample.entity.Car" view="_local"/> <collectionDatasource id="coloursDs" class="com.company.sample.entity.Colour" view="_local"> <query> select c from sample$Colour c where c.name like :(?i)custom$searchString </query> </collectionDatasource> </dsContext> <layout> <searchPickerField datasource="carDs" property="colour" optionsDatasource="coloursDs"/>In this case, the component will look for instances of
Colourentity according to the occurrence of the substring in itsnameattribute. The(?i)prefix is used for case-insensitive search (see Case-Insensitive Search for a Substring). The selected value will be set in thecolourattribute of theCarentity located in thecarDsdatasource.The
escapeValueForLikeattribute set totrueenables searching for the values that contain special symbols%,\, and_using like-clauses. In order to useescapeValueForLike = true, modify the query of the collection data source adding the escape value to it:select c from ref$Colour c where c.name like :(?i)custom$searchString or c.description like :(?i)custom$searchString escape '\'The
escapeValueForLikeattribute works for all databases except HSQLDB.
-
Using the
minSearchStringLengthattribute the minimum number of characters, which the user should enter to search for values, can be defined. -
In the screen controller, two component methods can be implemented that will be invoked:
-
If the number of entered characters is less than the value of
minSearchStringLengthattribute. -
If the search of characters entered by the user has returned no results.
Below is an example of implementing methods to display messages to the user:
@Inject private SearchPickerField colourField; @Override public void init(Map<String, Object> params) { colourField.setSearchNotifications(new SearchField.SearchNotifications() { @Override public void notFoundSuggestions(String filterString) { showNotification("No colours found for search string: " + filterString, NotificationType.TRAY); } @Override public void needMinSearchStringLength(String filterString, int minSearchStringLength) { showNotification("Minimum length of search string is " + minSearchStringLength, NotificationType.TRAY); } }); } -
-
SearchPickerFieldimplements LookupField and PickerField interfaces. Thus, it inherits the same functionality except the default list of actions added when defining the component in XML: forSearchPickerFieldthese arelookup and open actions.
- Attributes of searchPickerField
-
align - caption - captionProperty - datasource - description - editable - enable - escapeValueForLike - filterMode - height - icon - id - inputPrompt - metaClass - minSearchStringLength - newOptionAllowed - newOptionHandler - nullName - optionsDatasource - property - required - requiredMessage - stylename - tabIndex - visible - width
- Elements of searchPickerField
- Listeners of searchPickerField
4.5.2.1.32. SideMenu
SideMenu component provides means of customizing the main window layout, managing menu items, adding icons and badges and applying custom styles.

XML name of the component: sideMenu.
An example of component definition in an XML-descriptor of a screen:
<main:sideMenu id="sideMenu"
width="100%"
selectOnClick="true"/>CUBA Studio provides the screen template for main window with the sideMenu component and predefined styles within the side panel:
<layout>
<hbox id="horizontalWrap"
expand="workArea"
height="100%"
stylename="c-sidemenu-layout"
width="100%">
<vbox id="sideMenuPanel"
expand="sideMenu"
height="100%"
margin="false,false,true,false"
spacing="true"
stylename="c-sidemenu-panel"
width="250px">
<hbox id="appTitleBox"
spacing="true"
stylename="c-sidemenu-title"
width="100%">
<label id="appTitleLabel"
align="MIDDLE_CENTER"
value="mainMsg://application.logoLabel"/>
</hbox>
<embedded id="logoImage"
align="MIDDLE_CENTER"
stylename="c-app-icon"
type="IMAGE"/>
<hbox id="userInfoBox"
align="MIDDLE_CENTER"
expand="userIndicator"
margin="true"
spacing="true"
width="100%">
<main:userIndicator id="userIndicator"
align="MIDDLE_CENTER"/>
<main:newWindowButton id="newWindowButton"
description="mainMsg://newWindowBtnDescription"
icon="app/images/new-window.png"/>
<main:logoutButton id="logoutButton"
description="mainMsg://logoutBtnDescription"
icon="app/images/exit.png"/>
</hbox>
<main:sideMenu id="sideMenu"
width="100%"/>
<main:ftsField id="ftsField"
width="100%"/>
</vbox>
<main:workArea id="workArea"
height="100%">
<main:initialLayout margin="true"
spacing="true">
<label id="welcomeLabel"
align="MIDDLE_CENTER"
stylename="c-welcome-text"
value="mainMsg://application.welcomeText"/>
</main:initialLayout>
</main:workArea>
</hbox>
</layout>sideMenu attributes:
-
The
selectOnClickattribute, when set totrue, highlights the selected menu item on mouse click. The default value isfalse.
Methods of the SideMenu interface:
-
createMenuItem- creates new menu item, but does not add this item to menu.Idmust be unique for whole menu.
-
addMenuItem- adds menu item to the menu.
-
removeMenuItem- removes menu item from the items list. -
getMenuItem- returns menu item from the menu tree by itsid. -
hasMenuItems- returnstrueif the menu has items.
SideMenu component is used to display menu items. The MenuItem API enables creating menu items in the screen controller. The methods below can be used for dynamic update of menu items depending on the application business logic. The example of adding a menu item programmatically:
SideMenu.MenuItem item = sideMenu.createMenuItem("special");
item.setCaption("Daily offer");
item.setBadgeText("New");
item.setIcon("font-icon:GIFT");
sideMenu.addMenuItem(item,0);
Methods of the MenuItem interface:
-
setCaption- sets item caption.
-
setCaptionAsHtml- enables or disables HTML mode for caption.
-
setBadgeText- sets badge text for the item. Badges are shown as small widget on the right side of menu items, for example:int count = 5; SideMenu.MenuItem item = sideMenu.createMenuItem("count"); item.setCaption("Messages"); item.setBadgeText(count + " new"); item.setIcon("font-icon:ENVELOPE"); sideMenu.addMenuItem(item,0);
The badge text can be dynamically updated with the help of the Timer component:
public void updateCounters(Timer source) { sideMenu.getMenuItemNN("sales") .setBadgeText(String.valueOf(LocalTime.MIDNIGHT.minusSeconds(timerCounter-source.getDelay()))); timerCounter++; }
-
setIcon- sets menu icon.
-
setCommand- sets item command, or the action to be performed on this menu item click.
-
addChildItem/removeChildItem- adds/removes menu item to the children list.
-
setExpanded- expands or collapses sub-menu with children by default.
-
setStyleName- sets one or more user-defined style names of the component, replacing any previous user-defined styles. Multiple styles can be specified as a space-separated list of style names. The style names must be valid CSS class names.The standard
sideMenutemplate includes several predefined styles:c-sidemenu-layout,c-sidemenu-panelandc-sidemenu-title. The defaultc-sidemenustyle is supported only within theHalotheme or its extensions. TheHavanatheme does not supportsideMenustyling.
-
setTestId- setscuba-idvalue for UI testing.
- Attributes of sideMenu
-
align - caption - description - enable - height - icon - id - selectOnClick - stylename - tabIndex - visible - width
- Attributes of ftsfield
-
align - caption - description - enable - height - icon - id - stylename - visible - width
- API of sideMenu
- API of menuItem
-
addChildItem - removeChildItem - setBadgeText - setCaption - setCaptionAsHtml - setCommand - setExpanded - setIcon - setStyleName - setTestId
4.5.2.1.33. SourceCodeEditor
SourceCodeEditor is designed to display and enter source code. It is a multi-line text area featured with code highlighting and optional print margin and gutter with line numbers.
XML-name of the component: sourceCodeEditor.
SourceCodeEditor is implemented for Web Client.
Basically, SourceCodeEditor mostly replicates the functionality of the TextField component and has the following specific attributes:
-
if
handleTabKeyistrue, the Tab button on the keyboard is handled to indent lines, whenfalse, it is used to advance the cursor or focus to the next tab stop. This attribute should be set when the screen is initialized and will not work if changed at a runtime.
All following properties can be easily changed at a runtime:
-
highlightActiveLineis used to highlight the line the caret is on.
-
modeprovides the list of languages supported for the syntax highlight. This list is defined in theModeenumeration of theSourceCodeEditorinterface and includes the following languages: Java, HTML, XML, Groovy, SQL, JavaScript, Properties, and Text with no highlight.
-
printMarginattribute sets if the printing edge line should be displayed or hidden.
-
showGutteris used to hide or show the left gutter with line numbers.
Below is an example of SourceCodeEditor component adjustable at a runtime.
XML-descriptor:
<hbox spacing="true">
<checkBox id="highlightActiveLineCheck" align="BOTTOM_LEFT" caption="Highlight Active Line"/>
<checkBox id="printMarginCheck" align="BOTTOM_LEFT" caption="Print Margin"/>
<checkBox id="showGutterCheck" align="BOTTOM_LEFT" caption="Show Gutter"/>
<lookupField id="modeField" align="BOTTOM_LEFT" caption="Mode" required="true"/>
</hbox>
<sourceCodeEditor id="simpleCodeEditor" width="100%"/>The controller:
@Inject
private LookupField modeField;
@Inject
private SourceCodeEditor simpleCodeEditor;
@Inject
private CheckBox highlightActiveLineCheck;
@Inject
private CheckBox printMarginCheck;
@Inject
private CheckBox showGutterCheck;
@Override
public void init(Map<String, Object> params) {
highlightActiveLineCheck.setValue(simpleCodeEditor.isHighlightActiveLine());
highlightActiveLineCheck.addValueChangeListener(e -> simpleCodeEditor.setHighlightActiveLine(Boolean.TRUE.equals(e.getValue())));
printMarginCheck.setValue(simpleCodeEditor.isShowPrintMargin());
printMarginCheck.addValueChangeListener(e -> simpleCodeEditor.setShowPrintMargin(Boolean.TRUE.equals(e.getValue())));
showGutterCheck.setValue(simpleCodeEditor.isShowGutter());
showGutterCheck.addValueChangeListener(e -> simpleCodeEditor.setShowGutter(Boolean.TRUE.equals(e.getValue())));
Map<String, Object> modes = new HashMap<>();
for (SourceCodeEditor.Mode mode : SourceCodeEditor.Mode.values()) {
modes.put(mode.toString(), mode);
}
modeField.setOptionsMap(modes);
modeField.setValue(SourceCodeEditor.Mode.Text);
modeField.addValueChangeListener(e -> simpleCodeEditor.setMode((SourceCodeEditor.Mode) e.getValue()));
}The result will be:
SourceCodeEditor can also support code autocomplete provided by the Suggester class. To activate word completion, the setSuggester method should be invoked, for example:
@Inject
private SourceCodeEditor suggesterCodeEditor;
@Inject
private CollectionDatasource<User, UUID> usersDs;
@Override
public void init(Map<String, Object> params) {
suggesterCodeEditor.setSuggester((source, text, cursorPosition) -> {
List<Suggestion> suggestions = new ArrayList<>();
usersDs.refresh();
for (User user : usersDs.getItems()) {
suggestions.add(new Suggestion(source, user.getLogin(), user.getName(), null, -1, -1));
}
return suggestions;
});
}The result:
- Attributes of sourceCodeEditor
-
align - caption - colspan - datasource - description - editable - enable - handleTabKey - height - highlightActiveLine - icon - id - mode - printMargin - property - required - requiredMessage - rowspan - showGutter - stylename - tabIndex - visible - width
- Listeners of sourceCodeEditor
4.5.2.1.34. SuggestionPickerField
The SuggestionPickerField component is designed to search for entity instances according to a string entered by a user. It differs from SearchPickerField in that it refreshes the list of options on each entered symbol without the need to press Enter. The list of options is loaded in background according to the logic defined by the application developer on the server side.
SuggestionPickerField is also a PickerField and can contain actions represented by buttons on the right.
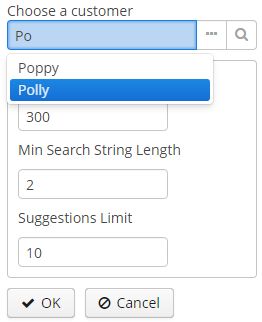
XML name of the component: suggestionPickerField.
The component is implemented for the Web Client.
SuggestionPickerField is used to select reference entity attributes, so you usually set its datasource and property attributes:
<dsContext>
<datasource id="orderDs"
class="com.company.sample.entity.Order"
view="order-view"/>
</dsContext>
<layout>
<suggestionPickerField id="suggestionPickerField"
captionProperty="name"
datasource="orderDs"
property="customer"/>
</layout>suggestionPickerField attributes:
-
asyncSearchDelayMs- sets the delay between the last key press action and asynchronous search.
-
metaClass- sets the link to the component’sMetaClassif the component is used without binding to a datasource, i.e., without setting datasource and property.
-
minSearchStringLength- sets the minimal string length which is required to perform suggestions search.
-
suggestionsLimit- sets the limit of suggestions to be displayed.
- Base SuggestionPickerField usage
-
In the most common case, it is sufficient to set
SearchExecutorto the component.SearchExecutoris a functional interface that contains a single method:List<E extends Entity> search(String searchString, Map<String, Object> searchParams):suggestionPickerField.setSearchExecutor((searchString, searchParams) -> { return Arrays.asList(entity1, entity2, ...); });WarningThe
search()method is executed in a background thread so it cannot access visual components or datasources used by visual components. Call DataManager or a middleware service directly; or process and return data loaded to the screen beforehand.The
searchStringparameter can be used to filter candidates using the string entered by the user:public class OrderEdit extends AbstractEditor<Order> { @Inject private SuggestionPickerField suggestionPickerField; @Inject private DataManager dataManager; @Override public void init(Map<String, Object> params) { suggestionPickerField.setSearchExecutor((searchString, searchParams) -> dataManager.loadList(LoadContext.create(Customer.class).setQuery( LoadContext.createQuery("select c from sample$Customer c where c.name like :name order by c.name") .setParameter("name", "%" + searchParams + "%")))); } } - ParametrizedSearchExecutor usage
-
In the previous examples,
searchParamsis an empty map. To define params, you should useParametrizedSearchExecutor:suggestionPickerField.setSearchExecutor(new SuggestionField.ParametrizedSearchExecutor<Customer>(){ @Override public Map<String, Object> getParams() { return ParamsMap.of(...); } @Override public List<Customer> search(String searchString, Map<String, Object> searchParams) { return executeSearch(searchString, searchParams); } }); - EnterActionHandler and ArrowDownActionHandler usage
-
Another way to use the component is to set
EnterActionHandlerorArrowDownActionHandler. These listeners are fired when a user presses Enter or Arrow Down keys when the popup with suggestions is hidden. They are also functional interfaces with single method and single parameter -currentSearchString. You can set up your own action handlers and useSuggestionField.showSuggestions()method which accepts the list of entities to show suggestions.suggestionPickerField.setArrowDownActionHandler(currentSearchString -> { List<Customer> suggestions = findSuggestions(); suggestionPickerField.showSuggestions(suggestions); }); suggestionPickerField.setEnterActionHandler(currentSearchString -> { List<Customer> suggestions = getDefaultSuggestions(); suggestionPickerField.showSuggestions(suggestions); });
- Attributes of suggestionPickerField
-
align - asyncSearchDelayMs - caption - captionProperty - colspan - datasource - description - editable - enable - height - icon - id - metaClass - minSearchStringLength - property - required - requiredMessage - responsive - rowspan - stylename - suggestionsLimit - tabIndex - visible - width
- Listeners of suggestionPickerField
4.5.2.1.35. Table
The Table component presents information in a table view, sorts data, manages table columns and headers and invokes actions for selected rows.
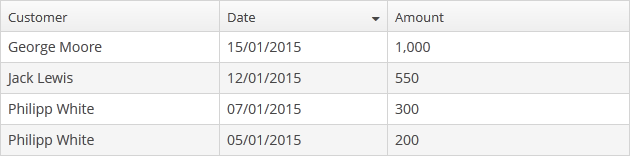
XML-name of the component: table
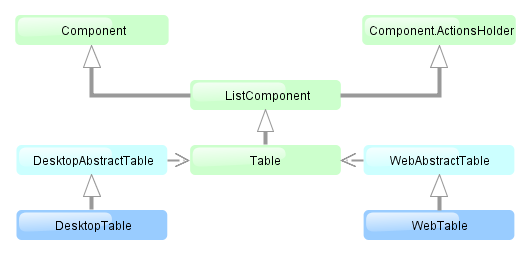
The component is implemented for both Web Client and Desktop Client.
An example of component definition in an XML-descriptor of a screen:
<dsContext>
<collectionDatasource id="ordersDs"
class="com.sample.sales.entity.Order"
view="orderWithCustomer">
<query>
select o from sales$Order o order by o.date
</query>
</collectionDatasource>
</dsContext>
<layout>
<table id="ordersTable" width="300px">
<columns>
<column id="date"/>
<column id="customer.name"/>
<column id="amount"/>
</columns>
<rows datasource="ordersDs"/>
</table>In the example the dsContext element defines collectionDatasource, which selects Order entities using JPQL query. The rows element defines the data source, while columns element defines which entity attributes are used as table columns.
table elements:
-
rows– a required element; itsdatasourceattribute defines the data source to be used by the table.Each row can have an icon in an additional column on the left. Create an implementation of the
ListComponent.IconProviderinterface in the screen controller and set it for the table:@Inject private Table<Customer> table; @Override public void init(Map<String, Object> params) { table.setIconProvider(new ListComponent.IconProvider<Customer>() { @Nullable @Override public String getItemIcon(Customer entity) { CustomerGrade grade = entity.getGrade(); switch (grade) { case PREMIUM: return "icons/premium_grade.png"; case HIGH: return "icons/high_grade.png"; case MEDIUM: return "icons/medium_grade.png"; default: return null; } } }); }
-
columns– a required element defining the set of columns for a table.Each column is described in a nested
columnelement with the following attributes:-
id− a mandatory attribute, contains the name of an entity attribute displayed in the column. Can be either an attribute of the entity from the data source or a linked entity – object graph traversal is indicated with a dot. For example:<columns> <column id="date"/> <column id="customer"/> <column id="customer.name"/> <column id="customer.address.country"/> </columns>
-
caption− an optional attribute containing the column caption. If not specified, a localized attribute name will be displayed.
-
collapsed− an optional attribute; hides the column by default when set totrue. Users can control column’s visibility using the menu available via a button in the top right part of the table when the table’s
button in the top right part of the table when the table’s columnControlVisibleattribute is notfalse. By default,collapsedisfalse.
-
width− an optional attribute controlling default column width. May contain only numeric values in pixels.
-
align− an optional attribute that sets text alignment of column cells. Possible values:LEFT,RIGHT,CENTER. Default isLEFT.
-
editable− an optional attribute allowing editing of the corresponding column in the table. In order for a column to be editable, the editable attribute of the entire table should be set totrueas well.
-
sortable− an optional attribute to disable sorting of the column. Takes effect if the whole table has sortable attribute set totrue(which is by default).
-
maxTextLength– an optional attribute allowing to limit the number of characters in a cell. If the difference between the actual and the maximum allowed number of characters does not exceed the 10 character threshold, the "extra" characters remain unhidden. To see the entire record, users need to click on its visible part. An example of a column with a 5 character limitation: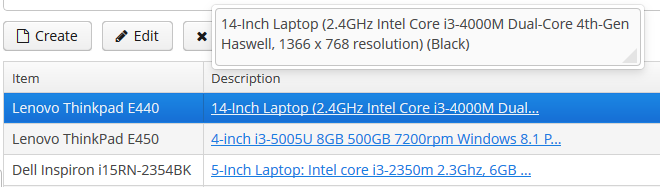
-
link- if set totrue, enables displaying a link to an entity editor in a table column (supported for Web Client only). Thelinkattribute may be set to true for primitive type columns, too; in this case, the main entity editor will be opened. This approach may be used to simplify navigation: the users will be able to open entity editors simply by clicking on some key attributes.
-
linkScreen- contains the identifier of the screen that is opened by clicking the link enabled in thelinkattribute.
-
linkScreenOpenType- sets the screen opening mode (THIS_TAB,NEW_TABorDIALOG).
-
linkInvoke- invokes the controller method instead of opening the screen.public void linkedMethod(Entity item, String columnId) { Customer customer = (Customer) item; showNotification(customer.getName()); }
-
captionProperty- the name of an entity attribute which should be shown in the column instead of specified by id. For example, if you have a reference to thePriorityentity with thenameandorderNoattributes, you can define the following column:<column id="priority.orderNo" captionProperty="priority.name" caption="msg://priority" />In this case, the column will display the priority name, but the sorting of the column will be done by the priority order.
-
an optional
generatorattribute contains the link to a method in the screen controller that creates a visual component to be shown in table cells:<columns> <column id="name"/> <column id="imageFile" generator="generateImageFileCell"/> </columns>public Component generateImageFileCell(Employee entity) { Embedded embedded = componentsFactory.createComponent(Embedded.class); embedded.setType(Embedded.Type.IMAGE); FileDescriptor userImageFile = entity.getImageFile(); FileDataProvider dataProvider = new FileDataProvider(userImageFile); embedded.setSource(userImageFile.getId() + "." + userImageFile.getExtension(), dataProvider); return embedded; }It can be used instead of providing an implementation of
Table.ColumnGeneratorto the addGeneratedColumn() method. -
columnelement may contain a nested formatter element that allows you to represent the attribute value in a format different from the standard for this Datatype:<column id="date"> <formatter class="com.haulmont.cuba.gui.components.formatters.DateFormatter" format="yyyy-MM-dd HH:mm:ss"/> </column>
-
-
rowsCount− an optional element adding theRowsCountcomponent for the table; this component enables loading the table data in pages. Page size can be defined by limiting the number of records in the data source usingCollectionDatasource.setMaxResults()method. Typically, this is performed by a Filter component linked to the table’s data source. However, if there is no generic filter, this method can be called directly from the screen controller.RowsCountcomponent can also show the total number of records returned by the current query from the datasource without extracting the records themselves. It invokesAbstractCollectionDatasource.getCount()when user clicks the ? icon, which results in performing a database query with the same conditions as the current query, but using aCOUNT(*)aggregate function instead. The number retrieved is displayed instead of the ? icon.
-
actions− an optional element describing the actions, related to the table. In addition to custom arbitrary actions, the element supports the following standard actions, defined inListActionTypeenum:create,edit,remove,refresh,add,exclude,excel.
table attributes:
-
multiselectattribute enables setting multiple selection mode for table rows. Ifmultiselectistrue, users can select multiple rows in the table using keyboard or mouse holding Ctrl or Shift keys. By default, multiple selection mode is switched off.
-
sortableattribute enables sorting data in the table. By default, it is set totrue. If sorting is allowed, clicking a column header will show a /
/ icon to the right of the column name. You can disable sorting for a particular column by using its sortable attribute.
icon to the right of the column name. You can disable sorting for a particular column by using its sortable attribute.Table sorting can be performed differently depending on whether all the records can be placed on one page or not. If they can, sorting is performed in memory without database queries. If there is more than one page, sorting is performed in the database by sending a new query with the corresponding
ORDER BYcondition.A table column may refer to a local attribute or a linked entity. For example:
<table id="ordersTable"> <columns> <column id="customer.name"/> <!-- the 'name' attribute of the 'Customer' entity --> <column id="contract"/> <!-- the 'Contract' entity --> </columns> <rows datasource="ordersDs"/> </table>In the latter case, the database sorting will be performed by attributes defined in the
@NamePatternannotation of the related entity. If the entity has no such annotation, the sorting will be performed in memory only within the current page.If the column refers to a non-persistent entity attribute, the database sorting will be performed by attributes defined in the
related()parameter of the@MetaPropertyannotation. If no related attributes are specified, the sorting will be performed in memory only within the current page.If the table is connected to a nested datasource that contains a collection of related entities, the collection attribute must be of ordered type (
ListorLinkedHashSet) for table to be sortable. If the attribute is of typeSet, thesortableattribute has no effect and the table cannot be sorted by users.
-
presentationsattribute controls the mechanism of presentations. By default, the value isfalse. If the attribute value istrue, a corresponding icon is added to the top right corner of the table . The mechanism of presentations is implemented for the Web Client only.
. The mechanism of presentations is implemented for the Web Client only.
-
If the
columnControlVisibleattribute is set tofalse, users cannot hide columns using the drop-down menu of the button in the right part of the table header. Currently displayed columns are marked with checkmarks in the menu.
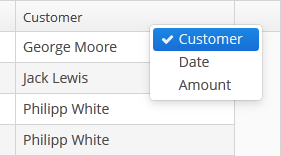
-
If the
reorderingAllowedattribute is set tofalse, users cannot change columns order by dragging them with a mouse.
-
If the
columnHeaderVisibleattribute is set tofalse, the table has no header.
-
If the
showSelectionattribute is set tofalse, a current row is not highlighted.
-
contextMenuEnabledattribute enables the context menu. By default this attribute is set totrue. The context menu shows table actions (if any) and the System Information item containing information on the selected entity (if the user hascuba.gui.showInfopermission).
-
Setting
multiLineCellstotrueenables multi-line display for cells containing several lines of text. In this mode, the web browser will load all the rows of the current table page at once, instead of lazy-loading the visible part of the table. It is required for proper scrolling in the Web Client. The default value isfalse.
-
aggregatableattribute enables aggregation for table rows. The following operations are supported:-
SUM– calculate the sum -
AVG– find the average value -
COUNT– calculate the total number -
MIN– find the minimum value -
MAX– find the maximum value
The
aggregationelement should be set for aggregated table columns with thetypeattribute, which sets the aggregation function. By default, only numeric data types are supported in aggregated columns, such asInteger, Double, LongandBigDecimal. The aggregated table values are shown in an additional row at the top of the table. An example of an aggregated table description:<table id="itemsTable" aggregatable="true"> <columns> <column id="product"/> <column id="quantity"/> <column id="amount"> <aggregation type="SUM"/> </column> </columns> <rows datasource="itemsDs"/> </table>The
aggregationelement can also contain thestrategyClassattribute specifying a class implementing theAggregationStrategyinterface (see below the example of setting an aggregation strategy programmatically).A Formatter can be specified to display the aggregated value in the format other than the standard for this Datatype:
<column id="amount"> <aggregation type="SUM"> <formatter class="com.company.sample.MyFormatter"/> </aggregation> </column>The
aggregationStyleattribute allows you to specify the location of the aggregation row:TOPorBOTTOM.TOPis used by default.In addition to the operations listed above, you can define a custom aggregation strategy by implementing the
AggregationStrategyinterface and passing it to thesetAggregation()method of theTable.Columnclass inside theAggregationInfoinstance. For example:public class TimeEntryAggregation implements AggregationStrategy<List<TimeEntry>, String> { @Override public String aggregate(Collection<List<TimeEntry>> propertyValues) { HoursAndMinutes total = new HoursAndMinutes(); for (List<TimeEntry> list : propertyValues) { for (TimeEntry timeEntry : list) { total.add(HoursAndMinutes.fromTimeEntry(timeEntry)); } } return StringFormatHelper.getTotalDayAggregationString(total); } @Override public Class<String> getResultClass() { return String.class; } }AggregationInfo info = new AggregationInfo(); info.setPropertyPath(metaPropertyPath); info.setStrategy(new TimeEntryAggregation()); Table.Column column = weeklyReportsTable.getColumn(columnId); column.setAggregation(info); -
-
editableattribute enables switching the table to in-place editing mode. In this mode, the columns witheditable = trueattribute show components to edit the attributes of the corresponding entity.The component type for each editable column is selected automatically based on the type of the corresponding entity attribute. For example, for string and numeric attributes, the application will use TextField, for
Date– DateField, for lists – LookupField, for links to other entities – PickerField.For a
Datetype editable column, you can additionally definedateFormatorresolutionattributes similar to the ones described for the DateField.optionsDatasource and captionProperty attributes can be additionally defined for an editable column showing a linked entity. If
optionsDatasourceis set, the application will use LookupField instead of PickerField.Custom configuration (including editing) of a cell can be performed using
Table.addGeneratedColumn()method – see below.
-
In Web Client with a Halo-based theme,
stylenameattribute enables setting predefined styles to theTablecomponent either in the XML descriptor or in the screen controller:<table id="table" stylename="no-stripes"> <columns> <column id="product"/> <column id="quantity"/> </columns> <rows datasource="itemsDs"/> </table>When setting a style programmatically, select one of the
HaloThemeclass constants with theTABLE_prefix:table.setStyleName(HaloTheme.TABLE_NO_STRIPES);Table styles:
-
borderless- removes the outer border of the table.
-
compact- reduces the white space inside the table cells.
-
no-header- hides the table column headers.
-
no-horizontal-lines- removes the horizontal divider lines between the table rows.
-
no-stripes- removes the alternating row colors.
-
no-vertical-lines- removes the vertical divider lines between the table columns.
-
small- small font size and reduced the white space inside the table cells.
-
Methods of the Table interface:
-
addColumnCollapsedListener() method is useful for tracking the columns visibility with the help of theColumnCollapsedListenerinterface implementation.
-
getSelected(),getSingleSelected()return instances of the entities corresponding to the selected rows of the table. A collection can be obtained by invokinggetSelected(). If nothing is selected, the application returns an empty set. Ifmultiselectis disabled, it is more convenient to usegetSingleSelected()method returning one selected entity ornull, if nothing is selected.
-
addGeneratedColumn()method allows you to define custom representation of data in a column. It takes two parameters: identifier of the column and an implementation of theTable.ColumnGeneratorinterface. Identifier can match one of the identifiers set for table columns in XML-descriptor – in this case the new column is inserted instead of the one defined in XML. If the identifier does not match any of the columns, a new column is added to the right.generateCell()method of theTable.ColumnGeneratorinterface is invoked for each row of the table. The method receives an instance of the entity displayed in the corresponding row.generateCell()method should return a visual component which will be displayed in the cell.Example of using the component:
@Inject protected Table carsTable; @Inject protected ComponentsFactory componentsFactory; @Override public void init(Map<String, Object> params) { carsTable.addGeneratedColumn("colour", new Table.ColumnGenerator() { @Override public Component generateCell(Entity entity) { LookupPickerField field = componentsFactory.createComponent(LookupPickerField.NAME); field.setDatasource(carsTable.getItemDatasource(entity), "colour"); field.setOptionsDatasource(coloursDs); field.addLookupAction(); field.addOpenAction(); return field; } }); }In the example above, all cells within the
colourcolumn in the table show the LookupPickerField component. The component should save its value into thecolourattribute of the entity which instance is displayed in the corresponding row. For this purposegetItemDatasource()method is used to get the datasource for the current entity instance from the table and pass it to theLookupPickerFieldcomponent.If you want to display just dynamic text, use special class
Table.PlainTextCellinstead of the Label component. It will simplify rendering and make the table faster.If
addGeneratedColumn()method receives the identifier of a column which is not declared in XML-descriptor, the header for the new column to be set as follows:carsTable.getColumn("colour").setCaption("Colour");Consider also using a more declarative approach with the generator XML attribute.
-
requestFocus()method allows you to set focus on the concrete editable field of a certain row. It takes two parameters: an entity instance which identifies the row and the column identifier. Example of requesting a focus:table.requestFocus(item, "count");
-
scrollTo()method allows you to scroll table to the concrete row. It takes one parameter: an entity instance identifying the row.Example of scrolling:
table.scrollTo(item);
-
setClickListener()method can save you from adding generated columns with components when you need to draw something in cells and receive notifications when a user clicks inside these cells. TheCellClickListenerimplementation passed to this method receives the selected entity and the column identifier. The cells content will be wrapped in span element withcuba-table-clickable-cellstyle which can be used to specify the cell representation.
-
setStyleProvider()method enables setting table cell display style. The method accepts an implementation ofTable.StyleProviderinterface as a parameter.getStyleName()method of this interface is invoked by the table for each row and each cell separately. If the method is invoked for a row, the first parameter contains the entity instance displayed by the row, the second parameter isnull. If the method is called for a cell, the second parameter contains the name of the attribute displayed by the cell.Example of setting a style:
@Inject protected Table customersTable; @Override public void init(Map<String, Object> params) { customersTable.setStyleProvider(new Table.StyleProvider() { @Nullable @Override public String getStyleName(Entity entity, @Nullable String property) { Customer customer = (Customer) entity; if (property == null) { // style for row if (hasComplaints(customer)) { return"unsatisfied-customer"; } } else if (property.equals("grade")) { // style for column "grade" switch (customer.getGrade()) { case PREMIUM: return "premium-grade"; case HIGH: return "high-grade"; case MEDIUM: return "medium-grade"; default: return null; } } return null; } }); }Then the cell and row styles set in the application theme should be defined. Detailed information on creating a theme is available in Themes. For web client, new styles are defined in the
styles.scssfile. Style names defined in the controller, together with prefixes identifying table row and column form CSS selectors. For example:.v-table-row.unsatisfied-customer { font-weight: bold; } .v-table-cell-content.premium-grade { background-color: red; } .v-table-cell-content.high-grade { background-color: green; } .v-table-cell-content.medium-grade { background-color: blue; }
-
addPrintable()method enables setting a custom presentation of the data within a column when exporting to an XLS file via theexcelstandard action or directly using theExcelExporterclass. The method accepts the column identifier and an implementation of theTable.Printableinterface for the column. For example:ordersTable.addPrintable("customer", new Table.Printable<Customer, String>() { @Override public String getValue(Customer customer) { return "Name: " + customer.getName; } });getValue()method of theTable.Printableinterface should return data to be displayed in the table cell. This is not necessarily a string – the method may return values of other types, for example, numeric data or dates, which will be represented in the XLS file accordingly.If formatted output to XLS is required for a generated column, an implementation of the
Table.PrintableColumnGeneratorinterface passed to theaddGeneratedColumn()method should be used. The value for a cell in an XLS document is defined in thegetValue()method of this interface:ordersTable.addGeneratedColumn("product", new Table.PrintableColumnGenerator<Order, String>() { @Override public Component generateCell(Order entity) { Label label = componentsFactory.createComponent(Label.NAME); Product product = order.getProduct(); label.setValue(product.getName() + ", " + product.getCost()); return label; } @Override public String getValue(Order entity) { Product product = order.getProduct(); return product.getName() + ", " + product.getCost(); } });If
Printablepresentation is not defined for a generated column in one way or another, then the column will either show the value of corresponding entity attribute or nothing if there is no associated entity attribute.
-
The
setItemClickAction()method allows you to define an action that will be performed when a table row is double-clicked. If such action is not defined, the table will attempt to find an appropriate one in the list of its actions in the following order:-
The action assigned to the Enter key by the
shortcutproperty -
The
editaction -
The
viewactionIf such action is found, and has
enabled = trueproperty, the action is executed.
-
-
The
setEnterPressAction()allows you to define an action executed when Enter is pressed. If such action is not defined, the table will attempt to find an appropriate one in the list of its actions in the following order:-
The action defined by the
setItemClickAction()method -
The action assigned to the Enter key by the
shortcutproperty -
The
editaction -
The
viewaction
If such action is found, and has
enabled = trueproperty, the action is executed. -
- Attributes of table
-
align - aggregatable - aggregationStyle - columnControlVisible - columnHeaderVisible - contextMenuEnabled - editable - enable - height - id - multiLineCells - multiselect - presentations - reorderingAllowed - settingsEnabled - showSelection - sortable - stylename - tabIndex - visible - width
- Elements of table
-
actions - buttonsPanel - columns - rows - rowsCount
- Attributes of column
-
align - caption - captionProperty - collapsed - dateFormat - editable - generator - id - link - linkInvoke - linkScreen - linkScreenOpenType - maxTextLength - optionsDatasource - resolution - sortable - visible - width
- Elements of column
- Attributes of aggregation
- Attributes of rows
- Predefined styles of table
-
borderless - compact - no-header - no-horizontal-lines - no-stripes - no-vertical-lines - small
- API
-
addGeneratedColumn - addPrintable - generateCell - getSelected - requestFocus - scrollTo - setEnterPressAction - setItemClickAction - setStyleProvider
- Listeners of table
4.5.2.1.36. TextArea
TextArea is a multi-line text editor field.
XML-name of the component: textArea
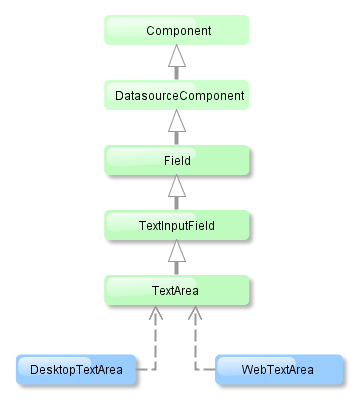
TextArea component is implemented for both Web Client and Desktop Client.
TextArea mostly replicates the functionality of the TextField component and has the following specific attributes:
-
colsandrowsset the number of columns and rows of text:<textArea id="textArea" cols="20" rows="5" caption="msg://name"/>The values of
widthandheighthave priority over the values ofcolsandrows.
-
resizable– if this attribute is set totrueand the number of rows is more than one, a user can change the size of the component:<textArea id="textArea" resizable="true" caption="msg://name" rows="5"/>
The area size change events can be tracked using the
ResizeListenerinterface.
-
wordwrap- set this attribute tofalseto turn off word wrapping.
TextArea supports TextChangeListener defined in its parent TextInputField interface. Text change events are processed asynchronously after typing in order not to block the typing.
textArea.addTextChangeListener(event -> {
int length = event.getText().length();
textAreaLabel.setValue(length + " of " + textArea.getMaxLength());
});
The TextChangeEventMode defines the way the changes are transmitted to the server to cause a server-side event. There are 3 predefined event modes:
-
LAZY(default) - an event is triggered when there is a pause in editing the text. The length of the pause can be modified withsetInputEventTimeout(). A text change event is forced before a possibleValueChangeEvent, even if the user did not keep a pause while entering the text. -
TIMEOUT- an event is triggered after a timeout period. If more changes are made during this period, the event sent to the server-side includes the changes made up to the last change. The length of the timeout can be set withsetInputEventTimeout().If a
ValueChangeEventwould occur before the timeout period, aTextChangeEventis triggered before it, on the condition that the text content has changed since the previousTextChangeEvent. -
EAGER- an event is triggered immediately for every change in the text content, typically caused by a key press. The requests are separate and are processed sequentially one after another. Change events are nevertheless communicated asynchronously to the server, so further input can be typed while event requests are being processed.- TextArea styles
-
In Web Client with a Halo-based theme, you can set predefined styles to the TextArea component using the
stylenameattribute either in the XML descriptor or in the screen controller:<textArea id="textArea" stylename="borderless"/>When setting a style programmatically, select one of the
HaloThemeclass constants with theTEXTAREA_prefix:textArea.setStyleName(HaloTheme.TEXTAREA_BORDERLESS);-
align-center- align the text inside the area to center.
-
align-right- align the text inside the area to the right.
-
borderless- removes the border and background from the text area.
-
- Attributes of textArea
-
align - caption - caseConversion - cols - datasource - datatype - description - editable - enable - height - icon - id - maxLength - property - required - requiredMessage - resizable - rows - settingsEnabled - stylename - tabIndex - trim - visible - width - wordwrap
- Predefined styles of textArea
- Listeners of textArea
4.5.2.1.37. TextField
TextField is a component for text editing. It can be used both for working with entity attributes and entering/displaying arbitrary textual information.
XML-name of the component: textField
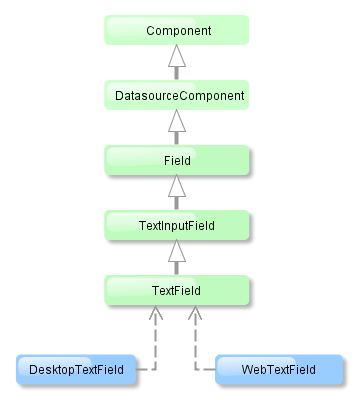
TextField is implemented for both Web Client and Desktop Client.
-
An example of a text field with a caption retrieved from the localized messages pack:
<textField id="nameField" caption="msg://name"/>The figure below shows an example of a simple text field.

-
In Web Client with a Halo-based theme, you can set predefined styles to the TextField component using the
stylenameattribute either in the XML descriptor or in the screen controller:<textField id="textField" stylename="borderless"/>When setting a style programmatically, select one of the
HaloThemeclass constants with theTEXTFIELD_prefix:textField.setStyleName(HaloTheme.TEXTFIELD_INLINE_ICON);TextField styles:
-
align-center- align the text inside the field to center.
-
align-right- align the text inside the field to the right.
-
borderless- removes the border and background from the text field.
-
inline-icon- moves the default caption icon inside the text field.
TextField supports automatic case conversion. The
caseConvertionattribute can have one of the following values:-
UPPER- the upper case, -
LOWER- the lower case, -
NONE- without conversion (the default value).
-
-
To create a text field connected to data, use datasource and property attributes.
<dsContext> <datasource id="customerDs" class="com.sample.sales.entity.Customer" view="_local"/> </dsContext> <layout> <textField datasource="customerDs" property="name" caption="msg://name"/>As you can see in the example, the screen describes the
customerDsdatasource forCustomerentity, which hasnameattribute. The text field component has a link to the data source specified in the datasource attribute; property attribute contains the name of the entity attribute that is displayed in the text field.
-
If the field is not connected to an entity attribute (i.e. the data source and attribute name are not set), you can set the data type using the
datatypeattribute. It is used to format field values. The attribute value accepts any data type registered in the application metadata – see Datatype. Typically,TextFielduses the following data types:-
decimal -
double -
int -
longAs an example, let’s look at a text field with an
Integerdata type.<textField id="integerField" datatype="int" caption="msg://integerFieldName"/>If a user enters a value that cannot be interpreted as an integer number, then when the field looses focus, the application will show an error message and revert field value to the previous one.
-
-
Text field can be assigned a validator – a class implementing
Field.Validatorinterface. The validator limits user input in addition to what is already done by thedatatype. For example, to create an input field for positive integer numbers, you need to create a validator class:public class PositiveIntegerValidator implements Field.Validator { @Override public void validate(Object value) throws ValidationException { Integer i = (Integer) value; if (i <= 0) throw new ValidationException("Value must be positive"); } }and assign it as a validator to the text field with
intdatatype:<textField id="integerField" datatype="int"> <validator class="com.sample.sales.gui.PositiveIntegerValidator"/> </textField>Unlike input check against the data type, validation is performed not when the field looses focus, but after invocation of the field’s
validate()method. It means that the field (and the linked entity attribute) may temporarily contain a value that does not satisfy validation conditions (a non-positive number in the example above). This should not be an issue, because validated fields are typically used in editor screens, which automatically invoke validation for all their fields before commit. If the field is located not in an editing screen, the field’svalidate()method should be invoked explicitly in the controller.
-
TextFieldsupportsTextChangeListenerdefined in its parentTextInputFieldinterface. Text change events are processed asynchronously after typing in order not to block the typing.textField.addTextChangeListener(event -> { int length = event.getText().length(); textFieldLabel.setValue(length + " of " + textField.getMaxLength()); }); textField.setTextChangeEventMode(TextInputField.TextChangeEventMode.LAZY);
-
The
TextChangeEventModedefines the way the changes are transmitted to the server to cause a server-side event. There are 3 predefined event modes:-
LAZY(default) - an event is triggered when there is a pause in editing the text. The length of the pause can be modified withsetInputEventTimeout(). A text change event is forced before a possibleValueChangeEvent, even if the user did not keep a pause while entering the text. -
TIMEOUT- an event is triggered after a timeout period. If more changes are made during this period, the event sent to the server-side includes the changes made up to the last change. The length of the timeout can be set withsetInputEventTimeout().If a
ValueChangeEventwould occur before the timeout period, aTextChangeEventis triggered before it, on the condition that the text content has changed since the previousTextChangeEvent. -
EAGER- an event is triggered immediately for every change in the text content, typically caused by a key press. The requests are separate and are processed sequentially one after another. Change events are nevertheless communicated asynchronously to the server, so further input can be typed while event requests are being processed.
-
-
EnterPressListenerallows you to define an action executed when Enter is pressed:textField.addEnterPressListener(e -> showNotification("Enter pressed"));
-
ValueChangeListeneris triggered on the value changes when the user finished the text input, i.e. after the Enter press or when the component loses focus. An event object of theValueChangeEventtype is passed to the listener. It has the following methods:-
getPrevValue()returns the value of the component before the change. -
getValue()method return the current value of the component.textField.addValueChangeListener(e -> showNotification("Before: " + e.getPrevValue() + ". After: " + e.getValue()));
-
-
If a text field is linked to an entity attribute (via
datasourceandproperty), and if the entity attribute has alengthparameter defined in the@ColumnJPA-annotation, then theTextFieldwill limit the maximum length of entered text accordingly.If a text field is not linked to an attribute, or if the attribute does not have
lengthvalue defined, or this value needs to be overridden, then the maximum length of the entered text can be limited usingmaxLengthattribute. The value of "-1" means there are no limitations. For example:<textField id="shortTextField" maxLength="10"/>
-
By default, text field trims spaces at the beginning and at the end of the entered string. I.e. if user enters " aaa bbb ", the value of the field returned by the
getValue()method and saved to the linked entity attribute will be "aaa bbb". You can disable trimming of spaces by setting thetrimattribute tofalse.It should be noted that trimming only works when users enter a new value. If the value of the linked attribute already has spaces in it, the spaces will be displayed until user edits the value.
-
Text field always returns
nullinstead of an entered empty string. Therefore, with thetrimattribute enabled, any string containing spaces only will be converted tonull. -
The
setCursorPosition()method can be used to focus the field and set the cursor position to the specified 0-based index.
- Attributes of textField
-
align - caption - caseConversion - datasource - datatype - description - editable - enable - height - icon - id - inputPrompt - maxLength - property - required - requiredMessage - stylename - tabIndex - trim - visible - width
- Elements of textField
- Predefined styles of textField
- Listeners of textField
-
EnterPressListener - TextChangeListener - ValueChangeListener
4.5.2.1.38. TimeField
TimeField is a field for displaying and entering time.
XML-name of the component: timeField.
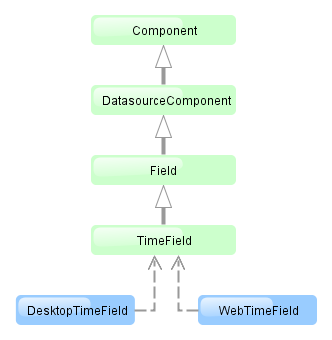
TimeField component is implemented for both Web Client and Desktop Client.
-
To create a time field associated with data, datasource and property attributes should be used:
<dsContext> <datasource id="orderDs" class="com.sample.sales.entity.Order" view="_local"/> </dsContext> <layout> <timeField datasource="orderDs" property="deliveryTime"/>As you can see in the example above, the screen defines the
orderDsdata source forOrderentity, which hasdeliveryTimeattribute. Thedatasourceattribute of the time input component contains a link to thedatasource, and thepropertyattribute – the name of the entity attribute displayed in the field.Related entity attribute should have
java.util.Dateorjava.sql.Timetype.
-
The time format is defined by the
timedatatype and is specified in the main localized messages pack in thetimeFormatkey. -
The time format can also be specified in the
timeFormatattribute. It can be either a format string, or a key in a message pack (with themsg://prefix).
-
Regardless of the mentioned above format display of seconds can be controlled using
showSecondsattribute. By default, seconds are displayed if the format containsss.<timeField datasource="orderDs" property="createTs" showSeconds="true"/>
- Attributes of timeField
-
align - caption - editable - enable - datasource - description - height - icon - id - property - required - requiredMessage - showSeconds - stylename - tabIndex - timeFormat - visible - width
- Elements of timeField
- Listeners of timeField
4.5.2.1.39. TokenList
TokenList component offers a simplified way of working with lists: instance names are listed vertically or horizontally, adding is done using drop-down list, removal – using the buttons located near each instance.
XML-name of the component: tokenList
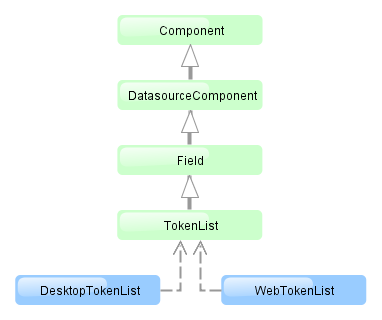
The component is implemented for both Web Client and Desktop Client.
Below is an example description of TokenList in an XML-descriptor of a screen:
<dsContext>
<datasource id="orderDs"
class="com.sample.sales.entity.Order"
view="order-edit">
<collectionDatasource id="productsDs" property="products"/>
</datasource>
<collectionDatasource id="allProductsDs"
class="com.sample.sales.entity.Product"
view="_minimal">
<query>select p from sales$Product p order by p.name</query>
</collectionDatasource>
</dsContext>
<layout>
<tokenList id="productsList" datasource="productsDs" inline="true" width="500px">
<lookup optionsDatasource="allProductsDs"/>
</tokenList>In the example above, the nested productsDs datasource which includes a collection of products within an order is defined, as well as allProductsDs datasource containing a collection of all products available in the database. The TokenList component with productsList identifier displays the content of the productsDs datasource and enables changing the collection by adding instances from allProductsDs.
tokenList attributes:
-
position– sets the position for the drop-down list. The attribute can take two values:TOP,BOTTOM. Default isTOP.

-
inlineattribute defines how the list with selected items will be displayed: vertically or horizontally.truecorresponds to horizontal alignment,false– to vertical. An example of a component with horizontal alignment:
-
simple– when set totrue, the items selection component will be hidden with only the Add button left. Clicking the Add button opens the screen with the list of entity instances which type is defined by the datasource. Selection screen identifier is selected according to the rules for thePickerField.LookupActionstandard action. Clicking the Clear button will remove all elements from theTokenListcomponent datasource.
-
clearEnabled- when set tofalse, the Clear button is hidden.
tokenList elements:
-
lookup− values selection component descriptor.Attributes of the
lookupelement:-
lookupattribute makes it possible to select items using an entity lookup screen: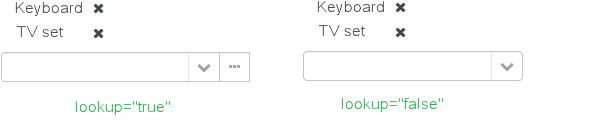
-
lookupScreenattribute sets the identifier of the screen used for items selection inlookup="true"mode. If this attribute is not set, screen identifier is selected according to the rules for thePickerField.LookupActionstandard action. -
openTypeattribute defines how the lookup screen will be opened, similar to what is described for thePickerField.LookupActionstandard action. Default value –THIS_TAB.
-
multiselect- if this attribute’s value is set totrue, thentruewill be passed to parameters map of the lookup screen for theMULTI_SELECTkey. This flag can be used to set the screen into multiple selection mode. This flag is defined in theWindowParamsenum so it is convenient to work with it in the following way:@Override public void init(Map<String, Object> params) { if (WindowParams.MULTI_SELECT.getBool(getContext())) { usersTable.setMultiSelect(true); } }The
multiselectattribute works only if thesimpleattribute is set totrue.
-
tokenList listeners:
-
ItemClickListenerallows you to track the click ontokenListitems. -
ValueChangeListenerenables tracking the changes of thetokenListvalue, as well as of any other components implementing theFieldinterface.
- Attributes of tokenList
-
align - caption - captionProperty - clearEnabled - datasource - description - editable - enable - height - icon - id - inline - position - simple - stylename - tabIndex - visible - width
- Elements of tokenList
- Attributes of lookup
-
captionProperty - filterMode - lookup - lookupScreen - multiselect - openType - optionsDatasource
- Attributes of button
- Listeners of tokenList
4.5.2.1.40. Tree
The Tree component is intended to display hierarchical structures represented by entities referencing themselves.

XML-name of the component: tree
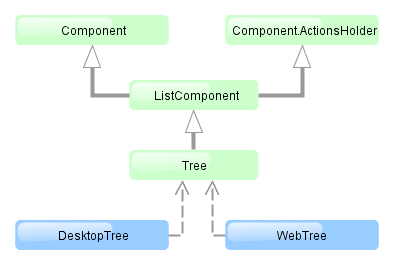
The component is implemented for both Web Client and Desktop Client.
For the Tree component, the datasource attribute of the treechildren element should contain a reference to a hierarchicalDatasource. Declaration of a hierarchicalDatasource should contain a hierarchyProperty attribute – the name of the entity attribute which is a reference to same entity.
Below is an example of the Tree component description in a screen XML-descriptor:
<dsContext>
<hierarchicalDatasource id="departmentsDs" class="com.sample.sales.entity.Department" view="browse"
hierarchyProperty="parentDept">
<query>
select d from sales$Department d order by d.createTs
</query>
</hierarchicalDatasource>
</dsContext>
<layout>
<tree id="departmentsTree" width="100%" height="100%">
<treechildren datasource="departmentsDs" captionProperty="name"/>
</tree>The name of the entity attribute to be displayed in the tree can be set using the captionProperty attribute of the treechildren element. If this attribute is not defined, the screen will show the entity instance name.
multiselect attribute enables setting multiple selection mode for tree items. If multiselect is true, users can select multiple items using keyboard or mouse holding Ctrl or Shift keys. By default, multiple selection mode is switched off.
The setItemClickAction() method may be used to define an action that will be performed when a tree node is double-clicked.
Each tree item can have an icon on the left. Create an implementation of the ListComponent.IconProvider interface in the screen controller and set it for the tree:
@Inject
private Tree<Region> tree;
@Override
public void init(Map<String, Object> params) {
tree.setIconProvider(new ListComponent.IconProvider<Region>() {
@Nullable
@Override
public String getItemIcon(Region entity) {
if (entity.getParent() == null) {
return "icons/root.png";
}
return "icons/leaf.png";
}
});
}4.5.2.1.41. TreeTable
TreeTable component is a hierarchical table displaying a tree-like structure in the leftmost column. The component is used for entities that have references to themselves. For example, it can be a file system or a company organization chart.
XML-name of the component: treeTable
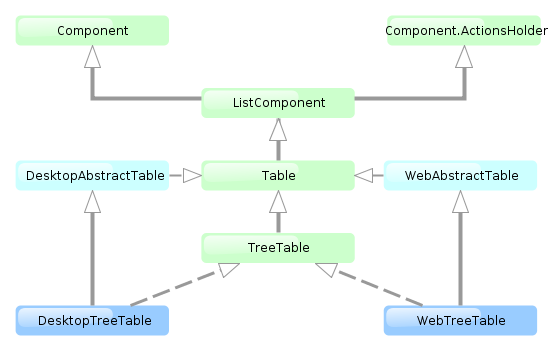
The component is implemented for both Web Client and Desktop Client.
For TreeTable, the hierarchicalDatasource should be set in the datasource attribute of the rows element. Declaration of a hierarchicalDatasource should contain hierarchyProperty attribute – the name of the entity attribute which references the same entity.
Below is an example of component description in a screen XML descriptor:
<dsContext>
<hierarchicalDatasource id="tasksDs" class="com.sample.sales.entity.Task" view="browse"
hierarchyProperty="parentTask">
<query>
select t from sales$Task t
</query>
</hierarchicalDatasource>
</dsContext>
<layout>
<treeTable id="tasksTable" width="100%">
<columns>
<column id="name"/>
<column id="dueDate"/>
<column id="assignee"/>
</columns>
<rows datasource="tasksDs"/>
</treeTable>The functionality of TreeTable is similar to a simple Table.
- treeTable attributes
-
align - aggregatable - aggregationStyle - columnControlVisible - contextMenuEnabled - editable - enable - height - id - multiLineCells - multiselect - presentations - reorderingAllowed - settingsEnabled - sortable - stylename - tabIndex - visible - width
- treeTable elements
-
actions - buttonsPanel - columns - rows - rowsCount
- column attributes
-
align - caption - captionProperty - collapsed - dateFormat - editable - id - link - linkInvoke - linkScreen - linkScreenOpenType - maxTextLength - optionsDatasource - resolution - sortable - visible - width
- column elements
- rows attribute
- treeTable listeners
4.5.2.1.42. TwinColumn
TwinColumn is a twin list component for multiple items selection. The left part of the list contains available unselected values, the right part – selected values. Users select the values by transferring them from the left to the right and backward using double click or dedicated buttons. A unique representation style and an icon can be defined for each value.
XML name of the component: twinColumn
The component is implemented for Web Client only.
Below is an example of a twinColumn component usage to select entity instances:
<dsContext>
<datasource id="carDs" class="com.company.sample.entity.Car" view="_local"/>
<collectionDatasource id="coloursDs" class="com.company.sample.entity.Colour" view="_local">
<query>select c from sample$Colour c</query>
</collectionDatasource>
</dsContext>
<layout>
<twinColumn id="coloursField" optionsDatasource="coloursDs" addAllBtnEnabled="true"/>In this example, the coloursField component will display names of Colour entity instances located in the coloursDs data source and its getValue() method will return a collection of selected instances.
addAllBtnEnabled attribute shows the buttons moving all items between the lists.
columns attribute is used to set the number of characters in a row, and the rows attribute – to set the number of rows in each list.
leftColumnCaption and rightColumnCaption attributes can be used to set captions for the columns.
The presentation of the items can be defined by implementing the TwinColumn.StyleProvider interface and returning a style name and icon path for each entity instance displayed in the component.
The list of component options can be specified arbitrarily using the setOptionsList(), setOptionsMap() and setOptionsEnum() methods as described for the OptionsGroup component.
- Attributes of twinColumn
-
align - addAllBtnEnabled - caption - captionProperty - columns - datasource - description - editable - enable - height - icon - id - leftColumnCaption - optionsDatasource - property - required - requiredMessage - rightColumnCaption - rows - stylename - tabIndex - visible - width
- Elements of twinColumn
- Listeners of twinColumn
4.5.2.2. Containers
4.5.2.2.1. Accordion
Accordion is a container for collapsible content that allows you to toggle between hiding and showing large amount of content. The Accordion container is implemented for Web Client.
XML-name of the component: accordion. An example description of an accordion in a screen XML-descriptor:
<accordion id="accordion" height="100%">
<tab id="tabStamford" caption="msg://tabStamford" margin="true" spacing="true">
<label value="msg://sampleStamford"/>
</tab>
<tab id="tabBoston" caption="msg://tabBoston" margin="true" spacing="true">
<label value="msg://sampleBoston"/>
</tab>
<tab id="tabLondon" caption="msg://tabLondon" margin="true" spacing="true">
<label value="msg://sampleLondon"/>
</tab>
</accordion>The accordion component should contain nested tab elements describing tabs. Each tab is a container with a vertical components layout similar to vbox. Accordion container can be used if the application page is limited in space or the tab title is too long to be displayed in the TabSheet. Accordion is featured with a smooth transition animation.
tab element attributes:
-
id– tab identifier. Please note that tabs are not components and their IDs are used only within theAccordionin order to work with tabs from the controller. -
caption – tab caption.
-
icon - defines icon location in theme catalog. Detailed information on recommended icon placement is available in Themes.
-
lazy– sets lazy loading for tab content.Lazy tabs do not load their content when the screen is opened, which reduces the number of components in memory. Components within a tab are loaded only when a user selects the tab. Additionally, if a lazy-tab includes visual components linked to a datasource containing a JPQL query, this query is not executed as well. As a result, screen opens faster, and data is loaded only when the user requests it by selecting this tab.
Please note that the components located on a lazy tab do not exist when the screen is opened. Therefore they cannot be injected into a controller and cannot be obtained by invoking
getComponent()in the controller’sinit()method. The lazy tab components can be accessed only after the user opens the tab. This moment may be intercepted usingAccordion.SelectedTabChangeListener, for example:@Inject private Accordion accordion; private boolean tabInitialized; @Override public void init(Map<String, Object> params) { accordion.addSelectedTabChangeListener(event -> { if ("tabCambridge".equals(event.getSelectedTab().getName())) { initCambridgeTab(); } }); } private void initCambridgeTab(){ if (tabInitialized) { return; } tabInitialized = true; // initialization code here // use getComponentNN("comp_id") here to get lazy tab's components }By default, tabs are not
lazy, which means that all their content is loaded when a screen is opened. -
In Web Client with a Halo-based theme, the
stylenameattribute allows you to set the predefinedborderlessstyle to theaccordioncomponent to remove borders and background:accordion.setStyleName(HaloTheme.ACCORDION_BORDERLESS);
An accordion tab can contain any other visual container, such as table, grid etc:
<accordion id="accordion" height="100%" width="100%" enable="true">
<tab id="tabNY" caption="msg://tabNY" margin="true" spacing="true">
<table id="nYTable" width="100%">
<columns>
<column id="borough"/>
<column id="county"/>
<column id="population"/>
<column id="square"/>
</columns>
<rows datasource="newYorkDs"/>
</table>
</tab>
</accordion>
4.5.2.2.2. BoxLayout
BoxLayout is a container with sequential placement of components.
There are three types of BoxLayout, identified by the XML-elements:
-
hbox− components are placed horizontally.
<hbox spacing="true" margin="true"> <dateField datasource="orderDs" property="date"/> <lookupField datasource="orderDs" property="customer" optionsDatasource="customersDs"/> <textField datasource="orderDs" property="amount"/> </hbox>
-
vbox− components are placed vertically.vboxhas 100% width by default.
<vbox spacing="true" margin="true"> <dateField datasource="orderDs" property="date"/> <lookupField datasource="orderDs" property="customer" optionsDatasource="customersDs"/> <textField datasource="orderDs" property="amount"/> </vbox>
-
flowBox− components are placed horizontally with line wrapping. If there is not enough space in a line, the components that do not fit will be displayed in the next line (the behavior is similar to SwingFlowLayout).
<flowBox spacing="true" margin="true"> <dateField datasource="orderDs" property="date"/> <lookupField datasource="orderDs" property="customer" optionsDatasource="customersDs"/> <textField datasource="orderDs" property="amount"/> </flowBox>
In Web Client with a Halo-based theme, BoxLayout may be used to create enhanced composite layouts. The stylename attribute with card or well value along with stylename="v-panel-caption" for an enclosed container will make a component look like Vaadin Panel.
-
cardstyle name makes a layout look like a card. -
wellstyle makes the card look "sunken" with shaded background.
<vbox stylename="well"
height="200px"
width="300px"
expand="message"
spacing="true">
<hbox stylename="v-panel-caption"
width="100%">
<label value="Widget caption"/>
<button align="MIDDLE_RIGHT"
icon="font-icon:EXPAND"
stylename="borderless-colored"/>
</hbox>
<textArea id="message"
inputPrompt="Enter your message here..."
width="280"
align="MIDDLE_CENTER"/>
<button caption="Send message"
width="100%"/>
</vbox>4.5.2.2.3. ButtonsPanel
ButtonsPanel is a container that streamlines the use and placement of the components (usually, buttons) for data management in a table.

XML-name of the component: buttonsPanel.
A sample definition of ButtonsPanel in screen XML-descriptor:
<table id="customersTable"
editable="false" width="100%">
<actions>
<action id="create"/>
<action id="edit"/>
<action id="remove"/>
<action id="excel"/>
</actions>
<buttonsPanel>
<button action="customersTable.create"/>
<button action="customersTable.edit"/>
<button action="customersTable.remove"/>
<button action="customersTable.excel"/>
</buttonsPanel>
<columns>
<column id="name"/>
<column id="email"/>
</columns>
<rows datasource="customersDs"/>
</table>buttonsPanel element can be located either inside a table, or in any other place of a screen.
If the buttonsPanel is located in a table, it is combined with the table’s rowsCount component thus using vertical space more effectively. Additionally, if a lookup screen is opened using Frame.openLookup() (for example, from the PickerField component) the buttons panel becomes hidden.
alwaysVisible attribute disables panel hiding in a lookup screen when it is opened by Frame.openLookup(). If the attribute value is true, the buttons panel is not hidden. By default, the attribute value is false.
Clicks on the buttonsPanel area can be intercepted with the help of the LayoutClickListener interface.
4.5.2.2.4. CssLayout
CssLayout is a container that enables full control over placement and styling of enclosed components using CSS.
XML-name of the component: cssLayout.
Below is an example of using cssLayout for simple responsive screen.
Displaying components on a wide screen:
Displaying components on a narrow screen:
Screen’s XML-descriptor:
<cssLayout responsive="true"
stylename="responsive-container"
width="100%">
<vbox margin="true"
spacing="true"
stylename="group-panel">
<textField caption="Field One" width="100%"/>
<textField caption="Field Two" width="100%"/>
<button caption="Button"/>
</vbox>
<vbox margin="true"
spacing="true"
stylename="group-panel">
<textField caption="Field Three" width="100%"/>
<textField caption="Field Four" width="100%"/>
<button caption="Button"/>
</vbox>
</cssLayout>Content of modules/web/themes/halo/halo-ext.scss file (see Extending an Existing Theme for how to create this file):
/* Define your theme modifications inside next mixin */
@mixin halo-ext {
@include halo;
.responsive-container {
&[width-range~="0-900px"] {
.group-panel {
width: 100% !important;
}
}
&[width-range~="901px-"] {
.group-panel {
width: 50% !important;
}
}
}
}-
stylenameattribute enables setting predefined styles to theCssLayoutcomponent either in the XML descriptor or in the screen controller.-
v-component-groupstyle is used to create a grouped set of components, i.e. a row of components which are joined seamlessly together:Unresolved directive in gui_vcl.adoc - include::../../source/gui_vcl/csslayout_3.xml[]
-
wellstyle makes container look "sunken" with shaded background. -
cardstyle name makes a layout look like a card. Combined with an additionalv-panel-captionstyle name for any enclosed layout, it provides a possibility to create enhanced composite layouts, for example:Unresolved directive in gui_vcl.adoc - include::../../source/gui_vcl/csslayout_4.xml[]and result will be the following:
-
Clicks on the CssLayout area can be intercepted with the help of the LayoutClickListener interface.
4.5.2.2.5. Frame
frame element is designed to include frames into a screen.
Attributes:
-
src− path to the frame XML-descriptor.
-
screen– frame identifier in screens.xml (if the frame is registered).
One of these attributes should be defined. If both attributes are defined, frame will be loaded from the file explicitly set in src.
4.5.2.2.6. GridLayout
GridLayout container places components on a grid.

XML-name of the component: grid.
Example container usage:
<grid spacing="true">
<columns count="4"/>
<rows>
<row>
<label value="Date" align="MIDDLE_LEFT"/>
<dateField datasource="orderDs" property="date"/>
<label value="Customer" align="MIDDLE_LEFT"/>
<lookupField datasource="orderDs" property="customer"
optionsDatasource="customersDs"/>
</row>
<row>
<label value="Amount" align="MIDDLE_LEFT"/>
<textField datasource="orderDs" property="amount"/>
</row>
</rows>
</grid>grid elements:
-
columns– a required element, describes grid columns. It should have either acountattribute, or a nestedcolumnelement for each column.In the simplest case, it is enough to set the number of columns in the
countattribute. Then, if the container width is explicitly defined in pixels or percents, free space will be divided between the columns equally.In order to divide screen space non-equally, a
columnelement with aflexattribute should be defined for each column.An example of a grid where the second and the fourth columns take all extra horizontal space and the fourth column takes three times more space:
<grid spacing="true" width="100%"> <columns> <column/> <column flex="1"/> <column/> <column flex="3"/> </columns> <rows> <row> <label value="Date"/> <dateField datasource="orderDs" property="date" width="100%"/> <label value="Customer"/> <lookupField datasource="orderDs" property="customer" optionsDatasource="customersDs" width="100%"/> </row> <row> <label value="Amount"/> <textField datasource="orderDs" property="amount" width="100%"/> </row> </rows> </grid>If
flexis not defined, or is set to 0, the width of the column will be set according to its contents given that at least one other column has a non-zeroflex. In the example above, the first and the third columns will get the width according to the maximum text length.TipIn order for the free space to appear, the entire container width should be set in either pixels or percents. Otherwise, column width will be calculated according to content length, and
flexattribute will have no effect.
-
rows− a required element, contains a set of rows. Each line is defined in its ownrowelement.rowelement can have aflexattribute similar to the one defined forcolumn, but affecting the distribution of free vertical space with a given total grid height.rowelement should contain elements of the components displayed in the grid’s current row cells. The number of components in a row should not exceed the defined number of columns, but it can be less.
Any component located in a grid container can have colspan and rowspan attributes. These attributes set the number of columns and rows occupied by the corresponding component. For example, this is how Field3 field can be extended to cover three columns:
<grid spacing="true">
<columns count="4"/>
<rows>
<row>
<label value="Name 1"/>
<textField/>
<label value="Name 2"/>
<textField/>
</row>
<row>
<label value="Name 3"/>
<textField colspan="3" width="100%"/>
</row>
</rows>
</grid>As a result, the components will be placed in the following way:

Clicks on the GridLayout area can be intercepted with the help of the LayoutClickListener interface.
4.5.2.2.7. GroupBoxLayout
GroupBoxLayout is a container that enables framing the embedded components and setting a universal header for them. Additionally, it can collapse content.
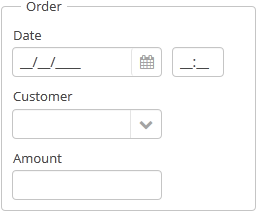
Component XML-name: groupBox.
An example container description in a screen XML-descriptor:
<groupBox caption="Order">
<dateField datasource="orderDs" property="date" caption="Date"/>
<lookupField datasource="orderDs" property="customer"
optionsDatasource="customersDs" caption="Customer"/>
<textField datasource="orderDs" property="amount" caption="Amount"/>
</groupBox>groupBox attributes:
-
caption– group header.
-
orientation– defines components placement direction − horizontal or vertical. The default value isvertical.
-
collapsable– if the value is set totrue, the component’s content can be hidden using/ buttons.
-
collapsed– if set totrue, component’s content will be collapsed initially. It is used withcollapsable="true".An example of a collapsed
GroupBox:
The expanded state change events of the
groupBoxcomponent can be intercepted with the help of theExpandedStateChangeListenerinterface.
-
showAsPanel– if set totrue, the component will look like Vaadin Panel. The default value isfalse.
By default, the groupBox container is 100% wide, similar to vbox.
In Web Client with a Halo-based theme, you can set predefined styles to the groupBox component using the stylename attribute either in the XML descriptor or in the screen controller. When setting a style programmatically, select one of the HaloTheme class constants with the LAYOUT_ or GROUPBOX_ prefix. The following styles should be used combined with showAsPanel attribute set to true:
-
borderlessstyle removes borders and the background color of thegroupBox:groupBox.setShowAsPanel(true); groupBox.setStyleName(HaloTheme.GROUPBOX_PANEL_BORDERLESS);
-
cardstyle name makes a layout look like a card.
-
wellstyle makes container look "sunken" with shaded background:<groupBox caption="Well-styled groupBox" showAsPanel="true" stylename="well" width="300px" height="200px"/>
- Attributes of groupBox
-
align - caption - collapsable - collapsed - expand - height - id - orientation - settingsEnabled - showAsPanel - spacing - stylename - width
- Predefined styles of groupBox
-
borderless - card - well
- Listeners of groupBox
4.5.2.2.8. HtmlBoxLayout
HtmlBoxLayout is a container that enables you to define locations of components in an HTML template. The layout template is included in a theme.
XML-name of the component: htmlBox.
Below is an example of using htmlBox for a simple screen.
Screen’s XML-descriptor:
<htmlBox align="TOP_CENTER"
template="sample"
width="500px">
<label id="logo"
value="Subscribe"
stylename="logo"/>
<textField id="email"
width="100%"
inputPrompt="email@test.test"/>
<button id="submit"
width="100%"
invoke="showMessage"
caption="Subscribe"/>
</htmlBox>template attribute defines the name of an HTML file located in the layouts subdirectory of your theme. You should create a theme extension or a custom theme before creating a template. For example, if your theme is Halo and the attribute contains my_template, the template file should be modules/web/themes/halo/layouts/my_template.html.
Content of the HTML template located in the modules/web/themes/halo/layouts/sample.html file:
<div location="logo" class="logo"></div>
<table class="component-container">
<tr>
<td>
<div location="email" class="email"></div>
</td>
<td>
<div location="submit" class="submit"></div>
</td>
</tr>
</table>A template should contain <div> elements with location attributes. This elements will display CUBA components defined in the XML descriptor with corresponding identifiers.
Content of modules/web/themes/halo/halo-ext.scss file (see Extending an Existing Theme for how to create this file):
@import "../halo/halo";
@mixin halo-ext {
@include halo;
.email {
width: 390px;
}
.submit {
width: 100px;
}
.logo {
font-size: 96px;
text-transform: uppercase;
margin-top: 50px;
}
.component-container {
display: inline-block;
vertical-align: top;
width: 100%;
}
}4.5.2.2.9. ScrollBoxLayout
ScrollBoxLayout − a container that supports content scrolling.
Component XML-name: scrollBox
An example container description in a screen XML-descriptor:
<groupBox caption="Order" width="300" height="170">
<scrollBox width="100%" height="100%" spacing="true" margin="true">
<dateField datasource="orderDs" property="date" caption="Date"/>
<lookupField datasource="orderDs" property="customer" optionsDatasource="customersDs" caption="Customer"/>
<textField datasource="orderDs" property="amount" caption="Amount"/>
</scrollBox>
</groupBox>-
The components placement direction can be defined by
orientationattribute −horizontal`or `vertical. Default isvertical.
-
scrollBarsattribute enables configuring scroll bars. It can behorizontal,vertical– for horizontal and vertical scrolling respectively,both– for scrolling in both directions. Setting the value tononeforbids scrolling in any direction.
|
Warning
|
The components placed in the At the same time, |
- Attributes of scrollBox
-
align - height - id - margin - orientation - scrollBars - spacing - stylename - width
4.5.2.2.10. SplitPanel
SplitPanel − a container divided into two areas by a movable separator.

Component XML-name: split.
An example description of a split panel in a screen XML-descriptor:
<split orientation="horizontal" pos="30" width="100%" height="100%">
<vbox margin="true" spacing="true">
<dateField datasource="orderDs" property="date" caption="Date"/>
<lookupField datasource="orderDs" property="customer" optionsDatasource="customersDs" caption="Customer"/>
</vbox>
<vbox margin="true" spacing="true">
<textField datasource="orderDs" property="amount" caption="Amount"/>
</vbox>
</split>split container must contain two nested containers or components. They will be displayed on both sides of the separator.
split attributes:
-
minSplitPosition,maxSplitPosition- defines a range of the available position of the split which can be set in pixels or percents.For example, you can restrict moving the splitter between 100 and 300 pixels from the left side of the component as follows:
<split id="splitPanel" maxSplitPosition="300px" minSplitPosition="100px" width="100%" height="100%"> <vbox margin="true" spacing="true"> <button caption="Button 1"/> <button caption="Button 2"/> </vbox> <vbox margin="true" spacing="true"> <button caption="Button 4"/> <button caption="Button 5"/> </vbox> </split>If you want to set the range programmatically, specify a unit of value with
Component.UNITS_PIXELSorComponent.UNITS_PERCENTAGE:splitPanel.setMinSplitPosition(100, Component.UNITS_PIXELS); splitPanel.setMaxSplitPosition(300, Component.UNITS_PIXELS);
-
orientation– defines component orientation.horizontal– nested components are placed horizontally,vertical– they are placed vertically.
-
pos– an integer number defining percentage of the first component area compared to the second one. For example,pos="30"means that the areas ration is 30/70. By default the areas are divided 50/50.
-
reversePosition- indicates that theposattribute specifies a position of the splitter from the opposite side of the component.
-
If the
lockedattribute is set totrue, users are unable to change the separator position.
-
The
stylenameattribute with thelargevalue makes the split handle wider.split.setStyleName(HaloTheme.SPLITPANEL_LARGE);
SplitPanel methods:
-
You can get a position of the splitter using the
getSplitPosition()method.
-
The events of moving the splitter can be intercepted with the help of
PositionUpdateListener. -
If you need to get a unit of splitter position, use
getSplitPositionUnit()method. It will returnComponent.UNITS_PIXELSorComponent.UNITS_PERCENTAGE. -
isSplitPositionReversed()returnstrueif position is set from the opposite side of the component.
- Attributes of split
-
align - height - id - locked - minSplitPosition - maxSplitPosition - orientation - pos - reversePosition - settingsEnabled - stylename - width
- Listeners of split
4.5.2.2.11. TabSheet
TabSheet container is a tabbed panel. The panel shows content of one tab at a time.
XML-name of the component: tabSheet.
An example description of a tabbed panel in a screen XML-descriptor:
<tabSheet>
<tab id="mainTab" caption="Tab1" margin="true" spacing="true">
<dateField datasource="orderDs" property="date" caption="Date"/>
<lookupField datasource="orderDs" property="customer" optionsDatasource="customersDs" caption="Customer"/>
</tab>
<tab id="additionalTab" caption="Tab2" margin="true" spacing="true">
<textField datasource="orderDs" property="amount" caption="Amount"/>
</tab>
</tabSheet>The tabSheet component should contain nested tab elements describing tabs. Each tab is a container with a vertical components layout similar to vbox.
tab element attributes:
-
id– tab identifier. Please note that tabs are not components and their IDs are used only within aTabSheetin order to work with tabs from the controller. -
caption – tab caption.
-
lazy– sets lazy loading for tab content.Lazy tabs do not load their content when the screen is opened, which reduces the number of components in memory. Components within a tab are loaded only when a user selects the tab. Additionally, if a lazy-tab includes visual components linked to a data source containing a JPQL query, this query is not executed as well. As a result, screen opens faster, and data is loaded only when the user requests it by selecting this tab.
Please note that the components located on a lazy tab do not exist when the screen is opened. Therefore they cannot be injected into a controller and cannot be obtained by invoking
getComponent()in the controller’sinit()method. The lazy tab components can be accessed only after the user opens the tab. This moment may be intercepted usingTabSheet.SelectedTabChangeListener, for example:@Inject private TabSheet tabsheet; private boolean detailsInitialized, historyInitialized; @Override public void init(Map<String, Object> params) { tabsheet.addSelectedTabChangeListener(event -> { if ("detailsTab".equals(event.getSelectedTab().getName())) { initDetails(); } else if ("historyTab".equals(event.getSelectedTab().getName())) { initHistory(); } }); } private void initDetails(){ if (detailsInitialized) { return; } // use getComponentNN("comp_id") here to get tab's components detailsInitialized=true; } private void initHistory(){ if (historyInitialized) { return; } // use getComponentNN("comp_id") here to get tab's components historyInitialized = true; }By default, tabs are not
lazy, which means that all their content is loaded when a screen is opened.
-
detachable– when it istrue, a tab can be detached to a separate window in a screen desktop implementation. It enables, for example, different parts of the application UI to be located on different monitors. A detachable tab has a special button in its header:

- TabSheet styles
-
In Web Client with a Halo-based theme, you can set predefined styles to the
TabSheetcontainer using thestylenameattribute either in the XML descriptor or in the screen controller:<tabSheet stylename="framed"> <tab id="mainTab" caption="Framed tab"/> </tabSheet>When setting a style programmatically, select one of the
HaloThemeclass constants with theTABSHEET_prefix:tabSheet.setStyleName(HaloTheme.TABSHEET_COMPACT_TABBAR);-
centered-tabs- centers the tabs inside the tab bar. Works best if all the tabs fit completely in the tab bar (i.e. no tab bar scrolling).
-
compact-tabbar- reduces the whitespace around the tabs in the tab bar.
-
equal-width-tabs- gives equal amount of space to all tabs in the tab bar (i.e. expand ratio == 1 for all tabs). The tab captions will be truncated if they do not fit into the tab. Tab scrolling will be disabled when this style is applied (all tabs will be visible at the same time).
-
framed- adds a border around the whole component as well as around individual tabs in the tab bar.
-
icons-on-top- displays tab icons on top of the tab captions (by default the icons are place on the left side of the caption).
-
only-selected-closeable- only the selected tab has the close button visible. Does not prevent closing the tab programmatically, it only hides the button from the end user.
-
padded-tabbar- adds a small amount of padding around the tabs in the tab bar, so that they don’t touch the outer edges of the component.
-
- Attributes of tabSheet
- Attributes of tab
-
caption - closable - detachable - enable - expand - margin - icon - id - lazy - spacing - stylename - visible
- Predefined styles of tabSheet
-
centered-tabs - compact-tabbar - equal-width-tabs - framed - framed - only-selected-closeable - padded-tabbar
- Listeners of tabSheet
4.5.2.3. Miscellaneous
This section describes different elements of the generic user interface that are related to visual components.
4.5.2.3.1. Formatter
|
Warning
|
In an XML-descriptor of a screen, a component’s formatter can be defined in a nested formatter element. The element has a single attribute:
-
class− the name of a class implementing acom.haulmont.cuba.gui.components.Formatter
If formatter’s constructor class has a org.dom4j.Element, parameter, then it will receive an XML element, describing this formatter. This can be used to parameterize a formatter instance. For example, using a formatted string. Particularly, DateFormatter and NumberFormatter classes in the platform can take the format string from the format attribute. Example of using the component:
<column id="date">
<formatter class="com.haulmont.cuba.gui.components.formatters.DateFormatter" format="yyyy-MM-dd HH:mm:ss"/>
</column>Additionally, DateFormatter class also recognizes a type attribute, which can have a DATE or DATETIME value. In this case, formatting is done using the Datatype mechanism using a dateFormat or a dateTimeFormat string respectively. For example:
<column id="endDate">
<formatter class="com.haulmont.cuba.gui.components.formatters.DateFormatter" type="DATE"/>
</column>|
Tip
|
If a formatter is implemented as an internal class, it should be declared with a
|
Formatter can be assigned to a component not only using a screen XML-descriptor , but also programmatically – by submitting a formatter instance into a setFormatter() component.
An example of declaring a custom formatter and using it to format values in a table column:
public class CurrencyFormatter implements Formatter<BigDecimal> {
protected GeneralConfiguration generalConfiguration;
protected Currency currentCurrency;
public CurrencyFormatter(GeneralConfiguration generalConfiguration) {
this.generalConfiguration = generalConfiguration;
currentCurrency = generalConfiguration.getCurrency();
}
@Override
public String format(BigDecimal value) {
return currentCurrency.format(value);
}
}protected void initTableColumns() {
Formatter<BigDecimal> currencyFormatter = new CurrencyFormatter(generalConfiguration);
table.getColumn("totalPrice").setFormatter(currencyFormatter);
}4.5.2.3.2. Presentations
The mechanism of presentations allows users to manage table settings.
Users can:
-
Save presentations with unique names. Table settings are automatically saved in an active presentation.
-
Edit and remove presentations.
-
Switch between presentations.
-
Set up a default presentation, which will be applied on the screen opening.
-
Create global presentations, available to all users. In order to create, change or remove global presentations, a user should have
cuba.gui.presentations.globalsecurity permission.
Presentations are available to components implementing the com.haulmont.cuba.gui.components.Component.HasPresentations interface. These components are:
4.5.2.3.3. Timer
Timer is a non-visual component allowing certain screen controller code to be run at specified time intervals. The timer works in a thread that handles user interface events, therefore it can update screen components. Timer stops working when a screen it was created for gets closed.
The component is implemented for the Web Client and the Desktop Client. For the web client, timer implementation is based on polling from web-browser, for the desktop client it is based on javax.swing.Timer.
The main approach for creating timers is by declaring them in a screen XML-descriptor – in the timers element which is located between dsContext and layout elements.
Timers are described using the timer element.
-
delayis a required attribute; it defines timer interval in milliseconds. -
autostart– an optional attribute; when it is set totrue, timer starts immediately after the screen gets opened. By default the value isfalse, which means that the timer will be started by invoking itsstart()method. -
repeating– an optional attribute, turns on repeating executions of the timer. If the attribute is set totrue, the timer runs in cycles at equal intervals defined in thedelayattribute. Otherwise, the timer runs only once –delaymilliseconds after the timer start. -
onTimer– optional attribute containing a name of a method called when the timer fires. The handling method should be defined in a screen controller with thepublicmodifier and have one parameter of typecom.haulmont.cuba.gui.components.Timer.
An example of using a timer to refresh table content periodically:
<window ...
<dsContext>
<collectionDatasource id="bookInstanceDs" ...
</dsContext>
<timers>
<timer delay="3000" autostart="true" repeating="true" onTimer="refreshData"/>
</timers>
<layout ...@Inject
private CollectionDatasource bookInstanceDs;
public void refreshData(Timer timer) {
bookInstanceDs.refresh();
}A timer can be injected into a controller field, or acquired using the Window.getTimer() method. Timer execution can be controlled using the timer’s start() and stop() methods. For an already active timer, start() invocation will be ignored. After stopping the timer using stop() method, it can be started again with start().
Example of defining a timer in an XML descriptor and using timer listeners in a controller:
<timers>
<timer id="helloTimer" delay="5000"/>
</timers>@Inject
private Timer helloTimer;
@Override
public void init(Map<String, Object> params) {
// add execution handler
helloTimer.addActionListener(timer -> {
showNotification("Hello", NotificationType.HUMANIZED);
});
// add stop listener
helloTimer.addStopListener(timer -> {
showNotification("Timer is stopped", NotificationType.HUMANIZED);
});
// start the timer
helloTimer.start();
}A timer can be created in a controller, for example:
@Inject
private ComponentsFactory componentsFactory;
@Override
public void init(Map<String, Object> params) {
// create timer
Timer helloTimer = componentsFactory.createTimer();
// add timer to the screen
addTimer(helloTimer);
// set timer parameters
helloTimer.setDelay(5000);
helloTimer.setRepeating(true);
// add execution handler
helloTimer.addActionListener(timer -> {
showNotification("Hello", NotificationType.HUMANIZED);
});
// add stop listener
helloTimer.addStopListener(timer -> {
showNotification("Timer is stopped", NotificationType.HUMANIZED);
});
// start the timer
helloTimer.start();
}4.5.2.3.4. Validator
Validator is designed to check values entered into visual components.
|
Warning
|
Validation and input type checking should be differentiated. If a given component (e.g. TextField) data type is set to anything different than string (this can happen when binding to an entity attribute or setting On the other hand, validation does not act immediately on data entry or focus loss, but rather when the component’s |
In a screen XML-descriptor, a component validator can be defined in a nested validator elements. The validator element can have the following attributes:
-
script− path to a Groovy script performing validation. -
class− name of a Java class implementing theField.Validatorinterface.
Groovy validator scripts and standard classes of Java validators, located in the com.haulmont.cuba.gui.components.validators package support message attribute − a message displayed to a user when validation fails. The attribute value should contain either a message or a message key from the messages pack of the current screen. For example:
<validator class="com.haulmont.cuba.gui.components.validators.PatternValidator"
message="msg://validationError"
pattern="\d{3}"/># messages.properties
validationError = Input errorThe validation mechanism is selected as follows:
-
If the value of the
scriptattribute is not set and thevalidatorelement itself does not contain text with a Groovy expression, then the system will use a class defined in theclassattribute as a validator. -
If the
validatorelement contains text, it will be used as a Groovy expression and executed using Scripting. -
Otherwise, the system will use Scripting to run a Groovy script defined in the
scriptattribute.
The value variable will be passed to a Groovy expression or script. It contains the value entered into a visual component. The expression or the script should return a boolean value: true − valid, false − not valid.
If a Java class is being used as a validator, it should have a default constructor without parameters or a constructor with the following set of parameters:
-
org.dom4j.Element,String– this constructor will receive the validator XML-element and the message pack name of the screen. -
org.dom4j.Element– this constructor will receive the validator XML-element.
|
Tip
|
If the validator is implemented as an internal class, it should be declared with a
|
The platform contains the set of implementations for the most frequently used validators (see com.haulmont.cuba.gui.components.validators package), which can be used in your project:
-
DateValidator -
DoubleValidator -
EmailValidator -
IntegerValidator -
LongValidator -
PatternValidator -
RangeValidator -
ScriptValidator -
StringValidator
A validator class can be assigned to a component not only using a screen XML-descriptor, but also programmatically – by submitting a validator instance into the component’s addValidator() method.
Example of creating a validator class for zip codes:
public class ZipValidator implements Field.Validator {
@Override
public void validate(Object value) throws ValidationException {
if (value != null && ((String) value).length() != 6)
throw new ValidationException("Zip must be of 6 characters length");
}
}Example of using a zip code validator and a standard pattern validator for fields of a FieldGroup component:
<fieldGroup>
<field property="zip" required="true">
<validator class="com.company.sample.gui.ZipValidator"/>
</field>
<field property="imei">
<validator class="com.haulmont.cuba.gui.components.validators.PatternValidator"
pattern="\d{15}"
message="IMEI validation failed"/>
</field>
</fieldGroup>Example of setting a validator programmatically in a screen controller:
if (Boolean.TRUE.equals(parameter.getRequired())) {
tokenList.addValidator(new Field.Validator() {
@Override
public void validate(Object value) throws ValidationException {
if (value instanceof Collection && CollectionUtils.isEmpty((Collection) value)) {
throw new ValidationException(getMessage("paramIsRequiredButEmpty"));
}
}
});
}4.5.2.4. XML-Attributes of Components
- align
-
Defines the component position relative to the parent container. Possible values are:
-
TOP_RIGHT -
TOP_LEFT -
TOP_CENTER -
MIDDLE_RIGHT -
MIDDLE_LEFT -
MIDDLE_CENTER -
BOTTOM_RIGHT -
BOTTOM_LEFT -
BOTTOM_CENTER
-
- caption
-
Sets the component’s caption.
The attribute value can either be a message or a key in a message pack. In case of a key, the value should begin with the
msg://prefix.There are two ways of setting a key:
-
A short key – in this case the message will be searched in the package of the current screen:
caption="msg://infoFieldCaption" -
Full key including package name:
caption="msg://com.company.sample.gui.screen/infoFieldCaption"
-
- captionProperty
-
Defines the name of an entity attribute which is displayed by a component.
captionPropertycan only be used for entities contained in a datasource (for example, defined by the optionsDatasource property of the LookupField component).If
captionPropertyis not defined, instance name is shown.
- colspan
-
Sets the number of grid columns that the component should occupy (default is 1).
This attribute can be defined for any component located immediately within a GridLayout container.
- datasource
-
Sets a data source defined in the
dsContextsection of the screen XML descriptor.When setting the
datasourceattribute for a component implementing theDatasourceComponentinterface, the property attribute should also be set.
- description
-
Defines a hint which is displayed in a popup when a user hovers the mouse cursor over the component.
- editable
-
Indicates that the component’s content can be edited (do not confuse with enable).
Possible values −
true,false. Default value istrue.Ability to edit content of a component bound to data (inheritor of
DatasourceComponentorListComponent) is also influenced by the security subsystem. If the security subsystem information indicates that the component should not be editable, the value of itseditableattribute is ignored.
- enable
-
Defines the component’s enabled/disabled state.
If a component is disabled, it does not accept input focus. Disabling a container disables all of its components as well. Possible values are
true,false. By default all components are enabled.
- expand
-
Defines a component within the container that should be expanded to use all available space in the direction of component placement. For a container with vertical placement, this attribute sets 100% height to a component; for the containers with horizontal placement - 100% width. Additionally, resizing a container will resize the expanded component.
- height
-
Sets the component’s height. Can be set in pixels or in percents of the parent container height. For example:
100px,100%,50. If it is specified without units, pixels are assumed.Setting a value in
%means that the component will occupy the corresponding height within an area provided by the parent container.When set to
AUTOor-1px, a default value will be used for the component height. For a container, default height is defined by the content: it is the sum of the heights of all nested components.
- icon
-
Sets a component icon.
The attribute value should contain a path to an icon file relative to the themes folder. For example:
icon="icons/create.png"If different icons should be displayed depending on the user’s language, you can set paths to the icons in the message pack and specify a message key in the
iconattribute, for example:icon="msg://addIcon"Font elements of Font Awesome can be used instead of files in web client with Halo theme (or derived from it). For this, specify the name of the required constant of the
com.vaadin.server.FontAwesomeclass in the icon property with thefont-icon:prefix, for example:icon="font-icon:BOOK"
- id
-
Sets an identifier of the component.
It is recommended to create identifiers according to the rules for Java-identifiers and use camelСase, for example:
userGrid,filterPanel. Theidattribute can be specified for any component and should be unique within a screen.
- inputPrompt
-
Defines a string which is displayed in the field when its value is
null.The attribute is used for TextField, LookupField, LookupPickerField, SearchPickerField components in web client only.
- margin
-
Defines indentation between the outer borders and the container content.
It can take value of two types:
-
margin="true"− enables margins for all sides. -
margin="true,false,true,false"− enables only the top and the bottom margin (the value format is "top,right,bottom,left").
By default margins are disabled.
-
- nullName
-
Selection of the option defined in the
nullNameattribute is equal to setting thenullvalue to the component.The attribute is used for LookupField, LookupPickerField, and SearchPickerField components.
Example of setting an attribute value in an XML-descriptor:
<lookupField datasource="orderDs" property="customer" nullName="(none)" optionsDatasource="customersDs" width="200px"/>Example of setting an attribute value in a controller:
<lookupField id="customerLookupField" optionsDatasource="customersDs" width="200px" datasource="orderDs" property="customer"/>customerLookupField.setNullOption("<null>");
- openType
-
Defines how a related screen will be opened. Corresponds to the
WindowManager.OpenTypeenumeration with the valuesNEW_TAB,THIS_TAB,NEW_WINDOW,DIALOG. Default value isTHIS_TAB.
- optionsDatasource
-
Sets the name of a data source which contains a list of options.
captionProperty attribute can be used together with
optionsDatasource.
- property
-
Sets the name of an entity attribute which value will be displayed and edited by this visual component.
propertyis always used together with the datasource attribute.
- required
-
Indicates that this field requires a value.
Possible values −
true,false. Default isfalse.The requiredMessage attribute can be used together with
required.
- requiredMessage
-
Used together with the required attribute. It sets a message that will be displayed to a user when the component has no value.
The attribute can contain a message or a key from a message pack, for example:
requiredMessage="msg://infoTextField.requiredMessage"
- responsive
-
Indicates that the component should react on change in the available space. Reaction can be customized with the help of styles.
Possible values −
true,false. Default isfalse.
- rowspan
-
Sets the number of grid lines that the component should occupy (default is 1).
This attribute can be set for any component located immediately within a GridLayout container.
- settingsEnabled
-
Defines if user settings of the component should be saved/restored.
Possible values −
true,false. Default istrue.
- spacing
-
Sets spacing between components within a container.
Possible values −
true,false.By default spacing is disabled.
- stylename
-
Defines a style name for a component. See Themes for details.
- tabIndex
-
Specifies whether the component is focusable and sets the relative order of the component in the sequence of focusable components on the screen.
It can can take integer values of positive or negative range:
-
negative valuemeans that the component should be focusable, but should not be reachable via sequential keyboard navigation; -
0means that the component should be focusable and reachable via sequential keyboard navigation, but its relative order follows its relative position on the screen; -
positive valuemeans the component should be focusable and reachable via sequential keyboard navigation; its relative order is defined by the value of the attribute: the sequential follows the increasing number of thetabIndex. If several components share the sametabIndexvalue, their relative order follows their relative position on the screen.
-
- visible
-
Sets visibility of the component. Possible values −
true,false.If a container is invisible all its components are invisible. By default all components are visible.
- width
-
Defines component’s width.
The value can be set in pixels or in percents of the width of the parent container. For example:
100px,100%,50. If specified without units, pixels are assumed. Setting a value in%means that the component will occupy the corresponding width within an area provided by the parent container.When set to
AUTOor-1px, a default value will be used for a component width. For a container, the default width is defined by the content: it is the sum of the widths of all nested components.
4.5.3. Datasources
Datasources provide data to data-aware components.
Visual components themselves do not access Middleware: they get entity instances from linked datasources. Furthermore, one datasource can work with multiple visual components if they need the same instance or set of instances.
-
When a user changes a value in the component, the new value is set for the entity attribute in the datasource.
-
When the entity attribute is modified in the code, the new value is set and displayed in the visual component.
-
User input can be monitored both by datasource listeners and value listeners on the component – they are notified sequentially.
-
To read or write the value of an attribute in the application code, it is recommended to use the datasource, rather than the component. Below is an example of reading the attribute:
@Inject private FieldGroup fieldGroup; @Inject private Datasource<Order> orderDs; @Named("fieldGroup.customer") private PickerField customerField; public void init(Map<String, Object> params){ Customer customer; // Get customer from component: not for common use Component component = fieldGroup.getFieldNN("customer").getComponentNN(); customer = ((HasValue)component).getValue(); // Get customer from component: recommended customer = customerField.getValue(); // Get customer from datasource customer = orderDs.getItem().getCustomer(); }As you can see, working with entity attribute values through a component is not very straightforward. In the first example, it requires type casting and specifying FieldGroup field
idas a string. The second example is more safe and direct, but requires you to know exactly the type of the field to be injected. At the same time, if the instance is obtained from the datasource via thegetItem()method, the values of attributes can be read and modified directly.
Datasources also track changes in entities contained therein and can send modified instances back to the middleware for storing in the database.
|
Warning
|
Typically, a visual component is bound to an attribute that directly belongs to the entity in the datasource. In the example above, the component is bound to the A component can also be associated with an attribute of a related entity, for example, |
The basic interfaces of datasources are described below.
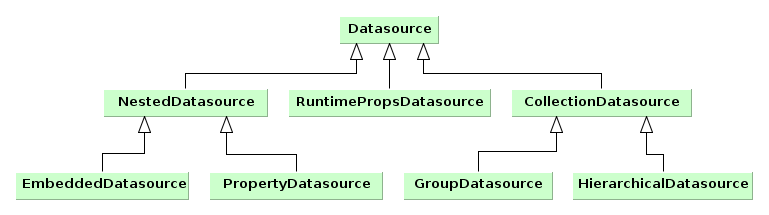
Figure 20. Datasource interfaces
-
Datasourceis a simple datasource designed to work with one entity instance. The instance is set by thesetItem()method and is accessed viagetItem().DatasourceImplclass is the standard implementation of such datasource, which is used, for instance, as a main datasource on entity edit screens. -
CollectionDatasourceis a datasource designed to work with a collection of entity instances. The collection is loaded with the invocation of therefresh()method, instance keys are accessible through thegetItemIds()method. ThesetItem()method sets the "current" instance of the collection andgetItem()returns it (for example, the one that corresponds to the currently selected table row).The way of loading collections is determined by implementation. The most typical one is loading from Middleware via DataManager; in this case,
setQuery(),setQueryFilter()are used to form a JPQL query.CollectionDatasourceImplclass is the standard implementation of such datasources, which is used on screens with entity lists.-
GroupDatasourceis a subtype ofCollectionDatasource, designed to work with the GroupTable component.Standard implementation is the
GroupDatasourceImplclass. -
HierarchicalDatasourceis a subtype ofCollectionDatasource, designed to work with the Tree and TreeTable components.Standard implementation is the
HierarchicalDatasourceImplclass.
-
-
NestedDatasourceis a datasource designed to work with instances that are loaded in an attribute of another entity. In this case, a datasource that contains a parent entity is accessible viagetMaster(), and meta property that corresponds to the parent attribute containing instances of this datasource is accessible viagetProperty().For example an
Orderinstance which contains a reference to theCustomerinstance is set in thedsOrderdatasource. Then, to link theCustomerinstance with visual components, it is enough to createNestedDatasourcewithdsOrderas parent and meta property to point to theOrder.customerattribute.-
PropertyDatasourceis a subtype ofNestedDatasource, designed to work with one instance or collection of related entities that are not embedded.Standard implementations: for working with one instance –
PropertyDatasourceImpl, with a collection –CollectionPropertyDatasourceImpl,GroupPropertyDatasourceImpl,HierarchicalPropertyDatasourceImpl. The latter also implements theCollectionDatasourceinterface, however some of its irrelevant methods likesetQuery()throwUnsupportedOperationException. -
EmbeddedDatasourceis a subtype ofNestedDatasource, which contains an instance of an embedded entity.Standard implementation is the
EmbeddedDatasourceImplclass.
-
-
RuntimePropsDatasourceis a specific datasource, designed to work with dynamic attributes of entities.
Typically, datasources are declared in the dsContext section of a screen descriptor.
4.5.3.1. Creating Datasources
Datasource objects can be created both declaratively, using an XML screen descriptor, and programmatically in a controller. Typically, standard implementation of datasources is used, however, you can create your own class that is inherited from a standard one, if necessary.
4.5.3.1.1. Declarative Creation
Typically, datasources are declared in the dsContext element of a screen descriptor. Depending on the relative position of declaration elements, datasources of two varieties are created:
-
if an element is located directly in
dsContext, a normalDatasourceorCollectionDatasource, which contains an independently loaded entity or collection, is created; -
if an element is located inside an element of another datasource,
NestedDatasourceis created and the external datasource becomes its parent.
Below is an example of declaring a datasource:
<dsContext>
<datasource id="carDs" class="com.haulmont.sample.entity.Car" view="carEdit">
<collectionDatasource id="allocationsDs" property="driverAllocations"/>
<collectionDatasource id="repairsDs" property="repairs"/>
</datasource>
<collectionDatasource id="colorsDs" class="com.haulmont.sample.entity.Color" view="_local">
<query>
<![CDATA[select c from sample$Color c order by c.name]]>
</query>
</collectionDatasource>
</dsContext>In the example above, carDs contains one entity instance, Car, and nested allocationsDs and repairsDs contain collections of related entities from the Car.driverAllocations and Car.repairs attributes, respectively. The Car instance together with related entities is set into the datasource from the outside. If this screen is an edit screen, it happens automatically when opening the screen. The colorsDs datasource contains a collection of instances of the Color entity, which is loaded by the datasource itself using the specified JPQL query with the _local view.
Below is the XML scheme.
dsContext – root element.
dsContext elements:
-
datasource– defines a datasource that contains a single entity instance.Attributes:
-
id– datasource identifier, must be unique for thisDsContext. -
class– Java class of an entity that will be contained in this datasource. -
view– name of entity view. If the datasource itself loads instances, then this view will be used during loading. Otherwise, this view makes signals to external mechanisms on how to load an entity for this datasource. -
allowCommit– if set tofalse, theisModified()method of this datasource always returnsfalseand thecommit()method does nothing. Thus, changes in entities that are contained in the datasource are ignored. By default, it is set totrue, i.e., changes are tracked and can be saved. -
datasourceClassis a custom implementation class, if necessary.
-
-
collectionDatasource– defines a datasource that contains a collection of instances.collectionDatasourceattributes:-
refreshMode– a datasource update mode, default isALWAYS. In theNEVERmode, whenrefresh()method is invoked, the datasource does not load data and only changes its state toDatasource.State.VALID, notifies listeners and sorts available instances. TheNEVERmode is useful if you need to programmatically fillCollectionDatasourcewith preloaded or created entities. For example:@Override public void init(Map<String, Object> params) { Set<Customer> entities = (Set<Customer>) params.get("customers"); for (Customer entity : entities) { customersDs.includeItem(entity); } customersDs.refresh(); } -
softDeletion– the false value disables the soft deletion mode when loading entities, i.e., deleted instances will also be loaded. Default value istrue.
collectionDatasourceelements:-
query– query to load entities
-
-
groupDatasource– completely similar tocollectionDatasource, but creates datasource implementation that is suitable to use in conjunction with the GroupTable component. -
hierarchicalDatasource– similar tocollectionDatasource, and creates datasource implementation that is suitable to use in conjunction with the Tree and TreeTable components.hierarchyPropertyis a specific attribute. It specifies an attribute name, upon which a hierarchy is built.
A datasource implementation class is selected implicitly based on the name of the XML element and, as mentioned above, the mutual arrangement of elements. However, if you need to apply a custom datasource, you can explicitly specify its class in the datasourceClass attribute.
4.5.3.1.2. Programmatic Creation
If you need to create a datasource in the Java code, it is recommended to use a special class, DsBuilder.
The DsBuilder instance is parameterized by an invocation chain of its methods in the fluent interface style. If the master and property parameters are set, then NestedDatasource will be created, otherwise – Datasource or CollectionDatasource.
Example:
CollectionDatasource ds = new DsBuilder(getDsContext())
.setJavaClass(Order.class)
.setViewName(View.LOCAL)
.setId("ordersDs")
.buildCollectionDatasource();4.5.3.1.3. Custom Implementation Classes
If you need to implement a custom mechanism of loading entities, create a custom datasource class inherited from CustomCollectionDatasource, CustomGroupDatasource, or CustomHierarchicalDatasource, and implement the getEntities() method.
For example:
public class MyDatasource extends CustomCollectionDatasource<SomeEntity, UUID> {
private SomeService someService = AppBeans.get(SomeService.NAME);
@Override
protected Collection<SomeEntity> getEntities(Map<String, Object> params) {
return someService.getEntities();
}
}To create a custom datasource instance declaratively, specify the custom class name in the datasourceClass attribute of the datasource XML element. In case of programmatic creation via DsBuilder, specify the class by invoking setDsClass() or as a parameter of one of the build*() methods.
4.5.3.2. CollectionDatasourceImpl Queries
The CollectionDatasourceImpl class and its subclasses, GroupDatasourceImpl and HierarchicalDatasourceImpl, are standard implementations of datasources that work with collections of entity instances. These datasources load data via DataManager by sending a JPQL queries to the middleware. The format of these queries is described below.
4.5.3.2.1. Returned values
A query should return entities of the type which is specified at the moment of creating a datasource. In case of declarative creation, the entity type is specified in the class attribute of an XML element, if DsBuilder is used – in the setJavaClass() or setMetaClass() method.
For example, a query of the datasource of the Customer entity may look as follows:
select c from sales$Customer cor
select o.customer from sales$Order oA query cannot return single attributes or aggregates, for example:
select c.id, c.name from sales$Customer c /* invalid – returns single fields, not the whole Customer object */If you need to execute a query which returns scalar values or aggregates and to display the results in visual components using standard data binding, use Value Datasources.
4.5.3.2.2. Query Parameters
A JPQL query in a datasource may contain parameters of several types. A parameter type is determined by a prefix of a parameter name. A prefix is a part of the name before the $ character. The interpretation of the name after $ is described below.
-
The
dsprefixThe parameter value is data from another datasource that is registered in the same
DsContext. For example:<collectionDatasource id="customersDs" class="com.sample.sales.entity.Customer" view="_local"> <query> <![CDATA[select c from sales$Customer c]]> </query> </collectionDatasource> <collectionDatasource id="ordersDs" class="com.sample.sales.entity.Order" view="_local"> <query> <![CDATA[select o from sales$Order o where o.customer.id = :ds$customersDs]]> </query> </collectionDatasource>In the example above, a query parameter of the
ordersDsdatasource will be a current entity instance located in thecustomersDsdatasource.If parameters with the
dsprefix are used, dependencies between datasources are created automatically. They lead to updating the datasource if its parameter are changed. In the example above, if the selected Customer is changed, the list of its Orders is changed automatically.Please note that in the example of the parameterized query, the left part of the comparison operator is the value of the
o.customer.ididentifier, and the right part – theCustomerinstance that is contained in thecustomersDsdatasource. This comparison is valid since when running a query at Middleware, the implementation of the Query interface, by assigning values to query parameters, automatically adds entity ID instead of a passed entity instance.A path through the entity graph to an attribute (from which the value should be used) can be specified in the parameter name after the prefix and name of a datasource, for example:
<query> <![CDATA[select o from sales$Order o where o.customer.id = :ds$customersDs.id]]> </query>or
<query> <![CDATA[select o from sales$Order o where o.tagName = :ds$customersDs.group.tagName]]> </query>
-
The
customprefix.A parameter value will be taken from the
Map<String, Object>object that is passed into therefresh()method of a datasource. For example:<collectionDatasource id="ordersDs" class="com.sample.sales.entity.Order" view="_local"> <query> <![CDATA[select o from sales$Order o where o.number = :custom$number]]> </query> </collectionDatasource>ordersDs.refresh(ParamsMap.of("number", "1"));Casting an instance to its identifier, if necessary, is performed similarly to parameters with the
dsprefix. The path through the entity graph in the parameter name is not supported in this case.
-
The
paramprefix.A parameter value is taken from the
Map<String, Object>object that is passed into theinit()method of a controller. For example:<query> <![CDATA[select e from sales$Order e where e.customer = :param$customer]]> </query>openWindow("sales$Order.lookup", WindowManager.OpenType.DIALOG, ParamsMap.of("customer", customersTable.getSingleSelected()));Casting an instance to its identifier, if necessary, is performed similarly to parameters with the
dsprefix. The path through the entity graph in the parameter name is supported.
-
The
componentprefix.A parameter value will be a current value of a visual component, which path is specified in the parameter name. For example:
<query> <![CDATA[select o from sales$Order o where o.number = :component$filter.orderNumberField]]> </query>The path to a component should include all nested frames.
Casting an instance to its identifier, if necessary, is similar to
dsparameters. The path through the entity graph in the parameter name is supported as the continuation of the path to a component in this case.TipThe datasource will not be refreshed automatically if the component value is changed.
-
The
sessionprefix.A parameter value will be a value of the user session attribute specified in the parameter name.
The value is extracted by the
UserSession.getAttribute()method, so predefined names of session attributes are also supported.-
userId– ID of the currently registered or substituted user; -
userLogin– login of the currently registered or substituted user in lowercase.
Example:
<query> <![CDATA[select o from sales$Order o where o.createdBy = :session$userLogin]]> </query>Casting an instance to its identifier, if necessary, is similar to
dsparameters. In this case, the path through the entity graph in the parameter name is not supported. -
4.5.3.2.3. Query Filter
A datasource query can be modified during the work of the application, depending on conditions entered by the user. This allows you to efficiently filter data at the level of selection from DB.
The easiest way to provide such ability is to connect a special visual component, Filter, to a datasource.
If by any reason the use of a universal filter is unwanted, a special XML markup can be embedded into a query text. This will allow to create a resulting query based on values entered by the user into any visual components of the screen.
In this filter the following elements can be used:
-
filter– a root element of the filter. It can directly contain only one condition.-
and,or– logical conditions, may contain any number of other conditions and statements. -
c– JPQL statement, which is added into thewheresection. It contains only the text and an optionaljoinattribute, which value will be added into a corresponding place of the query.
-
Conditions and statements are added into the resulting query only if parameters inside contain values, i.e., they are not null.
|
Warning
|
Example:
<query>
<![CDATA[select distinct d from app$GeneralDoc d]]>
<filter>
<or>
<and>
<c join=", app$DocRole dr">dr.doc.id = d.id and d.processState = :custom$state</c>
<c>d.barCode like :component$barCodeFilterField</c>
</and>
<c join=", app$DocRole dr">dr.doc.id = d.id and dr.user.id = :custom$initiator</c>
</or>
</filter>
</query>In this case, if state and initiator parameters are passed into the refresh() method of a datasource, and a visual component, barCodeFilterField, has some value specified, then the resulting query will be as follows:
select distinct d from app$GeneralDoc d, app$DocRole dr
where
(
(dr.doc.id = d.id and d.processState = :custom$state)
and
(d.barCode like :component$barCodeFilterField)
)
or
(dr.doc.id = d.id and dr.user.id = :custom$initiator)If, for example, the barCodeFilterField component is empty and only one parameter, initiator, was passed into the refresh() method, the query will be as follows:
select distinct d from app$GeneralDoc d, app$DocRole dr
where
(dr.doc.id = d.id and dr.user.id = :custom$initiator)4.5.3.2.4. Case-Insensitive Search for a Substring
It is possible to use a special feature of JPQL queries execution in datasources, described for the Query interface of the Middleware level: for easy creation of case-insensitive search condition of any substring, (?i) prefix can be used. However, due to the fact that the query value is usually passed implicitly, the following differences take place:
-
The
(?i)prefix should be specified before a parameter name and not inside the value. -
The parameter value will be automatically converted to lowercase.
-
If the parameter value does not have
%characters, they will be added to the beginning and the end.
Below is an example of how to process the following query:
select c from sales$Customer c where c.name like :(?i)component$customerNameFieldIn this case, the parameter value taken from the customerNameField component will be converted to lowercase and will be framed with % characters, and then an SQL query with a lower(C.NAME) like ? condition will be executed in the database.
Please note that with this search, an index created in the DB by the NAME field, will not be used.
4.5.3.3. Value Datasources
Value datasources enable execution of queries that return scalar values and aggregates. For example, you can load some aggregated statistics for customers:
select o.customer, sum(o.amount) from demo$Order o group by o.customerValue datasources work with entities of a special type named KeyValueEntity. This entity can contain an arbitrary number of attributes which are defined at runtime. So in the example above, the KeyValueEntity instances will contain two attributes: the first of type Customer and the second of type BigDecimal.
Value datasource implementations extend other widely used collection datasource classes and implement a specific interface: ValueDatasource. Below is a diagram showing the value datasource implementations and their base classes:
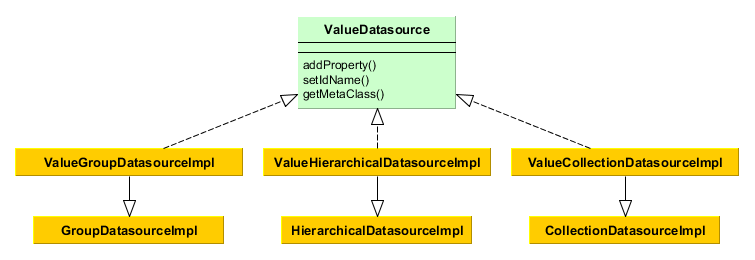
The ValueDatasource interface declares the following methods:
-
addProperty()- as the datasource can return entities with any number of attributes, you have to specify what attributes are expected by using this method. It accepts a name of the attribute and its type in the form of Datatype or a Java class. In the latter case, the class should be either an entity class or a class supported by one the datatypes. -
setIdName()is an optional method which allows you to define one of the attributes as an identifier attribute of the entity. It means thatKeyValueEntityinstances contained in this datasource will have identifiers obtained from the given attribute. Otherwise,KeyValueEntityinstances get randomly generated UUIDs. -
getMetaClass()returns a dynamic implementation of theMetaClassinterface that represents the current schema ofKeyValueEntityinstances. It is defined by previous calls toaddProperty().
Value datasources can be used declaratively in a screen XML descriptor. There are three XML elements corresponding to the implementation classes:
-
valueCollectionDatasource -
valueGroupDatasource -
valueHierarchicalDatasource
XML definition of a value datasource must contain the properties element that defines the attributes of KeyValueEntity instances that will be contained in the datasource (see the addProperty() method description above). The order of property elements should conform to the order of result set columns returned by the query. For example, in the following definition the customer attribute will get its value from o.customer column and the sum attribute from sum(o.amount) column:
<dsContext>
<valueCollectionDatasource id="salesDs">
<query>
<![CDATA[select o.customer, sum(o.amount) from demo$Order o group by o.customer]]>
</query>
<properties>
<property class="com.company.demo.entity.Customer" name="customer"/>
<property datatype="decimal" name="sum"/>
</properties>
</valueCollectionDatasource>
</dsContext>Value datasources are designed only for reading data, because KeyValueEntity is not persistent and cannot be saved by standard persistence mechanisms.
4.5.3.4. Datasource Listeners
Datasource listeners receive notifications of changes in the state of datasources and entities contained in them.
There are four types of listeners. Three of them: ItemPropertyChangeListener, ItemChangeListener and StateChangeListener are defined in the Datasource interface and can be used in any datasource. CollectionChangeListener is defined in CollectionDatasource and can be used only in datasources working with collections of entities.
Example of using datasource listeners:
public class EmployeeBrowse extends AbstractLookup {
private Logger log = LoggerFactory.getLogger(EmployeeBrowse.class);
@Inject
private CollectionDatasource<Employee, UUID> employeesDs;
@Override
public void init(Map<String, Object> params) {
employeesDs.addItemPropertyChangeListener(event -> {
log.info("Property {} of {} has been changed from {} to {}",
event.getProperty(), event.getItem(), event.getPrevValue(), event.getValue());
});
employeesDs.addStateChangeListener(event -> {
log.info("State of {} has been changed from {} to {}",
event.getDs(), event.getPrevState(), event.getState());
});
employeesDs.addItemChangeListener(event -> {
log.info("Datasource {} item has been changed from {} to {}",
event.getDs(), event.getPrevItem(), event.getItem());
});
employeesDs.addCollectionChangeListener(event -> {
log.info("Datasource {} content has been changed due to {}",
event.getDs(), event.getOperation());
});
}
}The listener interfaces are described below.
-
ItemPropertyChangeListeneris added by theDatasource.addItemPropertyChangeListener()method. The listener is invoked when an attribute of an entity contained in the datasource is changed. The modified entity instance itself, the name of changed attribute, old and new values can be obtained from the event object passed to the listener.The
ItemPropertyChangeListenercan be used to react to changes made in an entity instance by UI components, i.e. when a user edits input fields. -
ItemChangeListeneris added by theDatasource.addItemChangeListener()method. The listener is invoked when a selected entity instance returned by theDatasource.getItem()method is changed.For
Datasource, it happens when another instance (ornull) is set to the datasource withsetItem()method.For
CollectionDatasource, this listener is invoked when a selected element is changed in a linked visual component. For example, it may be a selected table row, tree element or item in a drop-down list. -
StateChangeListeneris added by theDatasource.addStateChangeListener()method. The listener is invoked when a state of the datasource is changed. The datasource can be in one of three states corresponding to theDatasource.Stateenumeration:-
NOT_INITIALIZED– datasource has just been created. -
INVALID– the whole DsContext, which this datasource is related to, is created. -
VALID– datasource is ready:Datasourcecontains an entity instance or null,CollectionDatasource– collection of instances or an empty collection.
Receiving a notification about changes in datasource state may be important for complex editors, which consist of several frames where it is difficult to trace the moment of setting an edited entity into the datasource. In this case,
StateChangeListenercan be used for the delayed initialization of certain screen elements:employeesDs.addStateChangeListener(event -> { if (event.getState() == Datasource.State.VALID) initDataTypeColumn(); }); -
-
CollectionChangeListeneris added by theCollectionDatasource.addCollectionChangeListener()method. The listener is invoked when a entity collection, which is stored in the datasource, is changed. The event object provides thegetOperation()method returning value of typeCollectionDatasource.Operation:REFRESH,CLEAR,ADD,REMOVE,UPDATE. It indicates the operation that caused the collection changes.
4.5.3.5. DsContext
All datasources that are created declaratively are registered in the DsContext object which belongs to a screen. A reference to DsContext can be obtained using the getDsContext() method of a screen controller or via Controller Dependency Injection.
DsContext is designed for the following tasks:
-
Organizes dependencies between datasources when navigation through a record set in one datasource (i.e. changing a "current" instance with the
setItem()method) causes a related datasource to be updated. These dependencies allow you to organize master-detail relationships between visual components on screens.Dependencies between datasources are organized using query parameters with the
ds$prefix. -
Collects all changed entity instances and sends them to Middleware in a single invocation of
DataManager.commit(), i.e. to save them into the database in a single transaction.As an example, let’s assume that some screen allows a user to edit an instance of the
Orderentity and a collection ofOrderLineinstances belonging to it. TheOrderinstance is located inDatasource; theOrderLinecollection – in nestedCollectionDatasource, which is created using theOrder.linesattribute. If user changes some attribute ofOrderand creates a new instance,OrderLine. Then, when a screen is committed to DataManager, two instances – changedOrderand newOrderLine– will be sent simultaneously. After that, they will together be merged into one persistent context and saved into the database on the transaction commit. TheOrderLineinstance is also contained in theOrder.linescollection, but if it’s not passed into persistent context independently, the cascade merging betweenOrderandOrderLinesat the ORM level should be set. Tight cascade relations at the ORM level sometimes cause unwanted consequences in unexpected places, so it is better to avoid them, as described in theDsContextmechanism.As a result of committing the transaction,
DsContextreceives a set of saved instances from Middleware (in the case of optimistic locking they, at least, have an increased value of theversionattribute), and sets these instances in datasources replacing old ones. It allows you to work with the latest instances immediately after committing without an extra datasource refresh that produces queries to Middleware and the database. -
Declares two listeners:
BeforeCommitListenerandAfterCommitListener. They receive notifications before and after committing modified instances.BeforeCommitListenerenables to supplement a collection of entities sent to DataManager to save arbitrary entities in the same transaction. A collection of saved instances that are returned fromDataManagercan be obtained after commit in theAfterCommitListenerlistener.This mechanism is required if some entities, with which a screen works, are not under control of datasources, but are created and changed directly in the controller code. For example, a visual component, FileUploadField, after uploading a file, creates a new entity instance,
FileDescriptor, which can be saved together with other screen entities by adding toCommitContextinBeforeCommitListener.In the following example, a new instance of
Customerwill be sent to Middleware and saved to the database together with other modified screen entities when the screen is committed:protected Customer customer; protected void createNewCustomer() { customer = metadata.create(Customer.class); customer.setName("John Doe"); } @Override public void init(Map<String, Object> params) { getDsContext().addBeforeCommitListener(context -> { if (customer != null) context.getCommitInstances().add(customer); } }
4.5.3.6. DataSupplier
DataSupplier – interface, through which the datasources refer to Middleware for loading and saving entities. The standard implementation simply delegates to DataManager. A screen can define its implementation of the DataSupplier in dataSupplier attribute of the window element.
A reference to DataSupplier can be obtained either by injection into a screen controller or through the DsContext or Datasource instances. In both cases, an own implementation is returned if defined for the screen.
4.5.4. Actions. The Action Interface
Action is an interface that abstracts an action (in other words, some function) from a visual component. It is particularly useful when the same action can be invoked from different visual components ((for example, from button and table context menu). In addition, this interface allows you to provide the action with additional properties, such as name, flags of accessibility and visibility, etc.
Below are the Action interface methods:
-
actionPerform()is invoked by a visual component associated with this action. An instance of the caller is passed to the method. -
getId()returns an identifier of the action. The identifier is usually set by a constructor of a class that implementsActionand does not change throughout the lifecycle of the created action object. -
Methods for getting and setting
caption,description,shortcut,icon,enabled,visibleproperties. Typically, all these properties are used by related visual components to set their own corresponding properties. -
addPropertyChangeListener(),removePropertyChangeListener()methods used to add and remove listeners which handle changes to the abovementioned properties. A listener receives notification ofjava.beans.PropertyChangeEventtype, which contains the name of the changed property, its old and new values. -
refreshState()- a method that can be implemented in a particular action class to initialize the abovementioned properties in accordance to some external factors, such as user rights. It is usually invoked in constructors of implementing classes or from related visual components. -
addOwner(),removeOwner(),getOwner(),getOwners()– methods used to control relation between the action and visual components.
It is recommended to implement actions using the declarative creation or by inheriting from the BaseAction class. Furthermore, there is a set of standard actions applicable for tables and picker components. You can also derive action classes from standard actions to modify their behavior or to intercept events.
Visual components associated with an action can be of two types:
-
Visual component with a single action implements the
Component.ActionOwnerinterface. These are Button and LinkButton.Action is linked to the component by the invocation of the
ActionOwner.setAction()component method. At this point, the component replaces its properties with corresponding properties of the action (see components overview for details). -
Visual component containing several actions implements the
Component.ActionsHolderinterface. These areWindow,Frame, Table and its inheritors, Tree, PopupButton, PickerField, LookupPickerField.The
ActionsHolder.addAction()method is used to add actions to the component. Implementation of this method in the component checks whether it already contains an action with the same identifier. If yes, then the existing action will be replaced with the new one. Therefore, it is possible, for example, to declare a standard action in a screen descriptor and then create a new one in the controller with overridden methods and add it to the component.
4.5.4.1. Declarative Creation of Actions
You can specify a set of actions in an XML screen descriptor for any component that implements the Component.ActionsHolder interface, including the entire screen or frame. This is done in the actions element, which contains nested action elements.
The action element can have the following attributes:
-
id− identifier, which should be unique within theActionsHoldercomponent. -
caption– action name. -
description– action description. -
enable– accessibility flag (true/false). -
icon– action icon. -
invoke- name of the controller method to be invoked. The method should bepublicvoid, and either not have arguments or have one argument of theComponenttype. If the method has aComponentargument, then an instance of the visual component that launches this action will be passed to it when invoked. -
shortcut- keyboard shortcut for invocation.Shortcut values can be hard-coded in the XML descriptor. Possible modifiers,
ALT,CTRL,SHIFT, are separated by the "-" character. For example:<action id="create" shortcut="ALT-N"/>To avoid the hard code, you can use the predefined shortcut aliases from the list below, for example:
<action id="edit" shortcut="${TABLE_EDIT_SHORTCUT}"/>-
TABLE_EDIT_SHORTCUT -
COMMIT_SHORTCUT -
CLOSE_SHORTCUT -
FILTER_APPLY_SHORTCUT -
FILTER_SELECT_SHORTCUT -
NEXT_TAB_SHORTCUT -
PREVIOUS_TAB_SHORTCUT -
PICKER_LOOKUP_SHORTCUT -
PICKER_OPEN_SHORTCUT -
PICKER_CLEAR_SHORTCUT
Another option is to use the full qualified name of the
Configinterface and method which returns shortcut:<action id="remove" shortcut="${com.haulmont.cuba.client.ClientConfig#getTableRemoveShortcut}"/> -
-
visible– visibility flag (true/false).
The examples of declaration are provided below.
-
Declaring actions at the screen level:
<window ...> <dsContext/> <actions> <action id="sayHelloAction" caption="msg://sayHello" shortcut="ALT-T" invoke="sayHello"/> </actions> <layout> <button action="sayHelloAction"/> </layout> </window>// controller public void sayHello(Component component) { showNotification("Hello!", NotificationType.TRAY); }In the example above, an action with
sayHelloActionidentifier and a name from message pack is declared. This action is bound with a button, which caption will be set to the action name. The action will invoke thesayHello()controller method when clicking on the button, or when pressing the ALT-T shortcut if at that moment the screen has input focus. -
Declaring actions for PopupButton:
<popupButton caption="Say something"> <actions> <action id="helloAction" caption="Say hello" invoke="sayHello"/> <action id="goodbyeAction" caption="Say goodbye" invoke="sayGoodbye"/> </actions> </popupButton> -
Declaring actions for Table:
<table id="usersTable" width="100%"> <actions> <action id="create"/> <action id="edit"/> <action id="copy" caption="msg://copy" icon="icons/copy.png" invoke="copy" trackSelection="true"/> <action id="changePassw" caption="msg://changePassw" icon="icons/change-pass.png" invoke="changePassword" trackSelection="true"/> </actions> <buttonsPanel> <button action="usersTable.create"/> <button action="usersTable.edit"/> <button action="usersTable.copy"/> <button action="usersTable.changePassw"/> </buttonsPanel> <rowsCount/> <columns> <column id="login"/> ... </columns> <rows datasource="usersDs"/> </table>In this example
copyandchangePasswactions are declared in addition tocreateandeditstandard actions of the table. These actions invoke corresponding methods of the controller. In addition, thetrackSelection="true"attribute is specified for them, which means that the action and corresponding button become disabled if no row is selected in the table. It is useful if the action is intended to be executed over a currently selected table row.An optional
openTypeattribute can be specified for create and edit actions to define edit screen opening mode, as described for thesetOpenType()method of the CreateAction class. -
Declaring PickerField actions:
<pickerField id="colourField" datasource="carDs" property="colour"> <actions> <action id="lookup"/> <action id="show" icon="icons/show.png" invoke="showColour" caption="" description="Show colour"/> </actions> </pickerField>In the example above, the standard
lookupaction and an additionalshowaction invoking theshowColour()method of the controller, are declared for thePickerFieldcomponent. SincePickerFieldbuttons that display actions use icons instead of captions, the caption attribute is explicitly set to an empty string, otherwise action name and button caption would be set to the action identifier. Thedescriptionattribute allows you to display a tooltip when hovering over the action button.
You can obtain references to any declared actions in the screen controller either directly by injection, or from components that implement the Component.ActionsHolder interface. This can be useful to set action properties programmatically. For example:
@Named("carsTable.create")
private CreateAction createAction;
@Named("carsTable.copy")
private Action copyAction;
@Inject
private PickerField colourField;
@Override
public void init(Map<String, Object> params) {
Map<String, Object> values = new HashMap<>();
values.put("type", CarType.PASSENGER);
createAction.setInitialValues(values);
copyAction.setEnabled(false);
Action showAction = colourField.getAction("show");
showAction.setEnabled(false);
}4.5.4.2. Standard Actions
Standard actions are classes that implement the Action interface and are intended to solve common tasks, such as invocation of an edit screen for an entity selected in a table. Standard actions have strictly defined identifiers; therefore, for the declaration of a standard action in XML, it is enough to specify its identifier.
There are two types of standard actions:
-
Actions over collections of entities that are displayed in tables or trees.
4.5.4.2.1. Standard Actions over Collection
For inheritors of ListComponent (Table, GroupTable, TreeTable and Tree) the set of standard actions is defined in ListActionType enumeration; their implementation classes are located in com.haulmont.cuba.gui.components.actions package.
The example of using standard actions in a table:
<table id="usersTable" width="100%">
<actions>
<action id="create"/>
<action id="edit"/>
<action id="remove"/>
<action id="refresh"/>
</actions>
<buttonsPanel>
<button action="usersTable.create"/>
<button action="usersTable.edit"/>
<button action="usersTable.remove"/>
<button action="usersTable.refresh"/>
</buttonsPanel>
<rowsCount/>
<columns>
<column id="login"/>
...
</columns>
<rows datasource="usersDs"/>
</table>These actions are described in details below.
CreateAction
CreateAction – action with create identifier. It is intended to create new entity instance and open its edit screen. If the edit screen successfully commits a new instance to the database, CreateAction adds this new instance to the table data source and makes it selected.
The following specific methods are defined in the CreateAction class:
-
setOpenType()allows you to specify new entity edit screen open mode.THIS_TABby default.Since it is quite often required to open edit screens in another mode (typically,
DIALOG), you can specify anopenTypeattribute with desired value in theactionelement when using declarative creation of thecreateaction. This eliminates the need to obtain action reference in the controller and set this property programmatically. For example:<table id="usersTable"> <actions> <action id="create" openType="DIALOG"/> -
setWindowId()allows you to specify the identifier of the entity edit screen. By default,{entity_name}.editis used, for examplesales$Customer.edit. -
setWindowParams()allows you to set edit screen parameters passed into itsinit()method.In order to get parameter values right before the action is invoked, you can create a subclass of the standard action and override its
getWindowParams()method returning the map of parameters from it. For example:customersTable.addAction(new CreateAction(customersTable) { @Override public Map<String, Object> getWindowParams() { Customer customer = metadata.create(Customer.class); customer.setCategory(CustomerCategory.NEW); return ParamsMap.of("customer", customer); } });This parameter can be further used directly in the datasource query via the
param$prefix or injected into the screen controller using the@WindowParamannotation. -
setInitialValues()allows you to set initial values of attributes of the entity being created. It takes aMapobject, where keys are attribute names, and values are attribute values. For example:Map<String, Object> values = new HashMap<>(); values.put("type", CarType.PASSENGER); carCreateAction.setInitialValues(values);An example of
setInitialValues()usage is also provided in the section of development recipes. -
afterCommit()is invoked by the action after the new entity has been successfully committed and the edit screen has been closed. This method does not have implementation and can be overridden in inheritors to handle this event. -
setAfterCommitHandler()allows you to provide a handler which will be called after the new entity has been successfully committed and the edit screen has been closed. This handler can be used instead of overridingafterCommit()to avoid creating the action subclass. For example:@Named("customersTable.create") private CreateAction customersTableCreate; @Override public void init(Map<String, Object> params) { customersTableCreate.setAfterCommitHandler(new CreateAction.AfterCommitHandler() { @Override public void handle(Entity entity) { showNotification("Committed", NotificationType.HUMANIZED); } }); } -
afterWindowClosed()is the last method invoked by the action after closing the edit screen regardless of whether the new entity has been committed or not. This method does not have implementation and can be overridden in inheritors to handle this event. -
setAfterWindowClosedHandler()allows you to provide a handler which will be called after closing the edit screen regardless of whether the new entity has been committed or not. This handler can be used instead of overridingafterWindowClosed()to avoid creating the action subclass.
EditAction
EditAction is an action with edit identifier, intended to open an edit screen for a selected entity instance. If the edit screen successfully commits the instance to the database, then EditAction updates this instance in the table datasource.
The following specific methods are defined in the EditAction class:
-
setOpenType()allows you to specify entity edit screen open mode.THIS_TABby default.Since it is quite often required to open edit screens in another mode (typically
DIALOG), you can specifyopenTypeattribute with desired value in theactionelement when creating the action declaratively. This eliminates the need to obtain action reference in the controller and set this property programmatically. For example:<table id="usersTable"> <actions> <action id="edit" openType="DIALOG"/> -
setWindowId()allows you to specify entity edit screen identifier.{entity_name}.editis used by default, for example,sales$Customer.edit. -
setWindowParams()allows you to set edit screen parameters, passed to itsinit()method.In order to get parameter values right before the action is invoked, you can create a subclass of the standard action and override its
getWindowParams()method returning the map of parameters from it. For example:table.addAction(new EditAction(table) { @Override public Map<String, Object> getWindowParams() { return ParamsMap.of("customer", getItem()); } });This parameter can be further used directly in the datasource query via the
param$prefix or injected into the screen controller using the@WindowParamannotation. -
afterCommit()is invoked by the action after the entity has been successfully committed and the edit screen has been closed. This method does not have implementation and can be overridden in inheritors to handle this event. -
setAfterCommitHandler()allows you to provide a handler which will be called after the new entity has been successfully committed and the edit screen has been closed. This handler can be used instead of overridingafterCommit()to avoid creating the action subclass. For example:@Named("customersTable.edit") private EditAction customersTableEdit; @Override public void init(Map<String, Object> params) { customersTableEdit.setAfterCommitHandler(new EditAction.AfterCommitHandler() { @Override public void handle(Entity entity) { showNotification("Committed", NotificationType.HUMANIZED); } }); } -
afterWindowClosed()is the last method invoked by the action after closing the edit screen regardless of whether the edited entity has been committed or not. This method does not have implementation and can be overridden in inheritors to handle this event. -
setAfterWindowClosedHandler()allows you to provide a handler which will be called after closing the edit screen regardless of whether the new entity has been committed or not. This handler can be used instead of overridingafterWindowClosed()to avoid creating the action subclass. -
getBulkEditorIntegration()provides a possibility of bulk editing for the table records. The table should have themultiselectattribute enabled. The BulkEditor component will be opened, if multiple table lines are selected when theEditActionis called.The returned
BulkEditorIntegrationinstance can be further modified by the following methods:-
setOpenType(), -
setExcludePropertiesRegex(), -
setFieldValidators(), -
setModelValidators(), -
setAfterEditCloseHandler().
@Named("clientsTable.edit") private EditAction clientsTableEdit; @Override public void init(Map<String, Object> params) { super.init(params); clientsTableEdit.getBulkEditorIntegration() .setEnabled(true) .setOpenType(WindowManager.OpenType.DIALOG); } -
RemoveAction
RemoveAction - action with remove identifier, intended to remove a selected entity instance.
The following specific methods are defined in the RemoveAction class:
-
setAutocommit()allows you to control the moment of entity removal from the database. By defaultcommit()method is invoked after triggering the action and removing the entity from the datasource. As result, the entity is removed from the database. You can setautocommitproperty into false usingsetAutocommit()method or corresponding parameter of the constructor. In this case you will need to explicitly invoke the datasourcecommit()method to confirm the removal after removing the entity from the datasource.The value of
autocommitdoes not affect datasources in theDatasource.CommitMode.PARENTmode, i.e. the datasources that provide composite entities editing. -
setConfirmationMessage()allows you to set message text for the removal confirmation dialog. -
setConfirmationTitle()allows you to set removal confirmation dialog title. -
afterRemove()is invoked by the action after the entity has been successfully removed. This method does not have implementation and can be overridden. -
setAfterRemoveHandler()allows you to provide a handler which will be called after the new entity has been successfully removed. This handler can be used instead of overridingafterRemove()to avoid creating the action subclass. For example:@Named("customersTable.remove") private RemoveAction customersTableRemove; @Override public void init(Map<String, Object> params) { customersTableRemove.setAfterRemoveHandler(new RemoveAction.AfterRemoveHandler() { @Override public void handle(Set removedItems) { showNotification("Removed", NotificationType.HUMANIZED); } }); }
RefreshAction
RefreshAction - an action with refresh identifier. It is intended to update (reload) entities collection. When triggered, it invokes refresh() method of a datasource associated with the corresponding component.
The following specific methods are defined in the RefreshAction class:
-
setRefreshParams()allows you to set parameters passed into theCollectionDatasource.refresh()method to be used in the query. By default, no parameters are passed.
AddAction
AddAction – action with add identifier, intended for selecting an existing entity instance and adding it to the collection. When triggered, opens entities lookup screen.
The following specific methods are defined in the AddAction class:
-
setOpenType()allows you to specify entity selection screen open mode.THIS_TABby default.Since it is often required to open the lookup screens in a different mode (usually
DIALOG), theopenTypeattribute can be specified in the action element, when creating theaddaction declaratively. This eliminates the need to get a reference to the action in the controller and set this property programmatically. For example:<table id="usersTable"> <actions> <action id="add" openType="DIALOG"/> -
setWindowId()allows you to specify entity selection screen identifier.{entity_name}.lookupby default, for example,sales$Customer.lookup. If such screen does not exist, attempts to open{entity_name}.browsescreen, for example,sales$Customer.browse. -
setWindowParams()allows you to set selection screen parameters, passed into itsinit()method.In order to get parameter values right before the action is invoked, you can create a subclass of the standard action and override its
getWindowParams()method returning the map of parameters from it. For example:table.addAction(new AddAction(table) { @Override public Map<String, Object> getWindowParams() { return ParamsMap.of("customer", getItem()); } });This parameter can be further used directly in the datasource query via the
param$prefix or injected into the screen controller using the@WindowParamannotation. -
setHandler()allows you to set an object implementingWindow.Lookup.Handlerinterface which will be passed to the selection screen. By default,AddAction.DefaultHandlerobject is used.
ExcludeAction
ExcludeAction - an action with exclude identifier. It allows a user to exclude entity instances from a collection without removing them from the database. The class of this action is an inheritor of RemoveAction, however, when triggered it invokes excludeItem() of CollectionDatasource instead of removeItem(). In addition, for an entity in a nested datasource, the ExcludeAction disconnects the link with the parent entity. Therefore this action can be used for editing one-to-many associations.
The following specific methods are defined in the ExcludeAction class in addition to RemoveAction:
-
setConfirm()– flag to show the removal confirmation dialog. You can also set this property via the action constructor. By default it is set tofalse.
ExcelAction
ExcelAction - an action with excel identifier, intended to export table data into XLS and download the resulting file. You can add this action only to Table, GroupTable and TreeTable components.
When creating the action programmatically, you can set the display parameter with an ExportDisplay interface implementation for file download. Standard implementation is used by default.
The following specific methods are defined in the ExcelAction class:
-
setFileName()- sets the Excel file name without extension. -
getFileName()- returns the Excel file name without extension.
4.5.4.2.2. Standard Actions of the Picker Field
For PickerField, LookupPickerField and SearchPickerField components, a set of standard actions is defined in the PickerField.ActionType enumeration. Implementations are inner classes of the PickerField interface, which are described in details below.
The example of standard actions usage in a picker component:
<searchPickerField optionsDatasource="coloursDs"
datasource="carDs" property="colour">
<actions>
<action id="clear"/>
<action id="lookup"/>
<action id="open"/>
</actions>
</searchPickerField>LookupAction
LookupAction – action with lookup identifier, intended for selecting an entity instance and setting it as the component’s value. When triggered, it opens an entities lookup screen.
The following specific methods are defined in the LookupAction class:
-
setLookupScreenOpenType()allows you to specify entity selection screen open mode.THIS_TABby default. -
setLookupScreen()allows you to specify entity selection screen identifier.{entity_name}.lookupby default, for example,sales$Customer.lookup. If such screen does not exist, attempts to open{entity_name}.browsescreen, for example,sales$Customer.browse. -
setLookupScreenParams()allows you to set selection screen parameters, passed into itsinit()method. -
afterSelect()is invoked by the action after the selected instance is set as the component’s value. This method does not have implementation and can be overridden. -
afterCloseLookup()is the last method invoked by the action after closing the lookup screen regardless of whether an instance has been selected or not. This method does not have implementation and can be overridden.
ClearAction
ClearAction - an action with clear identifier, intended for clearing (i.e. for setting to`null`) the value of the component.
OpenAction
OpenAction - action with open identifier, intended for opening an edit screen for the entity instance which is the current value of the component.
The following specific methods are defined in the OpenAction class:
-
setEditScreenOpenType()allows you to specify entity selection screen open mode.THIS_TABby default. -
setEditScreen()allows you to specify entity edit screen identifier.{entity_name}.editscreen is used by default, for example,sales$Customer.edit. -
setEditScreenParams()allows you to set edit screen parameters, passed to its `init()`method. -
afterWindowClosed()is invoked by the action after closing the edit screen. This method does not have implementation and can be overridden in inheritors to handle this event.
4.5.4.3. BaseAction
BaseAction is a base class for actions implementation. It is recommended to derive custom actions from it when declarative actions creation functionality is insufficient.
When creating a custom action class, you should implement actionPerform() method and pass action identifier to the BaseAction constructor. You can override any property getters: getCaption(), getDescription(), getIcon(), getShortcut(), isEnabled(), isVisible(). Standard implementations of these methods return values set by setter methods, except the getCaption() method. If the action name is not explicitly set by setCaption() method, it retrieves message using action identifier as key from the the localized message pack corresponding to the action class package. If there is no message with such key, then the key itself, i.e. the action identifier, is returned.
BaseAction can change its enabled and visible properties depending on user permissions and current context.
BaseAction is visible if the following conditions are met:
-
setVisible(false)method was not called; -
there is no
hideUI permission for this action.
The action is enabled if the following conditions are met:
-
setEnabled(false)method was not called; -
there are no
hideor read-only UI permissions for this action; -
isPermitted()method returns true; -
isApplicable()method returns true.
Usage examples:
-
Button action:
@Inject private Button helloBtn; @Override public void init(Map<String, Object>params) { helloBtn.setAction(new BaseAction("hello") { @Override public void actionPerform(Component component) { showNotification("Hello!", NotificationType.TRAY); } }); }In this example, the
helloBtnbutton caption will be set to the string located in the message pack with thehellokey. You can override thegetCaption()action method to initialize button name in a different way. -
Action of a programmatically created PickerField:
@Inject private ComponentsFactory componentsFactory; @Inject private BoxLayout box; @Override public void init(Map<String, Object>params) { PickerField pickerField = componentsFactory.createComponent(PickerField.NAME); pickerField.addAction(new BaseAction("hello") { @Override public String getCaption() { return null; } @Override public String getDescription() { return getMessage("helloDescription"); } @Override public String getIcon() { return"icons/hello.png"; } @Override public void actionPerform(Component component) { showNotification("Hello!", NotificationType.TRAY); } }); box.add(pickerField); }In this example an anonymous
BaseActionderived class is used to set the action of the picker field button. The button caption is not displayed, as an icon with a description, which pops up when hovering mouse cursor, is used instead. -
Table action:
@Inject private Table table; @Inject private Security security; @Override public void init(Map<String, Object> params) { table.addAction(new HelloAction()); } private class HelloAction extends BaseAction { public HelloAction() { super("hello"); } @Override public void actionPerform(Component component) { showNotification("Hello " + table.getSingleSelected(), NotificationType.TRAY); } @Override protected boolean isPermitted() { return security.isSpecificPermitted("myapp.allow-greeting"); } @Override public boolean isApplicable() { return target != null && target.getSelected().size() == 1; } }In this example, the
HelloActionclass is declared, and its instance is added to the table’s actions list. The action is enabled for users who havemyapp.allow-greetingsecurity permission and only when a single table row is selected. The latter is possible because BaseAction’stargetproperty is automatically assigned to the action when it is added to aListComponentdescendant (TableorTree). -
If you need an action, which becomes enabled when one or more table rows are selected, use BaseAction’s descendant -
ItemTrackingAction, which adds default implementation ofisApplicable()method:@Inject private Table table; @Override public void init(Map<String, Object> params) { table.addAction(new ItemTrackingAction("hello") { @Override public void actionPerform(Component component) { showNotification("Hello " + table.getSelected().iterator().next(), NotificationType.TRAY); } }); }
4.5.5. Dialogs and Notifications
Dialogs and notifications can be used to display messages to users.
Dialogs have a title with a closing button and are always displayed in the center of the application main window. Notifications can be displayed both in the center and in the corner of the window, and can automatically disappear.
4.5.5.1. Dialogs
- General-purpose dialogs
-
General-purpose dialogs are invoked by
showMessageDialog()andshowOptionDialog()methods of theFrameinterface. This interface is implemented by screen controller, so these methods can be invoked directly in the controller code.-
showMessageDialog()is intended to display a message. The method has the following parameters:-
title– dialog title. -
message- message. For HTML type (see below), you can use HTML tags for formatting the message. When using HTML, make sure you escape data loaded from the database to avoid code injection in web client. You can use\ncharacters for line breaks in non-HTML messages. -
messageType– message type. Possible types:-
CONFIRMATION,CONFIRMATION_HTML– confirmation dialog. -
WARNING,WARNING_HTML– warning dialog. The difference in message types is reflected in desktop user interface only.An example of showing a dialog:
showMessageDialog("Warning", "Something is wrong", MessageType.WARNING);
-
-
-
showOptionDialog()is intended to display a message and buttons for user actions. In addition to parameters described forshowMessageDialog(), the method takes an array or a list of actions. A button is created for each dialog action. After a button is clicked, the dialog closes invokingactionPerform()method of the corresponding action.It is convenient to use anonymous classes derived from
DialogActionfor buttons with standard names and icons. Five types of actions defined by theDialogAction.Typeenum are supported:OK,CANCEL,YES,NO,CLOSE. Names of corresponding buttons are extracted from the main message pack.Below is an example of a dialog invocation with
YesandNobuttons and with a caption and messages taken from the message pack of the current screen:showOptionDialog( getMessage("confirmCopy.title"), getMessage("confirmCopy.msg"), MessageType.CONFIRMATION, new Action[] { new DialogAction(DialogAction.Type.YES, Status.PRIMARY) { public void actionPerform(Component component) { copySettings(); } }, new DialogAction(DialogAction.Type.NO, Status.NORMAL) } );The
Statusparameter ofDialogActionis used to assign a special visual style for a button representing the action.Status.PRIMARYhighlights the corresponding button and makes it selected. TheStatusparameter can be omitted, in this case default highlighting is applied. If multiple actions withStatus.PRIMARYare passed to theshowOptionDialog, only the first action’s button will get thecuba-primary-actionstyle and focus.
-
- File upload dialog
-
The
FileUploadDialogwindow provides the base functionality for loading files into the temporary storage. It contains the drop zone for drag-and-dropping files from outside of the browser and the upload button.
The dialog is opened with the
openWindow()method, in case of successful upload it is closed withCOMMIT_ACTION_ID. You can track the close action of the dialog withCloseListenerorCloseWithCommitListenerand use thegetFileId()andgetFileName()methods to get the UUID and the name of uploaded file. Then you can create aFileDescriptorfor referencing the file from the data model objects or implement any other logic.FileUploadDialog dialog = (FileUploadDialog) openWindow("fileUploadDialog", OpenType.DIALOG); dialog.addCloseWithCommitListener(() -> { UUID fileId = dialog.getFileId(); String fileName = dialog.getFileName(); FileDescriptor fileDescriptor = fileUploadingAPI.getFileDescriptor(fileId, fileName); // your logic here });
4.5.5.2. Notifications
Notifications can be invoked using showNotification() method of the Frame interface. This interface is implemented by screen controlller, so this method can be invoked directly from the controller code.
showNotification() method takes the following parameters:
-
caption- notification text. In case of HTML-type (see below), you can format message text using HTML-tags. When using HTML, don’t forget to escape data to prevent code injection in the web-client. You can use\ncharacters for line breaks in non-HTML messages. -
description– an optional description displayed under the caption. You can also use\ncharacter or HTML-formatting. -
type– notification type. Possible values:-
TRAY,TRAY_HTML- a notification is displayed in the bottom right corner of the application and disappears automatically. -
HUMANIZED,HUMANIZED_HTML– a standard notification displayed in the center of the screen, disappears automatically. -
WARNING,WARNING_HTML– a warning. Disappears when clicked. -
ERROR,ERROR_HTML– a notification about an error. Disappears when clicked.
-
Examples of invoking a notification:
showNotification(getMessage("selectBook.text"), NotificationType.HUMANIZED);
showNotification("Validation error", "<b>Date</b> is incorrect", NotificationType.TRAY_HTML);4.5.6. Background Tasks
Background tasks mechanism is designed for performing tasks at the client tier asynchronously without blocking the user interface.
In order to use background tasks, do the following:
-
Define a task as an inheritor of the
BackgroundTaskabstract class. Pass a link to a screen controller which will be associated with the task and the task timeout to the task constructor.Closing the screen will interrupt the tasks associated with it. Additionally, the task will be interrupted automatically after the specified timeout.
Actual actions performed by the task are implemented in the
run()method. -
Create an object of
BackgroundTaskHandlerclass controlling the task by passing the task instance to thehandle()method of theBackgroundWorkerbean. A link toBackgroundWorkercan be obtained by an injection in a screen controller, or through theAppBeansclass. -
Run the task by invoking the
execute()method ofBackgroundTaskHandler.
Example:
@Inject
protected BackgroundWorker backgroundWorker;
@Override
public void init(Map<String, Object> params) {
// Create task with 10 sec timeout and this screen as owner
BackgroundTask<Integer, Void> task = new BackgroundTask<Integer, Void>(10, this) {
@Override
public Void run(TaskLifeCycle<Integer> taskLifeCycle) throws Exception {
// Do something in background thread
for (int i = 0; i < 5; i++) {
TimeUnit.SECONDS.sleep(1); // time consuming computations
taskLifeCycle.publish(i); // publish current progress to show it in progress() method
}
return null;
}
@Override
public void canceled() {
// Do something in UI thread if the task is canceled
}
@Override
public void done(Void result) {
// Do something in UI thread when the task is done
}
@Override
public void progress(List<Integer> changes) {
// Show current progress in UI thread
}
};
// Get task handler object and run the task
BackgroundTaskHandler taskHandler = backgroundWorker.handle(task);
taskHandler.execute();
}Detailed information about methods is provided in JavaDocs for BackgroundTask, TaskLifeCycle, BackgroundTaskHandler classes.
Please note the following:
-
BackgroundTask<T, V>is a parameterized class:-
T− the type of objects displaying task progress. Objects of this type are passed to the task’sprogress()method during an invocation ofTaskLifeCycle.publish()in the working thread. -
V− task result type passed to thedone()method. It can also be obtained by invokingBackgroundTaskHandler.getResult()method, which will wait for a task to complete.
-
-
canceled()method is invoked only during a controlled cancellation of a task, i.e. whencancel()is invoked in theTaskHandler. -
handleTimeoutException()is invoked when the task timeout expires. If the window where the task is running closes, the task is stopped without a notification. -
run()method of a task should support external interruptions. To ensure this, we recommend checking theTaskLifeCycle.isInterrupted()flag periodically during long processes and stopping execution when needed. Additionally, you should not silently discardInterruptedException(or any other exception) - instead you should either exit the method correctly or not handle the exception at all. -
BackgroundTaskobjects are stateless. If you did not create fields for temporary data when implementing task class, you can start several parallel processes using a single task instance. -
BackgroundHandlerobject (itsexecute()method) can only be started once. If you need to restart a task frequently, useBackgroundTaskWrapperclass. -
Use
BackgroundWorkWindoworBackgroundWorkProgressWindowclasses with a set of static methods to show a modal window with progress indicator and Cancel button. You can define progress indication type and allow or prohibit cancellation of the background task for the window. -
If you need to use certain values of visual components in the task thread, you should implement their acquisition in
getParams()method, which runs in the UI thread once, when a task starts. In the run() method, these parameters will be accessible via thegetParams()method of theTaskLifeCycleobject. -
If any exception occurs, the framework invokes
BackgroundTask.handleException()method in the UI thread, which can be used to display the error. -
Background tasks are affected by cuba.backgroundWorker.maxActiveTasksCount and cuba.backgroundWorker.timeoutCheckInterval application properties.
|
Warning
|
In Web Client, background tasks are implemented using HTTP push provided by the Vaadin framework. See https://vaadin.com/wiki/-/wiki/Main/Working+around+push+issues for information on how to set up your web servers for this technology. |
|
Tip
|
If you don’t use background tasks, but want to update UI state from a non-UI thread, use methods of the |
4.5.7. Themes
Themes are used to manage the visual presentation of the application.
4.5.7.1. Themes in Web Applications
A theme consists of SCSS files and other resources like images.
4.5.7.1.1. Using Existing Themes
The platform includes two ready to use themes: Halo and Havana. By default, the application will use the one specified in the cuba.web.theme application property. The user may select the other theme in the standard Help > Settings screen. If you want to disable the option of selecting themes, register the settings screen in the web-screens.xml file of your project and set the changeThemeEnabled = false parameter for it:
<screen id="settings" template="/com/haulmont/cuba/web/app/ui/core/settings/settings-window.xml">
<param name="changeThemeEnabled" value="false"/>
</screen>4.5.7.1.2. Extending an Existing Theme
A platform theme can be modified in the project. In the modified theme, you can:
-
Change branding images.
-
Add icons to use them in visual components.
-
Create new styles for visual components and use them in the stylename attribute. This requires some expertise in CSS.
-
Modify existing styles of the visual components.
-
Modify common parameters, such as background color, margins, spacing, etc.
Themes are defined in SCSS files. To modify (extend) a theme in the project, you should create a specific file structure in the web module. A convenient way to do this is to use CUBA Studio: open the Project properties section and click Create theme extension. Select the theme you want to extend in the popup window. As a result, the following directory structure will be created in the modules/web directory (for Halo theme extension):
themes/
halo/
branding/
app-icon-login.png
app-icon-menu.png
favicon.ico
halo-ext-defaults.scss
halo-ext.scss
styles.scssApart from that, the build.gradle script will be complemented with the buildScssThemes task, which is executed automatically each time the web module is built. The optional deployThemes task can be used to quickly apply changes in themes to the running application.
|
Tip
|
If your project contains an application component with extended theme, this extension will be used for the whole project. To avoid using the component’s theme you should create theme extension for the project too. The above is also true in case you have more than one application component with extended theme. |
- Changing branding
-
You can configure some branding properties, such as icons, login and main application window captions, and the website icon (
favicon.ico).To use custom images, replace default ones in the
modules/web/themes/halo/brandingdirectory.To set window captions and the login window welcome text, edit Project properties in CUBA Studio and click Branding at the bottom of the page. Set window captions and the login window welcome text using the appropriate links.
These parameters are saved in the main message pack of the gui module (i.e the
modules/gui/<root_package>/gui/messages.propertiesfile and its variants for different locales). Message packs allow you to use different image files for different user locales. The samplemessages.propertiesfile:application.caption = MyApp application.logoImage = branding/myapp-menu.png loginWindow.caption = MyApp Login loginWindow.welcomeLabel = Welcome to MyApp! loginWindow.logoImage = branding/myapp-login.pngThe path to
favicon.icois not specified since it must be located in the root directory of the theme. - Adding fonts
-
You can add custom fonts to your web theme. To add a font family, import it in the first line of the
styles.scssfile, for example:@import url(http://fonts.googleapis.com/css?family=Roboto); - Adding icons
-
Image files that will be used in the icon properties for actions and visual components, e.g. Button, can be added to your theme extension.
For example, to add an icon to the Halo theme extension, you have to add the image file to the
modules/web/themes/halodirectory described above (it is recommended to create a subfolder):themes/ halo/ images/ address-book.pngAfter that, you can use the icon in the application by specifying the path relatively to the theme directory in the icon property:
<action id="adresses" icon="images/address-book.png"/>Font elements of Font Awesome can be used instead of icons. You should specify the name of the required constant of the
com.vaadin.server.FontAwesomeclass in theiconproperty with afont-icon:prefix, for example:<action id="adresses" icon="font-icon:BOOK"/> - Adding icons from other font libraries
-
To enhance your theme extension, you may need to create icons and embed them into fonts, as well as use any external icons library.
In the web module create the
enumclass implementingcom.vaadin.server.FontIconinterface for the new icons:import com.vaadin.server.FontIcon; import com.vaadin.server.GenericFontIcon; public enum IcoMoon implements FontIcon { HEADPHONES(0XE900), SPINNER(0XE905); public static final String FONT_FAMILY = "IcoMoon"; private int codepoint; IcoMoon(int codepoint) { this.codepoint = codepoint; } @Override public String getFontFamily() { return FONT_FAMILY; } @Override public int getCodepoint() { return codepoint; } @Override public String getHtml() { return GenericFontIcon.getHtml(FONT_FAMILY, codepoint); } @Override public String getMIMEType() { throw new UnsupportedOperationException(FontIcon.class.getSimpleName() + " should not be used where a MIME type is needed."); } public static IcoMoon fromCodepoint(final int codepoint) { for (IcoMoon f : values()) { if (f.getCodepoint() == codepoint) { return f; } } throw new IllegalArgumentException("Codepoint " + codepoint + " not found in IcoMoon"); } }Add new styles to the theme extension. We recommend creating a special subfolder
fontsin the main folder of theme extension, for example,modules/web/themes/halo/com.company.demo/fonts. Put the styles and font files in their own subfolders, for example,fonts/icomoon. Files of fonts are represented by the following extensions:.eot,.svg,.ttf,.woff. The set of fontsicomoonfrom an open library, used in this example, consists of 4 joint used files:icomoon.eot,icomoon.svg,icomoon.ttf,icomoon.woff.Create a file with styles that includes
@font-faceand a CSS class with the icon style. Below is an example of theicomoon.scssfile, whereIcoMoonclass name corresponds to the value returned byFontIcon#getFontFamilymethod:@mixin icomoon-style { /* use !important to prevent issues with browser extensions that change fonts */ font-family: 'icomoon' !important; speak: none; font-style: normal; font-weight: normal; font-variant: normal; text-transform: none; line-height: 1; /* Better Font Rendering =========== */ -webkit-font-smoothing: antialiased; -moz-osx-font-smoothing: grayscale; } @font-face { font-family: 'icomoon'; src:url('icomoon.eot?hwgbks'); src:url('icomoon.eot?hwgbks#iefix') format('embedded-opentype'), url('icomoon.ttf?hwgbks') format('truetype'), url('icomoon.woff?hwgbks') format('woff'), url('icomoon.svg?hwgbks#icomoon') format('svg'); font-weight: normal; font-style: normal; } .IcoMoon { @Include icomoon-style; }Create a reference to the file with font styles in
halo-ext.scssor other file of theme extension:@import "fonts/icomoon/icomoon";Create new class
App.javaextendingDefaultAppin the root package of your web module and register it in web-spring.xml as thecuba_Appbean to override the bean for central class of the application infrastructure, for example:<bean name="cuba_App" class="com.company.sample.web.App" scope="prototype"/>Register new alias for icons in
App.java:import com.haulmont.cuba.web.DefaultApp; import com.haulmont.cuba.web.gui.components.WebComponentsHelper; public class App extends DefaultApp { static { WebComponentsHelper.registerFontIcon("ico-moon-icon", IcoMoon.class); } }Now you can use new icons by direct reference to their class and
enumelement in XML-descriptor of the screen:<button caption="Headphones" icon="ico-moon-icon:HEADPHONES"/>or in the Java controller:
spinnerBtn.setIcon("ico-moon-icon:SPINNER");As a result, new icons are added to the buttons:
- Creating new styles
-
Consider the example of setting the yellow background color to the field displaying the customer’s name.
In an XML descriptor, the FieldGroup component is defined:
<fieldGroup id="fieldGroup" datasource="customerDs"> <field property="name"/> <field property="address"/> </fieldGroup>The
fieldelements ofFieldGroupdo not have the stylename attribute, therefore we have to set the field’s style name in the controller:@Named("fieldGroup.name") private TextField nameField; @Override public void init(Map<String, Object> params) { nameField.setStyleName("name-field"); }In the
halo-ext.scssfile, add the new style definition to thehalo-extmixin:@import "../halo/halo"; @mixin halo-ext { @include halo; .name-field { background-color: lightyellow; } }After rebuilding the project, the fields will look as follows:
- Modifying existing styles of the visual components
-
To modify style parameters of existing components, add the corresponding CSS code to the
halo-extmixin of thehalo-ext.scssfile. Use developer tools of your web browser to find out CSS classes assigned to the elements of visual components. For example, to display the application menu items in bold, the contents of thehalo-ext.scssfile should be as follows:@import "../halo/halo"; @mixin halo-ext { @include halo; .v-menubar-menuitem-caption { font-weight: bold; } } - Modifying common parameters
-
Themes contain a number of SCSS variables that control application background colour, component size, margins and other parameters.
Below is the example of a Halo theme extension, since it is based on Valo theme from Vaadin, and provides the widest range of options for customization.
The
themes/halo/halo-ext-defaults.scssfile is intended for overriding theme variables. Most of the Halo variables correspond to those described in the Valo documentation. Below are the most common variables:$v-background-color: #fafafa; /* component background colour */ $v-app-background-color: #e7ebf2; /* application background colour */ $v-panel-background-color: #fff; /* panel background colour */ $v-focus-color: #3b5998; /* focused element colour */ $v-error-indicator-color: #ed473b; /* empty required fields colour */ $v-line-height: 1.35; /* line height */ $v-font-size: 14px; /* font size */ $v-font-weight: 400; /* font weight */ $v-unit-size: 30px; /* base theme size, defines the height for buttons, fields and other elements */ $v-font-size--h1: 24px; /* h1-style Label size */ $v-font-size--h2: 20px; /* h2-style Label size */ $v-font-size--h3: 16px; /* h3-style Label size */ /* margins for containers */ $v-layout-margin-top: 10px; $v-layout-margin-left: 10px; $v-layout-margin-right: 10px; $v-layout-margin-bottom: 10px; /* spacing between components in a container (if enabled) */ $v-layout-spacing-vertical: 10px; $v-layout-spacing-horizontal: 10px; /* basic table dimensions */ $v-table-row-height: 30px; $v-table-header-font-size: 13px; $v-table-cell-padding-horizontal: 7px; /* input field focus style */ $v-focus-style: inset 0px 0px 5px 1px rgba($v-focus-color, 0.5); /* required fields focus style */ $v-error-focus-style: inset 0px 0px 5px 1px rgba($v-error-indicator-color, 0.5); /* animation for elements is enabled by default */ $v-animations-enabled: true; /* popup window animation is disabled by default */ $v-window-animations-enabled: false; /* inverse header is controlled by cuba.web.useInverseHeader property */ $v-support-inverse-menu: true; /* show "required" indicators for components */ $v-show-required-indicators: false !default;The sample
halo-ext-defaults.scssfor a theme with a dark background and slightly minimized margins is provided below:$v-background-color: #444D50; $v-font-size--h1: 22px; $v-font-size--h2: 18px; $v-font-size--h3: 16px; $v-layout-margin-top: 8px; $v-layout-margin-left: 8px; $v-layout-margin-right: 8px; $v-layout-margin-bottom: 8px; $v-layout-spacing-vertical: 8px; $v-layout-spacing-horizontal: 8px; $v-table-row-height: 25px; $v-table-header-font-size: 13px; $v-table-cell-padding-horizontal: 5px; $v-support-inverse-menu: false;
- Migration from Havana to feature-rich Halo theme
-
Halo theme is more extensible and supports some new visual components, such as DataGrid or SideMenu. If you want to use these components and keep your components library up-to-date, it is recommended to use the Halo theme. At the same time, if you want to keep the old Havana enterprise look, you can use the following variables in
halo-ext-defaults.scss:$cuba-menubar-background-color: #315379; $cuba-menubar-border-color: #315379; $v-table-row-height: 25px; $v-selection-color: rgb(77, 122, 178); $v-table-header-font-size: 12px; $v-textfield-border: 1px solid #A5C4E0; $v-selection-item-selection-color: #4D7AB2; $v-app-background-color: #E3EAF1; $v-font-size: 12px; $v-font-weight: 400; $v-unit-size: 25px; $v-border-radius: 0px; $v-border: 1px solid #9BB3D3 !default; $v-font-family: Verdana,tahoma,arial,geneva,helvetica,sans-serif,"Trebuchet MS"; $v-panel-background-color: #ffffff; $v-background-color: #ffffff; $cuba-menubar-menuitem-text-color: #ffffff; $cuba-app-menubar-padding-top: 8px; $cuba-app-menubar-padding-bottom: 8px; $cuba-menubar-text-color: #ffffff; $cuba-menubar-submenu-padding: 1px; - Changing the application header
-
Halo theme supports the cuba.web.useInverseHeader property, which controls the colour of the application header. By default, this property is set to
true, which sets a dark (inverse) header.You can make a light header without any changes to the theme, simply by setting this property tofalse.
4.5.7.1.3. Creating a Custom Theme
You can create one or several application themes in the project and give the users an opportunity to select the most appropriate one. Creating new themes also allows you to override the variables in the *-theme.properties files, which define a few server-side parameters:
-
Default dialog window size.
-
Default input field width.
-
Dimensions of some components (Filter, FileMultiUploadField).
-
Correspondence between icon names and constants of the
com.vaadin.server.FontAwesomeenumeration for using Font Awesome in standard actions and screens of the platform, if cuba.web.useFontIcons is enabled.
- Creating a new theme
-
Below is the example of creating a Halo-based Facebook theme, which resembles the interface of a popular social network.
-
In CUBA Studio, open Project properties section and click Create theme extension. Select
haloand click Create. A Halo theme extension will be created in the project as described in the previous section. -
Rename the
themes/halodirectory in the web module tothemes/facebook, then move tofacebookand rename thehalo-ext.scssfile tofacebook.scss, similarly move and rename thehalo-ext-defaults.scssfile tofacebook-defaults.scss:themes/ facebook/ branding/ app-icon-login.png app-icon-menu.png com.company.application/ app-component.scss facebook.scss facebook-defaults.scss favicon.ico styles.scss -
Edit the
styles.scssfile:@import "../halo/halo-defaults"; @import "facebook-defaults"; @import "facebook"; .facebook { @include facebook; } .v-theme-version { display: none; } -
Edit the
facebook.scssfile:@import "../halo/halo"; @mixin facebook { @include halo; } -
Edit the
app-component.scssfile:@import "facebook"; @mixin com_company_application { @include facebook; } -
Copy the following variables to
facebook-defaults.scss:$v-background-color: #fafafa; $v-app-background-color: #e7ebf2; $v-panel-background-color: #fff; $v-focus-color: #3b5998; $v-border-radius: 0; $v-textfield-border-radius: 0; $v-font-family: Helvetica, Arial, 'lucida grande', tahoma, verdana, arial, sans-serif; $v-font-size: 14px; $v-font-color: #37404E; $v-font-weight: 400; $v-link-text-decoration: none; $v-shadow: 0 1px 0 (v-shade 0.2); $v-bevel: inset 0 1px 0 v-tint; $v-unit-size: 30px; $v-gradient: v-linear 12%; $v-overlay-shadow: 0 3px 8px v-shade, 0 0 0 1px (v-shade 0.7); $v-shadow-opacity: 20%; $v-selection-overlay-padding-horizontal: 0; $v-selection-overlay-padding-vertical: 6px; $v-selection-item-border-radius: 0; $v-line-height: 1.35; $v-font-size: 14px; $v-font-weight: 400; $v-unit-size: 25px; $v-font-size--h1: 22px; $v-font-size--h2: 18px; $v-font-size--h3: 16px; $v-layout-margin-top: 8px; $v-layout-margin-left: 8px; $v-layout-margin-right: 8px; $v-layout-margin-bottom: 8px; $v-layout-spacing-vertical: 8px; $v-layout-spacing-horizontal: 8px; $v-table-row-height: 25px; $v-table-header-font-size: 13px; $v-table-cell-padding-horizontal: 5px; $v-focus-style: inset 0px 0px 1px 1px rgba($v-focus-color, 0.5); $v-error-focus-style: inset 0px 0px 1px 1px rgba($v-error-indicator-color, 0.5); -
Create the
facebook-theme.propertiesfile in thesrcdirectory of the web module with the following content:@include=halo-theme.propertiesYou can use this file to override server-side theme variables from the
halo-theme.propertiesfile of the platform. -
Add the following properties to the
web-app.propertiesfile:cuba.web.theme = facebook cuba.themeConfig = havana-theme.properties halo-theme.properties facebook-theme.properties -
Rebuild the application and start the server. Now the user will see the application in Facebook theme on first login, and will be able to choose between Facebook, Halo and Havana in the Help > Settings menu.
-
- Modifying server-side theme parameters
-
In Halo theme, Font Awesome icons are used for standard actions and platform screens by default (if cuba.web.useFontIcons is enabled). In this case, you can replace a standard icon by setting the required mapping between the icon and the font element name in
<your_theme>-theme.propertiesfile. For example, to use "plus" icon for thecreateaction in the new Facebook theme, theweb/src/facebook-theme.propertiesfile should contain the following:@include=halo-theme.properties cuba.web.icons.create.png = PLUSThe fragment of the standard users browser screen in the Facebook theme with the modified
createaction: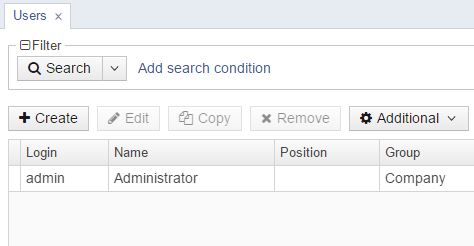
4.5.7.2. Themes in Desktop Applications
The base theme for desktop applications is Nimbus.
To add any changes to the standard theme, you need to create a res.nimbus package in the com.sample.sales.desktop package of the desktop module. Theme files will be stored in the res.nimbus package.
The icons folder contains icon files, the nimbus.xml file contains the description of the theme style.
The properties file of a desktop application should have cuba.desktop.resourceLocations property defined (defines a set of folders containing the style files):
cuba.desktop.resourceLocations = \
com/haulmont/cuba/desktop/res \
com/sample/sales/desktop/resBelow are examples of common tasks.
- Adding an icon
-
If you need to add a new icon to a desktop application, for example an icon for a button, you should create a
res.nimbus.iconspackage within thecom.sample.sales.desktoppackage of the desktop module and put the corresponding icon there.
Description of a button in the descriptor with a path to an icon set in the icon attribute:
<button id="button1" caption="Attention" icon="icons/attention.png"/>Below you can see a button with the attention.png icon.
- Redefining default values of theme properties
-
For example, let us change text field background color for mandatory fields.
The
nimbus.xmlfile with the following content should be created in theres.nimbuspackage:<theme xmlns="http://schemas.haulmont.com/cuba/desktop-theme.xsd"> <ui-defaults> <color property="cubaRequiredBackground" value="#f78260"/> </ui-defaults> </theme>The
ui-defaultselement redefines the values of platform theme properties set by default.The
ui-defaultselement includes both the properties contained in a standardNimbus(http://docs.oracle.com/javase/tutorial/uiswing/lookandfeel/_nimbusDefaults.html) theme and the properties created in the CUBA platform.In this example, we redefined the value of the CUBA property –
cubaRequiredBackground, which stores the background color for required fields. This change will affect all required input fields. - Creating a style for an element using standard tools
-
Let’s consider an example of highlighting a text in bold.
To create a style like that you need to define
styleelement in the theme filenimbus.xmlin the following way:<theme xmlns="http://schemas.haulmont.com/cuba/desktop-theme.xsd"> <style name="boldlabel"> <font style="bold"/> </style> </theme>styleelement can also contain other elements which can define different properties:background,foreground,icon.You should add stylename attribute with the name of the created style into the description of the corresponding label in an xml-descriptor.
<label id="label1" value="msg://labelVal" stylename="boldlabel"/>In such way the style will be applied only to the labels that have stylename attribute with the value of
boldlabel. - Creating a custom style
-
If standard style adjustment capabilities are insufficient, you can create a custom style.
Let us create a custom style that will be applied to the Button component. With this style, the the button caption will be underlined.
First, create a decorator class
UnderlinedLabelDecorator:public class UnderlinedButtonDecorator implements ComponentDecorator { @Override @SuppressWarnings("unchecked") public void decorate(Object component, Set<String> state) { DesktopButton item = (DesktopButton) component; JButton jButton = (JButton) item.getComponent(); Font originalFont = jButton.getFont(); Map attributes = originalFont.getAttributes(); attributes.put(TextAttribute.UNDERLINE, TextAttribute.UNDERLINE_ON); jButton.setFont(originalFont.deriveFont(attributes)); } }Define a custom style in
nimbus.xml:<theme xmlns="http://schemas.haulmont.com/cuba/desktop-theme.xsd"> <style name="button-underlined" component="com.haulmont.cuba.desktop.gui.components.DesktopButton"> <custom class="com.sample.sales.desktop.gui.decorators.UnderlinedButtonDecorator"/> </style> </theme>The
componentattribute of thestyleelement contains the name of the component that the style with the namebutton-underlinedcan be applied to.The
customelement should contain a path to the decorator class defined above.When creating an XML element for a button that should have the custom style, specify the style name in the
stylenameattribute:<button stylename="button-underlined" caption="decorated"/>The button with the custom style:

4.5.8. Web Client Specifics
Implementation of the generic user interface of the Web Client block is based on the Vaadin framework. The main classes available in the web client infrastructure are described below.
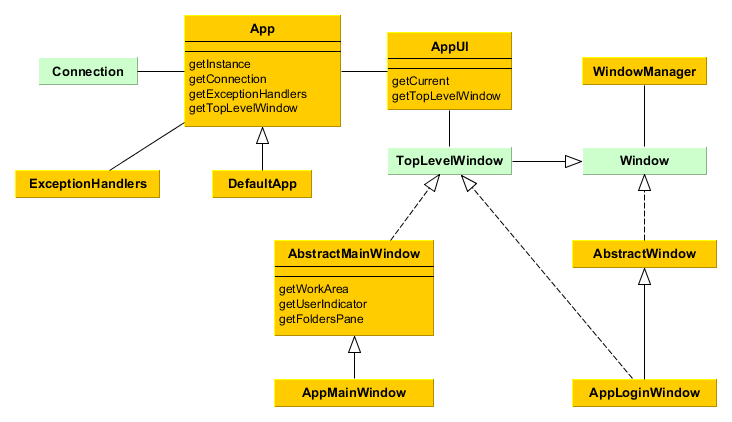
Figure 21. Web Client Infrastructure Classes
-
App- the central class of the application infrastructure. Contains links toConnectionand other infrastructure objects. Only one instance ofAppexists for a given HTTP session. You can get a reference to theAppinstance by using theApp.getInstance()static method. If you want to customize functionality ofAppin your project, create a class extendingDefaultAppin the root package of your web module and register it in web-spring.xml as thecuba_Appbean, for example:<bean name="cuba_App" class="com.company.sample.web.MyApp" scope="prototype"/> -
Connectionis an interface providing functionality of connecting to middleware and holding a user session.DefaultConnectionis a standard implementation of this interface. -
ExceptionHandlersclass contains a collection of client-level exception handlers. -
AppUIis a platform class inherited fromcom.vaadin.ui.UIclass. There is one instance of this class for each open tab of a web browser. Contains a link to aTopLevelWindowimplementation – either a login window or main window, depending on the connection state. You can get a reference to theAppUIfor the current browser tab by using theAppUI.getCurrent()static method. -
AppLoginWindow– the window displayed before a user logs in. You can customize the login window by extendingAppLoginWindowor create completely new one by extending AbstractWindow and implementing theTopLevelWindowmarker interface. In Studio, go to the Screens section and click Create login window. If you override theinit()method, make sure you invokesuper.init(params). -
AppMainWindow– main application window displayed after a user logs in. You can customize the main window by extendingAppMainWindowor create completely new one by extendingAbstractMainWindowand defining desired layout in XML descriptor. In Studio, go to the Screens section and click Create main window. If you override theinit()method, make sure you invokesuper.init(params).You can control certain main window parameters without redefinig the default implementation using the following application properties:
-
cuba.web.foldersPaneEnabled - enables creation of folders pane.
-
cuba.web.appWindowMode – sets default mode for the main window: tabbed or single screen (
TABBEDorSINGLE). Users can change the mode later using Help > Settings screen. -
cuba.web.maxTabCount – when the main window is in the tabbed mode, this property sets the maximum number of tabs that a user can open. The default value is 7.
-
-
WindowManager- the central class implementing application screens management logic.openWindow(),openEditor(),showMessageDialog()and other methods of theFrameinterface implemented by screen controllers delegate to the window manager.WindowManagerclass is located in the platform’s common gui module and is abstract. The web module has a dedicatedWebWindowManagerclass that implements web client specifics. You can get a reference toWindowManagerfrom anyWindowimplementation (e.g. a screen controller), or via theWindowManagerProviderbean.
If you want to handle the browser Back button, implement the CubaHistoryControl.HistoryBackHandler interface in your TopLevelWindow (login and/or main windows). Its onHistoryBackPerformed() method is invoked instead of standard browser behavior if the cuba.web.allowHandleBrowserHistoryBack application property is set to true.
4.5.8.1. Working with Vaadin Components
In order to work directly with Vaadin components that implement interfaces of the visual components library in Web Client, use the following methods of the Component interface:
-
unwrap()– retrieves an underlying Vaadin component for a given CUBA component. -
unwrapComposition()- retrieves a Vaadin component that is the outmost external container in the implementation of a given CUBA component. For simple components, such as Button, this method returns the same object asunwrap()-com.vaadin.ui.Button. For complex components, such as Table,unwrap()will return the corresponding object -com.vaadin.ui.Table, whileunwrapComposition()will returncom.vaadin.ui.VerticalLayout, which contains the table together with ButtonsPanel andRowsCountdefined with it.
The methods accept a class of the underlying component to be returned, for example:
com.vaadin.ui.TextField vTextField = textField.unwrap(com.vaadin.ui.TextField.class);You can also use the unwrap() and getComposition() static methods of the WebComponentsHelper class, passing a CUBA component into them.
Please note that if a screen is located in the project’s gui module, you can only work with generalized interfaces of CUBA components. In order to use unwrap() you should either put the entire screen into the web module, or use the controller companions mechanism.
4.5.8.2. Main Window Layout
The mechanism described below allows you to design the application main window layout with CUBA Generic UI technology by creating an XML-descriptor and Java controller, and using UI components and data sources.
The main window is defined by a specific screen with mainWindow identifier. Its controller should be derived from the AbstractMainWindow class.
The following special components may be used in the main window in addition to the standard UI components:
-
AppMenu- main application menu. -
FoldersPane- application and search folders panel. -
AppWorkArea- work area, the required component for opening screens in theTHIS_TAB,NEW_TABandNEW_WINDOWmodes. -
UserIndicator- the field which displays the name of the current user, as well as enables selecting substituted users, if any. -
NewWindowButton- the button which opens a new main window in a separate browser tab. -
LogoutButton- the application logout button. -
TimeZoneIndicator- the label displaying the current user’s time zone. -
FtsField- the full text search field.
In order to define the special components, add the xmlns:main namespace to the screen:
<window xmlns="http://schemas.haulmont.com/cuba/window.xsd"
xmlns:main="http://schemas.haulmont.com/cuba/mainwindow.xsd"
class="com.company.sample.gui.MainWindow">
<layout>
</layout>
</window>The AppWorkArea component is designed to show application screens. If the cuba.web.appWindowMode application property is TABBED (default), the work area shows a TabSheet with open screens. Otherwise a single open screen is shown. When no screens are opened, the work area shows components defined in the initialLayout internal element:
<main:workArea id="workArea" width="100%" height="100%">
<main:initialLayout spacing="true" margin="true">
<!-- content shown when there are no open screens -->
</main:initialLayout>
</main:workArea>The initial screen layout (initialLayout) is removed from AppWorkArea when the first application screen is opened, and added back when all screens are closed. You can add AppWorkArea.StateChangeListener to handle changing the work area between the initial layout and application screens. Such listener can, for example, refresh the initial layout data.
The platform provides 2 standard main window implementations. XML descriptor of the default main window with horizontal menu on top is available in /com/haulmont/cuba/web/app/mainwindow/mainwindow.xml, its corresponding controller class is AppMainWindow. Another available template contains the vertical side menu.
The standard implementation can be extended in the project, like any other application screen. Example of an extending screen:
<window xmlns="http://schemas.haulmont.com/cuba/window.xsd"
xmlns:ext="http://schemas.haulmont.com/cuba/window-ext.xsd"
extends="com/haulmont/cuba/web/app/mainwindow/mainwindow.xml"
class="com.haulmont.cuba.web.app.mainwindow.AppMainWindow">
<layout>
<vbox ext:index="0">
<label value="This is my main window!" stylename="h2"/>
</vbox>
</layout>
</window>This screen should be registered in web-screens.xml file with the mainWindow identifier.
The easiest way to extend the main screen is provided by CUBA Studio: click New on the GENERIC UI tab of the navigation panel and choose the template for the new main screen in the Generic UI templates visual designer. The new ext-mainwindow.xml file will be created in the Web module and automatically registered in web-screens.xml.
CUBA Platform provides 2 standard main window layout templates: with horizontal menu and with the side menu. The standard main window implementation may be fully replaced with a custom one. For example:
<window xmlns="http://schemas.haulmont.com/cuba/window.xsd"
xmlns:main="http://schemas.haulmont.com/cuba/mainwindow.xsd"
class="com.company.sample.gui.MainWindow">
<layout expand="middlePanel">
<hbox margin="true"
stylename="gray"
width="100%">
<label align="MIDDLE_CENTER"
value="Header"/>
</hbox>
<main:menu width="100%"/>
<split id="middlePanel"
orientation="horizontal"
pos="80"
width="100%">
<main:workArea id="workArea"
height="100%"
width="100%">
<main:initialLayout stylename="red">
<label align="MIDDLE_CENTER"
value="Work Area (Initial Layout)"/>
</main:initialLayout>
</main:workArea>
<main:foldersPane height="100%"
stylename="blue"
width="100%"/>
</split>
<hbox margin="true"
stylename="gray"
width="100%">
<label align="MIDDLE_CENTER"
value="Footer"/>
</hbox>
</layout>
</window>The resulting main window is shown below:
The same main window with an open screen:
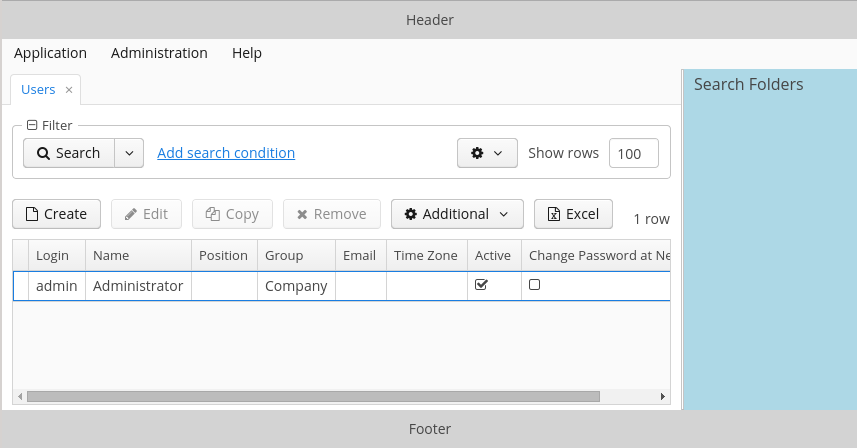
The cuba.web.showBreadCrumbs application property allows you to hide the navigation panel (breadcrumbs) above the opened screen.
4.5.9. Desktop Client Specifics
Implementation of the generic user interface in the Desktop Client block is based on Java Swing. The main classes available in the desktop client infrastructure are described below..Classes of the Desktop Client Infrastructure image::DesktopClientInfrastructure.png[align="center"]
-
App– central class of the desktop application infrastructure. Contains links toConnectionand mainTopLevelFrame, as well as methods for initialization and retrieval of application settings.In your application, you should create a custom class – inheritor of
Appand override the following methods:-
getDefaultAppPropertiesConfig()- should return a string where all application properties files should be listed separated by spaces:@Override protected String getDefaultAppPropertiesConfig() { return "/cuba-desktop-app.properties /desktop-app.properties"; } -
getDefaultHomeDir()- should return path to the folder, where temporary and work files should be stored. For example:@Override protected String getDefaultHomeDir() { return System.getProperty("user.home") + "/.mycompany/sales"; } -
getDefaultLogConfig()- should return name of the Logback configuration file, if it is defined for the project. For example:@Override protected String getDefaultLogConfig() { return "sales-logback.xml"; }Additionally, for your custom class inheriting from the
Appyou should definemain()method in the following way:public static void main(final String[] args) { SwingUtilities.invokeLater(new Runnable() { public void run() { app = new App(); app.init(args); app.show(); app.showLoginDialog(); } }); }
-
-
Connection- is a class that provides the functionality of connecting to middleware and storing a user session. -
LoginDialog– the dialog to enter credentials. In your application you can create an inheritor ofLoginDialogand redefine thecreateLoginDialog()method of theAppclass to use it. -
TopLevelFrame– inheritor ofJFrame, which is the top level window. The application has at least one instance of this class created when application is started and containing the main menu. This instance is returned by thegetMainFrame()method of theAppclass.When a user detaches tabs from the main window or a TabSheet (see
detachableattribute), additional instances ofTopLevelFramethat do not contain main menu are created. -
WindowManager- the central class implementing application screens management logic.openEditor(),showMessageDialog()and other methods of theFrameinterface implemented by screen controllers delegate to the window manager.WindowManagerclass is located in the platform’s common gui module and is abstract. The desktop desktop module has a dedicatedDesktopWindowManagerclass that implements desktop client specifics.Typically,
WindowManageris not used in the application code directly. -
ExceptionHandlers- contains a collection of client-level exception handlers.
4.5.9.1. Working with Swing Components
In order to work directly with Swing components that implement interfaces of the visual components library in Desktop Client, use the following methods of the Component interface:
-
unwrap()– retrieves an underlying Swing component for a given CUBA component. -
unwrapComposition()- retrieves a Swing component that is the outmost external container in the implementation of a given CUBA component. For simple components, such as Button, this method returns the same object asunwrap()-javax.swing.JButton. For complex components, such as Table,unwrap()will return the correspondingorg.jdesktop.swingx.JXTableinstance, whileunwrapComposition()will return an instance ofjavax.swing.JPanel, which contains a table together with ButtonsPanel andRowsCountdefined with it.
The methods accept a class of the underlying component to be returned, for example:
javax.swing.JButton jButton = button.unwrap(javax.swing.JButton.class);You can also use the unwrap() and getComposition() static methods of the DesktopComponentsHelper class, passing a CUBA component into them.
Please note that if a screen is located in the project’s gui module, you can only work with generalized interfaces of CUBA components. In order to use unwrap() you should either put the entire screen in the desktop module, or use the controller companions mechanism.
4.5.10. Custom Visual Components
This section contains an overview of different ways of creating custom web UI components in CUBA applications. The practical tutorial of using these approaches is located in the Creating Custom Visual Components section.
A new component can be created with the following technologies:
-
On the basis of a Vaadin add-on.
This is the simplest method. The following steps are required to use an add-on in your application:
-
Add a dependency to the add-on artifact to build.gradle.
-
Create the web-toolkit module in your project. This module contains a GWT widgetset file and allows you to create client-side parts of visual components.
-
Include the add-on widgetset to the widgetset of your project.
-
If the component’s look does not fit the application theme, create a theme extension and define some CSS for the new component.
See an example in the Using a Third-party Vaadin Component section.
-
-
As a wrapper of a JavaScript library.
This method is recommended if you already have a pure JavaScript component that does what you need. To use it in your application, you need to do the following:
-
Create a server-side Vaadin component in the web module. A server component defines an API for server code, access methods, event listeners, etc. The server component must extend the
AbstractJavaScriptComponentclass. Note that the web-toolkit module with a widgetset is not required when integrating a JavaScript component. -
Create a JavaScript connector. A connector is a function that initializes the JavaScript component and is responsible for interaction between JavaScript and the server-side code.
-
Create a state class. Its public fields define what data are sent from the server to the client. The class must extend
JavaScriptComponentState.
See an example in the Using a JavaScript library section.
-
-
As a new GWT component.
This is the recommended method of creating completely new visual components. The following steps are required to create and use a GWT component in your application:
-
Create the web-toolkit module.
-
Create a client-side GWT widget class.
-
Create a server-side Vaadin component.
-
Create a component state class that defines what data are sent between the client and the server.
-
Create a connector class that links the client code with the server component.
-
Create an RPC interface that defines a server API that is invoked from the client.
See an example in the Creating a GWT component section.
-
There are three levels of integration of a new component into the platform.
-
On the first level, the new component becomes available as a native Vaadin component. An application developer can use this component in screen controllers directly: create a new instance and add it to an unwrapped container. All methods of creating new components described above give you a component on this level of integration.
-
On the second level, the new component is integrated into CUBA Generic UI. In this case, from an application developer perspective, it looks the same as a standard component from the visual components library. The developer can define the component in a screen XML descriptor or create it through
ComponentsFactoryin a controller. See an example in the Integrating a Vaadin Component into the Generic UI section. -
On the third level, the new component is available on the Studio components palette and can be used in the WYSIWYG layout editor. See an example in the Support for Custom Visual Components in CUBA Studio section.
4.5.11. Keyboard Shortcuts
This section provides a list of keyboard shortcuts used in the generic user interface of the application. All the application properties listed below belong to the ClientConfig interface and can be used in Web Client and Desktop Client application blocks.
-
Main application window.
-
CTRL-SHIFT-PAGE_DOWN – switch to the next tab. Defined by the
cuba.gui.nextTabShortcutproperty. -
CTRL-SHIFT-PAGE_UP – switch to the previous tab. Defined by the
cuba.gui.previousTabShortcutproperty.
-
-
Screens.
-
Standard actions for list components (Table, GroupTable, TreeTable, Tree). In addition to these application properties, a shortcut for a particular action can be set by calling it’s
setShortcut()method.-
CTRL-\ – call the CreateAction. Defined by the
cuba.gui.tableShortcut.insertproperty. -
CTRL-ALT-\ – call the AddAction. Defined by the
cuba.gui.tableShortcut.addproperty. -
ENTER – call the EditAction. Defined by the
cuba.gui.tableShortcut.editproperty. -
CTRL-DELETE – call the RemoveAction and ExcludeAction. Defined by the
cuba.gui.tableShortcut.removeproperty.
-
-
Drop-down lists (LookupField, LookupPickerField).
-
SHIFT-DELETE – clear the value.
-
-
Standard actions for lookup fields (PickerField, LookupPickerField, SearchPickerField). In addition to these application properties, a shortcut for a particular action can be set by calling its
setShortcut()method.-
CTRL-ALT-L – call the LookupAction. Defined by the
cuba.gui.pickerShortcut.lookup. -
CTRL-ALT-O – call the OpenAction. Defined by the
cuba.gui.pickerShortcut.openproperty. -
CTRL-ALT-C – call the ClearAction. Defined by the
cuba.gui.pickerShortcut.clearproperty.
In addition to these shortcuts, lookup fields support action calls with CTRL-ALT-1, CTRL-ALT-2 and so on, depending on the number of actions. If you click CTRL-ALT-1 the first action in the list will be called; clicking CTRL-ALT-2 calls the second action, etc. The CTRL-ALT combination can be replaced with any other combination specified in
cuba.gui.pickerShortcut.modifiersproperty. -
-
Filter component.
-
SHIFT-BACKSPACE – open the filter selection popup. Defined by the
cuba.gui.filterSelectShortcutproperty. -
SHIFT-ENTER – apply the selected filter. Defined by the
cuba.gui.filterApplyShortcutproperty.
-
4.6. Polymer User Interface
The Polymer UI client block provides an ability to quickly create front-end portals with mobile-first responsive web UI. It is based on Google Polymer framework and enables tight integration with mobile browsers for adding web applications to the device home screen and for offline work.
The CUBA platform Polymer UI has the following features:
-
The Polymer build system is fully integrated into the project build system based on Gradle, so all building tools are downloaded and installed automatically. At the same time, once the Polymer module is created in the project, it can be developed further by front-end developers separately using the standard Polymer toolchain.
-
The platform provides a set of web components for working with the middleware through the standard CUBA REST API. The components are described below.
-
CUBA Studio enables easy creation of the Polymer client module and scaffolding of the application web components around the data model and middleware services of the project. Studio contains an extendable set of templates for creation of application level components.
Our current approach is to stick to Polymer’s techniques and tools which are used for creating Progressive Web Apps. The aim is to follow Polymer’s guidelines and best practices to provide similar learning curve and development experience. Polymer applications have component-based architecture and consist of Web Components.
By default the UI generated by Studio is based on paper-elements - a set of elements by Polymer team which implement Google’s material design guidelines. It is possible to use another components by specifying custom templates in Studio.
In order to start developing effectively you need to be familiar with basic Polymer concepts. Here is a very quick intro to the Polymer: https://github.com/Polymer/polymer/tree/1.x#polymer-in-1-minute. However it’s better to learn it more in depth: https://www.polymer-project.org/1.0/start/. Since the Polymer is built around the standards by learning it in most cases you learn the web platform itself.
4.6.2. Supported Browsers
See the list of supported browsers on the Polymer’s website
|
Warning
|
Please do not to use Polymer client if you are targeting legacy browsers. |
4.6.3. Polymer UI in Studio
In order to add the Polymer client module to your project, open it in CUBA Studio and click Create module > Create polymer client module on the Project Properties navigator tab. Studio will create the polymer-client module in the project and configure it in build.gradle. The module will contain an application stub that is able to connect to the REST API and login/logout user to the middleware.
After creating the module, start the application server and open http://localhost:8080/app-front in a web browser. You will be presented with a login form. After logging in, the main window with a vertical menu and responsive layout will be shown.
In order to create a UI screen working with an entity, select an entity in Studio navigator and click New > Polymer UI component. Select a template (e.g. Entity cards list with editor), fill in required properties and click Create. The web component will be created and added to the menu. Studio provides hot-deploy of Polymer components, so you just need to refresh the page in the browser and you will see the newly created screen in the menu.
4.6.4. Build System and Project Structure
The following tools are used in Polymer client build chain:
By default Gradle handles installation and invocation of these tools. It’s possible to use them directly, see Using Native Polymer Tools.
4.6.4.1. Directory Structure
polymer-client/ |-- src/ | |-- app-shell.html | |-- shared-styles.html |-- images | |-- app-icon/ | |-- favicon.ico |-- .gitignore |-- bower.json |-- gulpfile.js |-- index.html |-- manifest.json |-- package.json |-- polymer.json |-- service-worker.js |-- sw-precache-config.js
- src
-
Folder where components are placed.
- package.json
-
Lists dependencies on Node.js modules which will be used in a build purposes.
- bower.json
-
Lists dependencies on web libraries (primarily web components) which will be used in runtime.
- polymer.json
-
Polymer build configuration.
- gulpfile.js
-
Gulp build file. It’s a right place to add some processing like minification/preprocessors etc. More info: https://github.com/Polymer/polymer-build#polymerproject.
- index.html
-
An application entry point. Contains logic on loading polyfills and <appname>-shell.html import.
- manifest.json
-
Web app manifest. Contains information which used when application is being added to a device’s homescreen. More info: https://developer.mozilla.org/en-US/docs/Web/Manifest
- service-worker.js
-
Service worker stub.
- sw-precache-config.js
-
Config used by sw-precache library in order to generate service worker at build time (disabled by default). See Offline Capabilities.
4.6.4.2. Hot Deploy
When you run and deploy your application using CUBA Studio or gradle the build system will bundle your components according to the configuration in polymer.json file. By default it will bundle the whole application into a single app-shell.html file. When you change some of your app components Studio will hot deploy it to the tomcat. Also it will replace bundled app-shell.html with unbundled version in order changes to be picked. Keep it in mind if you deploy your application on production directly from tomcat/webapps.
4.6.4.3. Using Native Polymer Tools
You can use native Polymer framework toolchain when developing Polymer UI components. It can be convenient if a separate team of front-end developers works on the project. In this case Node.js should be installed on the system.
Install bower and gulp globally:
npm install bower gulp-cli -gThen you can build and run the web application without Gradle:
cd modules/polymer-client
npm install
bower install
gulp serveYou need to apply the following changes in the source code if you want to serve app by polymer server (instead of Tomcat):
-
Open
modules/polymer-client/index.htmland editbaseelement as follows:<base href="/"> -
Open
modules/polymer-client/src/<appname>-shell.htmland editcuba-appelement as follows:<cuba-app api-url="http://localhost:8080/app/rest/" on-cuba-token-expired="_handleTokenExpired"></cuba-app>
After that, the web application will be available at http://localhost:8081 and it will work with the REST API running at http://localhost:8080/app/rest/.
4.6.5. CUBA Web Components
The detailed API reference of CUBA elements can be found here.
4.6.5.1. Initialization
In order to use any cuba- element you need to initialize common library and connection to the REST API using cuba-app element :
<cuba-app api-url="/app/rest/"></cuba-app>It should be placed once in your app as early as possible. Do not change properties dynamically or detach/attach the element after initialization.
4.6.5.2. Working With Data
In order to load data just place some of cuba-data elements in HTML and specify required attributes.
Entities Loading
Use cuba-entities to load entities. Once entity-name and view attributes are specified the element loads list of entities and exposes it to the Polymer data binding via data property:
<cuba-entities entity-name="sec$User" view="_local" data="{{users}}"></cuba-entities>Then you can display the data as simple as:
<template is="dom-repeat" items="[[users]]" as="user">
<div>[[user.login]]</div>
</template>Entities Querying
Define a query as described here.
Use cuba-query element to retrieve query results. You can optionally pass parameters using params property:
<cuba-query id="query"
auto="[[auto]]"
entity-name="sec$User"
query-name="usersByName"
data="{{users}}">
</cuba-query>
<template is="dom-repeat" items="[[users]]" as="user">
<div>[[user.login]]</div>
</template>Service Invocation
Expose a service and it’s method as described here. Use cuba-service element to invoke the method:
<cuba-service service-name="cuba_ServerInfoService"
method="getReleaseNumber"
data="{{releaseNumber}}"
handle-as="text"></cuba-service>
Release number: [[releaseNumber]]Entity Creation
cuba-entity-form and cuba-service-form elements facilitate sending data to the backend.
In the example below we bind user object which should be persisted to the entity property.
<cuba-entity-form id="entityForm"
entity-name="sec$User"
entity="[[user]]"
on-cuba-form-response="_handleFormResponse"
on-cuba-form-error="_handleFormError">
<label>Login: <input type="text" name="login" value="{{user.login::input}}"></label>
<label>Name: <input type="text" name="login" value="{{user.name::input}}"></label>
<button on-tap="_submit">Submit</button>
</cuba-entity-form>
<paper-toast id="successToast">Entity created</paper-toast>
<paper-toast id="errorToast">Entity creation error</paper-toast>_submit: function() {
this.$.entityForm.submit();
},
_handleFormResponse: function() {
this.user = getUserStub();
this.$.successToast.open();
},
_handleFormError: function() {
this.$.errorToast.open();
}|
Tip
|
You should enable anonymous access in the REST API if you want to use the examples above without forcing users to log in. |
4.6.6. Styling
See the Polymer’s styling guide. The most noticeable difference between traditional approach is how global styles are specified. Since Polymer elements use Shadow DOM global styles do not leak inside the components. You need to use style-modules instead. There is a shares-styles.html file in Polymer client which is automatically being imported to any new component created in Studio.
4.6.7. Offline Capabilities
|
Warning
|
Experimental! The technologies listed below are not supported by all browsers yet (e.g. service workers are [not implemented](https://jakearchibald.github.io/isserviceworkerready) in Safari). |
Currently, together with the Polymer we offer to use Progressive Web Applications techniques such as web app manifest 2 to have native-like presence on the user’s homescreen. See the manifest.json file in Polymer client module.
There are two main approaches:
-
Service Workers which primarily used to cache the app itself. Take a look at
sw-precache-config.jsfile generated with Polymer client. In order to enable service worker generation changeassembletask of Polymer module in the following way:
...
task assemble(type: NodeTask, dependsOn: installBowerPackages) {
script = file("node_modules/gulp/bin/gulp.js")
args = ['build-sw']
...More info on how to setup and use service workers can be found here.
-
Local storage and Indexed DB which used to store data locally. This functionality exposed in the corresponding Polymer elements: app-localstorage-document app-indexeddb-mirror.
4.6.8. Troubleshooting
- Proxy
-
If you work behind a proxy you may need to configure bower and npm accordingly. In order to allow bower and npm to work behind a proxy create the following files in the
modules/polymer-client/directory:.bowerrc
{ "proxy":"http://<user>:<password>@<host>:<port>", "https-proxy":"http://<user>:<password>@<host>:<port>" }.npmrc
proxy=http://<user>:<password>@<host>:<port> https-proxy=http://<user>:<password>@<host>:<port>
4.7. Portal Components
In this manual, a portal is a client block, which can solve the following problems:
-
provide an alternative web-interface, which is usually intended for users outside of the organization;
-
provide an interface for integration with mobile applications and third-party systems.
A specific application may contain several portal modules intended for different purposes; for example, in an application, which automates business tasks, it can be a public web site for customers, an integration module for a mobile application for ordering a taxi, an integration module for a mobile application for drivers, etc.
The cuba application component includes the portal module, which is a template to create portals in projects. It provides basic functionality of the client block to work with Middleware. Besides, the universal REST API, included to the portal module as a dependency, is turned on by default.
Below is an overview of the main components provided by the platform in the portal module.
-
PortalAppContextLoader– the AppContext loader; must be registered in thelistenerelement of theweb.xmlfile. -
PortalDispatcherServlet– the central servlet that distributes requests to Spring MVC controllers, for both the web interface and REST API. The set of Spring context configuration files is defined by the cuba.dispatcherSpringContextConfig application property. This servlet must be registered inweb.xmland mapped to the root URL of the web application. -
App– the object that contains information on the current HTTP request and the reference toConnectionobject. TheAppinstance can be obtained in the application code by calling theApp.getInstance()static method. -
Connection– allows a user to log in/out of the Middleware. -
PortalSession– the object of a user session that is specific for the portal. It is returned by the UserSessionSource infrastructure interface and by thePortalSessionProvider.getUserSession()static method.It has an additional
isAuthenticated()method, which returnstrueif this session belongs to a non-anonymous user, i.e. a user explicitly registered with the login and password.When a user first accesses the portal, the
SecurityContextHandlerInterceptorcreates an anonymous session for him (or ties to an already existing one) by registering at Middleware with a user name specified in the cuba.portal.anonymousUserLogin application property. The registration is made by loginTrusted() method, so it is necessary to set the cuba.trustedClientPassword property in the portal block as well. Thus, any anonymous user of the portal can work with Middleware withcuba.portal.anonymousUserLoginuser rights.If the portal contains user registration page with name and password
SecurityContextHandlerInterceptorassigns the session of the explicitly registered user to the execution thread afterConnection.login()is executed, and the work with Middleware is performed on this user’s behalf. -
PortalLogoutHandler– handles the navigation to the logout page. It must be registered in theportal-security-spring.xmlproject file.
4.8. Platform Features
This section provides overview on various optional features provided by the platform.
4.8.1. REST API Version 1
|
Tip
|
We recommend using the REST API Version 2 for new projects. Version 1 exists for backward compatibilty only. |
The universal REST API of the platform enables loading and saving any entities defined in the application data model by sending simple HTTP requests. This provides easy way to integrate with a wide range of third-party applications – from the JavaScript code executed in the browser to arbitrary systems running on Java, .NET, PHP or any other platform.
Key API features:
-
Loading entity instances from the database by identifier or by JPQL query with parameters.
-
Saving new and modified instances, deleting instances.
-
Obtaining a description of the data model in HTML format.
-
Data representation in JSON and XML formats.
-
Middleware service calls.
-
User authentication.
4.8.1.1. Including in a Project
REST API is included as a dependency to the web and portal modules of the cuba application component.
For the web module the REST API functions will be available by default at the {host:port}/app/dispatch/api URL.
To create the portal module in your application project, open the project in CUBA Studio and click the Create portal module link on the Project properties navigator panel. After that, the REST API functions will be available at the {host:port}/app-portal/api URL.
REST API controllers are registered in the Spring context defined by the dispatcher-spring.xml file of of the corresponding module (portal-dispatcher-spring.xml or web-dispatcher-spring.xml):
<context:component-scan base-package="com.haulmont.cuba.restapi"/>4.8.1.2. Describing Functions
Here we suppose that you use REST API included in the portal module, so all requests have the URL starting with {host:port}/app-portal/api. If you use REST API in web module, the URL should start with {host:port}/app/dispatch/api.
All functions require an authenticated user session, which means that you must perform the login first and then pass the resulting session identifier to subsequent requests.
4.8.1.2.1. Login
Login can be performed by either GET or POST request.
- GET request
-
For GET request, create the URL
{host:port}/app-portal/api/loginwith the following parameters:-
u − user login
-
p − user password
-
l − user locale (optional)
For example:
http://localhost:8080/app-portal/api/login?u=admin&p=admin&l=ru -
- POST request
-
To perform login using POST, execute request by
{host:port}/app-portal/api/loginaddress, passing JSON (Content-Typeheader has the valueapplication/json) or form (Content-Typeheader has the valueapplication/x-www-form-urlencoded) in request body.Example of the JSON format:
{ "username" : "admin", "password" : "admin", "locale" : "en" }Example of the form:
username: admin password: admin locale: en
The service will return userSessionId in response body and status 200 or status 401 if the authentication fails.
To login through REST API, the user must have cuba.restApi.enabled specific permission. Notice that the user will have the permission if there are no roles explicitly revoking it.
4.8.1.2.2. Logout
Logout can also be performed by either GET or POST request.
- GET request
-
To perform login using GET, construct the URL
{host:port}/app-portal/api/logoutwith the session parameter containing the current session ID obtained by callinglogin.For example:
http://localhost:8080/app-portal/api/logout?session=64f7d59d-2cf5-acfb-f4d3-f55b7882da72 - POST request
-
To perform login using POST, send request to
{host:port}/app-portal/api/logoutURL, passing JSON (Content-Typeheader has the valueapplication/json) or form (Content-Typeheader has the valueapplication/x-www-form-urlencoded) in the request body.Example of the JSON format:
{ "session" : "64f7d59d-2cf5-acfb-f4d3-f55b7882da72" }Example of the form:
session: 64f7d59d-2cf5-acfb-f4d3-f55b7882da72
The service will return status 200.
4.8.1.2.3. Loading a Persistent Object Instance From the Database by Identifier
To load an object, you should perform GET request {host:port}/app-portal/api/find.<format> with the following parameters:
-
e − the description of the required object in
<entity-id>or<entity-id-view>format (see EntityLoadInfo). For example,sales$Order-43c61345-d23c-48fe-ab26-567504072f05-_local. Thus, the format allows you to specify required view of the loaded object. -
s − current session identifier.
format element of the request specifies the result format. It takes two values: xml and json.
Example of a request, which returns the result in xml format:
http://localhost:8080/app-portal/api/find.xml?e=sales$Order-60885987-1b61-4247-94c7-dff348347f93-orderWithCustomer&s=c38f6bf4-fae7-4ee6-a412-9d93ff243f23Example of request, which returns the result in json format:
http://localhost:8080/app-portal/api/find.json?e=sales$Order-60885987-1b61-4247-94c7-dff348347f93-orderWithCustomer&s=c38f6bf4-fae7-4ee6-a412-9d93ff243f234.8.1.2.4. Executing JPQL Query to Retrieve Data
To execute a query, the {host:port}/app-portal/api/query.<format> GET request should be performed with the following parameters:
-
e − the name of the entity.
-
q − a JPQL data query. The request may contain parameters. Their values are provided as values of same-named parameters of HTTP query.
-
s − the identifier of the current session.
-
view (optional) − the view, which should be used to load data.
-
max (optional) − maximum number of rows in resulting dataset (similar to JPA
setMaxResults). -
first (optional) − number of the first row of resulting dataset (similar to JPA
setFirstResult).
format specifies the format of obtaining the result. It takes two values: xml or json.
Examples:
http://localhost:8080/app-portal/api/query.json?e=sales$Customer&q=select+c+from+sales$Customer+c&s=748e5d3f-1eaf-4b38-bf9d-8d838587367d&view=_localhttp://localhost:8080/app-portal/api/query.json?e=sales$Customer&q=select+c+from+sales$Customer+c+where+c.name=:name&s=748e5d3f-1eaf-4b38-bf9d-8d838587367d&name=SmithFor each of the passed parameters, the type can be explicitly specified by adding the parameter of the same name and the _type suffix to the request. For example:
http://localhost:8080/app-portal/api/query.json?e=sales$Customer&q=select+c+from+sales$Customer+c+where+c.name=:name&s=748e5d3f-1eaf-4b38-bf9d-8d838587367d&name=Smith&name_type=stringSpecifying parameter type is optional, however it allows you to avoid parsing errors if the system cannot determine the type automatically. Normally, the type should be specified only for string parameters, which for some reason have a more specific format types (dates, numbers, UUID), but must be interpreted as strings. The list of available types can be found in meta-model description (Help > Data Model) or by obtaining the HTML-description of the model.
A query can also be executed using POST request to the {host:port}/app-portal/api/query.<format>?s=<sessionId> URL, where <sessionId> is the identifier of the current session. In this case, the query and its parameters are passed in the request body as follows.
Example POST request of JSON format, the Content-Type header must be set to application/json:
http://localhost:8080/app-portal/api/query.json?s=748e5d3f-1eaf-4b38-bf9d-8d838587367dThe request body:
{
"entity": "sales$Customer",
"query": "select c from sales$Customer c where c.name=:name",
"params": [
{
"name": "name",
"value": "Smith",
"type": "string"
}
]
}Example POST request of XML format, the Content-Type header must be set to text/xml:
http://localhost:8080/app-portal/api/query.xml?s=748e5d3f-1eaf-4b38-bf9d-8d838587367dThe request body:
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<QueryRequest xmlns="http://schemas.haulmont.com/cuba/restapi-query-request-v2.xsd">
<entity>sales$Customer</entity>
<query>select c from sales$Customer c where c.name=:name</query>
<params>
<param>
<name>name</name>
<value>Smith</value>
<type>string</type>
</param>
</params>
</QueryRequest>4.8.1.2.5. Committing New and Modified Instances, Removal
The commit function enables performing operations on objects passed to it and returning their new state. The format of the result depends on format (JSON or XML) used for the request (the Content-Type header).
- JSON format
-
application/jsonshould be used as the value of theContent-Typeheader.Creating a
Customerentity with an automatically generated identifier:{ "commitInstances": [ { "id": "NEW-sales$Customer", "name": "Lawrence", "email": "lawrence@mail.com" } ] }Creating a
Customerentity with a specified identifier:{ "commitInstances": [ { "id": "NEW-sales$Customer-b32a6412-d4d9-11e2-a20b-87b22b1460c7", "name": "Bradley", "email": "bradley@mail.com" } ] }Creating the
Orderentity, specifying a link to a newCustomerentity and filling theCustomerentity with attributes:{ "commitInstances": [ { "id": "NEW-sales$Order", "amount": 15, "customer": { "id": "NEW-sales$Customer-b32e43e8-d4d9-11e2-8c8b-2b2939d67fff" } }, { "id": "sales$Customer-b32e43e8-d4d9-11e2-8c8b-2b2939d67fff", "name": "Fletcher", "email": "fletcher@mail.com" } ] }Changing two
Customerentities simultaneously:{ "commitInstances": [ { "id": "sales$Customer-b32e43e8-d4d9-11e2-8c8b-2b2939d67fff", "email": "fletcher@mail.com" }, { "id": "sales$Customer-32261b09-b7f7-4b8c-88cc-6dee6fa8e6ab", "email": "lawrence@mail.com" } ] }Removing the
Customerentity with soft deletion support:{ "removeInstances": [ { "id": "sales$Customer-b32e43e8-d4d9-11e2-8c8b-2b2939d67fff" } ], "softDeletion": "true" }-
The
commitInstancesarray contains created and modified entities.-
When creating an entity,
idorNEW-<entityName>should be specified as the value of theNEW-<entityName>-<uuid>field. -
When changing an entity,
<entityName>-<uuid>should be specified as the value of theidfield. -
Next, attribute names and values for created or modified entity should be provided in the list of elements, separated by commas.
If any attribute should be set to
nullwhile editing the entity, you must specify the view that includes this attribute, in the identifier. For example:{ "commitInstances": [ { "id": "sales$Customer-b32a6412-d4d9-11e2-a20b-87b22b1460c7-customer-edit", "name": "John Doe", "channel": null } ] }Here, the
customer-editview must contain thechannelattribute, otherwise the value will not change.
-
-
The
removeInstancesarray contains removed entities. When removing an entity, you must specify the value of theidfield. Before deletion,merge()will be executed for the provided object, which enables checking if the version of the removed object has changed. -
The
softDeletionfield controls soft deletion mode.
The function is called by a POST request to
{host:port}/app-portal/api/commit?s=<sessionId>. JSON is passed in the request body. The function returns a JSON objects array. For example, the following JSON objects array will be returned when theemailfield of theCustomerentity is changed:[ {"id":"sales$Customer-32261b09-b7f7-4b8c-88cc-6dee6fa8e6ab", "createTs":"2013-06-14T14:07:15.040", "createdBy":"admin", "deleteTs":null, "deletedBy":null, "email":"fletcher@mail.com", "name":"Fletcher", "updateTs":"2013-06-14T15:07:03.463", "updatedBy":"admin", "version":"3" } ] -
- XML format
-
text/xmlshould be used as the value ofContent-Typeheader.XML format example:
<CommitRequest> <commitInstances> <instance id="sales$Order-9873c8a8-d4e7-11e2-85c0-33423bc08c84"> <field name="date">2015-01-30</field> <field name="amount">3500.00</field> <reference name="customer" id="sales$Customer-32261b09-b7f7-4b8c-88cc-6dee6fa8e6ab"/> </instance> </commitInstances> <removeInstances> <instance id="sales$Customer-d67c10f0-4d28-4904-afca-4bc45654985d"/> </removeInstances> <softDeletion>true</softDeletion> </CommitRequest>XML document fields semantics is defined in http://schemas.haulmont.com/cuba/6.5/restapi-commit-v2.xsd scheme.
In case of an XML request, fields are set to null with the help of the
null="true"attribute. In addition to that, the identifier must contain the view, which contains the attribute. For example:<CommitRequest> <commitInstances> <instance id="Order-9873c8a8-d4e7-11e2-85c0-33423bc08c84"> <field name="amount" null="true"/> <reference name="customer" null="true"/> </instance> </commitInstances> </CommitRequest>The function is called with a POST request to
{host:port}/app-portal/api/commit?s=<sessionId>. XML is passed in the request body. The request returns array of XML objects similar to the one below:<instances> <instance ...> <instance ...> </instances>The schema containing the description of the function call result is located at http://schemas.haulmont.com/cuba/6.5/restapi-instance-v2.xsd
4.8.1.2.6. Uploading Files to Storage
To upload a file to FileStorage, use the POST request {host:port}/app-portal/api/upload with the following parameters:
-
s − current session ID.
-
name - file name
-
ext - file extension
-
size - file size in bytes
File is sent in the request body.
4.8.1.2.7. Downloading Files from Storage
To download a file from FileStorage, use the GET request {host:port}/app-portal/api/download with the following parameters:
-
f − the ID of the corresponding
FileDescriptorinstance. -
s − current session ID.
For example:
http://localhost:8080/app-portal/api/download?s=abbfb51c-715d-ced5-cc00-ee355278ea21&f=dbea7543-7761-3680-9b6c-c06f7fdb37384.8.1.2.8. Obtaining Data Model Description in HTML Format
The /printDomain?s=<sessionId> GET request allows a developer to obtain data model description. The service returns a simple HTML, which contains basic data types list and description of all meta-model entities, their attributes and views defined for entities.
4.8.1.2.10. Service Calls
Service methods available for API calls are listed in a configuration file. The name of the file is defined by the cuba.restServicesConfig property.
A sample REST API services configuration file:
<services xmlns="http://schemas.haulmont.com/cuba/restapi-service-v2.xsd">
<service name="refapp_PortalTestService">
<method name="findAllCars"/>
<method name="updateCarVin"/>
</service>
</services>Service method call can be performed both by GET and POST requests. Additionally, POST requests allow passing entities or entity collections to the invoked method.
Service Call by GET Request
Request format:
{host:port}/app-portal/api/service.<format>?service=<serviceName>&method=<methodName>&view=<view>¶m0=<value 0>¶mN=<value N>¶m0_type=<type 0>¶mN_type=<type N>&s=<sessionId>-
format- defines the output format. Two values are accepted:xmlorjson. -
service- the name of the service called. -
method- the name of the method invoked. -
param0 .. paramN- parameter values of the method. -
param0_type .. paramN_type- parameter types of the method. -
s- the current session identifier.
If a service has a single method with the specified name and number of parameters, explicit parameter type definition is not required. In other cases, parameter type must be specified.
Service Call by POST Request
Request format:
{host:port}/app-portal/api/service?s=<sessionId>-
s- the current session identifier.
JSON or XML with the description of the method call is passed in the request body.
- JSON format
-
The
Content-Typeheader value isapplication/json.{ "service": "refapp_PortalTestService", "method": "updateCarVin", "view": "carEdit", "params": { "param0": { "id": "ref$Car-32261b09-b7f7-4b8c-88cc-6dee6fa8e6ab", "vin": "WV00001", "colour" : { "id": "ref$Colour-b32a6412-d4d9-11e2-a20b-87b22b1460c7", "name": "Red" }, "driverAllocations": [ { "id": "ref$DriverAllocation-b32e43e8-d4d9-11e2-8c8b-2b2939d67fff" }, { "id": "NEW-ref$DriverAllocation" } ] }, "param1": "WV00001", "param0_type": "com.haulmont.refapp.core.entity.Car", "param1_type": "java.lang.String" } }Properties of the passed object:
-
service- the name of the service called. -
method- the name of the method invoked. -
param0 .. paramN- method parameter values. -
param0_type .. paramN_type- method parameter types.
-
- XML format
-
The
Content-Typeheader value istext/xml.<ServiceRequest xmlns="http://schemas.haulmont.com/cuba/restapi-service-v2.xsd"> <service>refapp_PortalTestService</service> <method>updateCarVin</method> <view>carEdit</view> <params> <param name="param0"> <instance id="ref$Car-32261b09-b7f7-4b8c-88cc-6dee6fa8e6ab"> <field name="vin">WV00000</field> <reference name="colour"> <instance id="ref$Colour-b32a6412-d4d9-11e2-a20b-87b22b1460c7"> <field name="name">Red</field> </instance> </reference> <collection name="driverAllocations"> <instance id="ref$DriverAllocation-b32e43e8-d4d9-11e2-8c8b-2b2939d67fff"/> <instance id="NEW-ref$DriverAllocation"/> </collection> </instance> </param> <param name="param1">WV00001</param> <param name="param0_type">com.haulmont.refapp.core.entity.Car</param> <param name="param1_type">java.lang.String</param> </params> </ServiceRequest>The main elements of the passed document are:
-
service- the name of the service called. -
method- the name of the method invoked. -
param- the value of the parameter method or the parameter type. The name of the parameter (nameattribute) must have the formatparam0 .. paramNorparam0_type .. paramN_type.
If a service has a single method with the specified name and number of parameters, explicit parameter type definition is not required. In other cases, parameter types must be specified.
<param>element may contain both plain text (for setting primitive type values) and nested<instance>elements for entities or<instances>for entity collections.The XSD of the request is available at http://schemas.haulmont.com/cuba/6.5/restapi-service-v2.xsd.
-
Supported Service Method Parameter Types
-
primitive Java types.
long,int,boolean, etc. should be specified as the type name. -
primitive Java type wrappers. The full class name should be specified as the type name:
java.lang.Boolean,java.lang.Integer, etc. -
string (
java.lang.String). -
date (
java.util.Date). -
UUID (
java.util.UUID). -
BigDecimal (
java.math.BigDecimal) -
entity (for POST requests only). The full class name should be specified as the type name, e.g.
com.haulmont.cuba.security.entity.User. -
entity collections (for POST requests only). The full class or collection interface name should be specified as the type name, e.g.
java.util.List.
Service Call Result
The result may be in JSON or XML, depending on the method call declaration. Currently, methods can return primitive data types, entities and entity collections.
- Example of a JSON result
-
Primitive data type:
{ "result": "10" }Entity:
{ "result": { "id" : "ref$Colour-b32e43e8-d4d9-11e2-8c8b-2b2939d67fff", "name": "Red" } } - Example of XML result
-
Primitive data type:
<result> 10 </result>Entity:
<result> <instance id="ref$Colour-b32a6412-d4d9-11e2-a20b-87b22b1460c7"> <field name="name">Red</field> </instance> </result>The XSD of the result is available at http://schemas.haulmont.com/cuba/6.5/restapi-service-v2.xsd.
4.8.1.3. CORS Settings
By default, all CORS requests to the REST API are allowed. To restrict the origins list you can define a global CORS configuration in the Spring configuration file. If the REST API is attached to the portal module then modify the portal-dispatcher-spring.xml, if the REST API is included in the web module then modify the web-spring.xml.
<mvc:cors>
<mvc:mapping path="/api/**" allowed-origins="http://host1, http://host2"/>
</mvc:cors>4.8.2. REST API Version 2
Version 2 of the universal REST API provides the following functionality:
-
CRUD operations on entities.
-
Execution of predefined JPQL queries.
-
Execution of service methods.
-
Getting metadata (entities, views, enumerations, datatypes).
-
Getting current user permissions (access to entities, attributes, specific permissions).
-
Getting current user information (name, language, time zone, etc.).
-
Uploading and downloading files.
REST API Version 2 uses the OAuth2 protocol for authentication and supports anonymous access.
|
Tip
|
The detailed documentation for the API is written according to Swagger specification and is available at the following URL: http://files.cuba-platform.com/swagger. |
Any running CUBA application also exports the swagger documentation at the URLs http://HOST:PORT/APP_NAME/rest/v2/docs/swagger.yaml and http://HOST:PORT/APP_NAME/rest/v2/docs/swagger.json.
4.8.2.1. Predefined JPQL Queries Configuration
In the CUBA application, predefined JPQL queries must be specified in files registered in the cuba.rest.queriesConfig application property of the web or portal module (e.g in the web-app.properties file):
cuba.rest.queriesConfig = +com/company/myapp/rest-queries.xmlThe rest-queries.xml file must be placed in the root package of the web or portal module (e.g. com.company.myapp). Its content is defined by the rest-queries.xsd schema, for example:
<?xml version="1.0"?>
<queries xmlns="http://schemas.haulmont.com/cuba/rest-queries.xsd">
<query name="carByVin" entity="ref$Car" view="carEdit">
<jpql><![CDATA[select c from ref$Car c where c.vin = :vin]]></jpql>
<params>
<param name="vin" type="java.lang.String"/>
</params>
</query>
<query name="allColours" entity="ref$Colour" view="_local">
<jpql><![CDATA[select u from ref$Colour u order by u.name]]></jpql>
</query>
</queries>An example of how to configure and execute a query can be found in the Executing a JPQL Query chapter.
The platform also provides the predefined all query for getting all instances of a specified entity type. It can be used with /count to receive the total number of entity instances, for example:
http://localhost:8080/app/rest/v2/queries/sales$Order/all/count
4.8.2.2. Services Configuration
The list of service methods that are available via the REST API must be configured in the CUBA application in files registered in the cuba.rest.servicesConfig application property of the web or portal module (e.g in the web-app.properties file):
cuba.rest.servicesConfig = +com/company/myapp/rest-services.xmlThe content of the rest-services.xml must be placed in the root package of the web or portal module (e.g. com.company.myapp). Its content is defined by the rest-services-v2.xsd schema, for example:
<?xml version="1.0" encoding="UTF-8"?>
<services xmlns="http://schemas.haulmont.com/cuba/rest-services-v2.xsd">
<service name="myapp_SomeService">
<method name="sum">
<param name="number1"/>
<param name="number2"/>
</method>
<method name="emptyMethod"/>
<method name="overloadedMethod">
<param name="intParam" type="int"/>
</method>
<method name="overloadedMethod">
<param name="stringParam" type="java.lang.String"/>
</method>
</service>
</services>Method parameter types can be omitted if the service doesn’t contain an overloaded method with the same number of parameters. Otherwise, types must be defined.
An example of how to configure and invoke a service can be found in the Service Method Invocation (GET) chapter.
4.8.2.3. Data Model Versioning
REST API can handle data model changes. It is useful when, for example, some entity attribute was renamed, but REST API client doesn’t know about this modification and expects the attribute to have an old name.
For such cases REST API allows you to define transformation rules for entities JSON. If the client application sends the data model version in the request query parameter then the JSON in REST API method response or request body will be transformed according to transformation rules defined for that particular domain model version.
JSON transformation rules must be specified in files registered in cuba.rest.jsonTransformationConfig application property of the web or portal module (e.g in the web-app.properties file):
cuba.rest.jsonTransformationConfig = +com/company/myapp/rest-json-transformations.xmlThe rest-json-transformations.xml file must be placed in the web or portal module (e.g. in package com.company.myapp). Its content is defined by the rest-json-transformations.xsd schema. File example:
<?xml version="1.0"?>
<transformations xmlns="http://schemas.haulmont.com/cuba/rest-json-transformations.xsd">
<transformation modelVersion="1.0" oldEntityName="sales$OldOrder" currentEntityName="sales$NewOrder">
<renameAttribute oldName="oldNumber" currentName="number"/>
<renameAttribute oldName="date" currentName="deliveryDate"/>
<toVersion>
<removeAttribute name="discount"/>
</toVersion>
</transformation>
<transformation modelVersion="1.0" currentEntityName="sales$Contractor">
<renameAttribute oldName="summary" currentName="total"/>
<renameAttribute oldName="familyName" currentName="lastName"/>
<fromVersion>
<removeAttribute name="city"/>
<removeAttribute name="country"/>
</fromVersion>
<toVersion>
<removeAttribute name="phone"/>
</toVersion>
</transformation>
<transformation modelVersion="1.1" currentEntityName="sales$NewOrder">
<renameAttribute oldName="date" currentName="deliveryDate"/>
</transformation>
</transformations>Standard transformers configured in the config file can perform the following transformations of entity JSON:
-
rename entity
-
rename entity attribute
-
remove entity attribute
JSON transformation works for the following REST API endpoints:
-
/entities - getting entities list, getting a single entity, entity create, entity update, entity delete
-
/queries - entities JSON returned by the query will be transformed
-
/services - JSON transformations will be applied both to entities returned by the service method and to entities passed as a service method argument
JSON transformations are applied if the request to the REST API contains the modelVersion URL parameter with the data model version number.
See the Data Model Versioning Example to understand how to configure data model versioning and use it from the client application.
4.8.2.4. CORS Settings
By default, all CORS requests to the REST API are allowed. To restrict the origins list you can define the cuba.rest.allowedOrigins application property.
4.8.2.5. Anonymous Access
By default, anonymous access is disabled. To enable it, use the cuba.rest.anonymousEnabled application property. A request is considered to be anonymous if it doesn’t contain an Authentication header. In this case, the SecurityContext will contain an anonymous user session.
To set up permissions for anonymous user you must define roles for the user specified by the cuba.anonymousLogin application property.
4.8.2.6. Other REST API Settings
cuba.rest.client.id - defines a default REST API client id.
cuba.rest.client.secret - defines a default REST API client secret.
cuba.rest.client.tokenExpirationTimeSec - defines a token expiration time for the default client in seconds.
cuba.rest.maxUploadSize - defines a maximum file size that can be uploaded with the REST API.
4.8.2.7. Creating Custom OAuth2 Protected Controllers
If you need to create a custom REST controller protected with the OAuth2 authentication then you have to do the following:
-
Suppose you have the following REST controller:
package com.company.test.portal.myapi; import org.springframework.web.bind.annotation.GetMapping; import org.springframework.web.bind.annotation.RequestMapping; import org.springframework.web.bind.annotation.RestController; import com.company.test.services.SomeService; @RestController @RequestMapping("/myapi") public class MyController { @Inject protected SomeService someService; @GetMapping("/dosmth") public String doSmth() { return someService.getResult(); } } -
Create a new Spring configuration file with name
rest-dispatcher-spring.xmlunder the root package (com.company.test) of web or portal module. The content of the file must be as follows:<?xml version="1.0" encoding="UTF-8"?> <beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:context="http://www.springframework.org/schema/context" xmlns:security="http://www.springframework.org/schema/security" xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-4.3.xsd http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context-4.3.xsd http://www.springframework.org/schema/security http://www.springframework.org/schema/security/spring-security-4.1.xsd"> <!-- Define a base package for your controllers--> <context:component-scan base-package="com.company.test.portal.myapi"/> <security:http pattern="/rest/myapi/**" create-session="stateless" entry-point-ref="oauthAuthenticationEntryPoint" xmlns="http://www.springframework.org/schema/security"> <!-- Specify one or more protected URL patterns--> <intercept-url pattern="/rest/myapi/**" access="isAuthenticated()"/> <anonymous enabled="false"/> <csrf disabled="true"/> <cors configuration-source-ref="cuba_RestCorsSource"/> <custom-filter ref="resourceFilter" before="PRE_AUTH_FILTER"/> <custom-filter ref="cuba_AnonymousAuthenticationFilter" after="PRE_AUTH_FILTER"/> </security:http> </beans> -
Define an additive application property
cuba.restSpringContextConfigin the properties file of the module,.e.g.portal-app.properties:cuba.restSpringContextConfig = +com/company/test/rest-dispatcher-spring.xml -
The new controller runs in the context of the
CubaRestApiServlet. So the URL for controller methods will start with the/rest, i.e. the doSmth() method will be accesed by the URL:http://localhost:8080/app-portal/rest/myapi/dosmth.WarningURL of the custom controller MUST NOT start with the
/rest/v2.
4.8.2.8. Security Constraints for Collection Attributes
If an entity that is returned by the REST API has a collection attribute and entities in the collection are restricted by any constraint then a system attribute __securityToken may be returned in the result JSON. When you send such entity to REST API methods for update you have to specify the __securityToken property (the one you got on entity read) in the JSON object. Otherwise, the collection property may be saved incorrectly.
Example:
{
"id": "fa430b56-ceb2-150f-6a85-12c691908bd1",
"number": "OR-000001",
"items": [
{
"id": "82e6e6d2-be97-c81c-c58d-5e2760ae095a",
"description": "Item 1"
},
{
"id": "988a8cb5-d61a-e493-c401-f717dd9a2d66",
"description": "Item 2"
}
],
"__securityToken": "0NXc6bQh+vZuXE4Fsk4mJX4QnhS3lOBfxzUniltchpxPfi1rZ5htEmekfV60sbEuWUykbDoY+rCxdhzORaYQNQ=="
}4.8.2.9. Persistent Token Store
By default, OAuth tokens are stored in memory only. If you want to persist them in the database as well, you should set the cuba.rest.storeTokensInDb application property to true. The property value is stored in the database, so you can change its value in the Administration > Application Properties screen.
Expired tokens in the database store must be periodically deleted. The cron expression for scheduled removing of expired tokens is specified in the cuba.rest.deleteExpiredTokensCron application property.
4.8.2.10. REST API Usage Examples
This section contains REST API usage examples.
As mentioned earlier, a detailed information about REST API methods is written according to Swagger specification and is available at address http://files.cuba-platform.com/swagger.
4.8.2.10.1. Getting an OAuth Token
An OAuth token is required for any REST API method (except when you are using an anonymous access). A token can be obtained by the POST request on the address:
http://localhost:8080/app/rest/v2/oauth/token
An access to this endpoint is protected with a basic authentication. REST API client identifier and password is used for basic authentication. Please note that these are not an application user login and password. REST API client id and password are defined in the application properties cuba.rest.client.id and cuba.rest.client.secret (the default values are client and secret). You must pass the client id and secret, separated by a single colon (":") character, within a base64 encoded string in the Authorization header.
The request type must be application/x-www-form-urlencoded, the encoding is UTF-8.
The requst must contain the following parameters:
-
grant_type- alwayspassword. -
username- application user login. -
password- application user password.
POST /oauth/token
Authorization: Basic Y2xpZW50OnNlY3JldA==
Content-Type: application/x-www-form-urlencoded
grant_type=password&username=smith&password=qwerty123Method returns a JSON object:
{
"access_token": "29bc6b45-83cd-4050-8c7a-2a8a60adf251",
"token_type": "bearer",
"expires_in": 43198,
"scope": "rest-api"
}A token value is in the access_token property.
4.8.2.10.2. Getting an Entity Instances List
Let’s suppose that the system has a sales$Order entity and we need to get a list of this entity instances. Besides, we need to get not all the records, but only 50 records, starting with the 100th one. A response must contain not only simple properties of the sales$Order entity but also an information about the order customer (a reference field named customer). Orders must be sorted by date.
A base URL for getting all instances of the sales$Order entity is as follows:
http://localhost:8080/app/rest/v2/entities/sales$Order
To implement all the conditions described above the following request parameters must be specified:
-
view - a view, that will be used for loading entities. In our case the
order-edit-viewcontains acustomerreference. -
limit - a number of instances to be returned.
-
offset - a position of the first extracted record.
-
sort - an entity attribute name that will be used for sorting.
An OAuth token must be placed in the Authorization header with the Bearer type:
Authorization: Bearer 29bc6b45-83cd-4050-8c7a-2a8a60adf251
As a result, we get the following GET request URL:
http://localhost:8080/app/rest/v2/entities/sales$Order?view=order-edit-view&limit=50&offset=100&sort=date
The response will be like this:
[
{
"_entityName": "sales$Order",
"_instanceName": "00001",
"id": "46322d73-2374-1d65-a5f2-160461da22bf",
"date": "2016-10-31",
"description": "Vacation order",
"number": "00001",
"items": [
{
"_entityName": "sales$OrderItem",
"_instanceName": "Beach umbrella",
"id": "95a04f46-af7a-a307-de4e-f2d73cfc74f7",
"price": 23,
"name": "Beach umbrella"
},
{
"_entityName": "sales$OrderItem",
"_instanceName": "Sun lotion",
"id": "a2129675-d158-9e3a-5496-41bf1a315917",
"price": 9.9,
"name": "Sun lotion"
}
],
"customer": {
"_entityName": "sales$Customer",
"_instanceName": "Toby Burns",
"id": "4aa9a9d8-01df-c8df-34c8-c385b566ea05",
"firstName": "Toby",
"lastName": "Burns"
}
},
{
"_entityName": "sales$Order",
"_instanceName": "00002",
"id": "b2ad3059-384c-3e03-b62d-b8c76621b4a8",
"date": "2016-12-31",
"description": "New Year party set",
"number": "00002",
"items": [
{
"_entityName": "sales$OrderItem",
"_instanceName": "Jack Daniels",
"id": "0c566c9d-7078-4567-a85b-c67a44f9d5fe",
"price": 50.7,
"name": "Jack Daniels"
},
{
"_entityName": "sales$OrderItem",
"_instanceName": "Hennessy X.O",
"id": "c01be87b-3f91-7a86-50b5-30f2f0a49127",
"price": 79.9,
"name": "Hennessy X.O"
}
],
"customer": {
"_entityName": "sales$Customer",
"_instanceName": "Morgan Collins",
"id": "5d111245-2ed0-abec-3bee-1a196da92e3e",
"firstName": "Morgan",
"lastName": "Collins"
}
}
]Please note, that every entity in the response has a _entityName attribute with the entity name and an _instanceName attribute with the entity instance name.
4.8.2.10.3. New Entity Instance Creation
New sales$Order entity instance can be created with the POST request on the address:
http://localhost:8080/app/rest/v2/entities/sales$Order
An OAuth token must be placed in the Authorization header with the Bearer type.
The request body must contain a JSON object that describes a new entity instance, e.g.:
{
"number": "00017",
"date": "2016-09-01",
"description": "Back to school",
"items": [
{
"_entityName": "sales$OrderItem",
"price": 100,
"name": "School bag"
},
{
"_entityName": "sales$OrderItem",
"price": 9.90,
"name": "Pencils"
}
],
"customer": {
"id": "4aa9a9d8-01df-c8df-34c8-c385b566ea05"
}
}A collection of order items (items) and a customer reference are passed in the request body. Let’s examine how these attributes will be processed.
First, let’s have a quick look to the Order class:
package com.company.sales.entity;
import com.haulmont.chile.core.annotations.Composition;
import com.haulmont.chile.core.annotations.NamePattern;
import com.haulmont.cuba.core.entity.StandardEntity;
import com.haulmont.cuba.core.entity.annotation.OnDelete;
import com.haulmont.cuba.core.global.DeletePolicy;
import javax.persistence.*;
import java.util.Date;
import java.util.Set;
@NamePattern("%s|number")
@Table(name = "SALES_ORDER")
@Entity(name = "sales$Order")
public class Order extends StandardEntity {
private static final long serialVersionUID = 7565070704618724997L;
@Column(name = "NUMBER_")
protected String number;
@Temporal(TemporalType.DATE)
@Column(name = "DATE_")
protected Date date;
@Column(name = "DESCRIPTION")
protected String description;
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "CUSTOMER_ID")
protected Customer customer;
@Composition
@OnDelete(DeletePolicy.CASCADE)
@OneToMany(mappedBy = "order")
protected Set<OrderItem> items;
//getters and setters omitted
}The items collection property is annotated with the @Composition. REST API methods for entity creation and update will create a new entity instances for all members of such collections. In our case, two instances of OrderItem entity will be created with the Order entity.
The customer reference doesn’t have a @Composition annotation, that’s why the REST API will try to find a client with the given id and set it to the customer field. If the client is not found then an order won’t be created and the method will return an error.
In case of successful method execution a full object graph of the created entity is returned:
{
"_entityName": "sales$Order",
"id": "5d7ff8e3-7828-ba94-d6ba-155c5c4f2a50",
"date": "2016-09-01",
"description": "Back to school",
"version": 1,
"number": "00017",
"createdBy": "admin",
"createTs": "2016-10-13 18:12:21.047",
"updateTs": "2016-10-13 18:12:21.047",
"items": [
{
"_entityName": "sales$OrderItem",
"id": "3158b8ed-7b7a-568e-aec5-0822c3ebbc24",
"createdBy": "admin",
"price": 9.9,
"name": "Pencils",
"createTs": "2016-10-13 18:12:21.047",
"version": 1,
"updateTs": "2016-10-13 18:12:21.047",
"order": {
"_entityName": "sales$Order",
"id": "5d7ff8e3-7828-ba94-d6ba-155c5c4f2a50"
}
},
{
"_entityName": "sales$OrderItem",
"id": "72774b8b-4fea-6403-7b52-4a6a749215fc",
"createdBy": "admin",
"price": 100,
"name": "School bag",
"createTs": "2016-10-13 18:12:21.047",
"version": 1,
"updateTs": "2016-10-13 18:12:21.047",
"order": {
"_entityName": "sales$Order",
"id": "5d7ff8e3-7828-ba94-d6ba-155c5c4f2a50"
}
}
],
"customer": {
"_entityName": "sales$Customer",
"id": "4aa9a9d8-01df-c8df-34c8-c385b566ea05",
"firstName": "Toby",
"lastName": "Burns",
"createdBy": "admin",
"createTs": "2016-10-13 15:32:01.657",
"version": 1,
"updateTs": "2016-10-13 15:32:01.657"
}
}4.8.2.10.4. Existing Entity Instance Update
An existing sales$Order entity instance can be updated with the PUT request on the address:
http://localhost:8080/app/rest/v2/entities/sales$Order/5d7ff8e3-7828-ba94-d6ba-155c5c4f2a50
The last part of the query here is the entity identifier.
An OAuth token must be placed in the Authorization header with the Bearer type.
The request body must contain a JSON object containing only fields we want to update, e.g.:
{
"date": "2017-10-01",
"customer" : {
"id" : "5d111245-2ed0-abec-3bee-1a196da92e3e"
}
}The response body will contain a modified entity:
{
"_entityName": "sales$Order",
"id": "5d7ff8e3-7828-ba94-d6ba-155c5c4f2a50",
"date": "2017-10-01",
"updatedBy": "admin",
"description": "Back to school",
"version": 2,
"number": "00017",
"createdBy": "admin",
"createTs": "2016-10-13 18:12:21.047",
"updateTs": "2016-10-13 19:13:02.656",
"customer": {
"_entityName": "sales$Customer",
"id": "5d111245-2ed0-abec-3bee-1a196da92e3e",
"firstName": "Morgan",
"lastName": "Collins",
"createdBy": "admin",
"createTs": "2016-10-13 15:31:27.821",
"version": 1,
"updateTs": "2016-10-13 15:31:27.821",
"email": "collins@gmail.com"
}
}4.8.2.10.5. Executing a JPQL Query
Before the execution with the REST API a query must be described in the configuration file. The rest-queries.xml file must be created in the main package of the web module (e.g. com.company.sales). Then the file must be defined in the application properties file of the web module (web-app.properties).
cuba.rest.queriesConfig = +com/company/sales/rest-queries.xmlrest-queries.xml contents:
<?xml version="1.0"?>
<queries xmlns="http://schemas.haulmont.com/cuba/rest-queries.xsd">
<query name="ordersAfterDate" entity="sales$Order" view="order-edit-view">
<jpql><![CDATA[select o from sales$Order o where o.date >= :startDate and o.date <= :endDate]]></jpql>
<params>
<param name="startDate" type="java.util.Date"/>
<param name="endDate" type="java.util.Date"/>
</params>
</query>
</queries>To execute a JPQL query the following GET request must be executed:
http://localhost:8080/app/rest/v2/queries/sales$Order/ordersAfterDate?startDate=2016-11-01&endDate=2017-11-01
The request URL parts:
-
sales$Order- extracted entity name. -
ordersAfterDate- a query name from the configuration file. -
startDateandendDate- request parameters with the values.
An OAuth token must be placed in the Authorization header with the Bearer type.
The method returns a JSON array of extracted entity instances:
[
{
"_entityName": "sales$Order",
"_instanceName": "00002",
"id": "b2ad3059-384c-3e03-b62d-b8c76621b4a8",
"date": "2016-12-31",
"description": "New Year party set",
"number": "00002",
"items": [
{
"_entityName": "sales$OrderItem",
"_instanceName": "Jack Daniels",
"id": "0c566c9d-7078-4567-a85b-c67a44f9d5fe",
"price": 50.7,
"name": "Jack Daniels"
},
{
"_entityName": "sales$OrderItem",
"_instanceName": "Hennessy X.O",
"id": "c01be87b-3f91-7a86-50b5-30f2f0a49127",
"price": 79.9,
"name": "Hennessy X.O"
}
],
"customer": {
"_entityName": "sales$Customer",
"_instanceName": "Morgan Collins",
"id": "5d111245-2ed0-abec-3bee-1a196da92e3e",
"firstName": "Morgan",
"lastName": "Collins"
}
}
]A full list of possible request parameters is available in the Swagger documentation.
4.8.2.10.6. Service Method Invocation (GET)
Suppose there is an OrderService service in the system. The implementation looks as follows:
package com.company.sales.service;
import com.haulmont.cuba.core.EntityManager;
import com.haulmont.cuba.core.Persistence;
import com.haulmont.cuba.core.Transaction;
import org.springframework.stereotype.Service;
import javax.inject.Inject;
import java.math.BigDecimal;
@Service(OrderService.NAME)
public class OrderServiceBean implements OrderService {
@Inject
private Persistence persistence;
@Override
public BigDecimal calculatePrice(String orderNumber) {
BigDecimal orderPrice = null;
try (Transaction tx = persistence.createTransaction()) {
EntityManager em = persistence.getEntityManager();
orderPrice = (BigDecimal) em.createQuery("select sum(oi.price) from sales$OrderItem oi where oi.order.number = :orderNumber")
.setParameter("orderNumber", orderNumber)
.getSingleResult();
tx.commit();
}
return orderPrice;
}
}Before the execution with the REST API a service method invocation must be allowed in the configuration file. The rest-services.xml file must be created in the main package of the web module (e.g. com.company.sales). Then the file must be defined in the application properties file of the web module (web-app.properties).
cuba.rest.servicesConfig = +com/company/sales/rest-services.xmlrest-services.xml content:
<?xml version="1.0" encoding="UTF-8"?>
<services xmlns="http://schemas.haulmont.com/cuba/rest-services-v2.xsd">
<service name="sales_OrderService">
<method name="calculatePrice">
<param name="orderNumber"/>
</method>
</service>
</services>To invoke the service method the following GET request must be executed:
http://localhost:8080/app/rest/v2/services/sales_OrderService/calculatePrice?orderNumber=00001
The request URL parts:
-
sales_OrderService- a service name. -
calculatePrice- a method name. -
orderNumber- an argument name with the value.
An OAuth token must be placed in the Authorization header with the Bearer type.
A service method may return a result of simple datatype, an entity, an entities collection or a serializable POJO. In our case a BigDecimal is returned, so the response body contains just a number:
39.2
4.8.2.10.7. Service Method Invocation (POST)
REST API allows execution not only of methods that have arguments of simple datatypes, but also of methods with the following arguments:
-
entities
-
entities collections
-
POJOs
Suppose we added a new method to the OrderService created in the previous section:
@Override
public OrderValidationResult validateOrder(Order order, Date validationDate){
OrderValidationResult result=new OrderValidationResult();
result.setSuccess(false);
result.setErrorMessage("Validation of order "+order.getNumber()+" failed. validationDate parameter is: "+validationDate);
return result;
}OrderValidationResult class looks as follows:
package com.company.sales.service;
import java.io.Serializable;
public class OrderValidationResult implements Serializable {
private boolean success;
private String errorMessage;
public boolean isSuccess() {
return success;
}
public void setSuccess(boolean success) {
this.success = success;
}
public String getErrorMessage() {
return errorMessage;
}
public void setErrorMessage(String errorMessage) {
this.errorMessage = errorMessage;
}
}The new method has an Order entity in the arguments list and returns a POJO.
Before the invocation with the REST API the method must be allowed, so we add a record to the rest-services.xml configuration file (it was described in the Service Method Invocation (GET)).
<?xml version="1.0" encoding="UTF-8"?>
<services xmlns="http://schemas.haulmont.com/cuba/rest-services-v2.xsd">
<service name="sales_OrderService">
<method name="calculatePrice">
<param name="orderNumber"/>
</method>
<method name="validateOrder">
<param name="order"/>
<param name="validationDate"/>
</method>
</service>
</services>The validateOrder service method may be called with the POST request on the address:
http://localhost:8080/app/rest/v2/services/sales_OrderService/validateOrder
In case of the POST request parameters are passed in the request body. The request body must contain a JSON object, each field of this object corresponds to the service method argument.
{
"order" : {
"number": "00050",
"date" : "2016-01-01"
},
"validationDate": "2016-10-01"
}An OAuth token must be placed in the Authorization header with the Bearer type.
The REST API method returns a serialized POJO:
{
"success": false,
"errorMessage": "Validation of order 00050 failed. validationDate parameter is: 2016-10-01"
}4.8.2.10.8. Files Downloading
When downloading a file, passing a security token in the request header is often inconvenient. It is desirable to have a URL for downloading that may be put to the src attribute of the img tag.
As a solution, an OAuth token can also be passed in the request URL as a parameter with the access_token name.
For example, an image is uploaded to the application. Its FileDescriptor id is 44809679-e81c-e5ae-dd81-f56f223761d6.
In this case a URL for downloading the image will look like this:
http://localhost:8080/app/rest/v2/files/44809679-e81c-e5ae-dd81-f56f223761d6?access_token=a2f0bb4e-773f-6b59-3450-3934cbf0a2d6
4.8.2.10.9. JavaScript Usage Example
This section contains an example of using REST API v2 from JavaScript running on a HTML page. The page initially shows login form, and after successful login displays a message and a list of entities.
For simplicity, we will use modules/web/web/VAADIN folder for storing HTML/CSS/JavaScript files, as the corresponding folder in the deployed web application is used for serving static resources by default. So you will not need to make any configuration of your Tomcat application server. The resulting URL will start from http://localhost:8080/app/VAADIN, so do not use this approach in a real world application - create a separate web application with its own context instead.
Download jQuery and Bootstrap and copy to modules/web/web/VAADIN folder of your project. Create customers.html and customers.js files, so the content of the folder should look as follows:
bootstrap.min.css
customers.html
customers.js
jquery-3.1.1.min.jscustomers.html file content:
<html>
<head>
<script type="text/javascript" src="jquery-3.1.1.min.js"></script>
<link rel="stylesheet" href="bootstrap.min.css"/>
</head>
<body>
<div style="width: 300px; margin: auto;">
<h1>Sales</h1>
<div id="loggedInStatus" style="display: none" class="alert alert-success">
Logged in successfully
</div>
<div id="loginForm">
<div class="form-group">
<label for="loginField">Login:</label>
<input type="text" class="form-control" id="loginField">
</div>
<div class="form-group">
<label for="passwordField">Password:</label>
<input type="password" class="form-control" id="passwordField">
</div>
<button type="submit" class="btn btn-default" onclick="login()">Submit</button>
</div>
<div id="customers" style="display: none">
<h2>Customers</h2>
<ul id="customersList"></ul>
</div>
</div>
<script type="text/javascript" src="customers.js"></script>
</body>
</html>customers.js file content:
var oauthToken = null;
function login() {
var userLogin = $('#loginField').val();
var userPassword = $('#passwordField').val();
$.post({
url: 'http://localhost:8080/app/rest/v2/oauth/token',
headers: {
'Authorization': 'Basic Y2xpZW50OnNlY3JldA==',
'Content-Type': 'application/x-www-form-urlencoded'
},
dataType: 'json',
data: {grant_type: 'password', username: userLogin, password: userPassword},
success: function (data) {
oauthToken = data.access_token;
$('#loggedInStatus').show();
$('#loginForm').hide();
loadCustomers();
}
})
}
function loadCustomers() {
$.get({
url: 'http://localhost:8080/app/rest/v2/entities/sales$Customer?view=_local',
headers: {
'Authorization': 'Bearer ' + oauthToken,
'Content-Type': 'application/x-www-form-urlencoded'
},
success: function (data) {
$('#customers').show();
$.each(data, function (i, customer) {
$('#customersList').append("<li>" + customer.name + " (" + customer.email + ")</li>");
});
}
});
}Login and password from the user input are sent to the server by the POST request with the Base64-encoded client credentials in the Authorization header as explained in Getting an OAuth Token section. If the authentication is successful, the web page receives an access token value from the server, the token is stored in the oauthToken variable, the loginForm div is hidden and the loggedInStatus div is shown.
To show the list of customers, the request is sent to the server to get the instances of the sales$Customer entity, passing the oauthToken value in the Authorization header.
In case the request is processed successfully, the customers div is shown, and the customersList element is filled with items containing customer names and emails.
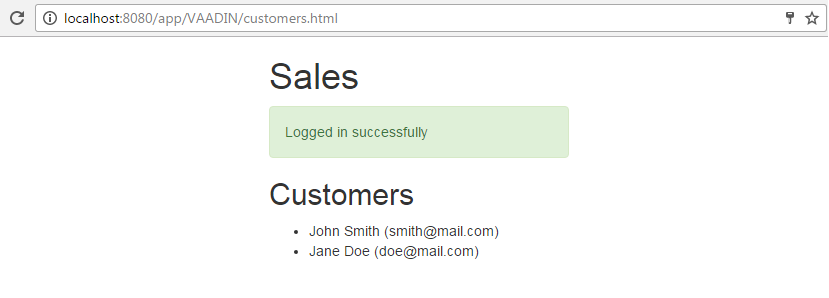
4.8.2.10.10. Getting Localized Messages
There are methods in the REST API for getting localized messages for entities, their properties and enums.
For example, to get a list of localized messages for the sec$User entity you have to execute the following GET request:
http://localhost:8080/app/rest/v2/messages/entities/sec$User
An OAuth token must be placed in the Authorization header with the Bearer type.
You can explicitly specify the desired locale using the Accept-Language http header.
The response will be like this:
{
"sec$User": "User",
"sec$User.active": "Active",
"sec$User.changePasswordAtNextLogon": "Change Password at Next Logon",
"sec$User.createTs": "Created At",
"sec$User.createdBy": "Created By",
"sec$User.deleteTs": "Deleted At",
"sec$User.deletedBy": "Deleted By",
"sec$User.email": "Email",
"sec$User.firstName": "First Name",
"sec$User.group": "Group",
"sec$User.id": "ID",
"sec$User.ipMask": "Permitted IP Mask",
"sec$User.language": "Language",
"sec$User.lastName": "Last Name",
"sec$User.login": "Login",
"sec$User.loginLowerCase": "Login",
"sec$User.middleName": "Middle Name",
"sec$User.name": "Name",
"sec$User.password": "Password",
"sec$User.position": "Position",
"sec$User.substitutions": "Substitutions",
"sec$User.timeZone": "Time Zone",
"sec$User.timeZoneAuto": "Autodetect Time Zone",
"sec$User.updateTs": "Updated At",
"sec$User.updatedBy": "Updated By",
"sec$User.userRoles": "User Roles",
"sec$User.version": "Version"
}To get the localization for enum, use the following URL:
http://localhost:8080/app/rest/v2/messages/enums/com.haulmont.cuba.security.entity.RoleType
If you omit the entity name or enum name part in the URL, you’ll get the localization for all entities or enums.
4.8.2.10.11. Data Model Versioning Example
- Entity attribute was renamed
-
Let’s suppose that the
oldNumberattribute of thesales$Orderentity was renamed tonewNumberanddatewas renamed todeliveryDate. In this case transformation config will be like this:<?xml version="1.0"?> <transformations xmlns="http://schemas.haulmont.com/cuba/rest-json-transformations.xsd"> <transformation modelVersion="1.0" currentEntityName="sales$Order"> <renameAttribute oldName="oldNumber" currentName="newNumber"/> <renameAttribute oldName="date" currentName="deliveryDate"/> </transformation> ... </transformations>If the client app needs to work with the old version of the
sales$Orderentity then it must pass themodelVersionvalue in the URL parameter:http://localhost:8080/app/rest/v2/entities/sales$Order/c838be0a-96d0-4ef4-a7c0-dff348347f93?modelVersion=1.0
The following result will be returned:
{ "_entityName": "sales$Order", "_instanceName": "00001", "id": "46322d73-2374-1d65-a5f2-160461da22bf", "date": "2016-10-31", "description": "Vacation order", "oldNumber": "00001" }The response JSON contains an
oldNumberanddateattributes although the entity in the CUBA application hasnewNumberanddeliveryDateattributes. - Entity name was changed
-
Next, let’s imagine, that in some next release of the application a name of the
sales$Orderentity was also changed. The new name issales$NewOrder.Transformation config for version
1.1will be like this:<?xml version="1.0"?> <transformations xmlns="http://schemas.haulmont.com/cuba/rest-json-transformations.xsd"> <transformation modelVersion="1.1" oldEntityName="sales$Order" currentEntityName="sales$NewOrder"> <renameAttribute oldName="oldNumber" currentName="newNumber"/> </transformation> ... </transformations>In addition to the config from the previous example an
oldEntityNameattribute is added here. It specifies the entity name that was valid for model version1.1. ThecurrentEntityNameattribute specifies the current entity name.Although an entity with a name
sales$Orderdoesn’t exist anymore, the following request will work:http://localhost:8080/app/rest/v2/entities/sales$Order/c838be0a-96d0-4ef4-a7c0-dff348347f93?modelVersion=1.1
The REST API controller will understand that it must search among
sales$NewOrderentities and after the entity with given id is found names of the entity and of thenewNumberattribute will be replaced in the result JSON:{ "_entityName": "sales$Order", "_instanceName": "00001", "id": "46322d73-2374-1d65-a5f2-160461da22bf", "date": "2016-10-31", "description": "Vacation order", "oldNumber": "00001" }The client app can also use the old version of data model for entity update and creation.
This POST request that uses old entity name and has old JSON in the request body will work:
http://localhost:8080/app/rest/v2/entities/sales$Order
{ "_entityName": "sales$Order", "_instanceName": "00001", "id": "46322d73-2374-1d65-a5f2-160461da22bf", "date": "2016-10-31", "description": "Vacation order", "oldNumber": "00001" } - Entity attribute must be removed from JSON
-
If some attribute was added to the entity, but the client that works with the old version of data model doesn’t expect this new attribute, then the new attribute can be removed from the result JSON.
Transformation configuration for this case will look like this:
<?xml version="1.0"?> <transformations xmlns="http://schemas.haulmont.com/cuba/rest-json-transformations.xsd"> <transformation modelVersion="1.5" currentEntityName="sales$Order"> <toVersion> <removeAttribute name="discount"/> </toVersion> </transformation> ... </transformations>Transformation in this config file contains a
toVersiontag with a nestedremoveAttributecommand. This means that when the transformation from the current state to specific version is performed (i.e. when you request a list of entities) then adiscountattribute must be removed from the result JSON.In this case if you perform the request without the
modelVersionattribute, the discount attribute will be returned:http://localhost:8080/app/rest/v2/entities/sales$Order/c838be0a-96d0-4ef4-a7c0-dff348347f93
{ "_entityName": "sales$Order", "_instanceName": "00001", "id": "46322d73-2374-1d65-a5f2-160461da22bf", "deliveryDate": "2016-10-31", "description": "Vacation order", "number": "00001", "discount": 50 }If you specify the
modelVersionthendiscountattribute will be removedhttp://localhost:8080/app/rest/v2/entities/sales$Order/c838be0a-96d0-4ef4-a7c0-dff348347f93?modelVersion=1.1
{ "_entityName": "sales$Order", "_instanceName": "00001", "id": "46322d73-2374-1d65-a5f2-160461da22bf", "deliveryDate": "2016-10-31", "description": "Vacation order", "oldNumber": "00001" } - Using custom transformer
-
You can also create and register a custom JSON transformer. As an example let’s examine the following situation: there was an entity
sales$OldOrderthat was renamed tosales$NewOrder. This entity has anorderDatefield. In the previous version, this date field contained a time part, but in the latest version of the entity, the time part is removed. REST API client that request the entity with an old model version1.0expects the date field to have the time part, so the transformer must modify the value in the JSON.First, that’s how the transformer configuration must look like:
<?xml version="1.0"?> <transformations xmlns="http://schemas.haulmont.com/cuba/rest-json-transformations.xsd"> <transformation modelVersion="1.0" oldEntityName="sales$OldOrder" currentEntityName="sales$NewOrder"> <custom> <fromVersion transformerBeanRef="sales_OrderJsonTransformerFromVersion"/> <toVersion transformerBeanRef="sales_OrderJsonTransformerToVersion"/> </custom> </transformation> ... </transformations>There are a
customelement and nestedtoVersionandfromVersionelements. These elements have a reference to the transformer bean. This means that custom transformer must be registered as a Spring bean. There is one important thing here: a custom transformer may use theRestTransformationsplatform bean (this bean gives an access to other entities transformers if it is required). But theRestTransformationsbean is registered in the Spring context of the REST API servlet, not in the main context of the web application. This means that custom transformer beans must be registered in the REST API Spring context as well.That’s how we can do that.
First, create a
rest-dispatcher-spring.xmlin the web or portal module (e.g. in packagecom.company.test).Next, register this file in the
app.propertiesof the web or portal module:cuba.restSpringContextConfig = +com/company/test/rest-dispatcher-spring.xmlThe
rest-dispatcher-spring.xmlmust contain custom transformer bean definitions:<?xml version="1.0" encoding="UTF-8"?> <beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-4.3.xsd"> <bean name="sales_OrderJsonTransformerFromVersion" class="com.company.test.transformer.OrderJsonTransformerFromVersion"/> <bean name="sales_OrderJsonTransformerToVersion" class="com.company.test.transformer.OrderJsonTransformerToVersion"/> </beans>The content of the
sales_OrderJsonTransformerToVersiontransformer is as follows:package com.company.test.transformer; import com.fasterxml.jackson.databind.JsonNode; import com.fasterxml.jackson.databind.ObjectMapper; import com.fasterxml.jackson.databind.node.ObjectNode; import com.google.common.base.Strings; import com.haulmont.restapi.transform.AbstractEntityJsonTransformer; import com.haulmont.restapi.transform.JsonTransformationDirection; public class OrderJsonTransformerToVersion extends AbstractEntityJsonTransformer { public RepairJsonTransformerToVersion() { super("sales$NewOrder", "sales$OldOrder", "1.0", JsonTransformationDirection.TO_VERSION); } @Override protected void doCustomTransformations(ObjectNode rootObjectNode, ObjectMapper objectMapper) { JsonNode orderDateNode = rootObjectNode.get("orderDate"); if (orderDateNode != null) { String orderDateNodeValue = orderDateNode.asText(); if (!Strings.isNullOrEmpty(orderDateNodeValue)) rootObjectNode.put("orderDate", orderDateNodeValue + " 00:00:00.000"); } } }This transformer finds the
orderDatenode in the JSON object and modifies its value by adding the time part to the value.When the
sales$OldOrderentity with a data model version1.0is requested, the result JSON will contain entities withorderDatefields that contain time part, although it is not stored in the database anymore.A couple more words about custom transformers. They must implement the
EntityJsonTransformerinterface. You can also extend theAbstractEntityJsonTransformerclass and override itsdoCustomTransformationsmethod. TheAbstractEntityJsonTransformercontains all functionality of the standard transformer.
4.8.3. Scheduled Tasks Execution
The platform offers two ways to run scheduled tasks:
-
By using the standard
TaskSchedulermechanism of the Spring Framework. -
By using platform’s own mechanism of scheduled tasks execution.
4.8.3.1. Spring TaskScheduler
This mechanism is described in details in the Task Execution and Scheduling section of the Spring Framework manual.
TaskScheduler can be used to run methods of arbitrary Spring beans in any application block both at the middleware and client tiers.
Example of configuration in spring.xml:
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:task="http://www.springframework.org/schema/task"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-3.0.xsd http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context-3.0.xsd http://www.springframework.org/schema/task http://www.springframework.org/schema/task/spring-task-3.0.xsd">
...
<task:scheduled-tasks scheduler="scheduler">
<task:scheduled ref="sales_Processor" method="someMethod" fixed-rate="60000"/>
<task:scheduled ref="sales_Processor" method="someOtherMethod" cron="0 0 1 * * MON-FRI"/>
</task:scheduled-tasks>
</beans>In the example above, two tasks are declared, which invoke someMethod() and someOtherMethod() of the sales_Processor bean. someMethod() will be invoked at fixed time intervals (60 seconds) from the moment of application startup. someOtherMethod() is invoked according to the schedule specified by Cron expression (for the description of the format of such expressions, see http://quartz-scheduler.org/documentation/quartz-1.x/tutorials/crontrigger).
The actual launch of tasks is performed by the bean specified in the scheduler attribute of the scheduled-tasks element. It is the bean of the CubaThreadPoolTaskScheduler class which is configured in the core and web modules of the cuba application component (see cuba-spring.xml, cuba-web-spring.xml). This class provides some CUBA-specific housekeeping functionality.
In order to provide SecurityContext to the code executed by Spring scheduled tasks on the middle tier, use System Authentication.
4.8.3.2. CUBA Scheduled Tasks
CUBA scheduled tasks mechanism is intended to perform scheduled execution of arbitrary Spring beans methods on Middleware. The purposes of this mechanism and its distinction from the above mentioned standard Spring Framework schedulers are:
-
The ability to configure tasks while running an application without restarting the server.
-
The coordination of singleton tasks in the Middleware cluster, including:
-
Reliable protection from simultaneous execution.
-
Binding tasks to servers by priorities.
-
A singleton task is a task which must be executed only on one server at a certain moment of time. For example, reading from a queue and sending emails.
4.8.3.2.1. Task Registration
Tasks are registered in the SYS_SCHEDULED_TASK database table, which corresponds to the ScheduledTask entity. There are browser and editor screens for working with tasks, which are available through the Administration → Scheduled Tasks menu.
Task attributes are described below:
-
Defined by – describes which software object implements the task. Possible values are:
-
Bean – the task is implemented by a method of a Spring managed bean. Additional attributes:
-
Bean name – the name of the managed bean.
WarningThe bean is listed and available for selection only if it is defined in the core module and has an interface, which contains methods appropriate for invocation from the task. Services and beans without an interface are not supported.
-
Method name – the bean interface method that is executed. The method must either have no parameters, or all parameters must be of
Stringtype. The return type of the method can either bevoidorString. In the latter case the returning value will be stored in the executions table (see Log finish below). -
Method parameters – the parameters of the chosen method. Only
Stringtype parameters are supported.
-
-
Class – the task is a class that implements the
java.util.concurrent.Callableinterface. The class must have a public constructor without parameters. Additional attributes:-
Class name – the name of the class.
-
-
Script – the task is a Groovy script. The script is executed by Scripting.runGroovyScript(). Additional attributes:
-
Script name – the name of the script.
-
-
-
User name – the name of a user on whose behalf the task will be executed. If not specified, the task will be executed on behalf of the user specified in the cuba.jmxUserLogin application property.
-
Singleton – indicates that the task is a singleton, i.e. should be run only on one application server.
-
Scheduling type – the means of task scheduling:
-
Cron – Cron expression is a sequence of six fields, separated by spaces: second, minute, hour, day, month, day of a week. The month and the day of a week can be represented by the first three letters of their English names. Examples:
-
0 0 * * * * – the beginning of every hour of every day
-
*/10 * * * * * – every 10 seconds
-
0 0 8-10 * * * – every day at 8, 9 and 10 o’clock
-
0 0/30 8-10 * * * – every day at 8:00, 8:30, 9:00, 9:30 and 10 o’clock
-
0 0 9-17 * * MON-FRI – every hour from 9 to 17 on working days
-
0 0 0 25 DEC ? – every Christmas at midnight.
-
-
Period – task execution interval in seconds.
-
Fixed Delay – task will be executed with the specified in Period delay after completion of the preceding execution.
-
-
Period – task execution interval or delay in seconds if Scheduling type is Period or Fixed Delay.
-
Timeout – time in seconds, upon the expiration of which it is considered that the execution of the task is completed, regardless of whether there is information about task completion or not. If the timeout is not set explicitly, it is assumed to be 3 hours.
-
Start date – the date/time of the first launch. If not specified, the task is launched immediately on server startup. If specified, the task is launched at
startDate + period * N, where N is an integer.It is reasonable to specify
Start dateonly for "infrequent" tasks, i.e. running once an hour, once a day, etc. -
Time frame – if
Start dateis specified,Time framedefines the time window in seconds, during which the task will be launched afterstartDate + period * Ntime expires. IfTime frameis not specified explicitly, it is equal toperiod / 2.If
Start dateis not specified,Time frameis ignored, i.e. the task will be launched at any time afterPeriodsince the previous execution of the task expires. -
Permitted servers – the list of comma-separated identifiers of servers that have the permission to run this task. If the list is not specified, the task may be executed on any server.
For singleton tasks, the order of the servers in the list defines the execution priority: the first server has a higher priority than the last. The server with a higher priority will intercept the execution of the singleton as follows: if the server with a higher priority detects that the task has been previously executed by a server with lower priority, it launches the task regardless of whether the
Periodhas elapsed or not.WarningServer priority works only if Scheduling type is
Periodand the Start date attribute is not specified. Otherwise, start occurs at the same time and the interception is impossible. -
Log start – flags if the task launch should be registered in the
SYS_SCHEDULED_EXECUTIONtable, which corresponds to theScheduledExecutionentity.In the current implementation, if the task is a singleton, the launch is registered regardless of this flag.
-
Log finish – flags if the task completion should be registered in the
SYS_SCHEDULED_EXECUTIONtable, which corresponds to theScheduledExecutionentity.In the current implementation, if the task is a singleton, completion is registered regardless of this flag.
-
Description – an arbitrary text description of the task.
The task also has activity flag, which can be set in the tasks list screen. Inactive tasks are ignored.
4.8.3.2.2. Tasks Handling Control
-
cuba.schedulingActive application property should be set to
trueto enable tasks processing. You can do it either in the Administration > Application Properties screen, or through theapp-core.cuba:type=SchedulingJMX bean (see itsActiveattribute). -
All changes to tasks made via system screens take effect immediately for all servers in the cluster.
-
The
removeExecutionHistory()method of theapp-core.cuba:type=SchedulingJMX bean can be used to remove old execution history. The method has two parameters:-
age– the time (in hours) elapsed after the task execution. -
maxPeriod– the maximumPeriod(in hours) for tasks that should have their execution history removed. This enables removing the history for frequently run tasks only, while keeping the history for tasks executed once a day.The method can be invoked automatically. Create a new task with the following parameters:
-
Bean name –
cuba_SchedulingMBean -
Method name –
removeExecutionHistory(String age, String maxPeriod) -
Method parameters – for example,
age= 72,maxPeriod= 12.
-
-
4.8.3.2.3. Scheduling Implementation Details
-
Tasks processing invocation (the
SchedulingAPI.processScheduledTasks()method) interval is specified incuba-spring.xmland is equal to 1 second by default. It sets the minimal interval between task launches, which should be twice higher, i.e. 2 seconds. Reducing these values is not recommended. -
The current implementation of the scheduler is based on the synchronization using row locks in the database table. This means that under significant load the database may not respond to the scheduler in time and it might be necessary to increase the launch interval (>1 second), thus the minimum period of launching tasks will be increased accordingly.
-
If the
Permitted serversattribute is not specified, singleton tasks are performed only on the master node of the cluster (in case other conditions are met). It should be kept in mind that a standalone server outside the cluster is also considered a master. -
The task will not be launched if its previous execution has not yet finished and the specified
Timeouthas not expired. For singleton tasks in the current implementation, this is achieved using the information in the database; for non-singletons, the execution status table is maintained in the server memory. -
The execution mechanism creates and caches user sessions for users, specified in the User name attribute of the tasks or in the cuba.jmxUserLogin application property. The session is available in the execution thread of a launched task through the standard UserSessionSource interface.
|
Warning
|
Precise time synchronization of Middleware servers is required for correct execution of singleton tasks! |
4.8.4. Email Sending
The platform provides email sending facilities with the following features:
-
Synchronous or asynchronous sending. In case of synchronous sending, the calling code waits till the message is sent to the SMTP server. In case of asynchronous sending, the message is persisted to the database and the control is returned immediately to the calling code. The actual sending is done later by a scheduled task.
-
Reliable tracking of message sending timestamp or errors in the database for both synchronous and asynchronous modes.
-
User interface to search and view information about sent messages, including all message attributes and content, sending status and the number of attempts.
See an example of using this mechanism in the Sending Emails development recipe.
4.8.4.1. Sending Methods
To send an email, the EmailerAPI bean should be used at the Middleware, and the EmailService service – at the client tier.
The basic methods of these components are described below:
-
sendEmail()– synchronous message sending. The calling code is blocked while sending the message to the SMTP server.The message can be transmitted in the form of a set of parameters (the comma-separated list of recipients, subject, content, array of attachments), and in the form of a special
EmailInfoobject, which encapsulates all this information and allows you to explicitly set the sender’s address and to form the message body using a FreeMarker template.EmailExceptionmay be thrown during synchronous sending, containing the information on the recipient addresses, where delivery has failed, and the corresponding error messages.During the execution of the method, a
SendingMessageinstance is created in the database for each recipient. It has the initialSendingStatus.SENDINGstatus, andSendingStatus.SENTafter successful sending. In case of a message sending error, the message status changes toSendingStatus.NOTSENT. -
sendEmailAsync()– asynchronous message sending. This method returns the list (by the number of recipients) ofSendingMessageinstances inSendingStatus.QUEUEstatus, which were created in the database. The actual sending is performed with the subsequent call of theEmailerAPI.processQueuedEmails()method, which should be invoked from a scheduled task with the desired frequency.
4.8.4.2. Email Attachments
The EmailAttachment object is a wrapper that holds the attachment as a byte array (the data field), the file name (the name field), and, if necessary, the attachment identifier which is unique for this message (the optional but useful contentId field).
The attachment identifier may be used to insert images in the message body. For this, a unique contentId (for example, myPic) is specified when creating EmailAttachment. Expression like cid:myPic can be used as a path to insert the attachment in the message body. So, to insert an image you can specify the following HTML element:
<img src="cid:myPic"/>4.8.4.3. Configuring Email Sending Parameters
Email sending parameters can be configured using the application properties listed below. All of them are runtime parameters and are stored in the database, but can be overridden for a specific Middleware block in its app.properties file.
All email sending parameters are available via the EmailerConfig configuration interface.
-
cuba.email.fromAddress– the default sender’s address. It is used if theEmailInfo.fromattribute is not specified.Default value:
DoNotReply@localhost -
cuba.email.smtpHost– the address of the SMTP server.Default value:
test.host -
cuba.email.smtpPort– the port of the SMTP server.Default value:
25 -
cuba.email.smtpAuthRequiredflags whether the SMTP server requires authentication. It corresponds to themail.smtp.authparameter, which is passed at the creation of thejavax.mail.Sessionobject.Default value:
false -
cuba.email.smtpSslEnabledflags whetherSSLprotocol is enabled. It corresponds to themail.transport.protocolparameter with thesmtpsvalue, which is passed at the creation of thejavax.mail.Sessionobject.Default value:
false -
cuba.email.smtpStarttlsEnable– flags the use of theSTARTTLScommand when authenticating on the SMTP server. It corresponds to themail.smtp.starttls.enableparameter, which is passed at the creation of thejavax.mail.Sessionobject.Default value:
false -
cuba.email.smtpUser– the user name for SMTP server authentication. -
cuba.email.smtpPassword– the user password for SMTP server authentication. -
cuba.email.delayCallCount– is used in asynchronous sending of emails to skip first few calls ofEmailManager.queueEmailsToSend()after server startup to reduce the load during application initialization. Email sending will start with the next call.Default value:
2 -
cuba.email.messageQueueCapacity– for asynchronous sending, the maximum number of messages read from the queue and sent in one call ofEmailManager.queueEmailsToSend().Default value:
100 -
cuba.email.defaultSendingAttemptsCountfor asynchronous sending, the default number of attempts to send an email. It is used if theattemptsCountparameter is not specified when callingEmailer.sendEmailAsync().Default value:
10 -
cuba.email.maxSendingTimeSec– the maximum expected time in seconds, which is required to send an email to the SMTP server. It is used for asynchronous sending to optimize the selection ofSendingMessageobjects from the DB queue.Default value: 120
-
cuba.email.sendAllToAdmin– indicates that all messages should be sent to the cuba.email.adminAddress address, regardless of the specified recipient’s address. It is recommended to use this parameter during system development and debugging.Default value:
false -
cuba.email.adminAddress– the address, to which all messages are sent if thecuba.email.sendAllToAdminproperty is switched on.Default value:
admin@localhost -
cuba.emailerUserLogin– the login of system user, used by asynchronous email sending code to be able to persist the information to the database. It is recommended to create a separate user (for example,emailer) without a password, so that it will be impossible to log in under his name via user interface. This is also convenient to search for messages related to email sending in the server log.Default value:
admin
You can also use properties from JavaMail API, adding them to the app.properties file of the core module. The mail.* properties are passed at the creation of the javax.mail.Session object.
You can view the current parameter values and send a test message using the app-core.cuba:type=Emailer JMX bean.
4.8.5. Dynamic Attributes
Dynamic attributes are additional entity attributes, that can be added without changing the database schema and restarting the application. Dynamic attributes are usually used to define new entity properties at deployment or production stage.
CUBA dynamic attributes implement the Entity-Attribute-Value model.
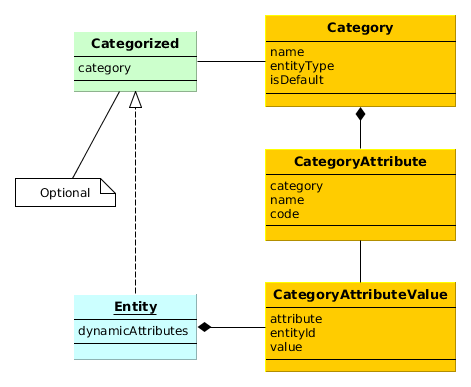
Figure 22. Dynamic Attributes Classes Diagram
-
Category- defines a category of objects and the corresponding set of dynamic attributes. The category must be assigned to some entity type.For example, there is an entity of the Car type. We can define two categories for it: Truck and Passenger. The Truck category will contain Load Capacity and Body Type attributes, and the Passenger category – Number of Seats and Child Seat.
-
CategoryAttribute- defines a dynamic attribute related to some category. Each attribute describes a single field of a definite type. The requiredCodefield contains the system name of the attribute. TheNamefield contains the human-readable attribute name. -
CategoryAttributeValue- dynamic attribute value for a particular entity instance. Dynamic attribute values are physically stored in the dedicatedSYS_ATTR_VALUEtable. Each table record has a reference to some entity (ENTITY_IDcolumn).
An entity instance can have dynamic attributes of all categories related to the entity type. So if you create two categories of the Car entity mentioned above, you will be able to specify any dynamic attribute from both categories for a Car instance. If you want to be able to classify an entity instance as belonging to a single category (a car can be either truck or passenger), the entity must implement Categorized interface. In this case an entity instance will have the reference to a category, and dynamic attributes from this category only.
Loading and saving of dynamic attribute values is handled by DataManager. The LoadContext.setLoadDynamicAttributes() method is used to indicate that dynamic attributes should be loaded for entity instances. By default, dynamic attributes are not loaded. At the same time, DataManager always saves dynamic attributes contained in entity instances passed to commit().
Dynamic attribute values are available through getValue() / setValue() methods for any persistent entity inherited from BaseGenericIdEntity. An attribute code with the + prefix should be passed to these methods, for example:
LoadContext lc = new LoadContext(Car.class).setId(id);
lc.setLoadDynamicAttributes(true);
Entity entity = dataManager.load(lc);
Double capacity = entity.getValue("+loadCapacity");
entity.setValue("+loadCapacity", capacity + 10);
dataManager.commit(entity);In fact, the direct access to attribute values in the application code is rarely needed. Any dynamic attribute can be automatically displayed in any Table or FieldGroup component bound to a datasource containing the entity, for which the dynamic attribute was created. The attribute editor described below allows you to specify screens and components that should show the attribute.
User permissions to access dynamic attributes can be set in the security role editor in the same way as for regular attributes. Dynamic attributes are displayed with the + prefix.
4.8.5.1. Managing Dynamic Attributes
Managing attributes categories and descriptions is done via special screens available in Administration > Dynamic Attributes menu.
The category browser shows the list of all registered categories.
Figure 23. Categories Browser
The category editor allows you to create a new category for an entity and define a set of dynamic attributes. The category name and the related entity type fields are mandatory. The Default checkbox indicates that this category will be automatically selected for a new instance of an entity implementing Categorized interface.
Figure 24. Category Editor
Dynamic attribute editor enables setting the name, system code, value type and the default value of the attribute.
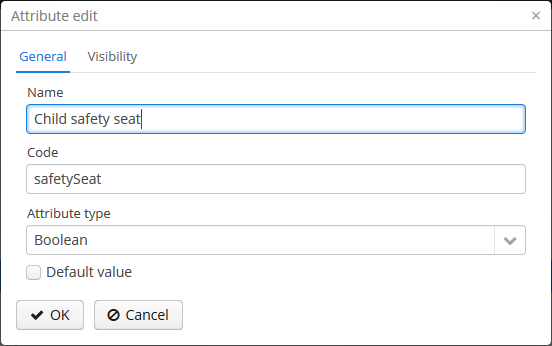
Figure 25. Dynamic Attribute Editor
For all value types, except Boolean, there is a Width field available to set up the field width in FieldGroup in pixels or as a percentage. If the Width field is empty, its assumed value is 100%.
For all value types, except Boolean and Enumeration, there is also an Is collection checkbox available. It allows you to create multi-valued dynamic attributes of a selected type.
For the Enumeration value type, the set of named values is defined in the Enumeration field via the list editor.
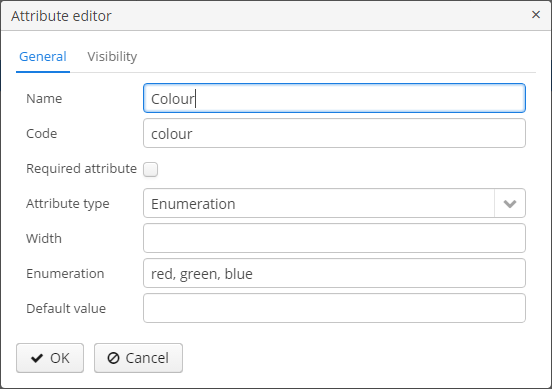
Figure 26. Dynamic Attribute Editor for
Enumeration type
A dynamic attribute also has visibility settings, which define the screens where it should be displayed. By default, the attribute is invisible on any screen.
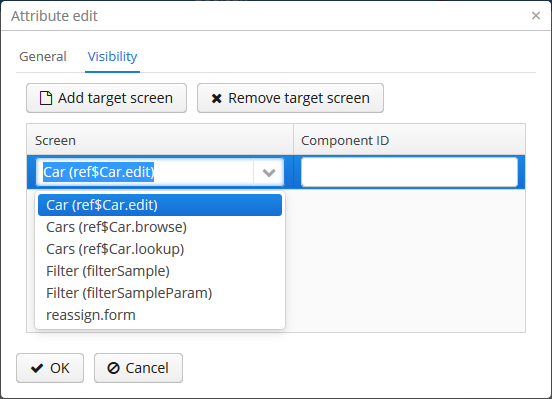
Figure 27. Dynamic Attribute Visibility Settings
In addition to the screen, you can also specify a component in which the attribute is to appear (for example, for screens, where several FieldGroup components show the fields of the same entity).
If the attribute is marked as visible on a screen, it will automatically appear in all field groups and tables displaying entities of the corresponding type on the screen.
Access to dynamic attributes can also be restricted by user role settings. Security settings for dynamic attributes are similar to those for regular attributes.
In order for changes in attribute and visibility settings to take effect, click Apply settings in the categories browser. Changes can also be applied via Administration > JMX Console by calling the clearDynamicAttributesCache() method of the app-core.cuba:type=CachingFacade JMX bean.
The dynamic attribute added to the screen automatically by specifying visibility settings is shown below:
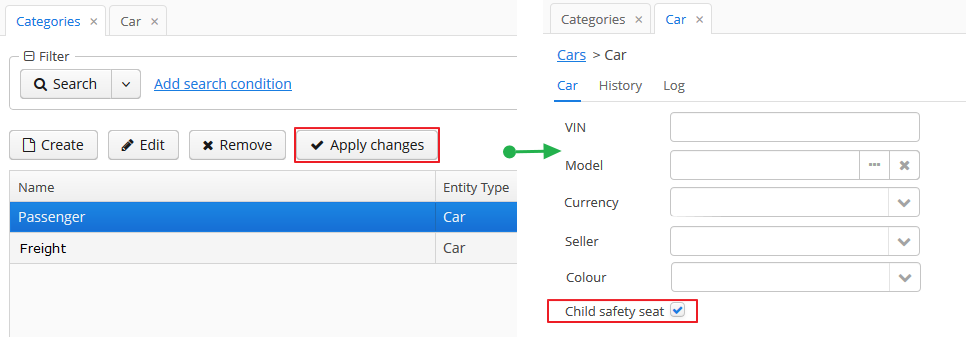
Dynamic attributes can be added to a screen manually. To do this, follow these steps:
-
In the
dsContextsection of the screen XML-descriptor, set theloadDynamicAttributesproperty totruefor a datasource that loads the entity (entities), for example:<dsContext> <datasource id="carDs" class="com.company.sample.entity.Car" view="_local" loadDynamicAttributes="true"/> </dsContext> -
Specify the dynamic attribute code with the
+prefix in thepropertyXML attribute of a component definition:<textField id="numberOfSeats" datasource="carDs" property="+numberOfSeats"/>
4.8.5.2. Categorized Entities
If an entity implements com.haulmont.cuba.core.entity.Categorized interface, you can use com.haulmont.cuba.gui.components.RuntimePropertiesFrame component for displaying dynamic attributes of this entity. This component allows a user to select a category for the particular entity instance and specify values of dynamic attributes of this category.
In order to use the RuntimePropertiesFrame component in an edit screen, do the following:
-
Two datasources should be declared in the
dsContextsection:-
runtimePropsDatasource- a specific datasource to load theCategoryAttributeValueinstances. ThemainDsattribute must refer to the main datasource, which contains the edited entity. -
A regular
collectionDatasourceto load the list of categories of this entity type.
Example:
<dsContext> <datasource id="carDs" class="com.company.sample.entity.Car" view="carEdit"/> <runtimePropsDatasource id="runtimePropsDs" mainDs="carDs"/> <collectionDatasource id="categories" class="com.haulmont.cuba.core.entity.Category" view="_local"> <query> select c from sys$Category c where c.entityType='sample$Car' </query> </collectionDatasource> </dsContext> -
-
Now, the
runtimePropertiesvisual component may be included in the XML-descriptor of the screen:<runtimeProperties id="runtimePropsFrame" runtimeDs="runtimePropsDs" categoriesDs="categories"/>
4.8.5.3. Dynamic Attributes in REST API
REST API supports loading and saving dynamic attributes. In order to load dynamic attributes of an entity instance, add the dynamicAttributes=true parameter to the find or query request:
app-portal/api/find.xml?e=sample$Car-9f789ba9-ca15-4758-a8b8-77e434f1d438&s=9f789ba9-ca15-4758-a8b8-77e434f1d438&dynamicAttributes=trueDynamic attributes are represented in JSON and XML documents in the same way as regular attributes, except for the preceding + symbol.
REST API also saves dynamic attributes passed to commit.
4.8.6. Pessimistic Locking
Pessimistic locking should be used when there is a high probability of simultaneous editing of a single entity instance. In such cases the standard optimistic locking, based on entity versioning, usually creates too many collisions.
Pessimistic locking explicitly locks an entity instance when it is opened in the editor. As a result, only one user can edit this particular entity instance in a given moment of time.
Pessimistic locking mechanism can also be used to manage simultaneous execution of arbitrary processes. The key benefit is that the locks are distributed, since they are replicated in the Middleware cluster. More information is available in JavaDocs for the LockManagerAPI and LockService interfaces.
Pessimistic locking can be enabled for any entity class on application development or production stage using Administration > Locks > Setup screen, or as follows:
-
Insert a new record with the following field values into the SYS_LOCK_CONFIG table with the following field values:
-
ID – an arbitrary UUID-type identifier.
-
NAME – the name of the object to be locked. For an entity, it should be the name of its meta class.
-
TIMEOUT_SEC – lock expiration timeout in seconds.
Example:
insert into sys_lock_config (id, create_ts, name, timeout_sec) values (newid(), current_timestamp, 'sales$Order', 300) -
-
Restart the server or call
reloadConfiguration()method of theapp-core.cuba:type=LockManagerJMX bean.
Current state of locks can be tracked via the app-core.cuba:type=LockManager JMX bean or through the Administration > Locks screen. This screen also enables unlocking of any object.
4.8.7. Entity Statistics
The entity statistics mechanism provides the information on the current number of entity instances in the database. This data is used to automatically select the best lookup strategy for linked entities and to limit the size of search results displayed in UI screens.
Statistics are stored in the SYS_ENTITY_STATISTICS table, corresponding to the EntityStatistics entity. Statistics can be updated manually by adding the the necessary records to the table, as well as automatically by using the refreshStatistics() method of the PersistenceManagerMBean JMX bean. When passing the entity name as a parameter, the statistics will be collected only for the corresponding entity; otherwise, the statistics will be collected for all entities. Collecting statistics may take a considerable amount of time and put excessive load on the database. Thus, it is better to do it manually or by using a scheduled task at an appropriate time.
Programmatic access to entity statistics is available via PersistenceManagerAPI interface on the middle tier and PersistenceManagerService on the the client tier. Statistics get cached into memory, and as a result, any direct changes to statistics in the database will only be applied after the server restart or after a calling to the PersistenceManagerMBean.flushStatisticsCache() method.
The description of the EntityStatistics attributes and their impact on the system behaviour is provided below:
-
name(NAME column) – the name of the entity meta-class, for example,sales$Customer. -
instanceCount(INSTANCE_COUNT column) – the approximate number of entity instances. -
fetchUI(FETCH_UI column) – the size of the data displayed on a page when extracting entity lists.For example, the Filter component uses this number in the Show N rows field.
-
maxFetchUI(MAX_FETCH_UI column) – the maximum number of entity instances that can be extracted and passed to the client tier.This limit is applied when showing entity lists in such components as LookupField or LookupPickerField, as well as tables without a filter, when no limitations are applied to the connected datasource via
CollectionDatasource.setMaxResults(). In this case the data source itself limits the number of extracted instances tomaxFetchUI. -
lookupScreenThreshold(LOOKUP_SCREEN_THRESHOLD column) – the threshold, measured in number of entities, which determines when lookup screens should be used instead of dropdowns for entity searches.The Filter component takes this parameter into account when choosing filter parameters. Until the threshold is reached, the system uses the LookupField component, and once the threshold is exceeded, the PickerField component is used. Hence, if lookup screens should be used for a specific entity in a filter parameter, it is possible to set the value of
lookupScreenThresholdto a value lower thaninstanceCount.
PersistenceManagerMBean JMX bean enables setting default values for all of the parameters mentioned above via DefaultFetchUI, DefaultMaxFetchUI, DefaultLookupScreenThreshold attributes. The system will use the corresponding default values when an entity has no statistics, which is a common case.
Besides, PersistenceManagerMBean.enterStatistics() method allows a user to enter statistics data for an entity. For example, the following parameters should be passed to the method to set a default page size to 1,000 and maximum number of loaded into LookupField instances to 30,000:
entityName: sales$Customer
fetchUI: 1000
maxFetchUI: 300004.8.8. Entity Log
This mechanism tracks entity persistence at the entity listeners level, i.e. it is guaranteed to track all changes passing through persistent context of the EntityManager. Direct changes to entities in the database using SQL, including the ones performed using NativeQuery or QueryRunner, are not tracked.
Modified entity instances are passed to registerCreate(), registerModify() and registerDelete() methods of the EntityLogAPI bean before they are saved to the database. Each method has auto parameter, allowing separation of automatic logs added by entity listeners from manual logs added by calling these methods from the application code. When these methods are called from entity listeners the value of auto parameter is true.
The logs contain information about the time of modification, the user who has modified the entity, and the new values of the changed attributes. Log entries are stored in the SEC_ENTITY_LOG table corresponding to the EntityLogItem entity. Changed attribute values are stored in the CHANGES column and are converted to instances of EntityLogAttr entity when they are loaded by the Middleware.
4.8.8.1. Setting Up Entity Log
The simplest way to set up the entity log is using the Administration > Entity Log > Setup application screen.
You can also set up Entity Log by entering some records in the database, if you want to include the configuration to the database initialization scripts.
Logging is configured using the LoggedEntity and LoggedAttribute entities corresponding to SEC_LOGGED_ENTITY and SEC_LOGGED_ATTR tables.
LoggedEntity defines the types of entities that should be logged. LoggedEntity has the following attributes:
-
name(NAME column) – the name of the entity meta-class, for example,sales$Customer. -
auto(AUTO column) – defines if the system should log the changes when EntityLogAPI is called withauto = trueparameter (i.e. called by entity listeners). -
manual(MANUAL column) – defines if the system should log the changes whenEntityLogAPIis called withauto = falseparameter.
LoggedAttribute defines the entity attribute to be logged and contains a link to the LoggedEntity and the attribute name.
To set up logging for a certain entity, the corresponding entries should be added into the SEC_LOGGED_ENTITY and SEC_LOGGED_ATTR tables. For example, logging the changes to name and grade attributes of the Customer entity can be enabled using:
insert into SEC_LOGGED_ENTITY (ID, CREATE_TS, CREATED_BY, NAME, AUTO, MANUAL)
values ('25eeb644-e609-11e1-9ada-3860770d7eaf', now(), 'admin', 'sales$Customer', true, true);
insert into SEC_LOGGED_ATTR (ID, CREATE_TS, CREATED_BY, ENTITY_ID, NAME)
values (newid(), now(), 'admin', '25eeb644-e609-11e1-9ada-3860770d7eaf', 'name');
insert into SEC_LOGGED_ATTR (ID, CREATE_TS, CREATED_BY, ENTITY_ID, NAME)
values (newid(), now(), 'admin', '25eeb644-e609-11e1-9ada-3860770d7eaf', 'grade');The logging mechanism is activated by default. If you want to stop it, set the Enabled attribute of the app-core.cuba:type=EntityLog JMX bean false and then invoke the its invalidateCache() operation. Alternatively, set the cuba.entityLog.enabled application property to false and restart the server.
4.8.8.2. Viewing the Entity Log
The entity log content can be viewed on a dedicated screen available at Administration > Entity Log.
The change log for a certain entity can also be accessed from any application screen by loading a collection of EntityLogItem and the associated EntityLogAttr instances into the datasources and creating the visual components connected to these datasources. For example:
<dsContext>
<datasource id="customerDs"
class="com.sample.sales.entity.Customer"
view="customerEdit"/>
<collectionDatasource id="logDs"
class="com.haulmont.cuba.security.entity.EntityLogItem"
view="logView">
<query>
select i from sec$EntityLog i
where i.entityRef.entityId = :ds$customerDs order by i.eventTs
</query>
<collectionDatasource id="logAttrDs"
property="attributes"/>
</collectionDatasource>
</dsContext>
<layout>
...
<split orientation="vertical" width="100%" height="100%">
<table id="logTable" width="100%" height="100%">
<columns>
<column id="eventTs"/>
<column id="user.login"/>
<column id="type"/>
</columns>
<rows datasource="logDs"/>
</table>
<table id="logAttrTable" width="100%" height="100%">
<columns>
<column id="name"/>
<column id="value"/>
</columns>
<rows datasource="logAttrDs"/>
</table>
</split>
...
</layout>Logged attributes should contain the @LocalizedValue annotation in order to display localized values. When annotated, the logging mechanism populates the EntityLogAttr.messagesPack field, and the table in the example above is able to use locValue column instead of value:
<table id="logAttrTable" width="100%" height="100%">
<columns>
<column id="name"/>
<column id="locValue"/>
</columns>
<rows datasource="logAttrDs"/>
</table>4.8.9. Entity Snapshots
The entity saving mechanism, much like the entity log, is intended to track data changes at runtime. It has the following distinct features:
-
The whole state (or snapshot) of a graph of entities defined by a specified view is saved.
-
Snapshot saving mechanism is explicitly called from the application code.
-
The platform allows the snapshots to be viewed and compared.
4.8.9.1. Saving Snapshots
In order to save a snapshot of a given graph of entities, you need to call the EntitySnapshotService.createSnapshot() method passing the entity which is an entry point to the graph and the view describing the graph. The snapshot will be created using the loaded entities without any calls to the database. As a result, the snapshot will not contain the fields that are not included in the view used to load the entity.
The graph of Java objects is converted into XML and saved in the SYS_ENTITY_SNAPSHOT table (corresponding to the EntitySnapshot enitity) together with the link to the primary entity.
Usually, snapshots need to be saved after editor screen commit. This may be achieved by overriding the postCommit() method of the screen controller, for example:
public class CustomerEditor extends AbstractEditor<Customer> {
@Inject
protected Datasource<Customer> customerDs;
@Inject
protected EntitySnapshotService entitySnapshotService;
...
@Override
protected boolean postCommit(boolean committed, boolean close) {
if (committed) {
entitySnapshotService.createSnapshot(customerDs.getItem(), customerDs.getView());
}
return super.postCommit(committed, close);
}
}4.8.9.2. Viewing Snapshots
Viewing snapshots for arbitrary entities is possible using the com/haulmont/cuba/gui/app/core/entitydiff/diff-view.xml frame. For example:
<frame id="diffFrame"
src="/com/haulmont/cuba/gui/app/core/entitydiff/diff-view.xml"
width="100%"
height="100%"/>The snapshots should be loaded into the frame from the edit screen controller:
public class CustomerEditor extends AbstractEditor<Customer> {
@Inject
protected EntityDiffViewer diffFrame;
...
@Override
protected void postInit() {
if (!PersistenceHelper.isNew(getItem())) {
diffFrame.loadVersions(getItem());
}
}
}The diff-view.xml frame shows the list of snapshots for the given entity, with an ability to compare them. The view for each snapshot includes the user, date and time. When a snapshot is selected from the list, the changes will be displayed compared to the previous snapshot. All attributes are marked as changed for the first snapshot. Selecting two snapshots shows the results of the comparison in a table.
The comparison table shows attribute names and their new values. When a row is selected, the detailed information on attribute changes across two snapshots is shown. Reference fields are displayed according to their instance name. When comparing collections, the new and removed elements are highlighted with green and red color respectively. Collection elements with changed attributes are displayed without highlighting. Changes to element positions are not recorded.
4.8.10. File Storage
File storage enables uploading, storing and downloading arbitrary files associated with the entities. In the standard implementation, the files are stored outside of the main database using a specialized structure within the file system.
File storage mechanism includes the following parts:
-
FileDescriptorentity – the descriptor of the uploaded file (not to be confused withjava.io.FileDescriptor) enables referencing the file from the data model objects. -
FileStorageAPIinterface – provides access to the file storage at the middle tier. Its main methods are:-
saveStream()– saves the contents of the file passed as theInputStreamaccording to the specifiedFileDescriptor. -
openStream()– returns the contents of the file defined by theFileDescriptorin the form of an openedInputStream.
-
-
FileUploadControllerclass – a Spring MVC controller, which enables sending files from the Client to the Middleware with HTTP POST requests. -
FileDownloadControllerclass – Spring MVC controller which enables retrieving files from the Middleware to the Client with HTTP GET requests. -
FileUpload and FileMultiUpload visual components – enable uploading files from the user’s computer to the client tier of the application and then transferring them to the Middleware.
-
FileUploadingAPIinterface – temporary storage for files uploaded to the client tier. It is used for uploading files to the client tier by the visual components mentioned above. The application code can useputFileIntoStorage()method for moving a file into the persistent storage of the Middleware. -
FileLoader - an interface for working with the file storage using the same set of methods on both middle and client tiers.
-
ExportDisplay– client tier interface allowing downloading various application resources to the user’s computer. Files can be retrieved from persistent storage using theshow()method, which requires aFileDescriptor. An instance ofExportDisplaymay be obtained either by calling theAppConfig.createExportDisplay()static method, or through injection into the controller class.
|
Tip
|
File transfer between the user’s computer and the storage in both directions is always performed by copying data between input and output streams. Files are never fully loaded into memory at any application level, which enables transferring files of almost any size. |
4.8.10.1. Uploading Files
Files from the user’s computer can be uploaded into the storage using the FileUpload and FileMultiUpload components. Usage examples are provided in this manual in the appropriate component descriptions, as well as in Loading and Displaying Images.
FileUpload component is also available within the ready-to-use FileUploadDialog window designed to load files in the temporary storage.
The temporary client-level storage (FileUploadingAPI) stores temporary files in the folder defined by cuba.tempDir application property. Temporary files can remain in the folder in case of any failures. The clearTempDirectory() method of the cuba_FileUploading bean is invoked periodically by the scheduler defined in the cuba-web-spring.xml file.
4.8.10.2. Downloading Files
Files can be downloaded from the file storage to the user’s computer by using the ExportDisplay interface. It can be obtained by calling the AppConfig.createExportDisplay() static method or via injection in the controller class. For example:
AppConfig.createExportDisplay(this).show(fileDescriptor);The show() method accepts an optional ExportFormat type parameter, which defines the type of the content and the file extension. If the format has not been provided, the extension is retrieved from the FileDescriptor, and the content type is set to application/octet-stream.
The file extension defines whether the file is downloaded via the browser’s standard open/save dialog (Content-Disposition = attachment), or if the browser will attempt to show the file in the browser window (Content-Disposition = inline). The list of extensions for files that should be shown in the browser window is defined by the cuba.web.viewFileExtensions application property.
ExportDisplay also enables downloading of arbitrary data if ByteArrayDataProvider is used as a parameter of the show() method. For example:
public class SampleScreen extends AbstractWindow {
@Inject
private ExportDisplay exportDisplay;
public void onDownloadBtnClick(Component source) {
String html = "<html><head title='Test'></head><body><h1>Test</h1></body></html>";
byte[] bytes;
try {
bytes = html.getBytes("UTF-8");
} catch (UnsupportedEncodingException e) {
throw new RuntimeException(e);
}
exportDisplay.show(new ByteArrayDataProvider(bytes), "test.html", ExportFormat.HTML);
}
}4.8.10.3. FileLoader Interface
The FileLoader interface allows you to work with file storage using the same set of methods on both middle and client tiers. Uploading and downloading of files is performed using streams:
-
saveStream()– saves anInputStreamcontents into file storage. -
openStream()– returns an input stream to load a file contents from file storage.
|
Tip
|
Both client-side and server-side implementations of |
As an example of using FileLoader let’s consider a simple task of saving a user input into the text file and displaying the file content in another field on the same screen.
The screen contains two textArea fields. Suppose the user inputs text in the first textArea, clicks the buttonIn below, and the text is saved to the FileStorage. The second textArea will display the content of the saved file on buttonOut click.
Below is the fragment of the screen XML descriptor:
<hbox margin="true"
spacing="true">
<vbox spacing="true">
<textArea id="textAreaIn"/>
<button id="buttonIn"
caption="Save text in file"
invoke="onButtonInClick"/>
</vbox>
<vbox spacing="true">
<textArea id="textAreaOut"
editable="false"/>
<button id="buttonOut"
caption="Show the saved text"
invoke="onButtonOutClick"/>
</vbox>
</hbox>The screen controller contains two methods invoked on buttons click:
-
In the
onButtonInClick()method we create a byte array from the firsttextAreainput. Then we create aFileDescriptorobject and define the new file name, extension, size, and creation date with its attributes.Then we save the new file with the
saveStream()method ofFileLoader, passing theFileDescriptorto it and providing the file content with anInputStreamsupplier. We also commit theFileDescriptorto the data store using theDataManagerinterface. -
In the
onButtonOutClick()method we extract the content of the saved file using theopenStream()method of theFileLoader. Then we display the content of the file in the secondtextArea.
import com.haulmont.cuba.core.entity.FileDescriptor;
import com.haulmont.cuba.core.global.DataManager;
import com.haulmont.cuba.core.global.FileLoader;
import com.haulmont.cuba.core.global.FileStorageException;
import com.haulmont.cuba.core.global.Metadata;
import com.haulmont.cuba.gui.components.AbstractWindow;
import com.haulmont.cuba.gui.components.ResizableTextArea;
import com.haulmont.cuba.gui.upload.FileUploadingAPI;
import org.apache.commons.io.IOUtils;
import javax.inject.Inject;
import java.io.ByteArrayInputStream;
import java.io.IOException;
import java.io.InputStream;
import java.util.Date;
public class FileLoaderScreen extends AbstractWindow {
@Inject
private Metadata metadata;
@Inject
private FileLoader fileLoader;
@Inject
private DataManager dataManager;
@Inject
private ResizableTextArea textAreaIn;
@Inject
private ResizableTextArea textAreaOut;
private FileDescriptor fileDescriptor;
public void onButtonInClick() {
byte[] bytes = textAreaIn.getRawValue().getBytes();
fileDescriptor = metadata.create(FileDescriptor.class);
fileDescriptor.setName("Input.txt");
fileDescriptor.setExtension("txt");
fileDescriptor.setSize((long) bytes.length);
fileDescriptor.setCreateDate(new Date());
try {
fileLoader.saveStream(fileDescriptor, () -> new ByteArrayInputStream(bytes));
} catch (FileStorageException e) {
throw new RuntimeException(e);
}
dataManager.commit(fileDescriptor);
}
public void onButtonOutClick() {
try {
InputStream inputStream = fileLoader.openStream(fileDescriptor);
textAreaOut.setValue(IOUtils.toString(inputStream));
} catch (FileStorageException | IOException e) {
throw new RuntimeException(e);
}
}
}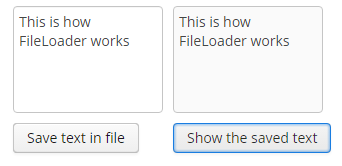
4.8.10.4. Standard File Storage Implementation
The standard implementation stores files in a dedicated folder structure within one or several file locations.
The roots of the structure can be defined in the cuba.fileStorageDir application property in the format of comma-separated paths list. For example:
cuba.fileStorageDir=/work/sales/filestorage,/mnt/backup/filestorageIf the property is not defined, the storage will be located in the filestorage sub-folder of the Middleware’s work directory. This folder is tomcat/work/app-core/filestorage in standard Tomcat deployment.
With several locations defined, the storage behaves as follows:
-
First folder in the list is considered as primary, others – as backup.
-
Stored files are first placed in the primary folder, and then copied to all of the backup directories.
The system checks that each folder is accessible before storing a file. If the primary directory is not accessible, the system throws an exception without storing the file. If any of the backup directories are not accessible, the file gets stored in available ones and the corresponding error is logged.
-
The files are read from the primary directory.
If the primary directory is not accessible, the system reads files from the first available backup directory containing the required files. A corresponding error is logged.
The storage folder structure is organized in the following way:
-
There are three levels of subdirectories representing the files upload date – year, month, and day.
-
The actual files are saved in the
daydirectory. The file names match the identifiers of the correspondingFileDescriptorobjects. The file extension matches that of the source file. -
The root folder of the structure contains a
storage.logfile with the information on each stored file, including the user and upload time. This log is not required for operation of the storage mechanism, but it could be useful for troubleshooting.
The app-core.cuba:type=FileStorage JMX bean displays the current set of storage roots and offers the following methods for troubleshooting:
-
findOrphanDescriptors()– finds all instances ofFileDescriptorin the database that do not have a matching file in the storage. -
findOrphanFiles()– finds all files in the storage that do not have a correspondingFileDescriptorinstance in the database.
4.8.11. Sequence Generation
This mechanism enables generating unique numerical sequences via a single API, independent of the DBMS type.
The main part of this mechanism is the UniqueNumbers bean with the UniqueNumbersAPI interface. The bean is available in the Middleware block. The interface has the following methods:
-
getNextNumber()– get the next value in a sequence. The mechanism enables simultaneous management of several sequences, identified by arbitrary strings. The name of the sequence from which you want to retrieve the value is passed in thedomainparameter.Sequences do not require initialization. When
getNextNumber()is called for the first time, the corresponding sequence will be created and 1 will be returned. -
getCurrentNumber()– obtain the current, i.e. the last generated value of the sequence. Thedomainparameter sets the sequence name. -
setCurrentNumber()– set the current value of the sequence. This value incremented by 1 will be returned by the next call togetNextNumber().
Below is an example of getting the next value in a sequence in a Middleware bean:
@Inject
private UniqueNumbersAPI uniqueNumbers;
private long getNextValue() {
return uniqueNumbers.getNextNumber("mySequence");
}The getNextNumber() method of the UniqueNumbersService service is used to get sequence values in client blocks.
The app-core.cuba:type=UniqueNumbers JMX bean with methods duplicating the methods of the UniqueNumbersAPI is used for sequence management.
The implementation of the sequence generation mechanism depends on the DBMS type. Sequence parameters can also be managed directly in the database, but in different ways.
-
For HSQL, Microsoft SQL Server 2012+, PostgreSQL and Oracle each
UniqueNumbersAPIsequence corresponds to aSEC_UN_{domain}sequence in the database. -
For Microsoft SQL Server before 2012 each sequence corresponds to a
SEC_UN_{domain}table with an IDENTITY field. -
For MySQL sequences correspond to records in the
SYS_SEQUENCEtable.
4.8.12. Running SQL Using QueryRunner
QueryRunner is a class designed to run SQL. It should be used instead of JDBC in all cases where using plain SQL is necessary and working with the ORM tools of the same purpose is not desired.
The platform’s QueryRunner is a variant of Apache DbUtils QueryRunner with the added ability to use Java Generics.
Usage example:
QueryRunner runner = new QueryRunner(persistence.getDataSource());
try {
Set<String> scripts = runner.query("select SCRIPT_NAME from SYS_DB_CHANGELOG",
new ResultSetHandler<Set<String>>() {
public Set<String> handle(ResultSet rs) throws SQLException {
Set<String> rows = new HashSet<String>();
while (rs.next()) {
rows.add(rs.getString(1));
}
return rows;
}
});
return scripts;
} catch (SQLException e) {
throw new RuntimeException(e);
}There are two ways of using QueryRunner: current transaction or separate transaction in autocommit mode.
-
To run a query in current transaction
QueryRunnermust be instantiated using a parameterless constructor. Then,query()orupdate()methods should be called with aConnectionparameter retrieved viaEntityManager.getConnection(). There is no need to close theConnectionafter the query, as it will be closed when the transaction is committed. -
To run a query in a separate transaction,
QueryRunnerinstance must be created using a constructor with theDataSourceparameter retrieved usingPersistence.getDataSource(). Then,query()orupdate()methods should be called without theConnectionparameter. Connection will be created from the specifiedDataSourceand immediately closed afterwards.
4.8.13. Integration with MyBatis
The platform includes MyBatis framework, which offers wider capabilities for running SQL and mapping query results to objects compared to ORM native query or QueryRunner.
The following beans must be added into spring.xml file of the core module to use MyBatis in the project:
<bean id="sqlSessionFactory" class="org.mybatis.spring.SqlSessionFactoryBean">
<property name="cubaDataSource" ref="cubaDataSource"/>
<property name="configLocation" value="cuba-mybatis.xml"/>
<property name="mapperLocations" value="classpath*:com/sample/sales/core/sqlmap/*.xml"/>
</bean>
<bean id="sqlSession" class="org.mybatis.spring.SqlSessionTemplate">
<constructor-arg index="0" ref="sqlSessionFactory" />
</bean>The MapperLocations parameter defines a path to mapperLocations mapping files (according to the rules of ResourceLoader Spring interface).
Below is the an example of a mapping file for loading an instance of Order together with a related Customer and a collection of Order items:
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.sample.sales">
<select id="selectOrder" resultMap="orderResultMap">
select
o.ID as order_id,
o.DATE as order_date,
o.AMOUNT as order_amount,
c.ID as customer_id,
c.NAME as customer_name,
c.EMAIL as customer_email,
i.ID as item_id,
i.QUANTITY as item_quantity,
p.ID as product_id,
p.NAME as product_name
from
SALES_ORDER o
left join SALES_CUSTOMER c on c.ID = o.CUSTOMER_ID
left join SALES_ITEM i on i.ORDER_ID = o.id and i.DELETE_TS is null
left join SALES_PRODUCT p on p.ID = i.PRODUCT_ID
where
c.id = #{id}
</select>
<resultMap id="orderResultMap" type="com.sample.sales.entity.Order">
<id property="id" column="order_id"/>
<result property="date" column="order_date"/>
<result property="amount" column="order_amount"/>
<association property="customer" column="customer_id" javaType="com.sample.sales.entity.Customer">
<id property="id" column="customer_id"/>
<result property="name" column="customer_name"/>
<result property="email" column="customer_email"/>
</association>
<collection property="items" ofType="com.sample.sales.entity.Item">
<id property="id" column="item_id"/>
<result property="quantity" column="item_quantity"/>
<association property="product" column="product_id" javaType="com.sample.sales.entity.Product">
<id property="id" column="product_id"/>
<result property="name" column="product_name"/>
</association>
</collection>
</resultMap>
</mapper>The following code can be used to retrieve query results from the example above:
Transaction tx = persistence.createTransaction();
try {
SqlSession sqlSession = AppBeans.get("sqlSession");
Order order = (Order) sqlSession.selectOne("com.sample.sales.selectOrder", orderId);
tx.commit();
} finally {
tx.end();
}4.8.14. Folders Panel
The folders panel provides quick access to frequently used information. It is a panel on the left side of the main application window containing a hierarchical structure of folders. Clicking on folders shows the corresponding system screens with certain parameters.
At the moment of this writing, the panel is available for the Web Client only.
The platform supports three types of folders: application folders, search folders and record sets. Application folders are displayed at the top of the panel as a separate folder tree. Search folders and record sets are displayed at the bottom of the panel in a combined tree.
-
Application folders:
-
Open screens with or without a filter.
-
The set of folders depend on the current user session. Folder visibility is defined by a Groovy script.
-
Application folders can be created and changed only by users with special permissions.
-
Folder headers may show the record count calculated by a Groovy script.
-
Folder headers are updated on timer events, which means that record count and display style for each folder can be updated.
-
-
Search folders:
-
Open screens with a filter.
-
Search folders can be local or global, accessible only by the user who created them or by all users, respectively.
-
Local folders can be created by any user, while global are created only by users with special permissions.
-
-
Record sets:
The following application properties can influence the functionality of the folder panel:
4.8.14.1. Application Folders
Creating application folders requires special permissions to create/edit application folders (cuba.gui.appFolder.global).
A simple application folder can be created via the folder panel context menu. Such folder will not be connected to the system screens and can be only used to group other folders within a folder tree.
A folder that opens a screen with a filter can be created as follows:
-
Open a screen and filter the records as necessary.
-
Select Save as application folder option in the Filter… button menu.
-
Fill in the folder attributes in the Add dialog:
-
Folder name.
-
Window title – a string to be added to the window title when opening it from the folder.
-
Parent folder – determines the location of the new folder in the folder tree.
-
Visibility script – a Groovy script defining folder visibility, executed at the start of user session.
The script should return a
Boolean. The folder is visible, if the script is not defined or returnstrueornull. Example of a Groovy script:userSession.currentOrSubstitutedUser.login == 'admin' -
Count script – a Groovy script defining the record count and display style for a folder. Executed at the start of the user session and on timer.
The script should return a numeric value, the integer part of which will be used as the record count value. If the script is not defined or returns
null, the counter will not be displayed. In addition to the returned value, the script can also set thestylevariable, which will be used as folder display style. Example of a Groovy script:def em = persistence.getEntityManager() def q = em.createQuery('select count(o) from sales$Order o') def count = q.getSingleResult() style = count > 0 ? 'emphasized' : null return countIn order for the style to be displayed, the application theme should contain this style for the
v-tree-nodeelement incuba-folders-pane, for example:.cuba-folders-pane .v-tree-node.emphasized { font-weight: bold; }
-
Scripts can use the following variables defined in the groovy.lang.Binding context:
-
folder– an instance ofAppFolderentity for which the script is executed. -
userSession– instance of UserSession for current user session. -
persistence– implementation of the Persistence interface. -
metadata– implementation of the Metadata interface.
The platform uses the same instance of groovy.lang.Binding for all scripts when the folders are being updated. So it is possible to pass variables between them in order to eliminate duplicate requests and increase performance.
Script sources can be stored within the attributes of the AppFolder entity or in separate files. In the latter case, the attribute should include a file path with a mandatory ".groovy" extension, as required by the Resources interface. If an attribute contains a string ending with ".groovy", the script will be loaded from the corresponding file; otherwise, the attribute content itself will be used as a script.
Application folders are instances of the AppFolder entity and are stored in the related SYS_FOLDER and SYS_APP_FOLDER tables.
4.8.14.2. Search Folders
Search folders can be created by the users similar to application folders. Group folders are created directly via the context menu of the folder panel. The folders connected to screens are created from the Filter… button menu, using the Save as search folder option.
Creating global search folders, requires the user to have Create/edit global search folders permission (cuba.gui.searchFolder.global).
Search folder’s filter can be edited once the folder is created by opening the folder and changing the Folder:{folder name} filter. Saving the filter will change the folder filter as well.
Search folders are instances of the SearchFolder entity stored in the related SYS_FOLDER and SEC_SEARCH_FOLDER tables.
4.8.14.3. Record Sets
Using records sets within a screen is possible, if the Filter has a corresponding Table component defined in the applyTo attribute. For example:
<layout>
<filter id="customerFilter"
datasource="customersDs"
applyTo="customersTable"/>
<groupTable id="customersTable"
width="100%">
<buttonsPanel>
<button action="customersTable.create"/>
...
</buttonsPanel>
...Add to set or Add to current set / Remove from set buttons should now appear in table context menu. If a table includes a buttonsPanel (as in the example above), the corresponding table buttons will also be added.
Record sets are the instances of the SearchFolder entity stored in the related SYS_FOLDER and SEC_SEARCH_FOLDER tables.
4.8.15. Screen Links
The Web Client block enables opening application screens via commands embedded into a URL. If the browser does not have an active application session with the registered user, the application will show the login screen first, and then, after successful authentication, proceed to the main application window with the requested screen.
The list of supported commands is defined in the cuba.web.linkHandlerActions application property. By default, these are open and o. When the HTTP request is being processed, the last part of the URL is analyzed, and if a match with one of the commands is detected, control is handed over to the LinkHandler bean. The standard implementation of this bean accepts the following parameters:
-
screen– name of the screen defined in screens.xml, for example:http://localhost:8080/app/open?screen=sec$User.browse -
item– an entity instance to be passed to the edit screen, encoded according to conventions of theEntityLoadInfoclass, i.e.entityName-instanceIdorentityName-instanceId-viewName. Examples:http://localhost:8080/app/open?screen=sec$User.edit&item=sec$User-60885987-1b61-4247-94c7-dff348347f93 http://localhost:8080/app/open?screen=sec$User.edit&item=sec$User-60885987-1b61-4247-94c7-dff348347f93-user.edit -
params– parameters passed to the screen controller’sinit()method. Parameters are encoded asname1:value1,name2:value2. Parameter values may include entity instances encoded according to the conventions of theEntityLoadInfoclass. Examples:http://localhost:8080/app/open?screen=sales$Customer.lookup¶ms=p1:v1,p2:v2 http://localhost:8080/app/open?screen=sales$Customer.lookup¶ms=p1:sales$Customer-01e37691-1a9b-11de-b900-da881aea47a6
LinkHandler bean may be redefined in the application project in order to provide specialized link handling. The LinkHandler bean is a prototype, so do not forget to specify the scope when defining your bean in spring.xml, for example:
<!-- web-spring.xml -->
<bean id="cuba_LinkHandler" class="com.company.sample.web.MyLinkHandler" scope="prototype"/>4.8.16. Entity Inspector
The entity inspector enables working with any application objects without having to create dedicated screens. The inspector dynamically generates the screens to browse and edit the instances of the selected entity.
This gives the system administrator an opportunity to review and edit the data that is not accessible from standard screens due to their design, and to create the data model and main menu sections linked to the entity inspector only, at prototyping stage.
The entry point for the inspector is the com/haulmont/cuba/gui/app/core/entityinspector/entity-inspector-browse.xml screen.
If a String-type parameter named entity with an entity name has been passed to the screen, the inspector will show a list of entities with the abilities for filtering, selection and editing. The parameter can be specified when registering the screen in screens.xml, for example:
screens.xml
<screen id="sales$Product.lookup"
template="/com/haulmont/cuba/gui/app/core/entityinspector/entity-inspector-browse.xml">
<param name="entity"
value="sales$Product"/>
</screen>menu.xml
<item id="sales$Product.lookup"/>Screen identifier defined as {entity_name}.lookup allows PickerField and LookupPickerField components to use this screen within the PickerField.LookupAction standard action.
Generally, the screen may be called without any parameters. In this case, the top part will contain an entity selection field. In the cuba application component, the inspector screen is registered with the entityInspector.browse identifier, so it can be simply referenced in a menu item:
<item id="entityInspector.browse"/>4.8.17. Export and Import Entities in JSON
The platform provides an API for exporting and importing graphs of entities in JSON format. It is available on Middleware via the EntityImportExportAPI interface and on the client tier via EntityImportExportService. These interfaces have an identical set of methods which are described below. The export/import implementation delegates to the EntitySerializationAPI interface which can also be used directly.
-
exportEntitiesToJSON()- serializes a collection of entities to JSON.@Inject private EntityImportExportService entityImportExportService; @Inject private GroupDatasource<Customer, UUID> customersDs; ... String jsonFromDs = entityImportExportService.exportEntitiesToJSON(customersDs.getItems()); -
exportEntitiesToZIP()- serializes a collection of entities to JSON and packs the JSON file into ZIP archive. In the following example, the ZIP archive is saved to the file storage using the FileLoader interface:@Inject private EntityImportExportService entityImportExportService; @Inject private GroupDatasource<Customer, UUID> customersDs; @Inject private Metadata metadata; @Inject private DataManager dataManager; ... byte[] array = entityImportExportService.exportEntitiesToZIP(customersDs.getItems()); FileDescriptor descriptor = metadata.create(FileDescriptor.class); descriptor.setName("customersDs.zip"); descriptor.setExtension("zip"); descriptor.setSize((long) array.length); descriptor.setCreateDate(new Date()); try { fileLoader.saveStream(descriptor, () -> new ByteArrayInputStream(array)); } catch (FileStorageException e) { throw new RuntimeException(e); } dataManager.commit(descriptor); -
importEntitiesFromJSON()- deserializes the JSON and persists deserialized entities according to the rules, described by theentityImportViewparameter (see JavaDocs on theEntityImportViewclass). If an entity is not present in the database, it will be created. Otherwise the fields of the existing entity that are specified in theentityImportViewwill be updated. -
importEntitiesFromZIP()- reads a ZIP archive that contains a JSON file, deserializes the JSON and persists deserialized entities like theimportEntitiesFromJSON()method.@Inject private EntityImportExportService entityImportExportService; @Inject private FileLoader fileLoader; private FileDescriptor descriptor; ... EntityImportView view = new EntityImportView(Customer.class); view.addLocalProperties(); try { byte[] array = IOUtils.toByteArray(fileLoader.openStream(descriptor)); Collection<Entity> collection = entityImportExportService.importEntitiesFromZIP(array, view); } catch (FileStorageException e) { throw new RuntimeException(e); }
4.8.18. Information about Software Components
The platform provides an ability to register the information about third party software components used in the application (credits) and to display this information in the UI. The information includes a software component name, a website link and the license text.
Application components of the platform contain their own files with descriptions, like cuba-credits.xml, reports-credits.xml. The cuba.creditsConfig application property can be used to specify a description file of the application.
The structure of the credits.xml file is as follows:
-
The
itemselement lists the used libraries with license texts included either as an embeddedlicenseelement, or as alicenseattribute with a link to the text in thelicensessection.It is possible to reference licenses declared in the current file as well as any other file declared in
cuba.creditsConfigvariable prior to the current one. -
The
licenseselement lists the texts of general licenses used (e.g. LGPL).
The entire list of third-party software components can be displayed using the com/haulmont/cuba/gui/app/core/credits/credits-frame.xml frame, which loads the information from the files defined in the cuba.creditsConfig property. An example of the frame within a screen:
<dialogMode width="500" height="400"/>
<layout expand="creditsBox">
<groupBox id="creditsBox"
caption="msg://credits"
width="100%">
<frame id="credits"
src="/com/haulmont/cuba/gui/app/core/credits/credits-frame.xml"
width="100%"
height="100%"/>
</groupBox>
</layout>If the dialog mode (WindowManager.OpenType.DIALOG) is used when opening the screen that contains the frame, the height must be specified; otherwise, the scrolling may work not correctly. See the dialogMode element in the example above.
4.9. Functionality Extension
The platform enables extending and overriding the following aspects of its functionality in applications:
-
Extending entity attributes set.
-
Extending screens functionality.
-
Extending and overriding business logic contained in Spring beans.
Below is an example of the first two operations, illustrated by adding the "Address" field to the User entity of the platform security subsystem.
4.9.1. Extending an Entity
In the application project, derive an entity class from com.haulmont.cuba.security.entity.User and add the required attribute with the corresponding access methods:
@Entity(name = "sales$ExtUser")
@Extends(User.class)
public class ExtUser extends User {
@Column(name = "ADDRESS", length = 100)
private String address;
public String getAddress() {
return address;
}
public void setAddress(String address) {
this.address = address;
}
}The new name of the entity should be specified in the @Entity annotation. Since the parent entity does not declare the inheritance strategy, it is assumed to be SINGLE_TABLE by default. It means that the child entity will be stored in the same table as the parent one, and the @Table annotation is not required. Other parent entity annotations ( @NamePattern, @Listeners, etc.) are automatically applied to the child entity, but can be overridden in its class.
An important element of the new entity class is the @Extends annotation, which takes the parent class as a parameter. It enables creating a registry of child entities and forces the platform mechanisms to use them everywhere instead of the parent ones. The registry is implemented by the ExtendedEntities class, which is a Spring bean named cuba_ExtendedEntities, and is also accessible via the Metadata interface.
Add a localized name of the new attribute to the com.sample.sales.entity package:
messages.properties
ExtUser.address=Addressmessages_ru.properties
ExtUser.address=АдресRegister the new entity in the persistence.xml file of the project:
<class>com.sample.sales.entity.ExtUser</class>Add the update script for the corresponding table to the database create and update scripts:
-- add column for "address" attribute
alter table SEC_USER add column ADDRESS varchar(100)
^
-- add discriminator column required for entity inheritance
alter table SEC_USER add column DTYPE varchar(100)
^
-- set discriminator value for existing records
update SEC_USER set DTYPE = 'sales$ExtUser' where DTYPE is null
^In order to use new entity attributes in screens, create views for the new entity with the same names as the views of the base entity. A new view should extend the base view and define new attributes, for example:
<view class="com.sample.sales.entity.ExtUser"
name="user.browse"
extends="user.browse">
<property name="address"/>
</view>An extended view is not required if the base one extends _local and you add only local attributes, so in the described case this step can be omitted.
4.9.2. Extending Screens
The platform supports creating new XML descriptors by inheriting them from the existing ones.
XML inheritance is implemented by specifying the parent descriptor path in the extends attribute of the root window element.
XML screen elements overriding rules:
-
If the extending descriptor has a certain element, the corresponding element will be searched for in the parent descriptor using the following algorithm:
-
If the overriding element is a
view, the corresponding element will be searched by thename,classandentityattributes. -
If the overriding element is a
property, the corresponding element will be searched by thenameattribute. -
In other cases, if the overrinding element has the
idattribute, the corresponding element with the sameidwill be searched for. -
If the search is successful, the found element is overridden.
-
Otherwise, the platform determines how many elements with the provided path and name are contained in the parent descriptor. If there is only one element, it is overridden.
-
If search yields no result and there is either zero or more than one element with the given path and name in the parent descriptor, a new element is added.
-
-
The text for the overridden or added element is copied from the extending element.
-
All attributes from the extending element are copied to the overridden or added element. If attribute names match, the value is taken from the extending element.
-
By default, the new element is added to the end of the list of adjacent elements. In order to add a new element to the beginning or with an arbitrary index, you can do the following:
-
Define an additional namespace in the extending descriptor:
xmlns:ext="http://schemas.haulmont.com/cuba/window-ext.xsd". -
Add the
ext:indexattribute with a desired index, for example:ext:index="0"to the extending element.
-
In order to debug the descriptor conversion, you can output the resulting XML to the server log by specifying the TRACE level for the com.haulmont.cuba.gui.xml.XmlInheritanceProcessor logger in the Logback configuration file.
Below is an example descriptor of the ExtUser entities browser screen:
<window xmlns="http://schemas.haulmont.com/cuba/window.xsd"
xmlns:ext="http://schemas.haulmont.com/cuba/window-ext.xsd"
extends="/com/haulmont/cuba/gui/app/security/user/browse/user-browse.xml">
<layout>
<groupTable id="usersTable">
<columns>
<column id="address" ext:index="2"/>
</columns>
</groupTable>
</layout>
</window>In this example, the descriptor is inherited from the standard User entities browser of the platform. The address column is added to the table with index 2, so it is displayed after login and name.
If you register a new screen in screens.xml with the same identifiers that were used for the parent screen, the new screen will be invoked everywhere instead of the old one.
<screen id="sec$User.browse"
template="com/sample/sales/gui/extuser/extuser-browse.xml"/>
<screen id="sec$User.lookup"
template="com/sample/sales/gui/extuser/extuser-browse.xml"/>Similarly, let us create an edit screen:
<window xmlns="http://schemas.haulmont.com/cuba/window.xsd"
xmlns:ext="http://schemas.haulmont.com/cuba/window-ext.xsd"
extends="/com/haulmont/cuba/gui/app/security/user/edit/user-edit.xml">
<layout>
<fieldGroup id="fieldGroup">
<column id="fieldGroupColumn2">
<field property="address" ext:index="4"/>
</column>
</fieldGroup>
</layout>
</window>Register it in screens.xml with the identifier of the parent screen:
<screen id="sec$User.edit"
template="com/sample/sales/gui/extuser/extuser-edit.xml"/>Once all the abovementioned actions are completed, the application will use ExtUser with the corresponding screens instead of the standard User entity of the platform.
Screen controller can be extended by creating a new class that is inherited from the base screen controller. Class name is specified in the class attribute of the root element of the extending XML descriptor; the usual rules of inheriting XML described above will apply.
4.9.3. Extending Business Logic
The main part of platform business logic is contained in Spring beans. This enables to easily extend or override it in the application.
To substitute a bean implementation, you should create your own class that implements the interface or extends the base platform class and register it in spring.xml of the application. You cannot apply the @Component annotation to the extending class; overriding beans is possible only in the XML configuration.
Below is an example of adding a method to the PersistenceTools bean.
First, create a class with the necessary method:
public class ExtPersistenceTools extends PersistenceTools {
public Entity reloadInSeparateTransaction(final Entity entity, final String... viewNames) {
Entity result = persistence.createTransaction().execute(new Transaction.Callable<Entity>() {
@Override
public Entity call(EntityManager em) {
return em.reload(entity, viewNames);
}
});
return result;
}
}Register the class in spring.xml of the project core module with the same identifier as the platform bean:
<bean id="cuba_PersistenceTools" class="com.sample.sales.core.ExtPersistenceTools"/>After that, the Spring context will always return ExtPersistenceTools instead of the base`PersistenceTools` instance. A checking code example:
Persistence persistence;
PersistenceTools tools;
persistence = AppBeans.get(Persistence.class);
tools = persistence.getTools();
assertTrue(tools instanceof ExtPersistenceTools);
tools = AppBeans.get(PersistenceTools.class);
assertTrue(tools instanceof ExtPersistenceTools);
tools = AppBeans.get(PersistenceTools.NAME);
assertTrue(tools instanceof ExtPersistenceTools);5. Application Development
This chapter contains practical information on how to create platform-based applications.
5.1. Recommended Code Style
Code Formatting
-
For Java and Groovy code, it is recommended to follow the standard style described in Code Conventions for the Java Programming Language. When programming in IntelliJ IDEA, you can just use the default style and Ctrl-Alt-L shortcut for formatting.
The maximum line length is 120 characters. The indentation is 4 characters; using spaces instead of tabs is enabled.
-
XML code: indentation is 4 characters; using spaces instead of tabs is enabled.
Naming Conventions
| Identifier | Naming Rule | Example |
|---|---|---|
Java and Groovy classes |
||
Screen controller class |
UpperCamelCase Browse screen controller Edit screen controller |
|
XML screen descriptors |
||
Component identifier, parameter names in queries |
lowerCamelCase, only letters and numbers. |
|
Datasource identifier |
lowerCamelCase, only letters and numbers ending with |
|
SQL scripts |
||
Reserved words |
lowercase |
|
Tables |
UPPER_CASE. The name is preceded by the project name to form a namespace. It is recommended to use singular form in table names. |
|
Columns |
UPPER_CASE |
|
Foreign key columns |
UPPER_CASE. Consists of the table referred by the column (without the project prefix) and the _ID suffix. |
|
Indexes |
UPPER_CASE. Consists of the IDX_ prefix, name of the table that the index is created for (with the project prefix) and names of the fields included in the index. |
|
5.2. Project File Structure
Below is the project file structure of a simple application, Sales, consisting of the Middleware, Web Client and Web Portal blocks.
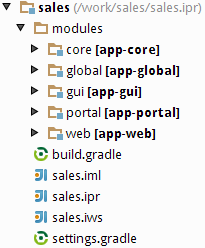
Figure 28. Project File Structure
The project root contains build scripts (build.gradle, settings.gradle) and IntelliJ IDEA project files.
The modules directory includes the subdirectories of the project modules − global, core, gui, portal, web.
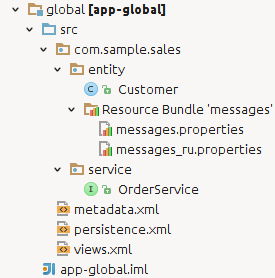
Figure 29. The global Module Structure
The global module contains the source code directory, src, with configuration files – metadata.xml, persistence.xml and views.xml. The com.sample.sales.service package contains interfaces of the Middleware services; the com.sample.sales.entity package contains entity classes and localization files for them.
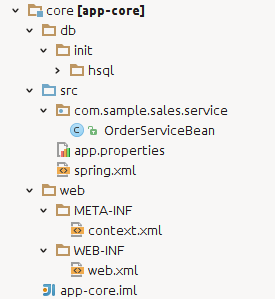
Figure 30. The core Module Structure
The core module contains the following directories:
-
db– directory with the database create and update scripts. -
src– source code directory; its root contains the application properties file of the Middleware block and the spring.xml configuration file. Thecom.samples.sales.corepackage contains the Middleware classes: implementations of services, managed beans and JMX beans. -
web– directory with the configuration files of the web application built from the Middleware block: context.xml and web.xml.
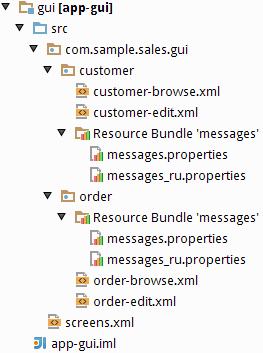
Figure 31. The gui Module Structure
The gui module includes the source code directory, src, with the screens.xml configuration file. The com.sample.sales.gui package contains XML descriptors and screen controllers, and localization files for them.
Figure 32. The web Module Structure
The web module contains the following directories:
-
src– source code directory with the application properties file of the Web Client block and configuration files – web-menu.xml, web-permissions.xml, web-screens.xml and web-spring.xml. Thecom.samples.sales.webpackage contains the main class of the Web Client block (inheritor ofDefaultApp) and the main localized messages pack. -
web– directory with configuration files of the web application built from the Web Client: context.xml and web.xml.
5.3. Build Scripts
Platform based projects are built using Gradle build system. Build scripts are two files in the project root directory:
-
settings.gradle– defines the project name and the set of modules. -
build.gradle– defines the build configuration.
This section describes the structure of the scripts and the purpose and parameters of Gradle tasks.
5.3.1. Structure of build.gradle
This section describes the structure and main elements of the build.gradle script.
- buildscript
-
The
buildscriptsection of the script defines the following:-
A version of the platform.
-
A set of repositories for loading project dependencies. See how to configure access to the repositories below.
-
Dependencies used by the build system, including the CUBA Gradle plugin.
Below the
buildscriptsection, a few variables are defined. They are used in the script later. -
- cuba
-
The CUBA-specific build logic is encapsulated in the
cubaGradle plugin. It is included in the root of the script and in theconfiguresection of all modules by the following statement:apply(plugin: 'cuba')The settings of the cuba plugin are defined in
cubasection:cuba { artifact { group = 'com.company.sales' version = '0.1' isSnapshot = true } tomcat { dir = "$project.rootDir/build/tomcat" } ide { copyright = '...' classComment = '...' vcs = 'Git' } }Let us consider the available options:
-
artifact- this section defines the group and version of the project artifacts being built. Artifact names are based on module names specified insettings.gradle.-
group- artifact group. -
version- artifact version. -
isSnapshot- iftrue, artifact names will have theSNAPSHOTsuffix.
-
-
tomcat- this section defines the settings of the Tomcat server which is used for fast deployment.-
dir- location of the Tomcat installation directory. -
port- listening port; 8080 by default. -
debugPort- Java debug listening port; 8787 by default. -
shutdownPort- port listening to theSHUTDOWNcommand; 8005 by default. -
ajpPort- AJP connector port; 8009 by default.
-
-
ide- this section contains instructions for Studio and IDE.-
vcs- a version control system for the project. OnlyGitandsvnare currently supported. -
copyright- copyright text to be inserted into beginning of each source file. -
classComment- comment text to be placed above class declarations in Java source files.
-
-
uploadRepository- this section defines the settings of the repository where assembled project artifacts will be uploaded to upon completion of theuploadArchivestask.-
url- the repository URL. If not specified, Haulmont’s repository is used. -
user- the repository user. -
password- the repository password.You can pass the upload repository parameters from the command line with the following arguments:
gradlew uploadArchives -PuploadUrl=http://myrepo.com/content/repositories/snapshots -PuploadUser=me -PuploadPassword=mypassword
-
-
- dependencies
-
This section contains a set of application components used by the project. Components are specified by their global module artifact. In the following example, three components are used:
com.haulmont.cuba(cuba component of the platform),com.haulmont.reports(reports premium add-on) andcom.company.base(a custom component):dependencies { appComponent("com.haulmont.cuba:cuba-global:$cubaVersion") appComponent("com.haulmont.reports:reports-global:$cubaVersion") appComponent("com.company.base:base-global:0.1-SNAPSHOT") } - configure
-
The
configuresections contain configuration of modules. The most important part of the configuration is the declaration of dependencies. For example:configure(coreModule) { dependencies { // standard dependencies using variables defined in the script above compile(globalModule) provided(servletApi) jdbc(hsql) testRuntime(hsql) // add a custom repository-based dependency compile('com.company.foo:foo:1.0.0') // add a custom file-based dependency compile(files("${rootProject.projectDir}/lib/my-library-0.1.jar")) // add all JAR files in the directory to dependencies compile(fileTree(dir: 'libs', include: ['*.jar'])) }Non-standard module dependencies can be specified in Studio on the Project properties > Advanced tab. See Studio context help for details.
5.3.2. Configuring Access to Repository
CUBA Studio Server window contains a field where you can select an artifact repository. By default, it contains two entries:
-
https://repo.cuba-platform.com/content/groups/work- a repository located at Haulmont’s server. It requires common credentials which are specified right in the build script (cuba/cuba123). -
https://dl.bintray.com/cuba-platform/main- a repository hosted at JFrog Bintray. It has anonymous access.
Both repositories have identical contents for the latest platform versions. We assume that Bintray is more reliable for worldwide access.
When you create a new project in CUBA Studio, it’s build.gradle contains the link to the repository which is selected in the Studio server window. In case of Bintray, the build script is also configured to use Maven Central, JCenter and Vaadin Add-ons repositories separately.
If your project uses CUBA Premium Add-ons, Studio adds one more repository:
-
In case of
repo.cuba-platform.comit ishttps://repo.cuba-platform.com/content/groups/premium -
In case of Bintray it is
https://cuba-platform.bintray.com/premium
Both Premium Add-ons repositories require a user name and a password which are provided by per-developer subscription. The first part of your license key before dash is the repository user name, the part after dash is the password. For example, if your key is 111111222222-abcdefabcdef, then the user name is 111111222222 and the password is abcdefabcdef.
When you build the project from Studio, it passes repository credentials to Gradle automatically. If you want to build the project outside Studio, you can pass premiumRepoUser and premiumRepoPass in the command line arguments with -P prefix. In case of Bintray, the user name must be followed by @cuba-platform.
Example of building with repo.cuba-platform.com:
gradlew assemble -PpremiumRepoUser=111111222222 -PpremiumRepoPass=abcdefabcdefExample of building with Bintray:
gradlew assemble -PpremiumRepoUser=111111222222@cuba-platform -PpremiumRepoPass=abcdefabcdefInstead of passing credentials each time you build the project from the command line, you can once set the following environment variables:
-
CUBA_PREMIUM_USER- will be used ifpremiumRepoUseris not passed. -
CUBA_PREMIUM_PASSWORD- will be used ifpremiumRepoPassis not passed.
5.3.3. Build Tasks
Tasks are executable units in Gradle. They are defined both in the plugins and in the build script itself. Below are CUBA-specific tasks; their parameters can be configured in build.gradle.
5.3.3.1. buildUberJar
buildUberJar – the task of the CubaUberJarBuilding type that creates JAR files containing the application code and all its dependencies together with embedded Jetty HTTP server. Separate JARs are created for each application block, e.g. app-core.jar for the middleware and app.jar for the web client.
The task must be declared in the root of build.gradle. The resulting JAR files are located in the build/distributions project subdirectory. See the UberJAR Deployment section for how to run the generated JAR files.
|
Tip
|
The task can be configured using the Deployment settings > Uber JAR page in Studio. |
Task parameters:
-
coreJettyEnvPath- required parameter that defines a relative path to a file which contains JNDI resource definitions for Jetty HTTP server. The file must at least contain definition of a JDBC data source for the main database. Studio can generate this file on the basis of entered database connection parameters. Can also be set at run time using the-jettyEnvPathcommand line argument. -
appProperties- a map defining application properties. These properties will be added to the/WEB-INF/local.app.propertiesfiles inside generated JARs. -
corePort- port for core JAR embedded HTTP server,8079if not defined. Can also be set at run time using the-portcommand line argument. -
webPort- port for web JAR embedded HTTP server,8080if not defined. Can also be set at run time using the-portcommand line argument. -
portalPort- port for portal JAR embedded HTTP server,8081if not defined. Can also be set at run time using the-portcommand line argument. -
appName- name of the application, which isappby default. You can change it for the whole project if you set Module prefix field on the Project Properties > Advanced tab in Studio, or you can set it only for thebuildUberJartask using this parameter. For example:task buildUberJar(type: CubaUberJarBuilding) { coreJettyEnvPath = 'modules/core/web/META-INF/jetty-env.xml' appProperties = ['cuba.automaticDatabaseUpdate' : true] appName = 'sales' }After changing the application name to
salesthe task will generatesales-core.jarandsales.jarfiles and the web client will be available athttp://localhost:8080/sales. You can also change web contexts at run time without changing the application name using the-contextNamecommand line argument.WarningPlease note that current implementation of Polymer UI requires manual setting of
<base>tag to the actual web context available at run time. So changing the context by using Module prefix,appNametask parameter or-frontContextNamecommand line argument can make the Polymer UI inaccessible. -
coreProject- a Gradle project representing the core module (Middleware). If not defined, the standard core module is used. -
webProject- a Gradle project representing the web module (Web Client). If not defined, the standard web module is used. -
portalProject- a Gradle project representing the portal module (Web Portal). If not defined, the standard portal module is used. -
polymerProject- a Gradle project representing the Polymer UI module. If not defined, the standard polymer-client module is used. -
coreWebXmlPath- a relative path to a file to be used as aweb.xmlfor the core JAR. -
webWebXmlPath- a relative path to a file to be used as aweb.xmlfor the web JAR. -
portalWebXmlPath- a relative path to a file to be used as aweb.xmlfor the portal JAR. -
excludeResources- a file pattern of resources to not include in JARs. -
mergeResources- a file pattern of resources to be merged in JARs. -
webContentExclude- a file pattern of web content to not include in web JAR.
5.3.3.2. buildWar
buildWar – the task of the CubaWarBuilding type, which builds a WAR file from the application code and its dependencies. It should be declared in the root of build.gradle. The resulting WAR file(s) are located in the build/distributions project subdirectory.
Any CUBA application consists of at least two blocks: Middleware and Web Client. So the most natural way to deploy an application is to create two separate WAR files: one for Middleware and one for Web Client. This also allows you to scale your application when the number of users grows. However, separate WAR files contain some duplicated dependencies that increase overall size. Besides, extended deployment options are often not needed and rather complicate the process. The CubaWarBuilding task can create both types of WAR files: one per block or single WAR containing both blocks. In the latter case, the application blocks are loaded into separate class loaders inside one web application.
- Creating separate WAR files for Middleware and Web Client
-
To create separate WAR files for Middleware and Web Client, use the following task configuration:
task buildWar(type: CubaWarBuilding) { appHome = '..' appProperties = ['cuba.automaticDatabaseUpdate': 'true'] singleWar = false }Task parameters:
-
appHome– the path to the application home directory. The home directory will contain the configuration, temporary and work directories of the application.In the
appHomeparameter, you can specify an absolute or relative path to the home directory, or a Java system variable, which should be set at server start. For example:appHome = '/work/sales_home'orappHome = '${app.home}'. -
appProperties- an optional map defining application properties. These properties will be added to the/WEB-INF/local.app.propertiesfiles inside generated WAR.appProperties = ['cuba.automaticDatabaseUpdate': 'true']will create the database at the first launch, if there wasn’t any. -
singleWar- should be set tofalsefor building separate WAR files. -
includeJdbcDriver- include JDBC driver which is currently used in the project.falseby default. -
includeContextXml- include Tomcatcontext.xmlfile which is currently used in the project.falseby default. -
coreContextXmlPath- the relative path to a file which should be used instead of project’scontext.xmlifincludeContextXmlis set totrue. -
hsqlInProcess- if set totrue, the database URL incontext.xmlwill be modified for HSQL in-process mode. -
coreProject- the Gradle project representing the core module (Middleware). If not defined, the standard core module is used. -
webProject- the Gradle project representing the web module (Web Client). If not defined, the standard web module is used. -
portalProject- the Gradle project representing the portal module (Web Portal). Set this property if the application project contains the portal module. For example,portalProject = project(':app-portal'). -
coreWebXmlPath,webWebXmlPath,portalWebXmlPath- a relative path to a file to be used as aweb.xmlof the corresponding application block.Example of using custom
web.xmlfiles:task buildWar(type: CubaWarBuilding) { singleWar = false // ... coreWebXmlPath = 'modules/core/web/WEB-INF/production-web.xml' webWebXmlPath = 'modules/web/web/WEB-INF/production-web.xml' }
-
- Creating a single WAR file
-
To create a single WAR file that comprises both Middleware and Web Client blocks, use the following task configuration:
task buildWar(type: CubaWarBuilding) { appHome = '..' webXmlPath = 'modules/web/web/WEB-INF/single-war-web.xml' }The following parameters should be specified in addition to the ones described above:
-
singleWar- should be omitted or set totrue. -
webXmlPath- the relative path to a file to be used as aweb.xmlof the single WAR. This file defines two servlet context listeners that load the application blocks:SingleAppCoreServletListenerandSingleAppWebServletListener. All initialization parameters are passed to them through context parameters.Example of
single-war-web.xml:<?xml version="1.0" encoding="UTF-8"?> <web-app xmlns="http://java.sun.com/xml/ns/javaee" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://java.sun.com/xml/ns/javaee http://java.sun.com/xml/ns/javaee/web-app_3_0.xsd" version="3.0"> <!--Application components--> <context-param> <param-name>appComponents</param-name> <param-value>com.haulmont.cuba</param-value> </context-param> <!-- Web Client parameters --> <context-param> <description>List of app properties files for Web Client</description> <param-name>appPropertiesConfigWeb</param-name> <param-value> classpath:cuba-web-app.properties classpath:web-app.properties /WEB-INF/local.app.properties </param-value> </context-param> <context-param> <description>Web resources version for correct caching in browser</description> <param-name>webResourcesTs</param-name> <param-value>${webResourcesTs}</param-value> </context-param> <!-- Middleware parameters --> <context-param> <description>List of app properties files for Middleware</description> <param-name>appPropertiesConfigCore</param-name> <param-value> classpath:cuba-app.properties classpath:app.properties /WEB-INF/local.app.properties </param-value> </context-param> <!-- Servlet context listeners that load the application blocks --> <listener> <listener-class>com.vaadin.server.communication.JSR356WebsocketInitializer</listener-class> </listener> <listener> <listener-class>com.haulmont.cuba.core.sys.singleapp.SingleAppCoreServletListener</listener-class> </listener> <listener> <listener-class>com.haulmont.cuba.web.sys.singleapp.SingleAppWebServletListener</listener-class> </listener> </web-app>
Single WAR contains only core and web modules (Middleware and Web Client). To deploy the portal module, use separate WAR files.
-
See also WAR deployment to Jetty section for step-by-step instructions on some variants of WAR deployment.
5.3.3.3. buildWidgetSet
buildWidgetSet - the task of the CubaWidgetSetBuilding which builds a custom GWT widgetset if the web-toolkit module exists in the project. This module enables development of custom visual components.
Available parameters:
-
style- the script output style:OBF,PRETTYorDETAILED.OBFby default. -
logLevel- the logging level:ERROR,WARN,INFO,TRACE,DEBUG,SPAM, orALL.INFOby default. -
draft- compile quickly with minimal optimizations.falseby default.
Example usage:
task buildWidgetSet(type: CubaWidgetSetBuilding) {
widgetSetClass = 'com.company.sample.web.toolkit.ui.AppWidgetSet'
style = 'PRETTY'
}5.3.3.4. createDb
createDb – the task of the CubaDbCreation type which creates application database by executing the corresponding scripts. It is declared in the core module. Parameters:
-
dbms– the DBMS type, specified as the stringhsql,postgres,mssql, ororacle. -
dbName– the database name. -
dbUser– the DBMS username. -
dbPassword– the DBMS user password. -
host– the DBMS host and port (optional) in thehost[:port]format. If not specified,localhostis used. -
connectionParams- an optional connection parameters string which will be appended to the end of the connection URL. -
masterUrl– the URL used to connect when creating the database. If not specified, the default value that depends on the DBMS type and thehostparameter is used. -
dropDbSql– the SQL command to delete the database. If not specified, the default value that depends on the DBMS type is used. -
createDbSql– the SQL command to create a database. If not specified, the default value that depends on the DBMS type is used. -
driverClasspath– the list of JAR files containing the JDBC driver. The items in the list are separated by ":" on Linux and by ";" on Windows. If not specified, the system uses the dependencies that are part of the current module’sjdbcconfiguration. Explicit definition ofdriverClasspathis necessary when using Oracle, because its JDBC driver is not available in the dependencies. -
oracleSystemPassword– the SYSTEM user password for Oracle.
Example for PostgreSQL:
task createDb(dependsOn: assemble, description: 'Creates local database', type: CubaDbCreation) {
dbms = 'postgres'
dbName = 'sales'
dbUser = 'cuba'
dbPassword = 'cuba'
}Example for MS SQL Server:
task createDb(dependsOn: assemble, description: 'Creates local database', type: CubaDbCreation) {
dbms = 'mssql'
dbName = 'sales'
dbUser = 'sa'
dbPassword = 'saPass1'
connectionParams = ';instance=myinstance'
}Example for Oracle:
task createDb(dependsOn: assemble, description: 'Creates database', type: CubaDbCreation) {
dbms = 'oracle'
host = '192.168.1.10'
dbName = 'orcl'
dbUser = 'sales'
dbPassword = 'sales'
oracleSystemPassword = 'manager'
driverClasspath = "$tomcatDir/lib/ojdbc6.jar"
}5.3.3.5. debugWidgetSet
debugWidgetSet - the task of the CubaWidgetSetDebug type which launches GWT Code Server for debugging widgets in the browser.
Example usage:
task debugWidgetSet(type: CubaWidgetSetDebug) {
widgetSetClass = 'com.company.sample.web.toolkit.ui.AppWidgetSet'
}Ensure that the web-toolkit module has a dependency on Servlet API library in the runtime configuration:
configure(webToolkitModule) {
dependencies {
runtime(servletApi)
}
...See Debugging Web Widgets for information on how to debug code in the browser.
5.3.3.6. deploy
deploy – the task of the CubaDeployment type which performs fast deployment of a module to Tomcat. It is declared in the core, web and portal modules. Parameters:
-
appName– name of the web application that will be created from the module. In fact, it is the name of a subdirectory insidetomcat/webapps. -
jarNames– the list of JAR file names (without versions) produced as a result of building a module and intended to be placed into theWEB-INF/libcatalog of the web application. All other module artifacts and dependencies will be copied totomcat/shared/lib.
For example:
task deploy(dependsOn: assemble, type: CubaDeployment) {
appName = 'app-core'
jarNames = ['cuba-global', 'cuba-core', 'app-global', 'app-core']
}5.3.3.7. deployThemes
deployThemes - the task of the CubaDeployThemeTask type which builds and deploys themes defined in the project to the running web application deployed by the deploy task. Changes in the themes are applied without the server restart.
For example:
task deployThemes(type: CubaDeployThemeTask, dependsOn: buildScssThemes) {
}5.3.3.8. deployWar
deployWar - the task of the CubaJelasticDeploy type which deploys the WAR file to Jelastic server.
For example:
task deployWar(type: CubaJelasticDeploy, dependsOn: buildWar) {
email = '<your@email.address>'
password = '<your password>'
context = '<app contex>'
environment = '<environment name or ID>'
hostUrl = '<Host API url>'
}Task parameters:
-
appName- the name of the web application. By default, it corresponds to the Modules prefix, e.g.,app. -
email- Jelastic server account login. -
password- Jelastic account password. -
context- the application context. Default value:ROOT. -
environment- the environment where the application WAR will be deployed. You can set either the environment name or its ID. -
hostUrl- URL of the API host. Typically it isapp.jelastic.<host name>. -
srcDir- the directory where the WAR is located. By default it is"${project.buildDir}/distributions/war".
5.3.3.9. enhance
enhance – the task of the CubaEnhancing type which performs bytecode enhancement (weaving) of entity classes. It is declared in the global module.
For example:
task enhance(type: CubaEnhancing)Optional parameters:
-
persistenceConfig- allows you to specify the set of persistence.xml files explicitly. If not set, the task will enhance all persistent entities listed in the*persistence.xmlfiles located in the CLASSPATH. -
metadataXml- allows you to specify the metadata.xml project file explicitly. If not set, the task will enhance all non-persistent entities listed in the*metadata.xmlfiles located in the module source tree.
5.3.3.10. restart
restart – the task that stops the local Tomcat server, runs fast deployment, and starts the server once again.
5.3.3.11. setupTomcat
setupTomcat – the task of the CubaSetupTomcat type which performs installation and initialization of the local Tomcat server for subsequent fast deployment of the application. This task is automatically added to the project when you apply the cuba Gradle plugin, so you don’t need to declare it in build.gradle. Tomcat installation directory is specified by the tomcat.dir property of the cuba section. By default, it is the project’s build/tomcat subdirectory.
5.3.3.12. start
start – the task of the CubaStartTomcat type which starts the local Tomcat server installed by the setupTomcat task. This task is automatically added to the project when you add the cuba plugin, so you don’t need to declare it in build.gradle.
5.3.3.13. startDb
startDb – the task of the CubaHsqlStart type which starts the local HSQLDB server. Parameters:
-
dbName– database name, default iscubadb. -
dbDataDir– database directory, default is thedeploy/hsqldbsubfolder of the project. -
dbPort– server port, default is 9001.
For example:
task startDb(type: CubaHsqlStart) {
dbName = 'sales'
}5.3.3.14. stop
stop – the task of CubaStopTomcat type which stops the local Tomcat server installed by the setupTomcat task. This task is automatically added to the project when you include the cuba plugin, so you don’t need to declare it in build.gradle.
5.3.3.15. stopDb
stopDb – the task of the CubaHsqlStop type which stops the local HSQLDB server. The parameters are similar to startDb.
5.3.3.16. tomcat
tomcat – the task of the Exec type which starts the local Tomcat server in the opened terminal window and keeps it open even if the start failed. This task may be useful for troubleshooting, e.g., to detect problems caused by Java version mismatch etc, on the server start.
5.3.3.17. updateDb
updateDb – the task of the CubaDbUpdate type which updates the database by executing the corresponding scripts. It is similar to the createDb task, except that the dropDbSql and createDbSql parameters are omitted.
5.3.3.18. zipProject
zipProject is the task of the CubaZipProject type which creates a ZIP archive of your project. The archive will not contain IDE project files, build results and Tomcat server. But HSQL database is included to the archive if present in the build directory.
This task is automatically added to the project when you apply the cuba Gradle plugin, so you don’t need to declare it in build.gradle.
5.3.4. Starting Build Tasks
Gradle tasks described in build scripts can be launched in the following ways:
-
If you are working with the project in CUBA Studio, all commands under the Build and Run main menu items actually connect to the Gradle daemon (launched at the start of Studio server) and run corresponding tasks.
-
Alternatively, you can use the executable
gradlewscript (Gradle wrapper) included in the project. The script should be located in the project root directory and can be created in Studio using the Build > Create Gradle wrapper command. -
One more way is to use the manually installed Gradle version 3.1. In this case, run the
gradleexecutable located in thebinsubdirectory of the Gradle installation.
|
Tip
|
It is recommended to run the To remove the daemon from memory, you can use the |
For example, in order to compile the Java files and build the JAR files for project artifacts, you need to run the following command:
gradlew --daemon assemble|
Warning
|
If your project uses Premium Add-ons, and you are starting build tasks outside Studio, pass the Premium Add-ons repository credentials in the command line arguments with See above for details. |
Typical build tasks in their normal usage sequence are provided below.
-
idea,eclipse– create IntelliJ IDEA or Eclipse project files. When this task is executed, dependencies with their source code are loaded from the artifact repository to the local Gradle cache. -
cleanIdea,cleanEclipse– remove IntelliJ IDEA or Eclipse project files. -
assemble– compile Java files and build JARs for project artifacts in thebuildsubdirectories of the modules. -
clean– removebuildsubdirectories of all project modules. -
setupTomcat – setup the Tomcat server to the path that is specified by the
cuba..tomcat.dirproperty of thebuild.gradlescript. -
deploy – deploy the application to the Tomcat server that has been pre-installed by the
setupTomcattask. -
createDb – create an application database and run the corresponding scripts.
-
updateDb – update the existing application database by running the corresponding scripts.
-
start – start the Tomcat server.
-
stop – stop the running Tomcat server.
-
restart – sequentially run the
stop,deploy,starttasks.
5.3.5. Setting Up a Private Artifact Repository
This section describes how to set up a private Maven repository and use it instead of the CUBA public repository for storing the platform artifacts and other dependencies. It is recommended in the following cases:
-
You have an unstable or slow connection to the internet. In spite of the fact that Gradle caches downloaded artifacts on the developer’s machine, you may need to connect to the artifact repository from time to time, for example when you run build for the first time or switch to a newer version of the platform.
-
You cannot have direct access to the internet due to a security policy of your organization.
-
You are not going to prolong your subscription to CUBA Premium Add-ons, but you need to be able to build your application in the future using the downloaded version of the artifacts.
The process of setting up a private repository consists of the following steps:
-
Install the repository manager software in a network connected to the internet.
-
Configure the private repository as a proxy for the CUBA public repository.
-
Make your project build script use the private repository. It can be done in Studio or right in
build.gradle. -
Perform full build of your project to cache all required artifacts in the private repository.
5.3.5.1. Install the Repository Manager
For the purpose of this example, we will use Sonatype Nexus OSS repository manager and Microsoft Windows operating system.
-
Download Sonatype Nexus OSS version 2.x (2.14.3 has been tested)
-
Unpack zip file to the directory
c:\nexus-2.14.3-02 -
Modify settings located in file
c:\nexus-2.14.3-02\conf\nexus.properties:-
You may configure server port; default is 8081
-
Configure repository data folder:
replace
nexus-work=${bundleBasedir}/../sonatype-work/nexuswith any convenient path to cached data, for example
nexus-work=${bundleBasedir}/nexus/sonatype-work/content
-
-
Navigate to the folder
c:\nexus-2.14.3-02\bin -
To start and stop Nexus as a service, install the wrapper (run command as Administrator):
nexus.bat install -
Launch nexus service.
-
Open
http://localhost:8081/nexusin the web browser and log in with the default credentials: loginadminand passwordadmin123.
5.3.5.2. Configure the Proxy Repository
Click to the Repositories link on the left panel.
On the opened Repositories page click the Add button, then choose Proxy Repository. A new repository will be added. Fill in required fields at Configuration tab:
-
Repository ID:
cuba-work -
Repository Name:
cuba-work -
Provider:
Maven2 -
Remote Storage Location:
https://repo.cuba-platform.com/content/groups/work -
Auto Blocking Enabled:
false -
Enable Authentication, set Username:
cuba, Password:cuba123 -
Click Save button.
Create a Repository Group, in Nexus click Add button, then choose Repository Group and do the following on Configuration tab:
-
Enter the Group ID:
cuba-group -
Enter the Group Name:
cuba-group -
Provider:
Maven2 -
Add the repository cuba-work from Available Repositories to Ordered Group Repositories
-
Click Save button.
If you have a subscription to the Premium Add-ons, add one more repository with the following settings:
-
Repository ID:
cuba-premium -
Repository Name:
cuba-premium -
Provider:
Maven2 -
Remote Storage Location:
https://repo.cuba-platform.com/content/groups/premium -
Auto Blocking Enabled:
false -
Enable Authentication, set the first part of your license key (before dash) in the Username field and the second part of your license key (after dash) in the Password field.
-
Click Save button.
-
Click Refresh button.
-
Select the cuba-group group.
-
On the Configuration tab, add cuba-premium repository to the group below cuba-work.
-
Click Save button.
5.3.5.3. Configuring CUBA Studio to Use the Private Repository
Now your private repository is ready to use. Find the cuba-group URL at the top of the screen, for example:
http://localhost:8081/nexus/content/groups/cuba-group
-
Open CUBA Studio Server window and paste the URL into the Repository field.
-
Click Auth button next the Repository field and enter login and password:
admin / admin123. -
Start Studio.
-
Open
http://localhost:8111/studioin your browser. -
Open your project.
-
Build the project.
During the first build your new repository downloads necessary artifacts and keeps them in the cache for the next usage. You may find them in c:\nexus-2.14.3-02\sonatype-work folder.
|
Warning
|
For CUBA Studio version 6.4 and below, before running Studio with the private repository for the first time, do the following:
|
5.3.5.4. Repository in an Isolated Network
If you need to develop on CUBA in a network without connection to the internet, do the following:
-
Install a copy of the repository manager in the target network.
-
Copy the cached content of the repository from the open network to the isolated one. If you followed the instructions above, the content is stored in
c:\nexus-2.14.3-02\sonatype-work
-
Restart the nexus service.
If you need to add artifacts of a new platform version to the isolated repository, go to the environment connected to the internet, make a build through its repository and then copy the contents to the isolated environment again.
5.3.5.5. CUBA Studio in an Isolated Network
In order to use CUBA Studio in an isolated network, follow the steps below:
-
Download Gradle (version 3.1 is required) and install it onto developers machines.
-
Open CUBA Studio Server window.
-
Press Advanced button and set path to the folder where you have installed Gradle.
-
Enter your internal repository URL in the Repository field, for example,
http://localhost:8081/nexus/content/groups/cuba-group. -
Click Auth button next the Repository field and enter repository login and password (
admin/admin123by default). -
Start Studio.
-
Open and build your project.
5.4. Creating a Project
The recommended way to create a new project is to use CUBA Studio. An example can be found in the Quick Start chapter of this manual.
Once the project is created, you can keep developing it in the Studio, or create IntelliJ IDEA or Eclipse project files and open the project in the IDE.
5.5. Logging
The platform uses Logback framework for logging.
To output to the log, use SLF4J API: get a logger for the current class and invoke one of its methods, for example:
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
public class Foo {
// create logger
private Logger log = LoggerFactory.getLogger(Foo.class);
private void someMethod() {
// output message with DEBUG level
log.debug("someMethod invoked");
}
}Logs for the Middleware, Web Client and Web Portal blocks are configured at the application server level; in fast deployment mode the server is Tomcat. Logs for the Desktop Client block are configured separately.
5.5.1. Setting up Logging in Tomcat
Running Gradle setupTomcat task installs the Tomcat server into the project directory and performs its additional configuration. Particularly, setenv.bat and setenv.sh files are created in the tomcat/bin subfolder, and logback.xml is created in the tomcat/conf subfolder.
Among other things, the setenv.* files define loading parameters for the logback.xml configuration file using the CATALINA_OPTS variable.
logback.xml defines logging configuration. The file has the following structure:
-
appenderelements define the "output device" for the log. The main appenders areFILEandCONSOLE. Thelevelparameter ofThresholdFilterdefines the message threshold. By default, it isDEBUGfor a file andINFOfor console. It means thatERROR,WARN,INFOandDEBUGmessages are written to a file, whileERROR,WARNandINFOare written to console.The path to the log file for the file appender is defined in the
fileparameter. The default istomcat/logs/app.log. -
loggerelements define the logger parameters that are used to print messages from the program code. Logger names are hierarchical, i.e. the settings of thecom.company.samplelogger have effect on thecom.company.sample.core.CustomerServiceBeanandcom.company.sample.web.CustomerBrowseloggers, if the loggers do not explicitly override the settings with their own.Minimum logging level is defined by the
levelattribute. For example, if the category isINFO, thenDEBUGandTRACEmessages will not be logged. It should be kept in mind that message logging is also affected by the level threshold set in the appender.
You can quickly change logger levels and appender thresholds for a running server using the * Administration* > Server log screen available in the web client. Any changes to the logging settings are effective only during server runtime and are not saved to a file. The screen also enables viewing and loading log files from the server logs folder (tomcat/logs).
The platform automatically adds the following information to the messages written to the file log:
-
application – the name of the web application that has logged the message. This information enables identifying messages from different application blocks (Middleware, Web Client), since they are written into the same file.
-
user – the login name of the user who invoked the code logging the message. This helps to track activity of a certain user in the log. If the code that logged a message was not invoked within a specific user session, the user information is not added.
For example, the following message has been written to the log by the code of the Middleware block (app-core), running under the admin user:
16:12:20.498 DEBUG [http-nio-8080-exec-7/app-core/admin] com.haulmont.cuba.core.app.DataManagerBean - loadList: ...5.5.2. Setting up Logging in The Desktop Client
For the desktop client, the logback.xml file should be located in the source files directory of the project’s desktop module. When an application is built, it is packed into the corresponding JAR file and is accessible in CLASSPATH.
Make the following steps to set up logging for your project:
-
Create a new file, for example
sample-logback.xml, in thesrcdirectory of the desktop module, and copy the contents ofcuba-logback.xmlto this new file.cuba-logback.xmlfile is located in one of the platform’s JAR files and can be easily found using search in the IDE. -
Define path to a log file in the
fileparameter of theFILEappender. -
Add settings for loggers of your project.
-
In the inheritor class of
com.haulmont.cuba.desktop.Appof your project, for exampleSampleApp, override thegetDefaultLogConfig()method and use it to return the path to your log file relative to the CLASSPATH root. For example:public class SampleApp extends App { ... @Override protected String getDefaultLogConfig() { return "sample-logback.xml"; } -
If necessary, you can override the location of the configuration file at the application start using logback.configurationFile system property.
5.6. Debugging
This section explains how to use step-by-step debugging in CUBA applications.
5.6.1. Connecting a Debugger
You can start Tomcat server in debug mode by either running the Gradle task
gradlew start
or by running the bin/debug.* command file of the installed Tomcat.
After this, the server will accept debugger connections over port 8787. Port number can be changed in the bin/setenv.* file, in the JPDA_OPTS variable.
For debugging in Intellij IDEA you need to create a new Remote type Run/Debug Configuration element in the application project and set its Port property to 8787.
5.6.2. Debugging Web Widgets
You can use GWT Super Dev Mode to debug web widgets on the browser side.
-
Setup the debugWidgetSet task in
build.gradle. -
Deploy the application and start Tomcat.
-
Run the
debugWidgetSettask:gradlew debugWidgetSetThe running GWT Code Server will recompile your widgetset on modification.
-
Open
http://localhost:8080/app?debug&superdevmodein Chrome web browser and wait for the widgetset is built for the first time. -
Open the debug console in Chrome:
-
After changing the Java code in the
web-toolkitmodule, refresh the web page in the browser. The widgetset will be rebuilt incrementally in approximately 8-10 seconds.
5.7. Testing
This section covers the ways of testing CUBA applications on different layers.
5.7.1. Unit Tests
Unit tests can be created and run both at the Middleware and the Client tiers. The platform includes JUnit and JMockit frameworks for this purpose.
Let us assume you have the following screen controller:
public class OrderEditor extends AbstractEditor {
@Named("itemsTable.add")
protected AddAction addAction;
@Override
public void init(Map<String, Object> params) {
addAction.setWindowId("sales$Product.browse");
addAction.setHandler(new Lookup.Handler() {
@Override
public void handleLookup(Collection items) {
// some code
}
});
}
}You can write the following test checking the init() method:
public class OrderEditorTest {
OrderEditor editor;
@Mocked
Window.Editor frame;
@Mocked
AddAction addAction;
@Before
public void setUp() throws Exception {
editor = new OrderEditor();
editor.setWrappedFrame(frame);
editor.addAction = addAction;
}
@Test
public void testInit() {
editor.init(Collections.<String, Object>emptyMap());
editor.setItem(new Order());
new Verifications() {
{
addAction.setWindowId("sales$Product.browse");
addAction.setHandler(withInstanceOf(Window.Lookup.Handler.class));
}
};
}
}5.7.2. Middleware Integration Tests
In the middle tier, you can create integration tests which run in a fully functional Spring container connected to the database. In such tests you can run code from any layer of the Middleware, from services to ORM.
First, create the test directory in your core module next to the src directory. Re-create IDE project files to be able to run tests from the IDE.
The platform contains the TestContainer class which can be used as a base class for the test container in the application project. Create a subclass in the test directory of your core module and, in its constructor, redefine parameters for loading components and application properties and test database connection parameters. For example:
public class SalesTestContainer extends TestContainer {
public SalesTestContainer() {
super();
appComponents = new ArrayList<>(Arrays.asList(
"com.haulmont.cuba"
// add CUBA premium add-ons here
// "com.haulmont.bpm",
// "com.haulmont.charts",
// "com.haulmont.fts",
// "com.haulmont.reports",
// and custom app components if any
));
appPropertiesFiles = Arrays.asList(
// List the files defined in your web.xml
// in appPropertiesConfig context parameter of the core module
"cuba-app.properties",
"sales-app.properties",
// Add this file which is located in CUBA and defines some properties
// specifically for test environment. You can replace it with your own
// or add another one in the end.
"test-app.properties");
dbDriver = "org.postgresql.Driver";
dbUrl = "jdbc:postgresql://localhost/sales_test";
dbUser = "cuba";
dbPassword = "cuba";
}
}We recommend using a separate test database, which can be created, for example, by the following Gradle task defined in build.gradle:
configure(coreModule) {
...
task createTestDb(dependsOn: assemble, description: 'Creates local Postgres database for tests', type: CubaDbCreation) {
dbms = 'postgres'
dbName = 'sales_test'
dbUser = 'cuba'
dbPassword = 'cuba'
}The test container should be used in test classes as a JUnit rule specified by the @ClassRule annotation:
public class CustomerLoadTest {
@ClassRule
public static SalesTestContainer cont = new SalesTestContainer();
private Customer customer;
@Before
public void setUp() throws Exception {
customer = cont.persistence().createTransaction().execute(em -> {
Customer customer = new Customer();
customer.setName("testCustomer");
em.persist(customer);
return customer;
});
}
@After
public void tearDown() throws Exception {
cont.deleteRecord(customer);
}
@Test
public void test() {
try (Transaction tx = cont.persistence().createTransaction()) {
EntityManager em = cont.persistence().getEntityManager();
TypedQuery<Customer> query = em.createQuery(
"select c from sales$Customer c", Customer.class);
List<Customer> list = query.getResultList();
tx.commit();
assertTrue(list.size() > 0);
}
}
}In the example above, the test container is initialized once for all test methods of this class, and disposed after all of them finished.
As the container startup takes some time, you may want to initialize the container once for all tests contained in several test classes. In this case, create a common singleton instance of your test container:
public class SalesTestContainer extends TestContainer {
public SalesTestContainer() {
...
}
public static class Common extends SalesTestContainer {
public static final SalesTestContainer.Common INSTANCE = new SalesTestContainer.Common();
private static volatile boolean initialized;
private Common() {
}
@Override
public void before() throws Throwable {
if (!initialized) {
super.before();
initialized = true;
}
setupContext();
}
@Override
public void after() {
cleanupContext();
// never stops - do not call super
}
}
}And use it in your test classes:
public class CustomerLoadTest {
@ClassRule
public static SalesTestContainer cont = SalesTestContainer.Common.INSTANCE;
...
}The TestContainer class contains the following methods that can be used in the test code (see the CustomerLoadTest example above):
-
persistence()– returns the reference to the Persistence interface. -
metadata()– returns the reference to the Metadata interface. -
deleteRecord()– this set of overloaded methods is aimed to be used in@Aftermethods to clean up the database after tests.
5.7.3. Client Tier Integration Tests
Client tier integration tests can be implemented using JMockit framework. It helps isolating the tests from the Middleware and creating the required infrastructure objects.
Client integration test class should be inherited from CubaClientTestCase. In the @Before method, you should call the inherited methods addEntityPackage(), setViewConfig() and then setupInfrastructure() to create Metadata and Configuration objects and deploy metadata for selected entities. Then, in the @Before method, you can extend the infrastructure with required mock objects using Expectations or NonStrictExpectations.
An example of an initialized @Before method from one of the platform tests:
@Before
public void setUp() throws Exception {
addEntityPackage("com.haulmont.cuba.security.entity");
addEntityPackage("com.haulmont.cuba.core.entity");
addEntityPackage("com.haulmont.cuba.gui.data.impl.testmodel1");
setViewConfig("/com/haulmont/cuba/gui/data/impl/testmodel1/test-views.xml");
setupInfrastructure();
metadataSession = metadata.getSession();
dataSupplier = new TestDataSupplier();
dataSupplier.commitCount = 0;
new NonStrictExpectations() {
@Mocked ClientConfig clientConfig;
@Mocked PersistenceHelper persistenceHelper;
{
configuration.getConfig(ClientConfig.class); result = clientConfig;
clientConfig.getCollectionDatasourceDbSortEnabled(); result = true;
persistenceManager.getMaxFetchUI(anyString); result = 10000;
PersistenceHelper.isNew(any); result = false;
}
};
}5.8. Development Recipes
This section provides solutions for certain practical tasks.
5.8.1. DataManager vs. EntityManager
Both DataManager and EntityManager can be used for operations on entities (CRUD). There are following distinction between these interfaces:
| DataManager | EntityManager |
|---|---|
DataManager is available on both middle and client tiers. |
EntityManager is available only on the middle tier. |
DataManager is a singleton bean. |
You should obtain a reference to EntityManager through the Persistence interface. |
DataManager defines a few high-level methods for working with detached entities: |
EntityManager mostly resembles the standard |
DataManager always starts new transactions internally. |
You have to open a transaction before working with EntityManager. |
DataManager loads partial entities according to views. |
EntityManager always loads all local attributes. If a view is used, it affects only reference attributes. |
DataManager queries can return entities only. Queries for single attributes or aggregates (SUM, COUNT) will fail. |
EntityManager can run any JPQL or native queries. |
DataManager applies all security restrictions when invoked on the client tier. |
EntityManager does not impose security restrictions. |
When you work with data on the client tier, you have only one option - DataManager. On the middleware, use EntityManager when you need to implement some atomic logic inside a transaction or run a query returning single attributes or aggregates. Otherwise, on the middleware you can use both.
If you need to overcome restrictions of DataManager when working on the client tier, create your own service and use EntityManager to work with data. In the service, you can check permissions using the Security interface and return data to the client in the form of persistent or non-persistent entities or arbitrary values.
5.8.2. Getting Localized Messages
This section covers ways of getting localized messages in different application components.
-
In screen XML-descriptors, component attributes for displaying static text (such as caption) can address localized messages using the rules of MessageTools.loadString() method. For example:
-
caption="msg://roleName"– gets a message defined by theroleNamekey in the message pack of the current screen. Screen message pack is defined by themessagesPackattribute of the rootwindowelement. -
caption="msg://com.company.sample.entity/Role.name"– gets a message defined by theRole.namekey in thecom.company.sample.entitymessage pack.
-
-
In screen controllers, localized strings can be retrieved in the following ways:
-
From the current screen message pack:
-
Using
getMessage()method inherited from the AbstractFrame base class. For example:String msg = getMessage("warningMessage"); -
Using
formatMessage()method inherited from theAbstractFramebase class. In this case, the extracted message is used to format submitted parameters according to the rules ofString.format()method. For example:messages.properties:
warningMessage = Invalid email address: '%s'Java controller:
String msg = formatMessage("warningMessage", email);
-
-
From an arbitrary messages pack via an injection of Messages infrastructure interface. For example:
@Inject private Messages messages; @Override public void init(Map<String, Object> params) { String msg = messages.getMessage(getClass(), "warningMessage"); ... }
-
-
For components managed by a Spring container (managed beans, services, JMX-beans, Spring MVC controllers of the portal module), localized messages can be retrieved with the help of the Messages infrastructure interface injection:
@Inject protected Messages messages; ... String msg = messages.getMessage(getClass(), "warningMessage"); -
In application code where injection is not possible, the
Messagesinterface can be obtained using the staticget()method of theAppBeansclass:protected Messages messages = AppBeans.get(Messages.class); ... String msg = messages.getMessage(getClass(), "warningMessage");
5.8.3. Assigning Initial Values
There are different ways to assign initial values to the attributes of new entity instances.
5.8.3.1. Entity Fields Initialization
Simple attributes (Boolean, Integer etc.) can be initialized in the declaration of the corresponding field of an entity class, for example:
public class User extends StandardEntity {
...
@Column(name = "ACTIVE")
protected Boolean active = true;
...
}Additionally, a specific initialization method with a @PostConstruct annotation can be created in the entity class. In this case, any global infrastructure interfaces and beans can be invoked during initialization, for example:
public class MyEntity extends StandardEntity {
...
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "USER_ID")
protected User creator;
...
@PostConstruct
protected void init() {
setCreator(AppBeans.get(UserSessionSource.class).getUserSession().getUser());
}
}5.8.3.2. Initialization Using CreateAction
If the initial value of an attribute depends on the data of the invoking screen, you can use setInitialValues() method of the CreateAction class.
Let us look at the example of two linked entities:
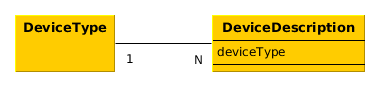
A fragment of a screen XML descriptor showing the lists of two entities simultaneously:
<dsContext>
<collectionDatasource id="typesDs"
class="com.haulmont.sample.entity.DeviceType"
view="_local">
<query>
select e from sample$DeviceType e
</query>
</collectionDatasource>
<collectionDatasource id="descriptionsDs"
class="com.haulmont.sample.entity.DeviceDescription"
view="_local">
<query>
select e from sample$DeviceDescription e where e.deviceType.id = :ds$typesDs
</query>
</collectionDatasource>
</dsContext>
<layout>
...
<table id="typeTable">
<actions>
<action id="create"/>
<action id="edit"/>
<action id="remove"/>
</actions>
<columns>
<column id="name"/>
</columns>
<rows datasource="typesDs"/>
</table>
...
<table id="descriptionTable">
<actions>
<action id="create"/>
<action id="edit"/>
<action id="remove"/>
</actions>
<columns>
<column id="description"/>
</columns>
<rows datasource="descriptionsDs"/>
</table>
</split>
</layout>The screen controller:
public class DeviceTypeBrowse extends AbstractLookup {
@Inject
private CollectionDatasource<DeviceType, UUID> typesDs;
@Named("descriptionTable.create")
private CreateAction descrCreateAction;
@Override
public void init(Map<String, Object> params) {
typesDs.addItemChangeListener(event -> {
descrCreateAction.setInitialValues(Collections.<String, Object>singletonMap("deviceType", event.getItem()));
});
}
}A listener is added in the controller for selected record change event in the typesDs datasource. When the selected record is changed, the system invokes the action’s setInitialValues() method and submits a map with one element whose key is the attribute name (deviceType) and value (the selected instance of DeviceType). Thus, during the execution of CreateAction, the deviceType attribute of the new DeviceDescription instance will contain the instance of the DeviceType that was selected in the table.
5.8.3.3. Using initNewItem Method
Initial values can also be defined in the initNewItem() method of the screen controller of the created entity.
Assume we have the following task: a project has an Employee entity that should be linked to a platform entity (User). When a new employee instance is being created, a new user instance should be created as well.

To achieve this, we declare the data source for the employee instance and the nested data source for the linked user in the employee edit screen XML descriptor:
<dsContext>
<datasource id="employeeDs"
class="com.haulmont.sample.entity.Employee"
view="employee-edit">
<datasource id="userDs"
property="user"/>
</datasource>
</dsContext>In the employee edit screen controller, we declare:
@Inject
private Metadata metadata;
private Group defaultGroup;
private Role defaultRole;
@Override
protected void initNewItem(Employee item) {
User user = metadata.create(User.class);
user.setGroup(defaultGroup);
final UserRole userRole = metadata.create(UserRole.class);
userRole.setUser(user);
userRole.setRole(defaultRole);
getDsContext().addBeforeCommitListener(context -> {
context.getCommitInstances().add(userRole);
});
item.setUser(user);
}Here, in the initNewItem() method, the new User instance is created and assigned the defaultGroup. Association with the defaultRole is set up using the new instance of UserRole entity. To save this relationship to the DB during screen commit the UserRole instance is added to the saved entities collection in the beforeCommit() method of DsContext.CommitListener.
The new instance of User is assigned to the corresponding attribute of the edited Employee entity and is thus included in the nested data source userDs. This gives us an opportunity to edit necessary user attributes in the employee screen and also leads to automatic saving of the user instance in the same transaction with the other entities when the screen is committed.
5.8.4. Editing Composite Entities
CUBA platform supports two types of relationship between entities: association and composition. They are called ASSOCIATION and COMPOSITION respectively in the CUBA Studio interface. Association is a relationship between the objects that can exist separately from each other. Composition, on the other hand, is used for "master-detail" relations, when the detail instances can exist only as part of the master. A case of an airport and its terminals may be considered an example of composition: a terminal that does not belong to any airport does not make sense.
Typically, the entities belonging to a composition are edited together since it is more convenient. For example, a user opens the airport editing screen and sees the list of terminals, so he can create and edit them, but all changes both for the airport and the terminals are saved to the database together in one transaction, and only after the user confirms saving of the master entity (the airport).
5.8.4.1. Implementing a Composition
Let us implement a composition using the Airport and the Terminal entities as an example:
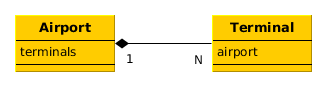
-
The
Terminalentity contains a mandatory link to theAirport:@Entity(name = "sample$Terminal") @Table(name = "SAMPLE_TERMINAL") public class Terminal extends StandardEntity { ... @ManyToOne(optional = false, fetch = FetchType.LAZY) @JoinColumn(name = "AIRPORT_ID") private Airport airport; public Airport getAirport() { return airport; } public void setAirport(Airport airport) { this.airport = airport; } } -
The
Airportentity contains one-to-many collection of terminals. The corresponding field is annotated with @Composition in order to implement composition, and @OnDelete for cascaded soft delete:@Entity(name = "sample$Airport") @Table(name = "SAMPLE_AIRPORT") public class Airport extends StandardEntity { ... @OneToMany(fetch = FetchType.LAZY, mappedBy = "airport") @OnDelete(DeletePolicy.CASCADE) @Composition protected List<Terminal> terminals; public List<Terminal> getTerminals() { return terminals; } public void setTerminals(List<Terminal> terminals) { this.terminals = terminals; } } -
The view of the airport editing screen should contain the
terminalsattributes collection:<view entity="sample$Airport" name="airport-edit" extends="_local"> <property name="terminals" view="_local"/> </view>For the
Terminalentity, we are using the_localview, although it contains theairportlink attribute (a link to an airport). Theairportattribute is set only at the creation of a newTerminalinstance and never changes after that, so we do not need to load it. -
Next, we define the datasources for the
Airportinstance and its terminals in the XML descriptor of the airport editor:<dsContext> <datasource id="airportDs" class="com.haulmont.sample.entity.Airport" view="airport-edit"> <collectionDatasource id="terminalsDs" property="terminals"/> </datasource> </dsContext> -
Define a table displaying terminals and standard actions for it in the XML descriptor of the airport editor:
<table id="terminalsTable"> <actions> <action id="create"/> <action id="edit"/> <action id="remove"/> </actions> <buttonsPanel> <button action="terminalsTable.create"/> <button action="terminalsTable.edit"/> <button action="terminalsTable.remove"/> </buttonsPanel> <columns> <column id="code"/> <column id="name"/> <column id="address"/> </columns> <rows datasource="terminalsDs"/> </table> -
It is sufficient to define the standard elements in the terminal editor:
datasourcefor theTerminalinstance and visual components related to thisdatasourcefor editing terminal attributes.
As a result, editing of an airport instance works as follows:
-
The airport edit screen shows a list of terminals.
-
A user can pick a terminal and open its editor. When OK is clicked in the terminal editor, the updated instance of the terminal is not saved to the database, but to the
terminalsDsdatasource of the airport editor. -
The user can create new terminals and delete existing ones. All changes will be saved to the
terminalsDsdatasource. -
When a user clicks OK in the airport edit screen, the updated
Airportinstance together with all the updatedTerminalinstances is submitted to the DataManager.commit() method on the Middleware and saved in the database within a single transaction.
5.8.4.2. Deep Composition
Composition can be deeper, with up to two nested levels. Let’s extend the example above by adding a MeetingPoint entity describing a meeting point at an airport terminal:
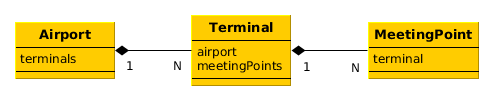
The Terminal entity contains the meetingPoints attribute – a collection of the MeetingPoint instances. In order for all three entities to become a single composition and be edited together, you should do the following in addition to the steps described above:
-
Mark the
meetingPointsattribute of theTerminalclass as@Compositionand@OnDeletesimilarly to theterminalsattribute of theAirportclass. -
Create a new view for the
Terminal:<view entity="sample$Terminal" name="terminal-edit" extends="_local"> <property name="meetingPoints" view="_local"/> </view>Use it in the
Airportview instead of_local:<view entity="sample$Airport" name="airport-edit" extends="_local"> <property name="terminals" view="terminal-edit"/> </view> -
Define datasources for an instance of the
Airportand nested entities for the entire composition depth in theAirportedit screen XML descriptor:<dsContext> <datasource id="airportDs" class="com.haulmont.sample.entity.Airport" view="airport-edit"> <collectionDatasource id="terminalsDs" property="terminals"> <collectionDatasource id="meetingPointsDs" property="meetingPoints"/> </collectionDatasource> </datasource> </dsContext>Here, the
meetingPointsDsdatasource is not associated with any visual components, however it is needed for correct operation of joint editing of the composition. -
Define the nested data source and a corresponding table for the
meetingPointscollection in the terminal edit screen XML descriptor.
As a result, the updated instances of the MeetingPoint, as well as the Terminal instances, will be saved to the database only with the Airport instance in the same transaction.
5.8.5. Running Code at Application Start
Sometimes you may need to run certain code immediately after the application start at the moment when all application functionality is already initialized and ready to work. For this, you can use the AppContext.Listener.
Assume we have the following task: a project has an Employee entity that should be linked one-to-one to a platform entity (User).
If the name attribute of the User entity is changed, for example, through a standard user management screen, the name attribute of the related Employee should change as well. This is a common task for "denormalized" data, which is typically solved using entity listeners. Our case is more complex, since we need to track changes of the platform’s User entity, and thus we cannot add an entity listener using @Listeners annotation. However, we can add a listener dynamically using the EntityListenerManager bean, and it is better to do this on application start.
Let us create the AppLifecycle bean implementing the AppContext.Listener interface in the application core module and register it by invoking AppContext.addListener() method in the object constructor:
@Component("sample_AppLifecycle")
public class AppLifecycle implements AppContext.Listener {
@Inject
private EntityListenerManager entityListenerManager;
public AppLifecycle() {
AppContext.addListener(this);
}
@Override
public void applicationStarted() {
entityListenerManager.addListener(User.class, "sample_UserEntityListener");
}
@Override
public void applicationStopped() {
}
}@Component("sample_UserEntityListener")
public class UserEntityListener implements BeforeUpdateEntityListener<User> {
@Inject
private Persistence persistence;
@Override
public void onBeforeUpdate(User user, EntityManager entityManager) {
if (persistence.getTools().getDirtyFields(user).contains("name")) {
TypedQuery<Employee> query = entityManager.createQuery(
"select e from sample$Employee e where e.user.id = ?1", Employee.class);
query.setParameter(1, user.getId());
Employee employee = query.getFirstResult();
if (employee != null) {
employee.setName(user.getName());
}
}
}
}As a result, the applicationStarted() method of this bean will be invoked immediately after the start of the Middleware block. In this method, the sample_UserEntityListener bean is registered as an entity listener for the User entity.
The onBeforeUpdate() method of the UserEntityListener class will be invoked every time before the changes in the User instances are saved to the database. The method checks if the name attribute exists among the updated attributes. If yes, a related Employee instance is loaded and its name is updated with the new value.
5.8.6. Loading and Displaying Images
Let’s consider a task of loading, storing and displaying employee photos:
-
An employee is represented by
Employeeentity. -
Image files are stored in the FileStorage. The
Employeeentity contains a link to the correspondingFileDescriptor. -
The
Employeeedit screen shows the picture and also supports uploading, downloading and clearing the picture.
Entity class with a link to the image file:
@Table(name = "SAMPLE_EMPLOYEE")
@Entity(name = "sample$Employee")
public class Employee extends StandardEntity {
...
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "IMAGE_FILE_ID")
protected FileDescriptor imageFile;
public void setImageFile(FileDescriptor imageFile) {
this.imageFile = imageFile;
}
public FileDescriptor getImageFile() {
return imageFile;
}
}A view for loading an Employee together with FileDescriptor should include all local attributes of FileDescriptor:
<view class="com.company.sample.entity.Employee"
name="employee-edit">
<property name="name"/>
...
<property name="imageFile"
view="_local">
</property>
</view>A fragment of the Employee edit screen XML descriptor:
<groupBox caption="Photo" spacing="true"
height="250px" width="250px" expand="embeddedImage">
<embedded id="embeddedImage" width="100%"
align="MIDDLE_CENTER"/>
<hbox align="BOTTOM_LEFT"
spacing="true">
<upload id="uploadField"/>
<button id="downloadImageBtn"
caption="Download"
invoke="onDownloadImageBtnClick"/>
<button id="clearImageBtn"
caption="Clear"
invoke="onClearImageBtnClick"/>
</hbox>
</groupBox>Components used to display, upload and download images are contained within the groupBox container. Its top part shows a picture using the embedded component, while its bottom part from left to right contains the upload component and buttons to download and clear the image. As a result, this part of the screen should look like this:
Now, let us have a look at the edit screen controller.
public class EmployeeEdit extends AbstractEditor<Employee> {
private Logger log = LoggerFactory.getLogger(EmployeeEdit.class);
@Inject
private DataSupplier dataSupplier;
@Inject
private FileStorageService fileStorageService;
@Inject
private FileUploadingAPI fileUploadingAPI;
@Inject
private ExportDisplay exportDisplay;
@Inject
private Embedded embeddedImage;
@Inject
private FileUploadField uploadField;
@Inject
private Button downloadImageBtn;
@Inject
private Button clearImageBtn;
@Inject
private Datasource<Employee> employeeDs;
private static final int IMG_HEIGHT = 190;
private static final int IMG_WIDTH = 220;
@Override
public void init(Map<String, Object> params) {
uploadField.addFileUploadSucceedListener(event -> {
FileDescriptor fd = uploadField.getFileDescriptor();
try {
fileUploadingAPI.putFileIntoStorage(uploadField.getFileId(), fd);
} catch (FileStorageException e) {
throw new RuntimeException("Error saving file to FileStorage", e);
}
getItem().setImageFile(dataSupplier.commit(fd));
displayImage();
});
uploadField.addFileUploadErrorListener(event ->
showNotification("File upload error", NotificationType.HUMANIZED));
employeeDs.addItemPropertyChangeListener(event -> {
if ("imageFile".equals(event.getProperty()))
updateImageButtons(event.getValue() != null);
});
}
@Override
protected void postInit() {
displayImage();
updateImageButtons(getItem().getImageFile() != null);
}
public void onDownloadImageBtnClick() {
if (getItem().getImageFile() != null)
exportDisplay.show(getItem().getImageFile(), ExportFormat.OCTET_STREAM);
}
public void onClearImageBtnClick() {
getItem().setImageFile(null);
displayImage();
}
private void updateImageButtons(boolean enable) {
downloadImageBtn.setEnabled(enable);
clearImageBtn.setEnabled(enable);
}
private void displayImage() {
byte[] bytes = null;
if (getItem().getImageFile() != null) {
try {
bytes = fileStorageService.loadFile(getItem().getImageFile());
} catch (FileStorageException e) {
log.error("Unable to load image file", e);
showNotification("Unable to load image file", NotificationType.HUMANIZED);
}
}
if (bytes != null) {
embeddedImage.setSource(getItem().getImageFile().getName(), new ByteArrayInputStream(bytes));
embeddedImage.setType(Embedded.Type.IMAGE);
BufferedImage image;
try {
image = ImageIO.read(new ByteArrayInputStream(bytes));
int width = image.getWidth();
int height = image.getHeight();
if (((double) height / (double) width) > ((double) IMG_HEIGHT / (double) IMG_WIDTH)) {
embeddedImage.setHeight(String.valueOf(IMG_HEIGHT));
embeddedImage.setWidth(String.valueOf(width * IMG_HEIGHT / height));
} else {
embeddedImage.setWidth(String.valueOf(IMG_WIDTH));
embeddedImage.setHeight(String.valueOf(height * IMG_WIDTH / width));
}
} catch (IOException e) {
log.error("Unable to resize image", e);
}
// refresh image
embeddedImage.setVisible(false);
embeddedImage.setVisible(true);
} else {
embeddedImage.setVisible(false);
}
}
}-
The
init()method first initializes theuploadFieldcomponent that is used for uploading new images. In the case of a successful upload, a newFileDescriptorinstance is retrieved from the component and the corresponding files are sent from the temporary client storage toFileStorageby invokingFileUploadingAPI.putFileIntoStorage(). After that, theFileDescriptoris saved to the database by invoking DataSupplier.commit(), and the saved instance is assigned to theimageFileattribute of the editedEmployeeentity. Then, the controller’sdisplayImage()method is invoked to display the uploaded image.After that, a listener is added in the
init()method to the datasource containing anEmployeeinstance. The listener enables or disables download and clear buttons, depending on the fact whether the file has been loaded or not. -
postInit()method performs file display and refreshes the button states, depending on the existence of a loaded file. -
onDownloadImageBtnClick()is invoked when thedownloadImageBtnbutton is clicked; it downloads the file using the ExportDisplay interface. -
onClearImageBtnClick()is invoked when theclearImageBtnis clicked; it clears theimageFileattribute of theEmployeeentity. The file is not deleted from storage. -
displayImage()loads the file from storage into a byte array, sets the content of theembeddedImagecomponent and recalculates its size to preserve image height to width ratio.It should be noted that loading files into byte arrays is acceptable for small files only. If the file size is not predictable, you should only download it using ExportDisplay, which sends the file through input and output streams and never keeps the entire file in memory.
5.8.6.1. Displaying Images in a Table Column
To amplify the previous task, let’s add pictures to the table as employees' icons on the Employee browse screen.
The pictures can be displayed in a separate column or inside any existing column. In both cases the Table.ColumnGenerator interface is used.
Below is a fragment of the Employee browse screen XML descriptor:
<groupTable id="employeesTable"
width="100%"
height="100%">
<actions>
<action id="create"/>
<action id="edit"/>
<action id="remove"/>
</actions>
<columns>
<column id="name"/>
</columns>
<rows datasource="employeesDs"/>
<rowsCount/>
<buttonsPanel id="buttonsPanel"
alwaysVisible="true">
<button id="createBtn"
action="employeesTable.create"/>
<button id="editBtn"
action="employeesTable.edit"/>
<button id="removeBtn"
action="employeesTable.remove"/>
</buttonsPanel>
</groupTable>To display pictures inline with an employee’s name in the name column, let’s change the standard representation of data in this column. We will use the HBoxLayout container and place the Embedded component into it:
import com.haulmont.cuba.core.entity.FileDescriptor;
import com.haulmont.cuba.gui.components.*;
import com.company.employeeimages.entity.Employee;
import com.haulmont.cuba.gui.export.FileDataProvider;
import com.haulmont.cuba.gui.xml.layout.ComponentsFactory;
import javax.inject.Inject;
import java.util.Map;
public class EmployeeBrowse extends AbstractLookup {
@Inject
private ComponentsFactory componentsFactory;
@Inject
private GroupTable<Employee> employeesTable;
@Override
public void init(Map<String, Object> params) {
employeesTable.addGeneratedColumn("name", entity -> {
Embedded embedded = componentsFactory.createComponent(Embedded.class);
embedded.setType(Embedded.Type.IMAGE);
embedded.setWidth("40px");
embedded.setHeight("40px");
FileDescriptor userImageFile = entity.getImageFile();
FileDataProvider dataProvider = new FileDataProvider(userImageFile);
embedded.setSource(userImageFile.getId() + "." + userImageFile.getExtension(), dataProvider);
Label userLogin = componentsFactory.createComponent(Label.class);
userLogin.setValue(entity.getName());
userLogin.setAlignment(Alignment.MIDDLE_LEFT);
HBoxLayout hBox = componentsFactory.createComponent(HBoxLayout.class);
hBox.setSpacing(true);
hBox.add(embedded);
hBox.add(userLogin);
return hBox;
});
}
}-
The
init()method invokes theaddGeneratedColumn()method that takes two parameters: an identifier of the column and an implementation of theTable.ColumnGeneratorinterface. The latter is used to define the custom representation of data in thenamecolumn. -
Inside this method we create an
Embeddedcomponent using theComponentsFactoryinterface. We set the type of the component (IMAGE) and its size parameters. -
Then we get the
FileDescriptorinstance with the picture stored in the File Storage. The link to this picture is stored in theimageFileattribute of theEmployeeentity. Data provider forFileDescriptoris used to set the source for theEmbeddedcomponent. -
We will display the
nameattribute in theLabelcomponent alongside the embedded picture. -
We will wrap both
EmbeddedandLabelcomponents into theHBoxLayoutcontainer, and make theaddGeneratedColumn()method return this container as the new table cell layout.
You can also use a more declarative approach with the generator XML attribute.
5.8.7. Sending Emails
This section contains a practical guide to sending emails using the CUBA email sending mechanism.
Let us consider the following task:
-
There are the
NewsItementity and theNewsItemEditscreen. -
The
NewsItementity contains the following attributes:date,caption,content. -
We want to send emails to some addresses every time a new instance of
NewsItemis created through theNewsItemEditscreen. An email should containNewsItem.captionas a subject and the message body should be created from a template includingNewsItem.content.
-
Add the following code to
NewsItemEdit.java:public class NewsItemEdit extends AbstractEditor<NewsItem> { // Indicates that a new item was created in this editor private boolean justCreated; @Inject protected EmailService emailService; // This method is invoked when a new item is initialized @Override protected void initNewItem(NewsItem item) { justCreated = true; } // This method is invoked after the screen commit @Override protected boolean postCommit(boolean committed, boolean close) { if (committed && justCreated) { // If a new entity was saved to the database, ask a user about sending an email showOptionDialog( "Email", "Send the news item by email?", MessageType.CONFIRMATION, new Action[] { new DialogAction(DialogAction.Type.YES) { @Override public void actionPerform(Component component) { sendByEmail(); } }, new DialogAction(DialogAction.Type.NO) } ); } return super.postCommit(committed, close); } // Queues an email for sending asynchronously private void sendByEmail() { NewsItem newsItem = getItem(); EmailInfo emailInfo = new EmailInfo( "john.doe@company.com,jane.roe@company.com", // recipients newsItem.getCaption(), // subject null, // the "from" address will be taken from the "cuba.email.fromAddress" app property "com/company/demo/templates/news_item.txt", // body template Collections.singletonMap("newsItem", newsItem) // template parameters ); emailService.sendEmailAsync(emailInfo); } }As you can see, the
sendByEmail()method invokes theEmailServiceand passes theEmailInfoinstance describing the the messages. The body of the messages will be created on the basis of thenews_item.txttemplate. -
Create the body template file
news_item.txtin thecom.company.demo.templatespackage of the core module:The company news: ${newsItem.content}This is a Freemarker template which will use parameters passed in the
EmailInfoinstance (newsItemin this case). -
Launch the application, open the
NewsItementity browser and click Create. The editor screen will be opened. Fill in the fields and press OK. The confirmation dialog with the question about sending emails will be shown. Click Yes. -
Go to the Administration > Email History screen of your application. You will see two records (by the number of recipients) with the
Queuestatus. It means that the emails are in the queue and not yet sent. -
To process the queue, set up a scheduled task. Go to the Administration > Scheduled Tasks screen of your application. Create a new task and set the following parameters:
-
Bean Name -
cuba_Emailer -
Method Name -
processQueuedEmails() -
Singleton - yes (this is important only for a cluster of middleware servers)
-
Period, sec - 10
Save the task and click Activate on it.
If you did not set up the scheduled tasks execution for this project before, nothing will happen on this stage - the task will not be executed until you start the whole scheduling mechanism.
-
-
Open the
modules/core/src/app.propertiesfile and add the following property:cuba.schedulingActive = trueRestart the application server. The scheduling mechanism is now active and invokes the email queue processing.
-
Go to the Administration > Email History screen. The status of the emails will be
Sentif they were successfully sent, or, most probably,SendingorQueueotherwise. In the latter case, you can open the application log inbuild/tomcat/logs/app.logand find out the reason. The email sending mechanism will take several (10 by default) attempts to send the messages and if they fail, set the status toNot sent. -
The most obvious reason that emails cannot be sent is that you have not set up the SMTP server parameters. You can set the parameters in the database through the
app-core.cuba:type=EmailerJMX bean or in the application properties file of your middleware. Let us consider the latter. Open themodules/core/src/app.propertiesfile and add the required parameters:cuba.email.fromAddress = do-not-reply@company.com cuba.email.smtpHost = mail.company.comRestart the application server. Go to Administration > JMX Console, find the
EmailerJMX bean and try to send a test email to yourself using thesendTestEmail()operation. -
Now your sending mechanism is set up correctly, but it will not send the messages in the
Not sentstate. So you have to create anotherNewsItemin the editor screen. Do it and then watch how the status of new messages in the Email History screen will change toSent.
5.8.8. Creating Custom Visual Components
As explained in the Custom Visual Components section, the standard set of visual components can be extended in your project. You have the following options:
-
Integrate a Vaadin add-on. Many third-party Vaadin components are distributed as add-ons and available at https://vaadin.com/directory.
-
Integrate a JavaScript component. You can create a Vaadin component using a JavaScript library.
-
Create a new Vaadin component with the client part written on GWT.
Futher on, you can integrate the resulting Vaadin component into CUBA Generic UI to be able to use it declaratively in screen XML descriptors and bind to datasources.
And the final step of integration is the support of the new component in the Studio WYSIWYG layout editor.
This section gives you examples of creating new visual components with all the methods described above. Integration to the Generic UI and support in Studio are the same for all methods, so these topics are described only for a new component created on the basis of a Vaadin add-on.
5.8.8.1. Using a Third-party Vaadin Component
This is an example of using the Stepper component available at http://vaadin.com/addon/stepper, in an application project. The component enables changing text field value in steps using the keyboard, mouse scroll or built-in up/down buttons.
Create a new project in CUBA Studio and name it addon-demo.
A Vaadin add-on may be integrated if the application project has a web-toolkit module. Create the module by clicking the Create web toolkit module link of the Project properties navigator section.
Then click the New UI component link. The UI component generation page will open. Select the Vaadin add-on value in the Component type section.
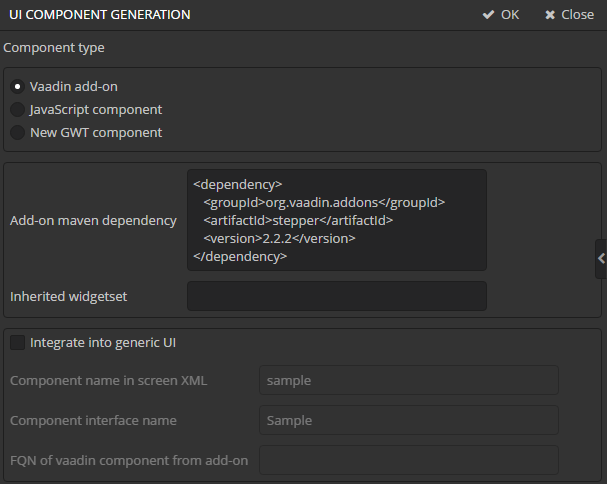
Fill in the following fields:
-
The Add-on Maven dependency field contains Maven coordinates of the Vaadin add-on. The add-on will be included as a dependency to the project. You can define coordinates in two formats:
-
As an XML copied from the add-on web site (http://vaadin.com/addon/stepper):
<dependency> <groupId>org.vaadin.addons</groupId> <artifactId>stepper</artifactId> <version>2.2.2</version> </dependency> -
In one line as you add dependencies in build.gradle:
org.vaadin.addons:stepper:2.2.2
-
-
The Inherited widgetset field contains a widgetset name of the add-on:
org.vaadin.risto.stepper.widgetset.StepperWidgetset -
Integrate into generic UI - deselect this checkbox as we do not integrate the component into the Generic UI in this example.
Press the OK button.
If you open the project in the IDE, you can see that Studio has changed two files:
-
In
build.gradle, the web module now contains a dependency on the add-on that contains the component.configure(webModule) { ... dependencies { ... compile("org.vaadin.addons:stepper:2.2.2") } -
The
AppWidgetSet.gwt.xmlfile of the web-toolkit module now inherits the add-on widgetset:<module> <inherits name="com.haulmont.cuba.web.toolkit.ui.WidgetSet" /> <inherits name="org.vaadin.risto.stepper.widgetset.StepperWidgetset" /> <set-property name="user.agent" value="safari" />TipYou can speed up the widgetset compilation by defining the
user.agentproperty. In this example, widgetset will be compiled only for browsers based on WebKit: Chrome, Safari, etc.
Now the component from the Vaadin add-on is included to the project. Let’s see how to use it in the project screens.
-
Create a new entity
Customerwith two fields:-
nameof type String -
scoreof type Integer
-
-
Generate standard screens for the new entity. Ensure that the In module field is set to
Web Module. Screens that use Vaadin components directly must be placed in the web module.TipActually, screens can be placed in the gui module as well, but then the code that uses the Vaadin component should be moved to a separate companion.
-
Next, we will add the
steppercomponent to the screen. You can place it in a FieldGroup or in a separate container. Let’s examine both methods.-
Add the
custom = "true"attribute to thescorefield of thefieldGroupcomponent of thecustomer-edit.xmlscreen.<?xml version="1.0" encoding="UTF-8" standalone="no"?> <window xmlns="http://schemas.haulmont.com/cuba/window.xsd" caption="msg://editCaption" class="com.company.addondemo.web.customer.CustomerEdit" datasource="customerDs" focusComponent="fieldGroup" messagesPack="com.company.addondemo.web.customer"> <dsContext> <datasource id="customerDs" class="com.company.addondemo.entity.Customer" view="_local"/> </dsContext> <layout expand="windowActions" spacing="true"> <fieldGroup id="fieldGroup" datasource="customerDs"> <column width="250px"> <field property="name"/> <field property="score" custom="true"/> </column> </fieldGroup> <frame id="windowActions" screen="editWindowActions"/> </layout> </window>Add the following code to the
CustomerEdit.javacontroller:package com.company.addondemo.web.customer; import com.haulmont.cuba.gui.components.AbstractEditor; import com.company.addondemo.entity.Customer; import com.haulmont.cuba.gui.components.Component; import com.haulmont.cuba.gui.components.FieldGroup; import com.haulmont.cuba.gui.components.VBoxLayout; import com.haulmont.cuba.gui.data.Datasource; import com.haulmont.cuba.gui.xml.layout.ComponentsFactory; import com.haulmont.cuba.web.gui.components.WebComponentsHelper; import com.vaadin.ui.Layout; import org.vaadin.risto.stepper.IntStepper; import javax.inject.Inject; import java.util.Map; public class CustomerEdit extends AbstractEditor<Customer> { @Inject private ComponentsFactory componentsFactory; @Inject private FieldGroup fieldGroup; @Inject private Datasource<Customer> customerDs; private IntStepper stepper = new IntStepper(); @Override public void init(Map<String, Object> params) { fieldGroup.createField("score"); Component box = componentsFactory.createComponent(VBoxLayout.class); fieldGroup.getFieldNN("score").setComponent(box); Layout layout = (Layout) WebComponentsHelper.unwrap(box); layout.addComponent(stepper); stepper.setSizeFull(); stepper.addValueChangeListener(event -> customerDs.getItem().setValue("score", event.getProperty().getValue()) ); } @Override protected void initNewItem(Customer item) { item.setScore(0); } @Override protected void postInit() { stepper.setValue(getItem().getScore()); } }The
init()method initializes the customscorefield. TheComponentsFactorycreates an instance of BoxLayout, retrieves a link to the Vaadin container via WebComponentsHelper, and adds the new component to it. TheBoxLayoutis then returned to be used in the custom field.Data binding is implemented programmatically by setting a current value to the
steppercomponent from the editedCustomerinstance in thepostInit()method. Additionally, the corresponding entity attribute is updated through the value change listener, when the user changes the value. -
The new component can be used in any part of the screen outside of the
FieldGroup. In order to do this, declare thescoreBoxcontainer in the XML-descriptor:<?xml version="1.0" encoding="UTF-8" standalone="no"?> <window xmlns="http://schemas.haulmont.com/cuba/window.xsd" caption="msg://editCaption" class="com.company.addondemo.web.customer.CustomerEdit" datasource="customerDs" focusComponent="fieldGroup" messagesPack="com.company.addondemo.web.customer"> <dsContext> <datasource id="customerDs" class="com.company.addondemo.entity.Customer" view="_local"/> </dsContext> <layout expand="windowActions" spacing="true"> <fieldGroup id="fieldGroup" datasource="customerDs"> <column width="250px"> <field property="name"/> </column> </fieldGroup> <hbox id="scoreBox" spacing="true"> <label value="Score" align="MIDDLE_LEFT"/> </hbox> <frame id="windowActions" screen="editWindowActions"/> </layout> </window>Inject the container to the screen controller, retrieve a link to the underlying Vaadin container and add the component to it:
package com.company.addondemo.web.customer; import com.haulmont.cuba.gui.components.*; import com.company.addondemo.entity.Customer; import com.haulmont.cuba.gui.data.Datasource; import com.haulmont.cuba.web.gui.components.WebComponentsHelper; import com.vaadin.ui.Layout; import org.vaadin.risto.stepper.IntStepper; import javax.inject.Inject; import java.util.Map; public class CustomerEdit extends AbstractEditor<Customer> { @Inject private FieldGroup fieldGroup; @Inject private Datasource<Customer> customerDs; @Inject private BoxLayout scoreBox; private IntStepper stepper = new IntStepper(); @Override public void init(Map<String, Object> params) { Layout box = (Layout) WebComponentsHelper.unwrap(scoreBox); box.addComponent(stepper); fieldGroup.addField(fieldGroup.createField("score")); stepper.setSizeFull(); stepper.addValueChangeListener(event -> customerDs.getItem().setValue("score", event.getProperty().getValue()) ); } @Override protected void initNewItem(Customer item) { item.setScore(0); } @Override protected void postInit() { stepper.setValue(getItem().getScore()); } }Data binding is implemented in the same way as described above.
-
-
To adapt the component style, create a theme extension in the project. Click the Create theme extension link in the Project properties navigator section. Select the
halotheme. After that, open thethemes/halo/halo-ext.scssfile located in the web module and add the following code:@import "../halo/halo"; /* Define your theme modifications inside next mixin */ @mixin halo-ext { @include halo; /* Basic styles for stepper inner text box */ .stepper input[type="text"] { @include box-defaults; @include valo-textfield-style; &:focus { @include valo-textfield-focus-style; } } } -
Start the application server. The resulting editor screen will look as follows:
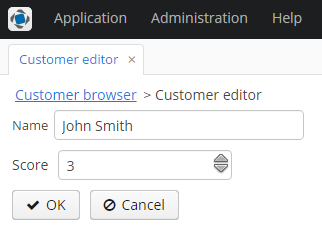
5.8.8.2. Integrating a Vaadin Component into the Generic UI
In the previous section, we have included the third-party Stepper component in the project. In this section, we will integrate it into CUBA Generic UI. This will allow developers to use the component declaratively in the screen XML and bind it to the data model entities through datasources.
Create a new project in CUBA Studio and name it addon-gui-demo. Type agd in the Project namespace field.
Create the web-toolkit module by clicking the Create web toolkit module link of the Project properties navigator section.
Then click the New UI component link. The UI component generation page will open. Select the Vaadin add-on value in the Component type section.
Fill in the Add-on Maven dependency and Inherited widgetset as described in the previous section.
Then fill in the fields of the bottom section:
-
Integrate into Generic UI - defines that a component should be integrated into the Generic UI.
-
Component XML element - an element to be used in screen XML descriptors. Enter
stepper. -
Component interface name - a name of the component Generic UI interface. Enter
Stepper. -
FQN of the Vaadin component from add-on - fully qualified class name of the Vaadin component from the add-on. In our case it is
org.vaadin.risto.stepper.IntStepper.
When you click OK, Studio will do the following:
-
Add the Vaadin add-on as a web module dependency in
build.gradle. -
Include add-on widgetset in
AppWidgetSet.gwt.xmlof web-toolkit module. -
Generate stubs for the following files:
-
Stepper- an interface of the component in the gui module. -
WebStepper- a component implementation in the web module. -
StepperLoader- a component XML-loader in the gui module. -
ui-component.xsd- a new component XML schema definition. If the file already exists, the information about the new component will be added to the existing file. -
cuba-ui-component.xml- the file that registers a new component loader in web module. If the file already exists, the information about the new component will be added to the existing file.
-
Open the project in the IDE.
Let’s walk through generated files add make necessary changes.
-
Open the
Stepperinterface in the gui module. Replace its content with the following code:package com.company.addonguidemo.gui.components; import com.haulmont.cuba.gui.components.Field; public interface Stepper extends Field { String NAME = "stepper"; boolean isManualInputAllowed(); void setManualInputAllowed(boolean value); boolean isMouseWheelEnabled(); void setMouseWheelEnabled(boolean value); int getStepAmount(); void setStepAmount(int amount); int getMaxValue(); void setMaxValue(int maxValue); int getMinValue(); void setMinValue(int minValue); }The base interface for the component is
Field, which is designed to display and edit an entity attribute. -
Open the
WebStepperclass - a component implementation in the web module. Replace its content with the following code:package com.company.addonguidemo.web.gui.components; import com.company.addonguidemo.gui.components.Stepper; import com.haulmont.cuba.web.gui.components.WebAbstractField; import org.vaadin.risto.stepper.IntStepper; public class WebStepper extends WebAbstractField<IntStepper> implements Stepper { public WebStepper() { this.component = new org.vaadin.risto.stepper.IntStepper(); } @Override public boolean isManualInputAllowed() { return component.isManualInputAllowed(); } @Override public void setManualInputAllowed(boolean value) { component.setManualInputAllowed(value); } @Override public boolean isMouseWheelEnabled() { return component.isMouseWheelEnabled(); } @Override public void setMouseWheelEnabled(boolean value) { component.setMouseWheelEnabled(value); } @Override public int getStepAmount() { return component.getStepAmount(); } @Override public void setStepAmount(int amount) { component.setStepAmount(amount); } @Override public int getMaxValue() { return component.getMaxValue(); } @Override public void setMaxValue(int maxValue) { component.setMaxValue(maxValue); } @Override public int getMinValue() { return component.getMinValue(); } @Override public void setMinValue(int minValue) { component.setMinValue(minValue); } }The chosen base class is
WebAbstractField, which implements the methods of theFieldinterface. -
The
StepperLoaderclass in gui module loads the component from its representation in XML.package com.company.addonguidemo.gui.xml.layout.loaders; import com.company.addonguidemo.gui.components.Stepper; import com.haulmont.cuba.gui.xml.layout.loaders.AbstractFieldLoader; public class StepperLoader extends AbstractFieldLoader<Stepper> { @Override public void createComponent() { resultComponent = factory.createComponent(Stepper.class); loadId(resultComponent, element); } @Override public void loadComponent() { String manualInput = element.attributeValue("manualInput"); if (manualInput != null) { resultComponent.setManualInputAllowed(Boolean.parseBoolean(manualInput)); } String mouseWheel = element.attributeValue("mouseWheel"); if (mouseWheel != null) { resultComponent.setMouseWheelEnabled(Boolean.parseBoolean(mouseWheel)); } String stepAmount = element.attributeValue("stepAmount"); if (stepAmount != null) { resultComponent.setStepAmount(Integer.parseInt(stepAmount)); } String maxValue = element.attributeValue("maxValue"); if (maxValue != null) { resultComponent.setMaxValue(Integer.parseInt(maxValue)); } String minValue = element.attributeValue("minValue"); if (minValue != null) { resultComponent.setMinValue(Integer.parseInt(minValue)); } } }The
AbstractFieldLoaderclass contains code for loading basic properties of theFieldcomponent. SoStepperLoaderloads only the specific properties of theSteppercomponent. -
The
cuba-ui-component.xmlfile in the web module registers the new component and its loader. Leave the file unchanged.<?xml version="1.0" encoding="UTF-8" standalone="no"?> <components> <component xmlns="http://schemas.haulmont.com/cuba/components.xsd"> <name>stepper</name> <componentLoader>com.company.addonguidemo.gui.xml.layout.loaders.StepperLoader</componentLoader> <class>com.company.addonguidemo.web.gui.components.WebStepper</class> </component> </components> -
The
ui-component.xsdfile in gui module contains XML schema definitions of custom visual components. Add thestepperattributes definition.<?xml version="1.0" encoding="UTF-8" standalone="no"?> <xs:schema xmlns="http://schemas.company.com/agd/0.1/ui-component.xsd" attributeFormDefault="unqualified" elementFormDefault="qualified" targetNamespace="http://schemas.company.com/agd/0.1/ui-component.xsd" xmlns:xs="http://www.w3.org/2001/XMLSchema"> <xs:element name="stepper"> <xs:complexType> <xs:attribute name="id" type="xs:string"/> <xs:attribute name="caption" type="xs:string"/> <xs:attribute name="width" type="xs:string"/> <xs:attribute name="height" type="xs:string"/> <xs:attribute name="datasource" type="xs:string"/> <xs:attribute name="property" type="xs:string"/> <xs:attribute name="manualInput" type="xs:boolean"/> <xs:attribute name="mouseWheel" type="xs:boolean"/> <xs:attribute name="stepAmount" type="xs:int"/> <xs:attribute name="maxValue" type="xs:int"/> <xs:attribute name="minValue" type="xs:int"/> </xs:complexType> </xs:element> </xs:schema>
Let’s see how to add the new component to a screen.
-
Create a new entity
Customer. The entity have two fields:-
nameof type String -
scoreof type Integer
-
-
Generate standard screens for the new entity.
-
Add the
steppercomponent to the editor screen. You can place it in a FieldGroup or in a separate container. We’ll examine both methods.-
Using the component inside a container.
-
Open the
customer-edit.xmlfile. -
Define the new namespace
xmlns:app="http://schemas.company.com/agd/0.1/ui-component.xsd". -
Remove the
scorefield fromfieldGroup. -
Add
steppercomponent to the screen.
As a result, the XML descriptor should look like this:
<?xml version="1.0" encoding="UTF-8" standalone="no"?> <window xmlns="http://schemas.haulmont.com/cuba/window.xsd" xmlns:app="http://schemas.company.com/agd/0.1/ui-component.xsd" caption="msg://editCaption" class="com.company.addonguidemo.gui.customer.CustomerEdit" datasource="customerDs" focusComponent="fieldGroup" messagesPack="com.company.addonguidemo.gui.customer"> <dsContext> <datasource id="customerDs" class="com.company.addonguidemo.entity.Customer" view="_local"/> </dsContext> <layout expand="windowActions" spacing="true"> <fieldGroup id="fieldGroup" datasource="customerDs"> <column width="250px"> <field property="name"/> </column> </fieldGroup> <app:stepper id="stepper" datasource="customerDs" property="score" caption="Score" minValue="1" maxValue="20"/> <frame id="windowActions" screen="editWindowActions"/> </layout> </window>In the example above, the
steppercomponent is associated with thescoreattribute of theCustomerentity. An instance of this entity is managed by thecustomerDsdatasource. -
-
Using the new component inside a FieldGroup:
<?xml version="1.0" encoding="UTF-8" standalone="no"?> <window xmlns="http://schemas.haulmont.com/cuba/window.xsd" caption="msg://editCaption" class="com.company.addonguidemo.gui.customer.CustomerEdit" datasource="customerDs" focusComponent="fieldGroup" messagesPack="com.company.addonguidemo.gui.customer"> <dsContext> <datasource id="customerDs" class="com.company.addonguidemo.entity.Customer" view="_local"/> </dsContext> <layout expand="windowActions" spacing="true"> <fieldGroup id="fieldGroup" datasource="customerDs"> <column width="250px"> <field property="name"/> <field property="score" custom="true"/> </column> </fieldGroup> <frame id="windowActions" screen="editWindowActions"/> </layout> </window>package com.company.addonguidemo.web.customer; import com.company.addonguidemo.gui.components.Stepper; import com.haulmont.cuba.gui.components.AbstractEditor; import com.company.addonguidemo.entity.Customer; import com.haulmont.cuba.gui.components.FieldGroup; import com.haulmont.cuba.gui.data.Datasource; import com.haulmont.cuba.gui.xml.layout.ComponentsFactory; import javax.inject.Inject; import java.util.Map; public class CustomerEdit extends AbstractEditor<Customer> { @Inject private ComponentsFactory componentsFactory; @Inject private FieldGroup fieldGroup; @Inject private Datasource<Customer> customerDs; @Override public void init(Map<String, Object> params) { Stepper stepper = componentsFactory.createComponent(Stepper.class); stepper.setDatasource(customerDs, "score"); stepper.setWidth("100%"); fieldGroup.getFieldNN("score").setComponent(stepper); } }
-
-
To adapt the component style, create a theme extension in the project. Click the Create theme extension link in the Project properties navigator section. Select the
halotheme. After that, open thethemes/halo/halo-ext.scssfile located in the web module and add the following code:@import "../halo/halo"; /* Define your theme modifications inside next mixin */ @mixin halo-ext { @include halo; /* Basic styles for stepper inner text box */ .stepper input[type="text"] { @include box-defaults; @include valo-textfield-style; &:focus { @include valo-textfield-focus-style; } } } -
Start the application server. The resulting editor screen will look as follows:
5.8.8.3. Using a JavaScript library
In this example, we will use the Slider component from the jQuery UI library. The slider will have two drag handlers that define a values range.
Create a new project in CUBA Studio and name it jscomponent.
Click the New UI component button on the Project properties navigator section. The UI component generation will open. Select the JavaScript component value in the Component type section.
Enter SliderServerComponent in the Vaadin component class name field.
Deselect the Integrate into Generic UI flag. The process of integration into the Generic UI is the same as described at Integrating a Vaadin Component into the Generic UI, so we won’t repeat it here.
After clicking the OK button Studio will generate the following files:
-
SliderServerComponent- a Vaadin component integrated with JavaScript. -
SliderState- a state class of the Vaadin component. -
slider-connector.js- a JavaScript connector for the Vaadin component.
Let’s examine the generated files and make necessary changes in the source code.
-
SlideStatestate class defines what data is transferred between the server and the client. In our case it is a minimal possible value, maximum possible value and selected values.package com.company.jscomponent.web.toolkit.ui.slider; import com.vaadin.shared.ui.JavaScriptComponentState; public class SliderState extends JavaScriptComponentState { public double[] values; public double minValue; public double maxValue; } -
Vaadin server-side component
SliderServerComponent.package com.company.jscomponent.web.toolkit.ui.slider; import com.vaadin.annotations.StyleSheet; import com.vaadin.ui.AbstractJavaScriptComponent; import com.vaadin.annotations.JavaScript; import elemental.json.JsonArray; @JavaScript({"slider-connector.js", "jquery-ui.js"}) @StyleSheet({"jquery-ui.css"}) public class SliderServerComponent extends AbstractJavaScriptComponent { public interface ValueChangeListener { void valueChanged(double[] newValue); } private ValueChangeListener listener; public SliderServerComponent() { addFunction("valueChanged", arguments -> { JsonArray array = arguments.getArray(0); double[] values = new double[2]; values[0] = array.getNumber(0); values[1] = array.getNumber(1); listener.valueChanged(values); }); } public void setValue(double[] value) { getState().values = value; } public double[] getValue() { return getState().values; } public double getMinValue() { return getState().minValue; } public void setMinValue(double minValue) { getState().minValue = minValue; } public double getMaxValue() { return getState().maxValue; } public void setMaxValue(double maxValue) { getState().maxValue = maxValue; } @Override protected SliderState getState() { return (SliderState) super.getState(); } public ValueChangeListener getListener() { return listener; } public void setListener(ValueChangeListener listener) { this.listener = listener; } }The server component defines getters and setters to work with the slider state and an interface of value change listeners. The class extends
AbstractJavaScriptComponent.The
addFunction()method invocation in the class constructor defines a handler for an RPC-call of thevalueChanged()function from the client.The
@JavaScriptand@StyleSheetannotations point to files that must be loaded on the web page. In our example, these are JavaScript files of the jquery-ui library, the connector and the stylesheet for jquery-ui. You should place these files to the Java package of the Vaadin server component.
Download an archive with jQuery UI from http://jqueryui.com/download and put files jquery-ui.js and jquery-ui.css from the archive to the Java package of the SliderServerComponent class. At the jQuery UI download page, you can select which components should be put into the archive. For this demo, it is enough to select only the Slider item of the Widgets group.
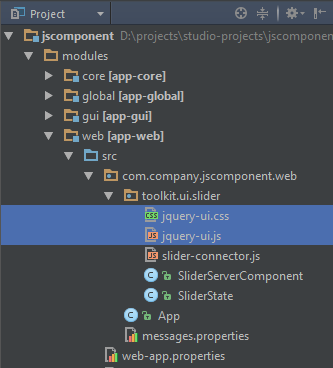
-
JavaScript connector
slider-connector.js.com_company_jscomponent_web_toolkit_ui_slider_SliderServerComponent = function() { var connector = this; var element = connector.getElement(); $(element).html("<div/>"); $(element).css("padding", "5px 10px"); var slider = $("div", element).slider({ range: true, slide: function(event, ui) { connector.valueChanged(ui.values); } }); connector.onStateChange = function() { var state = connector.getState(); slider.slider("values", state.values); slider.slider("option", "min", state.minValue); slider.slider("option", "max", state.maxValue); $(element).width(state.width); } }Connector is a function that initializes a JavaScript component when the web page is loaded. The function name must correspond to the server component class name where dots in package name are replaced with underscore characters.
Vaadin adds several useful methods to the connector function.
this.getElement()returns an HTML DOM element of the component,this.getState()returns a state object.Our connector does the following:
-
Initializes the
slidercomponent of the jQuery UI library. Theslide()function is invoked when the position of any drag handler changes. This function in turn invokes thevalueChanged()connector method.valuedChanged()is the method that we defined on the server side in theSliderServerComponentclass. -
Defines the
onStateChange()function. It is called when the state object is changed on the server side.
-
To demonstrate how the component works, let’s create the Product entity with three attributes:
-
nameof type String -
minDiscountof type Double -
maxDiscountof type Double
Generate standard screens for the entity. Ensure that the value of the In module field is Web Module.
The slider component will set minimal and maximum discount values of a product.
Open the product-edit.xml file. Make minDiscount and maxDiscount fields not editable by adding the editable="false" attribute to the corresponding elements. Then add the new custom slider field to the fieldGroup.
As a result, the XML descriptor of the editor screen should look as follows:
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<window xmlns="http://schemas.haulmont.com/cuba/window.xsd"
caption="msg://editCaption"
class="com.company.jscomponent.web.product.ProductEdit"
datasource="productDs"
focusComponent="fieldGroup"
messagesPack="com.company.jscomponent.web.product">
<dsContext>
<datasource id="productDs"
class="com.company.jscomponent.entity.Product"
view="_local"/>
</dsContext>
<layout expand="windowActions"
spacing="true">
<fieldGroup id="fieldGroup"
datasource="productDs">
<column width="250px">
<field property="name"/>
<field property="minDiscount" editable="false"/>
<field property="maxDiscount" editable="false"/>
<field id="slider" custom="true"/>
</column>
</fieldGroup>
<frame id="windowActions"
screen="editWindowActions"/>
</layout>
</window>Open the ProductEit.java file. Replace its content with the following code:
package com.company.jscomponent.web.product;
import com.company.jscomponent.web.toolkit.ui.slider.SliderServerComponent;
import com.haulmont.cuba.gui.components.AbstractEditor;
import com.company.jscomponent.entity.Product;
import com.haulmont.cuba.gui.components.Component;
import com.haulmont.cuba.gui.components.FieldGroup;
import com.haulmont.cuba.gui.components.VBoxLayout;
import com.haulmont.cuba.gui.data.Datasource;
import com.haulmont.cuba.gui.xml.layout.ComponentsFactory;
import com.haulmont.cuba.web.gui.components.WebComponentsHelper;
import com.vaadin.ui.Layout;
import javax.inject.Inject;
public class ProductEdit extends AbstractEditor<Product> {
@Inject
private FieldGroup fieldGroup;
@Inject
private ComponentsFactory componentsFactory;
@Inject
private Datasource<Product> productDs;
@Override
protected void initNewItem(Product item) {
super.initNewItem(item);
item.setMinDiscount(15.0);
item.setMaxDiscount(70.0);
}
@Override
public Product getItem() {
return super.getItem();
}
@Override
protected void postInit() {
super.postInit();
Component box = componentsFactory.createComponent(VBoxLayout.class);
Layout vBox = (Layout) WebComponentsHelper.unwrap(box);
SliderServerComponent slider = new SliderServerComponent();
slider.setValue(new double[]{getItem().getMinDiscount(), getItem().getMaxDiscount()});
slider.setMinValue(0);
slider.setMaxValue(100);
slider.setWidth("240px");
slider.setListener(newValue -> {
getItem().setMinDiscount(newValue[0]);
getItem().setMaxDiscount(newValue[1]);
});
vBox.addComponent(slider);
fieldGroup.getFieldNN("slider").setComponent(box);
}
}The initNewItem() method sets initial values for discounts of a new product.
Method init() initializes the slider custom field. It sets current, minimal and maximum values of the slider and defines the value change listener. When the drag handler moves, a new value will be set to the corresponding field of the editable entity.
Start the application server and open the product editor screen. Changing the drop handler position must change the value of the text fields.
5.8.8.4. Creating a GWT component
In this section, we will cover the creation of a simple GWT component (a rating field consisting of 5 stars) and its usage in application screens.

Create a new project in CUBA Studio and name it ratingsample.
Click the Create web-toolkit module link in the Project properties navigator section.
Click the Create new UI component link. The New UI component page will open. Select the New GWT component value in the Component type section.
Enter RatingFieldServerComponent in the Vaadin component class name field.
Deselect the Integrate into Generic UI flag. The process of integration into the Generic UI is the same as described at Integrating a Vaadin Component into the Generic UI, so we won’t repeat it here.
After clicking the OK button Studio generates the following files:
-
RatingFieldWidget.java- a GWT widget in web-toolkit module. -
RatingFieldServerComponent.java- a Vaadin component class. -
RatingFieldState.java- a component state class. -
RatingFieldConnector.java- a connector that links the client code with the server component. -
RatingFieldServerRpc.java- a class that defines a server API for the client.
Let’s look at the generated files and make necessary changes in them.
-
RatingFieldWidgetis a GWT widget. Replace its content with the following code:package com.company.ratingsample.web.toolkit.ui.client.ratingfield; import com.google.gwt.dom.client.DivElement; import com.google.gwt.dom.client.SpanElement; import com.google.gwt.dom.client.Style.Display; import com.google.gwt.user.client.DOM; import com.google.gwt.user.client.Event; import com.google.gwt.user.client.ui.FocusWidget; import java.util.ArrayList; import java.util.List; public class RatingFieldWidget extends FocusWidget { private static final String CLASSNAME = "ratingfield"; // API for handle clicks public interface StarClickListener { void starClicked(int value); } protected List<SpanElement> stars = new ArrayList<SpanElement>(5); protected StarClickListener listener; protected int value = 0; public RatingFieldWidget() { DivElement container = DOM.createDiv().cast(); container.getStyle().setDisplay(Display.INLINE_BLOCK); for (int i = 0; i < 5; i++) { SpanElement star = DOM.createSpan().cast(); // add star element to the container DOM.insertChild(container, star, i); // subscribe on ONCLICK event DOM.sinkEvents(star, Event.ONCLICK); stars.add(star); } setElement(container); setStylePrimaryName(CLASSNAME); } // main method for handling events in GWT widgets @Override public void onBrowserEvent(Event event) { super.onBrowserEvent(event); switch (event.getTypeInt()) { // react on ONCLICK event case Event.ONCLICK: SpanElement element = event.getEventTarget().cast(); // if click was on the star int index = stars.indexOf(element); if (index >= 0) { int value = index + 1; // set internal value setValue(value); // notify listeners if (listener != null) { listener.starClicked(value); } } break; } } @Override public void setStylePrimaryName(String style) { super.setStylePrimaryName(style); for (SpanElement star : stars) { star.setClassName(style + "-star"); } updateStarsStyle(this.value); } // let application code change the state public void setValue(int value) { this.value = value; updateStarsStyle(value); } // refresh visual representation private void updateStarsStyle(int value) { for (SpanElement star : stars) { star.removeClassName(getStylePrimaryName() + "-star-selected"); } for (int i = 0; i < value; i++) { stars.get(i).addClassName(getStylePrimaryName() + "-star-selected"); } } }A widget is a client-side class responsible for displaying the component in the web browser and handling events. It defines interfaces for working with the server side. In our case these are the
setValue()method and theStarClickListenerinterface. -
RatingFieldServerComponentis a Vaadin component class. It defines an API for the server code, accessor methods, event listeners and data sources connection. Developers use the methods of this class in the application code.package com.company.ratingsample.web.toolkit.ui; import com.company.ratingsample.web.toolkit.ui.client.ratingfield.RatingFieldServerRpc; import com.company.ratingsample.web.toolkit.ui.client.ratingfield.RatingFieldState; import com.vaadin.ui.AbstractField; // the field will have a value with integer type public class RatingFieldServerComponent extends AbstractField<Integer> { public RatingFieldServerComponent() { // register an interface implementation that will be invoked on a request from the client registerRpc((RatingFieldServerRpc) value -> setValue(value, true)); } // field value type @Override public Class<? extends Integer> getType() { return Integer.class; } // define own state class @Override protected RatingFieldState getState() { return (RatingFieldState) super.getState(); } @Override protected RatingFieldState getState(boolean markAsDirty) { return (RatingFieldState) super.getState(markAsDirty); } // we need to refresh the state when setValue is invoked from the application code @Override protected void setInternalValue(Integer newValue) { super.setInternalValue(newValue); if (newValue == null) { newValue = 0; } getState().value = newValue; } } -
The
RatingFieldStatestate class defines what data are sent between the client and the server. It contains public fields that are automatically serialized on server side and deserialized on the client.package com.company.ratingsample.web.toolkit.ui.client.ratingfield; import com.vaadin.shared.AbstractFieldState; public class RatingFieldState extends AbstractFieldState { { // change the main style name of the component primaryStyleName = "ratingfield"; } // define a field for the value public int value = 0; } -
The
RatingFieldServerRpcinterface defines a server API that is used from the client-side. Its methods may be invoked by the RPC mechanism built into Vaadin. We will implement this interface in the component.package com.company.ratingsample.web.toolkit.ui.client.ratingfield; import com.vaadin.shared.communication.ServerRpc; public interface RatingFieldServerRpc extends ServerRpc { //method will be invoked in the client code void starClicked(int value); } -
The
RatingFieldConnectorconnector links client code with the server.package com.company.ratingsample.web.toolkit.ui.client.ratingfield; import com.company.ratingsample.web.toolkit.ui.RatingFieldServerComponent; import com.company.ratingsample.web.toolkit.ui.client.ratingfield.RatingFieldServerRpc; import com.company.ratingsample.web.toolkit.ui.client.ratingfield.RatingFieldState; import com.vaadin.client.communication.StateChangeEvent; import com.vaadin.client.ui.AbstractFieldConnector; import com.vaadin.shared.ui.Connect; // link the connector with the server implementation of RatingField // extend AbstractField connector @Connect(RatingFieldServerComponent.class) public class RatingFieldConnector extends AbstractFieldConnector { // we will use a RatingFieldWidget widget @Override public RatingFieldWidget getWidget() { RatingFieldWidget widget = (RatingFieldWidget) super.getWidget(); if (widget.listener == null) { widget.listener = new RatingFieldWidget.StarClickListener() { @Override public void starClicked(int value) { getRpcProxy(RatingFieldServerRpc.class).starClicked(value); } }; } return widget; } // our state class is RatingFieldState @Override public RatingFieldState getState() { return (RatingFieldState) super.getState(); } // react on server state change @Override public void onStateChanged(StateChangeEvent stateChangeEvent) { super.onStateChanged(stateChangeEvent); // refresh the widget if the value on server has changed if (stateChangeEvent.hasPropertyChanged("value")) { getWidget().setValue(getState().value); } } }
The RatingFieldWidget class does not define the component appearance, it only assigns style names to key elements. To define an appearance of the component, we’ll create stylesheet files. Click the Create theme extension link on the Project properties navigator section. Select the halo theme in the dialog. Studio creates SCSS files for theme extension in the themes directory of the web module. The halo theme uses FonAwesome font glyphs instead of icons. We’ll use this fact.
It is recommended to put component styles into a separate file componentname.scss in the components/componentname directory in the form of SCSS mixture. Create the components/ratingfield directories structure in the themes/halo directory of the web module. Then create the ratingfield.scss file inside the ratingfield directory:
@mixin ratingfield($primary-stylename: ratingfield) {
.#{$primary-stylename}-star {
font-family: FontAwesome;
font-size: $v-font-size--h2;
padding-right: round($v-unit-size/4);
cursor: pointer;
&:after {
content: '\f006'; // 'fa-star-o'
}
}
.#{$primary-stylename}-star-selected {
&:after {
content: '\f005'; // 'fa-star'
}
}
.#{$primary-stylename} .#{$primary-stylename}-star:last-child {
padding-right: 0;
}
.#{$primary-stylename}.v-disabled .#{$primary-stylename}-star {
cursor: default;
}
}Include this file in the `halo-ext.scss`main theme file:
@import "../halo/halo";
@import "components/ratingfield/ratingfield";
/* Define your theme modifications inside next mixin */
@mixin halo-ext {
@include halo;
@include ratingfield;
}To demonstrate how the component works let’s create a new screen in the web module.
Name the screen file rating-screen.xml.
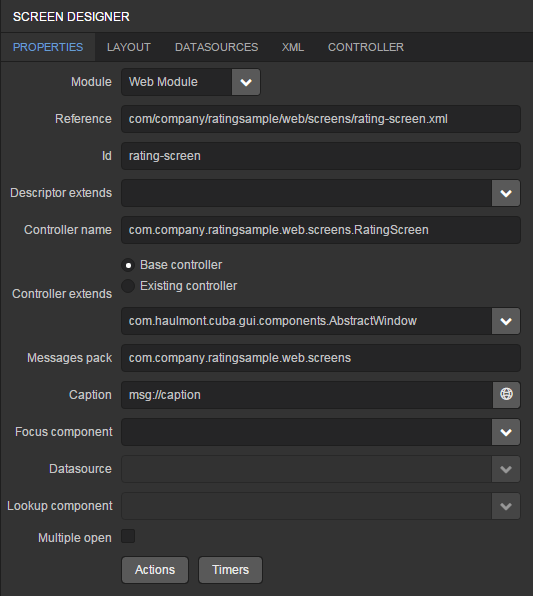
Add the screen to the application menu. Go to the Main menu navigator section and click the Edit button. The menu editor will open. Add the screen created earlier to the application menu.
Open the rating-screen.xml file in the IDE. We need a container for our component. Declare it in the screen XML:
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<window xmlns="http://schemas.haulmont.com/cuba/window.xsd"
caption="msg://caption"
class="com.company.ratingsample.web.screens.RatingScreen"
messagesPack="com.company.ratingsample.web.screens">
<layout expand="container">
<vbox id="container">
<!-- we'll add vaadin component here-->
</vbox>
</layout>
</window>Open the RatingScreen.java screen controller and add the code that puts the component to the screen.
package com.company.ratingsample.web.screens;
import com.company.ratingsample.web.toolkit.ui.RatingFieldServerComponent;
import com.haulmont.cuba.gui.components.AbstractWindow;
import com.haulmont.cuba.gui.components.BoxLayout;
import com.haulmont.cuba.web.gui.components.WebComponentsHelper;
import com.vaadin.ui.Layout;
import javax.inject.Inject;
import java.util.Map;
public class RatingScreen extends AbstractWindow {
@Inject
private BoxLayout container;
@Override
public void init(Map<String, Object> params) {
super.init(params);
com.vaadin.ui.Layout containerLayout = (Layout) WebComponentsHelper.unwrap(container);
RatingFieldServerComponent field = new RatingFieldServerComponent();
field.setCaption("Rate this!");
containerLayout.addComponent(field);
}
}Start the application server and see the result.
5.8.8.5. Support for Custom Visual Components in CUBA Studio
This section describes how to integrate a new custom visual component into CUBA Studio. As a result of the integration, the component will be available on the component palette of the WYSIWYG screen layout designer. Developers will be able to drag and drop the component to the canvas and edit its properties in the properties panel.
Let’s walk through the process of integrating the stepper component into Studio. Creation of this component was described in Integrating a Vaadin Component into the Generic UI.
Open the project containing the stepper component.
|
Tip
|
If you didn’t create this project, you can still reproduce the steps listed below in a new project. In this case, you will see how Studio supports the component, but you won’t be able to run the application. |
Click the Extend Studio link on the Project properties navigator section.
In the Extend Studio screen, fill in the following fields:
-
Configuration name - a configuration identifier. Enter
stepper. -
Component XML element - a component element name to use in screen XML descriptors. It is
stepperin our case.The Component class name and Component model class name fields are filled automatically based on the value of the Component XML element. Leave the values as is.
-
Component namespace URI - a namespace from the XSD that describes the Generic UI component. If you’ve generated the new component with Studio, then you can take the value of this field from the
ui-component.xsdfile located in the gui module. -
Component namespace prefix - a prefix for the component XML element.
-
Standard properties - standard properties that should be available for editing in the component properties panel of the Studio screen layout designer.
Select
caption,datasourceandpropertycheckboxes.Tipid,align,height,width,enable,stylenameandvisibleproperties are available to any component by default. -
Custom properties - this table is used for declaring component specific properties that should be edited in the component properties panel.
Add the following properties:
-
manualInput of type
Boolean, the default value istrue -
mouseWheel of type
Boolean, the default value istrue -
stepAmount, of type
Integer, the default value is0 -
maxValue, of type
Integer, the default value is0 -
minValue, of type
Integer, the default value is0
-
Press the OK button.
The custom visual components support is initialized when the Studio server start. Go to the Studio server window, stop the server, exit Studio, then reopen and start it again.
Re-create standard screens for the Customer entity to erase the results of our previous experiments.
Then go to the GENERIC UI navigator section and open the customer-edit.xml screen.
Remove the score field from fieldGroup because we will use a separate component for editing the score.
Find the new Stepper component on the components palette, then drag it to the screen below fieldGroup.
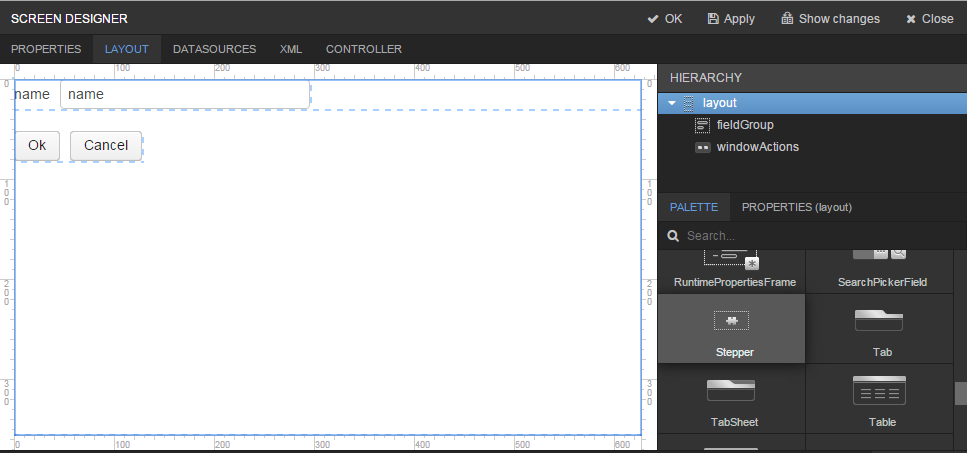
Select the stepper component and go to the component Properties tab.
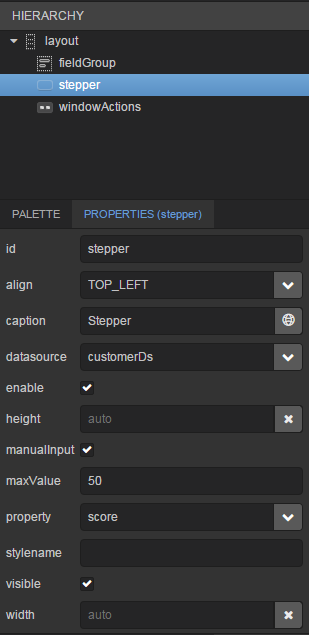
Fill in the fields:
-
id -
stepper -
caption -
Stepper -
datasource -
customerDs -
property -
score -
maxValue -
50
Go to the XML tab to see the result.
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<window xmlns="http://schemas.haulmont.com/cuba/window.xsd"
caption="msg://editCaption"
class="com.company.addonguidemo.gui.customer.CustomerEdit"
datasource="customerDs"
focusComponent="fieldGroup"
messagesPack="com.company.addonguidemo.gui.customer"
xmlns:app="http://schemas.company.com/agd/0.1/ui-component.xsd">
<dsContext>
<datasource id="customerDs"
class="com.company.addonguidemo.entity.Customer"
view="_local"/>
</dsContext>
<layout expand="windowActions"
spacing="true">
<fieldGroup id="fieldGroup"
datasource="customerDs">
<column width="250px">
<field property="name"/>
</column>
</fieldGroup>
<app:stepper id="stepper"
caption="Stepper"
datasource="customerDs"
maxValue="50"
property="score"/>
<frame id="windowActions"
screen="editWindowActions"/>
</layout>
</window>There is a new namespace with the app prefix in the screen XML, the stepper component is added to the screen, and its properties are set correctly.
5.8.9. Using Application Components
As mentioned in the Application Components section, any CUBA application can be used as a component of another application. An application component is a full-stack library providing functionality on all layers - from database schema to business logic and UI.
In this section, we’ll consider an example of creating an application component and using it in a project. The component will provide a "Customer Management" functionality and include the Customer entity and corresponding UI screens. The application will use the Customer entity from the component as a reference in its Order entity.
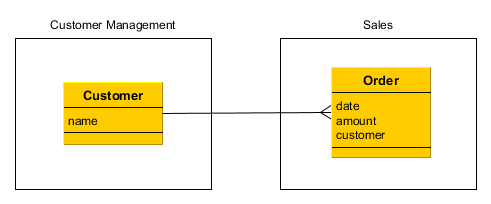
- Creating the Customer Management component
-
-
Create a new project in Studio and specify the following properties on the New project screen:
-
Project name -
customers -
Project namespace -
cust -
Root package -
com.company.customers
-
-
Edit Project properties and on the Advanced tab, set the Module prefix to
cust. This is necessary to assemble component artifacts with names different from the defaultapp. -
Create the
Customerentity with at least thenameattribute. Switch to the Instance name tab and specify addnameto the name pattern attributes.WarningIf your component contains
@MappedSuperclasspersistent classes, make sure they have descendants which are entities (i.e. annotated with@Entity) in the same project. Otherwise such base classes will not be properly enhanced and you will not be able to use them in applications. -
Generate DB scripts and create standard screens for the
Customerentity:cust$Customer.browseandcust$Customer.edit. After that, go to main menu designer and rename theapplicationmenu item tocustomerManagement. -
Click to the App component descriptor link on the Project properties panel. Save the generated descriptor by clicking OK.
-
Test the Customer Management functionality: Run > Create database, Run > Start application server, then open
http://localhost:8080/custin your web browser. -
Install the application component into the local Maven repository by executing the Run > Install app component menu command. This command just runs the
installGradle task after stopping Gradle daemons.
-
- Creating the Sales application
-
-
Create a new project in Studio and specify the following properties on the New project screen:
-
Project name -
sales -
Project namespace -
sales -
Root package -
com.company.sales
-
-
Edit Project properties and on the App components panel click the plus button next to Custom components. In the Custom application component dialog, select the
customersproject in the Registered project drop-down list. The list contains all project registered in Studio that have anapp-component.xmldescriptor. Click OK in the dialog. The Maven coordinates of the Customer Management component will appear in the list of custom components. Save the project properties by clicking OK. -
Create the
Orderentity and add thedateandamountattributes. Then add thecustomerattribute as a many-to-one association with theCustomerentity - it should be available in the Type drop-down list. -
Generate DB scripts and create standard screens for the
Orderentity. When creating standard screens, create aorder-with-customer-viewview that includes thecustomerattribute and use it for the screens. -
Test the application functionality: Run > Create database, Run > Start application server, then open
http://localhost:8080/appin your web browser. The application will contain two top level menu items: Customer Management and Application with the corresponding functionality.
-
- Modifying the Customer Management component
-
Suppose we have to change the component functionality (add an attribute to
Customer) and then reassemble the application to incorporate the changes.-
Open the
customersproject in Studio. -
Edit the
Customerentity and add theaddressattribute. When saving the entity, select both browser and editor screens to include the new attribute. -
Generate DB scripts - a script for altering table will be created. Save the scripts.
-
Test the changes in the component: Run > Update database, Run > Start application server, then open
http://localhost:8080/custin your web browser. -
Re-install the application component into the local Maven repository by executing the Run > Install app component menu command.
-
Close the
customersproject and opensales. -
Execute Build > Clean, then Build > Assemble project menu commands.
-
Execute Run > Update database - the update script from the Customer Management component will be executed.
-
Execute Run > Start application server and open
http://localhost:8080/appin your web browser - the application will contain theCustomerentity and screens with the newaddressattribute.
-
- Sharing the Customer Management component
-
You can share the application component by uploading it to a remote Maven repository.
-
Stop the Studio server.
-
Set up a repository as explained in Setting Up a Private Artifact Repository.
-
Open
build.gradleof thecustomersproject in a text editor. Replace the repository and its credentials inbuildscript/repositoriessection and add theuploadRepositoryto thecubasection:buildscript { ... repositories { maven { url 'http://repo.company.com/nexus/content/groups/work' // repository containing CUBA and your own artifacts credentials { username(rootProject.hasProperty('repoUser') ? rootProject['repoUser'] : 'admin') password(rootProject.hasProperty('repoPass') ? rootProject['repoPass'] : 'admin123') } } ... cuba { ... uploadRepository { url = 'http://repo.company.com/nexus/content/repositories/snapshots' // repository for uploading your artifacts user = 'admin' password = 'admin123' } } -
Open the command line and run
gradle assemblein thecustomersproject root directory. This ensures your new repository caches CUBA artifacts required for working in Studio. -
In the Studio server window, specify your repository and credentials instead of the standard CUBA repository. Start the Studio server.
-
Open the
customersproject in Studio. -
In the Studio Search dialog (Alt-/), find the
uploadArchivesGradle task and run it. You can also run this task from the command line. The Customer Management component artifacts will be uploaded to your repository. -
Remove the component artifacts from your local Maven repository to ensure that they will be downloaded from the remote repository when the
salesapplication is assembled the next time: just delete the.m2/repository/com/companyfolder located in your user home directory. -
Open the
customersproject in Studio. The repository URL in itsbuild.gradlewill be automatically changed to the one specified in the Studio server window. -
Now you can assemble and run the application - the Customer Management component will be downloaded from the remote repository.
-
6. Application Deployment
This chapter describes different aspects of CUBA applications deployment and operation.
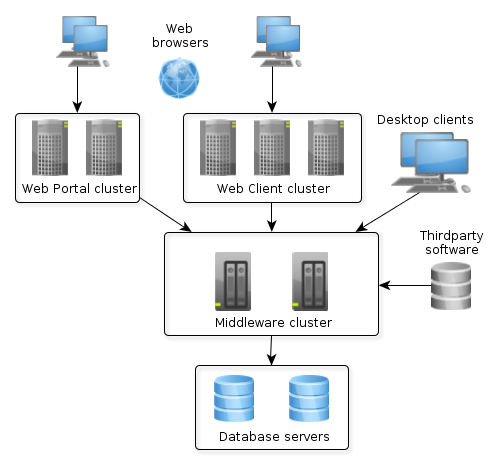
In the example above, the application prevents a single point of failure existence, provides load balancing and various client types connection. In the simplest case, however, the server part of an application can be installed on one computer that includes the database. Various deployment options depending on load and fault tolerance requirements are described in detail in Application Scaling.
6.1. Application Directories
This section describes file system directories used by various application blocks at runtime.
6.1.1. Configuration Directory
The configuration directory can contain resources that complement and override configuration, user interface and business logic after the application is deployed. Overriding is provided by the loading mechanism of the Resources infrastructure interface. Firstly it performs search in the configuration directory and then in CLASSPATH, so that resources from the configuration directory take precedence over identically named resources located in JAR files and class directories.
The configuration directory may contain the following resource types:
-
metadata.xml, persistence.xml, views.xml, remoting-spring.xml configuration files.
-
XML-descriptors of UI screens.
-
Controllers of UI screens in the form of Java or Groovy source code.
-
Groovy scripts or classes, and Java source code that is used by the application via the Scripting interface.
The location of the configuration directory is determined by the cuba.confDir application property. For the Middleware, Web Client and Web Portal blocks in fast deployment configuration in Tomcat, it is a subdirectory with the web application name in the tomcat/conf directory, for example, tomcat/conf/app-core for the Middleware.
6.1.2. Work Directory
The application uses the work directory to store data and configuration files.
For example, the filestorage subdirectory of the work directory is used by the file storage. In addition, the Middleware block saves generated persistence.xml and orm.xml files in the work directory on start.
Work directory location is determined by the cuba.dataDir application property. For the Middleware, Web Client and Web Portal blocks in fast deployment configuration in Tomcat, it is a subdirectory with the name of the web application in the tomcat/work directory.
6.1.3. Log Directory
The content and settings of the log files are determined by the configuration of the Logback framework. The configuration file location is determined by logback.configurationFile system property.
This directory can also be used to store arbitrary information about the running application. The log directory location is determined by cuba.logDir application property. For the Middleware, Web Client and Web Portal blocks in fast deployment configuration in Tomcat, it is the tomcat/logs directory.
See also Logging.
6.1.4. Temporary Directory
This directory can be used for creating arbitrary temporary files at application run time. The path to the temporary directory is determined by the cuba.tempDir application property. For the Middleware, Web Client and Web Portal blocks in fast deployment configuration in Tomcat, it is a subdirectory with the web application name in the tomcat/temp directory.
6.1.5. Database Scripts Directory
This directory of the deployed Middleware block stores the set of SQL scripts to create and update the DB.
The script directory structure reproduces the one described in Scripts to Create and Update the Database, but it also has an additional top level that separates application components and the application scripts. The numbering of top level directories is performed by project build tasks.
The DB scripts directory location is determined by cuba.dbDir application property. For fast deployment configuration in Tomcat, it is the WEB-INF/db subdirectory of the middleware web application directory: tomcat/webapps/app-core/WEB-INF/db.
6.2. Deployment Options
This section describes different ways to deploy CUBA applications:
6.2.1. Fast Deployment in Tomcat
Fast deployment is used by default when developing an application, as it provides minimum time for building, installation and starting the application. This option can also be used in production.
Fast deployment is performed using the deploy task that is declared for core and web modules in the build.gradle file. Before the first execution of deploy, a local Tomcat server should be set up and initialized using the setupTomcat task.
|
Warning
|
Please make sure your environment does not contain |
As result of fast deployment, the following structure is created in the directory that is specified by the cuba.tomcat.dir property of the build.gradle script (only important directories and files are listed below):
bin/
setenv.bat, setenv.sh
startup.bat, startup.sh
debug.bat, debug.sh
shutdown.bat, shutdown.sh
conf/
catalina.properties
server.xml
logback.xml
logging.properties
Catalina/
localhost/
app/
app-core/
lib/
hsqldb-2.2.9.jar
logs/
app.log
shared/
lib/
temp/
app/
app-core/
webapps/
app/
app-core/
work/
app/
app-core/-
bin– the directory that contains tools to start and stop the Tomcat server:-
setenv.bat,setenv.sh– the scripts that set environment variables. These scripts should be used for setting JVM memory parameters, specifying a configuration file for logging, configuring access to JMX, parameters to connect the debugger. -
startup.bat,startup.sh– the scripts that start Tomcat. The server starts in a separate console window on Windows and in background on *nix.To start the server in the current console window, use the following commands instead of
startup.*:> catalina.bat run$ ./catalina.sh run -
debug.bat,debug.sh– the scripts that are similar tostartup.*, but start Tomcat with an ability to connect the debugger. These scripts are launched when running the start task of the build script. -
shutdown.bat,shutdown.sh– the scripts that stop Tomcat.
-
-
conf– the directory that contains configuration files of Tomcat and its deployed applications.-
catalina.properties– the Tomcat properties. To load shared libraries from theshared/libdirectory (see below), this file should contain the following line:shared.loader=${catalina.home}/shared/lib/*.jar -
server.xml– Tomcat configuration descriptor. -
logback.xml– application logging configuration descriptor. -
logging.properties– Tomcat server logging configuration descriptor. -
Catalina/localhost– in this directory, context.xml application deployment descriptors can be placed. Descriptors located in this directory take precedence over the descriptors in theMETA-INFdirectories of the application. This approach is often convenient for production environment. For example, with this descriptor, it is possible to specify the database connection parameters that are different from those specified in the application itself.Server-specific deployment descriptor should have the application name and the
.xmlextension. So, to create this descriptor, for example, for theapp-coreapplication, copy the contents of thewebapps/app-core/META-INF/context.xmlfile to theconf/Catalina/localhost/app-core.xmlfile. -
app– web client application configuration directory. -
app-core– middleware application configuration directory.
-
-
lib– directory of the libraries that are loaded by the server’s common classloader. These libraries are available for both the server and all web applications deployed in it. In particular, this directory should have JDBC drivers of the utilized databases (hsqldb-XYZ.jar,postgresql-XYZ.jar, etc.) -
logs– application and server logs directory. The main log file of the application isapp.log(see Setting up Logging in Tomcat). -
shared/lib– directory of libraries that are available to all deployed applications. These libraries classes are loaded by the server’s special shared classloader. Its usage is configured in theconf/catalina.propertiesfile as described above.The deploy task of the build script copies all libraries not listed in the
jarNamesparameter, i.e. not specific for the given application, into this directory. -
temp/app,temp/app-core– web client and the middleware applications temporary directories. -
webapps– web application directories. Each application is located in its own subdirectory in the exploded WAR format.The deploy task of the build script create application subdirectories with the names specified in the
appNameparameters and, among other things, copy the libraries listed in thejarNamesparameter to theWEB-INF/libsubdirectory for each application. -
work/app,work/app-core– web client and the middleware applications work directories.
6.2.1.1. Using Tomcat in Production
By default, the fast deployment procedure creates the app and app-core web applications running on port 8080 of the local Tomcat instance. It means that the web client is available at http://localhost:8080/app.
You can use this Tomcat instance in production just by copying the tomcat directory to the server. All you have to do is to set up the server host name in both conf/app/local.app.properties and conf/app-core/local.app.properties files (create the files if they do not exist):
cuba.webHostName = myserver
cuba.webAppUrl = http://myserver:8080/appBesides, set up the connection to you production database. You can do it in the context.xml file of your web application (webapps/app-core/META-INF/context.xml), or copy this file to conf/Catalina/localhost/app-core.xml as described in the previous section to separate development and production settings.
You can create the production database from a development database backup, or set up the automatic creation and further updating of the database. See Creating and Updating the Database in Production.
If you want to change the Tomcat port or web context (the last part of the URL after /), use Studio:
-
Open the project in Studio.
-
Go to Project Properties > Edit > Advanced.
-
To change the web context, edit the Modules prefix field.
-
To change the Tomcat port, edit the Tomcat ports > HTTP port field.
If you want to use the root context for the web client (http://myserver:8080), rename app directories to ROOT
tomcat/
conf/
ROOT/
local.app.properties
app-core/
local.app.properties
webapps/
ROOT/
app-core/and use / as the web context name in conf/ROOT/local.app.properties:
cuba.webContextName = /6.2.2. WAR deployment to Jetty
You can deploy CUBA applications to WAR files using the buildWar build task and run them on any Java servlet container. An example of deployment of the WAR files to the Jetty web server is provided below.
-
Add the buildWar task to the end of build.gradle:
task buildWar(type: CubaWarBuilding) { appHome = '${app.home}' singleWar = false }TipPlease note that we build two separate WAR files for Middleware and Web Client blocks here. If you want to combine them into one WAR file with the
singleWar = trueparameter, provide the specialweb.xmlfile as described in this section. -
Start build process:
gradlew buildWarAs a result, the
app-core.warandapp.warfiles will be created in thebuild\distributions\warproject subdirectory. -
Create an application home directory, for example,
c:\work\app_home. -
Download and install Jetty to a local directory, for example
c:\work\jetty-home. This example has been tested onjetty-distribution-9.3.6.v20151106.zip. -
Create the
c:\work\jetty-basedirectory, open the command prompt in it and execute:java -jar c:\work\jetty-home\start.jar --add-to-start=http,jndi,deploy,plus,ext,resources -
Create the
c:\work\jetty-base\app-jetty.xmlfile with the following contents (for a PostgreSQL database namedtest):<?xml version="1.0"?> <!DOCTYPE Configure PUBLIC "-" "http://www.eclipse.org/jetty/configure_9_0.dtd"> <Configure id="Server" class="org.eclipse.jetty.server.Server"> <New id="CubaDS" class="org.eclipse.jetty.plus.jndi.Resource"> <Arg></Arg> <Arg>jdbc/CubaDS</Arg> <Arg> <New class="org.postgresql.ds.PGSimpleDataSource"> <Set name="ServerName">localhost</Set> <Set name="PortNumber">5432</Set> <Set name="DatabaseName">test</Set> <Set name="User">cuba</Set> <Set name="Password">cuba</Set> </New> </Arg> </New> </Configure> -
Add the following text to the beginning of
c:\work\jetty-base\start.inifile:--exec -Xdebug -agentlib:jdwp=transport=dt_socket,address=8787,server=y,suspend=n -Dapp.home=c:\work\app_home -Dlogback.configurationFile=c:\work\app_home\logback.xml # --------------------------------------- app-jetty.xml -
Copy the JDBC driver for your database to the
c:\work\jetty-base\lib\extdirectory. You can take the driver file from the CUBA Studiolibdirectory or from thebuild\tomcat\libproject directory. In case of PostgreSQL database, it ispostgresql-9.1-901.jdbc4.jar. -
Copy WAR files to the
c:\work\jetty-base\webappsdirectory. -
Open the command prompt in the
c:\work\jetty-basedirectory and run:java -jar c:\work\jetty-home\start.jar -
Open
http://localhost:8080/appin your web browser.
6.2.3. WAR deployment to Tomcat Windows Service
-
Add the buildWar task to the end of build.gradle:
task buildWar(type: CubaWarBuilding) { appHome = './app_home' singleWar = false includeContextXml = true includeJdbcDriver = true appProperties = ['cuba.automaticDatabaseUpdate': true] }If the target server parameters differ from what you have on the local Tomcat used for fast deployment, provide appropriate application properties. For example, if the target server runs on port 9999, the task definition should be as follows:
task buildWar(type: CubaWarBuilding) { appHome = './app_home' singleWar = false includeContextXml = true includeJdbcDriver = true appProperties = [ 'cuba.automaticDatabaseUpdate': true, 'cuba.webPort': 9999, 'cuba.connectionUrlList': 'http://localhost:9999/app-core' ] }You can also specify a different
context.xmlfile to setup the connection to the production database, for example:task buildWar(type: CubaWarBuilding) { appHome = './app_home' singleWar = false includeContextXml = true includeJdbcDriver = true appProperties = ['cuba.automaticDatabaseUpdate': true] coreContextXmlPath = 'modules/core/web/META-INF/production-context.xml' } -
Run the
buildWargradle task. As a result,app.warandapp-core.warfiles will be generated in thebuild/distibutionsdirectory of your project.gradlew buildWar -
Download and run Tomcat 8 Windows Service Installer.
-
Go to the
bindirectory of the installed server and runtomcat8w.exewith the administrative rights. Set Maximum memory pool to 1024MB on the Java tab. Then go to the General tab and restart the service.
-
Add
-Dfile.encoding=UTF-8to the Java Options field. -
Copy the generated
app.warandapp-core.warfiles to thewebappsdirectory of the server. -
Start the Tomcat service.
-
Open
http://localhost:8080/appin your web browser.
6.2.4. UberJAR Deployment
This is one of the simplest ways to run your CUBA application in a production environment. You need to build all-in-one JAR files for your application blocks using the buildUberJar Gradle task (see also the Deployment settings > Uber JAR page in Studio) and then you can run the application from the command line using the java executable:
java -jar app-core.jar java -jar app.jar
All parameters of the application are defined at the build time. The default port of the web client is 8080 and it will try to connect to the middleware running on localhost:8079. So after running the above commands in two separate terminal windows you will be able to connect to the web client at http://localhost:8080/app. If your project has Polymer UI, it will be available at http://localhost:8080/app-front.
You can change the parameters defined at the build time by providing application properties via Java system properties. Besides, ports and context names can be provided as command line arguments.
Command line arguments:
-
port- defines the port on which the embedded HTTP server will run. For example:java -jar app.jar -port 9090
Please note that if you specify a port for the core block, you need to provide the cuba.connectionUrlList application property with the corresponding address to the client blocks, for example:
java -jar app-core.jar -port 7070 java -jar -Dcuba.connectionUrlList=http://localhost:7070/app-core app.jar
-
contextName- a web context name for this application block. For example, in order to access your web client athttp://localhost:8080/sales, run the following command:java -jar app.jar -contextName sales
-
frontContextName- a web context name for the Polymer UI running in the web or portal client block.WarningPlease note that current implementation of Polymer UI requires manual setting of
<base>tag to the actual web context available at run time. So changing the context by using-frontContextNamecommand line argument can make the Polymer UI inaccessible. -
jettyEnvPath- a path to the Jetty environment file. It can be an absolute path or a path relative to the working directory.
6.2.5. Deployment to Jelastic Cloud
CUBA Studio allows you to deploy your application to the Jelastic cloud in a few easy steps.
|
Tip
|
Please note that only projects using PostgreSQL or HSQL databases are currently supported. |
-
Click the Deployment settings link on the Project properties section and switch to the CLOUD tab.
-
If the project is not yet set up for cloud deployment, you can use the field on top to create a free trial Jelastic account.
-
After completing your registration, enter the email, password and selected provider.
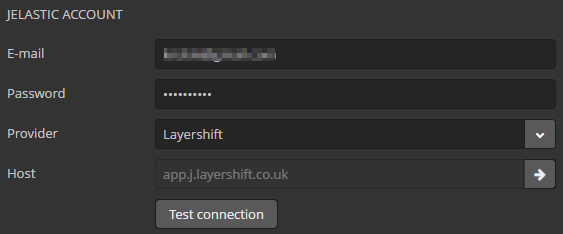
-
Environment field defines the environment in which the application WAR will be deployed. Click on the ellipsis button and select an existing environment or create a new one. You can check the selected environment for compatibility with your project. A compatible environment should have Java 8, Tomcat 8 and PostgreSQL 9.1+ (if the project uses PostgreSQL database). If your project uses PostgreSQL, you will receive an email with the database connection details. Please use them when generating custom
context.xmlfile, see Custom context.xml path field below. Besides, you should create an empty PostgreSQL database using the provider’s web interface link containing in the email. The database name should be specified later in custom context.xml (see below).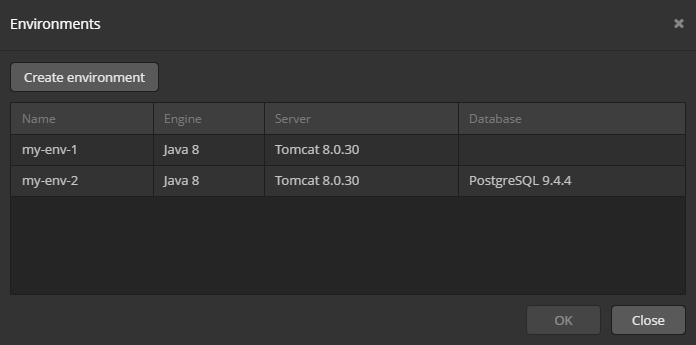
-
Press Generate button next to the Custom web.xml path field. Studio will generate a special
web.xmlof the single WAR comprising the Middleware and Web Client application blocks.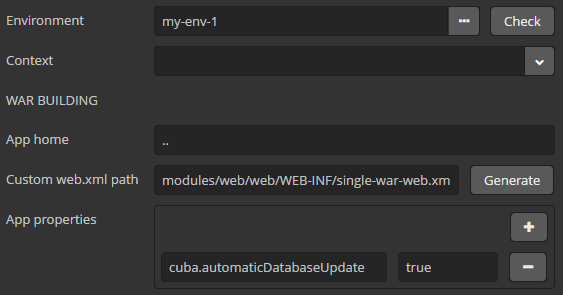
-
If your project uses HSQLDB, that is all - you can press OK and start deployment by clicking Run > Deploy to cloud main menu item. The deployment parameters can be later adjusted in build.gradle.
-
If your project uses PostgreSQL, go to the database administration web interface by the link in the email recieved after creation of the environment and create a database.
-
Press Generate button next to the Custom context.xml path field and specify the database user, password, host and name.
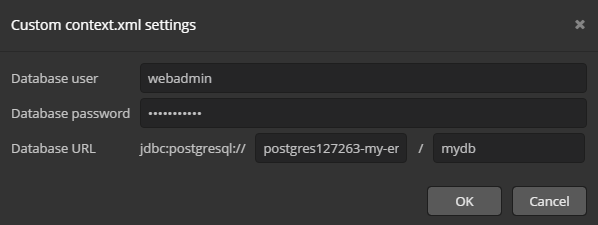
-
Leave the Include JDBC driver and Include context.xml checkboxes selected.
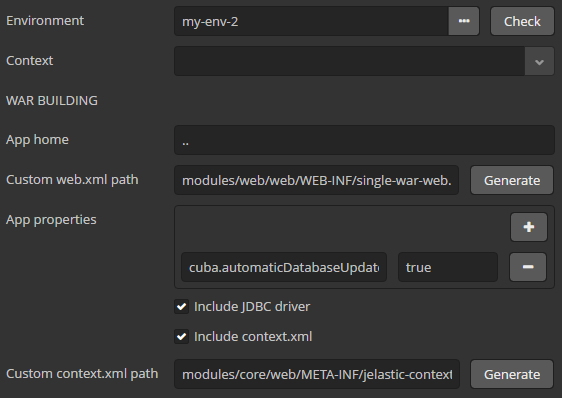
-
Now you can press OK and start deployment by clicking Run > Deploy to cloud main menu item.
-
After completing the deployment, use the link at the bottom left corner to open the application web interface.
6.2.6. Deployment to Bluemix Cloud
CUBA Studio provides support of IBM® Bluemix® cloud deployment in a few easy steps.
|
Tip
|
Bluemix cloud deployment is currently applicable only for projects using PostgreSQL database. HSQLDB is available with in-process option only, that means the database will be recreated on every application restart, and the user data will be lost. |
-
Create an account in the Bluemix. Download and install:
-
Bluemix CLI: http://clis.ng.bluemix.net/ui/home.html
-
Cloud Foundry CLI: https://github.com/cloudfoundry/cli/releases
-
Make sure the commands
bluemixandcfwork in the command line. If not, add your\IBM\Bluemix\binpath to thePATHenvironment variable.
-
-
Create a Space in the Bluemix with any space name. You can group several applications within one space, if needed.
-
In the Space create an application server: Create App → CloudFoundry Apps → Tomcat.
-
Specify the name of the application. The name should be unique as it will be used as part of the URL of your application.
-
To create a Database service, click Create service in the Space dashboard and choose ElephantSQL.
-
Open the application manager and connect the created DB Service to the application. Click Connect Existing. For the changes to take effect, the system requires to restage (update) the application. In our case it is not necessary, as the application will be redeployed.
-
After the DB Service is connected, DB credentials become available by the View Credentials button. The DB properties are also stored in the
VCAP_SERVICESenvironment variable of the application runtime and could be viewed by calling thecf envcommand. The created database is also accessible from outside of the Space, so you can work with it from your development environment. -
Setup your CUBA project to run with the PostgreSQL (the DBMS similar to one you have in the Bluemix).
-
Generate DB scripts and start the local Tomcat server. Make sure the application works.
-
Generate WAR-file to deploy the application to Tomcat.
-
Click Deployment Settings in the Project Properties section of Studio navigation panel.
-
Switch to the WAR tab.
-
Enable all the options using checkboxes, as for correct deployment it should be the Single WAR with JDBC driver and
context.xmlinside.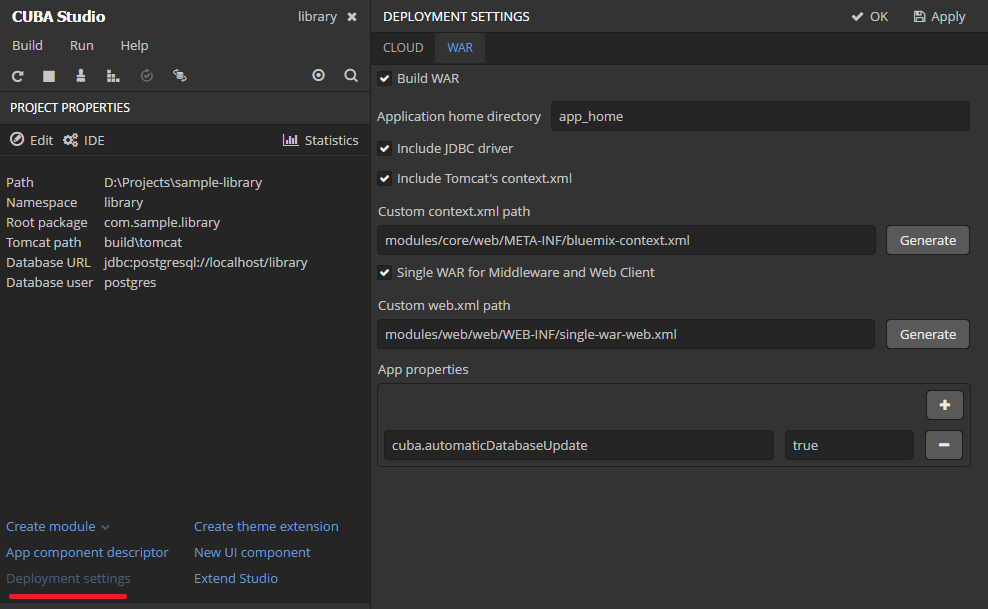
-
Click Generate button near the Custom context.XML field. In the opened dialog fill the credentials of the Database you have created in Bluemix.
Use the credentials from
uriof your DB service following the example below:{ "elephantsql": [ { "credentials": { "uri": "postgres://ldwpelpl:eFwXx6lNFLheO5maP9iRbS77Sk1VGO_T@echo-01.db.elephantsql.com:5432/ldwpelpl" } } ] }Database user:
ldwpelplDatabase password:
eFwXx6lNFLheO5maP9iRbS77Sk1VGO_TDatabase URL:
echo-01.db.elephantsql.com:5432Database name:
ldwpelpl -
Click Generate button to generate the custom
web.xmlfile required for the single WAR. -
Save the settings. Generate the WAR-file using the
buildWarGradle task in Studio or command line.
As a result, the
app.warappears in thebuild/distributions/war/sub-directory of the project.
-
-
In the root directory of the project create manually the
manifest.ymlfile. The contents of the file should be like follows:applications: - path: build/distributions/war/app.war memory: 1G instances: 1 domain: mybluemix.net name: cuba-app host: cuba-app disk_quota: 1024M buildpack: java_buildpack env: JBP_CONFIG_TOMCAT: '{tomcat: { version: 8.0.+ }}' JBP_CONFIG_OPEN_JDK_JRE: '{jre: { version: 1.8.0_+ }}'where
-
pathis the relative path to WAR-file. -
memory: the default memory limit is 1G. You may want to allocate less or more memory to your application, this can also be done via Bluemix WEB interface. Note that the allocated memory affects the Runtime Cost. -
nameis the name of the Tomcat application you have created in the Cloud above. -
host: the same as name. -
env: the environment variables used to set the Tomcat and Java versions.
-
-
In the command line switch to the root directory of your CUBA project.
cd your_project_directory -
Connect to Bluemix.
bluemix api https://api.ng.bluemix.net -
Log in to your Bluemix account.
cf login -
Deploy your WAR to your Tomcat.
cf pushThe
pushcommand gets all the required parameters from themanifest.ymlfile. -
You can find Tomcat server logs via Bluemix WEB-interface in the Logs tab on the application dashboard, as well as in command line using the command
cf logs cuba-app --recent -
After the deployment process is completed, your application will become accessible in browser using the URL
host.domain. This URL will be displayed in the ROUTE field in the table of your Cloud Foundry Apps.
6.2.7. Deployment to Heroku Cloud
The section describes how to deploy CUBA applications to the Heroku® cloud platform.
|
Tip
|
This tutorial covers deployment of a project using PostgreSQL database. |
6.2.7.1. WAR Deployment to Heroku
- Heroku account
-
First, create an account on Heroku using the web browser, free account
hobby-devis enough. Then login to the account and create new application using New button at the top of the page.Select unique name (or left the field blank to assign automatically) and choose a server location. Now you have an application, for example
morning-beach-4895, this is the Heroku application name.First time you will be redirected to the Deploy tab. Use Heroku Git deployment method.
- Heroku CLI
-
-
Install Heroku CLI on your computer.
-
Navigate to the folder containing your CUBA project. Further on we will use
$PROJECT_FOLDERfor it. -
Open command prompt in
$PROJECT_FOLDERand type:heroku login -
Enter your credentials when prompted. From now on you don’t need to enter credentials for this project anymore.
-
Install Heroku CLI deployment plugin:
heroku plugins:install heroku-cli-deploy
-
- PostgreSQL database
-
Using the web browser go to Heroku data page
You can choose existent Postgres database or create one. Next steps describe how to create a new database.
-
Find Heroku Postgres block and click Create one
-
On the next screen click Install Heroku Postgr…
-
Connect the database to Heroku application selected from a dropdown list
-
Select your Plan (for example:
hobby-dev)
Alternatively, you can install PostgreSQL using Heroku CLI:
heroku addons:create heroku-postgresql:hobby-dev --app morning-beach-4895Here
morning-beach-4895is your Heroku application name.Now you can find the new database on the Resources tab. The database is connected to the Heroku application. To obtain database credentials go to the Datasource page of your Heroku database, scroll down to Administration section and click View credentials button.
Host compute.amazonaws.com Database d2tk User nmmd Port 5432 Password 9c05 URI postgres://nmmd:9c05@compute.amazonaws.com:5432/d2tk
-
- Project deployment settings
-
-
We assume that you use PostgreSQL with your CUBA project.
-
Open your CUBA project in Studio, navigate to Deployment settings, go to WAR tab and then configure options as described below.
-
Select Build WAR
-
Set application home directory to '.' (dot)
-
Select Include JDBC driver
-
Select Include Tomcat’s context.xml
-
Click Generate button next to the Custom context.xml path field. Fill your database connection details in modal window.
-
Open the file generated
modules/core/web/META-INF/war-context.xmland check connection params and credentials:<Context> <!-- Database connection --> <Resource name="jdbc/CubaDS" type="javax.sql.DataSource" maxTotal="20" maxIdle="2" maxWaitMillis="5000" driverClassName="org.postgresql.Driver" url="jdbc:postgresql://compute.amazonaws.com/d2tk" username="nmmd" password="9c05"/> <!-- ... --> </Context> -
Select Single WAR for Middleware and Web Client
-
Click Generate button next to the Custom web.xml path field
-
Copy the code shown below and paste it into the App properties field:
[ 'cuba.automaticDatabaseUpdate' : true ] -
Save deployment settings.
-
-
- Build WAR file
-
Build WAR file by executing the
buildWarGradle task. You can do it right from the Studio Search dialog or from the command line:gradlew buildWarIn order to use
gradlewcommand in the command line, create Gradle wrapper using Studio Build menu command beforehand. - Application setup
-
-
Download Tomcat Webapp Runner from https://mvnrepository.com/artifact/com.github.jsimone/webapp-runner. The version of Webapp Runner must conform to the Tomcat version in use. For example, version 8.5.11.3 of Webapp Runner is suitable for Tomcat version 8.5.11. Rename JAR to
webapp-runner.jarand place it into$PROJECT_FOLDER. -
Download Tomcat DBCP from https://mvnrepository.com/artifact/org.apache.tomcat/tomcat-dbcp. Use the version corresponding to your Tomcat version, for example 8.5.11. Create
$PROJECT_FOLDER/libs, rename JAR totomcat-dbcp.jarand place it into the$PROJECT_FOLDER/libsfolder. -
Create a file named
Procfilein$PROJECT_FOLDER. The file should contain the following text:web: java $JAVA_OPTS -cp webapp-runner.jar:libs/* webapp.runner.launch.Main --enable-naming --port $PORT build/distributions/war/app.war
-
- Git setup
-
Open the command prompt in
$PROJECT_FOLDERand run the commands listed below:git init heroku git:remote -a morning-beach-4895 git add . git commit -am "Initial commit" - Application deployment
-
Open the command prompt and run the following command:
On *nix:
heroku jar:deploy webapp-runner.jar --includes libs/tomcat-dbcp.jar:build/distributions/war/app.war --app morning-beach-4895On Windows:
heroku jar:deploy webapp-runner.jar --includes libs\tomcat-dbcp.jar;build\distributions\war\app.war --app morning-beach-4895Open the Resources tab in Heroku dashboard. A new Dyno should appear with a command from your
Procfile:
The application is deploying now. You can monitor logs to track the process.
- Logs monitoring
-
Wait for a message
https://morning-beach-4895.herokuapp.com/ deployed to Herokuin command window.In order to track application logs, run the following command in the command line:
heroku logs --tail --app morning-beach-4895
After the deployment process is completed your application will be accessible in web browser by an URL like https://morning-beach-4895.herokuapp.com.
You can also open the application from the Heroku dashboard using the Open app button.
6.2.7.2. Deployment from GitHub to Heroku
This guide is intended for developers who have a CUBA project located on GitHub.
- Heroku account
-
Create an account on Heroku using the web browser, free account
hobby-devis enough. Then login to the account and create new application using New button at the top of the page.Select unique name (or left the field blank to assign automatically) and choose a server location. Now you have an application, for example
space-sheep-02453, this is a Heroku application name.First time you will be redirected to Deploy tab. Use GitHub deployment method. Follow the screen instructions how to authorize your GitHub account. Click Search button to list all available Git repositories then connect to desired repo. When your Heroku application is connected to GitHub you are able to activate Automatic Deploys. This allows to redeploy Heroku application automatically on each Git push event. In this tutorial the option is enabled.
- Heroku CLI
-
-
Install Heroku CLI
-
Open command prompt in any folder of your computer and type:
heroku login -
Enter your credentials when prompted. From now on you don’t need to enter credentials for this project.
-
- PostgreSQL database
-
-
Return to web browser with Heroku dashboard
-
Go to Resources tab
-
Click Find more add-ons button to find the database add-on
-
Find Heroku Postgres block and click it. Follow the instruction on the screen, click Login to install / Install Heroku Postgres.
Alternatively, you can install PostgreSQL using Heroku CLI:
heroku addons:create heroku-postgresql:hobby-dev --app space-sheep-02453where
space-sheep-02453is your Heroku application name.Now you can find the new database on the Resources tab. The database is connected to the Heroku application. To obtain database credentials go to the Datasource page of your Heroku database, scroll down to Administration section and click View credentials button.
Host compute.amazonaws.com Database zodt User artd Port 5432 Password 367f URI postgres://artd:367f@compute.amazonaws.com:5432/zodt
-
- Project deployment settings
-
-
Navigate to your local CUBA project folder (
$PROJECT_FOLDER) -
Copy the content of
modules/core/web/META-INF/context.xmltomodules/core/web/META-INF/heroku-context.xml -
Fill
heroku-context.xmlwith your actual database connection details (see example below):<Context> <Resource driverClassName="org.postgresql.Driver" maxIdle="2" maxTotal="20" maxWaitMillis="5000" name="jdbc/CubaDS" password="367f" type="javax.sql.DataSource" url="jdbc:postgresql://compute.amazonaws.com/zodt" username="artd"/> <Manager pathname=""/> </Context>
-
- Build configuration
-
Add the following Gradle task to your
$PROJECT_FOLDER/build.gradletask stage(dependsOn: ['setupTomcat', ':app-core:deploy', ':app-web:deploy']) { doLast { // replace context.xml with heroku-context.xml def src = new File('modules/core/web/META-INF/heroku-context.xml') def dst = new File('deploy/tomcat/webapps/app-core/META-INF/context.xml') dst.delete() dst << src.text // change port from 8080 to heroku $PORT def file = new File('deploy/tomcat/conf/server.xml') file.text = file.text.replace('8080', '${port.http}') // add local.app.properties for core application def coreConfDir = new File('deploy/tomcat/conf/app-core/') coreConfDir.mkdirs() def coreProperties = new File(coreConfDir, 'local.app.properties') coreProperties.text = ''' cuba.automaticDatabaseUpdate = true ''' // rename deploy/tomcat/webapps/app to deploy/tomcat/webapps/ROOT def rootFolder = new File('deploy/tomcat/webapps/ROOT') if (rootFolder.exists()) { rootFolder.deleteDir() } def webAppDir = new File('deploy/tomcat/webapps/app') webAppDir.renameTo( new File(rootFolder.path) ) // add local.app.properties for web application def webConfDir = new File('deploy/tomcat/conf/ROOT/') webConfDir.mkdirs() def webProperties = new File(webConfDir, 'local.app.properties') webProperties.text = ''' cuba.webContextName = / ''' } } - Procfile
-
A command that launches the application on Heroku side is passed by special file
Procfile. Create a file namedProcfilein$PROJECT_FOLDERwith following text:web: cd ./deploy/tomcat/bin && export 'JAVA_OPTS=-Dport.http=$PORT' && ./catalina.sh runThis provides JAVA_OPTS environment setting to Tomcat which starts by catalina script.
- Premium addons
-
If your project uses CUBA Premium Add-ons, set additional variables for the Heroku application.
-
Open the Heroku dashboard.
-
Go to the Settings tab.
-
Expand the Config Variables section clicking the Reveal Config Vars button.
-
Add new Config Vars using your license key parts (separated by dash) as username and password:
CUBA_PREMIUIM_USER | username CUBA_PREMIUM_PASSWORD | password
-
- Gradle wrapper
-
Your project requires Gradle wrapper. You can use CUBA Studio to add it: see the Build > Create or update Gradle wrapper main menu command.
-
Create the
system.propertiesfile in$PROJECT_FOLDERwith the following content (example corresponds to local JDK 1.8.0_121 installed):java.runtime.version=1.8.0_121 -
Check that files
Procfile,system.properties,gradlew,gradlew.batandgradleare not in.gitignore -
Add these files to repository and commit it
git add gradlew gradlew.bat gradle/* system.properties Procfile git commit -am "Added Gradle wrapper and Procfile" -
- Application deployment
-
Once you commit and push all changes to GitHub, Heroku starts redeploying the application.
git pushBuilding process is available in the dashboard on the Activity tab. Click View build log link to track the build log.
After building process is completed, your application will become accessible in browser using the
https://space-sheep-02453.herokuapp.com/. You can open the application from Heroku dashboard using the Open app button. - Logs monitoring
-
Heroku application log is shown by console command:
heroku logs --tail --app space-sheep-02453Tomcat logs are also available in web application: Menu > Administration > Server Log
6.3. Application Scaling
This section describes ways to scale a CUBA application that consists of the Middleware and the Web Client for increased load and stronger fault tolerance requirements.
|
Stage 1. Both blocks are deployed on the same application server. This is the simplest option implemented by the standard fast deployment procedure. In this case, maximum data transfer performance between the Web Client and the Middleware is provided, because when the cuba.useLocalServiceInvocation application property is enabled, the Middleware services are invoked bypassing the network stack. |
|
|
Stage 2. The Middleware and the Web Client blocks are deployed on separate application servers. This option allows you to distribute load between two application servers and use server resources better. Furthermore, in this case the load coming from web users has smaller effect on the other processes execution. Here, the other processes mean handling other client types (for example, Desktop), running scheduled tasks and, potentially, integration tasks which are performed by the middle layer. Requirements for server resources:
In this case and when more complex deployment options are used, the Web Client’s cuba.useLocalServiceInvocation application property should be set to |
|
Stage 3. A cluster of Web Client servers works with one Middleware server. This option is used when memory requirements for the Web Client exceed the capabilities of a single JVM due to a large number of concurrent users. In this case, a cluster of Web Client servers (two or more) is started and user connection is performed through a Load Balancer. All Web Client servers work with one Middleware server. Duplication of Web Client servers automatically provides fault tolerance at this level. However, the replication of HTTP sessions is not supported, in case of unscheduled outage of one of the Web Client servers, all users connected to it will have to login into the application again. Configuration of this option is described in Setting up a Web Client Cluster. |
|
Stage 4. A cluster of Web Client servers working with a cluster of Middleware servers. This is the most powerful deployment option providing fault tolerance and load balancing for the Middleware and the Web Client. Connection of users to the Web Client servers is performed through a load balancer. The Web Client servers work with a cluster of Middleware servers. They do not need an additional load balancer – it is sufficient to determine the list of URLs for the Middleware servers in the cuba.connectionUrlList application property. Another option is to use Apache ZooKeeper Integration Add-on for dynamic discovery of middleware servers. Middleware servers exchange the information about user sessions, locks, etc. In this case, full fault tolerance of the Middleware is provided – in case of an outage of one of the servers, execution of requests from client blocks will continue on an available server without affecting users. Configuration of this option is described in Setting up a Middleware Cluster. |
|
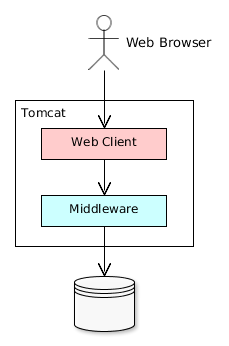
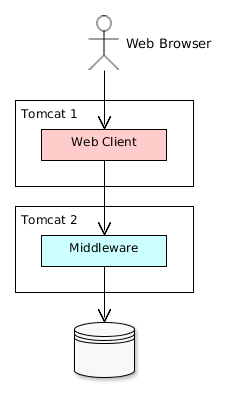
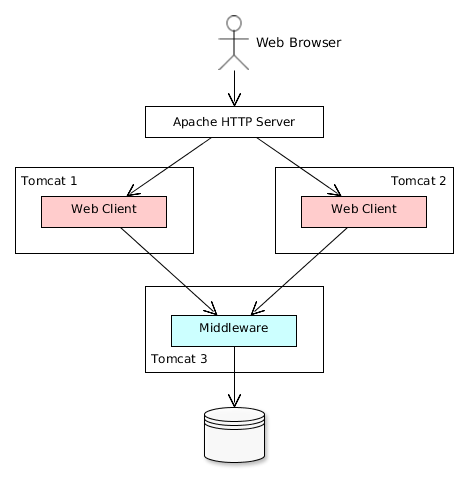
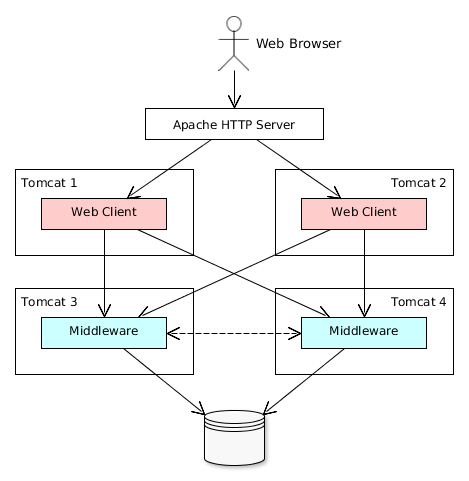
6.3.1. Setting up a Web Client Cluster
This section describes the following deployment configuration:
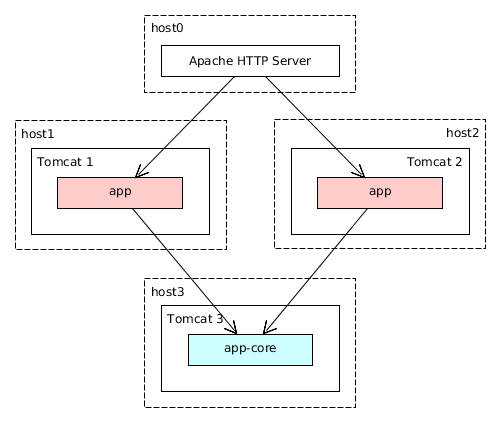
Servers host1 and host2 host Tomcat instances with the app web-app implementing the Web Client block. Users access the load balancer at http://host0/app, which redirects their requests to the servers. Server host3 hosts a Tomcat instance with the app-core web-app that implements the Middleware block.
6.3.1.1. Installing and Setting up a Load Balancer
Let us consider the installation of a load balancer based on Apache HTTP Server for Ubuntu 14.04.
-
Install Apache HTTP Server and its mod_jk module:
$ sudo apt-get install apache2 libapache2-mod-jk -
Replace the contents of the
/etc/libapache2-mod-jk/workers.propertiesfile with the following:workers.tomcat_home= workers.java_home= ps=/ worker.list=tomcat1,tomcat2,loadbalancer,jkstatus worker.tomcat1.port=8009 worker.tomcat1.host=host1 worker.tomcat1.type=ajp13 worker.tomcat1.connection_pool_timeout=600 worker.tomcat1.lbfactor=1 worker.tomcat2.port=8009 worker.tomcat2.host=host2 worker.tomcat2.type=ajp13 worker.tomcat2.connection_pool_timeout=600 worker.tomcat2.lbfactor=1 worker.loadbalancer.type=lb worker.loadbalancer.balance_workers=tomcat1,tomcat2 worker.jkstatus.type=status -
Add the lines listed below to
/etc/apache2/sites-available/000-default.conf:<VirtualHost *:80> ... <Location /jkmanager> JkMount jkstatus Order deny,allow Allow from all </Location> JkMount /jkmanager/* jkstatus JkMount /app loadbalancer JkMount /app/* loadbalancer </VirtualHost> -
Restart the Apache HTTP service:
$ sudo service apache2 restart
6.3.1.2. Setting up Web Client Servers
|
Tip
|
In the examples below, we provide paths to configuration files as if Fast Deployment in Tomcat is used. |
On the Tomcat 1 and Tomcat 2 servers, the following settings should be applied:
-
In
tomcat/conf/server.xml, add thejvmRouteparameter equivalent to the name of the worker specified in the load balancer settings fortomcat1andtomcat2:<Server port="8005" shutdown="SHUTDOWN"> ... <Service name="Catalina"> ... <Engine name="Catalina" defaultHost="localhost" jvmRoute="tomcat1"> ... </Engine> </Service> </Server> -
Set the following application properties in
tomcat/conf/app/local.app.properties:cuba.useLocalServiceInvocation = false cuba.connectionUrlList = http://host3:8080/app-core cuba.webHostName = host1 cuba.webPort = 8080 cuba.webContextName = appcuba.webHostName, cuba.webPort and cuba.webContextName parameters are not mandatory for WebClient cluster, but they allow easier identification of a server in other platform mechanisms, such as the JMX console. Additionally, Client Info attribute of the User Sessions screen shows an identifier of the Web Client that the current user is working with.
6.3.2. Setting up a Middleware Cluster
This section describes the following deployment configuration:
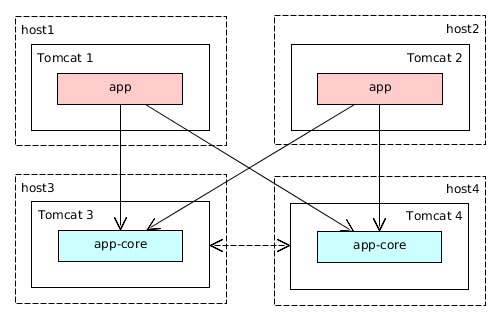
Servers host1 and host2 host Tomcat instances with the app web application implementing the Web Client block. Cluster configuration for these servers is described in the previous section. Servers host3 and host4 host Tomcat instances with the app-core web application implementing the Middleware block. They are configured to interact and share information about user sessions, locks, cash flushes, etc.
|
Tip
|
In the examples below, we provide paths to configuration files as if Fast Deployment in Tomcat is used. |
6.3.2.1. Setting up Connection to the Middleware Cluster
In order for the client blocks to be able to work with multiple Middleware servers, the list of server URLs should be specified in the cuba.connectionUrl application property. For the Web Client, this can be done in tomcat/conf/app/local.app.properties:
cuba.useLocalServiceInvocation = false
cuba.connectionUrlList = http://host3:8080/app-core,http://host4:8080/app-core
cuba.webHostName = host1
cuba.webPort = 8080
cuba.webContextName = appA middleware server is randomly determined on the first remote connection for a user session, and it is fixed for the whole session life time ("sticky session"). Requests from anonymous session and without session do not stick to a server and go to random servers.
The algorithm of selecting a middleware server is provided by the cuba_ServerSorter bean which is by default implemented by the RandomServerSorter class. You can provide your own implementation in your project.
6.3.2.2. Configuring Interaction between Middleware Servers
Middleware servers can maintain shared lists of user sessions and other objects and coordinate invalidation of caches. cuba.cluster.enabled property should be enabled on each server to achieve this. Example of the tomcat/conf/app-core/local.app.properties file is shown below:
cuba.cluster.enabled = true
cuba.webHostName = host3
cuba.webPort = 8080
cuba.webContextName = app-coreFor the Middleware servers, correct values of the cuba.webHostName, cuba.webPort and cuba.webContextName properties should be specified to form a unique Server ID.
Interaction mechanism is based on JGroups. The platform provides two configuration files for JGroups:
-
jgroups.xml- UDP-based stack of protocols which is suitable for local network with enabled broadcast communication. This configuration is used by default when the cluster is turned on. -
jgroups_tcp.xml- TCP-based stack of protocols which is suitable for any network. It requires explicit setting of cluster members addresses inTCP.bind_addrandTCPPING.initial_hostsparameters. In order to use this configuration, set cuba.cluster.jgroupsConfig application property.
In order to set up JGroups parameters for your environment, copy the appropriate jgroups.xml file from the root of cuba-core-<version>.jar to your project core module or to tomcat/conf/app-core and modify it.
ClusterManagerAPI bean provides the program interface for interaction between servers in the Middleware cluster. It can be used in the application – see JavaDocs and usages in the platform code.
6.3.2.3. Using ZooKeeper for Cluster Coordination
There is an application component that enables dynamic discovery of middleware servers for communication between middleware blocks and for requesting middleware from client blocks. It is based on integration with Apache ZooKeeper - a centralized service for maintaining configuration information. When this component is included in your project, you need to specify only one static address when running your application blocks - the address of ZooKeeper. Middleware servers will advertise themselves by publishing their addresses on the ZooKeeper directory and discovery mechanisms will request ZooKeeper for addresses of available servers. If a middleware server goes down, it will be automatically removed from the directory immediately or after a timeout.
6.3.3. Server ID
Server ID is used for reliable identification of servers in a Middleware cluster. The identifier is formatted as host:port/context:
tezis.haulmont.com:80/app-core192.168.44.55:8080/app-coreThe identifier is formed based on the configuration parameters cuba.webHostName, cuba.webPort, cuba.webContextName, therefore it is very important to specify these parameters for the Middleware blocks working within the cluster.
Server ID can be obtained using the ServerInfoAPI bean or via the ServerInfoMBean JMX interface.
6.4. Using JMX Tools
This section describes various aspects of using Java Management Extensions in CUBA-based applications.
6.4.1. Built-In JMX Console
The Web Client module of the cuba application component contains JMX objects viewing and editing tool. The entry point for this tool is com/haulmont/cuba/web/app/ui/jmxcontrol/browse/display-mbeans.xml screen registered under the jmxConsole identifier and accessible via Administration > JMX Console in the standard application menu.
Without extra configuration, the console shows all JMX objects registered in the JVM where the Web Client block of the current user is running. Therefore, in the simplest case, when all application blocks are deployed to one web container instance, the console has access to the JMX beans of all tiers as well as the JMX objects of the JVM itself and the web container.
Names of the application beans have a prefix corresponding to the name of the web-app that contains them. For example, the app-core.cuba:type=CachingFacade bean has been loaded by the app-core web-app implementing the Middleware block, while the app.cuba:type=CachingFacade bean has been loaded by the app web-app implementing the Web Client block.
Figure 33. JMX Console
JMX console can also work with the JMX objects of a remote JVM. This is useful when application blocks are deployed over several instances of a web container, for example separate Web Client and Middleware.
To connect to a remote JVM, a previously created connection should be selected in the JMX Connection field of the console, or a new connection can be created:
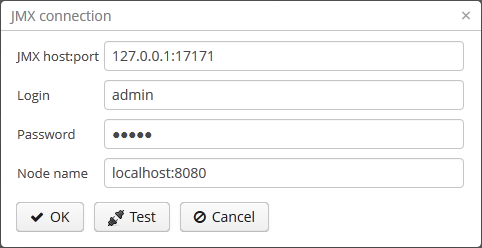
Figure 34. Editing a JMX Connection
To get a connection, JMX host, port, login and password should be specified. There is also the Host name field, which is populated automatically, if any CUBA-application block is detected at the specified address. In this case, the value of this field is defined as the combination of cuba.webHostName and cuba.webPort properties of this block, which enables identifying the server that contains it. If the connection is done to a 3rd party JMX interface, then the Host name field will have the "Unknown JMX interface" value. However it can be changed arbitrarily.
In order to allow a remote JVM connection, the JVM should be configured properly (see below).
6.4.2. Setting up a Remote JMX Connection
This section describes Tomcat startup configuration required for a remote connection of JMX tools.
6.4.2.1. Tomcat JMX for Windows
-
Edit
bin/setenv.batin the following way:set CATALINA_OPTS=%CATALINA_OPTS% ^ -Dcom.sun.management.jmxremote ^ -Djava.rmi.server.hostname=192.168.10.10 ^ -Dcom.sun.management.jmxremote.ssl=false ^ -Dcom.sun.management.jmxremote.port=7777 ^ -Dcom.sun.management.jmxremote.authenticate=true ^ -Dcom.sun.management.jmxremote.password.file=../conf/jmxremote.password ^ -Dcom.sun.management.jmxremote.access.file=../conf/jmxremote.accessHere, the
java.rmi.server.hostnameparameter should contain the actual IP address or the DNS name of the computer where the server is running;com.sun.management.jmxremote.portsets the port for JMX tools connection. -
Edit the
conf/jmxremote.accessfile. It should contain user names that will be connecting to the JMX and their access level. For example:admin readwrite -
Edit the
conf/jmxremote.passwordfile. It should contain passwords for the JMX users, for example:admin admin -
The password file should have reading permissions only for the user running the Tomcat. server. You can configure permissions the following way:
-
Open the command line and go to the conf folder
-
Run the command:`cacls jmxremote.password /P "domain_name\user_name":R`
where
domain_name\user_nameis the user’s domain and name -
After this command is executed, the file will be displayed as locked (with a lock icon) in Explorer.
-
-
If Tomcat is installed as a Windows service, than the service should be started on behalf of the user who has access permissions for jmxremote.password. It should be kept in mind that in this case the
bin/setenv.batfile is ignored and the corresponding JVM startup properties should be specified in the application that configures the service.
6.4.2.2. Tomcat JMX for Linux
-
Edit
bin/setenv.shthe following way:CATALINA_OPTS="$CATALINA_OPTS -Dcom.sun.management.jmxremote \ -Djava.rmi.server.hostname=192.168.10.10 \ -Dcom.sun.management.jmxremote.port=7777 \ -Dcom.sun.management.jmxremote.ssl=false \ -Dcom.sun.management.jmxremote.authenticate=true" CATALINA_OPTS="$CATALINA_OPTS -Dcom.sun.management.jmxremote.password.file=../conf/jmxremote.password -Dcom.sun.management.jmxremote.access.file=../conf/jmxremote.access"Here, the
java.rmi.server.hostnameparameter should contain the real IP address or the DNS name of the computer where the server is running;com.sun.management.jmxremote.portsets the port for JMX tools connection -
Edit
conf/jmxremote.accessfile. It should contain user names that will be connecting to the JMX and their access level. For example:admin readwrite -
Edit the
conf/jmxremote.passwordfile. It should contain passwords for the JMX users, for example:admin admin -
The password file should have reading permissions only for the user running the Tomcat server. Permissions for the current user can be configured the following way:
-
Open the command line and go to the conf folder.
-
Run the command:
chmod go-rwx jmxremote.password
-
6.5. Server Push Settings
CUBA applications use server push technology in the Background Tasks mechanism. It may require an additional setup of the application and proxy server (if any).
By default, server push uses the WebSocket protocol. The following application properties affect the platform server push functionality:
If users connect to the application server via a proxy that does not support WebSocket, set cuba.web.pushLongPolling to true and increase proxy request timeout to 10 minutes or more.
Below is an example of the Nginx web server settings for using WebSocket:
location / {
proxy_set_header X-Forwarded-Host $host;
proxy_set_header X-Forwarded-Server $host;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_read_timeout 3600;
proxy_connect_timeout 240;
proxy_set_header Host $host;
proxy_set_header X-RealIP $remote_addr;
proxy_pass http://127.0.0.1:8080/;
proxy_set_header X-Forwarded-Proto $scheme;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection "upgrade";
}7. Working with Databases
This section provides practical advice on working with databases during application development and in production.
For information on configuration parameters for working with particular DBMS, see the Database Components section.
7.1. Creating the DB Schema
In the process of application development you need to create and maintain the database schema that corresponds to the model entities. The platform offers an approach based on DB create and update scripts to solve this task. The practical steps to apply this approach are provided below.
The task to create and maintain the DB schema consists of two parts: creating the scripts and executing them.
Scripts can be created both manually and using Studio. The process of creating scripts in Studio is provided below. Run the Generate DB scripts command in the Entities section. In this case, Studio will connect to the database defined on the Project properties page and compare the available DB schema with the current data model.
If the database does not exist or does not have SYS_DB_CHANGELOG and SEC_USER tables, the system generates only DB initialization scripts. Otherwise, update scripts are created as well. Then, a page with the generated scripts is opened.
Update scripts are displayed on the Update scripts tab. Scripts with the new status reflect the difference between the current state of the data model and the DB schema. A separate script is created for each new or modified table. Some scripts also contain sets of referential integrity constraints. When the page is closed by clicking OK, the scripts are saved in the db/update/{db_type} directory of the core module.
Scripts that exist in the project and have been applied to the DB before are displayed with the applied status. They cannot be edited or removed.
The Update scripts tab can also display scripts with to be deleted status. These are the scripts available in the project, but not applied to the DB yet. These scripts are removed when you close the page by clicking OK. This is the standard behavior in case the scripts are created during previous scripts generation, but not applied by invoking Update database. In this case, you don’t need them any longer, because the current difference between the DB schema and the data model is reflected in newly generated scripts. However, if the scripts were authored by another developer and retrieved from a version control system, you should cancel the saving and apply the other party’s scripts to your DB first, and then generate new ones.
The Init tables, Init constraints and Init data tabs display DB create scripts that are located in the db/init/{db_type} directory of the core module.
The Init tables tab displays the 10.create-db.sql script that creates the tables. The code related to one and the same table is separated by begin {table_name} ... end {table_name} comments. When an entity in the model is changed, Studio will replace code only for the corresponding table between the comments, while leaving the rest of the code, where manual changes could have been made, untouched. Therefore, do not remove these comments when editing the code manually, otherwise Studio will not be able to properly apply the changes to the existing files.
The Init constraints tab displays the 20.create-db.sql script that creates integrity constraints. It also has table-separating comments that you should not remove.
The Init data tab displays the 30.create-db.sql script designed to provide additional information when initializing the DB. These may be, for example, functions, triggers or DML operators to fill the database with the necessary data. The contents of this script are created manually, if necessary.
|
Tip
|
At the initial stage of application development, when the data model is being actively changed, we recommend using only the DB creation scripts (located in the Init tables, Init constraints, Init data) tabs) and removing the update scripts in the Update scripts tab immediately after invoking the Generate DB scripts command. This is the most simple and reliable way to keep the DB up to date. Of course, it has a major drawback, since applying these scripts recreates the DB from scratch, and all data are lost. You can partially compensate this drawback at the development stage by adding commands to the Init data script that will create primary data upon initialization. Update scripts become a convenient and necessary tool for developing and maintaining the DB at a later stage, when the data model is relatively stable, and the development and production databases have the data that cannot not be lost as a result of recreating the DB from scratch. |
Use DB script execution by Gradle tasks to apply scripts: invoke Run > Create database to recreate the database and Run > Update database to apply the scripts. Please note that these items are available only if the application server is stopped. Of course, you can invoke the corresponding Gradle tasks (createDb and updateDb) at any time from the command line, but if the database or any of its objects are locked, script execution may fail.
7.2. MS SQL Server Specifics
Microsoft SQL Server uses cluster indexes for tables.
By default, a cluster index is based on the table’s primary key, however keys of the UUID type used by CUBA applications are poorly suited for clustered index. We recommend creating UUID primary keys with the nonclustered modificator:
create table SALES_CUSTOMER (
ID uniqueidentifier not null,
CREATE_TS datetime,
...
primary key nonclustered (ID)
)^7.3. Oracle Database Specifics
Due to the distribution policy of Oracle JDBC driver, it can only be downloaded manually from http://www.oracle.com/technetwork/database/features/jdbc/index-091264.html. After downloading, copy ojdbc6.jar file to the lib subdirectory of the CUBA Studio installation path and to the lib subdirectory of the installed Tomcat server. Then stop Studio, stop Gradle daemon by executing
gradle --stopin the command line, then start Studio again.
7.4. MySQL Database Specifics
The MySQL JDBC driver is not distributed with CUBA Studio due to the license restrictions, so you should do the following:
-
Download the driver archive from https://dev.mysql.com/downloads/connector/j
-
Extract JAR file and rename it to
mysql-connector-java.jar -
Copy the JAR file to the
~/.haulmont/studio/lib/directory and to thelibsubdirectory of the installed Tomcat server -
Stop Studio and Gradle daemon by executing
gradle --stopin the command line, then start Studio again
MySQL does not support partial indexes, so the only way to implement a unique constraint for a soft deleted entity is to use the DELETE_TS column in the index. But there is another problem: MySQL allows multiple NULLs in a column with a unique constraint. Since the standard DELETE_TS column is nullable, it cannot be used in the unique index. We recommend the following workaround for creating unique constraints for soft deleted entities:
-
Create a
DELETE_TS_NNcolumn in the database table. This column is not null and is initialized by a default value:create table DEMO_CUSTOMER ( ... DELETE_TS_NN datetime(3) not null default '1000-01-01 00:00:00.000', ... ) -
Create a trigger that will change
DELETE_TS_NNvalue whenDELETE_TSvalue is changed:create trigger DEMO_CUSTOMER_DELETE_TS_NN_TRIGGER before update on DEMO_CUSTOMER for each row if not(NEW.DELETE_TS <=> OLD.DELETE_TS) then set NEW.DELETE_TS_NN = if (NEW.DELETE_TS is null, '1000-01-01 00:00:00.000', NEW.DELETE_TS); end if -
Create a unique index including unique columns and
DELETE_TS_NN:create unique index IDX_DEMO_CUSTOMER_UNIQ_NAME on DEMO_CUSTOMER (NAME, DELETE_TS_NN)
7.5. Connecting to a Non-Default Database Schema
PostgreSQL and Microsoft SQL Server support connection to a specific database schema. By default, the schema is public on PostgreSQL and dbo on SQL Server.
PostgreSQL
In order to use non-default schema on PostgreSQL, specify the currentSchema parameter in the connectionParams property of the createDb and updateDb Gradle tasks, for example:
task createDb(dependsOn: assembleDbScripts, type: CubaDbCreation) {
dbms = 'postgres'
host = 'localhost'
dbName = 'my_db'
connectionParams = '?currentSchema=my_schema'
dbUser = 'cuba'
dbPassword = 'cuba'
}If you are using Studio, add this connection parameter to the Connection params field on the Project properties page. Studio will update build.gradle automatically. After that, you can update or re-create the database, and all tables will be created in the specified schema.
Microsoft SQL Server
On Microsoft SQL Server, providing a connection property is not enough, you have to link the schema with the database user. Below is an example of creating a new database and using a non-default schema in it.
-
Create a login:
create login JohnDoe with password='saPass1' -
Create a new database:
create database my_db -
Connect to the new database as
sa, create a schema, then create a user and give him owner rights:create schema my_schema create user JohnDoe for login JohnDoe with default_schema = my_schema exec sp_addrolemember 'db_owner', 'JohnDoe'
Now you should specify the currentSchema parameter in the connectionParams property of the updateDb Gradle task (or in Studio project properties). In fact, this property is not handled by SQL Server JDBC driver, but it tells Studio and CUBA Gradle plugin what schema to use.
task updateDb(dependsOn: assembleDbScripts, type: CubaDbUpdate) {
dbms = 'mssql'
dbmsVersion = '2012'
host = 'localhost'
dbName = 'my_db'
connectionParams = ';currentSchema=my_schema'
dbUser = 'JohnDoe'
dbPassword = 'saPass1'
}Keep in mind, that you cannot re-create the SQL Server database from Studio or by executing createDb in the command line, because non-default schema requires association with a user. But if you run Update database in Studio or updateDb in the command line, all required tables will be created in the existing database and specified schema.
7.6. Creating and Updating the Database in Production
This section describes different ways of creating and updating a database during application deployment and operation. To learn more about the structure and the rules of database scripts, please see Scripts to Create and Update the Database and Creating the DB Schema.
7.6.1. Execution of Database Scripts by Server
The execution of DB scripts by server mechanism can be used for both database initialization and its further update during the application development and data schema modification.
The following actions should be completed to initialize a new database:
-
Enable the cuba.automaticDatabaseUpdate application property by adding the following line to the local.app.properties file of the Middleware block:
cuba.automaticDatabaseUpdate = trueFor fast deployment to Tomcat, this file is located in the
tomcat/conf/app-coredirectory. If the file does not exist, create it. -
Create an empty database corresponding to the URL specified in the data source description in context.xml.
-
Start the application server containing the Middleware block. At application start, the database will be initialized and ready for work.
After that, each time when the application server starts, a scripts execution mechanism will compare the set of scripts located in the database scripts directory with the list of already executed scripts registered in the database. If new scripts are found, they will be executed and registered as well. Typically it is enough to include the update scripts in each new application version, and the database will be actualized each time when the application server is restarted.
When using the database scripts execution mechanism at server start, the following should be considered:
-
If any error occurs when running a script, the Middleware block stops initialization and becomes inoperable. The client blocks generate messages about inability to connect to the Middleware.
Check the app.log file located in the server’s log folder for a message about SQL execution from the
com.haulmont.cuba.core.sys.DbUpdaterEnginelogger and, possibly, further error messages to identify the error reasons. -
The update scripts, as well as the DDL and the SQL commands within the scripts separated with
"^", are executed in separate transactions. That is why when an update fails there is still a big chance that a part of the scripts or even individual commands of the last script will have been executed and committed to the database.With this in mind, creating a backup copy of the database immediately before starting the server is highly recommended. Then, when the error reason is fixed, the database can be restored and automatic process restarted.
If the backup is missing, you should identify which part of the script was executed and committed after the error is fixed. If the entire script failed to execute, the automatic process can be simply restarted. If some of the commands before the erroneous one were separated with the
"^"character, executed in a separate transaction and committed, then the remaining part of the commands should be run and this script should be registered in SYS_DB_CHANGELOG manually. After that, the server can be started and the automatic update mechanism will start processing the next unexecuted script.CUBA Studio generates update scripts with ";" delimiter for all database types except Oracle. If update script commands are separated by semicolons, the script is executed in one transaction and entirely rolled back in case of failure. This behavior ensures consistency between the database schema and the list of executed update scripts.
7.6.2. Initializing and Updating a Database from The Command Line
Database create and update scripts can be run from the command line using the com.haulmont.cuba.core.sys.utils.DbUpdaterUtil class included in the platform’s Middleware block. At startup, the following arguments should be specified:
-
dbType– DBMS type, possible values: postgres, mssql, oracle, mysql. -
dbVersion– DBMS version (optional argument). -
dbDriver- JDBC driver class name (optional argument). If not provided, the driver class name will be derived fromdbType. -
dbUser– database user name. -
dbPassword– database user password. -
dbUrl– database connection URL. For primary initialization, the specified database should be empty; the database is not cleared automatically in advance. -
scriptsDir– absolute path to the folder containing scripts in the standard structure. Typically, this is the database scripts directory supplied with the application. -
one of the possible commands:
-
create– initialize the database. -
check– show all unexecuted update scripts. -
update– update the database.
-
An example of a script for Linux running DbUpdaterUtil:
#!/bin/sh
DB_URL="jdbc:postgresql://localhost/mydb"
APP_CORE_DIR="./../webapps/app-core"
WEBLIB="$APP_CORE_DIR/WEB-INF/lib"
SCRIPTS="$APP_CORE_DIR/WEB-INF/db"
TOMCAT="./../lib"
SHARED="./../shared/lib"
CLASSPATH=""
for jar in `ls "$TOMCAT/"`
do
CLASSPATH="$TOMCAT/$jar:$CLASSPATH"
done
for jar in `ls "$WEBLIB/"`
do
CLASSPATH="$WEBLIB/$jar:$CLASSPATH"
done
for jar in `ls "$SHARED/"`
do
CLASSPATH="$SHARED/$jar:$CLASSPATH"
done
java -cp $CLASSPATH com.haulmont.cuba.core.sys.utils.DbUpdaterUtil \
-dbType postgres -dbUrl $DB_URL \
-dbUser $1 -dbPassword $2 \
-scriptsDir $SCRIPTS \
-$3This script is designed to work with the database named mydb running on the local PostgreSQL server. The script should be located in the bin folder of the Tomcat server and should be started with {username}, {password} and {command}, for example:
./dbupdate.sh cuba cuba123 updateScript execution progress is displayed in the console. If any error occurs, same actions as described in the previous section for the automatic update mechanism should be performed.
|
Warning
|
When updating the database from the command line, the existing Groovy scripts are started, but only their main part gets executed. Due to the lack of the server context, the script’s |
7.7. Connecting to HSQLDB with External Tools
HSQLDB, also called HyperSQL, is a convenient DBMS for application prototyping that does not require installation and is started automatically within CUBA Studio if the project has been configured to work with this DBMS. This section describes the ways of connecting to HSQLDB with external tools that allow working with DB schema and data directly via SQL.
7.7.1. Connecting with Squirrel SQL
SQuirreL SQL Client is an open-source Java application that enables working with databases via JDBC. You can download Squirrel SQL here: http://squirrel-sql.sourceforge.net.
Before starting Squirrel SQL, find the hsqldb-x.x.x.jar file in the lib folder of your CUBA Studio installation and copy it to the lib folder of Squirrel SQL.
Start Squirrel SQL and go to Drivers. Make sure that HSQLDB Server driver is active.
Open Aliases tab and click the Create a new Alias button.
Fill in the connection properties in the window that appears: Database URL, User Name and Password. The default user name is "sa", the password is empty. The database URL can be copied from the Project properties tab in CUBA Studio, or from the modules/core/web/META-INF/context.xml file of the application project.
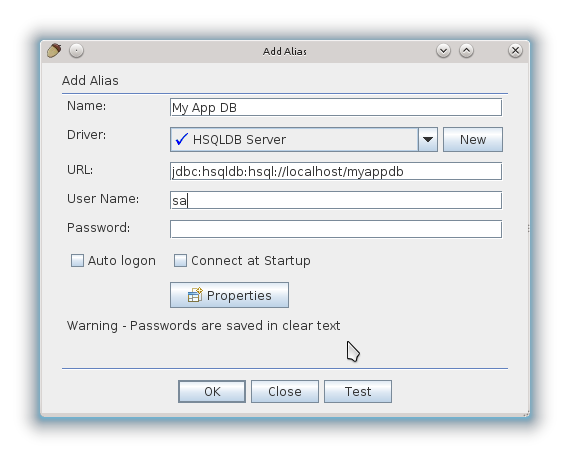
7.7.2. Connecting with IntelliJ IDEA Ultimate
IntelliJ IDEA Ultimate Edition offers convenient tools for working with databases. To connect to HSQLDB, start IDEA and open the Database panel on the right.
If you cannot find the panel, open View → Tool Windows → Database.
In the appeared window select the hsqldb-x.x.x.jar driver that you can copy from the lib folder of your CUBA Studio installation.
Then you should configure data source properties: database URL, User name and Password. Database URL can be copied from the Project properties properties tab in CUBA Studio or from the modules/core/web/META-INF/context.xml file of the application project. The default user name is "sa", the password is empty.
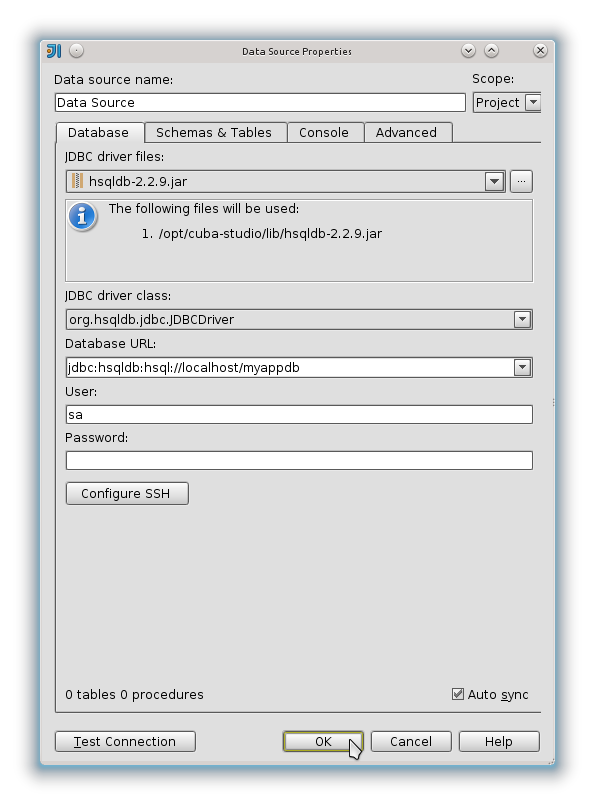
|
Tip
|
If you are using PostgreSQL as the DBMS and To solve this problem, go to the Advanced tab in the data source settings and set |
8. Security Subsystem
The CUBA platform uses the following methods to control access rights:
-
The role-based system for assigning user permissions. A set of roles and permissions can be configured by the system administrator during the system deployment or later in production.
-
A hierarchical structure of access groups with constraint inheritance.
-
Access control at the following levels:
-
Operations on entities (read, create, update, delete): for example, user
Smithcan view documents, but cannot create, update or delete them. -
Entity attributes (modify, read, access denied): user
Smithcan view all document attributes except foramount. -
Access to particular entity instances (access control at the row level): user
Smithcan view the documents that have been created in their department only.
-
-
Integration with LDAP with an ability to implement SSO (Single Sign-On) for Windows users.
8.1. Security Subsystem Components
The main CUBA security subsystem components are shown in the diagram below.
Figure 35. Security Subsystem Components Diagram
Below is an overview of these components.
Security management screens – screens available to system administrator for configuring user access rights.
Login screen − system login window. This window provides user authentication by username and password. The database stores password hashes for security.
The UserSession object is created upon login. This is the central security element associated with the currently authenticated user and containing information on data access rights.
The user login process is described in Login.
Roles − user roles. A role is a system object, which, on the one hand, matches the permission set required to perform specific functions, and on the other hand, the subset of users who must have these permissions.
The permissions can have the following types:
-
Screen Permissions − an ability to open a screen.
-
Entity Operation Permissions − an ability to perform operations with an entity: read, create, update, delete.
-
Entity Attribute Permissions − access to an arbitrary entity attribute: modify, read only, access denied.
-
Specific Permissions − permissions for some named functionality.
-
UI Permissions − control access to screen elements.
Access Groups − user access groups. The groups have a hierarchical structure, with each element defining a set of constraints, allowing controlling access to individual entity instances (at table row level). For example, users can view the documents that have been created in their department only.
8.1.1. Login Screen
The login screen provides ability to register within the system with a login name and password. The login name is case-insensitive.
The Web Client’s Remember Me checkbox can be configured by using the cuba.web.rememberMeEnabled application property. The drop-down list of supported languages on the standard login screen can be configured with the cuba.localeSelectVisible and cuba.availableLocales application properties.
See also the cuba.web.loginDialogDefaultUser, cuba.web.loginDialogDefaultPassword and cuba.web.loginDialogPoweredByLinkVisible application properties.
In Web Client, the standard login window can be customized or completely replaced in the project using the Screens > Create login window link in Studio. See also Web Client Specifics.
The platform has a mechanism for the protection against password brute force cracking. It is described in the Login section.
8.1.2. Users
Each system user has a corresponding instance of sec$User entity, containing unique login, password hash, reference to access group and list of roles, and other attributes. User management is carried out using the Administration > Users screen:
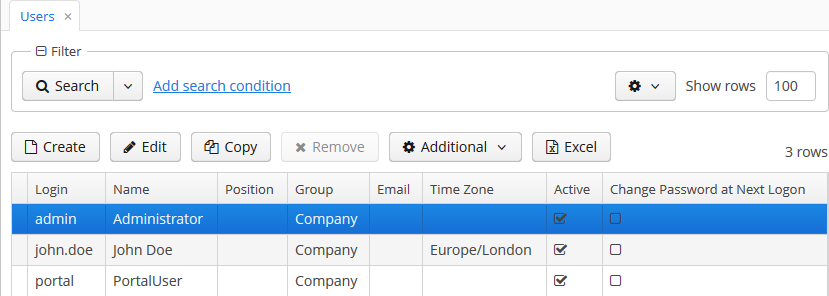
In addition to the standard actions to create, update and delete records, the following actions are available:
-
Copy – quickly creates a new user based on the selected one. The new user will have the same access group and role set. Both can be changed in the new user edit screen.
-
Copy settings – enables copying user interface settings from one user to several others. The settings include the table presentations, the SplitPanel separator position, filters and search folders.
-
Change password – allowing changing password for a selected user.
-
Reset passwords – enables performing the following actions on selected users:
-
If Generate new passwords flag is not selected in the Reset passwords for selected users dialog, the Change password at next logon flag will be assigned to selected users. These users will be asked to change the password on the next successful login.
-
If Generate new passwords flag is selected, new random passwords will be generated for selected users and displayed to the system administrator. The list of passwords can be exported to XLS and sent to related users. Additionally, the Change password at next logon flag will be set for each user, ensuring that users change the password on next login.
-
If Send emails with generated passwords flag is selected in addition to Generate new passwords, the automatically generated one-time passwords will be sent to corresponding users directly, and not shown to system administrator. The sending is done asynchronously so it requires a special scheduled task mentioned in section Sending Methods.
The template of password reset emails can be modified. Create custom templates in the core module, taking reset-password-subject.gsp and reset-password-body.gsp as an example. In order to localize templates, if needed, create files with locale suffixes, as it is done in the platform.
Then in the
app.propertiesof the core module specify the following properties:cuba.security.resetPasswordTemplateBody = <relative path to your file> cuba.security.resetPasswordTemplateSubject = <relative path to your file>For easier configuration in production, the templates can also be located or overridden in the configuration directory, with the properties added to the
local.app.propertiesfile.
-
The user edit screen is described below:
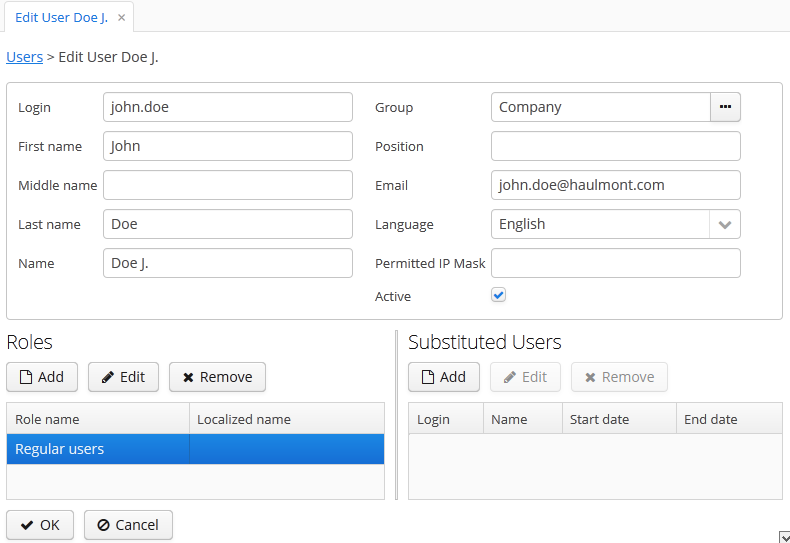
-
Login – unique login name (required).
-
Group – access group.
-
Last name, First name, Middle name – parts of user’s full name.
-
Name – automatically generated user’s full name. Based on full name parts above and a rule defined in the cuba.user.fullNamePattern application property. The name can also be changed manually.
-
Position – job position.
-
Language – the user interface language that will be set for the user, if the ability to choose a language on login is turned off using the cuba.localeSelectVisible application property.
-
Time Zone – the time zone that will be used for displaying and entering timestamp values.
-
Email – email address.
-
Active – if not set, the user is unable to login to the system.
-
Permitted IP Mask – IP address mask, defining addresses from which the user is allowed to login.
The mask is a list of IP addresses, separated with commas. Both the IPv4 and IPv6 address formats are supported. IPv4 address should consist of four numbers separated with periods. IPv6 address represents eight groups of four hexadecimal characters separated with colons.The "*" symbol can be used in place of an address part, to match any value. Only one type of address format (IPv4 or IPv6) can be used in the mask at the same time.
Example:
192.168.*.* -
Roles – user roles list.
-
Substituted Users – substituted users list.
8.1.2.1. User Substitution
The system administrator can give a user an ability to substitute another user. The substituting user will have the same session, but a different set of roles, constraints and attributes, assigned from the substituted user.
|
Tip
|
It is recommended to use the |
If the user has substituted users, a drop-down list will be shown in the application upper right corner instead of the plain text with the current user name:
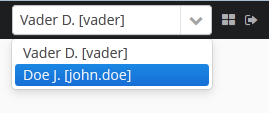
If another user is selected in this list, all opened screens will be closed and the substitution will be made active. The UserSession.getUser() method will still return the user that has logged in, however, the UserSession.getSubstitutedUser() method will return the substituted user. If there is no substitution, the UserSession.getSubstitutedUser() method will return null.
Substituted users can be managed through the Substituted Users table in the user edit screen. The user substitution screen is described below:
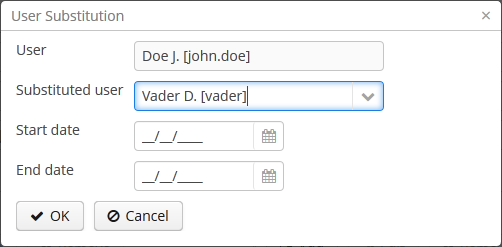
-
User – the edited user. This user will substitute another user.
-
Substituted user – the substituted user.
-
Start date, End date – optional substitution period. User substitution will be unavailable outside of this period. If no period is specified, substitution will be available until this table entry is removed.
8.1.2.2. Time Zone
By default, all temporal values are displayed in the server’s time zone. The server’s time zone is the one returned by TimeZone.getDefault() method of an application block. This default time zone is typically obtained from the operating system but can be set explicitly by user.timezone Java system property. For example, to set the time zone to GMT for web client and middleware running on Tomcat under Unix, add the following line to tomcat/bin/setenv.sh file:
CATALINA_OPTS="$CATALINA_OPTS -Duser.timezone=GMT"A user can view and edit timestamp values in a time zone different from server’s time zone. There are two ways to manage user’s time zone:
-
An administrator can do it in the User editor screen.
-
The user can change his time zone in the Help > Settings window.
In both cases, the time zone settings consist of two fields:
-
Time zone name dropdown allows a user to select the time zone explicitly.
-
Auto checkbox indicates that the time zone will be obtained from the current environment (web browser for the web client or OS for the desktop client).
If both fields are empty, no time zone conversions are performed for the user. Otherwise, the platform saves time zone in the UserSession object when user logs in and uses it for displaying and entering timestamp values. The application code can also use the value returned by UserSession.getTimeZone() for custom functionality.
If a time zone is in use for the current session, its short name and offset from GMT are displayed in the application main window next to the current user’s name.
|
Tip
|
Time zone conversions are performed only for DateTimeDatatype entity attributes, i.e., timestamps. Attributes storing date ( |
8.1.3. Permissions
The permission determines the user’s right to any system object or functionality, such as screen, entity operation, etc. The permission can either grant the user the right to the object, or revoke it (in essence, it is actually a prohibition).
|
Tip
|
By default, the user has the right to an object, unless explicitly denied by a permission. |
The permissions are granted by the sec$Permission entity instances and contain the following attributes:
-
type– permission type: determines the object type the permission is imposed on. -
target– permission object: determines the specific object the permission is imposed on. The format of the attribute depends on the permission type. -
value– permission value. The value range depends on the permission type.
The permission types are described below:
-
PermissionType.SCREEN– screen permission.The screen identifier should be specified in the
targetattribute; thevalueattribute can be 0 or 1 (the screen is denied or allowed, respectively).The screen permissions are checked when building the system main menu and with each invocation of the
openWindow(),openEditor(),openLookup()methods of the Frame interfaces.To check the screen permission in the application code, use the
isScreenPermitted()method of the Security interface. -
PermissionType.ENTITY_OP– entity operation permission.The entity name should be specified in the
targetattribute, followed by a colon, and then an operation type:create,read,update,delete. For example:library$Book:delete. Thevalueattribute can be 0 or 1 (the operation is denied or allowed, respectively).The entity operation permissions are checked when working with data through the DataManager, in data aware visual components, and in standard actions, which work with entity lists. As a result, the operation permissions affect the behavior of the client blocks and the REST API. The permissions are not checked when working with data on the Middleware directly via the EntityManager.
To check the entity operation permission in the application code, use the
isEntityOpPermitted()method of the Security interface. -
PermissionType.ENTITY_ATTR– entity attribute permission.The entity name should be specified in the
targetattribute, followed by a colon, and then an attribute name. For example:library$Book:name. Thevalueattribute can be 0, 1 or 2 (the attribute is hidden, read-only or read-write, respectively).The entity attribute permissions are only checked in the data aware visual components and the REST API.
To check the entity attribute permission in the application code, use the
isEntityAttrPermitted()method of the Security interface. -
PermissionType.SPECIFIC– permission on an arbitrary named functionality. Specific permissions can be used instead of roles for binary permitting/denying some project-specific functionality, as roles are designed for aggregating permissions.The functionality identifier should be specified in the
targetattribute; thevalueattribute can be 0 or 1 (denied or allowed, respectively).Specific permissions for this project are set in the configuration file permissions.xml.
For example:
@Inject private Security security; private void calculateBalance() { if (!security.isSpecificPermitted("myapp.calculateBalance")) return; ... } -
PermissionType.UI– arbitrary screen component permission.The screen identifier should be specified in the
targetattribute, followed by a colon, and then a component path. The format of the component path is described in the next section.
8.1.4. Roles
The role combines a set of permissions that can be granted to the user.
The user may have several roles, in which case a logical sum (OR) is devised from all of the assigned roles. For example, if a user has roles A, B and C, role A denies X, role B allows X, role C does not set explicit permissions on X, then X will be allowed.
If no user roles explicitly define permission on the object, the user will have the permission for this object. Therefore, the users have rights to all the objects if they have no roles that explicitly define the permission, or have at least one role that grants the permission.
|
Warning
|
If a user has a single role without explicitly set permissions, or does not have any roles at all, he will have all rights to all objects. |
The role list is displayed in the Administration > Roles screen. In addition to the standard actions to create, update, and delete records, the screen has the Assign to users button, allowing assigning the selected role to multiple users.
The role edit screen is described below. The role attributes are displayed in the upper part:

-
Name – unique role name or id (required). The name cannot be changed after the role has been created.
-
Localized name – user-friendly role name.
-
Description – arbitrary role description.
-
Type – role type, can be:
-
Standard – the role of this type grants only explicitly set permissions.
-
Super – the role of this type automatically grants all permissions. It should be assigned to system administrators, since it removes all prohibitions set by other roles.
-
Read-only – the role of this type automatically denies the permissions for the following entity operations: CREATE, UPDATE, DELETE. Therefore, the user with this role can only read the data and is unable to update it (unless there are other user roles explicitly allowing these operations).
-
Denying – the role of this type automatically denies the permissions for all objects, except entity attributes. In order to view or update something in the system, the user should be assigned an additional role that explicitly gives the necessary rights.
Permissions can be explicitly set for all the role types; for example, you can add the permissions to modify entities for the Read-only role. However, it does not make sense to prohibit anything for the Super role, because this special role type removes all prohibitions.
-
-
Default role – default role flag. All roles with this flag are automatically assigned to the newly created users.
The permission management tabs are described below.
-
The Screens tab configures screen permissions:
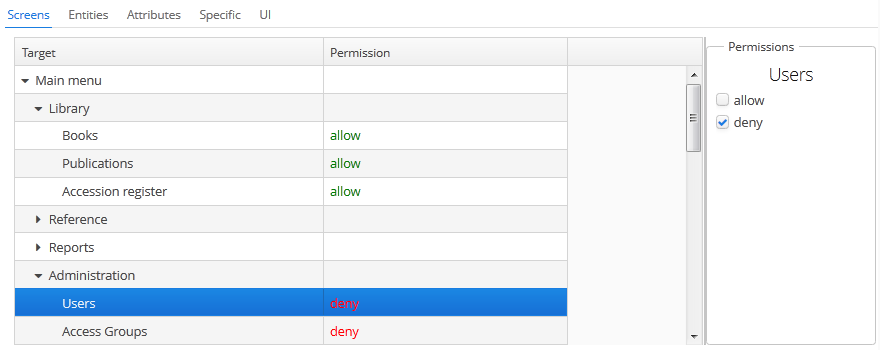
The tree in the left part of the tab reflects the structure of the application’s main menu. The last tree element is Other screens, which contains screens without a main menu item (for example, entity edit screens).
-
The Entities tab – configures entity operation permissions:
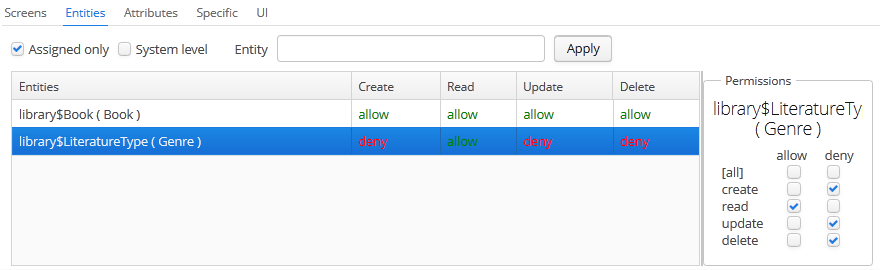
The Assigned only is selected by default, so that the table contains only the entities that have explicit permissions in this role. Therefore, the table for a new role will be empty. In order to add permissions, uncheck Assigned only and click Apply. The entity list can be filtered by entering a part of an entity name in the Entity field and clicking Apply.
System level checkbox enables viewing and selecting system entities marked with the
@SystemLevelannotation, which are not shown by default. -
The Attributes tab – configures entity attribute permissions:
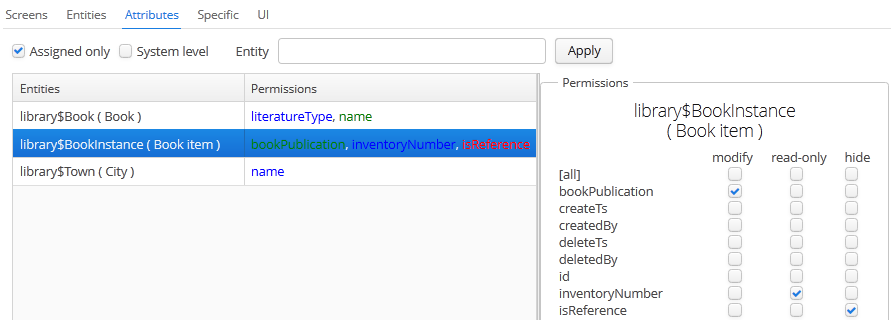
The Permissions column in the entity table shows the list of the attributes that have explicit permissions. The modify (full access) permissions are marked with green, read-only (read-only) – with blue, hide (the attribute is hidden) – with red.
Entity list can be managed similarly to the list in the Entities tab.
-
The Specific tab configures named functionality permissions:
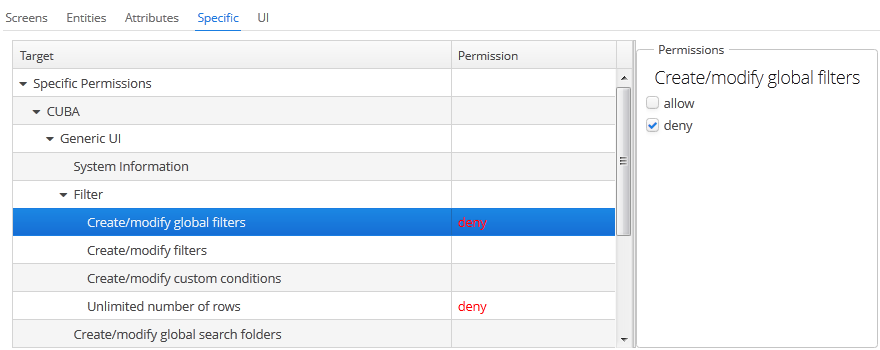
The permissions.xml project configuration file defines the object names to which specific permissions can be assigned.
-
The UI tab configures UI screen component permissions:
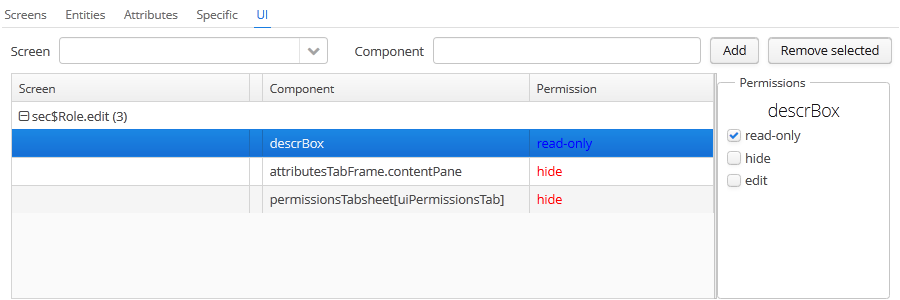
The permissions on this screen allow restricting access to any screen component, including the ones not associated with any data (for example, a container). The component identifiers must be known to create such permissions, therefore access to the screen source code is required.
In order to create a constraint, select the desired screen in the Screen drop-down list, specify the component path in the Component field, and click Add. Then set the access mode for the selected component in the Permissions panel.
The rules to forming the component path are listed below:
-
If the component belongs to the screen, simply specify the component identifier,
id. -
If the component belongs to the frame that is embedded within the screen, specify the frame identifier, and then the component identifier separated with period.
-
If configuring permission for the TabSheet tab or the FieldGroup field, specify the component identifier, and then the tab or field identifier in square brackets.
-
To configure permission for an action, specify the component, holding the action, and then the action identifier in angle brackets. For example:
customersTable<changeGrade>.
-
8.1.5. Access Groups
With access groups, users can be organized into a hierarchical structure and assigned constraints and arbitrary session attributes.
The user can be added to one group only, however the list of constraints and session attributes from all the groups up the hierarchy will be inherited.
User access groups can be managed from the Administration > Access Groups screen:
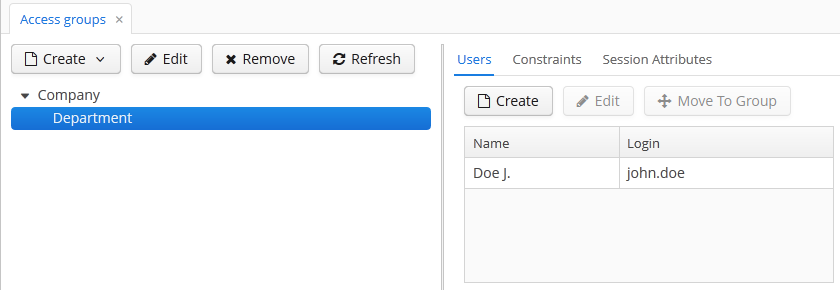
8.1.5.1. Constraints
Constraints restrict user access to entity instances. Unlike the permissions which are applied to classes of entities, constraints are applied to particular entity instances that do not match the contraint conditions. Constraints can be set for creation, reading, updating and deletion. Besides, one can add custom constraints not related to CRUD actions.
|
Tip
|
A user gets the constraints list from all groups starting with their own one, and up the hierarchy. Thus, the following principle is implemented: the lower the users are in the groups hierarchy, the more constraints they have. |
Note that constraints are checked for all operations performed from the client tier through the standard DataManager. If an entity does not match the constraints conditions during creation, modification or deletion, the RowLevelSecurityException is thrown.
There are three types of constraint check: check in database, check in memory, check in database and in memory.
-
For the constraints with check in database, conditions are specified using JPQL expression fragments. These fragments are appended to all entity instance selection queries. So the entities not matching the conditions are filtered on the database level. Constraints with database check can be used only for the read operation.
-
For the constraints with check in memory, the conditions are specified using Groovy expressions. The expressions are executed for every entity in the checked graph of objects, and if the entity does not match the conditions, it is filtered from the graph.
-
The constraints with check in database and in memory are combination of previous two types.
In order to create a constraint, open the Access Groups screen, select a group to create the constraint for, go to the Constraints tab and click Create:
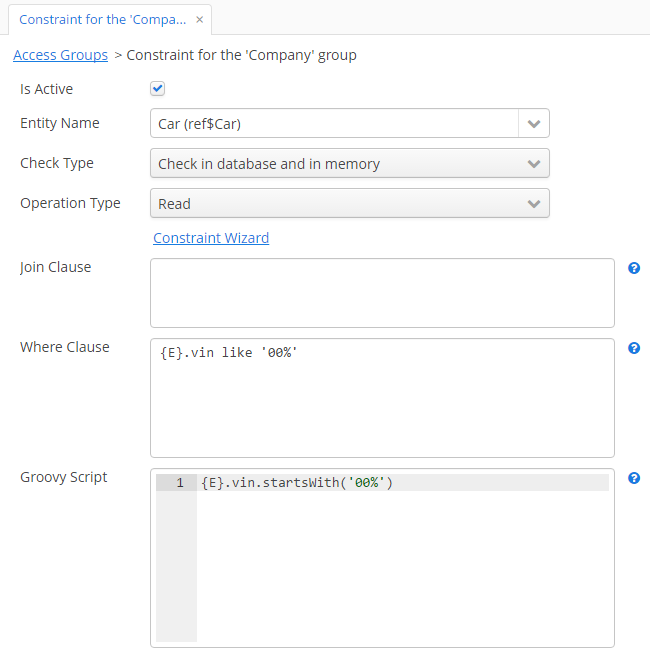
Select an entity from the Entity Name drop-down list, operation type from the Operation Type drop-down list, check type from the Check type drop-down list. Depending on selected check type, you have to set JPQL conditions in the Join Clause and Where Clause fields and/or Groovy condition in the Groovy Script field. You can use the Constraint Wizard, which enables visual creation of the JPQL and Groovy conditions. When you select custom operation type, the required Code field appears, and you should set a specific code, which will be used to identify the constraint.
|
Tip
|
The JPQL editor in the Join Clause and Where Clause fields supports autocompletion for entity names and their attributes. In order to invoke autocompletion, press Ctrl+Space. If the invocation is made after the period symbol, an entity attributes list matching the context will be shown, otherwise – a list of all data model entities. |
The following JPQL constraint rules apply:
-
The
{E}string should be used as an alias of the entity being extracted. On execution of the query, it will be replaced with a real alias, specified in the query. -
The following predefined constants can be used in JPQL parameters:
-
session$userLogin– login name of the current user (in case of substitution – the login name of the substituted user). -
session$userId– ID of the current user (in case of substitution – ID of the substituted user). -
session$userGroupId– group ID of the current user (in case of substitution − group ID of the substituted user). -
session$XYZ– arbitrary attribute of the current user session, where XYZ is the attribute name.
-
-
The Where Clause field content is added to the
wherequery clause usingandcondition. Addingwhereword is not needed, as it will be added automatically. -
The Join Clause field content is added to the
fromquery clause. It should begin with a comma,joinorleft join.
The simplest constraint example is shown on the figure above: users with this constraint will see only ref$Car entity instances that have VIN starting with '00'.
Another common example: if an entity refers to the User entity with many-to-many association, and you want the users to see only the instances they are referred to, you can use the member of JPQL operator in the Where Clause:
(select u from sec$User u where u.id = :session$userId) member of {E}.usersFor an in-memory constraint, the userSession variable of the UserSession type is passed to the Groovy script. So you can use it to get attributes of the current user session, for example:
{E}.createdBy == userSession.user.loginA developer can check the constraints conditions for the particular entity using the following methods of the Security interface:
-
isPermitted(Entity, ConstraintOperationType)- to check constraints by the operation type. -
isPermitted(Entity, String)- to check constraints by the string code.
Also, it is possible to link any item tracking action with a certain constraint. The constraintOperationType attribute should be set for the action XML element.
Example:
<table>
...
<actions>
<action id="create"/>
<action id="edit" constraintOperationType="update"/>
<action id="remove" constraintOperationType="delete"/>
</actions>
</table>8.1.5.2. Session Attributes
The access group can determine the session attribute list for the users in this group. These attributes can be used when setting the constraints. The availability of the session attributes can be checked in the application code at the development stage, so the final system behavior for particular user groups can be controlled at the operation stage.
When logging in, all the attributes set for the user group and for all the groups up the hierarchy will be placed into the user session. If an attribute is found in several levels of the hierarchy, the uppermost group value will be used. Hence, overriding the attribute values at the lower levels of the hierarchy is not possible. In case of the override attempt, the WARN level message will be written to the server log.
In order to create an attribute in the Access Groups screen, select the group to create the attribute for, go to the Session Attributes tab, and click Create:
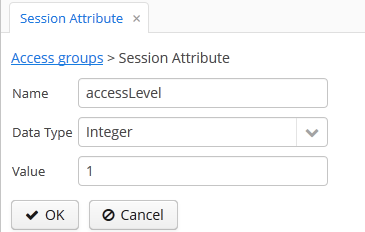
A unique attribute name, data type, and value must be specified.
A session attribute can be accessed in the application code in the following way:
@Inject
private UserSessionSource userSessionSource;
...
Integer accessLevel = userSessionSource.getUserSession().getAttribute("accessLevel");A session attribute can be used in the constraints as a JPQL parameter by adding the session$ prefix:
{E}.accessLevel = :session$accessLevel8.2. Access Control Examples
This section provides some practical recommendations on how to configure data access for users.
8.2.1. Configuring Roles
The recommended way to configure roles and permissions is as follows:
-
Create a
Defaultrole, which revokes all system rights. The simplest way to do it is to create a role of the Denying type. Select the Default role checkbox to automatically assign this role to all new users. -
Create a set of roles for granting specific rights to different user categories. There are two strategies for creating such roles:
-
Coarse-grained roles – each role has a permission set for the full range of user responsibilities in the system. For example,
Sales Manager,Accountant. Only one role is assigned to each user when using this strategy, excluding theDefaultrole. -
Fine-grained roles – each role has a small permission set to execute specific functions within the system. For example,
Task Creator,References Editor. Each user will then be assigned numerous roles according to their range of responsibilities.
The strategies can also be combined.Create a set of roles for granting specific rights to different user categories. There are two strategies for creating such roles:
-
-
It is possible to leave the system administrator without any assigned roles, in which case, they will have all the rights to all the system objects. Alternatively a Super type role, overriding any restriction imposed by other roles, can be assigned.It is possible to leave the system administrator without any assigned roles, in which case, they will have all the rights to all the system objects. Alternatively a Super type role, overriding any restriction imposed by other roles, can be assigned.
8.2.2. Creating Local Administrators
The hierarchical structure of access groups combined with the constraints inheritance enables creating local administrators, by delegating creation and configuration of users and their rights under organization departments.
The local administrators have access to the security subsystem screens; however they only see the users and groups in their access group and below. Local administrators can create subgroups and users and assign roles available in the system, however they will have at least the same constraints as the administrator who created them.
The global administrator in the root access group should create the roles that will be available to the local administrators for assigning to the users. The local administrators should not be able to create and update the roles.
An example access group structure is presented below:
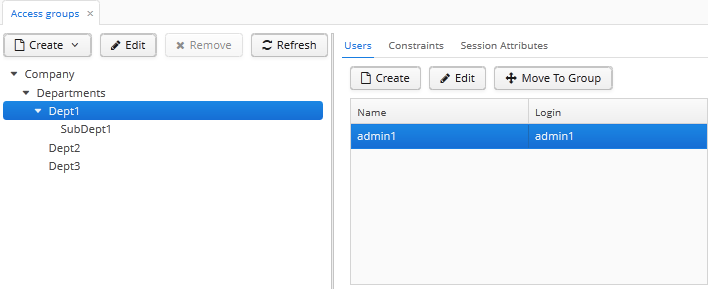
Problem:
-
The users under the
Departmentsgroup should only see the users of their own group and the groups below. -
Each subgroup –
Dept 1,Dept 2, etc. should have its own administrator, who can create users and assign them the available roles.
Solution:
-
Add the following constraints for the
Departmentsgroup: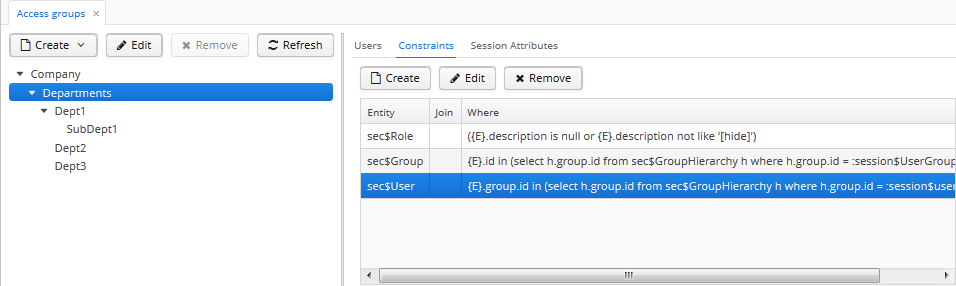
-
For the
sec$Groupentity:{E}.id in ( select h.group.id from sec$GroupHierarchy h where h.group.id = :session$userGroupId or h.parent.id = :session$userGroupId )With this constraint, the users will not be able to see the groups higher than their own.
-
For the
sec$Userentity:{E}.group.id in ( select h.group.id from sec$GroupHierarchy h where h.group.id = :session$userGroupId or h.parent.id = :session$userGroupId )With this constraint, the users will not be able to see the users in groups higher than their own.
-
For the
sec$Roleentity:({E}.description is null or {E}.description not like '[hide]')With this constraint, the users will not be able to view the roles that have the
[hide]string in thedescriptionattribute.
-
-
Create a role that denies editing roles and permissions:
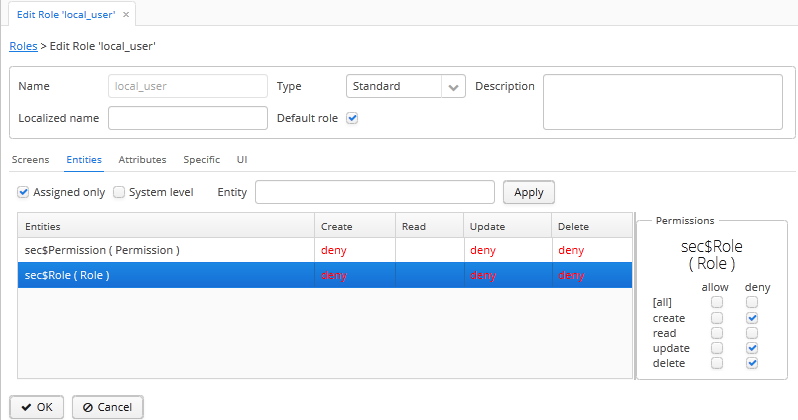
-
Select the Default role checkbox:
-
Add the
[hide]string to the Description field. -
In the Entities tab, deny create, update and delete operations for the
sec$Roleandsec$Permissionentities (to add permissions for thesec$Permissionobject, select the System level checkbox).
All created users, including the local administrators, will get the
local_userrole. This role is invisible to the users in theDepartmentsgroup, so even the local administrators are unable to unassign this role from themselves. Local administrators can only operate on the existing roles that have been created for them by the global administrator. Obviously, the roles available to department users should not remove restrictions imposed by thelocal_userrole. -
8.3. Integration with LDAP
CUBA applications can be integrated with LDAP to provide the following benefits:
-
Storing user passwords centrally in the LDAP database.
-
For Windows domain users, ability to log in using Single Sign-On without having to specify the username and password.
If the LDAP integration is enabled, a user still needs an account in the application. All the user permissions and properties (except password) are stored in the application database, LDAP is used only for authentication. When the user logs in to the application, the first authentication attempt is made via LDAP. If it fails, the application tries to authenticate the user by the password hash stored in the database. As a result, a user can log in to the system with this password even if he is not registered in LDAP or has a different LDAP password. However, it is recommended to leave the application password empty, so that the user could log in using the password from LDAP only (the password field in the user editor screen is not required if the cuba.web.externalAuthentication property is set to true).
A CUBA-based application interacts with LDAP via the CubaAuthProvider interface. The platform includes a single implementation of this interface, LdapAuthProvider, which supports LDAP authentication.
You can use the Jespa library with the corresponding CubaAuthProvider described in the Active Directory Integration Using Jespa section in order to enable advanced integration with Active Directory, including Single Sign-On for Windows domain users.
You can also create your own implementation of the CubaAuthProvider interface and use it by setting the following application properties:
cuba.web.externalAuthentication = true
cuba.web.externalAuthenticationProviderClass = com.company.sample.web.MyAuthProvider8.3.1. Basic LDAP Integration
If the cuba.web.externalAuthentication property is enabled, the LdapAuthProvider class is used by default. In this case, the Spring LDAP library is used for user authentication.
The following Web Client application properties are used to set up LDAP integration:
-
cuba.web.ldap.urls– LDAP server URL. -
cuba.web.ldap.base– base DN for user search. -
cuba.web.ldap.user– the distinguished name of a system user which has the right to read the information from the directory. -
cuba.web.ldap.password– the password for the system user defined in thecuba.web.ldap.userproperty. -
cuba.web.ldap.userLoginField- the name of an LDAP user attribute that is used for matching the login name.sAMAccountNameby default (suitable for Active Directory).
Example of local.app.properties file for the Web Client block:
cuba.web.externalAuthentication = true
cuba.web.ldap.urls = ldap://192.168.1.1:389
cuba.web.ldap.base = ou=Employees,dc=mycompany,dc=com
cuba.web.ldap.user = cn=System User,ou=Employees,dc=mycompany,dc=com
cuba.web.ldap.password = system_user_passwordIn case of the integration with Active Directory, when creating users in the application, specify their sAMAccountName without domain as a login.
8.3.2. Active Directory Integration Using Jespa
Jespa is a Java library that enables integration of Active Directory service and Java applications using NTLMv2. For details, see http://www.ioplex.com.
8.3.2.1. Including the Library
Download the library at http://www.ioplex.com and place the JAR in a repository registered in your build.gradle script. This can be mavenLocal() or an in-house repository.
Add the following dependencies to the web module configuration section in build.gradle:
configure(webModule) {
...
dependencies {
compile('com.company.thirdparty:jespa:1.1.17') // from a custom repository
compile('jcifs:jcifs:1.3.17') // from Maven Central
...Create a CubaAuthProvider implementation class in the web module:
package com.company.sample.web;
import com.haulmont.cuba.core.global.AppBeans;
import com.haulmont.cuba.core.global.Configuration;
import com.haulmont.cuba.core.global.GlobalConfig;
import com.haulmont.cuba.core.global.Messages;
import com.haulmont.cuba.core.sys.AppContext;
import com.haulmont.cuba.security.global.LoginException;
import com.haulmont.cuba.web.auth.CubaAuthProvider;
import com.haulmont.cuba.web.auth.DomainAliasesResolver;
import jespa.http.HttpSecurityService;
import jespa.ntlm.NtlmSecurityProvider;
import jespa.security.PasswordCredential;
import jespa.security.SecurityProviderException;
import org.apache.commons.lang.StringUtils;
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
import javax.inject.Inject;
import javax.servlet.*;
import javax.servlet.http.HttpServletRequest;
import java.io.IOException;
import java.util.HashMap;
import java.util.Locale;
import java.util.Map;
public class JespaAuthProvider extends HttpSecurityService implements CubaAuthProvider {
private static class DomainInfo {
private String bindStr;
private String acctName;
private String acctPassword;
private DomainInfo(String bindStr, String acctName, String acctPassword) {
this.acctName = acctName;
this.acctPassword = acctPassword;
this.bindStr = bindStr;
}
}
private static Map<String, DomainInfo> domains = new HashMap<>();
private static String defaultDomain;
private Log log = LogFactory.getLog(getClass());
@Inject
private Configuration configuration;
@Inject
private Messages messages;
@SuppressWarnings("deprecation")
@Override
public void init(FilterConfig filterConfig) throws ServletException {
initDomains();
Map<String, String> properties = new HashMap<>();
properties.put("jespa.bindstr", getBindStr());
properties.put("jespa.service.acctname", getAcctName());
properties.put("jespa.service.password", getAcctPassword());
properties.put("jespa.account.canonicalForm", "3");
properties.put("jespa.log.path", configuration.getConfig(GlobalConfig.class).getLogDir() + "/jespa.log");
properties.put("http.parameter.anonymous.name", "anon");
fillFromSystemProperties(properties);
try {
super.init(properties);
} catch (SecurityProviderException e) {
throw new ServletException(e);
}
}
@Override
public void destroy() {
}
@Override
public void doFilter(ServletRequest request, ServletResponse response, FilterChain chain)
throws IOException, ServletException {
HttpServletRequest httpServletRequest = (HttpServletRequest) request;
if (httpServletRequest.getHeader("User-Agent") != null) {
String ua = httpServletRequest.getHeader("User-Agent").toLowerCase();
boolean windows = ua.contains("windows");
boolean gecko = ua.contains("gecko") && !ua.contains("webkit");
if (!windows && gecko) {
chain.doFilter(request, response);
return;
}
}
super.doFilter(request, response, chain);
}
@Override
public void authenticate(String login, String password, Locale loc) throws LoginException {
DomainAliasesResolver aliasesResolver = AppBeans.get(DomainAliasesResolver.NAME);
String domain;
String userName;
int atSignPos = login.indexOf("@");
if (atSignPos >= 0) {
String domainAlias = login.substring(atSignPos + 1);
domain = aliasesResolver.getDomainName(domainAlias).toUpperCase();
} else {
int slashPos = login.indexOf('\\');
if (slashPos <= 0) {
throw new LoginException("Invalid name: %s", login);
}
String domainAlias = login.substring(0, slashPos);
domain = aliasesResolver.getDomainName(domainAlias).toUpperCase();
}
userName = login;
DomainInfo domainInfo = domains.get(domain);
if (domainInfo == null) {
throw new LoginException("Unknown domain: %s", domain);
}
Map<String, String> params = new HashMap<>();
params.put("bindstr", domainInfo.bindStr);
params.put("service.acctname", domainInfo.acctName);
params.put("service.password", domainInfo.acctPassword);
params.put("account.canonicalForm", "3");
fillFromSystemProperties(params);
NtlmSecurityProvider provider = new NtlmSecurityProvider(params);
try {
PasswordCredential credential = new PasswordCredential(userName, password.toCharArray());
provider.authenticate(credential);
} catch (SecurityProviderException e) {
throw new LoginException("Authentication error: %s", e.getMessage());
}
}
private void initDomains() {
String domainsStr = AppContext.getProperty("cuba.web.activeDirectoryDomains");
if (!StringUtils.isBlank(domainsStr)) {
String[] strings = domainsStr.split(";");
for (int i = 0; i < strings.length; i++) {
String domain = strings[i];
domain = domain.trim();
if (!StringUtils.isBlank(domain)) {
String[] parts = domain.split("\\|");
if (parts.length != 4) {
log.error("Invalid ActiveDirectory domain definition: " + domain);
break;
} else {
domains.put(parts[0], new DomainInfo(parts[1], parts[2], parts[3]));
if (i == 0)
defaultDomain = parts[0];
}
}
}
}
}
public String getDefaultDomain() {
return defaultDomain != null ? defaultDomain : "";
}
public String getBindStr() {
return getBindStr(getDefaultDomain());
}
public String getBindStr(String domain) {
initDomains();
DomainInfo domainInfo = domains.get(domain);
return domainInfo != null ? domainInfo.bindStr : "";
}
public String getAcctName() {
return getAcctName(getDefaultDomain());
}
public String getAcctName(String domain) {
initDomains();
DomainInfo domainInfo = domains.get(domain);
return domainInfo != null ? domainInfo.acctName : "";
}
public String getAcctPassword() {
return getAcctPassword(getDefaultDomain());
}
public String getAcctPassword(String domain) {
initDomains();
DomainInfo domainInfo = domains.get(domain);
return domainInfo != null ? domainInfo.acctPassword : "";
}
public void fillFromSystemProperties(Map<String, String> params) {
for (String name : AppContext.getPropertyNames()) {
if (name.startsWith("jespa.")) {
params.put(name, AppContext.getProperty(name));
}
}
}
}8.3.2.2. Setting Up Configuration
-
Follow the steps described in Installation → Step 1: Create the Computer Account for NETLOGON Communication of the Jespa Operator’s Manual, which is available at http://www.ioplex.com/support.html.
-
Set domain parameters in the
cuba.web.activeDirectoryDomainsproperty in the local.app.properties file. Each domain descriptor should have the following format:domain_name|full_domain_name|service_account_name|service_account_password. Domain descriptors are separated by semicolons.Example:
cuba.web.activeDirectoryDomains = MYCOMPANY|mycompany.com|JESPA$@MYCOMPANY.COM|password1;TEST|test.com|JESPA$@TEST.COM|password2 -
Enable the Active Directory integration by setting the
cuba.web.externalAuthenticationproperty in thelocal.app.propertiesfile:cuba.web.externalAuthentication = true -
Configure additional Jespa properties in the
local.app.propertiesfile (see Jespa Operator’s Manual). For example:jespa.log.level=3If the application is deployed to Tomcat, Jespa log file can be found in
tomcat/logs. -
Add the server address to the local intranet in the browser settings:
-
For Internet Explorer and Chrome: Settings > Security > Local intranet > Sites > Advanced
-
For Firefox:
about:config>network.automatic-ntlm-auth.trusted-uris=http://myapp.mycompany.com
-
8.4. Single-Sign-On for CUBA Applications
Single-sign-on (SSO) for CUBA applications allows a user to log in to the multiple running applications by entering a single login name and password once in a browser session.
When using SSO, there are two types of applications:
-
Identity Provider (IDP) is an application that provides user authentication. It contains a login form for entering user credentials and checks the credentials against the list of registered users. Only one Identity Provider is allowed in a SSO environment.
-
Service Provider (SP) is a regular application that redirects to IDP for user authentication. SP should contain the same list of users as IDP (passwords do not matter though). SP provides authorization using CUBA security roles and access groups. There may be any number of Service Providers in a SSO environment.
An application can be an Identity Provider and a Service Provider at the same time, so you don’t have to setup a dedicated IDP. The SSO functionality is provided by the cuba-idp module which is a part of the Web Client block. You can develop your applications as usual and setup SSO just on deployment stage if needed.
|
Warning
|
CUBA SSO uses custom HTTP-based protocol and currently does not provide integration with systems using standard authentication protocols like SAML or OIDC. |
In SSO environment, when a user enters a Service Provider URL, the SP redirects to the IDP page for entering login name and password. After successful authentication, IDP redirects back to the SP application and the user transparently logs in to SP.
In order to set up SSO, do the following:
-
On Identity Provider:
-
Add the following settings to the
web.xmlfile of the web module (if you do it on the deployment stage, this file is located by the following path:tomcat/webapps/app/WEB-INF/web.xml):<servlet> <servlet-name>idp</servlet-name> <servlet-class>com.haulmont.idp.sys.CubaIdpServlet</servlet-class> <load-on-startup>3</load-on-startup> </servlet> <servlet-mapping> <servlet-name>idp</servlet-name> <url-pattern>/idp/*</url-pattern> </servlet-mapping> <filter> <filter-name>idpSpringSecurityFilterChain</filter-name> <filter-class>org.springframework.web.filter.DelegatingFilterProxy</filter-class> <init-param> <param-name>contextAttribute</param-name> <param-value>org.springframework.web.servlet.FrameworkServlet.CONTEXT.idp</param-value> </init-param> <init-param> <param-name>targetBeanName</param-name> <param-value>springSecurityFilterChain</param-value> </init-param> </filter> <filter-mapping> <filter-name>idpSpringSecurityFilterChain</filter-name> <url-pattern>/idp/*</url-pattern> </filter-mapping> -
Set the application properties:
-
cuba.idp.serviceProviderUrls - a comma-separated list of service provider URLs (trailing
/are required). For example:cuba.idp.serviceProviderUrls = http://foo:8081/app/,http://bar:8082/app/ -
cuba.idp.serviceProviderLogoutUrls - a comma-separated list of URLs that are used to notify service providers about user logout or session expiration. Standard CUBA applications accept logout requests on the
/dispatch/idpc/logoutpath. For example:cuba.idp.serviceProviderLogoutUrls = http://foo:8081/app/dispatch/idpc/logout,http://bar:8082/app/dispatch/idpc/logout -
cuba.idp.trustedServicePassword - a password which is used in server-to-server communication between SP and IDP.
-
There is also a number of optional properties: cuba.idp.sessionExpirationTimeoutSec, cuba.idp.ticketExpirationTimeoutSec, cuba.idp.sessionExpirationCheckIntervalMs, cuba.idp.cookieMaxAgeSec, cuba.idp.cookieHttpOnly.
-
-
-
On Service Providers:
-
Set the application properties:
-
cuba.webAppUrl - an URL of the application (with the required trailing
/). This URL should also be among the URLs defined in the cuba.idp.serviceProviderUrls property of IDP. For example:cuba.webAppUrl = http://foo:8081/app/ -
cuba.web.externalAuthentication should be set to
trueto indicate that the application uses an external authentication. -
cuba.web.externalAuthenticationProviderClass should be set to
com.haulmont.cuba.web.auth.IdpAuthProvider. -
cuba.web.idp.baseUrl - on this URL the IDP accepts authentication requests. Standard CUBA IDP uses the
idp/path (the trailing/is requred). For example:cuba.web.idp.baseUrl = http://main:8080/app/idp/ -
cuba.web.idp.trustedServicePassword - the same as defined for IDP in its cuba.idp.trustedServicePassword property.
-
-
8.4.1. Customization of IDP
- IDP Login Form
-
The login form files are located in the
idpfolder of your web application. In case of deployment to Tomcat it is thetomcat/webapps/app/idpfolder. You can replace the standard files by creating files with the same name in theweb/idpfolder of your project’s web module.By default, the IDP login form uses a localization mechanism based on the webL10n JavaScript library and contains messages for English and Russian locales. In order to create messages for other languages, create file
modules/web/web/idp/l10n/locales.iniand define the list of message files in it:[*] @import url(messages.properties) [ru] @import url(messages_ru.properties) [es] @import url(messages_es.properties)Additional message files must be located in the same folder (
modules/web/web/idp/l10n). As a template for your message files use the corresponding files from the cuba-idp module which is available as a dependency JAR in your project.You can also completely replace the login form by creating your own
login.htmlandjs/login.jsfiles, or modify the styles in thecss/login.cssfile. - IDP Implementation
-
IDP entry points are implemented in the
cuba_IdpControllerandcuba_IdpServiceControllerSpring MVC controllers. You can create your own controllers and define them in theidp-dispatcher-spring.xmlfile of your web module with the same names to provide a customized behaviour.In the standard implementation, the IDP sessions are stored on Middleware and replicated in cluster. This functionality is provided by the
cuba_IdpSessionStorebean. You can customize the sessions storage by creating a bean with the same name in the core module of your project and registering it in the correspondingspring.xmlfile. See details in the Extending Business Logic section.
8.4.2. Single-Sign-On Example
In this section, we consider an example of setting up SSO for two applications: Foo and Bar. Foo will be an Identity Provider and Service Provider at the same time, Bar will be a Service Provider.
-
Both applications will be running on localhost, so start with creating aliases in your
hostsfile:127.0.0.1 foo 127.0.0.1 bar -
Create two projects in Studio and assign different sets of Tomcat ports.
Project HTTP port AJP port Shutdown port Foo
8081
8011
8051
Bar
8082
8012
8052
-
In the Foo project, edit the
modules/web/web/WEB-INF/web.xmlfile and add the following IDP configuration:<servlet> <servlet-name>idp</servlet-name> <servlet-class>com.haulmont.idp.sys.CubaIdpServlet</servlet-class> <load-on-startup>3</load-on-startup> </servlet> <servlet-mapping> <servlet-name>idp</servlet-name> <url-pattern>/idp/*</url-pattern> </servlet-mapping> <filter> <filter-name>idpSpringSecurityFilterChain</filter-name> <filter-class>org.springframework.web.filter.DelegatingFilterProxy</filter-class> <init-param> <param-name>contextAttribute</param-name> <param-value>org.springframework.web.servlet.FrameworkServlet.CONTEXT.idp</param-value> </init-param> <init-param> <param-name>targetBeanName</param-name> <param-value>springSecurityFilterChain</param-value> </init-param> </filter> <filter-mapping> <filter-name>idpSpringSecurityFilterChain</filter-name> <url-pattern>/idp/*</url-pattern> </filter-mapping> -
In the Foo project, edit the
web-app.propertiesfile of the web module and add the following properties:cuba.idp.serviceProviderUrls = http://foo:8081/app/,http://bar:8082/app/ cuba.idp.serviceProviderLogoutUrls = http://foo:8081/app/dispatch/idpc/logout,http://bar:8082/app/dispatch/idpc/logout cuba.idp.trustedServicePassword = mdgh12SSX_pic2 cuba.webAppUrl = http://foo:8081/app/ cuba.web.externalAuthentication = true cuba.web.externalAuthenticationProviderClass = com.haulmont.cuba.web.auth.IdpAuthProvider cuba.web.idp.baseUrl = http://foo:8081/app/idp/ cuba.web.idp.trustedServicePassword = mdgh12SSX_pic2 -
In the Bar project, edit the
web-app.propertiesfile of the web module and add the following properties:cuba.webAppUrl = http://bar:8082/app/ cuba.web.externalAuthentication = true cuba.web.externalAuthenticationProviderClass = com.haulmont.cuba.web.auth.IdpAuthProvider cuba.web.idp.baseUrl = http://foo:8081/app/idp/ cuba.web.idp.trustedServicePassword = mdgh12SSX_pic2 -
Start the Foo server by launching its
tomcat/bin/startup.*script. -
Go to
http://foo:8081/appin your web browser. You will be redirected to the IDP login page. Log in with theadmin/admincredentials. Create a new user, for exampleu1. -
Start the Bar server by launching its
tomcat/bin/startup.*script. -
Go to
http://bar:8082/appin the same web browser. If you are still logged in to the Foo application, you will be automatically logged in asadminto Bar. Create the sameu1user (password does not matter) in the Bar application. -
Now you can log in as
adminoru1to both applications via the single login form, and if you are logged in in one application, the login process for the second application will be automatic, bypassing the login form.
Appendix A: Configuration Files
This appendix describes the main configuration files included in CUBA-applications.
A.1. app-component.xml
app-component.xml file is required for using the current application as a component of another application. The file defines the dependencies on other components, describes the existing application modules, generated artifacts and exposed configuration parameters.
The app-component.xml file should be located in a package, specified in the App-Component-Id entry of the global module JAR manifest. This manifest entry allows the build system to find components for a project in the build class path. As a result, in order to use some component in your project, just define the component’s global artifact coordinates in the buildscript/dependencies section of your build.gradle.
By convention, the app-component.xml is located in the root package of the project (defined in metadata.xml) which is also equal to the projects’s artifact group (defined in build.gradle):
App-Component-Id == root-package == cuba.artifact.group == e.g. 'com.company.sample'Use CUBA Studio to generate the app-component.xml descriptor and the manifest entries for the current project automatically.
A.2. context.xml
context.xml file is the application deployment descriptor for the Apache Tomcat server. In a deployed application, this file is located in the META-INF subfolder of web application folder or the WAR file, for example, tomcat/webapps/app-core/META-INF/context.xml. In application project, the files of this type can be found in the /web/META-INF folders of the core, web and portal modules.
The main purpose of this file in the Middleware block is to define a datasource and assign a JNDI name, specified in the cuba.dataSourceJndiName application property.
An example of a data source declaration for PostgreSQL:
<Resource
name="jdbc/CubaDS"
type="javax.sql.DataSource"
maxActive="100"
maxIdle="2"
maxWait="5000"
driverClassName="org.postgresql.Driver"
username="cuba"
password="cuba"
url="jdbc:postgresql://localhost/sales"/>An example of a data source declaration for Microsoft SQL Server:
<Resource
name="jdbc/CubaDS"
type="javax.sql.DataSource"
maxActive="100"
maxIdle="2"
maxWait="5000"
driverClassName="net.sourceforge.jtds.jdbc.Driver"
username="sa"
password="saPass1"
url="jdbc:jtds:sqlserver://localhost/sales"/>An example of a data source declaration for Oracle:
<Resource
name="jdbc/CubaDS"
type="javax.sql.DataSource"
maxActive="100"
maxIdle="2"
maxWait="5000"
driverClassName="oracle.jdbc.OracleDriver"
username="sales"
password="sales"
url="jdbc:oracle:thin:@//localhost:1521/orcl"/>In all blocks implemented as web applications, this file may be used to disable serialization of HTTP-sessions:
<Manager className="org.apache.catalina.session.PersistentManager" debug="0" distributable="false"
saveOnRestart="false">
<Store className="org.apache.catalina.session.FileStore"/>
</Manager>A.3. dispatcher-spring.xml
The files of this type define configuration of an additional Spring Framework container for client blocks containing Spring MVC controllers.
The additional container for controllers is created with the main container (configured by spring.xml files) as its parent. Therefore, the beans of the controllers container can use the beans of the main container, while the beans of the main container cannot "see" the beans of the controllers container.
The dispatcher-spring.xml file of the project is specified in the cuba.dispatcherSpringContextConfig application property.
The platform web and portal modules already contain such configuration files: cuba-dispatcher-spring.xml and cuba-portal-dispatcher-spring.xml respectively. The former supports the work of controllers for files uploading and downloading. The latter supports the REST API controllers.
If you have created Spring MVC controllers in your project (for example, in the web module), add the following configuration:
-
Assuming that your controllers are located inside the
com.company.sample.web.controllerpackage, create themodules/web/src/dispatcher-config.xmlfile:<?xml version="1.0" encoding="UTF-8"?> <beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:context="http://www.springframework.org/schema/context" xsi:schemaLocation=" http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-4.2.xsd http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context-4.2.xsd"> <context:annotation-config/> <context:component-scan base-package="com.company.sample.web.controller"/> </beans> -
Include the file into the cuba.dispatcherSpringContextConfig application property in the
modules/web/src/web-app.propertiesfile:cuba.dispatcherSpringContextConfig = cuba-dispatcher-spring.xml dispatcher-spring.xml
A.4. menu.xml
The files of this type are used in the application blocks implementing the generic user interface, such as the Web Client and the Desktop Client. These files define the main menu structure of the application.
XML schema is available at http://schemas.haulmont.com/cuba/6.5/menu.xsd
The file location is specified in the cuba.menuConfig application property. When you create a new project in Studio, it creates the web-menu.xml file in the root package of the web module, for example modules/web/src/com/company/sample/web-menu.xml.
The file has the following structure:
menu-config – the root element.
Elements of menu-config form a tree structure:
-
menu– a folding menu containing menu items and other folding menus.menuattributes:-
id– identifier of an element, used for name localization (see below). -
description- a text shown as a tooltip on mouse hover. You can use localized messages from the main message pack. -
icon- icon of the menu element. See icon for details. -
insertBefore,insertAfter– determines whether the item should be inserted before or after a particular element or a menu item with specified identifier. This attribute is used to insert an element to an appropriate place in the menu defined in files of application components. Before and after elements cannot be used at the same time. -
stylename- defines a style name for the menu item. See Themes for details.
menuelements:-
menu -
item– menu item (see below). -
separator– separator.
-
-
item– menu item.itemattributes:-
id– unique identifier of an element, used for caption localization (see below). Can be used as screenidfor linking to one of the UI screen elements registered in screens.xml file, if no actions declared. When user clicks on a menu item, the corresponding screen will be opened in the main application window. -
bean- the name of bean which can be obtained byAppBeans(e.g.cuba_Messages). -
beanMethod- the name of method from bean (should be used together with thebeanattribute).<item bean="cuba_Messages" beanMethod="getMainMessagePack"/> -
class- fully qualified name of class which extendsRunnable.<item class="com.haulmont.cuba.core.sys.SecurityContextAwareRunnable"/> -
description- a text which is shown as a tooltip on mouse hover. You can also use localized messages from the main message pack.<item id="ref$Colour.browse" description="mainMsg://carsColours"/> -
screen- non-unique screen identifier (e.g.sec$User.browse). Can be used as item’sidif it wasn’t defined.<item screen="sec$User.browse"/> -
shortcut– a keyboard shortcut for this menu item. Possible modifiers –ALT,CTRL,SHIFT– are separated with “-”. For example:shortcut="ALT-C" shortcut="ALT-CTRL-C" shortcut="ALT-CTRL-SHIFT-C"Shortcuts can also be configured in application properties and then used in
menu.xmlfile in the following way:shortcut="${sales.menu.customer}" -
openType– screen open mode. The following modes are available:WindowManager.OpenType:NEW_TAB,THIS_TAB,DIALOG,NEW_WINDOW.Default value –
NEW_TAB.NEW_WINDOWmode is only supported in the Desktop Client. For the Web Client it is equivalent toNEW_TABmode. -
icon- icon of the menu element. See icon for details. -
insertBefore,insertAfter– determines whether the item should be inserted before or after a particular element or a menu item with specified identifier. -
resizable– only relevant toDIALOGscreen open mode. Controls window resizing ability. Possible values −true,false.By default, the main menu does not affect the ability to resize dialog windows.
-
stylename- defines a style name for the menu item. See Themes for details.
itemelements:-
param– screen parameters passed to the controller’sinit()method. The properties configured inmenu.xmloverride the parameters set in screens.xml with the same name.paramattributes:-
name– parameter name. -
value– parameter value. String value, may be converted to an arbitrary object according to the following rules:-
If a string is an entity identifier, specified according to the rules of the
EntityLoadInfoclass, the system loads the specified entity instance. -
If a string has the format
${some_name}, the value of the parameter will be set to thesome_nameapplication property. -
Strings
trueandfalseare converted to the correspondingBooleanvalues. -
Otherwise, the string itself becomes the parameter value.
-
-
-
permissions– an element defining a set of permissions required to make the menu item available to the current user. This mechanism should only be used when item availability should be tied to a specific permission, or to more than one arbitrary permissions. In most cases, the standard capabilities of the security subsystem should be sufficient to manage the menu item availability based on screen identifiers.The element should contain nested
permissionelements, each describing a single required permission. The menu item will only be accessible if all permissions are granted.permissionattributes:-
type– permission type. The following types are available forPermissionType:SCREEN,ENTITY_OP,ENTITY_ATTR,SPECIFIC,UI. -
target– an object checked for permission. Depends on permission type:-
SCREEN– screen identifier, for examplesales$Customer.lookup. -
ENTITY_OP– a string formatted as{entity_name}:{op}, where{op}–read,create,update,delete. For example:sales$Customer:create. -
ENTITY_ATTR– a string formatted as{entity_name}:{attribute}, for examplesales$Customer:name. -
SPECIFIC– specific permission identifier, for examplesales.runInvoicing. -
UI– path to a visual component of a screen.
-
-
-
Example of a menu file:
<menu-config xmlns="http://schemas.haulmont.com/cuba/menu.xsd">
<menu id="sales" insertBefore="administration">
<item id="sales$Customer.lookup"/>
<separator/>
<item id="sales$Order.lookup"/>
</menu>
</menu-config>menu-config.sales=Sales
menu-config.sales$Customer.lookup=CustomersIf the id is not set, the name of the menu element will be generated from the class name (if the class attribute is set) or the bean name and the bean method name (if the bean attribute is set), therefore setting the id attribute is recommended.
A.5. metadata.xml
Files of this type are used for registering custom datatypes and non-persistent entities and assigning meta annotations.
XML schema is available at http://schemas.haulmont.com/cuba/6.5/metadata.xsd.
The metadata.xml file of the project is specified in the cuba.metadataConfig application property.
The file has the following structure:
metadata – root element.
metadata elements:
-
datatypes- an optional descriptor of custom datatypes.datatypeselements:-
datatype- the datatype descriptor. It has one mandatory attribute:class, which defines the implementation class. Other attributes are optional and depend on the implementation. See Example of a Custom Datatype.
-
-
metadata-model– the project’s meta model descriptor.metadata-modelattribute:-
root-package– the project’s root package.metadata-modelelements: -
class– a non-persistent entity class.
-
-
annotations– contains assignments of entity meta annotations.annotationselements:-
entity– entity to assign meta annotation to.entityattributes:-
class– entity class.entityelements: -
annotation– meta annotation element.annotationattributes:-
name– meta annotation name. -
value– meta annotation value.
-
-
-
Example:
<metadata xmlns="http://schemas.haulmont.com/cuba/metadata.xsd">
<metadata-model root-package="com.sample.sales">
<class>com.sample.sales.entity.SomeTransientEntity</class>
<class>com.sample.sales.entity.OtherTransientEntity</class>
</metadata-model>
<annotations>
<entity class="com.haulmont.cuba.security.entity.User">
<annotation name="com.haulmont.cuba.core.entity.annotation.TrackEditScreenHistory"
value="true"/>
<annotation name="com.haulmont.cuba.core.entity.annotation.EnableRestore"
value="true"/>
</entity>
</annotations>
</metadata>A.6. permissions.xml
Files of this type are used in the Web Client and the Desktop Client blocks for registration of specific user permissions.
The file location is defined in the cuba.permissionConfig application property. When you create a new project in Studio, it creates the web-permissions.xml file in the root package of the web module, for example modules/web/src/com/company/sample/web-permissions.xml.
XML schema is available at http://schemas.haulmont.com/cuba/6.5/permissions.xsd.
The file has the following structure:
permission-config - root element.
permission-config elements:
-
specific- specific permissions descriptor.specificelements:-
category- permissions category which is used for grouping permissions in the role edit screen.idattribute is used as a key for retrieving a localized category name from the main message pack. -
permission- named permission.idattribute is used to obtain the permission value by theSecurity.isSpecificPermitted()method, and as a key for retrieving a localized permission name form the main message pack to display the permission in the role edit screen.
-
For example:
<permission-config xmlns="http://schemas.haulmont.com/cuba/permissions.xsd">
<specific>
<category id="app">
<permission id="app.doSomething"/>
<permission id="app.doSomethingOther"/>
</category>
</specific>
</permission-config>A.7. persistence.xml
Files of this type are standard for JPA, and are used for registration of persistent entities and configuration of ORM framework parameters.
The persistence.xml file of the project is defined in the cuba.persistenceConfig application property.
When the Middleware block starts, the specified files are combined into a single persistence.xml, stored in the application work folder. File order is important, because each subsequent file in the list can override previously defined ORM parameters.
Example of a file:
<persistence xmlns="http://java.sun.com/xml/ns/persistence" version="1.0">
<persistence-unit name="sales" transaction-type="RESOURCE_LOCAL">
<class>com.sample.sales.entity.Customer</class>
<class>com.sample.sales.entity.Order</class>
</persistence-unit>
</persistence>A.8. remoting-spring.xml
Files of this type configure an additional Spring Framework container for the Middleware block, used for exporting services and other middleware components accessed by the client tier (hereafter remote access container).
The remoting-spring.xml file of the project is specified in the cuba.remotingSpringContextConfig application property.
Remote access container is created with the main container (configured by spring.xml files) as its parent. Therefore, the beans of the remote access container can use the beans of the main container, while the beans of the main container cannot "see" the beans of the remote access container.
The primary goal of remote access is to make Middleware services accessible to the client level using the Spring HttpInvoker mechanism. The cuba-remoting-spring.xml file in the cuba application component defines the servicesExporter bean of RemoteServicesBeanCreator type, which receives all service classes from the main container and exports them. In addition to regular annotated services, remote access container exports a number of specific beans, such as LoginService.
Furthermore, the cuba-remoting-spring.xml file defines a base package that serves as a starting point for lookup of annotated Spring MVC controller classes used for file uploading and downloading.
The remoting-spring.xml file in the application project should only be created when specific Spring MVC controllers are used. Application project services will be imported by the standard servicesExporter bean defined in the cuba application component.
A.9. screens.xml
Files of this type are used in the generic user interface of the Web Client and the Desktop Client for registration of screen XML-descriptors.
XML schema is available at http://schemas.haulmont.com/cuba/6.5/screens.xsd.
The file location is specified in the cuba.windowConfig application property. When you create a new project in Studio, it creates the web-screens.xml file in the root package of the web module, for example modules/web/src/com/company/sample/web-screens.xml.
The file has the following structure:
screen-config – the root element.
screen-config elements:
-
screen– screen descriptor.screenattributes:-
id– screen identifier used to reference this screen from the application code (e.g. in theFrame.openWindow()and other methods) and in the menu.xml. -
template– path to screen’s XML-descriptor. Resources interface rules apply to loading the descriptor. -
class– if thetemplateattribute is not set, this attribute should contain the name of the class implementing eitherCallableorRunnable.In case of
Callable, thecall()method should return an instance ofWindow, which will be returned to the invoking code as the result of callingWindowManager.openWindow(). The class may contain a constructor with string parameters, defined by the nestedparamelement (see below). -
agent- if multiple templates are registered with the sameid, this attribute is used to choose a template to open. There are three standard agent types:DESKTOP,TABLET,PHONE. They enable selection of a screen template depending on the current device and display parameters. See Screen Agent for details. -
multipleOpen– optional attribute, allowing a screen to be opened multiple times. If set tofalseor not defined and the screen with this identifier has already been opened in the main window, the system will show the existing screen instead of opening a new one. If set totrue, any number of screen instances can be opened.screenelements: -
param– defines a screen parameter submitted as a map to the controller'sinit()method. Parameters, passed to theopenWindow()methods by the invoking code, override the matching parameters set inscreens.xml.paramattributes:-
name– parameter name. -
value– parameter value. Stringstrueandfalseare converted into the correspondingBooleanvalues.
-
-
-
include– includes a different file, e.g.screens.xml.includeattributes:-
file– path to a file according to the rules of the Resources interface.
-
Example of a screens.xml file:
<screen-config xmlns="http://schemas.haulmont.com/cuba/screens.xsd">
<screen id="sales$Customer.lookup" template="/com/sample/sales/gui/customer/customer-browse.xml"/>
<screen id="sales$Customer.edit" template="/com/sample/sales/gui/customer/customer-edit.xml"/>
<screen id="sales$Order.lookup" template="/com/sample/sales/gui/order/order-browse.xml"/>
<screen id="sales$Order.edit" template="/com/sample/sales/gui/order/order-edit.xml"/>
</screen-config>A.10. spring.xml
The files of this type configure the main Spring Framework container for each application block.
The spring.xml file of the project is specified in the cuba.springContextConfig application property.
Most of the configuration of the main container is performed using bean annotations (e.g. @Component, @Service, @Inject and others), therefore the only mandatory part of spring.xml in an application project is the context:component-scan element, which specifies the base Java package for lookup of annotated classes. For example:
<context:component-scan base-package="com.sample.sales"/>The remaining configuration depends on the block that a container is being configured for, e.g. the registration of JMX-beans for the Middleware block, or services import for client blocks.
A.11. views.xml
Files of this type are used to describe views, see Views.
XML schema is available at http://schemas.haulmont.com/cuba/6.5/view.xsd.
views – root element.
views elements:
-
view–viewdescriptor.viewattributes:-
class– entity class. -
entity– the name of the entity, for examplesales$Order. This attribute can be used instead of theclassattribute. -
name– view name, unique within the entity. -
systemProperties– enables inclusion of system attributes defined in base interfaces for persistent entitiesBaseEntityandUpdatable. Optional attribute,trueby default. -
overwrite– enables overriding a view with the same class and name already deployed in the repository. Optional attribute,falseby default. -
extends– specifies an entity view, from which the attributes should be inherited. For example, declaringextends="_local", will add all local attributes of an entity to the current view. Optional attribute.
viewelements:-
property–ViewPropertydescriptor.
propertyattributes:-
name– entity attribute name. -
view– for reference type attributes, specifies a view name the associated entity should be loaded with. -
fetch- for reference attributes, specifies how to fetch the related entity from the database. See Views for details.
propertyelements:-
property– associated entity attribute descriptor. This enables defining an unnamed inline view for an associated entity in the current descriptor.
-
-
include– include anotherviews.xmlfile.includeattributes:-
file– file path according to the Resources interface rules.
-
Example:
<views xmlns="http://schemas.haulmont.com/cuba/view.xsd">
<view class="com.sample.sales.entity.Order"
name="orderWithCustomer"
extends="_local">
<property name="customer" view="_minimal"/>
</view>
<view class="com.sample.sales.entity.Item"
name="itemsInOrder">
<property name="quantity"/>
<property name="product" view="_minimal"/>
</view>
<view class="com.sample.sales.entity.Order"
name="orderWithCustomerDefinedInline"
extends="_local">
<property name="customer">
<property name="name"/>
<property name="email"/>
</property>
</view>
</views>See also the cuba.viewsConfig application property.
A.12. web.xml
The web.xml file is a standard descriptor of a Java EE web application and should be created for the Middleware, Web Client and Web Portal blocks.
In an application project, web.xml files are located in the web/WEB-INF folders of the corresponding modules.
web.xml for the Middleware block (core project module) has the following content:
<web-app xmlns="http://java.sun.com/xml/ns/javaee"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://java.sun.com/xml/ns/javaee http://java.sun.com/xml/ns/javaee/web-app_3_0.xsd"
version="3.0">
<!-- Application properties config files -->
<context-param>
<param-name>appPropertiesConfig</param-name>
<param-value>
classpath:cuba-app.properties
classpath:app.properties
file:${catalina.home}/conf/app-core/local.app.properties
</param-value>
</context-param>
<listener>
<listener-class>com.haulmont.cuba.core.sys.AppContextLoader</listener-class>
</listener>
<servlet>
<servlet-name>remoting</servlet-name>
<servlet-class>com.haulmont.cuba.core.sys.remoting.RemotingServlet</servlet-class>
<load-on-startup>1</load-on-startup>
</servlet>
<servlet-mapping>
<servlet-name>remoting</servlet-name>
<url-pattern>/remoting/*</url-pattern>
</servlet-mapping>
<servlet>
<servlet-name>restapi</servlet-name>
<servlet-class>com.haulmont.cuba.core.sys.restapi.RestApiServlet</servlet-class>
<load-on-startup>1</load-on-startup>
</servlet>
<servlet-mapping>
<servlet-name>restapi</servlet-name>
<url-pattern>/api/*</url-pattern>
</servlet-mapping>
</web-app>The context-param elements define initializing parameters for the ServletContext object of the current web application. The list of application property files is also defined in the appPropertiesConfig parameter.
The listener element defines a listener class implementing the ServletContextListener interface. The Middleware block uses the AppContextLoader class as a listener. This class initializes the AppContext.
Servlet descriptions follow, including the RemotingServlet class, mandatory for the Middleware block. This servlet is accessible via the /remoting/* URL, and is related to the remote access container (see remoting-spring.xml).
web.xml for the Web Client block (web project module) has the following content:
<web-app xmlns="http://java.sun.com/xml/ns/javaee"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://java.sun.com/xml/ns/javaee http://java.sun.com/xml/ns/javaee/web-app_3_0.xsd"
version="3.0">
<context-param>
<description>Vaadin production mode</description>
<param-name>productionMode</param-name>
<param-value>false</param-value>
</context-param>
<context-param>
<param-name>appPropertiesConfig</param-name>
<param-value>
classpath:cuba-web-app.properties
classpath:web-app.properties
file:${catalina.home}/conf/app/local.app.properties
</param-value>
</context-param>
<listener>
<listener-class>com.vaadin.server.communication.JSR356WebsocketInitializer</listener-class>
</listener>
<listener>
<listener-class>com.haulmont.cuba.web.sys.WebAppContextLoader</listener-class>
</listener>
<servlet>
<servlet-name>app_servlet</servlet-name>
<servlet-class>com.haulmont.cuba.web.sys.CubaApplicationServlet</servlet-class>
<init-param>
<param-name>application</param-name>
<param-value>com.haulmont.sales.web.App</param-value>
</init-param>
<init-param>
<param-name>widgetset</param-name>
<param-value>com.haulmont.cuba.web.toolkit.ui.WidgetSet</param-value>
</init-param>
<init-param>
<param-name>UI</param-name>
<param-value>com.haulmont.cuba.web.AppUI</param-value>
</init-param>
<init-param>
<param-name>UIProvider</param-name>
<param-value>com.haulmont.cuba.web.sys.CubaUIProvider</param-value>
</init-param>
<async-supported>true</async-supported>
</servlet>
<servlet-mapping>
<servlet-name>app_servlet</servlet-name>
<url-pattern>/*</url-pattern>
</servlet-mapping>
<filter>
<filter-name>cuba_filter</filter-name>
<filter-class>com.haulmont.cuba.web.sys.CubaHttpFilter</filter-class>
<async-supported>true</async-supported>
</filter>
<filter-mapping>
<filter-name>cuba_filter</filter-name>
<url-pattern>/*</url-pattern>
</filter-mapping>
</web-app>The list of application property files is defined in the appPropertiesConfig parameter. The productionMode property disables the Vaadin framework debugging mode.
The Web Client block uses the WebAppContextLoader class as a ServletContextListener.
Next, the CubaApplicationServlet is defined, providing the generic user interface implementation based on the Vaadin framework. The servlet has a number of parameters, including:
-
application– defines a project specific client application class, inherited fromcom.haulmont.cuba.web.App. -
widgetset– defines a set of GWT components used on the browser side.
Later, the CubaHttpFilter required for functioning of the Web Client block is defined.
Appendix B: Application Properties
This appendix describes all available application properties in alphabetical order.
- cuba.additionalStores
-
Defines the names of additional data stores used in the application.
Used in all standard blocks.
Example:
cuba.additionalStores = db1, mem1
- cuba.allowQueryFromSelected
-
Allows the generic filter to use sequential filtering mode. See also Sequential Queries.
Default value:
trueStored in the database.
Interface:
GlobalConfigUsed in the Web Client and the Middleware blocks.
- cuba.anonymousLogin
-
Login name of the user on behalf of which the anonymous session is created (see cuba.anonymousSessionId).
Default value:
anonymousStored in the database.
Interface:
ServerConfigUsed in the Middleware block.
- cuba.anonymousSessionId
-
Defines the UUID of the anonymous user session which is available before user login. This session is always created automatically on the server startup. See also cuba.anonymousLogin.
Interface:
GlobalConfigUsed in all standard blocks.
- cuba.automaticDatabaseUpdate
-
Determines whether server should run DB update scripts at application start.
Default value:
falseStored in the database.
Interface:
ServerConfigUsed in the Middleware block.
- cuba.availableLocales
-
List of supported user interface languages.
Property format:
{language_name1}|{language_code_1};{language_name2}|{language_code_2};…Example:
cuba.availableLocales=French|fr;English|en{language_name}– name displayed in the list of available languages. For example, such lists can be found on the login screen and on the user edit screen.{language_code}– corresponds to language code returned by theLocale.getLanguage()method. Used as a suffix for message pack file names. For example,messages_fr.properties.The first language listed in the
cuba.availableLocalesproperty, will be selected in the list of available languages by default, if the list does not contain the user’s operating system language. Otherwise, user’s operating system language will be selected by default.Default value:
English|en;Russian|ru;French|frInterface:
GlobalConfigUsed in all standard blocks.
- cuba.backgroundWorker.maxActiveTasksCount
-
The maximum number of active background tasks.
Default value:
100Interface:
WebConfigUsed in the Web Client block.
- cuba.backgroundWorker.timeoutCheckInterval
-
Defines an interval in milliseconds for checking timeouts of background tasks.
Default value:
5000Interface:
ClientConfigUsed in the Web Client and Desktop Client.
- cuba.bruteForceProtection.enabled
-
Enables a mechanism for the protection against password brute force cracking.
Default value:
falseStored in the database.
Interface:
ServerConfigUsed in the Middleware block.
- cuba.bruteForceProtection.blockIntervalSec
-
Blocking interval in seconds after exceeding a maximum number of failed login attempts, if the cuba.bruteForceProtection.enabled property is on.
Default value: 60
Stored in the database.
Interface:
ServerConfigUsed in the Middleware block.
- cuba.bruteForceProtection.maxLoginAttemptsNumber
-
A maximum number of failed login attempts for the combination of user login and IP address, if the cuba.bruteForceProtection.enabled property is on.
Default value: 5
Stored in the database.
Interface:
ServerConfigUsed in the Middleware block.
- cuba.cluster.enabled
-
Enables interaction between Middleware servers in a cluster. See Configuring Interaction between Middleware Servers for details.
Default value:
falseUsed in the Middleware block.
- cuba.cluster.jgroupsConfig
-
Path to JGroups configuration file. The file is loaded using the Resources interface, so it can be located in classpath or in the configuration directory.
For example:
cuba.cluster.jgroupsConfig = my_jgroups_tcp.xmlDefault value:
jgroups.xmlUsed in the Middleware block.
- cuba.cluster.messageSendingQueueCapacity
-
Limits the queue of middleware cluster messages. When the queue exceeds its maximum size, new messages are rejected.
Default value:
Integer.MAX_VALUEUsed in the Middleware block.
- cuba.confDir
-
Defines location of the configuration folder for an application block.
Default value for the Middleware, Web Client and Web Portal blocks:
${catalina.home}/conf/${cuba.webContextName}In case of a standard Tomcat deployment, this points to a sub-folder with the name of the current web app in the
tomcat/conffolder, for example, tomcat/conf/app-core.Default value for the Desktop Client block:
${cuba.desktop.home}/conf.Interface:
GlobalConfigUsed in all standard blocks.
- cuba.connectionReadTimeout
-
Sets Middleware connection timeout for client blocks. Non-negative value is passed to the
setReadTimeout()method ofURLConnection.See also cuba.connectionTimeout.
Default value:
-1Used in the Web Client, Web Portal and Desktop Client blocks.
- cuba.connectionTimeout
-
Sets Middleware connection timeout for client blocks. Non-negative value is passed to the
setConnectTimeout()method ofURLConnection.See also cuba.connectionReadTimeout.
Default value:
-1Used in the Web Client, Web Portal and Desktop Client blocks.
- cuba.connectionUrlList
-
Sets Middleware server connection URL for client blocks.
Property value should contain one or more comma separated URLs
http[s]://host[:port]/app-core, wherehostis the server hostname,portis the server port, andapp-coreis the name of the the Middleware block web application. For example:cuba.connectionUrlList = http://localhost:8080/app-coreWhen using a cluster of Middleware servers, their addresses should be listed separated with commas:
cuba.connectionUrlList = http://server1:8080/app-core,http://server2:8080/app-coreSee details in Setting up Connection to the Middleware Cluster.
See also cuba.useLocalServiceInvocation.
Interface:
ClientConfigUsed in the Web Client, Web Portal and Desktop Client blocks.
- cuba.creditsConfig
-
Additive property defining a
credits.xmlfile containing information about the software components used by the application.The file is loaded using the Resources interface, so it can be located in classpath or in the configuration directory.
Used in the Web Client and the Desktop Client blocks.
Example:
cuba.creditsConfig = +com/company/base/credits.xml
- cuba.crossDataStoreReferenceLoadingBatchSize
-
Batch size for loading related entities from different data stores by DataManager.
Default value:
50Stored in the database.
Interface:
ServerConfigUsed in the Middleware block.
- cuba.dataManagerChecksSecurityOnMiddleware
-
Indicates that DataManager should apply security restrictions when invoked on the middleware.
Default value:
falseStored in the database.
Interface:
ServerConfigUsed in the Middleware block.
- cuba.dataSourceJndiName
-
Defines JNDI name of the
javax.sql.DataSourceobject used for connection to the application database.Default value:
java:comp/env/jdbc/CubaDSUsed in the Middleware block.
- cuba.dataDir
-
Defines the location of the work folder for an application block.
Default value for the Middleware, Web Client and Web Portal blocks:
${catalina.home}/work/${cuba.webContextName}In case of a standard Tomcat deployment, this points to a sub-folder with the name of the current web-app inside the
tomcat/workfolder, for example,tomcat/work/app-core.Default value for the Desktop Client block:
${cuba.desktop.home}/work.Interface:
GlobalConfigUsed in all standard blocks.
- cuba.dbDir
-
Defines the location of the database scripts folder.
Default value:
${catalina.home}/webapps/${cuba.webContextName}/WEB-INF/db, which points to theWEB-INF/dbsub-folder of the current web-app folder in Tomcat.Interface:
ServerConfigUsed in the Middleware block.
- cuba.dbmsType
-
Defines the DBMS type. Affects the choice of DBMS integration interface implementations and the search for database init and update scripts together with cuba.dbmsVersion.
See DBMS Types for details.
Default value:
hsqlUsed in the Middleware block.
- cuba.dbmsVersion
-
An optional property that sets the database version. Affects the choice of DBMS integration interface implementations and the search for database init and update scripts together with cuba.dbmsType.
See DBMS Types for details.
Default value:
noneUsed in the Middleware block.
- cuba.defaultQueryTimeoutSec
-
Defines default transaction timeout.
Default value:
0(no timeout).Stored in the database.
Interface:
ServerConfigUsed in the Middleware block.
- cuba.desktop.useServerTime
-
Enables adjustment of the time provided by the TimeSource interface of the Desktop Client block.The time will approximately equal to the time of the Middleware the client is connected to.
Default value:
trueInterface:
DesktopConfigUsed in the Desktop Client block.
- cuba.desktop.useServerTimeZone
-
Enables adjustment of the Desktop Client block’s JVM timezone to the timezone of the Middleware the client is connected to.
Default value:
trueInterface:
DesktopConfigUsed in the Desktop Client block.
- cuba.disableOrmXmlGeneration
-
Disables automatic generation of the
orm.xmlfile for extended entities.Default value:
false(orm.xmlwill be created automatically if any extended entity exist).Used in the Middleware block.
- cuba.dispatcherSpringContextConfig
-
Additive property defining a dispatcher-spring.xml file of a client block.
The file is loaded using the Resources interface, so it can be located in classpath or in the configuration directory.
Used in the Web Client and Web Portal blocks.
Example:
cuba.dispatcherSpringContextConfig = +com/company/sample/portal-dispatcher-spring.xml
- cuba.download.directories
-
Defines a list of folders from which the Middleware files can be downloaded from via
com.haulmont.cuba.core.controllers.FileDownloadController. For example, file downloading is utilized by the server log display mechanism found in the Administration > Server Log web client screen.The folder list should be separated with semicolon.
Default value:
${cuba.tempDir};${cuba.logDir}(files can be downloaded from the temporary folder and the logs folder).Used in the Middleware block.
- cuba.email.*
-
Email sending parameters described in Configuring Email Sending Parameters.
- cuba.fileStorageDir
-
Defines file storage folder structure roots. For more information, see Standard File Storage Implementation.
Default value:
nullUsed in the Middleware block.
- cuba.entityAttributePermissionChecking
-
If set to
false, turns off checking entity attribute permissions on Middleware.Default value:
falseStored in the database.
Used in the Middleware block.
- cuba.entityLog.enabled
-
Activates the entity log mechanism.
Default value:
trueStored in the database.
Interface:
EntityLogConfigUsed in the Middleware block.
- cuba.groovyEvaluationPoolMaxIdle
-
Sets the maximum number of unused compiled Groovy expressions in the pool during
Scripting.evaluateGroovy()method execution. It is recommended to increment this parameter when intensive execution of Groovy expressions is required, for example, for a large number of application folders.Default value: 8
Used in all standard blocks.
- cuba.groovyEvaluatorImport
-
Defines a list of classes imported by all Groovy expressions executed through Scripting.
Class names in the list should be separated with commas or semicolons.
Default value:
com.haulmont.cuba.core.global.PersistenceHelperUsed in all standard blocks.
Example:
cuba.groovyEvaluatorImport = com.haulmont.cuba.core.global.PersistenceHelper,com.abc.sales.CommonUtils
- cuba.gui.genericFilterChecking
-
Influences the behavior of the Filter component.
When set to
true, does not allow to apply a filter without specifying parameters.Default value:
falseStored in the database.
Interface:
ClientConfigUsed in the Web Client and Desktop Client blocks.
- cuba.gui.genericFilterControlsLayout
-
Sets a template for Filter controls layout. Each control has the following format:
[component_name | options-comma-separated], e.g.[pin | no-caption, no-icon].Available controls:
-
filters_popup- popup button for selecting a filter, combined with the Search button. -
filters_lookup- lookup field for selecting a filter. The Search button should be added as a separate control. -
search- Search button. Do not add if usefilters_popup. -
add_condition- link button for adding new conditions. -
spacer- an empty space between controls. -
settings- Settings button. Specify action names that should be displayed in Settings popup as options (see below). -
max_results- group of controls for setting maximum number of records to be selected. -
fts_switch- checkbox for switching to the Full-Text Search mode.
The following actions can be used as options of the
settingscontrol:save,save_as,edit,remove,pin,make_default,save_search_folder,save_app_folder.The actions can also be used as independent controls outside of the Settings popup. In this case, they can have the following options:
-
no-icon- if an action button should be dispalyed without an icon. For example:[save | no-icon]. -
no-caption- if an action button should be dispalyed without a caption. For example:[pin | no-caption].
Default value:
[filters_popup] [add_condition] [spacer] \ [settings | save, save_as, edit, remove, make_default, pin, save_search_folder, save_app_folder] \ [max_results] [fts_switch]Stored in the database.
Interface:
ClientConfigUsed in the Web Client and Desktop Client blocks.
-
- cuba.gui.genericFilterManualApplyRequired
-
Influences the behavior of the Filter component.
When set to
true, the screens containing filters will not load the corresponding datasources automatically, until user clicks the filter Apply button.The value of
cuba.gui.genericFilterManualApplyRequiredis ignored, when opening browser screens using an application or search folders, i.e. the filter is applied. The filter will not be applied, if theapplyDefaultvalue for a folder is explicitly set tofalse.Default value:
falseStored in the database.
Interface:
ClientConfigUsed in the Web Client and Desktop Client blocks.
- cuba.gui.genericFilterMaxResultsOptions
-
Defines the options for the Show rows drop-down list of the Filter component.
NULL option indicates that the list should contain an empty value.
Default value:
NULL, 20, 50, 100, 500, 1000, 5000Stored in the database.
Interface:
ClientConfigUsed in the Web Client and Desktop Client blocks.
- cuba.gui.genericFilterColumnsCount
-
Defines the number of columns with conditions for the Filter component.
Default value:
3Stored in the database.
Interface:
ClientConfigUsed in the Web Client and Desktop Client blocks.
- cuba.gui.genericFilterConditionsLocation
-
Defines the location of the conditions panel in the Filter component. Two locations are available:
top(above the filter control elements) andbottom(below the filter control elements).Default value:
topStored in the database.
Interface:
ClientConfigUsed in the Web Client and Desktop Client blocks.
- cuba.gui.genericFilterPopupListSize
-
Defines the number of items displayed in the popup list of the Search button. If the number of filters exceeds this value, Show more… action is added to the popup list. The action opens a new dialog window with a list of all possible filters.
Default value:
10Stored in the database.
Interface:
ClientConfigUsed in the Web Client and Desktop Client blocks.
- cuba.gui.layoutAnalyzerEnabled
-
Allows you to disable the screen analyzer available in the context menu of the main window tabs and the modal window captions.
Default value:
trueStored in the database.
Interface:
ClientConfigUsed in the Web Client and Desktop Client blocks.
- cuba.gui.lookupFieldPageLength
-
Defines the default number of options on one page of the drop-down list in the LookupField and LookupPickerField components. It can be overridden for a concrete instance of the component using the pageLength XML attribute.
Default value: 10
Stored in the database.
Interface:
ClientConfigUsed in the Web Client.
- cuba.gui.manualScreenSettingsSaving
-
If the property is set to
true, screens will not save their settings automatically on close. In this mode, a user can save or reset settings using the context menu which appears on clicking a screen tab or a dialog window caption.Default value:
falseInterface:
ClientConfigStored in the database.
Used in the Web Client and Desktop Client blocks.
- cuba.gui.showIconsForPopupMenuActions
-
Enables displaying action icons in Table context menu and PopupButton items.
Default value:
falseStored in the database.
Interface:
ClientConfigUsed in the Web Client block.
- cuba.gui.systemInfoScriptsEnabled
-
Enables the display of SQL-scripts for creating / updating / retrieving an entity instance in the System Information window.
Such scripts actually show the contents of the database rows that store the selected entity instance, regardless of security settings that may deny viewing of some attributes. That is why it is reasonable to revoke the CUBA / Generic UI / System Information specific permission for all user roles except the administrators, or set the
cuba.gui.systemInfoScriptsEnabledtofalsefor the whole application.Default value:
trueStored in the database.
Interface:
ClientConfigUsed in the Web Client and the Desktop Client blocks.
- cuba.gui.useSaveConfirmation
-
Defines the layout of the dialog displayed when a user attempts closing a screen with unsaved changes in datasources.
Value of
truecorresponds to a layout with three possible actions: Save changes, Don’t Save, Don’t close the screen.The value of
falsecorresponds to a form with two options: Close the screen without saving changes, Don’t close the screen.Default value:
trueStored in the database.
Interface:
ClientConfigUsed in the Web Client and Desktop Client blocks.
- cuba.httpSessionExpirationTimeoutSec
-
Defines HTTP-session inactivity timeout in seconds.
Default value:
1800Interface:
WebConfigUsed in the Web Client block.
TipIt is recommended to use the same values for cuba.userSessionExpirationTimeoutSec and
cuba.httpSessionExpirationTimeoutSecproperties.
- cuba.idp.serviceProviderLogoutUrls
-
For a SSO Identity Provider, sets a list of URLs that are used to notify service providers about user logout or session expiration. The values must be separated by commas.
For example:
cuba.idp.serviceProviderLogoutUrls = http://foo:8081/app/dispatch/idpc/logout,http://bar:8082/app/dispatch/idpc/logoutInterface:
IdpConfigUsed in the Web Client block.
- cuba.idp.serviceProviderUrls
-
For a SSO Identity Provider, sets a list of service provider URLs. The values must be separated by commas. Trailing '/' in URLs are required.
For example:
cuba.idp.serviceProviderUrls = http://foo:8081/app/,http://bar:8082/app/Interface:
IdpConfigUsed in the Web Client block.
- cuba.idp.sessionExpirationTimeoutSec
-
For a SSO Identity Provider, sets a timeout of IDP session inactivity in seconds.
Default value: 18000 (5 hours)
Interface:
IdpConfigUsed in the Web Client block.
- cuba.idp.sessionExpirationCheckIntervalMs
-
For a SSO Identity Provider, sets an interval of checking IDP session inactivity in milliseconds.
Default value: 30000 (30 sec)
Interface:
IdpConfigUsed in the Web Client block.
- cuba.idp.ticketExpirationTimeoutSec
-
For a SSO Identity Provider, sets a timeout of SSO ticket in seconds.
Default value: 180 (3 min)
Interface:
IdpConfigUsed in the Web Client block.
- cuba.idp.trustedServicePassword
-
For a SSO Identity Provider, sets a password which is used in server-to-server communication between SP and IDP.
Interface:
IdpConfigUsed in the Web Client block.
- cuba.inMemoryDistinct
-
Enables in-memory filtering of duplicate records instead of using
select distinctat the database level. Used by the DataManager.Default value:
falseStored in the database.
Interface:
ServerConfigUsed in the Middleware block.
- cuba.jmxUserLogin
-
Defines a user login that should be used for system authentication.
Default value:
adminUsed in the Middleware block.
- cuba.localeSelectVisible
-
Disables the user interface language selection when logging in.
If
cuba.localeSelectVisibleis set to false, the locale for a user session is selected in the following way:-
If the
Userentity instance has alanguageattribute defined, the system will use this language. -
If the user’s operating system language is included in the list of available locales (set by the cuba.availableLocales property), the system will use this language.
-
Otherwise, the system will use the first language defined in the cuba.availableLocales property.
Default value:
trueInterface:
GlobalConfigUsed in all standard blocks.
-
- cuba.logDir
-
Defines the location of the log folder for an application block.
Default value for the Middleware, Web Client and Web Portal blocks:
${catalina.home}/logsIn case of a standard Tomcat deployment, this property points to the
tomcat/logsfolder.Default value for the Desktop Client block:
${cuba.desktop.home}/logs.Interface:
GlobalConfigUsed in all standard blocks.
- cuba.mainMessagePack
-
Additive property defining a main message pack for an application block.
The value may include a single pack or a list of packs separated with spaces.
Used in all standard blocks.
Example:
cuba.mainMessagePack = +com.company.sample.gui com.company.sample.web
- cuba.maxUploadSizeMb
-
Maximum file size (in megabytes) that can be uploaded using the FileUploadField and FileMiltiUploadField components.
Default value:
20Stored in the database.
Interface:
ClientConfigUsed in the Web Client and the Desktop Client blocks.
- cuba.metadataConfig
-
Additive property defining a metadata.xml file.
The file is loaded using the Resources interface, so it can be located in classpath or in the configuration directory.
Used in all standard blocks.
Example:
cuba.metadataConfig = +com/company/sample/metadata.xml
- cuba.passwordEncryptionModule
-
Defines the name of the bean used for user password hashing.
Default value:
cuba_Sha1EncryptionModuleUsed in all standard blocks.
- cuba.passwordPolicyEnabled
-
Enables password policy enforcement. If the property is set to
true, all new user passwords will be checked according to the cuba.passwordPolicyRegExp property.Default value:
falseStored in the database.
Interface:
ClientConfigUsed in the client blocks: Web Client, Web Portal, Desktop Client.
- cuba.passwordPolicyRegExp
-
Defines a regular expression used by the password checking policy.
Default value:
((?=.*\\d)(?=.*\\p{javaLowerCase}) (?=.*\\p{javaUpperCase}).{6,20})The expression above ensures that password contains from 6 to 20 characters, uses numbers and Latin letters, contains at least one number, one lower case and one upper case letter. More information on regular expression syntax is available at https://en.wikipedia.org/wiki/Regular_expression and http://docs.oracle.com/javase/6/docs/api/java/util/regex/Pattern.html.
Stored in the database.
Interface:
ClientConfigUsed in the client level blocks: Web Client, Web Portal, Desktop Client.
- cuba.permissionConfig
-
Additive property defining a permissions.xml file.
Used in the Web Client and Desktop Client blocks.
Example:
cuba.permissionConfig = +com/company/sample/web-permissions.xml
- cuba.persistenceConfig
-
Additive property defining a persistence.xml file.
The file is loaded using the Resources interface, so it can be located in classpath or in the configuration directory.
Used in all standard blocks.
Example:
cuba.persistenceConfig = +com/company/sample/persistence.xml
- cuba.portal.anonymousUserLogin
-
Defines a user login that should be used for anonymous session in the Web Portal block.
The user with the specified login should exist in the security subsystem and should have the required permissions. User password is not required, because anonymous portal sessions are created via the loginTrusted() method with the password defined in the cuba.trustedClientPassword property.
Interface:
PortalConfigUsed in the Web Portal block.
- cuba.queryCache.enabled
-
If set to
false, the query cache functionality is disabled.Default value:
trueInterface:
QueryCacheConfigUsed in the Middleware block.
- cuba.queryCache.maxSize
-
Maximum number of query cache entries. A cache entry is defined by the query text, query parameters, paging parameters and soft deletion.
As the cache size grows close to the maximum, the cache evicts entries that are less likely to be used again.
Default value: 100
Interface:
QueryCacheConfigUsed in the Middleware block.
- cuba.remotingSpringContextConfig
-
Additive property defining a remoting-spring.xml file of the Middleware block.
The file is loaded using the Resources interface, so it can be located in classpath or in the configuration directory.
Used in the Middleware block.
Example:
cuba.remotingSpringContextConfig = +com/company/sample/remoting-spring.xml
- cuba.rest.productionMode
-
Activates the REST API production mode that does not return exception text to client.
Default value:
falseInterface:
RestConfigUsed in the Web Client and Web Portal block.
- cuba.rest.apiVersion
-
Defines the REST API v1 version. If the value is set to
1, the REST API of the platform versions before 5.4 is used. Setting the value to2enables the new REST API version with support for service calls. This property is not applicable to REST API v2.Default value:
2Interface:
RestConfigUsed in the Web Client and Web Portal block.
- cuba.restApiUrl
-
URL to the application’s REST API.
Default value:
http://localhost:8080/app-portal/apiStored in the database.
Interface:
GlobalConfigCan be used in all standard blocks.
- cuba.restServicesConfig
-
Additive property defining a file that contains a list of services available for application REST API calls.
The file is loaded using the Resources interface, so it can be located in classpath or in the configuration directory.
The XSD of the file is available at http://schemas.haulmont.com/cuba/6.5/restapi-service-v2.xsd.
Default value: none
Example:
cuba.restServicesConfig = +com/company/sample/app-rest-services.xmlUsed in the Web Client and Web Portal block.
- cuba.rest.allowedOrigins
-
Defines a comma-separated list of origins that can access the REST API Version 2.
Default value:
*Used in the Web Client and Web Portal blocks.
- cuba.rest.anonymousEnabled
-
Enables an anonymous access to the REST API Version 2 endpoints.
Default value:
falseUsed in the Web Client and Web Portal blocks.
- cuba.rest.client.id
-
Defines an identifier of the REST API client. Client in this case is not a platform user, but an application (some web portal or mobile app) that uses REST API Version 2. Client credentials are used for basic authentication when accessing the REST API token endpoint.
Default value:
clientUsed in the Web Client and Web Portal blocks.
- cuba.rest.client.secret
-
Defines a password of the REST API client. Client in this case is not a platform user, but an application (some web portal or mobile app) that uses REST API Version 2. Client credentials are used for basic authentication when accessing the REST API token endpoint.
Default value:
secretUsed in the Web Client and Web Portal blocks.
- cuba.rest.client.tokenExpirationTimeSec
-
Defines a REST API Version 2 token expiration timeout for the default client in seconds.
Default value:
43200(12 hours)Used in the Web Client and Web Portal blocks.
- cuba.rest.deleteExpiredTokensCron
-
Specifies cron expression for scheduled removing of expired tokens from the database.
Default value:
0 0 3 * * ?Used in the Middleware block.
- cuba.rest.jsonTransformationConfig
-
Additive property defining a file that contains JSON transformation configurations used by the REST API Version 2 when the client needs data in format of some particular data model version.
The file is loaded using the Resources interface, so it can be located in classpath or in the configuration directory.
The XSD of the file is available at http://schemas.haulmont.com/cuba/6.5/rest-json-transformations.xsd.
Default value: none
Example:
cuba.rest.jsonTransformationConfig = +com/company/sample/json-transformations.xmlUsed in the Web Client and Web Portal blocks.
- cuba.rest.maxUploadSize
-
Maximum file size (in bytes) that can be uploaded with the REST API Version 2.
Default value:
20971520(20 Mb)Used in the Web Client and Web Portal blocks.
- cuba.rest.servicesConfig
-
Additive property defining a file that contains a list of services available for application REST API Version 2 calls.
The file is loaded using the Resources interface, so it can be located in classpath or in the configuration directory.
The XSD of the file is available at http://schemas.haulmont.com/cuba/6.5/rest-services-v2.xsd.
Default value: none
Example:
cuba.rest.servicesConfig = +com/company/sample/app-rest-services.xmlUsed in the Web Client and Web Portal blocks.
- cuba.rest.storeTokensInDb
-
Enables storing of REST API security tokens in the database. By default, tokens are stored in memory only.
Stored in the database.
Interface:
ServerConfigDefault value:
falseUsed in the Middleware block.
- cuba.rest.queriesConfig
-
Additive property defining a file that contains a list of JPQL queries available for application REST API Version 2 calls.
The file is loaded using the Resources interface, so it can be located in classpath or in the configuration directory.
The XSD of the file is available at http://schemas.haulmont.com/cuba/6.5/rest-queries.xsd.
Default value: none
Example:
cuba.rest.queriesConfig = +com/company/sample/app-rest-queries.xmlUsed in the Web Client and Web Portal blocks.
- cuba.schedulingActive
-
Enables the CUBA scheduled tasks mechanism.
Default value:
falseStored in the database.
Interface:
ServerConfigUsed in the Middleware block.
- cuba.serialization.impl
-
Specifies an implementation of the
Serializationinterface which is used for serialization of objects transferred between the application blocks. The platform contains two implementations:-
StandardSerialization- standard Java serialization. -
KryoSerialization- serialization based on the Kryo framework.
Default value:
com.haulmont.cuba.core.sys.serialization.StandardSerializationUsed in all standard blocks.
-
- cuba.springContextConfig
-
Additive property defining a spring.xml file in all standard application blocks.
The file is loaded using the Resources interface, so it can be located in classpath or in the configuration directory.
Used in all standard blocks.
Example:
cuba.springContextConfig = +com/company/sample/spring.xml
- cuba.supportEmail
-
Specifies an email address to which exception reports from the default exception handler screen, as well as user messages from the Help > Feedback screen will be sent.
Report button in the exception handler screen will be hidden, if this property is set to an empty string.
In order to successfully send emails, the parameters described in Configuring Email Sending Parameters must also be configured.
Default value: empty string.
Stored in the database.
Interface:
WebConfigUsed in the Web Client block.
- cuba.tempDir
-
Defines the location of the temporary directory for an application block.
The default value for the Middleware, Web Client, Web Portal blocks:
${catalina.home}/temp/${cuba.webContextName}In case of a standard Tomcat deployment, this points to a sub-folder with the name of the current web-app in the
tomcat/tempfolder, for example,tomcat/temp/app-core.The default value for the Desktop Client block:
${cuba.desktop.home}/temp.Interface:
GlobalConfigUsed in all standard blocks.
- cuba.themeConfig
-
Defines a set of
*-theme.propertiesfiles that store theme variables, such as default popup window dimensions and input field width.The property takes a list of files separated by spaces. The files are loaded as defined by the Resources interface.
Default value for Web Client:
havana-theme.properties halo-theme.propertiesDefault value for Desktop Client:
nimbus-theme.propertiesUsed in the Web Client and Desktop Client block.
- cuba.triggerFilesCheck
-
Enables the processing of bean invocation trigger files.
The trigger file is a file that is placed in the
triggerssubdirectory of the application block’s temporary directory. The trigger file name consists of two parts separated with a period. The first part is the bean name, the second part is the method name of the bean to invoke. For example:cuba_Messages.clearCache. The trigger files handler monitors the folder for new trigger files, invokes the appropriate methods and then removes the files.By default, the trigger files processing is configured in the
cuba-web-spring.xmlfile and performed for the Web Client block only. At the project level, the processing for other modules can be performed by periodically invoking theprocess()method of thecuba_TriggerFilesProcessorbean.Default value:
trueUsed in blocks with the configured processing, default is Web Client.
- cuba.triggerFilesCheckInterval
-
Defines the period in milliseconds of trigger files processing if the cuba.triggerFilesCheck is set to
true.Default value:
5000Used in blocks with the configured processing, default is Web Client.
- cuba.trustedClientPassword
-
Defines password used by the
LoginService.loginTrusted()method. The Middleware layer can authenticate users who connect via the trusted client block without checking the user password.This property is used when user passwords are not stored in the database, while the client block performs the actual authentication itself. For example, by integrating with Active Directory.
Interfaces:
ServerConfig,WebAuthConfig,PortalConfigUsed in blocks: Middleware, Web Client, Web Portal.
- cuba.trustedClientPermittedIpList
-
Defines the list of IP addresses, from which the invocation of the
LoginService.loginTrusted()method is allowed. For example:cuba.trustedClientPermittedIpList = 127.0.0.1, 10.17.*.*Default value:
127.0.0.1Interfaces:
ServerConfigUsed in the Middleware block.
- cuba.uniqueConstraintViolationPattern
-
A regular expression which is used to find out that the exception is caused by a database unique constraint violation. The first or second group of the expression must return the constraint name. For example:
ERROR: duplicate key value violates unique constraint "(.+)"The constraint name can be used to display a localized message that indicates what entity is concerned. For this the main message pack should contain keys equal to constraint names. For example:
IDX_SEC_USER_UNIQ_LOGIN = A user with the same login already existsThis property allows you to define a reaction to unique constraint violations depending on DBMS locale and version.
Default value is returned by the
PersistenceManagerService.getUniqueConstraintViolationPattern()method for the current DBMS.Can be defined in the database.
Used in all client blocks.
- cuba.useCurrentTxForConfigEntityLoad
-
Enables using current transaction, if there is one at the moment, for loading entity instances via the configuration interfaces. This could have a positive impact on performance. Otherwise, a new transaction is always created and committed, and the detached instances are returned.
Default value:
falseUsed in the Middleware block.
- cuba.useInnerJoinOnClause
-
Indicates that EclipseLink ORM will use
JOIN ONclause for inner joins instead of conditions inWHEREclause.Default value: false
Used in the Middleware block.
- cuba.useLocalServiceInvocation
-
When set to
true, the Web Client and Web Portal blocks invoke the Middleware services locally, bypassing the network stack, which has a positive impact on system performance. It is possible when Tomcat fast deployment is used, as well as single WAR or single Uber-JAR. This property should be set to false for all other deployment options.Default value:
falseUsed in the Web Client and Web Portal blocks.
- cuba.useReadOnlyTransactionForLoad
-
Indicates that all
loadmethods of DataManager use read-only transactions.Default value:
trueStored in the database.
Interface:
ServerConfigUsed in the Middleware block.
- cuba.user.fullNamePattern
-
Defines the full name pattern for user.
Default value:
{FF| }{LL}The full name pattern can be formed from the user’s first, last and middle names. The following rules apply to the pattern:
-
The pattern parts are separated by
{} -
The pattern inside
{}must contain one of the following characters followed by the|character without any spaces:LL– long form of user’s last name (Smith)L– short form of user’s last name (S)FF– long form of user’s first name (John)F– short form of user’s first name (J)MM– long form of user’s middle name (Paul)M– short form of user’s middle name (P) -
The
|character can be followed by any symbols including spaces.
Used in the Web Client and Desktop Client blocks.
-
- cuba.user.namePattern
-
Defines the display name pattern for the
Userentity. The display name is used in different places, including the upper right corner of the system’s main window.Default value:
{1} [{0}]{0}is substituted with theloginattribute,{1}– with thenameattribute.Used in the Middleware, Web Client and Desktop Client blocks.
- cuba.userSessionExpirationTimeoutSec
-
Defines the user session expiration timeout in seconds.
Default value:
1800Interface:
ServerConfigUsed in the Middleware block.
TipIt is recommended to use the same values for
cuba.userSessionExpirationTimeoutSecand cuba.httpSessionExpirationTimeoutSec.
- cuba.userSessionProviderUrl
-
Defines the Middleware block URL used for logging users in.
This parameter should be set in additional middleware blocks that execute client requests, but do not share the user session cache. If there is no required session in the local cache at the start of the request, this block invokes the
LoginService.getSession()method at the specified URL, and caches the retrieved session.Interface:
ServerConfigUsed in the Middleware block.
- cuba.viewsConfig
- cuba.webAppUrl
-
Defines URL of the Web Client application.
In particular, used to generate external application screen links, as well as by the
ScreenHistorySupportclass.Default value:
http://localhost:8080/appStored in the database.
Interface:
GlobalConfigCan be used in all standard blocks.
- cuba.windowConfig
-
Additive property defining a screens.xml file.
The file is loaded using the Resources interface, so it can be located in classpath or in the configuration directory.
Used in the Web Client and Desktop Client blocks.
Example:
cuba.windowConfig = +com/company/sample/web-screens.xml
- cuba.web.allowHandleBrowserHistoryBack
-
Enables handling of browser Back button in the application if the login and/or main window implements the
CubaHistoryControl.HistoryBackHandlerinterface. If the property is true, the standard browser behavior is replaced with this method invocation.See Web Client Specifics.
Default value:
trueInterface:
WebConfigUsed in the Web Client block.
- cuba.web.appFoldersRefreshPeriodSec
-
Defines application folders refresh period in seconds.
Default value:
180Interface:
WebConfigUsed in the Web Client block.
- cuba.web.appWindowMode
-
Determines the initial mode for the main application window – tabbed or single screen (
TABBEDorSINGLErespectively). In single screen mode, screens opened in theNEW_TABmodewill replace the current screen, instead of opening a new tab. This can be useful for simple applications and inexperienced users.The user is able to change the mode later, using the Help > Settings screen.
Default value:
TABBEDInterface:
WebConfigUsed in the Web Client block.
- cuba.web.externalAuthentication
-
Indicates that the authentication is done through an external mechanism like LDAP or SSO Identity Provider. See also cuba.web.externalAuthenticationProviderClass.
Default value:
falseInterface:
WebAuthConfigUsed in the Web Client block.
- cuba.web.externalAuthenticationProviderClass
-
A class implementing the
CubaAuthProviderinterface which is used when cuba.web.externalAuthentication is set totrue.See Integration with LDAP and Single-Sign-On for CUBA Applications sections for examples.
Interface:
WebAuthConfigUsed in the Web Client block.
- cuba.web.foldersPaneDefaultWidth
-
Defines default width (in pixels) for the folders panel.
Default value:
200Interface:
WebConfigUsed in the Web Client block.
- cuba.web.foldersPaneEnabled
-
Enables the folders panel functionality.
Default value:
falseInterface:
WebConfigUsed in the Web Client block.
- cuba.web.foldersPaneVisibleByDefault
-
Determines whether the folders panel should be expanded by default.
Default value:
falseInterface:
WebConfigUsed in the Web Client block.
- cuba.web.idp.baseUrl
-
For a SSO Service Provider, sets the URL of an Identity Provider. Standard CUBA IDP uses the
idp/path (the trailing/is requred).For example:
cuba.web.idp.baseUrl = http://main:8080/app/idp/Interface:
WebAuthConfigUsed in the Web Client block.
- cuba.web.idp.trustedServicePassword
-
For a SSO Service Provider, sets a password which is used in server-to-server communication between SP and IDP. Must be equal to cuba.idp.trustedServicePassword.
Interface:
WebAuthConfigUsed in the Web Client block.
- cuba.web.mainTabSheetMode
-
Defines which component will be used for TABBED mode of main window. May have one of two possible string values from the
MainTabSheetModeenumeration:-
DEFAULT:CubaTabSheetcomponent is used. It loads and unloads components each time the user switches tabs. -
MANAGED:CubaManagedTabSheetis used. It doesn’t unload components from tab when the user selects other tab.
Default value:
DEFAULT.Interface:
WebConfig.Used in the Web Client block.
-
- cuba.web.linkHandlerActions
-
Defines a list of URL commands handled by the
LinkHandlerbean. See Screen Links for more information.The elements should be separated with the
|character.Default value:
open|oInterface:
WebConfigUsed in the Web Client block.
- cuba.web.loginDialogDefaultUser
-
Defines default user name, which will be automatically populated in the login screen. This is very convenient during development. This property should be set to
<disabled>value in production environment.Default value:
adminInterface:
WebConfigUsed in the Web Client block.
- cuba.web.loginDialogDefaultPassword
-
Defines default user password, which will be automatically populated in the login screen. This is very convenient during development. This property should be set to
<disabled>value in production environment.Default value:
adminInterface:
WebConfigUsed in the Web Client block.
- cuba.web.loginDialogPoweredByLinkVisible
-
Set to
falseto hide the "powered by CUBA Platform" link on the login dialog.Default value:
trueInterface:
WebConfigUsed in the Web Client block.
- cuba.web.maxTabCount
-
Defines the maximum number of tabs that can be opened in the main application window. The value of
0disables this limitation.Default value:
7Interface:
WebConfigUsed in the Web Client block.
- cuba.web.productionMode
-
Allows you to completely disable opening the Vaadin developer console in browser by adding
?debugto the application URL, and, therefore, disabling the JavaScript debug mode and reducing the amount of server information available from the browser.Default value:
falseInterface:
WebConfigUsed in the Web Client block.
- cuba.web.pushEnabled
-
Allows you to completely disable server push. The Background Tasks mechanism will not work in this case.
Default value:
trueInterface:
WebConfigUsed in Web Client.
- cuba.web.pushLongPolling
-
Enables switching to long polling instead of WebSocket for server push implementation.
Default value:
falseInterface:
WebConfigUsed in Web Client.
- cuba.web.rememberMeEnabled
-
Enables displaying Remember Me checkbox in the standard login screen of the web client.
Default value:
trueInterface:
WebConfigUsed in Web Client.
- cuba.web.resourcesRoot
-
Sets a directory for loading files to display by Embedded component. For example:
cuba.web.resourcesRoot = ${cuba.confDir}/resourcesDefault value:
nullInterface:
WebConfigUsed in Web Client.
- cuba.web.showBreadCrumbs
-
Enables hiding of the breadcrumbs panel which normally appears on top of the main window working area.
Default value:
trueInterface:
WebConfigUsed in the Web Client block.
- cuba.web.showFolderIcons
-
Enables the folders panel icons. When enabled, the following application theme files are used:
-
icons/app-folder-small.png– for application folders. -
icons/search-folder-small.png– for search folders. -
icons/set-small.png– for record sets.
Default value:
falseInterface:
WebConfigUsed in the Web Client block.
-
- cuba.web.table.cacheRate
-
Adjusts Table caching in the web browser. The amount of cached rows will be
cacheRatemultiplied with pageLength both below and above visible area.Default value:
2Interface:
WebConfigUsed in the Web Client block.
- cuba.web.table.pageLength
-
Sets the number of rows to be fetched from the server into the web browser when Table is rendered first time on refresh. See also cuba.web.table.cacheRate.
Default value:
15Interface:
WebConfigUsed in the Web Client block.
- cuba.web.theme
-
Defines the name of the theme used as default for the web client. See also cuba.themeConfig.
Default value:
havanaInterface:
WebConfigUsed in the Web Client block.
- cuba.web.useFontIcons
-
If this property is enabled for Halo theme, Font Awesome glyphs will be used for standard actions and platform screens instead of images.
The correspondence between the name in the icon attribute of a visual component or action and font element is defined in the
halo-theme.propertiesfile of the platform. Keys withcuba.web.iconsprefixes correspond to icon names, and their values - tocom.vaadin.server.FontAwesomeenumeration constants. For example, a font element for the standardcreateaction is defined as follows:cuba.web.icons.create.png = FILE_ODefault value:
trueInterface:
WebConfigUsed in the Web Client block.
- cuba.web.useInverseHeader
-
Controls the web client application header for Halo theme and its inheritors. If
true, the header will be dark (inverse), iffalse- the header takes the colour of the main application background.This property is ignored in case
$v-support-inverse-menu: false;property is set in the application theme. This makes sense for a dark theme, if the user has the option to choose between a light and a dark theme. In this case, the header will be inverse for the light theme, and the same as the main background in the dark theme.
Default value:
trueInterface:
WebConfigUsed in the Web Client block.
- cuba.web.viewFileExtensions
-
Defines a list of file extensions displayed in the browser when downloading the file using
ExportDisplay.show(). The|character should be used to separate the list items.Default value:
htm|html|jpg|png|jpeg|pdfInterface:
WebConfigUsed in the Web Client block.
- cuba.webContextName
-
Defines the web application context name. It is usually equivalent to the name of the directory or WAR-file containing this application block.
Interface:
GlobalConfigUsed in blocks: Middleware, Web Client, Web Portal.
For example, for the Middleware block, located in
tomcat/webapps/app-coreand available athttp://somehost:8080/app-core, the property should be set to the following value:cuba.webContextName = app-core
- cuba.webHostName
-
Defines the host name of the machine, on which this application block is running.
Default value:
localhostInterface:
GlobalConfigUsed in blocks: Middleware, Web Client, Web Portal.
For example, for the Middleware block, available at
http://somehost:8080/app-core, the property should be set to the following value:cuba.webHostName = somehost
- cuba.webPort
-
Defines the port, on which this application block is running.
Default value:
8080Interface:
GlobalConfigUsed in blocks: Middleware, Web Client, Web Portal.
For example, for the Middleware block, available at
http://somehost:8080/app-core, this property should be set to the following value:cuba.webPort = 8080
Appendix C: System Properties
System properties can be specified at JVM startup, using the command line argument -D. Additionally, system properties can be read or set using the getProperty() and setProperty() methods of the System class.
You can use system properties to set or override values of application properties. For example, the following command line argument will override the value of the cuba.connectionUrlList property which is normally set in the web-app.properties file:
-Dcuba.connectionUrlList=http://somehost:8080/app-core|
Warning
|
Keep in mind, that system properties affect the whole JVM, i.e all application blocks running on the JVM will get the same value of a property. |
Below are the system properties that are used by the platform but are not application properties.
- logback.configurationFile
-
Defines the location of the Logback framework configuration file.
For application blocks running on the Tomcat web server, this system property is configured in the
tomcat/bin/setenv.batandtomcat/bin/setenv.shfiles. By default, it points to thetomcat/conf/logback.xmlconfiguration file.For the Desktop Client block, the application code configures this property if it is not defined at JVM startup. By default it points to the
cuba-logback.xmlfile in the CLASSPATH root. See Setting up Logging in The Desktop Client.
- cuba.desktop.home
-
For the Desktop Client block, this property defines the root for the folders defined in the cuba.confDir, cuba.logDir, cuba.tempDir, and cuba.dataDir application properties.
If this property is not defined at JVM startup, the default value of ${user.home}/.haulmont/cuba will be used. A different location can be specified by overriding the
getDefaultHomeDir()method of thecom.haulmont.cuba.desktop.Appclass.
- cuba.unitTestMode
-
This system property is set to
truewhen theCubaTestCasebase class is running integration tests.Example:
if (!Boolean.valueOf(System.getProperty("cuba.unitTestMode"))) return "Not in test mode";
9. Glossary
- Application Tiers
- Application Properties
-
Application properties are named data values of various types that define different aspects of application configuration or functions. See Application Properties.
- Application Blocks
- Artifact
-
In the context of this manual, an artifact is a file (usually a JAR or ZIP file) that contains executable code or other code obtained as a result of building a project. An artifact has a name and a version number defined according to specific rules and can be stored in the artifact repository.
- Artifact Repository
-
A server that stores artifacts in a specific structure. The artifacts that the project depends on are loaded from the repository when that project is built.
- Base Projects
-
The same as application components. This term was used in the previous versions of the platform and documentation.
- Container
-
Containers control lifecycle and configuration of application objects. This is a base component of the dependency injection mechanism also known as Inversion of Control.
CUBA platform uses the Spring Framework container.
- DB
-
A relational database.
- Datasource
-
See Datasources.
- Dependency Injection
-
Also known as Inversion of Control (IoC) principle. A mechanism for retrieving links to the objects being used, which assumes that an object should only declare which objects it depends on, while the container creates all the necessary objects and injects them in the dependent object.
- Eager Fetching
-
Loading data from subclasses and related objects together with the requested entity.
- Entity
-
Main element of the data model, see Data Model.
- Entity Browser
-
A screen containing a table with a list of entities and buttons to create, edit and delete entities.
- EntityManager
-
A middle tier component for working with persistent entities.
See EntityManager.
- Interceptor
-
An element of aspect-oriented programming that enables changing or extending object method invocations.
- Java EE Web Profile
-
Simplified Java Enterprise Edition profile created for web applications that do not use technologies like EJB, JTA and others.
- JMX
-
Java Management Extensions − a technology that provides tools to manage applications, system objects and devices. Defines the standard for JMX-components.
Additional details are available at: http://www.oracle.com/technetwork/java/javase/tech/javamanagement-140525.html.
See also Using JMX Tools.
- JPA
-
Java Persistence API – a standard specification of the object-relational mapping technology (ORM). CUBA platform uses EclipseLink framework that implements this specification.
- JPQL
-
Platform independent object-oriented query language, defined as a part of the JPA specification.
Additional details are available at https://en.wikibooks.org/wiki/Java_Persistence/JPQL.
- Lazy loading
-
See Lazy Loading.
- Local attribute
-
An entity attribute that is not a reference or a collection of references to other entities. Values of all local entity attributes are typically stored in one table (with the exception of certain entity inheritance strategies).
- Localized message pack
-
See Message Packs.
- Managed Beans
-
Components that contain application business logic.
See Managed Beans.
- Main Message Pack
-
See Main Message Pack.
- MBeans
-
Managed Beans that have a JMX-interface. Typically, such beans have an internal state (e.g. cache, configuration data or statistics) that needs to be accessible through JMX.
- Middleware
-
Middle tier – the application tier that contains the business logic, works with the database and provides a common interface for higher client tier of an application.
- Optimistic locking
-
Optimistic locking – an approach to managing access to shared data by different users that assumes a very low probability of simultaneous access to the same entity instance. With this approach, locking itself is not applied, instead the system checks if a newer version of the data is available in the database at the moment when the changes are being saved. If so, an exception is thrown and the user must reload the entity instance.
- ORM
-
Object-Relational Mapping – a technology that links tables in a relational database to objects of a programming language.
See ORM Layer.
- Persistent context
-
A set of entity instances loaded from the database or just created. Persistent context serves as data cache within the current transaction. When transaction is committed, all persistent context entity changes are saved to a database.
See EntityManager.
- Screen Controller
-
A Java class containing screen initialization and event handling logic. Works in conjunction with screen’s XML-descriptor.
See Screen Controller.
- Services
-
Middleware services provide the business interface for client calls and form the Middleware boundary. Services can encapsulate the business logic or delegate the execution to Managed Beans.
See Services.
- Soft deletion
-
See Soft Deletion.
- UI
-
User Interface.
- View
-
See Views
- XML-descriptor
-
An XML file containing layout of visual components and datasources for a screen.
See XML-Descriptor.